





Feature Multi-Scale Enhancement and Adaptive Dynamic Fusion Network for Infrared Small Target Detection

Abstract
1. Introduction
- We propose FMADNet, a deep learning network that effectively distinguishes between targets and background. The network enhances the feature representation of infrared small targets and implements weighted fusion across multiple scales, significantly improving detection efficiency and stability, especially in complex backgrounds where targets may be occluded or obscured.
- The RMFE module analyzes complex and abstract data representations through a deep feature encoding architecture and processes multi-scale information.
- We designed the AFDF module, which facilitates dynamic upsampling learning and adaptively assigns weights to different features, optimizing feature fusion and improving detection performance.
2. Related Work
2.1. Single-Frame IRSTD
2.2. Multi-Frame IRSTD
2.3. Cross-Layer Feature Fusion
3. Materials and Methods
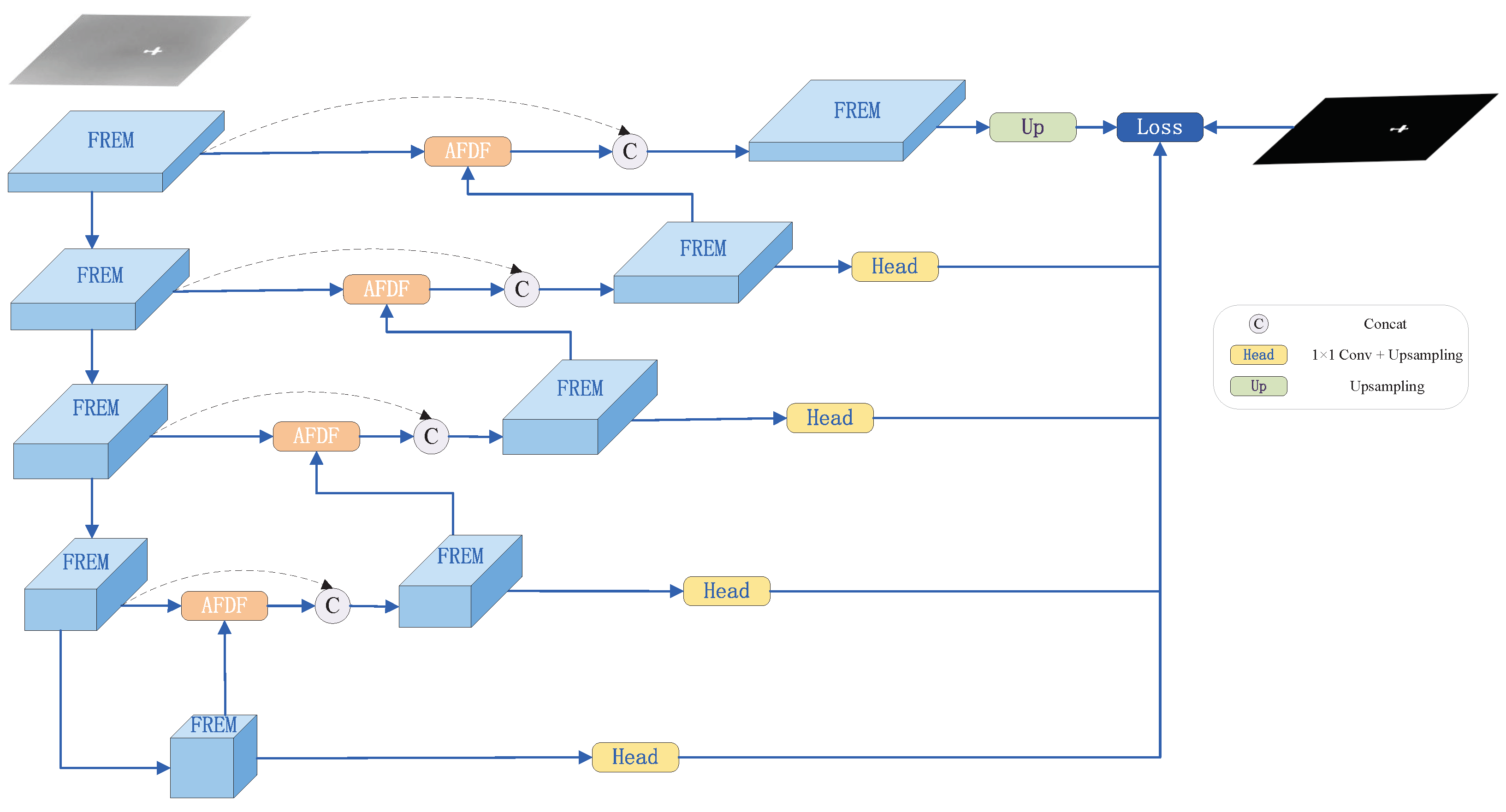
3.1. Overall Architecture
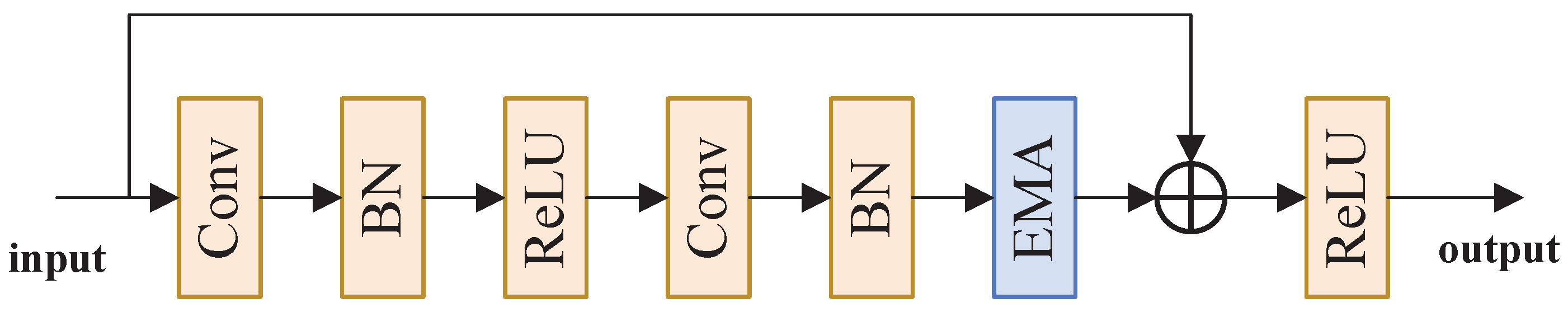
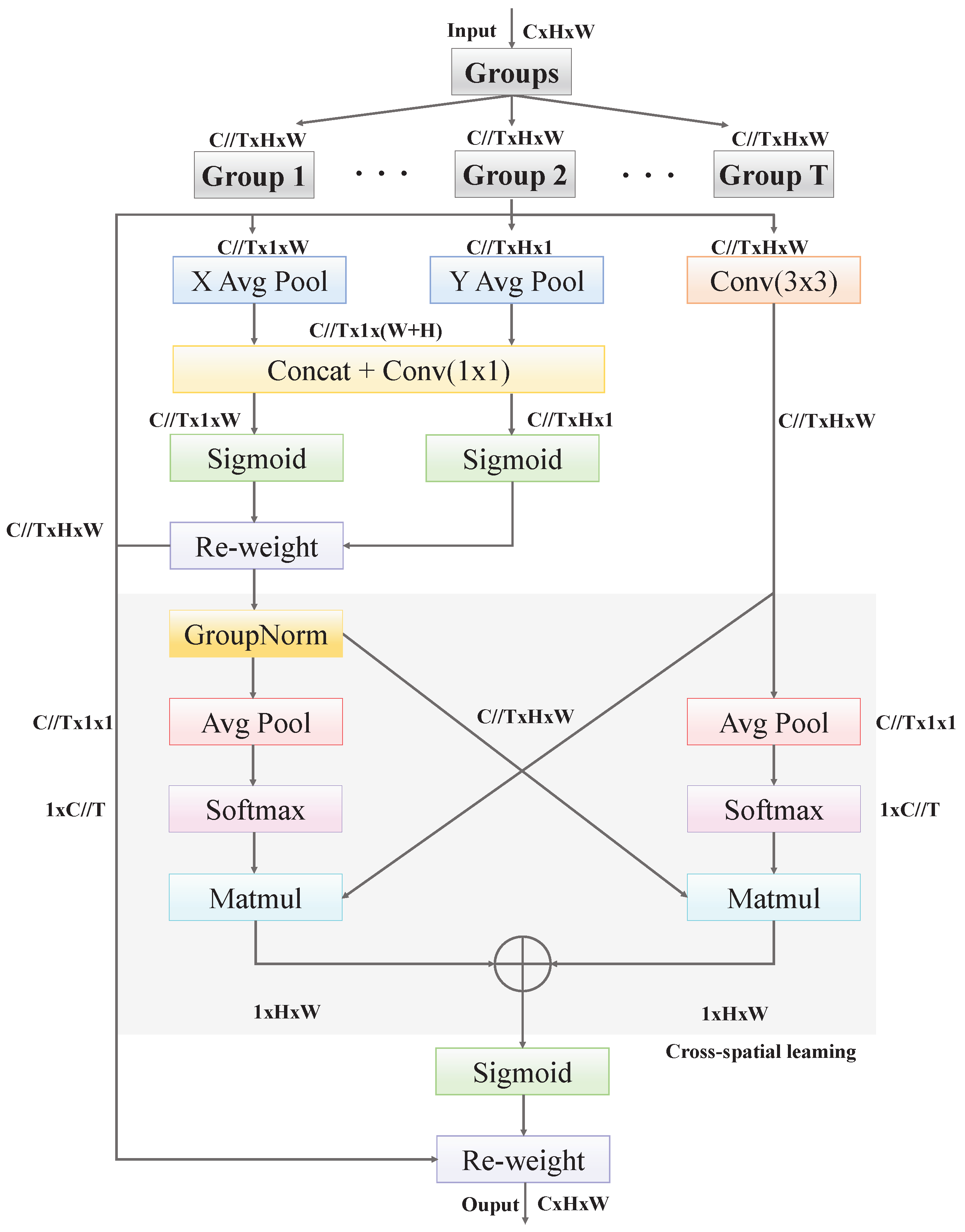
3.2. Residual Multi-Scale Feature Enhancement Module
3.3. Adaptive Feature Dynamic Fusion Module
4. Experimental Results
4.1. Evaluation Metrics
4.2. Dataset
4.3. Implementation Details
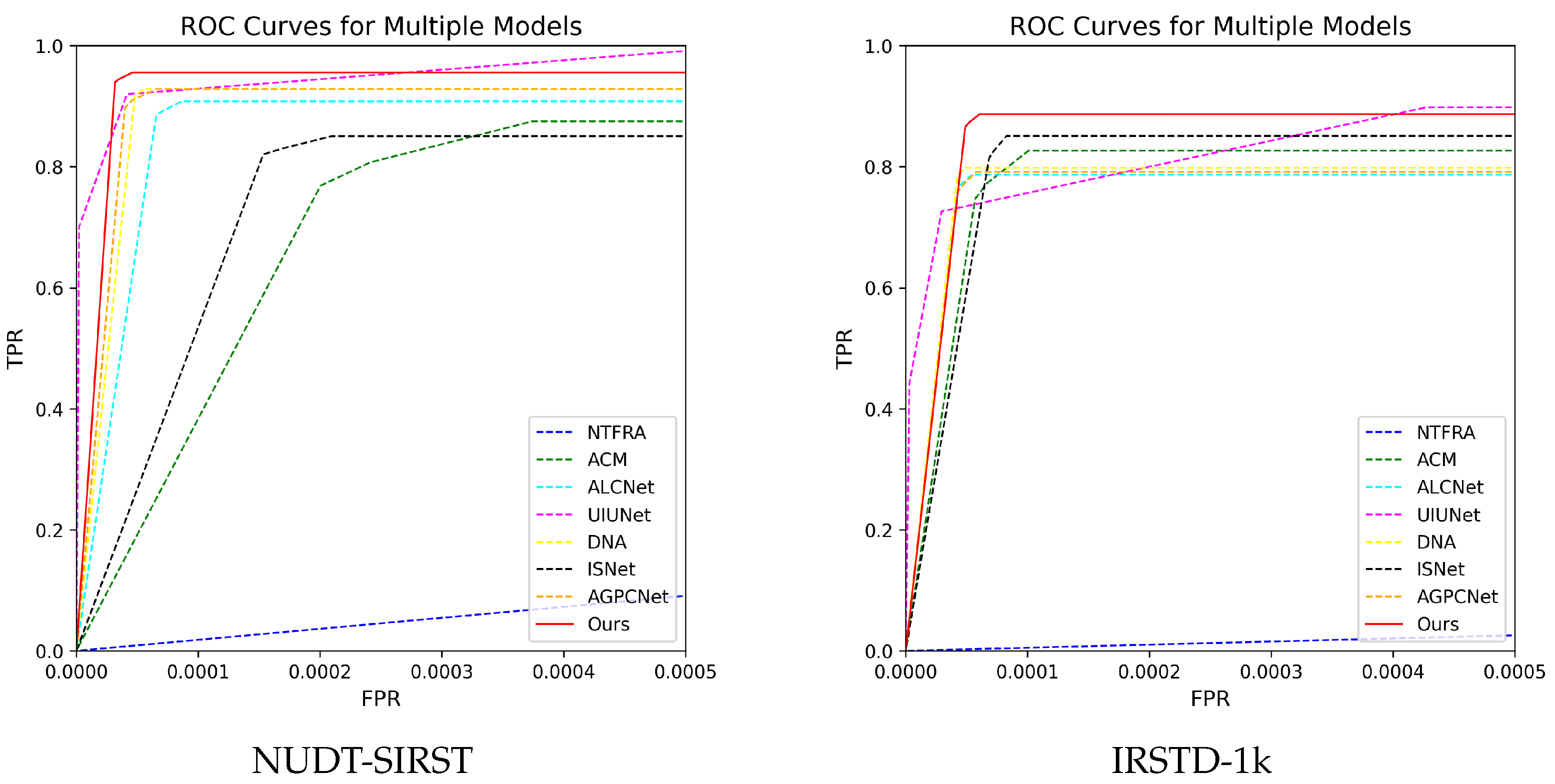
4.4. Comparision to the SOTA Methods
4.5. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, Y.; Lai, X.; Xia, Y.; Zhou, J. Infrared Dim Small Target Detection Networks: A Review. Sensors 2024, 24, 3885. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Li, Z.; Siddique, A. Infrared Maritime Small-Target Detection Based on Fusion Gray Gradient Clutter Suppression. Remote Sens. 2024, 16, 1255. [Google Scholar] [CrossRef]
- Guo, F.; Ma, H.; Li, L.; Lv, M.; Jia, Z. FCNet: Flexible Convolution Network for Infrared Small Ship Detection. Remote Sens. 2024, 16, 2218. [Google Scholar] [CrossRef]
- Ying, X.; Wang, Y.; Wang, L.; Sheng, W.; Liu, L.; Lin, Z.; Zhou, S. Local Motion and Contrast Priors Driven Deep Network for Infrared Small Target Superresolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5480–5495. [Google Scholar] [CrossRef]
- Deng, H.; Zhang, Y. FMR-YOLO: Infrared Ship Rotating Target Detection Based on Synthetic Fog and Multiscale Weighted Feature Fusion. IEEE Trans. Instrum. Meas. 2024, 73, 1–17. [Google Scholar] [CrossRef]
- Wang, F.; Qian, W.; Qian, Y.; Ma, C.; Zhang, H.; Wang, J.; Wan, M.; Ren, K. Maritime Infrared Small Target Detection Based on the Appearance Stable Isotropy Measure in Heavy Sea Clutter Environments. Sensors 2023, 23, 9838. [Google Scholar] [CrossRef]
- Kim, J.; Huh, J.; Park, I.; Bak, J.; Kim, D.; Lee, S. Small Object Detection in Infrared Images: Learning from Imbalanced Cross-Domain Data via Domain Adaptation. Appl. Sci. 2022, 12, 1201. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, J.; An, W. Infrared Dim and Small Target Detection via Multiple Subspace Learning and Spatial-Temporal Patch-Tensor Model. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3737–3752. [Google Scholar] [CrossRef]
- Zhong, Y.; Shi, Z.; Zhang, Y.; Zhang, Y.; Li, H. CSAN-UNet: Channel Spatial Attention Nested UNet for Infrared Small Target Detection. Remote Sens. 2024, 16, 1894. [Google Scholar] [CrossRef]
- Pan, X.; Jia, N.; Mu, Y.; Gao, X. Survey of small object detection. J. Image Graph. 2023, 28, 2587–2615. [Google Scholar] [CrossRef]
- Xiang, Y.; Gong, C.; Ge, L.; Wei, D.; Yin, W.; Feng, Y.; Xiwen, Y.; Huang, Z.; Xian, S.; Han, J. Progress in small object detection for remote sensing images. J. Image Graph. 2023, 28, 1662–1684. [Google Scholar]
- Wang, X.; Peng, Z.; Kong, D.; He, Y. Infrared Dim and Small Target Detection Based on Stable Multisubspace Learning in Heterogeneous Scene. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5481–5493. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, Y.; Zhu, C.; Wang, S.; Lan, Z.; Qiao, Y. An Adaptive Spatial-Temporal Local Feature Difference Method For Infrared Small-Moving Target Detection. In Proceedings of the 2023 8th IEEE International Conference on Network Intelligence and Digital Content (IC-NIDC), Beijing, China, 3–5 November 2023; pp. 346–351. [Google Scholar] [CrossRef]
- Yao, C.; Zhao, H. Adaptive Frame Sampling and Feature Alignment for Multi-Frame Infrared Small Target Detection. Appl. Sci. 2024, 14, 6360. [Google Scholar] [CrossRef]
- Luo, Y.; Ying, X.; Li, R.; Wan, Y.; Hu, B.; Ling, Q. Multi-scale Optical Flow Estimation for Video Infrared Small Target Detection. In Proceedings of the 2022 2nd International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Nanjing, China, 23–25 September 2022; pp. 129–132. [Google Scholar] [CrossRef]
- Hu, Y.; Ma, Y.; Pan, Z.; Liu, Y. Infrared Dim and Small Target Detection from Complex Scenes via Multi-Frame Spatial–Temporal Patch-Tensor Model. Remote Sens. 2022, 14, 2234. [Google Scholar] [CrossRef]
- Deng, H.; Zhang, Y.; Li, Y.; Cheng, K.; Chen, Z. BEmST: Multiframe Infrared Small-Dim Target Detection Using Probabilistic Estimation of Sequential Backgrounds. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Sun, X.; Xiong, W.; Shi, H. A Novel Spatiotemporal Filtering for Dim Small Infrared Maritime Target Detection. In Proceedings of the 2022 International Symposium on Electrical, Electronics and Information Engineering (ISEEIE), Chiang Mai, Thailand, 25–27 February 2022; pp. 195–201. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Z.; Zhang, P.; He, Y. Infrared Small Target Detection via Nonnegativity-Constrained Variational Mode Decomposition. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1700–1704. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Proceedings of the Optics & Photonics, Denver, CO, USA, 4 October 1999. [Google Scholar]
- Pang, D.; Shan, T.; Li, W.; Ma, P.; Tao, R.; Ma, Y. Facet Derivative-Based Multidirectional Edge Awareness and Spatial-Temporal Tensor Model for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Hao, X.; Liu, X.; Liu, Y.; Cui, Y.; Lei, T. Infrared Small-Target Detection Based on Background-Suppression Proximal Gradient and GPU Acceleration. Remote Sens. 2023, 15, 5424. [Google Scholar] [CrossRef]
- Liu, J.; He, Z.; Chen, Z.; Shao, L. Tiny and Dim Infrared Target Detection Based on Weighted Local Contrast. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1780–1784. [Google Scholar] [CrossRef]
- Han, J.; Moradi, S.; Faramarzi, I.; Zhang, H.; Zhao, Q.; Zhang, X.; Li, N. Infrared Small Target Detection Based on the Weighted Strengthened Local Contrast Measure. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1670–1674. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared Small Target Detection via Non-Convex Rank Approximation Minimization Joint l2,1 Norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- He, Y.; Li, M.; Zhang, J.; Yao, J. Infrared Target Tracking Based on Robust Low-Rank Sparse Learning. IEEE Geosci. Remote Sens. Lett. 2016, 13, 232–236. [Google Scholar] [CrossRef]
- Kong, X.; Yang, C.; Cao, S.; Li, C.; Peng, Z. Infrared Small Target Detection via Nonconvex Tensor Fibered Rank Approximation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–21. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, Z. Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 949–958. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional Local Contrast Networks for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape Matters for Infrared Small Target Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 867–876. [Google Scholar] [CrossRef]
- Zhang, M.; Bai, H.; Zhang, J.; Zhang, R.; Wang, C.; Guo, J.; Gao, X. RKformer: Runge-Kutta Transformer with Random-Connection Attention for Infrared Small Target Detection. In Proceedings of the 30th ACM International Conference on Multimedia, MM ’22, Lisboa, Portugal, 10–14 October 2022; pp. 1730–1738. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense Nested Attention Network for Infrared Small Target Detection. IEEE Trans. Image Process. 2023, 32, 1745–1758. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for Infrared Small Object Detection. IEEE Trans. Image Process. 2023, 32, 364–376. [Google Scholar] [CrossRef]
- Zhang, T.; Li, L.; Cao, S.; Pu, T.; Peng, Z. Attention-Guided Pyramid Context Networks for Detecting Infrared Small Target Under Complex Background. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4250–4261. [Google Scholar] [CrossRef]
- Pan, P.; Wang, H.; Wang, C.; Nie, C. ABC: Attention with Bilinear Correlation for Infrared Small Target Detection. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 2381–2386. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Pang, D.; Ma, P.; Shan, T.; Li, W.; Tao, R.; Ma, Y.; Wang, T. STTM-SFR: Spatial–Temporal Tensor Modeling With Saliency Filter Regularization for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Luo, Y.; Li, X.; Chen, S.; Xia, C.; Zhao, L. IMNN-LWEC: A Novel Infrared Small Target Detection Based on Spatial–Temporal Tensor Model. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–22. [Google Scholar] [CrossRef]
- Du, J.; Li, D.; Deng, Y.; Zhang, L.; Lu, H.; Hu, M.; Shen, X.; Liu, Z.; Ji, X. Multiple Frames Based Infrared Small Target Detection Method Using CNN. In Proceedings of the 2021 4th International Conference on Algorithms, Computing and Artificial Intelligence, ACAI ’21, Sanya, China, 22–24 December 2022. [Google Scholar] [CrossRef]
- Chen, S.; Ji, L.; Zhu, J.; Ye, M.; Yao, X. SSTNet: Sliced Spatio-Temporal Network With Cross-Slice ConvLSTM for Moving Infrared Dim-Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–12. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to Upsample by Learning to Sample. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 6004–6014. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Kang, M.; Ting, C.M.; Ting, F.F.; Phan, R.C.W. ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 2024, 147, 105057. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Ref. | IoU (%) ↑ | nIoU (%) ↑ | F1 (%) ↑ | |
|---|---|---|---|---|---|
| NUDT-SIRST | NTFRA [27] | TGRS | 8.61 | 17.22 | 15.86 |
| ACM [29] | WACV | 58.89 | 57.20 | 74.13 | |
| ALCNet [30] | TGRS | 80.49 | 81.37 | 89.19 | |
| UIUNet [34] | TIP | 85.26 | 84.75 | 92.04 | |
| DNANet [33] | TIP | 85.48 | 85.89 | 92.17 | |
| ISNet [31] | CVPR | 66.03 | 70.29 | 79.54 | |
| AGPCNet [35] | TAES | 85.00 | 86.88 | 91.89 | |
| Ours | - | 89.66 | 90.21 | 94.55 | |
| IRSTD-1k | NTFRA [27] | TGRS | 2.40 | 21.18 | 4.69 |
| ACM [29] | WACV | 62.21 | 55.61 | 76.70 | |
| ALCNet [30] | TGRS | 66.17 | 64.21 | 79.64 | |
| UIUNet [34] | TIP | 61.70 | 57.64 | 76.31 | |
| DNANet [33] | TIP | 68.01 | 68.98 | 80.96 | |
| ISNet [31] | CVPR | 65.44 | 63.00 | 79.11 | |
| AGPCNet [35] | TAES | 65.73 | 63.31 | 79.32 | |
| Ours | - | 73.47 | 68.13 | 84.71 |
| Methods | Ref. | FLOPs ↓ (G) | Params ↓ (M) | FPS ↑ | IoU ↑ (%) |
|---|---|---|---|---|---|
| ACM [29] | WACV | 0.38 | 0.29 | 86.45 | 58.89 |
| ALCNet [30] | TGRS | 7.08 | 0.38 | 26.18 | 80.49 |
| UIUNet [34] | TIP | 54.46 | 50.54 | 44.18 | 85.26 |
| DNANet [33] | TIP | 14.09 | 4.70 | 57.69 | 85.48 |
| ISNet [31] | CVPR | 31.26 | 1.09 | 36.81 | 66.03 |
| AGPCNet [35] | TAES | 43.11 | 12.36 | 14.11 | 85.00 |
| Ours | - | 6.98 | 4.31 | 47.23 | 89.66 |
| NUDT-SIRST | IRSTD-1k | |||||
|---|---|---|---|---|---|---|
| IoU (%) | nIoU (%) | F1 (%) | IoU (%) | nIoU (%) | F1 (%) | |
| U-Res | 85.36 | 85.93 | 92.10 | 67.17 | 66.96 | 80.36 |
| U-RMFE | 85.92 | 86.68 | 92.43 | 72.29 | 67.05 | 83.91 |
| U-Res + AFDF | 87.70 | 88.31 | 93.45 | 68.87 | 67.07 | 81.57 |
| FMADNet | 89.66 | 90.21 | 94.55 | 73.47 | 68.13 | 84.71 |
| NUDT-SIRST | IRSTD-1k | |||||
|---|---|---|---|---|---|---|
| IoU (%) | nIoU (%) | F1 (%) | IoU (%) | nIoU (%) | F1 (%) | |
| CE Loss | 88.68 | 89.83 | 94.00 | 68.74 | 67.57 | 81.48 |
| BCE Loss | 89.59 | 89.79 | 94.51 | 68.15 | 68.47 | 81.06 |
| Dice Loss | 88.71 | 89.52 | 94.02 | 70.36 | 66.20 | 82.60 |
| SoftIoU Loss | 89.66 | 90.21 | 94.55 | 73.47 | 68.13 | 84.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, Z.; Sheng, Z.; Mao, Y. Feature Multi-Scale Enhancement and Adaptive Dynamic Fusion Network for Infrared Small Target Detection. Remote Sens. 2025, 17, 1548. https://doi.org/10.3390/rs17091548
Xiong Z, Sheng Z, Mao Y. Feature Multi-Scale Enhancement and Adaptive Dynamic Fusion Network for Infrared Small Target Detection. Remote Sensing. 2025; 17(9):1548. https://doi.org/10.3390/rs17091548
Chicago/Turabian StyleXiong, Zenghui, Zhiqiang Sheng, and Yao Mao. 2025. "Feature Multi-Scale Enhancement and Adaptive Dynamic Fusion Network for Infrared Small Target Detection" Remote Sensing 17, no. 9: 1548. https://doi.org/10.3390/rs17091548
APA StyleXiong, Z., Sheng, Z., & Mao, Y. (2025). Feature Multi-Scale Enhancement and Adaptive Dynamic Fusion Network for Infrared Small Target Detection. Remote Sensing, 17(9), 1548. https://doi.org/10.3390/rs17091548