
SwinNowcast: A Swin Transformer-Based Model for Radar-Based Precipitation Nowcasting

Abstract
:1. Introduction
- We propose a novel precipitation nowcasting model, SwinNowcast, which independently extracts global and local features from precipitation data and effectively fuses them, thereby enhancing the model’s predictive capability across precipitation events of varying intensities;
- We integrate multi-scale feature extraction units with global feature extraction units to enhance the model’s ability to perceive precipitation events at different scales. This integration enables the model to simultaneously extract critical features across multiple scales, thereby capturing spatiotemporal dependencies in precipitation data more comprehensively;
- We propose a novel gated attention feature fusion unit (GAFFU), which addresses the imbalance between global and local features through a gating mechanism. GAFFU effectively integrates complementary information from different scales, thereby improving the effectiveness of feature representation.
- The proposed SwinNowcast demonstrates significant performance improvements over six state-of-the-art (SOTA) models on publicly available precipitation datasets.
2. Methods
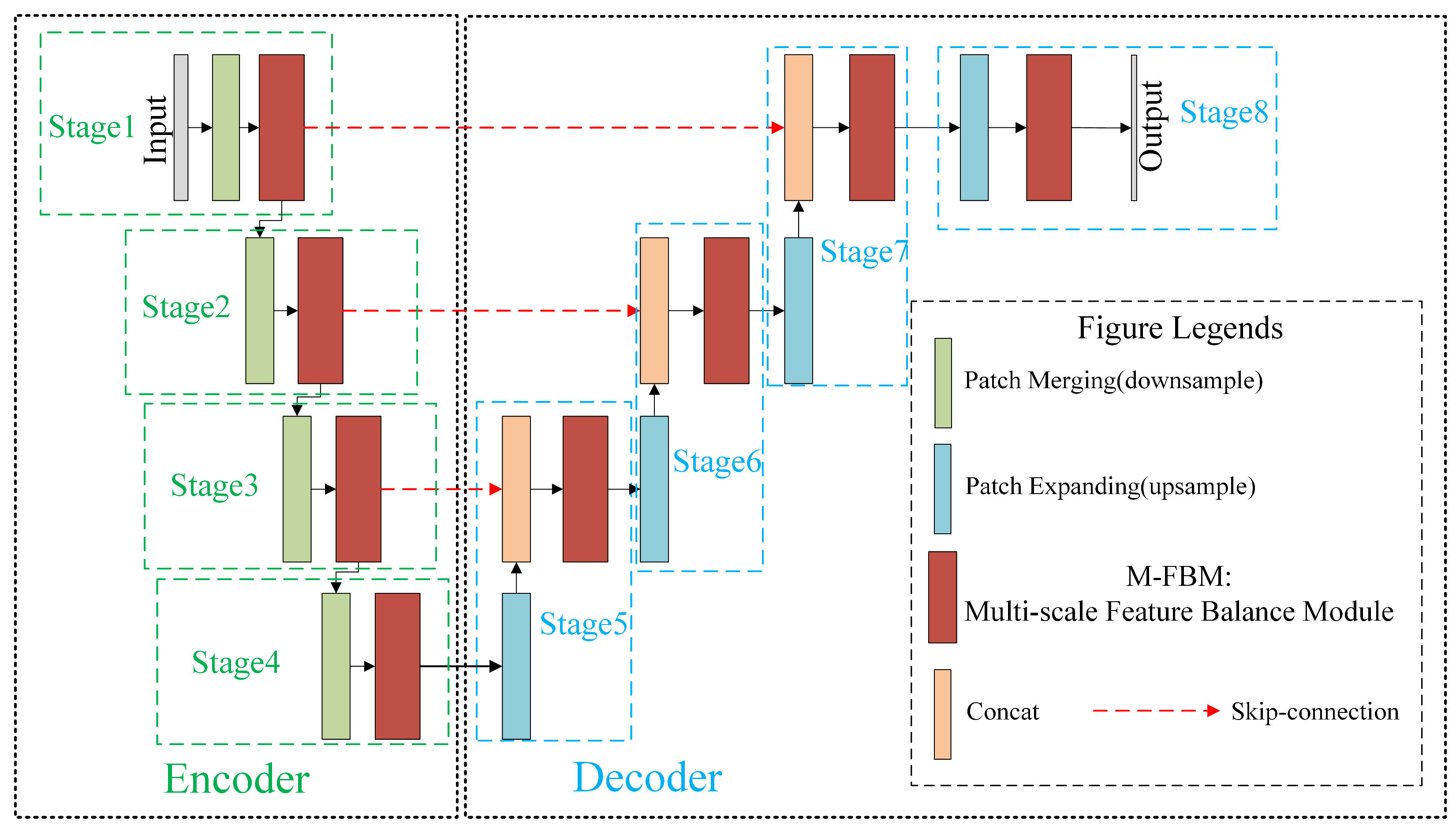
2.1. Overall Architecture Design
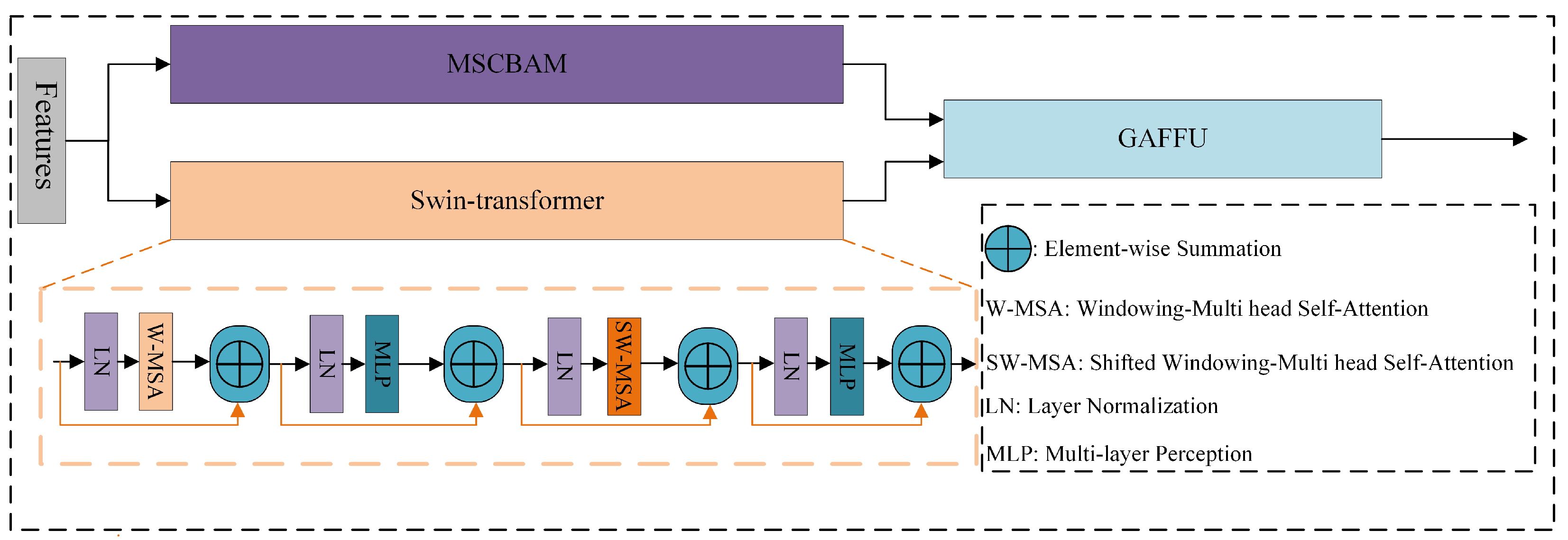
2.2. Multi-Scale Feature Balancing Module (M-FBM)
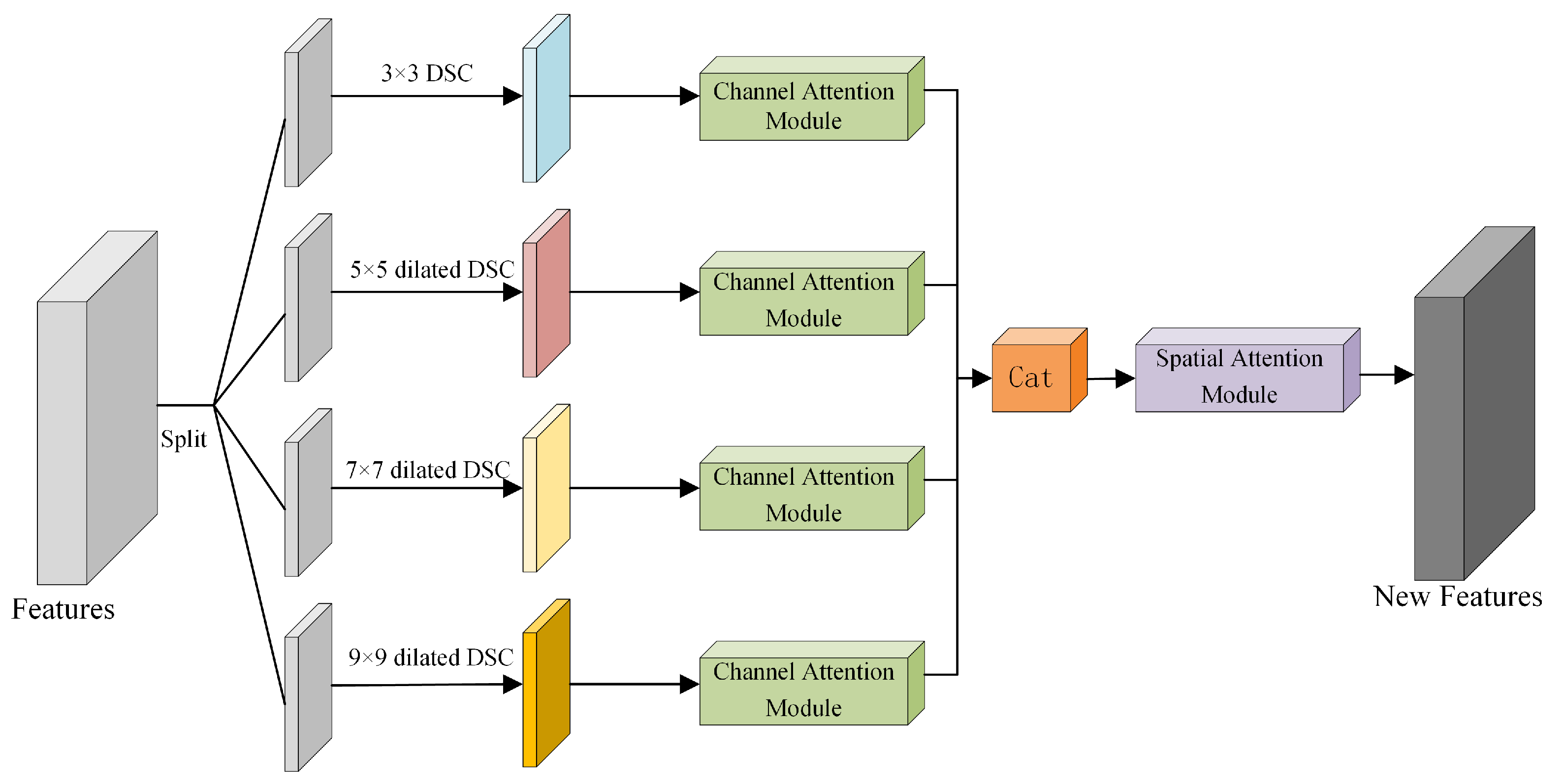
2.2.1. Multi-Scale Convolutional Block Attention Module (MSCBAM)
2.2.2. Gated Attention Feature Fusion Unit (GAFFU)
- Gating computation: X and Y are first concatenated and passed through a convolutional layer to generate a fused tensor. Then, this tensor is partitioned along the channel dimension into two gating factors:Here, denotes the Sigmoid activation function, while Z and R correspond to the update gate and reset gate, respectively.
- Gated fusion: The gating factors are utilized to integrate the main and residual branches:Here, ⊗ denotes element-wise multiplication. The computed dynamically integrates the features of both branches at the numerical level, regulating the retention or suppression of new input or residual information based on the values of Z and R.
- Local and global attention: Local and global attention features are separately computed based on the gated output :Here, denotes the output of the local attention submodule, which emphasizes local regions, while corresponds to the output of the global attention submodule, encoding the global context.
- Attention fusion: The outputs of local and global attention are summed and subsequently processed through the Sigmoid activation function to generate the attention weight map:w takes values within the range [0, 1] and serves as an indicator of feature importance across different spatial locations.
- Feature reweighting: The gated output features are adaptively weighted according to the attention map:Fundamentally, the features in are rescaled by w and its complementary factor , emphasizing regions identified as crucial by the attention network while maintaining overall structural integrity. Consequently, the final output is a feature map that seamlessly integrates multi-source inputs and is adaptively refined through both local and global attention mechanisms.
3. Data and Experimental Configuration
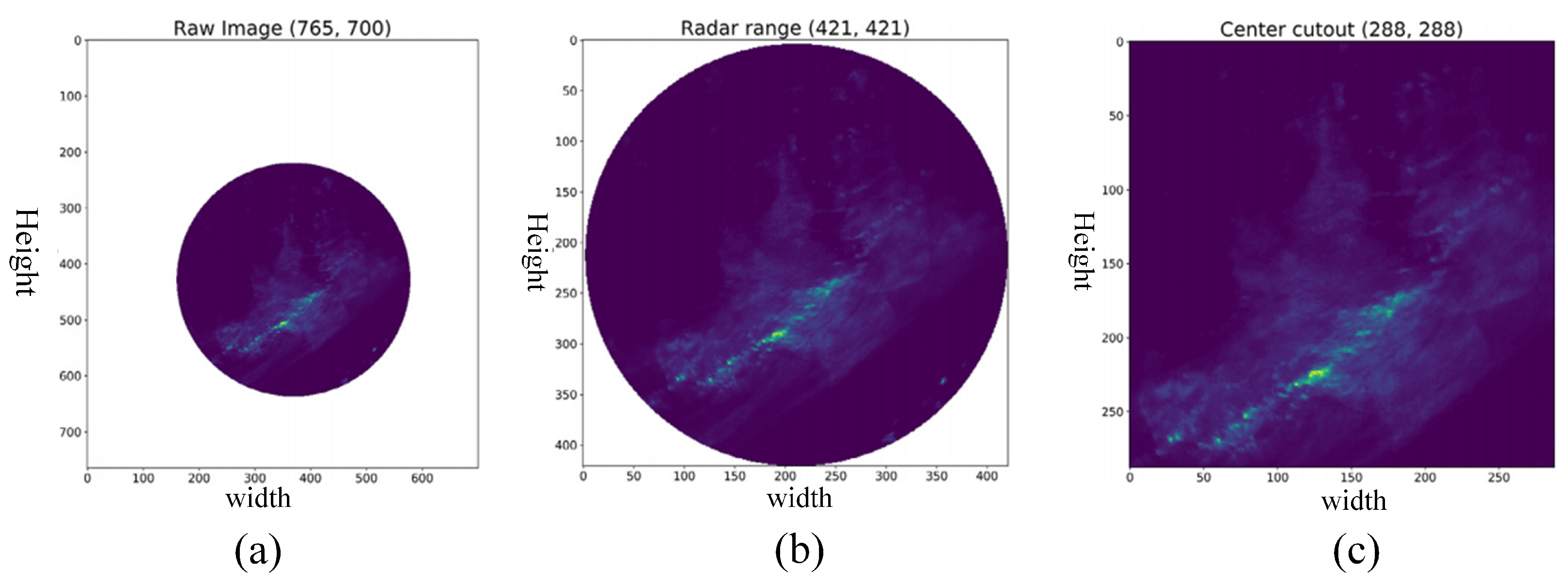
3.1. Dateset
3.2. Implementation Details
3.3. Evaluation Metrics
4. Experimental Results and Analysis
4.1. Quantitative Comparison
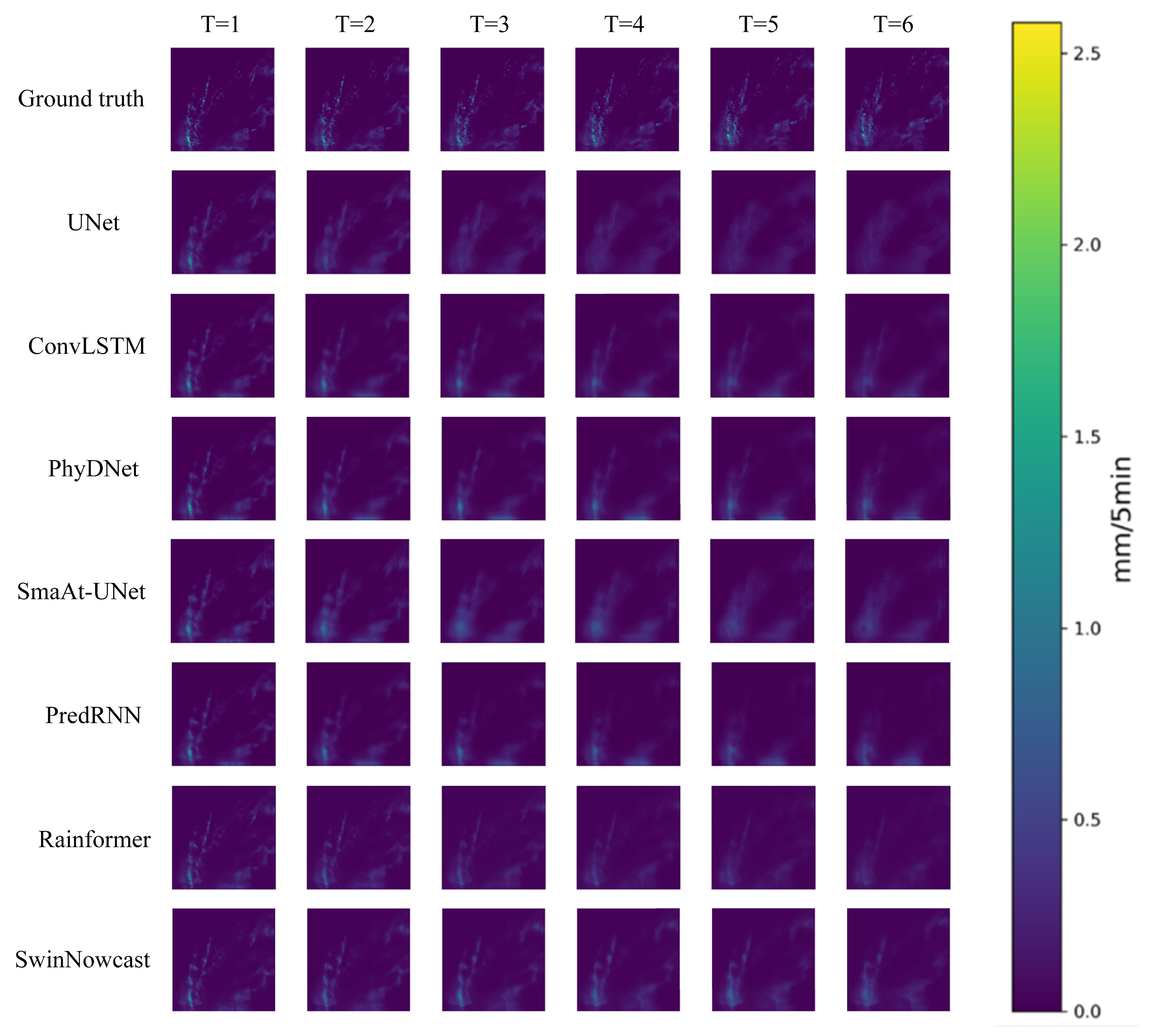
4.2. Qualitative Comparison
4.3. Ablation Experiment
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, S.; Zhang, K.; Chao, L.; Chen, G.; Xia, Y.; Zhang, C. Investigating the feasibility of using satellite rainfall for the integrated prediction of flood and landslide hazards over Shaanxi Province in northwest China. Remote Sens. 2023, 15, 2457. [Google Scholar] [CrossRef]
- Sun, J.; Xue, M.; Wilson, J.W.; Zawadzki, I.; Ballard, S.P.; Onvlee-Hooimeyer, J.; Joe, P.; Barker, D.M.; Li, P.W.; Golding, B.; et al. Use of NWP for nowcasting convective precipitation: Recent progress and challenges. Bull. Am. Meteorol. Soc. 2014, 95, 409–426. [Google Scholar] [CrossRef]
- Hering, A.; Morel, C.; Galli, G.; Sénési, S.; Ambrosetti, P.; Boscacci, M. Nowcasting thunderstorms in the Alpine region using a radar based adaptive thresholding scheme. In Proceedings of the ERAD, Visby, Sweden, 6–10 September 2004; Volume 1. [Google Scholar]
- Soman, S.S.; Zareipour, H.; Malik, O.; Mandal, P. A review of wind power and wind speed forecasting methods with different time horizons. In Proceedings of the North American Power Symposium, Arlington, TX, USA, 26–28 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1–8. [Google Scholar]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat, F. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Tian, L.; Li, X.; Ye, Y.; Xie, P.; Li, Y. A generative adversarial gated recurrent unit model for precipitation nowcasting. IEEE Geosci. Remote Sens. Lett. 2019, 17, 601–605. [Google Scholar] [CrossRef]
- Xie, P.; Li, X.; Ji, X.; Chen, X.; Chen, Y.; Liu, J.; Ye, Y. An energy-based generative adversarial forecaster for radar echo map extrapolation. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Veillette, M.; Samsi, S.; Mattioli, C. Sevir: A storm event imagery dataset for deep learning applications in radar and satellite meteorology. Adv. Neural Inf. Process. Syst. 2020, 33, 22009–22019. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 1. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Guen, V.L.; Thome, N. Disentangling physical dynamics from unknown factors for unsupervised video prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11474–11484. [Google Scholar]
- Ma, Z.; Zhang, H.; Liu, J. Preciplstm: A meteorological spatiotemporal lstm for precipitation nowcasting. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–8. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Philip, S.Y. Predrnn++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5123–5132. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Proceedings, Part III 18, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Trebing, K.; Stańczyk, T.; Mehrkanoon, S. SmaAt-UNet: Precipitation nowcasting using a small attention-UNet architecture. Pattern Recognit. Lett. 2021, 145, 178–186. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Yang, Y.; Mehrkanoon, S. Aa-transunet: Attention augmented transunet for nowcasting tasks. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Tan, Y.; Zhang, T.; Li, L.; Li, J. Radar-Based Precipitation Nowcasting Based on Improved U-Net Model. Remote Sens. 2024, 16, 1681. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bai, C.; Sun, F.; Zhang, J.; Song, Y.; Chen, S. Rainformer: Features extraction balanced network for radar-based precipitation nowcasting. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Gao, Z.; Shi, X.; Wang, H.; Zhu, Y.; Wang, Y.B.; Li, M.; Yeung, D.Y. Earthformer: Exploring space-time transformers for earth system forecasting. Adv. Neural Inf. Process. Syst. 2022, 35, 25390–25403. [Google Scholar]
- Wang, J.; Wang, X.; Guan, J.; Zhang, L.; Zhang, F.; Chang, T. STPF-Net: Short-Term Precipitation Forecast Based on a Recurrent Neural Network. Remote Sens. 2023, 16, 52. [Google Scholar] [CrossRef]
- Bojesomo, A.; AlMarzouqi, H.; Liatsis, P. A novel transformer network with shifted window cross-attention for spatiotemporal weather forecasting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 45–55. [Google Scholar] [CrossRef]
- Xiong, T.; Wang, W.; He, J.; Su, R.; Wang, H.; Hu, J. Spatiotemporal Feature Fusion Transformer for Precipitation Nowcasting via Feature Crossing. Remote Sens. 2024, 16, 2685. [Google Scholar] [CrossRef]
- Liu, H.; Fung, J.C.; Lau, A.K.; Li, Z. Enhancing quantitative precipitation estimation of NWP model with fundamental meteorological variables and Transformer based deep learning model. Earth Space Sci. 2024, 11, e2023EA003234. [Google Scholar] [CrossRef]
- Ji, H.; Guo, L.; Zhang, J.; Wei, Y.; Guo, X.; Zhang, Y. EDH-STNet: An Evaporation Duct Height Spatiotemporal Prediction Model Based on Swin-Unet Integrating Multiple Environmental Information Sources. Remote Sens. 2024, 16, 4227. [Google Scholar] [CrossRef]
- Piran, M.J.; Wang, X.; Kim, H.J.; Kwon, H.H. Precipitation nowcasting using transformer-based generative models and transfer learning for improved disaster preparedness. Int. J. Appl. Earth Obs. Geoinf. 2024, 132, 103962. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic feature pyramid network for object detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Oahu, HI, USA, 1–4 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2184–2189. [Google Scholar]
- Tuyen, D.N.; Tuan, T.M.; Le, X.H.; Tung, N.T.; Chau, T.K.; Van Hai, P.; Gerogiannis, V.C.; Son, L.H. RainPredRNN: A new approach for precipitation nowcasting with weather radar echo images based on deep learning. Axioms 2022, 11, 107. [Google Scholar] [CrossRef]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and checkerboard artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Vatamány, L.; Mehrkanoon, S. Graph dual-stream convolutional attention fusion for precipitation nowcasting. Eng. Appl. Artif. Intell. 2025, 141, 109788. [Google Scholar] [CrossRef]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6824–6835. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1597–1600. [Google Scholar]
- Overeem, A.; Holleman, I.; Buishand, A. Derivation of a 10-year radar-based climatology of rainfall. J. Appl. Meteorol. Climatol. 2009, 48, 1448–1463. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, H.; Zhang, J.; Gao, Z.; Wang, J.; Philip, S.Y.; Long, M. Predrnn: A recurrent neural network for spatiotemporal predictive learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2208–2225. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CSI | HSS | FAR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.5 | 5 | 10 | 0.5 | 5 | 10 | 0.5 | 5 | 10 | |
| UNet | 0.6827 | 0.2315 | 0.1048 | 0.3494 | 0.1837 | 0.0942 | 0.2342 | 0.3724 | 0.5309 |
| ConvLSTM | 0.6858 | 0.3260 | 0.1833 | 0.3477 | 0.2412 | 0.1539 | 0.2425 | 0.3860 | 0.5474 |
| PhyDNet | 0.6976 | 0.3602 | 0.1618 | 0.3564 | 0.2601 | 0.1385 | 0.2178 | 0.3936 | 0.4907 |
| SmaAt-UNet | 0.6613 | 0.2963 | 0.1706 | 0.3320 | 0.2238 | 0.1448 | 0.2683 | 0.4039 | 0.5587 |
| PredRNN | 0.6794 | 0.3350 | 0.1889 | 0.3494 | 0.2462 | 0.1579 | 0.2015 | 0.3927 | 0.5619 |
| Rainformer | 0.7403 | 0.2143 | 0.0755 | 0.3824 | 0.1732 | 0.0699 | 0.1590 | 0.1976 | 0.2691 |
| SwinNowcast (ours) | 0.7494 | 0.3731 | 0.1955 | 0.3868 | 0.2675 | 0.1627 | 0.1574 | 0.3131 | 0.4742 |
| Method | CSI | HSS | FAR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.5 | 5 | 10 | 0.5 | 5 | 10 | 0.5 | 5 | 10 | |
| UNet | 0.7365 | 0.3143 | 0.1427 | 0.3788 | 0.2349 | 0.1241 | 0.1893 | 0.3328 | 0.5242 |
| ConvLSTM | 0.7448 | 0.4203 | 0.2487 | 0.3828 | 0.2918 | 0.1982 | 0.4522 | 0.3303 | 0.4844 |
| PhyDNet | 0.7537 | 0.4478 | 0.2341 | 0.3882 | 0.3052 | 0.1888 | 0.1741 | 0.3440 | 0.4495 |
| SmaAt-UNet | 0.7208 | 0.3827 | 0.2420 | 0.3701 | 0.2723 | 0.1938 | 0.2042 | 0.3844 | 0.5445 |
| PredRNN | 0.7432 | 0.4195 | 0.2564 | 0.3844 | 0.2914 | 0.2031 | 0.1612 | 0.3361 | 0.4860 |
| Rainformer | 0.7925 | 0.3039 | 0.0919 | 0.4090 | 0.2298 | 0.0838 | 0.1324 | 0.1638 | 0.2727 |
| SwinNowcast (ours) | 0.7989 | 0.4584 | 0.2539 | 0.4125 | 0.3108 | 0.2017 | 0.1230 | 0.2594 | 0.3941 |
| Method | CSI | HSS | FAR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.5 | 5 | 10 | 0.5 | 5 | 10 | 0.5 | 5 | 10 | |
| UNet | 0.6689 | 0.1761 | 0.0468 | 0.3382 | 0.1453 | 0.0442 | 0.2473 | 0.4504 | 0.7164 |
| ConvLSTM | 0.6614 | 0.2720 | 0.1271 | 0.3323 | 0.2088 | 0.1118 | 0.2620 | 0.4395 | 0.6408 |
| PhyDNet | 0.6735 | 0.3124 | 0.0915 | 0.3422 | 0.2329 | 0.0831 | 0.2337 | 0.4413 | 0.6184 |
| SmaAt-UNet | 0.6314 | 0.2530 | 0.1367 | 0.3093 | 0.1968 | 0.1191 | 0.3101 | 0.4602 | 0.6730 |
| PredRNN | 0.6506 | 0.2858 | 0.1373 | 0.3334 | 0.2172 | 0.1197 | 0.2145 | 0.4419 | 0.6490 |
| Rainformer | 0.7201 | 0.1312 | 0.0114 | 0.3712 | 0.1132 | 0.0111 | 0.1740 | 0.2592 | 0.4778 |
| SwinNowcast (ours) | 0.7306 | 0.3281 | 0.1338 | 0.3765 | 0.2425 | 0.1172 | 0.1702 | 0.3640 | 0.5654 |
| Method | CSI | HSS | FAR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.5 | 5 | 10 | 0.5 | 5 | 10 | 0.5 | 5 | 10 | |
| UNet | 0.6115 | 0.0889 | 0.0103 | 0.2984 | 0.0782 | 0.0100 | 0.3055 | 0.5358 | 0.7450 |
| ConvLSTM | 0.6047 | 0.1819 | 0.0733 | 0.2923 | 0.1485 | 0.0674 | 0.3184 | 0.5330 | 0.7395 |
| PhyDNet | 0.6172 | 0.2254 | 0.0352 | 0.3048 | 0.1783 | 0.0335 | 0.2862 | 0.5109 | 0.7465 |
| SmaAt-UNet | 0.5888 | 0.1351 | 0.0137 | 0.2812 | 0.1147 | 0.0133 | 0.3328 | 0.5082 | 0.7692 |
| PredRNN | 0.5900 | 0.2028 | 0.0760 | 0.2944 | 0.1630 | 0.0696 | 0.2675 | 0.5264 | 0.7583 |
| Rainformer | 0.6580 | 0.0577 | 0.0030 | 0.3383 | 0.0527 | 0.0030 | 0.1930 | 0.3892 | 0.6419 |
| SwinNowcast (ours) | 0.6736 | 0.2292 | 0.0647 | 0.3451 | 0.1817 | 0.0601 | 0.2002 | 0.4190 | 0.6702 |
| Method | #Params (M) | GFLOPs | Inference Time (ms/Sample) |
|---|---|---|---|
| UNet | 7.77 | 17.63 | 2.18 |
| ConvLSTM | 0.74 | 368.09 | 22.89 |
| PhyDNet | 3.09 | 302.69 | 49.46 |
| SmaAt-UNet | 3.16 | 9.77 | 5.43 |
| PredRNN | 0.45 | 670.96 | 69.49 |
| Rainformer | 185.67 | 56.25 | 35.35 |
| SwinNowcast | 104.13 | 42.82 | 43.25 |
| MSCBAM | GAFFU | Inception | GFU | CSI | HSS | FAR |
|---|---|---|---|---|---|---|
| × | × | ✓ | ✓ | 0.7395 | 0.3821 | 0.1579 |
| ✓ | × | × | × | 0.7320 | 0.3781 | 0.1640 |
| ✓ | × | × | ✓ | 0.7469 | 0.3857 | 0.1554 |
| × | ✓ | ✓ | × | 0.7491 | 0.3866 | 0.1577 |
| ✓ | ✓ | × | × | 0.7494 | 0.3868 | 0.1574 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Lu, Z.; Li, Y.; Liu, X. SwinNowcast: A Swin Transformer-Based Model for Radar-Based Precipitation Nowcasting. Remote Sens. 2025, 17, 1550. https://doi.org/10.3390/rs17091550
Li Z, Lu Z, Li Y, Liu X. SwinNowcast: A Swin Transformer-Based Model for Radar-Based Precipitation Nowcasting. Remote Sensing. 2025; 17(9):1550. https://doi.org/10.3390/rs17091550
Chicago/Turabian StyleLi, Zhuang, Zhenyu Lu, Yizhe Li, and Xuan Liu. 2025. "SwinNowcast: A Swin Transformer-Based Model for Radar-Based Precipitation Nowcasting" Remote Sensing 17, no. 9: 1550. https://doi.org/10.3390/rs17091550
APA StyleLi, Z., Lu, Z., Li, Y., & Liu, X. (2025). SwinNowcast: A Swin Transformer-Based Model for Radar-Based Precipitation Nowcasting. Remote Sensing, 17(9), 1550. https://doi.org/10.3390/rs17091550