1. Introduction
Hyperspectral imagery (HSI) captures reflectance values over a wide range of electromagnetic spectra for each pixel in the image. This rich spectral information allows for distinguishing or classifying materials with subtle differences in their reflectance signatures. HSI classification plays an important role in many remote-sensing applications, being a theme common to environmental mapping, crop analysis, plant and mineral exploration, and biological and chemical detection, among others [
1].
Over the last two decades, many machine learning techniques including artificial neural networks (ANNs) and support vector machines (SVMs) have been successfully applied to hyperspectral image classification (e.g., [
2–
5]). In particular, neural architectures have demonstrated great potential to model mixed pixels which result from low spatial resolution of hyperspectral cameras and multiple scattering [
3]. However, there are several limitations involved with ANNs that use the back-propagation algorithm, the most popular technique, as the learning algorithm. Neural network model development for hyperspectral data is a computationally expensive procedure since hyperspectral images typically are represented as three-dimensional cubes with hundreds of spectral channels [
6]. In addition, ANNs require a good deal of hyperparameter turning such as the number of hidden layers, the number of nodes in each layer, learning rate,
etc. In recent years, SVM-based approaches have been extensively used for hyperspectral image classification since SVMs have often been found to outperform traditional statistical and neural methods, such as the maximum likelihood and the multilayer perceptron neural network classifiers [
5]. Furthermore, SVMs have demonstrated excellent performance for classifying hyperspectral data when a relative low number of labeled training samples are available [
4,
5,
7]. However, the SVM parameters (
i.e., regularization and kernel parameters) have to be tuned for optimal classification performance.
Extreme learning machine (ELM) [
8] as an emerging learning technique belongs to the class of single-hidden layer feed-forward neural networks (SLFNs). Traditionally, a gradient-based method such as back-propagation algorithm is used to train such networks. ELM randomly generates the hidden node parameters and analytically determines the output weights instead of iterative tuning, which makes the learning extremely fast. ELM is not only computationally efficient but also tends to achieve similar or even better generalization performance than SVMs. However, ELM can produce a large variation in classification accuracy with the same number of hidden nodes due to the randomly assigned input weights and bias. In [
9], kernel extreme learning machine (KELM) which replaces the hidden layer of ELM with a kernel function was proposed to solve this problem. It is worth noting that the kernel function used in KELM does not need to satisfy Mercer’s theorem and KELM provides a unified solution to multiclass classification problems.
The utilization of ELM for hyperspectral image classification has been fairly limited in the literature. In [
10], ELM and optimally pruned ELM (OP-ELM) were applied to soybean variety classification in hyperspectral images. In [
11], ELM was used for land cover classification, which achieved comparable classification accuracies to a back-propagation neural network on two datasets considered. KELM was used in [
12] for multi- and hyperspectral remote-sensing images classification. The results indicate that KELM is similar to, or more accurate than, SVMs in terms of classification accuracy and offer notably low computational cost. However, in these works, ELM was employed as a pixel-wise classifier, which indicates that only the spectral signature has been exploited while ignoring the spatial information at neighboring locations. Yet, for HSI, it is highly probable that two adjacent pixels belong to the same class. Considering both spectral and spatial information has been verified to improve the HSI classification accuracy significantly [
13,
14]. There are two major categories utilizing spatial features: to extract some type of spatial features (e.g., texture, morphological profiles, and wavelet features), and to directly use pixels in a small neighborhood for joint classification assuming that these pixels usually share the same class membership. In the first category (feature dimensionality increased), Gabor features have been successfully used for hyperspectral image classification [
15–
18] recently due to the ability to represent useful spatial information. In [
15,
16], three-dimensional (3-D) Gabor filters were applied to hyperspectral images to extract 3-D Gabor features; in [
17,
18], two-dimensional (2-D) Gabor features were extracted in a principal component analysis (PCA)-projected subspace. In our previous work [
19], a preprocessing algorithm based on multihypothesis (MH) prediction was proposed to integrate spectral and spatial information for noise-robust hyperspectral image classification, which falls into the second category (feature dimensionality not increased). In addition, object-based-classification approaches (e.g., [
20–
22]) are important methods in spectral-spatial classification as well. These approaches group the spatially adjacent pixels into homogeneous objects and then perform classification on objects as the minimum processing unit [
20].
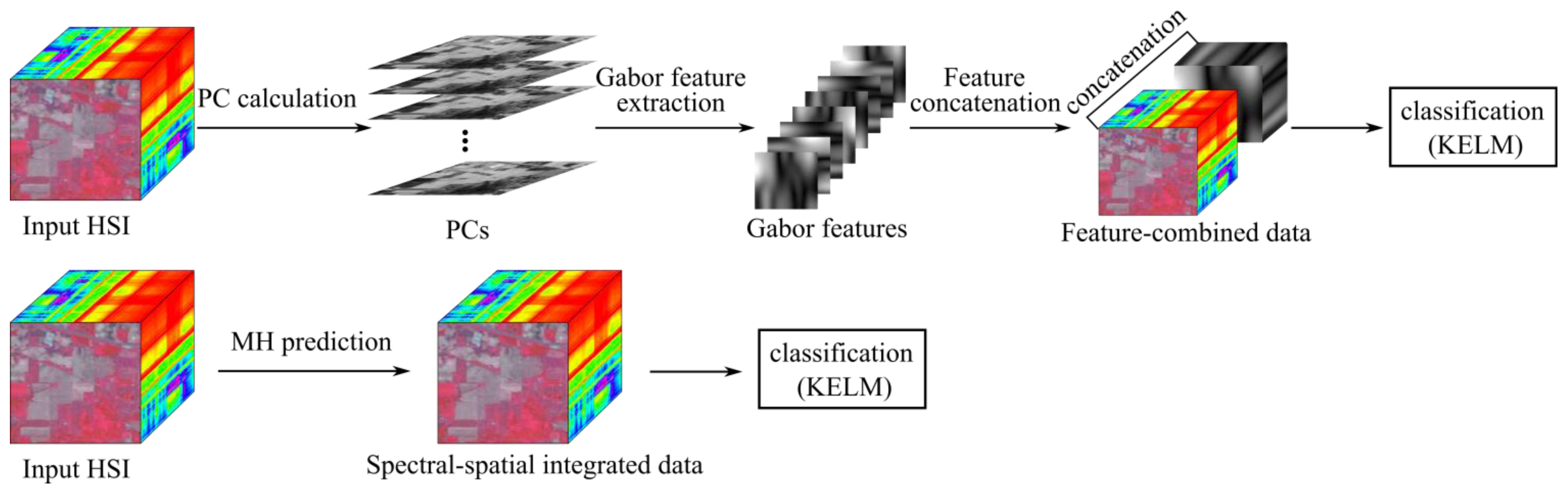
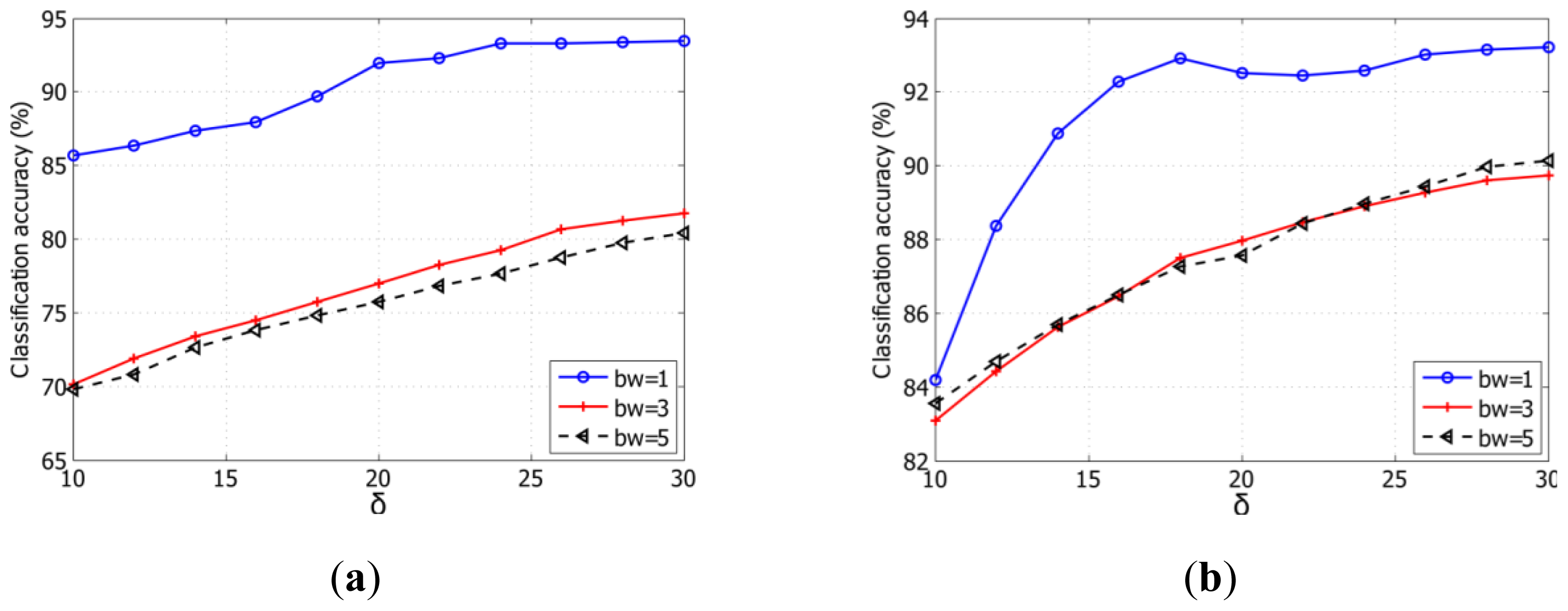
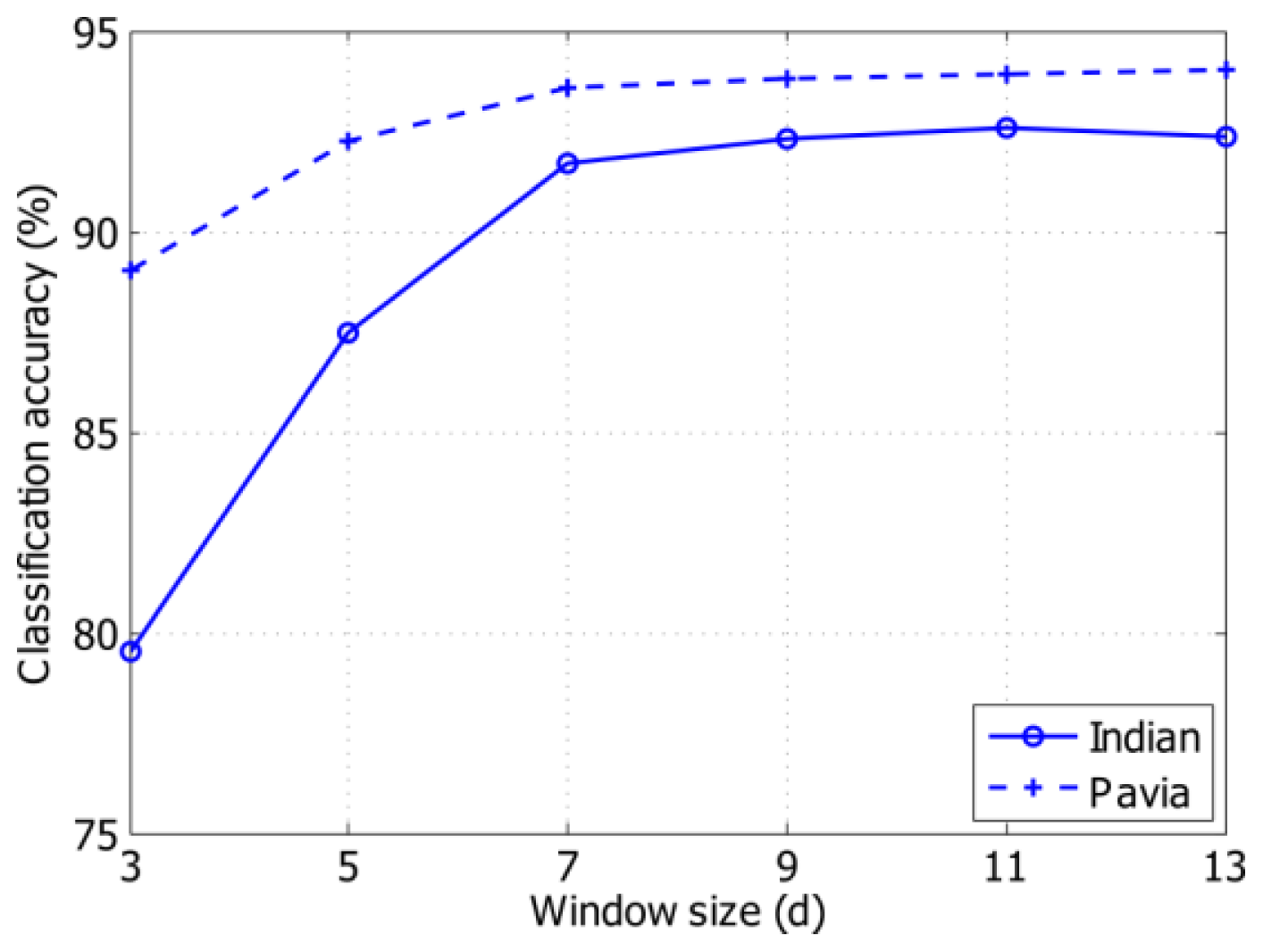
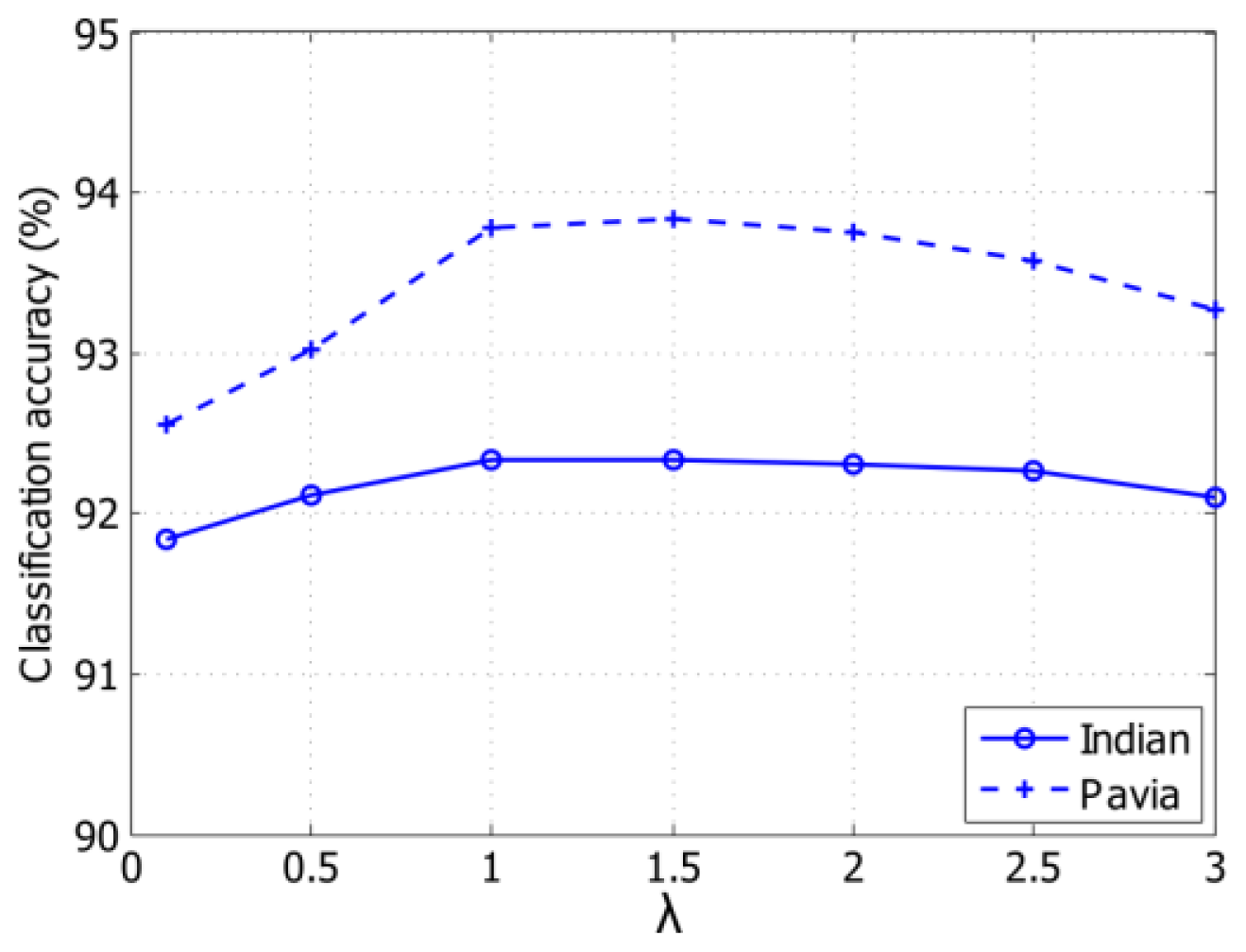
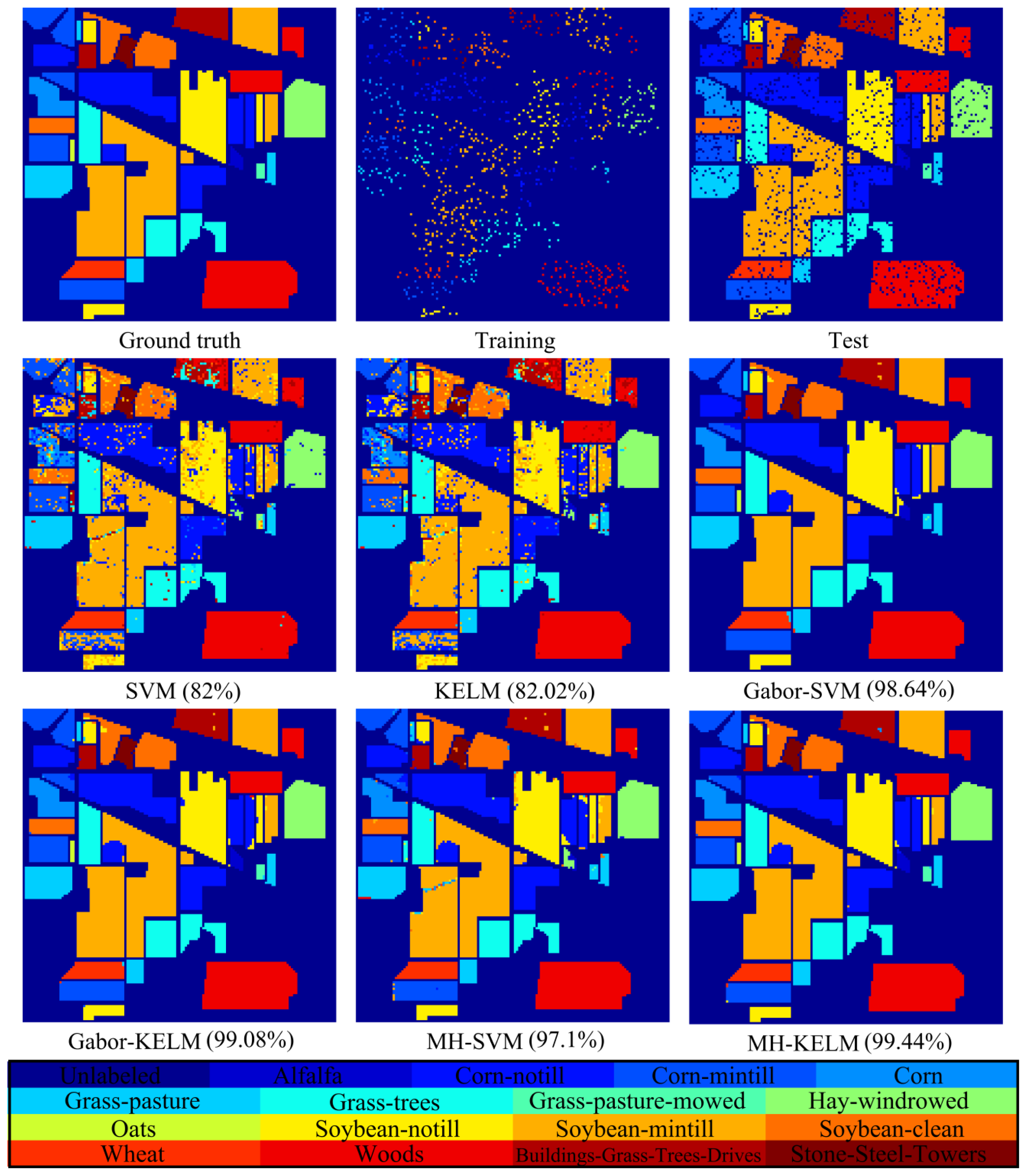
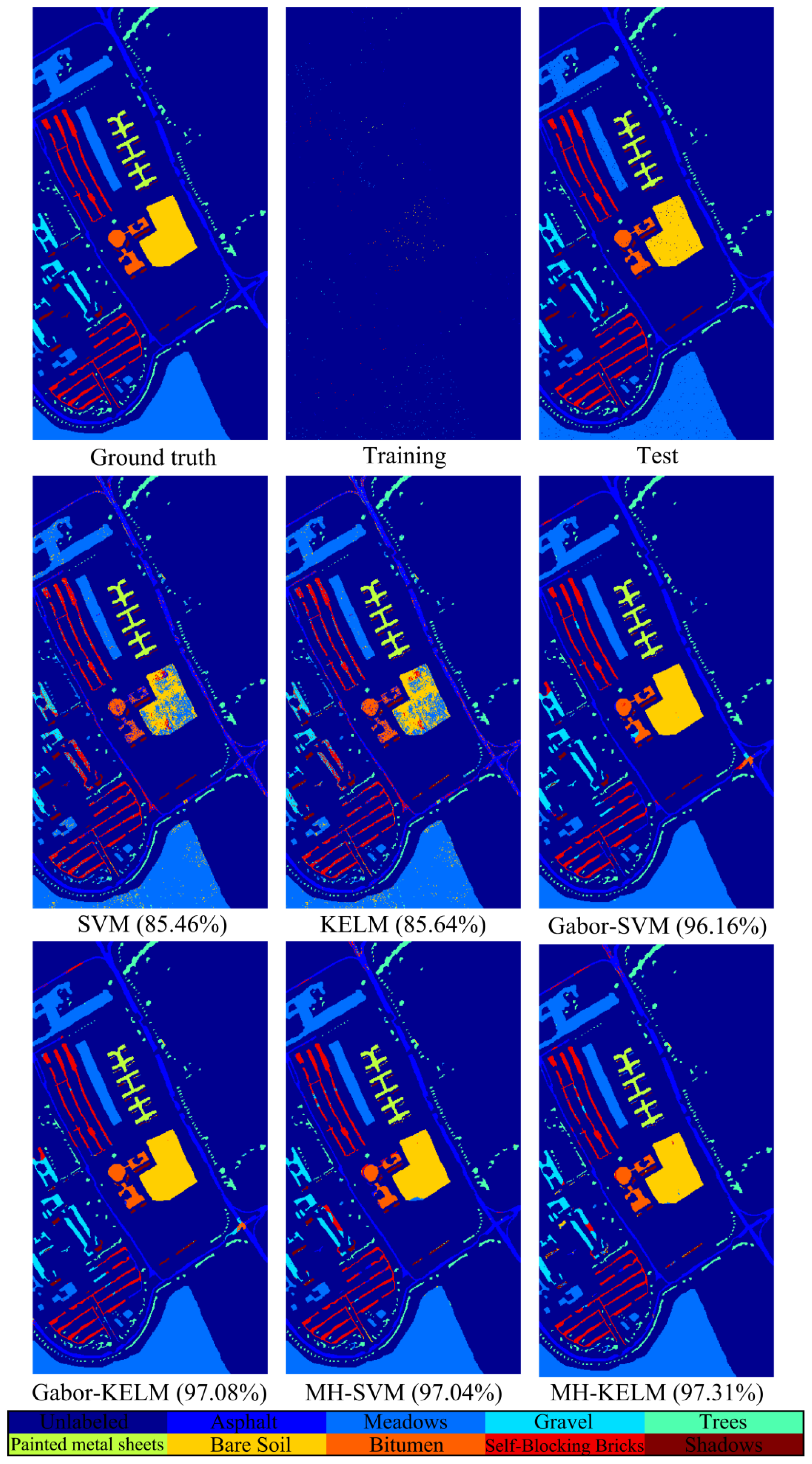
In this paper, we investigate the benefits of using spatial features (i.e., Gabor features and MH prediction) for KELM classifier under the small sample size (SSS) condition. Two real hyperspectral datasets will be employed to validate the proposed classification method. We will demonstrate that Gabor-filtering-based KELM and MH-prediction-based KELM yield superior classification performance over the conventional pixel-wise classifiers (e.g., SVM and KELM) as well as Gabor-filtering-based SVM and MH-prediction-based SVM in challenging small training sample size conditions. In addition, the proposed methods (i.e., KELM-based methods) are faster than the SVM-based methods since KELM runs at much faster learning and testing speed than the traditional SVM.
The remainder of this paper is organized as follows. Section 2 introduces the Gabor filter, MH prediction for spatial features extraction, KELM classifier, and our proposed methods. Section 3 presents the hyperspectral data and experimental setup as well as comparison of the proposed methods and some traditional techniques. Finally, Section 4 makes several concluding remarks.
4. Conclusions
In this paper, we proposed to integrate spectral and spatial information to improve the performance of KELM classifier by using Gabor features and MH prediction preprocessing. Specifically, a simple two-dimensional Gabor filter was implemented to extract spatial features in the PCA-projected domain. MH prediction preprocessing makes use of the spatial piecewise-continuous nature of hyperspectral imagery to integrate spectral and spatial information. The proposed classification techniques, i.e., Gabor-KELM and MH-KELM, have been compared with the conventional pixel-wise classifiers, such as SVM and KELM, as well as Gabor-SVM and MH-SVM, under the SSS condition for hyperspectral data. Experimental results have demonstrated that the proposed methods can outperform the conventional pixel-wise classifiers as well as Gabor-filtering-based SVM and MH-prediction-based SVM in challenging small training sample size conditions. Specifically, the proposed spectral-spatial classification methods achieved over 16% and 9% classification accuracy improvement over the pixel-wise classification methods for the Indian Pines dataset and the University of Pavia dataset, respectively. MH-KELM outperformed MH-SVM by about 5% for the Indian Pines dataset and Gabor-KELM outperformed Gabor-SVM by about 1.3% for the University of Pavia dataset at all training sample sizes. Moreover, KELM exhibits very fast training and testing speed, which is an important attribute for hyperspectral analysis applications. Although the proposed methods carry additional burden on spatial feature extraction, the computational cost can be reduced by parallel computing.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}