1. Introduction
Flooding is among one of the most destructive disasters which results in tremendous economic and human losses worldwide [
1,
2,
3,
4]. It is of great significance to map accurately the extent of inundated areas and the land cover types under water [
4,
5], which can assist in flood monitoring, relief works planning and damage assessment.
Due to its synoptic view and continuous coverage of flooding events, remote sensing has been recognized as a powerful and effective tool to provide inundation maps in near real time according to many researches [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]. Generally, remotely sensed data used for flood monitoring are mainly collected from radar and optical satellites. The advantage of radar remote sensing is that it enables data acquisition regardless of weather conditions and time of day [
7]. Space-borne sensors such as Synthetic Aperture Radar (SAR) [
8] are capable of penetrating the cloud, and can provide views of the extent of inundation even when thick clouds exist above the disaster-stricken areas [
1,
2,
6,
7,
8]. Brivio
et al. [
9] utilized visual interpretation and thresholding algorithms for multi-temporal ERS-1 (European Remote Sensing satellite) SAR data in the determination of inundated areas at the peak of the flood. Results showed that only 20% of the flooded areas were determined due to the time delay between the flood peak and the satellite overpass [
9]. To tackle this limitation, Brivio
et al. [
9] proposed a new procedure with the synthetic use of SAR data and digital topographic data from a Geographical Information System (GIS) technique and a high proportion, 96.7%, of the flooded areas was detected [
9].
Although optical sensors are unable to penetrate thick clouds which is a major drawback in flood monitoring, the images acquired under cloud free conditions can still be utilized to extract flooded areas with high accuracy [
10,
11,
12]. Besides, optical remote sensing can provide true color images which are much easier for visual interpretation than radar data. Widely used optical remote sensing data are mainly from Landsat series,
i.e., Thematic Mapper (TM), Enhanced Thematic Mapper Plus (ETM+), SPOT (Systeme Probatoire d’Observation de la Terre) series (
i.e., SPOT-4, SPOT-5), and Ikonos due to their ideal combination of spatial and temporal resolutions, easy access, and ease in data processing and analysis [
4]. Wang
et al. [
10] used medium resolution (30 m) TM images to delineate the maximum flood event caused by Hurricane Floyd in North Carolina. Animi [
11] proposed a model based on Artificial Neural Network to generate a floodplain map using high-resolution (1 m) Ikonos imagery and digital elevation model (DEM). Gianinetto
et al. [
12] utilized multisensor data (TM and SPOT-4) to map Hurricane Katrina’s widespread destruction in New Orleans and adopted a change detection method to extract the land cover types under water. Above all, optical remote sensing can also play an important role in flood mapping given cloud free conditions.
Nevertheless, mixed pixels are common in medium spatial resolution data such as TM and ETM+, and such pixels have been recognized as a problem for remote sensing applications [
13,
14,
15,
16,
17,
18,
19,
20]. In terms of flood monitoring using medium resolution data, flooded and non-flooded features may co-exist within one pixel, resulting in the challenge to extract these small and fragmented flooded patches especially under complex urban landscapes. To deal with the mixed pixel problem, several approaches such as linear spectral mixture analysis (LSMA) [
13], fuzzy-set possibilities [
14], and Bayesian possibilities [
15] have been developed to partition the proportions of each pixel between classes. Among these methods, LSMA appears to be the most promising and has been widely used to extract sub-pixel information with physical meaning [
13,
16,
17,
18,
19]. LSMA assumes that the reflectance of each pixel can be modeled as a linear combination of a few spectrally pure land cover components, known as endmembers [
13]. The aim of LSMA is to decompose a mixed pixel into the spectra of endmembers and estimate the fractional abundance of each endmember within a pixel. However, LSMA uses an invariant set of endmembers to model the entire landscape while the spectrum of each endmember is assumed to be constant across the image scene [
20,
21,
22,
23]. It neglects the fact that the same material may have different spectral curves, which cannot account for within-class spectral variability. As an extension of LSMA, multiple endmember spectral mixture analysis (MESMA) allows the type and number of endmembers to vary for each pixel, which takes into account the spectral and spatial variability of the real complex landscapes [
20,
21,
22,
23,
24,
25,
26,
27]. MESMA has been used in remote sensing fields especially in urban vegetation mapping [
20,
21,
22,
23,
24,
25,
26,
27], but to our knowledge, it has been rarely used in flood monitoring. Thus, this study aims to justify the performance of MESMA in extracting flooded areas from medium resolution remote sensing data.
Given the fact that most LSMA and MESMA applications have focused on the extraction of fractional information rather than thematic land cover types [
21,
22,
23,
24,
25,
26,
27], this study attempted to introduce an image classifier, Random Forest (RF) [
28], to classify the fraction maps generated from MESMA into different land cover categories. In general, Random Forest classifier has several advantages over other classification methods [
29,
30,
31,
32,
33,
34,
35,
36,
37,
38]. It is easy to parameterize, it is non-sensitive to over-fitting and is good at dealing with outliers in the training data [
29]. When compared to statistical methods such as the maximum likelihood classifier (MLC), Random Forest requires no assumptions of data distribution [
29], which can improve the classification performance. When compared to other machine learning methods such as support vector machine (SVM), RF has the advantage of easier parameterization and better generalization capability [
30]. The successful use of SVM depends on several experiments to search for the optimal combination of kernel function type, punishment coefficient, and the kernel parameter Gamma [
30]. However, the parameterization of SVM can be time consuming and cannot match that of RF. Meanwhile, RF has shown similar or even higher classification accuracy than SVM according to several studies [
29,
30]. RF has been widely used in remote sensing fields due to the above advantages. Rodriguez-Galiano
et al. [
32] utilized Random Forest for the Mediterranean land cover classification using multi-seasonal imagery and multi-seasonal texture, and the results indicated a high Kappa index of 0.92. Feng
et al. [
29] adopted Random Forest and texture analysis for urban vegetation mapping using high resolution UAV images and the results also showed a high classification accuracy of 90.6%. However, the usage of Random Forest in flood mapping has not been well documented and we are motivated to justify its performance in this study.
Overall, the main objective of this study is to propose a hybrid method based on MESMA and RF classifier for flood mapping using medium resolution optical satellite data. Specifically, this paper aims to (i) extend the application of MESMA to the field of flood mapping and verify its performance; (ii) justify whether Random Forest classifier can show good performance in flood mapping; (iii) discuss the merits and demerits of the proposed method based on the comparison with other state of art studies.
2. Study Area and Datasets
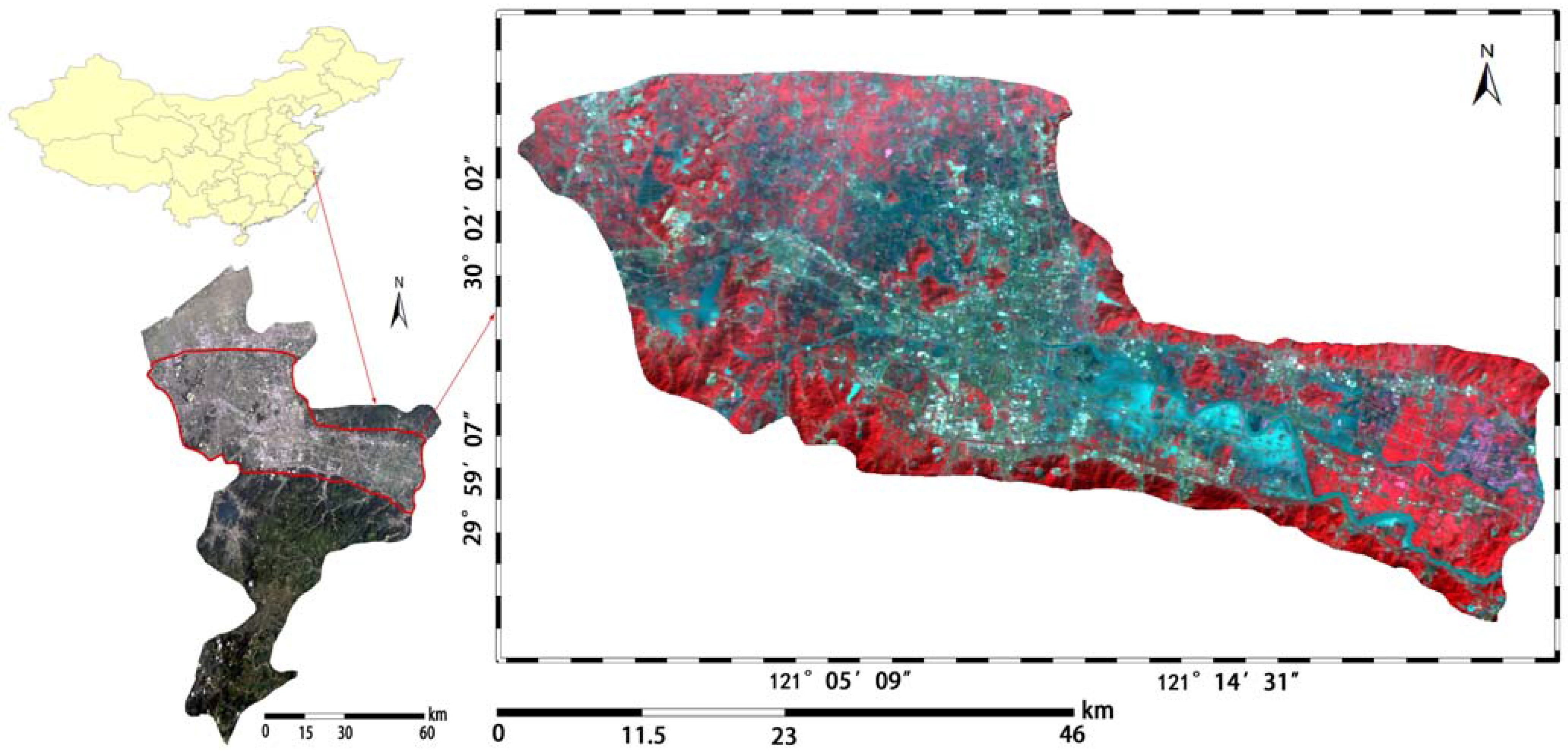
The study area is Yuyao City in Zhejiang Province in eastern China (
Figure 1), which is located at the south shore of Hangzhou Bay whose coordinates are 29°–30°N, 120°–121°E. Yuyao City is located in a relatively open and flat plain while the Yuyao River flows through the middle of the whole city from west to east. The study region has a total area of 521.2 km
2 with an elevation range of 1 to 331 m and a slope range of 0° to 39.4°. The main land cover types include woodland (e.g., broad-leaved forest and coniferous forest), cropland (e.g., paddy rice, oilseed rape, leaf mustard), built up area (e.g., urban and suburban regions), bare soil (e.g., non-vegetated bare ground) and water (e.g., rivers, lakes, and reservoirs). Besides, the study area has an annual temperature of 16.2 °C and an average annual precipitation of 1547 mm. There is a typhoon season between May and October with an average precipitation of 5.5 mm/day in the last 60 years. Influenced by Typhoon Fitow, Yuyao experienced extreme precipitation on 7 October 2013, which led to the most serious floods in the last 60 years [
30]. Typhoon Fitow brought about an accumulated rainfall of 496.4 mm in three days and the mean precipitation is about 165.5 mm/day. Most downtown areas were inundated for more than 5 days while about 833 thousand people were impacted by the disaster and the direct economic losses were more than 69.61 billion RMB (about 11.33 billion USD).
Figure 1.
Study area. Red-Green-Blue composition: near-infrared, red and green bands of the multispectral charge coupled device camera (HJ-CCD) after the flood.
Figure 1.
Study area. Red-Green-Blue composition: near-infrared, red and green bands of the multispectral charge coupled device camera (HJ-CCD) after the flood.
Remote sensing data used in this study were acquired by HJ-1B satellite of China on 11 October 2013. HJ-1B belongs to a small satellite constellation (HJ-1A/1B), was launched in September 2008 and is targeted for rapid mapping and monitoring of natural hazards and disasters [
39]. Sensors on board HJ-1B consist of a multispectral charge coupled device camera (HJ-CCD) and an infrared camera (HJ-IRS) which have similar wavelengths to that of Landsat TM. The revisit time is four days which can meet the requirements of dynamically monitoring the flood events. The basic parameters of HJ-1B data can be viewed in
Table 1.
Table 1.
Parameters of HJ-1B data.
Table 1.
Parameters of HJ-1B data.
| Sensor | Band | Wavelength/μm | Spatial Resolution/m | Image Breadth/km |
|---|
| CCD | 1 | 0.43–0.52 | 30 | |
| | 2 | 0.52–0.60 | 30 | 360 |
| | 3 | 0.63–0.69 | 30 | |
| | 4 | 0.76–0.90 | 30 | |
| IRS | 5 | 0.75–1.10 | 150 | |
| | 6 | 1.55–1.75 | 150 | 720 |
| | 7 | 3.50–3.90 | 150 | |
| | 8 | 10.5–12.5 | 300 | |
Since Band-4 and Band-5 have similar wavelengths, we only utilized Band-4 in the analysis due to its higher spatial resolution. Besides, the data quality of Band-7 is quite low due to severe stripe noises and Band-8 belongs to a thermal infrared band; they were discarded in the following research. Thus, we only focused on the visible, near-infrared and short wave infrared wavelengths and Band-1–4 and Band-6 were selected for further analysis.
5. Discussion
Experimental results demonstrated that both the flood map and pre-flood land cover map can be derived accurately from the proposed method, which provides reliable and valuable information for flood management and hazard assessment. The advantage of the proposed method lies in the integration of MESMA and RF classifier. Specifically, due to its capability to account for the spectral and spatial variability of complex landscapes [
21], the adoption of MESMA can tackle the mixed pixel problem of flood mapping when using medium resolution remote sensing data. In previous studies [
20,
21,
22,
23,
24,
25,
26,
27], MESMA was successfully utilized in several application fields, such as mapping vegetation types under complex urban environment [
21], mapping burn severity in Mediterranean countries from moderate resolution satellite data [
22], and mapping urban land cover types using HyMap hyperspectral data [
26],
etc. This study introduced MESMA into the field of flood mapping, which broadens its range of application and provides a new clue on deriving inundated areas accurately from medium resolution data. Besides, the adoption of the robust and efficient RF classifier also contributes to the high performance of this research. In previous studies of flood mapping [
8], statistical classifier such as MLC was widely used. However, MLC is inferior to RF classifier according to several studies [
29,
30,
31], therefore, we introduced RF classifier to improve the classification accuracy in the field of flood mapping.
Meanwhile, it is necessary to compare with other literature on flood mapping to further verify the performance of the proposed approach. These state of art studies include water index (WI) [
44,
45], linear spectral mixture analysis [
47], artificial neural network (ANN) [
11] and object based image analysis (OBIA) [
8]. To begin with, water index (e.g., NDWI) has been widely used for the detection of open surface water and inundated areas. The advantage of the water index lies in its simplicity and practicality, which can enhance open water features and suppress built up, vegetation and soil noise at the same time [
44]. Memon
et al. (2012) [
48] used three water indexes for delineating and mapping of surface water using MODIS (Terra) near real time images during the 2012 floods in Pakistan. The three water indexes included NDWI, Red and Short Wave Infra-Red (RSWIR) water index [
49] and Green and Short Wave Infra-Red (GSWIR) water index [
50]. Experimental results indicated the accuracy of NDWI, RSWIR, and GSWIR was 73.12%, 85.80%, and 81.54%, respectively, which was lower than the proposed MESMA+RF approach (94%). This was mainly due to the fact that the vegetation has relatively high reflectance in the NIR region, so the water indexes could not take water under vegetation into account [
48]. Therefore, the co-existence of flooded water and vegetation within one pixel would lead to the underestimation of flooded areas when using water indexes. However, MESMA can derive the sub-pixel water information from the mixed pixels, which accounts for a higher accuracy than with the water index thresholding methods.
Juan
et al. (2012) [
47] utilized linear spectral mixture analysis as part of the proposed sub-pixel analysis methodology to identify flooded areas from MODIS remote sensing data. The proposed methodology was demonstrated to be effective for mapping the flood extent with an accuracy of 80% [
47]. However, the proposed approach of our paper outperformed that of Juan
et al. One possible reason lies in that Juan
et al. only adopted the LSMA model, which used an invariant set of endmembers (water, vegetation,
etc.) to model the complex flooded landscape and could not account for the within-class variance [
21]. On the other hand, MESMA allowed the type and number of endmembers to vary on each pixel [
22], which could yield more accurate fractional information than LSMA.
Artificial neural network was employed in Amini’s study (2010) [
11] to classify the high-resolution Ikonos image to determine the inundated classes after flooding. A multi-layer perceptron neural network was chosen due to its ability to implement nonlinear decision functions and the fact that no prior conjectures needed to be made for the input data [
11]. Results showed that the utilization of ANN achieved an accuracy of 70% and outperformed MLC with an accuracy increase of 15% [
11]. Meanwhile, the proposed MESMA+RF method outperformed that of Amini. One possible interpretation is that ANN has the drawback of a low generalization capability due to over-fitting of the training data, which leads to the decline of performance in predicting new datasets. However, RF uses a bootstrap strategy to generate independent training samples to tackle the problem of over-fitting, which accounts for the higher accuracy when compared with ANN.
In addition, as one important method in remote sensing image classification, object based image analysis has also been applied in detecting inundated areas. Mallinis
et al. (2013) [
8] utilized Geographic Object-Based Image Analysis (GEOBIA) and Landsat TM data for flood area delineation. Results indicated that the proposed GEOBIA based method showed high performance and attained an overall accuracy of 92.67% in inundated-areas detection [
8]. The advantage of OBIA in flood mapping is the ability to incorporate semantic knowledge in the classification process, thus restricting limitations resulting from imagery characteristics and temporal availability [
8]. The RF classifier used in this paper is a pixel-based method, although it has a similar accuracy to that of OBIA, it may still cause a “salt and pepper” effect in the classification results. Therefore, future study should be focused on incorporating OBIA into the RF classifier to further increase the accuracy of flood mapping.
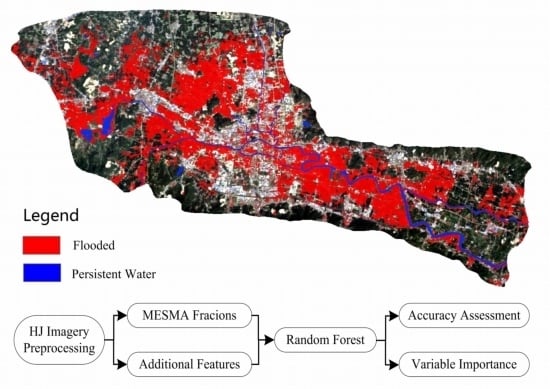
Although the above discussion verifies the high performance of the proposed approach of the study, there are still some limitations which can be stated as follows. First, the optical sensor’s inability to penetrate the canopies of forests can cause the underestimation of flooded areas in the woodland region. The fact that only 0.075 km
2 of woodland was detected as flooded in this study supported this point of view. This is in accordance with Wang’s study [
10], which found that scattered “holes” or “islands” exited in the submerged forest areas. To tackle this issue, radar data should be incorporated and future study should focus on the fusion of multi-sensor (optical and radar) data to increase flood mapping accuracy. Second, the underestimation of flooded areas in the built up regions was also a problem. This is due to the fact that some submerged roads are too narrow to be detected in the medium resolution HJ data (30 m). The buildings adjacent to the submerged roads usually have a very high reflectance and will cover the signal of the flooded roads within one pixel. Although MESMA can tackle the mixed pixel problem to some degree, however, high resolution remote sensing data should be used in order to generate more accurate flood maps in built up areas such as city blocks and factories.
Meanwhile, the proposed MESMA+RF method can be extended to other remote sensing applications such as the extraction of imperious surface from medium resolution satellite data and land cover mapping using airborne hyperspectral remote sensing data.
6. Conclusions
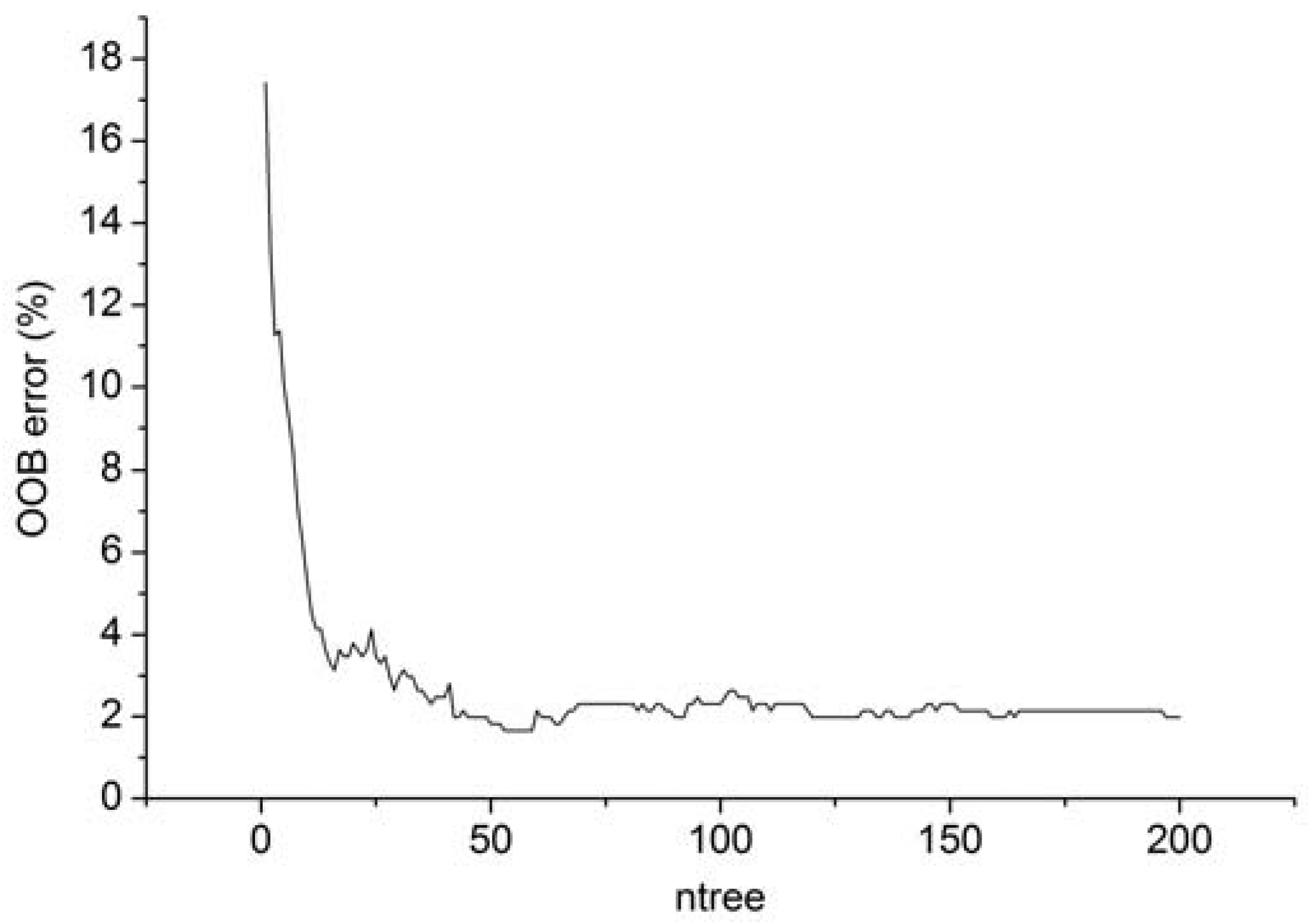
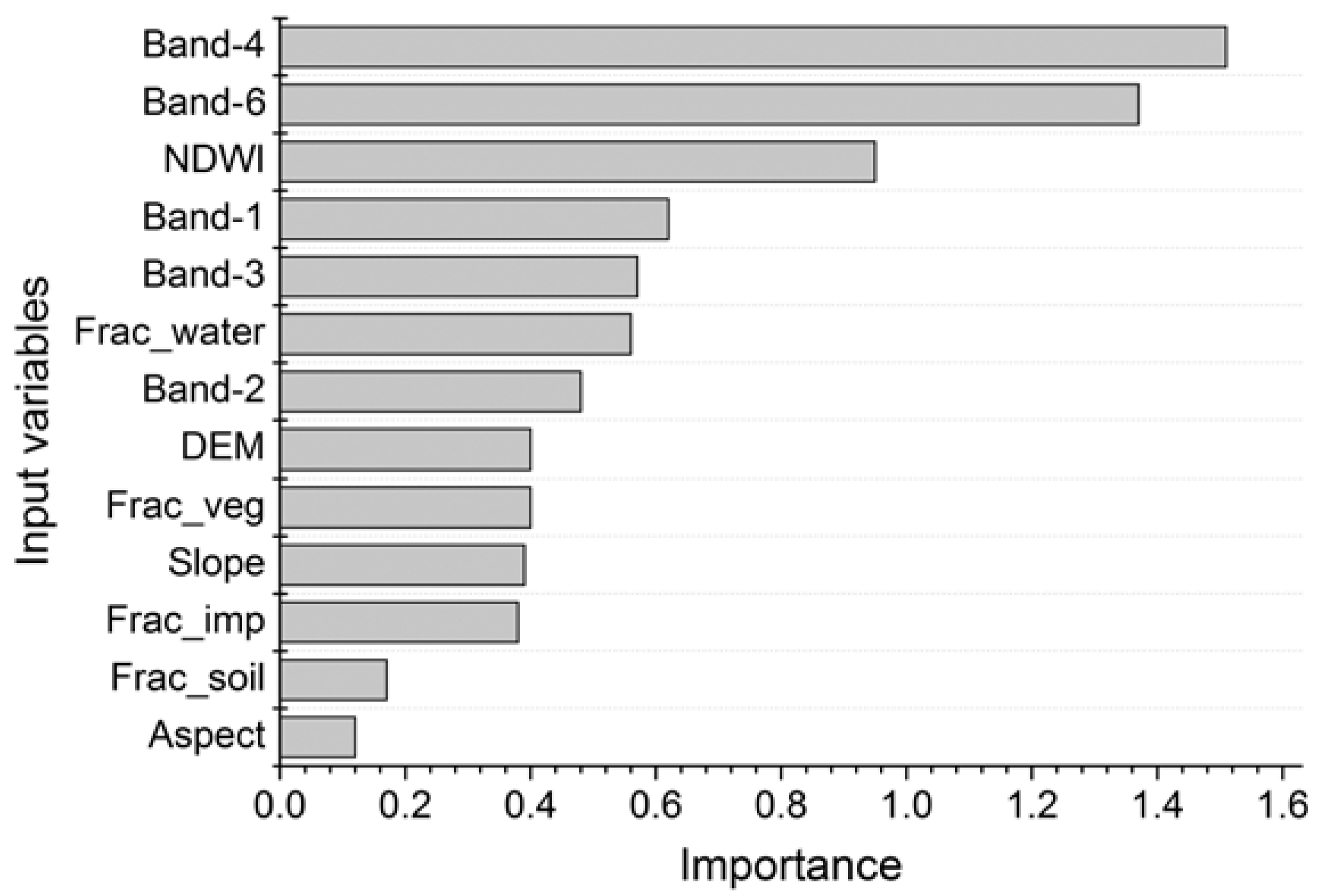
This paper proposed a hybrid method for flood mapping using medium resolution optical remote sensing data based on multiple endmember spectral mixture analysis and Random Forest classifier. A spectral library was first established using four image endmembers, including water, vegetation, impervious surface, and soil. A total of 35 optimal endmembers were selected and 3111 SMA models were constructed for each pixel to derive the fractional information. In order to increase the separability between different land cover types, the original reflectance bands, NDWI, DEM, slope, and aspect together with the fraction maps derived through MESMA were combined to construct the multi-dimensional feature space. A Random Forest classifier consisting of 200 decision trees was utilized to extract the inundated areas of Yuyao City, China. Experimental results indicated that the proposed hybrid method showed good performance with an overall accuracy of 94% and a Kappa index of 0.88. The inclusion of fractions from MESMA can improve the classification accuracy with an increase of 2.5%. Comparison experiments with other methods including maximum likelihood classifier and NDWI thresholding verified the effectiveness of the proposed method.
Above all, the hybrid method of this paper can extract inundated areas accurately using medium resolution multispectral optical data. Meanwhile, the proposed method can be expanded to the field of hyperspectral image analysis. Future studies should include more study cases to further verify the role of MESMA in the improvement of classification accuracy. A statistical sampling method should also be considered to further increase the reliability of the results of the accuracy assessment. Additionally, multi-sensor and high resolution remote sensing data are required to increase flood mapping accuracy.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







