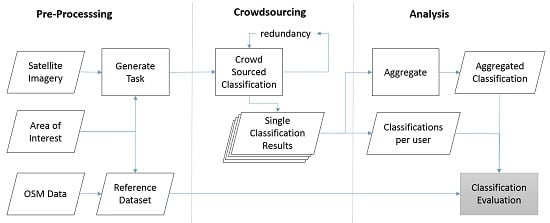
The results of the case study performed on crowdsourced classifications in the context of the Mapping South Kivu projects are presented in this section in two parts. First, an overall classification of the results is described in the next section (
Section 4.1), followed by a detailed analysis of the factors influencing the crowdsourced classification performance (
Section 4.2), and then the predictive analysis of the classification results (
Section 4.3).
4.1. Overall Classification Performance
The overall classifications results are summarised in
Table 6. In total, 35,560 classifications were performed by 539 volunteers. The majority of the contributions (23,192) are “no” classifications, whilst 8368 classifications are labelled as “yes”.
As shown in
Table 7, whilst the different aggregation methods show only little variations regarding accuracy, they differ considerably regarding sensitivity and precision. As expressed by the F1 score, the best compromise between sensitivity and precision is reached using aggregation method (3) majority, tie is “yes”. Applying this method, we reach an accuracy of 89%, a sensitivity of 73% and a precision of 89%. Aggregation methods (1) and (2) show very good results regarding precision, but very low values for sensitivity. Aggregation method (4) shows the opposite characteristics.
On average, each user contributed 66 classifications, and the median is around 21.
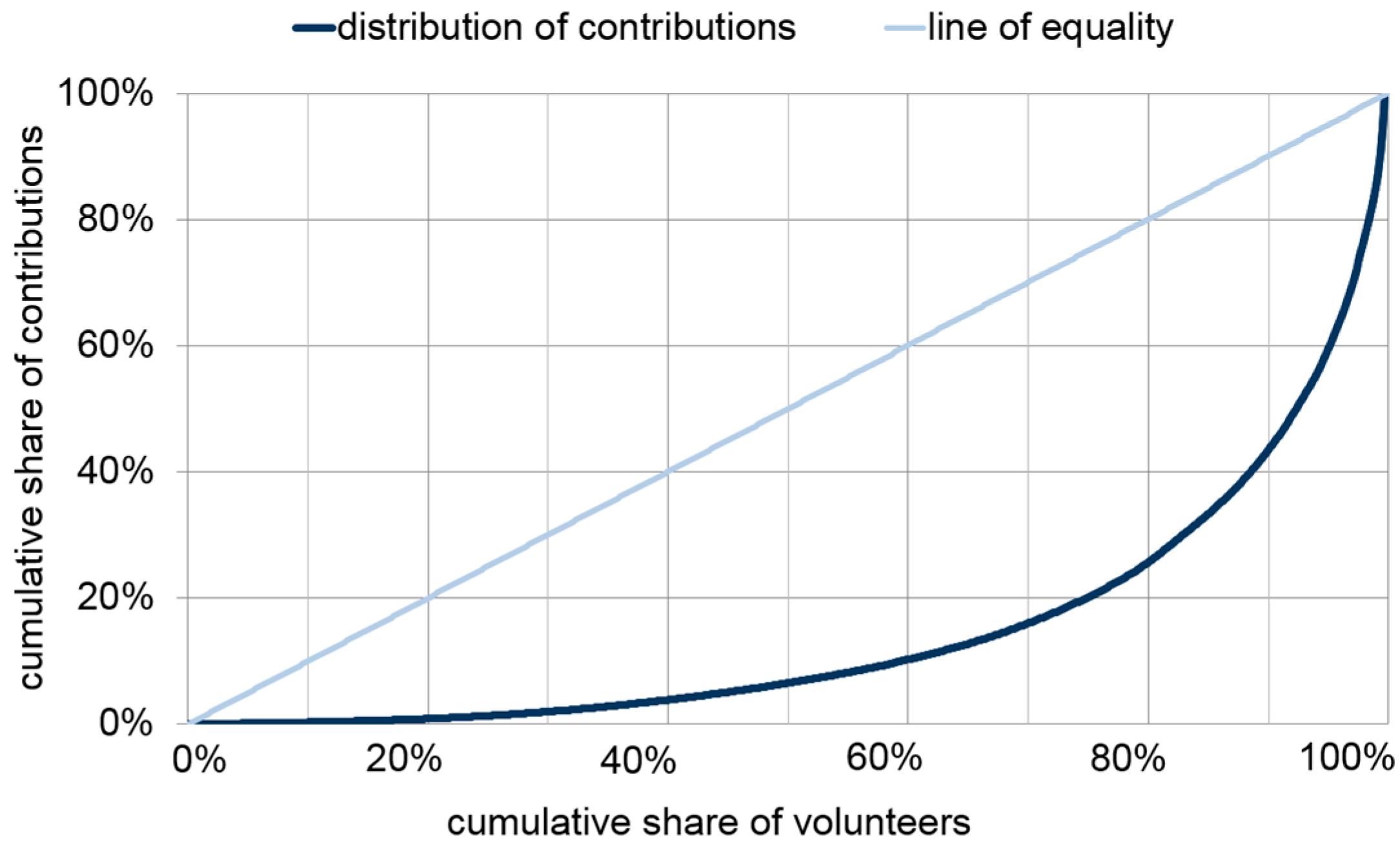
Figure 6 presents the degree of inequality of contributions per user. The diagram illustrates that around 75% of the volunteers contributed only 20% of the classifications, whilst 25% of the volunteers contributed 80% of the classifications.
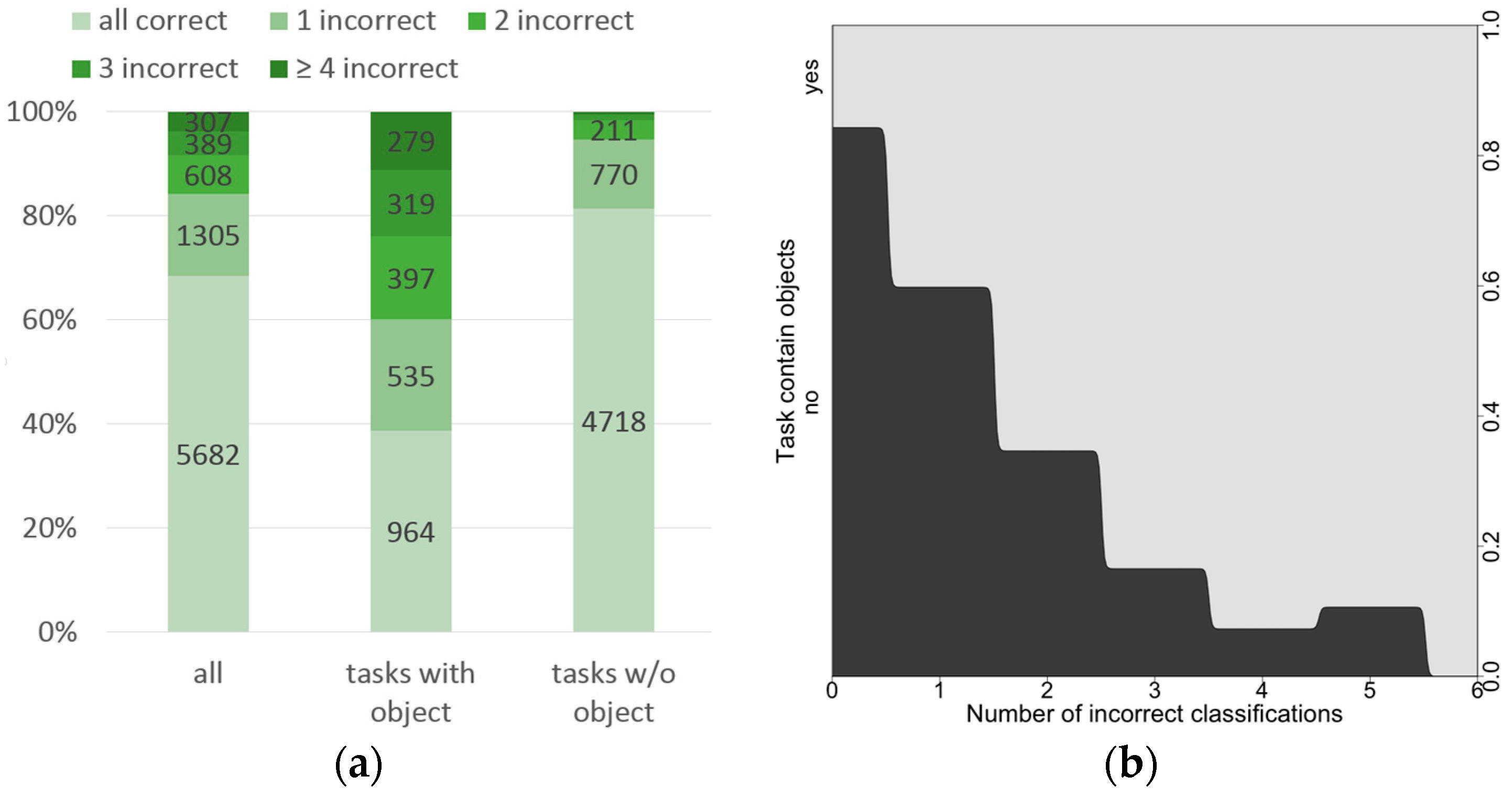
Figure 7a shows the distribution of all classifications per task for all tasks, for tasks with objects and for tasks without objects. Using the number of incorrect classifications as a proxy for the task difficulty, we can see that about 69% of all tasks can be considered as “easy cases” (all crowdsourced classifications were correct), 28% as “medium cases” (1 to 3 incorrect classifications) and only 4% as “difficult cases” (four or more classifications were incorrect). About 12% of all tasks with objects are “difficult cases”, whilst this is the case only in less than 0.5% of all tasks without objects. Thus, tasks that contain geographic objects are more difficult than tasks without objects and thus more incorrectly classified by volunteers. This is clearly confirmed by the condition plot of
Figure 7b. A considerable amount of volunteers appears to have missed roads or settlements, thus incorrectly classifying tasks that have such features. However, tasks without objects (e.g., forests) are mostly classified correctly, suggesting that volunteers tend to not mistake other image elements for buildings or roads.
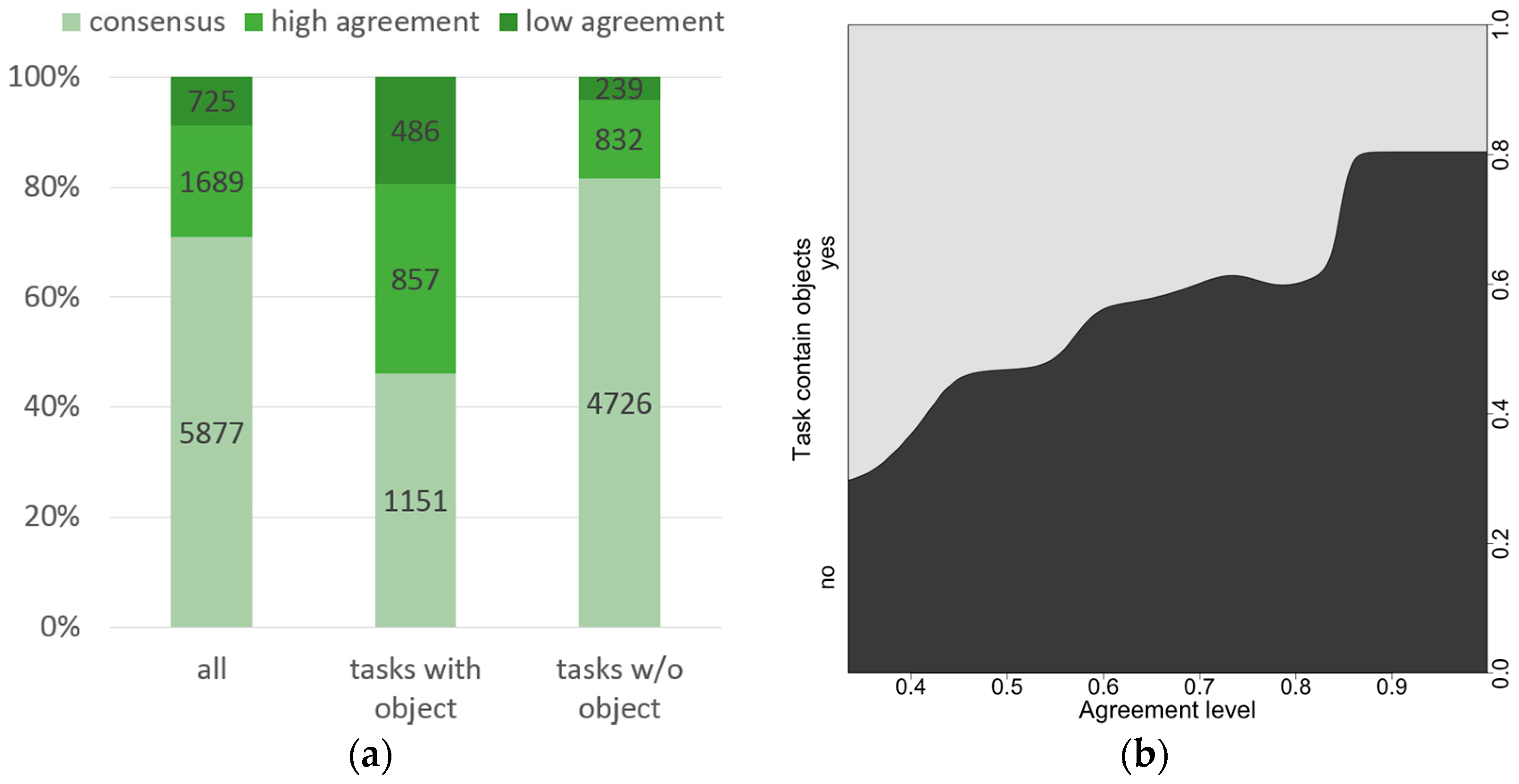
In order to further explore this distinction between tasks with and without objects,
Figure 8 shows the distribution of tasks concerning different user agreement levels. Tasks with objects have an above-average proportion of cases where there was a low agreement in the classifications of volunteers. In contrast, tasks without object tend to have more consensual cases. Assuming that disagreement is also connected to tasks that are more difficult to analyse, it seems these are happening more frequently in tasks that contain objects.
Moreover, the level of agreement in the classification of the volunteers and the possible influence on the performance of the classification was investigated.
Table 8 presents the results of the comparison for the different levels of agreement (“consensus”, “high”, and “low”) and the respective statistical measures. In tasks for which all volunteers came to the same classification result (consensus), the performance achieved was clearly superior according to all metrics. The same pattern can be seen comparing tasks with high level of agreement with tasks with a low level of agreement. In
Figure 9, the violin plot clearly shows that the distributions of tasks incorrectly classified tend to have lower levels of agreement in comparison with tasks that were correctly classified.
The results of this overall analysis show that the volunteers achieved a reasonable performance in general. However, there are big differences between tasks with and without objects and varying levels of task difficulty, as indicated both by the number of incorrect classifications and by the agreement level between volunteers. We thus further investigate geographic factors that may influence the performance of crowdsourced classifications in the next section.
4.2. Geographic Factors that Influence Crowdsourced Classification Performance
In this section, we analyse the influence of geographic factors on classification performance. The analysis is divided into two parts. First, the impact of road length and settlement area on the number of false negatives per task are investigated. In the second part, we focus on the influence of waterways on the number of false positives per task.
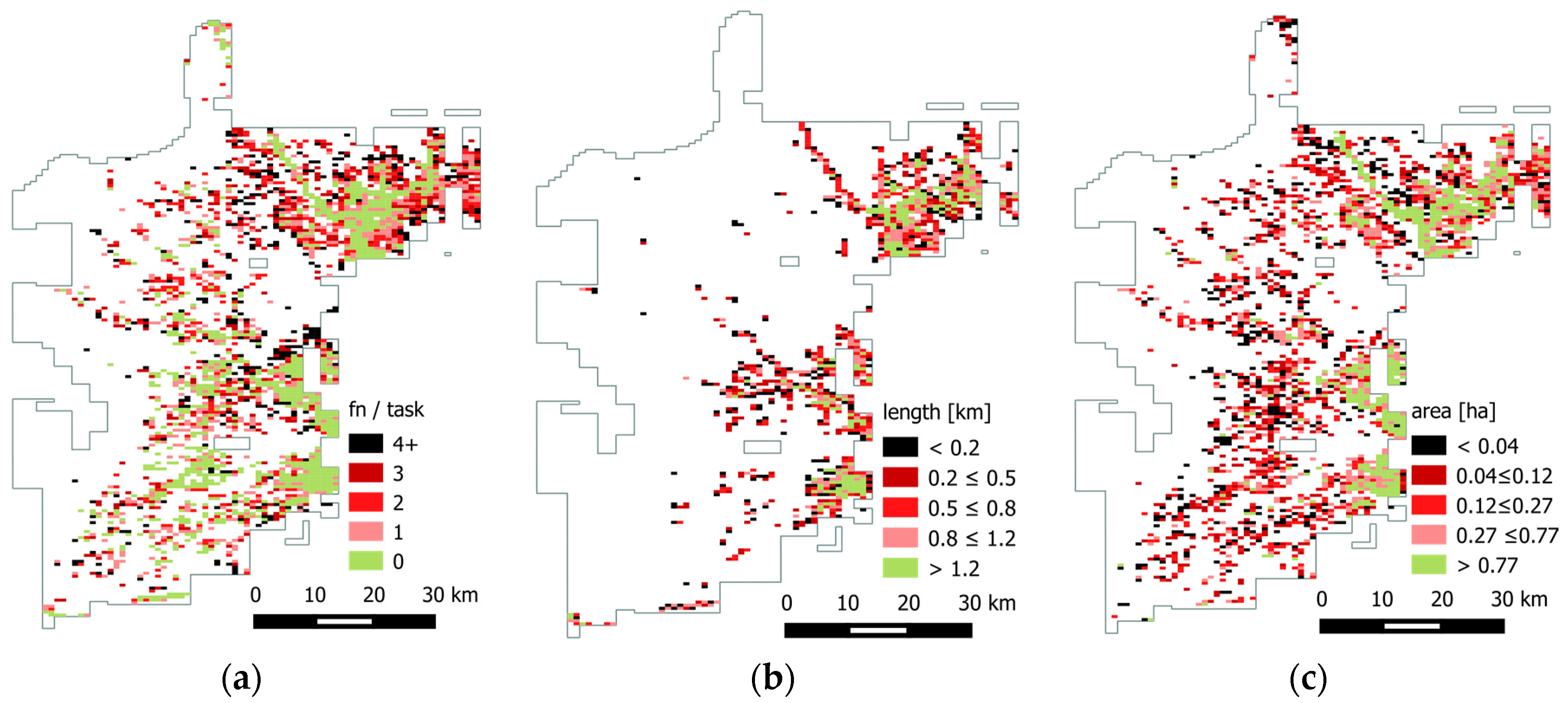
Figure 10a provides an overview of the spatial distribution of all tasks with objects and the corresponding number of incorrect classifications per task, which is used here as a proxy for task difficulty. Green areas indicate regions that were classified correctly, in accordance with the reference data. Dark red and black areas mark tasks with a high level of difficulty, the “hard cases”.
Figure 10b maps the distribution of the road length in each task. Dark red and black tasks indicate shorter roads (which are supposedly more difficult to detect), whilst lighter colours indicate longer and more visible roads. The same scheme is applied in the settlement area map of
Figure 10c. A visual inspection of the maps may suggest that easy tasks tend to be associated with longer roads and larger settlements (green regions). This is especially apparent for the settled areas along the eastern border of the area of interest.
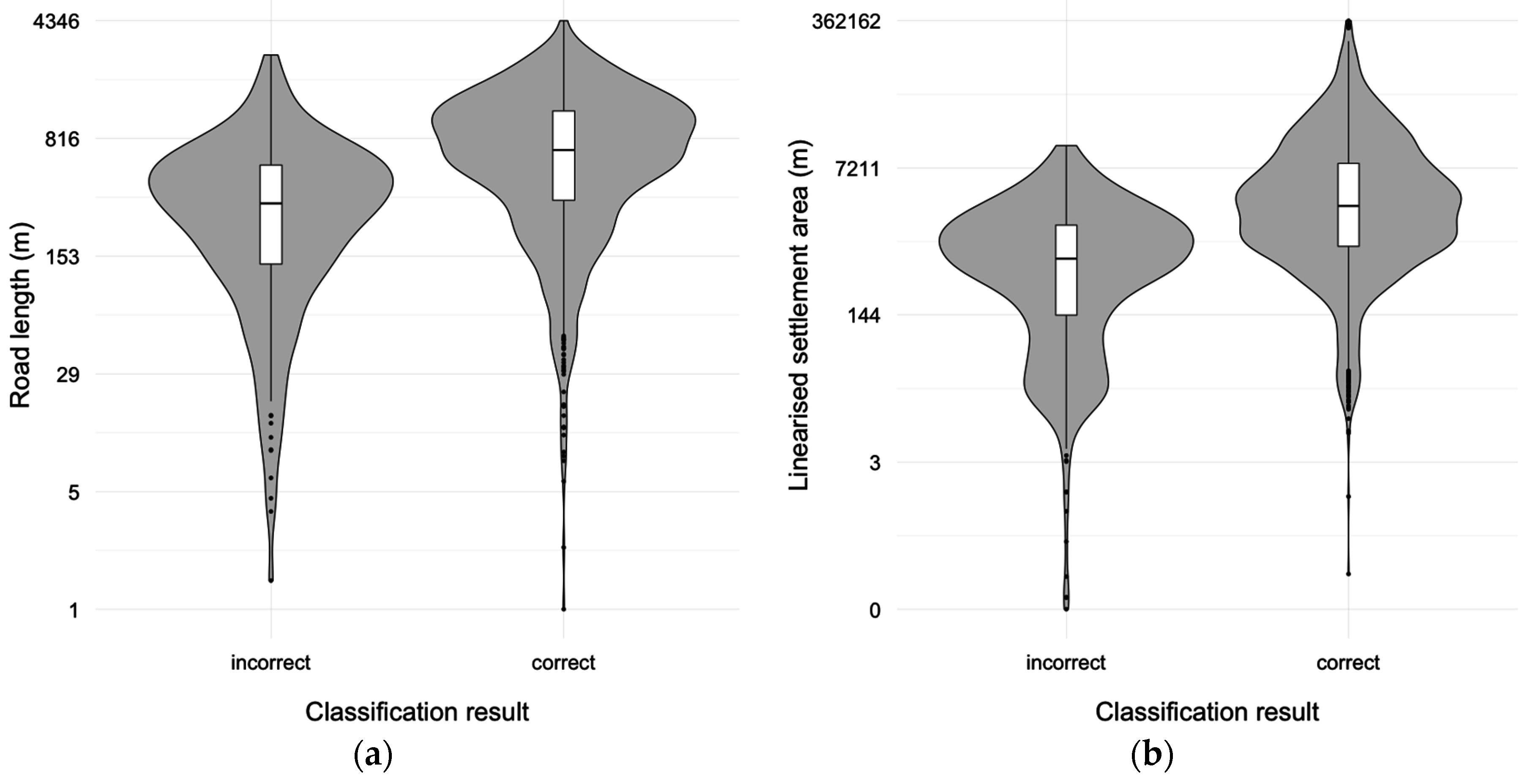
The violin plots of
Figure 11 seem to confirm slightly different distributions for tasks classified correctly or incorrectly by volunteers as regards to road length (
Figure 11a), and settlement area (
Figure 11b). Tasks classified correctly in the aggregated results tend to show higher values for road length and settlement area in comparison with incorrectly classified tasks. Furthermore, an application of the Wilcoxon–Mann–Whitney test supports the alternative hypothesis that the distributions of road length and settlement area for correctly classified tasks in comparison with incorrectly classified ones (length: W = 3,605,300,
p < 0.0005; area: W = 4,407,000,
p < 0.0005). This suggests that the most difficult tasks for volunteers tend to contain smaller roads and smaller settlements.
The results seem to indicate that different task difficulties are associated with different characteristics of geographic features such as road length and settlement area. We thus performed a qualitative analysis of common errors related to these groups. As follows, we present detailed information for the “difficult cases” and general information on the “medium” and “easy” cases.
In our dataset, 279 tasks containing objects could not be correctly classified by a single user. This was mostly due to “difficult cases” that contain very small features that are more likely to be missed. Especially small buildings that show a low contrast compared to their surrounding were often not identified by volunteers. In areas covered by dense forest, small settlements appear as bright spots in the imagery. Nevertheless, these spots are often misinterpreted as clearings in the forest. Since these settlements usually contain only a few buildings it is not possible to use the spatial collocation as an additional criterion (
Figure 12a). This problem becomes even more apparent for roads (
Figure 12b). Apart from the given conditions on the ground, the quality of satellite imagery provided in a task can also constitute an influencing factor for task difficulty. Partial cloud coverage as presented in
Figure 12c or poor imagery quality can easily cause volunteers to miss features. These limitations apply to all crowdsourced tasks that rely on satellite imagery. The last factor we observed in the case study is related to the design of the crowdsourcing task. The presented micro-tasking classification approach causes the overall task to be split into smaller subtasks. As a result, settlements and roads might be cut into smaller parts or only partially displayed (
Figure 12d). This can cause buildings or roads to be difficult to identify as the overall context is not visible in the single task given to the volunteer. Moreover, features that appear at the edge of the task geometry can be more easily missed.
In our qualitative analysis, another geographic feature emerged as possibly associated with incorrect classifications: the existence of waterways, which can easily be mistaken for roads. In order to further investigate this association,
Figure 13 shows the spatial distribution of all false positive features regarding their number of incorrect classifications and the spatial distribution of tasks containing waterways. The visual interpretation indicates a possible relation between the presence of waterways and misclassification. An investigation using Pearson’s chi-square independence test has confirmed that the hypothesis of independence between the existence of waterways and an incorrect classification result can be rejected (χ
2(1) = 170.74,
p < 0.0005).
In the pursuit of qualitatively examining this issue,
Figure 14 shows two examples of false positive tasks in which waterways were apparently misidentified as roads. Besides this, some bright spots in waterways have been mistaken by roofs of buildings due to cascades or water foam. Altogether, there are only a few tasks related to waterways in which the number of incorrect classifications per task is greater than three. This indicates that, despite the strong association, in general, the existence of waterways may constitute only a small factor for incorrect classifications.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}