1. Introduction
Distinguished from color and multispectral imaging systems, hundreds of narrow contiguous bands about 10 nm wide are obtained in hyperspectral imaging system. With its abundant spectral information, hyperspectral imagery (HSI) has drawn great attention in the field of remote sensing [
1,
2,
3,
4]. Today most HSI data are acquired from aircraft (e.g., HYDICE, HyMap,
etc.), whereas efforts are being conducted to launch new sensors on orbital level (e.g., EnMAP, PRISMA,
etc.). Currently, we have Hyperion and CHRIS/PROBA. With the development of HSI sensors, hyperspectral remote sensing images are widely available in various areas.
Target detection is one of the most important applications of hyperspectral images. Based on the availability of a prior target information, target detection can be divided into two categories, supervised and unsupervised. The accuracy of supervised target detection methods is highly related to that of the target spectra, which are frequently hard to obtain [
5]. Therefore, the unsupervised target detection, also referred to as anomaly detection (AD), has experienced a rapid development in the past 20 years [
6,
7].
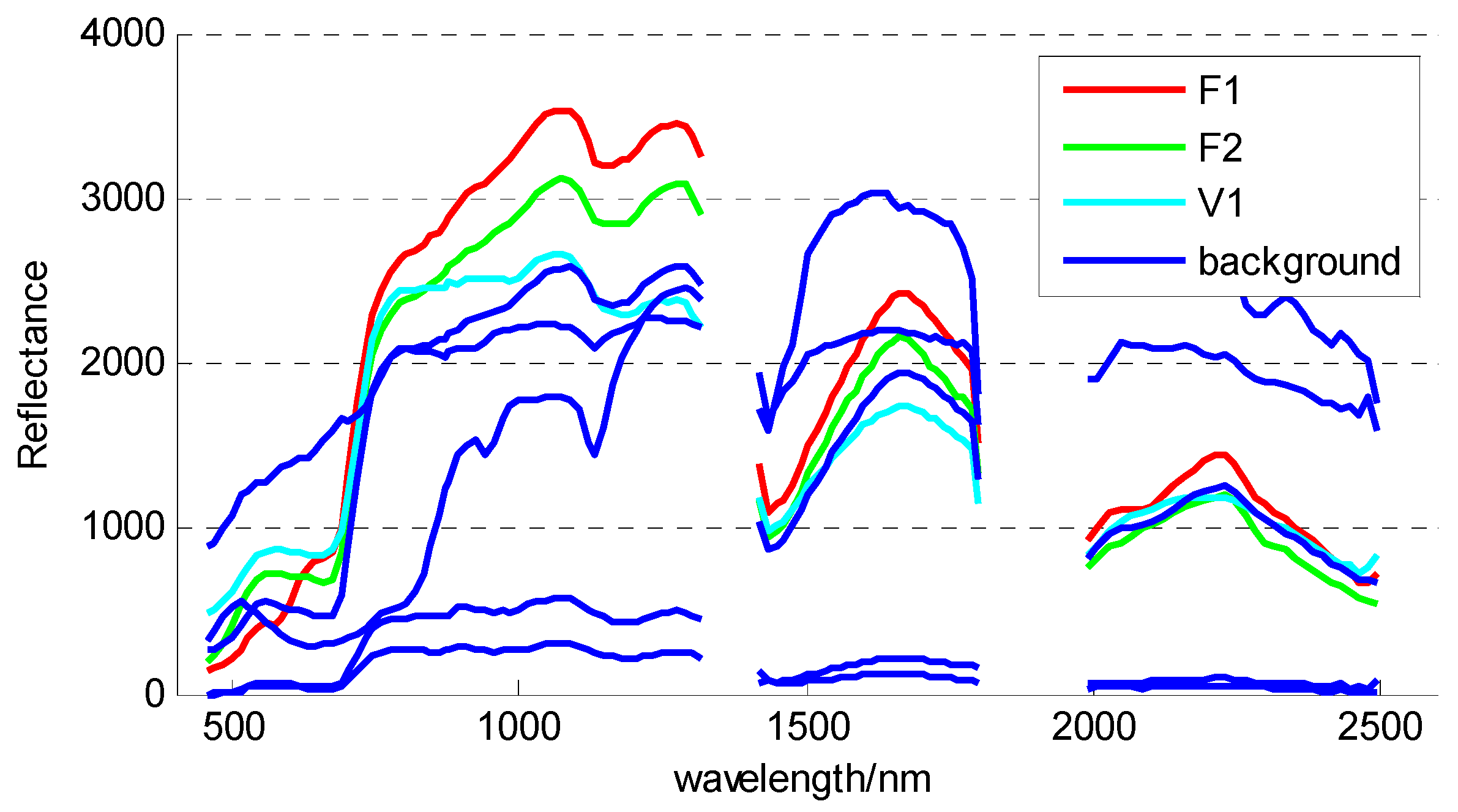
The goal of hyperspectral anomaly detection is to label the anomalies automatically from the HSI data. The anomalies are always small objects with low probabilities of occurrence and their spectra are significantly different from their neighbors. These two main features are widely utilized for AD. The Reed-Xiaoli (RX) algorithm [
8], as the benchmark AD method, assumes that the background follows a multivariate normal distribution. Based on this assumption, the Mahalanobis distance between the spectrum of the pixel under test (PUT) and its background samples is used to retrieve the detection result. Two versions named global RX (GRX) and local RX (LRX), which estimate the global and local background statistics (
i.e., mean and covariance matrix), respectively, have been studied. However, the performance of RX is highly related to the accuracy of the estimated covariance matrix of background. Derived from the RX algorithm, many other modified methods have been proposed [
9,
10]. To list, kernel strategy was introduced into the RX method to tackle non-linear AD problem [
11,
12]; weight RX and a random-selection-based anomaly detector were developed to reduce target contamination problem [
13,
14]; the effect of windows was also discussed [
15,
16]; and sub-pixel anomaly detection problem was targeted [
17,
18]. Generally speaking, two major problems exist in the RX and its modified algorithms: (1) in most cases, the normal distribution does not hold in real hyperspectral data; and (2) backgrounds are sometimes contaminated with the signal of anomalies.
To avoid obtaining accurate covariance matrix of background, cluster based detector [
19], support vector description detector (SVDD) [
20,
21], graph pixel selection based detector [
22], two-dimensional crossing-based anomaly detector (2DCAD) [
23], and subspaces based detector [
24] were proposed. Meanwhile, sparse representation (SR), first proposed in the field of classification [
25,
26], was introduced to tackle supervised target detection [
27]. In the theory of SR, spectrum of PUT can be sparsely represented by an over-complete dictionary consisting of background spectra. Large dissimilarity between the reconstructed residuals corresponding to the target dictionary and background dictionary respectively is obtained for a target sample, and small dissimilarity for a background sample. No explicit assumption on the statistical distribution characteristic of the observed data is required in SR. A collaborative-representation-based detector (CRD) was later proposed [
28]. Unlike SR, it utilizes neighbors to collaboratively represent the PUT. The effectiveness of sparse-representation-based detector (SRD) and CRD are highly correlated with the used dictionary, and dual-window method is a common way to build the background dictionary. A dictionary chosen by the characteristic of its neighbors was proposed through joint sparse representation [
29], and a learned dictionary (LD) using sparse coding was recently applied to represent the spectra of background [
30]. However, these methods mainly exploit spectral information and have a high false alarm rate under the presence of noise, as well as a low detection rate when the background dictionary is contaminated by anomalies.
Recently, a novel technique, low-rank matrix decomposition (LRMD) has emerged as a powerful tool for image analysis, web search and computer vision [
31]. In the field of hyperspectral remote sensing, LRMD exploits the intrinsic low-rank property of hyperspectral image, and decomposes it into two components: a low-rank clean matrix, and a sparse matrix. The low-rank matrix can be used for denoising [
32,
33] and recovery [
34], and the sparse matrix for anomaly detection [
35]. A tradeoff parameter is used to balance the two parts in robust principal component analysis (RPCA) based anomaly detector, and the low-rank and sparse matrix detector (LRaSMD) requires initiated rank of the low-rank matrix as well as the sparsity of the sparse matrix [
36]. However, the results of RPCA and LRaSMD are always sensitive to the initiated tradeoff parameters.
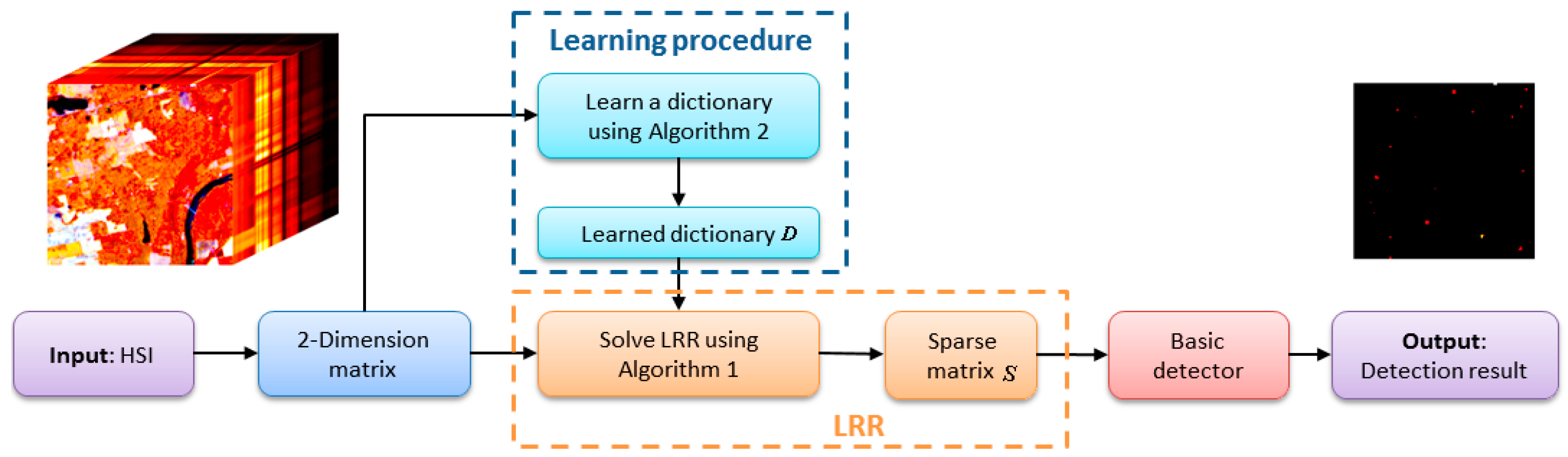
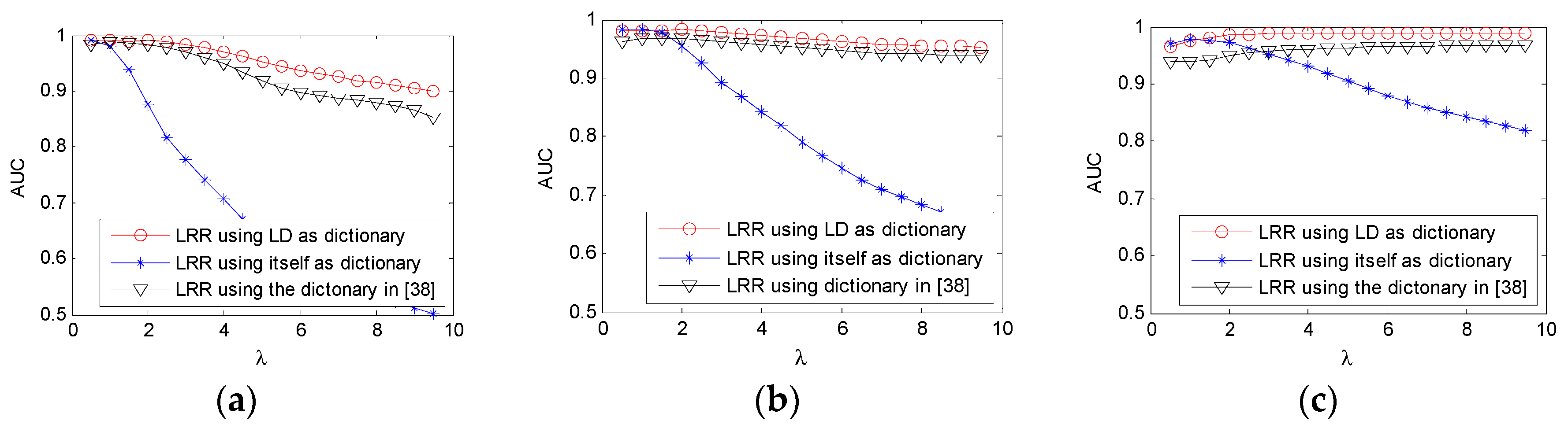
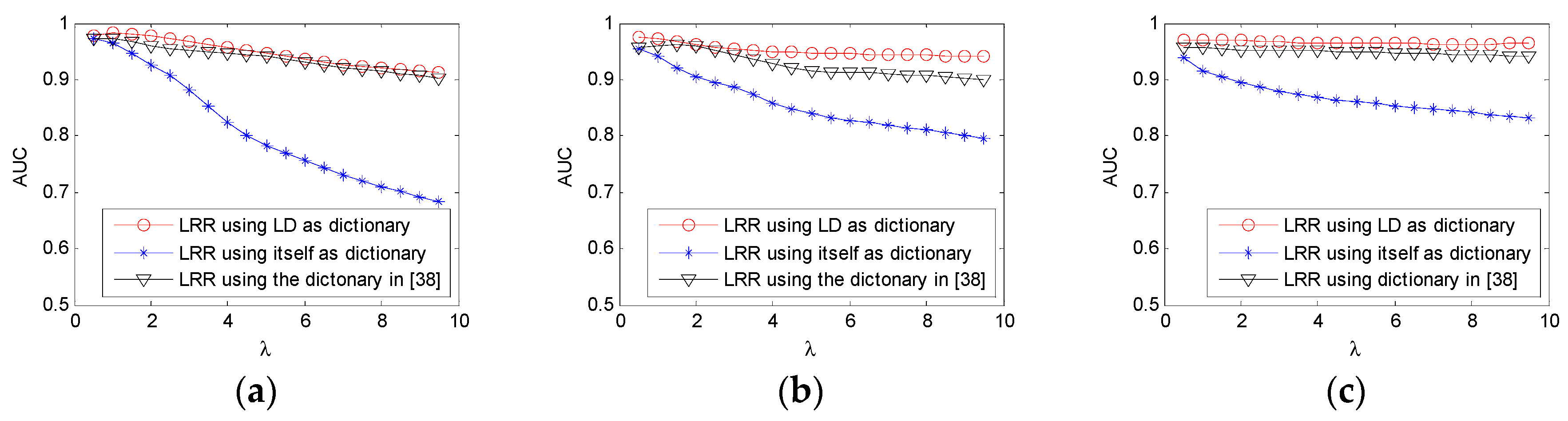
The low-rank representation (LRR) model [
37] was first introduced to tackle the hyperspectral AD problem [
38]. Unlike the model of RPCA, the LRR model assumes that the data are drawn from multiple subspaces, which is better suited for HSI due to the mixed nature of real data. In the model of LRR, a dictionary, which linearly spans the data space, is required. In most cases, the whole data matrix itself is used as the dictionary matrix. When the tradeoff parameter is not properly chosen, an unsatisfactory decomposition result is obtained. In this paper, to improve its robustness, we analyze the effect of the dictionary on the LRR model and learn a dictionary from the whole HSI using sparse coding method [
39,
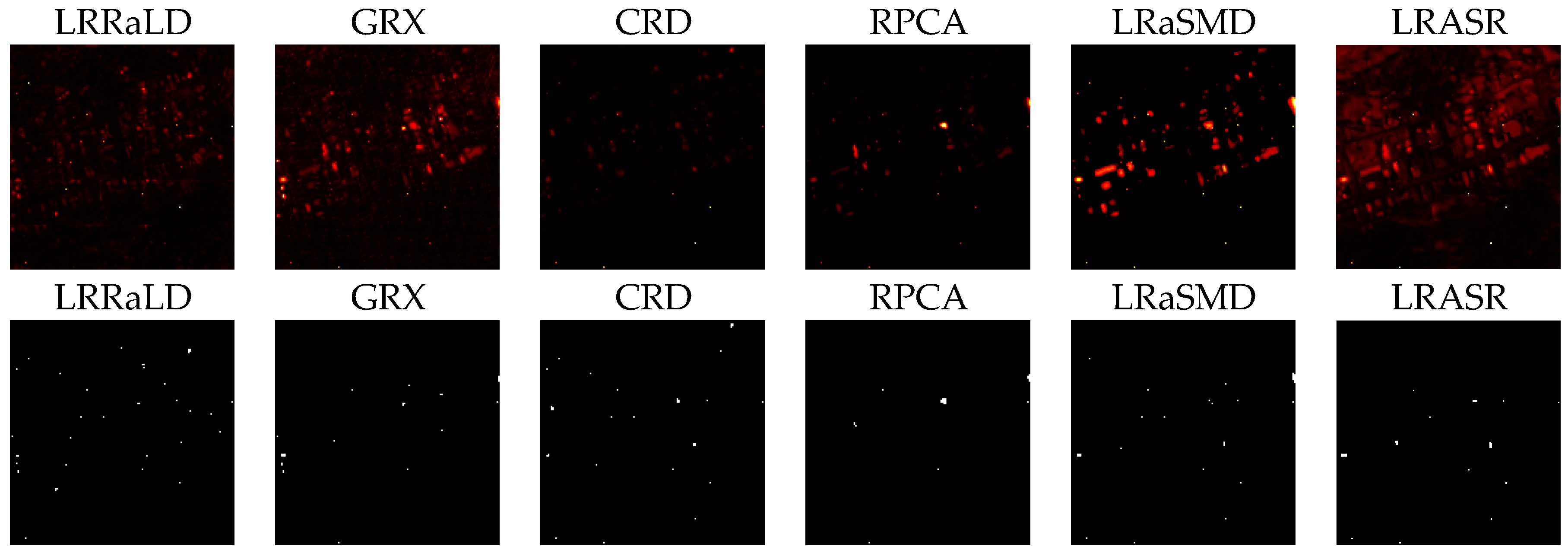
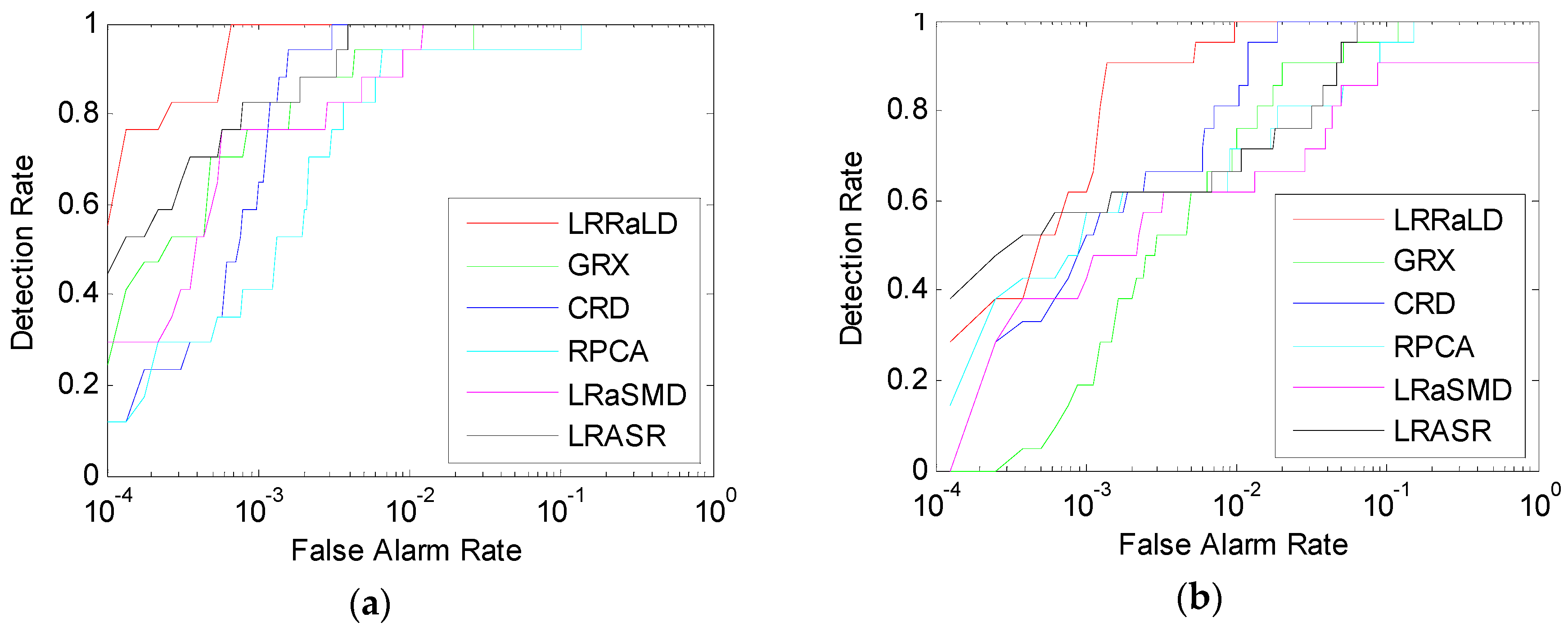
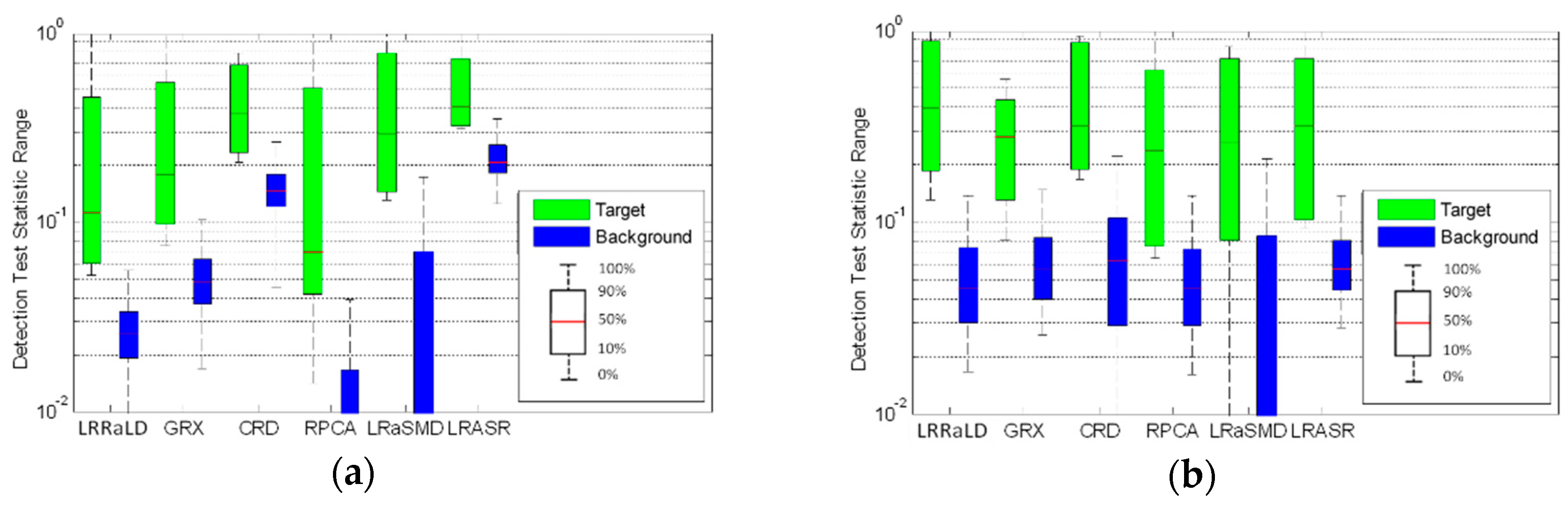
40] before applying the LRR model. A random selection method is used during the update procedure to mitigate the contaminating problem to get pure background spectra. When using the learned dictionary, the decomposition result will be more robust to the tradeoff parameter. A sparse matrix is obtained after decomposition, and basic anomaly detection method is then applied to retrieve the detection result. Finally, we will compare the proposed anomaly detector based on LRR and LD (LRRaLD) with the benchmark GRX method [
8], the state-of-the-art CRD [
28], and three other detectors based on LRMD including RPCA [
35], LRaSMD [
36] and the detector based on low-rank and sparse representation (LRASR) [
38] to better illustrate its effectiveness.
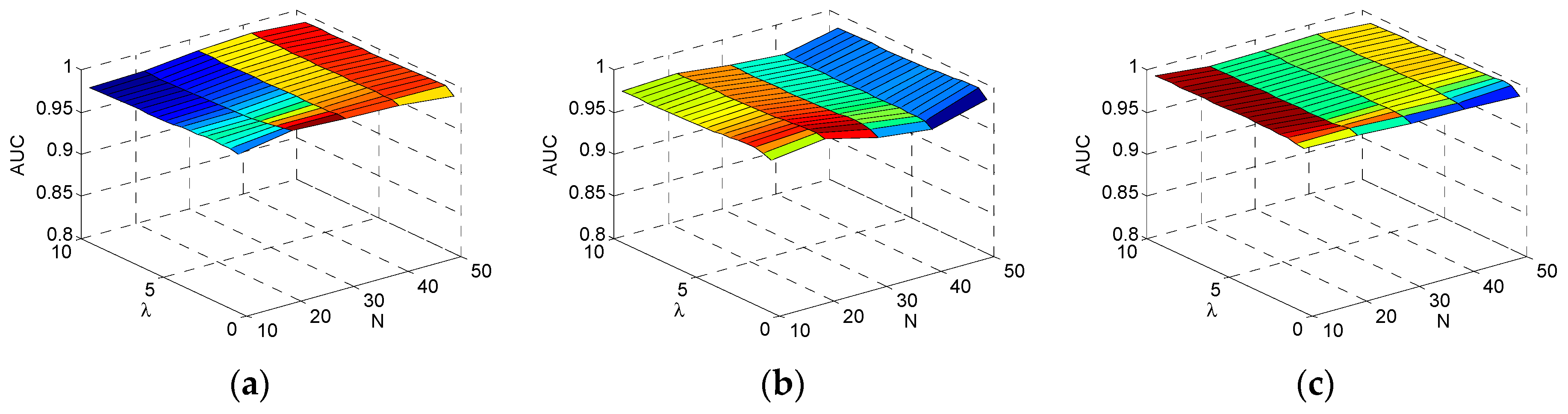
The contribution of the paper can be mainly described as follows: (1) compared to other AD algorithms, the intrinsic low-rank property of HSI is better exploited with the LRR model; (2) and the problem of sensitivity to parameters exists in detectors based on LRMD method. To mitigate this problem, a learning dictionary standing for the spectra of background is adopted in the LRR model to better separate the sparse anomaly part from the low-rank background part. The adopting of LD makes the proposed method more robust to its parameters and more efficient.
The remainder of this paper is organized as follows. In
Section 2, basic theory of LRR model and its solver are reviewed. In
Section 3, the proposed anomaly detector based on LRR and LD is described in detail. In
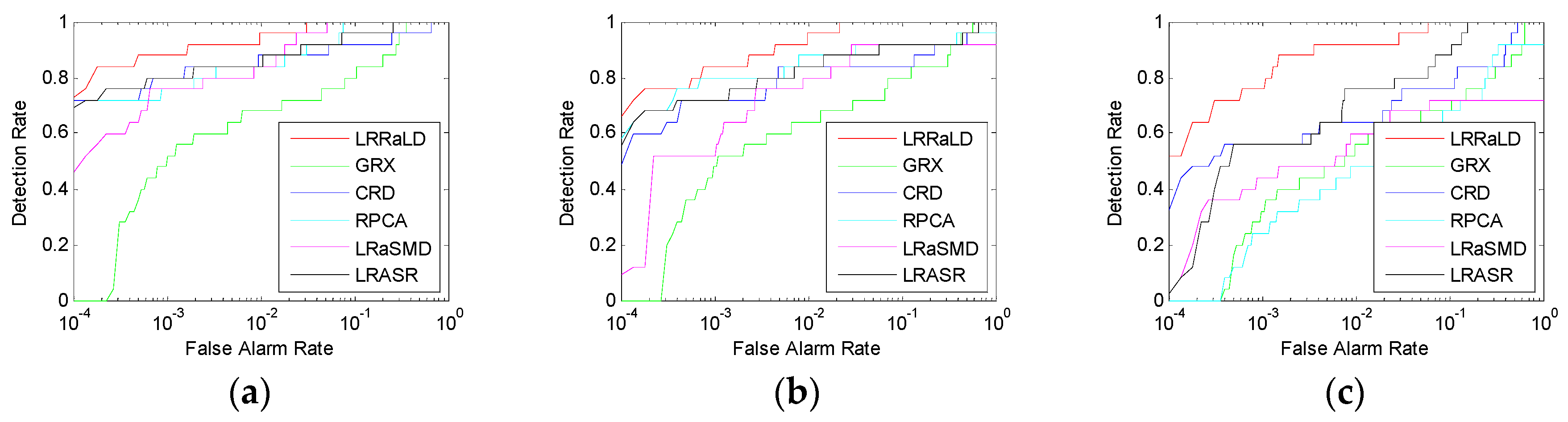
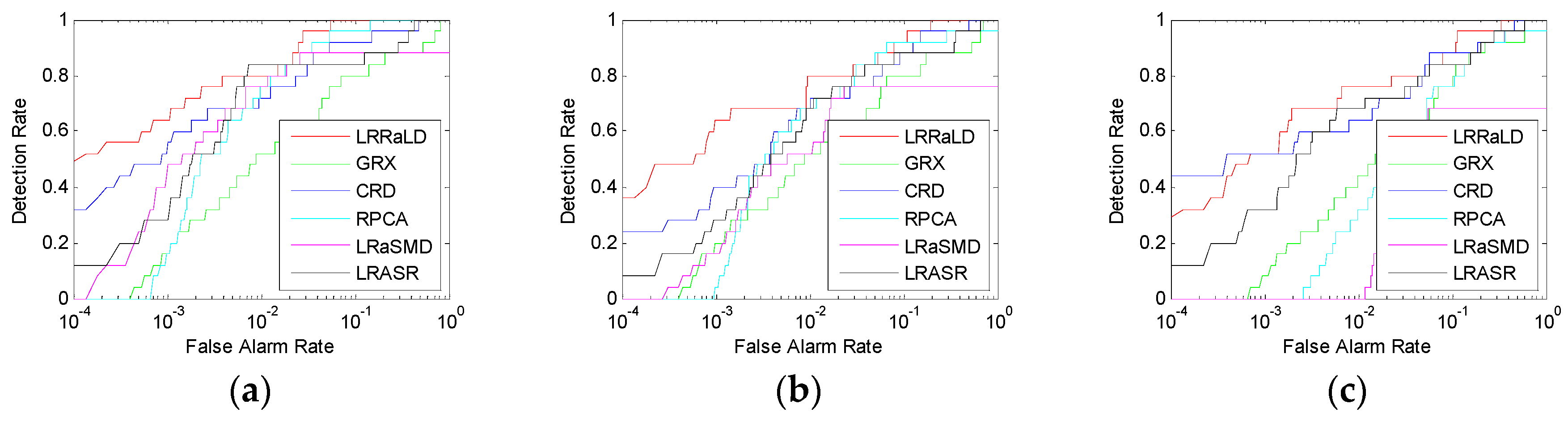
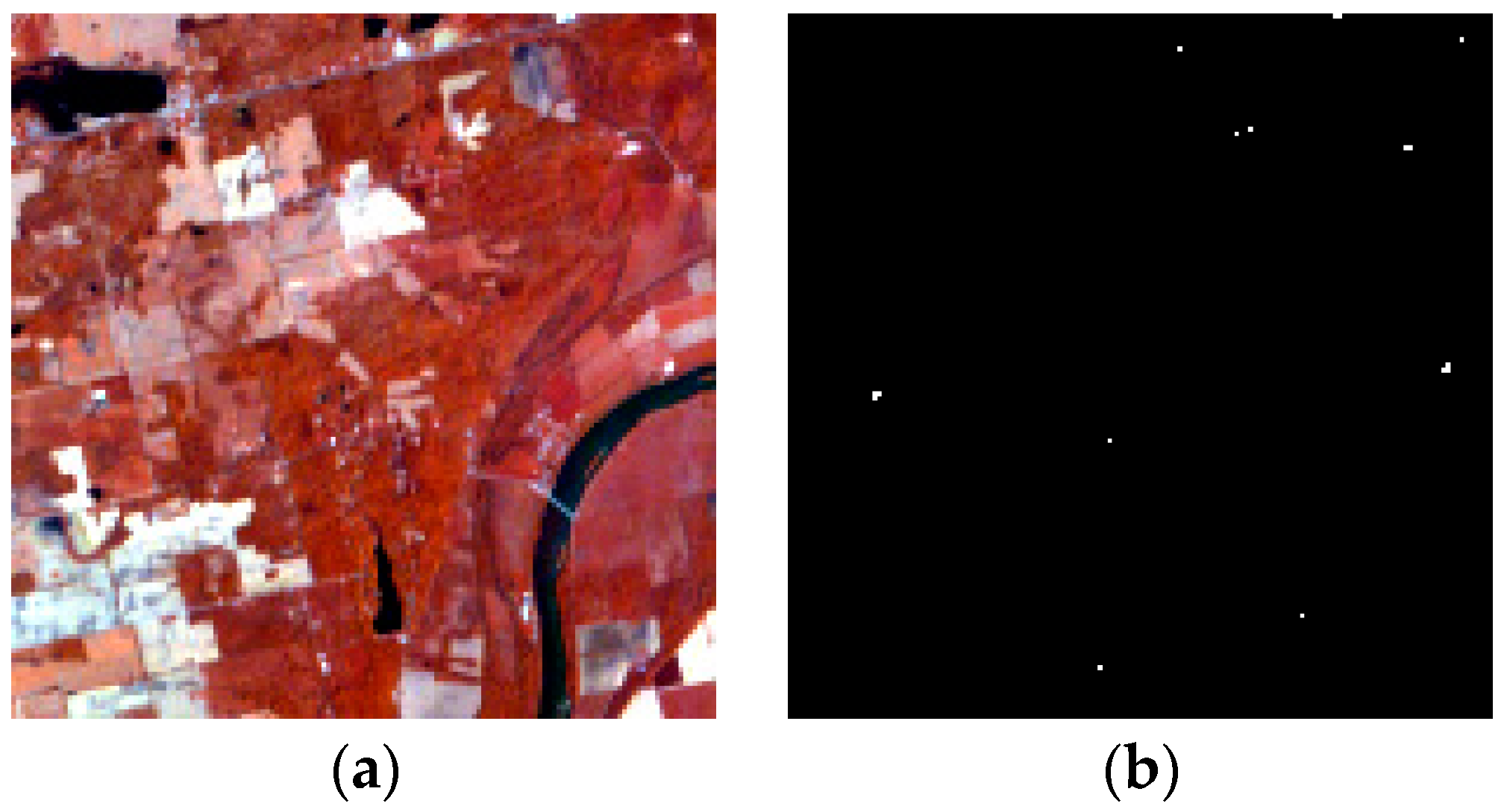
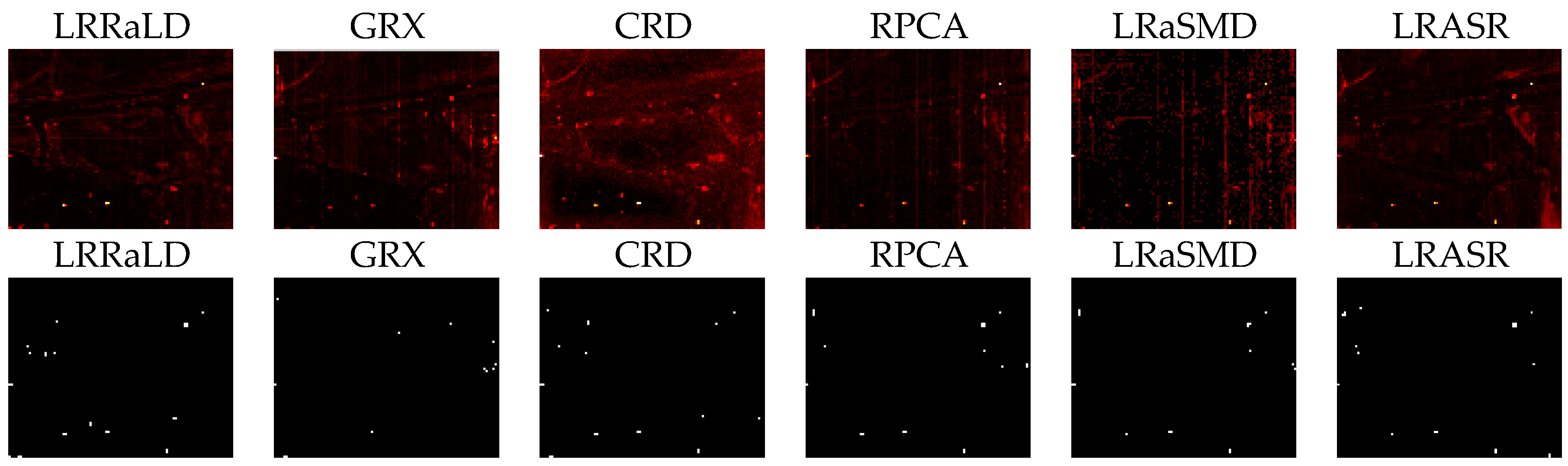
Section 4, experiments for synthetic and real hyperspectral data sets are conducted. In
Section 5, conclusion is drawn.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}