1. Introduction
With the increase of maritime traffic, the accidental and deliberate discharge of oil from ships is attracting growing concern. Using satellite-based synthetic aperture radar (SAR) has been proven to be a cost effective way to survey marine pollution over large-scale sea areas [
1,
2].
Current and future satellites with SAR sensors that can be used for monitoring oil spills include ERS-1/2, RADARSAT-1/2, ENVISAT (ASAR), ALOS1/2 (PALSAR), TerraSAR-X, Cosmos Skymed-1/2, RISAT-1, Sentinel-1, SAOCOM-1 and the RADARSAT constellation mission. Based on the SAR systems, many commercial or governmental agencies have been building SAR oil-spill detection service, such as the multi-mission maritime monitoring services of Kongsberg Satellite Services (KSAT), Airbus defense and space’s oil spill detection service, CleanSeaNet [
3] and Integrated Satellite Tracking of Pollution (ISTOP). To be more operational, automatic oil spill classification system with real-time, fully operational and wider water coverage capability is needed [
1], as Solberg et al. state [
4] “The currently manual services is just a first step toward a fully operational system covering wider waters”.
Due to their ability to smooth sea surface, oil spills usually appear as dark spots on SAR images. However, other sea features, such as low wind areas and biogenic slicks, also produce smooth sea surface and result in dark formations on SAR imagery. These sea features are usually called “look-alikes”. The existence of look-alikes imposes huge challenge on SAR oil spill detection systems. In an automatic or semiautomatic SAR oil spill detection system, three steps are sequentially performed to identify oil spills [
1,
5,
6,
7,
8]: (i) dark-spot detection for identifying all candidates that belong to either oil spills or look-alikes; (ii) feature extraction for collecting object-based features, such as the mean intensity value of dark-spots, for discriminating oil spills and look-alikes; and (iii) classification for separating oil spills and look-alikes using the features extracted.
After identifying all candidates and collecting their features, classification approaches predominantly determines the performance of oil spill detection systems. Many classifiers have been used to detect oil spills including a combination of statistical modeling and rule-based approaches [
1,
4,
5,
9,
10], artificial neural network (ANN) models [
11,
12,
13,
14,
15,
16], decision tree (DT) models [
3,
8,
15,
17], fisher discrimination or multi regression analysis approaches [
18], fuzzy classifiers [
3,
19], support vector machine (SVM) classifiers [
9,
20] and K-nearest neighbors (KNN) based classifiers [
17,
21]. A comparison of SVM, ANN, tree-based ensemble classifiers (bagging, bundling and boosting), generalized additive model (GAM) and penalized linear discriminant analysis on a relatively fair standard has been conducted [
22] with the conclusion that the tree-based classifiers, i.e., bagging, bundling and boosting approaches, generally perform better than the other approaches, i.e., SVM, ANN and GAM.
Most classifiers that have been adopted for oil spill detection are supervised classifiers which need training samples to “teach” themselves before performing classification tasks. To get good generalization performance, a large number of training samples are needed to deal with the curse of dimensionality [
23]. In the case of oil spill classification, high feature dimensionality are usually needed to cover the complex characteristics of look-alikes and oil spills [
1,
6].
Although effective classifier learning requires a large number of labeled samples, verifying/labeling and accumulating enough number of samples for training an automatic system with reasonable performance could be very difficult, costly and time-consuming for the following reasons. First, oil spills are rare and fast-changing events, which tend to disappear before being verified by ships or aircrafts, because, after a short time span, mostly within several hours [
24], the oil spills will become difficult to distinguish. Second, verifying an oil spill using airplane/vessel is usually very expensive. Third, verified/labeled samples from different SAR platforms may not be sharable, because of the different imaging parameters, such as band, polarization mode, spatial resolution, etc. Even for images from the same SAR platform, the standards of confidence levels, pre and post procedures, etc. must be normalized so that the samples from different institutions can be shared.
Limited by difficulties in verifying oil spills, researchers rely mainly on human experts to manually label the targets. For example,
Table 1 indicates that the largest number of verified oil spills is only 29 adopted by Solberg et al. [
10], and other researchers predominantly used the expert-labeled samples, although they did not explicitly report the proportion of the verified samples. Nevertheless, using expert-labeled samples is problematic for the following reasons. First, expert-labeling produces inconsistency between the labels (or confidence levels) given by different experts [
1,
25]. Second, training the system with expert-labeled samples leads to system that can hardly outperform the experts who “teach” the system.
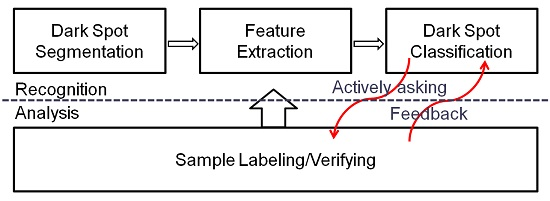
Considering the cost and difficulties in verifying oil spill candidates, one key issue in learning an oil spill classification system is to effectively reduce the number of verified samples required for classifier training without compromising the accuracy and robustness of the resulting classifier. Suppose that the current verified samples are insufficient for building an accurate oil spill detection system, and that new samples are required to be verified for increasing the size of the training set. In a conventional supervised classification system, we will not be able to know which samples have higher priority to be verified, because, as indicated in
Figure 1, the communication between the conventional classification system and the sample collecting system is one-way directed, where the collected samples are used to train the classifier with no feedback from the classifier on what kind of samples are more informative and urgently needed. Without knowing the values and importance of the samples to the classifiers, the costly verification effort may only lead to training samples that are redundant, useless or even misleading. Although verifying more samples can increase the possibility of obtaining relevant training sample, it will greatly increase the time span and cost for building the system.
The need for reducing training samples without compromising the accuracy of resulting classifiers motivates us to study the potential of introducing AL into the oil spill detection systems. AL is a growing area of research in machine learning [
27], and has been widely used in many real-world problems [
27,
28,
29] and remote sensing classification [
30,
31,
32,
33,
34,
35,
36]. The insight from AL is that allowing a machine learning algorithm to designate the samples for training could make it achieve higher accuracy with fewer training samples. As indicated by
Figure 1, in an AL-boosted system, the interaction between the classification system and the training sample collecting system are bi-directional, where the classifier will “ask for” the most relevant samples to be verified/labeled in order to construct the classifier in an efficient and effective manner. Considering the cost and difficulty to verify the oil spill candidate, such an active learning process can greatly reduce the cost and time for building a detection system by reducing the number of candidates that needed to be verified without compromising the robustness and accuracy of the resulting classifier.
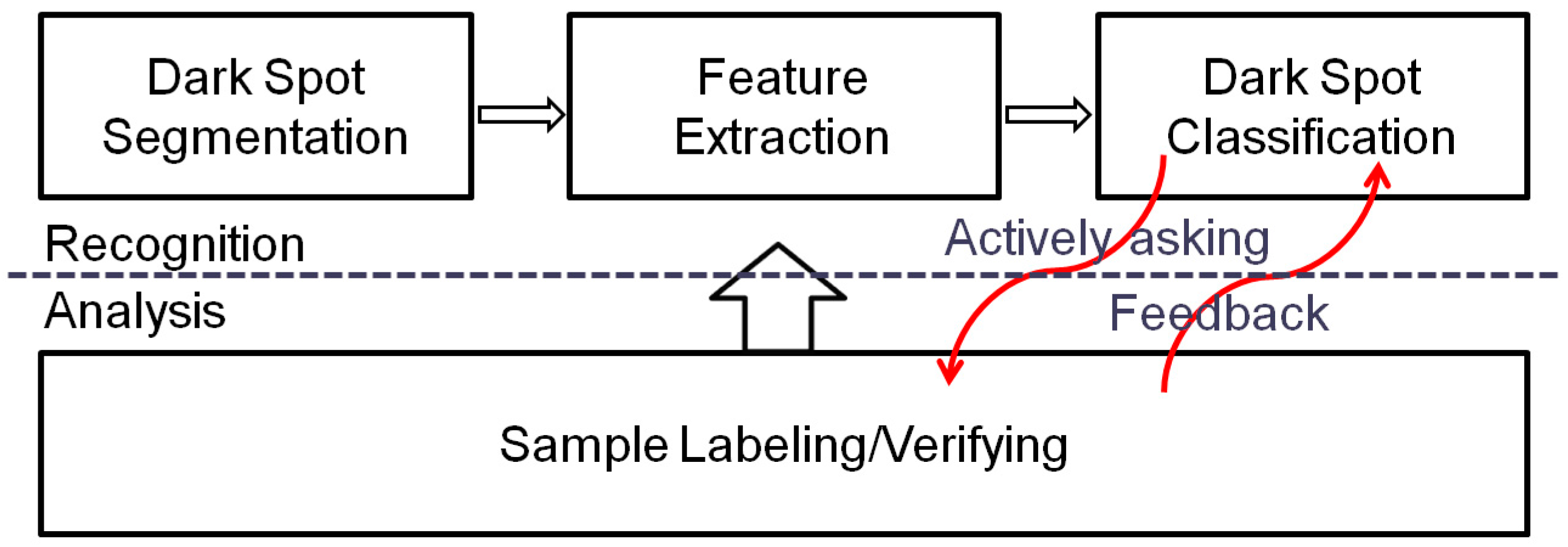
In this paper, we explore the potential of AL in training classifiers for the purpose of oil spill identification using 10 years (2004–2013) of RADARSAT data off the east and west coasts of Canada, which contains 198 RADARSAT-1 and RADARSAT-2 ScanSAR full scene images. Based on these images, we obtain 267 labeled samples, of which there are 143 oil spills and 124 look-alikes. We split these labeled samples into a simulating-set and a test-set, using the simulating-set to simulate an AL process involving a number of AL iterations, and using the test-set to calculate the performance of classifiers in each iteration. We start with a small number of training samples for initializing the classifiers, and with the AL iteration, we progressively select more samples and add them to the training set. Such a process ends when all samples in the simulating-set has been selected. Since the most important issue in AL is how to effectively select the most informative samples, we design six different active sample selection (ACS) methods to choose informative training samples. Moreover, we also explore the ACS approach with varying sample preference and the approach to reduce information redundancy among the selected samples. Four commonly used classifiers (KNN, SVM, LDA and DT) are coupled with ACS methods to explore the interaction between classifiers and ACS methods. Three kinds of measures are adopted to highlight different aspect of classification performance of these AL-boosted classifiers. Finally, to reduce the bias caused by the splitting of simulating set and test set in an effective manner, we adopt a six-fold cross validation approach to randomly split the labeled samples into six folds, using five for simulating and one for testing until all the folds have been used for testing once. To our best knowledge, this work is the first, effort except our very preliminary work [
37], to explore the potential of AL for oil spill classification.
3. Results and Discussion
3.1. Performance of ACS Methods
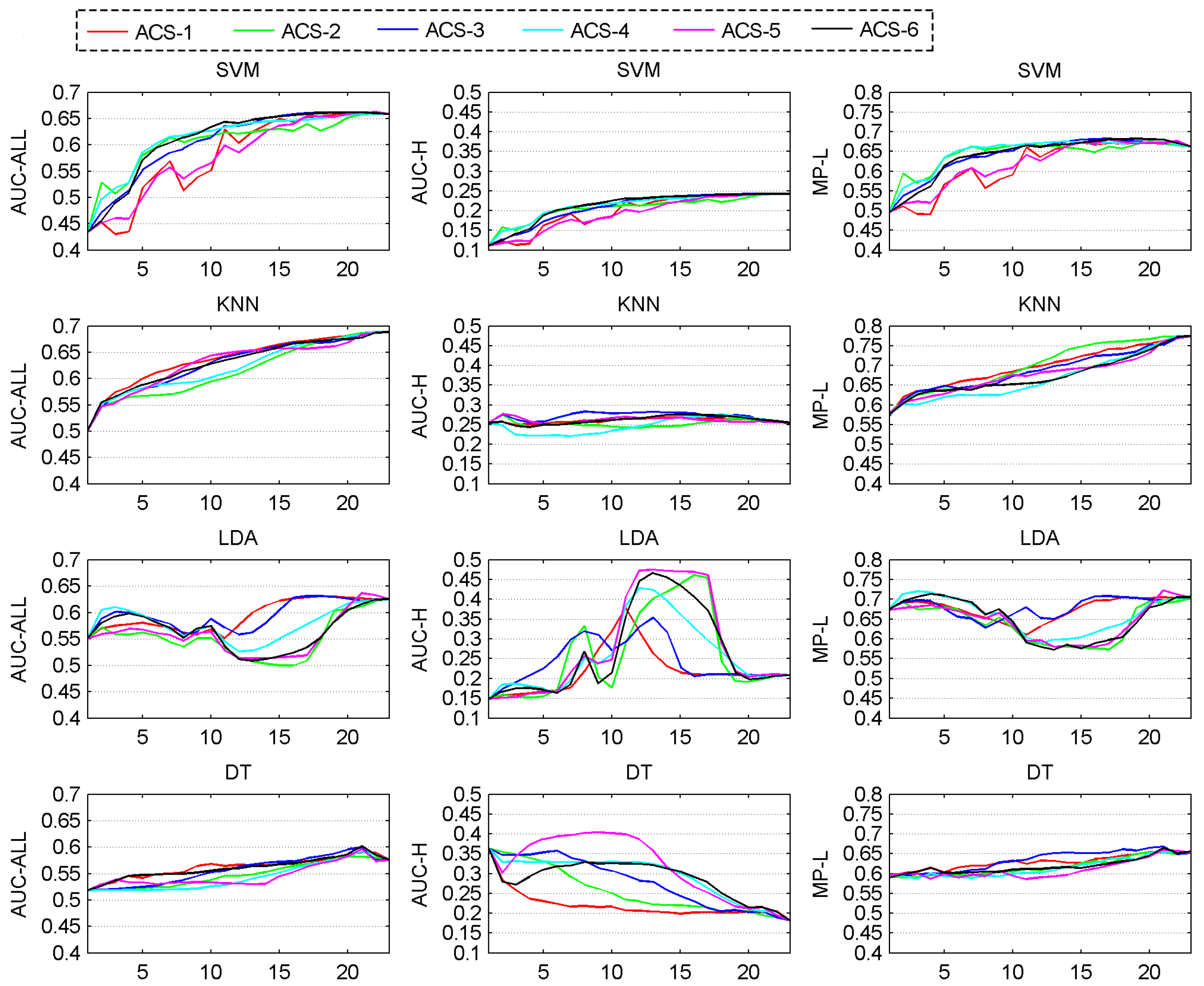
We want ACS methods to help a classifier improve its performance stably and as quickly as possible. Thus, the ideal curve of a classifier’s performance over iterations should be stably ascending, steep in the fore part and flat in the back part.
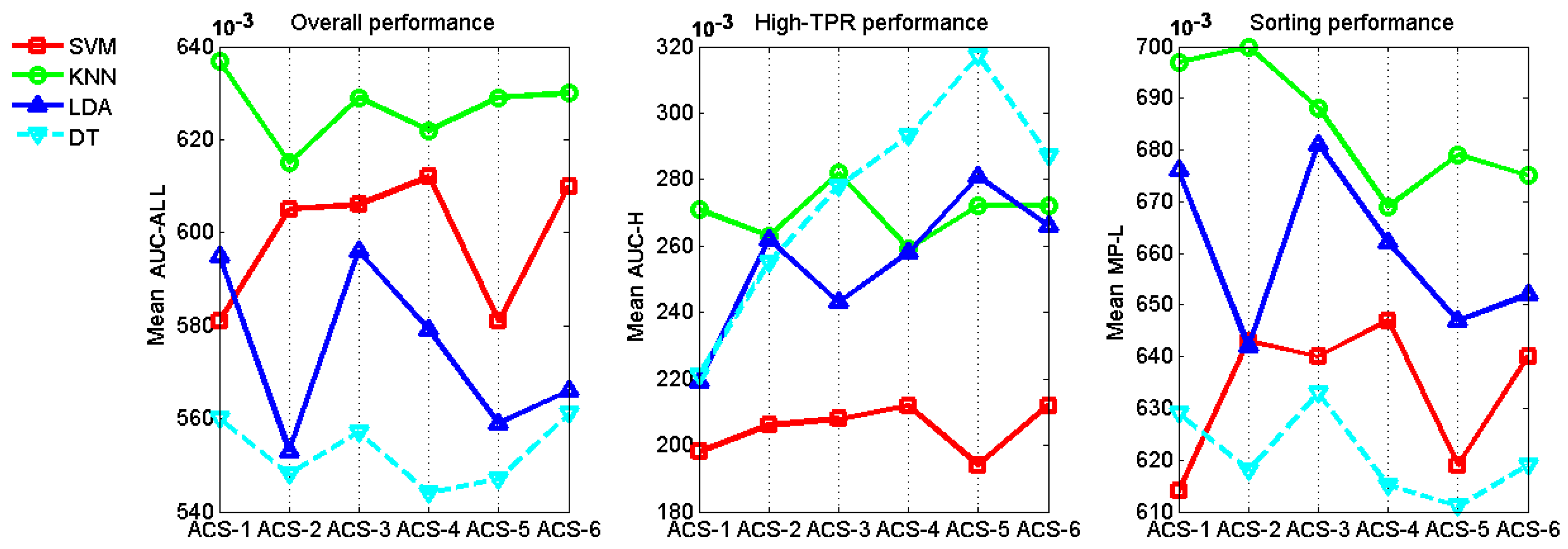
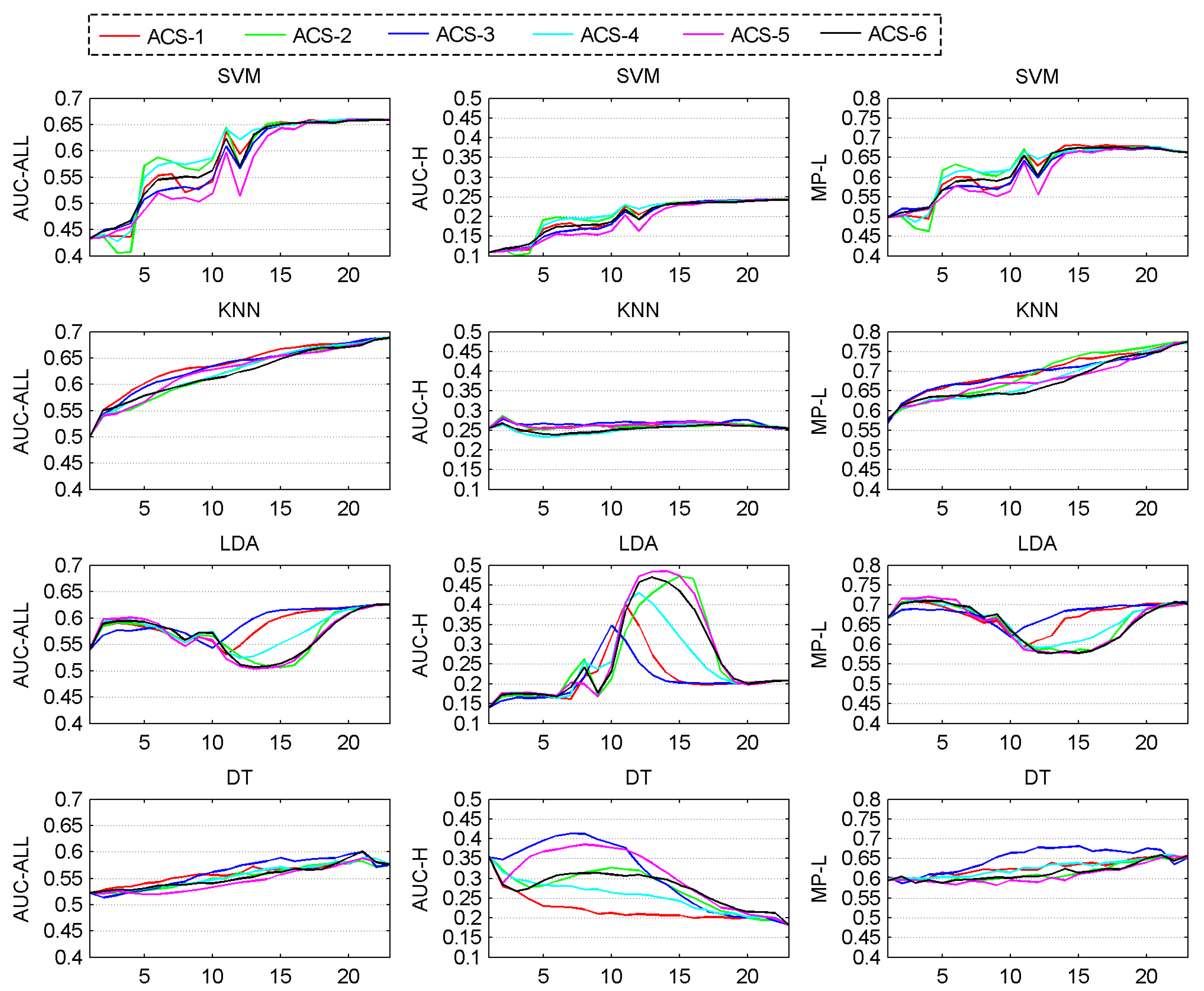
Figure 5 shows the graphs of performance evolving over iterations of ACS methods coupled with SVM, KNN, LDA and DT classifier. By averaging the performance values of each curve in
Figure 5, we get the mean performance values in
Figure 6. The classifiers show different characteristics.
One observation is that in the case of high-PTR performance, KNN, LDA and DT which show bad (flat, unstable or descending) trends in
Figure 5 have much better performance number in
Figure 6 than SVM which shows good trend (stably ascending, steep in the fore part and flat in the back part) in curves. This might cause confusion when we choose a better classifier to work with ACS methods, because any variance of factors such as pre-processing, feature selection, parameter setting for classifiers, might dramatically change the mean performance value of a classifier and comparing classifiers in mean performance is very difficult to be on a fair base, we here suggest that more trust should be put on the trends of curves which more likely present the intrinsic features and less trust on the performance values that could be affected by too many factors. Based on this principle,
Figure 5 shows five bad situations (KNN in high-PRT performance, LDA in all three kinds of performance and DT in high-PRT performance), in which ACS methods work badly and three good situations (SVM in all three kinds of performance), in which ACS methods work well.
KNN-based ACS methods show almost horizontal curves in the high-PTR performance, which means the increasing of training samples from any ACS method will not bring obvious improvement in high-PTR performance o KNN. DT-based ACS methods show almost descending curves in the high-PTR performance, which means the increasing of training samples causes the drop of performance. These phenomena might arise partly from the fact that the distributions of oil spill and look-alikes are heavily overlapping. When improving a system pursuing high-PTR performance, KNN and DT classifier should be considered carefully.
LDA-based ACS methods show dramatic fluctuations in their performance curves. LDA classifier takes the Gaussian assumption for the underlying distribution of oil spills and look-alikes. The big fluctuations means newly added samples change dramatically the shape of distributions learned previously. To deal with this problem, keeping a smooth change of distribution shape should also be considered in future when adding samples from ACS methods.
SVM-based ACS methods show good (stable and ascending, especially ascending quickly in the fore part and becoming flat in the back part of iterations) patterns in all three kinds of performance. That would be a merit when more than one services (each asks for a different performance) are demanded. In this case, only one (not the number of services) system needed to be built.
In the case of overall performance and sorting performance, randomly selecting samples (ACS-1) is always the best or second best when it is coupled with KNN, LDA or DT classifier, but not with SVM classifier. That may be because that KNN, LDA and DT are classifiers that try to make a decision based on some statistics from all samples in a certain region, while SVM makes the decision only on a few key samples (support vectors). Obviously, randomly selected samples (as from ACS-1) are more likely to maintain the statistics of the underlying distribution from which our training and test dataset come, but less likely to contain some key samples for SVM classifier.
The results in
Figure 5 and
Figure 6 also show that choosing a good ACS method for a specified classifier should be based on considering at least two important factors: the kind of performance chosen for optimization and the learning stages. A classifier may prefer different ACS methods in different performance measures. For example, the DT classifier favors ACS-1 in the overall performance and sorting performance but favors ACS-5 in the high-PTR performance. A classifier may also prefer different ACS methods in different stages of learning process. For example, SVM classifier favors ACS-2 and ACS-4 (methods that prefer choosing samples of more certainty) at the first half of the iterations in our study but ACS-5 and ACS-6 (methods that prefer choosing samples of more uncertainty and that choose samples half of more certainty and half of more uncertainty) at the second half.
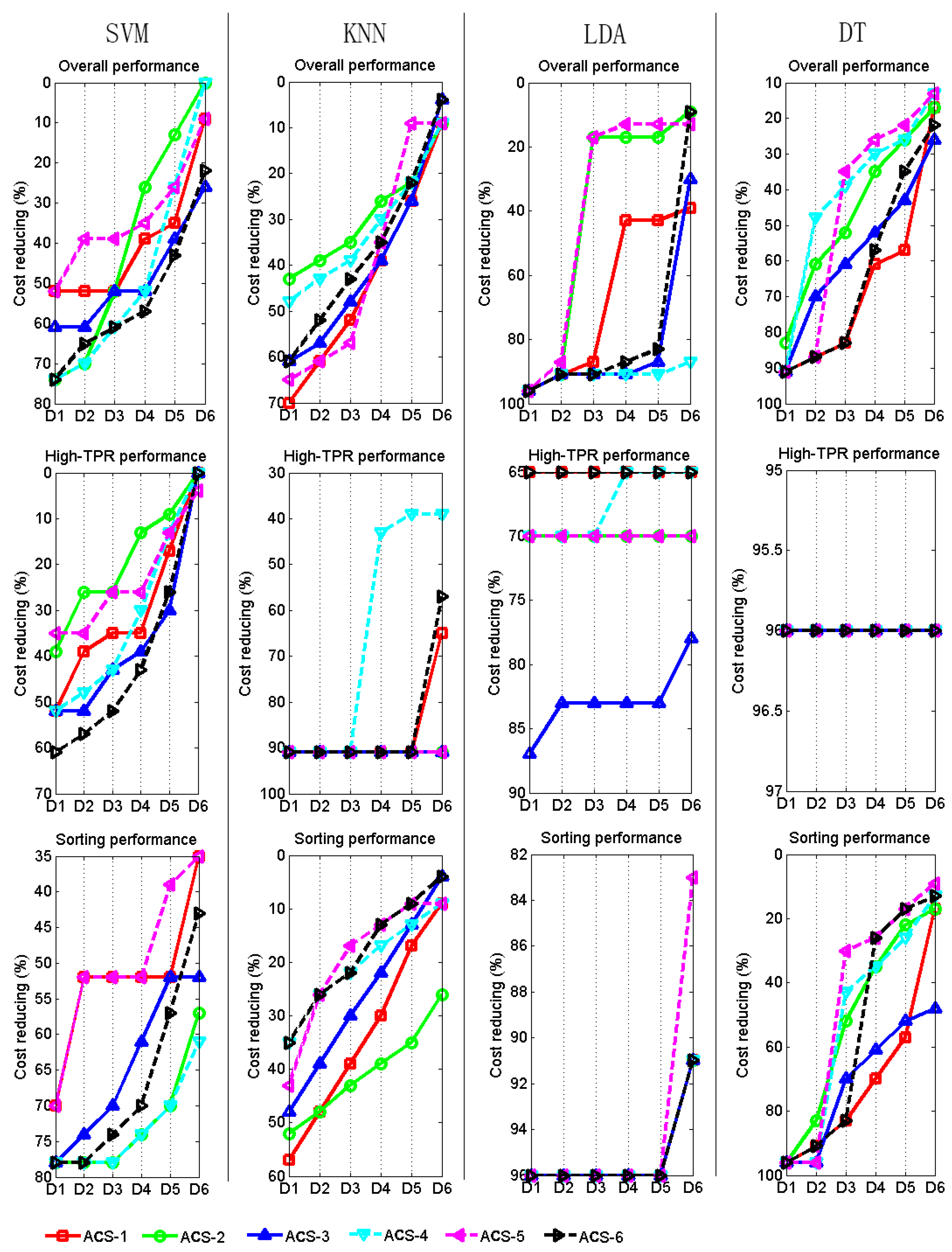
3.2. Cost Reduction Using ACS Methods
Figure 7 shows the cost reduction of using ACS methods to boost SVM, KNN, LDA and DT classifiers for achieving different destination performance. By selecting the maximum cost reduction for each classifier to achieve each destination performance, we obtain
Table 5.
It should be noted that a big cost reduction in
Figure 5 and
Table 5 does not always means that ACS methods work successfully in that situation. The gray elements in
Table 5 show five bad situations (also mentioned in
Section 3.1), in which the cost reductions are very big but the ACS methods actually work so poorly that it is not necessary to analyze the cost reduction of these situations.
It can be seen that a considerable cost reduction can be achieved using ACS to boost classifiers. Taking the SVM, for instance, to get D5 destination performance, the maximum 43%, 30% and 70% reductions of cost can be obtained in overall performance, high-PTR performance and sorting performance, respectively. For D6 destination performance, the maximum 26%, 4% and 61% reductions of cost can be obtained in overall performance, high-PTR performance and sorting performance, respectively.
It can be seen in
Figure 7 that, for SVM classifier, ACS-6 shows the best performance curve in overall performance and high-PTR performance, while ACS-2 and ACS-4 show the best curves in sorting performance. For DT classifier, ACS-1 works best in overall performance and sorting performance. For KNN classifier, ACS-1 work best in overall performance and ACS-2 works best in sorting performance.
There is still great potential to improve the cost reduction performance by improving the data preparation and tuning of classifiers, such as feature selecting, preprocessing, optimizing the parameters of model and using other definition of the informativeness preferred by the classifier.
Another method that may further improve the reduction of cost is to carry out the system serving and system training at the same time after the system has already had a sound performance. It can be seen in
Table 5 that, using a sound designated performance (such as one of D1–D5), leads to a bigger cost reduction than selecting the perfect designated performance D6. Moreover, the income of service might cover the cost of continuing the system training once the system has been put into working.
3.3. Reducing Redundancy Amongst Samples (RRAS)
With SVM classifier, it can be seen in
Table 6 that RRAS reduces the mean performance of most ACS methods except ACS-1. Because the key samples (support vectors) only exist in a relatively small region near the decision boundary for SVM classifier, increasing the diversity of samples by RRAS would not help choose samples from the key region, which is very small compared with the whole feature space. Compared to not using RRBS (
Figure 5), performance fluctuations in
Figure 8 are increased at the former part of iterations and weakened at the end part of iterations, and ACS-2, ACS-4 change from the first and second best methods to the first and second worst at the first few iterations of all graphs. These phenomena could also be caused by the increased randomness of selected samples by RRAS. It seems that RRAS is not suitable for SVM-based ACS methods in our case.
For KNN classifier, the RRAS does not bring significant improvement in the shape of curves in
Figure 8 compared to curves in
Figure 5, but does slightly increase the mean performance values of more than half of ACS methods (see
Table 6). For KNN classifier, the more thorough the training sample dataset can represent the true underlying distribution, the higher performance it can obtain. The RRAS can improve the representative ability of selected samples by first grouping all samples into clusters and then selecting one from each cluster as the representative sample and therefore seems suitable for some KNN-based ACS methods.
In
Table 6, there are some performance improvements and drops for ACS methods with LDA and DT classifier, but it is hard to analyze the reasons.
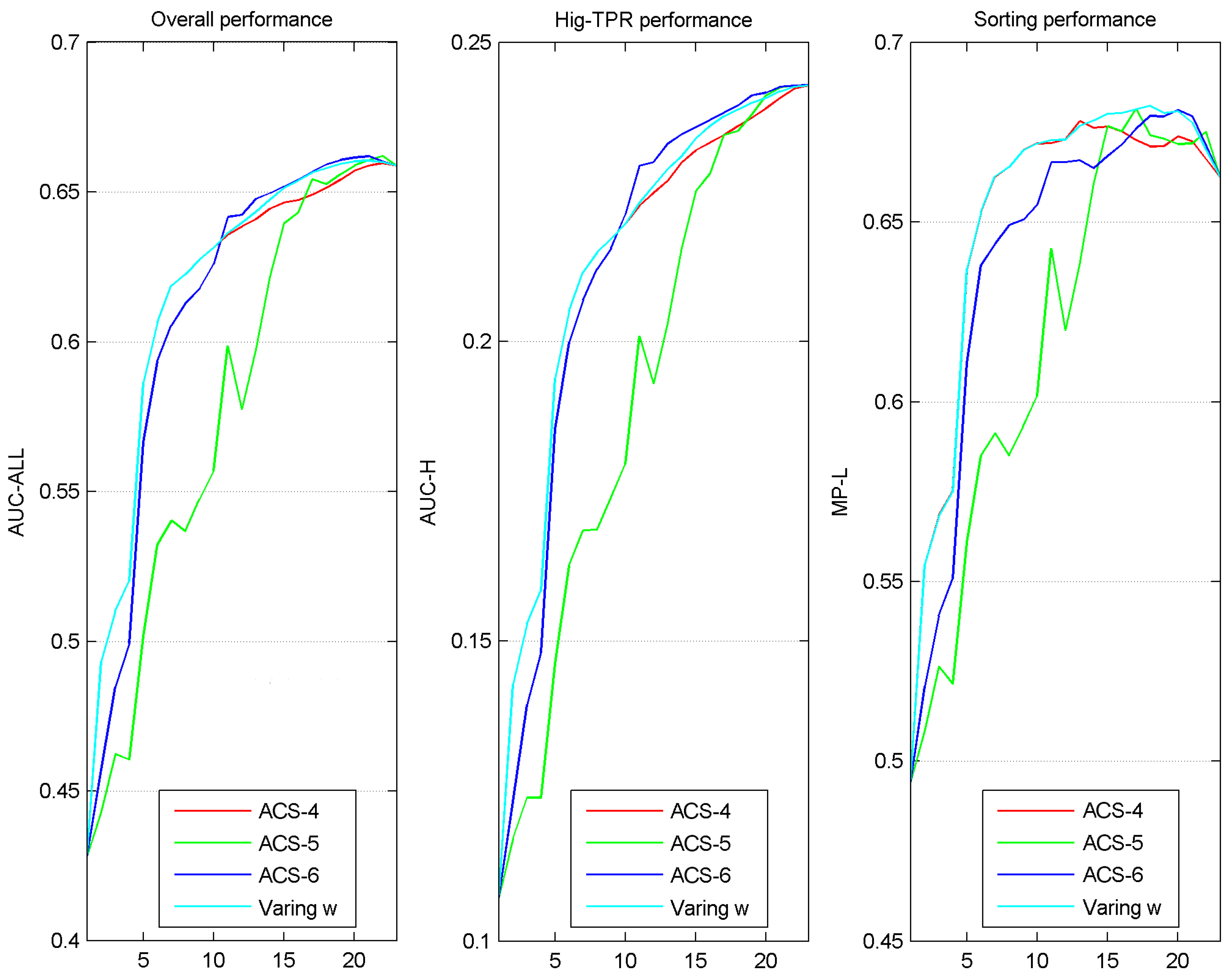
3.4. Adjusting Sample Preference in Iterations
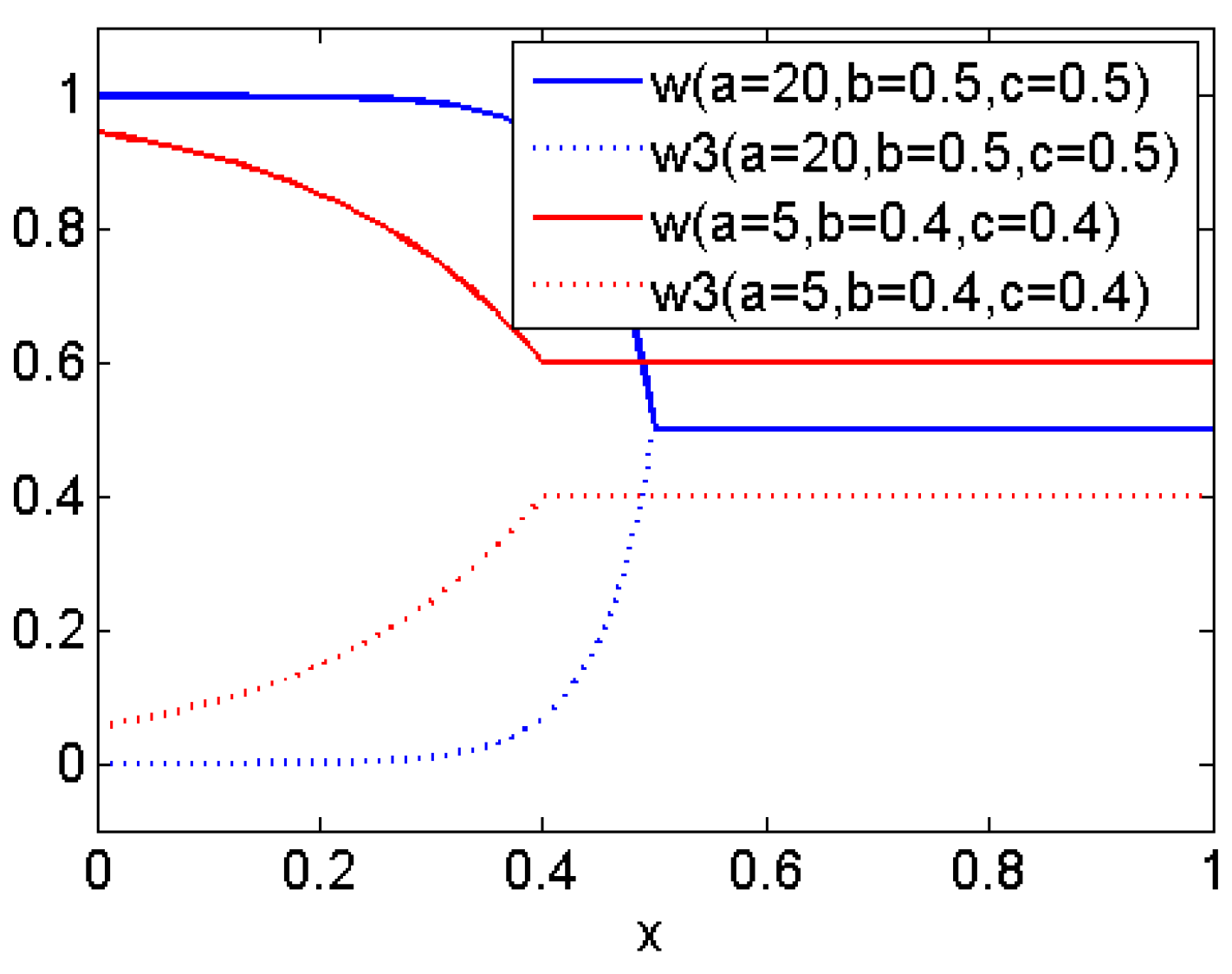
Figure 9 shows the performance-evolution graph of the ACS method with varying parameter for sample selection, coupled with SVM. It can be seen that the ACS method with parameter w varying according to Function (1), at most iterations, matches or outperforms any of the other fixed-w methods (ACS-4 is with w = 1, ACS-5 with w = 0, and ACS-6 with w = 0.5). Here, we set the parameters of Function (1) as a = 20, b = 0.5, c = 0.5. The varying-w method obtained mean performance values (by averaging performance numbers on its curves in
Figure 9) 0.614, 0.213 and 0.650 for overall performance, high-TPR performance and sorting performance, respectively. These mean values are all better than the best ones of SVM classifier in
Figure 6, i.e., 0.612, 0.212 and 0.647.
Although adjusting parameter w in an iteration-based manner seems to be a good strategy for improving system performance in our study, the use of such a strategy must have a theoretical or empirical basis. Otherwise, there is no guarantee that such good results might also be achieved in other datasets. Although the exploration-and-exploitation criterion [
59] is a commonly accepted one (our method here is derived from it), it is only suitable for SVM classifier in this study. The unsuitability for KNN, LDA and DT classifier can be seen clearly in
Figure 5, in which, when coupled with these classifiers, ACS methods preferring samples of certainty does not perform well at the former part of iterations and so do the ACS methods preferring samples of uncertainty at the end part. Criteria similar to exploration-and-exploitation suitable for SVM need to be found and verified for other classifiers in the future.
4. Conclusions
In this study based on a ten-year RADARSAT dataset covering west and east coasts of Canada, AL has shown its great potential of training sample reduction (for example, a 4% to 78% reduction on training samples can be achieved in different settings when using AL to boost SVM classifier) in constructing oil spill classifiers. That means the real-world projects of constructing oil spill classification systems (especially when it is hard to accumulate a large number of training samples, such as when supervising new water area) or improving existed systems may benefit from using AL methods. In the cases where AL are used for classifier training, we boldly suggest that the expensive, time-sensitive, and difficult field verification work should be conduct only for those targets that are identified by AL as the “important” targets to significantly improve the classifier training efficiency. AL could reduce training data, whether they are obtained by expert-labeling or by field-verifying. Generally, field-verified data are better than expert-labeled data for training due to the higher verification accuracy of the field investigation approach. Nevertheless, when it is hard or impossible to do fieldwork, asking experts for labeling is also acceptable. Both labeling approaches benefit from the efficient learning process of the AL method for classifier construction.
Our study shows that not all classifiers can benefit from using AL methods according to all measures. In some cases (in this paper, KNN in high-PRT measure, LDA in all three kinds of performance measures and DT in high-PRT measure), the AL methods may not help improve performance, or even reduce it.
Of the four classifiers tested in this paper, the SVM is the best for using AL methods for the following reasons. First, it can benefit greatly from some basic ACS methods (in our case, ACS-2, ACS-4 and ACS-6), showing perfect performance evolving curves with steeply ascending fore parts and flat back parts. Second, the good ACS methods for SVM in one kind of performance measure will also be good in other kinds of performance measures. That would be a merit when more than one services asking for different kinds of performance are demanded. In this case, only one system needed to be built and that surely will greatly reduce costs. Third, its performance could be further improved by ACS method using exploration-and-exploitation criterion, which considers different sample preference in different learning stages.
The exploration-and-exploitation criterion is suitable for SVM but not for KNN, LDA and DT classifiers. The criteria considering different sample preference in different learning stages and being suitable for other classifiers may also exist and should be found and studied in the future.
The thorough knowledge of a classifier’s preference on training samples is the key to achieve efficient AL-based classification system, because all AL operations, such as choosing AL strategy and ACS methods, adjusting sample selection preference in iterations, depend on knowing a classifier’s sample favoritism to identify the best samples that satisfy the demands of the classifier. Thus, further study should also focus on investigating the sample preference mechanism of a classifier to build a high-performance AL-based frame on it.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}