Improving Classification Accuracy of Multi-Temporal Landsat Images by Assessing the Use of Different Algorithms, Textural and Ancillary Information for a Mediterranean Semiarid Area from 2000 to 2015

 ,
,  and
and 
Abstract
:
1. Introduction
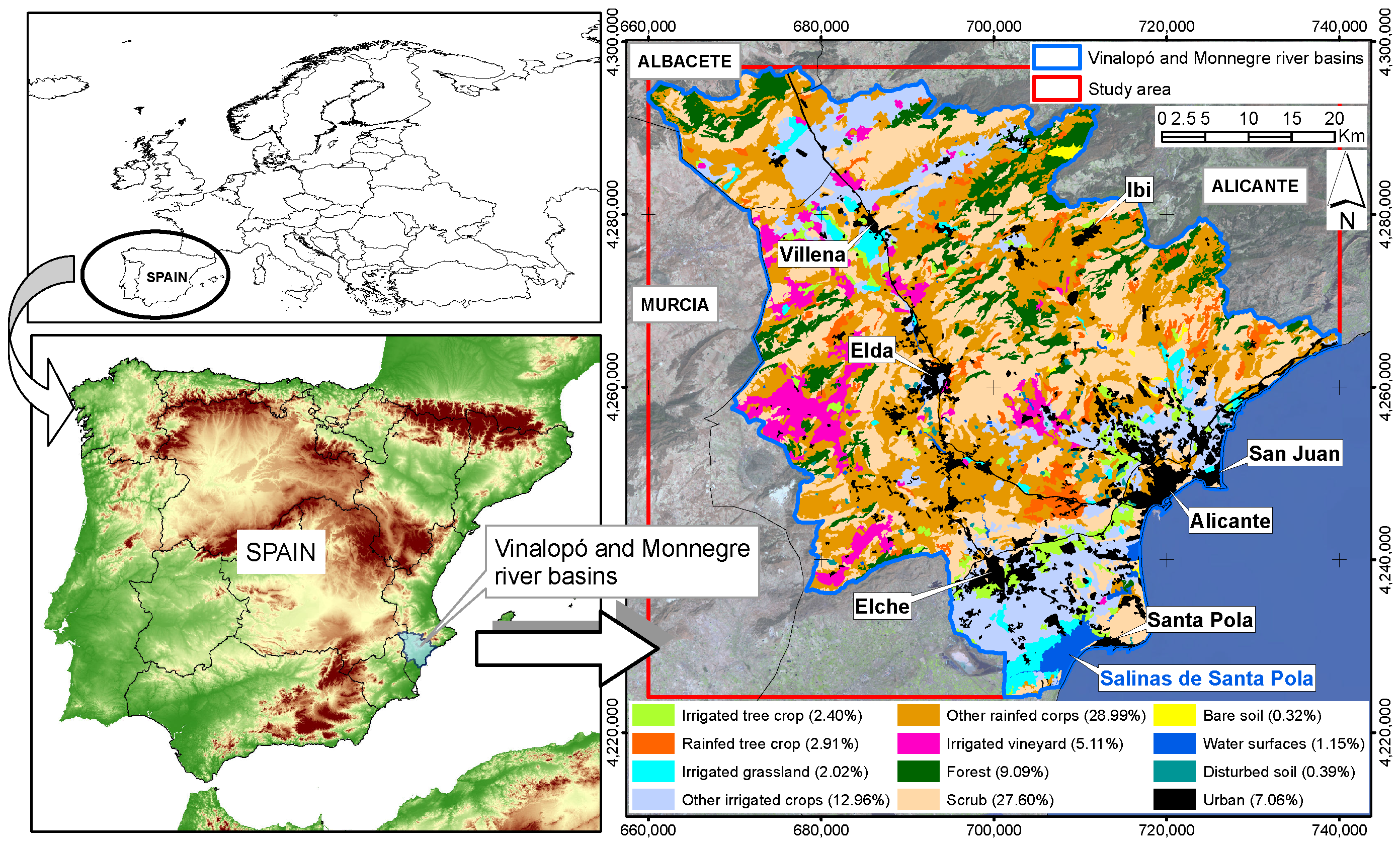
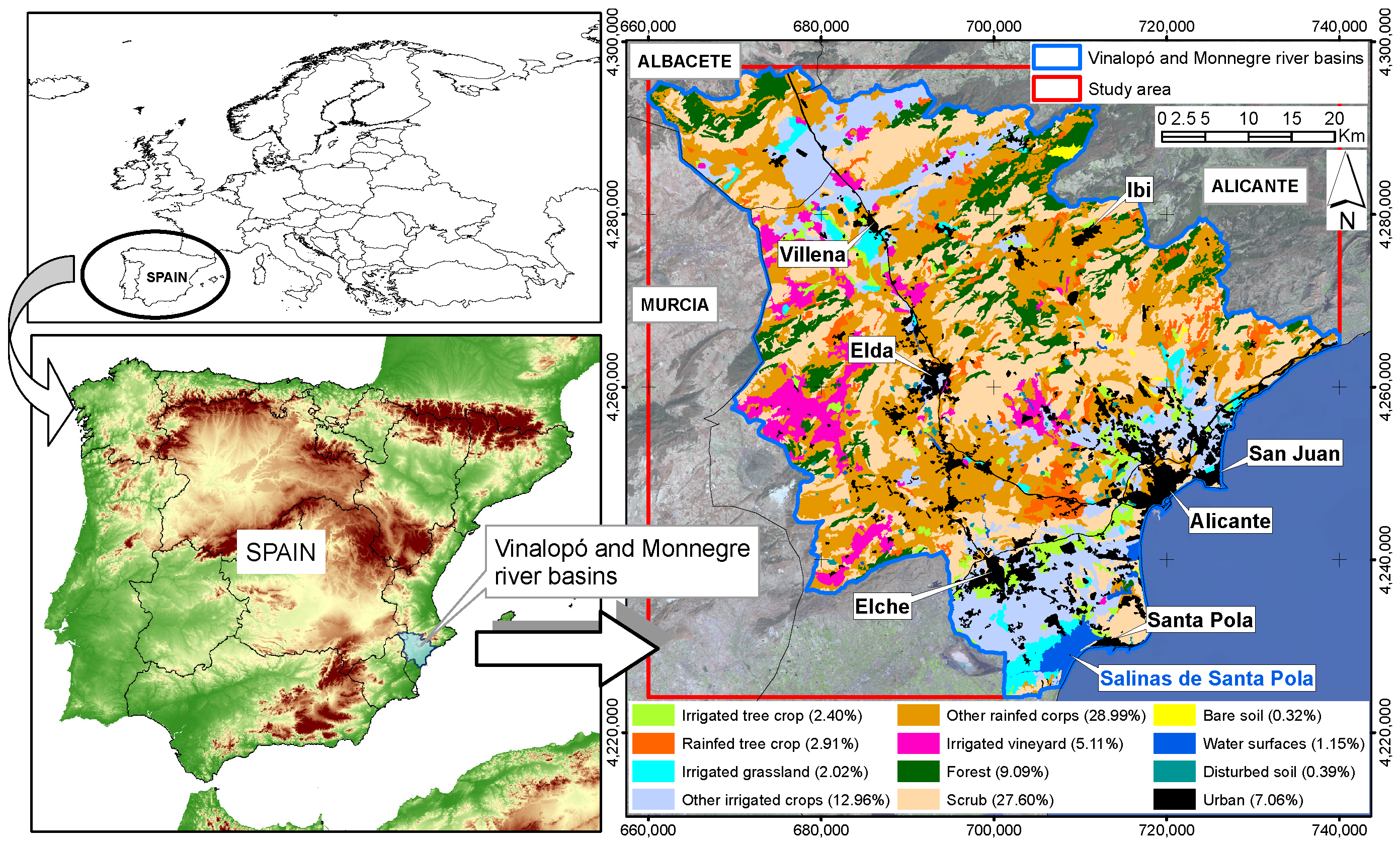
2. Study Area
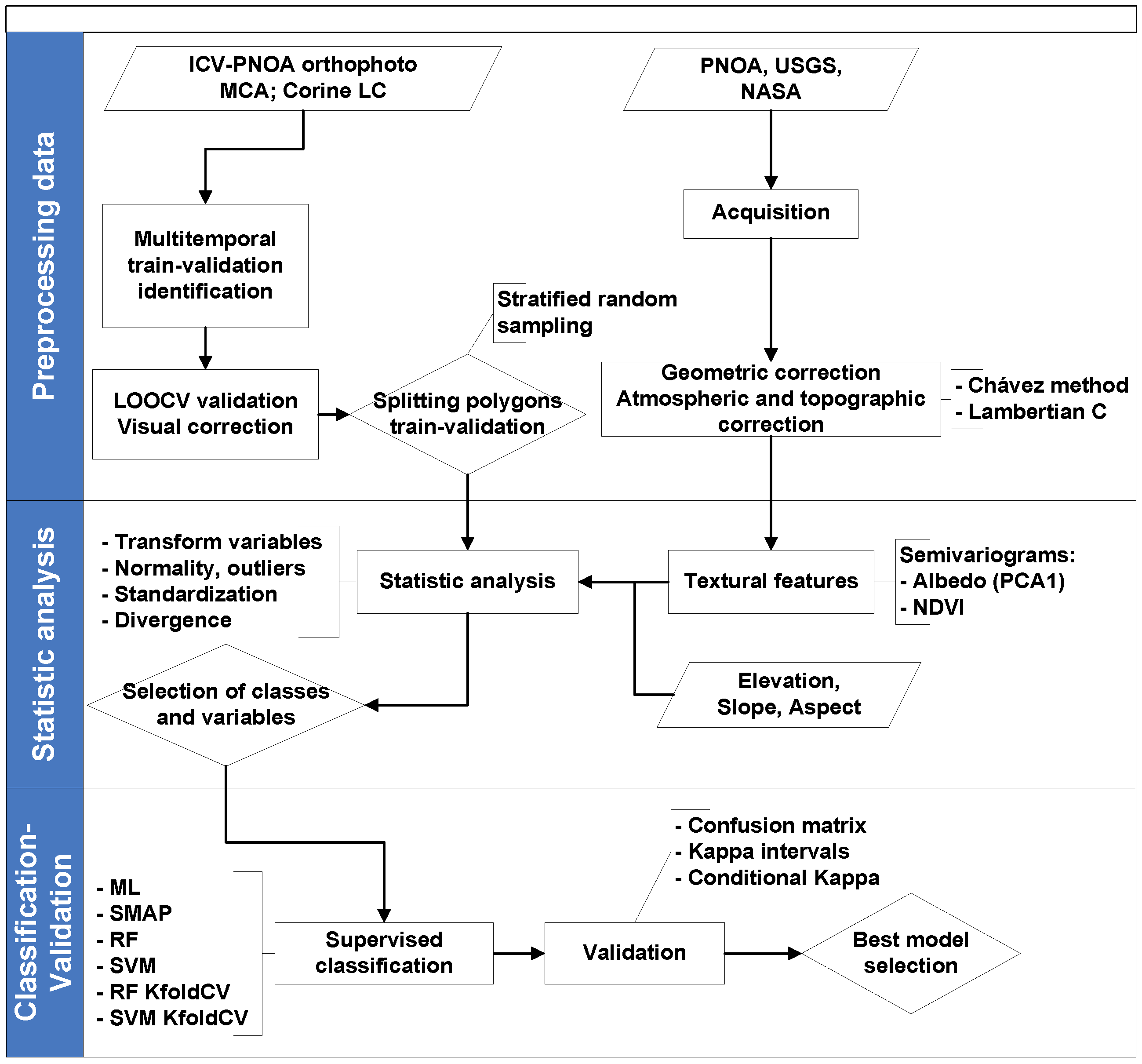
3. Material and Methods
3.1. Data Sources
3.2. Classification Methods
3.2.1. Maximum Likelihood
3.2.2. Random Forest
3.2.3. Support Vector Machines
3.2.4. Sequential Maximum A Posteriori
3.3. Multi-Seasonal Approach
3.4. Feature Sets
3.5. Training and Validation Areas
- Mapa de Cultivos y Aprovechamientos (crops and land-use map) published by the Spanish Ministerio de Agricultura, Pesca y Alimentación (Ministry of Agriculture, Fisheries and Food) with field data collected between 2001 and 2007 at a 1:50,000 scale.
- Corine Land Cover maps [24] for 2000 and 2006 at a 1:200,000 scale.
- 2002 orthophotography from the Sistema de Información Geográfica de Parcelas Agrícolas (Agricultural Plots Geographic Information System) project at a 1:5000 scale by the Spanish Ministerio de Agricultura, Pesca y Alimentación (Ministry of Agriculture, Fisheries and Food).
- Orthophotography series available in the Instituto Cartográfico de Valencia (Cartographic Institute of Valencia) and the Plan Nacional de Ortofotografía Aérea (Spanish Orthophotography National Plan, PNOA) for 2005, 2007 and 2012 at a 1:10,000 scale by the Spanish Instituto Geográfico Nacional (National Geographic Institute).
- Orthophotography from the PNOA for 2009 and 2014 at a 1:5000 scale.
3.6. Classification Process
3.7. Validation of Classifications and Evaluation of Hypothesis
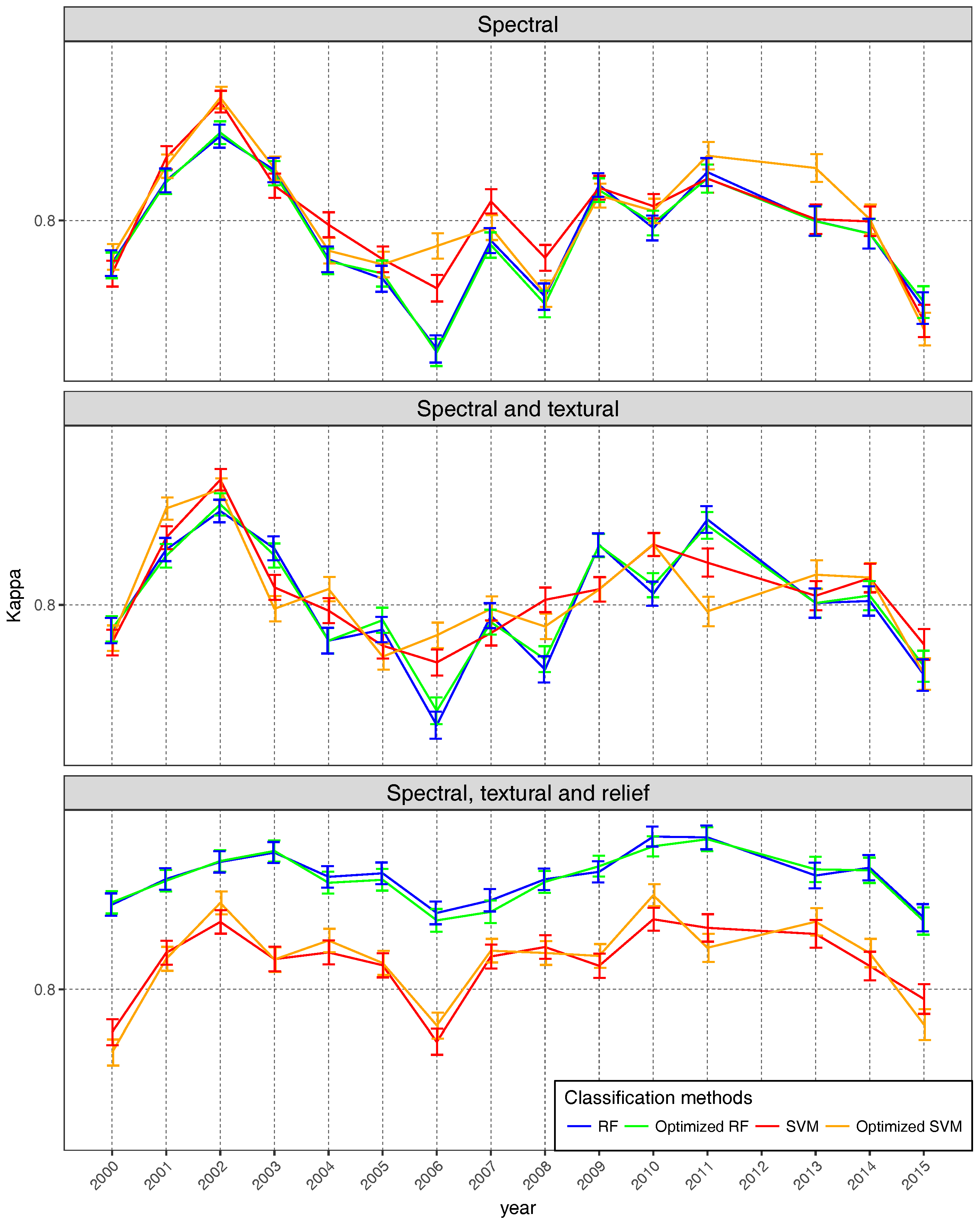
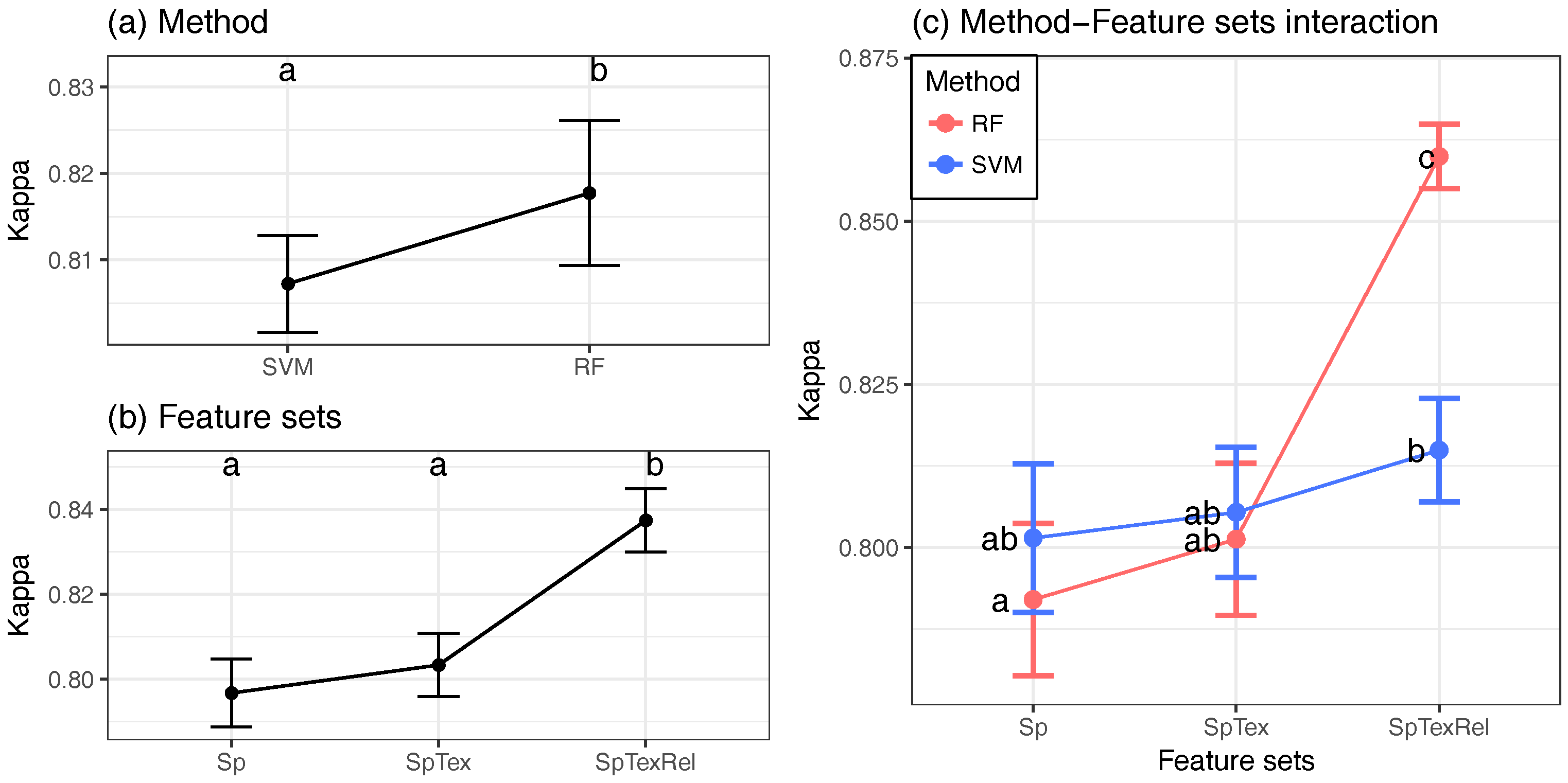
- To evaluate how the results improve when RF and SVM parameters are optimized, a factorial ANOVA was conducted to compare the effects of the classification method (method), optimization (optimized), feature sets (varset) and the interactions between them. method included two levels (RF; SVM); optimized included two levels (Yes; No); and varset three levels (Sp: Spectral information; SpTex: Spectral and Textural information; SpTexRel: Spectral, Textural and contextual information). In this case, classifications were performed using the maximum number of images available per year: four in 2000, 2001, 2009, 2010, 2014, 2015; three in 2002, 2003, 2011, 2013; and two in 2004, 2005, 2006, 2007 and 2008. That makes 180 classifications.
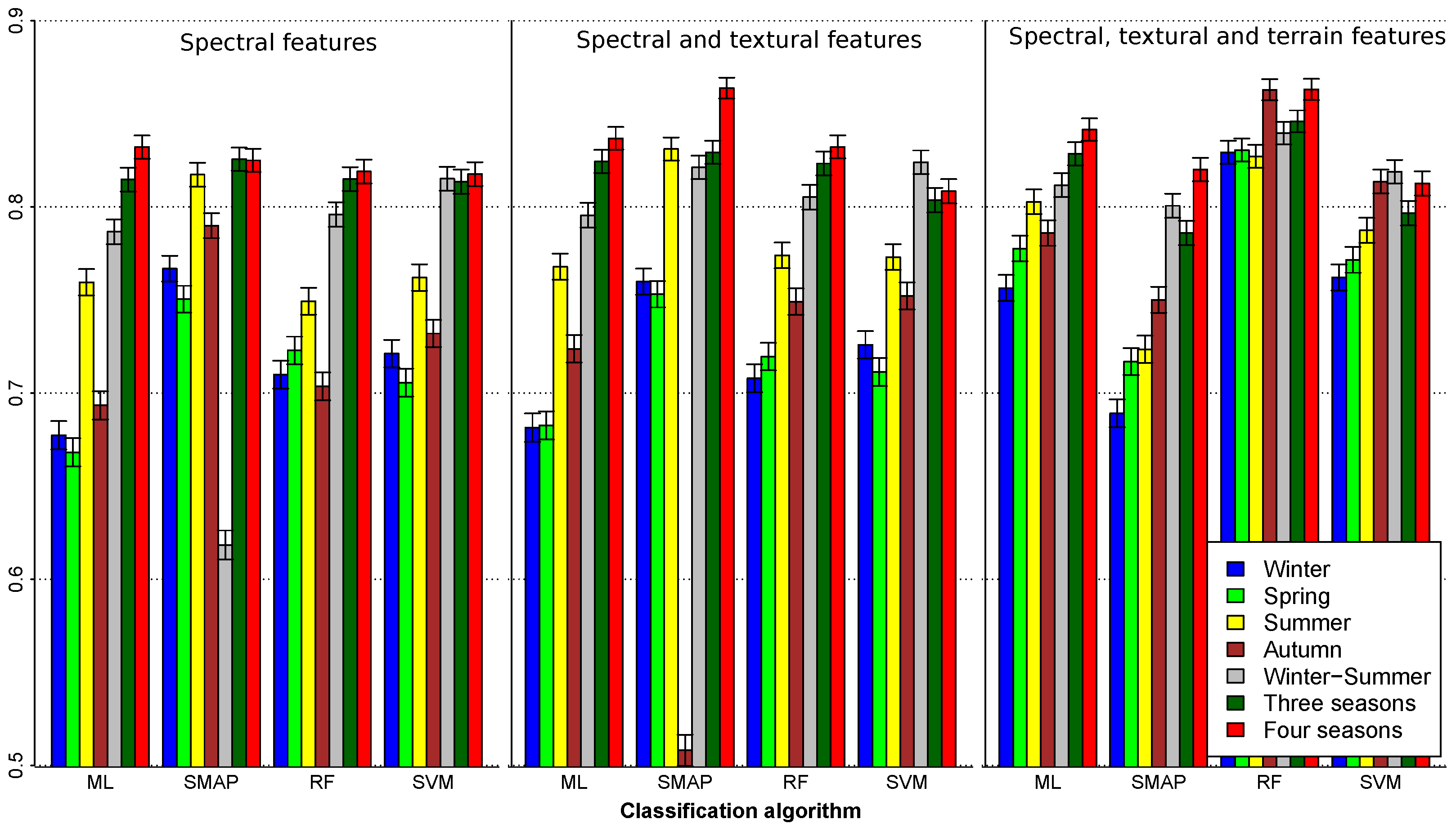
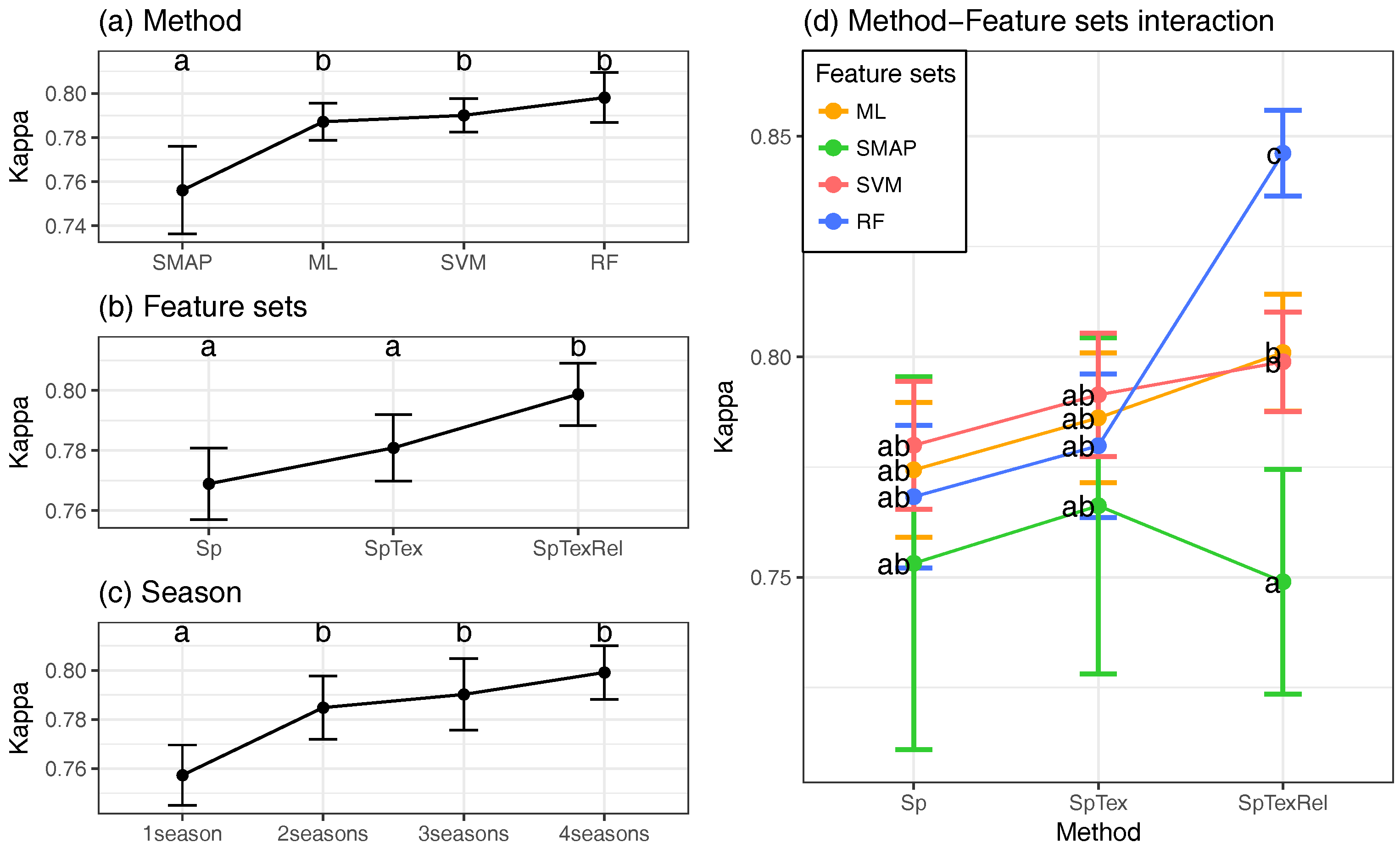
- To evaluate how classification accuracy improves in the final models, a factorial ANOVA was conducted to compare the main effects of method, varset, the number of seasonal images (season) and the interaction effect between them. In this case, method included four levels (RF; SVM; ML; SMAP) and season four levels (One season; Two seasons; Three seasons; Four seasons). In this case, only the years when 4 images were available (2000, 2001, 2009, 2010, 2014 and 2015) were taken into account, making 288 classifications.
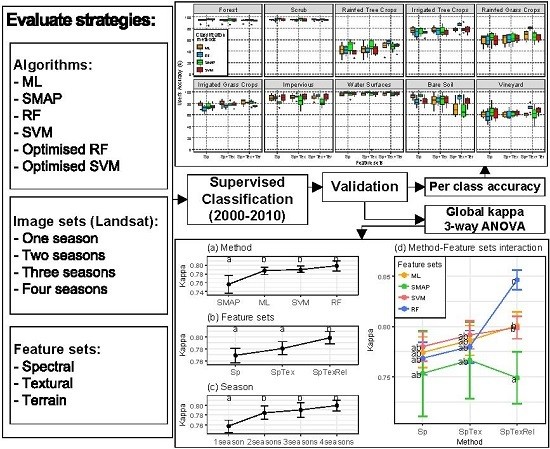
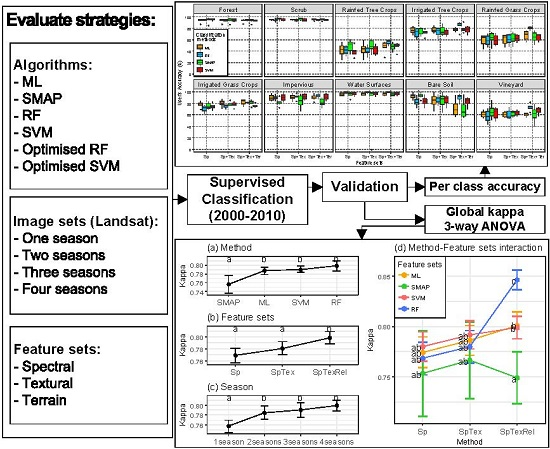
4. Results and Discussion
4.1. Classification of 2009 Image
4.2. Parameter Optimization
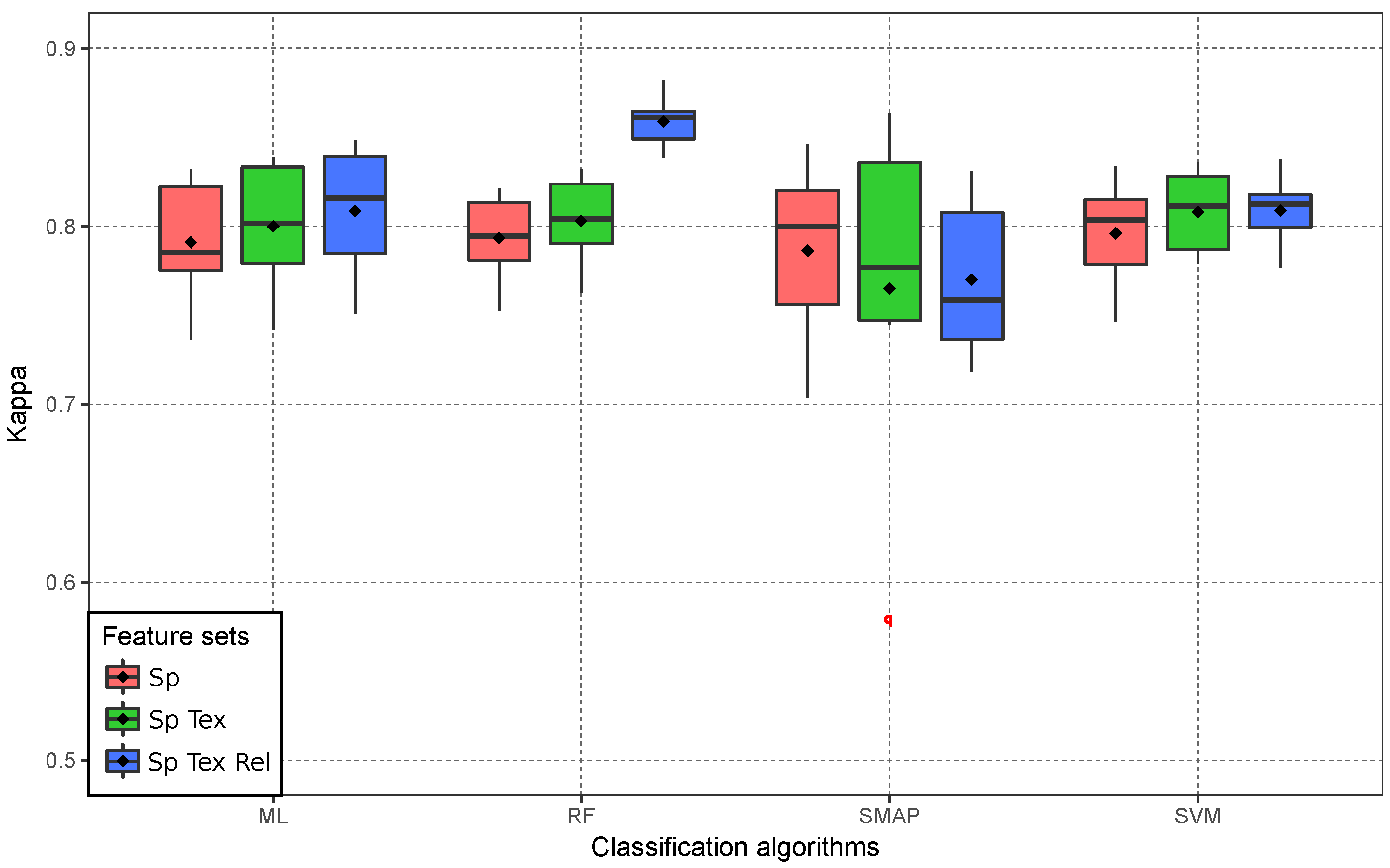
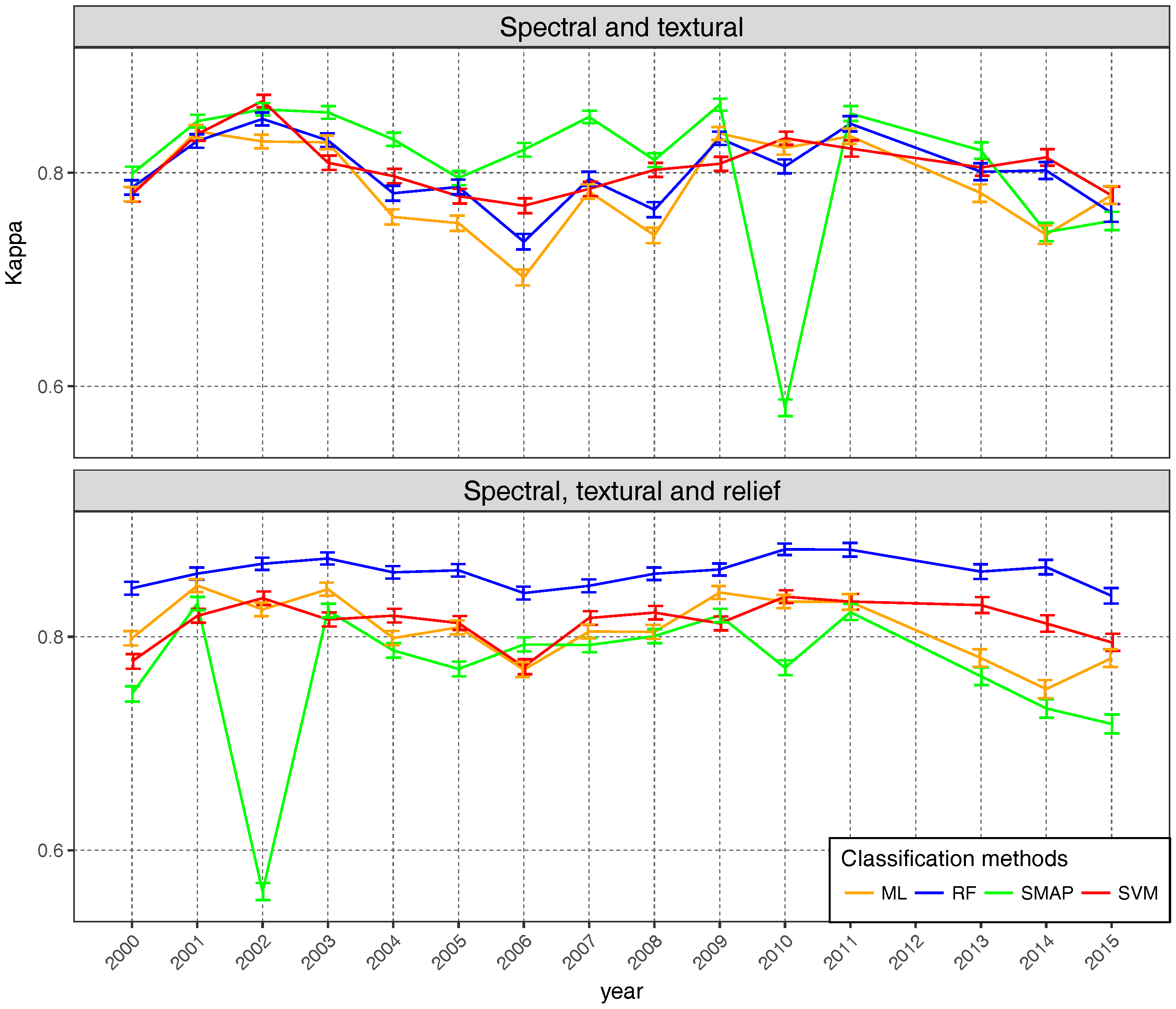
4.3. Global Validation
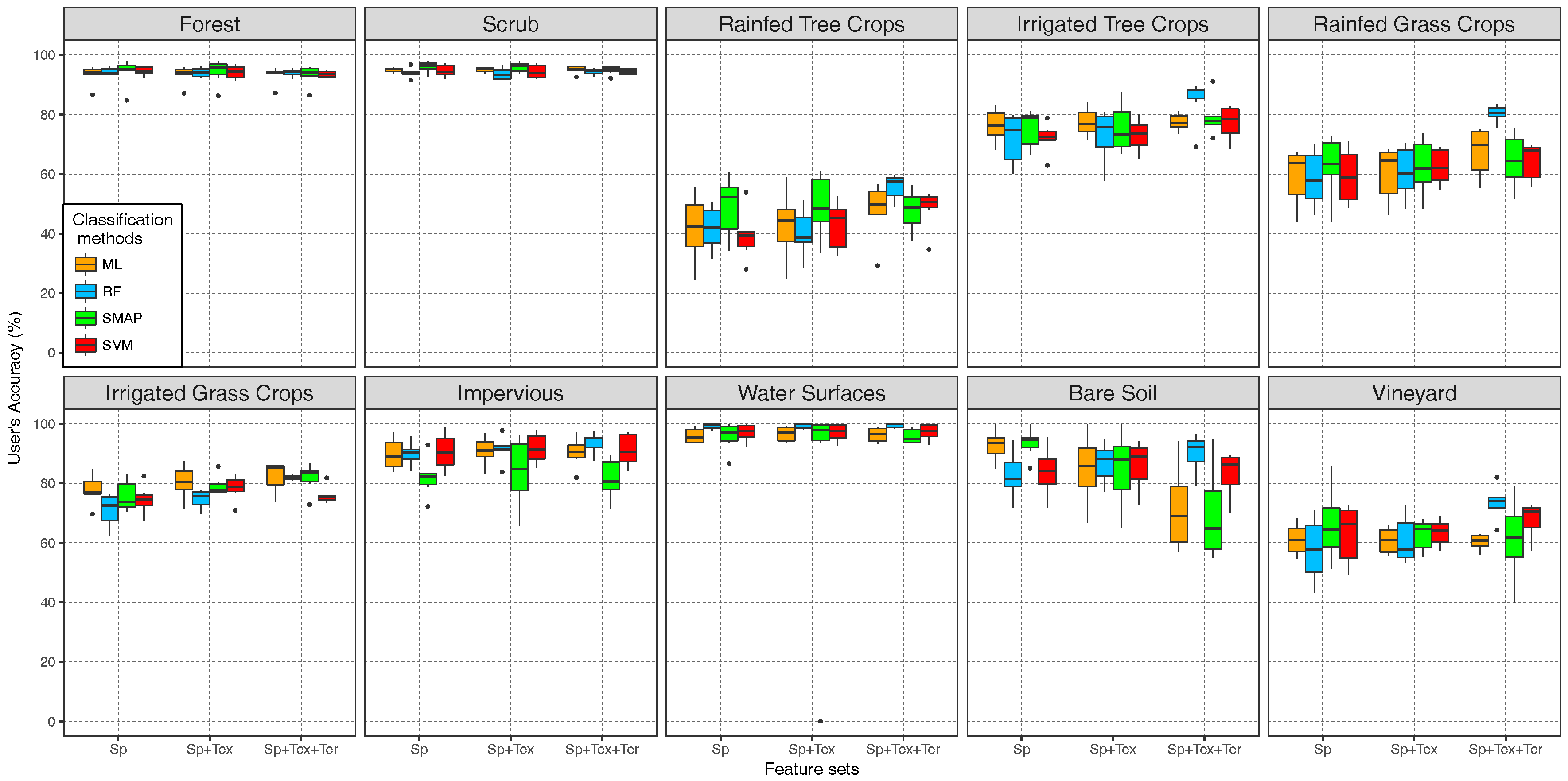
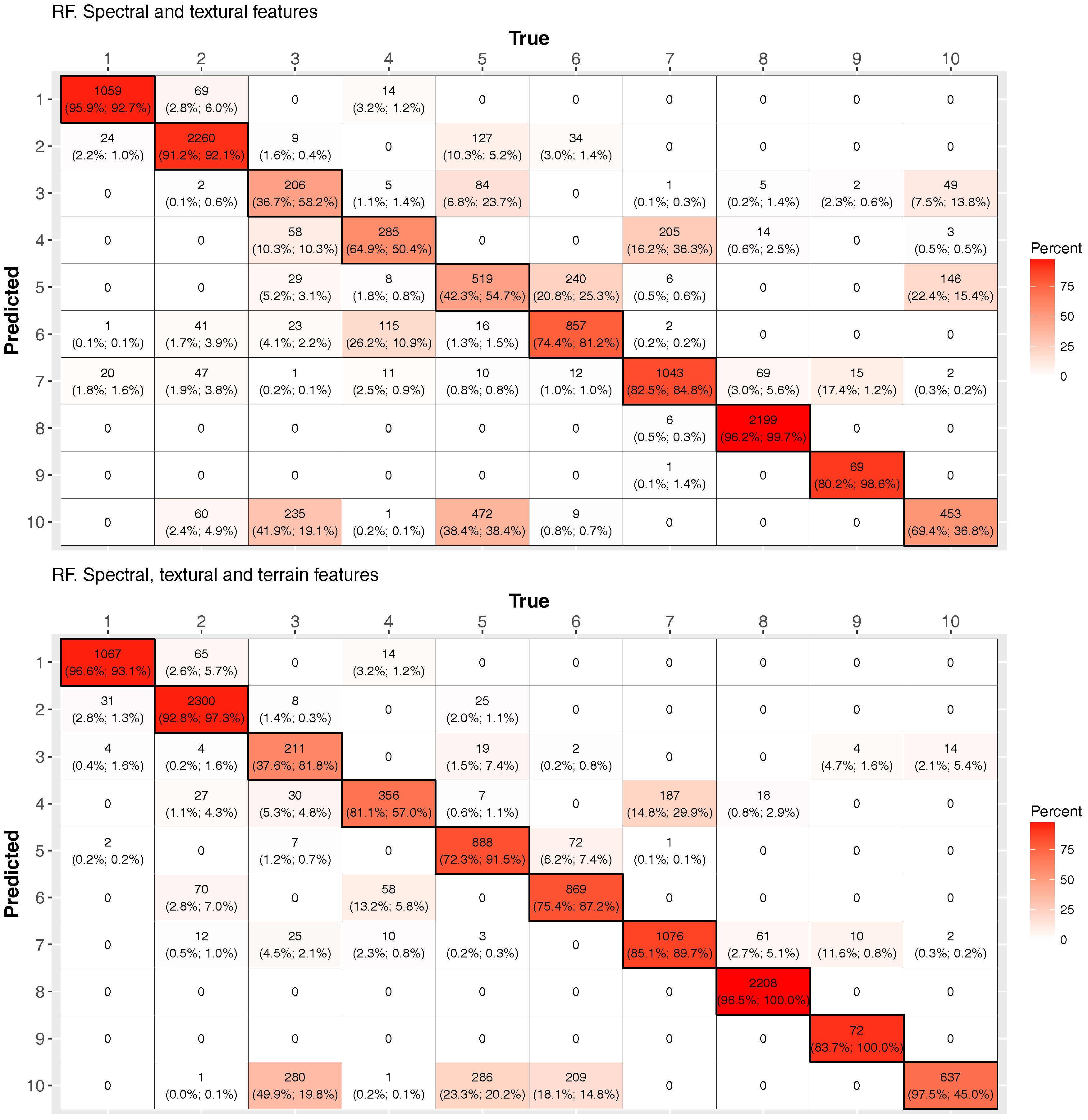
4.4. Per Class Validation
4.5. Visual Validation
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Alrababah, M.; Alhamad, M. Land use/cover classification of arid and semi-arid Mediterranean landscapes using Landsat ETM. Int. J. Remote Sens. 2006, 27, 2703–2718. [Google Scholar] [CrossRef]
- Di Palma, F.; Amato, F.; Nolè, G.; Martellozzo, F.; Murgante, B. A SMAP Supervised Classification of Landsat Images for Urban Sprawl Evaluation. ISPRS Int. J. Geoinform. 2016, 5, 109. [Google Scholar] [CrossRef]
- Berberoglu, S.; Curran, P.; Lloyd, C.; Atkinson, P. Texture classification of Mediterranean land cover. Int. J. Appl. Earth Obs. Geoinform. 2007, 9, 322–334. [Google Scholar] [CrossRef]
- Senf, C.; Leitão, P.J.; Pflugmacher, D.; Van der Linden, S.; Hostert, P. Mapping land cover in complex Mediterranean landscapes using Landsat: Improved classification accuracies from integrating multi-seasonal and synthetic imagery. Remote Sens. Environ. 2015, 156, 527–536. [Google Scholar] [CrossRef]
- Maselli, F.; Conese, C.; Petkov, L.; Resti, R. Inclusion of prior probabilities derived from a nonparametric process into the maximum likelihood classifier. Photogramm. Eng. Remote Sens. 1992, 58, 201–207. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector network. Mach. Learn. 1995, 20, 1–5. [Google Scholar] [CrossRef]
- McCauley, J.; Engel, B. Comparison of scene segmentations: SMAP, ECHO, and maximum likelihood. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1313–1316. [Google Scholar] [CrossRef]
- Ehsani, A. Evaluation of sequential maximum a posteriori (SMAP) Method for Land Cover Classification. In Proceedings of the Geomatics 90 (National Conference & Exhibition), Tehran, Iran, 30 May–1 June 2011. [Google Scholar]
- Li, M.; Im, J.; Beier, C. Machine learning approaches for forest classification and change analysis using multi-temporal Landsat TM images over Huntington Wildlife Forest. GISci. Remote Sens. 2013, 50, 361–384. [Google Scholar]
- Sluiter, R.; Pebesma, E.J. Comparing techniques for vegetation classification using multi- and hyperspectral images and ancillary environmental data. Int. J. Remote Sens. 2010, 31, 6143–6161. [Google Scholar] [CrossRef]
- He, J.; Harris, J.; Sawada, M.; Behnia, P. A comparison of classification algorithms using Landsat-7 and Landsat-8 data for mapping lithology in Canada’s Arctic. Int. J. Remote Sens. 2015, 36, 2252–2276. [Google Scholar] [CrossRef]
- Rodríguez-Galiano, V. Metodología Basada en Teledetección, SIG Y Geoestadística Para Cartografía Y Análisis De Cambios De Cubiertas Del Suelo De La Provincia De Granada. Ph.D. Thesis, Department of Geodynamics, University of Granada, Granada, Spain, 2011. [Google Scholar]
- Rodriguez-Galiano, V.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Ehsani, A.; Quiel, F. Efficiency of Landsat ETM+ Thermal Band for Land Cover Classification of the Biosphere Reserve “Eastern Carpathians” (Central Europe) Using SMAP and ML Algorithms. Int. J. Environ. Res. 2010, 4, 741–750. [Google Scholar]
- Kumar, U.; Dasgupta, A.; Mukhopadhyay, C.; Ramachandra, T. Advanced Machine Learning Algorithms based Free and Open Source Packages for Landsat ETM+ Data Classification. In Proceedings of the OSGEO-India: FOSS4G 2012- First National Conference: Open Source Geospatial Resources to Spearhead Development and Growth, Andhra Pradesh, India, 25–27 October 2012; pp. 1–7. [Google Scholar]
- Elumnoh, A.; Shrestha, R. Application of DEM data to Landsat image classification: Evaluation in a tropical wet-dry landscape of Thailand. Photogramm. Eng. Remote Sens. 2000, 66, 297–304. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Zhou, Q.; Robson, M. Contextual information is ultimately necessary if one is to obtain accurate image classifications. Int. J. Remote Sens. 2001, 22, 612–625. [Google Scholar]
- Eisavi, V.; Homayouni, S.; Yazdi, A.M.; Alimohammadi, A. Land cover mapping based on random forest classification of multitemporal spectral and thermal images. Environ. Monit. Assess. 2015, 187, 187–291. [Google Scholar] [CrossRef] [PubMed]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef]
- CHJ. Plan Hidrológico de la Demarcación Hidrográfica del Júcar; Technical Report; Cemarcación Hidrográfica del Júcar, Ministerio de Medio Ambiente: Singapore, 2015. [Google Scholar]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide - Addendum 2000; Technical Report No. 40; European Environment Agency: Copenhagen, Denmark, 2000. [Google Scholar]
- Chávez, P. An improved dark-object substraction technique for atmospheric scattering correction of multispectral data. Remote Sens. Environ. 1988, 24, 459–479. [Google Scholar] [CrossRef]
- Teillet, P.; Guindon, B.; Goodenough, D. On the slope-aspect correction of multispectral scanner data. Can. J. Remote Sens. 1982, 8, 84–106. [Google Scholar] [CrossRef]
- Swain, P.; Davis, S.E. Remote Sensing: The Quantitative Approach; McGraw-Hill: New York, NY, USA, 1976; p. 396. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Gislason, P.; Benediktsson, J.; Sveinsson, J. Random Forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Miller, J. Contextual land-cover classification: Incorporating spatial dependence in land-cover classification models using random forests and the Getis statistic. Remote Sens. Lett. 2010, 1, 45–54. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Prasad, A.; Iverson, L.; Liaw, A. Newer Classification and Regression Tree Techniques: Bagging and Random Forests for Ecological Prediction. Ecosystems 2006, 9, 181–199. [Google Scholar] [CrossRef]
- Cutler, D.; Edwards, T., Jr.; Beard, K.; Cutler, A.; Hess, K.; Gibson, J.; Lawler, J. Random forest for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Cánovas-García, F.; Alonso-Sarría, F.; Gomariz-Castillo, F.; Onate Valdivieso, F. Modification of the random forest algorithm to avoid statistical dependence problems when classifying remote sensing imagery. Comput. Geosci. 2017, 103, 1–11. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin, Germany, 2009. [Google Scholar]
- Camps-Valls, G.; Bruzzone, L. (Eds.) Kernel Methods for Remote Sensing Data Analysis, 1st ed.; John Wiley & Sons, Ltd.: Chichester, UK, 2009. [Google Scholar]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Vapnik, V. Statistical Learning Theory, 1st ed.; Wiley Interscience: Hoboken, NJ, USA, 1998; p. 736. [Google Scholar]
- Gualtieri, J.; Cromp, R. Support Vector Machines for Hyperspectral Remote Sensing Classification. In Proceedings of the 27th AIPR Workshop: Advances in Computer Assisted Recognition, Washington, DC, USA, 14–16 October 1998. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Tso, B.; Mather, P. Classification Methods for Remotely Sensed Data, 2nd ed.; Taylor & Francis: Didcot, UK; Abingdon, UK, 2009; p. 352. [Google Scholar]
- Auria, L.; Moro, R. Support Vector Machines (SVM) as a Technique for Solvency Analysis; Discussion Papers of DIW Berlin 811; German Institute for Economic Research: Berlin, Germany, 2008. [Google Scholar]
- Bouman, C.; Shapiro, M. Multispectral Image Segmentation using a Multiscale Image Model. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing, San Francisco, CA, USA, 23–26 March 1992; pp. III565–III568. [Google Scholar]
- Bouman, C.; Shapiro, M. A Multiscale Random Field Model for Bayesian Image Segmentation. IEEE Trans. Image Process. 1994, 3, 162–177. [Google Scholar] [CrossRef] [PubMed]
- Cheng, H.; Bouman, C.A. Multiscale Bayesian Segmentation Using a Trainable Context Model. IEEE Trans. Image Process. 2001, 10, 511–525. [Google Scholar] [CrossRef] [PubMed]
- Mather, P.; Koch, M. Computer Processing of Remotely-Sensed Images: An Introduction, 4th ed.; Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- Molinaro, A.; Simon, R.; Pfeiffer, R. Prediction error estimation: A comparison of resampling methods. Bioinformatics 2005, 21, 3301–3307. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M.; Johnson, K. Over-Fitting and Model Tuning. In Applied Predictive Modeling; Springer: New York, NY, USA, 2013; pp. 61–92. [Google Scholar]
- Caputo, B.; Sim, K.; Furesjo, F.; Smola, A. Appearance-based object recognition using SVMS: Which kernel should I use? In Proceedings of the NIPS Workshop on Statitsical Methods for Computational Experiments in Visual Processing and Computer Vision, Whistler, BC, Canada, 12–14 December 2002. [Google Scholar]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. kernlab—An S4 Package for Kernel Methods in R. J. Stat. Softw. 2004, 11, 1–20. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R. Classification and Regression Trees. 1984. Available online: https://pdfs.semanticscholar.org/df5a/9aeb6ad2ebda81afc7e0377bcd770a3c19f9.pdf (accessed on 17 October 2017).
- Neteler, M.; Mitasova, H. Open Source GIS. A GRASS GIS Approach, 3rd ed.; The International Series in Engineering and Computer Science; Springer: New York, NY, USA, 2008; Volume 773, p. 486. [Google Scholar]
- Neteler, M.; Bowman, M.; Landa, M.; Metz, M. GRASS GIS: A multi-purpose open source GIS. Environ. Model. Softw. 2012, 31, 124–130. [Google Scholar] [CrossRef]
- Venables, W.; Smith, D. The R Development Core Team. In An Introduction to R; 2012; Available online: http://www.math.vu.nl/stochastics/onderwijs/statlearn/R-Binder.pdf (accessed on 17 October 2017).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2012. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Congalton, R.; Mead, R. A Quantitative Method to Test for Consistency and Correctness in Photointerpretation. Photogramm. Eng. Remote Sens. 1983, 49, 69–74. [Google Scholar]
- Chuvieco, E. Fundamentals of Satellite Remote Sensing. An Environmental Approach; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Landis, J.; Koch, G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Congalton, R.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; Mapping Science, Taylor & Francis: Didcot, UK; Abingdon, UK, 1998. [Google Scholar]
- Long, J.; Ervin, L. Using Heteroscedasticity Consistent Standard Errors in the Linear Regression Model. Am. Stat. 2000, 54, 217–224. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Sensor | Date | Sensor | Date | Sensor | Date | Sensor | Date | Sensor |
|---|---|---|---|---|---|---|---|---|---|
| 2000 | 2001 | 2002 | 2003 | 2004 | |||||
| 29-Jan-00 | ETM+ | 1-Dec-01 | TM | 6-Feb-03 | ETM+ | 6-Feb-03 | ETM+ | 4-Mar-04 | TM |
| 21-Jun-00 | ETM+ | 21-Apr-01 | ETM+ | 24-Apr-02 | ETM+ | 10-March-03 | TM | 13-Apr-04 | ETM+ |
| 8-Aug-00 | ETM+ | 26-Jul-01 | ETM+ | 19-Jun-02 | TM | 29-May-03 | TM | 19-Aug-04 | ETM+ |
| 27-Oct-00 | ETM+ | 30-Oct-01 | ETM+ | - | - | 26-Sep-03 | TM | 15-Nov-04 | TM |
| 2005 | 2006 | 2007 | 2008 | 2009 | |||||
| 4-Mar-04 | TM | 24-Jan-07 | TM | 24-Jan-07 | TM | 14-Feb-09 | TM | 14-Feb-09 | TM |
| 18-May-05 | ETM+ | 6-Jun-06 | ETM+ | 8-May-07 | ETM+ | 19-Jun-08 | TM | 5-May-09 | TM |
| 26-Jun-05 | TM | 16-Jul-06 | TM | 4-Aug-07 | TM | 15-Sep-08 | ETM+ | 24-Jul-09 | TM |
| 12-Dec-05 | ETM+ | 13-Nov-06 | ETM+ | 16-Nov-07 | ETM+ | 1-Oct-08 | ETM | 10-Sep-09 | TM |
| 2010 | 2011 | 2013 | 2014 | 2015 | |||||
| 16-Nov-10 | TM | 4-Feb-11 | TM | - | - | 16-Mar-14 | OLI | 2-Feb-15 | OLI |
| 24-May-10 | TM | 9-Apr-11 | TM | 14-Apr-13 | OLI | 4-Jun-14 | OLI | 7-Jun-15 | OLI |
| 11-Jul-10 | TM | 28-Jun-11 | TM | 19-Jul-13 | OLI | 22-Jul-14 | OLI | 9-Jul-15 | OLI |
| 29-Sep-10 | TM | - | - | 14-Nov-13 | OLI | 26-Oct-14 | OLI | 30-Nov-15 | OLI |
| Training Areas | Validation Areas | |||||
|---|---|---|---|---|---|---|
| Use | N | Area | % | N | Area | % |
| Forest | 19 | 328.21 | 13.66 | 10 | 98.35 | 9.79 |
| Scrub | 22 | 302.43 | 12.59 | 12 | 213.50 | 21.26 |
| Rainfed tree crops | 13 | 77.89 | 3.24 | 7 | 51.39 | 5.12 |
| Irrigated tree crops | 14 | 148.01 | 6.16 | 8 | 39.78 | 3.96 |
| Rainfed grassland | 15 | 231.85 | 9.65 | 8 | 111.01 | 11.05 |
| Irrigated grassland | 10 | 293.20 | 12.20 | 5 | 103.74 | 10.33 |
| Impervious surfaces | 16 | 423.84 | 17.64 | 7 | 112.86 | 11.24 |
| Water surfaces | 11 | 391.12 | 16.28 | 6 | 207.72 | 20.69 |
| Bare soil | 4 | 7.56 | 0.31 | 2 | 8.02 | 0.80 |
| Vineyard | 17 | 198.62 | 8.27 | 8 | 57.81 | 5.76 |
| Total | 141 | 2402.73 | 100 | 73 | 1004.18 | 100 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomariz-Castillo, F.; Alonso-Sarría, F.; Cánovas-García, F. Improving Classification Accuracy of Multi-Temporal Landsat Images by Assessing the Use of Different Algorithms, Textural and Ancillary Information for a Mediterranean Semiarid Area from 2000 to 2015. Remote Sens. 2017, 9, 1058. https://doi.org/10.3390/rs9101058
Gomariz-Castillo F, Alonso-Sarría F, Cánovas-García F. Improving Classification Accuracy of Multi-Temporal Landsat Images by Assessing the Use of Different Algorithms, Textural and Ancillary Information for a Mediterranean Semiarid Area from 2000 to 2015. Remote Sensing. 2017; 9(10):1058. https://doi.org/10.3390/rs9101058
Chicago/Turabian StyleGomariz-Castillo, Francisco, Francisco Alonso-Sarría, and Fulgencio Cánovas-García. 2017. "Improving Classification Accuracy of Multi-Temporal Landsat Images by Assessing the Use of Different Algorithms, Textural and Ancillary Information for a Mediterranean Semiarid Area from 2000 to 2015" Remote Sensing 9, no. 10: 1058. https://doi.org/10.3390/rs9101058
APA StyleGomariz-Castillo, F., Alonso-Sarría, F., & Cánovas-García, F. (2017). Improving Classification Accuracy of Multi-Temporal Landsat Images by Assessing the Use of Different Algorithms, Textural and Ancillary Information for a Mediterranean Semiarid Area from 2000 to 2015. Remote Sensing, 9(10), 1058. https://doi.org/10.3390/rs9101058