1. Introduction
Geospatial object detection from remote sensing imagery is an important tool when analyzing object-related information [
1,
2,
3]. High spatial resolution (HSR) remote sensing imaging sensors can now acquire aerial and satellite images with abundant detail and complex spatial structural information, which can be used in a wide range of civil and engineering applications, such as segmentation [
4], scene annotation [
5], object detection [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22] (e.g., airplane detection [
6,
12], urban area detection [
13], vehicle detection [
21,
22]), scene classification and recognition [
23,
24,
25,
26,
27], etc. Differing from natural imagery obtained by the camera on the ground from a horizontal view, HSR remote sensing imagery is obtained by satellite-borne or space-borne sensors from a top-down view, which is an approach that can be easily influenced by weather and illumination conditions. In addition, differing from the anteroposterior object position from natural imagery, the position of the objects in HSR remote sensing imagery is mostly left–right. Before executing the object detection task, the term “object” for HSR remote sensing imagery should be defined. Specifically, objects in HSR remote sensing imagery include not only man-made objects (e.g., vehicles, ships, buildings, etc.) with sharp boundaries that are independent of the background environment, but also landscape objects, such as land-use/land-cover (LULC) parcels with vague boundaries [
28]. As HSR remote sensing imagery contains various geospatial objects, the accurate detection of multi-class geospatial objects is of vital importance. However, multi-class geospatial object detection from HSR remote sensing imagery is a significant and challenging task for three main reasons. The first reason is the imaging conditions of HSR remote sensing imagery, which include large variations in the visual appearance of objects, caused by viewpoint variation, occlusion, background clutter, illumination, shadow, etc. The second reason is the small-size and scale-variable properties of the multi-class geospatial objects compared with the large-scale complex backgrounds in HSR remote sensing imagery. The third reason is the relative dearth of manually annotated samples for the geospatial object training data. Because of the challenging nature of multi-class geospatial object detection from HSR remote sensing imagery, a large amount of effort has been devoted to detecting and localizing geospatial objects [
29].
Most of the traditional object detection methods regard the object detection problem as a classification problem, which consists of feature extraction and feature classification stages. For the remote sensing imagery object detection methods, the spectral-based object detection methods treat the detection as a two-class classification task, namely, the object and the background. The spectral-based detection methods includes the spectral matched filter (SMF), the matched subspace detector (MSD), the adaptive coherence/cosine detectors (ACDs), the sparse-representation based detectors, etc. These methods mainly focus on the differences of the target and the background [
10]. There are four kinds of object detection methods, namely, template matching based methods, knowledge-based methods, OBIA-based methods, and machine learning methods [
15]. Template matching-based methods can be divided into two classes-rigid template matching and deformable template matching, which involve two main procedures, namely, template generation and similarity measurement. The knowledge-based object detection methods use prior knowledge, including geometric information and contextual information, which generally translates the object detection problem into a hypothesis testing problem. OBIA-based object detection methods involve two main steps—image segmentation and object classification—where the appropriate segmentation scale is the key factor influencing the object detection result. For the machine learning based methods, they typically include feature extraction, optional feature fusion, dimension reduction, and classifier training stages. The feature extraction stage relying on the proposals generated with selective search (SS) [
30] usually involves extracting handcrafted features such as spectral features, texture features, and local image features (e.g., scale-invariant feature transform (SIFT) or histogram of oriented gradients (HOG) [
16]). The feature classification stage mainly deals with training a classifier, such as support vector machine (SVM) [
31], conditional random fields [
10], sparse coding based classifiers [
14,
32], bag-of-words (BoW) classifiers [
23,
27,
31], etc. The core idea of these methods is to train a classifier to discriminate the predicted labels, i.e., object or not. In summary, these methods are heavily reliant on the manually designed feature descriptors and human-labeled training samples, and perform well when there is a large amount of training data and the feature representation is efficient. In addition to the involvement of human ingenuity in the feature design for specific object detection tasks, these approaches separate the object detection tasks into non-related region proposal generation and object localization stages, which greatly increases the training load of the algorithm.
Recent developments in deep learning [
29,
33,
34] have provided an automatic feature extraction and feature representation framework for various tasks, including classification and object detection [
23,
26,
32]. Due to the recent development of large public natural image datasets such as ImageNet [
30], and high-performance computing systems such as graphics processing units (GPUs), CNN-based algorithms have achieved great success in large-scale visual recognition tasks. The CNN is an efficient hierarchical feature representation framework, in which the higher layers demonstrate semantic abstraction properties [
18,
35,
36,
37]. Recent advances in object detection with deep learning techniques have been driven by the success of the region proposal method, namely, region-based CNN (R-CNN) [
38], which is an effective and efficient solution. Based on the powerful feature extraction ability of deep learning, replacing the inexpensive SS-based region proposal methods with deep and powerful CNN-based methods is an important development. R-CNN [
38], fast region-based convolutional neural network(Fast R-CNN) [
39], and Faster R-CNN [
40] are typical deep learning based object detection algorithms, which are a series of object detection solutions by respectively solving the corresponding problems. R-CNN transfers the object detection problem from the traditional shallow SVM algorithm to the more expressive CNN classifier. Fast R-CNN is an improvement based on R-CNN, which improves the object detection procedure by outputting the bounding boxes and the corresponding labels at the same time from the CNN classifier. However, Fast R-CNN is still hindered by the time consumption of the proposal generation procedure and the detection procedure. In order to avoid utilizing the time-consuming SS strategy when generating the region proposals, the region proposal network (RPN) has been proposed in the Faster R-CNN object detection algorithm. Faster R-CNN further improves Fast R-CNN by sharing features between the region proposal generation procedure and the detection procedure, which can greatly reduce the time consumption for computing the proposals.
Although object detection algorithms have been developed in natural imagery object detection fields, high-efficiency multi-class geospatial object detection for HSR remote sensing imagery has not yet been achieved. Based on the feature-sharing and time-saving properties of the Faster R-CNN algorithm, developing a highly efficient and robust integrated multi-class geospatial object detection framework for HSR remote sensing imagery is significant and necessary. The RPN is a kind of fully convolutional network (FCN) used to generate region proposals, and is designed to efficiently predict proposals with a wide range of scales and aspect ratios using “anchor” boxes. Compared with the traditional region proposal generation methods, the RPN considers the multi-scale properties and the rotation properties during the region generation procedure, which increases the accuracy of the object location and helps improve the detection efficiency. Faster R-CNN integrates the region proposal generation procedure and the detection procedure by sharing features, which can greatly reduce the time consumption for computing the proposals. In order to realize the joint optimization between region proposal generation and detection, an alternating training algorithm [
40] is utilized for collaborative optimization of the region proposal generation and detection procedures. However, the Faster R-CNN based object detection algorithm still faces difficult convergence problems when the number of annotated training samples is limited for HSR remote sensing imagery.
To tackle the problem of limited annotated samples for HSR remote sensing imagery objects, a novel object detection framework, namely, R-P-Faster R-CNN, is proposed here for multi-class geospatial object detection from HSR remote sensing imagery. R-P-Faster R-CNN adequately utilizes a pre-training mechanism to increase the robustness when the number of annotated samples is limited. It is noted that ImageNet is a large natural image dataset which contains various categories and large quantities of images. Training the deep network on ImageNet can help to obtain a good convergence value for the algorithm. Transferring the pre-trained network parameters from the large-scale ImageNet to quantity-limited HSR remote sensing imagery has been demonstrated to be highly efficient [
41]. In order to effectively detect the multi-class geospatial objects from HSR remote sensing imagery, a pre-training mechanism based on transfer learning is introduced to the multi-class geospatial object detection for HSR remote sensing imagery. The main contributions of this paper are summarized as follows:
- (a)
An Effective Integrated Region Proposal Network (RPN) and Object Detection Strategy for HSR Remote Sensing Imagery. Considering the feature extraction advantages of the deep learning based methods, we propose a learning-based RPN which effectively integrates the region proposal generation procedure and the object detection procedure by sharing the convolutional features of these two stages. To make the integrated object detection framework more efficient, the network adopts an alternating training strategy. The integrated strategy makes the proposed object detection framework an end-to-end object detection framework for HSR remote sensing imagery.
- (b)
A Robust and Efficacious Compensation Strategy for the Lack of Labeled Samples for HSR Remote Sensing Imagery Object Detection. There are currently very few multi-class geospatial object detection datasets available. However, there are a lot of similarities between the large natural image datasets and the quantity-limited HSR remote sensing imagery datasets. Pre-training the large-scale deep learning based object detection framework on a natural imagery dataset, and then transferring the pre-trained network parameters for the HSR remote sensing imagery, can provide good initial values and ensure the convergence for the HSR remote sensing imagery object detection.
- (c)
An Efficient Training Time Conservation Strategy for HSR Remote Sensing Imagery Object Detection. To improve the time efficiency of HSR remote sensing imagery object detection, a pre-training mechanism and a transfer mechanism are conducted on the HSR remote sensing imagery, which gradually provides more appropriate initial values for the HSR remote sensing imagery object detection. In addition, the integration of the region proposal generation procedure and detection procedure also saves a lot of training time for the HSR remote sensing imagery.
The proposed R-P-Faster R-CNN algorithm was evaluated and compared with the conventional HSR remote sensing imagery object detection methods, as well as the current non-end-to-end CNN-based object detection methods. For the experiments, we adopted the NWPU VHR-10 dataset, which is a 10-class HSR remote sensing imagery geospatial object detection dataset. The experimental results confirmed that the proposed method can achieve a satisfactory detection result with limited labeled training samples.
The rest of this paper is organized as follows.
Section 2 presents the related object detection works. The proposed highly efficient and robust integrated multi-class geospatial object detection algorithm—R-P-Faster R-CNN—is described in detail in
Section 3.
Section 4 presents a description of the dataset and the experimental settings.
Section 5 and
Section 6 present the analysis of the experimental results and a discussion of the results, respectively. Finally, the conclusions are drawn in
Section 7.
2. Related Works
Geospatial object detection from remote sensing imagery has been extensively studied during the past years. A number of handcrafted feature based object detection methods and automatic feature learning based object detection methods have been studied with natural image datasets [
37]. Object detection based on remote sensing imagery has also been studied [
12,
16,
42]. The spectral-based object detection methods treat the detection as a two-class classification task, namely, the object and the background. The spectral-based detection methods include the SMF, the MSD, the ACDs, the sparse representation based detectors, etc. These methods mainly focus on the differences between the target and the background [
10]. OBIA-based object detection involves classifying or mapping remote sensing imagery into meaningful objects (i.e., grouping relatively local homogeneous pixels). OBIA involves two steps: image segmentation and object classification. To obtain a satisfactory OBIA object detection result, the core task is to obtain a proper segmentation scale to represent the objects. For the OBIA-based object detection methods, the object features, such as spectral information, size, shape, texture, geometry, and contextual semantic features, can be extracted [
15]. For example, Liu et al. [
43] detected inshore ships in optical satellite images by using the shape and context information that was extracted in the segmented image. Liu et al. [
44] presented robust automatic vehicle detection in QuickBird satellite images by applying morphological filters for separating the vehicle objects from the background. However, all these methods are performed in an unsupervised manner, and they are effective only for detecting the designed object category in simple scenarios.
With the development of remote sensing imagery techniques and machine learning techniques, researchers have addressed multi-class geospatial object detection from complex-background remote sensing imagery. The conventional object detection methods for HSR imagery are stage-wise and depend on handcrafted features by experience. Most of these methods treat the object detection problem as a classification problem, where the classification is performed using the handcrafted features and a predefined classifier [
12]. For example, Han et al. [
45] proposed to detect multi-class geospatial objects based on visual saliency modeling and discriminative learning of sparse coding. Cheng et al. [
16] used HOG features and latent SVM to train deformable part based mixture models for each object category. However, all these methods are based on the use of prior information to design the handcrafted features, which usually requires a large number of human-labeled training examples. For these handcrafted feature based object detection algorithms, the main problem is their non-automatic properties.
The advanced machine learning techniques have made geospatial object detection easier with the automatic feature learning framework. Deep learning is now recognized as a good choice for remote sensing imagery object detection. However, the limited annotated samples for object detection has motivated some researchers to develop weakly supervised learning frameworks. Han et al. [
42] proposed a weakly supervised learning framework based on Bayesian principles and an unsupervised feature learning method via deep Boltzmann machines (DBMs) to build a high-level feature representation for various geospatial objects. Zhang et al. [
12] undertook aircraft detection from large-scale remote sensing imagery with a coupled CNN model by sharing features between CRPNet and LOCNet to reduce the time consumption, perfectly combining the coupled CNN and the weakly supervised learning framework. In addition, the rotation-invariant properties of objects has also been studied with deep learning. Cheng et al. [
46] improved the CNN-based object detection algorithm by adequately considering the rotation-invariant properties of the images. In summary, the traditional CNN-based HSR remote sensing imagery object detection framework usually consists of several common stages, i.e., convolutional layers, nonlinear layers, pooling layers, and the corresponding loss function. Although these geospatial object detection frameworks can perform well in multi-class or single-class remote sensing imagery object detection, a unified framework for multi-class HSR imagery geospatial object detection is still needed.
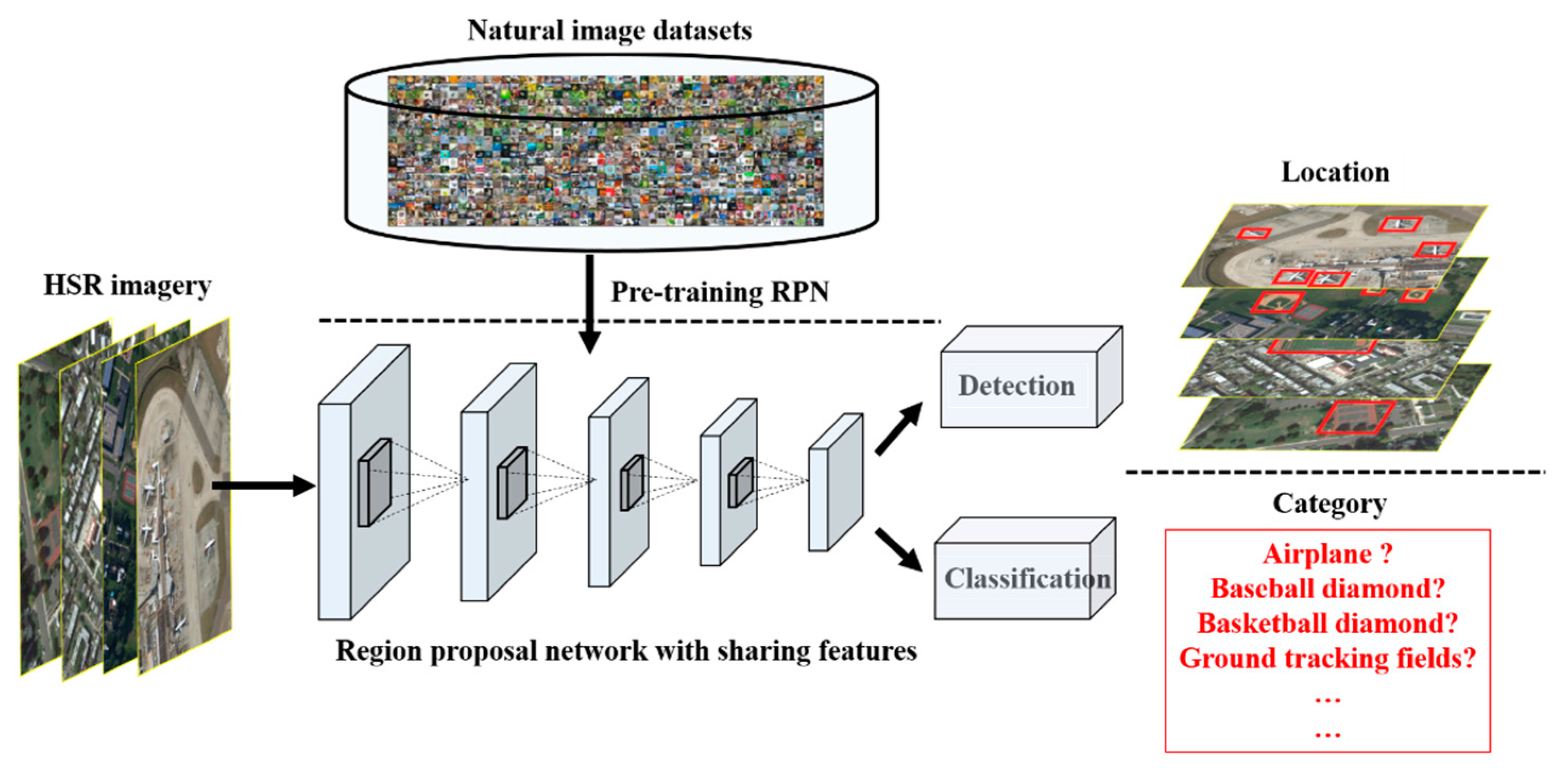
3. Overview of the Proposed R-P-Faster R-CNN Framework
The proposed R-P-Faster R-CNN framework consists of three main procedures, namely, the effective Faster R-CNN procedure, the robust and efficacious pre-training procedure to compensate for the deficiency of labeled training samples, and the effective time conservation procedure. The effective Faster R-CNN procedure consists of two stages, namely, the RPN generation stage and the Fast R-CNN detection and location stage. The RPN realizes three main functions, namely, outputting the locations and scores of the region proposals, transforming the different-scale and different-ratio proposals into low-dimensional feature vectors, and outputting the classification probability of a region proposal and the regression values of the locations. Fast R-CNN takes the convolutional features and the predicted bounding boxes as the input, which is a location refinement stage on the basis of the RPN. The robust and efficacious compensation for the deficiency of labeled samples for Faster R-CNN works by first transferring the pre-trained network parameters from the ImageNet dataset, and then from the PASCAL VOC dataset, which can not only alleviate the deficiency of the labeled samples, but can also provide good initialization values for the Faster R-CNN object detection framework. The effective time conservation procedure of the proposed R-P-Faster R-CNN framework refers to the specific network structure and the network training mechanism.
3.1. Effective Integrated Region Proposal Network and Object Detection Faster R-CNN Framework
Faster R-CNN includes two stages, namely, the RPN stage and the Fast R-CNN detection stage. Faster R-CNN integrates the RPN and Fast R-CNN by sharing the convolutional features, and optimizes the whole network with a multi-task loss function in an alternating training manner. This process is described as follows.
3.1.1. Overall Architecture
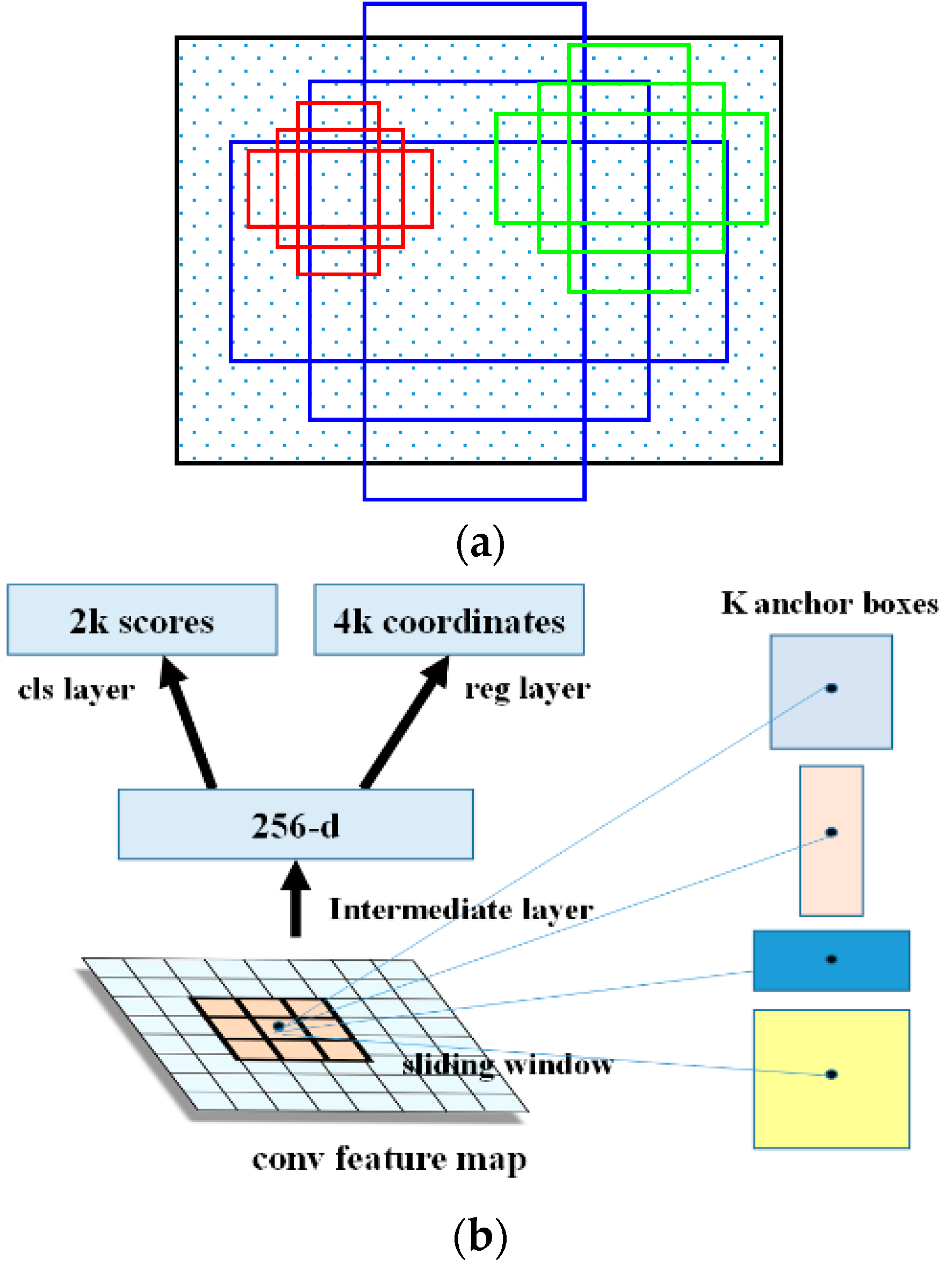
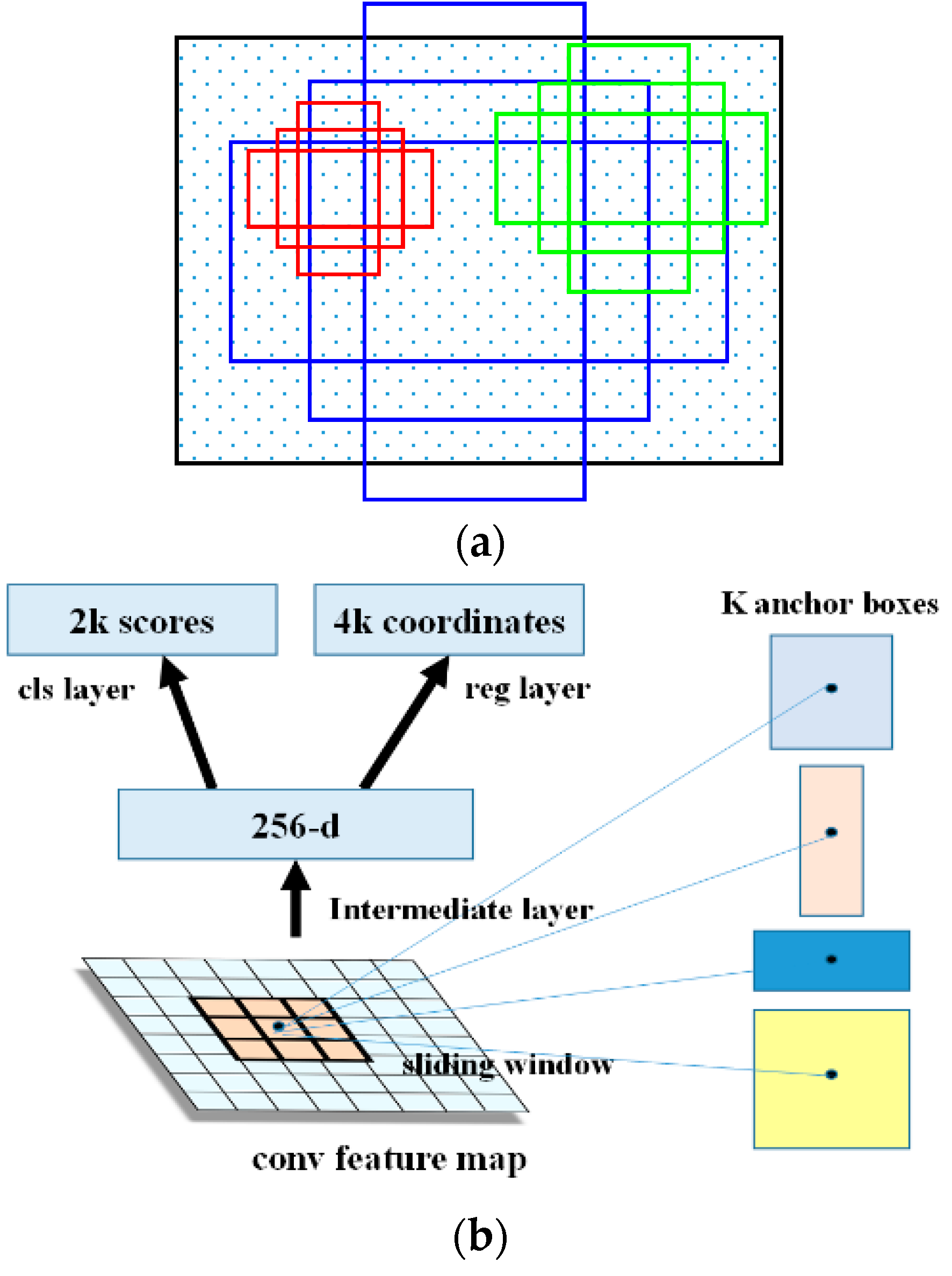
The overall architecture of Faster R-CNN is composed of two components, namely, the RPN and Fast R-CNN. The RPN is the core innovation of the Faster R-CNN based object detection framework. It is a kind of FCN that deals with the arbitrary-size input images and generates a set of rectangular object proposals. The outstanding characteristic of the RPN is the utilization of anchors. Anchors are the centers of the sliding windows, and they ensemble the different-ratio and multi-scale region proposals to import into the RPN. With the anchors, the RPN can realize multi-scale information incorporation. For every location of the image, there are nine possible region proposals, namely, areas of
and length-to-width ratios of
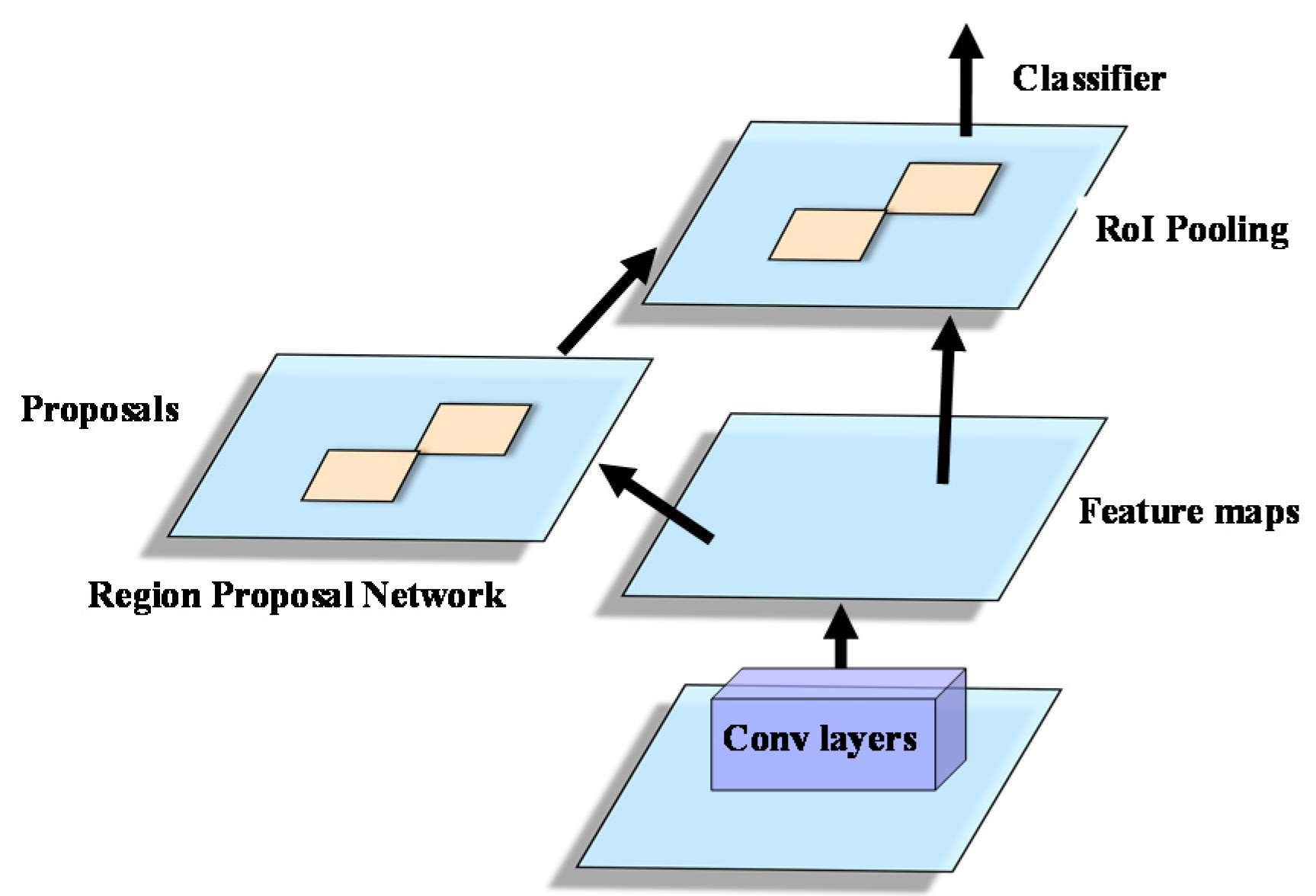
. The framework of Faster R-CNN is shown in
Figure 1.
In order to generate the convolutional feature maps in the last shared convolutional layer, the convolutional features are imported into two sibling fully connected layers, namely, the box-regression layer (reg) and the box-classification layer (cls). Suppose that the number of maximum possible proposals for each location is denoted as
, then there will be
outputs encoding the coordinates of
boxes for the regression layer and
scores for the classification layer, estimating the probability of object or not. The principles of the anchors and the RPN are shown in
Figure 2.
For the RPN, the judgement condition of whether the extracted region proposal is the required bounding box depends on the value of the intersection-over-union (IoU). When the IoU is larger than 0.7, it is considered as a foreground region proposal, and when the IoU is smaller than 0.3, it is considered as a background region proposal. During the region proposal generation procedure, the FCN-based RPN generates a large number of cross-boundary proposal boxes. To alleviate the redundancy phenomenon of the region proposals, non-maximum suppression (NMS) [
45] is utilized to select the most useful region proposals. In addition, the RPN also has two other advantages. One advantage is the translation-invariant property of the anchors, which are constructed based on the assumption that if one translates an object in an image, the proposal should translate and the same function should be able to predict the proposal in either location. Specifically, the translation-invariant property also reduces the model size as the number of anchors is a fixed small value. The other advantage is that the multi-scale anchors act as regression references. Differing from the time-consuming image pyramids for processing multi-scale features, the RPN processes the multi-scale feature maps by sliding windows of multiple scales on the feature maps.
The loss function for an image is defined as:
where
is the index of an anchor in a mini-batch, and
is the predefined probability of anchor
being an object. The ground-truth label is 1 if the anchor is positive, and is 0 if the anchor is negative.
is a vector representing the four parameterized coordinates of the predicted bounding box, and
is that of the ground-truth box associated with a positive anchor. The classification loss
is the log loss over the two classes (object vs. not object). For the regression loss, we use
, where R is the robust loss function. The classification loss and the regression loss are weighted by a balancing parameter
. Usually, the cls term is normalized by the mini-batch size, and the reg term is normalized by the number of anchor locations. By default, the value of
is set as 10, and thus both the cls and reg terms are roughly equally weighted.
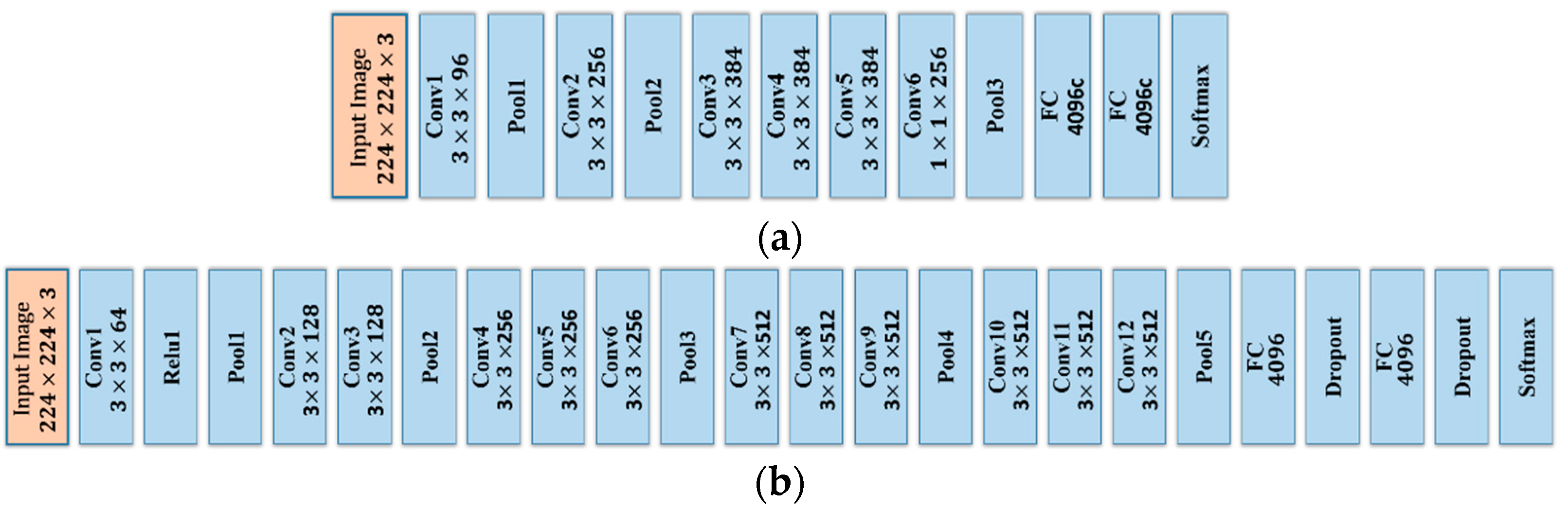
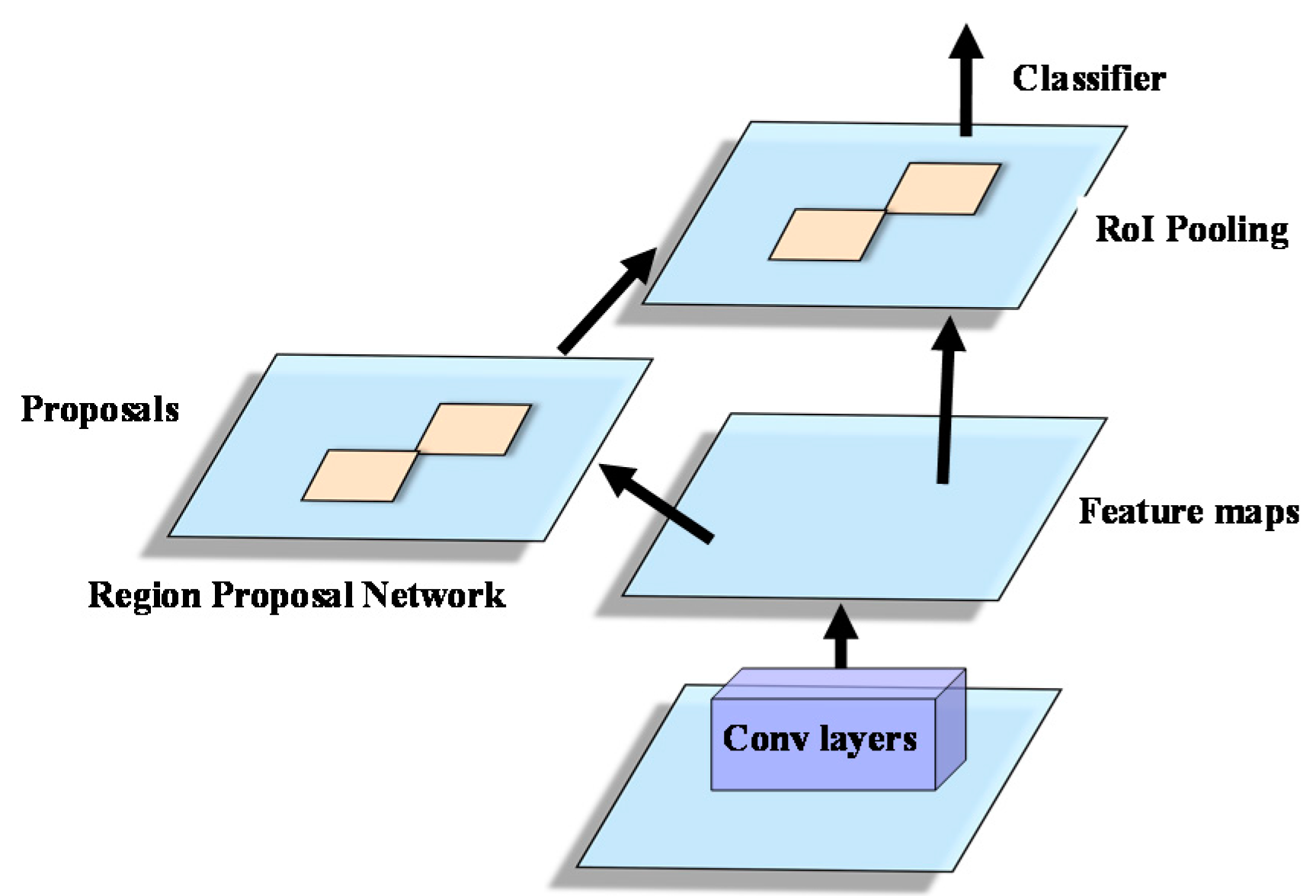
Differing from the RPN stage, Fast R-CNN is a location refinement procedure. Fast R-CNN takes as input an entire image and a set of object proposals to score. The network first processes the whole image with several convolutional (conv) and max pooling layers to produce a conv feature map. Then, for each object proposal, a region of interest (RoI) pooling layer extracts a fixed-length feature vector from the feature map. Fast R-CNN adopts either the Zeiler and Fergus (ZF) model or the visual geometry group (VGG) model to realize the detection procedure. The ZF model and the VGG model are typical deep network based recognition models, which include several convolutional layers, pooling layers, and nonlinear layers. The structures of the ZF and VGG models are shown in
Figure 3. Suppose that the size of the spatial window is
, then, after the sliding window operation of the RPN, a lower-dimensional feature vector is obtained of 256-d for ZF and 512-d for VGG. After the sliding window operation, the features of the RPN are fed into two sibling fully connected layers: a box-regression layer and a box-classification layer. In the Faster R-CNN procedure, the value of
n is equal to 3, and the effective receptive fields on the input image are 171 and 228 pixels for ZF and VGG, respectively.
3.1.2. The Integration Strategy for the RPN and Fast R-CNN—Sharing Convolutional Features
Both the RPN stage and the Fast R-CNN stage can be trained separately, but each stage will consume a lot of time. In order to conserve the running time as much as possible, integrating the RPN stage and the Fast R-CNN stage for Faster R-CNN with a convolutional feature-sharing strategy rather than learning two separate networks can greatly reduce the running time consumption of the proposed algorithm. To realize the integration of the RPN and Fast R-CNN, alternating optimization is utilized to learn shared convolutional features between the region proposal generation stage and the object detection stage.
Faster R-CNN adopts a four-step alternating training procedure to realize the convolutional feature sharing via alternating optimization. In the first step, the network is initialized with an ImageNet-pre-trained model and fine-tuned end-to-end for the region proposal task. In the second step, a separate detection network trained by Fast R-CNN uses the proposals generated by the step-1 RPN. In this step, the network is also initialized by the ImageNet-pre-trained model. At this time, these two steps do not share convolutional layers. In the third step, the detector network is utilized to initialize the RPN training, but the shared convolutional layers are fixed and only the layers unique to the RPN are fine-tuned. At this time, the two networks share convolutional layers. At the last step, keeping the shared convolutional layers fixed, the unique layers of Fast R-CNN are fine-tuned. Through these four steps, the two networks share the same convolutional layers and an integration of the RPN and Fast R-CNN is achieved.
3.1.3. The Training Procedure of the Faster R-CNN Integrated Framework
During the training procedure of the Faster R-CNN integrated framework, the images are usually re-scaled, with the shorter side as pixels. On the re-scaled images, the total stride for both the ZF and VGG nets on the last convolutional layer is 16 pixels. For the anchors, there are three scales with box areas of , , and pixels, and three aspect ratios of 1:1, 1:2, and 2:1. During the training stage, the anchor boxes crossing the image boundaries are all ignored so that they do not contribute to the total loss. During the test stage, the fully convolutional RPN is applied to the entire image, which may generate cross-boundary proposal boxes, which are clipped to the image boundary. During the training stage, the number of proposals is also an important factor influencing the detection accuracy. If the proposals are highly overlapped with each other, the redundant computation is high. NMS on the proposal regions based on the cls scores is utilized to reduce the number of region proposals.
3.2. Robust and Efficacious Pre-Training Framework for Compensation of the Deficiency of Labeled Training Samples for HSR Remote Sensing Imagery Object Detection
The overall structure of the effective integrated region proposal network and object detection Faster R-CNN framework was introduced in the previous section. This structure is effective for natural image object detection especially when there is a large amount of labeled training samples. However, for the HSR remote sensing imagery object detection task, the limited annotated samples is a significant factor influencing the detection performance. It is noted that the ImageNet dataset is a large and complicated natural image dataset, which contains 1000 categories with abundant information. Compared with this large and complicated natural image dataset, the current multi-class geospatial object detection datasets of HSR remote sensing imagery have the characteristics of small quantities, simple categories, complicated backgrounds, variable objects, etc. As the labeled samples of the multi-class geospatial object datasets of HSR remote sensing imagery are always deficient, to make up the defects for the HSR remote sensing imagery object detection, a compensation strategy—robust and efficacious pre-training mechanism—is needed to improve the performance of the multi-class geospatial object datasets of HSR remote sensing imagery.
Transfer learning is an effective technique in the deep learning research field for solving the problem of limited annotated samples in the target domain. Through learning the parameters of the deep network, a pre-training mechanism helps the deep network for object detection to quickly obtain the optimal values. To realize the multi-class geospatial object detection of HSR remote sensing imagery, a double pre-training mechanism is subsequently utilized on the ImageNet dataset and PASCAL VOC dataset, and then the pre-trained network parameters are transferred to the HSR remote sensing imagery. Similar to the four-step training stage of Faster R-CNN, the proposed R-P-Faster R-CNN realizes the optimization procedure with double pre-training. For the optimization procedure of the multi-class geospatial object detection stage, the multi-class geospatial object detection of HSR remote sensing imagery also adopts the four-step alternating training to obtain the detection results based on the PASCAL VOC dataset. Training and optimizing the network parameters on a large natural imagery dataset is a robust and efficacious approach for deep network based transfer learning.
Although the natural imagery dataset and the HSR remote sensing imagery dataset has some dissimilarities in the imaging mode and shooting angles, the categories of the HSR remote sensing imagery are similar or contained within the natural imagery dataset. Numerous experiments have verified that the effectiveness of the pre-training mechanism and transferring learning for the image recognition tasks. This similarity ensures the efficacious pre-training mechanism robust to the HSR remote sensing imagery object detection.
The specific procedure of the proposed R-P-Faster R-CNN is shown in
Figure 4.
3.3. Effective Training Time Conservation Framework
Compared with the conventional stage-wise object detection algorithms, the training time conservation of the proposed R-P-Faster R-CNN framework can be illustrated from two aspects. The first aspect is the convolutional feature-sharing mechanism of Faster R-CNN, which reduces the time consumption of the proposed R-P-Faster R-CNN framework by sharing the convolutional features between the RPN procedure and the detection procedure with a four-step optimization strategy. Fast R-CNN saves the time consumption at the detection stage by transferring the region proposal generation after the convolutional feature maps are generated. However, Faster R-CNN saves the time consumption at both the region proposal generation procedure and the detection procedure, and it saves the time consumption of the region proposal generation procedure by introducing the RPN. The time consumption of the convolutional feature-sharing strategy mainly reflects the test period.
The second aspect is the pre-training mechanism for multi-class geospatial object detection of HSR remote sensing imagery. It is noted that deep network needs a large amount of data to fit the complicated and nonlinear data distribution. Both gathering and constructing the large imagery dataset is tough for current HSR remote sensing imagery object detection task. However, the category and image similarities between HSR remote sensing imagery and natural imagery dataset provides the possibilities for cross-domain transferring learning. Transfer learning is an effective measure in the deep learning area especially where there are huge amount of data to train and complex network structures to model. Transferring the optimized network parameters from the natural imagery dataset to the HSR remote sensing imagery and pre-training the proposed object detection framework for HSR remote sensing imagery is easy for a network to quickly reach its optimal solutions, which guarantees the effectiveness of the proposed object detection framework in time conservation.
Based on the above two time conservation strategies of the proposed R-P-Faster R-CNN for HSR remote sensing imagery object detection, both the network structure and the pre-training strategy are optimal comparatively, which can provide effective time conservation measures for HSR remote sensing imagery object detection.
5. Results
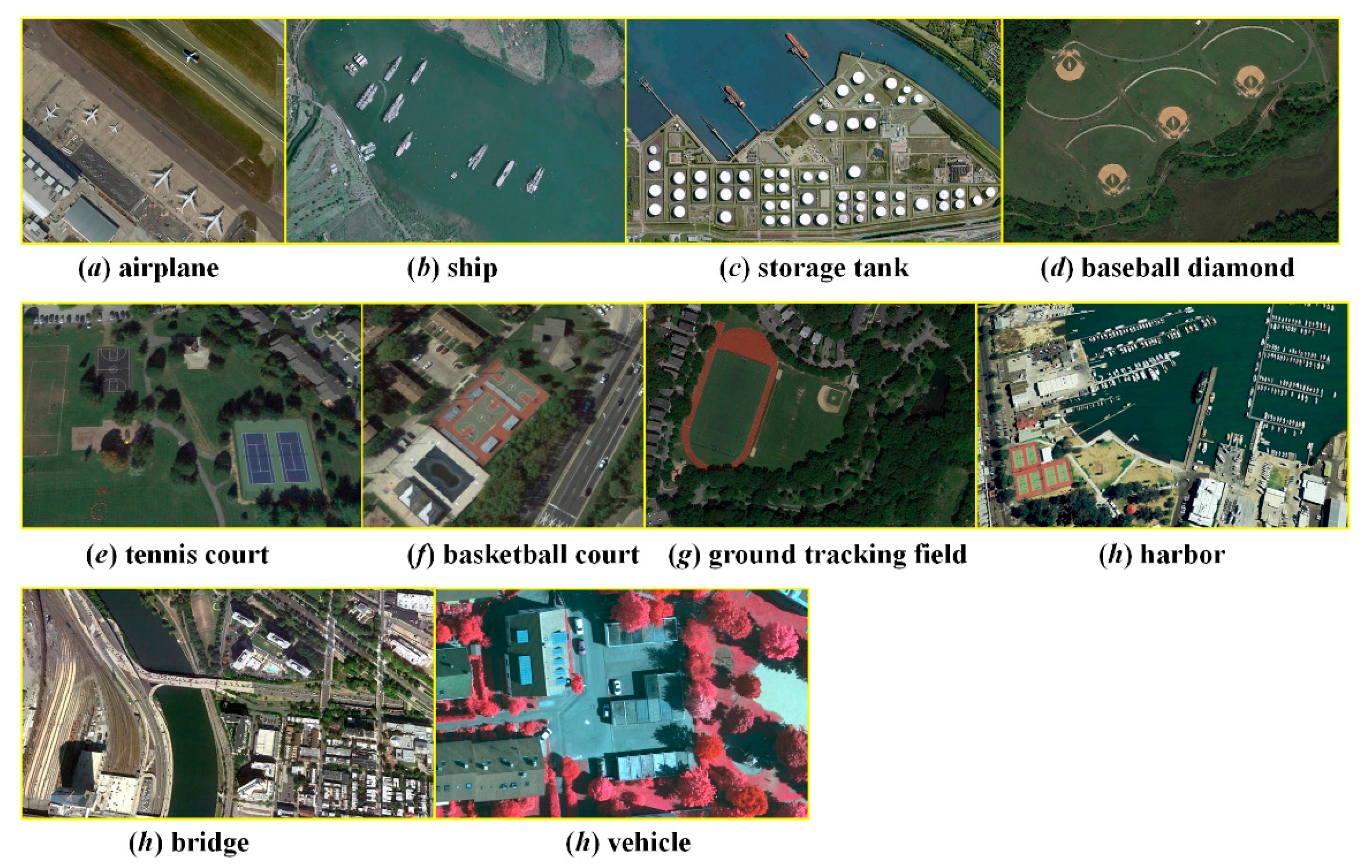
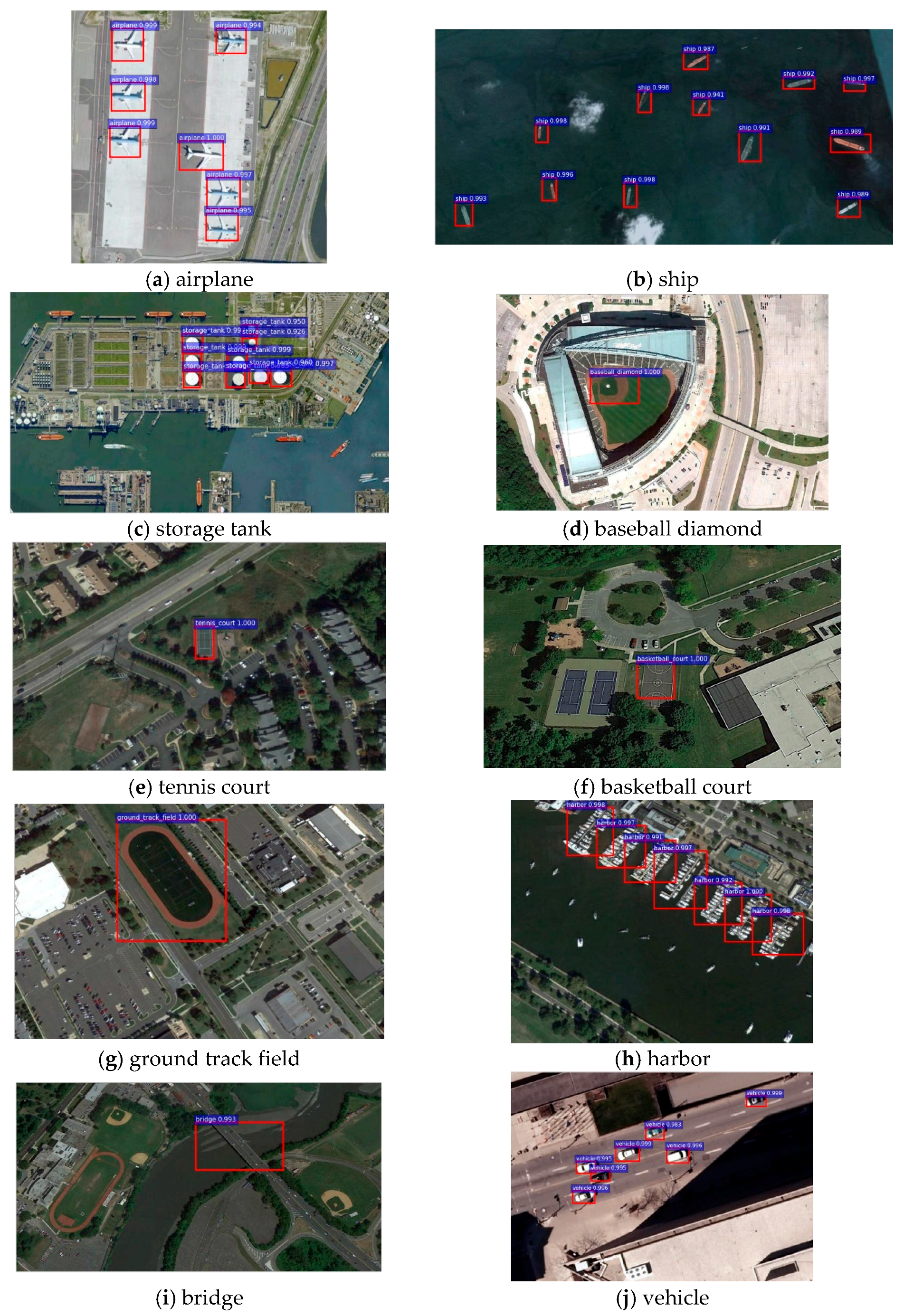
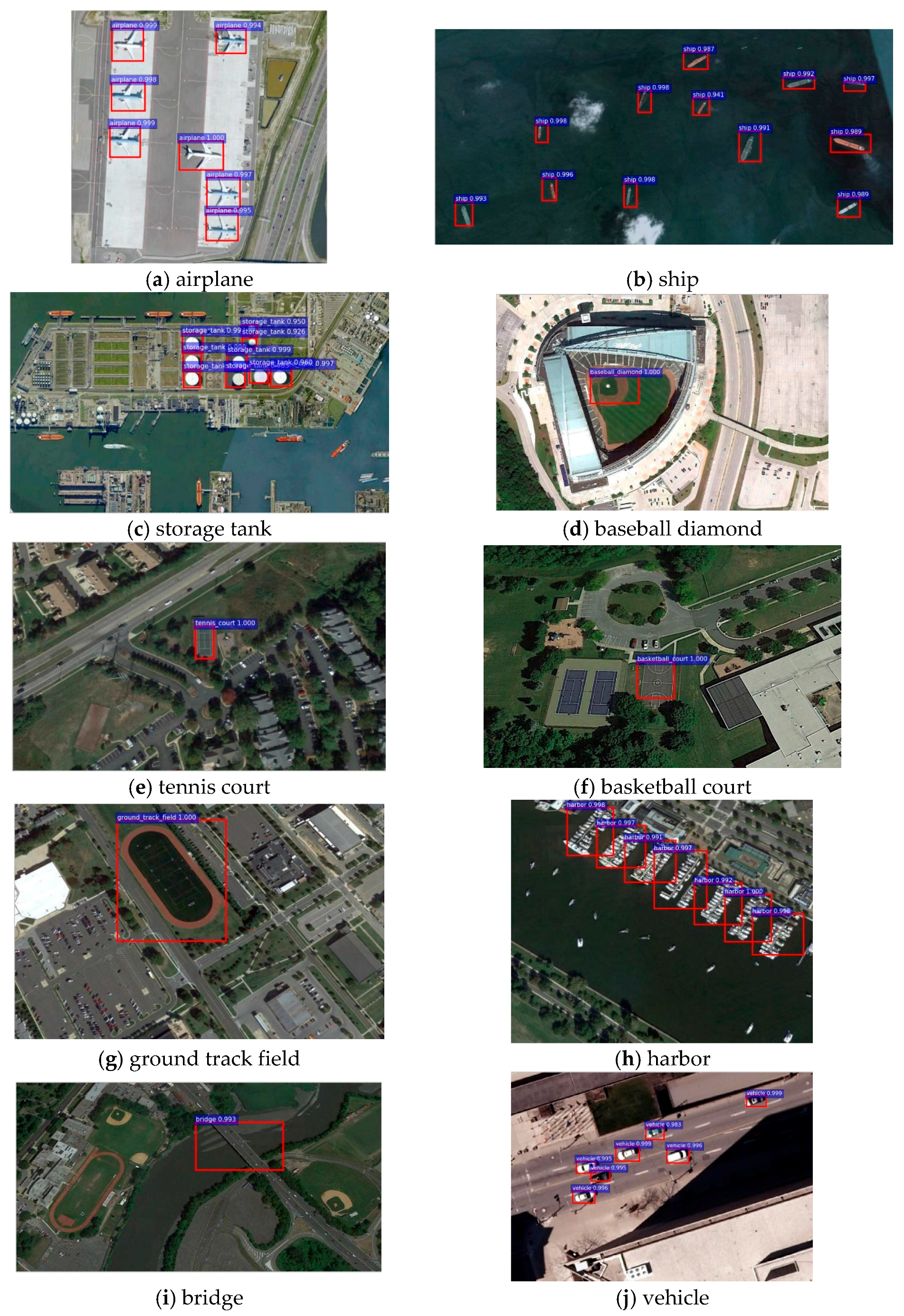
Detection examples for the NWPU VHR-10 dataset with the proposed R-P-Faster R-CNN algorithm are shown in
Figure 6.
Figure 6 shows the qualitative detection results of airplane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, and vehicle for the proposed R-P-Faster R-CNN (single) (VGG16) algorithm, separately. In
Figure 6, it can be seen that the proposed R-P-Faster R-CNN algorithm demonstrates better detection performance on the classes of airplane, baseball diamond, and ground track field.
Figure 6 also shows that the proposed R-P-Faster R-CNN (single) (VGG16) shows a better detection performance on the small vehicle objects. However, the proposed R-P-Faster R-CNN demonstrates a less satisfactory location detection performance on the object class of storage tank.
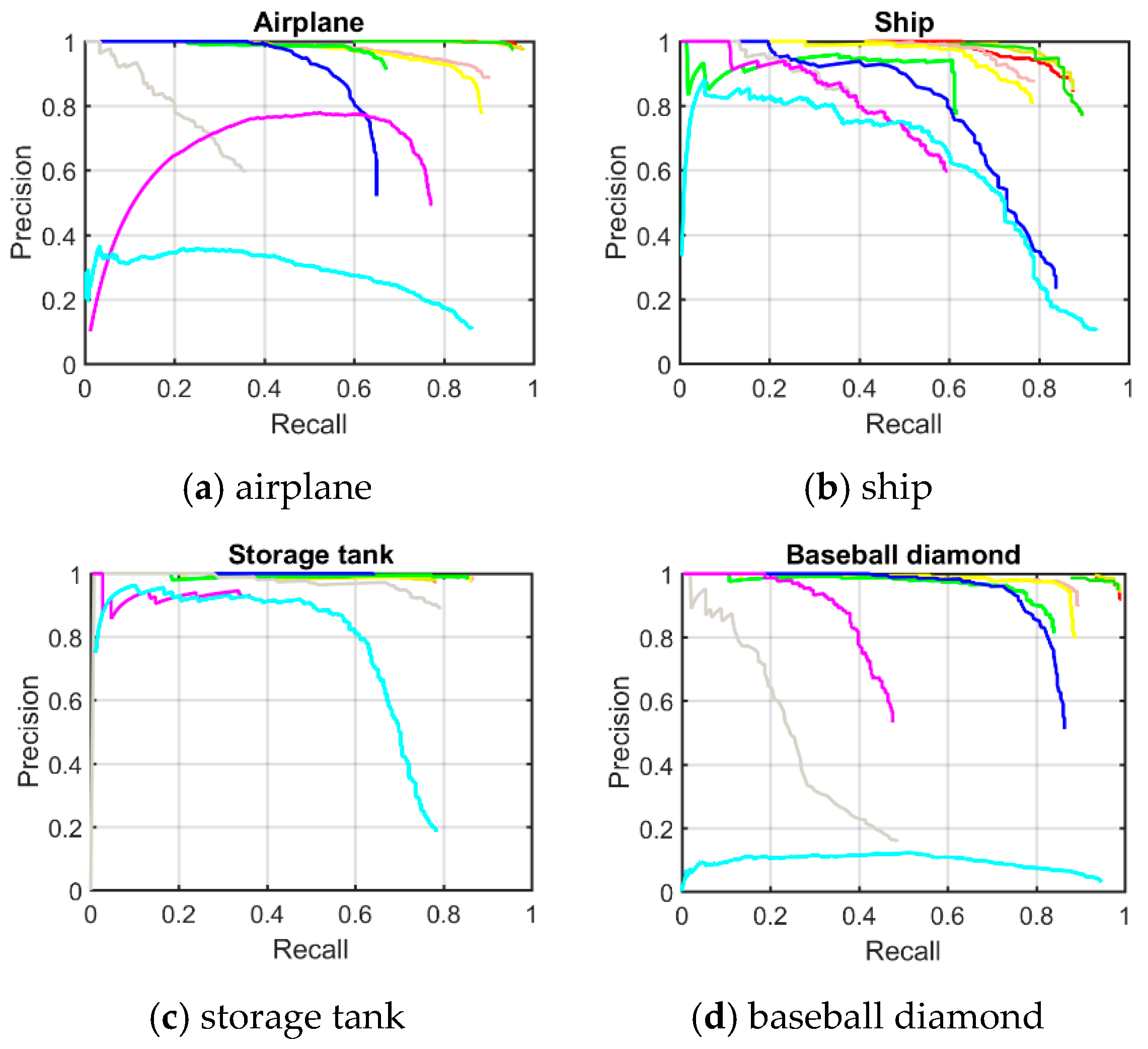
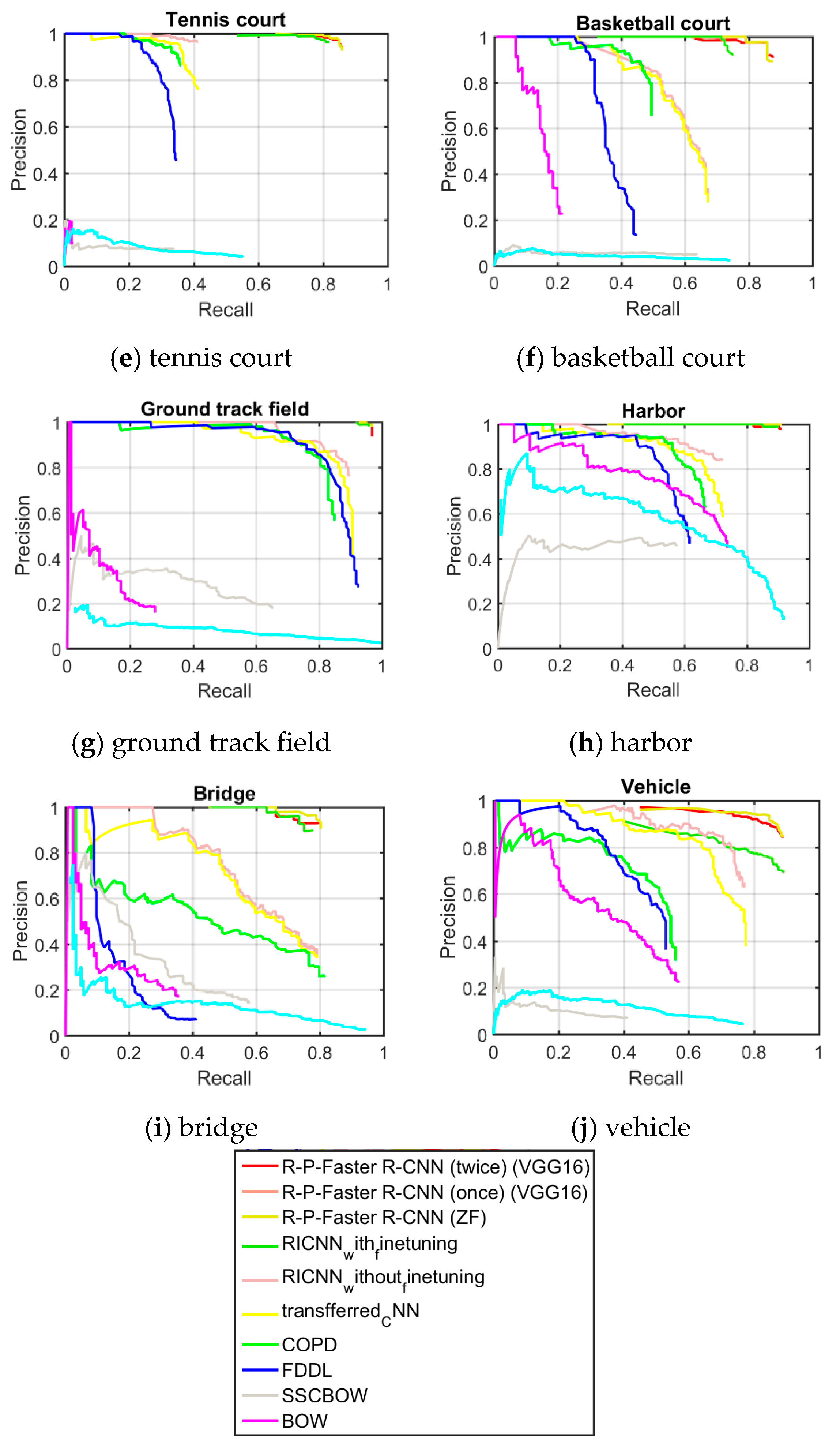
Quantitative comparisons of the 10 different methods are shown in
Table 1,
Table 2 and
Table 3, and
Figure 7 and
Figure 8, as measured by AP values, Accuracy, Kappa, average running time per image, and PRCs, respectively. For the proposed R-P-Faster R-CNN algorithm, two pre-training approaches were adopted for the VGG16 architecture, namely, a single fine-tuning mechanism and a double fine-tuning mechanism. In
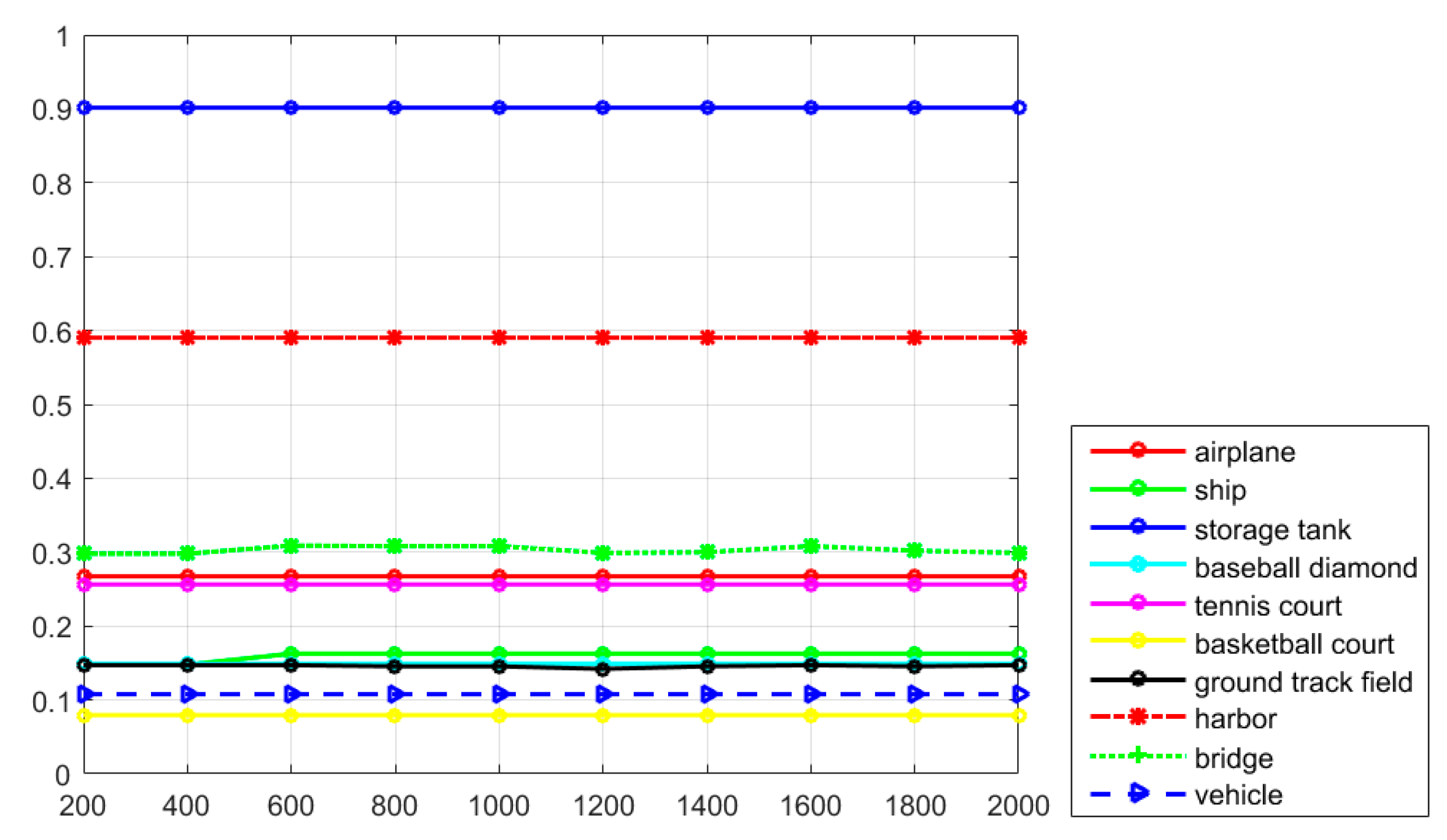
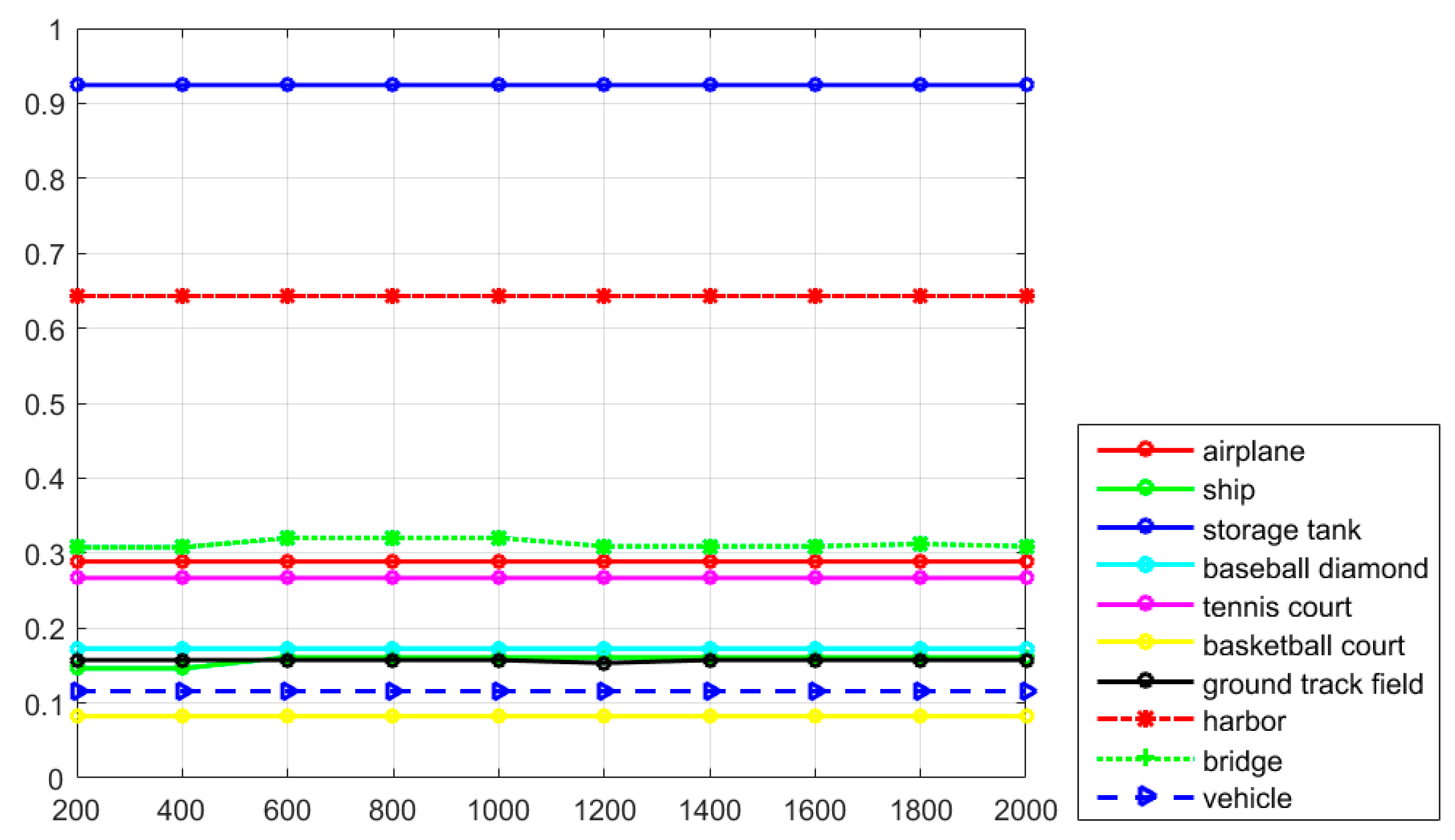
Table 1, it can be seen that the proposed R-P-Faster R-CNN fine-tuned once on the ImageNet dataset obtains the best mean AP value of 76.5% among all the object detection methods. To make a concrete analysis, in
Table 1, it can be seen that the proposed R-P-Faster R-CNN algorithm obtains better AP values for the classes of airplane, tennis court, basketball court, harbor, bridge, and vehicle. For the storage tank class, the RICNN with fine-tuning algorithm shows a much better detection performance than the other algorithms. In
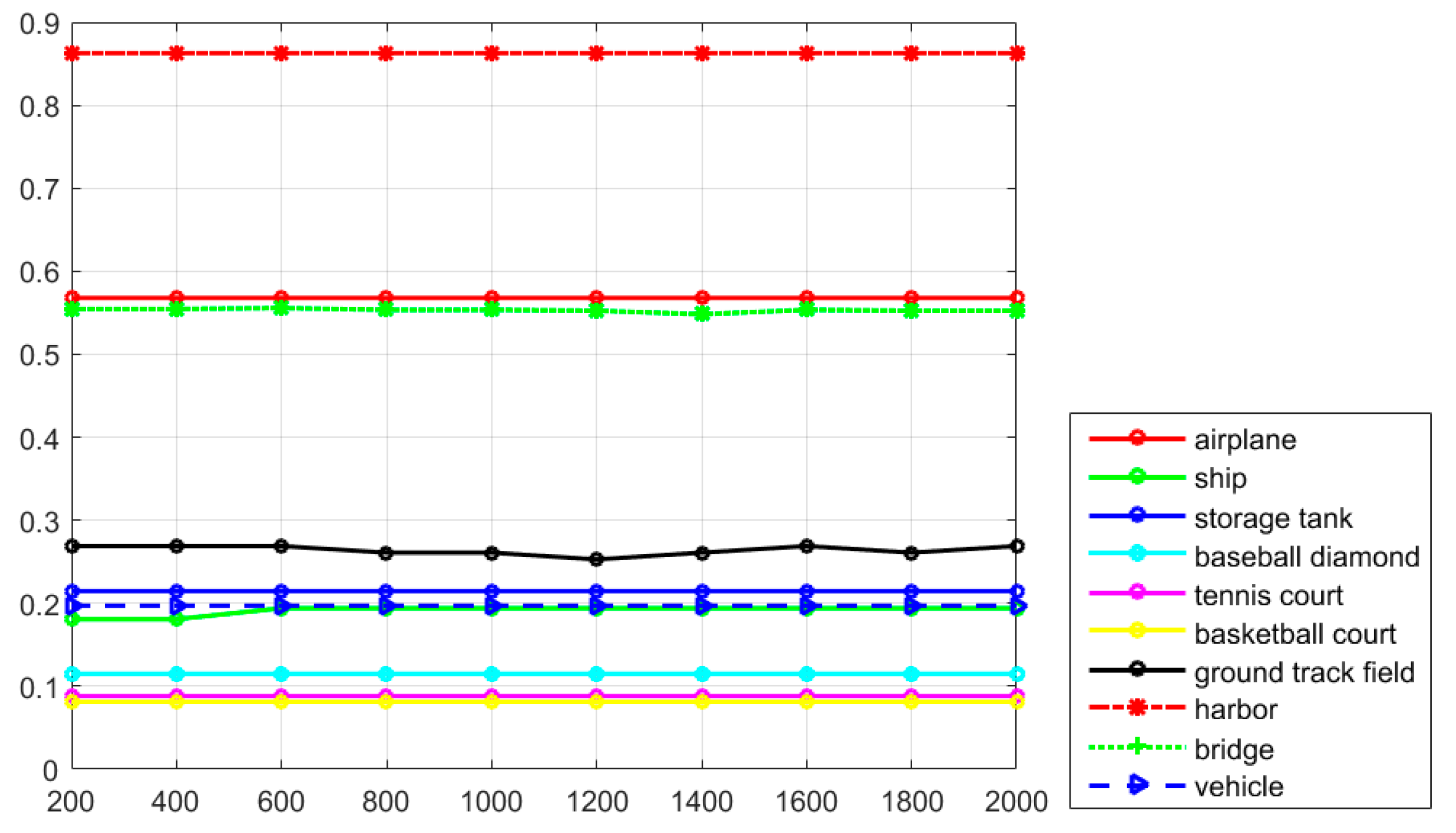
Table 2, it can be seen that the proposed R-P-Faster R-CNN algorithm also obtains the best Accuracy and Kappa values among comparison algorithms, which confirms the overall superior performance. After comparing the AP values of the different detection methods, the recall values of the proposed R-P-Faster R-CNN algorithm should also be compared.
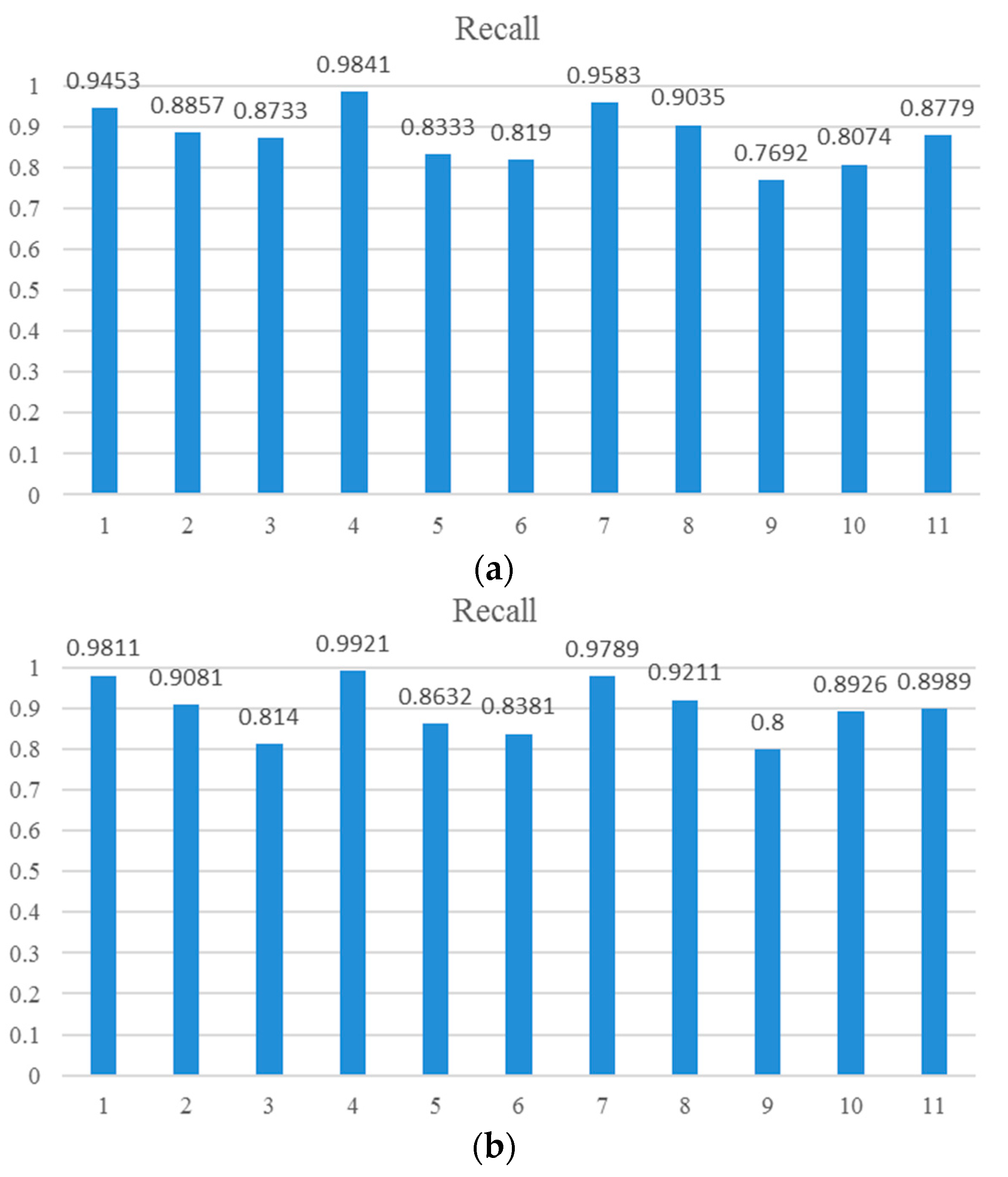
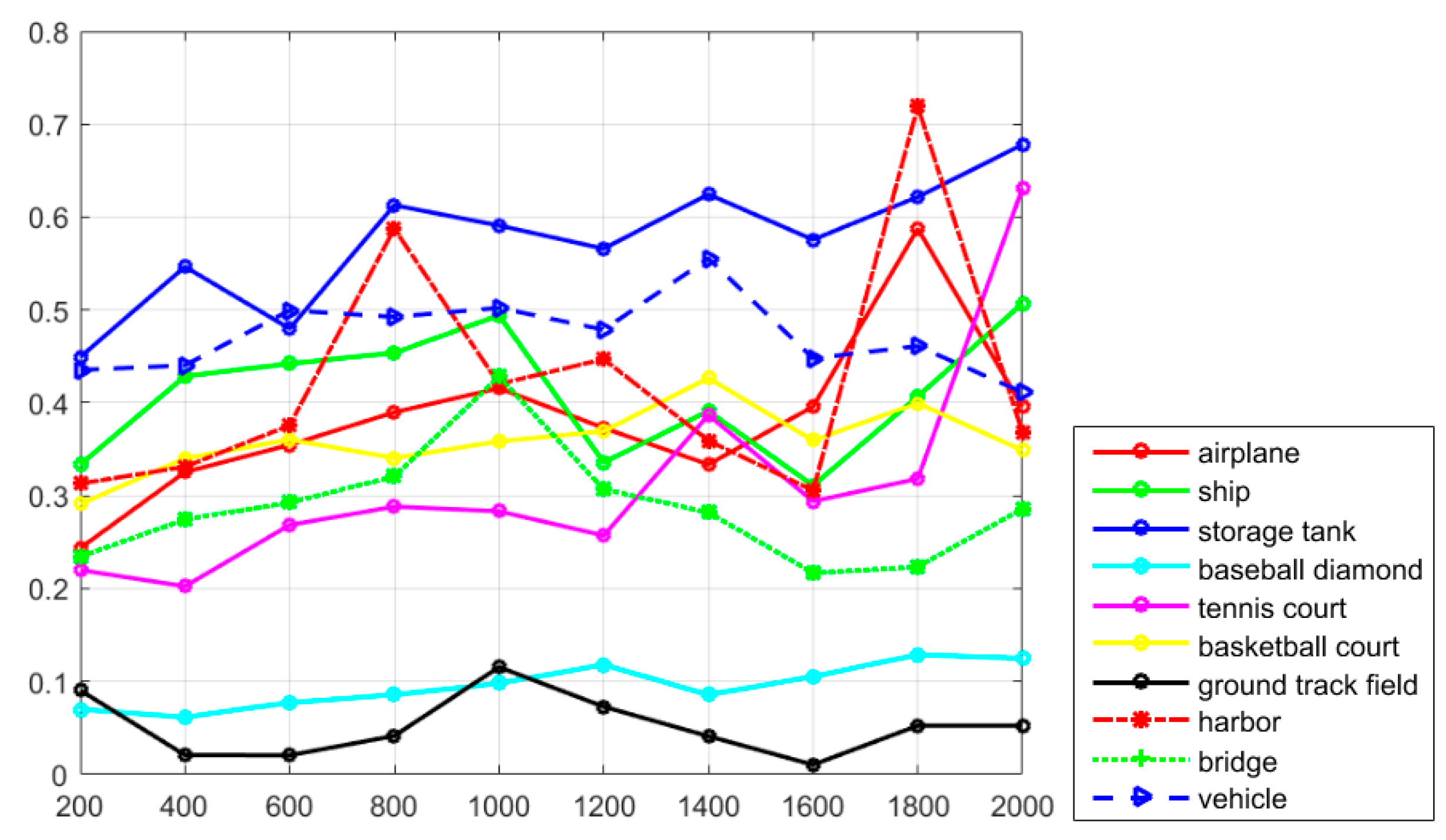
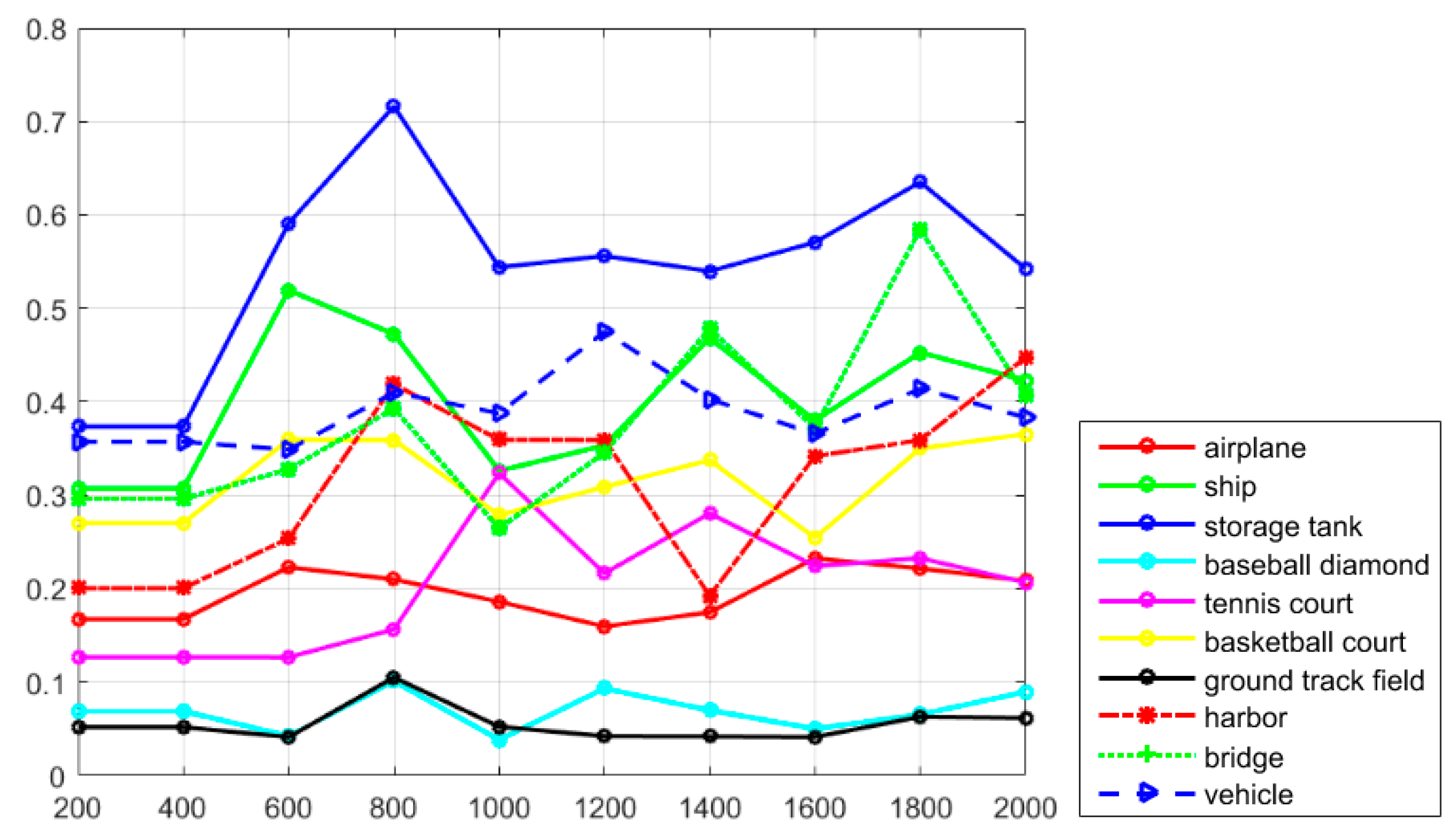
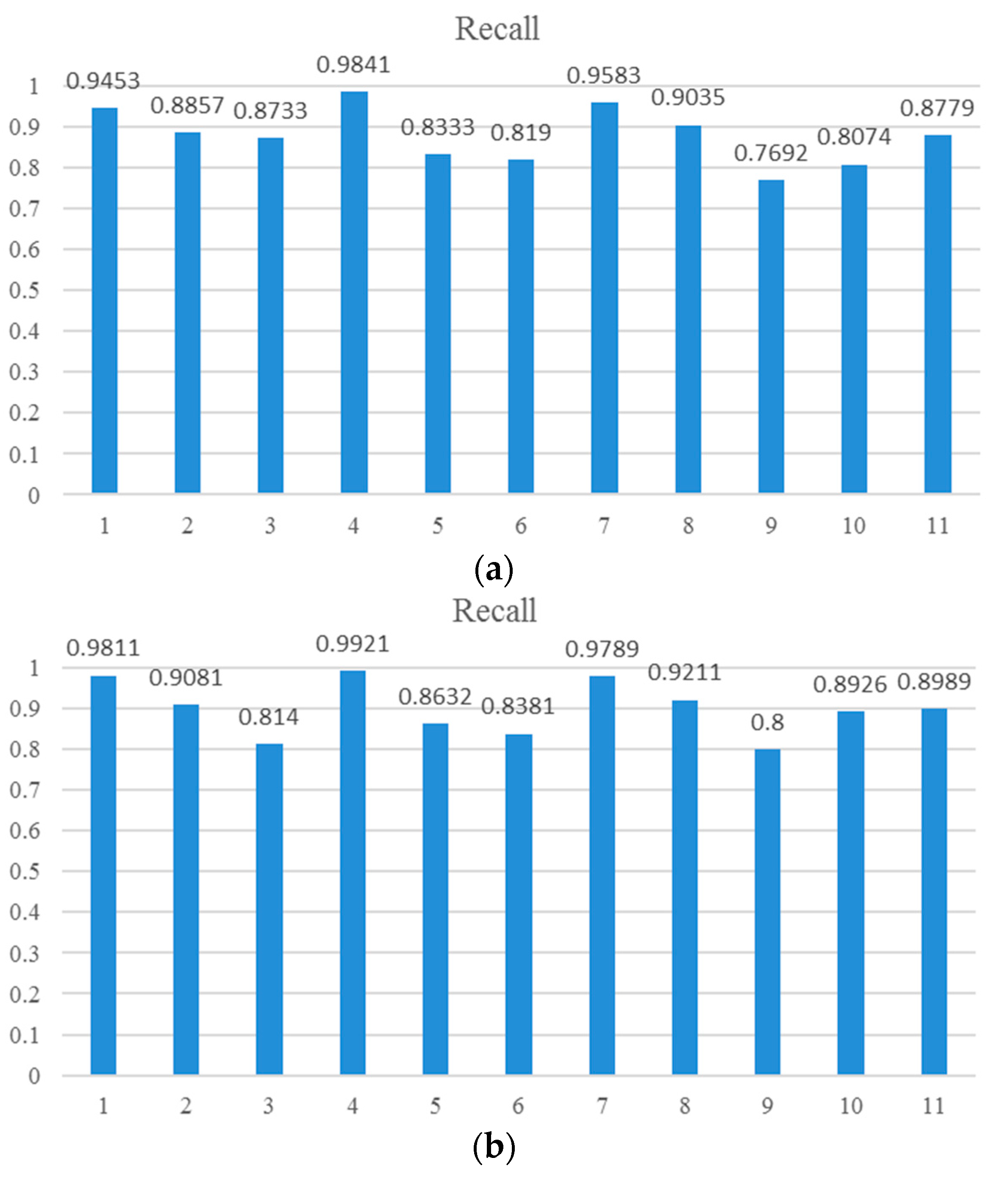
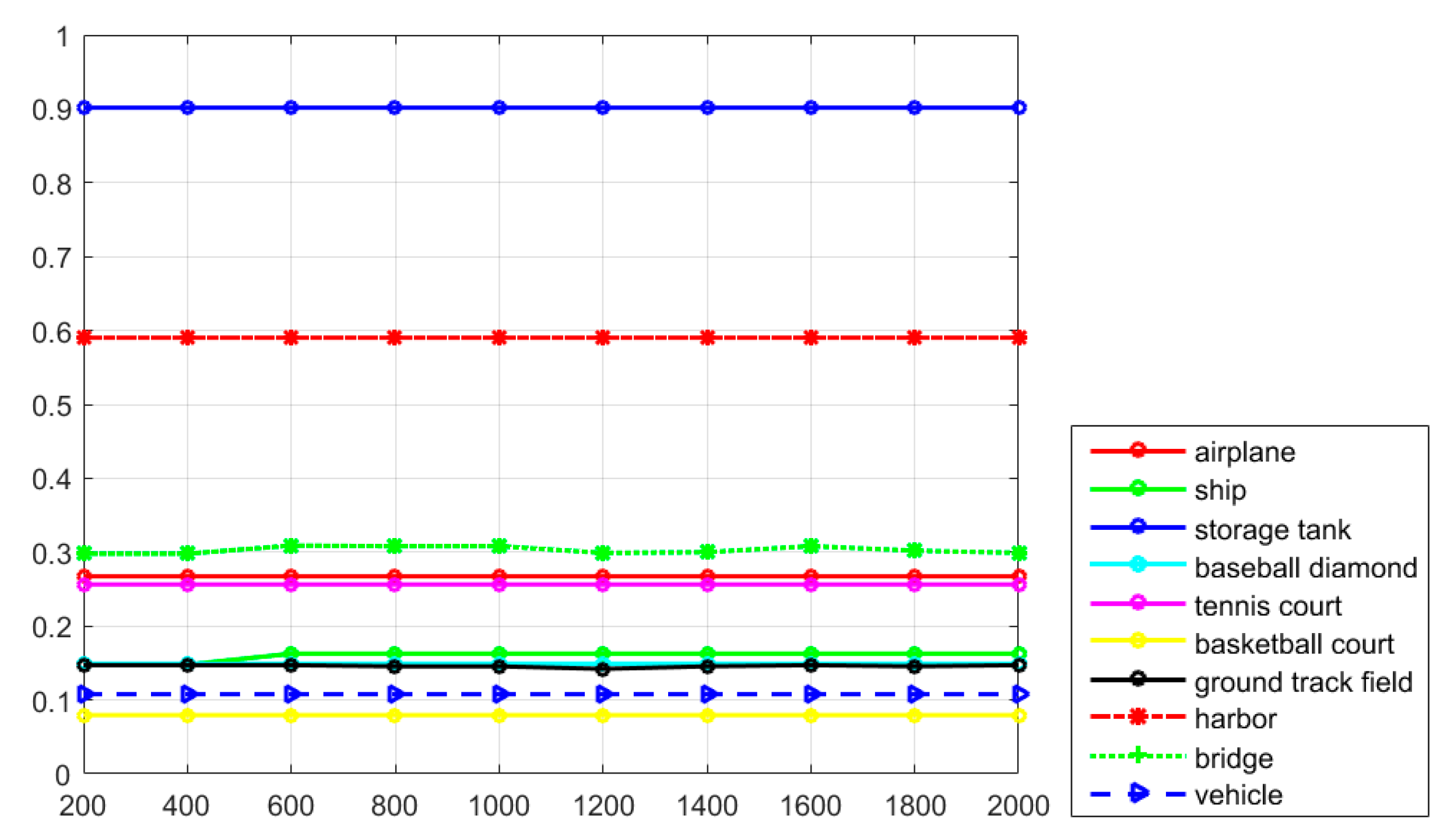
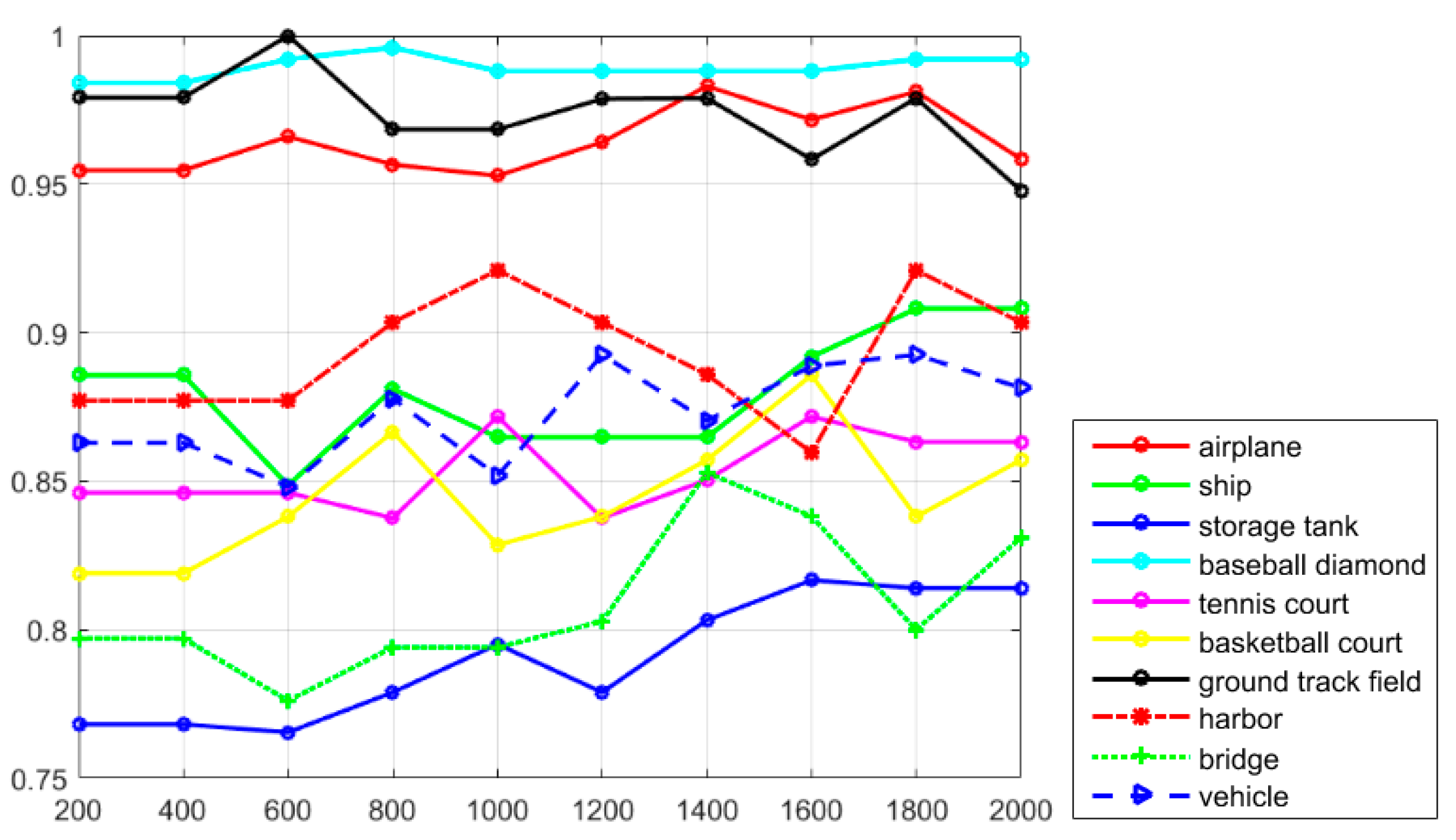
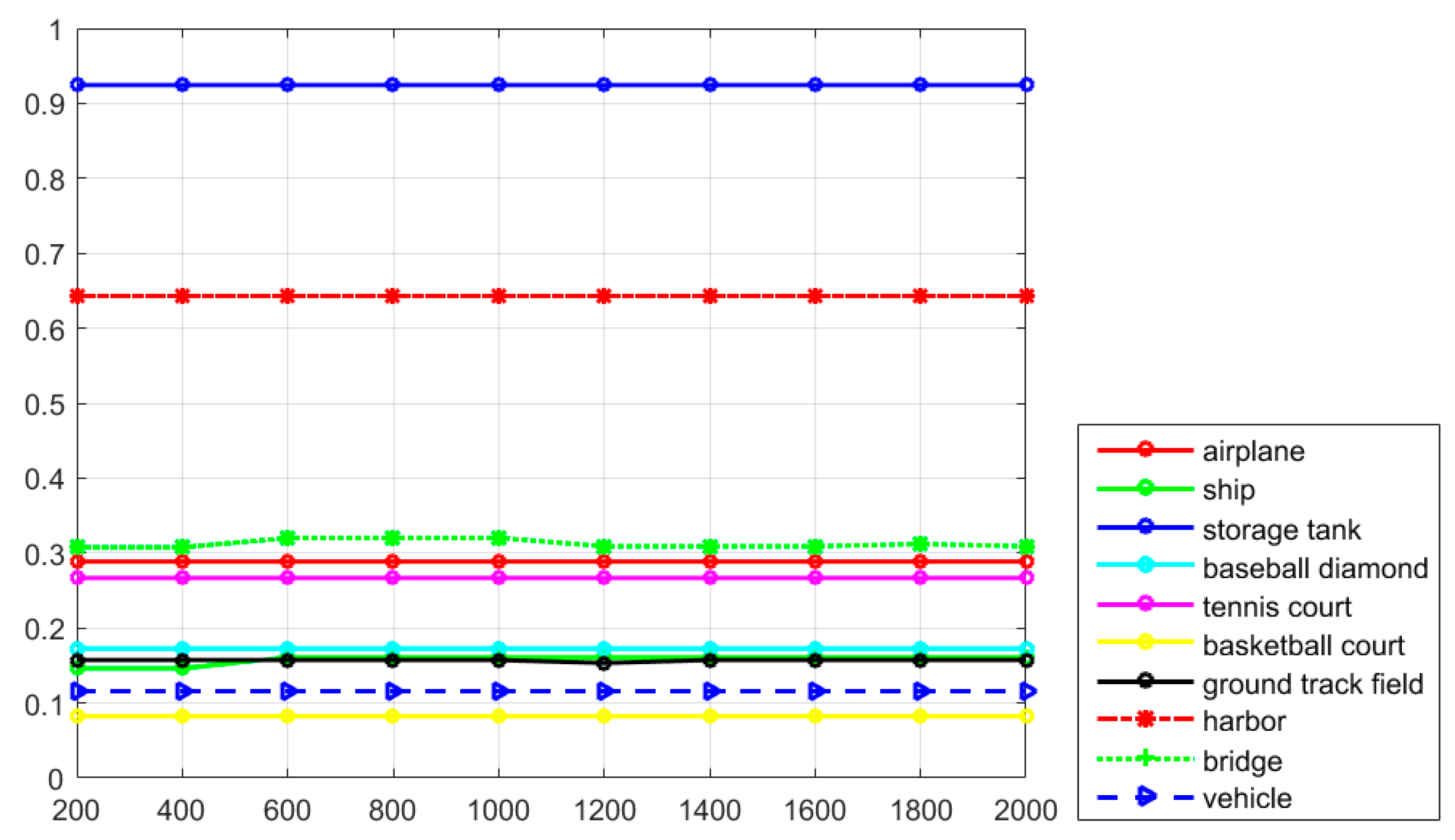
Figure 7 shows the recall values of the proposed R-P-Faster R-CNN algorithm with the ZF model and VGG-16 model. From the overall view, it can be seen that the recall value of the proposed R-P-Faster R-CNN with VGG model is higher than with the ZF model. In
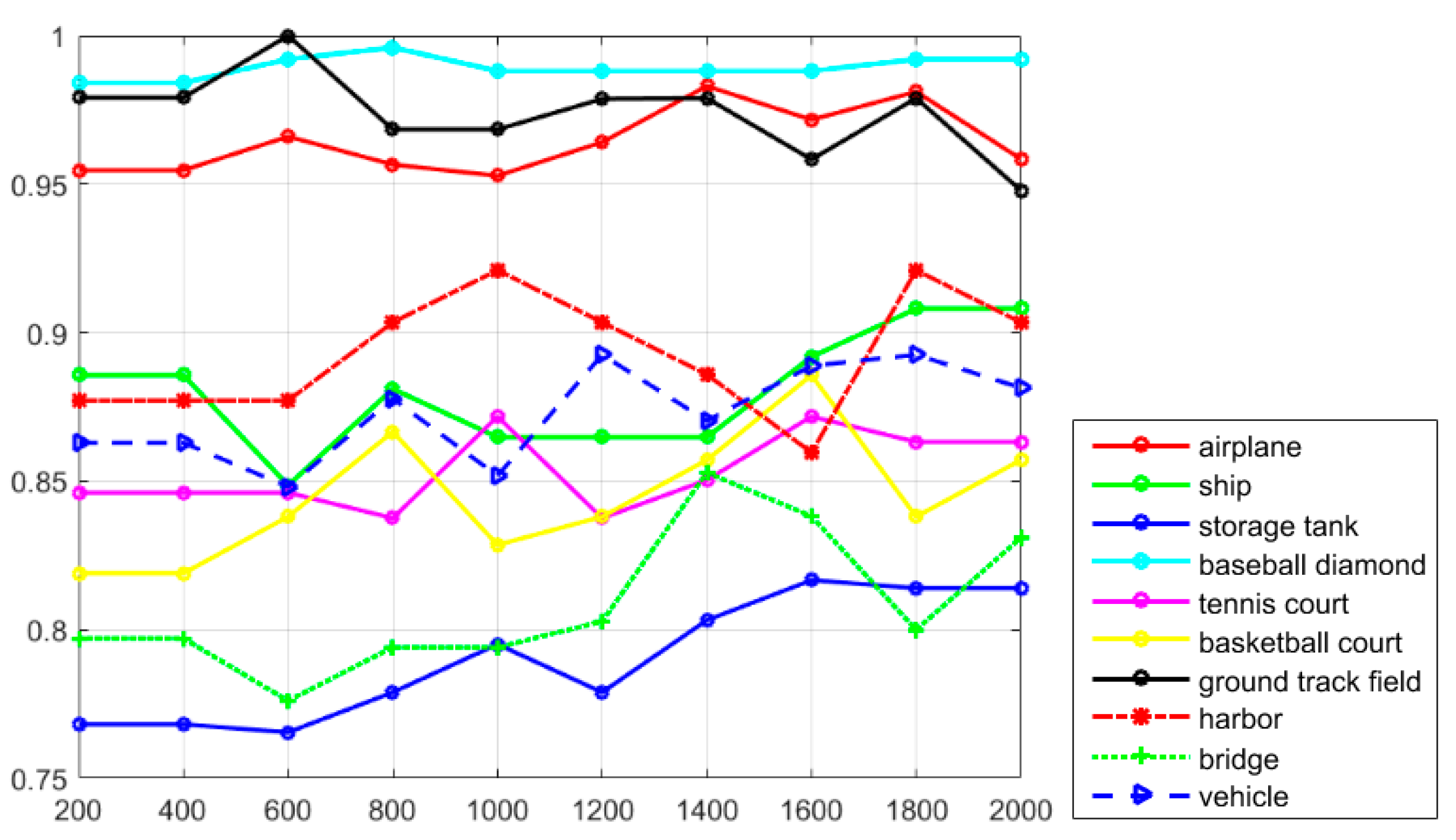
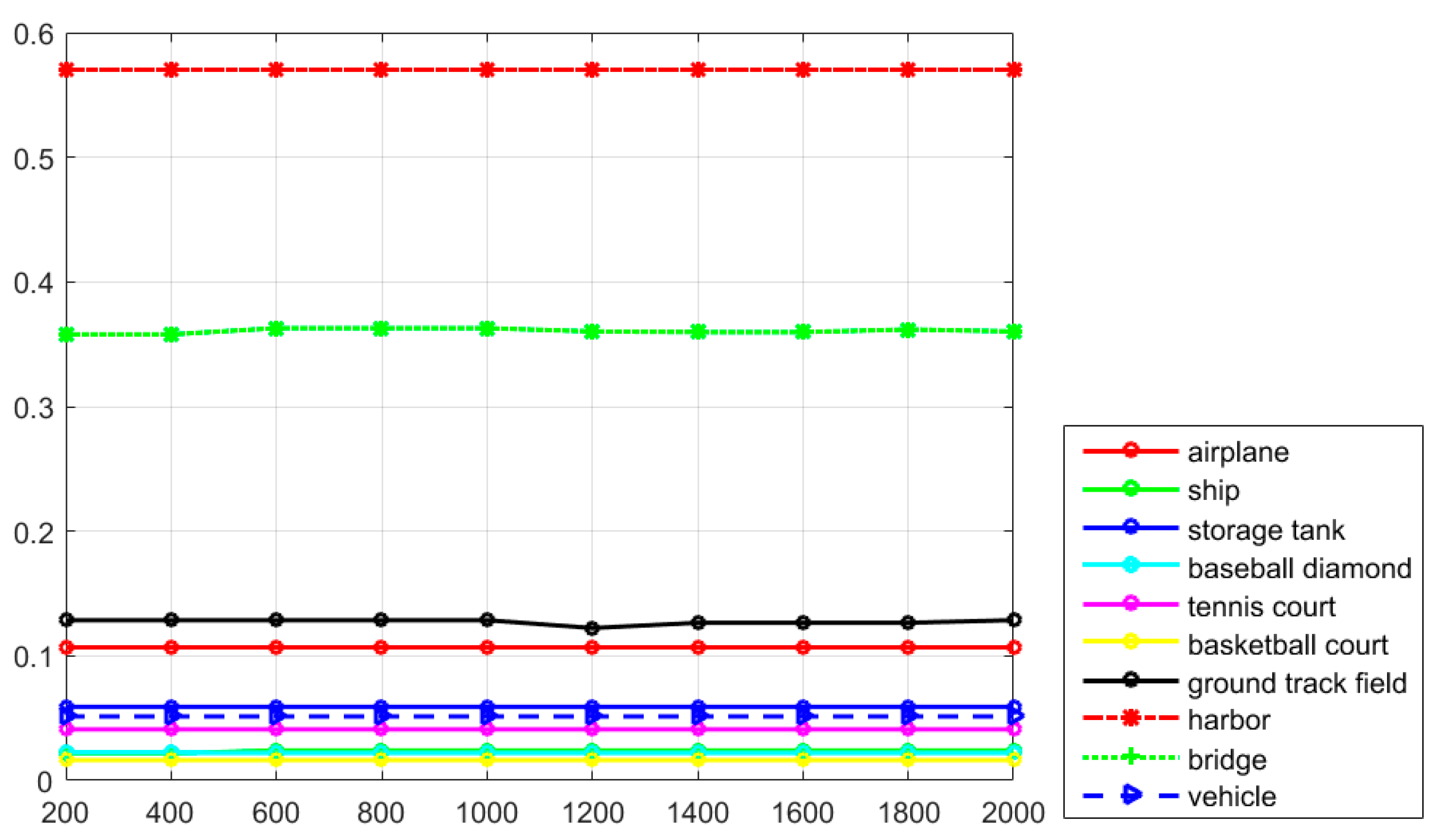
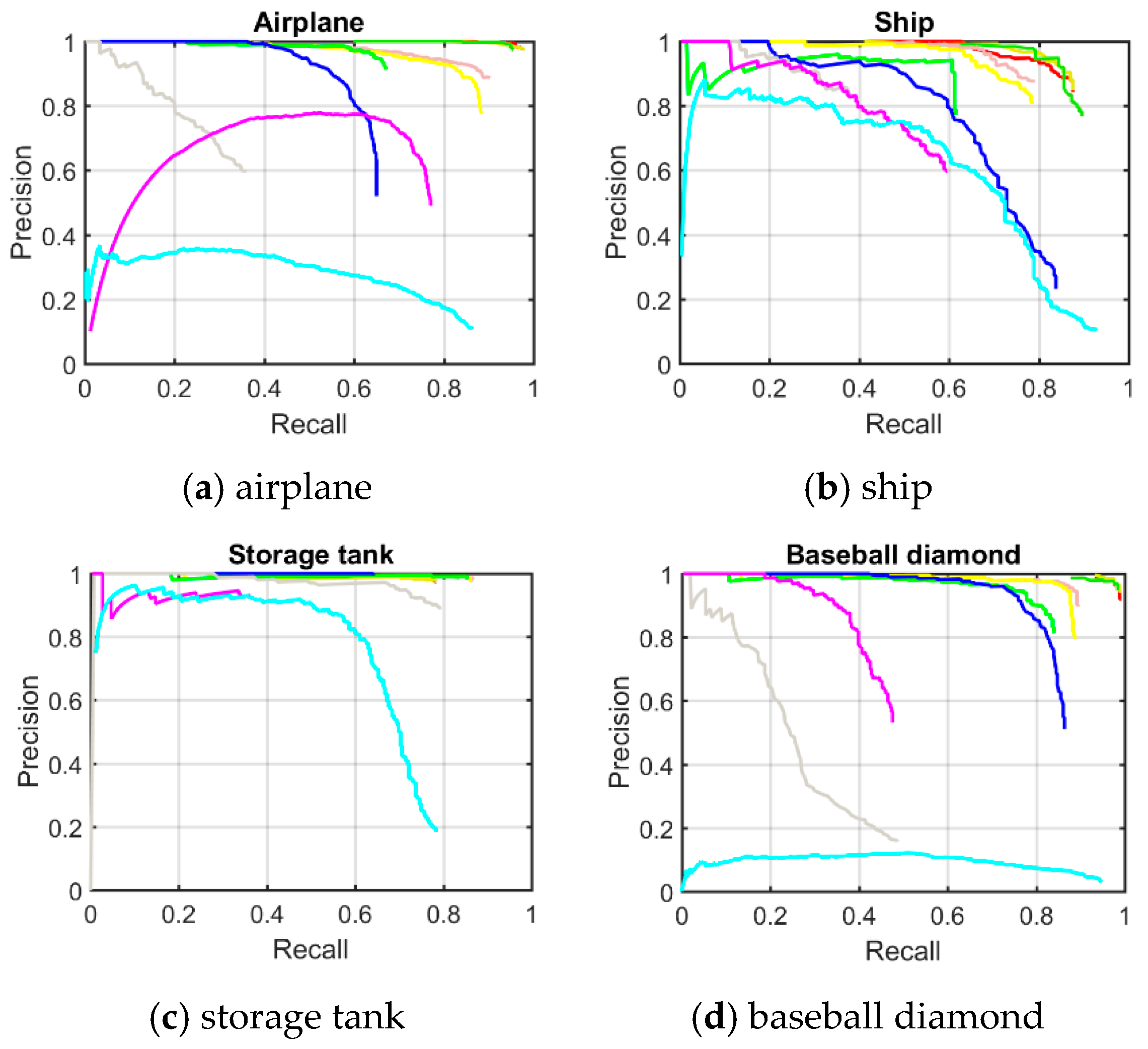
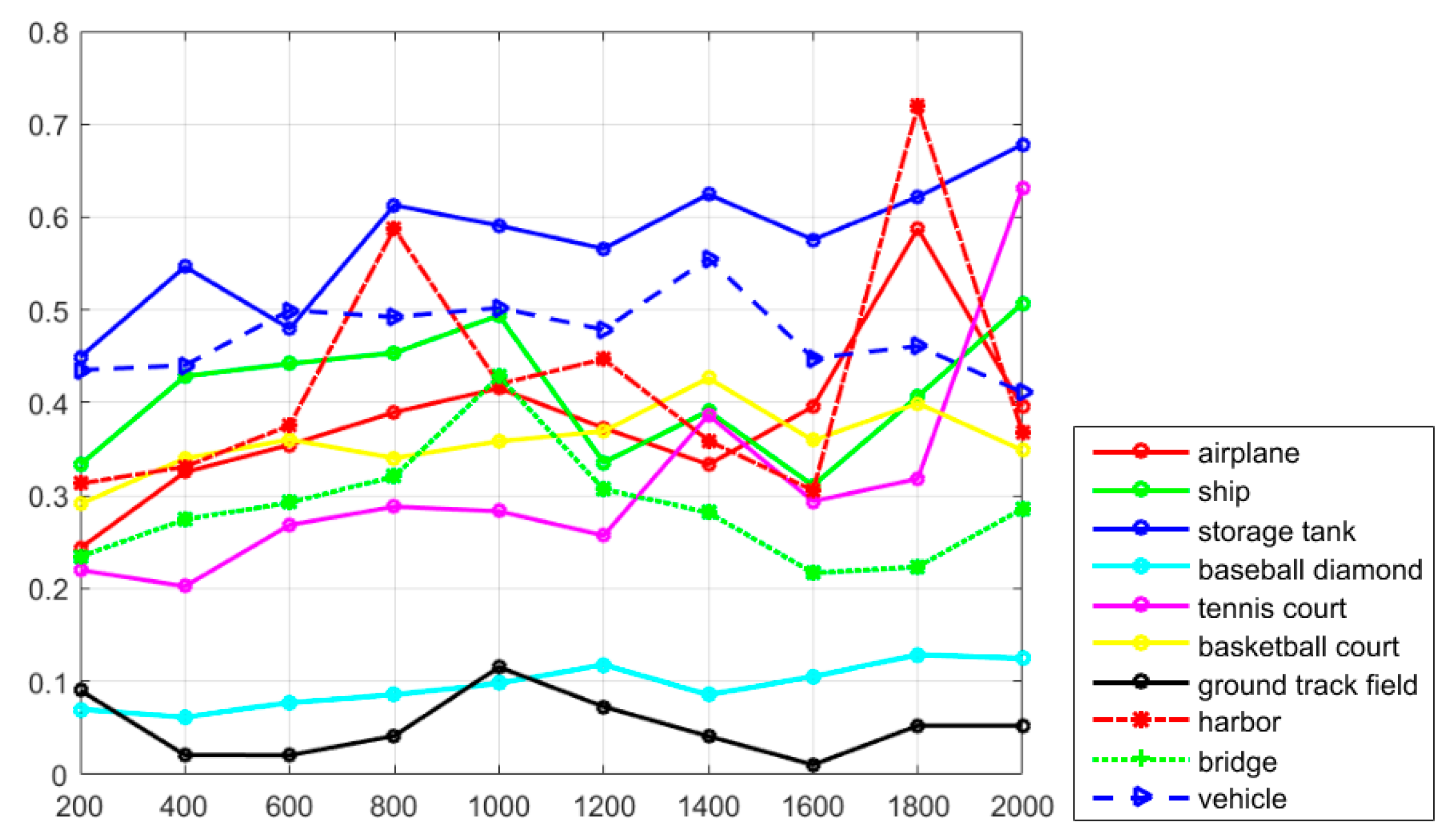
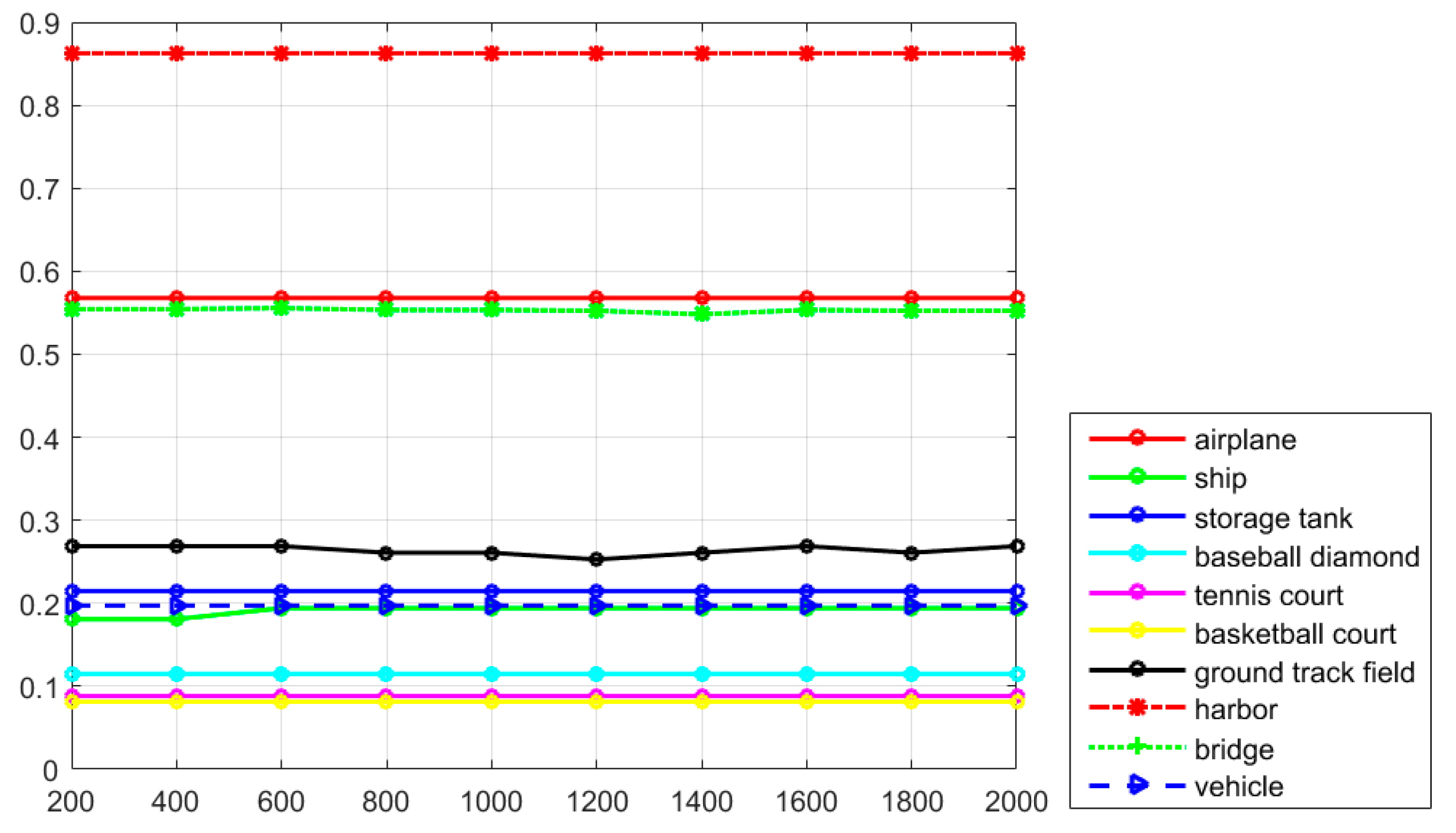
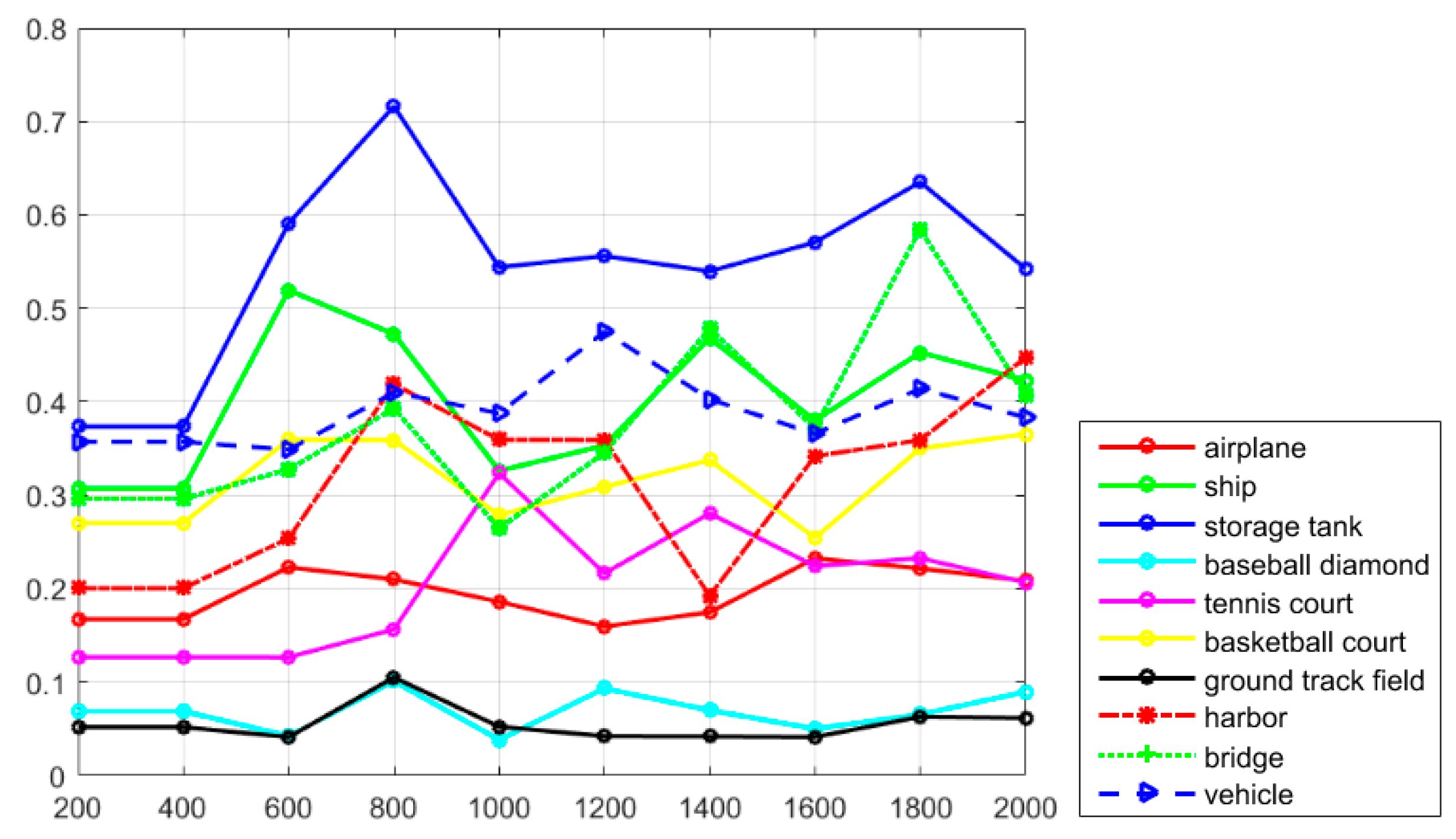
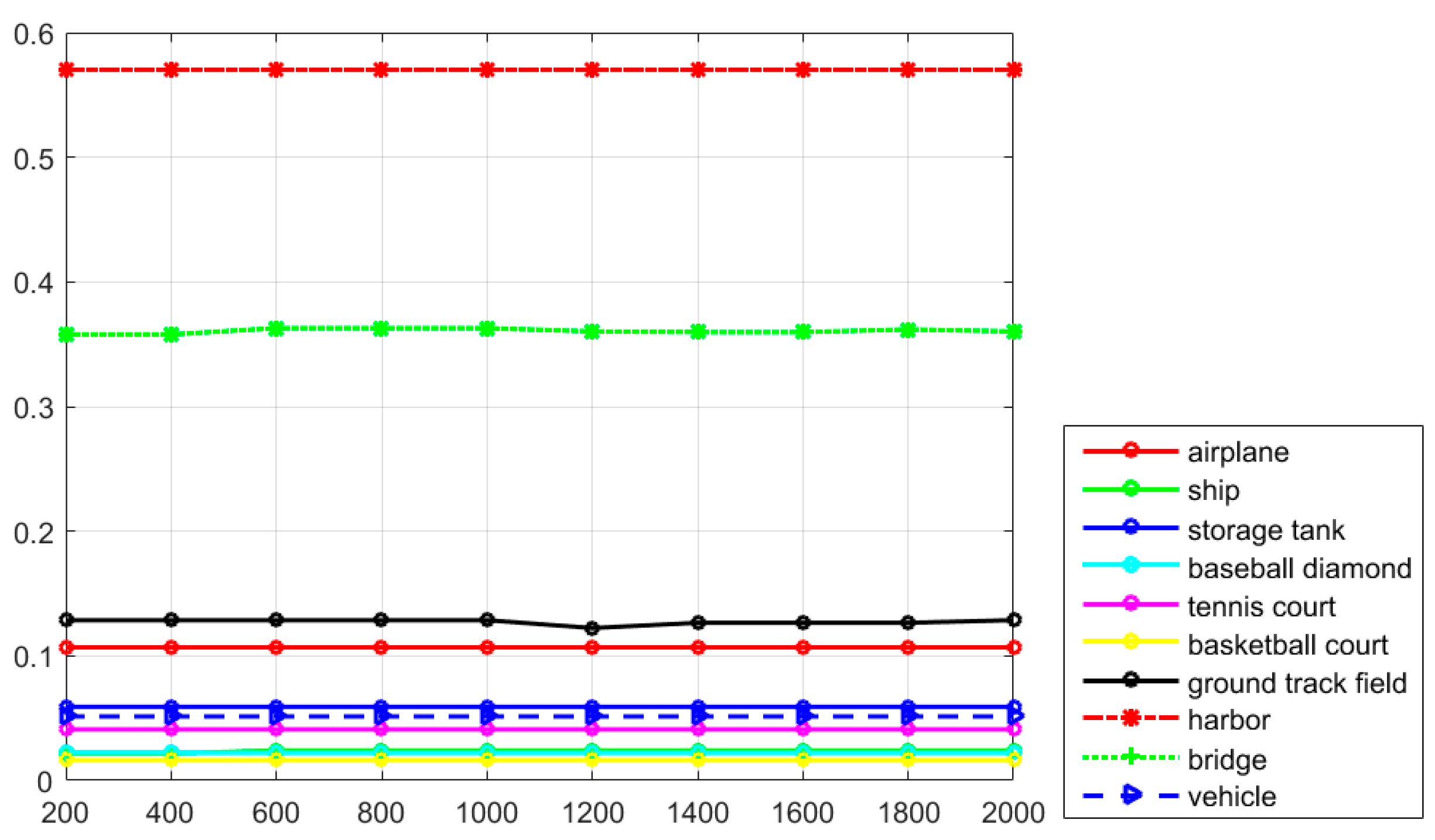
Figure 7, it can be seen that the classes of airplane, baseball diamond, ground track field, and harbor obtain high recall values of greater than 90%, but the classes of storage tank, basketball court, and bridge present worse recall values. The curve at the top of the PRCs indicates a better performance. In
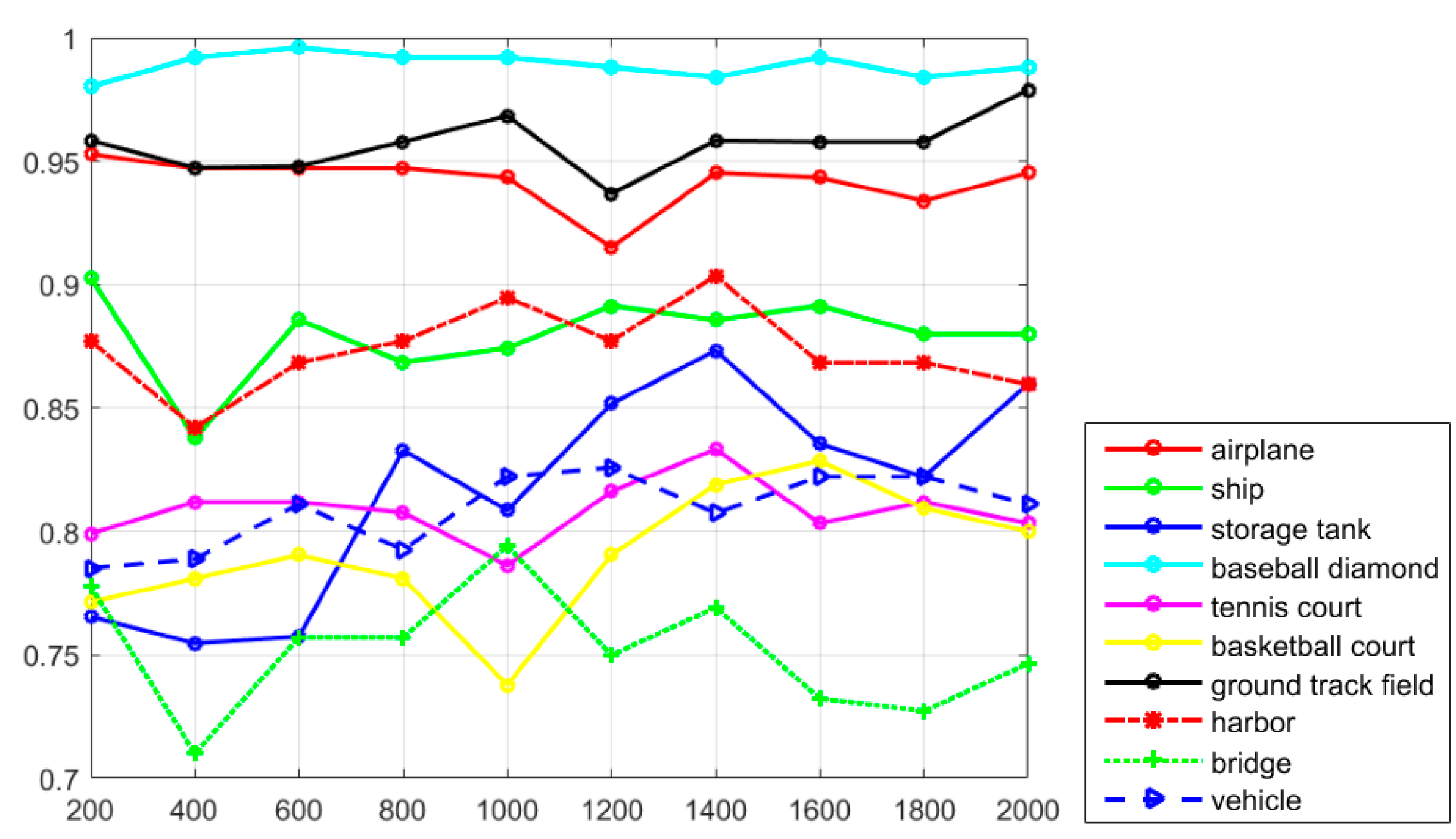
Figure 8, it can be seen that most of the classes show a better detection performance, but the classes of airplane, baseball diamond, tennis court, ground track field, harbor, and vehicle demonstrate the best tendency. By jointly analyzing the AP values, the recall rate, and the PRCs, it can be seen that the proposed R-P-Faster R-CNN algorithm shows a superior detection performance for the classes of airplane, baseball diamond, ground track field, and harbor.
In addition to the evaluation indexes, the computational efficiency is also an important factor for evaluating the performance of the proposed R-P-Faster R-CNN algorithm. In
Table 3, it can be seen that the proposed R-P-Faster R-CNN (VGG16) algorithm with the best detection performance takes about 0.15 s, which confirms that it is an efficient detection method.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}