1. Introduction
With the recent launch of remote sensing satellites around the world, a large volume of multi-level, multi-angle, and multi-resolution HSR remote sensing images can now be obtained, where the remote sensing big data brings new understandings for the traditional definition of big data [
1,
2,
3]. These multi-source remote sensing images allow the ground object observation from multiple perspectives. The rapid development of HSR remote sensing imaging sensors has provided us with a large number of HSR remote sensing images with abundant detail and structural information, and a higher spatial resolution [
1]. In addition, these multi-source HSR remote sensing images also provide a huge amount of data without corresponding labels, which may consume a large amount of human labor for labeling. Traditional HSR remote sensing imagery understanding is based on recognizing pixel-based or object-based ground elements, but this cannot describe the whole content of the scene images and cannot well bridge the “semantic gap” between the low-level features and the high-level semantics [
4]. Scene classification for HSR remote sensing imagery is aimed at obtaining the semantic category information of the scene images, where the core idea of HSR remote sensing imagery scene classification is to bridge the semantic gap and to explore the high-level semantic category information contained within the scenes [
5,
6,
7,
8].
To adequately bridge the semantic gap between the low-level features and the high-level semantics, various scene classification methods have been proposed in recent years. The traditional HSR remote sensing imagery scene classification methods include bag of visual words (BOVW) [
9,
10,
11,
12], spatial pyramid matching (SPM) [
13], latent Dirichlet allocation (LDA) [
14,
15,
16], and probabilistic latent semantic allocation (PLSA) [
17,
18]. These methods adopt manual feature extraction techniques, namely the spectral features, textural features, and structural features (e.g., scale invariant feature transformation, SIFT [
19]), to realize scene semantic recognition. However, all these approaches adopt manually designed feature descriptors for the predefined algorithms [
4,
5,
6,
7,
8,
9,
10], which require expert engineering experience.
Recently, with the development of deep learning [
20,
21,
22,
23,
24,
25,
26,
27], much effort has been dedicated to developing automatic and discriminative feature extraction and representation frameworks for HSR remote sensing imagery scene classification [
26,
27,
28,
29,
30,
31,
32,
33,
34]. Previous works have proven that CNN are excellent deep learning model for HSR remote sensing imagery scene semantic recognition [
26,
28,
29,
30,
32,
35,
36,
37,
38] or image classification [
39,
40], and they can efficiently and automatically extract features derived from the data. A CNN is a hierarchical feature representation framework consisting of multiple alternate convolutional and pooling layers, with a back-propagation mechanism to tune the whole network to obtain the final classification result [
35]. However, according to the current research status, research into CNN models for HSR remote sensing imagery scene classification can be summarized into two research trends.
The first research trend of CNN models is focused on carefully designing an effective and accurate network architecture to obtain a satisfactory HSR remote sensing scene classification result. For instance, to improve HSR remote sensing imagery scene classification performance, Zhang et al. [
33,
35] proposed an improved gradient boosting CNN ensemble framework to reuse the weights in each random convolutional network. Compared with the large and complicated natural imagery scene datasets, as introduced in [
20], the current HSR remote sensing imagery scene datasets have the characteristics of small quantities, simple categories, simple content, multi-scale objects et al., which results in the manually designed CNN models being faced with many critical challenges when the labeled samples are limited. To better deal with the above situations, another effective and meaningful research trend of HSR remote sensing imagery scene classification with CNN models is the introduction of the pre-training mechanism. A pre-trained CNN architecture involves first training the existing CNN model upon a large natural imagery dataset, and then a transfer mechanism is used to convey the network parameters from the natural imagery dataset to the HSR remote sensing imagery dataset [
32], considering some of the specific similarities between HSR remote sensing imagery scene dataset and natural imagery scene dataset. Marco et al. [
28] were the first to prove that the transfer of a pre-trained CNN can achieve a promising classification performance. Hu et al. [
32] further explored that the transferability of the natural image features from the pre-trained CNN applicable to the limited amount of HSR remote sensing scene datasets with the feature coding methods. The advantage of the second research trend of pre-trained CNN models is their effective extensible properties for dealing with the HSR remote sensing imagery scenes with limited labeling. However, the pre-trained CNN models seldom consider fusing the multi-scale information of the last convolved feature maps.
Although the pre-training mechanism can help CNN models achieve satisfactory classification performances for HSR remote sensing imagery scenes with limited labeled samples, the choice of a proper network architecture for making strong and correct assumptions about the nature of the input data is a big challenge for the current HSR remote sensing imagery scene classification techniques. Thus, research into a simple network architecture with a powerful modelling capability is urgently needed. AlexNet, as a simple, typical, foundational, and one of the state-of-the-art CNN architecture, was first proposed by Hinton and was successfully utilized in the 2012 ImageNet Competition [
21]. Compared with the other structure-complex and deep CNN architectures (e.g., GoogLeNet [
22], VGG et al. [
23]), AlexNet is a structure-simple CNN architecture, which is easy to train and optimize. When fine-tuned with HSR remote sensing imagery datasets, a fast and satisfactory classification result can be obtained. However, considering the multi-scale characteristic in some specific semantic scenes with key objects, the properties of the current pre-trained AlexNet architecture are limited. In order to further improve the classification performance and adequately consider the multi-scale information with the AlexNet architecture, an improved pre-trained AlexNet architecture is needed.
In order to better deal with the multi-scale information of the convolved feature maps of the HSR remote sensing scene images and fuse this information, a multi-scale pooling strategy, named spatial pyramid pooling (SPP) [
13,
41,
42,
43], is incorporated into the pre-trained AlexNet classification architecture. SPP is a pooling strategy proposed by He et al. [
44] for object detection tasks, which was developed from the SPM model proposed by Lazebnik et al. in [
13], and extended research done in [
41,
42,
43,
44]. The SPP strategy operates on the multi-scale convolved feature maps, and concatenates the different-scale convolved feature maps, which adequately takes the multi-scale spatial information of the same scenes into consideration and can narrow the semantic differences for the scenes with multi-scale information.
Although the pre-trained AlexNet architecture can handle scenes containing multi-scale information with the SPP strategy, the relatively simple pre-trained AlexNet architecture still lacks an efficient side supervision (SS) technique to prevent overfitting of the AlexNet architecture. To further improve the performance of the pre-trained AlexNet architecture, an effective improvement is needed to be incorporated into the pre-trained AlexNet architecture. The SS strategy firstly derived from [
45] is an effective companion operation which incorporates deep supervision into both the hidden layers of the deep CNN and the final output layer to propagate this supervision to the previous layers, simultaneously minimizing the classification error. In addition, SS can also reduce the gradient vanishing phenomenon and prevent overfitting of the CNN architecture. By introducing the SPP and SS strategies into the pre-trained AlexNet architecture, the multi-scale operation and the simultaneous minimization operation can be handled at the same time for the pre-trained AlexNet architecture, which enables the pre-trained AlexNet architecture with better properties to better deal with HSR remote sensing imagery scene classification.
The main contributions of this paper can be summarized as follows.
- (a)
The end-to-end AlexNet classification architecture. Differing from the complicated and stepwise operation of the AlexNet classification architecture, the proposed pre-trained AlexNet-SPP-SS model is an end-to-end operation. Pre-trained AlexNet-SPP-SS deals with the label-limited HSR remote sensing imagery scene classification task with fast and effective one-step heterologous parameter transferring and pre-training operations, enabling the whole procedure to be more convenient, reducing the complicated intermediate operations, and reducing the resource consumption.
- (b)
The effective multi-scale pyramid pooling scene interpretation capability. The SPP strategy is incorporated into the end-to-end pre-trained AlexNet architecture, and solves the multi-scale scene interpretation task by fusing the different-scale convolved feature maps, which adequately considers the spatial information in different scales and increases the scene interpretation ability.
- (c)
The simultaneous supervision processing framework. To make the end-to-end pre-trained AlexNet architecture more transparent in dealing with the heterologous parameter transferring in quantity-limited HSR remote sensing imagery scene classification, the SS strategy is incorporated by introducing intermediate supervision to the layers of the pre-trained AlexNet architecture, to reduce the gradient vanishing phenomenon and prevent overfitting of the whole architecture.
To test the performance of the proposed pre-trained AlexNet-SPP-SS model, extensive experiments were conducted on HSR remote sensing datasets—the UC Merced dataset and the Google image dataset of SIRI-WHU—with the pre-trained network parameters transferred from natural image datasets, demonstrating that the proposed pre-trained AlexNet-SPP-SS model can perform better than the pre-trained AlexNet architecture, the AlexNet-SPP architecture, and the AlexNet-SS architecture, as well as the traditional handcrafted feature based HSR remote sensing imagery scene classification approaches.
The rest of this paper is organized as follows. In
Section 2, the typical AlexNet architecture is introduced. In
Section 3, the SPP strategy, the SS strategy, and the proposed AlexNet-SPP-SS model are described in detail. The experimental datasets, the experimental results, and an analysis are given in
Section 4 and
Section 5.
Section 6 presents a discussion.
Section 7 draws our conclusions.
3. The Proposed AlexNet-SPP-SS Architecture for High Spatial Resolution Remote Sensing Imagery Scene Classification
It is noted that the simplicity and convenience of the pre-training mechanism in the AlexNet architecture make the pre-trained AlexNet architecture a good choice in dealing with HSR remote sensing imagery scene classification. In order to further mine the properties of the pre-trained AlexNet for the HSR remote sensing imagery scene classification tasks, and to adequately consider the multi-scale properties of the ground objects as well as the simultaneous processing capacity, an improved pre-trained CNN architecture named the pre-trained AlexNet-SPP-SS architecture is proposed in this paper. The proposed pre-trained AlexNet-SPP-SS model is introduced below.
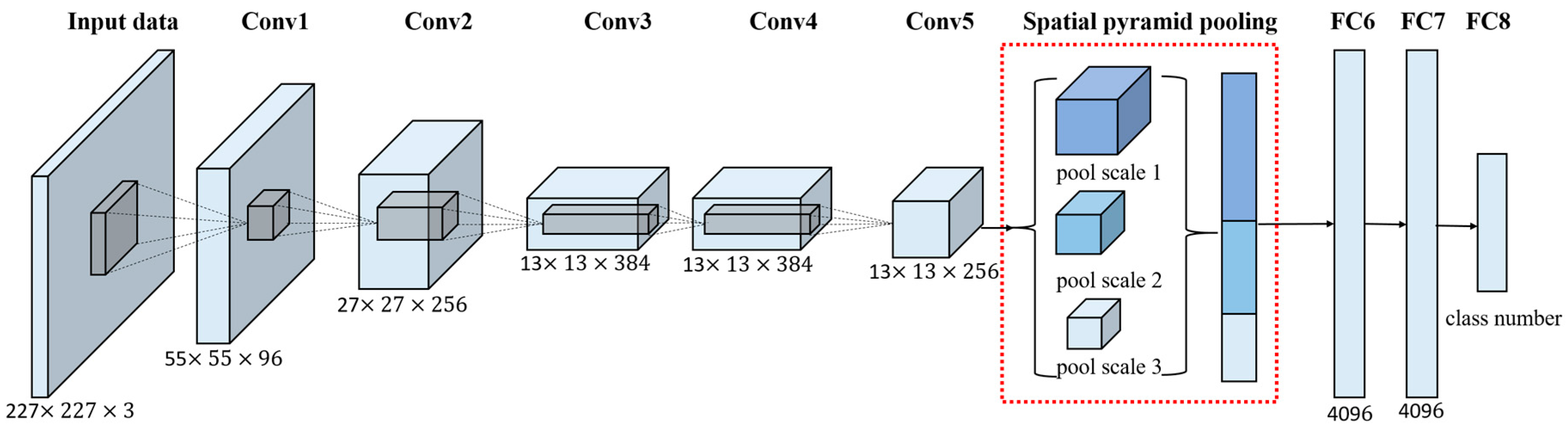
3.1. The Effective Multi-Scale Pyramid Pooling Ground Objects Scene Interpretation Strategy—Spatial Pyramid Pooling (SPP)
SPP developed from the SPM model [
13] for object recognition and scene classification [
41,
42,
43], to improve the performance of the CNN architecture [
44], SPP deals with the multi-scale convolved feature maps to generate a fixed-length pooling representation, regardless of the image size, and concatenates the pooled feature maps into a long single vector. As the multi-scale convolved feature maps contain abundant complementary spatial information, especially the scenes containing key ground objects, the incorporation of the SPP strategy can enhance the scene interpretation capability. The SPP strategy also has the outstanding advantage of generating a fixed-length pooling feature representation, regardless of image size, and is thus able to deal with the images of arbitrary scales.
The advantages of incorporating the SPP strategy into the pre-trained AlexNet architecture can be summarized from three aspects. The first advantage of SPP is that it computes the convolved feature maps only once from the entire image, and it pools the convolved features in arbitrary-scale regions to generate a fixed-length representation. The second advantage of SPP is that it can utilize multi-scale spatial bins, which is an approach that has been shown to be robust to object deformation, while the sliding window pooling only uses a single window size. The third advantage of SPP is that it can pool features extracted at different scales. These advantages enable the pre-trained AlexNet architecture to interpret HSR remote sensing imagery scenes with multi-scale ground objects. The multi-scale processing procedure of the SPP strategy is shown in
Figure 2.
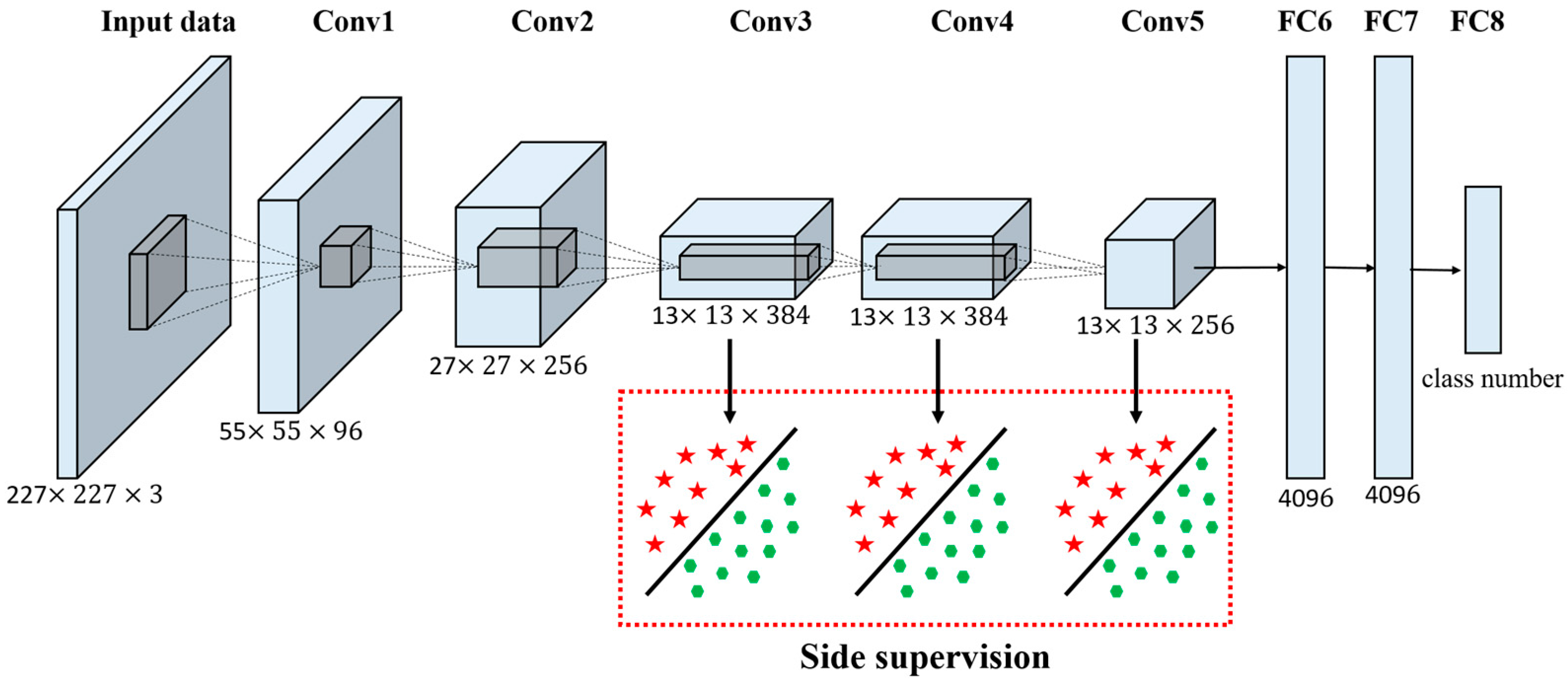
3.2. The Simultaneous Supervision Processing Framework: the Side Supervision (SS) Strategy
The pre-trained AlexNet architecture is an effective end-to-end HSR remote sensing imagery scene classification framework, but it only deals with the classification task with the final supervision term. It is noted that the goal of the pre-trained AlexNet architecture is to learn layers of filters and weights for the minimization of the classification error at the final output layer. However, the single supervision term limits the ability of the pre-trained AlexNet architecture to deal with the simultaneous and transparent classification error minimization. To alleviate the phenomenon of non-simultaneous and non-transparent processing in the pre-trained AlexNet architecture, a supervision [
45] strategy is incorporated into the pre-trained AlexNet architecture. SS is a strong convex strategy, which enforces the feature robustness and discriminative ability through both final-layer supervision and intermediate-layer supervision. Specifically, the core idea of SS is aimed at providing integrated direct supervision to the hidden layers, which is in contrast to the standard approach of providing supervision only at the output layer and propagating this supervision back to earlier layers. The SS is added by the companion objective function for each hidden layer, and can be regarded as an additional constraint within the learning process.
For the pre-trained AlexNet architecture, there are three obvious problems with the current architecture. The first problem is the non-transparency in the intermediate layers during the overall classification procedure, which makes the training process difficult to observe. The second problem refers to the robustness and discriminative ability of the learned features, especially in the latter layers of the network, which can significantly influence the performance. The third problem is the low training effectiveness in the face of “exploding” and “vanishing” gradients. In order to better deal with the problems existing in the current pre-trained AlexNet architecture, there are two significant advantages of introducing the SS companion objective functions into the pre-trained AlexNet architecture. The first advantage is that the SS functions are strong convex regularization functions for both the large training data in deeper networks and the small training data in relatively shallower networks, which can increase the robustness and discriminative ability of the learned features in the pre-trained AlexNet architecture. The second advantage is that SS can make the intermediate layers transparent during the training process.
In order to allow a better understanding of the pre-trained AlexNet architecture with the SPP and SS strategies, an illustration is given below. Suppose that the input sample
denotes the raw input data and
denotes the corresponding ground truth label for sample
. Suppose that there are
layers in total in the pre-trained AlexNet architecture, the weight combinations for the pre-trained AlexNet architecture are
. Meanwhile, for each classifier in each hidden layer of the pre-trained AlexNet architecture, the corresponding weights are
. In the pre-trained AlexNet architecture, the relationships between the weight parameters and the filters are respectively shown in Equations (2) and (3):
In Equations (2) and (3), M denotes the total layer number of the pre-trained AlexNet architecture;
refers to the specific layer of the pre-trained AlexNet architecture;
are the network weights to be learned;
refers to the convolved responses on the previous feature map; and
is the pooling function on
. The total objective function for the pre-trained AlexNet architecture is shown in Equation (4).
where
and
refer to the output objective and the summed companion objectives, which are defined in Equations (5) and (6), respectively.
where
refers to the classifier weight of the output layer. The final combined objective function of the pre-trained AlexNet architecture is defined in Equation (7).
where
and
are respectively the margin and squared hinge loss of the support vector machine (SVM) classifier.
and
are respectively the margin and squared hinge loss of the SVM classifier at each hidden layer. The overall loss of the output layer
is as shown in Equation (8):
In Equation (7),
as the companion loss of the intermediate layers is as shown in Equation (9).
For Equations (8) and (9), they are both squared hinge losses of the prediction errors. From the above formulations, it can be understood intuitively that, in Equations (8) and (9), the pre-trained AlexNet architecture not only learns the convolutional kernels , but enforces a constraint at each hidden layer to directly make a good label prediction and give a strong push for having discriminative and sensible features at each individual layer. It is noted that for each , the directly depends on , which is dependent on up to the th layer. The second term often goes to zero during the course of training. In this way, the overall goal of producing a good classification result at the output layer is not altered and the companion objective just acts as a proxy or regularization. To achieve this goal, the threshold is usually set in the second term of Equation (6). The working mechanism of this companion function is that the hinge losses of the overall function and the companion objective function vanish and no longer play a role in the learning process when the overall value of the hidden layer reaches or is below . balances the importance of the error in the output objective and the companion objective.
To summarize, the working mechanism of the pre-trained AlexNet architecture with SS strategy is that the output performance of the entire network is achieved with a “satisfactory” level of performance on the part of the hidden layer classifiers. For the pre-trained AlexNet architecture with SS strategy, the optimization procedure is conducted using the SGD algorithm and the gradient functions in a similar way to the original AlexNet architecture. To better demonstrate the working details and the processing manner of the pre-trained AlexNet architecture, a flowchart is provided in
Figure 3.
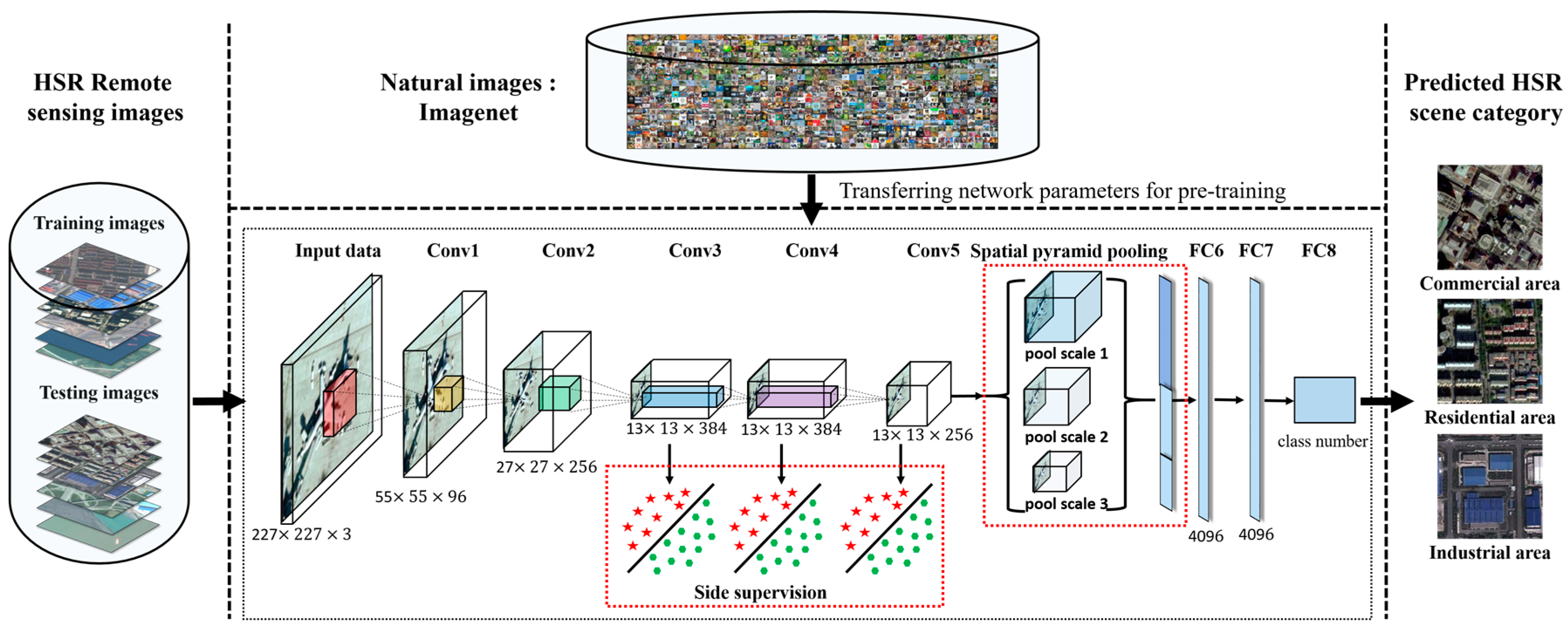
3.3. The Proposed Pre-Trained AlexNet-SPP-SS Model for High Spatial Resolution Remote Sensing Imagery Scene Classification
As a simple and effective HSR remote sensing imagery scene classification model, the AlexNet architecture has some disadvantages in dealing with both the non-transparency phenomenon of the intermediate layers and scene classification tasks with the multi-scale thematic scenes. To quickly make the objective function converge to an optimal value, the network weight parameters transferred from the natural images are retrained in the HSR remote sensing imagery scene classification tasks, where the pre-trained AlexNet architecture is derived from pre-training AlexNet architecture on large-scale natural imagery datasets. The similar semantic scene information helps the pre-trained AlexNet architecture to obtain a fast and satisfactory result for the HSR remote sensing scene images. In order to deal with the multi-scale phenomenon of the specific multi-scale semantic scenes, SPP, as a kind of effective multi-scale pooling operation is added into the pre-trained AlexNet architecture. To better represent the intermediate layer information of the pre-trained AlexNet architecture, SS, as a kind of useful intermediate supervision incorporation strategy, can help the pre-trained AlexNet architecture improve the classification performance not only from the aspect of the robustness of the network weights but also from the aspect of the transparency of the intermediate layers. Based on the advantages of the SPP and the SS strategies, and for the purpose of further improving the HSR remote sensing imagery scene classification performance with the pre-trained AlexNet architecture, the pre-trained AlexNet-SPP-SS model is proposed to first incorporate the SPP and SS strategies into the pre-trained AlexNet architecture.
The pre-trained AlexNet-SPP-SS architecture is a combinatorial CNN network architecture, which incorporates the supervision layers as the intermediate layers of the pre-trained AlexNet architecture and also combines the SPP layers into the AlexNet architecture to allow the pre-trained AlexNet architecture to have the ability to both deal with the multi-scale information of the pre-trained AlexNet architecture and simultaneously process the SS information. In an overall view, the pre-trained AlexNet-SPP-SS model, as shown in
Figure 4, endows the HSR remote sensing imagery with limited samples to obtain an improved scene classification performance.
5. Results
In order to evaluate the performance of the proposed pre-trained AlexNet-SPP-SS model and compare with the performances of the traditional classification methods on the UC Merced dataset, the scene classification results are listed in
Table 1.
From
Table 1, it can be seen that the pre-trained-AlexNet-SPP and the pre-trained-AlexNet-SS obtain better scene classification performances than the pre-trained-AlexNet architecture, which proves that the incorporation of either SPP or SS can improve the scene classification performance. The pre-trained-AlexNet-SPP-SS achieves the best scene classification result of 96.67 ± 0.94%. Compared with the traditional scene classification methods, the pre-trained AlexNet-SPP architecture and the pre-trained AlexNet-SPP-SS architecture obtain accuracy of 95.95 ± 1.01% and 95.71 ± 1.21%. This proves that the incorporation of the combination of SPP and SS further improves the pre-trained-AlexNet classification performance in the HSR remote sensing imagery.
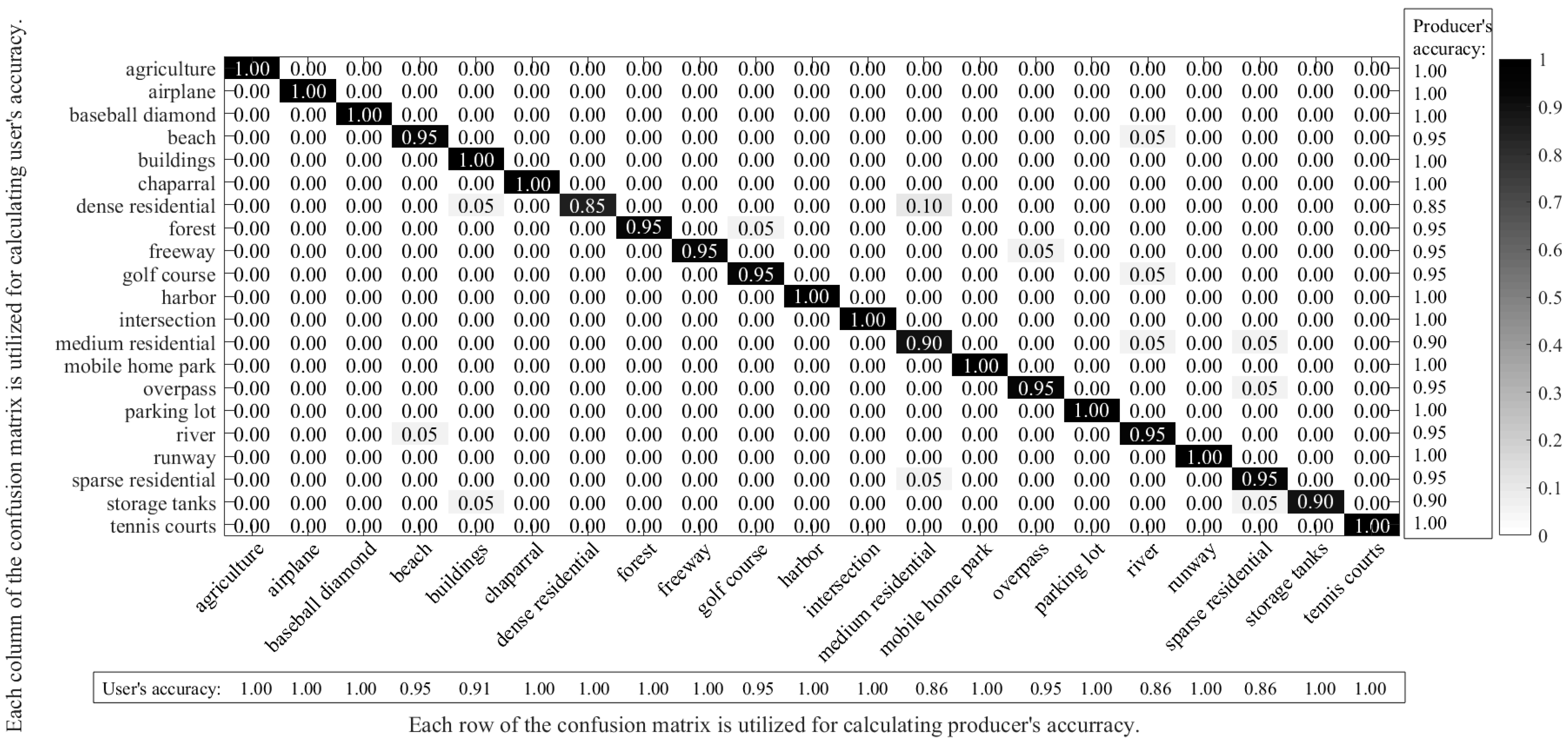
In order to better demonstrate the performance of the proposed pre-trained AlexNet-SPP-SS model for the UC Merced dataset, a confusion matrix is shown in
Figure 8.
Figure 8 demonstrates the confusion matrix of the pre-trained AlexNet-SPP-SS model, where the accuracy of the row represents the producer’s accuracy and the column represents the user’s accuracy. From
Figure 8, it can be seen that most of the classes obtain a satisfactory classification result over 90%, but the dense residential class shows a severe misclassification. By analyzing the confusion matrix of the pre-trained AlexNet-SPP-SS model, it can be seen that the samples of the dense residential classes are mainly misclassified as the building and medium residential classes. For the UC Merced dataset, the pre-trained AlexNet-SPP-SS model easily misclassifies the dense residential, building, and medium residential classes, as a result of their similar ground object distributions.
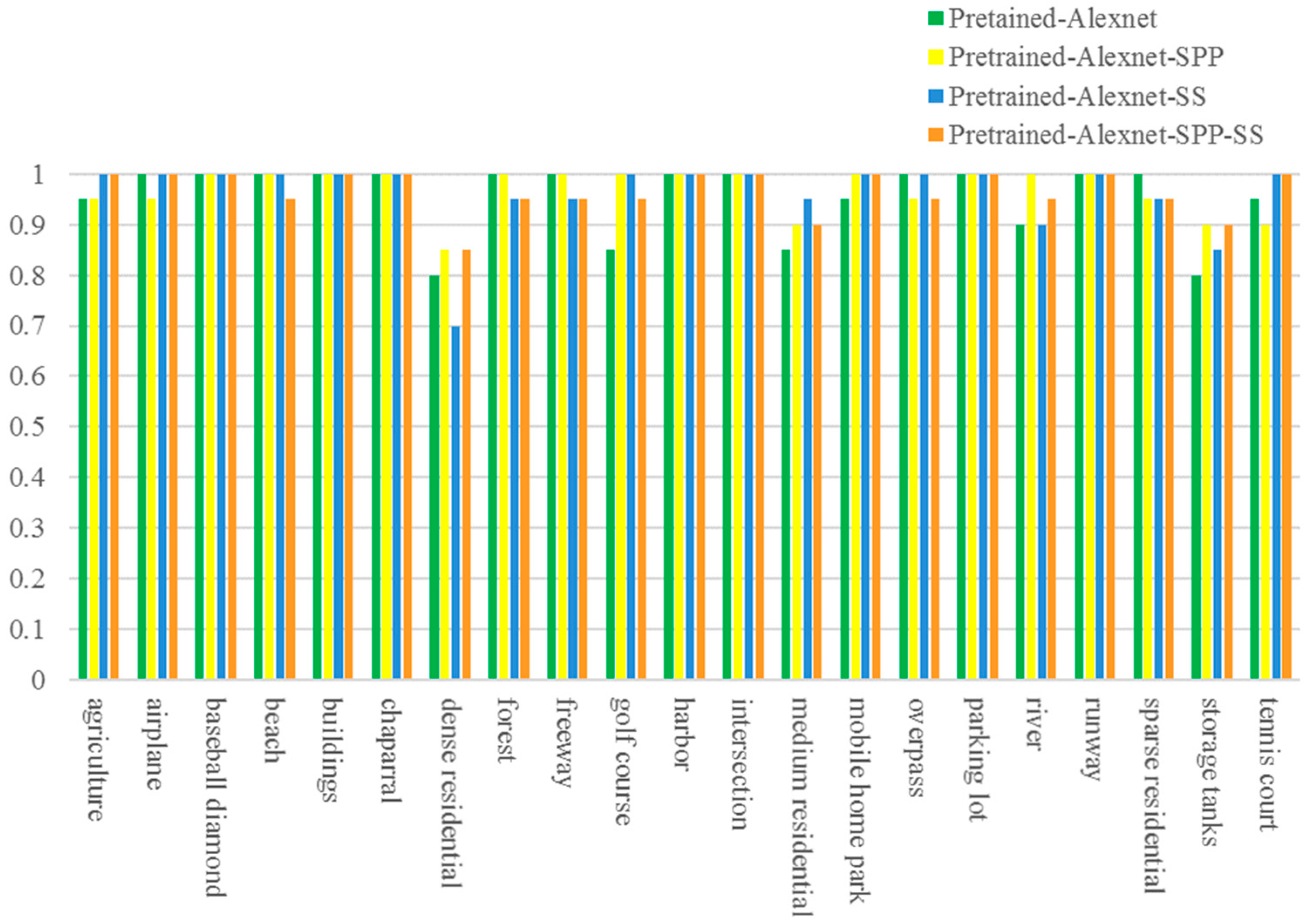
To further demonstrate the performances of the proposed pre-trained AlexNet-SPP-SS model on the UC Merced dataset, the scene classification accuracies for each thematic category are compared with the AlexNet, the pre-trained AlexNet, the pre-trained AlexNet-SPP, and the pre-trained AlexNet-SS in
Figure 9.
Figure 8 demonstrates the confusion matrix of the pre-trained AlexNet-SPP-SS model, where the accuracy of the row represents the producer’s accuracy and the column represents the user’s accuracy. From
Figure 8, it can be seen that the pre-trained AlexNet-SPP-SS model obtains a better classification accuracy than the pre-trained AlexNet, the pre-trained AlexNet-SPP, and the pre-trained AlexNet-SS in an overall view. However, the classes of dense residential and sparse residential obtain a worse classification accuracy as they contain confusing scene images that are difficult to classify. Taking a more in-depth and detailed analysis of the classification accuracy for certain classes, for example, all the classes except for the forest and tennis court classes, it can be seen that a better classification performances is obtained when adopting the SPP strategy. This is mainly due to the performance promotion of the SPP strategy considering the multi-scale information of the HSR remote sensing scene images with key ground objects. However, the classes of forest and tennis court show less improvement on the pre-trained AlexNet and the pre-trained AlexNet-SPP-SS models, because the scene images possesses heterogenous ground object distributions covering the main parts of the images. From
Figure 9, it can be seen that the pre-trained AlexNet-SS performs better than the pre-trained AlexNet for most classes, except for the dense residential, forest, freeway, and sparse residential classes.
From
Table 2, for the Google image dataset of SIRI-WHU, it can be seen that the pre-trained-AlexNet-SPP-SS model achieves the best scene classification result of 95.07 ± 1.09%. The reason why the pre-trained-AlexNet-SPP-SS method obtains a better scene classification result can be attributed to the multi-scale spatial information consideration and the side-supervision incorporation in the relatively simple pre-trained AlexNet architecture.
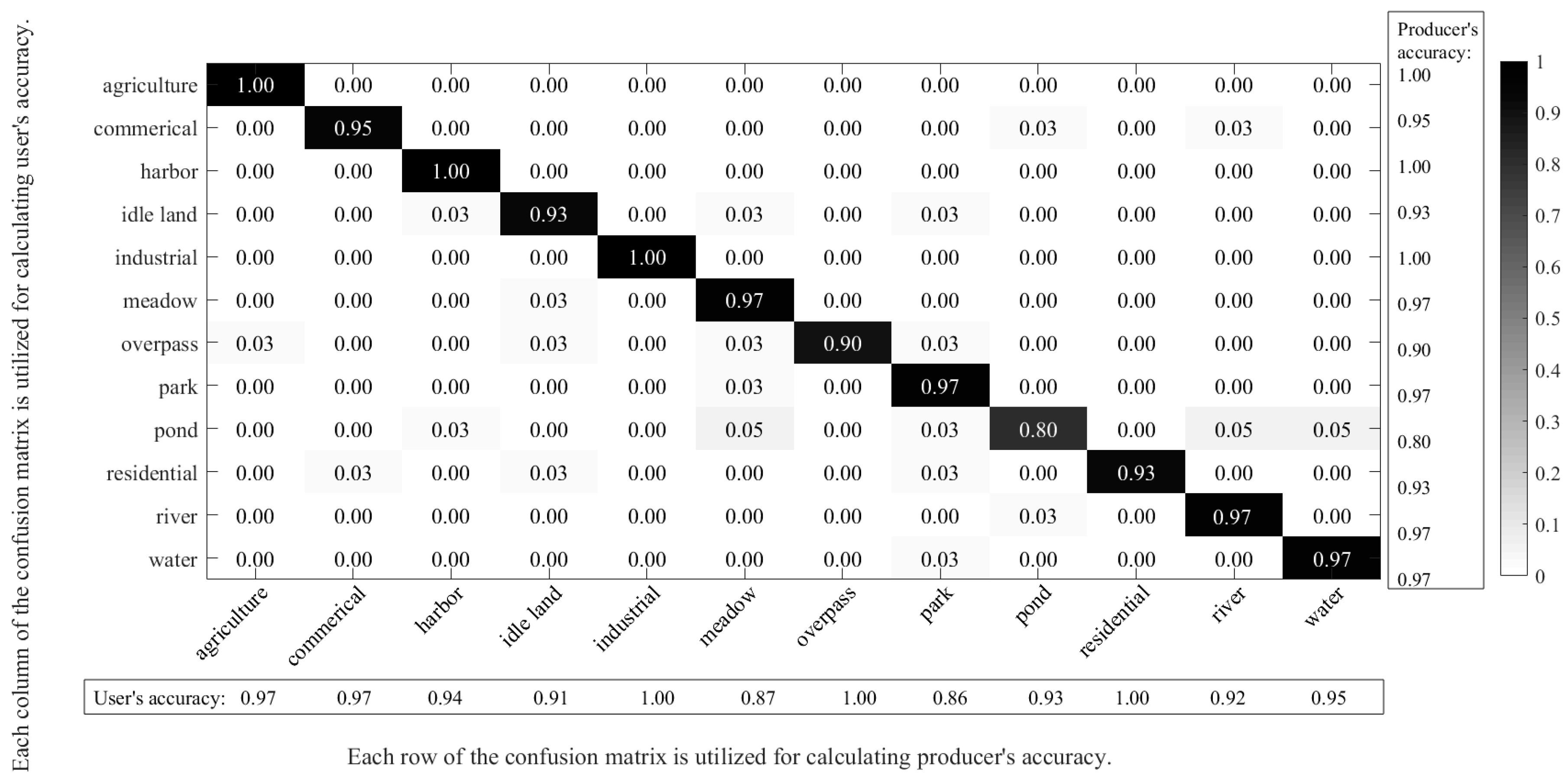
In order to better demonstrate the specific performances of the proposed pre-trained AlexNet-SPP-SS model for the Google Image dataset of SIRI-WHU, a confusion matrix is shown in
Figure 9.
From
Figure 10, it can be seen that the classes of agriculture, harbor, and industrial obtain satisfactory classification results, but the pond class shows a severe misclassification. By analyzing the confusion matrix of the pre-trained AlexNet-SPP-SS model, it can be seen that the pre-trained AlexNet-SPP-SS model easily misclassifies the pond, meadow, idle land, and agriculture classes, as a result of their similar ground object distributions.
In
Figure 11, to further demonstrate the performances of the proposed pre-trained AlexNet-SPP-SS model on the Google image dataset of SIRI-WHU, the scene classification accuracies for each thematic category are compared with the results of AlexNet, the pre-trained AlexNet, the pre-trained AlexNet-SPP, and the pre-trained AlexNet-SS.
From
Figure 11, it can be seen that the pre-trained AlexNet-SPP-SS model obtains a better classification accuracy than the pre-trained AlexNet, the pre-trained AlexNet-SPP, and the pre-trained AlexNet-SS, in an overall view. However, the classes of meadow and pond obtain a worse classification accuracy as they contain confusing scene images that are similar to agriculture and river, respectively. Taking a more in-depth and detailed analysis of the classification accuracy for certain classes, for example, all the classes except for the harbor and park classes, it can be seen that a better classification performances when adopting the SPP strategy. This is mainly due to the performance promotion of the SPP strategy considering multi-scale information of the HSR remote sensing scene images with key ground objects. However, for the classes of overpass and water, SPP shows less improvement in the pre-trained AlexNet and the pre-trained AlexNet-SPP-SS, because the scene images possesses heterogeneous ground object distributions covering the main part of the images. For the Google image dataset of SIRI-WHU, the pre-trained AlexNet-SS performs better than the pre-trained AlexNet for most of the classes, except for the pond and industrial classes.
From
Table 3, for the WHU-RS dataset, it can be seen that the pre-trained-AlexNet-SPP-SS model achieves the best scene classification result of 95.00 ± 1.12%. The pre-trained AlexNet-SPP and pre-trained AlexNet-SS architectures also obtain superior scene classification performances, which can be attributed to the multi-scale spatial information consideration and the side-supervision incorporation in the relatively simple pre-trained AlexNet architecture.
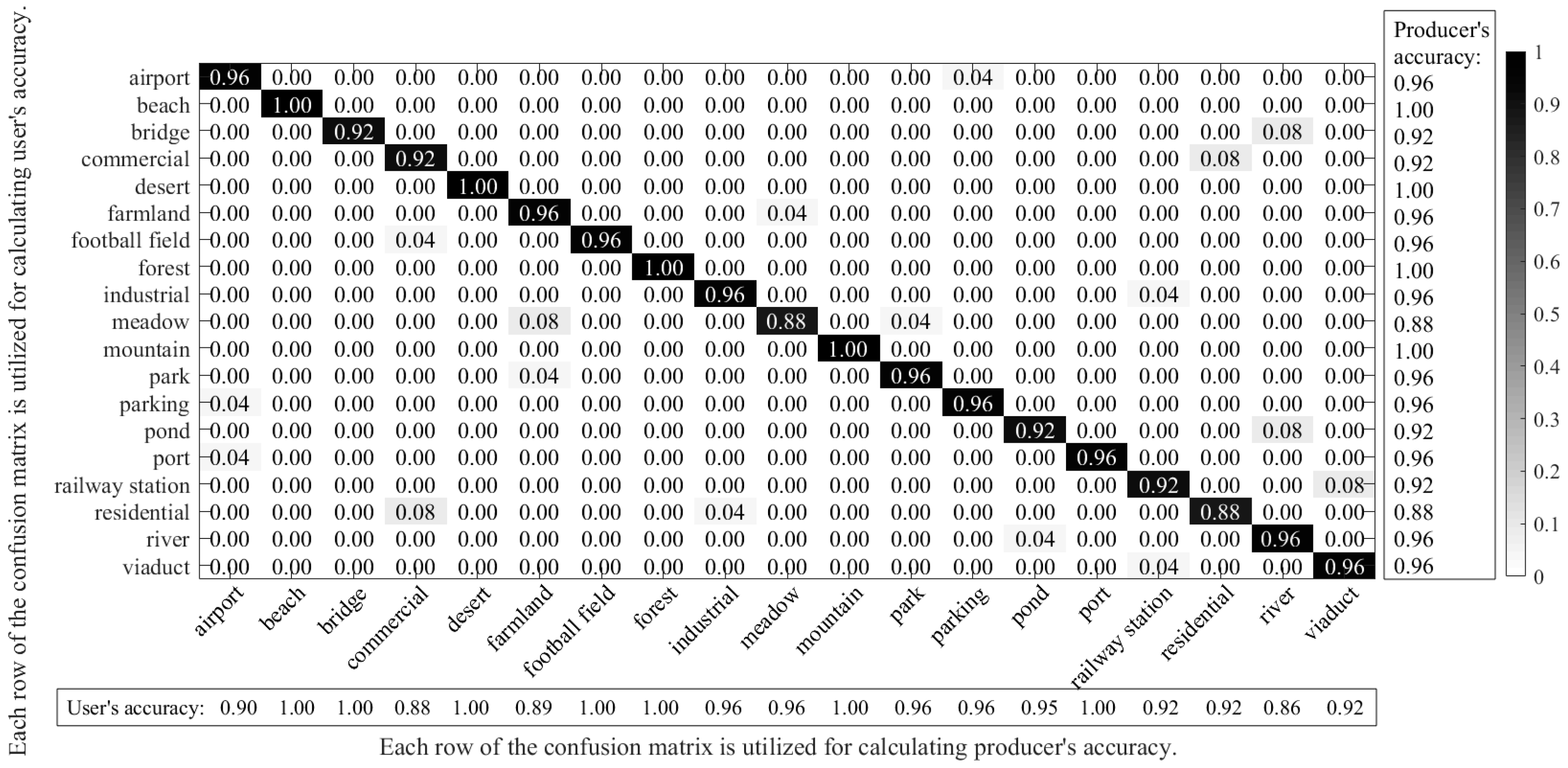
In order to better demonstrate the specific performances of the proposed pre-trained AlexNet-SPP-SS model for the WHU-RS dataset, a confusion matrix is shown in
Figure 12.
From
Figure 12, it can be seen that the classes of beach, desert, forest, and mountain obtain satisfactory classification results, but the classes of meadow and residential show severe misclassifications. By analyzing the confusion matrix of the pre-trained AlexNet-SPP-SS model, it can be seen that the pre-trained AlexNet-SPP-SS model easily misclassifies the farmland, meadow, commercial, residential, railway station, and viaduct classes, as a result of their similar ground object distributions.
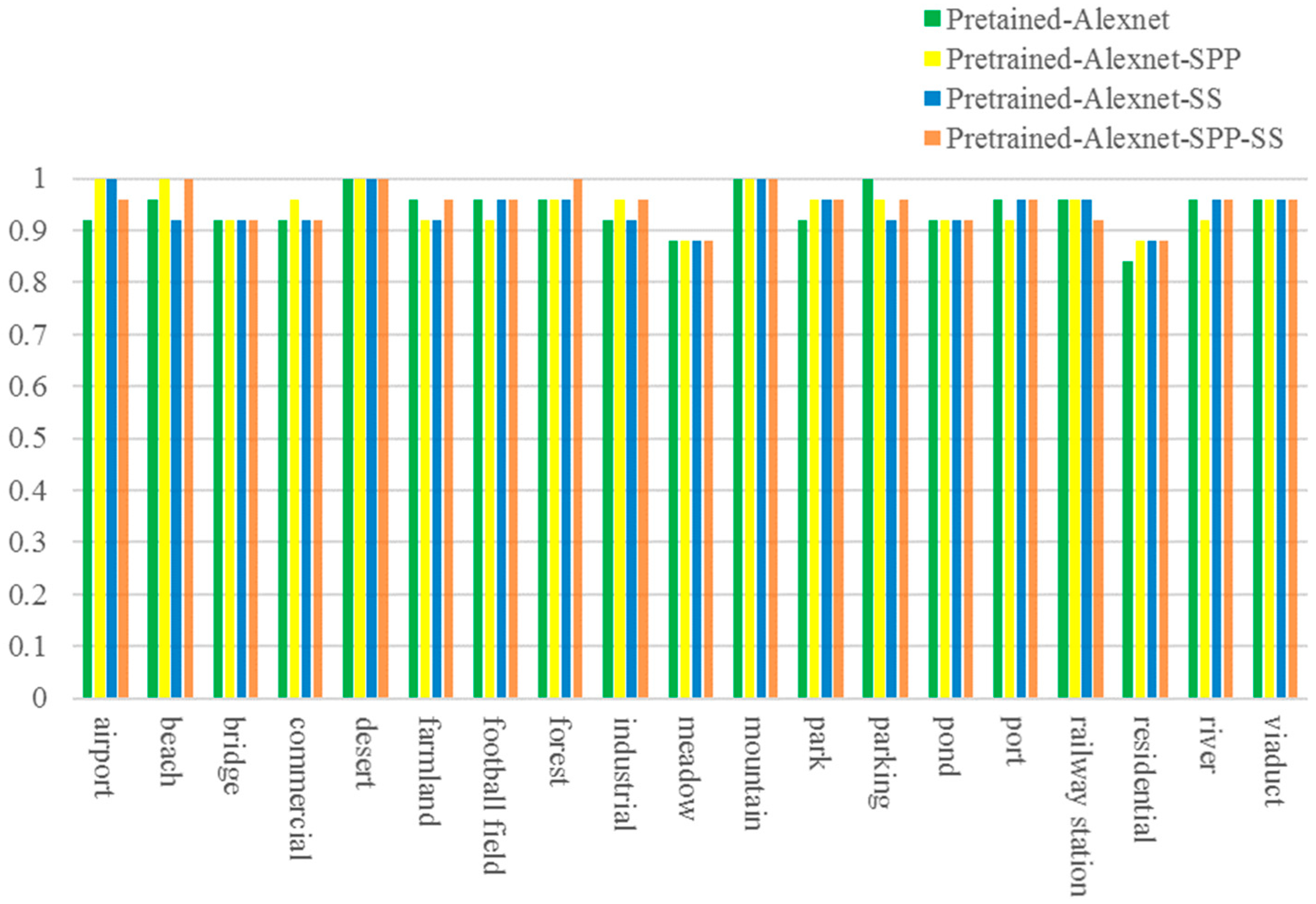
In
Figure 13, to further demonstrate the performances of the proposed pre-trained AlexNet-SPP-SS model on the WHU-RS dataset, the scene classification accuracies for each thematic category are compared with the results of AlexNet, the pre-trained AlexNet, the pre-trained AlexNet-SPP, and the pre-trained AlexNet-SS.
From
Figure 13, it can be seen that the pre-trained AlexNet-SPP-SS model obtains a better classification accuracy than the pre-trained AlexNet, the pre-trained AlexNet-SPP, and the pre-trained AlexNet-SS, in an overall view. However, the classes of bridge, commercial, meadow, pond, and, residential obtain a worse classification accuracy as they contain confusing scene images that are similar to agriculture, residential, commercial, and river, respectively. Taking a more in-depth and detailed analysis of the classification accuracy for certain classes, for example, all the classes except for the farmland, football field, and river classes, it can be seen that a better classification performances when adopting the SPP strategy. This is mainly due to the performance promotion of the SPP strategy considering multi-scale information of the HSR remote sensing scene images with key ground objects. However, for the classes of bridge, forest, pond, railway station, and viaduct, SPP shows less improvement in the pre-trained AlexNet and the pre-trained AlexNet-SPP-SS, because the scene images possesses heterogenous ground object distributions covering the main part of the images. For the WHU-RS dataset, the pre-trained AlexNet-SS performs better than the pre-trained AlexNet for most of the classes, except for the beach, farmland, and parking classes.
6. Discussion
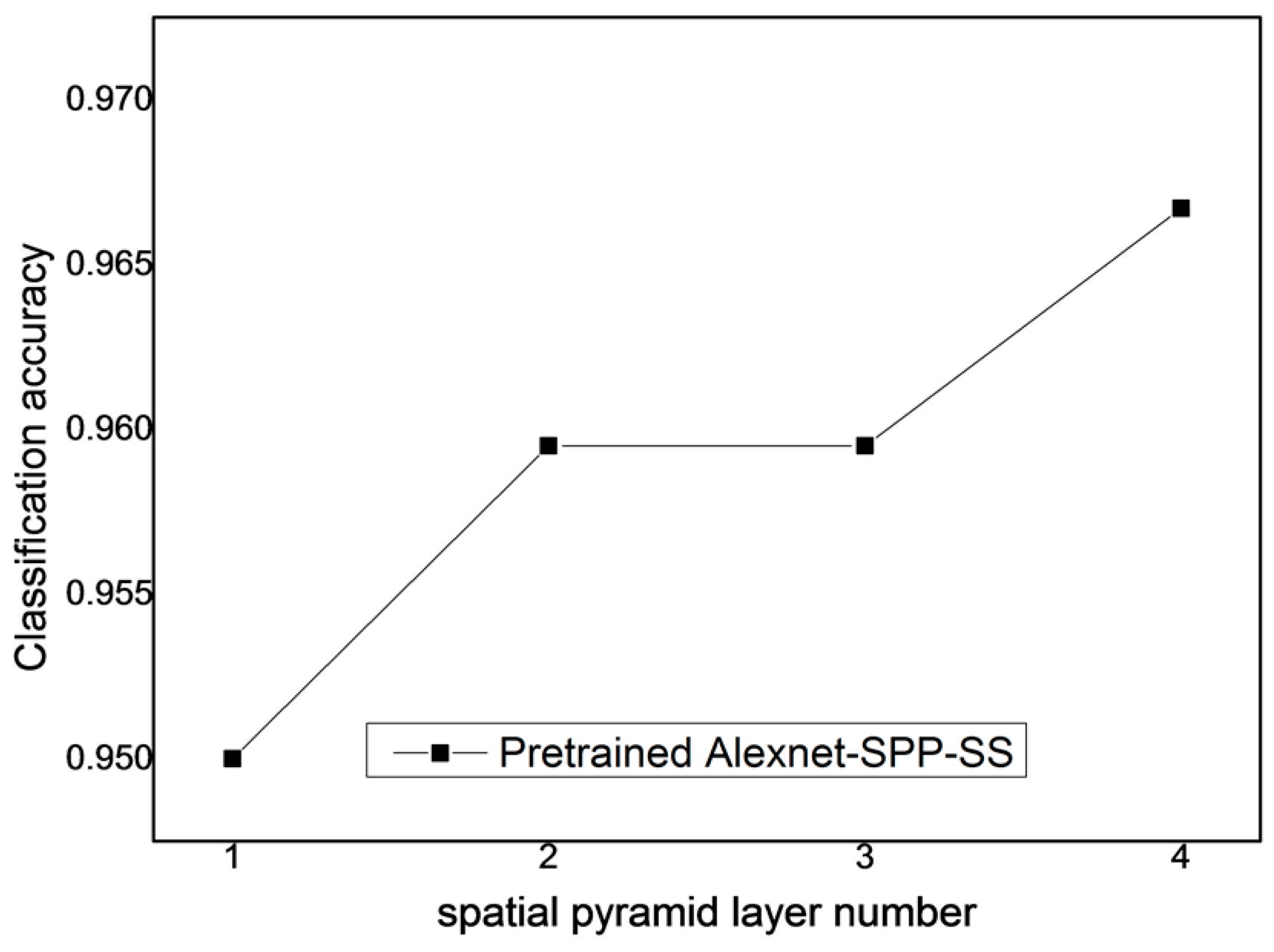
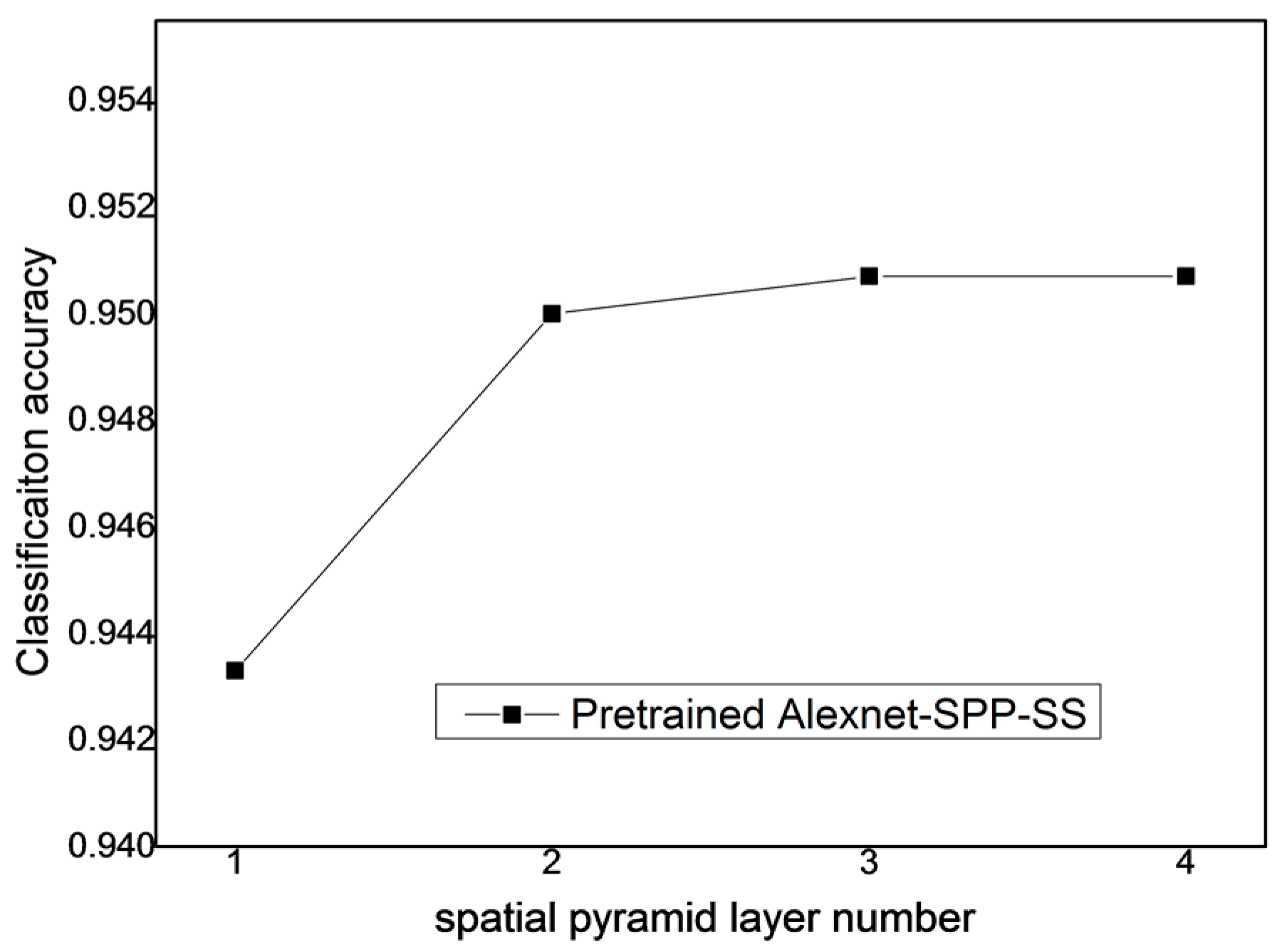
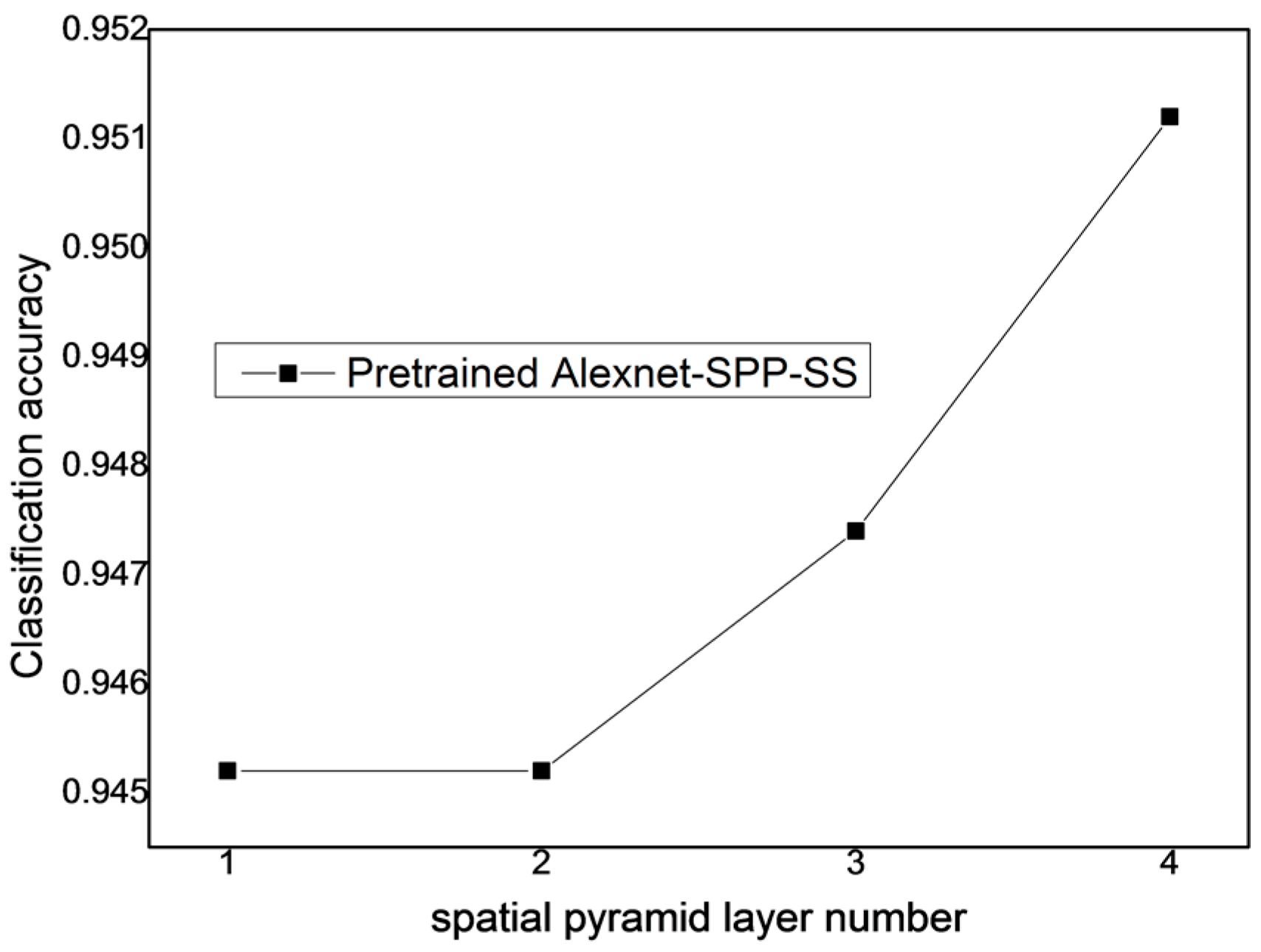
From the above, it is known that the SPP strategy can improve the performance of the pre-trained AlexNet-SPP-SS model. To study the effect of the SPP layer number of the proposed pre-trained AlexNet-SPP-SS model for the UC Merced dataset, the Google image dataset of SIRI-WHU dataset, and the WHU-RS dataset, the other parameters generated by the pre-trained AlexNet and SS strategy were kept the same. The number of SPP layers was then varied over the range of [1–4] for the proposed pre-trained AlexNet-SPP-SS model.
From
Figure 14, it can be seen that when the spatial pyramid layer number is equal to 4, the pre-trained AlexNet-SPP-SS model obtains the best classification performance with the UC Merced dataset. In addition, this experiment also indicates that the pre-trained AlexNet-SPP-SS model can better deal with the multi-scale convolutional feature information, as a result of the information fusion ability of the SPP strategy.
From
Figure 15, it can be seen that when the spatial pyramid layer number is equal to 3 or 4, the pre-trained AlexNet-SPP-SS model obtains the best classification performance for the Google image dataset of SIRI-WHU. Furthermore, the experimental results of the pre-trained AlexNet-SPP-SS model demonstrate that the SPP strategy has the ability to fuse the information of the multi-scale convolved feature maps and promotes the classification performance.
From
Figure 16, it can be seen that when the spatial pyramid layer number is equal to 4, the pre-trained AlexNet-SPP-SS model obtains the best classification performance for the WHU-RS dataset. Furthermore, the experimental results of the pre-trained AlexNet-SPP-SS model demonstrate that the SPP strategy has the ability to fuse the information of the multi-scale convolved feature maps and promotes the classification performance.
Although the performance of the pre-trained AlexNet-SPP-SS model was analyzed with the regard to the spatial pyramid layer number, further research into the classification performance of the pre-trained AlexNet-SPP-SS model with different training sample ratios is needed. For a further comparison of the proposed pre-trained AlexNet architecture with the other AlexNet architecture related models, the classification performances with the varying numbers of the training samples are reported in
Figure 17,
Figure 18 and
Figure 19, for the UC Merced dataset, the Google Image dataset of SIRI-WHU, and WHU-RS dataset, respectively.
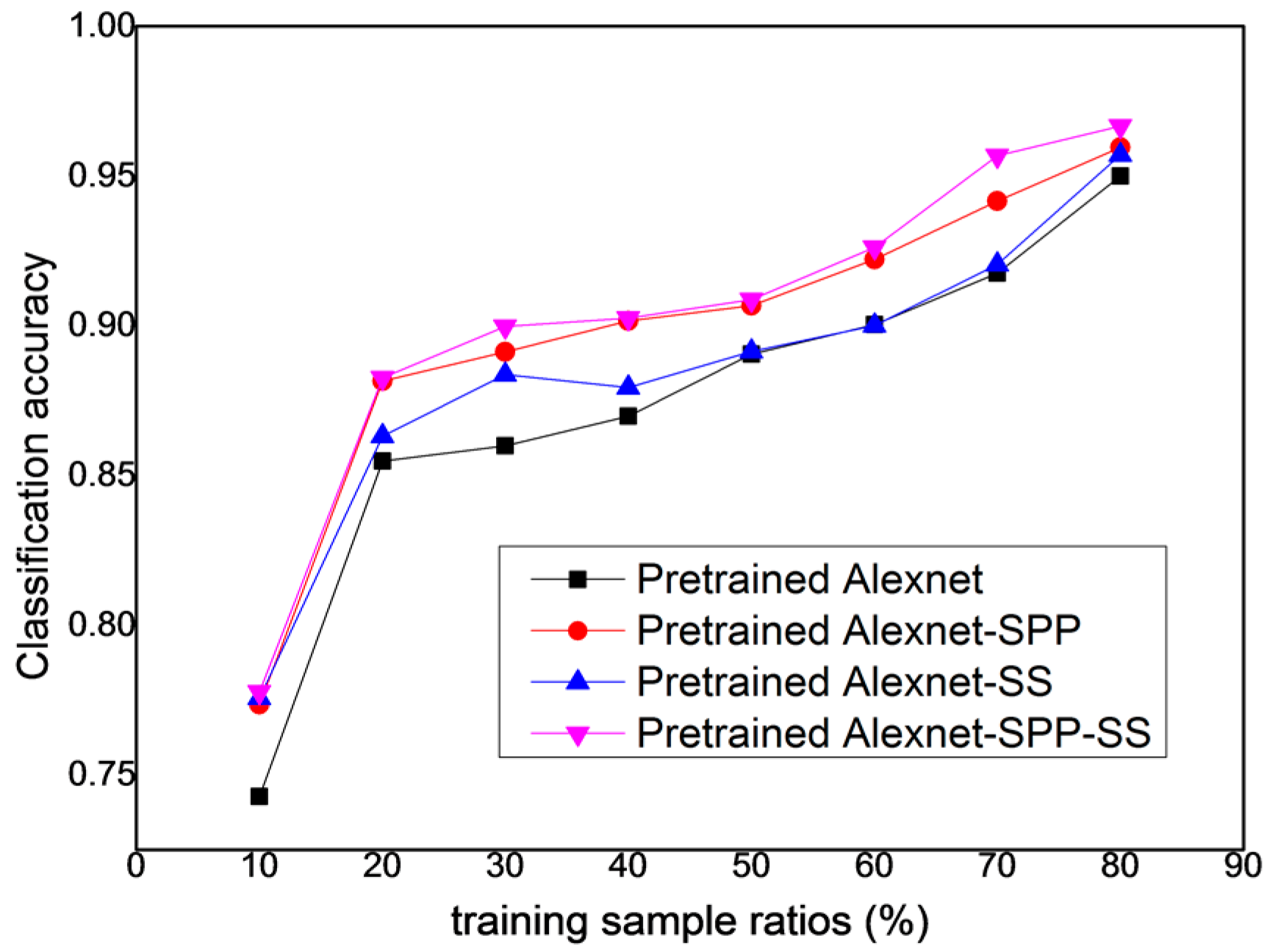
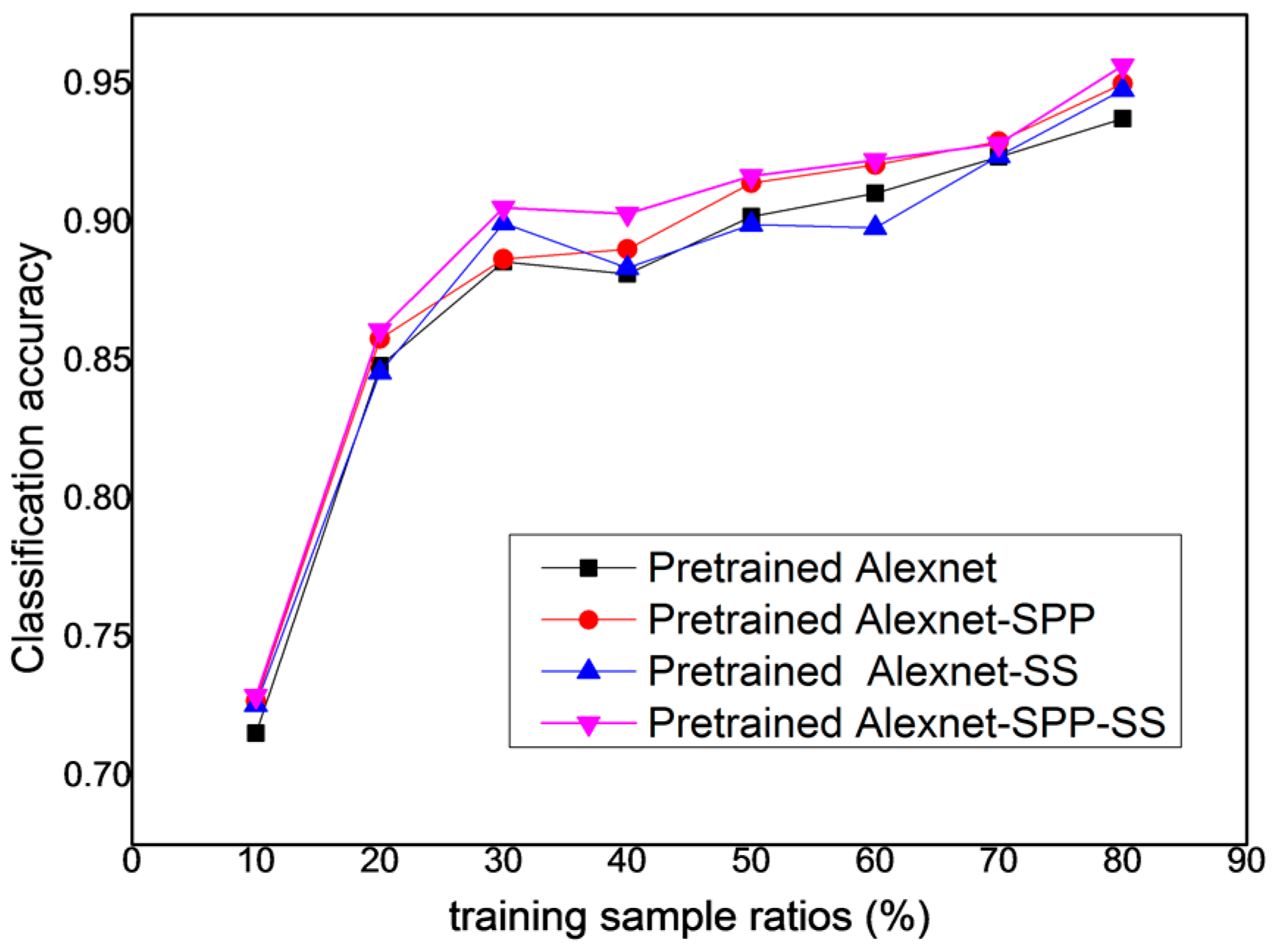
From
Figure 17, it can be seen that the pre-trained AlexNet-SPP-SS model performs better over the training sample ratios of [10, 20, 30, 40, 50, 60, 70, 80] than the pre-trained AlexNet, the pre-trained AlexNet-SPP, and the pre-trained AlexNet-SS for the UC Merced dataset. This figure also demonstrates that, in most of the training sample ratios, the pre-trained AlexNet-SPP-SS model performs better than the other models. In addition, the pre-trained AlexNet-SS model performs slightly better than the pre-trained AlexNet model in most of the training sample ratios.
From
Figure 18, it can be seen that the pre-trained AlexNet-SPP-SS model performs better over the training sample ratios of [10, 20, 30, 40, 50, 60] than the pre-trained AlexNet, the pre-trained AlexNet-SPP, and the pre-trained AlexNet-SS models for the Google image dataset of SIRI-WHU. In this figure, for the Google Image dataset of SIRI-WHU, the performance of the pre-trained AlexNet-SS model is slightly better than the pre-trained AlexNet-SPP model, which can be attributed to the introduction of the side supervision.
From
Figure 19, it can be seen that the pre-trained AlexNet-SPP-SS model performs better over the training sample ratios of [10, 20, 30, 40, 50] than the pre-trained AlexNet, the pre-trained AlexNet-SPP, and the pre-trained AlexNet-SS models for the Google image dataset of SIRI-WHU. In this figure, for the WHU-RS dataset, the performance of the pre-trained AlexNet-SPP model is slightly better than the pre-trained AlexNet-SS model. When the training sample ratio is small, the pre-trained AlexNet-SPP model and the pre-trained AlexNet-SS model perform much better than the pre-trained AlexNet model.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}