
Mapping Regional Urban Extent Using NPP-VIIRS DNB and MODIS NDVI Data

Abstract
:
1. Introduction
2. Materials
2.1. Defining Urban Extent
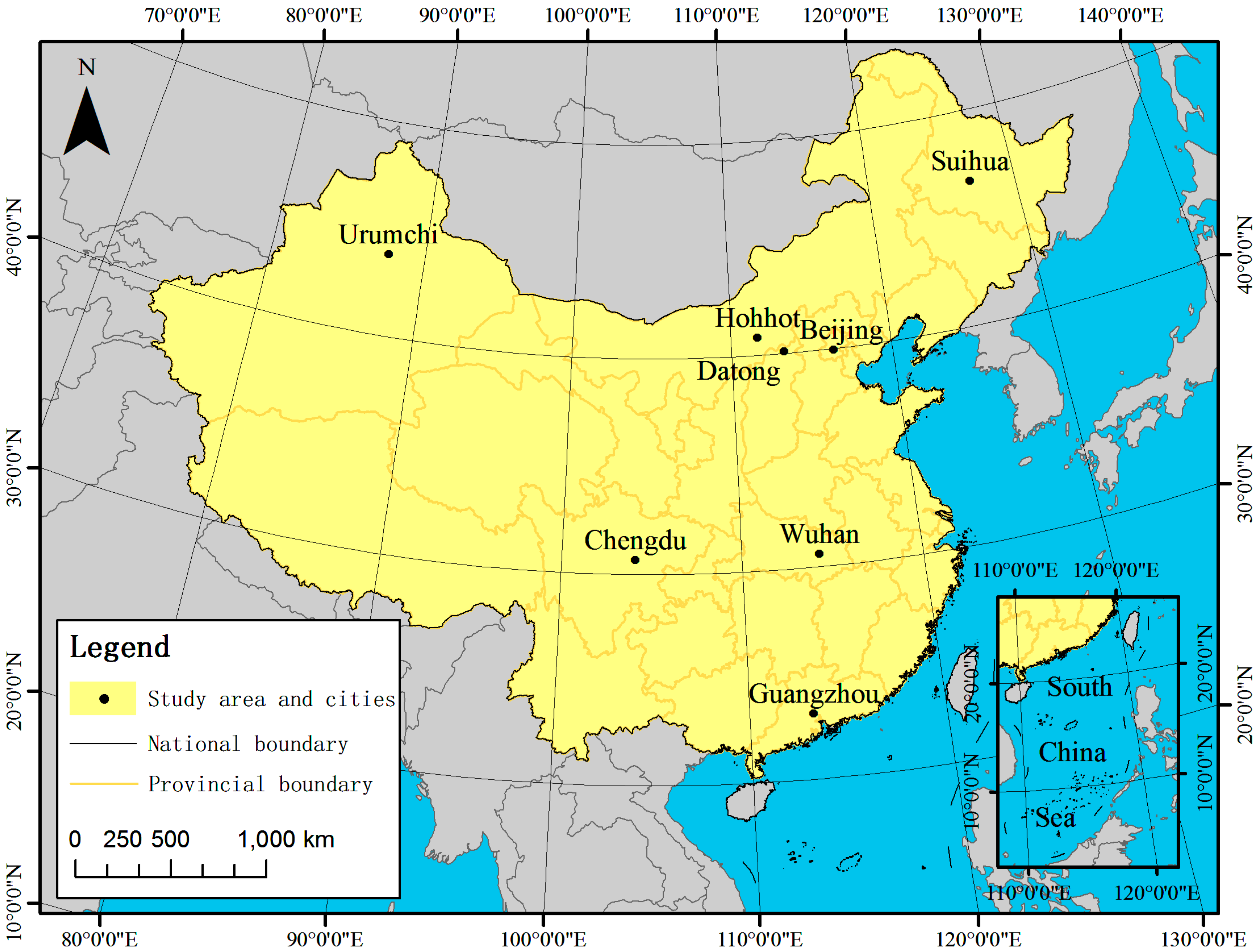
2.2. Study Area
2.3. Data Acquisition and Pre-Processing
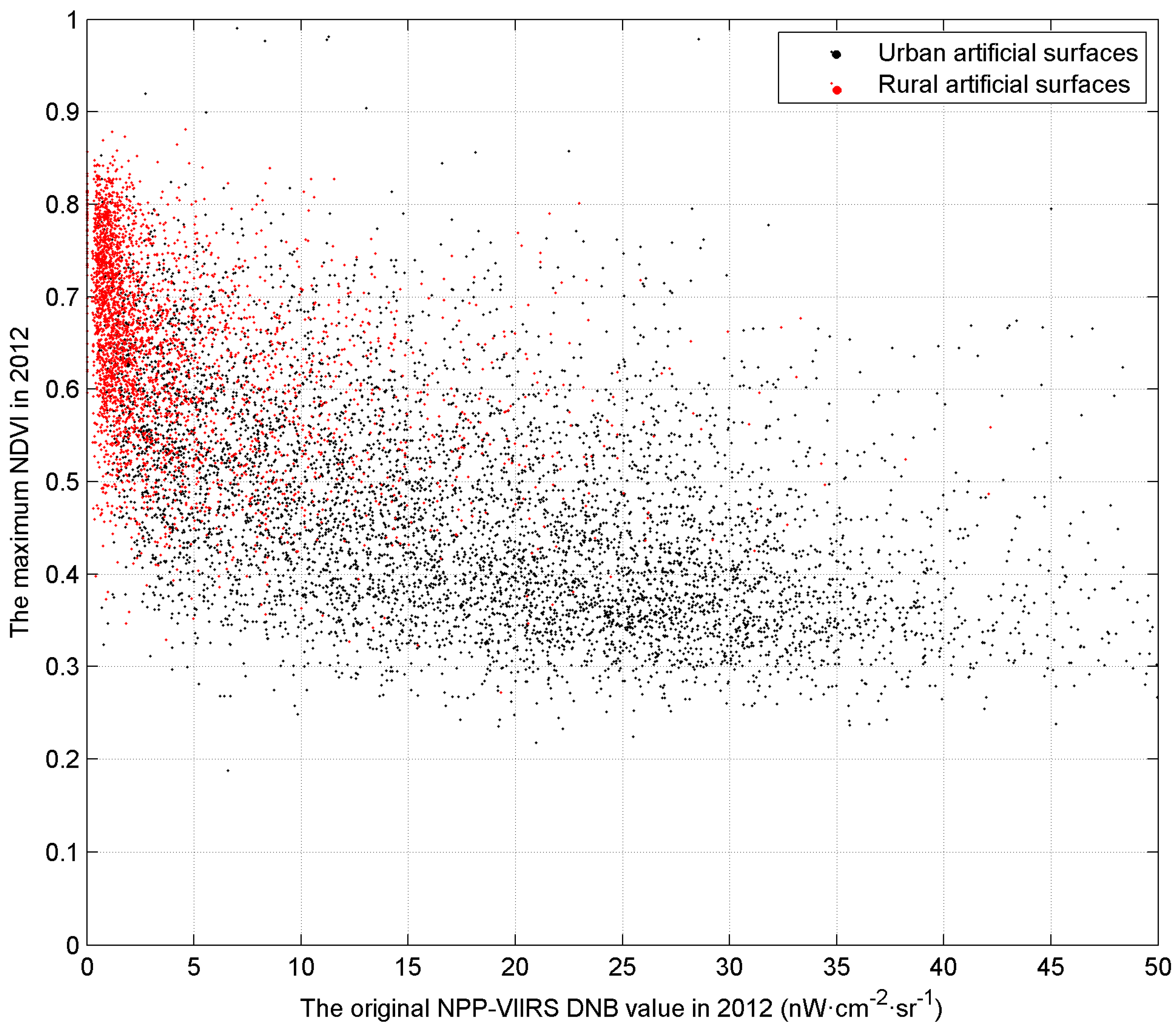
2.3.1. Generating the Maximum NDVI
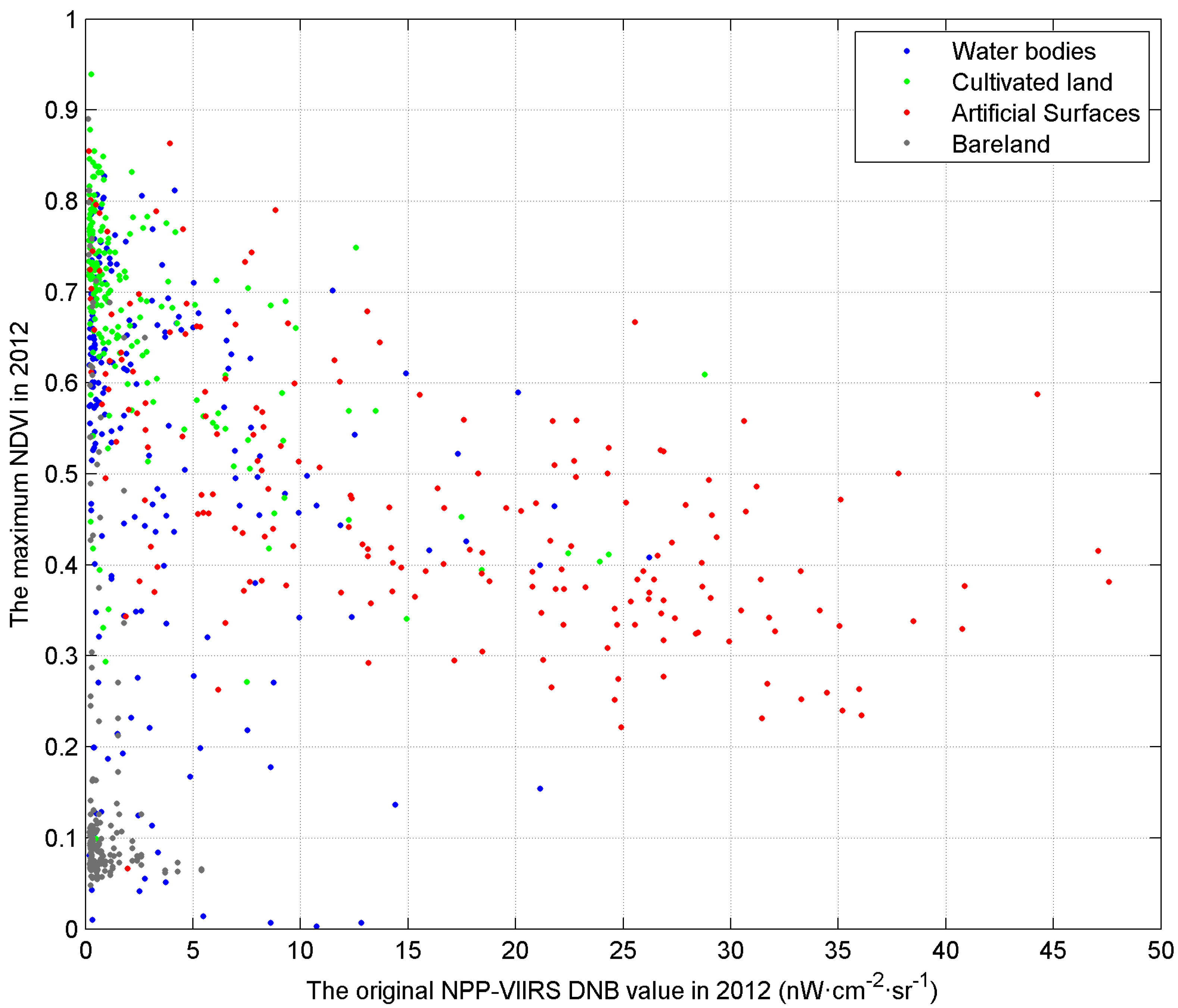
2.3.2. Removing Background Noise and Filtering Extreme Values in NPP-VIIRS DNB
2.3.3. Aggregating GLC30-2010 from 30 m to 480 m
3. Methods
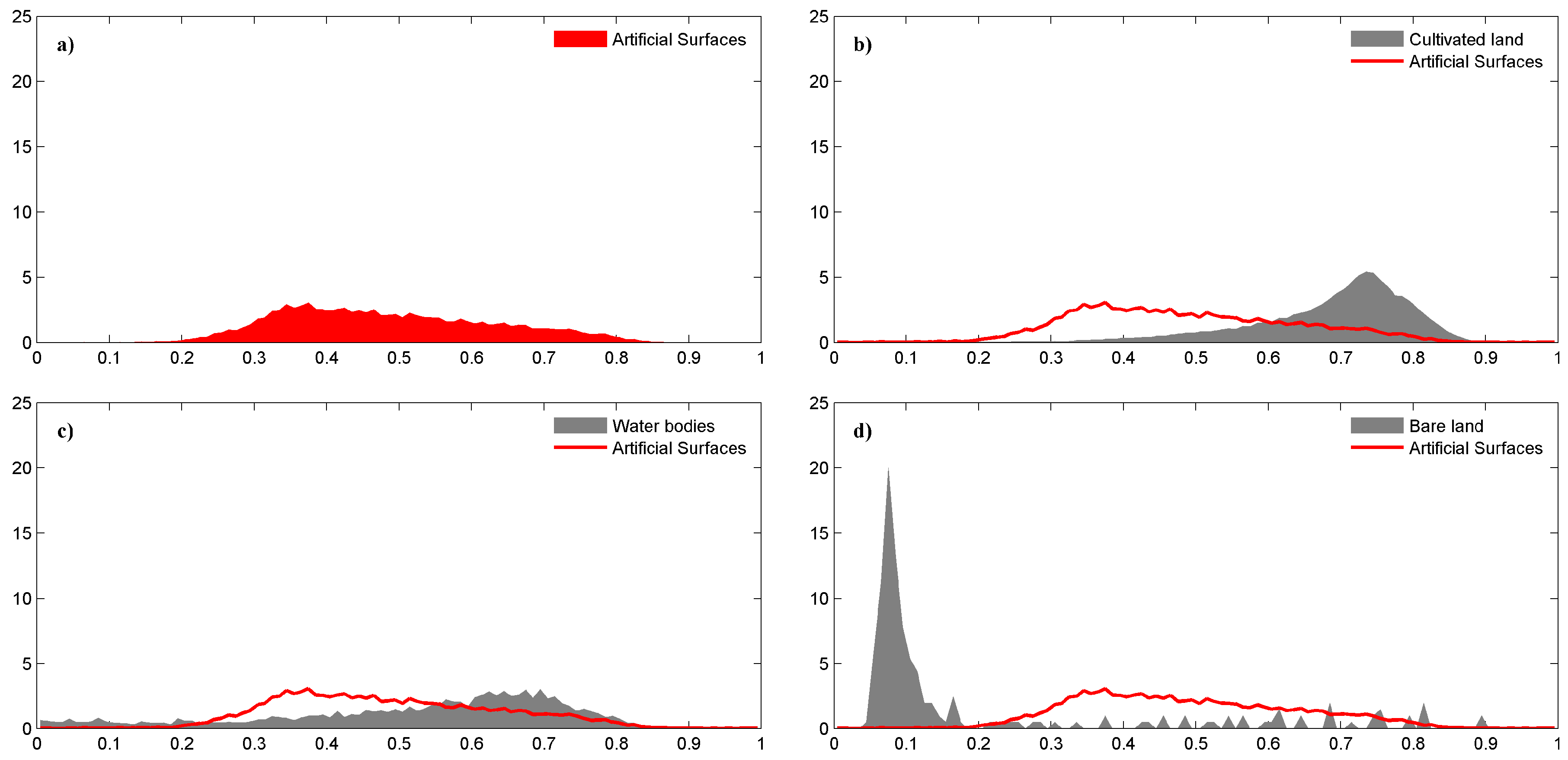
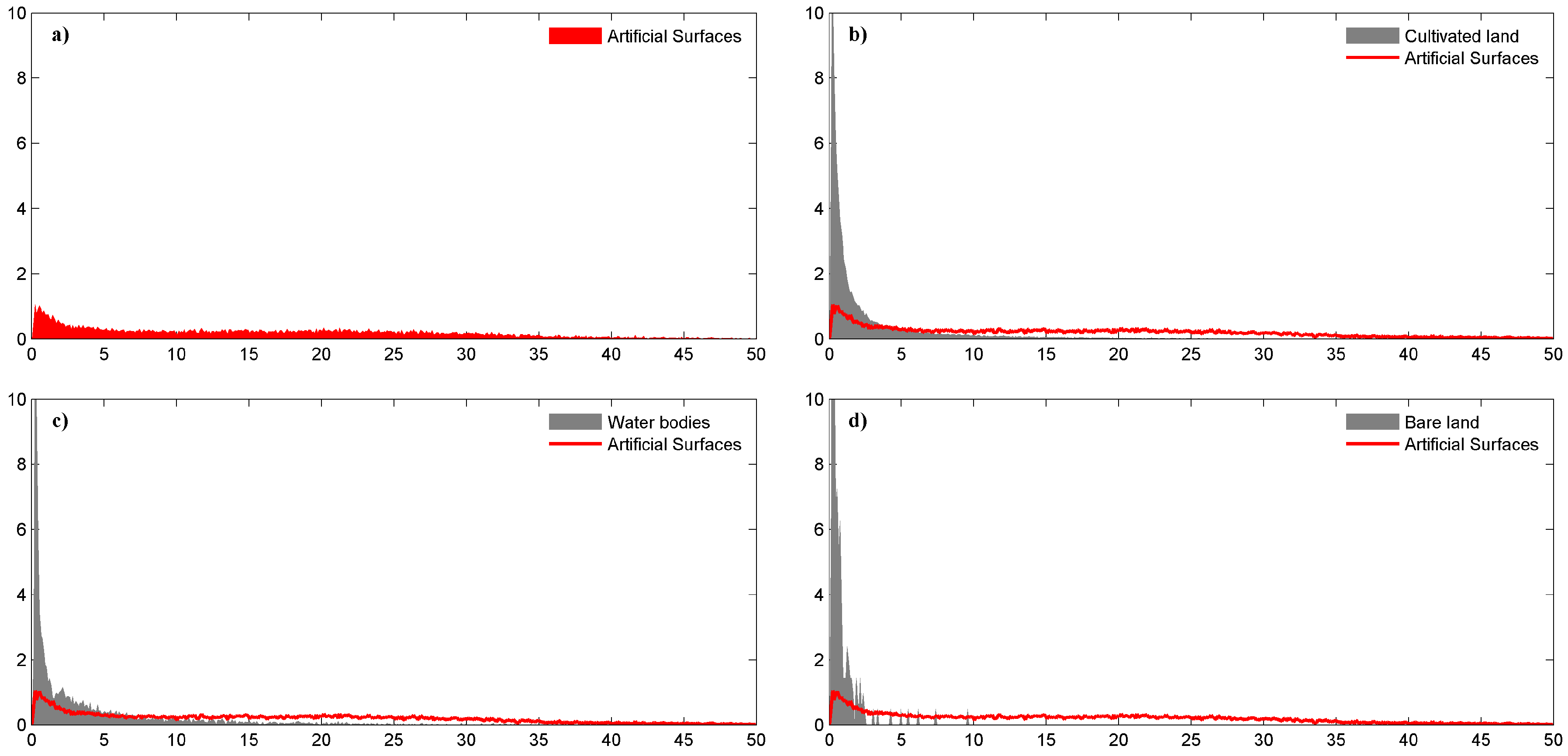
3.1. Sampling
3.2. Training and Predicting
3.3. Accessing Accuracy
4. Results
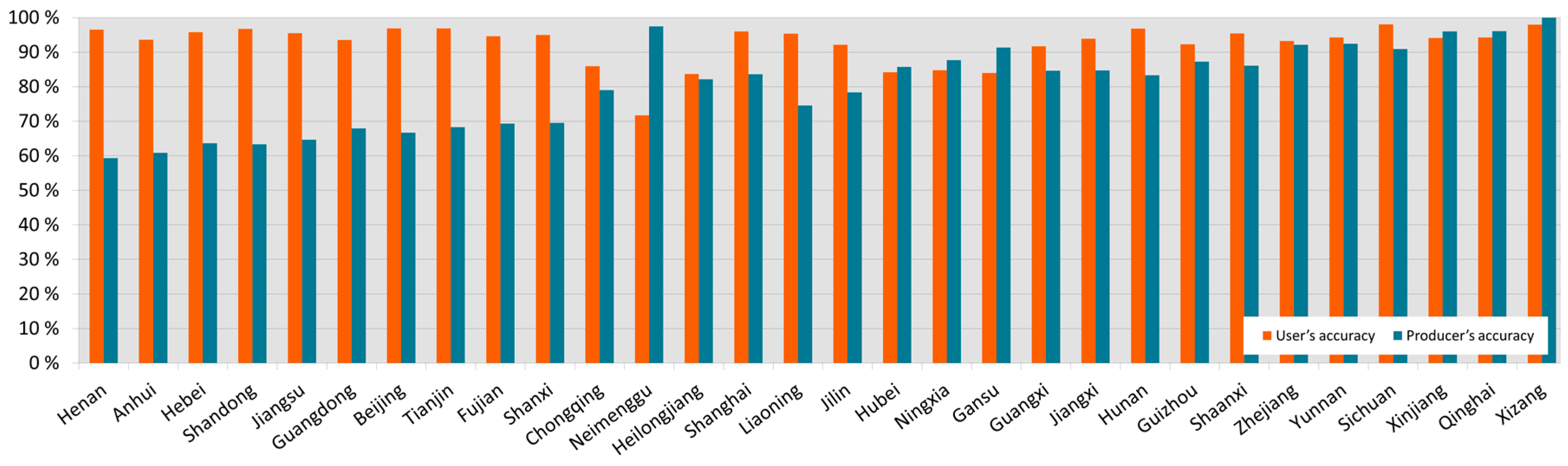
4.1. Urban Land Classification Accuracy on the Pixel Level
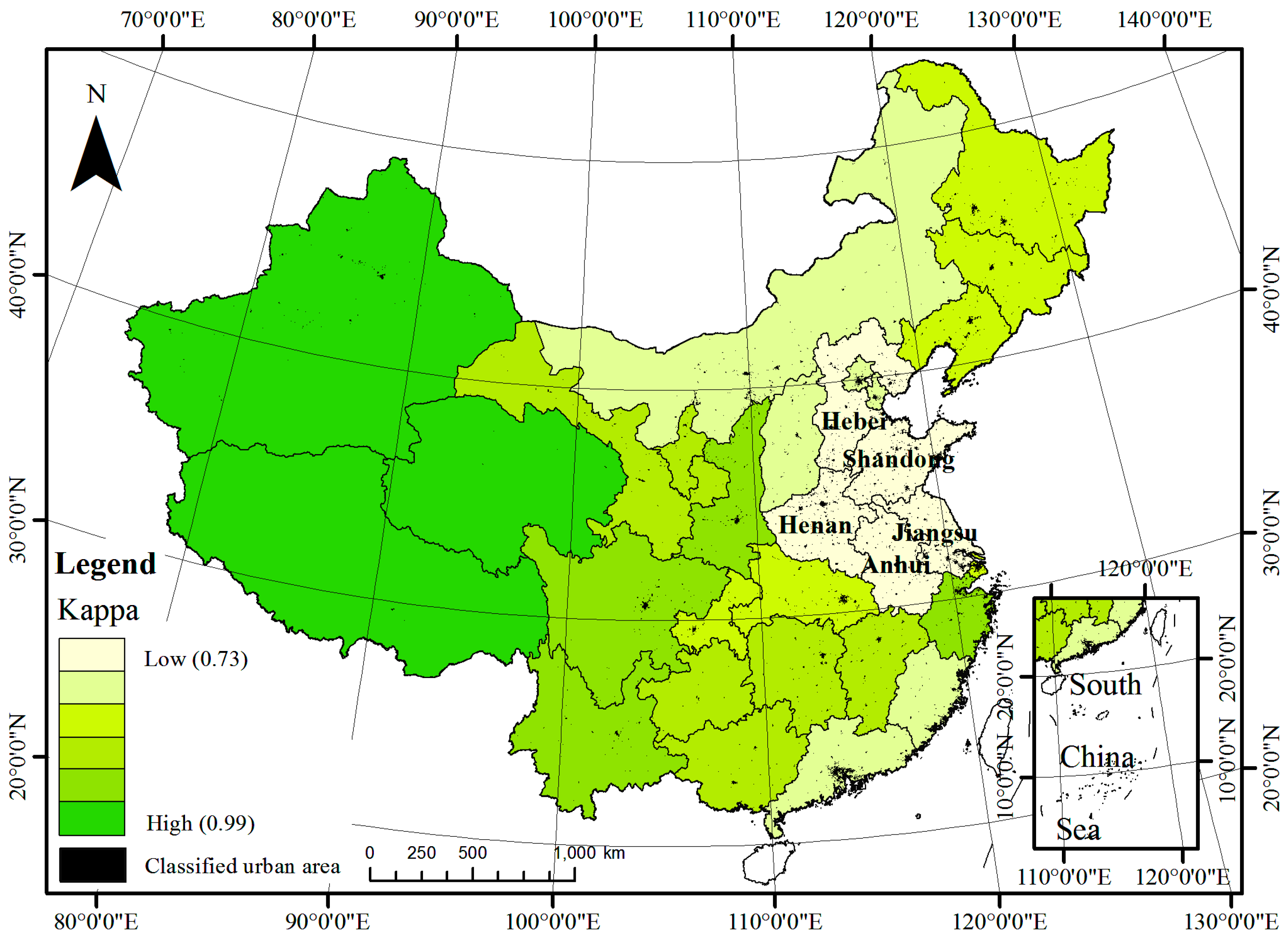
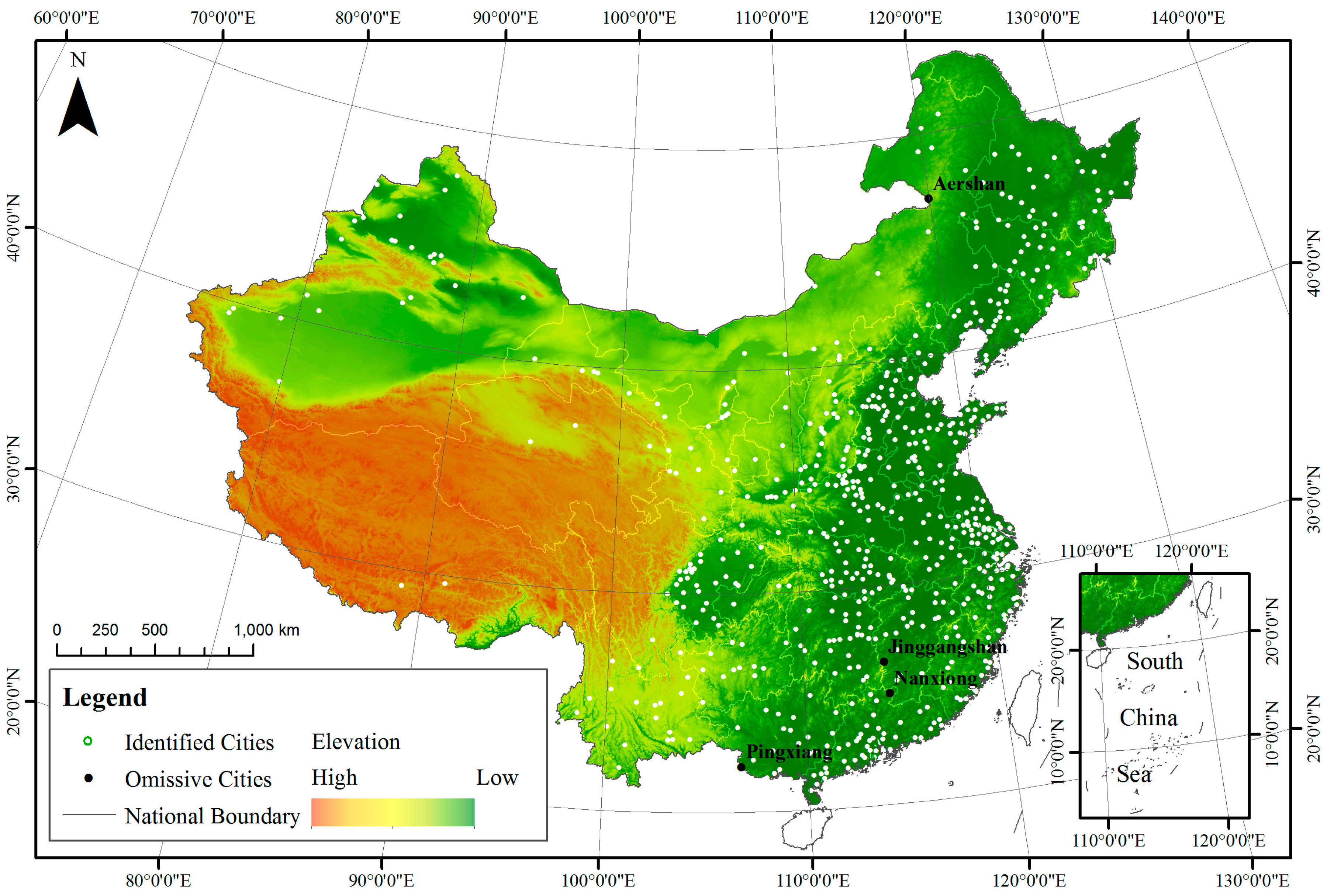
4.2. Urban Land Classification Accuracy on the City Level
5. Discussion
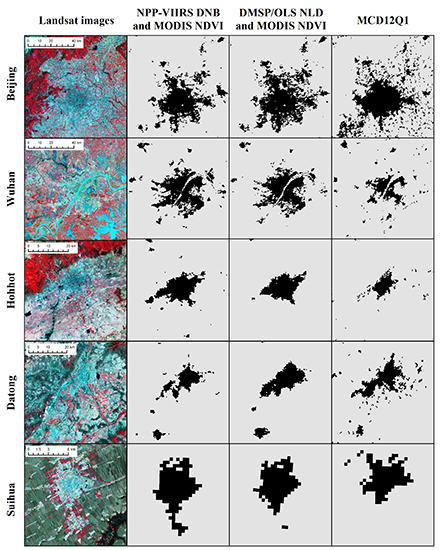
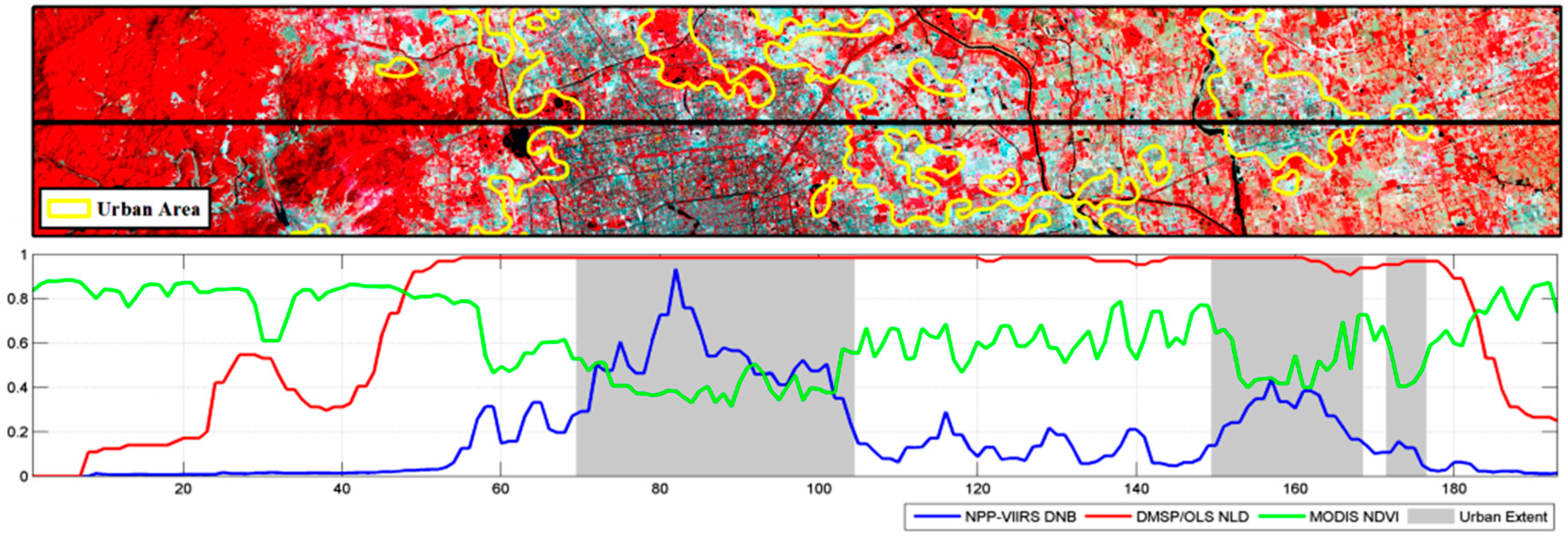
5.1. Comparative Analysis of Urban Extent under Different Nighttime Light Data
5.2. Case Analysis: Performance of Combining NPP-VIIRS DNB and MODIS NDVI
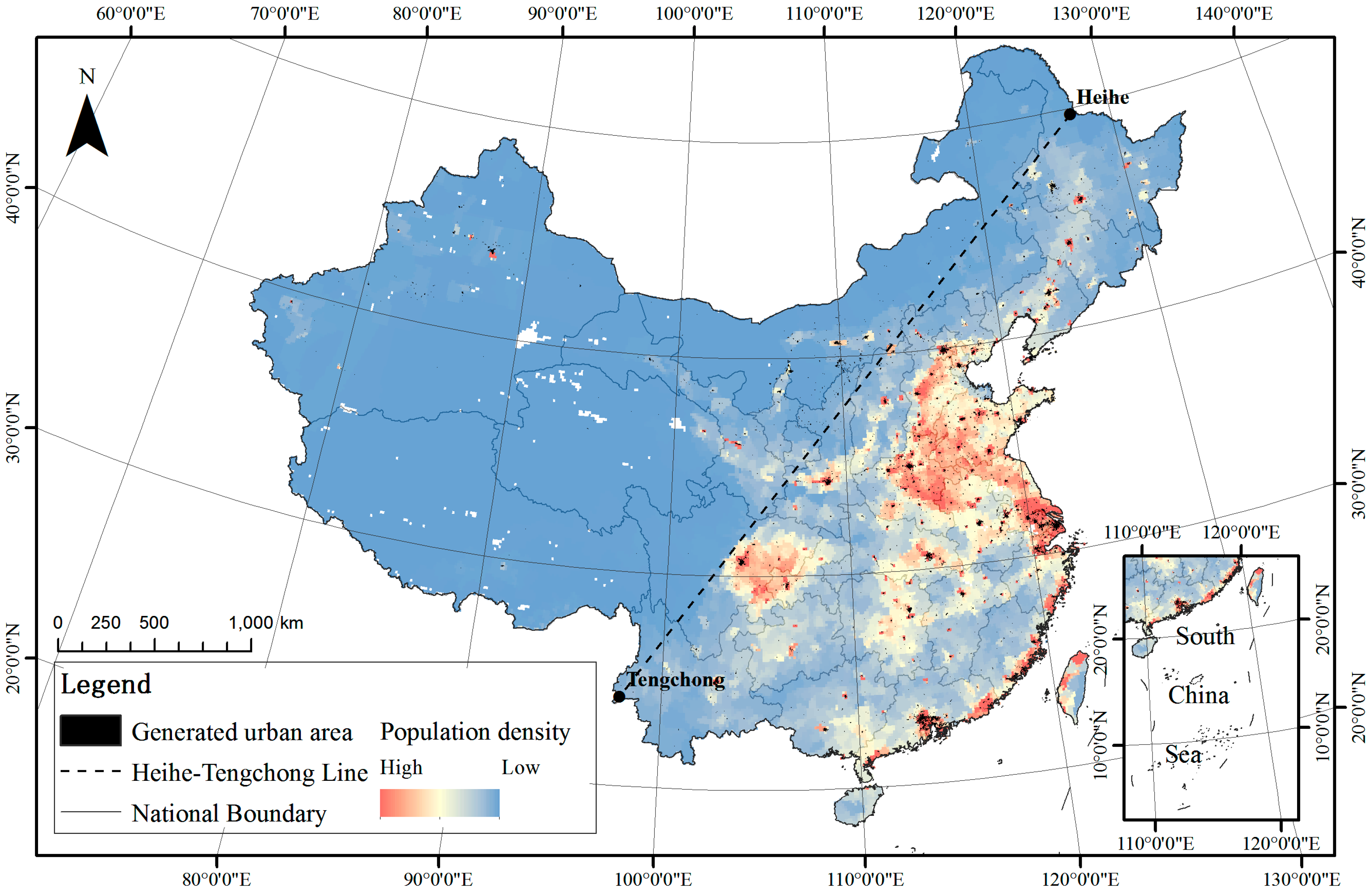
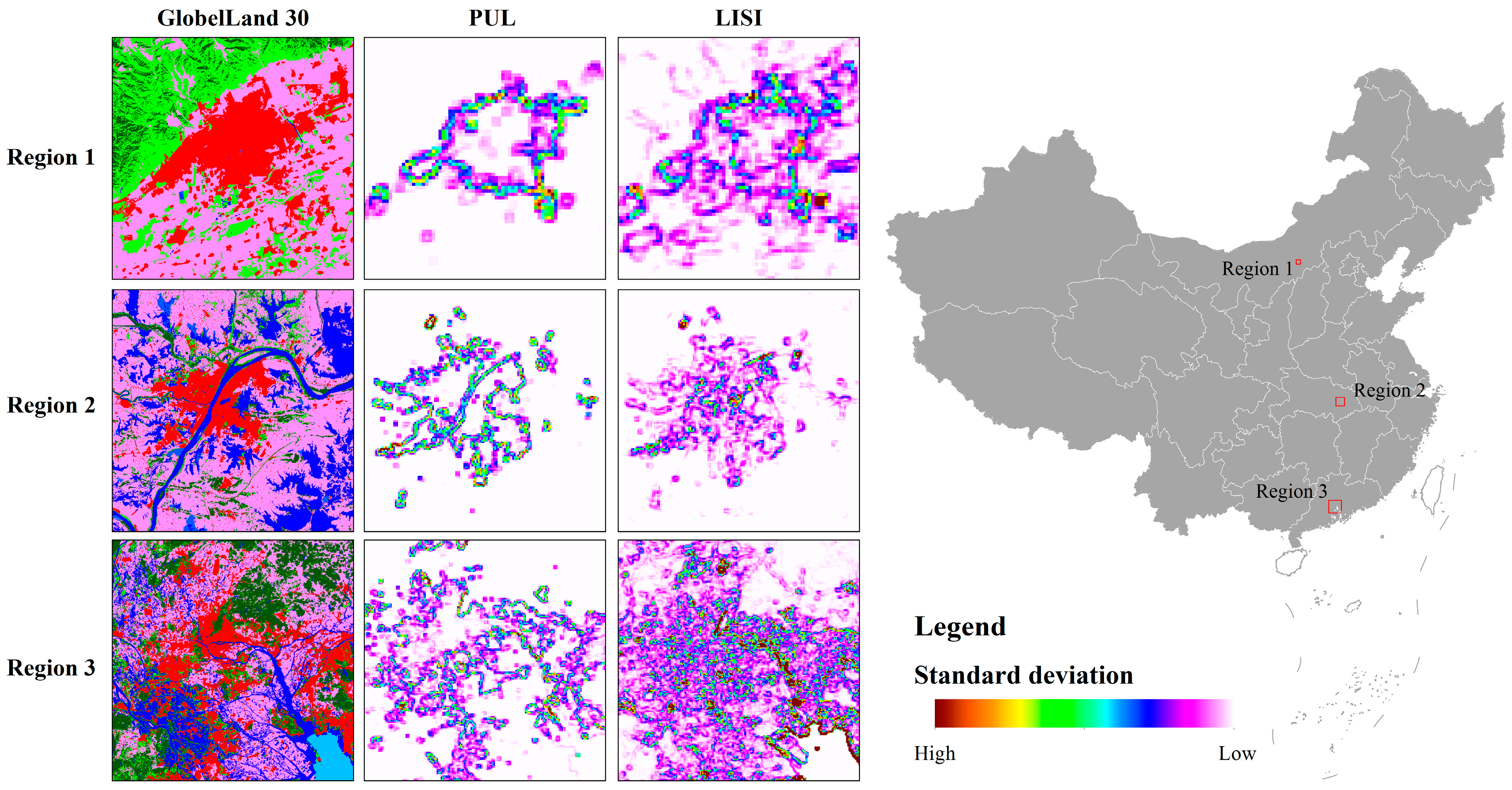
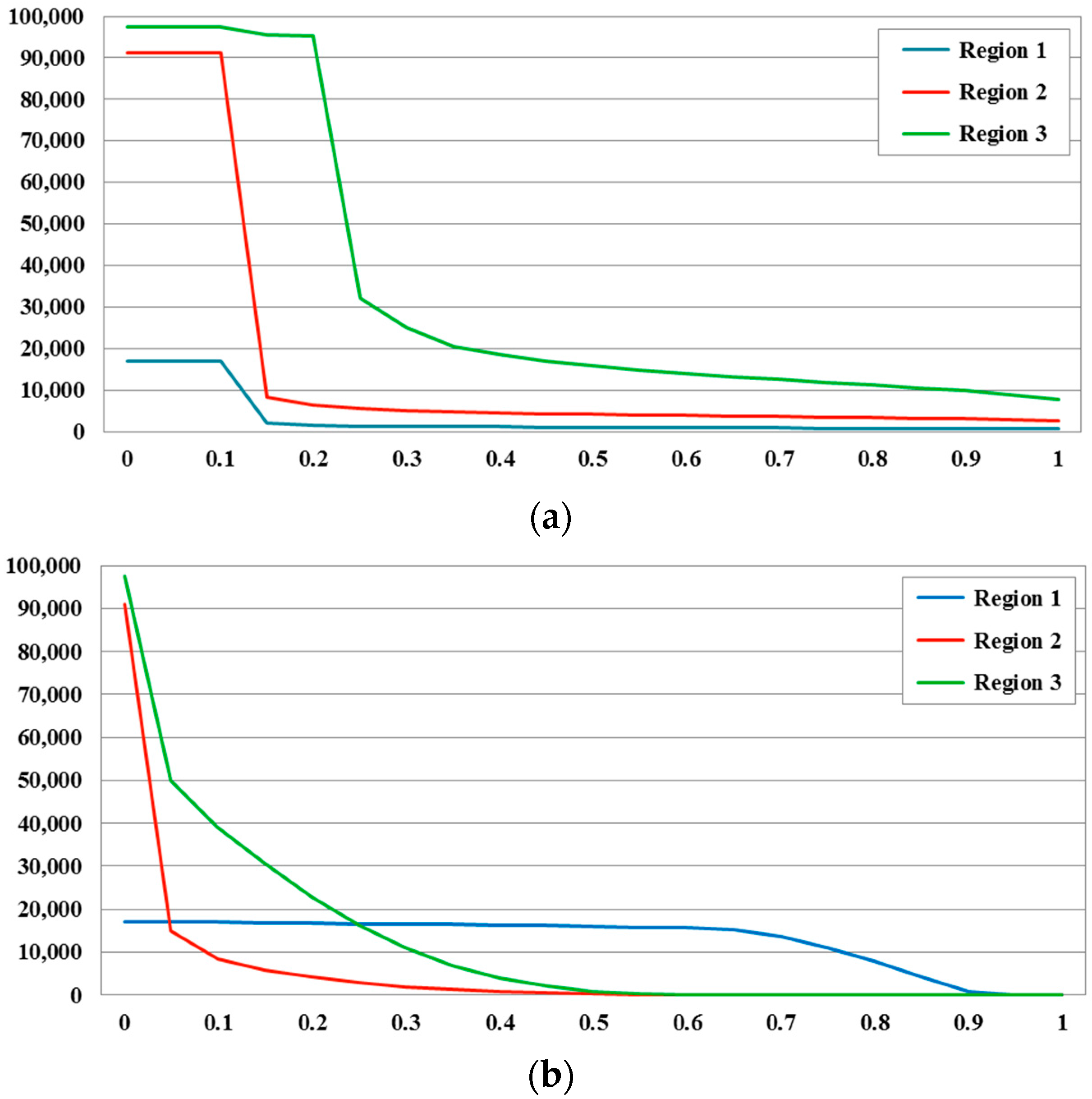
5.3. Reliability Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Seto, K.C.; Fragkias, M.; Guneralp, B.; Reilly, M.K. A meta-analysis of global urban land expansion. PLoS ONE 2011, 6, e23777. [Google Scholar] [CrossRef] [PubMed]
- Small, C. High spatial resolution spectral mixture analysis of urban reflectance. Remote Sens. Environ. 2003, 88, 170–186. [Google Scholar] [CrossRef]
- Grimm, N.B.; Faeth, S.H.; Golubiewski, N.E.; Redman, C.L.; Wu, J.; Bai, X.; Briggs, J.M. Global change and the ecology of cities. Science 2008, 319, 756–760. [Google Scholar] [CrossRef] [PubMed]
- Seto, K.C.; Güneralp, B.; Hutyra, L.R. Global forecasts of urban expansion to 2030 and direct impacts on biodiversity and carbon pools. Proc. Natl. Acad. Sci. USA 2012, 109, 16083–16088. [Google Scholar] [CrossRef] [PubMed]
- Kalnay, E.; Cai, M. Impact of urbanization and land-use change on climate. Nature 2003, 423, 528–531. [Google Scholar] [CrossRef] [PubMed]
- Karl, T.R.; Trenberth, K.E. Modern global climate change. Science 2003, 302, 1719–1723. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.L.; Zhao, H.M.; Li, P.X.; Yin, Z.Y. Remote sensing image-based analysis of the relationship between urban heat island and land use/cover changes. Remote Sens. Environ. 2006, 104, 133–146. [Google Scholar] [CrossRef]
- Shao, M.; Tang, X.; Zhang, Y.; Li, W. City clusters in China: Air and surface water pollution. Front. Ecol. Environ. 2008, 4, 353–361. [Google Scholar] [CrossRef]
- Kaufmann, R.K.; Seto, K.C.; Schneider, A.; Liu, Z.; Zhou, L.; Wang, W. Climate response to rapid urban growth: Evidence of a human-induced precipitation deficit. J. Clim. 2007, 20, 2299–2306. [Google Scholar] [CrossRef]
- Mills, G. Cities as agents of global change. Int. J. Climatol. 2007, 27, 1849–1857. [Google Scholar] [CrossRef]
- Jin, K.; Wang, F.; Chen, D.; Jiao, Q.; Xia, L.; Fleskens, L.; Mu, X. Assessment of urban effect on observed warming trends during 1955–2012 over China: A case of 45 cities. Clim. Chang. 2015, 132, 631–643. [Google Scholar] [CrossRef]
- Schneider, A.; Friedl, M.A.; Potere, D. Mapping global urban areas using MODIS 500-m data: New methods and datasets based on ‘urban ecoregions’. Remote Sens. Environ. 2010, 114, 1733–1746. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z.; Yang, L.; Merchant, J.W. Development of a global land cover characteristics database and IGBP discover from 1 km AVHRR data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Bartholomé, E.; Belward, A.S. Glc2000: A new approach to global land cover mapping from earth observation data. Int. J. Remote Sens. 2005, 26, 1959–1977. [Google Scholar] [CrossRef]
- Arino, O.; Gross, D.; Ranera, F.; Bourg, L. Globcover: ESA service for global land cover from meris. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007. [Google Scholar]
- Bontemps, S.; Defourney, P.; Van Bogaert, E.; Arino, O.; Kalogirou, V.; Perez, J.P. GLOBCOVER 2009 Products Description and Validation Report. Available online: http://due.esrin.esa.int/files/GLOBCOVER2009_Validation_Report_2.2.pdf (accessed on 10 March 2017).
- Schneider, A.; Friedl, M.A.; Potere, D. A new map of global urban extent from MODIS satellite data. Environ. Res. Lett. 2009, 4, 44003–44011. [Google Scholar] [CrossRef]
- Jun, C.; Ban, Y.; Li, S. China: Open access to earth land-cover map. Nature 2014, 514, 434. [Google Scholar] [CrossRef] [PubMed]
- Herold, M.; Scepan, J.; Müller, A.; Günther, S. Object-oriented mapping and analysis of urban land use/cover using IKONOS data. In Proceedings of the 22nd Symposium of the European-Association-of-Remote-Sensing-Laboratories, Prague, Czech Republic, 4–6 June 2002; pp. 531–538. [Google Scholar]
- Lu, D.; Weng, Q. Extraction of urban impervious surfaces from an IKONOS image. Int. J. Remote Sens. 2009, 30, 1297–1311. [Google Scholar] [CrossRef]
- Lu, D.S.; Hetrick, S.; Moran, E. Land cover classification in a complex urban-rural landscape with Quickbird imagery. Photogr. Eng. Remote Sens. 2010, 76, 1159–1168. [Google Scholar] [CrossRef]
- Lin, J.; Liu, X.; Li, K.; Li, X. A maximum entropy method to extract urban land by combining MODIS reflectance, MODIS NDVI, and DMSP-OLS data. Int. J. Remote Sens. 2014, 35, 6708–6727. [Google Scholar] [CrossRef]
- Shao, Z.; Liu, C. The integrated use of DMSP-OLS nighttime light and MODIS data for monitoring large-scale impervious surface dynamics: A case study in the Yangtze river delta. Remote Sens. 2014, 6, 9359–9378. [Google Scholar] [CrossRef]
- Deng, C.; Wu, C. The use of single-date MODIS imagery for estimating large-scale urban impervious surface fraction with spectral mixture analysis and machine learning techniques. ISPRS J. Photogramm. Remote Sens. 2013, 86, 100–110. [Google Scholar] [CrossRef]
- Knight, J.; Voth, M. Mapping impervious cover using multi-temporal MODIS NDVI data. IEEE J.-Stars 2011, 4, 303–309. [Google Scholar] [CrossRef]
- Salmon, B.P.; Olivier, J.C.; Kleynhans, W.; Wessels, K.J.; Bergh, F.V.D.; Steenkamp, K.C. The use of a multilayer perceptron for detecting new human settlements from a time series of MODIS images. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 873–883. [Google Scholar] [CrossRef]
- Yang, F.; Matsushita, B.; Fukushima, T.; Yang, W. Temporal mixture analysis for estimating impervious surface area from multi-temporal MODIS NDVI data in Japan. ISPRS J. Photogramm. Remote Sens. 2012, 72, 90–98. [Google Scholar] [CrossRef] [Green Version]
- Wan, B.; Guo, Q.; Fang, F.; Su, Y.; Wang, R. Mapping US urban extents from MODIS data using one-class classification method. Remote Sens. 2015, 7, 10143–10163. [Google Scholar] [CrossRef]
- Weng, Q.; Lu, D.; Schubring, J. Estimation of land surface temperature–vegetation abundance relationship for urban heat island studies. Remote Sens. Environ. 2004, 89, 467–483. [Google Scholar] [CrossRef]
- Guo, W.; Lu, D.; Wu, Y.; Zhang, J. Mapping impervious surface distribution with integration of SNNP VIIRS-DNB and MODIS NDVI data. Remote Sens. 2015, 7, 12459–12477. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.E.; Kihn, E.A.; Kroehl, H.W.; Davis, E.R. Mapping city lights with nighttime data from the DMSP operational linescan system. Photogramm. Eng. Remote Sens. 1997, 63, 727–734. [Google Scholar]
- Yu, B.; Shi, K.; Hu, Y.; Huang, C. Poverty evaluation using NPP-VIIRS nighttime light composite data at the county level in China. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1–13. [Google Scholar] [CrossRef]
- Shi, K.; Yu, B.; Huang, Y.; Hu, Y.; Yin, B.; Chen, Z.; Chen, L.; Wu, J. Evaluating the ability of NPP-VIIRS nighttime light data to estimate the gross domestic product and the electric power consumption of China at multiple scales: A comparison with DMSP-OLS data. Remote Sens. 2014, 6, 1705–1724. [Google Scholar] [CrossRef]
- Sutton, P.C. A scale-adjusted measure of “urban sprawl” using nighttime satellite imagery. Remote Sens. Environ. 2003, 86, 353–369. [Google Scholar] [CrossRef]
- Zhou, Y.; Smith, S.J.; Elvidge, C.D.; Zhao, K.; Thomson, A.; Imhoff, M. A cluster-based method to map urban area from DMSP/OLS nightlights. Remote Sens. Environ. 2014, 147, 173–185. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Tuttle, B.T.; Sutton, P.S.; Baugh, K.E.; Howard, A.T.; Milesi, C.; Bhaduri, B.L.; Nemani, R. Global distribution and density of constructed impervious surfaces. Sensors 2007, 7, 1962–1979. [Google Scholar] [CrossRef]
- Zhang, Q.; Seto, K.C. Mapping urbanization dynamics at regional and global scales using multi-temporal DMSP/OLS nighttime light data. Remote Sens. Environ. 2011, 115, 2320–2329. [Google Scholar] [CrossRef]
- Ma, T.; Zhou, Y.; Zhou, C.; Haynie, S.; Pei, T.; Xu, T. Night-time light derived estimation of spatio-temporal characteristics of urbanization dynamics using DMSP/OLS satellite data. Remote Sens. Environ. 2015, 158, 453–464. [Google Scholar] [CrossRef]
- Ou, J.; Liu, X.; Li, X.; Li, M.; Li, W. Evaluation of NPP-VIIRS nighttime light data for mapping global fossil fuel combustion CO2 emissions: A comparison with DMSP-OLS nighttime light data. PLoS ONE 2015, 10, e0138310. [Google Scholar] [CrossRef] [PubMed]
- Elvidge, C.D.; Baugh, K.E.; Zhizhin, M.; Hsu, F.C. Why VIIRS data are superior to DMSP for mapping nighttime lights. Proc. Asia-Pac. Adv. Netw. 2013, 35, 62–69. [Google Scholar] [CrossRef]
- Lu, D.; Tian, H.; Zhou, G.; Ge, H. Regional mapping of human settlements in southeastern China with multisensor remotely sensed data. Remote Sens. Environ. 2008, 112, 3668–3679. [Google Scholar] [CrossRef]
- Zhang, Q.; Schaaf, C.; Seto, K.C. The vegetation adjusted NTL urban index: A new approach to reduce saturation and increase variation in nighttime luminosity. Remote Sens. Environ. 2013, 129, 32–41. [Google Scholar] [CrossRef]
- Hillger, D.; Kopp, T.; Lee, T.; Lindsey, D.; Seaman, C.; Miller, S.; Solbrig, J.; Kidder, S.; Bachmeier, S.; Jasmin, T. First-light imagery from suomi NPP VIIRS. Am. Meteorol. Soc. 2013, 94, 1019–1029. [Google Scholar] [CrossRef]
- Shi, K.; Huang, C.; Yu, B.; Yin, B.; Huang, Y.; Wu, J. Evaluation of NPP-VIIRS night-time light composite data for extracting built-up urban areas. Remote Sens. Lett. 2014, 5, 358–366. [Google Scholar] [CrossRef]
- Li, X.; Xu, H.; Chen, X.; Li, C. Potential of NPP-VIIRS nighttime light imagery for modeling the regional economy of China. Remote Sens. 2013, 5, 3057–3081. [Google Scholar] [CrossRef]
- Chen, X.; Nordhaus, W. A test of the new VIIRS lights data set: Population and economic output in Africa. Remote Sens. 2015, 7, 4937–4947. [Google Scholar] [CrossRef]
- Sharma, R.C.; Tateishi, R.; Hara, K.; Gharechelou, S.; Iizuka, K. Global mapping of urban built-up areas of year 2014 by combining MODIS multispectral data with VIIRS nighttime light data. Int. J. Digit. Earth 2016, 9, 1–17. [Google Scholar] [CrossRef]
- Dou, Y.; Liu, Z.; He, C.; Yue, H. Urban land extraction using VIIRS nighttime light data: An evaluation of three popular methods. Remote Sens. 2017, 9, 175. [Google Scholar] [CrossRef]
- Duranton, G.; Puga, D. From sectoral to functional urban specialisation. J. Urban Econ. 2005, 57, 343–370. [Google Scholar] [CrossRef]
- Cohen, B. Urbanization in developing countries: Current trends, future projections, and key challenges for sustainability. Technol. Soc. 2006, 28, 63–80. [Google Scholar] [CrossRef]
- Potere, D.; Schneider, A. A critical look at representations of urban areas in global maps. GeoJournal 2007, 69, 55–80. [Google Scholar] [CrossRef]
- China Statistical Yearbook 2013. Available online: http://www.stats.gov.cn/tjsj/ndsj/2013/indexee.htm (accessed on 23 March 2017).
- Vegetation Indices 16-Day l3 Global 500m (mod13a1v005). NASA EOSDIS Land Processes DAAC, USGS Earth Resources Observation and Science (EROS) Center, Sioux Falls, South Dakota (https://lpdaac.usgs.gov). Available online: https://e4ftl01.cr.usgs.gov/MOLT/MOD13A1.005/ (accessed on 7 May 2016).
- VIIRS Day/Night Band (DNB). The Earth Observation Group, NOAA National Geophysical Data Center. Available online: http://www.ngdc.noaa.gov/dmsp/data/viirs_fire/viirs_html/viirs_ntl.html (accessed on 7 May 2016).
- Version 4 DMSP-OLS Nighttime Lights Time Series (f182012). The Earth Observation Group, NOAA’s National Geophysical Data Center. Available online: http://ngdc.noaa.gov/eog/dmsp/downloadV4composites.html (accessed on 7 May 2016).
- Globeland30-2010. National Geomatics Center of China. Available online: http://www. globeland30.com (accessed on 7 May 2016).
- Shi, K.; Yu, B.; Hu, Y.; Huang, C.; Chen, Y.; Huang, Y.; Chen, Z.; Wu, J. Modeling and mapping total freight traffic in China using NPP-VIIRS nighttime light composite data. Gisci. Remote Sens. 2015, 52, 274–289. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Globeland30 Knowledge Map. Available online: http://118.89.167.84/cn/reliability.html (accessed on 13 April 2017).
- Munoz-Mari, J.; Bruzzone, L.; Camps-Valls, G. A support vector domain description approach to supervised classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2007, 45, 2683–2692. [Google Scholar] [CrossRef]
- Schoelkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Xu, H. Land-cover change detection using one-class support vector machine. Photogramm. Eng. Remote Sens. 2010, 76, 255–263. [Google Scholar] [CrossRef]
- Zhang, X.; Li, P.; Cai, C. Regional urban extent extraction using multi-sensor data and one-class classification. Remote Sens. 2015, 7, 7671–7694. [Google Scholar] [CrossRef]
- Tax, D.M.J.; Duin, R.P.W. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Krell, M.M.; Woehrle, H. New one-class classifiers based on the origin separation approach. Pattern Recogn. Lett. 2015, 53, 93–99. [Google Scholar] [CrossRef]
- Sanchez-Hernandez, C.; Boyd, D.S.; Foody, G.M. One-class classification for mapping a specific land-cover class: SVDD classification of fenland. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1061–1073. [Google Scholar] [CrossRef]
- Li, W.; Guo, Q.; Elkan, C. A positive and unlabeled learning algorithm for one-class classification of remote-sensing data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 717–725. [Google Scholar] [CrossRef]
- Manevitz, L.M.; Yousef, M. One-class SVMs for document classification. J. Mach. Learn. Res. 2001, 2, 139–154. [Google Scholar]
- Elkan, C.; Noto, K. Learning classifiers from only positive and unlabeled data. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Guo, Q.; Li, W.; Liu, D.; Chen, J. A framework for supervised image classification with incomplete training samples. Photogramm. Eng. Remote Sens. 2012, 78, 595–604. [Google Scholar] [CrossRef]
- Guo, Q.; Li, W.; Liu, Y.; Tong, D. Predicting potential distributions of geographic events using one-class data: Concepts and methods. Int. J. Geogr. Inf. Sci. 2011, 25, 1697–1715. [Google Scholar] [CrossRef]
- Schneider, A.; Friedl, M.A.; Woodcock, C.E. Mapping urban areas by fusing multiple sources of coarse resolution remotely sensed data. In Proceedings of the 2003 IEEE International Geoscience and Remote Sensing Symposium, Toulouse, France, 21–25 July 2003; Volume 2624, pp. 2623–2625. [Google Scholar]
- Naganjaneyulu, S.; Kuppa, M.R. A novel framework for class imbalance learning using intelligent under-sampling. Prog. Artif. Intell. 2013, 2, 73–84. [Google Scholar] [CrossRef]
- Alejo, R.; Valdovinos, R.M.; García, V.; Pacheco-Sanchez, J.H. A hybrid method to face class overlap and class imbalance on neural networks and multi-class scenarios. Pattern Recogn. Lett. 2013, 34, 380–388. [Google Scholar] [CrossRef]
- Leichtle, T.; Geiß, C.; Lakes, T.; Taubenböck, H. Class imbalance in unsupervised change detection—A diagnostic analysis from urban remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2017, 60, 83–98. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Fleiss, J.L. Statistical Methods for Rates and Proportions, 2nd ed.; John Wiley: New York, NY, USA, 1981. [Google Scholar]
- Janssen, L.L.F.; Wei, V.D.; Frans, J.M. Accuracy assessment of satellite derived land cover data: A review. Photogramm. Eng. Remote Sens. 1994, 60, 419–426. [Google Scholar]
- Heihe-Tengchong Line. Available online: https://en.wikipedia.org/wiki/Heihe%E2%80%93Tengchong_Line (accessed on 23 March 2017).
- Land Cover Type Yearly l3 Global 500 m sin Grid (MCD12Q1V051). NASA EOSDIS Land Processes DAAC, USGS Earth Resources Observation and Science (EROS) Center, Sioux Falls, South Dakota (https://lpdaac.usgs.gov). Available online: https://e4ftl01.cr.usgs.gov/MOTA/MCD12Q1.051/ (accessed on 7 May 2016).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Product | Time | Spatial Resolution | Description |
|---|---|---|---|---|
| (1) | MODIS NDVI (MOD13A1) | 2012 | 463 m | 16-day composite. |
| (2) | NPP-VIIRS DNB | 2012 | 15 arc-seconds (491 m) | Composited by the NPP-VIIRS DNB data with low moonlight during 18–26 April 2012 and 11–23 October 2012. |
| (3) | DMSP/OLS NLD | 2012 | 30 arc-seconds (985 m) | Yearly nighttime stable light composite. |
| (4) | GLC30-2010 | 2010 | 30 m | Generated by hybrid classification from global multispectral remote sensing images of 30 m resolution (Landsat TM, ETM7 (SLC-off), HJ-1A/B, etc.) in 2010. |
| Classified Data | Reference Data | User’s Accuracy | Kappa Coefficient | ||
|---|---|---|---|---|---|
| Non-Urban | Urban | Total | |||
| Non-urban | 19,823 | 33 | 19,856 | 99.83% | 0.842 |
| Urban | 15 | 129 | 144 | 89.58% | |
| Total | 19,838 | 162 | 20,000 | ||
| Producer’s Accuracy | 99.92% | 79.63% | 99.76% (OA 1) | ||
| Grouped by Administrative Levels | Reference Number | Predicted Number | Omission Rate (%) |
|---|---|---|---|
| Municipality Directly under the Central Government | 4 | 4 | 0 |
| Vice-provincial City | 15 | 15 | 0 |
| Prefecture-level City | 266 | 266 | 0 |
| County-level City | 362 | 358 | 1.10 |
| Total | 647 | 643 | 0.62 |
| Cities | Reference Samples | Urban Extent Generated by | Omission Rate (%) |
|---|---|---|---|
| Beijing | 99 | Group 1: NPP-VIIRS DNB and MODIS NDVI | 39.39 |
| Group 2: DMSP/OLS NLD and MODIS NDVI | 27.27 | ||
| Group 3: MCD12Q1 in MODIS products | 28.28 | ||
| Wuhan | 41 | Group 1: NPP-VIIRS DNB and MODIS NDVI | 2.44 |
| Group 2: DMSP/OLS NLD and MODIS NDVI | 4.88 | ||
| Group 3: MCD12Q1 in MODIS products | 46.34 | ||
| Hohhot | 39 | Group 1: NPP-VIIRS DNB and MODIS NDVI | 5.13 |
| Group 2: DMSP/OLS NLD and MODIS NDVI | 35.90 | ||
| Group 3: MCD12Q1 in MODIS products | 53.85 | ||
| Datong | 50 | Group 1: NPP-VIIRS DNB and MODIS NDVI | 6 |
| Group 2: DMSP/OLS NLD and MODIS NDVI | 16 | ||
| Group 3: MCD12Q1 in MODIS products | 20 | ||
| Suihua | 35 | Group 1: NPP-VIIRS DNB and MODIS NDVI | 8.57 |
| Group 2: DMSP/OLS NLD and MODIS NDVI | 37.14 | ||
| Group 3: MCD12Q1 in MODIS products | 57.14 |
| Threshold | Region 1 | Region 2 | Region 3 | |||
|---|---|---|---|---|---|---|
| OA | Kappa | OA | Kappa | OA | Kappa | |
| 0.4 | 98.6% | 0.898 | 98.3% | 0.817 | 94.8% | 0.781266 |
| 0.5 | 98.2% | 0.864 | 98.5% | 0.824 | 95.1% | 0.783642 |
| 0.6 | 98.1% | 0.849 | 98.6% | 0.830 | 94.5% | 0.744323 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Wan, B.; Guo, Q.; Hu, M.; Zhou, S. Mapping Regional Urban Extent Using NPP-VIIRS DNB and MODIS NDVI Data. Remote Sens. 2017, 9, 862. https://doi.org/10.3390/rs9080862
Wang R, Wan B, Guo Q, Hu M, Zhou S. Mapping Regional Urban Extent Using NPP-VIIRS DNB and MODIS NDVI Data. Remote Sensing. 2017; 9(8):862. https://doi.org/10.3390/rs9080862
Chicago/Turabian StyleWang, Run, Bo Wan, Qinghua Guo, Maosheng Hu, and Shunping Zhou. 2017. "Mapping Regional Urban Extent Using NPP-VIIRS DNB and MODIS NDVI Data" Remote Sensing 9, no. 8: 862. https://doi.org/10.3390/rs9080862
APA StyleWang, R., Wan, B., Guo, Q., Hu, M., & Zhou, S. (2017). Mapping Regional Urban Extent Using NPP-VIIRS DNB and MODIS NDVI Data. Remote Sensing, 9(8), 862. https://doi.org/10.3390/rs9080862