1. Introduction
Urban land-use/land-cover (LULC) classification plays an important role in various applications, including urban change studies and urban planning [
1]. With the continuous development of Earth observation technology, there is now a variety of remote sensing sensors with different functions. These multiple sensors provide us with ample data for urban LULC classification. However, the recent studies of urban LULC classification have mainly used a specific source of remote sensing data [
2]. Hyperspectral images can provide both detailed structural and spectral information about urban scenes [
3]. Therefore, many researchers have used hyperspectral images in urban LULC classification [
3,
4,
5,
6,
7,
8]. However, with the influence of urbanization, urban classes are becoming more and more diversified and classification using a single sensor has some drawbacks. Hyperspectral images have abundant spectral information, allowing the spectral characteristics of ground objects to be characterized well [
9,
10]. However, different objects possess similar spectral characteristics [
11]. As such, it is difficult to distinguish the objects with similar spectral characteristics. Unlike hyperspectral sensors, light detection and ranging (LiDAR) has the advantage of acquiring dense, discrete, detailed, and accurate 3D point coverage over both the objects and ground surfaces [
12]. Therefore, LiDAR can provide elevation information for urban LULC classification to distinguish objects with similar spectral characteristics but different elevations. It is possible to greatly improve the accuracy of the classification by fusing the two types of data [
13].
In recent years, a number of researchers have fused hyperspectral images with LiDAR data. The classification accuracy of urban LULC has been greatly improved as a result of synthesizing the spectral, spatial, and elevation information. In Liao et al. [
14], the urban LULC was acquired by classifying the spatial features, elevation features, spectral features and fusion features, respectively, and the final result was obtained by majority voting. In Ghamisi et al. [
15], the attribute profile was considered to model the spatial information of the LiDAR and hyperspectral data. Two classification techniques have been considered to build the final classification map, i.e., random forest (RF) and support vector machine (SVM). In Wang et al. [
16], both maximum likelihood and SVM classifiers were used to classify the combined synthesized waveform/hyperspectral image features. In [
17,
18,
19,
20], RF was used to classify the features extracted from the hyperspectral images and LiDAR data to generate the classification map of the urban area. In general, hyperspectral and LiDAR data fusion mostly uses different feature extraction methods and multiple classifiers or RF (which is also a multi-classifier ensemble system) to complete the classification. Previous studies have focused on voting for different classifiers with equal weights. However, due to the different abilities of the different classifiers to distinguish different types of objects, the voting approach using equal weights is unreasonable.
To solve the problem, this paper proposes optimal decision fusion for urban LULC classification based on adaptive differential evolution (ODF-ADE) to optimize the weights of the different classifiers for hyperspectral remote sensing imagery and LiDAR data. In ODF-ADE, the differential evolution (DE) algorithm—a powerful population-based stochastic search and global optimization technique [
21,
22]—is used to find the optimal weights of the different classification maps. DE uses genetic operators such as crossover, mutation and selection to guarantee strong global convergence ability and robustness, and is suitable for complex optimization problems. The DE algorithm has been widely applied for many real applications such as numerical optimization [
22,
23,
24,
25], mechanical engineering [
26], feedforward neural network training [
27], digital filter design [
28], image processing [
29,
30] and pattern recognition [
31,
32]. Furthermore, it has also been used in a number of applications in remote sensing such as clustering [
33,
34], endmember extraction [
35] and subpixel mapping [
36].
The contributions of this paper are as follows:
(1)
The optimal decision fusion framework. ODF-ADE is built for use with hyperspectral imagery and LiDAR data. Before the voting operation, the classification maps are generated by the support vector machine (SVM) [
37], the maximum likelihood classifier (MLC) [
38] and multinomial logistic regression (MLR) [
39], which have different advantages in dealing with samples of different distributions. In line with this strategy, the weight optimization problem is transformed into an optimization problem in the feature space by maximizing the objective function, which is constructed using the minimum Euclidean distance between each pixel and the corresponding predicted class in the training samples. Due to the population-based stochastic search and global optimization technique of the DE algorithm, it is used to optimize the constructed objective function. By initializing a set of weights and using crossover and mutation operations for optimization, the performance of the objective function can be improved.
(2)
Adaptive differential evolution. There are two control parameters involved in DE: the scaling factor
and the crossover rate
. These parameters are often kept fixed throughout the optimization process and can significantly influence the optimization performance of DE [
40,
41]. An adaptive DE method is proposed to solve the optimal decision fusion problem, in which an adaptive strategy is utilized to determine the scaling factor
and crossover rate
. The parameters that need to be determined are encoded into an individual, i.e., an individual has a set of parameters and uses genetic operators such as crossover, mutation and selection for the evolution process. The better individuals with better parameters are more likely to survive and produce offspring. This method reduces the time required for finding the appropriate parameters and can produce flexible DE for optimal decision fusion.
(3) Post-processing based on conditional random fields (CRF). The commonly used classifiers do not consider the correlations between neighboring pixels, leading to the presence of much low-level noise in the classification map. As an improved model for Markov random fields (MRF), conditional random fields (CRF) has the ability to consider the spatial contextual information in both the labels and observed image data. In order to consider the spatial contextual information and preserve the spatial details in classification, pairwise CRF with an 8-neighborhood is used to smooth the final classification map. The pairwise potential uses the spatial smoothing and local class label cost terms to favor spatial smoothing in the local neighborhood and to take the spatial contextual information into account.
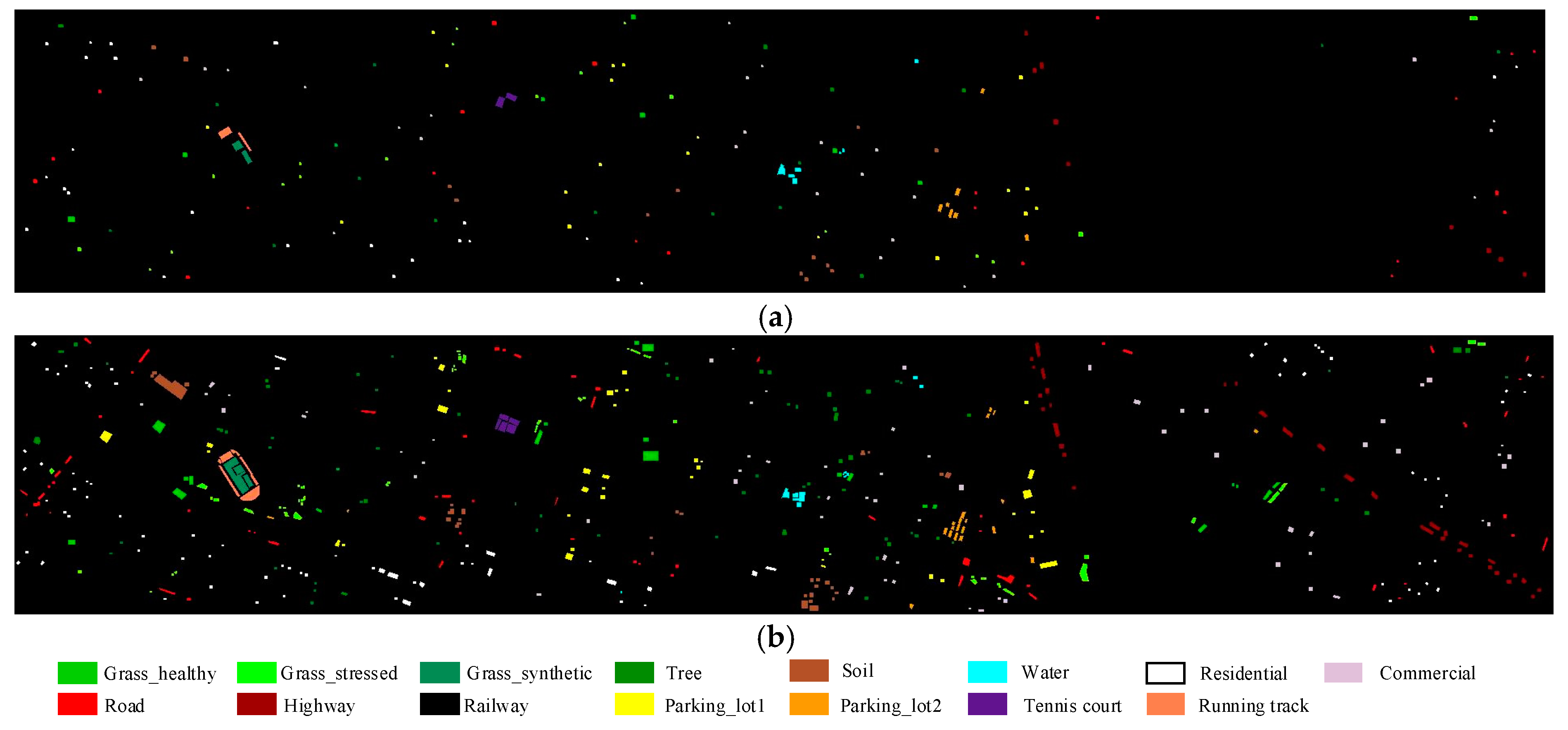
The experimental results obtained in this study demonstrate the efficiency of the proposed ODF-ADE fusion algorithm with the datasets provided by the Data Fusion Technical Committee (DFTC) of the IEEE Geoscience and Remote Sensing Society.
The rest of this paper is organized as follows:
Section 2 briefly introduces the basics of the DE algorithm.
Section 3 describes the proposed ODF-ADE approach for the fusion of hyperspectral and LiDAR data. The experimental results and analysis are given in
Section 4.
Section 5 discusses the main properties of ODF-ADE in theoretical and empirical terms. Finally, the conclusions are provided in
Section 6.
2. Differential Evolution (DE) Algorithm
DE was proposed in 1995 by Storn and Price [
21]. Like the other evolutionary algorithms, DE is a stochastic model for the simulation of biological evolution through repeated iterations which preserves the individuals that adapt to the environment. However, compared to the other evolutionary algorithms, DE retains a global search strategy based on the population, with real encoding and simple mutation strategies to reduce the complexity of the genetic operations. The DE algorithm is mainly used for solving global optimization problems. The main steps are mutation, crossover and selection operations, to evolve from a randomly generated initial population to the final individual solution [
42]. In the proposed method, we use classical DE [
21,
23] because this strategy is the most often used in practice. As shown in
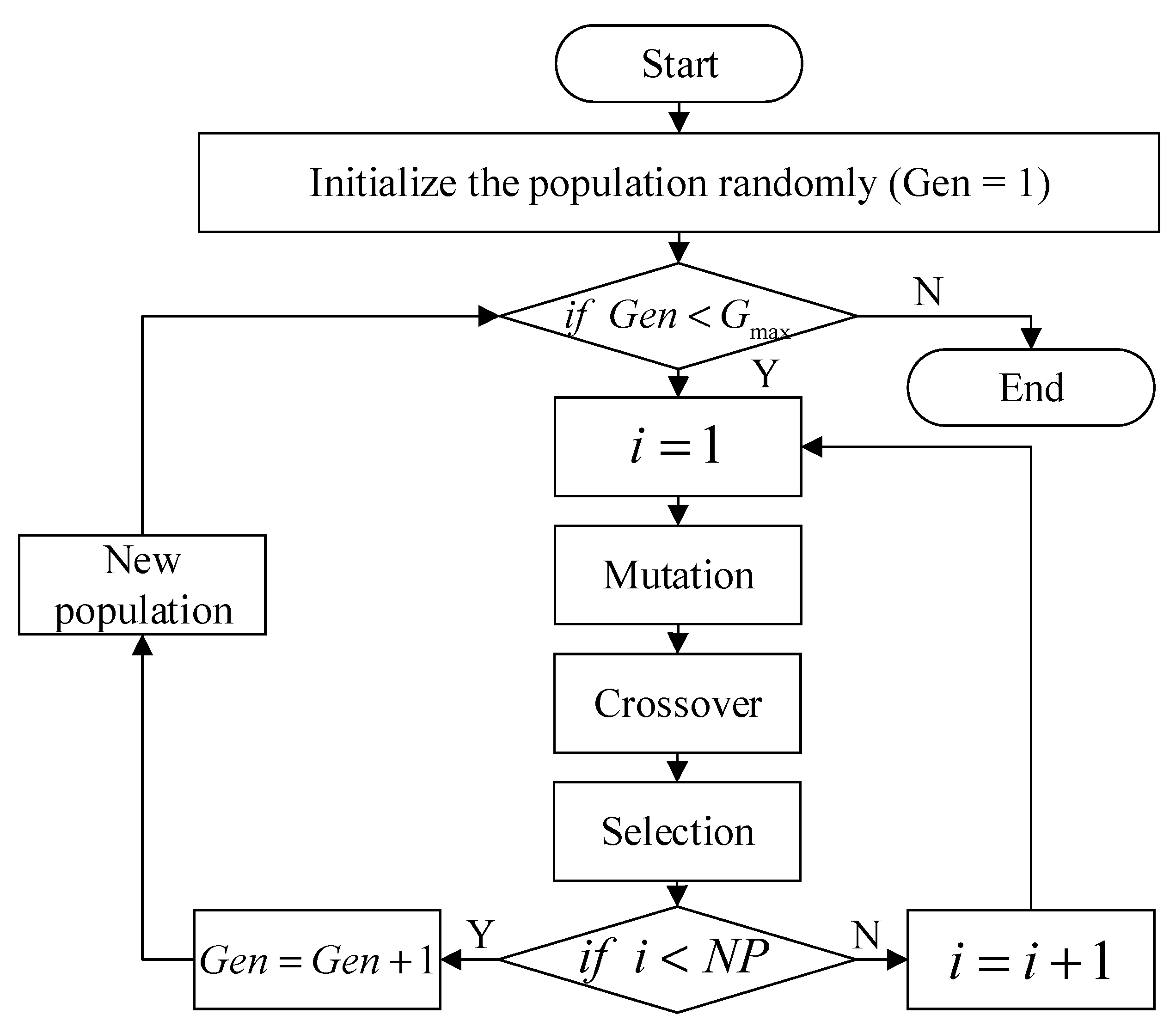
Figure 1, DE can be described as follows:
The minimization optimization problem in the continuous feature space can be represented as:
where
indicates the dimension of the problem, and
and
indicate the minimum and maximum of the
th element of the individual vector
, respectively. The process of DE can be described as the following four steps:
- Step 1
Initialization: Initialize the population randomly, where the size of the population is .
- Step 2
Mutation: With the difference vector of two individuals randomly chosen from the population as the source of random changes in the third individual, generate the mutant individual by obtaining the sum of the difference vector and the third individual according to a scaling factor .
- Step 3
Crossover: Mix the parameters of a predetermined target individual and the mutant vector to produce a trial individual by the crossover probability .
- Step 4
Selection: If the fitness value of the test individual is better than the fitness value of the target individual, the test individual replaces the target individual in the next generation; otherwise, the target body remains alive.
In the evolutionary process of each generation, each individual vector is considered as the target individual once. The algorithm retains the excellent individuals while eliminating the inferior individuals and guides the search process to the global optimum solution approximation through continuous iteration calculation.
3. ODF-ADE Methodology
Before describing the proposed method, the notations used throughout this paper are defined (
Table 1).
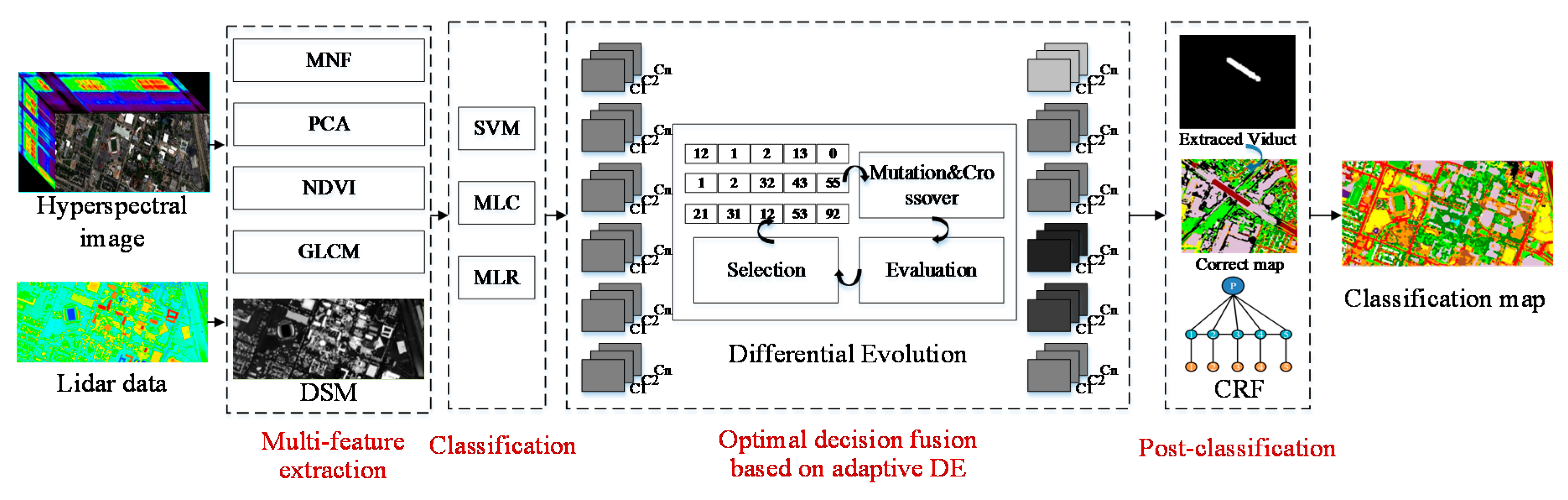
To solve the problem of the inadequate utilization of resources caused by equal voting, the proposed framework uses adaptive DE to optimize the weights of the different classification maps to achieve a better effect. Firstly, the normalized difference vegetation index (NDVI), the gray-level co-occurrence matrix (GLCM) textures and the digital surface model (DSM) elevation feature are added to the spectral features extracted by principal component analysis (PCA) or minimum noise fraction (MNF), to form the feature vector. Three classification algorithms (i.e., MLC, SVM, and MLR) are then used to obtain the initial classification maps. A more accurate classification map is generated by weighted voting using the adaptive DE algorithm. The final classification map is generated after post-processing. The main procedure of the data fusion framework is shown in
Figure 2 and is described as follows.
3.1. Multi-Feature Extraction
In order to represent the features of objects from different angles, MNF or PCA are used to reduce the dimensionality of the hyperspectral image, and the NDVI is used to distinguish the vegetation. To utilize the spatial information, the GLCM is computed. Finally, the DSM is used to represent the elevation information. And the final feature maps are stacked by these features (i.e., MNF + NDVI + GLCM + DSM/PCA + NDVI + GLCM + DSM).
The NDVI is a simple ratio that can be used to analyze remote sensing measurements, to assess whether the target being observed contains live green vegetation or not. In general, if there is much more reflected radiation in the near-infrared wavelengths than in the red wavelengths, then the vegetation in that pixel is likely to be healthy.
A gray-level co-occurrence matrix or gray-level co-occurrence distribution is a matrix that is defined over an image as the distribution of the co-occurring pixel values (grayscale values) at a given offset. The gray-level co-occurrence matrices can measure the texture of the image and they are typically large and sparse, various metrics are used to obtain a more useful set of features. Therefore, the gray-level co-occurrence matrix can be utilized to increase the separability between classes. Homogeneity, also called inverse disparity, measures the local gray uniformity of an image. If the textures of the different regions are similar and the local gray-level of the image is uniform, then the homogeneity will be larger. Therefore the homogeneity of GLCM is used to describe the spatial texture feature.
The DSM refers to a ground elevation model which incorporates the ground surface, buildings, bridges and trees. In comparison, a digital elevation model (DEM) contains only the elevation information of the terrain and does not contain other surface information. The DSM contains the elevation information of any surface elements (soil, vegetation, artificial structures etc.). Therefore, the DSM data obtained from the LiDAR data are added to characterize the elevation information.
3.2. Urban LULC Classification by Different Classifiers
SVM is established based on the Vapnik-Chervonenkis (VC) dimension theory and risk minimization principle to obtain the best classification result, thereby finding the best balance between model complexity (i.e., learning accuracy of the specific training samples) and learning ability (i.e., the ability to identify any sample without error), according to the limited sample information. SVM has many unique advantages in solving small-sample, nonlinear and high-dimensional pattern recognition.
MLC is an image classification method based on statistical knowledge and computing probability. Firstly, the nonlinear discriminant function set is established according to Bayes’ decision criterion. It is then assumed that all kinds of distribution functions are normal distributions. Finally, the training area is selected to calculate the attribution probability of each sample area to obtain the classification map. When classifying, MLC not only considers the distance of the sample to the class center, but also takes into account the distribution characteristics.
MLR is a particular solution to the classification problem that assumes that a linear combination of the observed features and some problem-specific parameters can be used to determine the probability of each particular outcome of the dependent variable. The best values of the parameters for a given problem are usually determined from training data. The algorithm adopts an MLL prior to modeling the spatial information present in the class label images.
These three algorithms, which are all robust, can make full use of the prior information of the samples and are therefore suitable for the classification of complex objects in urban areas. The six classification images are obtained with the two sets of features—MNF + NDVI + GLCM + DSM, PCA + NDVI + GLCM + DSM—by these three classifiers.
3.3. Optimal Decision Fusion Based on Adaptive DE
After the classification maps are obtained by the classification step, they can be used to generate a more accurate classification map by decision fusion, e.g., majority voting. Different classifiers have different abilities to distinguish different objects. In order to avoid the unreasonable use of resources caused by majority voting, weighted voting is used for the decision-level fusion. The DE algorithm allows for global optimization and can be applied to optimize the weights. In addition, a self-adaptive parameter selection method is proposed to adaptively choose the appropriate parameters during the course of DE.
3.3.1. Initial Population
After obtaining the classification maps of the different classifiers, the population can be initialized as
, where
represents the
th individual in the
th generation and NP is the size of the population. As shown in
Figure 3, each individual
denotes the weight of each class for each classification map. The weights also need to be initialized. The two variables are defined as
and
, which represent the number of land-cover labels and classification maps, respectively.
equals
and denotes the number of chromosomes that one individual
contains. The initial population
is generated randomly from 0 to 1.
3.3.2. Calculation of the Objective Function
In this paper, the objective function is constructed using the sum of the minimum Euclidean distances between each pixel and the corresponding predicted class in the training samples. In the proposed algorithm the purpose of DE is to obtain the maximum value of the objective function.
The classification map is obtained by the usual majority voting. Using as the basis, voting is undertaken with the weight of chromosome . If the pixels in belong to class , then the weight value of each classification map refers to the corresponding weight of class , respectively. The new classification map is obtained by traversing the whole image.
If the predicted label of pixel
is class
, which is part of classification maps
(
denotes the number of classification maps that predict the label is
), then:
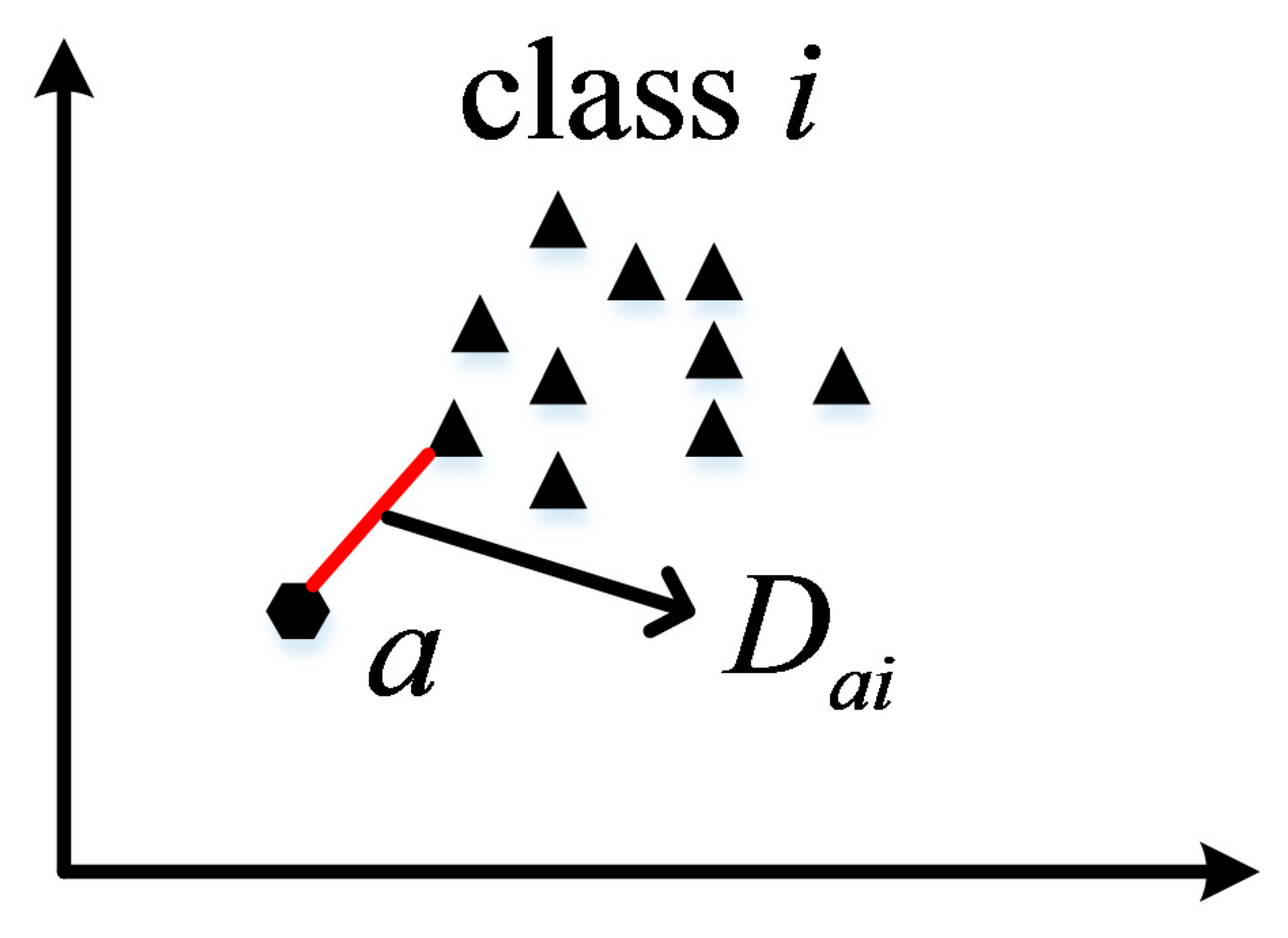
As shown in
Figure 4,
denotes the weight of class
of classification map
and
denotes the minimum distance between pixel
and training data
, for which the label is class
:
where
n represents the number of
,
represents the
th pixel of
,
represents the image vector of pixel
and
represents the image vector of pixel
.
denotes the Euclidean distance between
and
. The smaller the value of
and the greater the value of
, the greater the value of
, which means a lager weight.
The fitness of the individual
is calculated as follows:
where
denotes the total number of image pixels.
3.3.3. Adaptive Mutation and Crossover
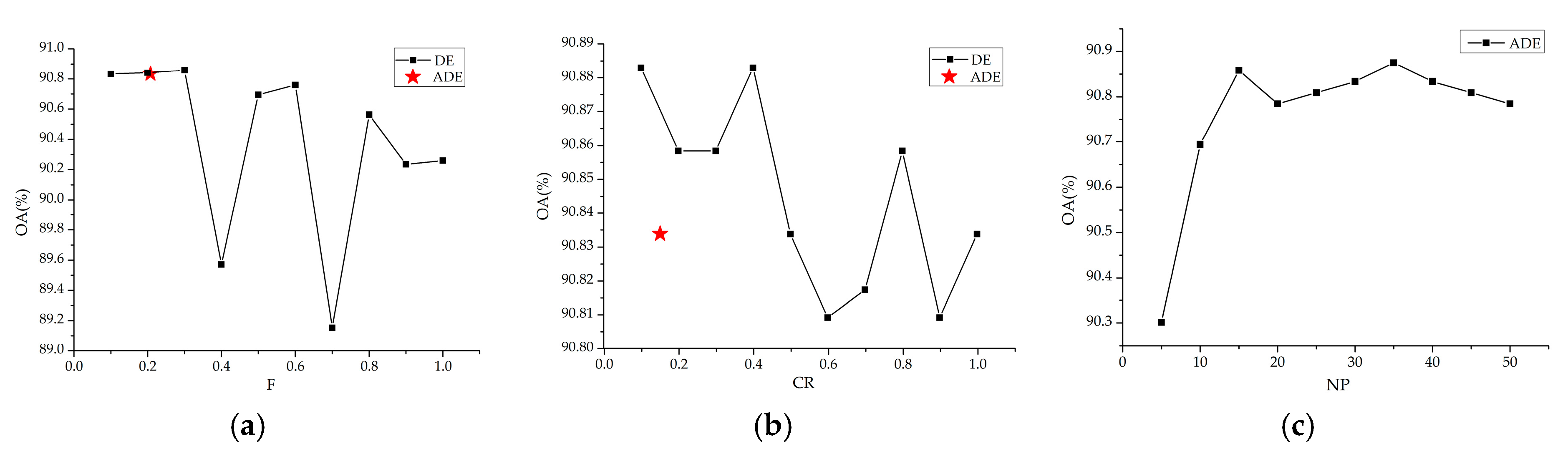
DE generates the mutant individual by obtaining the sum of the difference vector and the third individual according to a scaling factor . The trial individual is produced by mixing the parameters of a predetermined target individual and the mutant vector using the crossover probability . Suitable control parameters are always different for different real problems. However, in some cases, the time for finding these appropriate parameters can be unacceptably long.
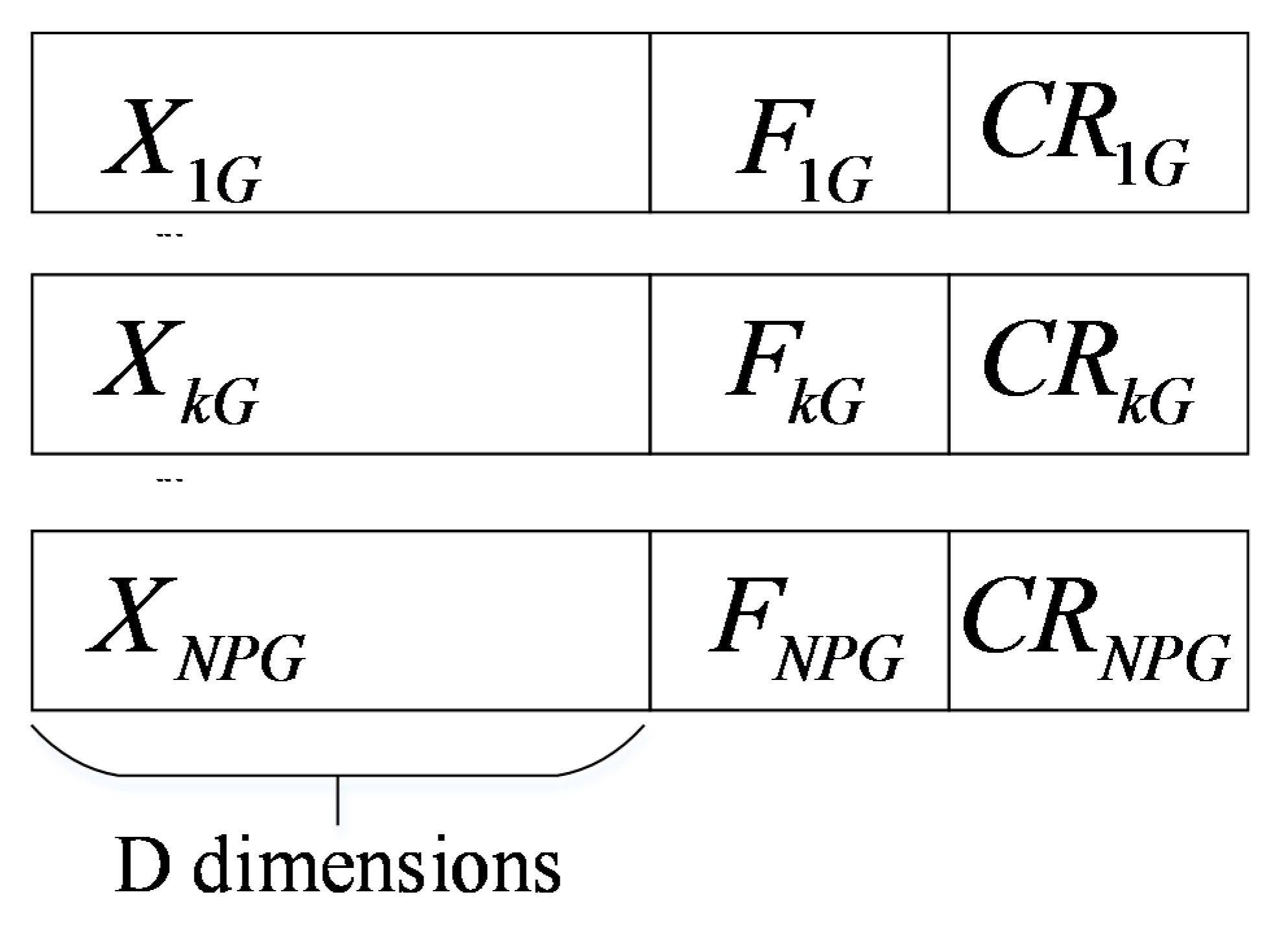
To solve the problem, a self-adaptive strategy for the control parameters is used. As shown in
Figure 5, the control parameters F and CR are encoded to each individual. This means that each individual has its corresponding F and CR values, which can be adjusted during evolution [
42]. The weight optimization solution is represented by the D-dimensional vector
and two control parameters
and
in the
th generation, where
.
For each vector
at generation
, its associated mutant vector
can be generated via the strategy DE/rand/1/bin (rand refers to the mutation strategy, which uses a random selection of individuals to prevent the population from getting into the deadlock of local searching, 1 represents the number of differential vectors and bin refers to the binomial crossover strategy to expand the search space), which is the strategy most often used in practice [
30,
43,
44]. The mutation operators are as follows:
where the indices
,
and
are mutually exclusive integers randomly generated within the range
,
.
The higher the objective function in Equation (5), the more likely the individual is to survive and produce offspring which results in better individuals and increases the probability of finding the optimal solution. To adaptively determine the mutation rate
according to the derivative of the objective value of each individual, the process is as follows:
The new control parameters in the
th generation
and
are updated as follows, with probability
:
where
, denotes the uniform random values within the range (0,1),
is the maximum iteration number,
is the iteration number and
is a parameter to decide the nonconforming degree, for which the experiential value is set to three [
45].
After the mutation phase, a crossover operation is applied to generate a trial vector
for the mutant vector
as follows:
is updated using the following [
38]:
where
denotes the uniform random values within the range (0,1).
and
are obtained before the mutation is performed. Therefore, they influence the mutation, crossover and selection operations of the new vector
.
3.3.4. Selection
After the calculation of the objective function using Equation (5), a selection operation is performed. The objective function value of each trial vector
is compared with that of its corresponding target vector
in the current population. If the weight vector, which is obtained in this generation, has a higher or equal objective function value compared with the corresponding target vector, the trial vector will replace the target vector and form the new population of the next generation. Otherwise, the target vector will remain in the population for the next generation. The selection operation can be expressed as follows:
3.3.5. Stopping Condition
If generation does not meet the maximum generation number , go to Step 2. Otherwise, output the best individuals as the weight of each class for each classification map. Finally, obtain the final classification result using the optimized weights.
3.4. Post-Classification
(1) Decision fusion for viaducts. Viaducts are common in urban areas. However, due to the similarity of the construction materials, they can be easily confused with tall buildings. Therefore, the proposed framework employs an object-based method to extract and classify the viaducts in the urban area, so as to improve the overall classification accuracy. Viaducts are easy to extract due to the gradually changing characteristic of the viaducts in elevation. Region growing is a simple region-based image segmentation method. This approach to segmentation examines the neighboring pixels of the initial seed points (which are selected manually) and determines whether the pixel neighbors should be added to the region or not. The process is iterated in the same manner as the general data clustering algorithms. As a result, the region growing method performed in the DSM image is used to extract the viaducts to complete the operation.
(2) Post-classification by CRF. The spatial contextual information of remote sensing imagery is very important for the classification task [
46,
47]. Those prior operations which do not consider the correlations between neighboring pixels lead to the presence of much low-level noise in the classification map. As an improved model of MRF, CRF has the ability to consider the spatial contextual information in both the labels and observed image data. In order to consider the spatial contextual information and preserve the spatial details in the classification, pairwise CRF with an 8-neighborhood is used to smooth the final classification map. The pairwise potential uses the spatial smoothing and local class label cost terms to favor spatial smoothing in the local neighborhood and to take the spatial contextual information into account. The local class label cost term also has the ability to alleviate an oversmooth classification result since it considers the different label information of the neighboring pixels at each iterative step in the classification.
6. Conclusions
Based on DE theory, this paper has proposed a new optimal decision fusion strategy for the fusion of hyperspectral images and LiDAR data, namely ODF-ADE. In line with this strategy, the optimal decision fusion problem is transformed into an optimization problem in the feature space by maximizing the objective value. The traditional voting algorithm always uses equal weights to fuse the classification maps, which results in the differences among the different classifiers not being fully utilized. In the proposed method, DE, which has the ability of global optimization, is used to obtain the weights of the different classification maps. In addition, in the traditional DE it is necessary to choose appropriate control parameters, employing the prior experience of the user, for population size NP, crossover rate CR and scaling factor F. This is quite a difficult task because the best settings for the control parameters are not easy to determine for complex problems. In the proposed method, a self-adaptive strategy is utilized to determine the parameters.
The data sets of the 2013 Data Fusion Contest were used to test the effectiveness of the proposed algorithm. The experimental results show that ODF-ADE cannot only make full use of the advantages of LiDAR data, but it can also obtain more reasonable classification maps using the weighted voting. ODF-ADE can overcome the shortcomings of classification using data from a single sensor and can achieve good results in urban LULC classification.
In our future work, the number of classification maps and the diversity of these maps will be increased to obtain a better result. Ensemble voting will also be considered to further improve the classification result and additional information about LiDAR may be considered in the feature work.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}