
Statistical Methods for the Analysis of Food Composition Databases: A Review


Abstract
:1. Introduction
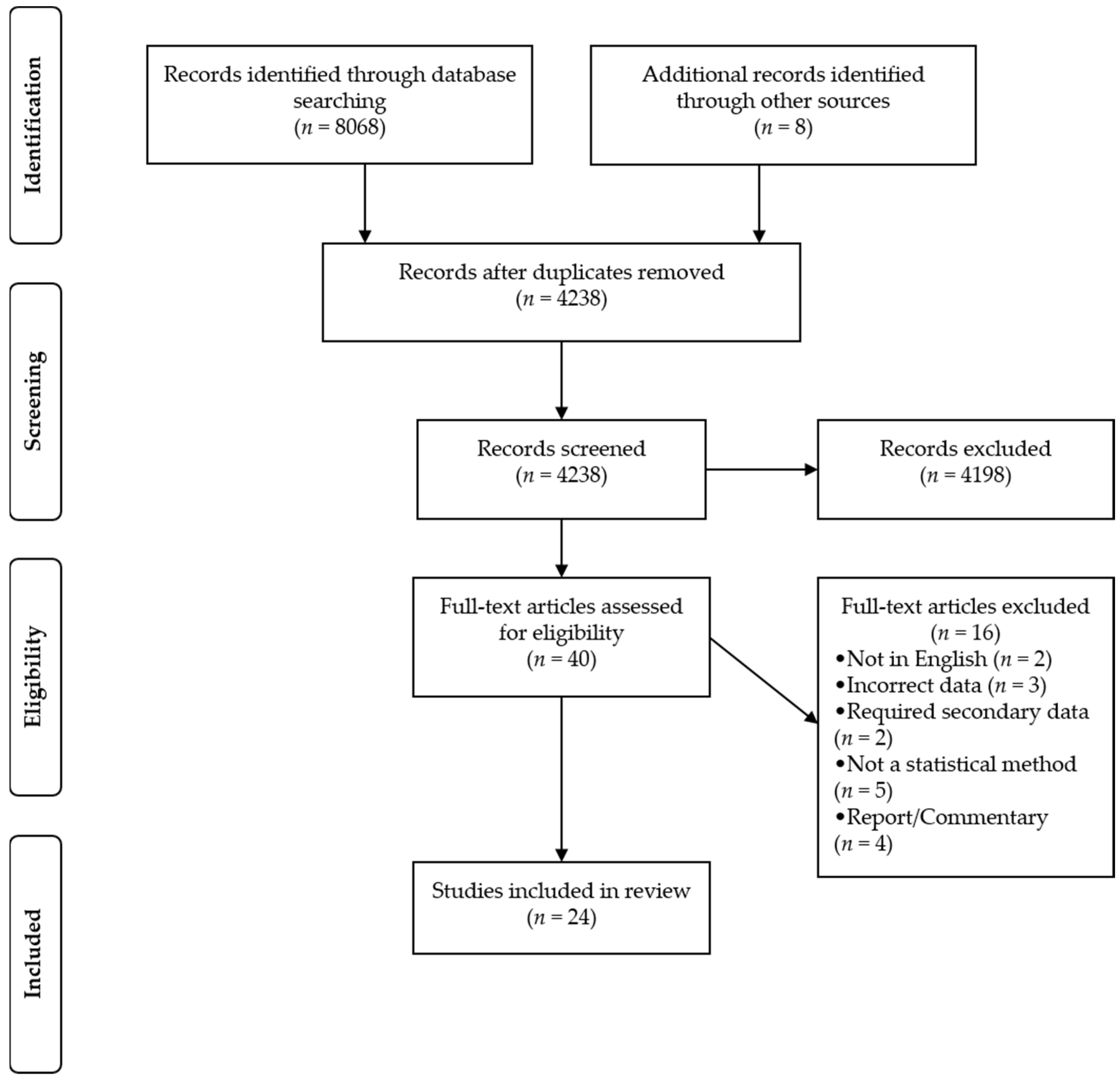
2. Materials and Methods
2.1. Search Methods
2.2. Study Selection
- The title, abstract, or methods of the article described an application of a statistical method (mathematical formulas, models, and/or techniques).
- The data used was from a food composition database/dataset.
- The statistical analysis required the extensive use of secondary data such as dietary guidelines, recommended dietary intakes, cost data, data from supermarkets and restaurants, and consumption data.
- Chemical analyses, as part of the study, were conducted to obtain the nutrient values.
- An English translation of the article was unavailable.
- The article was not a primary study (i.e., reviews, commentaries, etc.).
2.3. Data Extraction
3. Results
3.1. Standard Statistical Methods
3.2. Regression Methods
3.3. Clustering
3.4. Dimension Reduction Techniques
3.5. Other Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Greenfield, H.; Southgate, D.A.T. Food Composition Data. Production Management and Use, 2nd ed.; Food and Agriculture Organization of the United Nations: Rome, Italy, 2003. [Google Scholar]
- Elmadfa, I.; Meyer, A.L. Importance of food composition data to nutrition and public health. Eur. J. Clin. Nutr. 2010, 64 (Suppl. S3), S4–S7. [Google Scholar] [CrossRef] [Green Version]
- Reedy, J.; Subar, A.F.; George, S.M.; Krebs-Smith, S.M. Extending Methods in Dietary Patterns Research. Nutrients 2018, 10, 571. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Tapera, T.M.; Gou, J. Application of a new dietary pattern analysis method in nutritional epidemiology. BMC Med. Res. Methodol. 2018, 18, 119. [Google Scholar] [CrossRef]
- Zhao, J.; Li, Z.; Gao, Q.; Zhao, H.; Chen, S.; Huang, L.; Wang, W.; Wang, T. A review of statistical methods for dietary pattern analysis. Nutr. J. 2021, 20, 37. [Google Scholar] [CrossRef]
- Granato, D.; Ares, G. Mathematical and Statistical Methods in Food Science and Technology; John Wiley & Sons, Ltd.: West Sussex, UK, 2014. [Google Scholar] [CrossRef]
- Cruz, A.G.; Cadena, R.S.; Alvaro, M.B.V.B.; Sant’Ana, A.S.; Oliveira, C.A.F.; Faria, J.A.F.; Bolini, H.M.A.; Ferreira, M.M.C. Assessing the use of different chemometric techniques to discriminate low-fat and full-fat yogurts. LWT-Food Sci. Technol. 2013, 50, 210–214. [Google Scholar] [CrossRef]
- da Silva Torres, E.A.F.; Garbelotti, M.L.; Moita Neto, J.M. The application of hierarchical clusters analysis to the study of the composition of foods. Food Chem. 2006, 99, 622–629. [Google Scholar] [CrossRef]
- Kim, J.H.; Kim, W.C.; Kim, J. A practical solution to improve the nutritional balance of Korean dine-out menus using linear programming. Public Health Nutr. 2019, 22, 957–966. [Google Scholar] [CrossRef]
- Rudelt, A.; French, S.; Harnack, L. Fourteen-year trends in sodium content of menu offerings at eight leading fast-food restaurants in the USA. Public Health Nutr. 2014, 17, 1682–1688. [Google Scholar] [CrossRef] [Green Version]
- Colchero, M.A.; Guerrero-López, C.M.; Molina, M.; Unar-Munguía, M. Affordability of food and beverages in Mexico between 1994 and 2016. Nutrients 2019, 11, 78. [Google Scholar] [CrossRef] [Green Version]
- Sucharew, H.; Macaluso, M. Progress Notes: Methods for Research Evidence Synthesis: The Scoping Review Approach. J. Hosp. Med. 2019, 14, 416–418. [Google Scholar] [CrossRef] [Green Version]
- Kirk, D.; Catal, C.; Tekinerdogan, B. Precision nutrition: A systematic literature review. Comput. Biol. Med. 2021, 133, 104365. [Google Scholar] [CrossRef] [PubMed]
- Sak, J.; Suchodolska, M. Artificial Intelligence in Nutrients Science Research: A Review. Nutrients 2021, 13, 322. [Google Scholar] [CrossRef] [PubMed]
- Akbay, A.; Elhan, A.; Ozcan, C.; Demirtas, S. Hierarchical cluster analysis as an approach for systematic grouping of diet constituents on basis of fatty acid, energy and cholesterol content: Application on consumable lamb products. Med. Hypotheses 2000, 55, 147–154. [Google Scholar] [CrossRef] [PubMed]
- Atsa’am, D.D.; Oyelere, S.S.; Balogun, O.S.; Wario, R.; Blamah, N.V. K-means cluster analysis of the West African species of cereals based on nutritional value composition. Afr. J. Food Agric. Nutr. Dev. 2021, 21, 17195–17212. [Google Scholar] [CrossRef]
- Balakrishna, Y.; Manda, S.; Mwambi, H.; van Graan, A. Identifying Nutrient Patterns in South African Foods to Support National Nutrition Guidelines and Policies. Nutrients 2021, 13, 3194. [Google Scholar] [CrossRef]
- Chu, C.-M.; Lee, M.-S.; Hsu, Y.-H.; Yu, H.-L.; Wu, T.-Y.; Chang, S.-C.; Lyu, L.-C.; Chou, F.-J.; Shao, Y.-P.; Wahlqvist, M.L. Quality assurance with an informatics auditing process for Food Composition Tables. J. Food Compost. Anal. 2009, 22, 718–727. [Google Scholar] [CrossRef]
- Davis, D.R.; Epp, M.D.; Riordan, H.D. Changes in USDA Food Composition Data for 43 Garden Crops, 1950 to 1999. J. Am. Coll. Nutr. 2004, 23, 669–682. [Google Scholar] [CrossRef]
- Ispirova, G.; Eftimov, T.; Korošec, P.; Seljak, B.K. MIGHT: Statistical methodology for missing-data imputation in food composition databases. Appl. Sci. 2019, 9, 4111. [Google Scholar] [CrossRef] [Green Version]
- Ispirova, G.; Eftimov, T.; Seljak, B.K. Evaluating missing value imputation methods for food composition databases. Food Chem. Toxicol. 2020, 141, 111368. [Google Scholar] [CrossRef]
- Khan, A.S. Processes in ranking nutrients of foods in a food data base. Nutr. Health 1996, 11, 59–72. [Google Scholar] [CrossRef]
- Kim, S.; Sung, J.; Foo, M.; Jin, Y.S.; Kim, P.J. Uncovering the nutritional landscape of food. PLoS ONE 2015, 10, e0118697. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Bahadur, R.; Ahuja, J.; Pehrsson, P.; Harnly, J. Macro-and micronutrients in raw plant foods: The similarities of foods and implication for dietary diversification. J. Food Compost. Anal. 2021, 102, 103993. [Google Scholar] [CrossRef]
- Liu, C.; Sun, Y.; Li, Y.; Yang, W.; Zhang, M.; Xiong, C.; Yang, Y. The relationship between cold-hot nature and nutrient contents of foods. Nutr. Diet. 2012, 69, 64–68. [Google Scholar] [CrossRef]
- Mayer, A.M. Historical changes in the mineral content of fruits and vegetables. Br. Food J. 1997, 99, 207–211. [Google Scholar] [CrossRef]
- Nguyen, P.K.; Lin, S.; Heidenreich, P. A systematic comparison of sugar content in low-fat vs regular versions of food. Nutr. Diabetes 2016, 6, e193. [Google Scholar] [CrossRef] [Green Version]
- Nikitina, M.A.; Chernukha, I.M.; Uzakov, Y.M.; Nurmukhanbetova, D.E. Cluster analysis for databases typologization characteristics. News Natl. Acad. Sci. Repub. Kaz. Ser. Geol. Tech. Sci. 2021, 2, 114–121. [Google Scholar] [CrossRef]
- Pennington, J.A.T.; Fisher, R.A. Classification of fruits and vegetables. J. Food Compost. Anal. 2009, 22, S23–S31. [Google Scholar] [CrossRef]
- Pennington, J.A.T.; Fisher, R.A. Food component profiles for fruit and vegetable subgroups. J. Food Compost. Anal. 2010, 23, 411–418. [Google Scholar] [CrossRef]
- Phanich, M.; Pholkul, P.; Phimoltares, S. Food Recommendation System Using Clustering Analysis for Diabetic Patients. In Proceedings of the 2010 International Conference on Information Science and Applications, Seoul, Korea, 21–23 April 2010; pp. 1–8. [Google Scholar]
- do Prado, S.B.R.; Giuntini, E.B.; Grande, F.; de Menezes, E.W. Techniques to evaluate changes in the nutritional profile of food products. J. Food Compost. Anal. 2016, 53, 1–6. [Google Scholar] [CrossRef]
- Similä, M.; Ovaskainen, M.-L.; Virtanen, M.J.; Valsta, L.M. Nutrient content patterns of Finnish foods in a food composition database. J. Food Compost. Anal. 2006, 19, 217–224. [Google Scholar] [CrossRef]
- Westrich, B.J.; Altmann, M.A.; Potthoff, S.J. Minnesota’s Nutrition Coordinating Center uses mathematical optimization to estimate food nutrient values. Interfaces 1998, 28, 86–99. [Google Scholar] [CrossRef]
- White, P.J.; Broadley, M.R. Historical variation in the mineral composition of edible horticultural products. J. Hortic. Sci. Biotechnol. 2005, 80, 660–667. [Google Scholar] [CrossRef]
- Windham, C.T.; Windham, M.P.; Wyse, B.W.; Hansen, R.G. Cluster-Analysis to Improve Food Classification within Commodity Groups. J. Am. Diet. Assoc. 1985, 85, 1306–1314. [Google Scholar] [CrossRef]
- Xie, A.; Huang, H.; Kong, F. Relationship between food composition and its cold/hot properties: A statistical study. J. Agric. Food Res. 2020, 2, 100043. [Google Scholar] [CrossRef]
- Yarbrough Al-Bander, S.; Nix, L.; Katz, R.; Korn, M.; Sebastian, A. Food chloride distribution in nature and its relation to sodium content. J. Am. Diet. Assoc. 1988, 88, 472–475. [Google Scholar] [CrossRef]
- Ahuja, J.K.C.; Goldman, J.D.; Perloff, B.P. The effect of improved food composition data on intake estimates in the United States of America. J. Food Compost. Anal. 2006, 19, S7–S13. [Google Scholar] [CrossRef]
- Marles, R.J. Mineral nutrient composition of vegetables, fruits and grains: The context of reports of apparent historical declines. J. Food Compost. Anal. 2017, 56, 93–103. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. A Math Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- Howard, M.C. A Review of Exploratory Factor Analysis Decisions and Overview of Current Practices: What We Are Doing and How Can We Improve? Int. J. Hum. Comput. Interact. 2016, 32, 51–62. [Google Scholar] [CrossRef]
- Minich, D.M. A Review of the Science of Colorful, Plant-Based Food and Practical Strategies for “Eating the Rainbow”. J. Nutr. Metab. 2019, 2019, 2125070. [Google Scholar] [CrossRef]
- Melkumova, L.E.; Shatskikh, S.Y. Comparing Ridge and LASSO estimators for data analysis. Procedia Eng. 2017, 201, 746–755. [Google Scholar] [CrossRef]
- Schonlau, M.; Zou, R.Y. The random forest algorithm for statistical learning. Stata J. 2020, 20, 3–29. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Y. A Comprehensive Survey of Clustering Algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef] [Green Version]
- Reid, R.D.; Sanders, N.R. Operations Management: An Integrated Approach, 5th ed.; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- de Bruyn, J.; Ferguson, E.; Allman-Farinelli, M.; Darnton-Hill, I.; Maulaga, W.; Msuya, J.; Alders, R. Food composition tables in resource-poor settings: Exploring current limitations and opportunities, with a focus on animal-source foods in sub-Saharan Africa. Br. J. Nutr. 2016, 116, 1709–1719. [Google Scholar] [CrossRef] [Green Version]
- Drewnowski, A.; Amanquah, D.; Gavin-Smith, B. Perspective: How to Develop Nutrient Profiling Models Intended for Global Use: A Manual. Adv. Nutr. 2021, 12, 609–620. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Study | Year | Country of Data | Objectives | Methods | Main results |
|---|---|---|---|---|---|
| Akbay et al. [15] | 2000 | United States of America | To divide lamb meat into groups distinct in dietary fat and associated nutrients, to offer healthier dietary replacements. | Agglomerative hierarchical cluster analysis with average linkage | Two main clusters were found in the lamb meat data. One of the clusters divided into two families and four subfamilies based on fatty acids, cholesterol, and energy composition. |
| Atsa’am et al. [16] | 2021 | West Africa | To determine subgroupings within the ‘cereals’ category of foods. | K-means clustering with Euclidean distance | Six subgroups within the ‘cereals’ category were found which separated the grains by type and preparation method. |
| Balakrishna et al. [17] | 2021 | South Africa | To determine nutrient co-occurrence patterns and compositionally similar food groupings. | Spearman’s rank correlation, principal component analysis | Significant correlations were found among the nutrients. Eight nutrient patterns were obtained, which mirrored the South African food-based dietary guidelines. |
| Chu et al. [18] | 2009 | Taiwan | To detect unlikely nutrient values (errors) in a food composition database. | Ranking coefficients of variation for each nutrient by food subgroup and detecting outliers | Compared to manual assessment, error detection increased 38-fold with the computerised process. |
| Davis et al. [19] | 2004 | United States of America | To determine possible changes in nutrient composition for garden crops between 1950 and 1990. | Wilcoxon signed-rank test | Of the 13 nutrients analysed for 43 food items, 6 exhibited statistically significant declines from 1950 to 1990. Declines ranged from 6% to 38%. |
| Ispirova et al. [20] | 2019 | Italy, United Kingdom, Switzerland, Sweden, Slovenia, Belgium, Denmark, Netherlands, United States of America, Canada | To decrease the error of data borrowing when imputing missing nutrient values from other food composition databases. | Non-negative matrix factorization, null hypothesis testing | When borrowing from other food composition databases, the proposed methodology produced smaller absolute errors more often than regular borrowing methods. |
| Ispirova et al. [21] | 2020 | Italy, United Kingdom, Switzerland, Sweden, Slovenia, Belgium, Denmark, The Netherlands, United States of America, Canada | To evaluate imputation methods for missing data in food composition databases. | Non-negative matrix factorization, multiple imputations by chained equations, nonparametric missing value imputation using random forest, k-nearest neighbour | Imputation methods using statistical prediction performed better than traditional approaches of fill-in with the mean and fill-in with the median. Overall, the missing value imputation using the random forest technique performed the best by yielding the smallest error. |
| Khan [22] | 1996 | Australia | To identify thresholds that would rank food items according to a low, medium, or high nutrient content. | Measures of central tendency | No optimum ranking scheme was recommended, but guidelines were provided. Three different criteria were deemed suitable in line with the proposed guidelines. |
| Kim et al. [23] | 2015 | United States of America | To investigate the relationships between food items and between nutrients to inform nutrition. | Network-based approaches, hierarchical clustering with average linkage, pairwise correlations | Clustering revealed a hierarchical organisation of food that was consistent with common nutritional knowledge but also found unexpected relationships between food items. Similarly, significant positive pairwise correlations were found to exist between nutrients. |
| Li et al. [24] | 2021 | United States of America | To categorise raw plant foods according to nutritional similarity. | Spearman’s rank correlation, principal component analysis, soft independent modelling of class analogies (SIMCA), agglomerative hierarchical clustering | Four clusters were identified that consisted of foods from different food groups. Better separation was achieved using clusters rather than traditional food groups. |
| Liu et al. [25] | 2012 | China | All foods in traditional Chinese medicine are categorised into ‘the four natures’: cold, cool, warm, and hot. The purpose of this paper is to examine the association between the nutrient content of these foods and their cold-hot nature category. | Logistic regression | Fat, carbohydrate, and selenium were significantly associated with the hot nature of foods while iron and copper were significantly associated with the cold nature of foods. The results suggest that the nutrient contents of foods may be one of the distinguishing factors for the categorisation of the cold-hot nature of foods. |
| Mayer [26] | 1997 | United Kingdom | To determine if the nutritional composition of fruits and vegetables had changed between the 1930s and 1980s. | Student’s t-test | There was a reduction in the nutrient content for several food items over the 50 years. |
| Nguyen et al. [27] | 2016 | United States of America | To determine whether ‘healthier’ versions of common foods have more sugar than ‘regular’ counterparts. | Friedman test, post-hoc Wilcoxon signed-rank test | The sugar content of foods classified as ‘low-fat’ and ‘non-fat’ was higher than that of regular versions. |
| Nikitina et al. [28] | 2021 | Unknown | To cluster cottage cheese products and confectionary by carbohydrate content. | K-means clustering | Five clusters were found which identified foods with low, medium, and high carbohydrate contents. |
| Pennington and Fisher [29] | 2009 | United States of America | To empirically group fruits and vegetables based on food components of public health significance and thereafter, relate them to four classification variables: botanic family, colour, part of the plant, and total antioxidant capacity. | Agglomerative hierarchical clustering with Ward’s linkage, multivariate analysis of variance (MANOVA) | Eight clusters were identified that could be used to classify the 104 fruits and vegetables. Clusters were best defined by a combination of classification variables, such as colour and part of the plant, and were predictive of the nutritional profile. |
| Pennington and Fisher [30] | 2010 | United States of America | To determine fruit and vegetable subgroups with significantly higher concentrations of 24 food components. | Kruskal–Wallis, one-way analysis of variance (ANOVA) | Concentrations of the 24 food components differed between the subgroups and can be used to aid nutritional guidelines. |
| Phanich et al. [31] | 2010 | Thailand | To develop a food recommendation system for diabetic patients enabling diabetic patients to find suitable substitutions, similar in nutrient composition and characteristics, for food items. | Self-Organising Map (SOM), k-means clustering | The resulting clusters contained foods that provided similar amounts of eight selected nutrients. Patients were able to use the developed software to select healthier alternatives to current food choices. |
| do Prado et al. [32] | 2016 | Brazil | To compare the change in the nutrient composition of specific Brazilian food groups between 2003 and 2013. | Percentage change, hierarchical cluster analysis, principal component analysis | The results showed that using pre-established food groups alone may be inaccurate in assessing changes in nutritional composition. Hierarchical cluster analysis combined with percentage change allowed efficient identification of the changes in the nutritional composition of food items. |
| Similä et al. [33] | 2006 | Finland | To obtain information about nutrient co-occurrence patterns among food items. | Factor analysis | Four nutrient content patterns, which was consistent with prior knowledge, were identified. The patterns were characterised by (1) fish, meat, dairy products, legumes, seeds, and nuts; (2) vegetable fats; (3) staple foods; and (4) offal foods (liver, kidney). |
| Westrich et al. [34] | 1998 | United States of America | To estimate unknown nutrient values in commercial food products. | Linear programming optimisation, quadratic programming optimisation | The proposed optimisation software was able to estimate missing nutrient values four times faster than conventional methods with the same degree of accuracy. The linear programming method was found to be faster than the quadratic programming method. |
| White and Broadley [35] | 2005 | United Kingdom, United States of America | To determine nutrient composition changes in fruits and vegetables between the 1930s and 1980s. | Student’s t-test | Average concentrations of certain minerals in fruits and vegetables had significantly decreased between the 1930s and 1980s. |
| Windham et al. [36] | 1985 | United States of America | To group foods within the dairy, grain, and fat commodity groups depending on nutrients of current concern. | Fuzzy c-means clustering | Five clusters within each commodity group were identified. Nutrient content was similar within subgroups and overcame the problem of objective and accurate grouping when dealing simultaneously with many nutrients. The use of fuzzy clustering avoided the use of arbitrary cut-offs when determining foods high and low in specific nutrients. |
| Xie et al. [37] | 2020 | United States of America, China | To determine the nutrients affecting the cold-hot nature property of food items as per traditional Chinese medicine. | Multivariate ordinal regression, ANOVA | Six components (folate, vitamin B6, calcium, vitamin A, and caffeine) were found to be predictive of the cold, plain, and hot nature of foods. |
| Yarbrough Al-Bander et al. [38] | 1988 | United Kingdom | To explore the distribution of chloride content in uncooked foods and determine its correlation with sodium content. | Wilcoxon signed-rank test, linear regression | Chloride and sodium content exhibited large variation among the 216 uncooked food items. Chloride and sodium content were strongly correlated. |
| Characteristic | n | % |
|---|---|---|
| Primary statistical method | ||
| Standard statistical methods a | 8 | 33.3 |
| Regression methods | 3 | 12.5 |
| Clustering | 7 | 29.1 |
| Dimension reduction techniques | 2 | 8.3 |
| Other b | 4 | 16.7 |
| Aims c | ||
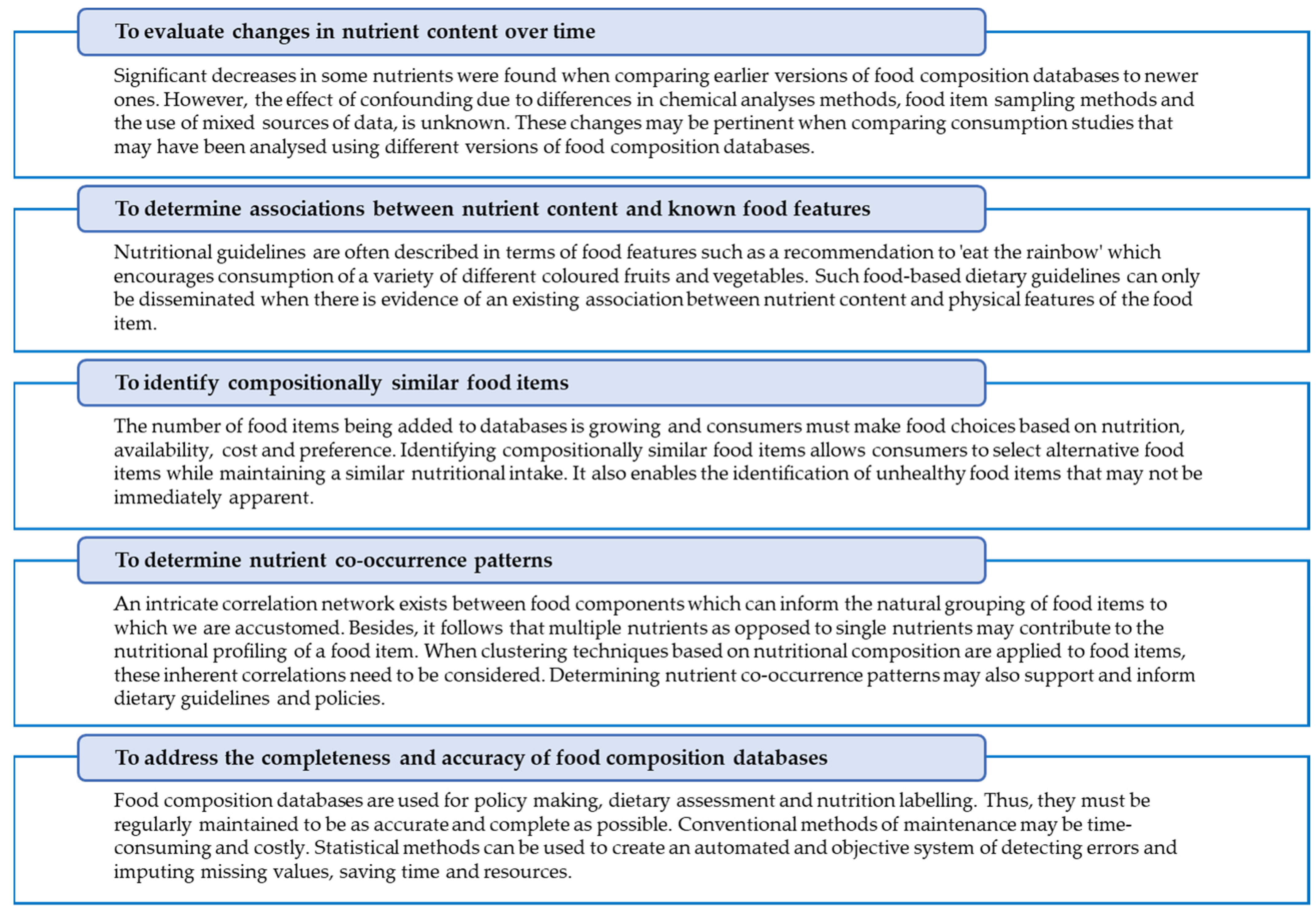
| To evaluate changes in nutrient content over time | 4 | 16.7 |
| To determine associations between nutrient content and known food features | 6 | 25.0 |
| To identify compositionally similar food items | 9 | 37.5 |
| To determine nutrient co-occurrence patterns | 5 | 20.8 |
| To address the completeness and accuracy of food composition databases | 4 | 16.7 |
| Country of data used c | ||
| United States of America | 13 | 54.2 |
| United Kingdom | 5 | 20.8 |
| Other d | 11 | 45.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balakrishna, Y.; Manda, S.; Mwambi, H.; van Graan, A. Statistical Methods for the Analysis of Food Composition Databases: A Review. Nutrients 2022, 14, 2193. https://doi.org/10.3390/nu14112193
Balakrishna Y, Manda S, Mwambi H, van Graan A. Statistical Methods for the Analysis of Food Composition Databases: A Review. Nutrients. 2022; 14(11):2193. https://doi.org/10.3390/nu14112193
Chicago/Turabian StyleBalakrishna, Yusentha, Samuel Manda, Henry Mwambi, and Averalda van Graan. 2022. "Statistical Methods for the Analysis of Food Composition Databases: A Review" Nutrients 14, no. 11: 2193. https://doi.org/10.3390/nu14112193