
Tailoring the Nutritional Composition of Italian Foods to the US Nutrition5k Dataset for Food Image Recognition: Challenges and a Comparative Analysis
 , , , , ,
, , , , ,  and
and
Abstract
1. Introduction
- (1)
- Elucidating challenges and solutions in linking the nutritional composition of Italian foods with food images from Nutrition5k;
- (2)
- Assessing the presence of potential differences in nutrient content estimated across the Italian and US FCDBs and their determinants, within a comparative analysis.
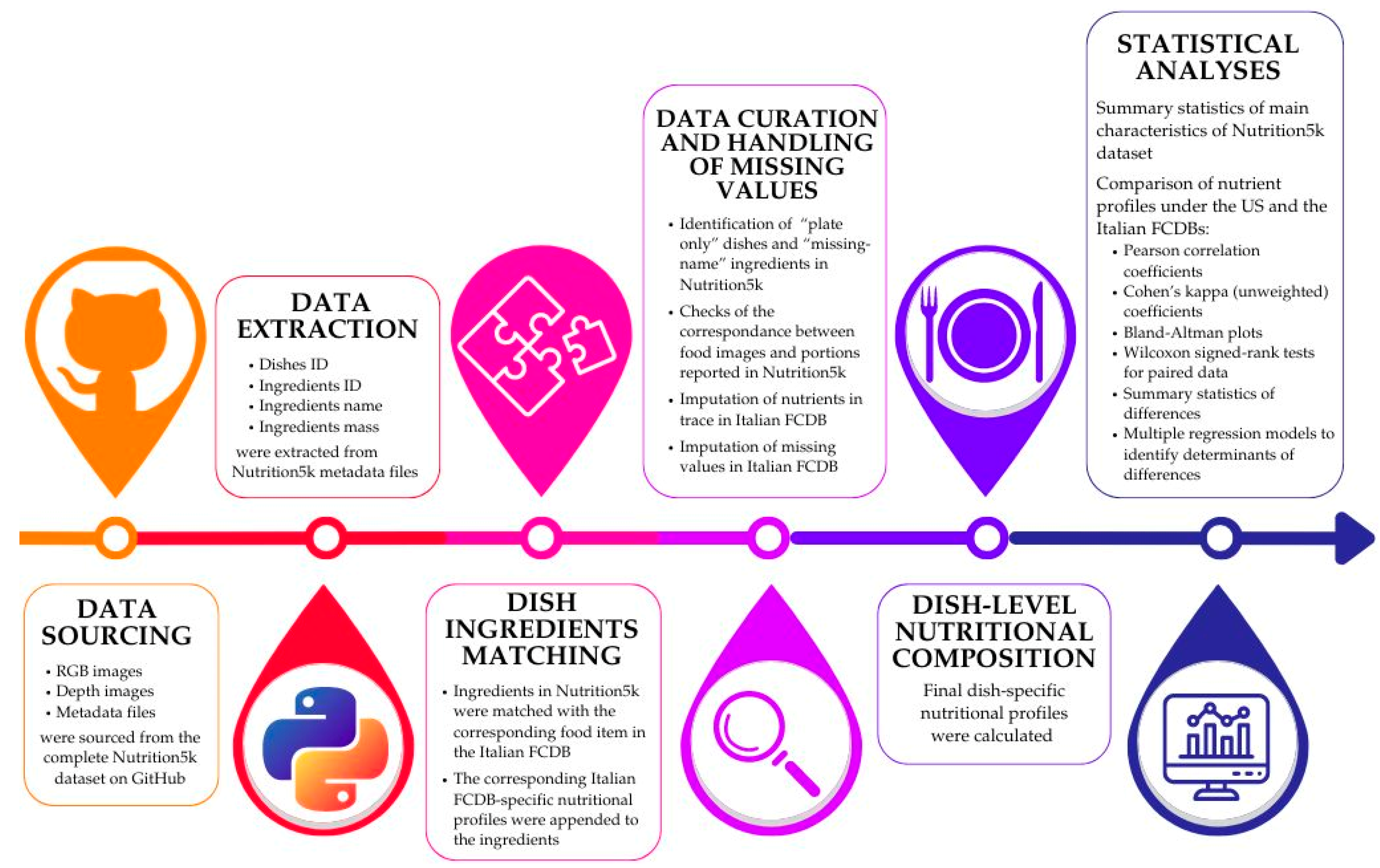
2. Materials and Methods
2.1. Data Extraction and Preliminary Data Management
2.2. Exact and Indirect Matching of Ingredients with Their Nutritional Composition
- Available carbohydrates = carbohydrate-by-difference—total dietary fiber;
- Vitamin A components:
- ○
- β-carotene equivalents = 1 β-carotene + 0.5 α-carotene + 0.5 β-cryptoxanthin;
- ○
- Retinol equivalent = retinol + 1/6 β-carotene equivalents;
- Alpha-tocopherol equivalents = α-tocopherol + 0.4 β-tocopherol + 0.1 γ-tocopherol + 0.01 δ-tocopherol + 0.3 α-tocotrienol + 0.05 β-tocotrienol + 0.01 γ-tocotrienol;
- Short-chain saturated fatty acids: butyric fatty acid (C4:0) + caproic fatty acid (C6:0) + caprylic fatty acid (C8:0) + capric fatty acid (C10:0).
2.2.1. Exact Matching between Ingredients in Nutrition5k and Food Items in the Italian FCDB
2.2.2. Indirect Matching: Similarity between Ingredients in Nutrition5k and Food Items in the Italian FCDB
2.2.3. Indirect Matching: Dish Ingredients Present in Nutrition5k Were Missing Food Items in the Italian FCDB
2.2.4. Indirect Matching: Dish Ingredients Present in Nutrition5k Were Too Generic for Matching: Mean Values of the Corresponding Nutrients
2.2.5. Indirect Matching: Single Dish Ingredients in Nutrition5k Were Composite Recipes
2.3. Manual Data Curation
2.3.1. “Plate Only” and “Missing-Name Ingredients”
2.3.2. Ingredients Portion: Checks
2.3.3. Nutrients in Trace
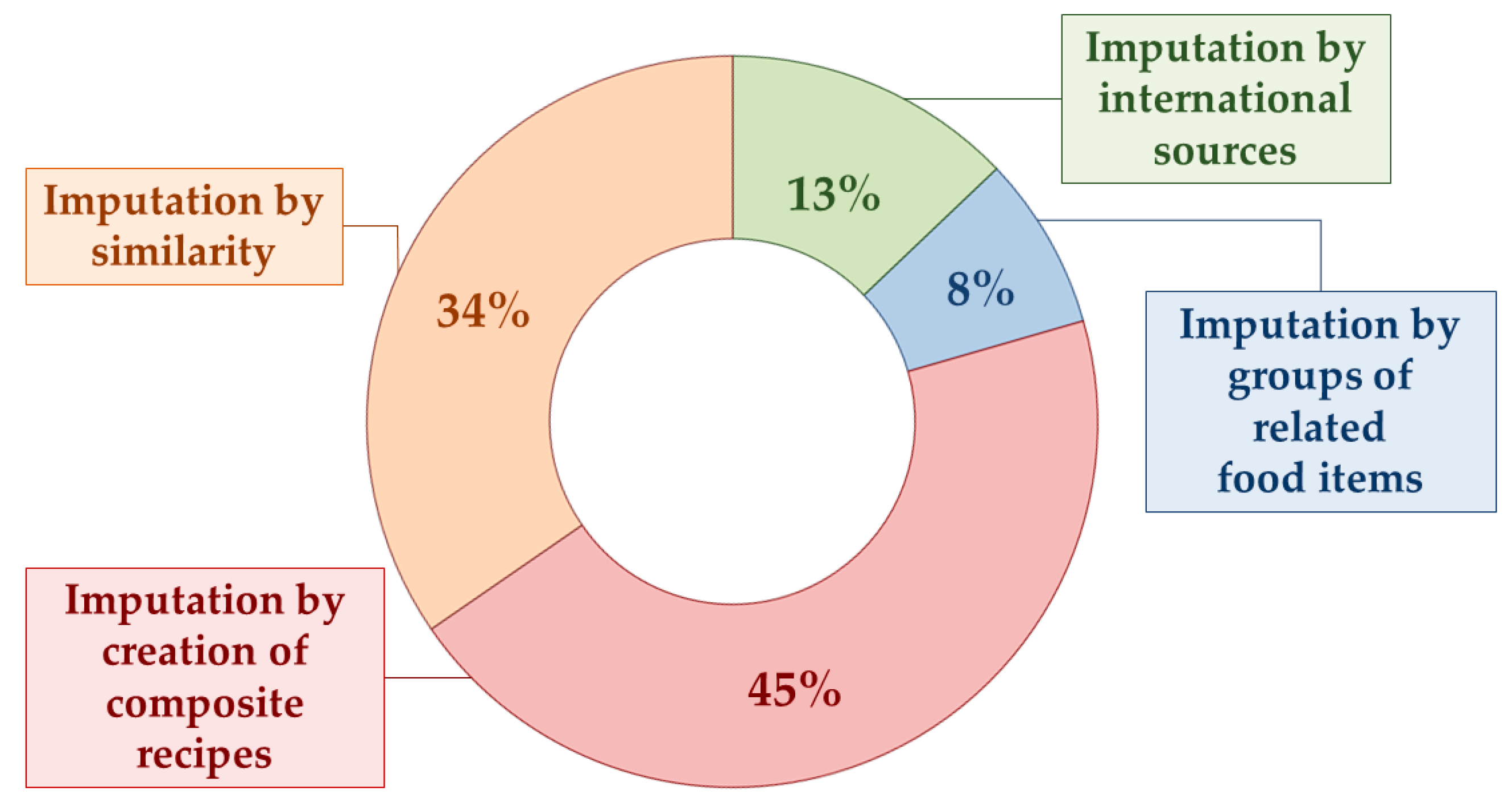
2.4. Missing Values
- Imputation by similar food items: missing values were replaced with other values based on a similar food item (e.g., values for blueberries used for raspberries), or another form of the same food (e.g., values for “boiled” used for “steamed”);
- Imputation by calculation: missing values were imputed by calculation from incomplete or partial analyses of a food (e.g., carbohydrates or fats by difference, or chloride calculated from the value for sodium);
- Imputation by assumption: when the source or origin of the values may be referred to as “assumed” or “presumed” zero (e.g., vitamin B12 in vegetables), missing values were replaced with zero;
- Imputation by recipe calculation: missing values were substituted with values derived from recipes, calculated from the nutrient content of the ingredients and corrected for preparation factors (i.e., yield and retention factors);
- Imputation by borrowed values: when original sources were adequate, missing values were replaced with values taken from other tables and databases, including FCDBs from the USA, UK, Denmark, France, and New Zealand [16,22,23,30,31]. In some cases, the borrowed values were adapted to the different macronutrient content (e.g., calculation based on a reference profile for individual fatty acids, and/or individual soluble carbohydrates, and/or individual amino acids).
2.5. Dish-Level Nutritional Composition
2.6. Statistical Analysis
- Scatterplot of each nutrient’s distributions under the two FCDBs, Pearson correlation coefficients, and hypothesis testing on the correlation coefficients;
- Percentages of agreement on the classification of dishes into quintiles for each nutrient, and Cohen’s kappa (unweighted) coefficient for each nutrient to take into account the possibility of agreement occurring by chance; the cut-offs for quintiles were separately calculated on Nutrition5k and the Italian FCDB; interpretation of Cohen’s kappa results followed stricter criteria used in a recent publication [32]: 0.01–0.39 as none to slight, 0.40–0.59 as weak, 0.60–0.79 as moderate, and 0.80–1.00 as strong to very strong agreement;
- Bland–Altman plot for each nutrient and corresponding 95% limits of agreement;
- (Raw, absolute) differences between nutrients calculated with the Italian and US FCDBs (i.e., nutrients in the Italian FCDB–nutrients in the US FCDB), summary statistics of the difference distributions (minimum, 1st quartile, median, 3rd quartile, mean, standard deviation, and maximum values), kernel density estimation plots of the difference distributions, Kolmogorov–Smirnov normality test on the difference distributions (as the huge number of available dishes prevented us from using the Shapiro–Wilk method), and Wilcoxon signed-rank test for paired data for each nutrient (as the normality assumption was not satisfied for any of the investigated nutrients);
- Differences in absolute values between nutrients calculated with the Italian and US FCDBs, to identify the nutrient-specific top 25 dishes showing the most extreme differences, regardless of the sign.
3. Results
3.1. Data Curation of Dishes and Dish Ingredients in Nutrition5k
3.2. Exact and Indirect Matching between Ingredients in Nutrition5k and Food Items in the Italian FCDB
3.2.1. Indirect Matching: Similarity between Ingredients in Nutrition5k and Food Items in the Italian FCDB
3.2.2. Indirect Matching: Dish Ingredients Present in Nutrition5k Were Missing Food Items in the Italian FCDB
3.2.3. Indirect Matching: Dish Ingredients Present in Nutrition5k Were Too Generic for Matching: Mean Values of the Corresponding Nutrients
3.2.4. Indirect Matching: Single Dish Ingredients in Nutrition5k Were Composite Recipes
3.3. Ingredients Portion: Checks
3.4. Handling of Missing Values
3.5. Distribution of Dish Ingredients by Frequency of Use and Mass
3.6. Distribution of Mass, Energy and Macronutrient Contents across Available Dishes in Nutrition5k after Italian Nutritional Values Were Linked
3.7. Nutrition5k Dataset with Italian versus US Nutritional Values: A Comparison
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Merchant, A.T.; Dehghan, M. Food Composition Database Development for between Country Comparisons. Nutr. J. 2006, 5, 2. [Google Scholar] [CrossRef] [PubMed]
- Slimani, N.; Deharveng, G.; Unwin, I.; Southgate, D.A.T.; Vignat, J.; Skeie, G.; Salvini, S.; Parpinel, M.; Møller, A.; Ireland, J.; et al. The EPIC Nutrient Database Project (ENDB): A First Attempt to Standardize Nutrient Databases across the 10 European Countries Participating in the EPIC Study. Eur. J. Clin. Nutr. 2007, 61, 1037–1056. [Google Scholar] [CrossRef]
- Egan, M.B.; Fragodt, A.; Raats, M.M. The Importance of Harmonising and Sustaining Food Composition Data across Europe. Nutr. Bull. 2006, 31, 349–353. [Google Scholar] [CrossRef]
- Castanheira, I.; André, C.; Oseredczuk, M.; Ireland, J.; Owen, L.; Robb, P.; Earnshaw, A.; Calhau, M.A. Improving Data Quality in Food Composition Databanks: A EuroFIR Contribution. Accredit. Qual. Assur. 2007, 12, 117–125. [Google Scholar] [CrossRef]
- Hinojosa-Nogueira, D.; Pérez-Burillo, S.; Navajas-Porras, B.; Ortiz-Viso, B.; de la Cueva, S.P.; Lauria, F.; Fatouros, A.; Priftis, K.N.; González-Vigil, V.; Rufián-Henares, J.Á. Development of an Unified Food Composition Database for the European Project “Stance4health”. Nutrients 2021, 13, 4206. [Google Scholar] [CrossRef]
- Summer, S.; Ollberding, N.; Guy, T.; Setchell, K.; Brown, N.; Kalkwarf, H. Cross-Border Use of Food Databases: Equivalence of US and Australian Databases for Macronutrients. J. Acad. Nutr. Diet. 2013, 113, 1340–1345. [Google Scholar] [CrossRef] [PubMed]
- Kovalskys, I.; Fisberg, M.; Gómez, G.; Rigotti, A.; Cortés, L.Y.; Yépez, M.C.; Pareja, R.G.; Herrera-Cuenca, M.; Zimberg, I.Z.; Tucker, K.L.; et al. Standardization of the Food Composition Database Used in the Latin American Nutrition and Health Study (Elans). Nutrients 2015, 7, 7914–7924. [Google Scholar] [CrossRef]
- Hakala, P.; Knuts, L.R.; Vuorinen, A.; Hammar, N.; Becker, W. Comparison of Nutrient Intake Data Calculated on the Basis of Two Different Databases. Results and Experiences from a Swedish-Finnish Study. Eur. J. Clin. Nutr. 2003, 57, 1035–1044. [Google Scholar] [CrossRef]
- Willett, W. Nutritional Epidemiology, 3rd ed.; Oxford University Press: New York, NY, USA, 2013; ISBN 9780199754038. [Google Scholar]
- Pala, V.; Sieri, S.; Palli, D.; Salvini, S.; Berrino, F.; Bellegotti, M.; Frasca, G.; Tumino, R.; Sacerdote, C.; Fiorini, L.; et al. Diet in the Italian EPIC Cohorts: Presentation of Data and Methodological Issues. Tumori 2003, 89, 594–607. [Google Scholar] [CrossRef]
- Edefonti, V.; De Vito, R.; Parpinel, M.; Ferraroni, M. Dietary Patterns and Cancer Risk: An Overview with Focus on Methods. N. Engl. J. Stat. Data Sci. 2024, 2, 30–53. [Google Scholar] [CrossRef]
- Zeb, A.; Soininen, J.-P.; Sozer, N. Data Harmonisation as a Key to Enable Digitalisation of the Food Sector: A Review. Food Bioprod. Process. 2021, 127, 360–370. [Google Scholar] [CrossRef]
- Morgenstern, J.D.; Rosella, L.C.; Costa, A.P.; De Souza, R.J.; Anderson, L.N. Perspective: Big Data and Machine Learning Could Help Advance Nutritional Epidemiology. Adv. Nutr. 2021, 12, 621–631. [Google Scholar] [CrossRef] [PubMed]
- Lo, F.P.W.; Sun, Y.; Qiu, J.; Lo, B. Image-Based Food Classification and Volume Estimation for Dietary Assessment: A Review. IEEE J. Biomed. Health Inform. 2020, 24, 1926–1939. [Google Scholar] [CrossRef] [PubMed]
- Thames, Q.; Karpur, A.; Norris, W.; Xia, F.; Panait, L.; Weyand, T.; Sim, J. Nutrition5k: Towards Automatic Nutritional Understanding of Generic Food. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 899–8907. [Google Scholar] [CrossRef]
- U.S. Department of Agriculture, Agricultural Research Service. Available online: https://fdc.nal.usda.gov/ (accessed on 15 July 2024).
- Greenfield, H.; Southgate, D.A. Food Composition Data: Production, Management, and Use, 2nd ed.; Food and Agriculture Organization: Rome, Italy, 2003; ISBN 9251049491. [Google Scholar]
- Drewnowski, A.; Heber, D. Nutrient Composition of Foods: The First Step in Precision Nutrition. In Precision Nutrition, 1st ed.; Academic Press: Cambridge, MA, USA, 2024; Chapter 1; pp. 3–22. [Google Scholar]
- Finglas, P.M.; Berry, R.; Astley, S. Assessing and Improving the Quality of Food Composition Databases for Nutrition and Health Applications in Europe: The Contribution of EuroFIR. Adv. Nutr. 2014, 5, 608S–614S. [Google Scholar] [CrossRef]
- Ispirova, G.; Eftimov, T.; Seljak, B.K. Evaluating Missing Value Imputation Methods for Food Composition Databases. Food Chem. Toxicol. 2020, 141, 111368. [Google Scholar] [CrossRef]
- Gnagnarella, P.; Salvini, S.; Parpinel, M. Food Composition Database for Epidemiological Studies in Italy. Available online: https://bda.ieo.it/ (accessed on 15 July 2024).
- Frida Food Data. National Food Institute, Technical University of Denmark. Available online: https://frida.fooddata.dk (accessed on 15 July 2024).
- Public Health England. Composition of Foods Integrated Dataset (CoFID). Available online: https://www.gov.uk/government/publications/composition-of-foods-integrated-dataset-cofid (accessed on 15 July 2024).
- Salvini, S.; Parpinel, M.; Gnagnarella, P.; Maisonneuve, P.; Turrini, A. Banca Dati Di Composizione Degli Alimenti per Studi Epidemiologici in Italia; Prima Edizione: Toluca, Mexico, 1998; ISBN 889002710X. [Google Scholar]
- Gnagnarella, P.; Parpinel, M.; Salvini, S.; Franceschi, S.; Palli, D.; Boyle, P. The Update of the Italian Food Composition Database. J. Food Compos. Anal. 2004, 17, 509–522. [Google Scholar] [CrossRef]
- FAO/Infoods—Food And Agriculture Organization of the United States/International Network of Food Data Systems. Guidelines for Food Matching; FAO: Rome, Italy, 2012; p. 27. [Google Scholar]
- Turconi, G.; Roggi, C. Atlante Fotografico Alimentare—Uno Strumento per Le Indagini Nutrizionali; Edizioni Medische Scientifiche Internazionali: Rome, Italty, 2007; ISBN 9788886669542. [Google Scholar]
- Il Cucchiaio D’argento. Available online: https://www.cucchiaio.it/ (accessed on 15 July 2024).
- Giallo Zafferano. Available online: https://www.giallozafferano.it/ (accessed on 15 July 2024).
- ANSES. Ciqual French Food Composition Table. Available online: https://ciqual.anses.fr/ (accessed on 15 July 2024).
- New Zealand Food Composition Database Online Search. The New Zealand Institute for Plant & Food Research Limited and Ministry of Health. Available online: https://www.foodcomposition.co.nz/search (accessed on 15 July 2024).
- Puyvelde, H.V.; Perez-cornago, A.; Casagrande, C.; Versele, V.; Skeie, G.; Schulze, M.B.; Johansson, I. Comparing Calculated Nutrient Intakes Using Different Food Composition Databases: Results from the European Prospective Investigation into Cancer and Nutrition (EPIC) Cohort. Nutrients 2020, 12, 2906. [Google Scholar] [CrossRef]
- Yohai, V.J. High Breakdown-Point and High Efficiency Robust Estimates for Regression. Ann. Stat. 1987, 15, 642–656. [Google Scholar] [CrossRef]
- Python Software Foundation. Python Language Reference, Version 3.10. Available online: https://www.python.org (accessed on 15 July 2024).
- R Foundation for Statistical Computing. R: A Language and Environment for Statistical Computing. 2024. Available online: https://www.r-project.org (accessed on 15 July 2024).
- Gamer, M.; Lemon, J. Irr: Various Coefficients of Interrater Reliability and Agreement, R Package Version 0.84.1. 2019. Available online: https://cran.r-project.org/web/packages/irr (accessed on 15 July 2024).
- Lehnert, B. BlandAltmanLeh: Plots (Slightly Extended) Bland-Altman Plots, R Package Version 0.3.1. 2015. Available online: https://cran.r-project.org/web/packages/BlandAltmanLeh (accessed on 15 July 2024).
- Wang, J.; Zamar, R.; Marazzi, A.; Yohai, V.; Al, E. Robust: Port of the S+ “Robust Library”, R Package Version 0.7-4. 2024. Available online: https://cran.r-project.org/web/packages/robust/index.html (accessed on 15 July 2024).
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; ISBN 9781441930088. [Google Scholar]
- Maechler, M. Sfsmisc: Utilities from “Seminar Fuer Statistik” ETH Zurich”. R Package Version 1.1-18. Available online: https://cran.r-project.org/package=sfsmisc (accessed on 15 July 2024).
- Unwin, I.; Jansen-Van Der Vliet, M.; Westenbrink, S.; Presser, K.; Infanger, E.; Porubska, J.; Roe, M.; Finglas, P. Implementing the EuroFIR Document and Data Repositories as Accessible Resources of Food Composition Information. Food Chem. 2016, 193, 90–96. [Google Scholar] [CrossRef]
- Vásquez-Caicedo, A.L.; Bell, S.; Hartman, B. European Food Information Resource Network: Report on Collection of Rules on Use of Recipe Calculation Procedures Including the Use of Yield and Retention Factors for Imputing Nutrient Values for Composite Foods; European Food Information Resource Network: Brussels, Belgium, 2005; Volume 6, pp. 1–185. [Google Scholar]
- Picó, C.; Serra, F.; Rodríguez, A.M.; Keijer, J.; Palou, A. Biomarkers of Nutrition and Health: New Tools for New Approaches. Nutrients 2019, 11, 1092. [Google Scholar] [CrossRef]
- Martínez, C.F.; Esposito, S.; Di Castelnuovo, A.; Costanzo, S.; Ruggiero, E.; De Curtis, A.; Persichillo, M.; Hébert, J.R.; Cerletti, C.; Donati, M.B.; et al. Association between the Inflammatory Potential of the Diet and Biological Aging: A Cross-Sectional Analysis of 4510 Adults from the Moli-Sani Study Cohort. Nutrients 2023, 15, 1503. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mass (g) | Energy (kcal) 1 | Proteins (g) | Fats (g) | Carbohydrates (g) | |
|---|---|---|---|---|---|
| Minimum | 3.0 | 1.1 | 0.0 | 0.0 | 0.0 |
| First quartile | 73.0 | 62.5 | 1.9 | 0.6 | 2.7 |
| Median | 145.0 | 162.7 | 8.0 | 7.0 | 9.2 |
| Third quartile | 257.0 | 324.7 | 21.7 | 17.1 | 20.3 |
| Maximun | 1102.0 | 1488.4 | 133.7 | 130.7 | 117.7 |
| Mean | 182.7 | 220.8 | 14.5 | 11.5 | 14.2 |
| SD | 143.1 | 205.7 | 17.3 | 13.9 | 15.5 |
| Energy (kcal) | Proteins (g) | ||||||||||||
| US FCDB | US FCDB | ||||||||||||
| Italian FCDB | Q1 | Q2 | Q3 | Q4 | Q5 | Italian FCDB | Q1 | Q2 | Q3 | Q4 | Q5 | ||
| Q1 | 18.17 | 1.84 | 0.0 | 0.0 | 0.0 | Q1 | 18.35 | 1.44 | 0.0 | 0.22 | 0.0 | ||
| Q2 | 1.56 | 15.61 | 2.84 | 0.0 | 0.0 | Q2 | 1.66 | 16.15 | 2.22 | 0.02 | 0.0 | ||
| Q3 | 0.28 | 2.26 | 14.13 | 3.30 | 0.02 | Q3 | 0.0 | 2.30 | 15.47 | 2.14 | 0.04 | ||
| Q4 | 0.0 | 0.26 | 2.80 | 13.63 | 3.32 | Q4 | 0.0 | 0.14 | 2.26 | 15.67 | 1.94 | ||
| Q5 | 0.0 | 0.06 | 0.22 | 3.06 | 16.67 | Q5 | 0.0 | 0.0 | 0.02 | 1.96 | 18.03 | ||
| kappa: 0.73 | kappa: 0.80 | ||||||||||||
| Fats (g) | Carbohydrates (g) | ||||||||||||
| US FCDB | US FCDB | ||||||||||||
| Italian FCDB | Q1 | Q2 | Q3 | Q4 | Q5 | Italian FCDB | Q1 | Q2 | Q3 | Q4 | Q5 | ||
| Q1 | 17.81 | 2.20 | 0.0 | 0.0 | 0.0 | Q1 | 16.89 | 3.02 | 0.12 | 0.0 | 0.0 | ||
| Q2 | 2.28 | 13.97 | 3.56 | 0.20 | 0.0 | Q2 | 2.70 | 12.17 | 4.40 | 0.70 | 0.02 | ||
| Q3 | 0.0 | 2.94 | 12.19 | 4.76 | 0.10 | Q3 | 0.20 | 4.50 | 11.07 | 4.00 | 0.22 | ||
| Q4 | 0.0 | 0.64 | 3.76 | 11.15 | 4.46 | Q4 | 0.22 | 0.36 | 4.08 | 11.75 | 3.62 | ||
| Q5 | 0.0 | 0.18 | 0.48 | 3.90 | 15.45 | Q5 | 0.0 | 0.0 | 0.3 | 3.56 | 16.13 | ||
| kappa: 0.63 | kappa: 0.60 | ||||||||||||
| Energy Difference (kcal) | Proteins Difference (g) | Fats Difference (g) | Carbohydrates Difference (g) | |
|---|---|---|---|---|
| Minimum | −279.24 | −25.82 | −34.81 | −52.00 |
| First quartile | −18.08 | −1.46 | −0.73 | −5.08 |
| Median | −0.73 | 0.0 | 0.0 | −2.10 |
| Third quartile | 15.59 | 0.83 | 1.80 | −0.27 |
| Maximun | 754.0 | 24.91 | 91.53 | 62.65 |
| Mean | 3.50 | −0.51 | 0.62 | −2.54 |
| SD | 65.01 | 4.02 | 6.14 | 6.89 |
| Difference of Energy Content (kcal) | Difference of Proteins Content (g) | Difference of Fats Content (g) | Difference of Carbohydrates Content (g) | ||||||||||
| Characteristic | N | Beta | 95% CI | p-Value | Beta | 95% CI | p-Value | Beta | 95% CI | p-Value | Beta | 95% CI | p-Value |
| Intercept | 5004 | −0.48 | −1.15, 0.19 | 0.550 2 | −0.16 | −0.19, −0.12 | <0.001 2 | 0.03 | −0.02, 0.09 | 0.600 2 | −1.50 | −1.59, −1.42 | <0.001 |
| Total mass (25 g increase) | 5004 | 0.02 | −0.06, 0.10 | 0.811 2 | 0.10 | 0.10, 0.11 | <0.001 2 | 0.10 | 0.10, 0.11 | <0.001 2 | −0.37 | −0.38, −0.35 | <0.001 2 |
| Number of ingredients | 5004 | 0.00 | −0.09, 0.08 | 0.969 2 | −0.15 | −0.16, −0.15 | <0.001 2 | −0.04 | −0.04, −0.03 | <0.001 2 | 0.11 | 0.10, 0.12 | <0.001 2 |
| Differential use of raw/cooked ingredients | <0.001 3 | <0.001 3 | <0.001 3 | <0.001 3 | |||||||||
| No difference in ingredients | 1768 | — | — | — | — | — | — | — | — | ||||
| One ingredient difference | 1500 | −2.87 | −3.81, −1.93 | 0.011 2 | 0.13 | 0.08, 0.18 | 0.036 2 | −0.53 | −0.61, −0.46 | <0.001 2 | 0.51 | 0.39, 0.62 | <0.001 2 |
| More ingredients difference | 1736 | −10.87 | −12.17, −9.57 | <0.001 2 | −0.21 | −0.28, −0.13 | 0.020 2 | −1.83 | −1.94, −1.73 | <0.001 2 | 1.54 | 1.38, 1.69 | <0.001 2 |
| Recreated recipes in dish | <0.001 3 | <0.001 3 | <0.001 3 | 0.351 3 | |||||||||
| No | 3661 | — | — | — | — | — | — | — | — | ||||
| Yes | 1343 | −4.06 | −7.89, −0.23 | 0.375 2 | 0.66 | 0.46, 0.85 | 0.005 2 | 0.71 | 0.41, 1.02 | 0.050 2 | 0.52 | 0.17, 0.88 | 0.217 2 |
| Interaction between differential use of raw/cooked ingredients and recreated recipes | 5004 | <0.001 3 | 0. 002 3 | <0.001 3 | 0.252 3 | ||||||||
| One difference: Yes | 399 | 18.99 | 14.85, 23.14 | <0.001 2 | 0.60 | 0.39, 0.81 | 0. 018 2 | 1.04 | 0.71, 1.37 | 0.008 2 | −0.49 | −0.89, −0.09 | 0.304 2 |
| More differences: Yes | 863 | 16.73 | 12.67, 20.79 | 0.001 2 | 0.42 | 0.21, 0.63 | 0.098 2 | 1.88 | 1.56, 2.21 | <0.001 2 | −0.69 | −1.07, −0.30 | 0.136 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bianco, R.; Marinoni, M.; Coluccia, S.; Carioni, G.; Fiori, F.; Gnagnarella, P.; Edefonti, V.; Parpinel, M. Tailoring the Nutritional Composition of Italian Foods to the US Nutrition5k Dataset for Food Image Recognition: Challenges and a Comparative Analysis. Nutrients 2024, 16, 3339. https://doi.org/10.3390/nu16193339
Bianco R, Marinoni M, Coluccia S, Carioni G, Fiori F, Gnagnarella P, Edefonti V, Parpinel M. Tailoring the Nutritional Composition of Italian Foods to the US Nutrition5k Dataset for Food Image Recognition: Challenges and a Comparative Analysis. Nutrients. 2024; 16(19):3339. https://doi.org/10.3390/nu16193339
Chicago/Turabian StyleBianco, Rachele, Michela Marinoni, Sergio Coluccia, Giulia Carioni, Federica Fiori, Patrizia Gnagnarella, Valeria Edefonti, and Maria Parpinel. 2024. "Tailoring the Nutritional Composition of Italian Foods to the US Nutrition5k Dataset for Food Image Recognition: Challenges and a Comparative Analysis" Nutrients 16, no. 19: 3339. https://doi.org/10.3390/nu16193339
APA StyleBianco, R., Marinoni, M., Coluccia, S., Carioni, G., Fiori, F., Gnagnarella, P., Edefonti, V., & Parpinel, M. (2024). Tailoring the Nutritional Composition of Italian Foods to the US Nutrition5k Dataset for Food Image Recognition: Challenges and a Comparative Analysis. Nutrients, 16(19), 3339. https://doi.org/10.3390/nu16193339