
A Siamese Vision Transformer for Bearings Fault Diagnosis


Abstract
:1. Introduction
- (1)
- The proposed SViT based on a Siamese network and ViT obtains satisfactory prediction accuracy in limited data and domain generation tasks.
- (2)
- We obtain a new loss function by combining the KL divergence of the two directions to improve the proposed model’s performance.
- (3)
- A novel training strategy, random mask, focusing on increasing the diversity of input data distribution is designed to enhance the generation ability of the model.
- (4)
- The experimental result shows that the proposed method achieves effective accuracy rates and has satisfactory anti-noise and domain generation ability.
2. Siamese Vision Transformer
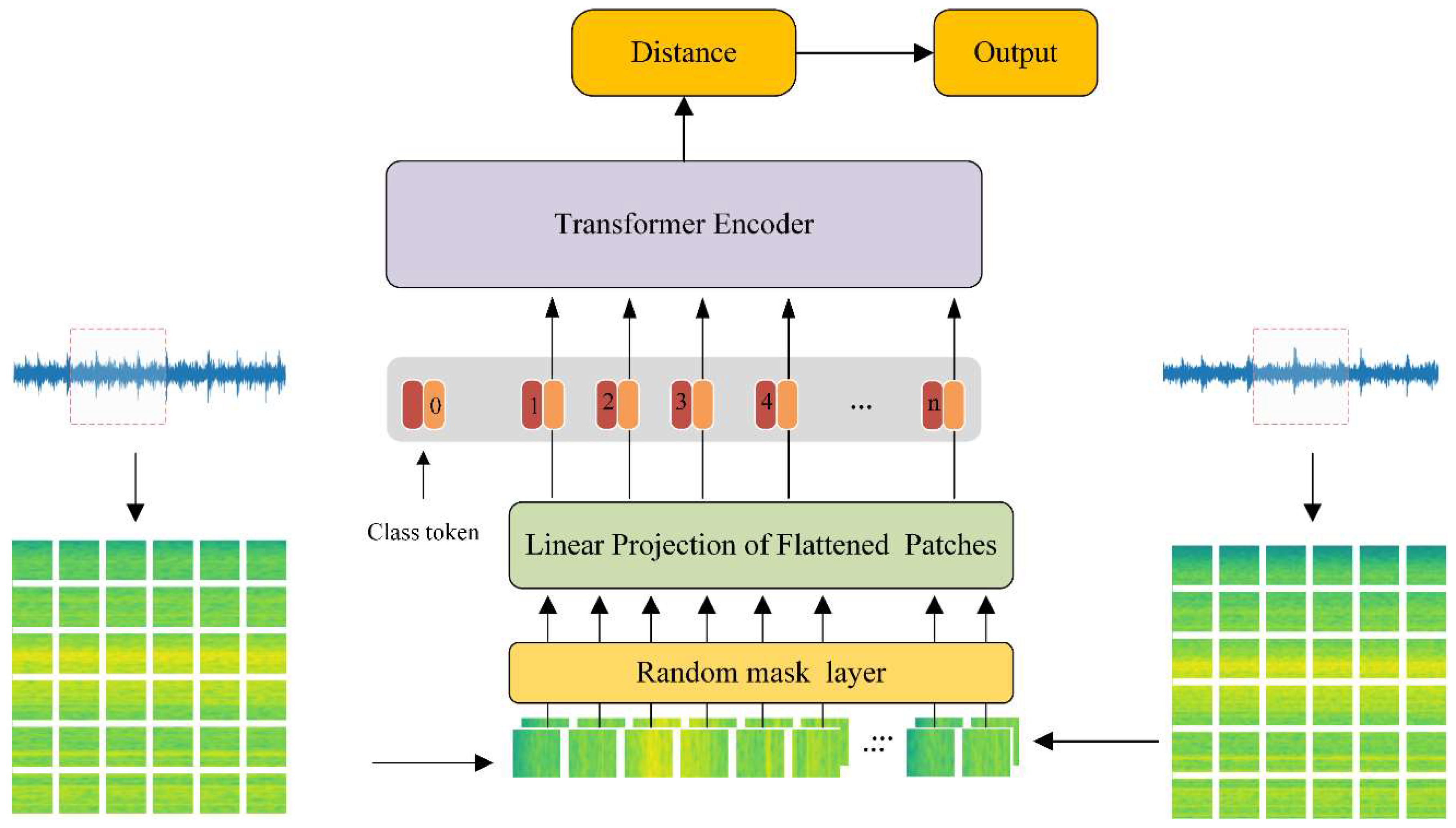
2.1. The Framework of the Proposed Method
2.2. Data Processing
2.3. Siamese Network
2.4. Vision Transformer
2.4.1. Patch Embedding Layer
2.4.2. Transformer Encoder
- MLP layer
- Multiheaded self-attention layer
2.4.3. MLP Head
2.5. Bidirectional KL Divergence
2.6. Random Mask Strategy
3. Experiments, Results and Discussion
3.1. Experimental Setup
3.2. Comparison Models and Evaluation Metric
3.3. Case Study 1: CWRU Bearing Datasets
3.3.1. Evaluating the Effectiveness of DKLD
3.3.2. The Effect of the Number of Transformer Encoder Layers
3.3.3. Ablation Experiments
3.3.4. Comparison of Results with Different Samples Sizes
3.3.5. Performance in Noisy Environment
3.3.6. Domain Generation Experiments
3.4. Case Study 2: Paderborn Dataset
3.4.1. Data Description
3.4.2. Results and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abdelkader, R.; Kaddour, A.; Bendiabdellah, A.; Derouiche, Z. Rolling bearing fault diagnosis based on an improved denoising method using the complete ensemble empirical mode decomposition and the optimized thresholding operation. IEEE Sens. J. 2018, 18, 7166–7172. [Google Scholar] [CrossRef]
- Qiao, M.; Yan, S.; Tang, X.; Xu, C. Deep Convolutional and LSTM Recurrent Neural Networks for Rolling Bearing Fault Diagnosis Under Strong Noises and Variable Loads. IEEE Access 2020, 8, 66257–66269. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S.X. A Survey of Fault Diagnosis and Fault-Tolerant Techniques—Part I: Fault Diagnosis With Model-Based and Signal-Based Approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, S.; Zhou, P.; Zhao, L.; Li, S. Novel prescribed performance-tangent barrier Lyapunov function for neural adaptive control of the chaotic PMSM system by backstepping. Int. J. Electr. Power Energy Syst. 2020, 121, 105991. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Bai, Q.; Li, S.; Yang, J.; Song, Q.; Li, Z.; Zhang, X. Object Detection Recognition and Robot Grasping Based on Machine Learning: A Survey. IEEE Access 2020, 8, 181855–181879. [Google Scholar] [CrossRef]
- Socher, R.; Bengio, Y.; Manning, C.D. Deep learning for NLP (without magic). In Proceedings of the Tutorial Abstracts of ACL 2012, Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-r.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Gao, Z.; Wang, Z.; Liu, W. Real-time recognition method for 0.8 cm darning needles and KR22 bearings based on convolution neural networks and data increase. Appl. Sci. 2018, 8, 1857. [Google Scholar] [CrossRef]
- Tibaduiza, D.; Torres-Arredondo, M.A.; Vitola, J.; Anaya, M.; Pozo, F. A Damage Classification Approach for Structural Health Monitoring Using Machine Learning. Complexity 2018, 2018, 1–14. [Google Scholar] [CrossRef]
- Zhao, K.; Jiang, H.; Li, X.; Wang, R. An optimal deep sparse autoencoder with gated recurrent unit for rolling bearing fault diagnosis. Meas. Sci. Technol. 2020, 31, 015005. [Google Scholar] [CrossRef]
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- He, J.; Ouyang, M.; Yong, C.; Chen, D.; Guo, J.; Zhou, Y. A Novel Intelligent Fault Diagnosis Method for Rolling Bearing Based on Integrated Weight Strategy Features Learning. Sensors 2020, 20, 1774. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.; Wang, Y.; Gu, J. Cross-domain intelligent fault classification of bearings based on tensor-aligned invariant subspace learning and two-dimensional convolutional neural networks. Knowl.-Based Syst. 2020, 209, 106214. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, T.; Jiang, B.; Yang, X. Intelligent bearing fault diagnosis using PCA-DBN framework. Neural Comput. Appl. 2020, 32, 10773–10781. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Zhiyi, H.; Haidong, S.; Lin, J.; Junsheng, C.; Yu, Y. Transfer fault diagnosis of bearing installed in different machines using enhanced deep auto-encoder. Measurement 2020, 152, 107393. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Wang, R.; Feng, Z.; Huang, S.; Fang, X.; Wang, J. Research on Voltage Waveform Fault Detection of Miniature Vibration Motor Based on Improved WP-LSTM. Micromachines 2020, 11, 753. [Google Scholar] [CrossRef]
- Zhang, A.; Li, S.; Cui, Y.; Yang, W.; Dong, R.; Hu, J. Limited Data Rolling Bearing Fault Diagnosis With Few-Shot Learning. IEEE Access 2019, 7, 110895–110904. [Google Scholar] [CrossRef]
- Li, C.; Li, S.; Zhang, A.; He, Q. Meta-Learning for Few-Shot Bearing Fault Diagnosis under Complex Working Conditions. Neurocomputing 2021, 439, 197–211. [Google Scholar] [CrossRef]
- Li, Q.; Tang, B.; Deng, L.; Wu, Y.; Wang, Y. Deep balanced domain adaptation neural networks for fault diagnosis of planetary gearboxes with limited labeled data. Measurement 2020, 156, 107570. [Google Scholar] [CrossRef]
- Hang, Q.; Yang, J.; Xing, L. Diagnosis of Rolling Bearing Based on Classification for High Dimensional Unbalanced Data. IEEE Access 2019, 7, 79159–79172. [Google Scholar] [CrossRef]
- Fu, Q.; Wang, H. A Novel Deep Learning System with Data Augmentation for Machine Fault Diagnosis from Vibration Signals. Appl. Sci. 2020, 10, 5765. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, M.; Xu, Y.; Lu, W.; Yang, J.; Zhang, T. Metric-based meta-learning model for few-shot fault diagnosis under multiple limited data conditions. Mech. Syst. Signal Process. 2021, 155, 107510. [Google Scholar] [CrossRef]
- Lu, S.; Ma, R.; Sirojan, T.; Phung, B.T.; Zhang, D. Lightweight transfer nets and adversarial data augmentation for photovoltaic series arc fault detection with limited fault data. Int. J. Electr. Power Energy Syst. 2021, 130, 107035. [Google Scholar] [CrossRef]
- Duan, L.; Xie, M.; Bai, T.; Wang, J. A new support vector data description method for machinery fault diagnosis with unbalanced datasets. Expert Syst. Appl. 2016, 64, 239–246. [Google Scholar] [CrossRef]
- Huang, N.; Chen, Q.; Cai, G.; Xu, D.; Zhang, L.; Zhao, W. Fault Diagnosis of Bearing in Wind Turbine Gearbox Under Actual Operating Conditions Driven by Limited Data With Noise Labels. IEEE Trans. Instrum. Meas. 2021, 70, 3502510. [Google Scholar] [CrossRef]
- Bai, R.X.; Xu, Q.S.; Meng, Z.; Cao, L.X.; Xing, K.S.; Fan, F.J. Rolling bearing fault diagnosis based on multi-channel convolution neural network and multi-scale clipping fusion data augmentation. Measurement 2021, 184, 109885. [Google Scholar] [CrossRef]
- Zheng, H.; Wang, R.; Yang, Y.; Yin, J.; Li, Y.; Li, Y.; Xu, M. Cross-domain fault diagnosis using knowledge transfer strategy: A review. IEEE Access 2019, 7, 129260–129290. [Google Scholar] [CrossRef]
- Yan, R.; Shen, F.; Sun, C.; Chen, X. Knowledge transfer for rotary machine fault diagnosis. IEEE Sens. J. 2019, 20, 8374–8393. [Google Scholar] [CrossRef]
- Li, J.; Shen, C.; Kong, L.; Wang, D.; Xia, M.; Zhu, Z. A New Adversarial Domain Generalization Network Based on Class Boundary Feature Detection for Bearing Fault Diagnosis. IEEE Trans. Instrum. Meas. 2022, 71, 1–9. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhao, Z.; Zhang, X.; Liu, Y.; Sun, C.; Li, M.; Wang, S.; Chen, X. Conditional adversarial domain generalization with a single discriminator for bearing fault diagnosis. IEEE Trans. Instrum. Meas. 2021, 70, 1–15. [Google Scholar] [CrossRef]
- Wang, H.; Bai, X.; Tan, J.; Yang, J. Deep prototypical networks based domain adaptation for fault diagnosis. J. Intell. Manuf. 2020, 33, 973–983. [Google Scholar] [CrossRef]
- Zheng, H.; Yang, Y.; Yin, J.; Li, Y.; Wang, R.; Xu, M. Deep domain generalization combining a priori diagnosis knowledge toward cross-domain fault diagnosis of rolling bearing. IEEE Trans. Instrum. Meas. 2020, 70, 1–11. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M.; Miao, Q.; Cao, Y. A novel time–frequency Transformer based on self–attention mechanism and its application in fault diagnosis of rolling bearings. Mech. Syst. Signal Process. 2022, 168, 108616. [Google Scholar] [CrossRef]
- Weng, C.; Lu, B.; Yao, J. A One-Dimensional Vision Transformer with Multiscale Convolution Fusion for Bearing Fault Diagnosis. In Proceedings of the 2021 Global Reliability and Prognostics and Health Management (PHM-Nanjing), Nanjing, China, 15–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Tang, X.; Xu, Z.; Wang, Z. A Novel Fault Diagnosis Method of Rolling Bearing Based on Integrated Vision Transformer Model. Sensors 2022, 22, 3878. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a ”siamese” time delay neural network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1993; pp. 737–744. [Google Scholar]
- Chicco, D. Siamese Neural Networks: An Overview. In Artificial Neural Networks. Methods in Molecular Biology; Cartwright, H., Ed.; Springer Protocols; Humana: New York, NY, USA, 2020; Volume 2190, pp. 73–94. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Courier Corporation: North Chelmsford, MA, USA, 1997. [Google Scholar]
- MacKay, D.J.; Mac Kay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- He, Q.; Li, S.; Li, C.; Zhang, J.; Zhang, A.; Zhou, P. A Hybrid Matching Network for Fault Diagnosis under Different Working Conditions with Limited Data. Comput. Intell. Neurosci. 2022, 2022, 3024590. [Google Scholar] [CrossRef]
- Xu, H.; Ding, S.; Zhang, X.; Xiong, H.; Tian, Q. Masked Autoencoders are Robust Data Augmentors. arXiv 2022, arXiv:2206.04846. [Google Scholar]
- Lou, X.; Loparo, K.A. Bearing fault diagnosis based on wavelet transform and fuzzy inference. Mech. Syst. Signal Process. 2004, 18, 1077–1095. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification. In Proceedings of the European Conference of the Prognostics and Health Management Society, Bilbao, Spain, 5–8 July 2016; pp. 05–08. [Google Scholar]
- Qin, Y.; Yao, Q.; Wang, Y.; Mao, Y. Parameter sharing adversarial domain adaptation networks for fault transfer diagnosis of planetary gearboxes. Mech. Syst. Signal Process. 2021, 160, 107936. [Google Scholar] [CrossRef]
- Li, S.; Yang, W.; Zhang, A.; Liu, H.; Huang, J.; Li, C.; Hu, J. A Novel Method of Bearing Fault Diagnosis in Time-Frequency Graphs Using InceptionResnet and Deformable Convolution Networks. IEEE Access 2020, 8, 92743–92753. [Google Scholar] [CrossRef]
- Wu, X.; Zhang, Y.; Cheng, C.; Peng, Z. A hybrid classification autoencoder for semi-supervised fault diagnosis in rotating machinery. Mech. Syst. Signal Process. 2021, 149, 107327. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A New Deep Learning Model for Fault Diagnosis with Good Anti-Noise and Domain Adaptation Ability on Raw Vibration Signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NO. | Layer Type | Input Size | Output Size |
|---|---|---|---|
| Size/Stride | (Width × Depth) | ||
| 1 | Input | / | 64 × 64 × 1 |
| 2 | Patch layer | 64 × 64 × 1 | 8 × 8 × 64 |
| 3 | Patch Flatten | 8 × 8 × 64 | 64 × 64 |
| 4 | Fully-connected | 64 × 64 | 32 × 64 |
| 5 | Class torken &position endoer | 32 × 64 | 32 × 65 |
| 6 | Transformer Encoder | 32 × 65 | 32 × 65 |
| 7 | Transformer Encoder | 32 × 65 | 32 × 65 |
| 8 | Fully-connected | 32 × 1 | 1 |
| Cross-Entropy | DKLD | |
|---|---|---|
| Equation | ||
| Gradient |
| Input Type | Method Name | Implementation Details |
|---|---|---|
| Time-based | WDCNN | Details referred to [55]. |
| Siamese CNN | Details referred to [21]. | |
| PSDAN | Implementation details referred to [52]. | |
| FSM3 | Details referred to [26]. | |
| Time-Frequency | DeIN | Details referred to [53]. |
| HCAE | Implementation details referred to [54] | |
| SViT (our) | As shown in Table 1. |
| Layers | WDCNN (Kernel Size/Stride) | Siamese CNN (Kernel Size/Stride) | PSDAN (Kernel Size/Stride) | FSM3 (Kernel Size/Stride) | DeIN (Kernel Size/Stride) | HCAE (Kernel Size/Stride) |
|---|---|---|---|---|---|---|
| 1 | Convolution (64 × 16/16) | Convolution (64 × 16/16) | Convolution (128 × 32/1) | Convolution (64 × 1/16) | Convolution (2 × 2 × 64/2) | Convolution (3 × 3 × 16/2) |
| 2 | Pooling (2 × 16/2) | Pooling (2 × 16/2) | Pooling (4 × 32/4) | Pooling (2 × 1/2) | Offset_low (3 × 3) | Convolution (3 × 3 × 32/2) |
| 3 | Convolution (3 × 32/1) | Convolution (3 × 32/1) | Convolution (32 × 64/1) | Convolution (3 × 1/1) | Inception_Resnet 16 | Convolution (3 × 3 × 32/2) |
| 4 | Pooling (2 × 32/1) | Pooling (2 × 32/1) | Pooling (4 × 64/4) | Pooling (2 × 1/2) | Reduction | Convolution (3 × 3 × 32/2) |
| 5 | Convolution (3 × 64/1) | Convolution (3 × 64/1) | Convolution (8 × 128/1) | Convolution (3 × 1/1) | Offset_pooling (3 × 3) | Flatten layer |
| 6 | Pooling (2 × 64/2) | Pooling (2 × 64/2) | Pooling (4 × 128/4) | Pooling (2 × 1/2) | Pooling (3 × 3/1) | Fully-connected (512 × 64) |
| 7 | Convolution (3 × 64/1) | Convolution (3 × 64/1) | Convolution (3 × 128/1) | Convolution (3 × 1/1) | Convolution (1 × 1/1) | Fully-connected (64 × 32) |
| 8 | Pooling (2×64/2) | Pooling (2×64/2) | Pooling (4 × 128/4) | Pooling (2 × 1/2) | Dropout | Classifier (fully-connectied-Softmax) (32 × 10) |
| 9 | Convolution (3 × 64/1) | Convolution (3 × 64/1) | Convolution (3 × 128/1) | Convolution (3 × 1/1) | Offset_top (3 × 3) | Transposed convolution (3 × 3 × 32/2) |
| 10 | Pooling (2 × 64/2) | Pooling (2 × 64/2) | Pooling (4 × 128/4) | Flatten | GlobalMax_Pooling | Transposed convolution (3 × 3 × 32/2) |
| 11 | Flatten-layer | Flatten-layer | Flatten-layer | Fully Connected | Softmax | Transposed convolution (3 × 3 × 32/2) |
| 12 | Fully-connected (192 × 100) | Fully-connected (192 × 100) | Fully-Connected (512 × 256) | Convolution (3 × 1/1) | Inception-resnet8 | Transposed convolution (3 × 3 × 16/2) |
| 13 | Fully-connected (100 × 10) | Distance layer | Fully-Connected (256 × 128) | Convolution (3 × 1/1) | Reduction | Reconstruction |
| 14 | - | Fully-connected (100 × 1) | Fully-Connected (128 × 10) (128 × 2) | Flatten | Inception-resnet4 | - |
| 15 | - | - | _ | Fully Connected | Dropout | - |
| 16 | - | - | _ | - | Convolution (2 × 2/1) | - |
| 17 | - | - | _ | Offset_top | - | |
| 18 | - | - | _ | Pooling | - | |
| 19 | - | - | _ | softmax | - |
| Fault Location | None | Ball | Inner Race | Outer Race | Load | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fault Diameter (inch) | 0 | 0.007 | 0.014 | 0.021 | 0.007 | 0.014 | 0.021 | 0.007 | 0.014 | 0.021 | ||
| Class Labels | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| Dataset A | Train | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 1 |
| Test | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | ||
| Dataset B | Train | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 2 |
| Test | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | ||
| Dataset C | Train | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 60 0 | 3 |
| Test | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | ||
| Datasets | Load/HP | Rotational Speed/rpm | Damage Size/10−3 in. |
|---|---|---|---|
| A | 1 | 1772 | 7, 14, 21 |
| B | 2 | 1750 | 7, 14, 21 |
| C | 3 | 1730 | 7, 14, 21 |
| Methods | A-B | A-C | B-A | B-C | C-A | C-B | Average |
|---|---|---|---|---|---|---|---|
| SViT | 97.35 | 93.64 | 95.42 | 97.76 | 88.75 | 93.31 | 94.37 |
| (w/o) Random mask | 94.89 | 87.26 | 85.67 | 90.14 | 87.64 | 82.75 | 88.06 |
| (w/o) Siamese network | 95.13 | 91.73 | 92.11 | 95.82 | 86.46 | 92.15 | 92.23 |
| (w/o) Random mask &Siamese network | 92.01 | 82.41 | 81.43 | 87.21 | 78.82 | 80.21 | 83.68 |
| Methods | A-B | A-C | B-A | B-C | C-A | C-B | Average |
|---|---|---|---|---|---|---|---|
| WDCNN | 97.08 | 91.48 | 93.00 | 91.80 | 78.84 | 85.88 | 89.68 |
| Siamese CNN | 99.24 | 90.40 | 88.28 | 90.12 | 60.36 | 65.36 | 82.29 |
| PSADAN | 98.10 | 92.67 | 90.67 | 90.86 | 79.38 | 92.37 | 90.68 |
| FSM3 | 98.14 | 91.54 | 93.54 | 97.36 | 89.44 | 96.24 | 94.38 |
| DeIN | 93.14 | 70.76 | 76.33 | 83.17 | 79.68 | 76.56 | 79.94 |
| HCAE | 98.67 | 82.67 | 89.37 | 90.37 | 80.67 | 76.34 | 86.35 |
| SViT (our) | 99.54 | 93.82 | 94.24 | 99.85 | 92.24 | 98.78 | 96.41 |
| Class 1 | Class 2 | Class 3 | Class 4 | Class 5 | Class 6 | Class 7 | Class 8 | Class 9 | Class 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| WDCNN | 76.67 | 78.60 | 79.17 | 79.47 | 77.67 | 79.41 | 79.93 | 76.49 | 81.27 | 80.13 |
| Siamese CNN | 58.30 | 58.53 | 58.79 | 61.97 | 58.78 | 64.67 | 63.10 | 59.08 | 59.94 | 60.54 |
| PSADAN | 75.96 | 83.21 | 80.20 | 79.00 | 79.47 | 81.46 | 77.05 | 80.07 | 78.71 | 79.34 |
| FSM3 | 88.16 | 91.90 | 92.39 | 92.18 | 86.82 | 87.42 | 89.84 | 88.45 | 89.93 | 88.06 |
| DeIN | 79.04 | 81.63 | 80.20 | 77.53 | 81.51 | 77.78 | 81.31 | 80.00 | 79.80 | 78.55 |
| HCAE | 78.21 | 82.56 | 79.19 | 80.67 | 82.23 | 78.48 | 85.32 | 82.90 | 78.07 | 79.80 |
| SViT (our) | 91.30 | 92.47 | 93.40 | 93.16 | 93.46 | 91.45 | 93.29 | 90.20 | 93.96 | 90.07 |
| Class 1 | Class 2 | Class 3 | Class 4 | Class 5 | Class 6 | Class 7 | Class 8 | Class 9 | Class 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| WDCNN | 76.67 | 78.33 | 82.33 | 80.00 | 77.67 | 81.00 | 79.67 | 77.00 | 76.67 | 79.33 |
| Siamese CNN | 55.00 | 58.33 | 61.33 | 63.00 | 58.00 | 64.67 | 61.00 | 59.67 | 62.33 | 60.33 |
| PSADAN | 79.00 | 77.67 | 78.33 | 79.00 | 80.00 | 82.00 | 78.33 | 77.67 | 81.33 | 80.67 |
| FSM3 | 89.33 | 87.00 | 89.00 | 90.33 | 90.00 | 88.00 | 91.33 | 89.33 | 89.33 | 91.00 |
| DeIN | 76.67 | 80.00 | 78.33 | 81.67 | 79.33 | 79.33 | 78.33 | 80.00 | 80.33 | 83.00 |
| HCAE | 81.33 | 77.33 | 78.67 | 80.67 | 78.67 | 82.67 | 83.33 | 85.67 | 78.33 | 80.33 |
| SViT (our) | 91.00 | 90.00 | 89.67 | 95.33 | 95.33 | 92.67 | 92.67 | 92.00 | 93.33 | 90.67 |
| Class 1 | Class 2 | Class 3 | Class 4 | Class 5 | Class 6 | Class 7 | Class 8 | Class 9 | Class 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| WDCNN | 76.67 | 78.46 | 80.72 | 79.73 | 77.67 | 80.20 | 79.80 | 76.74 | 78.90 | 79.73 |
| Siamese CNN | 56.60 | 58.43 | 60.03 | 62.48 | 58.39 | 64.67 | 62.03 | 59.37 | 61.11 | 60.43 |
| PSADAN | 77.45 | 80.34 | 79.26 | 79.00 | 79.73 | 81.73 | 77.69 | 78.85 | 80.00 | 80.00 |
| FSM3 | 88.74 | 89.38 | 90.66 | 91.25 | 88.38 | 87.71 | 90.58 | 88.89 | 89.63 | 89.51 |
| DeIN | 77.83 | 80.81 | 79.26 | 79.55 | 80.41 | 78.55 | 79.80 | 80.00 | 80.07 | 80.71 |
| HCAE | 79.74 | 79.86 | 78.93 | 80.67 | 80.41 | 80.52 | 84.32 | 84.26 | 78.20 | 80.07 |
| SViT (our) | 91.15 | 91.22 | 91.50 | 94.23 | 94.39 | 92.05 | 92.98 | 91.09 | 93.65 | 90.37 |
| Datasets | Rotational [rpm] | Load Torque [Nm] | Radial Force [N] | Name of Setting |
|---|---|---|---|---|
| D | 1500 | 0.7 | 1000 | N15_M07_F10 |
| E | 1500 | 0.1 | 1000 | N15_M01_F10 |
| F | 1500 | 0.7 | 400 | N15_M07 _F04 |
| Fault Location | None | Out Race | Inner Race |
|---|---|---|---|
| File NO. | K001 K002 | Artificial (KA01) | Artificial (KI01) |
| Real damages (KA04) | Real damages (KI14) |
| Dates Sets | Splitting | None (Class 1) | Inner Race (Class 2) | Out Race (Class 3) |
|---|---|---|---|---|
| D | Training | 600 | 600 | 600 |
| Testing | 40 | 40 | 40 | |
| E | Training | 600 | 600 | 600 |
| Testing | 40 | 40 | 40 | |
| F | Training | 600 | 600 | 600 |
| Testing | 40 | 40 | 40 |
| Methods | D-E | D-F | E-D | E-F | F-D | F-E | Average |
|---|---|---|---|---|---|---|---|
| WDCNN | 90.13 | 97.5 | 94.99 | 93.33 | 95.83 | 91.16 | 93.82 |
| Siamese CNN | 88.98 | 95.83 | 95.83 | 92.5 | 96.13 | 88.19 | 92.91 |
| PSADAN | 94.26 | 92.82 | 97.42 | 95.33 | 96.01 | 90.24 | 94.35 |
| FSM3 | 97.57 | 98.04 | 99.45 | 99.14 | 96.89 | 94.68 | 97.62 |
| DeIN | 90.53 | 98.12 | 91.77 | 89.82 | 98.24 | 94.55 | 93.84 |
| HCAE | 95.67 | 96.84 | 99.67 | 96.26 | 95.76 | 93.67 | 96.31 |
| SViT (our) | 98.03 | 98.06 | 99.83 | 99.33 | 97.06 | 96.34 | 98.11 |
| Class 1 | Class 2 | Class 3 | |
|---|---|---|---|
| WDCNN | 78.64 | 79.73 | 78.31 |
| Siamese CNN | 59.21 | 61.02 | 61.03 |
| PSADAN | 81.51 | 76.66 | 80.10 |
| FSM3 | 89.68 | 89.86 | 88.80 |
| DeIN | 80.30 | 79.03 | 79.83 |
| HCAE | 80.64 | 81.15 | 80.39 |
| SViT (our) | 92.84 | 92.36 | 91.65 |
| Class 1 | Class 2 | Class 3 | |
|---|---|---|---|
| WDCNN | 79.17 | 78.67 | 78.83 |
| Siamese CNN | 62.17 | 57.67 | 61.33 |
| PSADAN | 80.83 | 78.83 | 78.50 |
| FSM3 | 89.83 | 88.67 | 89.83 |
| DeIN | 80.17 | 79.17 | 79.83 |
| HCAE | 79.83 | 79.67 | 82.67 |
| SViT (our) | 90.83 | 92.67 | 93.33 |
| Class 1 | Class 2 | Class 3 | |
|---|---|---|---|
| WDCNN | 78.90 | 79.19 | 78.57 |
| Siamese CNN | 60.65 | 59.30 | 61.18 |
| PSADAN | 81.17 | 77.73 | 79.29 |
| FSM3 | 89.76 | 89.26 | 89.31 |
| DeIN | 80.23 | 79.10 | 79.83 |
| HCAE | 80.23 | 80.40 | 81.51 |
| SViT (our) | 91.83 | 92.51 | 92.49 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Q.; Li, S.; Bai, Q.; Zhang, A.; Yang, J.; Shen, M. A Siamese Vision Transformer for Bearings Fault Diagnosis. Micromachines 2022, 13, 1656. https://doi.org/10.3390/mi13101656
He Q, Li S, Bai Q, Zhang A, Yang J, Shen M. A Siamese Vision Transformer for Bearings Fault Diagnosis. Micromachines. 2022; 13(10):1656. https://doi.org/10.3390/mi13101656
Chicago/Turabian StyleHe, Qiuchen, Shaobo Li, Qiang Bai, Ansi Zhang, Jing Yang, and Mingming Shen. 2022. "A Siamese Vision Transformer for Bearings Fault Diagnosis" Micromachines 13, no. 10: 1656. https://doi.org/10.3390/mi13101656