
Architecture of Computing System based on Chiplet

 ,
,  ,
, 
Abstract
:1. Introduction
2. Computing Architecture Based on Chiplet
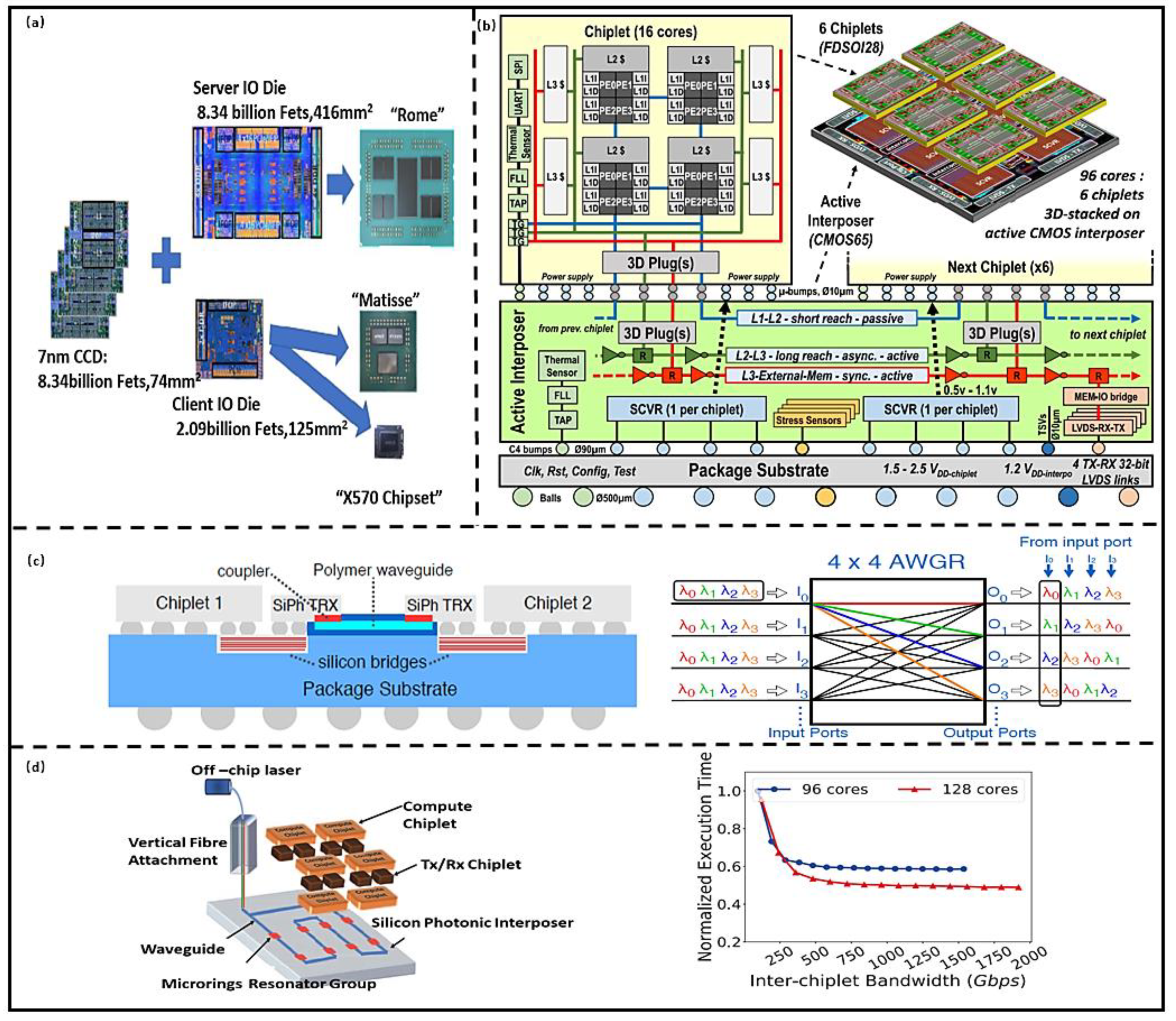
2.1. Computing Architecture Integrated with 2.5D Technology
2.2. Computing Architecture Integrated with 3D Technology
2.3. Summary
3. Memory Architecture Based on Chiplet
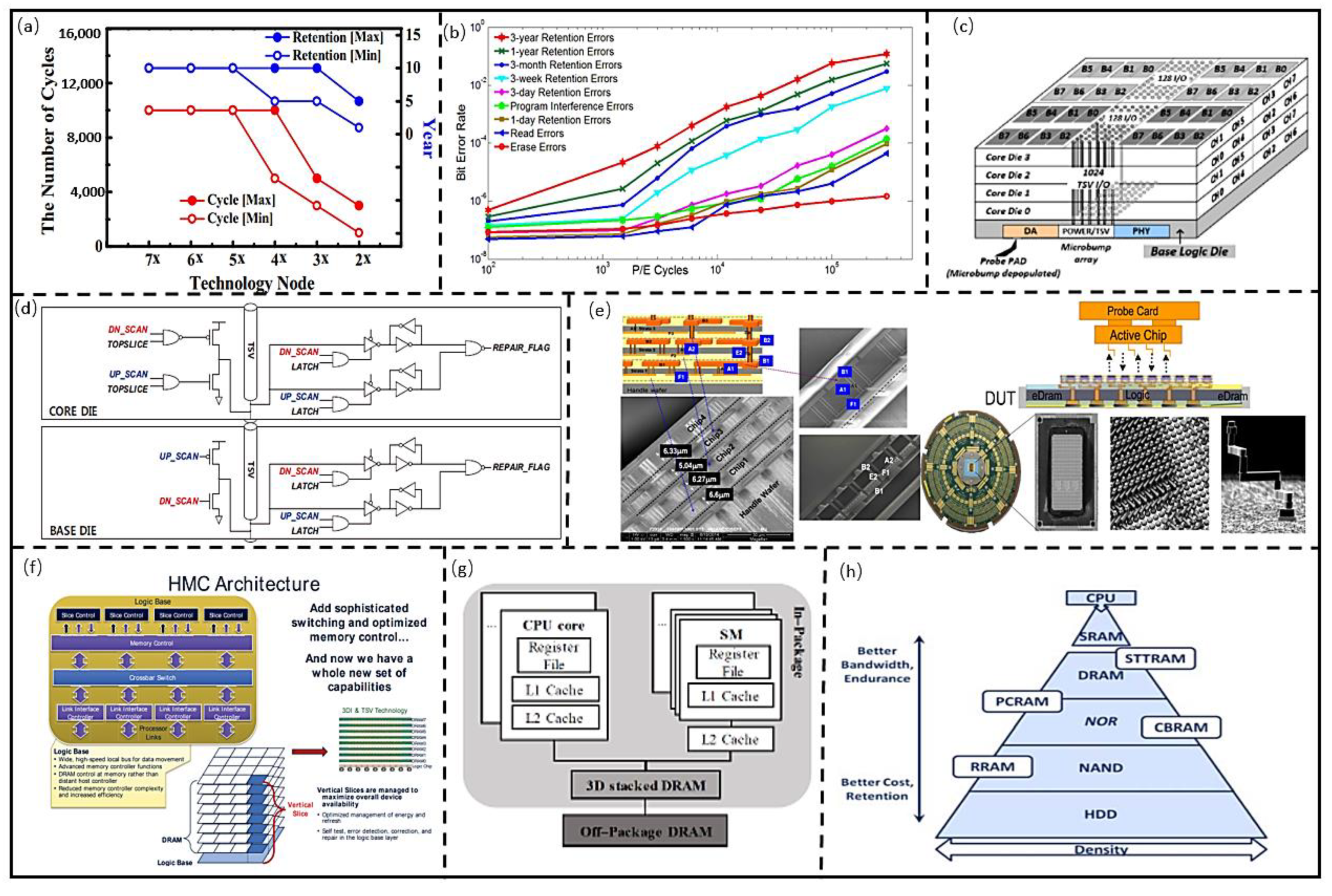
3.1. Memory Architecture for Storing Data
3.2. Memory Architecture for Processing Data
3.2.1. PIM Architectures Based on Mainstream Memory
3.2.2. PIM Architectures Based on Emerging Nonvolatile Memory
3.3. Summary
4. Conclusions and Perspectives
- (1)
- Advanced integration technology. The Chiplet-based 2.5D and 3D integration technologies will be widely used in high-performance computing systems. The AI-based optimization layout technology for Chiplet can not only improve the integration density but also enhance the thermal routing capability of computing systems.
- (2)
- Standardized interconnection protocols. The standardized interconnection protocols can achieve the normalization and modularization of Chiplet in computing systems, which can decrease the research and development cycle and cost for Chiplet-based computing systems.
- (3)
- Scalable and reconfigurable architecture design technology. The scalable and reconfigurable technology can effectively improve the utilization efficiency of Chiplet, and then improve the utilization range of computing systems, which can also decrease the research and development cycle and cost.
Author Contributions
Funding
Conflicts of Interest
References
- Mosquera-Lopez, C.; Agaian, S.; Velez-Hoyos, A.; Thompson, I. Computer-Aided Prostate Cancer Diagnosis From Digitized His topathology: A Review on Texture-Based Systems. IEEE Rev. Biomed. Eng. 2015, 8, 98–113. [Google Scholar] [CrossRef] [PubMed]
- Traub, M.; Maier, A.; Barbehön, K.L. Future Automotive Architecture and the Impact of IT Trends. IEEE Softw. 2017, 34, 27–32. [Google Scholar] [CrossRef]
- Okeme, P.A.; Skakun, A.D.; Muzalevskii, R.A. Transformation of Factory to Smart Factory; IEEE ElConRus: Moscow, Russia, 2021; pp. 1499–1503. [Google Scholar]
- Design and Visualization. Available online: https://www.nvidia.cn/design-visualization/solutions/engineering-simulation/ (accessed on 26 November 2021).
- The Tick-Tock Model Through the Years. Available online: https://www.intel.com/content/www/us/en/silicon-innovations/intel-tick-tock-model-general.html (accessed on 26 November 2021).
- Nothing Stacks up to EPYC. Available online: https://www.amd.com/zh-hans (accessed on 26 November 2021).
- Vangal, S.; Paul, S.; Hsu, S.; Agarwal, A.; Kumar, S.; Krishnamurthy, R.; Krishnamurthy, H.; Tschanz, J.; De, V.; Kim, C.H. Wide-Range Many-Core SoC Design in Scaled CMOS: Challenges and Opportunities. IEEE Trans. VLSI Syst. 2021, 29, 843–856. [Google Scholar] [CrossRef]
- IEEE Electronics Packaging Society. Available online: https://eps.ieee.org/technology/heterogeneous-integration-roadmap/2019-edition.html (accessed on 26 November 2021).
- Naffziger, S.; Lepak, K.; Paraschou, M.; Subramony, M. 2.2 AMD Chiplet Architecture for High-Performance Server and Desktop Products. In Proceedings of the IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 16–20 February 2020; pp. 44–45. [Google Scholar]
- Moore, S.K. Chiplets are the future of processors: Three advances boost performance, cut costs, and save powe. IEEE Spectr. 2020, 55, 11–12. [Google Scholar] [CrossRef]
- Stow, D.; Xie, Y.; Siddiqua, T.; Loh, G.H. Cost-effective design of scalable high-performance systems using active and passive interposers. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 13–16 November 2017; pp. 728–735. [Google Scholar]
- Schulte, M.J.; Ignatowski, M.; Loh, G.H. Achieving Exascale Capabilities through Heterogeneous Computing. IEEE Micro 2015, 35, 26–36. [Google Scholar] [CrossRef]
- Esmaeilzadeh, H.; Blem, E.; Amant, R.S.; Sankaralingam, K.; Burger, D. Dark Silicon and the End of Multicore Scaling. In Proceedings of the 38th International Symposium on Computer Architecture (ISCA), San Jose, CA, USA, 4–8 June 2011; IEEE: Washington, DC, USA; pp. 365–376. [Google Scholar]
- Pal, S.; Petrisko, D.; Kumar, R.; Gupta, P. Design Space Exploration for Chiplet-Assembly-Based Processors. IEEE Trans. VLSI Syst. 2020, 8, 1062–1073. [Google Scholar] [CrossRef]
- Matsumoto, Y.; Morimoto, T.; Hagimoto, M.; Uchida, H.; Hikichi, N.; Imura, F.; Nakagawa, H.; Aoyagi, M. Cool System scalable 3-D stacked heterogeneous Multi-Core / Multi-Chip ar chitecture for ultra low-power digital TV applications. In Proceedings of the IEEE COOL Chips XV, Yokohama, Japan, 18–20 August 2012; pp. 1–3. [Google Scholar]
- Lau, J.H. Semiconductor Advanced Packaging; Springer: Berlin, Germany, 2021; pp. 414–415. [Google Scholar]
- Nurvitadhi, E.; Kwon, D.; Jafari, A.; Boutros, A.; Sim, J.; Tomson, P.; Sumbul, H.; Chen, C.; Knag, P.; Kumar, R.; et al. Why Compete When You Can Work Together: FPGA-ASIC Integration for Persistent RNNs. In Proceedings of the IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019; pp. 199–207. [Google Scholar]
- Microprocessor Report. Available online: https://www.linleygroup.com/mpr/archive.php?j=MPR&year=2015 (accessed on 26 November 2021).
- Arunkumar, A.; Bolotin, E.; Cho, B.; Milic, U.; Ebrahimi, E.; Villa, O.; Jaleel, A.; Jean, C.J.; Nellans, D. MCM-GPU: Multi-chip-module GPUs for continued performance scalability. In Proceedings of the ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017; pp. 320–332. [Google Scholar]
- Mounce, G.; Lyke, J.; Horan, S.; Powell, W.; Doyle, R.; Some, R. Chiplet based approach for heterogeneous processing and packaging architectures. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 5–12 April 2016; pp. 1–12. [Google Scholar]
- Vijayaraghavan, T.; Eckert, Y.; Loh, G.H.; Schulte, M.J.; Ignatowski, M.; Beckmann, B.M.; Brantley, W.C.; Greathouse, J.L.; Huang, W.; Karunanithi, A.; et al. Design and Analysis of an APU for Exascale Computing. In Proceedings of the IEEE International Symposium on High Performance Computer Architecture (HPCA), Austin, TX, USA, 4–8 February 2017; pp. 85–96. [Google Scholar]
- Lin, M.-S.; Huang, T.-C.; Tsai, C.-C.; Tam, K.-H.; Hsieh, K.C.-H.; Chen, C.-F.; Huang, W.-H.; Hu, C.-W.; Chen, Y.-C.; Goel, S.K.; et al. A 7-nm 4-GHz Arm¹-Core-Based CoWoS¹ Chiplet Design for High-Performance Computing. IEEE. J. Solid-State Circuits 2020, 55, 956–966. [Google Scholar] [CrossRef]
- Chun, S.R.; Kuo, T.H.; Tsai, H.Y.; Liu, C.-S.; Wang, C.-T.; Hsieh, J.-S.; Lin, T.-S.; Ku, T.; Yu, D. InFO_SoW (System-on-Wafer) for High Performance Computing. In Proceedings of the 2020 IEEE 70th Electronic Components and Technology Conference (ECTC), Orlando, FL, USA, 3–30 June 2020; pp. 1–6. [Google Scholar]
- Ganusov, K.; Iyer, M.A.; Cheng, N.; Meisler, A. Agilex™ Generation of Intel® FPGAs. In Proceedings of the 2020 IEEE Hot Chips 32 Symposium (HCS), Palo Alto, CA, USA, 16–18 August 2020; pp. 1–26. [Google Scholar]
- Keser, B.; Kroehnert, S. Embedded Multi-die Interconnect Bridge. In Advances in Embedded and Fan-Out Wafer Level Packaging Technologies; Keser, B., Kroehnert, S., Eds.; Wiley-IEEE Press: Chandler, AZ, USA, 2019; Volume 23, pp. 487–499. [Google Scholar]
- Zaruba, F.; Schuiki, F.; Benini, L. A 4096-core RISC-V Chiplet Architecture for Ultra-efficient Floating-point Computing. In Proceedings of the IEEE Hot Chips 32 Symposium (HCS), Palo Alto, CA, USA, 16–18 August 2020; pp. 1–24. [Google Scholar]
- Kadomoto, J.; Irie, H.; Sakai, S. A RISC-V Processor with an Inter-Chiplet Wireless Communication Interface for Shape-Changeable Computers. In Proceedings of the IEEE Symposium in Low-Power and High-Speed Chips (COOL CHIPS), Kokubunji, Japan, 15–17 April 2020; pp. 1–3. [Google Scholar]
- Burd, T.; Beck, N.; White, S.; Paraschou, M.; Naffziger, S. Zeppelin: An SoC for multichip architectures. IEEE J. Solid-State Circuits 2019, 54, 40–42. [Google Scholar] [CrossRef]
- Coudrain, P.; Charbonnier, J.; Garnier, A.; Vivet, P.; Vélard, R.; Vinci, A.; Ponthenier, F.; Farcy, A.; Segaud, R.; Chausse, P.; et al. Active Interposer Technology for Chiplet-Based Advanced 3D System Architectures. In Proceedings of the 2019 IEEE 69th Electronic Components and Technology Conference (ECTC), Las Vegas, NV, USA, 28–31 May 2019; pp. 569–578. [Google Scholar]
- Vivet, P.; Guthmuller, E.; Thonnart, Y.; Pillonnet, G.; Fuguet, C.; Miro-Panades, I.; Moritz, G.; Durupt, J.; Bernard, C.; Varreau, D.; et al. IntAct: A 96-Core Processor With Six Chiplets 3D-Stacked on an Active Interposer With Distributed Interconnects and Integrated Power Management. IEEE. J. Solid-State Circuits 2021, 56, 79–97. [Google Scholar] [CrossRef]
- Gomes, W.; Khushu, S.; Ingerly, D.B.; Stover, P.N.; Chowdhury, N.I.; O’Mahony, F.; Balankutty, A.; Dolev, N.; Dixon, M.G.; Jiang, L.; et al. 8.1 Lakefield and Mobility Compute: A 3D Stacked 10 nm and 22FFL Hybrid Processor System in 12 × 12 mm2, 1 mm Package-On-Package. In Proceedings of the IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Ingerly, D.B.; Enamul, K.; Gomes, W.; Jones, D.; Kolluru, K.C.; Kandas, A.; Kim, G.-S.; Ma, H.; Pantuso, D.; Petersburg, C.; et al. Foveros: 3D Integration and the use of Face-to-Face Chip Stacking for Logic Devices. In Proceedings of the IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 7–11 December 2019; pp. 19.6.1–19.6.4. [Google Scholar]
- Fotouhi, P.; Werner, S.; Lowe-Power, J.; Yoo, S.J.B. Enabling scalable chiplet-based uniform memory architectures with silicon photonics. In Proceedings of the International Symposium on Memory Systems (MEMSYS ‘19), New York, NY, USA, 30 September–3 October 2019. [Google Scholar]
- Narayan, A.; Thonnart, Y.; Vivet, P.; Joshi, A.; Coskun, A.K. System-level Evaluation of Chip-Scale Silicon Photonic Networks for Emerging Data-Intensive Applications. 2020 Design. In Proceedings of the Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020. [Google Scholar]
- Ausavarungnirun, R.; Chang, K.K.; Subramanian, L.; Loh, G.H.; Mutlu, O. Staged memory scheduling: Achieving high performance and scalability in heterogeneous systems. In Proceedings of the 39th Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 9–13 June 2012; pp. 416–427. [Google Scholar]
- Mutlu, O.; Moscibroda, T. Stall-Time Fair Memory Access Scheduling for Chip Multiprocessors. In Proceedings of the 40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 2007), Chicago, IL, USA, 1–5 December 2007; pp. 146–160. [Google Scholar]
- Subramanian, L.; Seshadri, V.; Kim, Y.; Jaiyen, B.; Mutlu, O. MISE: Providing performance predictability and improving fairness in shared main memory systems. In Proceedings of the IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), Shenzhen, China, 23–27 February 2013. [Google Scholar]
- Hong, S. Memory technology trend and future challenges. In Proceedings of the International Electron Devices Meeting, San Francisco, CA, USA, 6–8 December 2010. [Google Scholar]
- Kim, K. Future memory technology: Challenges and opportunities. In Proceedings of the International Symposium on VLSI Technology, Systems and Applications (VLSI-TSA), Taipei, Taiwan, 3–5 December 2007; pp. 5–9. [Google Scholar]
- Koh, Y. NAND Flash Scaling Beyond 20 nm. In Proceedings of the IEEE International Memory Workshop, Monterey, CA, USA, 10–14 May 2009; pp. 1–3. [Google Scholar]
- Cai, Y.; Haratsch, E.F.; Mutlu, O.; Mai, K. Error Patterns in MLC NAND Flash Memory: Measurement, Characterization, and Analysis. In Proceedings of the 2012 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 12–16 March 2012. [Google Scholar]
- Loi, G.L.; Agrawal, B.; Srivastava, N.; Lin, S.; Sherwood, T.; Banerjee, K. A thermally-aware performance analysis of vertically integrated (3-D) processor-memory hierarchy. In Proceedings of the 2006 43rd ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 24–28 July 2006; pp. 991–996. [Google Scholar]
- Jun, H.; Cho, J.; Lee, K.; Son, H.-Y.; Kim, K.; Jin, H.; Kim, K. HBM (High Bandwidth Memory) DRAM Technology and Architecture. In Proceedings of the 2017 IEEE International Memory Workshop (IMW), Monterey, CA, USA, 14–17 May 2017. [Google Scholar]
- Lee, J.C.; Kim, J.; Kim, K.W.; Ku, Y.J.; Kim, D.S.; Jeong, C.; Yun, Y.S.; Kim, H.; Cho, H.S.; Oh, S.; et al. High bandwidth memory(HBM) with TSV technique. In Proceedings of the 2016 International SoC Design Conference (ISOCC), Jeju, Korea, 23–26 November 2016; pp. 181–182. [Google Scholar]
- Kirihata, T.; Golz, J.; Wordeman, M.; Batra, P.; Maier, G.W.; Robson, N.; Graves-Abe, T.L.; Berger, D.; Iyer, S.S. Three-Dimensional Dynamic Random Access Memories Using Through-Silicon-Vias. IEEE.J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 373–384. [Google Scholar] [CrossRef]
- Pawlowski, J.T. Hybrid memory cube (HMC). In Proceedings of the IEEE Hot Chips 23 Symposium (HCS), Stanford, CA, USA, 17–19 August 2011; pp. 1–24. [Google Scholar]
- Shulaker, M.; Hills, G.; Park, R.; Howe, R.T.; Saraswat, K.; Wong, H.-S.P.; Mitra, S. Three-dimensional integration of nanotechnologies for computing and data storage on a single chip. Nature 2017, 547, 74–78. [Google Scholar] [CrossRef] [PubMed]
- Sandhu, G.S. Emerging memories technology landscape. In Proceedings of the 2013 13th Non-Volatile Memory Technology Symposium (NVMTS), Minneapolis, MN, USA, 12–14 August 2013; pp. 1–5. [Google Scholar]
- Pedram, A.; Richardson, S.; Horowitz, M.; Galal, S.; Kvatinsky, S. Dark Memory and Accelerator-Rich System Optimization in the Dark Silicon Era. IEEE Des. Test 2017, 34, 39–50. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Liu, X.Y.; Mao, H.Z.; Pu, J.; Pedram, A.; Horowitz, M.A.; Dally, W.J. EIE: Efficient Inference Engine on Compressed Deep Neural Network. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 243–254. [Google Scholar]
- Deering, S.; Estrin, D.L.; Farinacci, D.; Jacobson, V.; Liu, C.; Wei, L. The PIM architecture for wide-area multicast routing. IEEE/ACM Trans. Netw. 1996, 4, 153–162. [Google Scholar] [CrossRef]
- Yantır, H.E.; Eltawil, A.M.; Salama, K.N. Efficient Acceleration of Stencil Applications through In-Memory Computing. Micromachines 2020, 11, 622. [Google Scholar] [CrossRef] [PubMed]
- Santoro, G.; Turvani, G.; Graziano, M. New Logic-In-Memory Paradigms: An Architectural and Technological Perspective. Micromachines 2019, 10, 368. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, A.; Kosta, A.; Kodge, S.; Kim, D.E.; Roy, K. CASH-RAM: Enabling In-Memory Computations for Edge Inference Using Charge Accumulation and Sharing in Standard 8T-SRAM Arrays. IEEE J. Emerg. Sel. Top. Circuits Syst. 2020, 10, 295–305. [Google Scholar] [CrossRef]
- Sinangil, M.E.; Erbagci, B.; Naous, R.; Akarvardar, K.; Sun, D.; Khwa, W.-S.; Liao, H.-J.; Wang, Y.; Chang, J. A 7-nm Compute-in-Memory SRAM Macro Supporting Multi-Bit Input, Weight and Output and Achieving 351 TOPS/W and 372.4 GOPS. IEEE J. Solid-State Circuits 2021, 56, 188–198. [Google Scholar] [CrossRef]
- Ali, M.; Chakraborty, I.; Saxena, U.; Agrawal, A.; Ankit, A.; Roy, K. A 35.5–127.2 TOPS/W Dynamic Sparsity-Aware Reconfigurable-Precision Compute-in-Memory SRAM Macro for Machine Learning. IEEE Solid-State Circuits Lett. 2021, 4, 129–132. [Google Scholar] [CrossRef]
- Srinivasa, S.R.; Ramanathan, A.K.; Li, X.; Chen, W.-H.; Gupta, S.K.; Chang, M.-F.; Ghosh, S.; Sampson, J.; Narayanan, V. ROBIN: Monolithic-3D SRAM for Enhanced Robustness with In-Memory Computation Support. IEEE Trans. Circuits Syst. I 2019, 66, 2533–2545. [Google Scholar] [CrossRef]
- Yu, C.; Yoo, T.; Kim, H.; Kim, T.T.H.; Chuan, K.C.T.; Kim, B. A Logic-Compatible eDRAM Compute-In-Memory with Embedded ADCs for Processing Neural Networks. IEEE Trans. Circuits Syst. I 2021, 68, 667–679. [Google Scholar] [CrossRef]
- Werner, S.; Sebastian, P.; Xian, F.X. 3D photonics as enabling technology for deep 3D DRAM stacking. In Proceedings of the International Symposium on Memory Systems, Washington, DC, USA, 30 September–3 October 2019. [Google Scholar]
- Ali, M.F.; Jaiswal, A.; Roy, K. In-Memory Low-Cost Bit-Serial Addition Using Commodity DRAM Technology. IEEE Trans. Circuits Syst. I 2020, 67, 155–165. [Google Scholar] [CrossRef]
- Salkhordeh, R.; Mutlu, O.; Asadi, H. An Analytical Model for Performance and Lifetime Estimation of Hybrid DRAM-NVM Main Memories. IEEE Trans. Comput. 2019, 68, 1114–1130. [Google Scholar] [CrossRef] [Green Version]
- Liang, Y.; Yin, L.; Xu, N. A Field Programmable Process-In-Memory Architecture Based on RRAM Technology. In Proceedings of the 2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020; pp. 2323–2326. [Google Scholar]
- Li, H.; Li, K.-S.; Lin, C.-H.; Hsu, J.-L.; Chiu, W.-C.; Chen, M.-C.; Wu, T.-T.; Sohn, J.; Eryilmaz, S.B.; Shieh, J.-M.; et al. Four-layer 3D vertical RRAM integrated with FinFET as a versatile computing unit for brain-inspired cognitive information processing. In Proceedings of the IEEE Symposium on VLSI Technology, Honolulu, HI, USA, 14–16 June 2016; pp. 1–2. [Google Scholar]
- Yin, X.; Chen, X.; Niemier, M.; Hu, X.S. Ferroelectric FETs-Based Nonvolatile Logic-in-Memory Circuits. IEEE Trans. VLSI Syst. 2019, 27, 159–172. [Google Scholar] [CrossRef]
- Soliman, T.; Muller, F.; Kirchner, T.; Hoffmann, T.; Ganem, H.; Karimov, E.; Ali, T.; Lederer, M.; Sudarshan, C.; Kampfe, T.; et al. Ultra-Low Power Flexible Precision FeFET Based Analog In-Memory Computing. In Proceedings of the IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 12–18 December 2020; pp. 29.2.1–29.2.4. [Google Scholar]
- Angizi, S.; He, Z.; Awad, A.; Fan, D. MRIMA: An MRAM-Based In-Memory Accelerator. IEEE Trans. CADICS 2020, 39, 1123–1136. [Google Scholar] [CrossRef]
- Shreya, S.; Jain, A.; Kaushik, B.K. Computing-in-memory using voltage-controlled spin-orbit torque based MRAM array. Microelectronics 2021, 109, 1–8. [Google Scholar] [CrossRef]
- Dong, X.; Muralimanohar, N.; Jouppi, N.; Kaufmann, R.; Xie, Y. Leveraging 3D PCRAM technologies to reduce checkpoint overhead for future exascale systems. In Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis, Portland, OR, USA, 14–20 November 2009; pp. 1–12. [Google Scholar]
- Vetter, J.S.; Mittal, S. Opportunities for Nonvolatile Memory Systems in Extreme-Scale High-Performance Computing. Comput. Sci. Eng. 2015, 17, 73–82. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J.S. A survey of software techniques for using non-volatile memories for storage and main memory systems. IEEE Trans. Parallel Distrib. 2016, 27, 1537–1550. [Google Scholar] [CrossRef]
- Xia, F.; Jiang, D.; Xiong, J.; Sun, N. A Survey of Phase Change Memory Systems. J. Comput. Sci. Technol. 2015, 30, 121–144. [Google Scholar] [CrossRef]
- Boukhobza, J.; Rubini, S.; Chen, R.; Shao, Z. Emerging NVM: A Survey on Architectural Integration and Research Challenges. ACM Trans. Des. Autom. Electron. Syst. 2018, 23, 1–32. [Google Scholar] [CrossRef]
- Shim, W.; Yu, S. System-Technology Codesign of 3-D NAND Flash-Based Compute-in-Memory Inference Engine. IEEE J. Explor. Solid-State Comput. Devices Circuits 2021, 7, 61–69. [Google Scholar] [CrossRef]
- Koike, H.; Tanigawa, T.; Watanabe, T.; Nasuno, T.; Noguchi, Y.; Yasuhira, N.; Yoshiduka, T.; Ma, Y.; Honjo, H.; Nishioka, K.; et al. 40 nm 1T–1MTJ 128 Mb STT-MRAM with Novel Averaged Reference Voltage Generator Based on Detailed Analysis of Scaled-Down Memory Cell Array Design. IEEE Trans. Magn. 2021, 57, 1–9. [Google Scholar] [CrossRef]
- Dong, Q.; Sinangil, M.E.; Erbagci, B.; Sun, D.; Khwa, W.-S.; Liao, H.-J.; Wang, Y.; Chang, J. 15.3 A 351TOPS/W and 372.4GOPS Compute-in-Memory SRAM Macro in 7 nm FinFET CMOS for Machine-Learning Applications. In Proceedings of the IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 16–20 February 2020; pp. 242–244. [Google Scholar]
- Endoh, T.; Koike, H.; Ikeda, S.; Hanyu, T.; Ohno, H. An Overview of Nonvolatile Emerging Memories— Spintronics for Working Memories. IEEE J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 109–119. [Google Scholar] [CrossRef]
- Hsieh, M.C.; Liao, Y.C.; Chin, Y.W.; Lien, C.-H.; Chang, T.-S.; Chih, Y.-D.; Natarajan, S.; Tsai, N.-J.; King, Y.-C.; Lin, C.J. Ultra high density 3D via RRAM in pure 28nm CMOS process. In Proceedings of the IEEE International Electron Devices Meeting, Washington, DC, USA, 9–11 December 2013; pp. 10.3.1–10.3.4. [Google Scholar]
- Akinaga, H.; Shima, H. Resistive Random Access Memory (ReRAM) Based on Metal Oxides. Proc. IEEE 2010, 98, 2237–2251. [Google Scholar] [CrossRef]
- Marinella, M.J. Radiation Effects in Advanced and Emerging Nonvolatile Memories. IEEE Trans. Nucl. Sci. 2021, 68, 546–572. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intel [24] | TSMC [22] | AMD [9] | CEA-Leti [30] | Intel [25] | Bologna [26] | |
|---|---|---|---|---|---|---|
| Product Name | Agilex | - | Ryzen | INTACT | Lakefield | Manticore |
| Launched Time | 201904 | 201908 | 201908 | 202002 | 202006 | 202012 |
| Chiplet Technology (nm) | 10 | 7 | 7 + 12 | FDSOI 28 | 10 + 22 FFL | GF 22 FDX |
| Chiplet Number | scalable | 2 | >2 | 6 | 1 | 4 |
| Number of cores/Chiplet | Cortex-A53 | 4 Cortex-A72 | 64 (Server) 16 (Cilient) | 16 | 1 Core+ 4 Atom | 1024 RISC-V |
| Area (mm2) | - | 4.4 × 6.2 | - | 4 × 5.6 | - | 9 |
| Bandwidth (Max) | 32 Gb/s | 320 GB/s | ~55 GB/s | 527 GB/s | ~34 GB/s | 1 TB/s |
| Bandwidth density | 1.6 Tb/s/mm2 | - | 3 Tbit/s/mm2 | - | - | |
| Frequency (GHz) | 1.5 | 4 | ~1 | 1.15 | ~1 | 1 |
| Integrated type | 2.5D | 2.5D | 3D | 3D | 3D | 2.5D |
| Interposer type | Passive | Passive | N/A | Active | Active | Yes |
| Interconnect pitch (µm) | 55 | 40 | - | 20 | 50 | 20 |
| Delay | ~60 ps | - | <9 ns | 0.6 ns/mm | - | - |
| Integration technology | EMIB | CoWoS | F2F | Foveros | - | |
| Yield | High | High | High | High | High | High |
| Scalability | High | High | High | - | ||
| Configurability | Good | Yes | Yes | Yes | alternative | High efficiency/performance |
| Reusability | High | High | High | High | High | High |
| Testability | Good | Good | Good | |||
| Power efficiency | - | 0.56 pJ/b | 2 pJ/b | 0.59 pj/b | 0.2 pJ/b | 50 Gdopflop/sW |
| Application | Data Center, Networking, Edge Computing | HPC | Server and Desktop Products | Cloud Computing Accelerators | Mobile, PC | Data Center, Networking, Edge Computing. |
| SRAM Chiplet [69,70] | DRAM Chiplet [71,72] | NOR Chiplet [69] | NAND Chiplet [73] | MRAM Chiplet [74] | PCRAM Chiplet [75,76] | RRAM Chiplet [77,78] | FeRAM Chiplet [67] | |
|---|---|---|---|---|---|---|---|---|
| Technology [79] | 7 nm | 14 nm | 28 nm | 32 nm | 28 nm | 28 nm | 28 nm | - |
| Cell area | 160–280 F2 | 10 F2 | 10 F2 | 4 F2 | 10–20 F2 | 5–20 F2 | 4–10 F2 | 15–20 F2 |
| Voltage (V) | <1 | ~1 | ~10 | ~15 | <1.5 | <2 | 1–3 | ~1 |
| Current (A) | ~10−5 | ~10−5 | ~10−7 | ~10−7 | ~10−5 | ~10−4 | ~10−4 | ~10−6 |
| Read time (ns) | ~1 | ~10 | ~10 | ~10 | ~10 | ~10 | ~10 | <10 |
| Write time | ~1 ns | ~10 ns | 10 μs–1 ms | ~1 ms | ~10 ns | ~50 ns | ~10 ns | ~10 ns |
| Write energy | ~fj | ~10 fj | ~100 pj | ~10 pj | 0.1 pj | ~10 pj | ~0.1 pj | ~0.1 pj |
| Endurance | ~1016 | ~1016 | ~105 | ~105 | ~1015 | ~109 | 106–1012 | ~1010 |
| Retention | N/A | ~64 ms | >10 y | >10 y | >10 y | >10 y | >10 y | >10 y |
| Static power | High | High | Medium | Medium | Low | Low | Low | Low |
| Dynamic power | Low | Low | Medium | Medium | Medium | Medium | Medium | Medium |
| Anti-radiation | Low | Low | Very low | Very low | High | High | High | High |
| No volatility | NO | NO | Yes | Yes | Yes | Yes | Yes | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, G.; Zheng, Y.; Xing, C.; Chen, D.; Li, G.; Yang, Y. Architecture of Computing System based on Chiplet. Micromachines 2022, 13, 205. https://doi.org/10.3390/mi13020205
Shan G, Zheng Y, Xing C, Chen D, Li G, Yang Y. Architecture of Computing System based on Chiplet. Micromachines. 2022; 13(2):205. https://doi.org/10.3390/mi13020205
Chicago/Turabian StyleShan, Guangbao, Yanwen Zheng, Chaoyang Xing, Dongdong Chen, Guoliang Li, and Yintang Yang. 2022. "Architecture of Computing System based on Chiplet" Micromachines 13, no. 2: 205. https://doi.org/10.3390/mi13020205
APA StyleShan, G., Zheng, Y., Xing, C., Chen, D., Li, G., & Yang, Y. (2022). Architecture of Computing System based on Chiplet. Micromachines, 13(2), 205. https://doi.org/10.3390/mi13020205