
Belt Tear Detection for Coal Mining Conveyors

 ,
,  ,
,  and
and 
Abstract
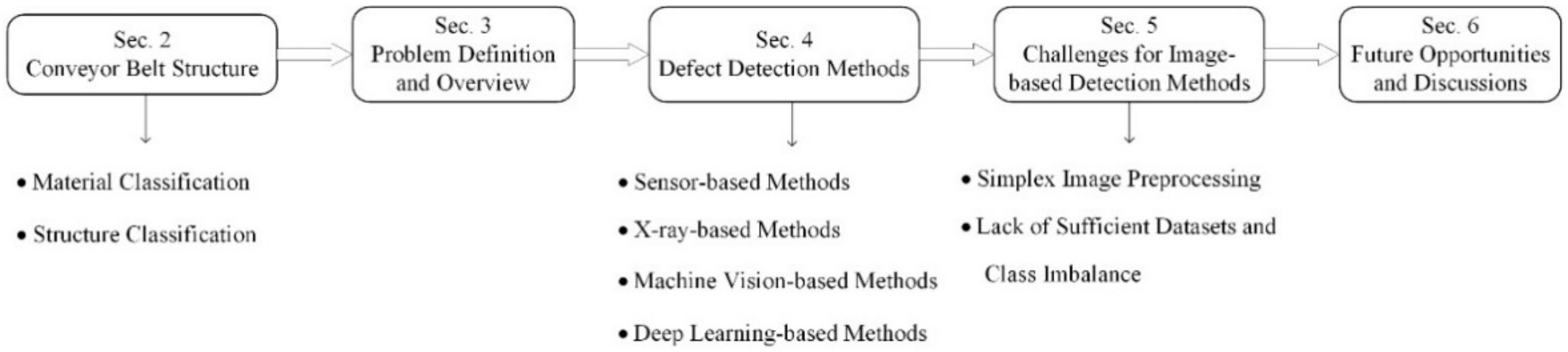
:1. Introduction
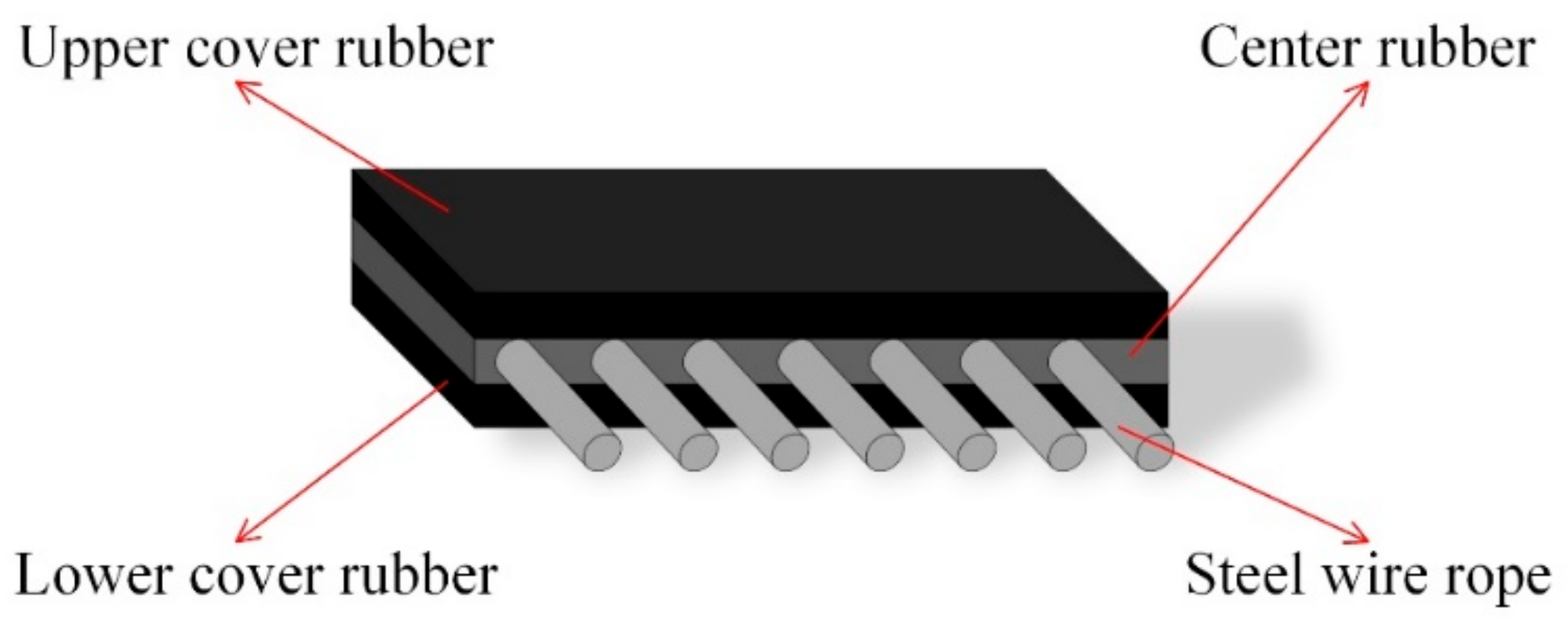
2. Basic Structure of Conveyor Belts
3. Defect Detection for Conveyor Belts
3.1. Problem Definition
3.2. Mainstream Techniques
3.3. Detecting Sensors
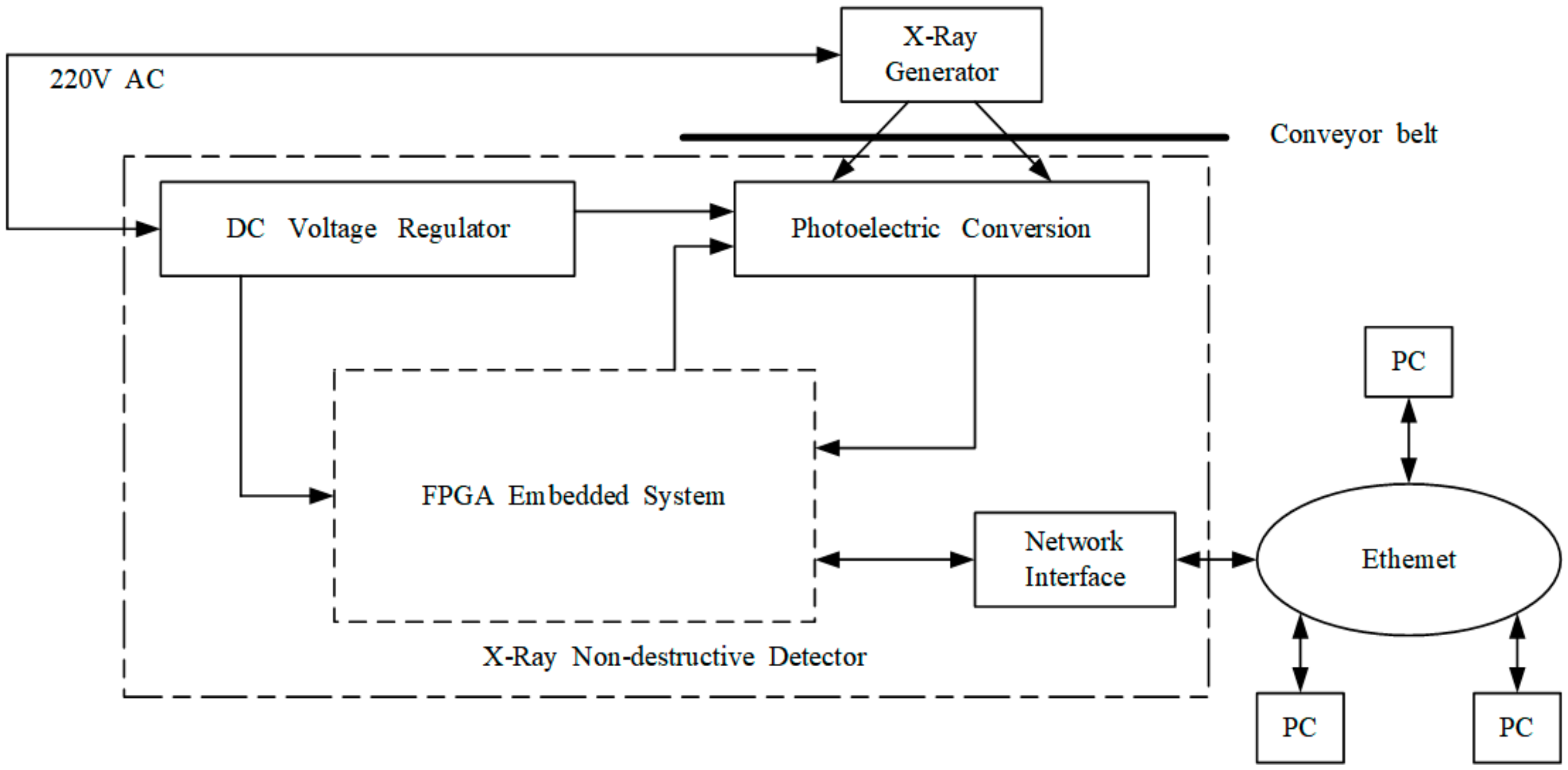
3.3.1. X-ray/Spectrum
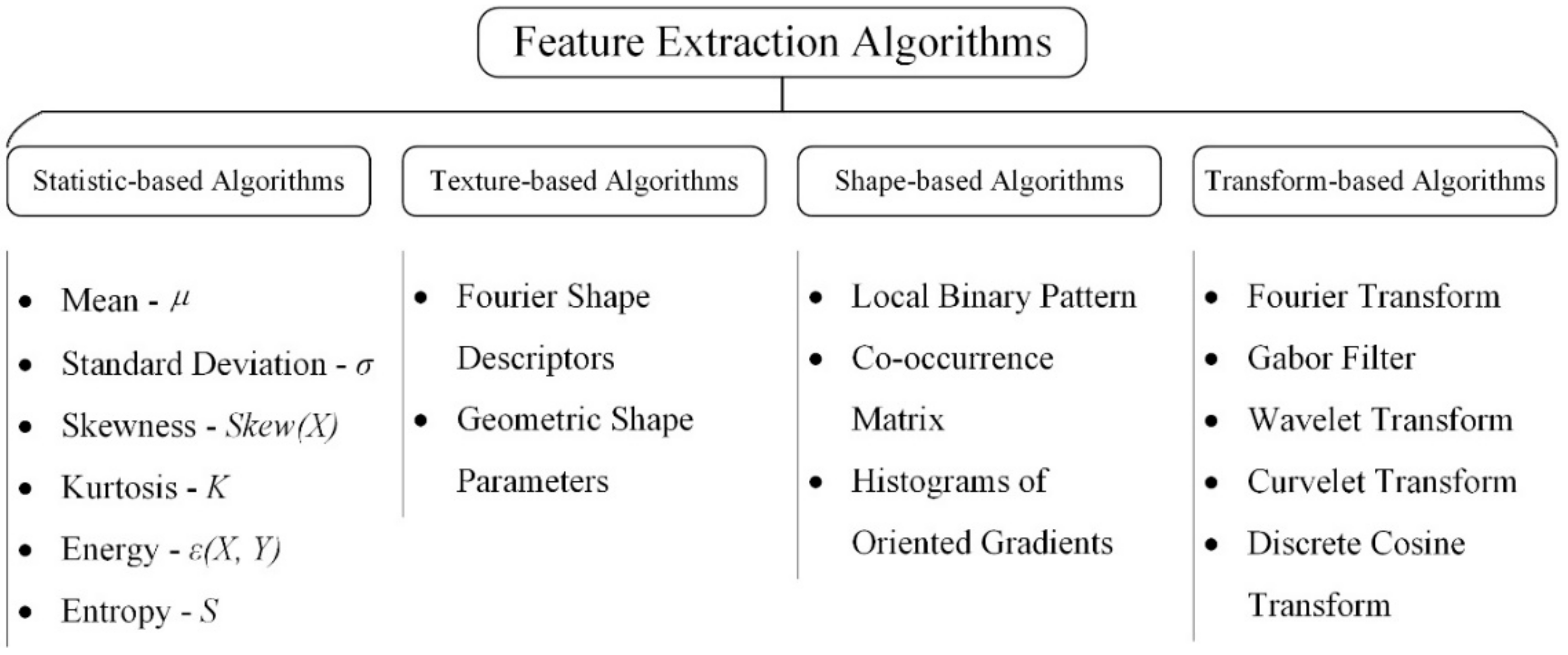
3.3.2. 2D/3D Images
3.3.3. Machine Vision
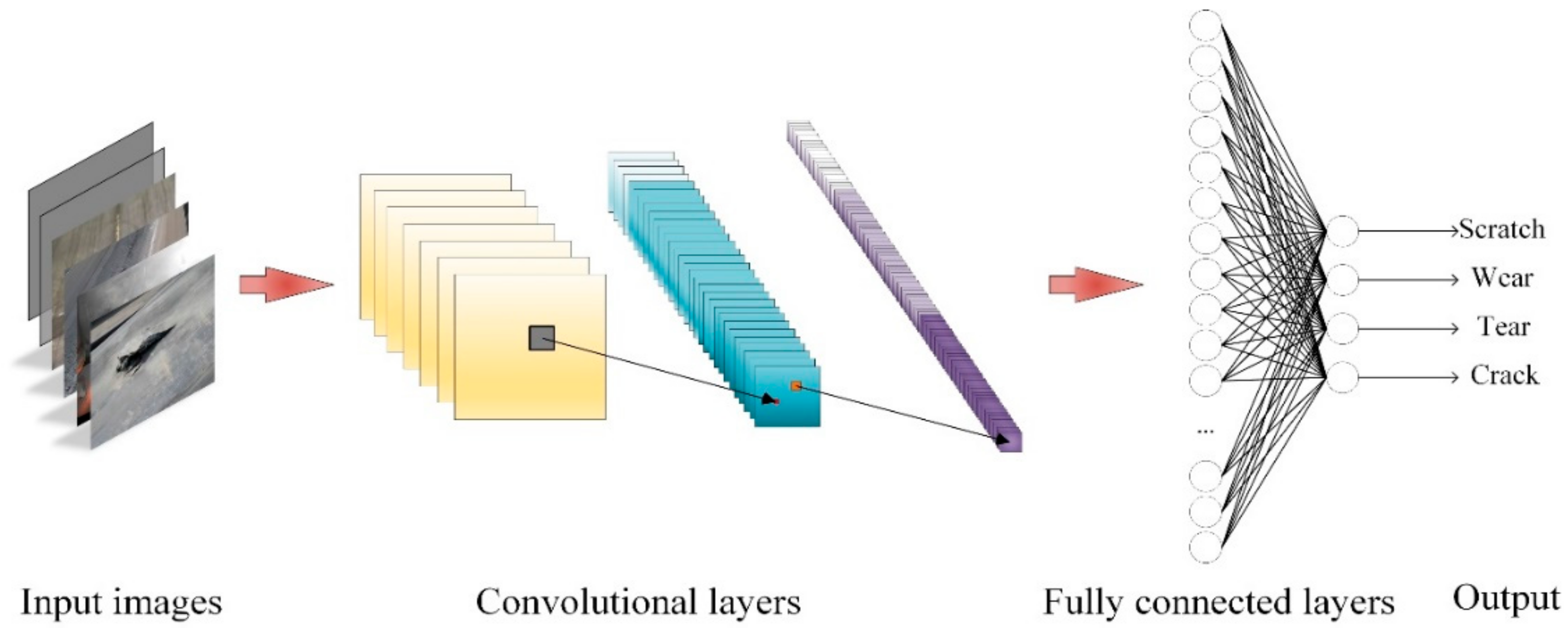
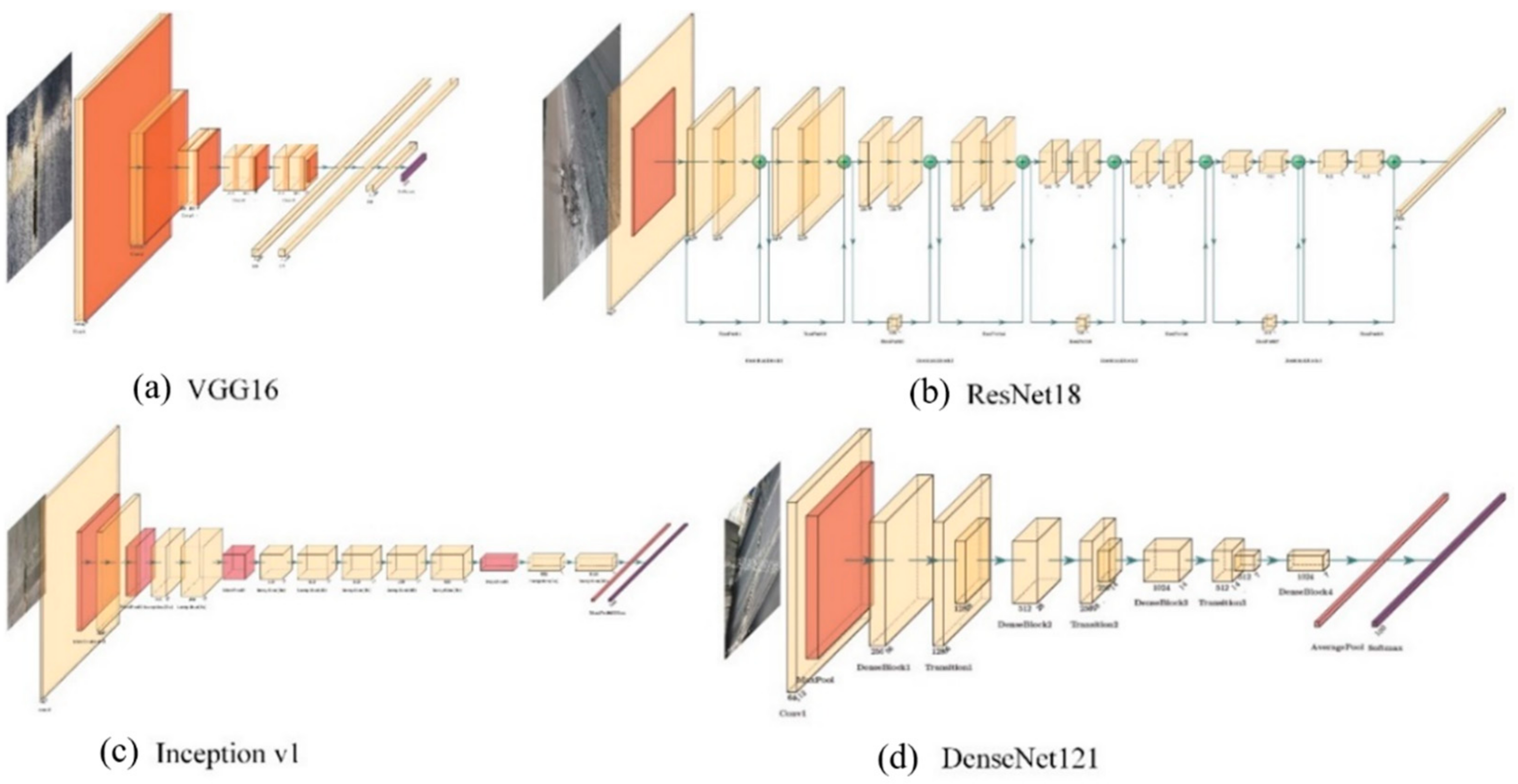
3.3.4. Deep Learning
3.4. Next-Generation Detection Methods
3.5. Experimental Evaluation
4. Challenges and Solutions
4.1. Challenges for Image Preprocessing
4.2. Challenges in Dataset Imbalance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Feyzullahoglu, E.; Arslan, E. Abrasive wear behaviors of several rubber conveyor belt materials used in different working conditions. KGK Kautsch. Gummi Kunstst. 2014, 67, 47–52. [Google Scholar]
- Imbernon, L.; Pauchet, R.; Pire, M.; Albouy, P.-A.; Tencé-Girault, S.; Norvez, S. Strain-induced crystallization in sustainably crosslinked epoxidized natural rubber. Polymer 2016, 93, 189–197. [Google Scholar] [CrossRef]
- Hakami, F.; Pramanik, A.; Ridgway, N.; Basak, A.K. Developments of rubber material wear in conveyer belt system. Tribol. Int. 2017, 111, 148–158. [Google Scholar] [CrossRef] [Green Version]
- Zakharov, A.; Geike, B.; Grigoryev, A.; Zakharova, A. Analysis of Devices to Detect Longitudinal Tear on Conveyor Belts. In E3S Web of Conferences; EDP Sciences: Kemerovo, Russia, 2020; Volume 174, p. 03006. [Google Scholar]
- Harrison, A. A new development in conveyor belt monitoring. Aust. Mach. Prod. Eng. 1980, 32, 17. [Google Scholar]
- Harrison, A. 15 years of conveyor belt nondestructive evaluation. Bulk Solids Handl. 1996, 16, 13–19. [Google Scholar]
- Blazej, R.; Jurdziak, L.; Zimroz, R. Novel Approaches for Processing of Multi-Channels NDT Signals for Damage Detection in Conveyor Belts with Steel Cords. Key Eng. Mater. 2013, 569–570, 978–985. [Google Scholar] [CrossRef]
- Kozłowski, T.; Błażej, R.; Jurdziak, L.; Kirjanów-Błażej, A. Magnetic methods in monitoring changes of the technical condition of splices in steel cord conveyor belts. Eng. Fail. Anal. 2019, 104, 462–470. [Google Scholar] [CrossRef]
- Kozłowski, T.; Wodecki, J.; Zimroz, R.; Błażej, R.; Hardygóra, M. A Diagnostics of Conveyor Belt Splices. Appl. Sci. 2020, 10, 6259. [Google Scholar] [CrossRef]
- Kuzik, L.J.; Blum, D.W. Scanning steel cord conveyor belts with the “BELT C.A.T.™” MDR system. Bulk Solids Handl. J. 1996, 16, 437–441. [Google Scholar]
- Błażej, R.; Jurdziak, L.; Kozłowski, T.; Kirjanów, A. The use of magnetic sensors in monitoring the condition of the core in steel cord conveyor belts—Tests of the measuring probe and the design of the DiagBelt system. Measurement 2018, 123, 48–53. [Google Scholar] [CrossRef]
- Huang, Y.; Cheng, W.; Tang, C.; Wang, C. Study of multi-agent-based coal mine environmental monitoring system. Ecol. Indic. 2015, 51, 79–86. [Google Scholar] [CrossRef]
- Miao, C.; Shi, B.; Wan, P.; Li, J. Study on nondestructive detection system based on x-ray for wire ropes conveyer belt. In Proceedings of the International Symposium on Photoelectronic Detection and Imaging 2007: Laser, Ultraviolet, and Terahertz Technology, Beijing, China, 9–12 September 2007. [Google Scholar]
- Guan, Y.; Zhang, J.; Shang, Y.; Wu, M.; Liu, X. Embedded Sensor of Forecast Conveyer Belt Breaks; IEEE: Jinan China, 2008; Volume 5, pp. 617–621. [Google Scholar] [CrossRef]
- Wang, J.; Miao, C.; Wang, W.; Lu, X. Research of x-Ray Nondestructive Detector for High-Speed Running Conveyor Belt with Steel Wire Ropes; SPIE: Beijing, China, 2007. [Google Scholar] [CrossRef]
- Wang, M.-S.; Chen, Z.-S. Researching on the linear X-ray detector application of in the field of steel-core belt conveyor inspection system. In Proceedings of the 2011 International Conference on Electric Information and Control Engineering, Yichang, China, 16–18 September 2011. [Google Scholar]
- Yun, Y.; Zhang, H.; Li, C. Automatic Detection Apparatus Development of Steel Cord Conveyor Belt. Key Eng. Mater. 2010, 455, 516–520. [Google Scholar] [CrossRef]
- Fu, L.Q.; Wu, X.J. Visual Monitoring System of Steel-Cord Conveyor Belt. Adv. Mater. Res. 2012, 472–475, 2698–2701. [Google Scholar] [CrossRef]
- Wang, Y.D. Study on Mechanical Automation with X-Ray Power Conveyor Belt Nondestructive Detection System Design. Adv. Mater. Res. 2013, 738, 256–259. [Google Scholar] [CrossRef]
- Yang, Y.; Hou, C.; Qiao, T.; Zhang, H.; Ma, L. Longitudinal tear early-warning method for conveyor belt based on infrared vision. Measurement 2019, 147, 106817. [Google Scholar] [CrossRef]
- Yang, R.; Qiao, T.; Pang, Y.; Yang, Y.; Zhang, H.; Yan, G. Infrared spectrum analysis method for detection and early warning of longitudinal tear of mine conveyor belt. Measurement 2020, 165, 107856. [Google Scholar] [CrossRef]
- Qiao, T.; Chen, L.; Pang, Y.; Yan, G.; Miao, C. Integrative binocular vision detection method based on infrared and visible light fusion for conveyor belts longitudinal tear. Measurement 2017, 110, 192–201. [Google Scholar] [CrossRef]
- Yu, B.; Qiao, T.; Zhang, H.; Yan, G. Dual band infrared detection method based on mid-infrared and long infrared vision for conveyor belts longitudinal tear. Measurement 2018, 120, 140–149. [Google Scholar] [CrossRef]
- Hou, C.; Qiao, T.; Zhang, H.; Pang, Y.; Xiong, X. Multispectral visual detection method for conveyor belt longitudinal tear. Measurement 2019, 143, 246–257. [Google Scholar] [CrossRef]
- Li, M.; Du, B.; Zhu, M.; Zhao, K. Intelligent detection system for mine belt tearing based on machine vision. In Proceedings of the 2011 Chinese Control and Decision Conference (CCDC), Mianyang, China, 23–25 May 2011. [Google Scholar] [CrossRef]
- Yang, Y.; Miao, C.; Li, X.; Mei, X. On-line conveyor belts inspection based on machine vision. Opt. Int. J. Light Electron Opt. 2014, 125, 5803–5807. [Google Scholar] [CrossRef]
- Li, J.; Miao, C. The conveyor belt longitudinal tear on-line detection based on improved SSR algorithm. Optik 2016, 127, 8002–8010. [Google Scholar] [CrossRef]
- Fei, Z.E.N.G.; Zhang, S. A method for determining longitudinal tear of conveyor belt based on feature fusion. In Proceedings of the 2019 6th International Conference on Information Science and Control Engineering (ICISCE), Shanghai, China, 20–22 December 2019; pp. 65–69. [Google Scholar]
- Hao, X.-L.; Liang, H. A multi-class support vector machine real-time detection system for surface damage of conveyor belts based on visual saliency. Measurement 2019, 146, 125–132. [Google Scholar] [CrossRef]
- Hou, C.; Qiao, T.; Qiao, M.; Xiong, X.; Yang, Y.; Zhang, H. Research on Audio-Visual Detection Method for Conveyor Belt Longitudinal Tear. IEEE Access 2019, 7, 120202–120213. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, L.; Sun, H.; Zhu, C. Longitudinal tear detection of conveyor belt under uneven light based on Haar-AdaBoost and Cascade algorithm. Measurement 2021, 168, 108341. [Google Scholar] [CrossRef]
- Li, W.; Li, C.; Yan, F. Research on belt tear detection algorithm based on multiple sets of laser line assistance. Measurement 2021, 174, 109047. [Google Scholar] [CrossRef]
- Lv, Z.; Zhang, X.; Hu, J.; Lin, K. Visual detection method based on line lasers for the detection of longitudinal tears in conveyor belts. Measurement 2021, 183, 109800. [Google Scholar] [CrossRef]
- Qiao, T.; Liu, W.; Pang, Y.; Yan, G. Research on visible light and infrared vision real-time detection system for conveyor belt longitudinal tear. IET Sci. Meas. Technol. 2016, 10, 577–584. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2015; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. arXiv 2019, arXiv:1807.11626, 2820–2828. [Google Scholar]
- He, K.; Gkioxari, G.; Doll, P. Mask R-CNN. ICCV 2017, 6, 2980–2988. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Ross, G.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Pont-Tuset, J.; Arbelaez, P.; Barron, J.T.; Marques, F.; Malik, J. Multiscale Combinatorial Grouping for Image Segmentation and Object Proposal Generation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 128–140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carreira, J.; Sminchisescu, C. Constrained parametric min-cuts for automatic object segmentation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector; Springer: Cham, Germany, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Zhang, M.; Shi, H.; Zhang, Y.; Yu, Y.; Zhou, M. Deep learning-based damage detection of mining conveyor belt. Measurement 2021, 175, 109130. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks; PMLR: Long Beach, CA, USA, 2019. [Google Scholar]
- Qu, D.; Qiao, T.; Pang, Y.; Yang, Y.; Zhang, H. Research On ADCN Method for Damage Detection of Mining Conveyor Belt. IEEE Sens. J. 2020, 21, 8662–8669. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, Y.; Miao, C.; Li, X.; Xu, G. Research on Deviation Detection of Belt Conveyor Based on Inspection Robot and Deep Learning. Complexity 2021, 2021, 1–15. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. Knowledge and Data Engineering. IEEE Trans. 2009, 21, 1263–1284. [Google Scholar]
- Ali, A.; Shamsuddin, S.M.; Ralescu, A. Classification with class imbalance problem: A review. Int. J. Adv. Soft Compu. Appl. 2015, 7, 176–204. [Google Scholar]
- Seiffert, C.; Khoshgoftaar, T.M.; Van Hulse, J.; Napolitano, A. RUSBoost: A Hybrid Approach to Alleviating Class Imbalance. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2009, 40, 185–197. [Google Scholar] [CrossRef]
- Bekkar, M.; Alitouche, T. Imbalanced Data Learning Approaches Review. Int. J. Data Min. Knowl. Manag. Process 2013, 3, 15. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Van Hulse, J.; Khoshgoftaar, T.M.; Napolitano, A. Experimental perspectives on learning from imbalanced data. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 935–942. [Google Scholar] [CrossRef]
- Malhotra, R. A systematic review of machine learning techniques for software fault prediction. Appl. Soft Comput. 2015, 27, 504–518. [Google Scholar] [CrossRef]
- Graczyk, M.; Lasota, T.; Trawiński, B.; Trawiński, K. Comparison of Bagging, Boosting and Stacking Ensembles Applied to Real Estate Appraisal; Springer: Berlin/Heidelberg, Germany, 2010; pp. 340–350. [Google Scholar] [CrossRef]
- McCallum, A.; Nigam, K. A Comparison of Event Models for Naive Bayes Text Classification. Work. Learn. Text Categ. 2001, 752, 41–48. [Google Scholar]
- Fernández, A.; del Río, S.; Chawla, N.V.; Herrera, F. An insight into imbalanced Big Data classification: Outcomes and challenges. Complex Intell. Syst. 2017, 3, 105–120. [Google Scholar] [CrossRef] [Green Version]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance Problems in Object Detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3388–3415. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Liu, Y.; Wang, X. Gradient Harmonized Single-Stage Detector. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI2019), Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Yang, F.; Choi, W.; Lin, Y. Exploit All the Layers: Fast and Accurate CNN Object Detector with Scale Dependent Pooling and Cascaded Rejection Classifiers. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Institute of Electrical and Electronics Engineers (IEEE): Seattle, WA, USA, 2016; pp. 2129–2137. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 354–370. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Zhong, C. Adaptive Feature Pyramid Networks for Object Detection. IEEE Access 2021, 9, 107024–107032. [Google Scholar] [CrossRef]
- Qin, P.; Li, C.; Chen, J.; Chai, R. Research on improved algorithm of object detection based on feature pyramid. Multimed. Tools Appl. 2018, 78, 913–927. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, W.; Duan, C.; Chen, H. A pooling-based feature pyramid network for salient object detection. Image Vis. Comput. 2021, 107, 104099. [Google Scholar] [CrossRef]
- Xiao, L.; Wu, B.; Hu, Y. Surface Defect Detection Using Image Pyramid. IEEE Sens. J. 2020, 20, 7181–7188. [Google Scholar] [CrossRef]
- Singh, B.; Davis, L.S. An Analysis of Scale Invariance in Object Detection—SNIP. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 July 2018. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Cheplygina, V.; de Bruijne, M.; Pluim, J.P.W. Not-so-supervised: A survey of semi-supervised, multi-instance, and transfer learning in medical image analysis. Med. Image Anal. 2019, 54, 280–296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valverde, J.; Imani, V.; Abdollahzadeh, A.; De Feo, R.; Prakash, M.; Ciszek, R.; Tohka, J. Transfer Learning in Magnetic Resonance Brain Imaging: A Systematic Review. J. Imaging 2021, 7, 66. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Mosalam, K.M. Deep Transfer Learning for Image-Based Structural Damage Recognition. Comput. Civ. Infrastruct. Eng. 2018, 33, 748–768. [Google Scholar] [CrossRef]
- Pikuliak, M.; Šimko, M.; Bieliková, M. Cross-lingual learning for text processing: A survey. Expert Syst. Appl. 2020, 165, 113765. [Google Scholar] [CrossRef]
- Liu, R.; Shi, Y.; Ji, C.; Jia, M. A Survey of Sentiment Analysis Based on Transfer Learning. IEEE Access 2019, 7, 85401–85412. [Google Scholar] [CrossRef]
- Feng, C.; Zhang, H.; Wang, S.; Li, Y.; Wang, H.; Yan, F. Structural Damage Detection using Deep Convolutional Neural Network and Transfer Learning. KSCE J. Civ. Eng. 2019, 23, 4493–4502. [Google Scholar] [CrossRef]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent Progress on Generative Adversarial Networks (GANs): A Survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. arXiv 2016, arXiv:1606.03657. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial Autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial Feature Learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Taxonomy | Devices | Theory Description and Advantages/Disadvantages |
|---|---|---|
| Sensor-based methods | Magnetic induction sensor, electromagnetic induction sensor | Convert belt damages into electromagnetic signals; then, analyze signal patterns to indirectly obtain the state of the conveyor belt. Simple principle, high cost and low precision. |
| X-ray/spectrum-based methods | X-ray emitter and receiver, industrial hyperspectral camera | X-ray penetrates conveyor belt and is captured by a special receiver, and the conveyor belt damage can be recognized by analyzing X-ray images. Hyperspectral cameras can image in infrared light, which decreases the influences of dusty and dark environments. X-ray-based methods can internally inspect the belt directly and precisely; complicated devices, high cost, harmful to humans. Spectrum-based methods are less influenced by environment; high cost, low precision. |
| Machine vision-based/deep learning-based methods | CCD, COMS or 3D industrial cameras | Industrial cameras take pictures of the conveyor belt surface in real time, which are simultaneously processed by a specially designed algorithm; not complicated devices, medium cost, complex algorithms. |
| Method | Pros | Cons |
|---|---|---|
| X-ray [13,14,15,16,17,18,19] | Can detect internal damage of steel cord belt. | (1) Expensive and complicated equipment; (2) Requires large space to deploy; (3) X-ray is harmful to humans, and extra protection is required; (4) Instable detection. |
| Infrared [20] (one camera) | (1) Acquires infrared images; (2) Can detect early wear of conveyor belt. | (1) Based on image binarization and morphological, low robustness; (2) Uses special camera, poor portability. |
| Spectrum [21] (one camera) | (1) Acquires infrared images; (2) Obtains features in frequency domain. | (1) Domain transformation may lead to information loss; (2) Complicated computation. |
| Infrared [22] (two cameras) | (1) Novel optical path; obtains synchronous infrared and normal images; (2) Acquires extra information in fusion images. | (1) Direct image fusion; no information filtering. |
| Spectrum [23] (two cameras) | (1) Novel optical path; uses two infrared cameras to obtain different spectrum images; (2) Can detect belt tear in severe conditions. | (1) Uses expensive equipment; (2) Image resolution is low. |
| Spectrum [24] (two cameras) | Acquires images of different spectra; can obtain abundant useful features. | (1) Uses expensive equipment and requires large space to deploy cameras; (2) Complicated algorithm and computation. |
| Method | Pros | Common Cons |
|---|---|---|
| Segmentation [25,26,28,30] | (1) Based on image segmentation; (2) The logic of the algorithms is simple. | (1) Designs of artificial features and some of methods need to set special threshold, which leads to poor robustness; (2) Some algorithms contain complicated manually designed features; (3) Some methods adopt linear cameras to acquire high-resolution images; hence, the algorithm speed is limited and cannot realize real-time detection. |
| SSR [27] | Based on reflection image model and SSR algorithm to extract belt tear features. | |
| Classifier [29,31] | (1) These algorithms extract belt tear features and apply classic classifiers, which have stable performance; (2) Have made efforts to address poor robustness. | |
| Edge or corner features [32,33] | (1) Based on edge or corner features, which can focus on the region of belt tear; (2) Adopt linear cameras to obtain high-resolution images. |
| Method | Pros | Cons |
|---|---|---|
| R-CNN | (1) Typical two-stage algorithm; after many improvements, algorithm is well developed and for applications that require high precision; (2)Based on region proposal networks; significantly improves detection precision. | (1) Region proposal networks make redundant bounding boxes, which leads to low speed; (2) The models are complex, and computational cost is high. |
| YOLO | (1) Simultaneously predicts object class and location as a regression process and gets rid of the region proposal stage, which simplifies the architecture and increases the speed; (2) Introduces multi-scale feature maps, which can enhance performance. | (1) The performance (except for speed) of YOLO series is worse than that of R-CNN series; (2) Anchors are fixed to a certain ratio; generalization is poor; (3) Poor performance for small object detection. |
| SSD | (1) A compromise between speed and precision; can achieve excellent performance in certain applications; (2) Multi-scale feature map fusion, which addresses poor robustness to a certain extent; (3) Less sensitive to the feature extraction ability of backbone networks than two-stage algorithms. | (1) Many hyperparameters need to be set properly; (2) Separated feature maps, which leads to complicated computation. |
| Method | Backbone | Custom Dataset | VOC2007 + VOC2012 | ||
|---|---|---|---|---|---|
| FPS | mAP(%)@.5 | FPS | mAP(%)@.5 | ||
| Multi-SVM | Null | 28.4 | 61.3 | 24.3 | 47.1 |
| AdaBoost | Null | 23.7 | 39.8 | 19.3 | 43.7 |
| YOLOv5m | Focus+CSP | 128 | 82.5 | 117 | 63.2 |
| YOLOX-X | Modified CSPv5 | 57.4 | 78.4 | 55.8 | 65.3 |
| SSD300 | VGG16 | 59.1 | 81.7 | 57.4 | 72.6 |
| Faster R-CNN | ResNet-101 | 7.4 | 86.4 | 6.2 | 74.9 |
| Strategy | Description |
|---|---|
|
|
|
|
|
|
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Liu, X.; Zhou, H.; Stanislawski, R.; Królczyk, G.; Li, Z. Belt Tear Detection for Coal Mining Conveyors. Micromachines 2022, 13, 449. https://doi.org/10.3390/mi13030449
Guo X, Liu X, Zhou H, Stanislawski R, Królczyk G, Li Z. Belt Tear Detection for Coal Mining Conveyors. Micromachines. 2022; 13(3):449. https://doi.org/10.3390/mi13030449
Chicago/Turabian StyleGuo, Xiaoqiang, Xinhua Liu, Hao Zhou, Rafal Stanislawski, Grzegorz Królczyk, and Zhixiong Li. 2022. "Belt Tear Detection for Coal Mining Conveyors" Micromachines 13, no. 3: 449. https://doi.org/10.3390/mi13030449
APA StyleGuo, X., Liu, X., Zhou, H., Stanislawski, R., Królczyk, G., & Li, Z. (2022). Belt Tear Detection for Coal Mining Conveyors. Micromachines, 13(3), 449. https://doi.org/10.3390/mi13030449