
Enabling Intelligent IoTs for Histopathology Image Analysis Using Convolutional Neural Networks




Abstract
:1. Introduction
2. Background
2.1. Related Works in Medical Imaging
2.2. Related Works in Computational Pathology
2.3. Hardware-Friendly Neural Networks
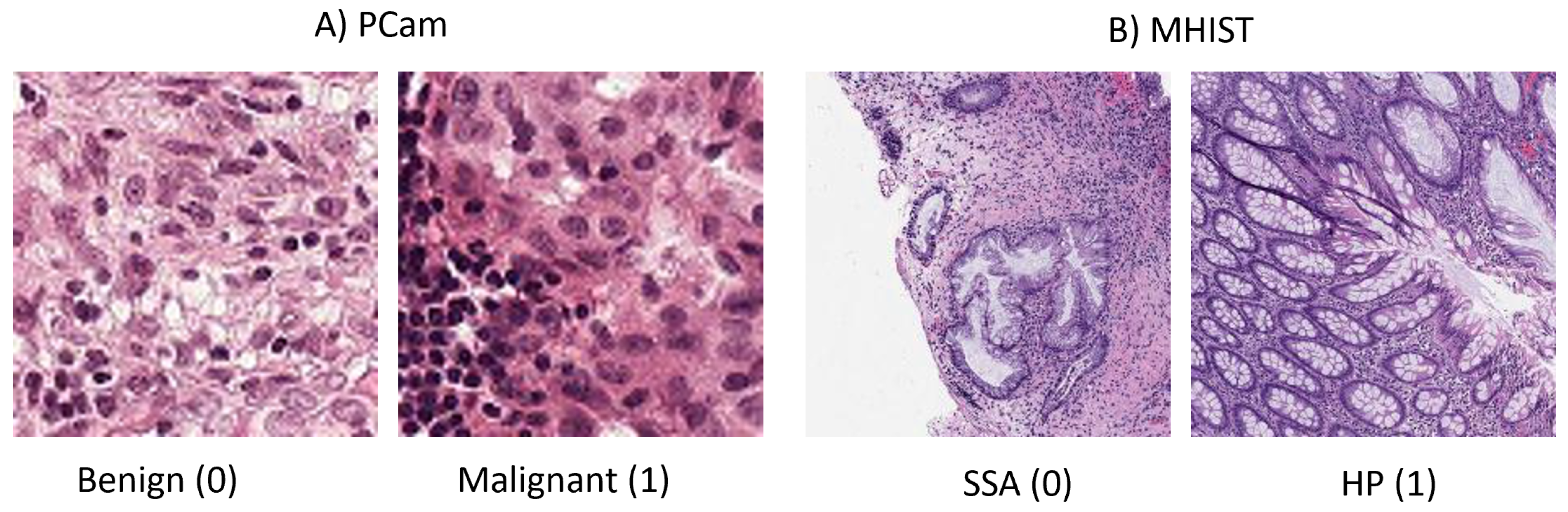
3. Dataset
3.1. PCam Dataset
3.2. MHIST Dataset
4. Proposed Approach
4.1. Model
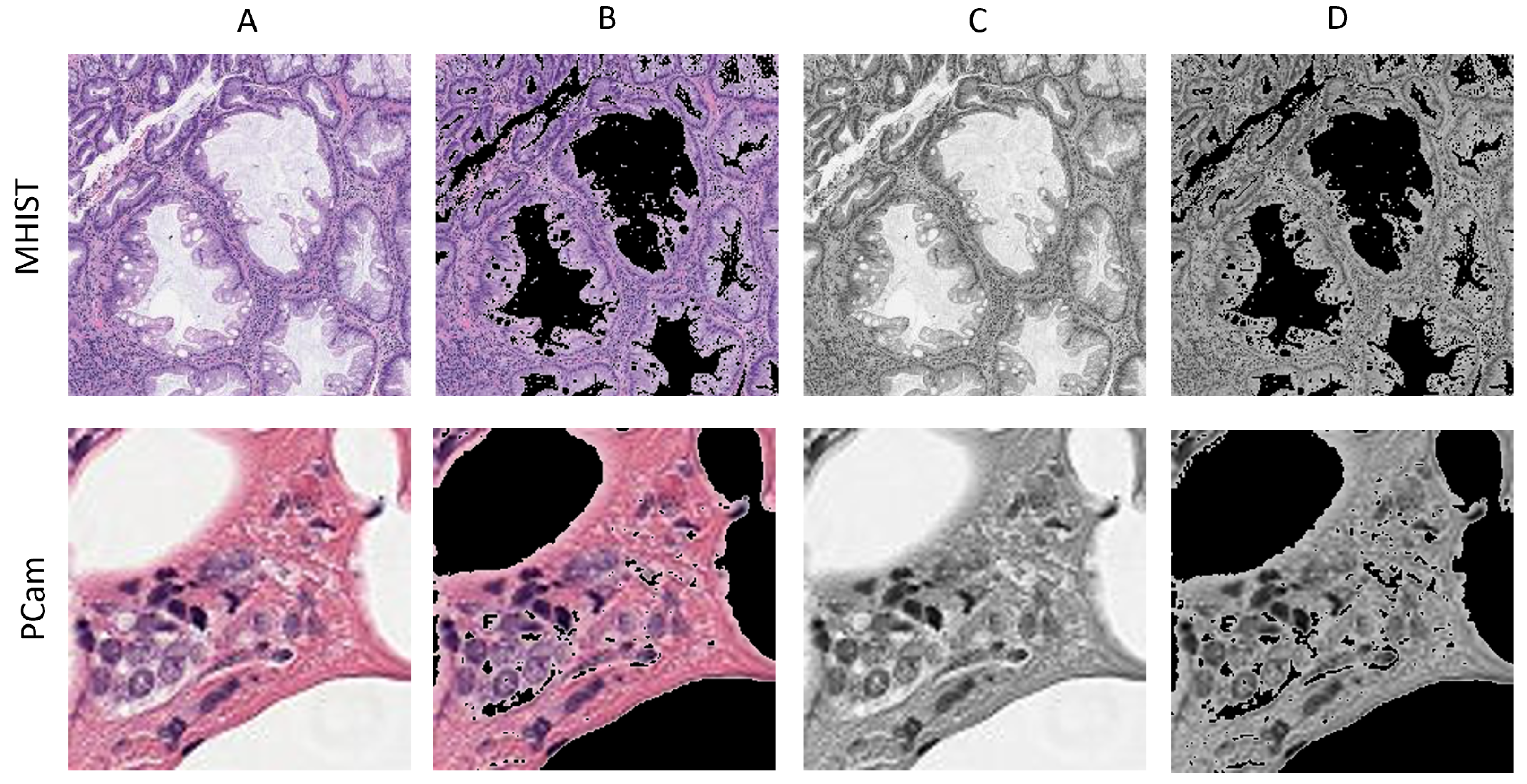
4.2. Four Color Modes
4.3. Pre-Processing and Training Details
5. Evaluation
5.1. Accuracy Evaluation
5.1.1. 32-Bit Precision Results
5.1.2. Low Bit-Width Precision Results
5.1.3. Comparison to Previous Work
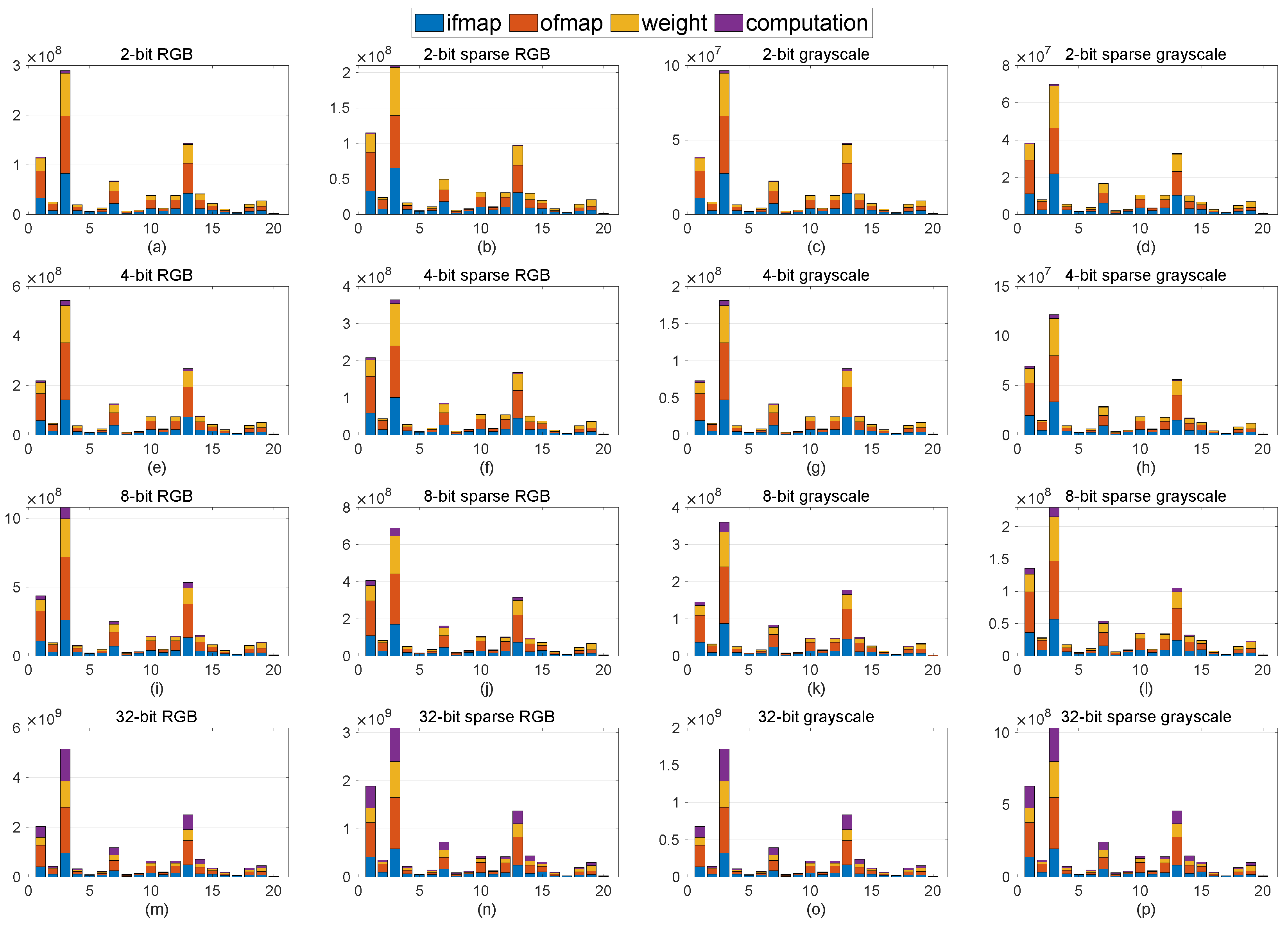
5.2. Energy Estimation
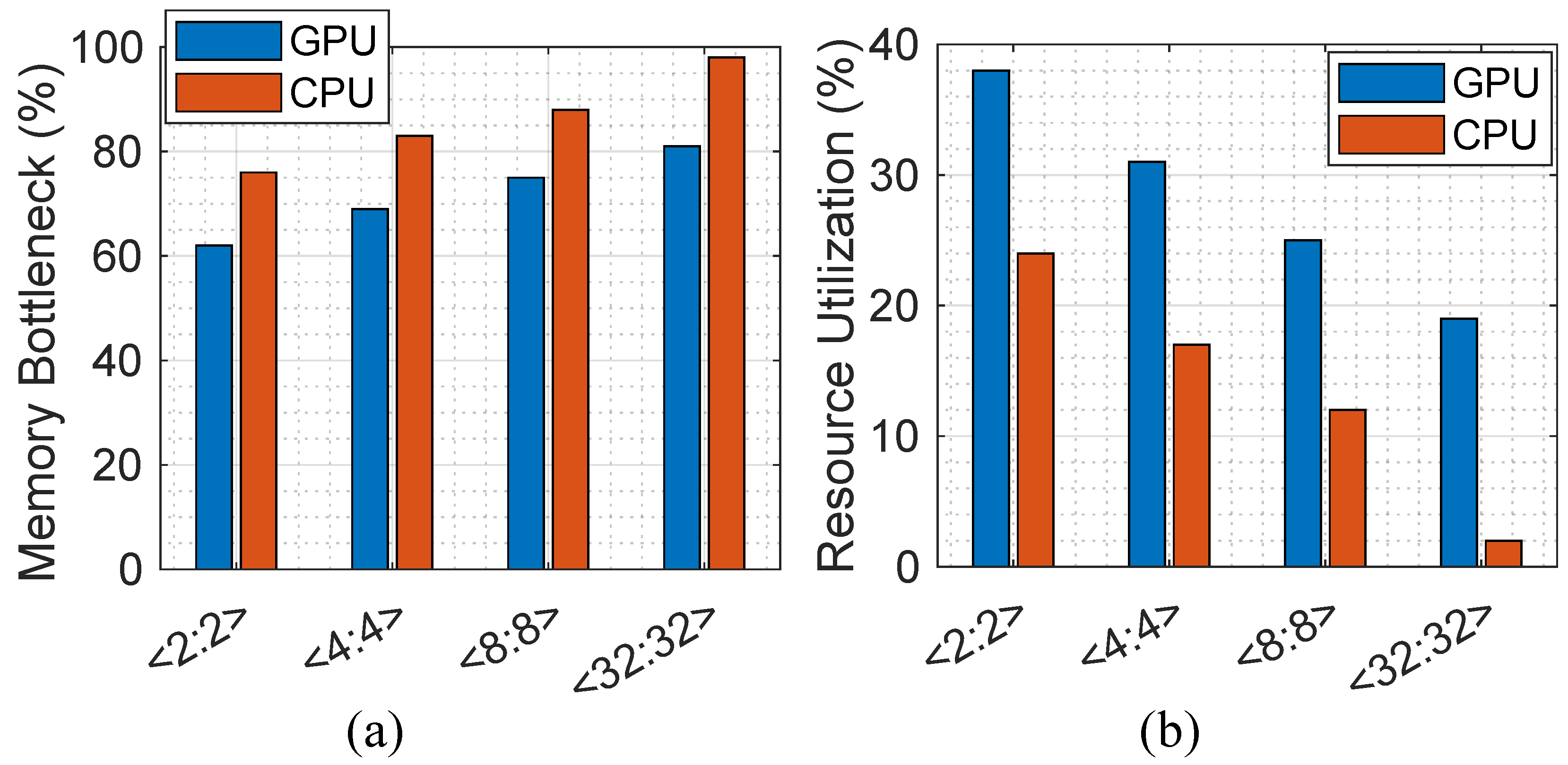
5.3. Hardware Utilization
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine learning |
| DL | Deep learning |
| CNN | Convolutional neural networks |
| RGB | Red, green, blue color mode |
| SP | Sparsity color mode |
| GS | Grayscale color mode |
| <W:A> | <Weight:activation> bit-width configuration |
| PCam | The PatchCamelyon dataset |
| MHIST | The Minimalist Histopathology dataset |
| MACs | Multiply-and-accumulate operation |
| NumPy | A python library that supports operations on large and multidimensional matrices |
| PIL | A python image library that supports manipulating and saving images |
| Ensemble | A group of DL models evaluating one task, e.g., classification |
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Kim, D.; Ham, B. Network quantization with element-wise gradient scaling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6448–6457. [Google Scholar] [CrossRef]
- Sullivan, G.J. Efficient scalar quantization of exponential and Laplacian random variables. IEEE Trans. Inf. Theory 1996, 42, 1365–1374. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bi, W.L.; Hosny, A.; Schabath, M.B.; Giger, M.L.; Birkbak, N.J.; Mehrtash, A.; Allison, T.; Arnaout, O.; Abbosh, C.; Dunn, I.F.; et al. Artificial intelligence in cancer imaging: Clinical challenges and applications. Cancer J. Clin. 2019, 69, 127–157. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Yun, J.; Cho, Y.; Shin, K.; Jang, R.; Bae, H.j.; Kim, N. Deep Learning in Medical Imaging. Neurospine 2019, 16, 657–668. [Google Scholar] [CrossRef] [PubMed]
- Wiestler, B.; Menze, B. Deep learning for medical image analysis: A brief introduction. Neuro-Oncol. Adv. 2020, 2, 35–41. [Google Scholar] [CrossRef] [PubMed]
- Muhammad, S.; Muhammad, A.; Adnan, M.; Muhammad, Q.; Majdi, A.; Khan, M.K. Medical Image Analysis using Convolutional Neural Networks A Review. J. Med Syst. 2018, 42, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.K.; Greenspan, H.; Davatzikos, C.; Duncan, J.S.; Van Ginneken, B.; Madabhushi, A.; Prince, J.L.; Rueckert, D.; Summers, R.M. A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises. Proc. IEEE 2021, 109, 820–838. [Google Scholar] [CrossRef]
- Yu, H.; Yang, L.T.; Zhang, Q.; Armstrong, D.; Deen, M.J. Convolutional neural networks for medical image analysis: State-of-the-art, comparisons, improvement and perspectives. Neurocomputing 2021, 444, 92–110. [Google Scholar] [CrossRef]
- Varoquaux, G.; Cheplygina, V. Machine learning for medical imaging: Methodological failures and recommendations for the future. NPJ Digit. Med. 2022, 5, 1–8. [Google Scholar] [CrossRef]
- Lakhani, P.; Gray, D.L.; Pett, C.R.; Nagy, P.; Shih, G. Hello World Deep Learning in Medical Imaging. J. Digit. Imaging 2018, 31, 283–289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, X.; Gao, K.; Liu, B.; Pan, C.; Liang, K.; Yan, L.; Ma, J.; He, F.; Zhang, S.; Pan, S.; et al. Advances in Deep Learning-Based Medical Image Analysis. Health Data Sci. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Xue, C.; Yu, L.; Chen, P.; Dou, Q.; Heng, P.A. Robust Medical Image Classification from Noisy Labeled Data with Global and Local Representation Guided Co-training. IEEE Trans. Med. Imaging 2022, 41, 1371–1382. [Google Scholar] [CrossRef] [PubMed]
- Srinidhi, C.L.; Ciga, O.; Martel, A.L. Deep neural network models for computational histopathology: A survey. Med. Image Anal. 2021, 67, 101813. [Google Scholar] [CrossRef] [PubMed]
- Duggento, A.; Conti, A.; Mauriello, A.; Guerrisi, M.; Toschi, N. Deep computational pathology in breast cancer. Semin. Cancer Biol. 2021, 72, 226–237. [Google Scholar] [CrossRef] [PubMed]
- Bera, K.; Schalper, K.A.; Rimm, D.L.; Velcheti, V.; Madabhushi, A. Artificial intelligence in digital pathology—New tools for diagnosis and precision oncology. Nat. Rev. Clin. Oncol. 2019, 16, 703–715. [Google Scholar] [CrossRef]
- AlGhamdi, H.M.; Koohbanani, N.A.; Rajpoot, N.; Raza, S.E.A. A Novel Cell Map Representation for Weakly Supervised Prediction of ER & PR Status from H&E WSIs. Proc. Mach. Learn. Res. 2021, 156, 10–19. [Google Scholar]
- Luz, D.S.; Lima, T.J.; Silva, R.R.; Magalhães, D.M.; Araujo, F.H. Automatic detection metastasis in breast histopathological images based on ensemble learning and color adjustment. Biomed. Signal Process. Control 2022, 75, 103564. [Google Scholar] [CrossRef]
- Mohamed, M.; Cesa, G.; Cohen, T.S.; Welling, M. A data and compute efficient design for limited-resources deep learning. arXiv 2020, arXiv:2004.09691. [Google Scholar] [CrossRef]
- Roohi, A. Processing-in-memory acceleration of convolutional neural networks for energy-effciency, and power-intermittency resilience. In Proceedings of the 20th International Symposium on Quality Electronic Design (ISQED), IEEE, Santa Clara, CA, USA, 6–7 March 2019; pp. 8–13. [Google Scholar] [CrossRef]
- Garifulla, M.; Shin, J.; Kim, C.; Kim, W.H.; Kim, H.J.; Kim, J.; Hong, S. A Case Study of Quantizing Convolutional Neural Networks for Fast Disease Diagnosis on Portable Medical Devices. Sensors 2021, 22, 219. [Google Scholar] [CrossRef]
- Roohi, A.; Taheri, M.; Angizi, S.; Fan, D. RNSiM: Efficient Deep Neural Network Accelerator Using Residue Number Systems. In Proceedings of the 2021 IEEE/ACM International Conference on Computer Aided Design (ICCAD), Munich, Germany, 1–4 November 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Roohi, A.; Sheikhfaal, S.; Angizi, S.; Fan, D.; DeMara, R.F. Apgan: Approximate gan for robust low energy learning from imprecise components. IEEE Trans. Comput. 2019, 69, 349–360. [Google Scholar] [CrossRef]
- Veeling, B.S.; Linmans, J.; Winkens, J.; Cohen, T.; Welling, M. Rotation equivariant CNNs for digital pathology. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 210–218. [Google Scholar] [CrossRef] [Green Version]
- Wei, J.; Suriawinata, A.; Ren, B.; Liu, X.; Lisovsky, M.; Vaickus, L.; Brown, C.; Baker, M.; Tomita, N.; Torresani, L.; et al. A petri dish for histopathology image analysis. In Proceedings of the International Conference on Artificial Intelligence in Medicine, Halifax, NS, Canada, 14–17 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 11–24. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. In Proceedings of the International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar] [CrossRef]
- Alali, M.H.; Roohi, A.; Deogun, J.S. Enabling efficient training of convolutional neural networks for histopathology images. In Proceedings of the Image Analysis, ICIAP 2022 Workshops, Paris, France, 27–28 October 2022; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 533–544. [Google Scholar] [CrossRef]
- Yang, T.J.; Chen, Y.H.; Emer, J.; Sze, V. A method to estimate the energy consumption of deep neural networks. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 1916–1920. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Train | Val | Test | Total |
|---|---|---|---|---|
| NonMetastasis (0) | 131,072 | 16,399 | 16,391 | 163,862 |
| Metastasis (1) | 131072 | 16369 | 16,377 | 163,818 |
| Total | 262,144 | 32,768 | 32,768 | 327,680 |
| Class | Train | Val | Test | Total |
|---|---|---|---|---|
| HP | 1545 | 155 | 462 | 2162 |
| SSA | 630 | 90 | 270 | 990 |
| Total | 2175 | 245 | 732 | 3152 |
| Dataset | Color Mode | W-Bits | A-Bits | Accuracy |
|---|---|---|---|---|
| PCam | RGB | 2 | 2 | 0.84 |
| PCam | RGB | 4 | 4 | 0.84 |
| PCam | RGB | 8 | 8 | 0.85 |
| PCam | Grayscale | 2 | 2 | 0.88 |
| PCam | Grayscale | 4 | 4 | 0.89 |
| PCam | Grayscale | 8 | 8 | 0.89 |
| PCam | Sp. on Grayscale | 2 | 2 | 0.88 |
| PCam | Sp. on Grayscale | 4 | 4 | 0.89 |
| PCam | Sp. on Grayscale | 8 | 8 | 0.90 |
| PCam | Sp. on RGB | 2 | 2 | 0.86 |
| PCam | Sp. on RGB | 4 | 4 | 0.84 |
| PCam | Sp. on RGB | 8 | 8 | 0.85 |
| MHIST | RGB | 2 | 2 | 0.74 |
| MHIST | RGB | 4 | 4 | 0.77 |
| MHIST | RGB | 8 | 8 | 0.77 |
| MHIST | Grayscale | 2 | 2 | 0.69 |
| MHIST | Grayscale | 4 | 4 | 0.77 |
| MHIST | Grayscale | 8 | 8 | 0.71 |
| MHIST | Sp. on Grayscale | 2 | 2 | 0.65 |
| MHIST | Sp. on Grayscale | 4 | 4 | 0.73 |
| MHIST | Sp. on Grayscale | 8 | 8 | 0.69 |
| MHIST | Sp. on RGB | 2 | 2 | 0.63 |
| MHIST | Sp. on RGB | 4 | 4 | 0.76 |
| MHIST | Sp. on RGB | 8 | 8 | 0.70 |
| Dataset | Color Mode | Accuracy |
|---|---|---|
| PCam | RGB | 0.84 |
| PCam | Grayscale | 0.89 |
| PCam | Sparsity on Grayscale | 0.90 |
| PCam | Sparsity on RGB | 0.83 |
| MHIST | RGB | 0.76 |
| MHIST | Grayscale | 0.73 |
| MHIST | Sparsity on Grayscale | 0.63 |
| MHIST | Sparsity on RGB | 0.69 |
| Dataset | Accuracy (Current) | Accuracy [29] | <W:A> |
|---|---|---|---|
| PCam-rgb | 0.84 | 0.81 | <2:2> |
| PCam-gs | 0.88 | 0.86 | <2:2> |
| PCam-gs-sp | 0.88 | 0.84 | <2:2> |
| PCam-rgb-sp | 0.86 | 0.82 | <2:2> |
| MHIST-rgb | 0.77 | 0.66 | <8:8> |
| MHIST-gs | 0.71 | 0.66 | <8:8> |
| MHIST-gs-sp | 0.73 | 0.66 | <4:4> |
| MHIST-rgb-sp | 0.70 | 0.67 | <8:8> |
| Color Mode | TN | TP | FN | FP | TNR | TPR | Acc | <A:W> |
|---|---|---|---|---|---|---|---|---|
| PCam:RGB | 0.78 | 0.93 | 0.22 | 0.07 | 0.91 | 0.81 | 0.84 | <8:8> |
| PCam:GS | 0.86 | 0.93 | 0.14 | 0.07 | 0.92 | 0.87 | 0.89 | <4:4> |
| PCam:SP-RGB | 0.80 | 0.91 | 0.20 | 0.09 | 0.90 | 0.82 | 0.85 | <8:8> |
| PCam:SP-GS | 0.87 | 0.91 | 0.13 | 0.09 | 0.91 | 0.88 | 0.89 | <8:8> |
| PCam:RGB [baseline] | 0.78 | 0.93 | 0.22 | 0.07 | 0.92 | 0.81 | 0.84 | <32:32> |
| MHIST:RGB | 0.78 | 0.73 | 0.22 | 0.27 | 0.74 | 0.77 | 0.77 | <8:8> |
| MHIST:GS | 0.82 | 0.68 | 0.18 | 0.32 | 0.72 | 0.79 | 0.77 | <4:4> |
| MHIST:SP-RGB | 0.75 | 0.77 | 0.25 | 0.23 | 0.77 | 0.76 | 0.76 | <4:4> |
| MHIST:SP-GS | 0.77 | 0.65 | 0.23 | 0.35 | 0.69 | 0.74 | 0.73 | <4:4> |
| MHIST:RGB [baseline] | 0.89 | 0.63 | 0.11 | 0.37 | 0.71 | 0.86 | 0.76 | <32:32> |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alali, M.H.; Roohi, A.; Angizi, S.; Deogun, J.S. Enabling Intelligent IoTs for Histopathology Image Analysis Using Convolutional Neural Networks. Micromachines 2022, 13, 1364. https://doi.org/10.3390/mi13081364
Alali MH, Roohi A, Angizi S, Deogun JS. Enabling Intelligent IoTs for Histopathology Image Analysis Using Convolutional Neural Networks. Micromachines. 2022; 13(8):1364. https://doi.org/10.3390/mi13081364
Chicago/Turabian StyleAlali, Mohammed H., Arman Roohi, Shaahin Angizi, and Jitender S. Deogun. 2022. "Enabling Intelligent IoTs for Histopathology Image Analysis Using Convolutional Neural Networks" Micromachines 13, no. 8: 1364. https://doi.org/10.3390/mi13081364
APA StyleAlali, M. H., Roohi, A., Angizi, S., & Deogun, J. S. (2022). Enabling Intelligent IoTs for Histopathology Image Analysis Using Convolutional Neural Networks. Micromachines, 13(8), 1364. https://doi.org/10.3390/mi13081364