
Automatic Bounding Box Annotation with Small Training Datasets for Industrial Manufacturing


Abstract
1. Introduction
2. Related Work
2.1. Object Detection
2.2. Small Datasets
2.3. Bounding Box Annotation
3. Material and Methods
3.1. Use Case
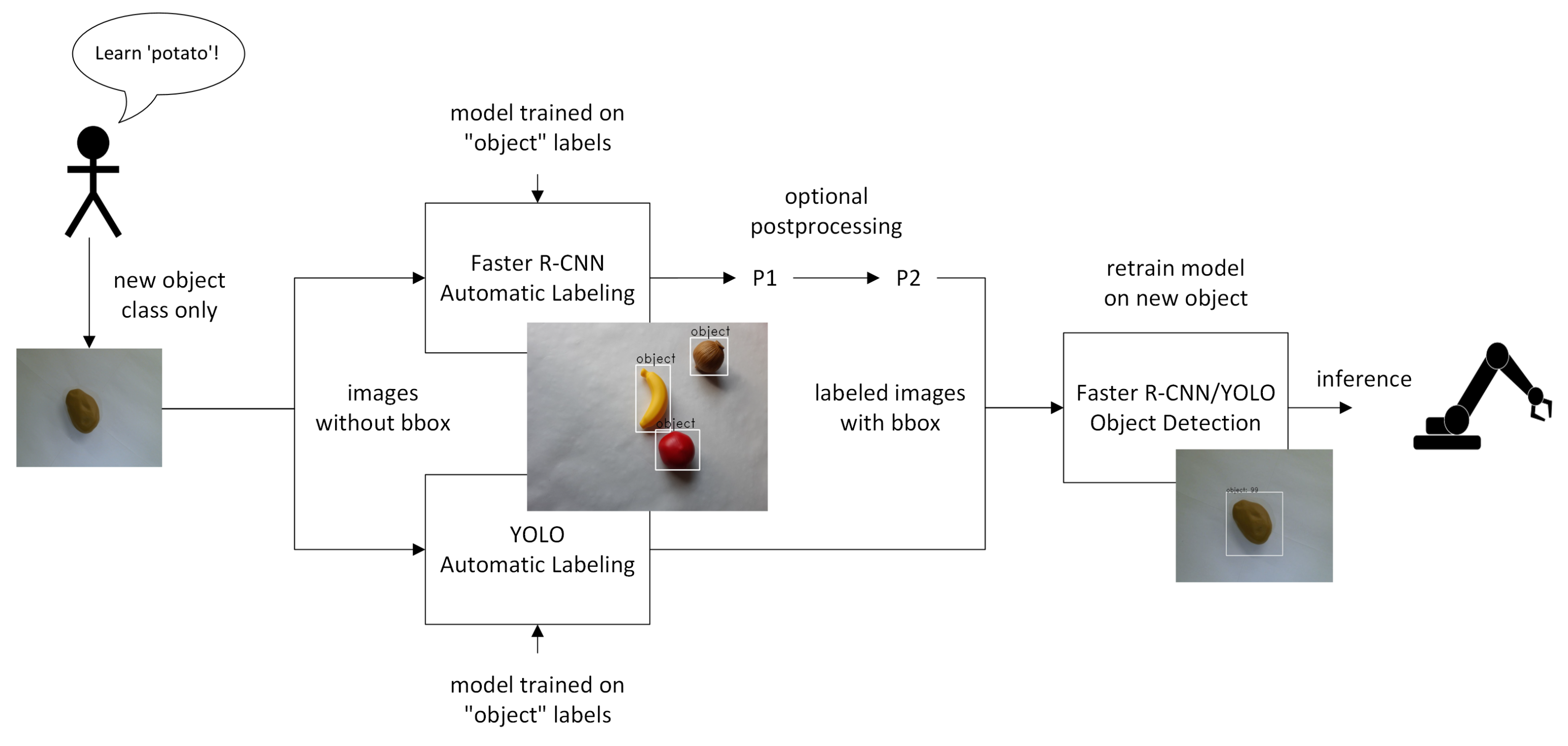
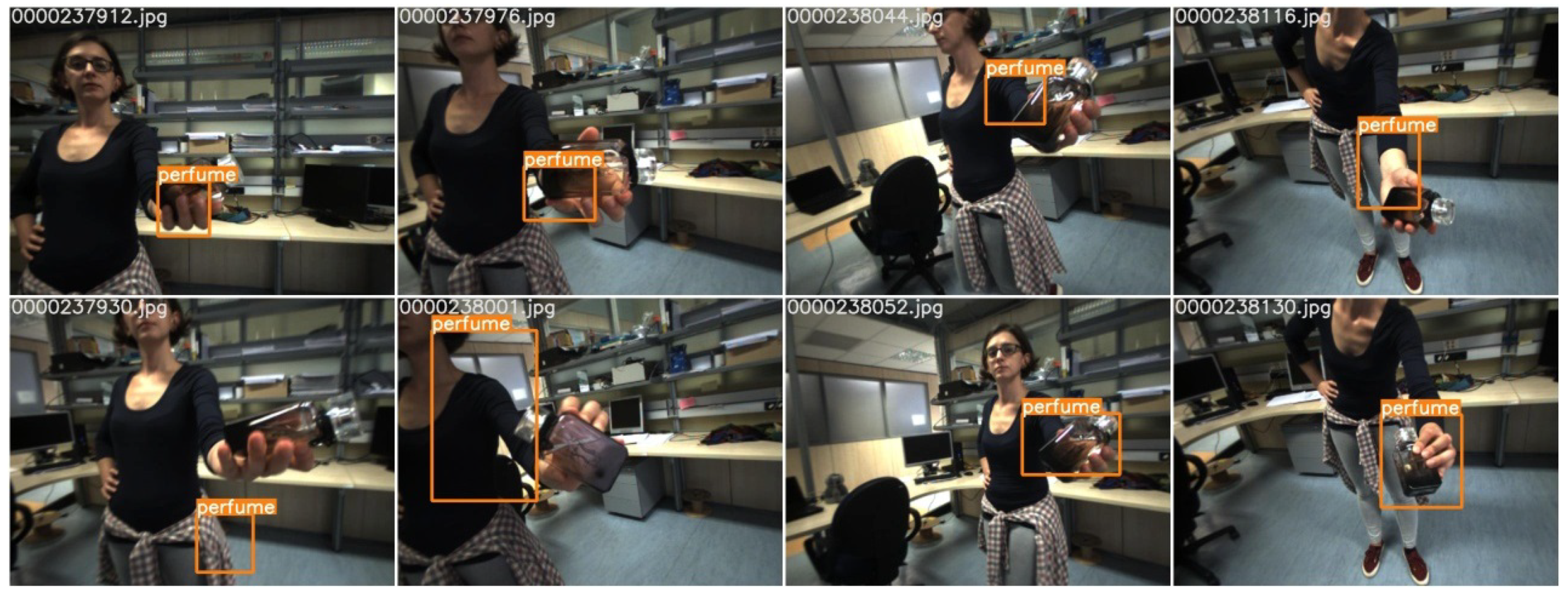
3.2. Our Approach
- (P1)
- If the model erroneously predicts more than one bounding box per image, merge all bounding boxes into one, which is the smallest bounding box containing all others;
- (P2)
- Add some additional slack; that is, increase the bounding box by a few pixels on each side.
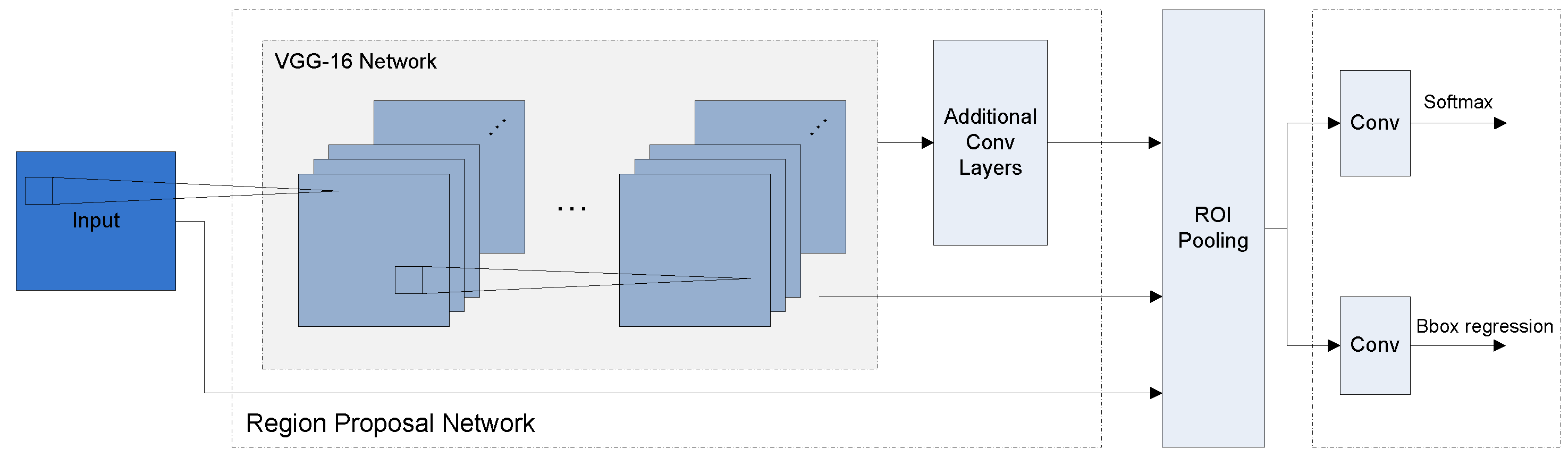
3.2.1. Faster R-CNN
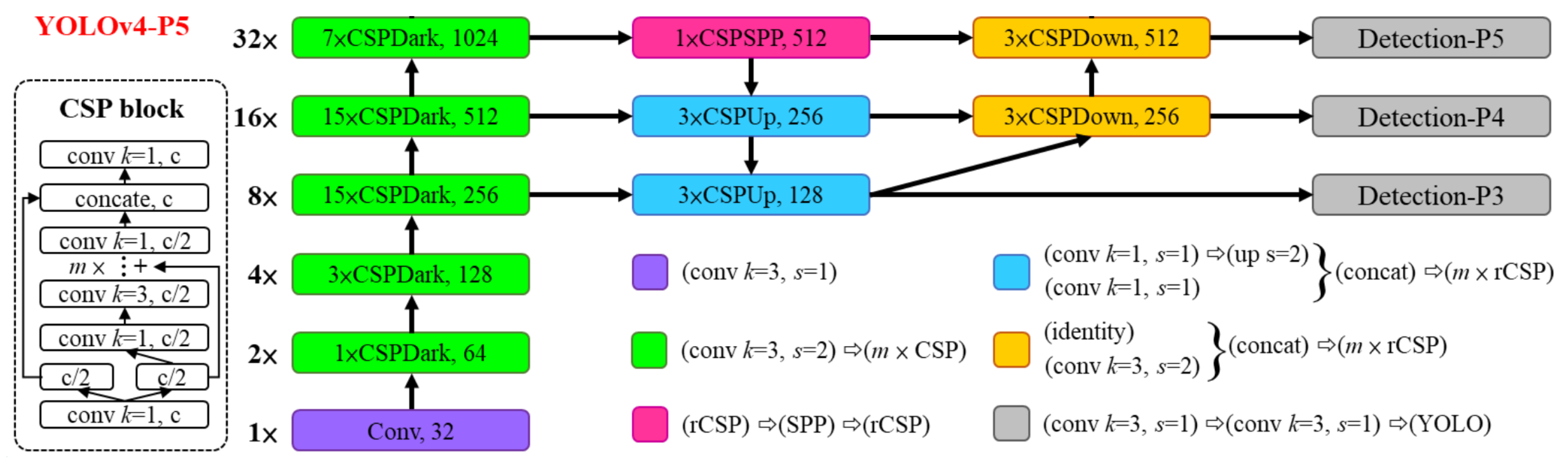
3.2.2. YOLOv4-p5
3.3. Datasets
3.3.1. Fruits
3.3.2. iCubWorld
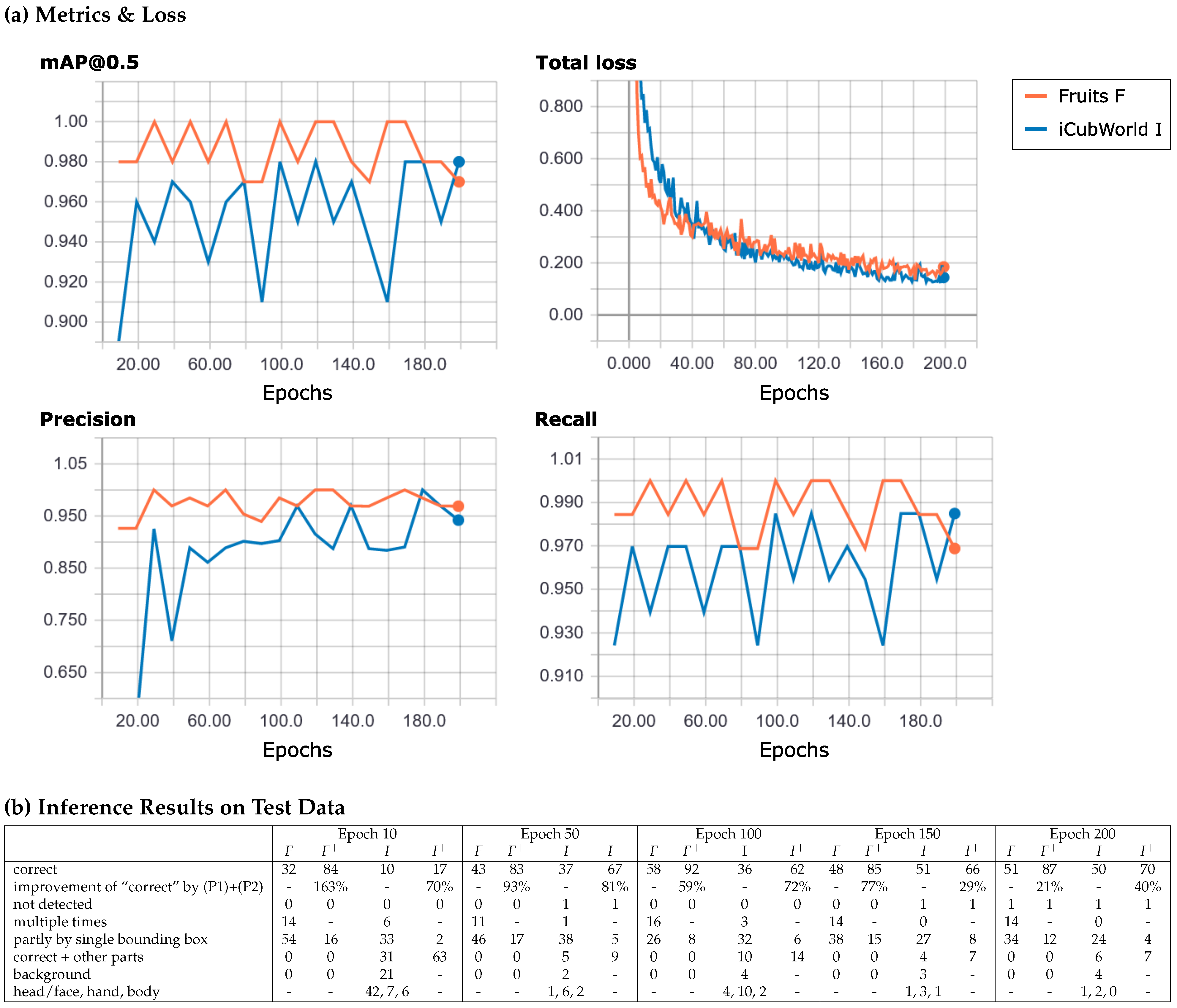
4. Results and Discussion
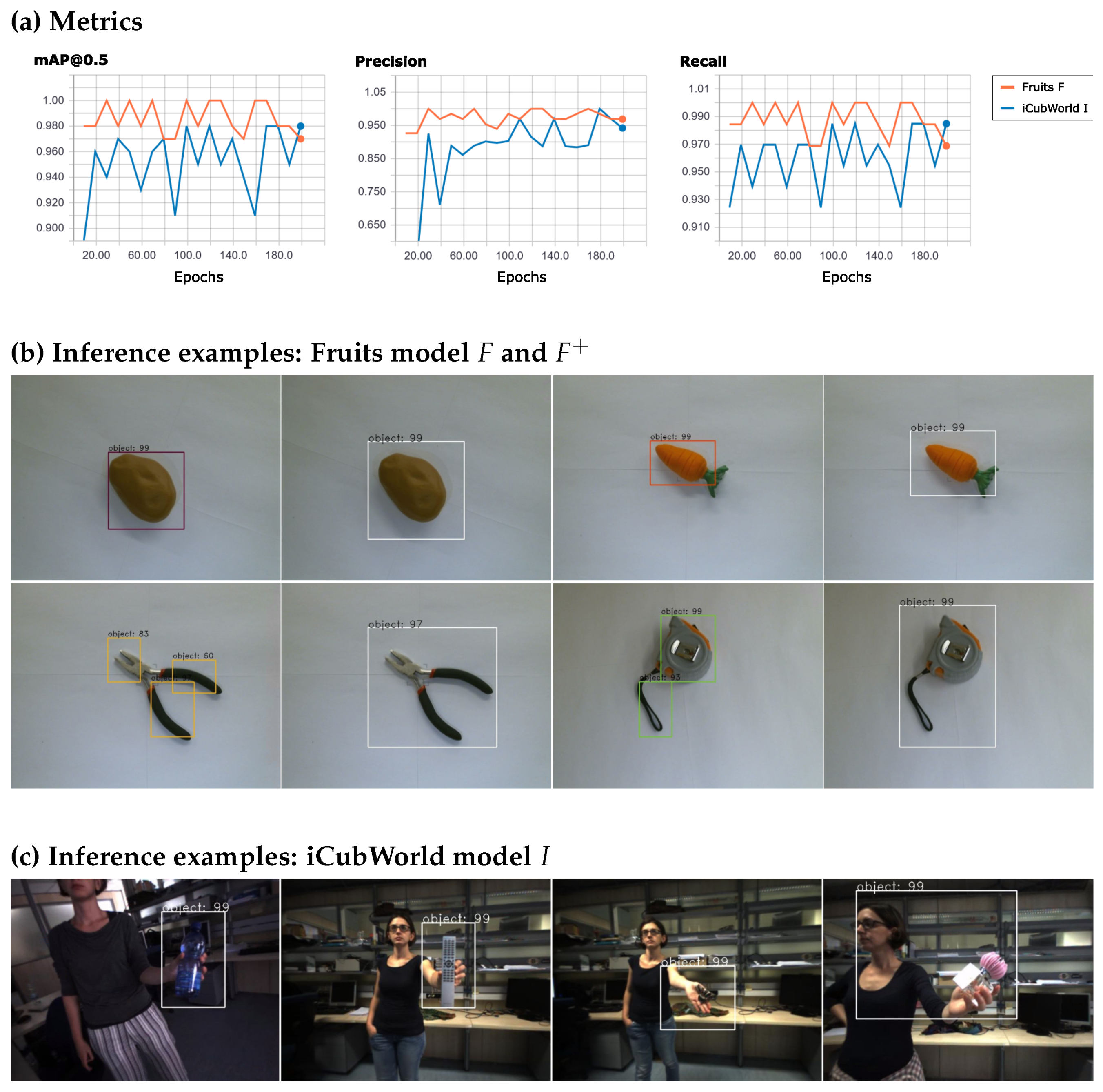
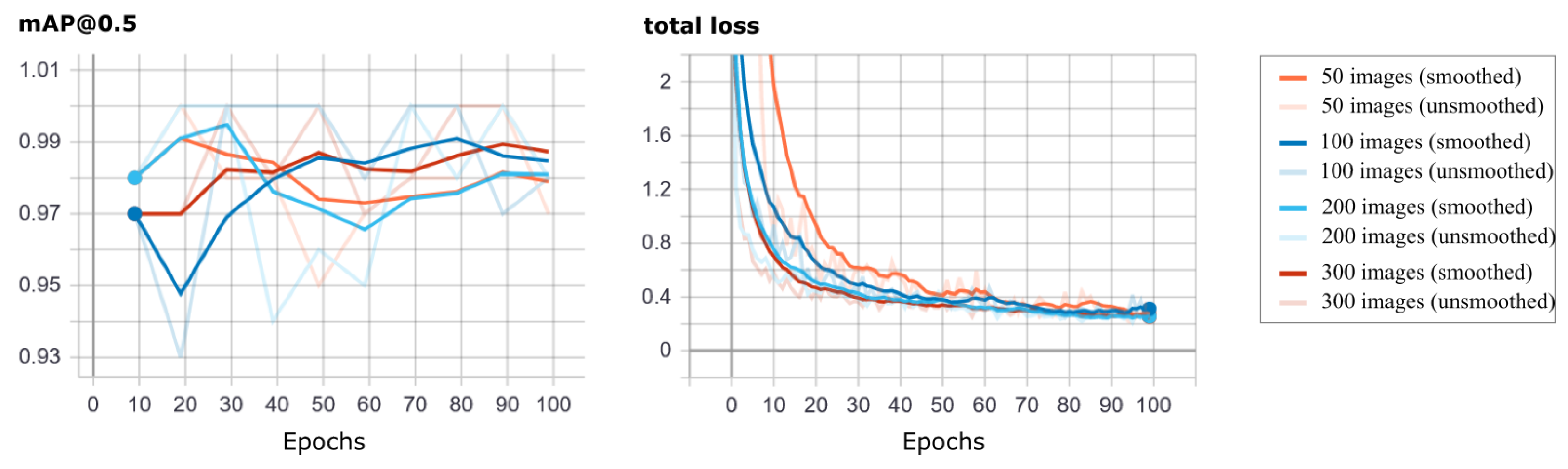
4.1. Experiments with Faster R-CNN
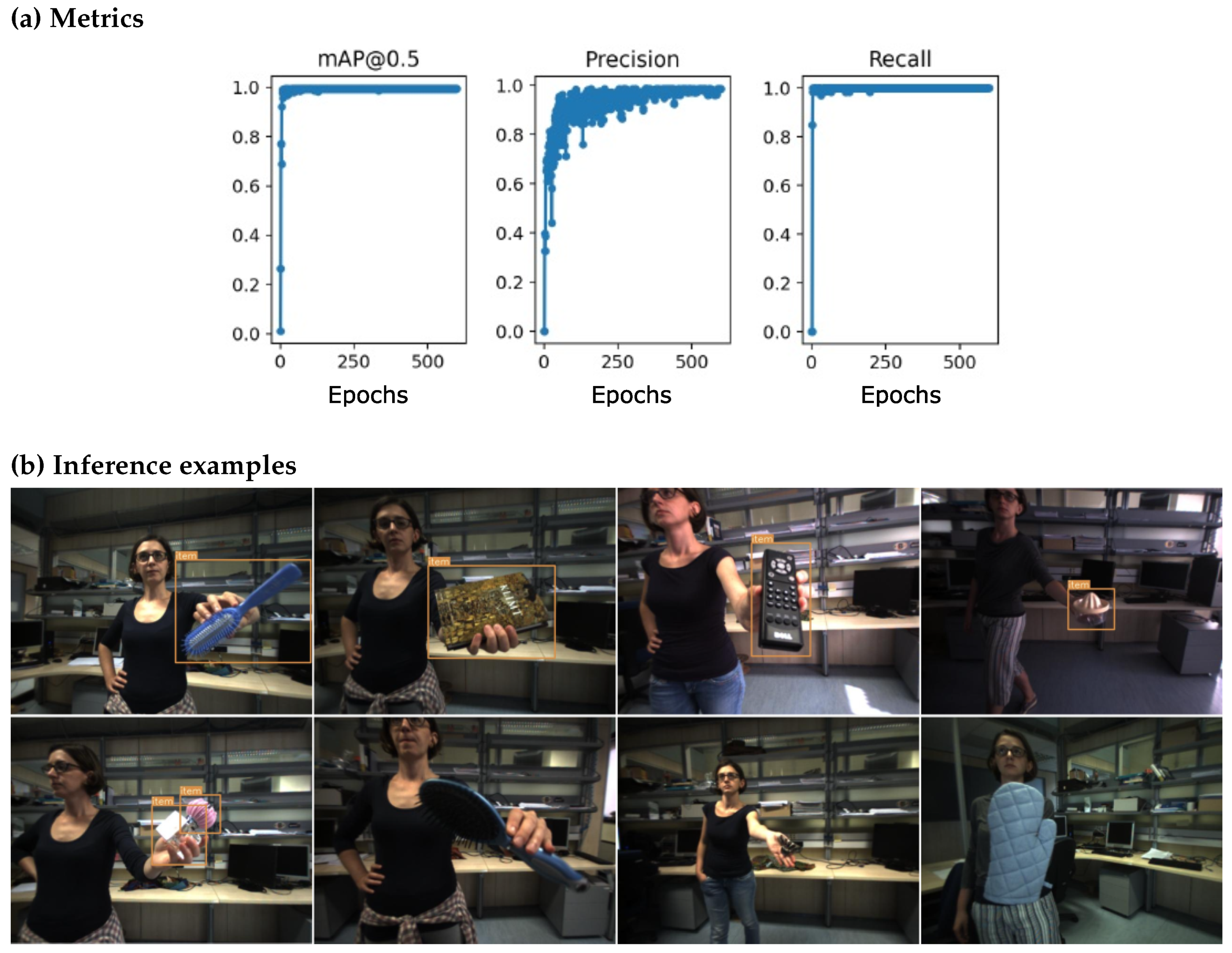
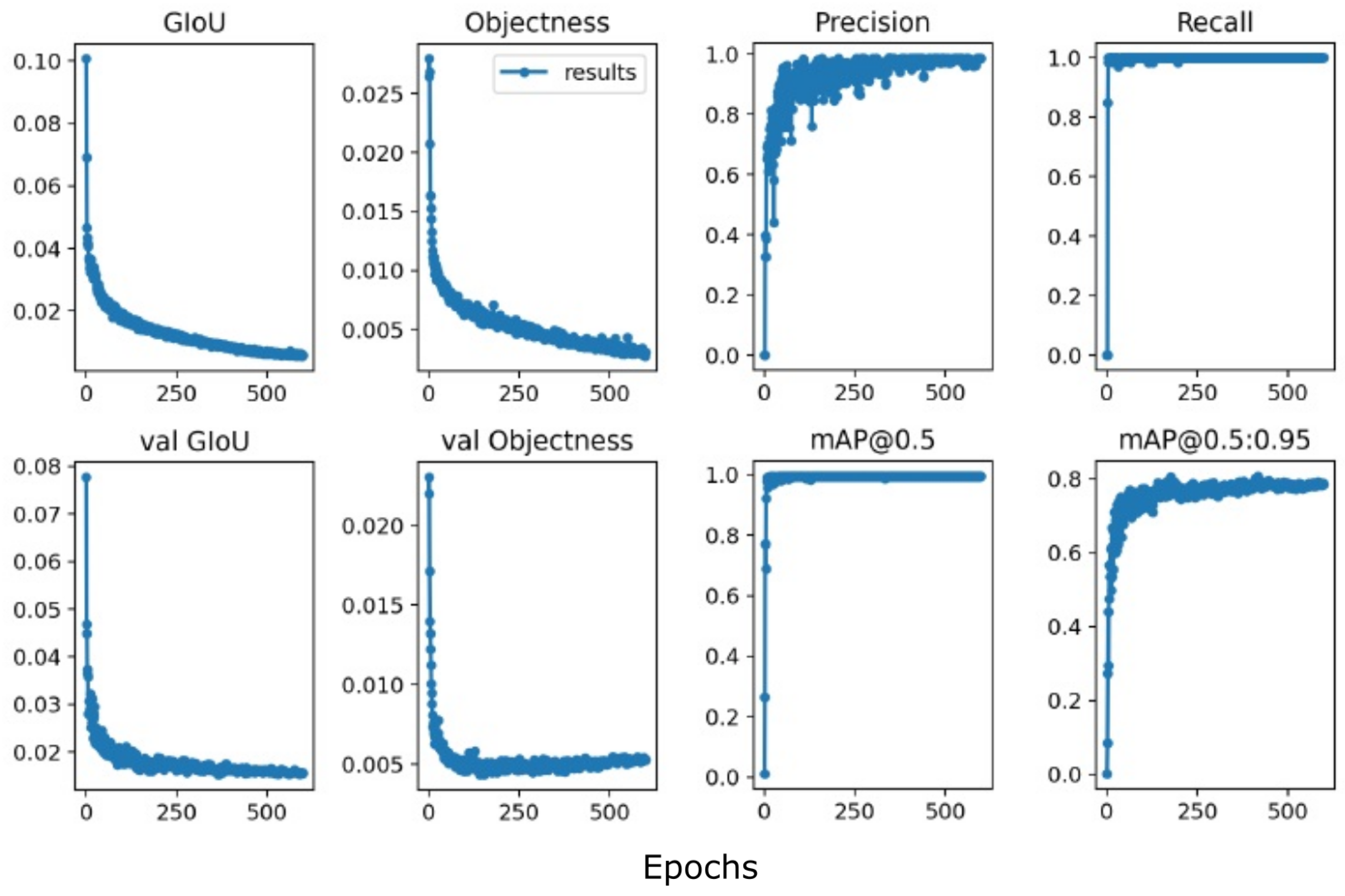
4.2. Experiments with Scaled-YOLOv4-p5
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

- Correct:
- Good detection, i.e., correct label, good bounding box, and no false positives/negatives.
- Improvement in “correct” by (P1) and (P2):
- The improvement in the correctly identified bounding boxes from F to and I to , respectively.
- Not detected:
- The object is not detected.
- Multiple times:
- Multiple bounding boxes covering the object or parts of it are inferred.
- Partly by single bounding box:
- The object is detected by a single bounding box but the box misses parts of the object. We explicitly emphasize that this mostly corresponds to only very small missing parts (see also Section 4.1).
- Correct and other parts:
- The object is well detected but other parts of the image are detected as well (see also the remaining two categories). We also count here objects that are detected by a bounding box that is at least twice as large as necessary, containing also, e.g., the person’s hand in the iCubWorld dataset.
- Background:
- The background is detected. For the iCubWorld dataset, we do not include here the detection of (parts of) the person presenting the object. This is covered by the next category.
- Head/face, hand, and body:
- The head/face, hand, or other parts of the body of the person presenting the object are detected (only applies to the iCubWorld dataset).

References
- Mehrabi, M.; Ulsoy, A.; Koren, Y. Reconfigurable Manufacturing Systems: Key to Future Manufacturing. J. Intell. Manuf. 2000, 11, 403–419. [Google Scholar] [CrossRef]
- Matheson, E.; Minto, R.; Zampieri, E.; Faccio, M.; Rosati, G. Human–Robot Collaboration in Manufacturing Applications: A Review. Robotics 2019, 8, 100. [Google Scholar] [CrossRef]
- Alonso, M.; Izaguirre, A.; Graña, M. Current research trends in robot grasping and bin picking. In Proceedings of the 13th International Conference on Soft Computing Models in Industrial and Environmental Applications, San Sebastian, Spain, 6–8 June 2018; Springer: Berlin, Germany, 2018; pp. 367–376. [Google Scholar]
- Ojer, M.; Lin, X.; Tammaro, A.; Sanchez, J.R. PickingDK: A Framework for Industrial Bin-Picking Applications. Appl. Sci. 2022, 12, 9200. [Google Scholar] [CrossRef]
- Scheirer, W.J.; de Rezende Rocha, A.; Sapkota, A.; Boult, T.E. Toward open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1757–1772. [Google Scholar] [CrossRef] [PubMed]
- Bendale, A.; Boult, T.E. Towards open set deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Paradise, NV, USA, 27–30 June 2016; pp. 1563–1572. [Google Scholar]
- Bendale, A.; Boult, T. Towards open world recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1893–1902. [Google Scholar]
- Geiß, M.; Baresch, M.; Chasparis, G.; Schweiger, E.; Teringl, N.; Zwick, M. Fast and Automatic Object Registration for Human-Robot Collaboration in Industrial Manufacturing. arXiv 2022, arXiv:2204.00597. [Google Scholar]
- Lee, C.Y.; Chien, C.F. Pitfalls and protocols of data science in manufacturing practice. J. Intell. Manuf. 2022, 33, 1189–1207. [Google Scholar] [CrossRef]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Siméoni, O.; Puy, G.; Vo, H.V.; Roburin, S.; Gidaris, S.; Bursuc, A.; Pérez, P.; Marlet, R.; Ponce, J. Localizing Objects with Self-Supervised Transformers and No Labels. arXiv 2021, arXiv:2109.14279. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Jiang, H.; Learned-Miller, E. Face detection with the faster R-CNN. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 650–657. [Google Scholar] [CrossRef]
- Simon, M.; Amende, K.; Kraus, A.; Honer, J.; Samann, T.; Kaulbersch, H.; Milz, S.; Michael Gross, H. Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, Singapore, 29 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3626–3633. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vision 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, Y.; Chu, J.; Leng, L.; Miao, J. Mask-refined R-CNN: A network for refining object details in instance segmentation. Sensors 2020, 20, 1010. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Kim, J.a.; Sung, J.Y.; Park, S.h. Comparison of Faster-RCNN, YOLO, and SSD for real-time vehicle type recognition. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Republic of Korea, 1–3 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-Shot Learning. arXiv 2020, arXiv:cs.LG/1904.05046. [Google Scholar] [CrossRef]
- Antonelli, S.; Avola, D.; Cinque, L.; Crisostomi, D.; Foresti, G.L.; Galasso, F.; Marini, M.R.; Mecca, A.; Pannone, D. Few-Shot Object Detection: A Survey. ACM Comput. Surv. 2022, 54, 1–37. [Google Scholar] [CrossRef]
- Köhler, M.; Eisenbach, M.; Gross, H.M. Few-Shot Object Detection: A Comprehensive Survey. arXiv 2021, arXiv:2112.11699. [Google Scholar] [CrossRef]
- Jiaxu, L.; Taiyue, C.; Xinbo, G.; Yongtao, Y.; Ye, W.; Feng, G.; Yue, W. A Comparative Review of Recent Few-Shot Object Detection Algorithms. arXiv 2021, arXiv:2111.00201. [Google Scholar] [CrossRef]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-Scale Positive Sample Refinement for Few-Shot Object Detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Proceedings, Part XVI, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 456–472. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. LSTD: A Low-Shot Transfer Detector for Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence; Association for the Advancement of Artificial Intelligence: Palo Alto, CA, USA, 2018; Volume 32. [Google Scholar] [CrossRef]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly Simple Few-Shot Object Detection. In Proceedings of the 37th International Conference on Machine Learning (ICML’20), Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Montreal, QC, Canada, 10–17 October 2021; pp. 8782–8791. [Google Scholar]
- Wu, A.; Han, Y.; Zhu, L.; Yang, Y. Universal-Prototype Enhancing for Few-Shot Object Detection. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9567–9576. [Google Scholar]
- Karlinsky, L.; Shtok, J.; Harary, S.; Schwartz, E.; Aides, A.; Feris, R.; Giryes, R.; Bronstein, A.M. RepMet: Representative-based metric learning for classification and one-shot object detection. arXiv 2018. [Google Scholar] [CrossRef]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-Shot Object Detection With Attention-RPN and Multi-Relation Detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4012–4021. [Google Scholar] [CrossRef]
- Osokin, A.; Sumin, D.; Lomakin, V. OS2D: One-Stage One-Shot Object Detection by Matching Anchor Features. In Proceedings of the Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 635–652. [Google Scholar]
- Hsieh, T.I.; Lo, Y.C.; Chen, H.T.; Liu, T.L. One-Shot Object Detection with Co-Attention and Co-Excitation. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Li, B.; Yang, B.; Liu, C.; Liu, F.; Ji, R.; Ye, Q. Beyond Max-Margin: Class Margin Equilibrium for Few-shot Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7359–7368. [Google Scholar] [CrossRef]
- Han, G.; He, Y.; Huang, S.; Ma, J.; Chang, S.F. Query Adaptive Few-Shot Object Detection with Heterogeneous Graph Convolutional Networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3243–3252. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-Shot Object Detection via Feature Reweighting. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–29 November 2019; pp. 8419–8428. [Google Scholar] [CrossRef]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Meta-Learning to Detect Rare Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–29 November 2019; pp. 9924–9933. [Google Scholar] [CrossRef]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta R-CNN: Towards General Solver for Instance-Level Low-Shot Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–29 November 2019; pp. 9576–9585. [Google Scholar] [CrossRef]
- Xiao, Y.; Marlet, R. Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Proceedings, Part XVII, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 192–210. [Google Scholar] [CrossRef]
- Cheng, J.; Chen, S.; Liu, K.; Yang, L.; Wang, D. BackgroundNet: Small Dataset-Based Object Detection in Stationary Scenes. In Proceedings of the Advances in Swarm Intelligence; Tan, Y., Shi, Y., Niu, B., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 272–281. [Google Scholar]
- Baharuddin, M.Z.; How, D.N.T.; Sahari, K.S.M.; Abas, A.Z.; Ramlee, M.K. Object Detection Model Training Framework for Very Small Datasets Applied to Outdoor Industrial Structures. In Proceedings of the Advances in Visual Informatics; Badioze Zaman, H., Smeaton, A.F., Shih, T.K., Velastin, S., Terutoshi, T., Jørgensen, B.N., Aris, H., Ibrahim, N., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 540–551. [Google Scholar]
- Howard, J.; Gugger, S. Fastai: A Layered API for Deep Learning. Information 2020, 11, 108. [Google Scholar] [CrossRef]
- Smith, L.N. A disciplined approach to neural network hyper-parameters: Part 1—Learning rate, batch size, momentum, and weight decay. arXiv 2018, arXiv:cs.LG/1803.09820. [Google Scholar]
- Wright, L.; Demeure, N. Ranger21: A synergistic deep learning optimizer. arXiv 2021, arXiv:2106.13731. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Cheng, Q.; Zhang, Q.; Fu, P.; Tu, C.; Li, S. A survey and analysis on automatic image annotation. Pattern Recognit. 2018, 79, 242–259. [Google Scholar] [CrossRef]
- Papadopoulos, D.P.; Uijlings, J.R.; Keller, F.; Ferrari, V. We do not need no bounding-boxes: Training object class detectors using only human verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Paradise, NV, USA, 26 June–1 July 2016; pp. 854–863. [Google Scholar]
- Wu, J.; Gur, Y.; Karargyris, A.; Syed, A.B.; Boyko, O.; Moradi, M.; Syeda-Mahmood, T. Automatic bounding box annotation of chest X-ray data for localization of abnormalities. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 799–803. [Google Scholar] [CrossRef]
- Adhikari, B.; Peltomaki, J.; Puura, J.; Huttunen, H. Faster bounding box annotation for object detection in indoor scenes. In Proceedings of the 2018 7th European Workshop on Visual Information Processing (EUVIP), Tampere, Finland, 26–28 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ge, C.; Wang, J.; Wang, J.; Qi, Q.; Sun, H.; Liao, J. Towards automatic visual inspection: A weakly supervised learning method for industrial applicable object detection. Comput. Ind. 2020, 121, 103232. [Google Scholar] [CrossRef]
- Kiyokawa, T.; Tomochika, K.; Takamatsu, J.; Ogasawara, T. Fully automated annotation with noise-masked visual markers for deep-learning-based object detection. IEEE Robot. Autom. Lett. 2019, 4, 1972–1977. [Google Scholar] [CrossRef]
- Apud Baca, J.G.; Jantos, T.; Theuermann, M.; Hamdad, M.A.; Steinbrener, J.; Weiss, S.; Almer, A.; Perko, R. Automated Data Annotation for 6-DoF AI-Based Navigation Algorithm Development. J. Imaging 2021, 7, 236. [Google Scholar] [CrossRef] [PubMed]
- Le, T.N.; Sugimoto, A.; Ono, S.; Kawasaki, H. Toward interactive self-annotation for video object bounding box: Recurrent self-learning and hierarchical annotation based framework. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 2–5 March 2020; pp. 3231–3240. [Google Scholar]
- Konyushkova, K.; Uijlings, J.; Lampert, C.H.; Ferrari, V. Learning intelligent dialogs for bounding box annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9175–9184. [Google Scholar]
- Adhikari, B.; Huttunen, H. Iterative bounding box annotation for object detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4040–4046. [Google Scholar] [CrossRef]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Gupta, B.B.; Chen, X.; Wang, X. A Survey of Deep Active Learning. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Wong, V.W.H.; Ferguson, M.; Law, K.H.; Lee, Y.T.T. An assistive learning workflow on annotating images for object detection. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1962–1970. [Google Scholar] [CrossRef]
- Wei, X.S.; Zhang, C.L.; Li, Y.; Xie, C.W.; Wu, J.; Shen, C.; Zhou, Z.H. Deep Descriptor Transforming for Image Co-Localization. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 3048–3054. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Paradise, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Rubinstein, M.; Joulin, A.; Kopf, J.; Liu, C. Unsupervised joint object discovery and segmentation in internet images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1939–1946. [Google Scholar]
- Mnyusiwalla, H.; Triantafyllou, P.; Sotiropoulos, P.; Roa, M.A.; Friedl, W.; Sundaram, A.M.; Russell, D.; Deacon, G. A Bin-Picking Benchmark for Systematic Evaluation of Robotic Pick-and-Place Systems. IEEE Robot. Autom. Lett. 2020, 5, 1389–1396. [Google Scholar] [CrossRef]
- Fanello, S.; Ciliberto, C.; Santoro, M.; Natale, L.; Metta, G.; Rosasco, L.; Odone, F. icub world: Friendly robots help building good vision data-sets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 700–705. [Google Scholar]
- Ulrich, M.; Follmann, P.; Neudeck, J.H. A comparison of shape-based matching with deep-learning-based object detection. tm-Tech. Mess. 2019, 86, 685–698. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Datasets Used in Our Study | |||||
|---|---|---|---|---|---|
| Dataset | No. Images | No. Classes | Training Classes Contained | ||
| Train and val | Test | Train and val | Test | in Test Data | |
| Fruits | 330 | 100 | 5 | 20 | Some contained |
| iCubWorld | 659 | 82 | 7 | 20 | All contained |
| (b) Faster R-CNN Models Used in Our Study | |||||
| Model | Training Dataset | Post-Processing (P1) and (P2) | |||
| F | Fruits | no | |||
| Fruits | yes | ||||
| I | iCubWorld | no | |||
| iCubWorld | yes | ||||
| F | LOST [11] | |
|---|---|---|
| Correct prediction | 87% | 65% |
| Not detected | 1% | 12% |
| Partly detected | 12% | 23% |
| Inference time per image | ∼1.5 s (CPU) | ∼3.5 s (GPU) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geiß, M.; Wagner, R.; Baresch, M.; Steiner, J.; Zwick, M. Automatic Bounding Box Annotation with Small Training Datasets for Industrial Manufacturing. Micromachines 2023, 14, 442. https://doi.org/10.3390/mi14020442
Geiß M, Wagner R, Baresch M, Steiner J, Zwick M. Automatic Bounding Box Annotation with Small Training Datasets for Industrial Manufacturing. Micromachines. 2023; 14(2):442. https://doi.org/10.3390/mi14020442
Chicago/Turabian StyleGeiß, Manuela, Raphael Wagner, Martin Baresch, Josef Steiner, and Michael Zwick. 2023. "Automatic Bounding Box Annotation with Small Training Datasets for Industrial Manufacturing" Micromachines 14, no. 2: 442. https://doi.org/10.3390/mi14020442
APA StyleGeiß, M., Wagner, R., Baresch, M., Steiner, J., & Zwick, M. (2023). Automatic Bounding Box Annotation with Small Training Datasets for Industrial Manufacturing. Micromachines, 14(2), 442. https://doi.org/10.3390/mi14020442