

K8sSim: A Simulation Tool for Kubernetes Schedulers and Its Applications in Scheduling Algorithm Optimization

Abstract
:1. Introduction
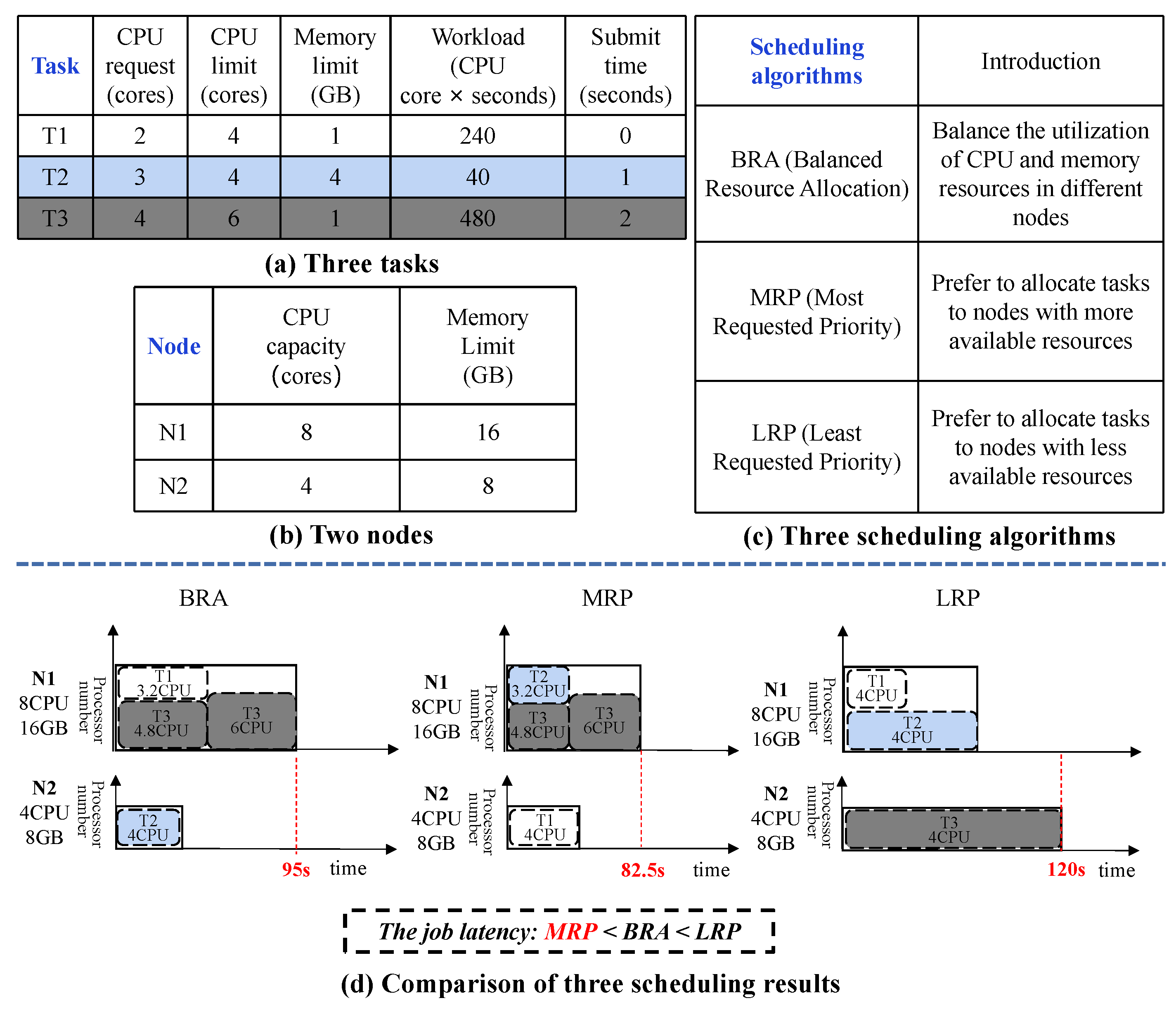
- The selection of scheduling algorithms has considerable impacts on workload performance. Thus, how to accurately evaluate the performance of different scheduling algorithms is a key challenge.
- It takes a prohibitively long time to select the optimal algorithm because applying one algorithm in one single job may take at least a few minutes to complete. Thus, how to quickly obtain the performance of each scheduling algorithm is also a key challenge.
- ▷
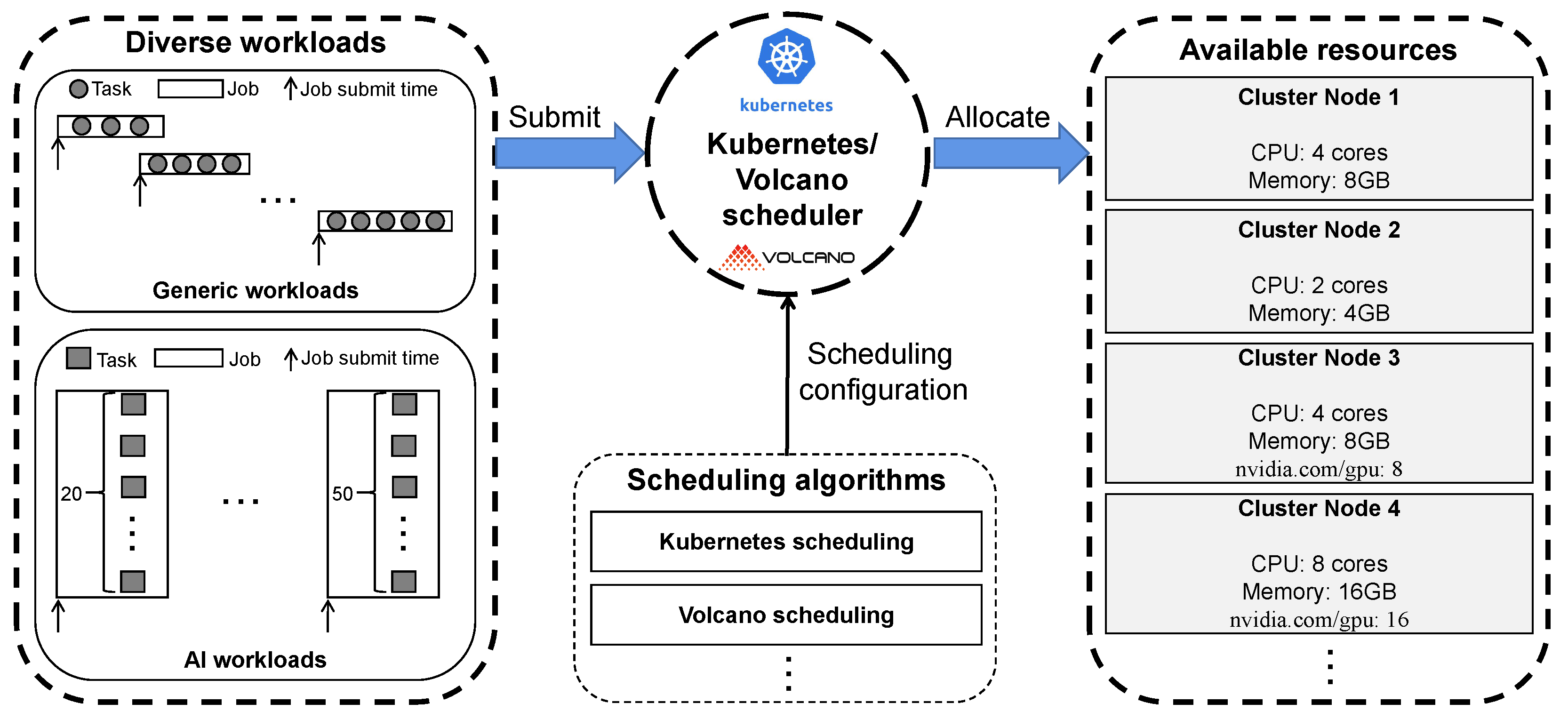
- Simulation driven by real-world workload traces. We study and analyze the real Alibaba cluster traces [11]. Then we obtain the characteristics of real cluster workloads, such as job arrival pattern, the number of tasks in a job, the resource (CPU, GPU and memory) request and resource limit of each task, and the running time of each task. According to this crucial information, we generate two different workloads for effectively evaluating the performance of different scheduling algorithms: TaskQueue workloads and JobQueue workloads.
- ▷
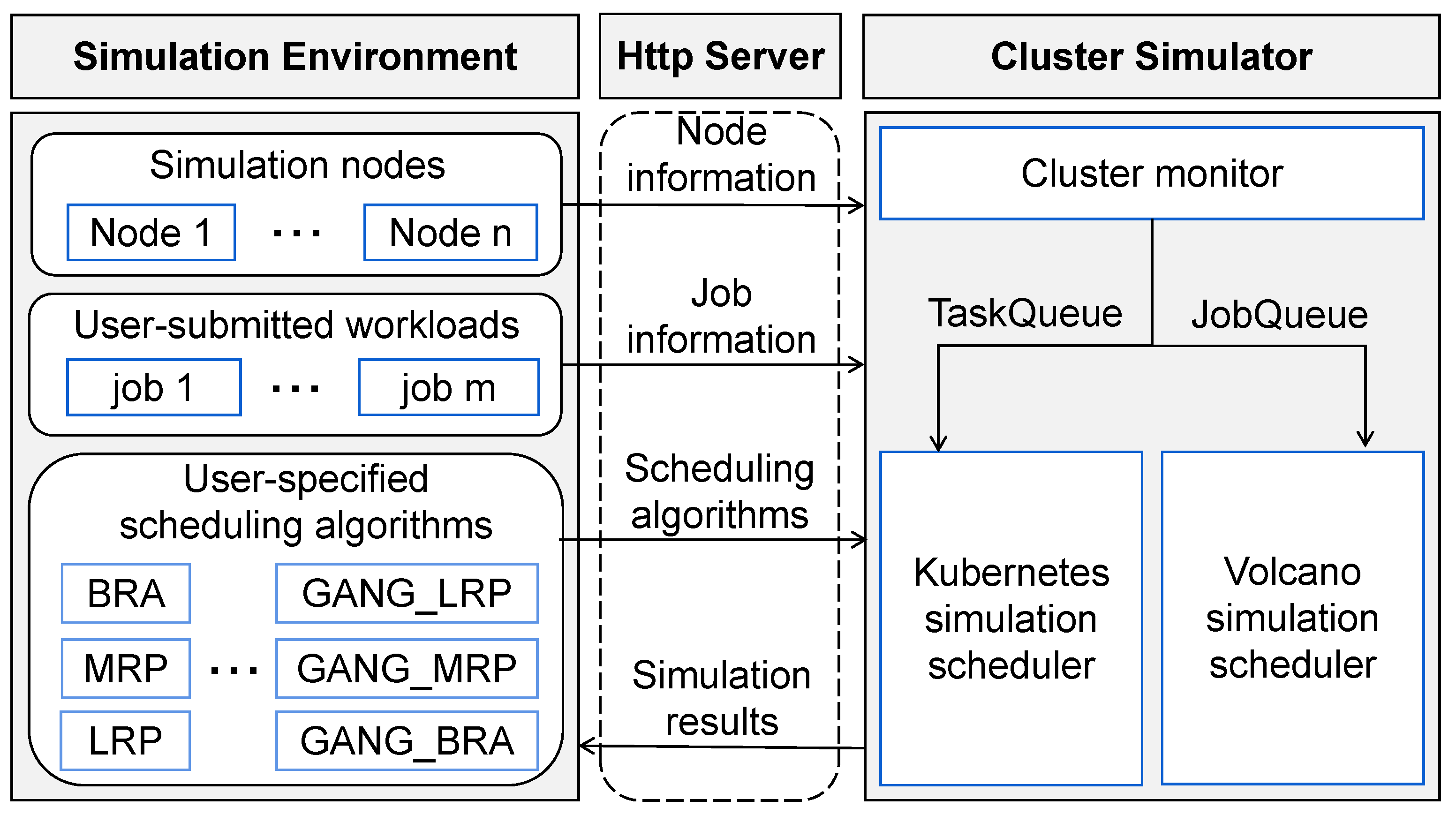
- Proposed K8sSim framework. In order to quickly evaluate the performance impacts of different scheduling algorithms, we propose and implement a cluster simulator framework called K8sSim. It have three key components: Http Server, simulation environment and cluster simulator. Among them, the Http Server is used to communicate between the simulation environment and the cluster simulator. The simulation environment is used to provide the information of simulation nodes’ configuration, user-submitted workloads and user-specified scheduling algorithms. The cluster simulator is the core of the whole framework, which is responsible for classifying and scheduling workloads. Most importantly, the cluster simulator implements the Kubernetes simulation scheduler and Volcano simulation scheduler so as to simulate TaskQueue and JobQueue workloads’ scheduling, respectively.
- ▷
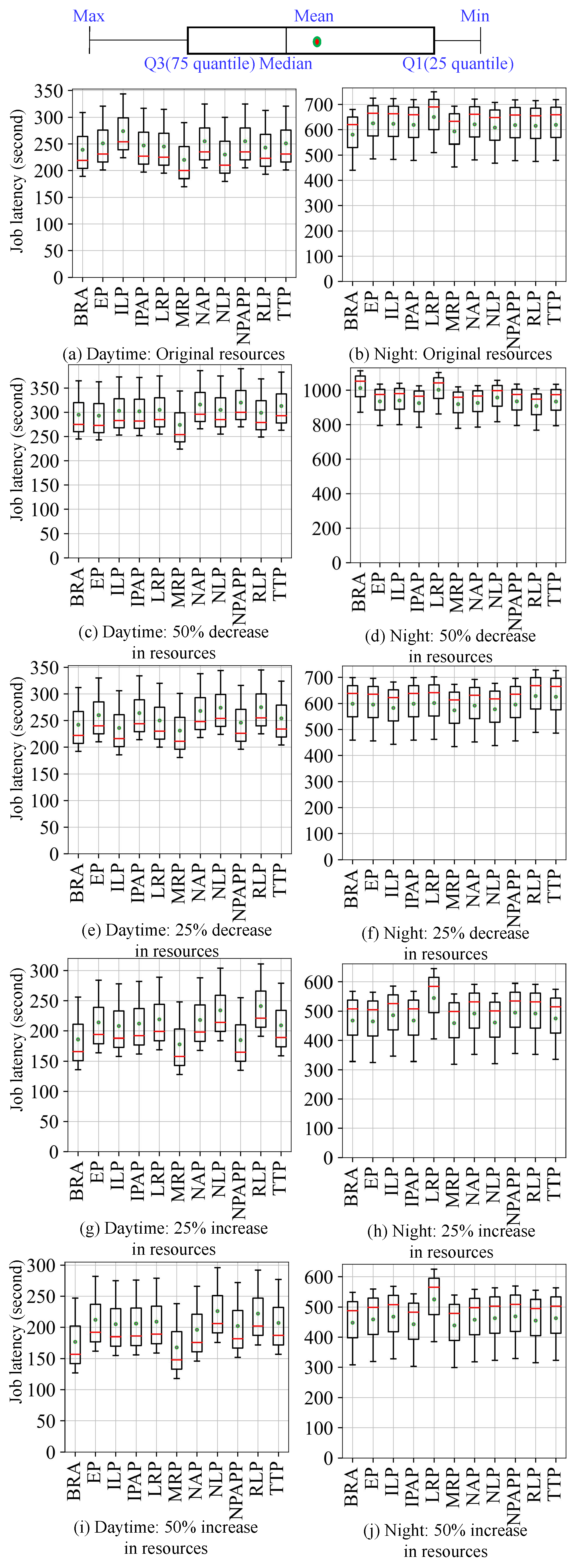
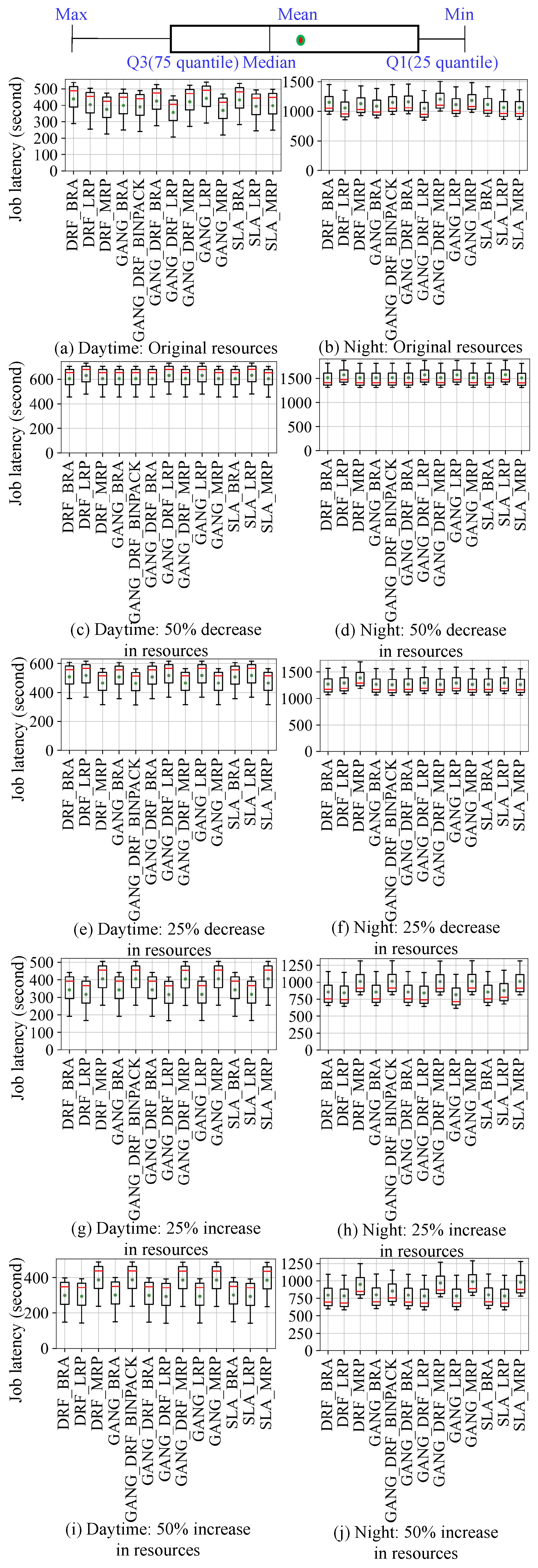
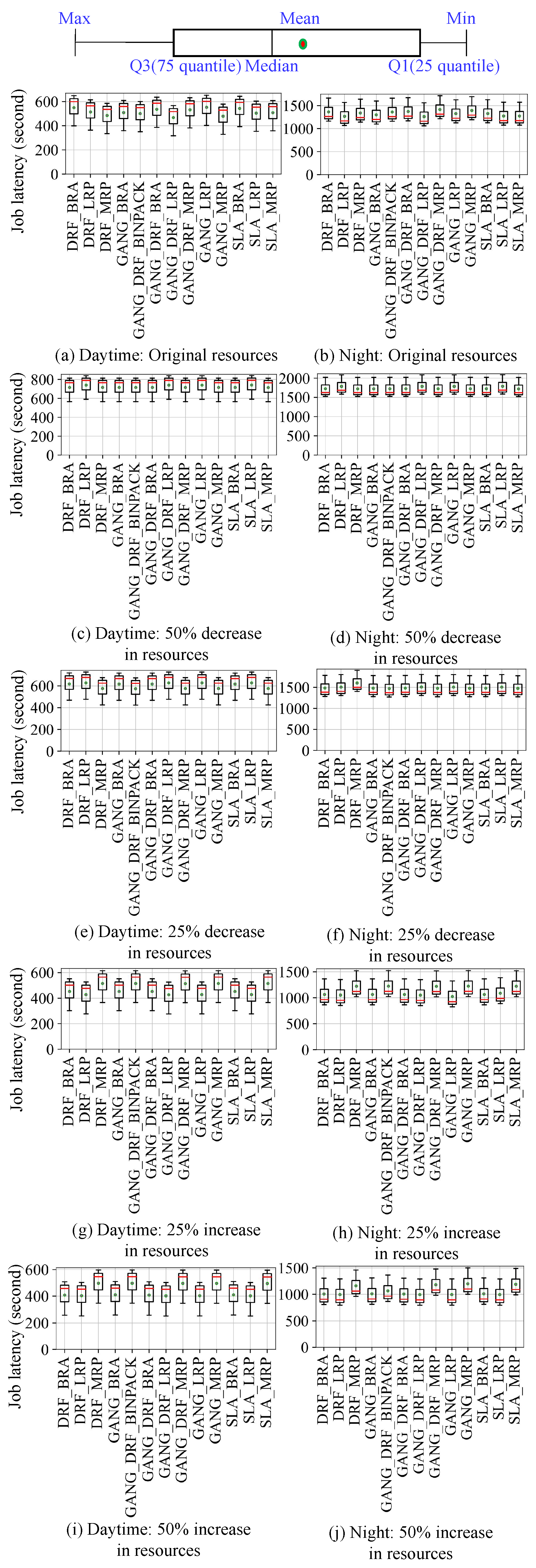
- Evaluation of effectiveness and acceleration of K8sSim. First, we implement 11 Kubernetes scheduling algorithms and 13 Volcano scheduling algorithms in K8sSim. Then, in order to evaluate its effectiveness and acceleration effect, we conduct a series of experiments in the real Kubernetes cluster and the simulation environment. Note that we define a novel indicator to more intuitively show the effectiveness of K8sSim. Finally, the experimental results demonstrate that (i) compared to the real cluster, K8sSim can accurately evaluate the performance of different scheduling algorithms with similar , and (ii) by comparing the scheduling times of different algorithms in the two environments, we observe that in all considered scenarios, K8sSim can accelerates this time by an average of 38.56× (acceleration by up to 72.80×).
2. Background and Related Work
2.1. Background
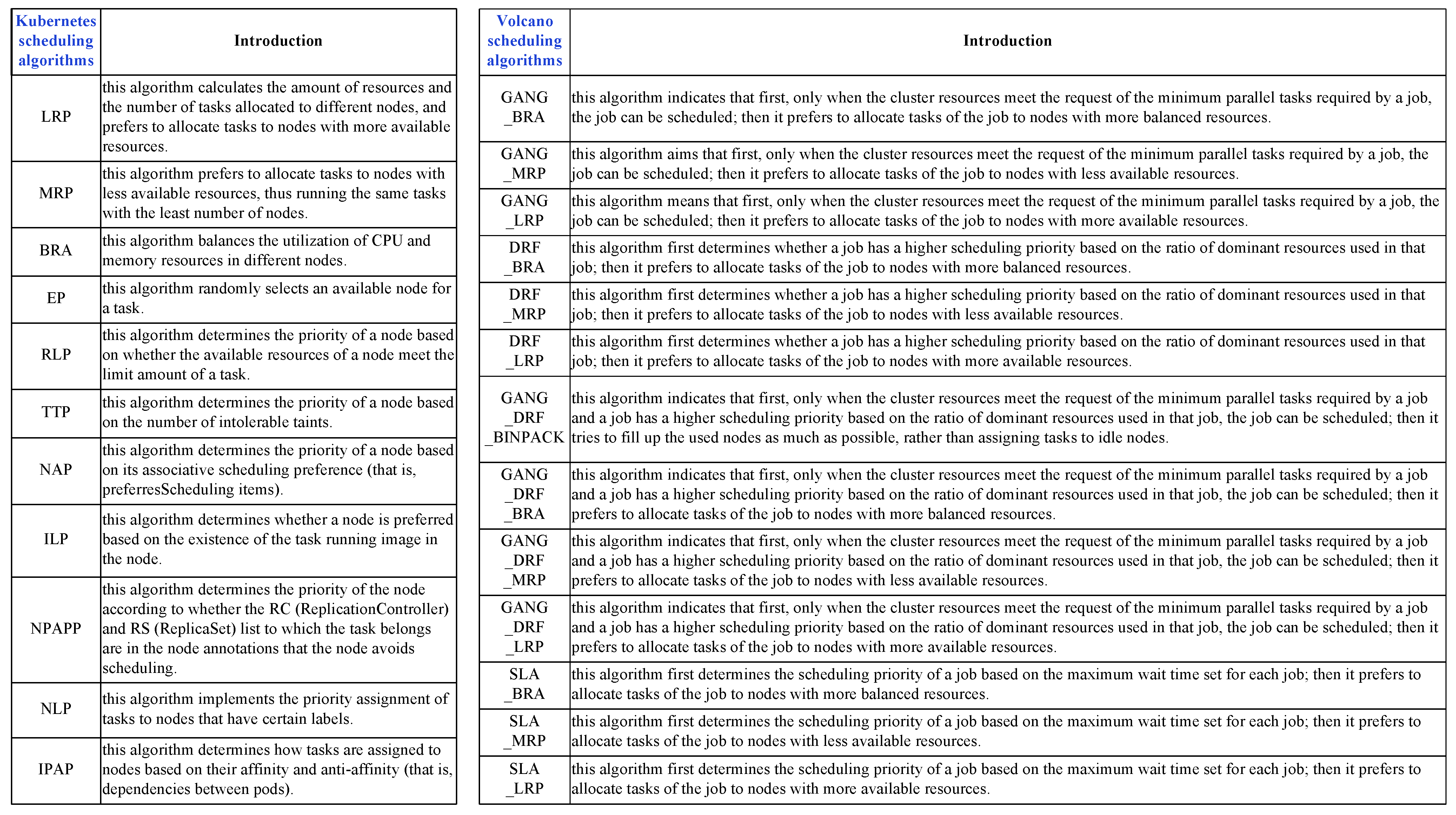
2.2. Existing Benchmark Test Sets
2.3. Existing Cluster Simulators
3. Our Proposed Cluster Simulator Framework
3.1. Overview
3.2. Http Server
3.3. Simulation Environment
3.4. Cluster Simulator
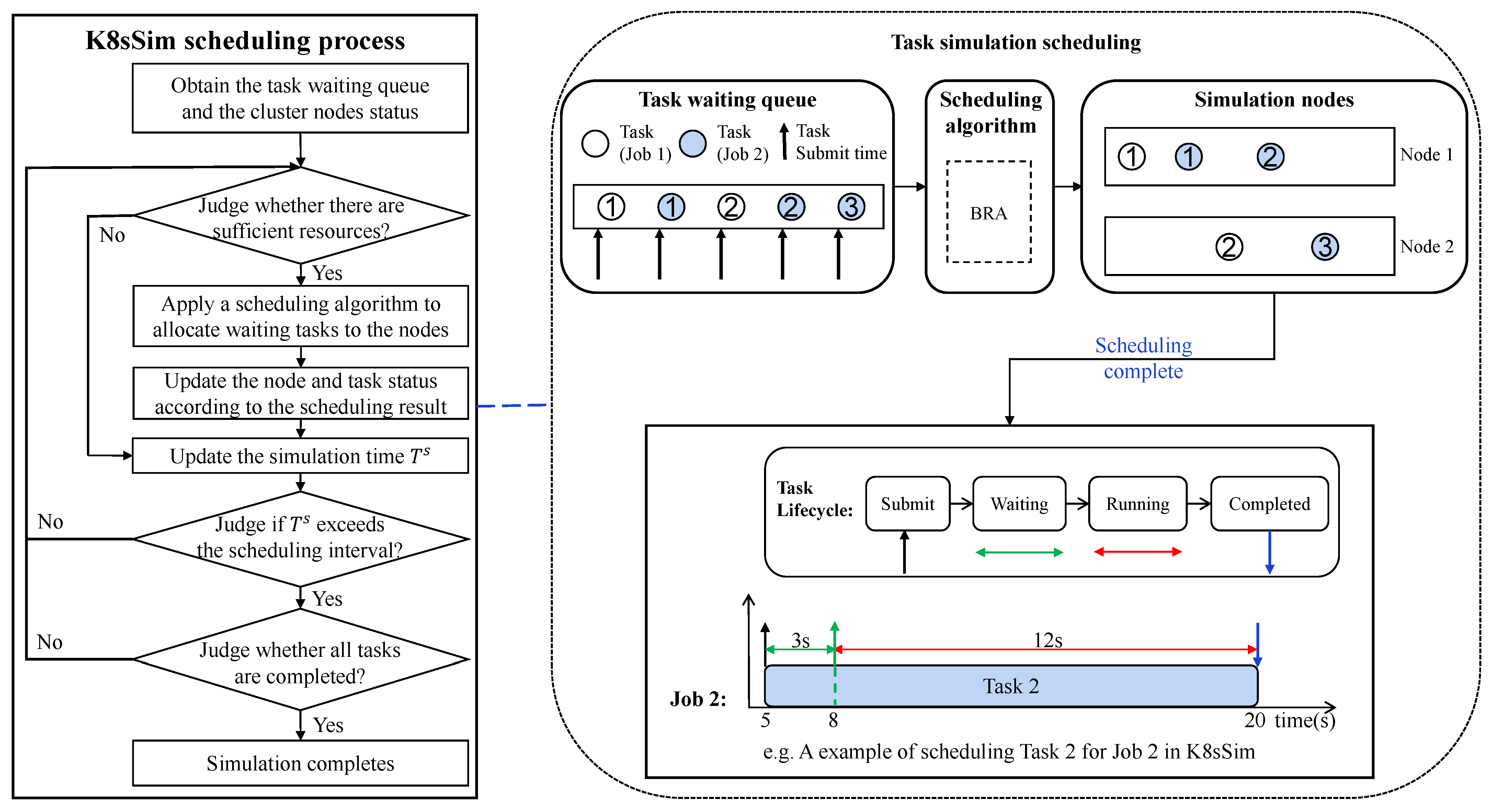
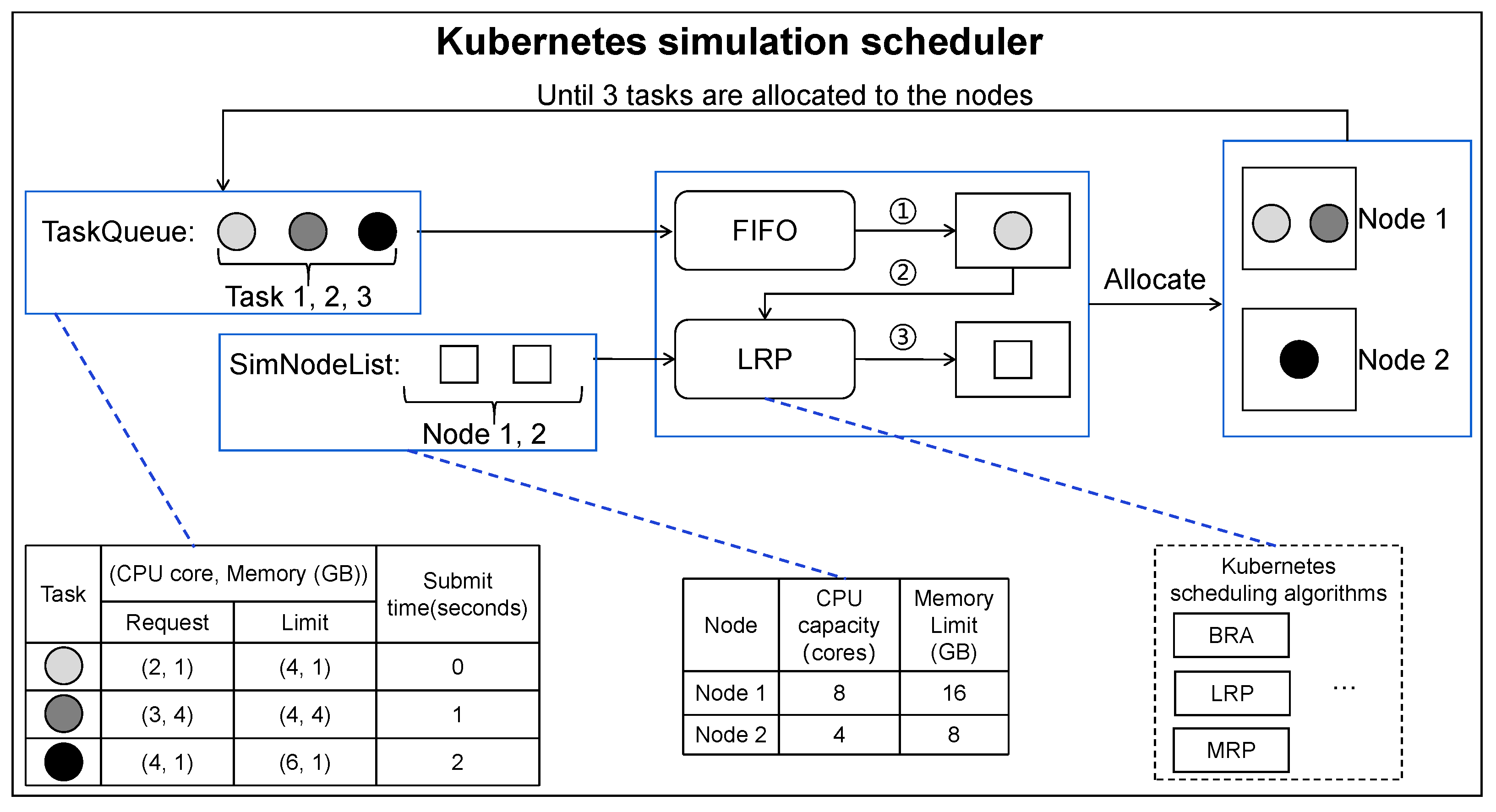
3.4.1. Kubernetes Simulation Scheduler
| Algorithm 1 Kubernetes scheduling simulation. |
| Require:: the scheduling algorithm; T: the set of tasks waiting for being scheduled; N: the set of nodes. 1. for each task in T do 2. TaskQueue.Push(task); 3. end for 4. TaskQueue.Load(); 5. while not TaskQueue.Empty() do 6. task ← FIFO(TaskQueue); 7. TaskQueue.Pop(task); 8. bindingNode ← Allocate(N, task, ); 9. Bind(bindingNode, task); 10. end while 11. return GetSchedulingResults(). |
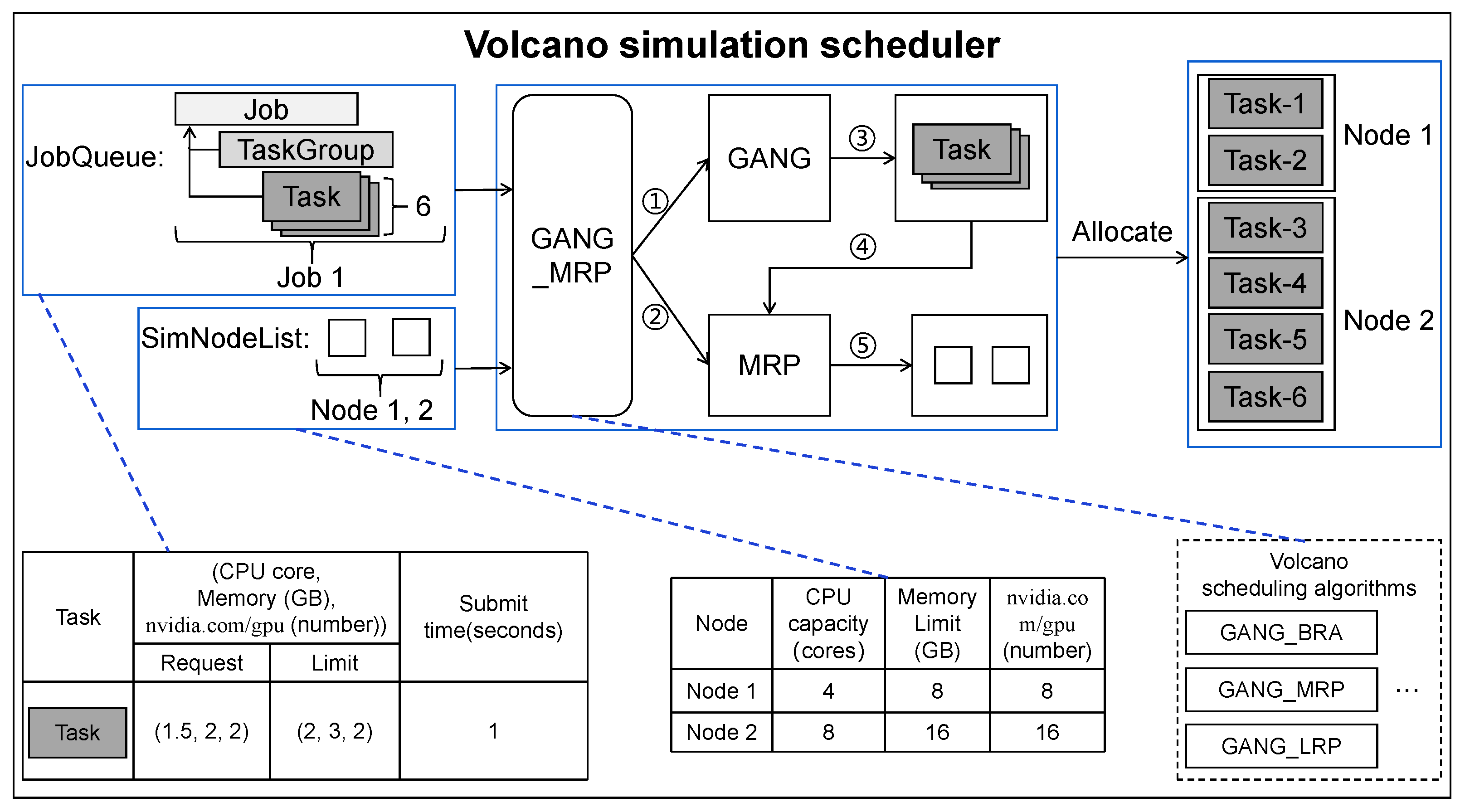
3.4.2. Volcano Simulation Scheduler
| Algorithm 2 Volcano scheduling simulation. |
| Require:: the scheduling algorithm; J: the set of jobs waiting for being scheduled; N: the set of nodes. 1. for each job in J do 2. JobQueue.Push(job); 3. end for 4. JobQueue.Load(); 5. while not JobQueue.Empty() do 6. job ← FIFO(JobQueue); 7. JobQueue.Pop(job); 8. tasks ← Job.GetTasks(job); 9. NodeTaskPairs←Allocate(N, tasks, ); 10. if .hasGang() then 11. if NodeTaskPairs.Len()≥Job.RequireNum() then 12. ←Allocate(N, tasks, ); 13. Schedule(); 14. end if 15. else 16. Schedule(NodeTaskPairs); 17. end if 18. if not Job.ScheduleAllTask() then 19. JobQueue.Push(job); 20. end if 21. end while 22. return GetSchedulingResults(). |
4. Evaluation
4.1. Evaluation Settings
- ▷
- Intel(R) Xeon(R) CPU E5-2680 v4 @2.40GHz processor, 56 Cores, 256 GB memory (physical machine);
- ▷
- 1 Master Node + 8 Worker Nodes (9 virtual nodes):
- 16 Cores and 32 GB memory/Master Node, 2 Cores and 4 GB memory/Two Worker Nodes, 4 Cores and 8 GB memory/Four Worker Nodes, and 8 Cores and 16 GB memory/Two Worker Nodes;
- Linux Ubuntu 18.04 LTS;
- Python 3.8.5, Go 1.17.6, Docker 20.10.14, Volcano v1.0, and Kubernetes v1.19.0;
- ▷
- AMD Ryzen 7 3700X 8-Core @3.59GHz Processor, 16 GB of DRAM (a machine for conducting simulations).
- ▷
- For generating TaskQueue workloads, the basis is as follows:
- Driven by Alibaba cluter-trace-v2018 [11] that records the information in the mixed CPU cluster with 4034 nodes running in 8 days;
- Two typical application scenarios: Daytime (6:00 to 24:00) and Night (0:00 to 6:00);
- 19,500 jobs, 6.92 million tasks submitted in the Daytime, and 28,300 jobs, 7.00 million tasks submitted at Night (in the trace).
- ▷
- For generating JobQueue workloads, the basis is as follows:
- Driven by Alibaba cluter-trace-gpu-v2020 [11] that records the information collected from Alibaba API (artificial intelligence platform) with over 6500 GPUs (about 1800 machines) in a month;
- Two typical application scenarios: Daytime (8:00 to 24:00) and Night (0:00 to 8:00);
- 1,759,052 jobs, 12.54 million tasks submitted in the daytime, and 2,462,675 jobs, 17.55 million tasks submitted at night (in the trace).
- ▷
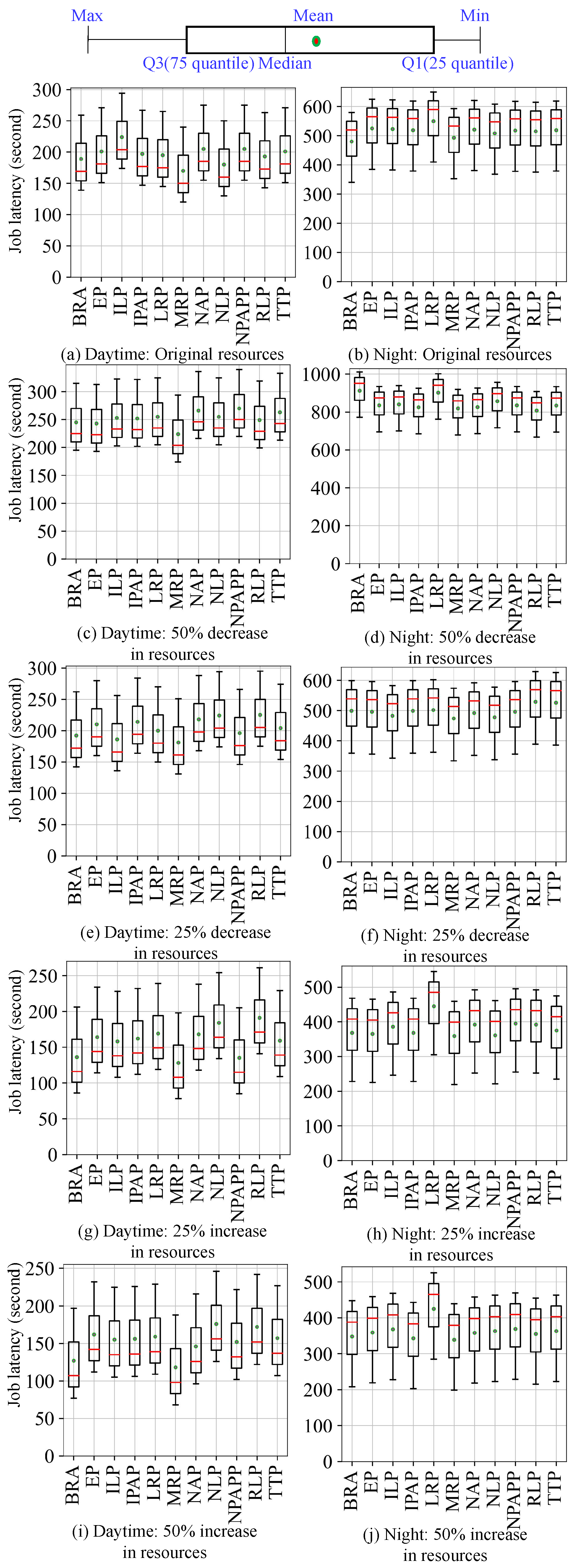
- Job performance: measured by the average job latency (obtained by calculating the average job latency for multiple jobs in a workload, as shown in Equation (1)).
- ▷
- Simulation efficiency: measured by comparing the scheduling results of the simulator and the real cluster (that is, evaluating how close the simulator is to the real cluster).
- ▷
- Simulation acceleration: measured by comparing the simulation running time and the real running time of each scheduling algorithm (obtained by calculating the total execution time from the start of the first job to the end of all jobs in a workload, as shown in Equation (2)).
4.2. Evaluate Effectiveness of Cluster Simulator
4.3. Acceleration of Cluster Simulator
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Sheng, V.S. Fog-enabled event processing based on IoT resource models. IEEE Trans. Knowl. Data Eng. 2018, 31, 1707–1721. [Google Scholar] [CrossRef]
- Han, R.; John, L.K.; Zhan, J. Benchmarking big data systems: A review. IEEE Trans. Serv. Comput. 2017, 11, 580–597. [Google Scholar] [CrossRef]
- Chekired, D.A.; Togou, M.A.; Khoukhi, L.; Ksentini, A. 5G-slicing-enabled scalable SDN core network: Toward an ultra-low latency of autonomous driving service. IEEE J. Sel. Areas Commun. 2019, 37, 1769–1782. [Google Scholar] [CrossRef]
- Kulshrestha, T.; Saxena, D.; Niyogi, R.; Cao, J. Real-time crowd monitoring using seamless indoor-outdoor localization. IEEE Trans. Mob. Comput. 2019, 19, 664–679. [Google Scholar] [CrossRef]
- Han, R.; Zong, Z.; Zhang, F.; Vazquez-Poletti, J.L.; Jia, Z.; Wang, L. Cloudmix: Generating diverse and reducible workloads for cloud systems. In Proceedings of the2017 IEEE 10th International Conference on Cloud Computing (CLOUD), Honololu, HI, USA, 25–30 June 2017; pp. 496–503. [Google Scholar]
- Mehnaz, S.; Bertino, E. Privacy-preserving real-time anomaly detection using edge computing. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 469–480. [Google Scholar]
- Wang, J.; Zhang, J.; Bao, W.; Zhu, X.; Cao, B.; Yu, P.S. Not just privacy: Improving performance of private deep learning in mobile cloud. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 2407–2416. [Google Scholar]
- Zhao, Z.; Barijough, K.M.; Gerstlauer, A. Deepthings: Distributed adaptive deep learning inference on resource-constrained iot edge clusters. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2348–2359. [Google Scholar] [CrossRef]
- Han, R.; Zhang, Q.; Liu, C.H.; Wang, G.; Tang, J.; Chen, L.Y. LegoDNN: Block-grained scaling of deep neural networks for mobile vision. In Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, New Orleans, LA, USA, 25–29 October 2021; pp. 406–419. [Google Scholar]
- Kubernetes. Available online: http://kubernetes.io (accessed on 24 September 2022).
- Alibaba Clusterdata. Available online: https://github.com/alibaba/clusterdata (accessed on 5 November 2022).
- Liu, Z.; Zuo, X.; Li, Z.; Han, R. SparkAIBench: A Benchmark to Generate AI Workloads on Spark. In Proceedings of the International Symposium on Benchmarking, Measuring and Optimization, Denver, CO, USA, 14–16 November 2019; Springer: Cham, Switzerland, 2019; pp. 215–221. [Google Scholar]
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking cloud serving systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154. [Google Scholar]
- Varghese, B.; Subba, L.T.; Thai, L.; Barker, A. Container-based cloud virtual machine benchmarking. In Proceedings of the 2016 IEEE International Conference on Cloud Engineering (IC2E), Berlin, Germany, 4–8 April 2016; pp. 192–201. [Google Scholar]
- Palit, T.; Shen, Y.; Ferdman, M. Demystifying cloud benchmarking. In Proceedings of the 2016 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Uppsala, Sweden, 17–19 April 2016; pp. 122–132. [Google Scholar]
- Bermbach, D.; Kuhlenkamp, J.; Dey, A.; Ramachandran, A.; Fekete, A.; Tai, S. BenchFoundry: A benchmarking framework for cloud storage services. In Proceedings of the International Conference on Service-Oriented Computing, Malaga, Spain, 13–16 November 2017; Springer: Cham, Switzerland, 2017; pp. 314–330. [Google Scholar]
- Shukla, A.; Chaturvedi, S.; Simmhan, Y. Riotbench: An iot benchmark for distributed stream processing systems. Concurr. Comput. Pract. Exp. 2017, 29, e4257. [Google Scholar] [CrossRef] [Green Version]
- Luo, C.; Zhang, F.; Huang, C.; Xiong, X.; Chen, J.; Wang, L.; Gao, W.; Ye, H.; Wu, T.; Zhou, R.; et al. AIoT bench: Towards comprehensive benchmarking mobile and embedded device intelligence. In Proceedings of the International Symposium on Benchmarking, Measuring and Optimization, Seattle, WA, USA, 10–13 December 2018; pp. 31–35. [Google Scholar]
- Das, A.; Patterson, S.; Wittie, M. Edgebench: Benchmarking edge computing platforms. In Proceedings of the 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), Zurich, Switzerland, 17–20 December 2018; pp. 175–180. [Google Scholar]
- Hao, T.; Huang, Y.; Wen, X.; Gao, W.; Zhang, F.; Zheng, C.; Wang, L.; Ye, H.; Hwang, K.; Ren, Z.; et al. Edge AIBench: Towards comprehensive end-to-end edge computing benchmarking. In Proceedings of the International Symposium on Benchmarking, Measuring and Optimization, Seattle, WA, USA, 10–13 December 2018; pp. 23–30. [Google Scholar]
- Lee, C.I.; Lin, M.Y.; Yang, C.L.; Chen, Y.K. IoTBench: A benchmark suite for intelligent Internet of Things edge devices. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 170–174. [Google Scholar]
- McChesney, J.; Wang, N.; Tanwer, A.; De Lara, E.; Varghese, B. Defog: Fog computing benchmarks. In Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, Arlington, VA, USA, 7–9 November 2019; pp. 47–58. [Google Scholar]
- Li, J.Q.; Du, Y.; Gao, K.Z.; Duan, P.Y.; Gong, D.W.; Pan, Q.K.; Suganthan, P.N. A hybrid iterated greedy algorithm for a crane transportation flexible job shop problem. IEEE Trans. Autom. Sci. Eng. 2021, 19, 2153–2170. [Google Scholar] [CrossRef]
- Du, Y.; Li, J.; Li, C.; Duan, P. A reinforcement learning approach for flexible job shop scheduling problem with crane transportation and setup times. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Li, J.Q.; Chen, X.L.; Duan, P.Y.; Pan, Q.K. Knowledge-based reinforcement learning and estimation of distribution algorithm for flexible job shop scheduling problem. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 1–15. [Google Scholar] [CrossRef]
- Han, R.; Zong, Z.; Chen, L.Y.; Wang, S.; Zhan, J. Adaptiveconfig: Run-time configuration of cluster schedulers for cloud short-running jobs. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 1519–1526. [Google Scholar]
- Han, R.; Liu, C.H.; Zong, Z.; Chen, L.Y.; Liu, W.; Wang, S.; Zhan, J. Workload-adaptive configuration tuning for hierarchical cloud schedulers. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2879–2895. [Google Scholar] [CrossRef]
- Zong, Z.; Wen, L.; Hu, X.; Han, R.; Qian, C.; Lin, L. MespaConfig: Memory-Sparing Configuration Auto-Tuning for Co-Located In-Memory Cluster Computing Jobs. IEEE Trans. Serv. Comput. 2021, 15, 2883–2896. [Google Scholar] [CrossRef]
- Han, R.; Wen, S.; Liu, C.H.; Yuan, Y.; Wang, G.; Chen, L.Y. EdgeTuner: Fast Scheduling Algorithm Tuning for Dynamic Edge-Cloud Workloads and Resources. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, London, UK, 2–5 May 2022; pp. 880–889. [Google Scholar]
- Ran, Y.; Hu, H.; Zhou, X.; Wen, Y. Deepee: Joint optimization of job scheduling and cooling control for data center energy efficiency using deep reinforcement learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 645–655. [Google Scholar]
- Calheiros, R.N.; Ranjan, R.; De Rose, C.A.; Buyya, R. Cloudsim: A novel framework for modeling and simulation of cloud computing infrastructures and services. arXiv 2009, arXiv:0903.2525. [Google Scholar]
- Yi, D.; Zhou, X.; Wen, Y.; Tan, R. Toward efficient compute-intensive job allocation for green data centers: A deep reinforcement learning approach. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 634–644. [Google Scholar]
- Yi, D.; Zhou, X.; Wen, Y.; Tan, R. Efficient compute-intensive job allocation in data centers via deep reinforcement learning. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1474–1485. [Google Scholar] [CrossRef]
- Wiseman, Y.; Feitelson, D.G. Paired gang scheduling. IEEE Trans. Parallel Distrib. Syst. 2003, 14, 581–592. [Google Scholar] [CrossRef]
- Ghodsi, A.; Zaharia, M.; Hindman, B.; Konwinski, A.; Shenker, S.; Stoica, I. Dominant resource fairness: Fair allocation of multiple resource types. In Proceedings of the 8th USENIX Symposium on Networked Systems Design and Implementation (NSDI 11), Boston, MA, USA, 30 March–1 April 2011. [Google Scholar]
- Mirobi, G.J.; Arockiam, L. Service level agreement in cloud computing: An overview. In Proceedings of the 2015 International Conference on Control, Instrumentation, Communication and Computational Technologies (ICCICCT), Kumaracoil, India, 18–19 December 2015; pp. 753–758. [Google Scholar]
- Volcano. Available online: https://volcano.sh/en/ (accessed on 24 September 2022).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Job Scheduling Scenarios | ||
|---|---|---|---|
| 1 | TaskQueue workloads (driven by Alibaba trace 2018) | Daytime | Original resources |
| 2 | 50% decrease | ||
| 3 | 25% decrease | ||
| 4 | 25% increase | ||
| 5 | 50% increase | ||
| 6 | Night | Original resources | |
| 7 | 50% decrease | ||
| 8 | 25% decrease | ||
| 9 | 25% increase | ||
| 10 | 50% increase | ||
| 11 | JobQueue workloads (driven by Alibaba trace 2020) | Daytime | Original resources |
| 12 | 50% decrease | ||
| 13 | 25% decrease | ||
| 14 | 25% increase | ||
| 15 | 50% increase | ||
| 16 | Night | Original resources | |
| 17 | 50% decrease | ||
| 18 | 25% decrease | ||
| 19 | 25% increase | ||
| 20 | 50% increase | ||
| Scenario | Real Running Time (s)/Simulation Running Time (s) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BRA | EP | ILP | IPAP | LRP | MRP | NAP | NLP | NPAPP | RLP | TTP | |
| 1 | 1868.64/43.1 | 1987.29/49.6 | 2214.69/46.3 | 1947.74/49.5 | 1927.97/43.2 | 1680.79/44.1 | 2026.84/43.8 | 1779.66/43.6 | 2026.84/43.5 | 1908.19/43.7 | 1987.29/42.9 |
| 2 | 2422.32/52.15 | 2402.54/60.02 | 2501.41/56.02 | 2491.52/59.9 | 2521.19/52.27 | 2214.69/53.36 | 2629.94/53 | 2521.19/52.76 | 2669.49/52.64 | 2461.86/52.88 | 2600.28/51.91 |
| 3 | 1898.3/47.52 | 2076.27/54.68 | 1838.98/51.05 | 2115.82/54.57 | 1977.4/47.63 | 1789.55/48.62 | 2155.37/48.29 | 2214.69/48.07 | 1937.85/47.96 | 2224.58/48.18 | 2016.95/47.3 |
| 4 | 1344.63/40.95 | 1621.47/47.12 | 1562.15/43.99 | 1601.69/47.03 | 1670.9/41.04 | 1265.54/41.9 | 1661.02/41.61 | 1819.21/41.42 | 1334.75/41.33 | 1888.42/41.52 | 1572.03/40.76 |
| 5 | 1255.65/38.79 | 1601.69/44.64 | 1532.49/41.67 | 1542.37/44.55 | 1572.03/38.88 | 1166.67/39.69 | 1443.5/39.42 | 1740.11/39.24 | 1502.82/39.15 | 1700.56/39.33 | 1552.26/38.61 |
| 6 | 4745.76/79.2 | 5190.68/81.6 | 5170.9/76.2 | 5131.35/77.1 | 5437.85/74.7 | 4874.29/82.5 | 5151.13/76.2 | 5022.6/79.5 | 5121.47/80.1 | 5091.81/77.1 | 5131.35/79.5 |
| 7 | 5411.86/109.06 | 5778.95/112.36 | 5813.56/104.93 | 5709.74/106.17 | 6242.65/102.86 | 5668.22/113.6 | 5716.66/104.93 | 5931.21/109.47 | 5778.95/110.3 | 5592.09/106.17 | 5772.03/109.47 |
| 8 | 4933.61/89.73 | 4903.95/92.45 | 4775.42/86.33 | 4933.61/87.35 | 4963.27/84.64 | 4686.44/93.47 | 4864.4/86.33 | 4725.99/90.07 | 4903.95/90.75 | 5230.22/87.35 | 5200.56/90.07 |
| 9 | 3638.42/76.03 | 3608.76/78.34 | 3816.38/73.15 | 3638.42/74.02 | 4399.72/71.71 | 3549.43/79.2 | 3875.7/73.15 | 3569.21/76.32 | 3905.37/76.9 | 3875.7/74.02 | 3707.63/76.32 |
| 10 | 3440.68/72.07 | 3549.43/74.26 | 3638.42/69.34 | 3391.24/70.16 | 4201.98/67.98 | 3351.69/75.08 | 3539.55/69.34 | 3588.98/72.35 | 3648.3/72.89 | 3509.89/70.16 | 3588.98/72.35 |
| Scenario | Real Running Time (s)/Simulation Running Time (s) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DRF_BRA | DRF_LRP | DRF_MRP | GANG_BRA | GANG_DRF_ BINPACK | GANG_DRF_ BRA | GANG_DRF_ LRP | GANG_DRF_ MRP | GANG_LRP | GANG_MRP | SLA_BRA | SLA_LRP | SLA_MRP | |
| 11 | 2891.5/119.2 | 2662.8/119.6 | 2471.7/118.4 | 2628.3/118 | 2565.7/120 | 2806.9/120.4 | 2349.5/118.8 | 2778.7/119.2 | 2913.4/126.8 | 2427.8/120.4 | 2853.9/119.2 | 2597/118.4 | 2622/122 |
| 12 | 3984.8/131.1 | 4144.5/131.6 | 3980.1/130.2 | 3980.1/129.8 | 3984.8/132 | 3984.8/132.4 | 4144.5/130.7 | 3984.8/131.1 | 4144.5/139.5 | 3984.8/132.4 | 3984.8/131.1 | 4153.9/130.2 | 3975.4/134.2 |
| 13 | 3345.7/124 | 3402.1/124.4 | 3063.8/123.1 | 3336.3/122.7 | 3049.7/124.8 | 3341/125.2 | 3406.8/123.6 | 3063.8/124 | 3402.1/131.9 | 3063.8/125.2 | 3336.3/124 | 3402.1/123.1 | 3059.1/126.9 |
| 14 | 2250.8/113.2 | 2086.4/113.6 | 2664.3/112.5 | 2250.8/112.1 | 2669/114 | 2250.8/114.4 | 2081.7/112.9 | 2659.6/113.2 | 2086.4/120.5 | 2669/114.4 | 2250.8/113.2 | 2086.4/112.5 | 2664.3/115.9 |
| 15 | 1964.2/107.3 | 1931.3/107.6 | 2546.9/106.6 | 1973.6/106.2 | 2546.9/108 | 1964.2/108.4 | 1926.6/106.9 | 2542.2/107.3 | 1931.3/114.1 | 2542.2/108.4 | 1973.6/107.3 | 1926.6/106.6 | 2537.5/109.8 |
| 16 | 7581.1/192.6 | 6954.5/193.2 | 7437/179.4 | 7158.2/192.6 | 7565.4/181.2 | 7631.2/193.2 | 6907.5/191.4 | 7931.9/192 | 7336.7/190.8 | 7784.7/178.8 | 7352.4/190.2 | 7001.5/178.8 | 7001.5/187.2 |
| 17 | 9961.9/249.6 | 10361.3/250.4 | 9950.2/232.5 | 9950.2/249.6 | 9961.9/234.8 | 9961.9/250.4 | 10361.3/248.1 | 9961.9/248.8 | 10361.3/247.3 | 9961.9/231.7 | 9961.9/246.5 | 10384.8/231.7 | 9938.4/242.6 |
| 18 | 8364.2/218.2 | 8505.2/218.9 | 9144.3/203.3 | 8340.7/218.2 | 8282.5/205.3 | 8352.5/218.9 | 8517/216.9 | 8315.4/217.5 | 8505.2/216.2 | 8322/202.6 | 8340.7/215.5 | 8505.2/202.6 | 8308.8/212.1 |
| 19 | 5627.1/184.9 | 5545.8/185.5 | 6660.9/172.2 | 5627.1/184.9 | 6672.6/174 | 5627.1/185.5 | 5532.6/183.7 | 6649.1/184.3 | 5361.6/183.2 | 6672.6/171.6 | 5627.1/182.6 | 5776/171.6 | 6660.9/179.7 |
| 20 | 5239.4/175.3 | 5157.2/175.8 | 6249.7/163.3 | 5262.9/175.3 | 5624.7/164.9 | 5239.4/175.8 | 5145.4/174.2 | 6381.3/174.7 | 5157.2/173.6 | 6512.8/162.7 | 5262.9/173.1 | 5145.4/162.7 | 6447/170.4 |
| Scenario | Reductions (Real Running Time/Simulation Running Time) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BRA | EP | ILP | IPAP | LRP | MRP | NAP | NLP | NPAPP | RLP | TTP | |
| 1 | 43.36× | 40.07× | 47.83× | 39.35× | 44.63× | 38.11× | 46.27× | 40.82× | 46.59× | 43.67× | 46.32× |
| 2 | 46.45× | 40.03× | 44.65× | 41.6× | 48.23× | 41.5× | 49.62× | 47.79× | 50.72× | 46.56× | 50.09× |
| 3 | 39.95× | 37.97× | 36.03× | 38.77× | 41.52× | 36.81× | 44.63× | 46.07× | 40.41× | 46.17× | 42.64× |
| 4 | 32.84× | 34.41× | 35.52× | 34.06× | 40.71× | 30.21× | 39.92× | 43.92× | 32.3× | 45.49× | 38.57× |
| 5 | 32.37× | 35.88× | 36.78× | 34.62× | 40.43× | 29.39× | 36.62× | 44.35× | 38.39× | 43.24× | 40.2× |
| 6 | 59.92× | 63.61× | 67.86× | 66.55× | 72.8× | 59.08× | 67.6× | 63.18× | 63.94× | 66.04× | 64.55× |
| 7 | 49.62× | 51.43× | 55.41× | 53.78× | 60.69× | 49.9× | 54.48× | 54.18× | 52.39× | 52.67× | 52.73× |
| 8 | 54.98× | 53.04× | 55.31× | 56.48× | 58.64× | 50.14× | 56.34× | 52.47× | 54.04× | 59.87× | 57.74× |
| 9 | 47.85× | 46.07× | 52.17× | 49.16× | 61.35× | 44.82× | 52.98× | 46.77× | 50.79× | 52.36× | 48.58× |
| 10 | 47.74× | 47.8× | 52.47× | 48.34× | 61.81× | 44.64× | 51.04× | 49.61× | 50.05× | 50.03× | 49.61× |
| Scenario | Reductions (Real Running Time/Simulation Running Time) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DRF_BRA | DRF_LRP | DRF_MRP | GANG_BRA | GANG_DRF_ BINPACK | GANG_DRF_ BRA | GANG_DRF_ LRP | GANG_DRF_ MRP | GANG_LRP | GANG_MRP | SLA_BRA | SLA_LRP | SLA_MRP | |
| 11 | 24.26× | 22.26× | 20.88× | 22.27× | 21.38× | 23.31× | 19.78× | 23.31× | 22.98× | 20.16× | 23.94× | 21.93× | 21.49× |
| 12 | 30.4× | 31.49× | 30.57× | 30.66× | 30.19× | 30.1× | 31.71× | 30.4× | 29.71× | 30.1× | 30.4× | 31.9× | 29.62× |
| 13 | 26.98× | 27.35× | 24.89× | 27.19× | 24.44× | 26.69× | 27.56× | 24.71× | 25.79× | 24.47× | 26.91× | 27.64× | 24.11× |
| 14 | 19.88× | 18.37× | 23.68× | 20.08× | 23.41× | 19.67× | 18.44× | 23.49× | 17.31× | 23.33× | 19.88× | 18.55× | 22.99× |
| 15 | 18.31× | 17.95× | 23.89× | 18.58× | 23.58× | 18.12× | 18.02× | 23.69× | 16.93× | 23.45× | 18.39× | 18.07× | 23.11× |
| 16 | 39.36× | 36× | 41.45× | 37.17× | 41.75× | 39.5× | 36.09× | 41.31× | 38.45× | 43.54× | 38.66× | 39.16× | 37.4× |
| 17 | 39.91× | 41.38× | 42.8× | 39.86× | 42.43× | 39.78× | 41.76× | 40.04× | 41.9× | 42.99× | 40.41× | 44.82× | 40.97× |
| 18 | 38.33× | 38.85× | 44.98× | 38.23× | 40.34× | 38.16× | 39.27× | 38.23× | 39.34× | 41.08× | 38.7× | 41.98× | 39.17× |
| 19 | 30.43× | 29.9× | 38.68× | 30.43× | 38.35× | 30.33× | 30.12× | 36.08× | 29.27× | 38.88× | 30.82× | 33.66× | 37.07× |
| 20 | 29.89× | 29.34× | 38.27× | 30.02× | 34.11× | 29.8× | 29.54× | 36.53× | 29.71× | 40.03× | 30.4× | 31.63× | 37.83× |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, S.; Han, R.; Qiu, K.; Ma, X.; Li, Z.; Deng, H.; Liu, C.H. K8sSim: A Simulation Tool for Kubernetes Schedulers and Its Applications in Scheduling Algorithm Optimization. Micromachines 2023, 14, 651. https://doi.org/10.3390/mi14030651
Wen S, Han R, Qiu K, Ma X, Li Z, Deng H, Liu CH. K8sSim: A Simulation Tool for Kubernetes Schedulers and Its Applications in Scheduling Algorithm Optimization. Micromachines. 2023; 14(3):651. https://doi.org/10.3390/mi14030651
Chicago/Turabian StyleWen, Shilin, Rui Han, Ke Qiu, Xiaoxin Ma, Zeqing Li, Hongjie Deng, and Chi Harold Liu. 2023. "K8sSim: A Simulation Tool for Kubernetes Schedulers and Its Applications in Scheduling Algorithm Optimization" Micromachines 14, no. 3: 651. https://doi.org/10.3390/mi14030651