
CS-GA-XGBoost-Based Model for a Radio-Frequency Power Amplifier under Different Temperatures

Abstract
:1. Introduction
2. CS-GA-XGBoost
2.1. XGBoost
2.2. Genetic Algorithm (GA)
2.3. Cuckoo Search (CS)
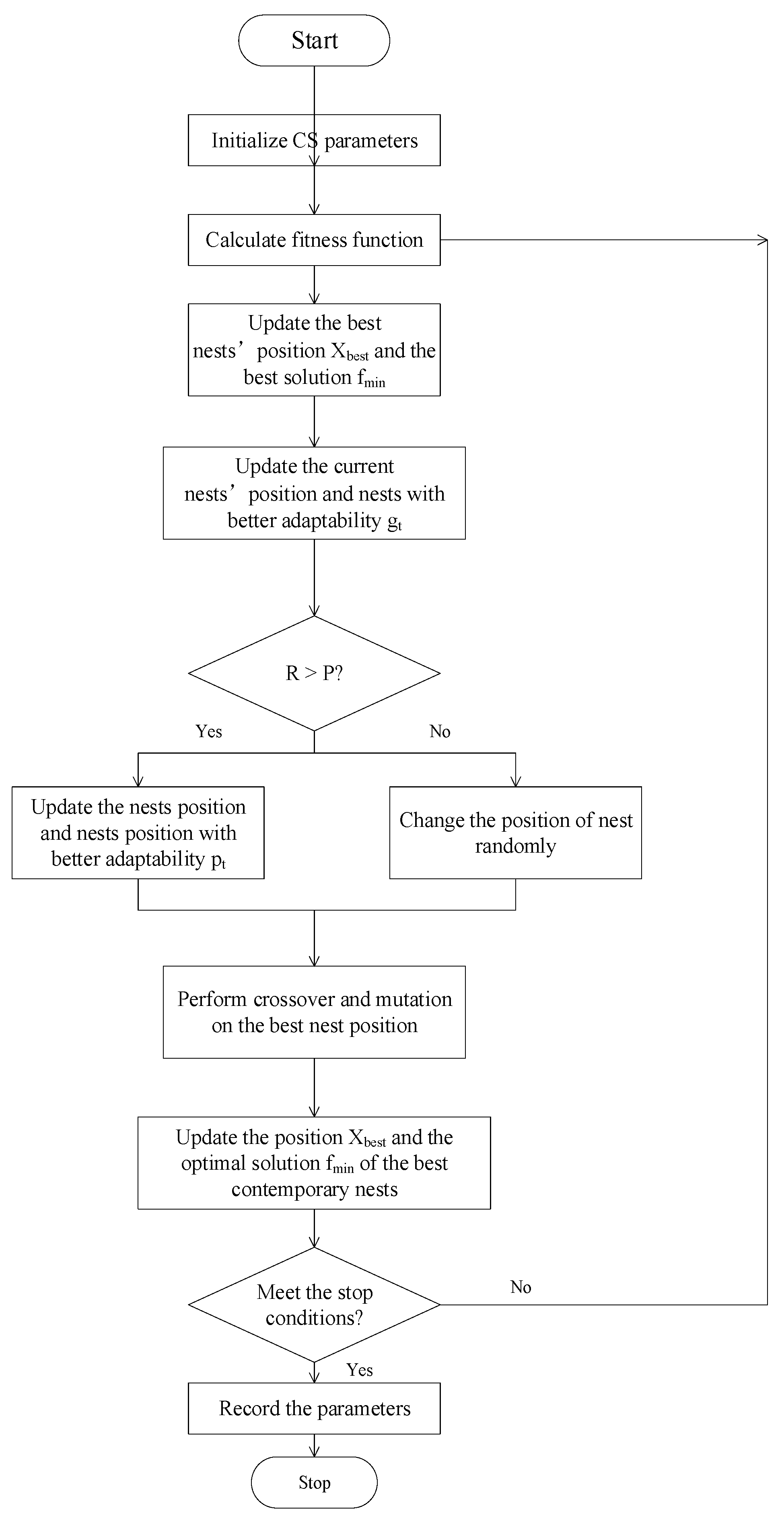
2.4. CS-GA
- (1)
- Initialize the algorithm. Initialize parameters such as nest size N, dimension D, discovery probability P, nest boundary value lb, and ub.
- (2)
- Calculate the fitness value of the bird’s nest.
- (3)
- Update the optimal nest position Xbest and the optimal solution fmin.
- (4)
- Update the current birds’ nest location and compare it with the previous generation to update their nest gt with better adaptability.
- (5)
- If R > P, update the birds’ nest position and compare with the birds’ nest position gt, and update the birds’ nest position pt with better adaptability. If R < P, randomly change the position of the bird’s nest.
- (6)
- Perform GA’s crossover and mutation on the best set of bird nest positions.
- (7)
- Update the current optimal nest position Xbest and the optimal solution fmin.
- (8)
- Determine the stop conditions. If it meets, record the parameters and end. Otherwise, return to step (2) for a new round of training.
2.5. CS-GA-XGBoost
- (1)
- Data acquisition. By measuring a 2.5-GHz-GaN class-E PA, obtain the input and output data required for modeling.
- (2)
- Data division. Divide the obtained experimental data equally into two parts: training and validation data.
- (3)
- Build a CS-GA-XGBoost model.
- (4)
- Model training and calculating training errors. To evaluate the performance of different modeling techniques, mean squared error (MSE) is selected as the model accuracy evaluation standard [30]:where represents the actual value and represents the predicted value. The smaller the MSE is, the more accurate the model is.
- (5)
- Model validation and calculating the validation errors. Suppose the validation error is greater than the expected error. In that case, the model is underfitting [31], and the parameters must be adjusted before returning to step (3) for remodeling. Suppose the validation error is less than expected, while the difference between the training and validation errors is more significant than one order of magnitude. In that case, it indicates that the model is overfitting [31], and it is also necessary to adjust the parameters and return to step (3) to remodel. Suppose the validation error is less than the expected error, and the difference between the training and validation errors is less than one order of magnitude. In that case, the model performance is good [31], and the modeling is completed.
3. Results and Discussion
3.1. Experimental Setup
3.2. Modeling Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, S.; Yang, C.; Wang, J. Modeling of Key Specifications for RF Amplifiers Using the Extreme Learning Machine. Micromachines 2022, 13, 693. [Google Scholar] [CrossRef]
- Cai, J.; Ling, J.; Yu, C.; Liu, J.; Sun, L. Support Vector Regression-Based Behavioral Modeling Technique for RF Power Transistors. IEEE Microw. Wirel. Compon. Lett. 2018, 28, 428–430. [Google Scholar] [CrossRef]
- Cai, J.; Yu, C.; Sun, L.; Chen, S.; King, J.B. Dynamic Behavioral Modeling of RF Power Amplifier Based on Time-Delay Support Vector Regression. IEEE Trans. Microw. Theory Tech. 2019, 67, 533–543. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, S.; Fang, W.; Huang, W.; Yang, Z.; Fu, C.; Liu, C. Automatic Piecewise Extreme Learning Machine-Based Model for S-Parameters of RF Power Amplifier. Micromachines 2023, 14, 840. [Google Scholar] [CrossRef]
- Zhou, S. Experimental investigation on the performance degradations of the GaN class-F power amplifier under humidity conditions. Semicond. Sci. Technol. 2021, 36, 035025. [Google Scholar] [CrossRef]
- Majid, I.; Nadeem, A.E.; e Azam, F. Small signal S-parameter estimation of BJTs using artificial neural networks. In Proceedings of the 8th International Multitopic Conference, Lahore, Pakistan, 24–26 December 2004. [Google Scholar]
- Liu, T.J.; Boumaiza, S.; Ghannouchi, F.M. Dynamic behavioral modeling of 3G power amplifiers using real-valued time-delay neural networks. IEEE Trans. Microw. Theory Tech. 2004, 52, 1025–1033. [Google Scholar] [CrossRef]
- Li, M.; Liu, J.; Jiang, Y.; Feng, W. Complex-Chebyshev Functional Link Neural Network Behavioral Model for Broadband Wireless Power Amplifiers. IEEE Trans. Microw. Theory Tech. 2012, 60, 1978–1989. [Google Scholar] [CrossRef]
- Hu, X.; Liu, Z.; Yu, X.; Zhao, Y.; Chen, W.; Hu, B.; Du, X.; Li, X.; Helaoui, M.; Wang, W.; et al. Convolutional Neural Network for Behavioral Modeling and Predistortion of Wideband Power Amplifiers. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 3923–3937. [Google Scholar] [CrossRef]
- Li, H.; Cao, Y.; Li, S.; Zhao, J.; Sun, Y. XGBoost Model and Its Application to Personal Credit Evaluation. IEEE Intell. Syst. 2020, 35, 51–61. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Pang, J.; Zhu, A. Boosted Model Tree-Based Behavioral Modeling for Digital Predistortion of RF Power Amplifiers. IEEE Trans. Microw. Theory Tech. 2021, 69, 3976–3988. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Zhu, A. Reducing Power Consumption of Digital Predistortion for RF Power Amplifiers Using Real-Time Model Switching. IEEE Trans. Microw. Theory Tech. 2022, 70, 1500–1508. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y. A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects. IEEE Access 2022, 10, 99129–99149. [Google Scholar] [CrossRef]
- Chen, T.; Geustrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Dikmese, D.; Anttila, L.; Campo, P.P.; Valkama, M.; Renfors, M. Behavioral Modeling of Power Amplifiers with Modern Machine Learning Techniques. In Proceedings of the 2019 IEEE MTT-S International Microwave Conference on Hardware and Systems for 5G and Beyond (IMC-5G), Atlanta, GA, USA, 15–16 August 2019. [Google Scholar]
- Ryu, S.-E.; Shin, D.-H.; Chung, K. Prediction Model for Dementia Risk Based on XGBoost Using Derived Variable Extraction and Hyper Parameter Optimization. IEEE Access 2020, 8, 177708–177720. [Google Scholar] [CrossRef]
- Ogunleye, A.; Wang, Q.-G. XGBoost Model for Chronic Kidney Disease Diagnosis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 17, 2131–2140. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Tong, G.; Yin, H.; Xiong, N. A Pedestrian Detection Method Based on Genetic Algorithm for Optimize XGBoost Training Parameters. IEEE Access 2019, 7, 118310–118321. [Google Scholar] [CrossRef]
- Yu, S.; Matsumori, M.; Lin, X. Prediction Accuracy Improvement on Disease Disk and Cost Prediction Model. In Proceedings of the 2022 International Symposium on Electrical, Electronics and Information Engineering (ISEEIE), Chiang Mai, Thailand, 25–27 February 2022. [Google Scholar]
- Wang, S.; Roger, M.; Sarrazin, J.; Lelandais-Perrault, C. Hyperparameter Optimization of Two-Hidden-Layer Neural Networks for Power Amplifier Behavioral Modeling Using Genetic Algorithms. IEEE Microw. Wirel. Compon. Lett. 2019, 29, 802–805. [Google Scholar] [CrossRef]
- Zhang, J.; Wen, H.; Wang, H.; Zhang, G.; Wen, H.; Jiang, H.; Rong, J. An insulator pollution degree detection method based on crisscross optimization algorithm with blending ensemble learning. In Proceedings of the 2022 4th International Conference on Electrical Engineering and Control Technologies (CEECT), Shanghai, China, 16–18 December 2022. [Google Scholar]
- Sharma, S.; Kapoor, R.; Dhiman, S. A Novel Hybrid Metaheuristic Based on Augmented Grey Wolf Optimizer and Cuckoo Search for Global Optimization. In Proceedings of the 2021 2nd International Conference on Secure Cyber Computing and Communications (ICSCCC), Jalandhar, India, 21–23 May 2021. [Google Scholar]
- Lai, J.-P.; Lin, Y.-L.; Lin, H.-C.; Shih, C.-Y.; Wang, Y.-P.; Pai, P.-F. Tree-Based Machine Learning Models with Optuna in Predicting Impedance Values for Circuit Analysis. Micromachines 2023, 14, 265. [Google Scholar] [CrossRef]
- Glover, F. Tabu Search—Part I. ORSA J. Comput. 1989, 1, 190–206. [Google Scholar] [CrossRef]
- Zamli, K.Z. Enhancing generality of meta-heuristic algorithms through adaptive selection and hybridization. In Proceedings of the 2018 International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 6–7 March 2018. [Google Scholar]
- Gilabert, P.L.; Silveira, D.D.; Montoro, G.; Gadringer, M.E.; Bertran, E. Heuristic Algorithms for Power Amplifier Behavioral Modeling. IEEE Microw. Wirel. Compon. Lett. 2007, 17, 715–717. [Google Scholar] [CrossRef]
- Grefensette, J.J. Optimization of Control Parameters for Genetic Algorithms. IEEE Trans. Syst. Man Cybern. 1986, 16, 122–128. [Google Scholar] [CrossRef]
- Singh, R.P.; Dixit, M.; Silakari, S. Image Contrast Enhancement Using GA and PSO: A Survey. In Proceedings of the International Conference on Computational Intelligence and Communication Networks, Bhopal, India, 14–16 November 2014. [Google Scholar]
- Yang, X.-S.; Deb, S. Cuckoo Search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009. [Google Scholar]
- Suryasarman, P.; Liu, P.; Springer, A. Optimizing the identification of Digital Predistorters for Improved Power Amplifier Linearization Performance. IEEE Trans. Circuits Syst. II Express Briefs 2014, 61, 671–675. [Google Scholar] [CrossRef]
- Mahalingam, P.; Kalpana, D.; Thyagarajan, T. Overfit Analysis on Decision Tree Classifier for Fault Classification in DAMADICS. In Proceedings of the 2021 IEEE Madras Section Conference (MASCON), Chennai, India, 27–28 August 2021. [Google Scholar]
- Shekar, B.H.; Dagnew, D. Grid Search-Based Hyperparameter Tuning and Classification of Microarray Cancer Data. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Temperature (°C) | Model | Training MSE | Validation MSE | Modeling Time (s) |
|---|---|---|---|---|
| −40 | XGBoost (* md = 1; * lr = 0.10; * ns = 60) | 1.82 × 10−2 | 1.27 × 10−2 | 13.91 |
| GA-XGBoost (md = 2; lr = 0.20; ns = 59) | 2.06 × 10−3 | 1.74 × 10−3 | 5.331 | |
| CS-XGBoost (md = 3; lr = 0.25; ns = 61) | 3.58 × 10−4 | 3.01 × 10−4 | 12.88 | |
| CS-GA-XGBoost (md = 3; lr = 0.28; ns = 57) | 3.75 × 10−5 | 3.14 × 10−5 | 0.309 | |
| 25 | XGBoost (md = 1; lr = 0.31; ns = 32) | 1.73 × 10−2 | 1.39 × 10−2 | 12.89 |
| GA-XGBoost (md = 2; lr = 0.20; ns = 60) | 1.85 × 10−3 | 1.78 × 10−3 | 6.339 | |
| CS-XGBoost (md = 3; lr = 0.27; ns = 50) | 2.01 × 10−4 | 2.13 × 10−4 | 11.17 | |
| CS-GA-XGBoost (md = 3; lr = 0.33; ns = 45) | 4.23 × 10−5 | 4.68 × 10−5 | 0.299 | |
| 125 | XGBoost (md = 1; lr = 0.15; ns = 45) | 1.55 × 10−2 | 1.47 × 10−2 | 16.39 |
| GA-XGBoost (md = 2; lr = 0.19; ns = 58) | 1.73 × 10−3 | 2.70 × 10−3 | 5.279 | |
| CS-XGBoost (md = 3; lr = 0.20; ns = 25) | 3.73 × 10−4 | 3.08 × 10−4 | 12.01 | |
| CS-GA-XGBoost (md = 3; lr = 0.3; ns = 33) | 5.06 × 10−5 | 5.61 × 10−5 | 0.339 |
| Temperature (°C) | Model | Training MSE | Validation MSE | Modeling Time (s) |
|---|---|---|---|---|
| −40 | Gradient Boosting (md = 4; or = 82; ns = 0.15) | 1.14 × 10−2 | 1.81 × 10−2 | 10.46 |
| Random Forest (md = 3; ns = 55) | 1.98 × 10−1 | 3.51 × 10−1 | 10.76 | |
| SVR (c = 32; γ = 0.11) | 2.99 × 10−1 | 2.32 × 10−1 | 11.99 | |
| CS-GA-XGBoost (* md = 3; * lr = 0.28; * ns = 57) | 3.75 × 10−5 | 3.14 × 10−5 | 0.309 | |
| 25 | Gradient Boosting (md = 3; lr = 115; ns = 0.11) | 1.10 × 10−2 | 1.34 × 10−2 | 10.83 |
| Random Forest (md = 2; ns = 81) | 3.84 × 10−1 | 4.04 × 10−1 | 13.21 | |
| SVR (c = 45; γ = 0.10) | 2.01 × 10−1 | 2.33 × 10−1 | 13.90 | |
| CS-GA-XGBoost (md = 3; lr = 0.33; ns = 45) | 4.23 × 10−5 | 4.68 × 10−5 | 0.299 | |
| 125 | Gradient Boosting (md = 3; lr = 120; ns = 0.18) | 1.71 × 10−2 | 1.97 × 10−2 | 10.36 |
| Random Forest (md = 3; ns = 62) | 3.46 × 10−1 | 4.92 × 10−1 | 10.97 | |
| SVR (c = 49; γ = 0.15) | 2.13 × 10−1 | 2.04 × 10−1 | 14.43 | |
| CS-GA-XGBoost (md = 3; lr = 0.3; ns = 33) | 5.06 × 10−5 | 5.61 × 10−5 | 0.339 |
| Temperature (°C) | Model | Training MSE | Validation MSE | Modeling Time (s) |
|---|---|---|---|---|
| −40 | XGBoost (* md = 2; * lr = 0.10; * ns = 32) | 4.42 × 10−1 | 4.82 × 10−1 | 191.3 |
| GA-XGBoost (md = 3; lr = 0.19; ns = 32) | 1.42 × 10−2 | 2.82 × 10−2 | 34.87 | |
| CS-XGBoost (md = 5; lr = 0.28; ns = 71) | 9.51 × 10−3 | 9.76 × 10−3 | 188.5 | |
| CS-GA-XGBoost (md = 5; lr = 0.28; ns = 71) | 3.08 × 10−5 | 1.65 × 10−5 | 6.582 | |
| 25 | XGBoost (md = 2; lr = 0.12; ns = 28) | 3.03 × 10−1 | 3.74 × 10−1 | 188.3 |
| GA-XGBoost (md = 3; lr = 0.23; ns = 38) | 1.27 × 10−2 | 2.64 × 10−2 | 36.87 | |
| CS-XGBoost (md = 5; lr = 0.35; ns = 58) | 9.56 × 10−3 | 9.88 × 10−3 | 169.8 | |
| CS-GA-XGBoost (md = 5; lr = 0.35; ns = 58) | 2.69 × 10−5 | 1.72 × 10−5 | 5.485 | |
| 125 | XGBoost (md = 2; lr = 0.15; ns = 25) | 2.18 × 10−1 | 2.96 × 10−1 | 189.2 |
| GA-XGBoost (md = 3; lr = 0.29; ns = 31) | 3.14 × 10−2 | 4.19 × 10−2 | 33.87 | |
| CS-XGBoost (md = 4; lr = 0.38; ns = 35) | 9.53 × 10−3 | 0.86 × 10−3 | 170.8 | |
| CS-GA-XGBoost (md = 5; lr = 0.31; ns = 65) | 3.87 × 10−5 | 3.02 × 10−5 | 6.183 |
| Temperature (°C) | Model | Training MSE | Validation MSE | Modeling Time (s) |
|---|---|---|---|---|
| −40 | Gradient Boosting (* md = 3; * lr = 0.17; * ns = 71) | 1.94 × 10−2 | 1.41 × 10−2 | 129.3 |
| Random Forest (md = 5; ns = 31) | 1.16 × 10−1 | 1.21 × 10−1 | 189.4 | |
| SVR (c = 22; γ = 0.11) | 5.17 × 10−1 | 5.64 × 10−1 | 196.3 | |
| CS-GA-XGBoost (md = 5; lr = 0.28; ns = 71) | 3.08 × 10−5 | 1.65 × 10−5 | 6.582 | |
| 25 | Gradient Boosting (md = 3; lr = 0.15; ns = 82) | 1.84 × 10−2 | 176 × 10−2 | 126.9 |
| Random Forest (md = 5; ns = 18) | 1.17 × 10−1 | 1.33 × 10−1 | 197.2 | |
| SVR (c = 18; γ = 0.16) | 5.44 × 10−1 | 6.83 × 10−1 | 194.3 | |
| CS-GA-XGBoost (md = 5; lr = 0.35; ns = 58) | 2.69 × 10−5 | 1.72 × 10−5 | 5.485 | |
| 125 | Gradient Boosting (md = 3; lr = 0.12; ns = 58) | 1.54 × 10−2 | 1.32 × 10−2 | 125.9 |
| Random Forest (md = 5; ns = 22) | 1.27 × 10−1 | 1.37 × 10−1 | 189.2 | |
| SVR (c = 11; γ = 0.21) | 5.06 × 10−1 | 7.50 × 10−1 | 195.3 | |
| CS-GA-XGBoost (md = 5; lr = 0.31; ns = 65) | 3.87 × 10−5 | 3.02 × 10−5 | 6.183 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhou, S. CS-GA-XGBoost-Based Model for a Radio-Frequency Power Amplifier under Different Temperatures. Micromachines 2023, 14, 1673. https://doi.org/10.3390/mi14091673
Wang J, Zhou S. CS-GA-XGBoost-Based Model for a Radio-Frequency Power Amplifier under Different Temperatures. Micromachines. 2023; 14(9):1673. https://doi.org/10.3390/mi14091673
Chicago/Turabian StyleWang, Jiayi, and Shaohua Zhou. 2023. "CS-GA-XGBoost-Based Model for a Radio-Frequency Power Amplifier under Different Temperatures" Micromachines 14, no. 9: 1673. https://doi.org/10.3390/mi14091673