
A Defect Detection Algorithm for Optoelectronic Detectors Utilizing GLV-YOLO

 ,
, 
Abstract
1. Introduction
2. Related Work
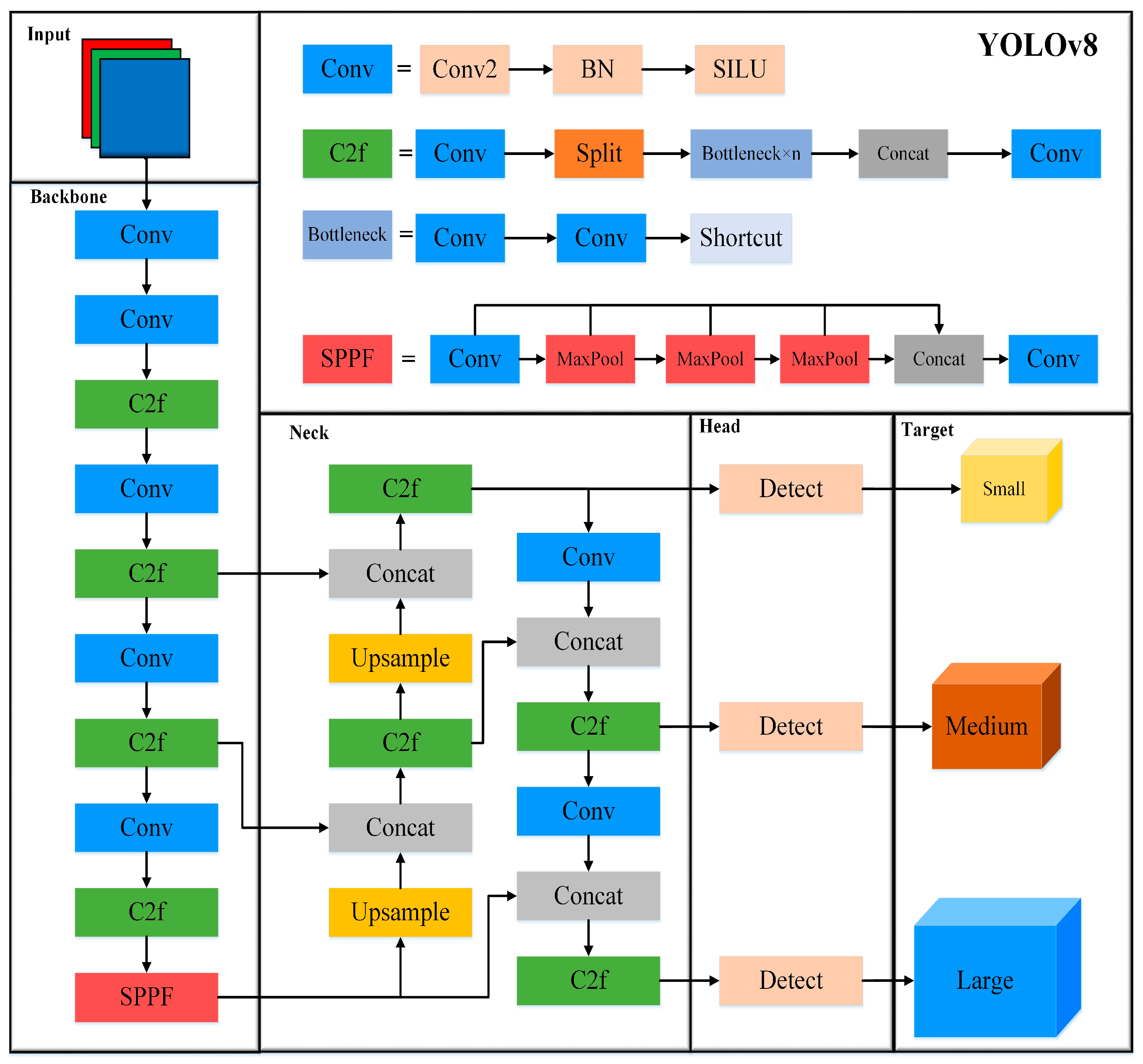
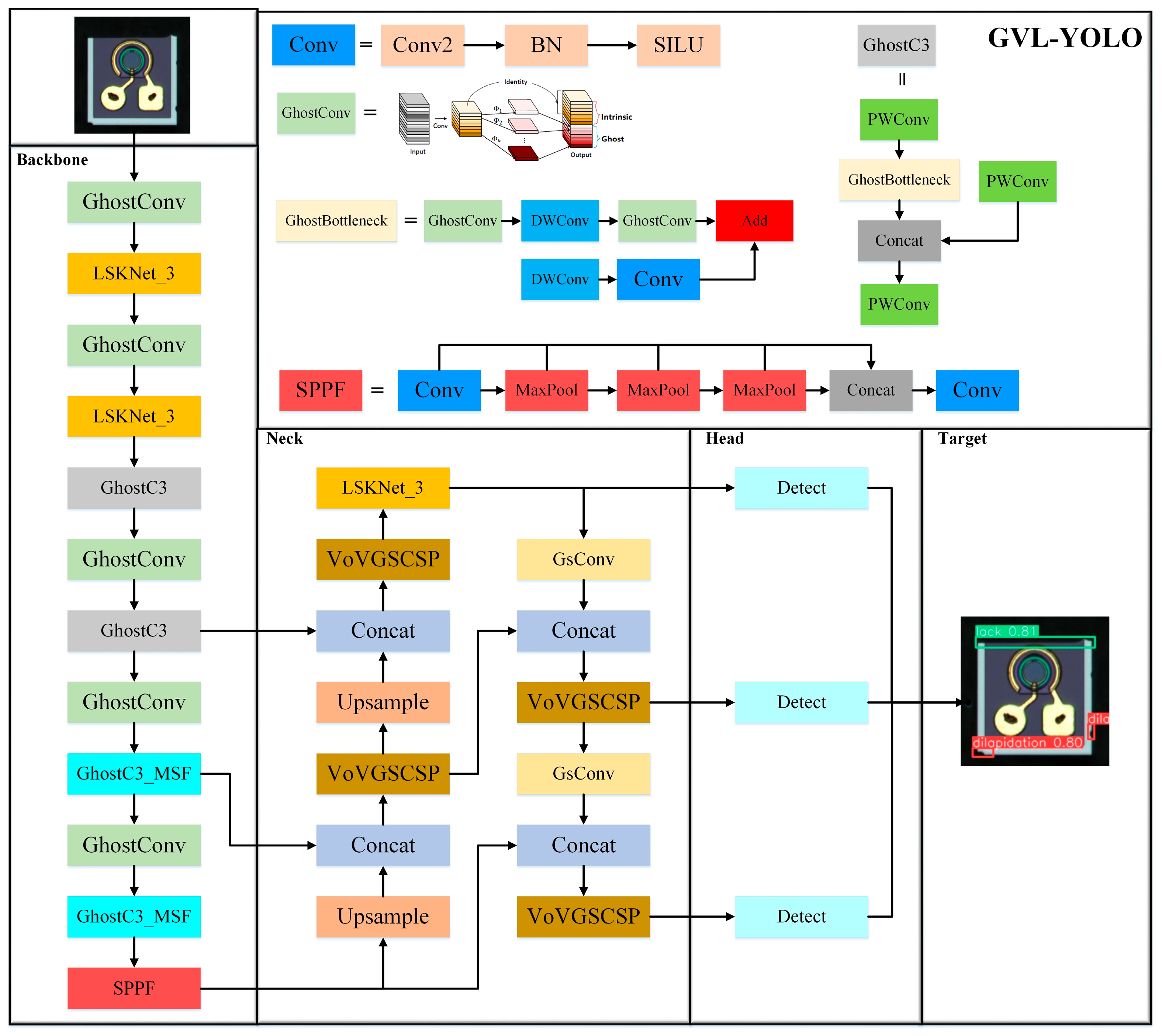
3. Proposed Method
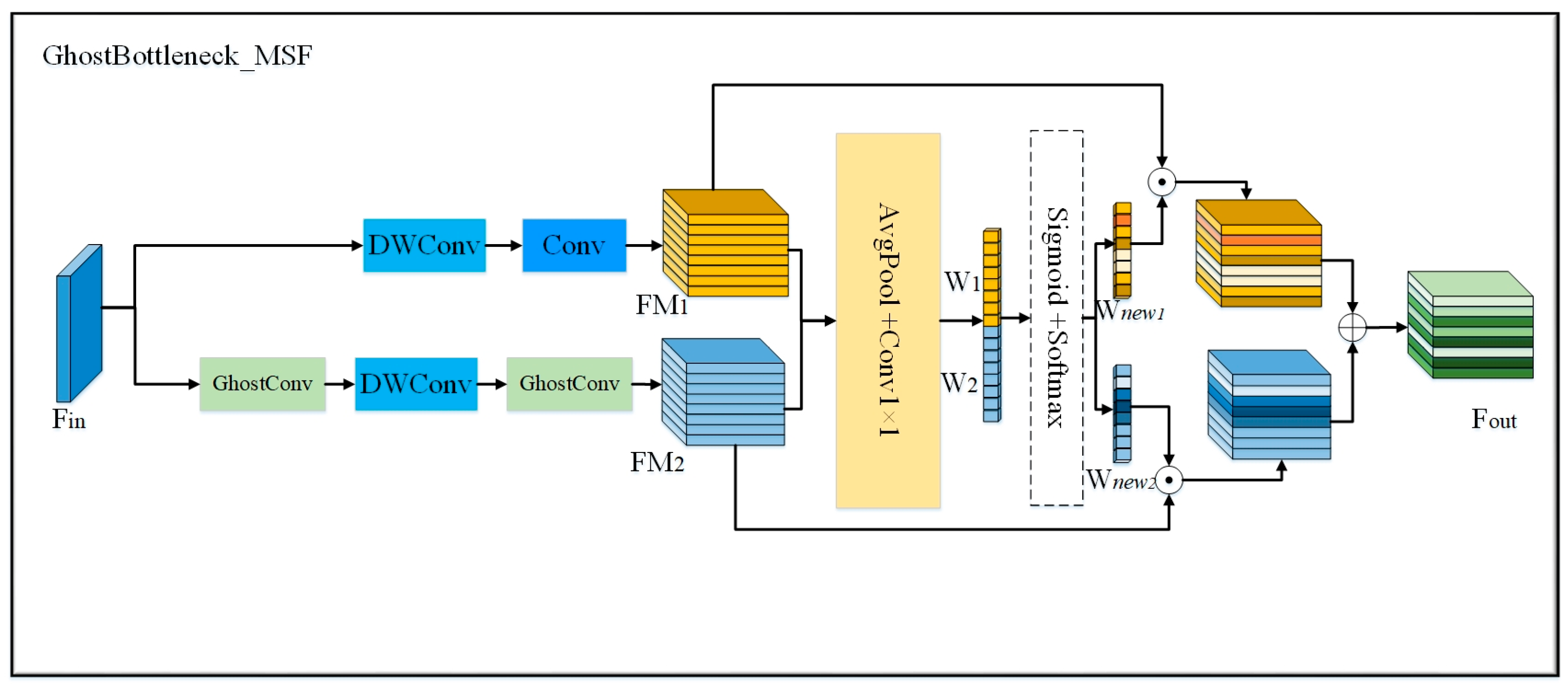
3.1. Lightweight Backbone Network
3.2. Lightweight Modules in the Neck Layer
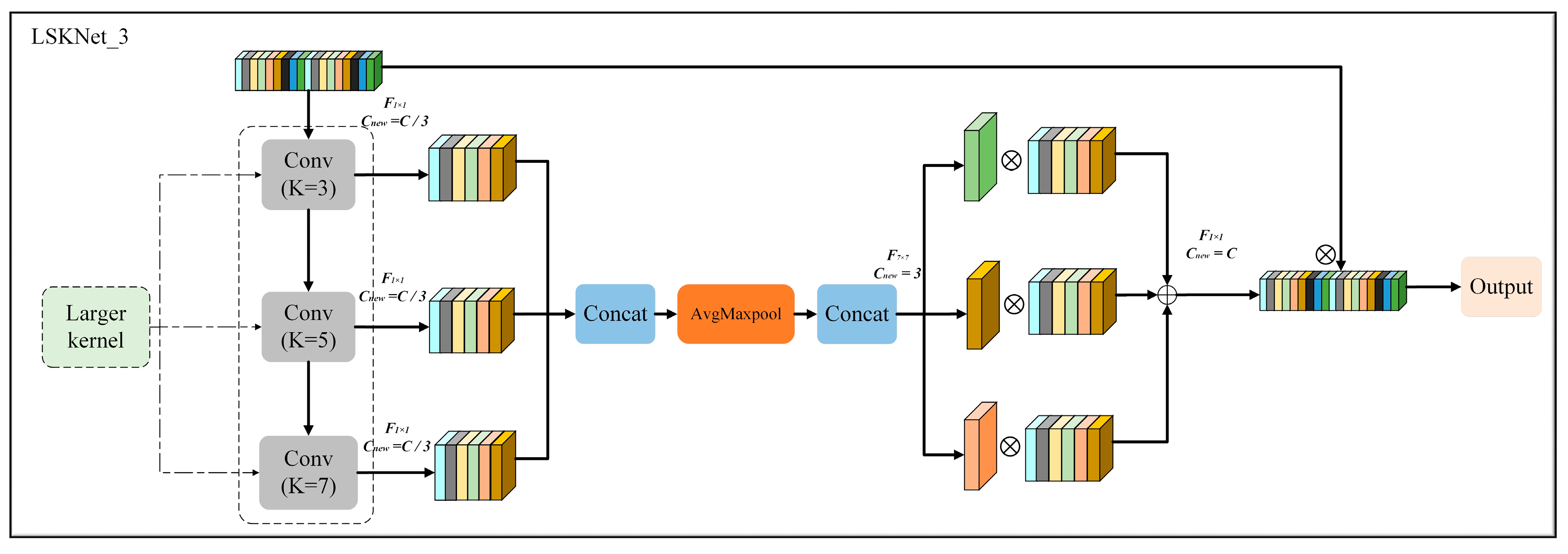
3.3. The Introduction of the LSKNet_3 Attention Mechanism
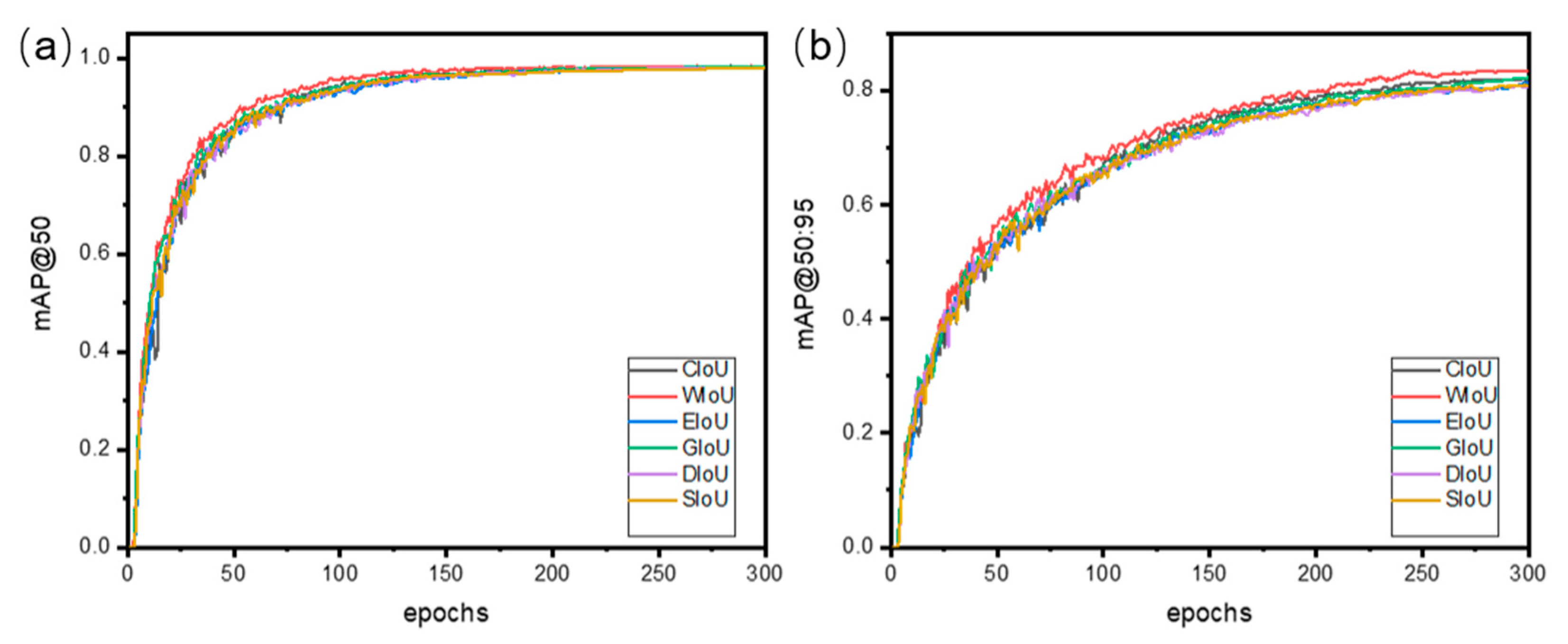
3.4. Loss Function
4. Experiments and Analysis
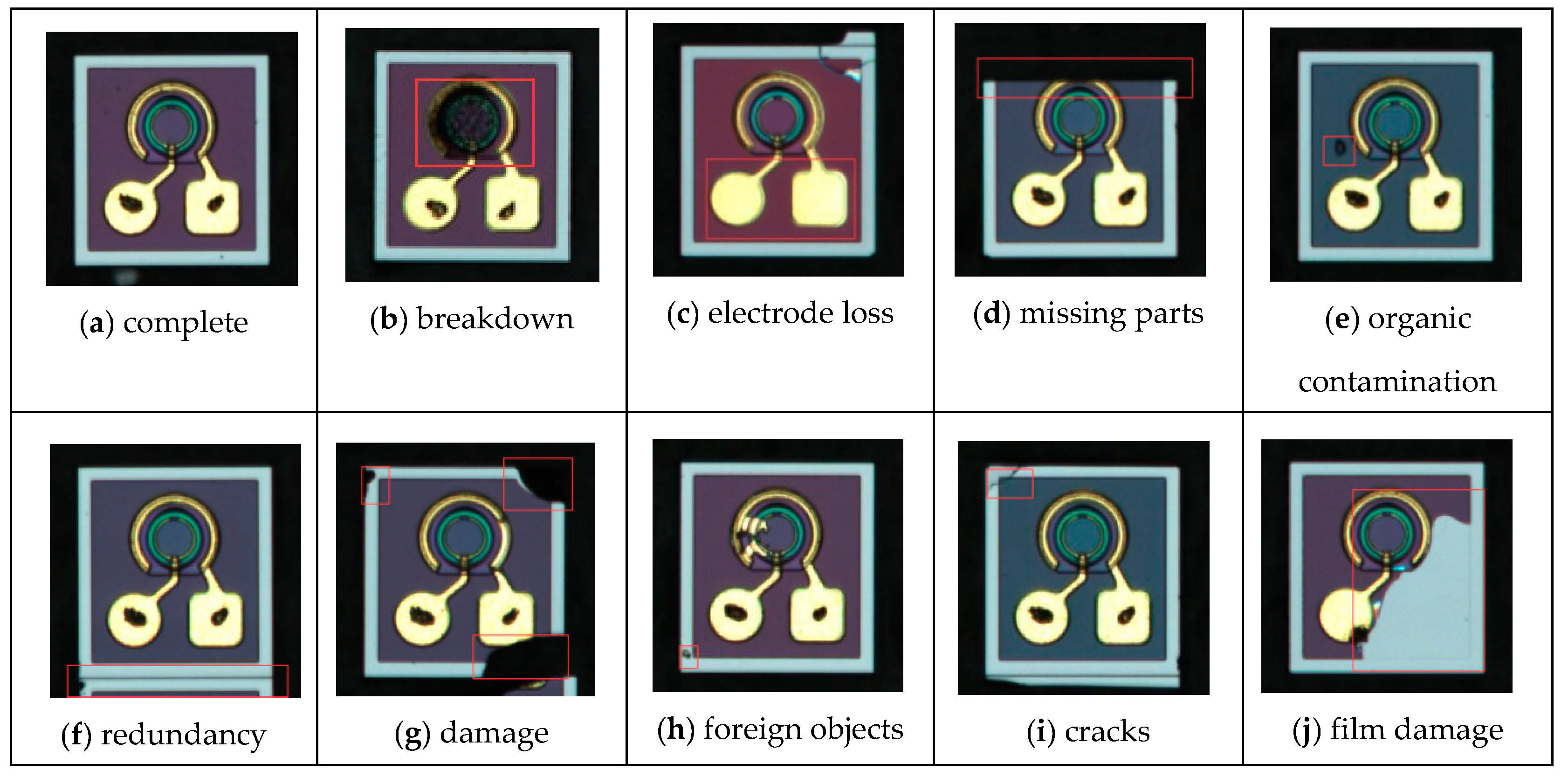
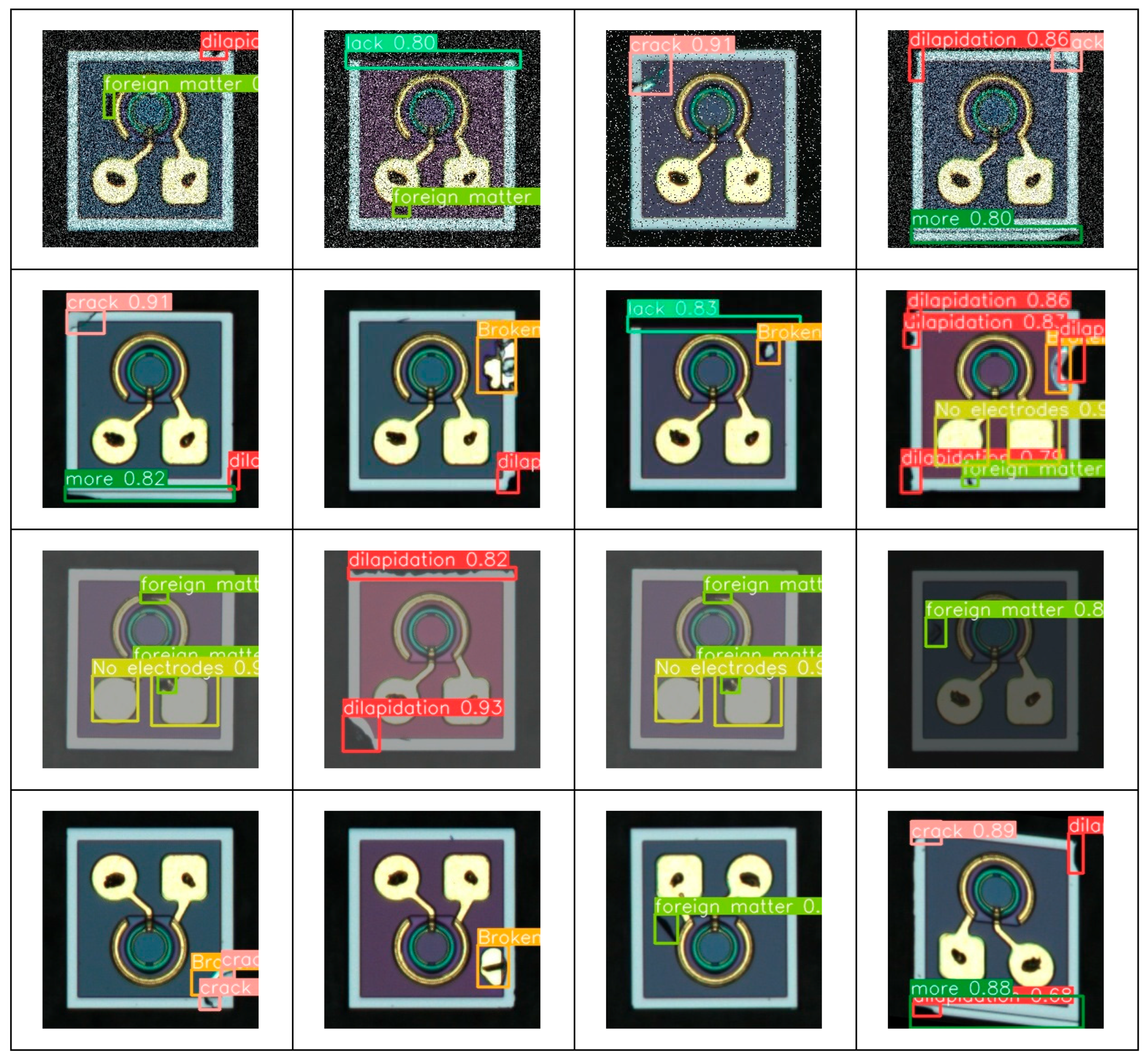
4.1. Dataset
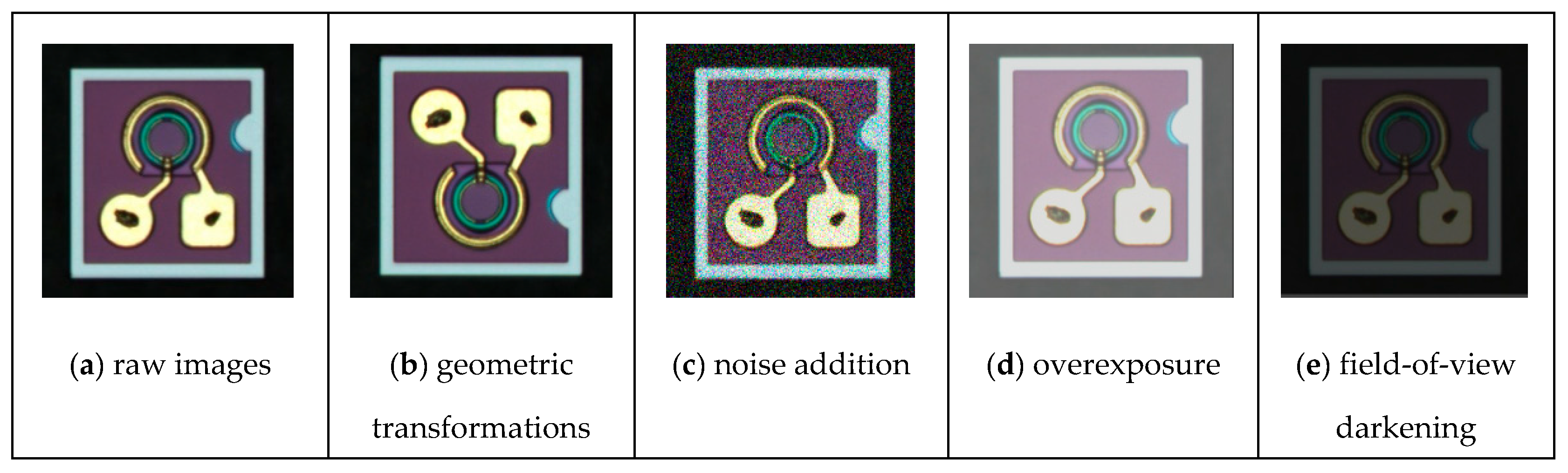
4.2. Image Preprocessing
4.3. Computational Environment and Simulation Parameters
4.4. Model Evaluation Metrics
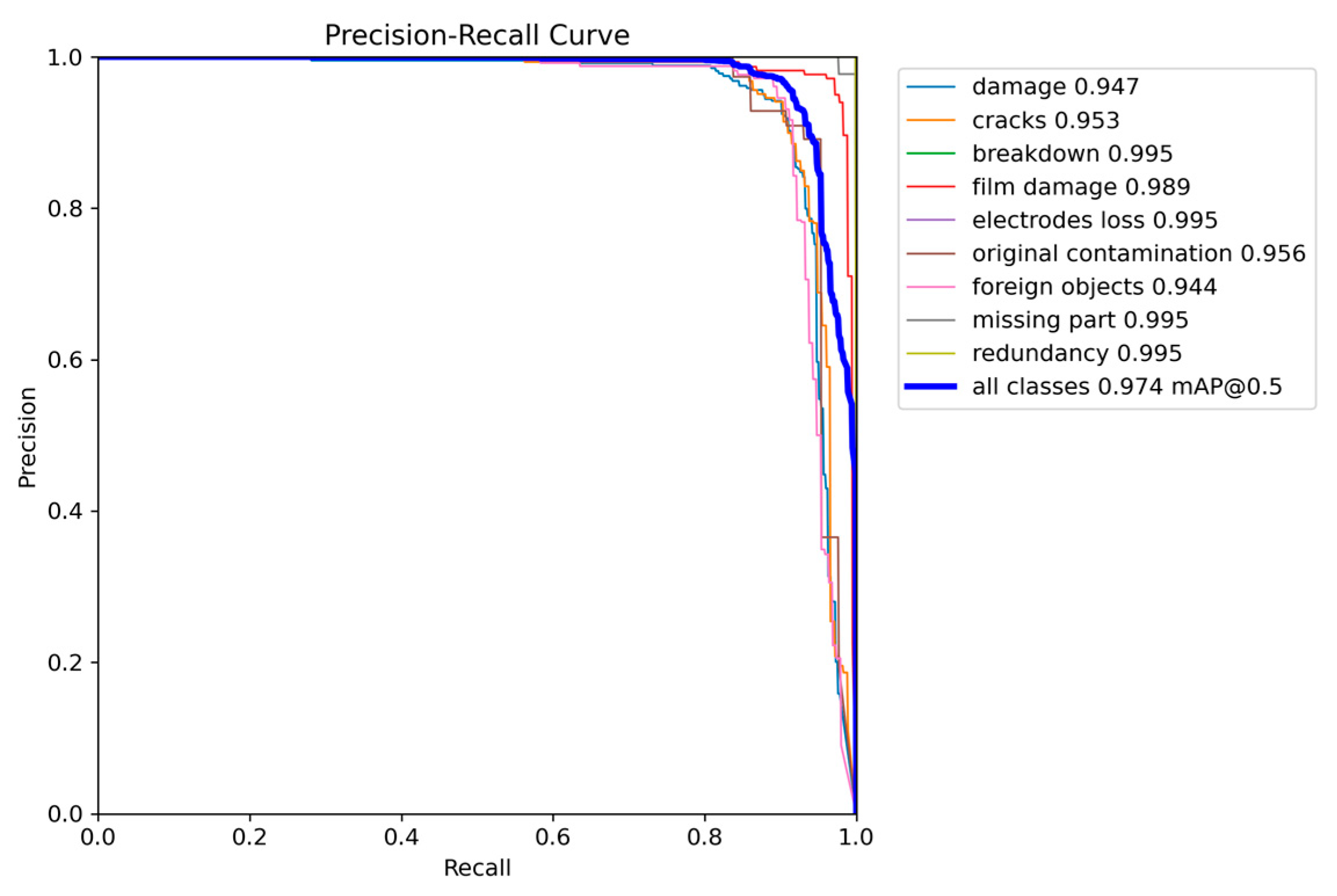
4.5. The Experimental Results of the Model Architecture
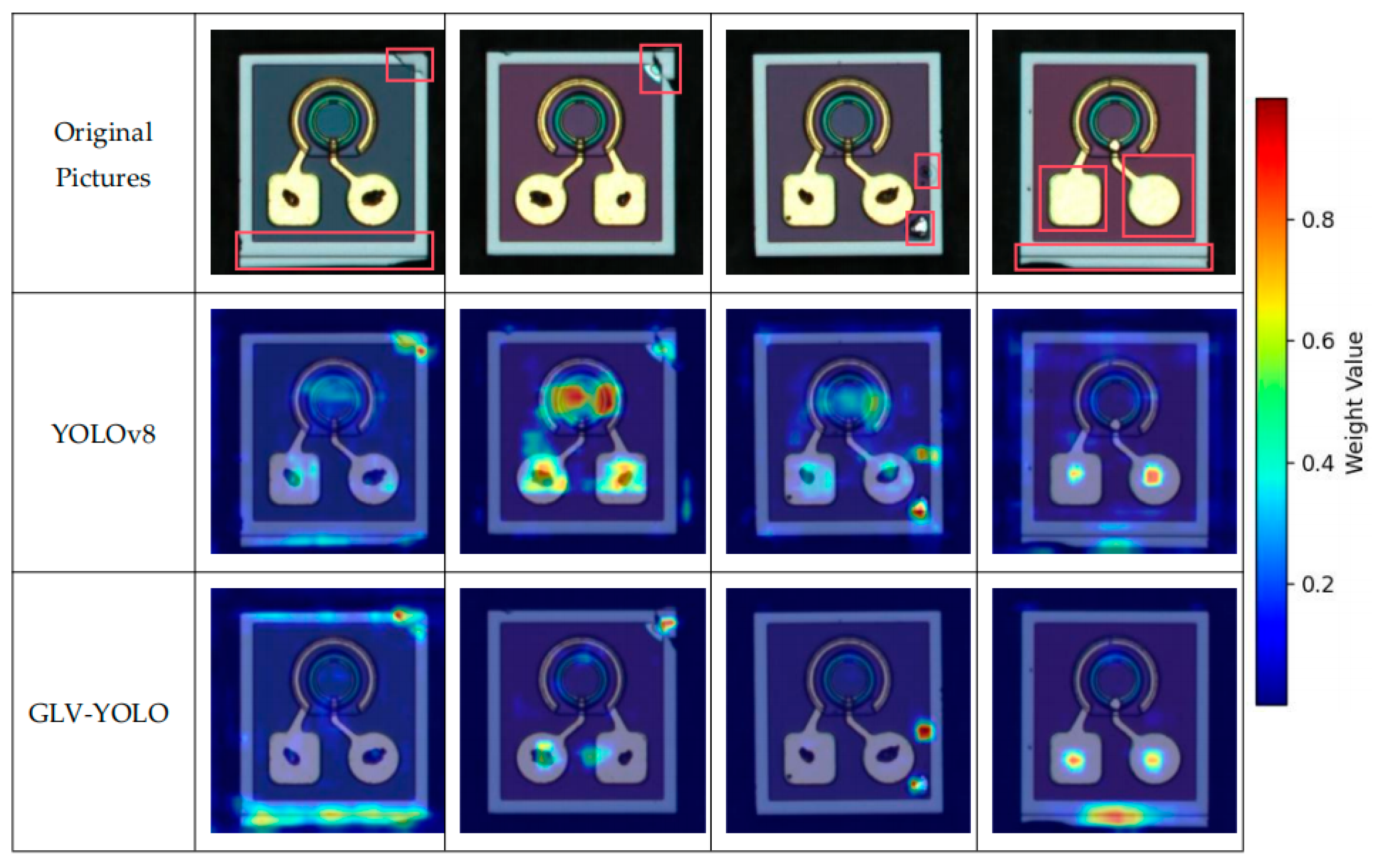
4.6. Results Analysis
4.7. Comparison with Other Models
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Oanh Vu, T.K.; Tran, M.T.; Tu, N.X.; Thanh Bao, N.T.; Kim, E.K. Electronic transport mechanism and defect states for p-InP/i-InGaAs/n-InP photodiodes. J. Mater. Res. Technol. 2022, 19, 2742–2749. [Google Scholar] [CrossRef]
- Kim, B.C.; Park, K.; Jung, B. An FIR Filter Using Segmented Photodiodes for Silicon Photodiode Equalization. IEEE Photonics Technol. Lett. 2016, 28, 2515–2518. [Google Scholar] [CrossRef]
- Sarcan, F.; Doğan, U.; Althumali, A.; Vasili, H.B.; Lari, L.; Kerrigan, A.; Kuruoğlu, F.; Lazarov, V.K.; Erol, A. A novel NiO-based p-i-n ultraviolet photodiode. J. Alloys Compd. 2023, 934, 167806. [Google Scholar] [CrossRef]
- Pelamatti, A.; Goiffon, V.; Moreira, A.D.I.; Magnan, P.; Virmontois, C.; Saint-Pé, O.; Boisanger, M.B. Comparison of Pinning Voltage Estimation Methods in Pinned Photodiode CMOS Image Sensors. IEEE J. Electron Devices Soc. 2016, 4, 99–108. [Google Scholar] [CrossRef]
- Lee, J.; Georgitzikis, E.; Hermans, Y.; Papadopoulos, N.; Chandrasekaran, N.; Jin, M.; Siddik, A.B.; De Roose, F.; Uytterhoeven, G.; Kim, J.H.; et al. Thin-film image sensors with a pinned photodiode structure. Nat. Electron. 2023, 6, 590–598. [Google Scholar] [CrossRef]
- Fortsch, M.; Zimmermann, H.; Pless, H. 220-MHz monolithically integrated optical sensor with large-area integrated PIN photodiode. IEEE Sens. J. 2006, 6, 385–390. [Google Scholar] [CrossRef]
- Smithard, J.; Rajic, N.; Van der Velden, S.; Norman, P.; Rosalie, C.; Galea, S.; Mei, H.; Lin, B.; Giurgiutiu, V. An Advanced Multi-Sensor Acousto-Ultrasonic Structural Health Monitoring System: Development and Aerospace Demonstration Materials. Materials 2017, 10, 832. [Google Scholar] [CrossRef]
- Zaman Sarker, M.S.; Itoh, S.; Hamai, M.; Takai, I.; Andoh, M.; Yasutomi, K.; Kawahito, S. Design and Implementation of A CMOS Light Pulse Receiver Cell Array for Spatial Optical Communications Sensors. Sensors 2011, 11, 2056–2076. [Google Scholar] [CrossRef]
- Jursinic, P. A PIN photodiode ionizing radiation detector with small angular dependence and low buildup. Radiat. Meas. 2023, 166, 106963. [Google Scholar] [CrossRef]
- Roch, A.L.; Virmontois, C.; Goiffon, V.; Tauziède, L.; Belloir, J.M.; Durnez, C.; Magnan, P. Radiation-Induced Defects in 8T-CMOS Global Shutter Image Sensor for Space Applications. IEEE Trans. Nucl. Sci. 2018, 65, 1645–1653. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, W.; Wang, D.; Jin, G.Y. Structural, optical and electrical behavior of millisecond pulse laser damaged silicon-based positive-intrinsic-negative photodiode. Optik 2017, 131, 110–115. [Google Scholar] [CrossRef]
- Ye, J.; El Desouky, A.; Elwany, A. On the applications of additive manufacturing in semiconductor manufacturing equipment. J. Manuf. Process. 2024, 124, 1065–1079. [Google Scholar] [CrossRef]
- Kim, J.; Nam, Y.; Kang, M.C.; Kim, K.; Hong, J.; Lee, S.; Kim, D.N. Adversarial Defect Detection in Semiconductor Manufacturing Process. IEEE Trans. Semicond. Manuf. 2021, 34, 365–371. [Google Scholar] [CrossRef]
- Park, J.; Lee, J. Automated visual inspection of particle defect in semiconductor packaging. J. Mech. Sci. Technol. 2024, 38, 4447–4453. [Google Scholar] [CrossRef]
- Chia, J.Y.; Thamrongsiripak, N.; Thongphanit, S.; Nuntawong, N. Machine learning-enhanced detection of minor radiation-induced defects in semiconductor materials using Raman spectroscopy. J. Appl. Phys. 2024, 135, 025701. [Google Scholar] [CrossRef]
- Jiang, J.; Cao, P.; Lu, Z.; Lou, W.; Yang, Y. Surface Defect Detection for Mobile Phone Back Glass Based on Symmetric Convolutional Neural Network Deep Learning. Appl. Sci. 2020, 10, 3621. [Google Scholar] [CrossRef]
- Zhang, H.; Li, R.; Zou, D.; Liu, J.; Chen, N. An automatic defect detection method for TO56 semiconductor laser using deep convolutional neural network. Comput. Ind. Eng. 2023, 179, 109148. [Google Scholar] [CrossRef]
- Wu, S.; Zhu, Y.; Liang, P. DSCU-Net: MEMS Defect Detection Using Dense Skip-Connection U-Net. Symmetry 2024, 16, 300. [Google Scholar] [CrossRef]
- Yang, S.; Xie, Y.; Wu, J.; Huang, W.; Yan, H.; Wang, J.; Wang, B.; Yu, X.; Wu, Q.; Xie, F. CFE-YOLOv8s: Improved YOLOv8s for Steel Surface Defect Detection. Electronics 2024, 13, 2771. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, L.; Li, H.; Xue, X.; Liu, H. Research on a Metal Surface Defect Detection Algorithm Based on DSL-YOLO. Sensors 2024, 24, 6268. [Google Scholar] [CrossRef]
- Liu, M.; Chen, Y.; Xie, J.; He, L.; Zhang, Y. LF-YOLO: A Lighter and Faster YOLO for Weld Defect Detection of X-Ray Image. IEEE Sens. J. 2023, 23, 7430–7439. [Google Scholar] [CrossRef]
- Ren, F.; Fei, J.; Li, H.; Doma, B.T. Steel Surface Defect Detection Using Improved Deep Learning Algorithm: ECA-SimSPPF-SIoU-Yolov5. IEEE Access 2024, 12, 32545–32553. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, M.; Zhang, B.; Shi, X.; Chang, Q. GBCD-YOLO: A High-Precision and Real-Time Lightweight Model for Wood Defect Detection. IEEE Access 2024, 12, 12853–12868. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Neubeck, A.; Gool, L.V. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 16748–16759. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. J. Real-Time Image Process. 2024, 21, 62. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R.J.A. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. arXiv 2021. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defect Type | Sample Count |
|---|---|
| breakdown | 60 |
| electrode loss | 690 |
| missing parts | 360 |
| organic contamination | 480 |
| redundancy | 585 |
| damage | 3384 |
| foreign objects | 1782 |
| cracks | 1755 |
| film damage | 1947 |
| Simulation Parameters | Parameter Values |
|---|---|
| Epochs | 300 |
| Batch size | 32 |
| Learning rate | 0.01 |
| Optimizer | SGD |
| Model | GhostNet (Backbone) | GsConv + VoV (Neck) | LSKNet_3 | mAP0.5 (%) | mAP0.5–0.95 (%) | Param. | P (%) | R (%) | GFLOPs |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8n | × | × | × | 95.8 | 72.9 | 3,157,200 | 95.6 | 90.9 | 8.9 |
| Model 1 | √ | × | × | 94.9 | 70.6 | 2,445,167 | 93.2 | 89.3 | 7.2 |
| Model 2 | × | √ | × | 96.3 | 76.3 | 2,737,107 | 94.3 | 92.6 | 7.9 |
| Model 3 | × | × | √ | 98.5 | 84.1 | 3,199,881 | 96.9 | 96.6 | 9.0 |
| Model 4 | √ | √ | × | 95.3 | 72.8 | 2,169,671 | 95.4 | 90.3 | 6.3 |
| Model 5 | √ | √ | √ | 98.9 | 83.4 | 2,187,390 | 96.4 | 97 | 7.0 |
| Loss Function | CIoU [28] | WIoU | EIoU [33] | GIoU [34] | DIoU [35] | SIoU [36] |
|---|---|---|---|---|---|---|
| mAP@50 (%) | 98.2 | 98.9 | 98.2 | 98.2 | 97.9 | 98 |
| mAP@50:95 (%) | 81.9 | 83.4 | 81.4 | 82.3 | 80.7 | 80.8 |
| Model | mAP0.5 (%) | mAP0.5–0.95 (%) | FLOPs (G) | Parameters (Million) | Weights_file (Mb) | FPS |
|---|---|---|---|---|---|---|
| Yolov3tiny | 91.8 | 58.6 | 19.1 | 12.1 | 11.7 | 140 |
| Yolov5s | 91.1 | 59.2 | 16 | 7.0 | 13.6 | 24 |
| Yolov7tiny | 89.2 | 54.4 | 3.46 | 6.03 | 11.7 | 55 |
| Yolov8n | 95.8 | 72.9 | 8.9 | 3.16 | 5.94 | 65 |
| Yolov8s | 98.7 | 83.7 | 28.7 | 11.2 | 21.4 | 60 |
| GLV-YOLO | 98.9 | 83.4 | 7.0 | 2.18 | 4.7 | 46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Lyu, Q.; Zeng, H.; Ling, Z.; Zhai, Z.; Lyu, H.; Riffat, S.; Chen, B.; Wang, W. A Defect Detection Algorithm for Optoelectronic Detectors Utilizing GLV-YOLO. Micromachines 2025, 16, 267. https://doi.org/10.3390/mi16030267
Zhao X, Lyu Q, Zeng H, Ling Z, Zhai Z, Lyu H, Riffat S, Chen B, Wang W. A Defect Detection Algorithm for Optoelectronic Detectors Utilizing GLV-YOLO. Micromachines. 2025; 16(3):267. https://doi.org/10.3390/mi16030267
Chicago/Turabian StyleZhao, Xinfang, Qinghua Lyu, Hui Zeng, Zhuoyi Ling, Zhongsheng Zhai, Hui Lyu, Saffa Riffat, Benyuan Chen, and Wanting Wang. 2025. "A Defect Detection Algorithm for Optoelectronic Detectors Utilizing GLV-YOLO" Micromachines 16, no. 3: 267. https://doi.org/10.3390/mi16030267
APA StyleZhao, X., Lyu, Q., Zeng, H., Ling, Z., Zhai, Z., Lyu, H., Riffat, S., Chen, B., & Wang, W. (2025). A Defect Detection Algorithm for Optoelectronic Detectors Utilizing GLV-YOLO. Micromachines, 16(3), 267. https://doi.org/10.3390/mi16030267