
Fraud Detection Using the Fraud Triangle Theory and Data Mining Techniques: A Literature Review




Abstract
1. Introduction
1.1. Related Work
1.2. Contribution
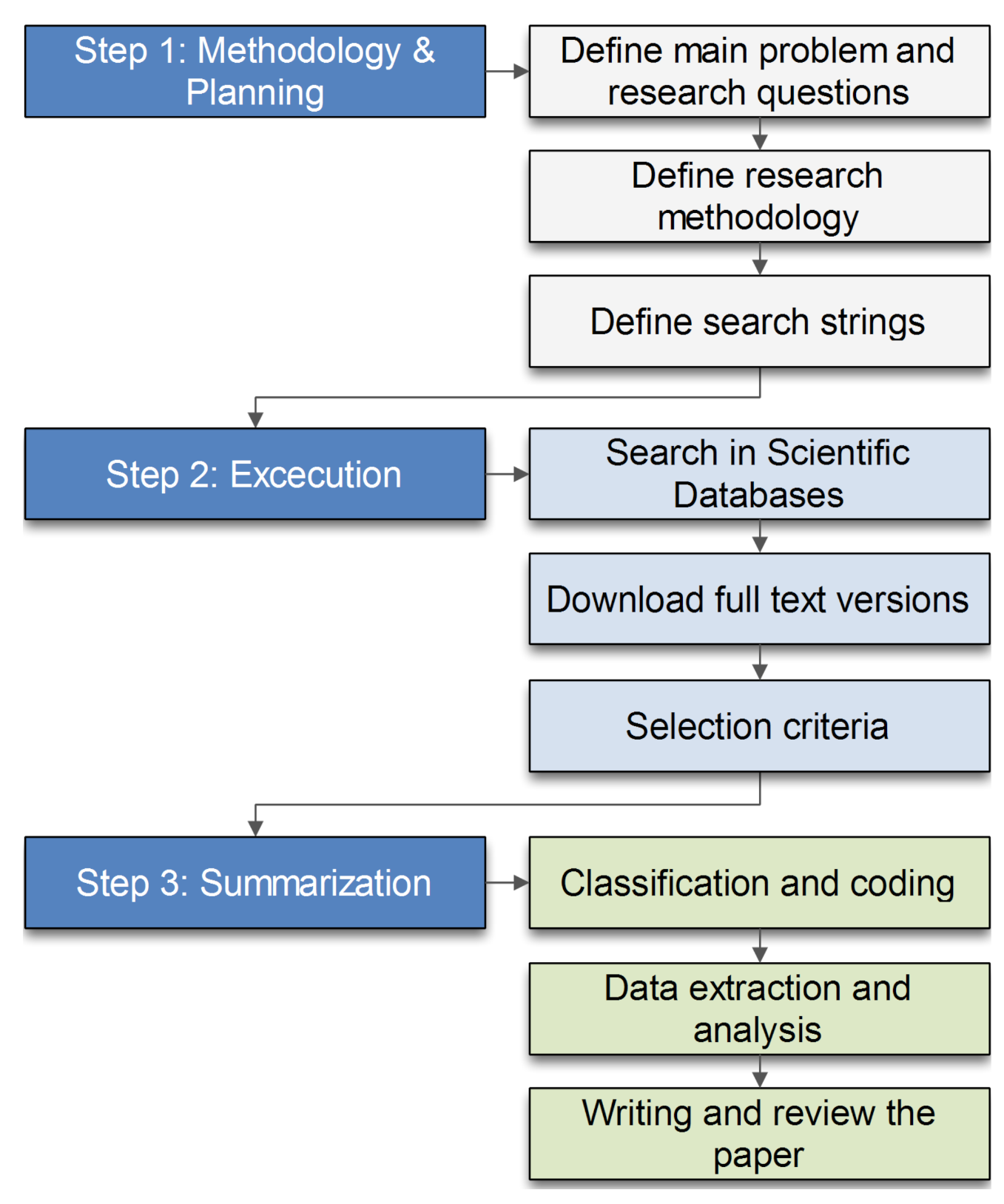
2. Materials and Methods
2.1. Research Questions
- RQ1: How can fraud be detected by analyzing human behavior by applying fraud theories?
- RQ2: What machine or deep learning techniques are used to detect fraud?
- RQ3: Using machine learning techniques, how can fraud cases be detected by analyzing human behavior associated with the Fraud Triangle Theory?
2.2. Keywords
2.3. Search Strategy
2.3.1. Search Method
2.3.2. Search Terms
2.3.3. Selection of Papers
2.4. Study Selection
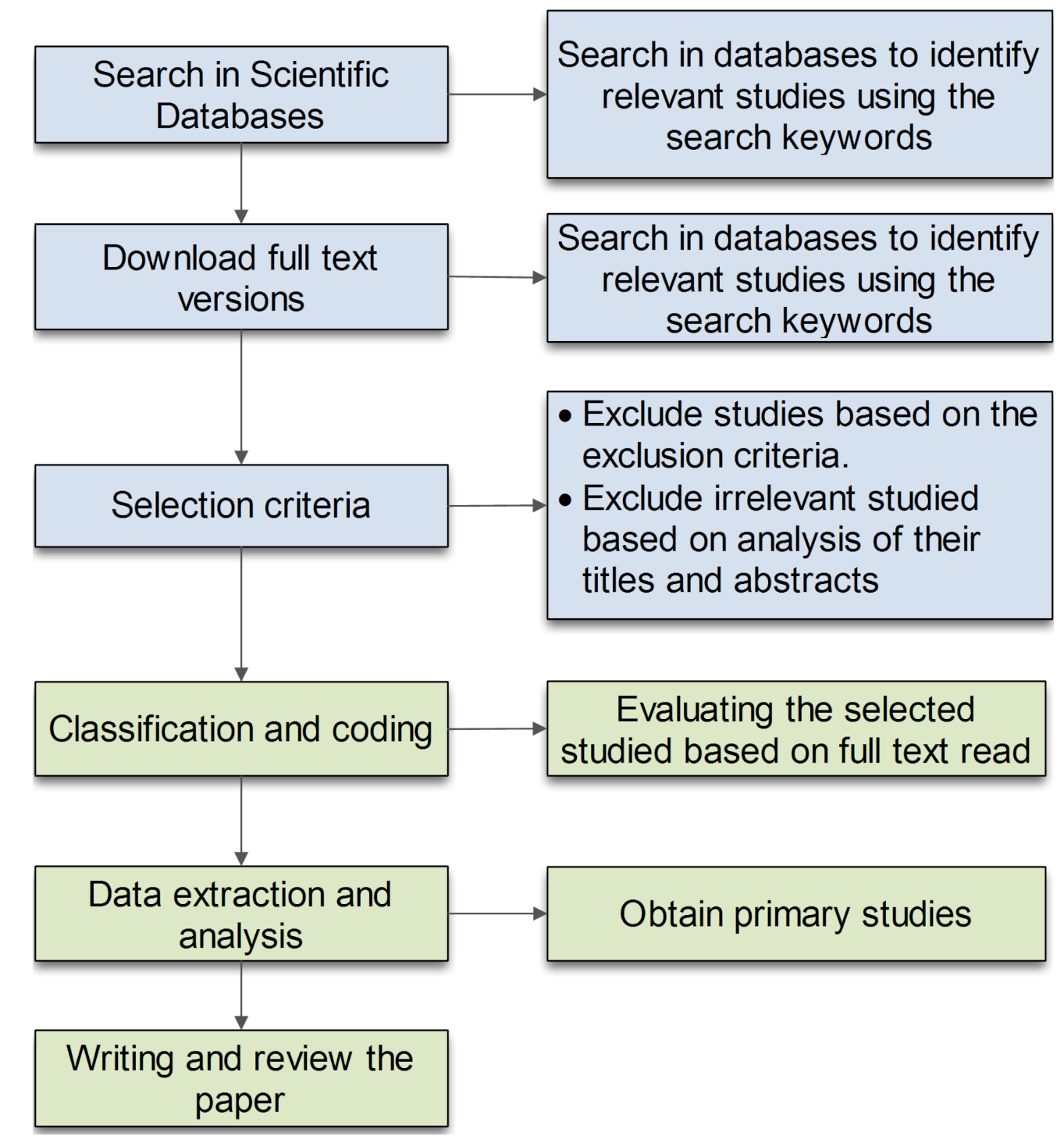
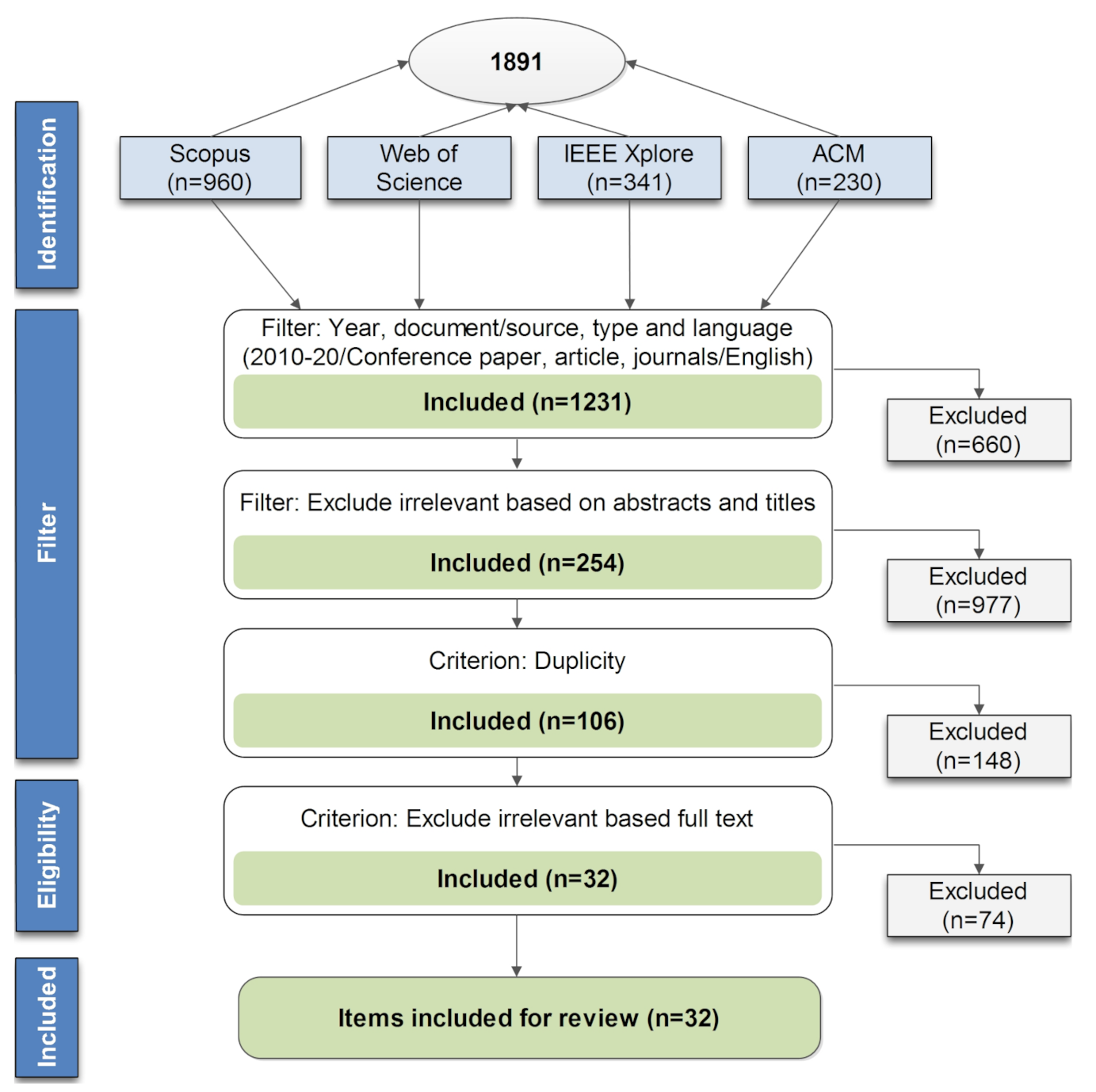
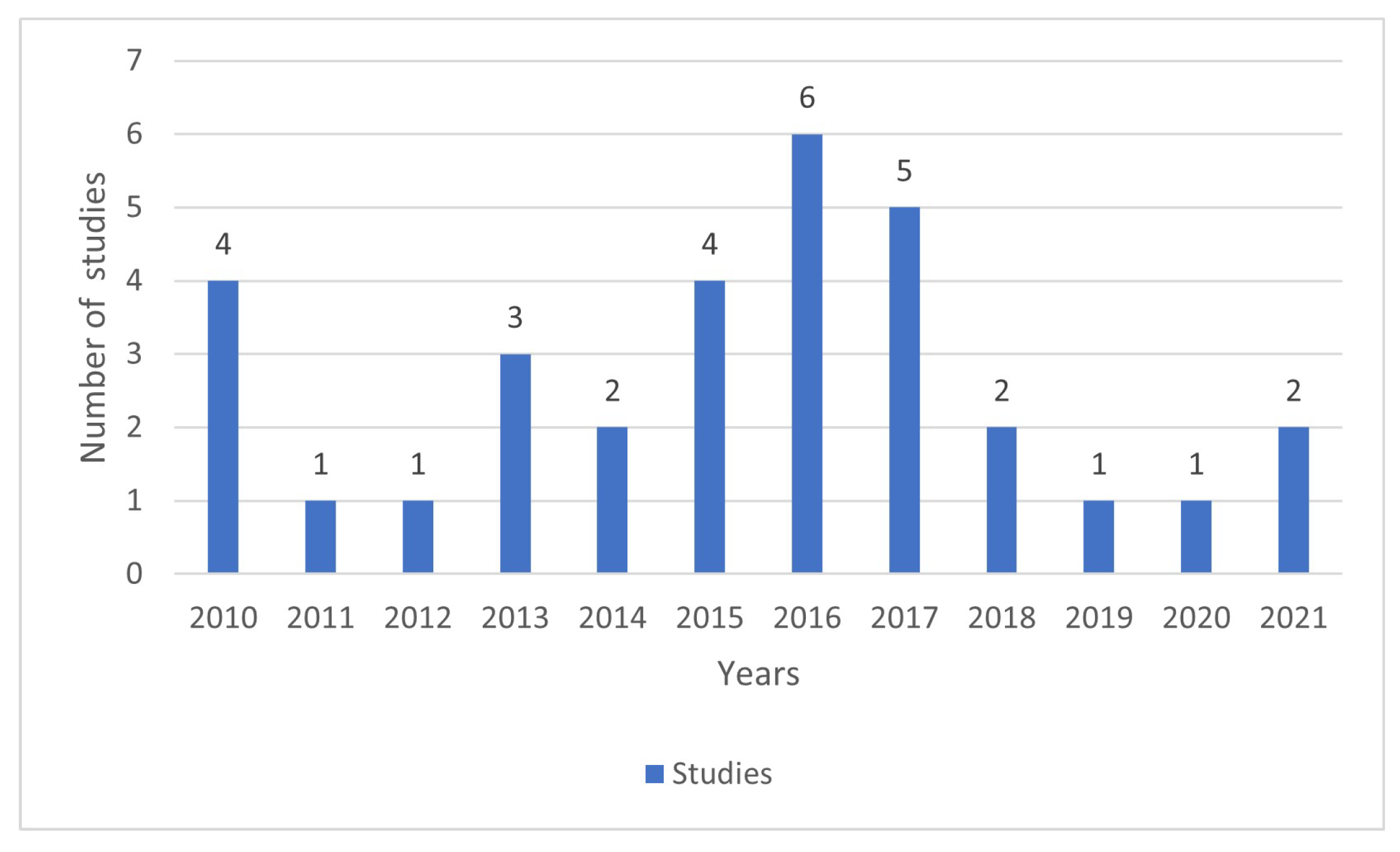
- Identification: The keywords were selected from the databases listed above according to the research questions mentioned in the search method section. The search string was applied only to the title and abstract, as a full-text search would produce many irrelevant results [37]. The search period went from 2010 to 2021.
- Filter: All possible primary studies’ titles, abstracts, and keywords were checked against the inclusion and exclusion criteria. If it was difficult to determine whether an article should be included or not, it was reserved for the next phase.
- Eligibility: At this stage, a complete reading of the text was carried out to determine if the article should be included according to the inclusion and exclusion criteria.
- Data extraction: After the filtering process, data were extracted from the selected studies to answer RQ1–RQ3.
2.5. Quality Assessment
- Are the topics covered in the article relevant for fraud detection? Yes: It explicitly describes the topics related to fraud detection by applying ML techniques through the FTT. Partially: Only a few are mentioned. No: It neither describes nor mentions topics related to fraud detection using ML techniques through the FTT.
- Were the limitations for the study of fraud detection detailed? Yes: It clearly explained the limitations related to fraud detection by applying ML techniques through the FTT. Partially: It mentioned the limitations but did not explain why. No: It did not mention the limitations.
- Did the study address systematic research? Yes: The study was developed systematically and applied an adequate methodology to obtain reliable findings. Partially: The study was developed systematically and used a proper methodology but did not provide details. No: The study was not explained in a clear way and the authors did not apply an adequate methodology.
2.6. Data Extraction and Analysis
2.7. Synthesis
3. Results
3.1. RQ1: How Can Fraud Be Detected by Analyzing Human Behavior by Applying Fraud Theories?
3.2. RQ2: What Machine or Deep Learning Techniques Are Used to Detect Fraud?
3.3. RQ3: Using Machine Learning Techniques, How Can Fraud Cases Be Detected by Analyzing Human Behavior Associated with the Fraud Triangle Theory?
3.4. Quality Assessment
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shaikh, A.K.; Nazir, A. A novel dynamic approach to identifying suspicious customers in money transactions. Int. J. Bus. Intell. Data Min. 2020, 17, 143–158. [Google Scholar]
- Panigrahi, P.K. A framework for discovering internal financial fraud using analytics. In Proceedings of the 2011 International Conference on Communication Systems and Network Technologies, Katra, India, 3–5 June 2011; pp. 323–327. [Google Scholar]
- Silowash, G.; Cappelli, D.; Moore, A.; Trzeciak, R.; Shimeall, T.; Flynn, L. Common Sense Guide to Prevention and Detection of Insider Threats, 4th ed.; Carnegie Mellon University CyLab: Pittsburgh, PA, USA, 2012. [Google Scholar]
- Kassem, R. Detecting asset misappropriation: A framework for external auditors. Int. J. Account. Audit. Perform. Eval. 2014, 10, 1–42. [Google Scholar] [CrossRef]
- Sayal, K.; Singh, G. What Role Does Human Behaviour Play in Corporate Frauds? Econ. Political Wkly. 2020, 55. Available online: https://www.epw.in/engage/article/what-role-does-human-behaviour-play-corporate (accessed on 1 September 2021).
- Gabrielli, G.; Medioli, A. An overview of instruments and tools to detect fraudulent financial statements. Univ. J. Account. Financ. 2019, 7, 76–82. [Google Scholar] [CrossRef][Green Version]
- Dimitrijević, D.; Kalinić, Z. Software Tools Usage in Fraud Detection and Prevention in Governmental and External Audit Organizations in the Republic of Serbia1. In Knowledge–Economy–Society; Cracow University of Economics: Cracow, Poland, 2017; p. 71. [Google Scholar]
- Vynokurova, O.; Peleshko, D.; Bondarenko, O.; Ilyasov, V.; Serzhantov, V.; Peleshko, M. Hybrid Machine Learning System for Solving Fraud Detection Tasks. In Proceedings of the 2020 IEEE Third International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Lebichot, B.; Paldino, G.M.; Bontempi, G.; Siblini, W.; He, L.; Oble, F. Incremental learning strategies for credit cards fraud detection: Extended abstract. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, Australia, 6–9 October 2020; pp. 785–786. [Google Scholar] [CrossRef]
- Saia, R. A Discrete Wavelet Transform Approach to Fraud Detection. In Proceedings of the International Conference on Network and System Security, Helsinki, Finland, 21–23 August 2017. [Google Scholar]
- Vynokurova, O.; Peleshko, D.; Zhernova, P.; Perova, I.; Kovalenko, A. Solving Fraud Detection Tasks Based on Wavelet-Neuro Autoencoder. In Proceedings of the International Scientific Conference “Intellectual Systems of Decision Making and Problem of Computational Intelligence”, Zalizniy Port, Ukraine, 25–29 May 2021; pp. 535–546. [Google Scholar] [CrossRef]
- Omair, B.; Alturki, A. Taxonomy of Fraud Detection Metrics for Business Processes. IEEE Access 2020, 8, 71364–71377. [Google Scholar] [CrossRef]
- Omair, B.; Alturki, A. Multi-Dimensional Fraud Detection Metrics in Business Processes and their Application. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 570. [Google Scholar] [CrossRef]
- Ruankaew, T. The Fraud Factors. Int. J. Manag. Adm. Sci. (IJMAS) 2013, 2, 1–5. [Google Scholar]
- Mansor, N.; Abdullahi, R. Fraud triangle theory and fraud diamond theory. Understanding the convergent and divergent for future research. Int. J. Acad. Res. Account. Financ. Manag. Sci. 2015, 1, 38–45. [Google Scholar]
- Burke, D.D.; Sanney, K.J. Applying the fraud triangle to higher education: Ethical implications. J. Legal Stud. Educ. 2018, 35, 5. [Google Scholar] [CrossRef]
- Awang, N.; Hussin, N.S.; Razali, F.A.; Lyana, S.; Talib, A. Fraud Triangle Theory: Calling for New Factors. Editor. Board 2020, 7, 54–64. [Google Scholar]
- Wolfe, D.T.; Hermanson, D.R. The fraud diamond: Considering the four elements of fraud. CPA J. 2004, 74, 38. [Google Scholar]
- Ruankaew, T. Beyond the fraud diamond. Int. J. Bus. Manag. Econ. Res. (IJBMER) 2016, 7, 474–476. [Google Scholar]
- Christian, N.; Basri, Y.; Arafah, W. Analysis of fraud triangle, fraud diamond and fraud pentagon theory to detecting corporate fraud in Indonesia. Int. J. Bus. Manag. Technol. 2019, 3, 73–78. [Google Scholar]
- Manolopoulos, Y.; Spathis, C.; Kirkos, E. Data Mining techniques for the detection of fraudulent financial statements. Expert Syst. Appl. 2007, 32, 995–1003. [Google Scholar]
- Meenatkshi, R.; Sivaranjani, K. Fraud detection in financial statement using data mining technique and performance analysis. JCTA 2016, 9, 407–413. [Google Scholar]
- Al-Hashedi, K.G.; Magalingam, P. Financial fraud detection applying data mining techniques: A comprehensive review from 2009 to 2019. Comput. Sci. Rev. 2021, 40, 100402. [Google Scholar] [CrossRef]
- Deng, W.; Huang, Z.; Zhang, J.; Xu, J. A Data Mining Based System For Transaction Fraud Detection. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 15–17 January 2021; pp. 542–545. [Google Scholar]
- Phua, C.; Lee, V.; Smith, K.; Gayler, R. A comprehensive survey of data mining-based fraud detection research. arXiv 2010, arXiv:1009.6119. [Google Scholar]
- Zhou, X.; Cheng, S.; Zhu, M.; Guo, C.; Zhou, S.; Xu, P.; Xue, Z.; Zhang, W. A state of the art survey of data mining-based fraud detection and credit scoring. In MATEC Web of Conferences; EDP Sciences: Les Ulis, France, 2018; Volume 189, p. 03002. [Google Scholar]
- Gupta, S.; Mehta, S.K. Data Mining-based Financial Statement Fraud Detection: Systematic Literature Review and Meta-analysis to Estimate Data Sample Mapping of Fraudulent Companies Against Non-fraudulent Companies. Glob. Bus. Rev. 2021. [Google Scholar] [CrossRef]
- Ngai, E.W.; Hu, Y.; Wong, Y.H.; Chen, Y.; Sun, X. The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature. Decis. Support Syst. 2011, 50, 559–569. [Google Scholar] [CrossRef]
- Yue, D.; Wu, X.; Wang, Y.; Li, Y.; Chu, C.H. A review of data mining-based financial fraud detection research. In Proceedings of the 2007 International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, 21–25 September 2007; pp. 5519–5522. [Google Scholar]
- Sasirekha, M.; Thaseen, I.S.; Banu, J.S. An Integrated Intrusion Detection System for Credit Card Fraud Detection. In Advances in Computing and Information Technology; Springer: Berlin/Heidelberg, Germany, 2012; pp. 55–60. [Google Scholar]
- Dyba, T.; Kitchenham, B.A.; Jorgensen, M. Evidence-based software engineering for practitioners. IEEE Softw. 2005, 22, 58–65. [Google Scholar] [CrossRef]
- Staples, M.; Niazi, M. Experiences using systematic review guidelines. J. Syst. Softw. 2007, 80, 1425–1437. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; EBSE 2007-001, Keele University and Durham University Joint Report; Kitchenham: Newcastle, UK, 2007; Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.117.471&rep=rep1&type=pdf (accessed on 1 September 2021).
- Cronin, P.; Ryan, F.; Coughlan, M. Undertaking a literature review: A step-by-step approach. Br. J. Nurs. 2008, 17, 38–43. [Google Scholar] [CrossRef]
- Zhang, H.; Babar, M.A.; Tell, P. Identifying relevant studies in software engineering. Inf. Softw. Technol. 2011, 53, 625–637. [Google Scholar] [CrossRef]
- Rouhani, B.D.; Mahrin, M.N.; Nikpay, F.; Ahmad, R.B.; Nikfard, P. A systematic literature review on Enterprise Architecture Implementation Methodologies. Inf. Softw. Technol. 2015, 62, 1–20. [Google Scholar] [CrossRef]
- Li, Y.; Peng, R.; Wang, B. Challenges in Context-Aware Requirements Modeling: A Systematic Literature Review. In Proceedings of the Asia Pacific Requirements Engeneering Conference, Melaka, Malaysia, 9–10 November 2017; pp. 140–155. [Google Scholar]
- Hoyer, S.; Zakhariya, H.; Sandner, T.; Breitner, M.H. Fraud prediction and the human factor: An approach to include human behavior in an automated fraud audit. In Proceedings of the 2012 45th Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2012; pp. 2382–2391. [Google Scholar]
- Sánchez, M.; Torres, J.; Zambrano, P.; Flores, P. FraudFind: Financial fraud detection by analyzing human behavior. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 281–286. [Google Scholar]
- Sandhu, N. Behavioural red flags of fraud—A qualitative assessment. J. Hum. Values 2016, 22, 221–237. [Google Scholar] [CrossRef]
- Mackevičius, J.; Giriūnas, L. Transformational research of the fraud triangle. Ekonomika 2013, 92, 150–163. [Google Scholar] [CrossRef]
- Zulaikha, Z.; Hadiprajitno, P.; Rohman, A.; Handayani, R. Effect of attitudes, subjective norms and behavioral controls on the intention and corrupt behavior in public procurement: Fraud triangle and the planned behavior in management accounting. Accounting 2021, 7, 331–338. [Google Scholar] [CrossRef]
- Omar, N.B.; Din, H.F.M. Fraud diamond risk indicator: An assessment of its importance and usage. In Proceedings of the 2010 International Conference on Science and Social Research (CSSR 2010), Kuala Lumpur, Malaysia, 5–7 December 2010; pp. 607–612. [Google Scholar]
- Sravanthi, T.; Sruthi, M.; Reddy, S.T.; Prakash, T.C.; Reddy, C.V.K. Fiscal Scam Illuminating Through Analyzing Human Behaviour. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; Volume 981, p. 022057. [Google Scholar]
- Wang, S. A comprehensive survey of data mining-based accounting-fraud detection research. In Proceedings of the 2010 International Conference on Intelligent Computation Technology and Automation, Changsha, China, 11–12 May 2010; Volume 1, pp. 50–53. [Google Scholar]
- Yao, J.; Zhang, J.; Wang, L. A financial statement fraud detection model based on hybrid data mining methods. In Proceedings of the 2018 International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 26–28 May 2018; pp. 57–61. [Google Scholar]
- Jayabrabu, R.; Saravanan, V.; Tamilselvi, J.J. A framework for fraud detection system in automated data mining using intelligent agent for better decision making process. In Proceedings of the 2014 International Conference on Green Computing Communication and Electrical Engineering (ICGCCEE), Coimbatore, India, 6–8 March 2014; pp. 1–8. [Google Scholar]
- Ahmed, M.; Mahmood, A.N. A novel approach for outlier detection and clustering improvement. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; pp. 577–582. [Google Scholar]
- Kumar, V.; Sriganga, B. A review on data mining techniques to detect insider fraud in banks. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2014, 4, 370–380. [Google Scholar]
- Vikram, A.; Chennuru, S.; Rao, H.R.; Upadhyaya, S. A solution architecture for financial institutions to handle illegal activities: A neural networks approach. In Proceedings of the 37th Annual Hawaii International Conference on System Science, Big Island, HI, USA, 5–8 January 2004; pp. 181–190. [Google Scholar]
- Mishra, A. Fraud Detection: A Study of AdaBoost Classifier and K-Means Clustering. 2021. Available online: https://www.researchsquare.com/article/rs-247874/latest.pdf (accessed on 1 September 2021).
- Rizki, A.A.; Surjandari, I.; Wayasti, R.A. Data mining application to detect financial fraud in Indonesia’s public companies. In Proceedings of the 2017 3rd International Conference on Science in Information Technology (ICSITech), Bandung, Indonesia, 25–26 October 2017; pp. 206–211. [Google Scholar]
- Kim, Y.J.; Baik, B.; Cho, S. Detecting financial misstatements with fraud intention using multi-class cost-sensitive learning. Expert Syst. Appl. 2016, 62, 32–43. [Google Scholar] [CrossRef]
- Ravisankar, P.; Ravi, V.; Rao, G.R.; Bose, I. Detection of financial statement fraud and feature selection using data mining techniques. Decis. Support Syst. 2011, 50, 491–500. [Google Scholar] [CrossRef]
- Seemakurthi, P.; Zhang, S.; Qi, Y. Detection of fraudulent financial reports with machine learning techniques. In Proceedings of the 2015 Systems and Information Engineering Design Symposium, Charlottesville, VA, USA, 24 April 2015; pp. 358–361. [Google Scholar]
- Mohanty, L.T.K.M.G. Enron Corpus Fraud Detection. Int. J. Recent Technol. Eng. (IJRTE) 2019, 8, 315–317. [Google Scholar]
- Li, H.; Wong, M.L. Financial fraud detection by using Grammar-based multi-objective genetic programming with ensemble learning. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015; pp. 1113–1120. [Google Scholar]
- Sorkun, M.C.; Toraman, T. Fraud detection on financial statements using data mining techniques. Intell. Syst. Appl. Eng. 2017, 5, 132–134. [Google Scholar] [CrossRef]
- El Bouchti, A.; Chakroun, A.; Abbar, H.; Okar, C. Fraud detection in banking using deep reinforcement learning. In Proceedings of the 2017 Seventh International Conference on Innovative Computing Technology (INTECH), Luton, UK, 16–18 August 2017; pp. 58–63. [Google Scholar]
- Mardani, S.; Akbari, M.K.; Sharifian, S. Fraud detection in process aware information systems using MapReduce. In Proceedings of the 2014 6th Conference on Information and Knowledge Technology (IKT), Shahrood, Iran, 27–29 May 2014; pp. 88–91. [Google Scholar]
- Mallika, R. Fraud Detection Using Supervised Learning Algorithms. Int. J. Adv. Res. Comput. Commun. Eng. 2017, 6. [Google Scholar] [CrossRef]
- Save, P.; Tiwarekar, P.; Jain, K.N.; Mahyavanshi, N. A novel idea for credit card fraud detection using decision tree. Int. J. Comput. Appl. 2017, 161. [Google Scholar] [CrossRef]
- Holton, C. Identifying disgruntled employee systems fraud risk through text mining: A simple solution for a multi-billion dollar problem. Decis. Support Syst. 2009, 46, 853–864. [Google Scholar] [CrossRef]
- Jans, M.; Lybaert, N.; Vanhoof, K. Internal fraud risk reduction: Results of a data mining case study. Int. J. Account. Inf. Syst. 2010, 11, 17–41. [Google Scholar] [CrossRef]
- Heryadi, Y.; Warnars, H.L.H.S. Learning temporal representation of transaction amount for fraudulent transaction recognition using CNN, Stacked LSTM, and CNN-LSTM. In Proceedings of the 2017 IEEE International Conference on Cybernetics and Computational Intelligence (CyberneticsCom), Phuket, Thailand, 20–22 November 2017; pp. 84–89. [Google Scholar]
- Yaram, S. Machine learning algorithms for document clustering and fraud detection. In Proceedings of the 2016 International Conference on Data Science and Engineering (ICDSE), Cochin, India, 23–25 August 2016; pp. 1–6. [Google Scholar]
- John, S.N.; Anele, C.; Kennedy, O.O.; Olajide, F.; Kennedy, C.G. Realtime fraud detection in the banking sector using data mining techniques/algorithm. In Proceedings of the 2016 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 15–17 December 2016; pp. 1186–1191. [Google Scholar]
- West, J.; Bhattacharya, M. Some Experimental Issues in Financial Fraud Detection: An Investigation. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 1155–1158. [Google Scholar]
- Lin, C.C.; Chiu, A.A.; Huang, S.Y.; Yen, D.C. Detecting the financial statement fraud: The analysis of the differences between data mining techniques and experts’ judgments. Knowl.-Based Syst. 2015, 89, 459–470. [Google Scholar] [CrossRef]
- Mekonnen, S.; Padayachee, K.; Meshesha, M. A Privacy Preserving Context-Aware Insider Threat Prediction and Prevention Model Predicated on the Components of the Fraud Diamond. In Proceedings of the 2015 Annual Global Online Conference on Information and Computer Technology (GOCICT), Louisville, KY, USA, 4–6 November 2015; pp. 60–65. [Google Scholar] [CrossRef]
- Asuncion, A.; Newman, D. UCI Machine Learning Repository; School of Information and Computer Science, University of California: Irvine, CA, USA, 2007; Available online: http://www.ics.uci.edu/~mlearn/MLReposit-ory.html (accessed on 1 September 2021).
- ENRON. (This Dataset Contains 517,431 Emails with 3500 Folders from 151 Users). Available online: https://www.cs.cmu.edu/~enron/ (accessed on 1 September 2021).
- Omair, B.; Alturki, A. A Systematic Literature Review of Fraud Detection Metrics in Business Processes. IEEE Access 2020, 8, 26893–26903. [Google Scholar] [CrossRef]
- Pourhabibi, T.; Ong, K.L.; Kam, B.; Boo, Y.L. Fraud detection: A systematic literature review of graph-based anomaly detection approaches. Decis. Support Syst. 2020, 133, 113303. [Google Scholar] [CrossRef]
- Homer, E. Testing the fraud triangle: A systematic review. J. Financ. Crime 2019, 27, 172–187. [Google Scholar] [CrossRef]
- Dybå, T.; Dingsøyr, T. Strength of Evidence in Systematic Reviews in Software Engineering. In Proceedings of the Second ACM-IEEE International Symposium on Empirical Software Engineering and Measurement, Bari, Italy, 5–7 October 2008; pp. 178–187. [Google Scholar] [CrossRef]
- Dybå, T.; Dingsøyr, T. Empirical studies of agile software development: A systematic review. Inf. Softw. Technol. 2008, 50, 833–859. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title 1 | Title 2 | Title 3 |
|---|---|---|
| 1 | fraud | FR |
| 2 | fraud detection | FD |
| 3 | fraud triangle theory | FTT |
| 4 | fraud diamond theory | FDT |
| 5 | human behavior | HB |
| 6 | behavior patterns | BP |
| 7 | data mining | DT |
| 8 | machine learning | ML |
| 9 | deep learning | DL |
| No | Inclusion Criteria |
| IC1 | Indexed publications not older than 10 years. |
| IC2 | Scope of study: Computer Science |
| IC3 | Primary studies (journal or articles). |
| IC4 | Papers that discuss aspects regarding fraud detection. |
| IC5 | The investigations considered have information relevant to the research questions. |
| No | Exclusion Criteria |
| EC1 | Papers in which the language is different from English cannot be selected. |
| EC2 | Papers that are not available for reading and data collection (papers that are only accessible by paying or are not provided by the search engine) cannot be selected. |
| EC3 | Duplicated papers cannot be selected. |
| EC4 | Publications that do not meet any of the inclusion criteria cannot be selected. |
| EC5 | Publications that do not describe scientific methodology cannot be selected. |
| No | Extracted Data | Description | Type |
|---|---|---|---|
| 1 | Identity of the study | Unique identity for the study | General |
| 2 | Bibliographic references | Authors, year of publication, title, and source of publication | General |
| 3 | Type of study | Book, journal paper, conference paper, workshop paper | General |
| 4 | The theories employed | Description of the detection of fraud by applying the FTT and HB | RQ1 |
| 5 | The techniques considered | Description of the detection of fraud by applying ML/DM techniques | RQ2 |
| 6 | Combination of techniques and theories used | Description of the analysis of theories and techniques used to detect fraud | RQ3 |
| 7 | Findings and Contributions | Indication of the findings and contributions of the study | General |
| Source | Papers Found | Abstract and Title | Duplicity | Selected |
|---|---|---|---|---|
| Scopus | 960 | 77 | 48 | 16 |
| IEEE | 341 | 68 | 31 | 7 |
| WoC | 360 | 61 | 16 | 9 |
| ACM | 230 | 48 | 11 | 4 |
| Total | 1891 | 254 | 106 | 32 |
| # | Cited | # | Cited | # | Cited | # | Cited |
|---|---|---|---|---|---|---|---|
| [38] | 905 | [48] | 6 | [58] | 43 | [68] | 954 |
| [39] | 16 | [49] | 6 | [59] | 23 | [55] | 6 |
| [40] | 20 | [50] | 431 | [60] | 258 | ||
| [41] | 3 | [51] | 9 | [61] | 5 | ||
| [42] | 55 | [52] | 0 | [62] | 133 | ||
| [43] | 18 | [53] | 16 | [63] | 90 | ||
| [70] | 120 | [54] | 55 | [64] | 29 | ||
| [45] | 11 | [65] | 7 | [46] | 22 | ||
| [56] | 7 | [66] | 3 | [47] | 22 | ||
| [57] | 209 | [67] | 4 | [69] | 6 |
| # | Ref | Fraud Detection | Human Behavior | ML/DM Techniques | Fraud Theory |
|---|---|---|---|---|---|
| 1 | [38] | RQ1 | RQ1 | RQ1 | |
| 2 | [39] | RQ1 | RQ1 | RQ1 | |
| 3 | [40] | RQ1 | RQ1 | RQ1 | |
| 4 | [41] | RQ1 | RQ1 | RQ1 | |
| 5 | [42] | RQ1 | RQ1 | RQ1 | |
| 6 | [43] | RQ1 | RQ1 | RQ1 | |
| 7 | [70] | RQ1 | RQ1 | RQ1 | |
| 8 | [45] | RQ2 | RQ2 | ||
| 9 | [46] | RQ2 | RQ2 | ||
| 10 | [47] | RQ2 | RQ2 | ||
| 11 | [48] | RQ2 | RQ2 | ||
| 12 | [49] | RQ2 | RQ2 | ||
| 13 | [50] | RQ2 | RQ2 | ||
| 14 | [51] | RQ2 | RQ2 | ||
| 15 | [52] | RQ2 | RQ2 | ||
| 16 | [53] | RQ2 | RQ2 | ||
| 17 | [54] | RQ2 | RQ2 | ||
| 18 | [55] | RQ2 | RQ2 | ||
| 19 | [56] | RQ2 | RQ2 | ||
| 20 | [57] | RQ2 | RQ2 | ||
| 21 | [58] | RQ2 | RQ2 | ||
| 22 | [59] | RQ2 | RQ2 | ||
| 23 | [60] | RQ2 | RQ2 | ||
| 24 | [61] | RQ2 | RQ2 | ||
| 25 | [62] | RQ2 | RQ2 | ||
| 26 | [63] | RQ2 | RQ2 | ||
| 27 | [64] | RQ2 | RQ2 | ||
| 28 | [65] | RQ2 | RQ2 | ||
| 29 | [66] | RQ2 | RQ2 | ||
| 30 | [67] | RQ2 | RQ2 | ||
| 31 | [68] | RQ2 | RQ2 | ||
| 32 | [69] | RQ3 | RQ3 | RQ3 | RQ3 |
| RQ | Study Identifier | Frequency | Percentage |
|---|---|---|---|
| 1 | [38,39,40,41,42,43,70] | 7 | 21.88 |
| 2 | [45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68] | 24 | 75 |
| 3 | [69] | 1 | 3.13 |
| Ref. | Techniques a | Dataset | Main Focus |
|---|---|---|---|
| [45] | NN, DT, BN | N/A | Summarized and compared different datasets and algorithms for automated accounting fraud detection. |
| [46] | RF | Financial and non-financial data | Presented a hybrid detection model using machine learning and text mining methods for detecting financial fraud. |
| [47] | KDD | N/A | Automated fraud detection framework that allows fraud identification using intelligent agents, data fusion techniques, and data mining techniques. |
| [48] | KM | UCI Machine Learning Repository [71] | Modified k-means clustering algorithm for detecting outliers and removing them from the dataset to improve grouping precision. |
| [49] | C.45, KM, SVM, NB, CART | N/A | Categorized the different types of fraud and explained the best available data mining techniques. |
| [50] | NN | N/A | Used neural networks to correlate information from a variety of technologies and database sources to identify suspicious account activity. |
| [51] | KM Clustering and AdaBoost Classifier | Worldline and the Université Libre de Bruxelles | Presented a study on the use of clustering and classifier techniques and compared their precision for fraud detection. |
| [52] | SVM, ANN | Indonesian stock exchange (IDX) | Through the application of data mining algorithms, such SVM and ANN, the essential indicators for detecting financial fraud are profitability and efficiency. |
| [53] | MLR, SVM, and BN | N/A | Development of three multiple-class classifiers—MLR, SVM, and BN—as well as predictive tools for detecting and classifying misstatements according to the presence of intent of fraud. |
| [54] | MLFF, SVM, GP, GMDH, LR, PNN | N/A | Used data mining techniques that were tested on a dataset involving 202 Chinese companies and compared them with and without the selection of functions. |
| [55] | BLR, SVM, NN, ensemble techniques, and LDA | 10-K financial reports of documents (EDGAR) | For fraud detection in financial reporting, various techniques of natural language processing, and supervised machine learning are applied. |
| [56] | ANN | [72] | Identified a person of interest from a published corpus of Enron email data for research. |
| [57] | LR, NN, SVM, BN, DT, AdaBoost, and LogitBoost | [71] | Method based on Grammatical Genetic Programming (GBGP) through multi-objective optimization and set learning. They compared the proposed method with LR, NN, SVM, BN, DT, AdaBoost, and LogitBoost on four FFD datasets. |
| [58] | LR, ANN, KNN, SVM, Decision Stem, M5P Tree, J48 Tree, RF, and Decision Table | N/A | Explored the use of data mining methods to detect electronic ledger fraud through financial statements. |
| [59] | DRL | N/A | Applied DRL theory through two applications in banking and discussed its implementation for fraud detection. |
| [60] | Petri-Net, Heuristic | N/A | Used the Process Information Systems (PAIS) software in organizations for fraud detection. |
| [61] | DT, NB | N/A | Credit card fraud detection using supervised learning algorithms. |
| [62] | Luhn’s and Hunt’s | N/A | System that detects fraud in the processing of credit card transactions. |
| [63] | NB | Email data | Designed an artifact (hardware) for detecting communications from disgruntled employees using automated text mining techniques. |
| [64] | MLCC | International financial service provider | Analyzed the use of a data mining approach in order to reduce the risk of internal fraud. |
| [65] | CNN, SLSTM, hybrid of CNN–LSTM. | Card transactions from an Indonesian bank | Explored three deep learning models for the recognition of fraudulent card transactions. |
| [66] | DT, RF, NB | Twitter and Facebook | Implementation of the document grouping algorithm as a set of classification algorithms along with appropriate industry use cases. |
| [67] | Association, clustering, forecasting, and classification | N/A | Detection of bank fraud through the use of data mining techniques. |
| [68] | GP, NN, SVM | UCSD-FICO | Key performance metrics used for Financial Fraud Detection (FFD) with a focus on credit card fraud. |
| # | QA-1 | QA-2 | QA-3 | Total Score | Max S |
|---|---|---|---|---|---|
| [38] | P | P | Y | 2 | 66.67 |
| [39] | P | P | Y | 2 | 66.67 |
| [40] | N | N | N | 0 | 0 |
| [41] | P | Y | Y | 2 | 66.67 |
| [42] | N | N | N | 0 | 0 |
| [43] | N | N | N | 0 | 0 |
| [70] | P | P | Y | 2 | 66.67 |
| [45] | P | Y | Y | 2.5 | 83.33 |
| [46] | P | Y | Y | 2.5 | 83.33 |
| [47] | N | N | N | 0 | 0 |
| [48] | P | P | Y | 2 | 66.67 |
| [49] | P | Y | Y | 2.5 | 83.33 |
| [50] | P | P | Y | 2 | 66.67 |
| [51] | P | P | Y | 2 | 66.67 |
| [52] | P | P | Y | 2 | 66.67 |
| [53] | P | P | Y | 2 | 66.67 |
| [54] | N | N | N | 0 | 0 |
| [55] | P | P | Y | 2 | 66.67 |
| [56] | P | Y | Y | 2.5 | 83.33 |
| [57] | P | Y | Y | 2.5 | 83.33 |
| [58] | N | N | N | 0 | 0 |
| [59] | P | P | Y | 2 | 66.67 |
| [60] | P | Y | Y | 2.5 | 83.33 |
| [61] | N | N | N | 0 | 0 |
| [62] | N | N | N | 0 | 0 |
| [63] | P | Y | Y | 2.5 | 83.33 |
| [64] | 0 | 0 | 0 | 0 | 0 |
| [65] | P | P | Y | 2 | 66.67 |
| [66] | N | N | N | 0 | 0 |
| [67] | P | Y | Y | 2.5 | 83.33 |
| [68] | P | Y | Y | 2.5 | 83.33 |
| [69] | P | Y | Y | 2.5 | 83.33 |
| Total | 10.5 | 16.5 | 22 | 49 | |
| Max QA | 21.42 | 33.68 | 44.9 | 100 | |
| Total Score | 47.62 | 73.81 | 100 |
| SLR Work | Year | Context | Period | Data Sources | # of Screened Works/Primary Studies | Quality Assessment of Primary Studies |
|---|---|---|---|---|---|---|
| [25] | 2010 | Data-mining-based fraud detection | 2000–2010 | N/A | N/A | No evaluation criteria applied |
| [73] | 2020 | Fraud-detection metrics in business processes | N/A | 1, 4, 5, 7, 9, 14 | 12,000/75 | No well-defined evaluation criteria applied |
| [26] | 2018 | Data-mining-based fraud detection and credit scoring | N/A | N/A | N/A | No evaluation criteria applied |
| [74] | 2020 | Graph-based anomaly-detection approaches | 2007–2018 | 1, 2, 5, 9 | 585/39 | No evaluation criteria applied |
| [75] | 2019 | Fraud Triangle Theory | No specific | 7 | 1169/33 | Based on evaluation criteria proposed by authors |
| [28] | 2011 | Data mining techniques in financial fraud detection | 1997–2008 | 1, 2, 5, 9, 11, 12, 13 | 1200/49 | No well-defined evaluation criteria applied |
| [29] | 2007 | Data-mining-based financial fraud detection | N/A | N/A | N/A | No evaluation criteria applied |
| This SLR | 2021 | Fraud detection using the Fraud Triangle Theory and data mining techniques | 2010–2021 | 1, 2, 4, 10 | 1891/32 | Based on evaluation criteria proposed by [76] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez-Aguayo, M.; Urquiza-Aguiar, L.; Estrada-Jiménez, J. Fraud Detection Using the Fraud Triangle Theory and Data Mining Techniques: A Literature Review. Computers 2021, 10, 121. https://doi.org/10.3390/computers10100121
Sánchez-Aguayo M, Urquiza-Aguiar L, Estrada-Jiménez J. Fraud Detection Using the Fraud Triangle Theory and Data Mining Techniques: A Literature Review. Computers. 2021; 10(10):121. https://doi.org/10.3390/computers10100121
Chicago/Turabian StyleSánchez-Aguayo, Marco, Luis Urquiza-Aguiar, and José Estrada-Jiménez. 2021. "Fraud Detection Using the Fraud Triangle Theory and Data Mining Techniques: A Literature Review" Computers 10, no. 10: 121. https://doi.org/10.3390/computers10100121
APA StyleSánchez-Aguayo, M., Urquiza-Aguiar, L., & Estrada-Jiménez, J. (2021). Fraud Detection Using the Fraud Triangle Theory and Data Mining Techniques: A Literature Review. Computers, 10(10), 121. https://doi.org/10.3390/computers10100121