

Computers 2026, 15(8), 473; https://doi.org/10.3390/computers15080473 (registering DOI) - 24 Jul 2026
Abstract
Accurate classification and efficient retrieval of histopathological images are essential for the diagnosis of lung adenocarcinoma (LUAD). Existing deep learning approaches for Content-Based Histopathological Image Retrieval (CBHIR) typically generate single-scale embeddings, missing the richer spatial context from earlier network stages. We propose a
[...] Read more.
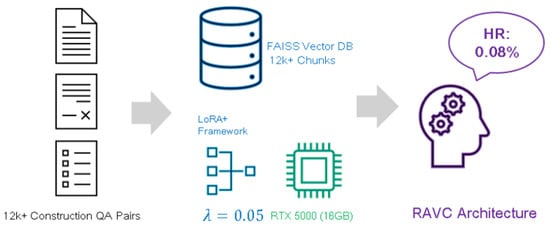
Accurate classification and efficient retrieval of histopathological images are essential for the diagnosis of lung adenocarcinoma (LUAD). Existing deep learning approaches for Content-Based Histopathological Image Retrieval (CBHIR) typically generate single-scale embeddings, missing the richer spatial context from earlier network stages. We propose a unified framework composed of: (1) a ConvNeXt V2 backbone with an integrated Convolutional Block Attention Module (CBAM) for multi-scale feature extraction, (2) an Adaptive Weighted Fusion Neck with learnable softmax-normalized weights, and (3) a novel Hybrid Representation Head producing an 18,496-dimensional descriptor by concatenating global, spatial, and attention-weighted features. Evaluated on the WSSS4LUAD dataset (10,087 patches, four tissue classes), our model achieves 85.03% accuracy (5-fold CV: 83.35 ± 0.93%), F1-score of 0.8116, mean Average Precision (MAP) of 0.8323 for retrieval, and an Expected Calibration Error (ECE) of 0.0378. Ablation experiments confirm that all proposed modules contribute positively, with the Attention Branch being the most impactful (Δ = −2.13%). The framework further provides Gradient-weighted Class Activation Mapping (Grad-CAM) explainability for clinical interpretability.
Full article
(This article belongs to the Section AI-Driven Innovations)
►
Show Figures
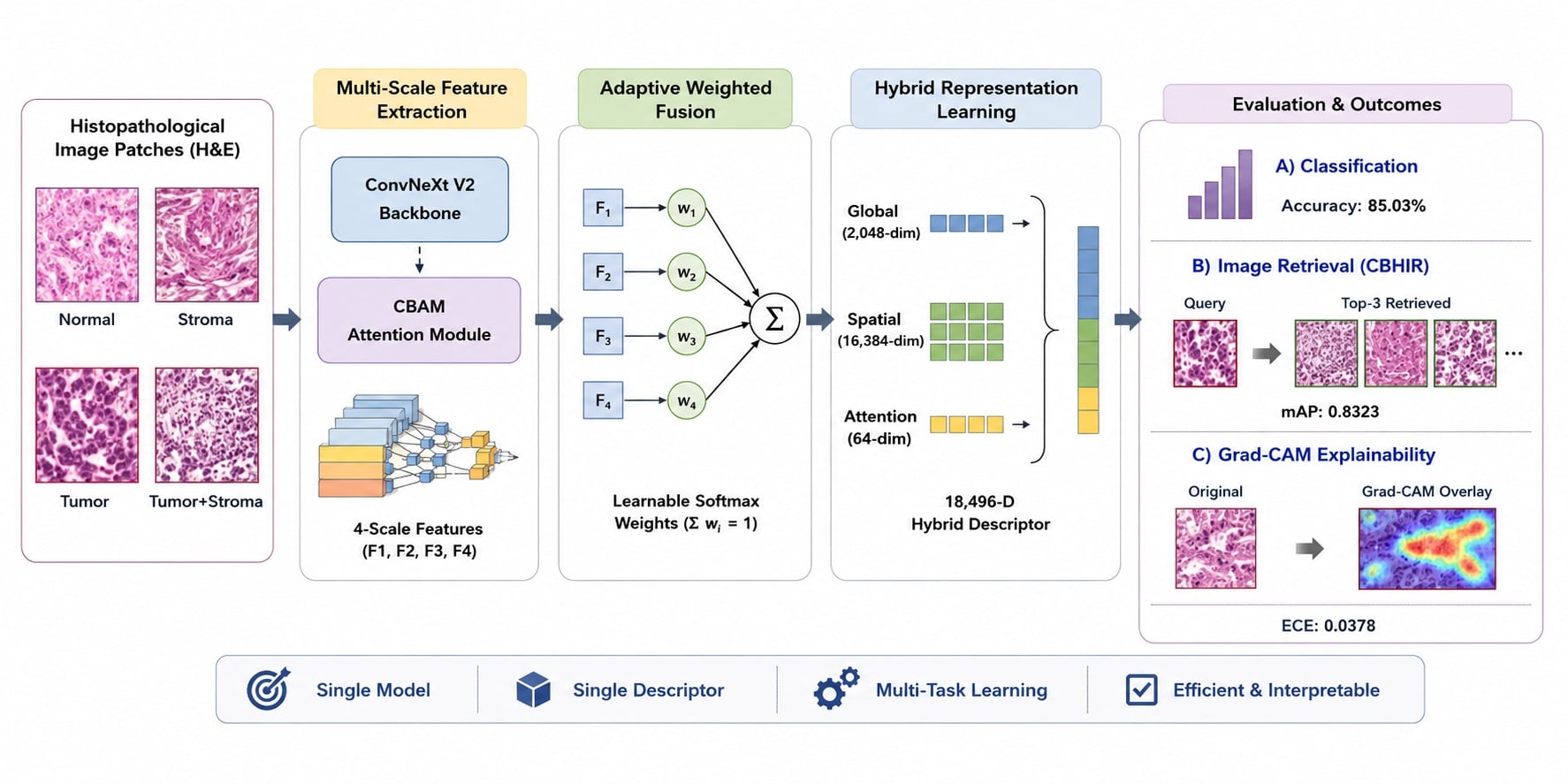
Graphical abstract














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}