5.1. Exprimental Setup
In order to demonstrate the effectiveness of our proposed method, we conducted experiments. We used CPLEX 12.10 as the solution solver for the ILP, scheduling up to one hour in real-time on a PC with an AMD Ryzen 7 PRO 4750G CPU and 64 GB main memory. If an optimal solution could not be found in one hour, the best solution at the time was used. The list-scheduling algorithms were implemented in Python with the Numpy library. Due to various resource constraints, we compared the error of conventional resource constrained-scheduling, which does not consider the error, and the proposed variable-cycle scheduling, which minimizes the output error. The number of accuracy-controllable approximation multipliers is restricted as a resource constraint. Adders, ALUs, etc., are assumed to be used without restriction because of their large sharing overhead.
In a conventional resource-constrained scheduling that minimizes the number of execution cycles, the schedule is based on the assumption that each operation is performed in a fixed number of cycles. Therefore, the minimum number of cycles can be found when all the multiplications are scheduled in one cycle (n cycles) and the minimum number of cycles when all the multiplications are scheduled in two cycles (m cycles). We increase the number of functional units as a resource constraint until the minimum number of cycles (n and m) does not change. The proposed method is given the time constraint between n to m cycles under each resource constraint and performs variable-cycle scheduling where each of the multiplications is performed in one or two cycles with the aim of minimizing the output error.
We used MediaBench [
31] as a benchmark program. In the ILP-scheduling method and list-scheduling algorithm, the delay for each operation is scheduled assuming that approximate multiplication is performed in one cycle, exact multiplication in two cycles, and operations other than multiplication in one cycle. We synthesized the circuits in which each of the approximate multipliers has 32-bit accuracy control, taken from [
13] based on the scheduling results. Then, we compared the area and the error for the synthesized circuits for a xc7z020clg484-1 device with Vivado 2020.1 provided by Xilinx. The error was evaluated by Monte Carlo simulation. We compared the following methods:
All-exact (AE): each of the multiplications is performed without approximation and takes two cycles.
All-approximated (AA): each of the multiplications is approximated and performed in one cycle.
Mixed: each multiplication is determined as being either exact or approximated in two cycles or one cycle, respectively.
Mixed-chain: each multiplication is determined as being either exact or approximated in two cycles or one cycle, respectively, and considering chaining.
5.2. Exprrimental Results
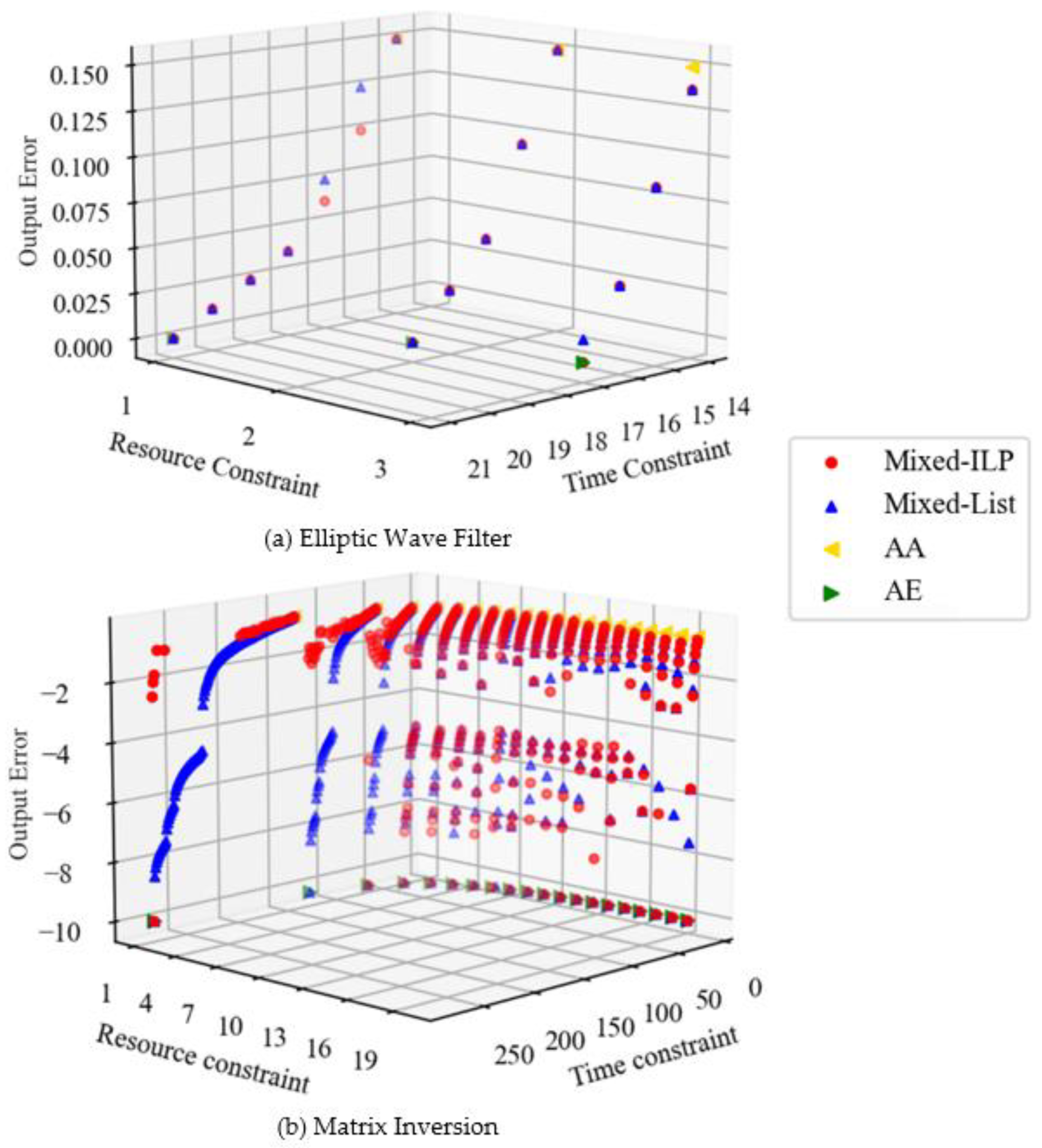
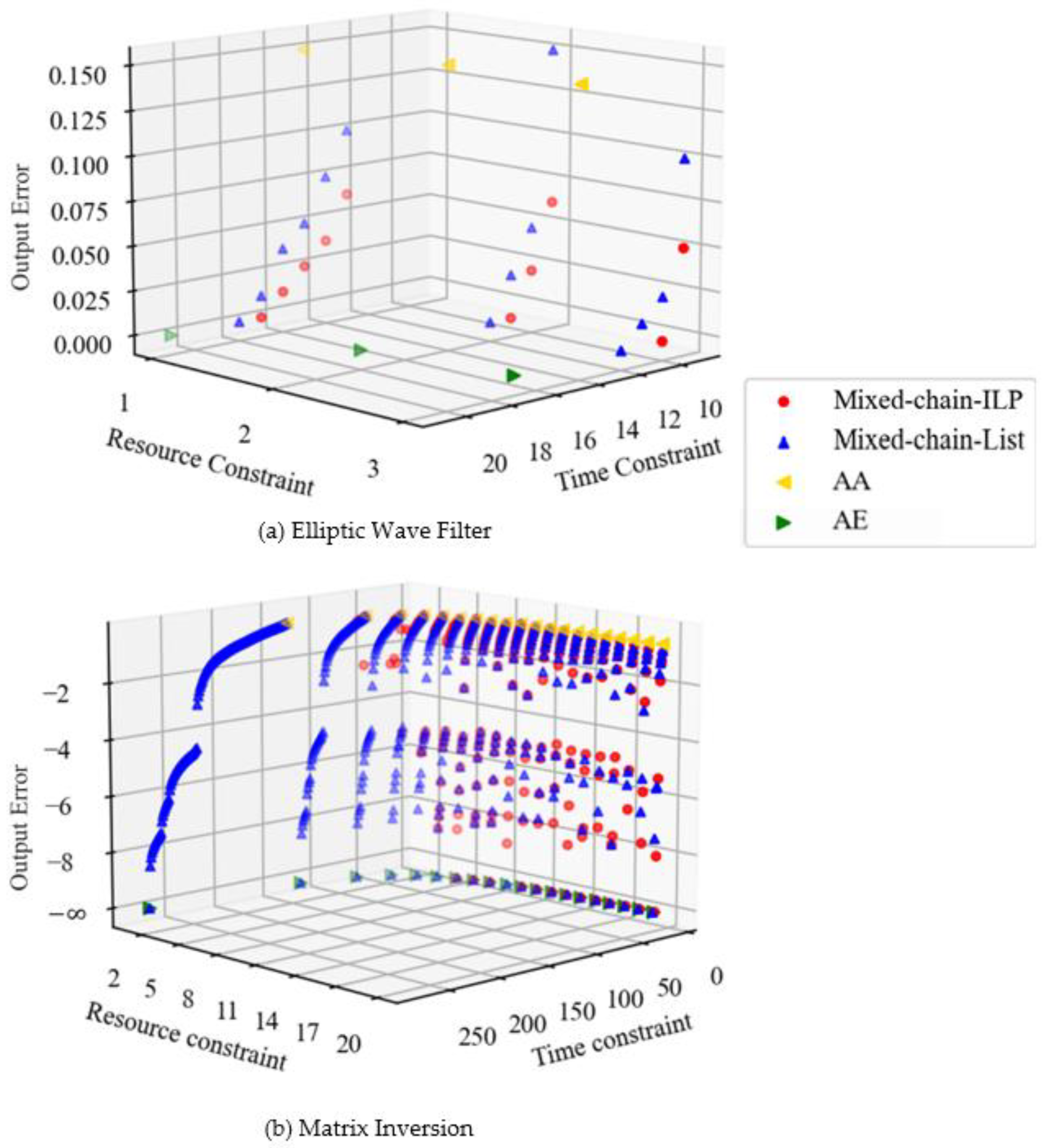
Figure 4 shows the scheduling results for each benchmark. The output error is denoted as the relative value of the error included in the output for the exact result. In
Figure 4b, the output error is shown in logarithmic terms and is denoted as
when all multiplications are performed in two cycles (i.e., when there is no error). The higher the point, the more stringent the time constraint. The fewer the number of functional units that are constraints of the resource, the larger the difference between the number of cycles required to perform all the multiplications in one cycle and in two cycles. The scheduling results with a wide distribution of errors provide more options for circuit design. Because of this, it possible to find a solution that meets the designer’s requirements based on the area, execution time, and output error.
The Elliptic Wave Filter is regular and poses a short critical path of DFG compared to Matrix Inversion. Therefore, when the time constraint is increased and the number of approximate multiplications is reduced, the error of Mixed decreases slowly, as shown in
Figure 4a. By comparison, Matrix Inversion is a complex DFG. In such a case, the magnitude of the error differs greatly depending on which multiplication is approximated. In Matrix Inversion, there is a multiplication on the critical path that has a large impact on the output error. Therefore, the distribution of the graph becomes narrower when the resource constraint is increased and the execution time is short. AA and AE in
Figure 4 do not take error into account, and there is a trade-off between area and execution time. By comparison, Mixed minimizes the output error due to resource and time constraints, and a trade-off is established between area, execution time, and output error.
Table 2 shows the comparison between list-scheduling algorithm and the ILP-based technique. In the table, Nodes represents the total number of operations for each benchmark. Mult means the number of multiplications among them. Designs indicates the number of design problems for a variety of resource and time constraints. Wins, Losses, and Draws represent the number of designs of our proposed algorithm that outperform the ILP-based technique in terms of accuracy, even slightly; the number of designs of the ILP-based technique that outperform our proposed algorithm; and the number where the same solutions are found, respectively. The number of times it takes more than one hour for ILP indicates the number of times the optimal solution is not obtained with ILP. In the Elliptic Wave Filter, there are three cases where the approximate solution for list scheduling is inferior to the optimal solution for ILP, but all the results in
Figure 4a are close to the optimal solution. In Matrix Inversion, about half of the ILPs are not able to find the optimal solution in one hour. Most have no solution or a solution that is far from optimal and is inferior to the approximate solution of list scheduling. In contrast, list scheduling obtained solutions with a wide distribution regardless of the number of nodes. It can be said to be effective even for large applications.
Table 3 shows the longest, shortest, and mean runtimes required for scheduling for each benchmark. ILP was unable to find an optimal solution in one hour when the number of nodes exceeded 50. However, list scheduling was able to find an approximate solution within three minutes even when the number of nodes exceeded 300. With ILP, scheduling can already take a long time for Cosine with 42 nodes; thus, if the number of nodes exceeds 300, it is expected to take several days to a month or more. As the number of nodes increases, the runtime increases exponentially, making ILP impractical. With list scheduling, there is a difference between the longest and shortest runtime with Matrix Inversion, which has a wide range of given time constraints. It is possible to obtain a near-optimal solution in a short time.
Table 4 shows the logic synthesis results of some of the scheduling results in Auto Regression Filter using Vivado 2020.1 on the xc7z020clg484-1 device. In the conventional method, we synthesized a circuit with AE performing in 12 cycles. In ILP and list scheduling, we synthesize Mixed circuits performing in 12 cycles. In these circuits, the performance of the circuit (number of cycles) was scheduled with the same constraints. Circuits designed with the two proposed methods both achieved low area and power by approximation. Furthermore, it is clear from the PSNR values that the magnitude of the error is minute. Therefore, the proposed method can design circuits with the same performance as that of the conventional method, having a low area and low power, without much loss of accuracy. Comparison of the PSNR of the proposed method shows that the approximate solution of list scheduling is almost equal to the optimal solution of ILP. The difference in area and power between the proposed methods, despite their equal accuracy, can be attributed mainly to the optimization of synthesis tools.
Figure 5 shows the scheduling results when chaining is considered. AA and AE here do not have chaining and are plotted at the same locations as in
Figure 4. Comparing
Figure 4a and
Figure 5a, the execution time has been reduced and the error has been reduced. This is due to the fact that they are not only adding, but also chaining exact multiplication and addition. Comparing
Figure 4b and
Figure 5b, we can see that the results are similar to those of the Elliptic Wave Filter. Moreover, in the case of chaining, a wide distribution in terms of error is obtained even when resource constraints are large.
Table 5 shows the results of comparing the list-scheduling solution with the ILP solution in terms of output error for each benchmark and summarizes the results, as shown in
Figure 5. Compared to
Table 1, there was no significant increase in the number of times the ILP exceeded one hour. The number of times the approximate solution for list scheduling is inferior to the optimal solution for ILP has increased. This is because the approximate algorithm does not perform chaining as effectively as ILP. However, as the number of nodes increases, the number of times that list scheduling outperforms ILP increases, indicating that the approximate algorithm is more effective for large-scale applications.
Table 6 shows the longest and shortest runtimes required for chaining considered scheduling for each benchmark. In ILP, the runtime does not increase that much even when chaining is taken into account. In list scheduling, the runtime is approximately doubled by chaining. This is simply due to the increase in processing. However, list scheduling can still be solved in polynomial time.
The overall experimental results show that the proposed method can take advantage of approximate multipliers whose accuracy can be dynamically controlled in high-level synthesis. Although conventional scheduling explores circuits that meet the requirements through the trade-off between resource and performance, the proposed method incorporates approximate computing searches for circuits that meet requirements that are lower than those of the trade-off between resource, performance, and accuracy. Due to its flexibility, high-level synthesis can identify a more efficient circuit suitable for an application.
Our proposed ILP and list-scheduling methods have different characteristics in target applications. Although the ILP method can obtain an optimal schedule, the computational time becomes very long with the increase in the number of operations in applications. In contrast, the list-scheduling method can quickly find a circuit schedule while it sometimes fails to obtain an optimal schedule. In summary, the ILP method is preferred for use in a large application, and the list-scheduling method is suitable for a small application. In addition, we considered an optimization technique in high-level synthesis, and the two proposed methods show its practicality by chaining.
The circuit synthesis results show that the proposed method achieves lower power and lower cost with the same performance by applying approximations. Furthermore, it can be said that both the ILP and list-scheduling methods have small errors, although approximations are applied. This means that the proposed method improves resource and power use without much impact on the application. However, there is a large difference in power and resources used between list scheduling and ILP, even though the accuracy is almost the same. This indicates that it is necessary to consider memory resources and other factors when scheduling, and this is one of the issues to be addressed in the future. In addition, this research can be applied to ASICs. However, since we only experimented with FPGAs, this is also an issue to be addressed in the future.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}