1. Introduction
Software estimation has long been considered a core issue that directly affects success or failure. According to the Standish Group [
1], the failure rate of a part of a project or of a whole project is likely to be up to 83.9% (as of 2019). One of the reasons for this failure is inaccurate cost and effort estimates. In fact, to obtain software projects, companies participating in tenders must submit bids that include cost, manpower, and software development time. To be able to win the tender, the companies participating need to give a reasonable estimate of the cost, manpower, and time required to carry out the project. Reasonability here does not mean underestimating the price, because in so doing the company will not gain (if not lose) when completing the project. It is also not reasonable to overestimate the price, because then it is certain that the company will not win the bid. Therefore, a project estimate is considered reasonable only if it accurately reflects the project’s actual value.
Throughout the software development process, no matter what software management model a company uses, project leaders often have to plan the work for software development milestones, plan the next milestone, and recalculate the work done in the previous milestone. All of these tasks require software estimation skills. Many methods have previously been proposed to solve the software estimation problem. Due to the increasing demand for more efficient and accurate estimation methods that can work with more complex software projects, such estimation methods need to be refined. Software estimation methods can be classified into three main groups: non-algorithmic, algorithmic, and machine learning approaches [
2,
3]. In the non-algorithmic category, there are two representative methods: expert judgement (EJ) [
4] and analogy [
5]; with these methods, experts play the most significant role in judgement. Of course, previous samples (historical dataset) also play another important role. In the algorithmic category, an algorithm takes the first role. software lifecycle management (SLIM) [
6], the Constructive Cost Model (COCOMO) [
7], and function point analysis (FPA) and the International Function Point User Group (IFPUG FPA) [
8,
9] are representative models. The IFPUG FPA method arose as an alternative to other solutions. Other methods based on IFPUG FPA —such as COSMIC [
10], FiSMA [
11], MarkII [
12], and NESMA [
13]—were proposed to improve some aspects of the original method. In the last category, machine learning techniques have been used in recent years to supplement or replace the other two techniques. Most software cost estimation techniques use statistical methods, which cannot provide strong rationales and results. Machine learning approaches may be appropriate in this area because they can increase the accuracy of estimates by training the estimation rules and repeating the running cycles. Examples include fuzzy logic modelling, regression trees, artificial neural networks (ANNs), and case-based reasoning (CBR). These methods have explored the applicability of machine learning techniques to software effort estimation; they have objective and analytical formulas that are not limited to a specific number of factors. However, most methods only evaluate the limitations of modelling techniques on a particular dataset, reducing the generalisability of the observed results. Some researchers also overlook statistical testing of the results obtained or evaluation of the models against the same dataset used to generate the models [
14].
This paper is organised as follows:
Section 1 is the introduction. The problem formulation and the contributions are described in
Section 2.
Section 3 illustrates the related works.
Section 4 presents the background, with a brief overview of the FPA method, Bayesian ridge regression model, and voting regressor model. The proposed research methodology is expressed in
Section 5, in which we introduce the dataset and data processing, experimental setup, and evaluation criteria.
Section 6 presents the experimental results and discussion.
Section 7 describes the threats to validity. We finalise our paper in
Section 8 with the conclusion.
2. Problem Formulation
FPA has been used for over four decades, and has proven to be a dependable and consistent method [
15] of sizing software for project estimation and productivity or efficiency comparisons. Although it has made significant contributions in the software industry, it still has many problems. In an earlier systematic literature review [
16], we mentioned some limitations of FPA. The inadequacy of complexity weight is still a major problem. In addition, the locality of the dataset that builds the FPA approach (IBM projects) does not reflect the entire global software industry. Many previous studies have suggested a new functional complexity weight [
17,
18] in different ways. In [
18], Xia et al. proposed a new functional complexity table based on an IFPUG FPA calibration model called Neuro-Fuzzy Function Point Calibration Model (NFFPCM), which integrates the power of neural networks and fuzzy logic. Nevertheless, the method needs to be changed in line with changes in the modern software industry.
Another issue that needs to be mentioned is the specificity of each piece of software. Differences in the purpose of the software being developed lead to different approaches. With FPA, a method that applies to all software estimation cases needs to be revisited; this was the motivation for us to propose a new, up-to-date, nonlocal functional complexity weight that reflects the software industry.
After counting the function points (FPs), we can calculate the effort and then write a report [
9] based on these FPs. At this point, the FPA counting process is considered complete. However, one question is whether we can further improve the effort after the calculation of the counting process. Recent studies [
19,
20,
21,
22,
23] show that combining an ensemble model and other approaches provides better results than using a single model. This study applies an ensemble model to the result after the counting and calculating effort to improve the accuracy gained from FP counting based on the proposed functional complexity weight.
This study aims to propose an algorithm called the calibration of functional complexity weight (CFCW) algorithm. The proposed algorithm is based on the FPA method combined with regression methods implemented in the International Software Benchmarking Standards Group (ISBSG) dataset Release 2020 R1 [
24].
Many companies around the world contribute to the ISBSG dataset, so the locality problem can be solved. In addition, the 2020 database update addresses the out-of-date issue. Many recent studies (for example, [
25,
26,
27]) used the industry sector (IS) as a categorical variable for dataset segmenting in their research. Our study tested a second approach—the calibration of functional complexity weight with optimisation based on an ensemble model called the voting regressor (CFCWO).
Based on the above issues, we propose three research questions:
- RQ1:
Is the accuracy of the proposed CFCW algorithm better than that of the IFPUG FPA or NFFPCM methods?
- RQ2:
Does the advanced CFCWO algorithm outperform the CFCW algorithm?
- RQ3:
How accurate is the estimation for each sector compared to an ungrouped dataset?
To answer these research questions, we conducted an experimental study to evaluate the estimation accuracy of the proposed approaches.
Contributions
The main contributions of this research are as follows:
In the first phase, a new CFCW algorithm for the calibration of functional complexity weight is proposed;
In the second phase, the result from the first phase is optimised by using a voting regressor to estimate the final software effort—the CFCWO algorithm is proposed;
The IFPUG FPA method is compared to the CFCW algorithm for ungrouped data and data grouped by IS;
The CFCW algorithm is compared to the CFCWO algorithm for ungrouped data and data grouped by IS.
3. Related Work
FPA is a standardised method for determining the size of software based on its functional requirements; it is designed to be applicable regardless of programming language or implementation technology. Albrecht [
8] recommends FPA to measure the size of a system that processes data from end-users. Since its introduction, much research has been carried out to improve its accuracy.
Al-Hajri et al. [
17] introduced a modification weighting system for measuring FP using an ANN model (backpropagation technique). In their study, a weighting system was built based on four steps: (1) using the original weighting system as a baseline to establish new weights; (2) using the DETs/RETs of the original system’s FPA to calculate the new values, training these new values with an ANN, and then predicting the values of the new weights; (3) applying the new weights and the original weights in the FPA model; and (4) calculating the size of FPs as a function of the original weights and the new weights. Wei et al. [
28] proposed a different sizing approach by integrating the new calibrated FP weight proposed in [
18] into a complexity assessment system for object-oriented development effort estimation. Misra et al. [
29] proposed a metrics suite that helps in determining the complexity of object-oriented projects by evaluation of message complexity, attribute complexity, weighted class complexity, and code complexity.
Dewi et al. [
30] produced a formula for estimating the cost of software development projects, especially in the field of public service applications; the authors modified the complexity adjustment factor to 16 instead of the 14 used in the standard FPA method and; as a result, the accuracy was improved by 7.19%.
In the study of Leal et al. [
31], the authors investigated the use of nearest-neighbours linear regression methods for estimation in software engineering. These methods were compared with multilayer perceptron neural networks, radial basis function neural networks, support-vector regression, and bagging predictors. The dataset used in the study was a NASA software project. Based on the relative error and the estimation rate, the nearest-neighbours linear regression methods outperformed the others.
In a survey of applying ANNs to software estimation, Hamza et al. [
32] provided an overview of the use of ANN methods to estimate development effort for software development projects; the authors offered four main ANN models, including (1) feedforward neural networks; (2) recurrent neural networks; (3) radial basis function networks; and (4) neuro-fuzzy networks. The survey also explains why those methods are used and how accurate they are.
In the endeavour of estimating the effort needed for the next phase or the remaining effort needed to finish a project, Lenarduzzi et al. [
33] conducted an empirical study on the estimation of software development effort. The estimation was broken down by phase so that estimation could be used throughout the software development lifecycle. This means that the effort needed for the next phase at any given point in the software development lifecycle is estimated. Additionally, they estimated the effort required for the remaining part of a software development process. The ISBSG dataset was used in the study. The results show statistically significant correlations between effort expended in one period and effort expended in the following period, effort expended in one period and total effort expended, and accumulated effort up to the present stage and remaining effort. The results also indicate that these estimation models have different degrees of goodness of fit. Further attributes, such as the functional size, do not significantly improve estimation quality.
In [
25,
34], the authors presented an influence analysis of selected factors (FP count approach, business area, IS, and relative size) on the estimation of the work effort for which the FPA method is primarily used. They also studied the factors that influence productivity and the productivity estimation capability in the FPA method. Based on these selected factors and experimentally, the authors proved that the selected factors have specific effects on work effort estimation accuracy.
In [
35], from software features, the authors used various machine learning algorithms to build a software effort estimation model. ANNs, support-vector machines, K-star, and linear regression machine learning algorithms were appraised on a PROMISE dataset (called Usp05-tf) with actual software efforts. The results revealed that the machine learning approach could be applied to predict software effort. In the study, the results from the support-vector machines were the best.
In [
36], the authors conducted a comparison between soft computing and statistical regression techniques in terms of a software development estimation regression problem. Support-vector regression and ANNs were used as soft computing methodologies, and stepwise multiple linear regression and log-linear regression were used as statistical regression methods. Experiments were performed using the NASA93 dataset from the PROMISE software repository, with multiple dataset pre-processing steps performed. The authors relied on the holdout technique associated with 25 random repetitions with confidence interval calculation within a 95% statistical confidence level. The 30 pre-evaluation criteria were used to compare the results. The results of the study show that the support-vector regression model has a significant impact on precision.
6. Results and Discussion
In this section, we evaluate the accuracy of the proposed CFCW and CFCWO from the experimental results. We compare the IFPUG FPA and NFFPCM models to CFCW and CFCWO algorithms. All experiments for all sectors and for data grouped by IS were calculated.
The calibrated functional complexity weight values obtained from the experiment are listed in
Table 3. According to the values of the individual parameters EI, EI, EQ, ELF, and ILF, the calibrated values of the scales differ from the original values. The minimum percentage deviation is approximately 2% on an ungrouped dataset, while the maximum deviation is nearly 242% against standard weights. The individual ISs show an even greater variance in deviations.
Figure 5 shows a comparison of efforts estimated by the IFPUG FPA, NFFPCM, CFCW, and CFCWO methods versus the real SWE. The effort estimated by the CFCWO approach was closest to the SWE (in all cases). This means that the proposed CFCWO approach also outperforms the IFPUG FPA, NFFPCM, and CFCW methods.
Table 4 shows the MAE value when using the IFPUG FPA, NFFPCM, CFCW, and CFCWO algorithms, along with the percentage improvement value of the CFCW method compared to the IFPUG FPA method, and the percentage improvement value of the CFCWO algorithm compared to the CFCW algorithm. Accordingly, the lowest improvement value of the CFCW method compared to the IFPUG FPA method was in the government sector, with 6.48%, while the highest was in the communication sector, with 51.55%. Overall, the estimated effort by the CFCW algorithm improved by 5.46%, while that by the CFCWO algorithm was enhanced by 11.89%.
According to this MAE evaluation criterion, the NFFPCM does outperform IFPUG FPA in most sectors, except for communication. The CFCW results are always better than that of NFFPCM, and the CFCWO is the same.
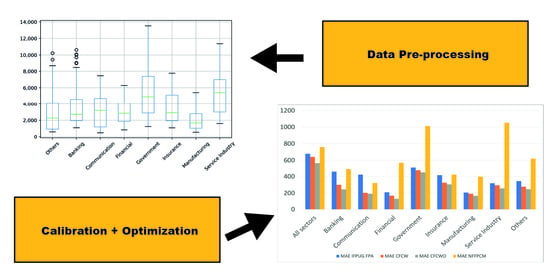
Figure 6 shows a comparison of the results from a visual perspective. The MAE of the CFCWO algorithm is always the smallest, indicating the best estimation accuracy.
Table 5 shows the percentage difference based on the MAE evaluation criteria for each IS compared to the same algorithm applied to all sectors.
Table 6 shows the MAPE evaluation values of the proposed approach and the improvement of the CFCW and CFCWO methods compared to the IFPUG FPA method. Each value in the CFCW column is always smaller than that in the FPA column, and each value in the CFCWO column is smaller than that in the CFCW column. This means that the CFCW method is better than the FPA method, and the CFCWO algorithm is better than the CFCW algorithm. The superiority of the CFCW and CFCWO methods in comparison to the IFPUG FPA method is shown in the last two columns. Accordingly, the progress of the CFCW algorithm vs. the FPA algorithm for all sectors is 4.01% (for individual sectors, the minimum value is 1.08% in the government sector, while the maximum value is 37.51% in the communication sector). Finally, the superiority of the CFCWO method compared to the CFCW method for all sectors is 6.56% (for individual sectors, the minimum value of 4.10% is also in the government sector, while the maximum value of 14.67% is in the banking sector).
Figure 7 shows a visual representation of the results. For the CFCWO method, the values are always less than the others, indicating the most accurate estimation.
Table 7 shows the percentage difference based on the MAPE evaluation criteria for each IS compared to the same algorithm applied to all sectors.
In the same way, the results for the RMSE evaluation criterion were compared (see
Table 8 and
Table 9, as well as
Figure 8). The only difference was that the lowest improvement value of the CFCW method compared to the IFPUG FPA method was in the government sector, at 8.77%, while the highest was in the communication sector, at 54.15%. Overall, by using the CFCW algorithm, the estimated results improved by 10.39%, and the CFCWO algorithm enhanced the estimate by 24.62%. The NNFPCM model’s results, in this case, were better than those of the IFPUG FPA method in some sectors (banking, communication, government, and insurance).
We can observe two interesting points to summarize this section: (1) values always descend from the IFPUG FPA method to the CFCW method to the CFCWO method for each evaluation criterion, and (2) the evaluation criteria values of the ISs are always smaller than the values for all sectors.
Based on these statements and the analysis of previous results, we can proceed to answer the research questions.
- RQ1:
Is the accuracy of the proposed CFCW algorithm better than that of the standard IFPUG FPA or NFFCPM methods?
For each evaluation criterion shown in
Table 4,
Table 6 and
Table 8, we can observe that the value in the CFCW column is always smaller than the value in the corresponding IFPUG FPA or NFFPCM column.
Figure 6,
Figure 7 and
Figure 8, depicting the results of the MAE, MAPE, and RMSE evaluation criteria, respectively, also show that the estimation errors for the CFCW algorithm are always better than the estimation errors for the IFPUG FPA and NFFCMP methods. This means that the proposed CFCW algorithm outperforms the IFPUG FPA and NFFCMP methods. The percentage improvement of the CFCW method in terms of accuracy compared with the IFPUG FPA method was MAE = 5.46%, MAPE = 4.10%, and RMSE = 10.39% for all sectors. When CFCW is compared to NFFCMP, those figures are MAE = 15.39%, MAPE = 28.41%, and RMSE = 19.9% for all sectors.
- RQ2:
Does the advanced CFCWO algorithm outperform the CFCW algorithm?
To answer this research question, we also evaluated
Table 4,
Table 6 and
Table 8. As we can see, the percentage improvement of the CFCWO method in terms of accuracy compared with the CFCW method was MAE = 11.89%, MAPE = 6.56%, and RMSE = 24.62% for all sectors. As in the previous comparison, there was a greater improvement in the accuracy of the CFCWO algorithm estimate for each sector. The largest percentage differences were MAE = 22.18% (financial sector), MAPE = 18.53% (communication sector), and RMSE = 26.77% (banking sector). The mean percentage differences of the individual sectors compared to the ungrouped dataset were MAE = 11.08%, MAPE = 9.59%, and RMSE = 12.28%.
- RQ3:
How accurate is the estimation for each sector compared to an ungrouped dataset?
The answer to this question is shown in
Table 5,
Table 7 and
Table 9. As we can see, the accuracy of the estimate in all individual sectors for all evaluation criteria is higher than for an ungrouped dataset.
When CFCW is compared to IFPUG FPA, improvement in the accuracy of the CFCW estimate can be seen for the individual sectors, where the largest percentage differences are MAE = 51.55% (communication sector), MAPE = 30.76% (banking sector) and RMSE = 54.15% (communication sector); the mean percentage differences of the individual sectors compared to the ungrouped dataset are MAE = 22.52%, MAPE = 16.26%, and RMSE = 27.75%.
When CFCW is compared to NFFCMP, improvement in the accuracy of the CFCW estimate can be seen for the individual sectors, where the largest percentage differences are MAE = 72.00% (service industry), MAPE = 67.69% (financial), and RMSE = 71.79% (service industry); the mean percentage differences of the individual sectors compared to the ungrouped dataset are MAE = 49.98%, MAPE = 49.03%, and RMSE = 38.25%.
Paired-samples
t-tests were used for evaluating statistical significance comparisons [
58,
59] to see whether the CFCWO method is significantly different from the other methods, in order to confirm the evaluation conclusions (see
Table 10). The notations
,
, and
reflect the statistical superiority, inferiority, and similarity of the CFCWO approach compared to each of the other methods (FPA and NFFPCM), respectively. We can conclude that the difference in estimating accuracy between the CFCWO and each alternative approach is significant when the
p-value is less than 0.05.
All used evaluation criteria results in this study were used as the sample test set for each method in this study.
7. Threats to Validity
Internal validity in this study, which can affect the validity of conclusions drawn from experimental research, is an incorrect/inaccurate evaluation method to assess the proposed method; specifically, it refers to the technique of statistical sample validation. The threat to the validity was controlled using the k-fold cross-validation method, which guarantees that the proposed method is accurately assessed. Another internal threat that may affect the validity of the obtained results is the choice of parameters in the machine learning technique. In this study, we use the default parameter settings of the Bayesian ridge regressor technique for the proposed algorithm.
External validity in this study is concerned with the range of validity of the results obtained, and whether the results obtained could be applied in a different context. The ISBSG repository August 2020 R1 dataset was used to assess the predictive ability of the proposed method. This dataset contains many software projects collected from different organisations worldwide that differ in terms of features, fields, size, and number of features.
Unbiased evaluation criteria are used to evaluate the performance accuracy of the proposed method. This study used evaluation criteria such as the MAE, MAPE, and RMSE, which are unbiased evaluation criteria according to previous research [
60,
61]. Therefore, we can conclude that the experimental results of this study are highly generalizable.
8. Conclusions and Future Work
A standard IFPUG FPA method calibration algorithm based on the Bayesian ridge regressor model for calibration (CFCW) and the voting regressor model for optimising effort estimation (CFCWO) with and without dataset grouping is presented in this study. This paper aimed to answer three research questions: In answer to RQ1, we can see a percentage accuracy improvement with the proposed CFCW algorithm compared to the IFPUG FPA method, depending on the evaluation criteria and whether a grouped or ungrouped dataset was used. For the ungrouped dataset, the percentage accuracy improvement for MAE = 5.46%, MAPE = 4.10%, and RMSE = 10.39%. The mean percentage difference of the individual sectors compared to the ungrouped dataset was MAE = 22.52%, MAPE = 16.26%, and RMSE = 27.75%, showing an even greater improvement in the accuracy of the estimates. This demonstrates that the IFPUG FPA method needs calibration, and can be calibrated. When CFCW is compared to NFFCMP, MAE = 15.39%, MAPE = 28.41%, and RMSE = 19.9% for all sectors.
The second proposed algorithm, CFCWO, brings further improvement, and outperforms the CFCW algorithm, answering RQ2. The percentage improvement varies according to the evaluation criteria and dataset. For the ungrouped dataset, the percentage accuracy improvement is MAE = 11.89%, MAPE = 6.56%, and RMSE = 24.62%. The mean percentage difference of the individual sectors compared to the ungrouped dataset is MAE = 11.08%, MAPE = 9.59%, and RMSE = 12.28%. The results also show that it makes sense to work with data belonging to a specific group. In our case, we grouped the data according to the IS. The answer to RQ3 is that the estimate’s accuracy in all individual sectors for all evaluation criteria is higher than for an ungrouped dataset.
The functional complexity weight values reflect the modern software industry trend of improving work performance thanks to the development of computer technology, programming languages, and CASE tools. This manifests itself in functional complexity weight values that are smaller than the original value. In addition, the demand for sophistication and complexity of software functions also increases over time in certain areas, manifesting in calibrated functional complexity weight values that are more significant than the original values.
IFPUG FPA is a calculation method that estimates the size, cost, and effort in the field of software development; it plays a significant role in today’s software industry. However, software engineering is a rapidly evolving field; today’s actual values may not accurately reflect tomorrow’s software values. Therefore, the weights proposed in this paper need to be updated according to the new trend. The ISBSG dataset is an up-to-date database of companies around the globe; it reflects the modern software industry that is constantly updated. Therefore, in the future, when project data are updated, the IFPUG FPA weighting values should be recalibrated to reflect the latest software industry trends.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}