1. Introduction
The Java programming language has continued to cement its position as one of the most popular languages since its first release in 1995 [
1,
2,
3,
4,
5]. Over the last quarter of a century, the language has evolved through approximately 18 major revisions [
6]. Initially being developed with a model of execution that did not rely upon ahead-of-time compilation to machine instructions, its early architecture specifically relied upon an interpretation of its intermediate formats bytecode [
7,
8,
9] with possible just-in-time (JIT) compilation [
10]. The robustness of Java, its cross-platform capabilities and security features [
11] has seen the Java Virtual Machine (JVM) in its early days be the target for many languages, for example, Ada [
12], Eiffel [
13], ML [
14], Scheme [
15], and Haskell [
16] as cited in [
17,
18,
19]. Nonetheless, performance analysis of early releases of the language was characterised as providing poor performance relative to traditional compiled languages [
7,
9], with early comparisons of execution time performance of Java code showing significant underperformance relative to C or C
code [
7,
20,
21,
22,
23]. The Java interpreter was especially slow [
8,
24] in contrast to code compiled to native code [
25,
26,
27], or even Java JIT-compiled code [
27], performance challenges that persist with contemporary language interpreters [
28,
29,
30].
Over the last two decades, the language has integrated significant optimisations regarding its runtime environment. The JVM has transitioned from the separated execution models defined by the interpreter, client, and server virtual machines (VM) to a tiered system that integrates all three. Previous to Java 7, an application’s life cycle resided within an interpretive environment, the client or server VM. The tiered VM model of execution harnessing the performance opportunities associated with all three execution models [
31]. Tiered execution allows an application to start quickly in the interpreter, transition to the client C1 compiler, and then to the server C2 compiler for extremely hot code. Some recent performance benchmarking of the JVM indicates that, for a small number of application cases, performance has surpassed that offered by ahead-of-time compiled code or is relatively no worse [
4,
32,
33,
34,
35,
36,
37,
38,
39]. Regarding energy performance, Java has been listed as one of the top five languages [
40,
41]. However, underperformance relative to native code persists [
37], with C++, for example, offering more significant performance opportunities [
38].
The performance of the JVM interpreter remains of significant contemporary importance [
42], not just because of its role within the modern JRE and the information that it provides for guiding just-in-time compilation, but also due to the extent to which it is relied upon for the execution of code on a vast array of platforms. In addition, the contemporary JVM is a popular target for many languages, primarily because of its ability to provide an environment to efficiently and competitively execute bytecode, for example; Scala, Groovy, Clojure, Jython, JRuby, Kotlin, Ceylon, X10, and Fantom [
43]. The availability of JVM interpreters allows languages to target architectures without the need to construct dedicated compilers, leveraging decades of research and significantly reducing the costs associated with modern language development. Interpreters can substantially facilitate the development of modern languages, new features, and the testing of alternative paradigms. The Truffle language implementation framework is an example of a contemporary framework that enables the implementation of languages on interpreters that then utilise the GraalVM and its associated optimised JRE [
44]. Also, the growing envelope of paradigms and workloads that target the JVM present new optimisation possibilities for current compilers [
45,
46]. In addition, interpreters are more adaptable than compilers [
47], offering simplicity and portability [
48], compact code footprint, significantly reduced hardware complexity, as well as a substantial reduction in their development costs [
49]. Tasks such as debugging and profiling can be accomplished easier through an interpreter compared to a compiler [
47]. Finally, expensive and non-trivial tasks such as register allocation and call-stack management, for example, are not required [
50].
This paper considers the JRE and its associated interpreter as a target for optimisation opportunity discovery. We propose that the JVM interpreter, instead of other language interpreters, will benefit from such analysis. This is partly due to its maturity and the considerable amount of research that has been undertaken, from which optimisation techniques have been identified. We have focused on optimisation opportunities associated with changing the GNU compiler release used within the JRE build toolchain and the effect on the JRE and its associated JVM’s interpreter. In this current work, we consider this question relative to six open source releases of OpenJDK, specifically; release versions 9 through 14; and the use of four GNU compiler release versions, specifically versions 5.5.0, 6.5.0, 7.3.0, and 8.3.0. We undertook the analysis on a cluster of Raspberry Pi4 Model B lightweight development boards. We undertake this analysis on a more recent contemporary benchmark suite, the Renaissance Benchmark Suite. The specific research questions motivating this work are as follows:
- RQ1:
When constrained to using a particular release of a JRE, does building with alternative compiler versions affect runtime performance?
- RQ2:
When free to migrate between JRE versions, which JRE provides the best runtime performance, and what build toolchain compiler was associated with the runtime performance gains?
- RQ3:
Do workload characteristics influence the choice of JRE and GCC compiler?
This paper is structured as follows.
Section 2 presents the background that this research builds upon and the specific related work. In
Section 3, we present our methodology. We detail our results in
Section 4. In
Section 5, we present a discussion of our results. In the final section,
Section 6, we present our conclusions and future work direction.
2. Background and Related Work
The Java interpreter still plays a fundamental role in the boundary of the significant structural changes integrated into the modern JVM. The interpreter acts as the entry point, controlling initial Java code execution, with the tiered JVM model activating greater levels of just-in-time compilation based on the profiling of the behaviour within the interpreter. Although, the interpreter’s role within the lifespan of a Java application is not finished in the early stage of application execution. It can be delegated back to [
51] when the later stages within tiered compilation identify previously hot methods for deoptimisation.
There are many ways by which Java interpreters have been implemented. The main difference across implementations is how instruction dispatch is handled. Three general strategies have dominated instruction dispatch implementations: switch-based, direct threading, and inline direct threading [
48,
52]. The switch-based model is the simplest of all. Nevertheless, it is the most inefficient due to the number of control transfer instructions, a minimum of three for each bytecode instruction. Direct threaded dispatch sees the internal opcode structure updated by the address of their implementation, resulting in the elimination of the instruction switch and the encapsulating dispatch loop. A differentiating characteristic between both approaches is that direct threaded code instructions control the program counter [
53], whereas the switch expression takes responsibility for its updating. Finally, inline threaded implementations eliminate dispatch overhead associated with control transfer instructions by amalgamating instruction sequences contained within the bytecode’s basic blocks. The effect eliminates the dispatch overhead associated with all instructions composing the basic block, bar the last bytecode instruction. Casey et al., in [
52], and Gagnon et al., in [
48] provide an overview of all three techniques. Early research on interpreter performance identified that instruction dispatching is primarily the most expensive bottleneck regarding bytecode execution.
2.1. Historical JVM Enhancements
Addressing the underperformance of the Java interpreter, the early work relative to the JVM deployment history concentrated on optimisation techniques focused on the cost implications associated with the interpreter dispatch loop, which bore a considerable cost penalty in simple switch-based implementations. Early historical optimisations of the Java interpreter that integrated direct threading were shown to provide significant performance gains over simple switch dispatch [
54]. The findings concerning those threaded implementations report increases in runtime performance in the order of up to 200% over switch-based implementations [
54]. Those results and observations agree with the earlier works by Ertl and Gregg in [
55,
56], in which they focused on the performance of a wide variety of interpreters such as Gforth, OCaml, Scheme48, YAP, and XLISP. Nevertheless, the JVM interpreter’s direct-threading optimisation encounters underperformance regarding branch misprediction due to the large number of indirect branches introduced into direct threaded code [
52].
Continuing to explore the effects of threaded interpreters and intending to reduce the dispatch overhead further, Gagnon et al., in [
48] considered the inlining of Java bytecode instruction implementations that compose basic blocks. Their work reported significant performance gains from inline threaded interpretation over direct threaded. A side effect of direct-threaded interpretation is that the number of indirect branches considerably impacts microarchitectural performance, for example, the branch target buffer (BTB) [
52]. The work of Casey et al., in [
52] addressed those limitations by implementing instruction replication and extending beyond basic block boundaries with super-instructions. Nevertheless, aggressive superinstruction implementations increase cache miss-rates [
57]. Continuing to explore opportunities associated with threading: context-threaded interpretation of Java bytecode was proposed by Berndl et al., in [
57]. Context-threading eliminates the indirect branches but adds a subroutine call and a return from that subroutine call. These instructions are optimised on modern architectures and outperform indirect branch-heavy direct threaded code.
Microarchitectural characteristics associated with JVM interpreter behaviour, particularly instruction and data cache effects, have been the focus in [
53,
54,
55,
56]. Earlier work by Hsieh et al., in [
24] had highlighted that the interpreter bytecode is considered data along with the data associated with the application and is accessible through the data caches, ultimately providing more opportunity for increases in data cache misses for the interpreter.
Java’s early underperformance had motivated JVM designers to look at native execution alternatives. Microprocessor designs, such as PicoJava and MicroJava, facilitated the native execution of Java bytecode [
58]. Due to cost constraints, PicoJava and MicroJava lacked instruction-level parallelism (ILP) circuitry. The work of Watanabe and Li in [
25] proposed an alternative architecture incorporating ILP circuitry. The JVM top-of-stack is a considerable bottleneck that inhibits ILP exploitation of the Java bytecode [
25,
59]. Li et al., in [
59] propose a virtual register architecture within Java processor designs due to the distinct shortage of physical registers. The debate on whether a stack architecture or a register architecture can provide a more efficient implementation for interpreters has also been considered [
60]. Work by Shi et al., [
60] highlights many advantages of a virtual register architecture compared to a more traditional stack architecture.
2.2. Evolution of OpenJDK
Since its first release in 1995, the Java language and, in particular, the JVM specification have been implemented and shipped by many vendors (Sun, CA, USA; Oracle, TX, USA; IBM, NY, USA; Microsoft, WC, USA; AZUL, CA, USA). The codebase of the Sun implementation started its journey to being open-source in 2006. In 2007 the Open Java Development Kit (OpenJDK) was founded, which serves as the reference implementation of the platform [
61].
The
openjdk.java.net (accessed on 5 May 2022) details the evolution of changes to the components defining OpenJDK through a catalogue of JDK Enhancement Proposals (JEP) that detail all OpenJDK changes from OpenJDK version 8 (OpenJDK8) through to the latest OpenJDK version 19 (OpenJDK19). The proposals serve as an “authoritative”, “record” detailing “what” has “changed” within an OpenJDK version and “why” that change was accepted and implemented [
62].
The JEP index currently lists 326 enhancement proposals. Of those, 149 (46%) relate to OpenJDK9 through 14. Of those, 58 (18%) enhancement proposals concern proposed changes to OpenJDK10 through to 14. A JEP proposal is associated with a JDK component, for example, core (detailing changes targeted at core libraries), spec (detailing changes targeted at a specification), tools, security, hotspot, and client (detailing changes targeted at client libraries). Components also have associated sub-components; for example, hotspot has associated sub-components for GC (garbage collector changes), runtime, compiler (for changes related to the JIT-compilers), and JVM tool interface changes.
A number of the more significant changes that have been completed and delivered as part of the JEP, specifically related to the JRE, have seen the OpenJDK version 10 (OpenJDK10) G1 garbage collector (G1GC) updated to allow for the parallelisation of full collections. The initial implementation of G1GC “avoided full collections” and fell back to a full garbage reclamation, using a mark-sweep-compact algorithm when the JVM did not release memory quickly enough. Specifically, OpenJDK10 saw the mark-sweep-compact algorithm become fully parallel [
63].
OpenJDK version 12 (OpenJDK12) implemented two further enhancements to the G1GC: “abortable mixed collections” [
64], and optimisation in regards to the “speedy reclamation of committed memory” [
65]. Regarding abortable mixed collections, before the OpenJDK12, G1GC collections, once started, could not terminate until they reclaimed all live objects across all the regions defined within its collection set were reclaimed. The implemented enhancement saw the G1GC collection set divided into two regions, one mandatory and the other optional when “pause time targets” had not been exceeded [
64]. Regarding speedy reclamation defined through JEP346, the implementation enhanced memory management through the release of heap memory back to the operating system when the JVM was in an idle state. This implementation targeted cloud-based services where the financial cost of application execution included the cost of physical resources such as memory [
65]. Further enhancements concerning memory management and JVM configurations involved the enhancement of the G1GC in OpenJDK version 14 (OpenJDK14). The enhancement ensured that the G1GC performance was increased for JVM configurations running on multi-socket processor cores, particularly for cores that implement non-uniform memory access (NUMA) strategies [
66].
Before OpenJDK10, OpenJDK gave attention to reducing the “dynamic memory footprint” across multiple JVM’s. In that regard, OpenJDK implemented Class Data Sharing archives. Although those archives were limited to bootstrap classes, access was only available through the bootstrap class loader [
67]. OpenJDK10 expanded class data sharing to allow application class data sharing across multiple JVMs. With that said, to gain the benefits from application class data sharing, the JVM runtime flag
−XX:+UseAppCDS needs to be passed to the JVM. OpenJDK12 and, in particular, JEP341 [
68] turned on application class data sharing at the build stage of the OpenJDK. Finally, JEP350 [
69] allows the dumping of application class data when an application completes execution, an enhancement first implemented in OpenJDK version 13 (OpenJDK13).
A list of JDK enhancement proposals related to OpenJDK9 through 14 for the hotspot-runtime and hotspot-gc components are listed in
Table 1. The reader can find a detailed list of all JEP enhancements affecting all OpenJDK components at [
62].
2.3. Performance Regression
Focusing specifically on performance measurement of the effects of altering and integrating different build tools within the JDK build cycle, the literature is considerably void. That said, the build specifications associated with OpenJDK versions list GNU GCC compiler versions known to work concerning its building [
70]. These specify that versions of OpenJDK should build successfully with GNU GCC native compiler versions from at least 5.0 through to 11.2. OpenJDK does not indicate their performance or regression effects when integrated into the OpenJDK build toolchain.
With that said, the most recent insights suggest that conventional compilers and optimisers fail to produce optimal code [
71]. In addition, a more recent focus on the GNU GCC compiler collection has shown that the GNU GCC release used within a build toolchain can produce significantly different performance [
72]. The work of Marcon et al., although not analysing JRE performance, analyses the effects of changing the GNU GCC compiler version in the build toolchain for the Geant4 simulation toolkit [
73] (as cited in [
72]), a simulation toolkit that is used for the analysis of high energy physics experiments and predominately used for experiments performed on the Large Hadron Collider. Their work considered three versions of GNU GCC, versions 4.8.5, 6.2.0 and 8.2.0; and the four standard GCC compiler optimisation flags,
−O1,
−O2,
−O3, and
−Os. From a high level, their results show that building with a more recent version of GCC can increase performance in the order of 30% in terms of execution time. Marcon et al. also considered the effects associated with static and dynamic compilation. Their results show statistically significant differences in performance between the statically and dynamically compiled systems. Their work also reports less profound effects from switching between GCC 6.2.0 and 8.2.0. The greatest effects are associated relative with GCC 4.8.5.
To our knowledge, no other work has addressed and measured the effects associated with switching GCC compiler in a build toolchain relative to a large codebase such as that of OpenJDK. In addition, no analysis of such changes are available relative to a contemporary set of workloads.
Although little work has concentrated on the effects of changing the underlying compiler toolkit associated with building OpenJDK, the literature has considered and reported the impact that Java-to-bytecode compilers have on producing optimised bytecode. For example, Daly et al., in [
19] consider the effect that the variant of the Java compiler has in regards to its emitted Java bytecode. Their findings showed that different Java-to-bytecode compilers implement vastly different bytecode optimisations. Similar to the work presented in [
19], Horgan et al., [
74] consider the effects associated with Java-to-bytecode compiler choice and the dynamic instruction execution frequencies. Their results have shown that Java-to-bytecode compiler choice produces minimum dynamic differences in bytecode usage. The work of Gregg et al., in [
54] is similar to that presented in [
19] in that they compared the differences in bytecode distributions associated with different Java-to-bytecode compilers. Their findings showed that most Java-to-bytecode compilers fail to implement what is regarded as the simplest of optimisations to the emitted bytecode, for example, loop optimisation by removing tail
goto branches. Gregg et al. reported that the Java-to-bytecode compilers have little effect on the dynamic bytecode frequencies.
Contemporary work has reported that Java source code compilation to JVM bytecode by the javac compiler returns minor optimisations and no aggressive optimisations on the intermediate bytecode representation. Such optimisation opportunities are delegated to the JIT-compiler [
38]. Furthermore, switching javac compiler versions is not an explanatory factor for execution speed variations in Java applications running on JVMs [
19]. As such, optimising bytecode to benefit the interpreter needs to be performed between source compilation and initial execution, for example; [
22,
75,
76] or within the interpretive environment itself. More importantly, the delegation of bytecode optimisation to the JIT compiler results in a loss of opportunities that might positively affect interpreted execution.
2.4. This Study
Although previous studies have considered optimisations associated with the underperformance of the JVM interpreter and the effect that different variants of Java-to-bytecode compilers have on bytecode performance. None to our knowledge have evaluated the impact the compiler used within the JRE build toolchain has on the performance of the JRE and its associated JVM interpreter. As outlined previously, this is of contemporary importance for many reasons. Although, and as cited in [
9], Cramer et al., in [
8] identified that for all the optimisations targeting interpretation/execution of actual bytecode, approximately 35% of execution time is spent doing other tasks other than interpreting/executing bytecodes, for example, memory management, synchronisation, and running native methods. Of all these mentioned tasks, object synchronisation is identified by Gu et al., in [
7] as being the most costly, accounting for approximately 58% of non-bytecode execution. All of those execution tasks are controlled, defined and implemented across the full JRE implementation; this, in part, has motivated this work in that we investigate several questions relative to OpenJDK JRE performance. Specifically, what effects does altering GNU GCC versions in the OpenJDK build toolchain have on JRE performance. In this regard, this research evaluates three hypotheses:
Hypothesis 1 (H1). There are statistically significant differences in OpenJDK JRE and associated JVM interpreter performance depending on the GNU GCC version used in the build toolchain.
Hypothesis 2 (H2). There are statistically significant differences in performance across all OpenJDK JREs and their associated JVM interpreters, and those differences are in part associated with the version of GNU GCC used in the versions build toolchain.
Hypothesis 3 (H3). Workload characteristics influence the choice of JRE and GCC compiler.
3. Methods
This section provides an overview of the JDK, JRE, JVM, and GNU GCC implementations analysed in this study. We also provide an overview of the collection of benchmark application workloads relied upon for assessing JRE and JVM interpreter performance. We follow this with a specification of the hardware cluster and operating system on which we evaluated JRE runtime environment performance. We then present an a priori analysis of the stability of each cluster machine relative to each other. Finally, we summarise the statistical procedures used to generate our main results.
3.1. JDK, JRE, JVM, and GNU GCC Implementations
We analysed six major version releases of the OpenJDK and, specifically, their associated JREs regarding their performance evolution. In particular, OpenJDK9 through to 14 JREs. We built all OpenJDK versions from source, with four builds for each JRE using GNU GCC compiler release versions 5.5.0, 6.5.0, 7.3.0, and 8.3.0. All JDK builds used a previous immediate version for the build requirement bootstrap JDK. The initial build of OpenJDK9 relies on the pre-built OpenJDK8 binary distribution. All subsequent OpenJDK versions built relied upon one of our built JDK and were used as the bootstrap JDK. The building of OpenJDK10, for example, depends on our OpenJDK9 built from source. We downloaded all source bundles from the OpenJDK project’s repository, which the reader can find at
https://openjdk.java.net (accessed on 5 May 2022). We downloaded all GNU Compiler Collection releases from
https://gcc.gnu.org (accessed on 5 May 2022).
Specifically, regarding the JRE JVM interpreter, two implementation choices are available at build time: the production Template interpreter and a C++ interpreter bundled primarily for ease of implementation and testing of proposed research optimisations. In this work, we focus our concentration on the behaviour of the JRE with an integrated Template Interpreter. Interpreter mode was communicated to each JVM using the
−Xint runtime flag. Concerning JVM tuning, and in line with benchmark specifications such as SPECjvm2008, no additional JVM tuning is activated [
77], except for communicating
−Xms for heap space allocation, which we have controlled at 2 GB across all JVM variants. An evaluation of all JEP showed that OpenJDK had implemented no fundamental changes regarding the JVM Template Interpreter, and the interpreter can be considered constant across OpenJDK9 through to 14.
We used the default Garbage-First Garbage Collector (G1GC) for heap management across all JRE JVM executions. Changes to the behaviour and operation of the G1GC have occurred across OpenJDK10 through to OpenJDK14. In particular, OpenJDK10 saw the parallelisation of full G1GC cycles; OpenJDK12 saw the introduction of abortable G1GC collections and the speedy release of memory back to the operating system when the JVM was idle, and finally, OpenJDK14 saw the introduction of “NUMA-Aware memory allocation.” Concerning the parallelisation of full G1GC cycles, we initiated all JRE instances with the default number of threads set to 4 by default across all OpenJDK, from OpenJDK10 through 14. In addition, NUMA awareness does not impact the operational characteristics of the JRE and associated JVM interpreters assessed in this study, as the Raspberry Pi 4 model B system-on-chip is not a multi-socket processor. The speedy reclamation of committed memory implemented in OpenJDK12 applies to cases where the JVM is idle, which is relevant for cloud-based applications and not relevant in our system setting.
No JVM warmup iterations were required, as all JVM executions were run in interpreter mode and “the interpreter does not need a warmup” [
42]. We ran all benchmark workloads and their iterations on newly initialised JVMs.
3.2. Benchmarks
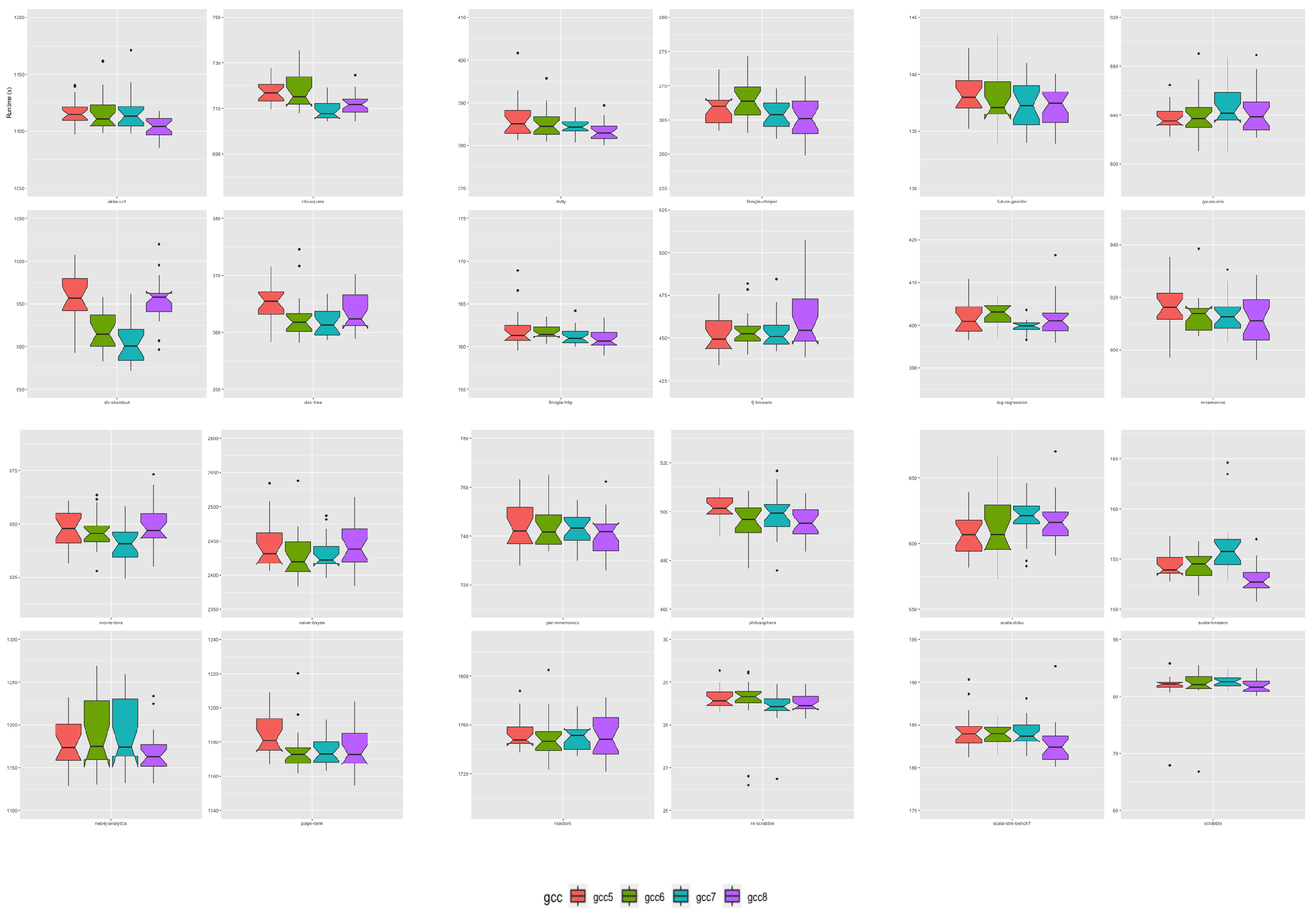
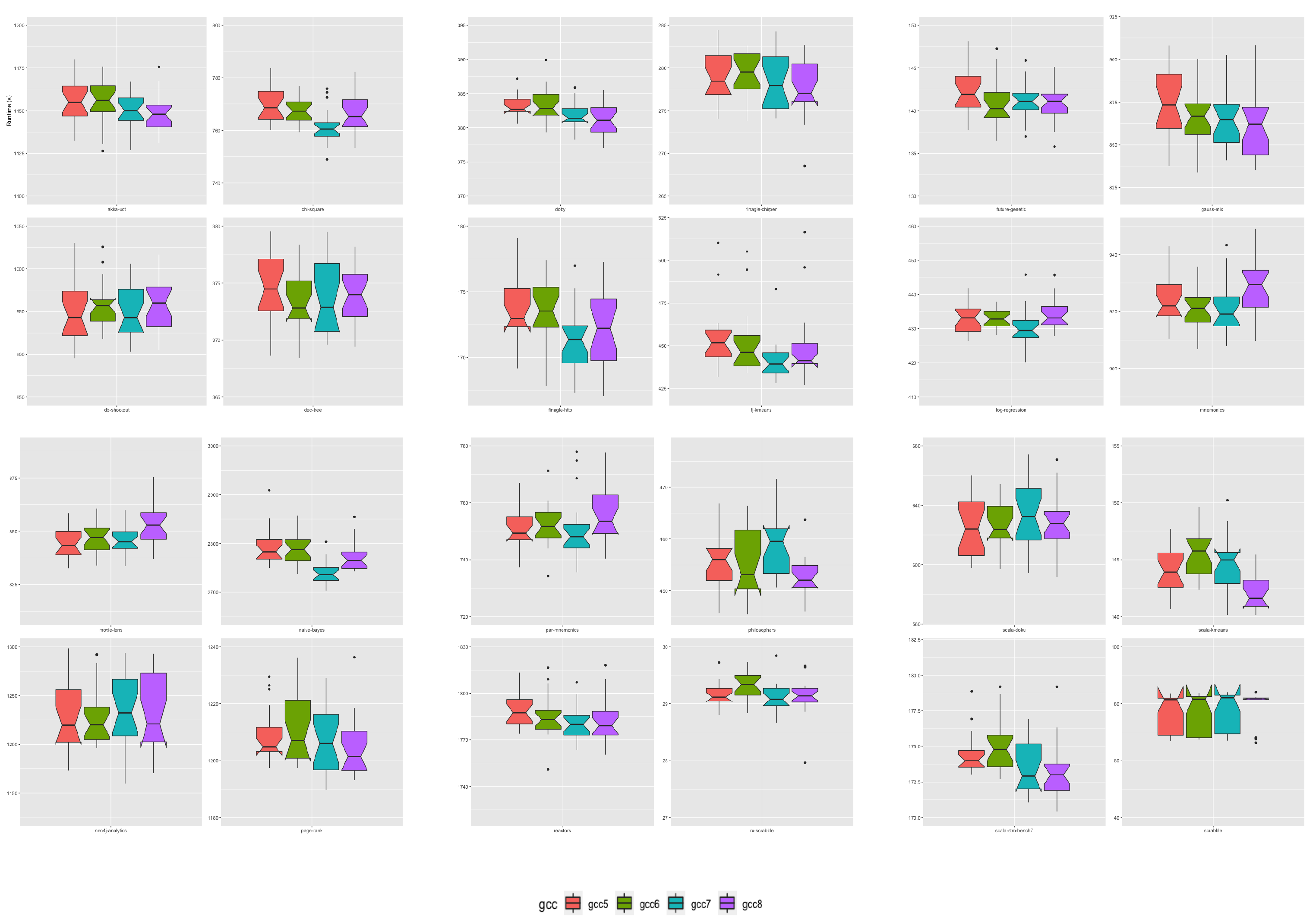
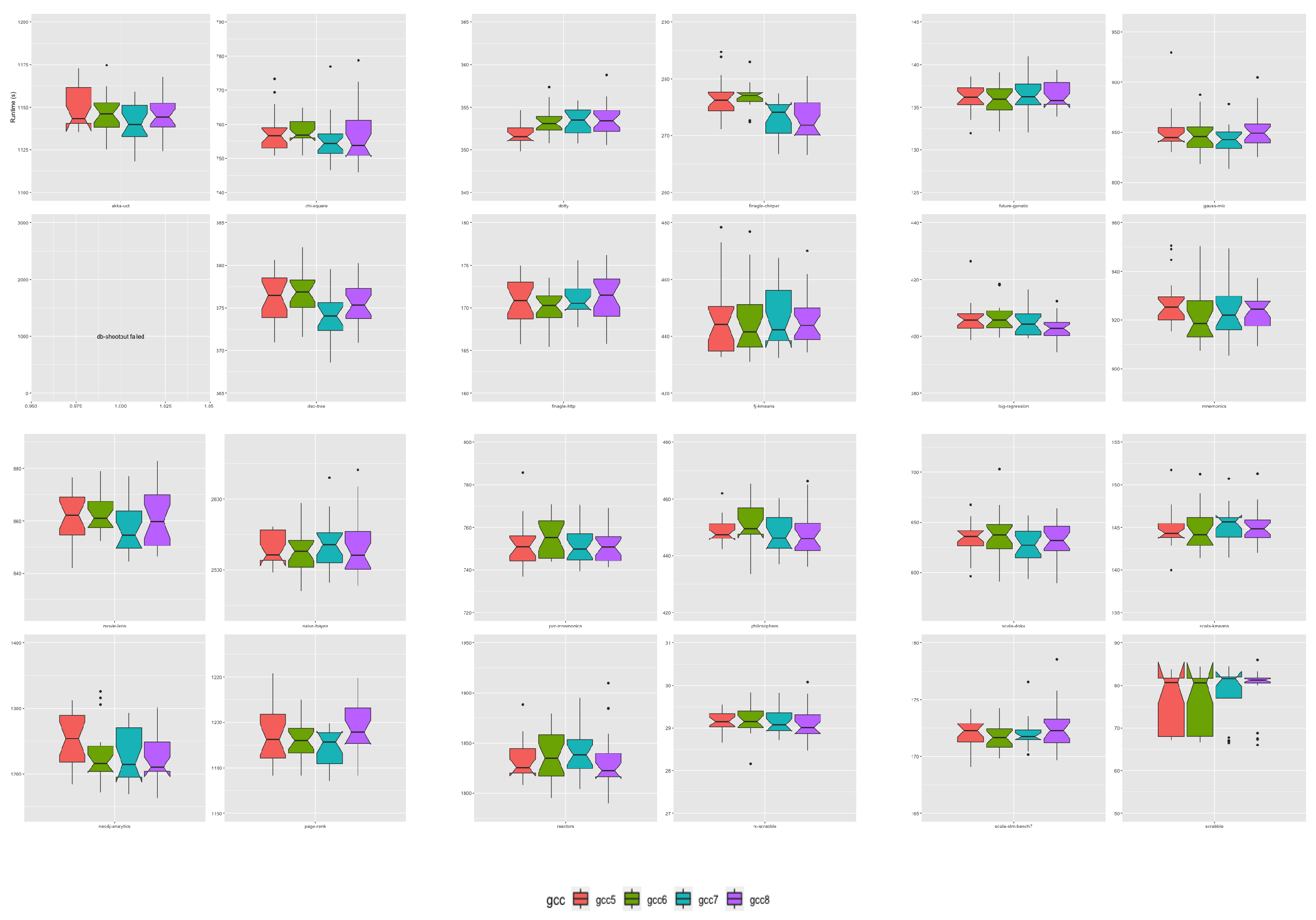
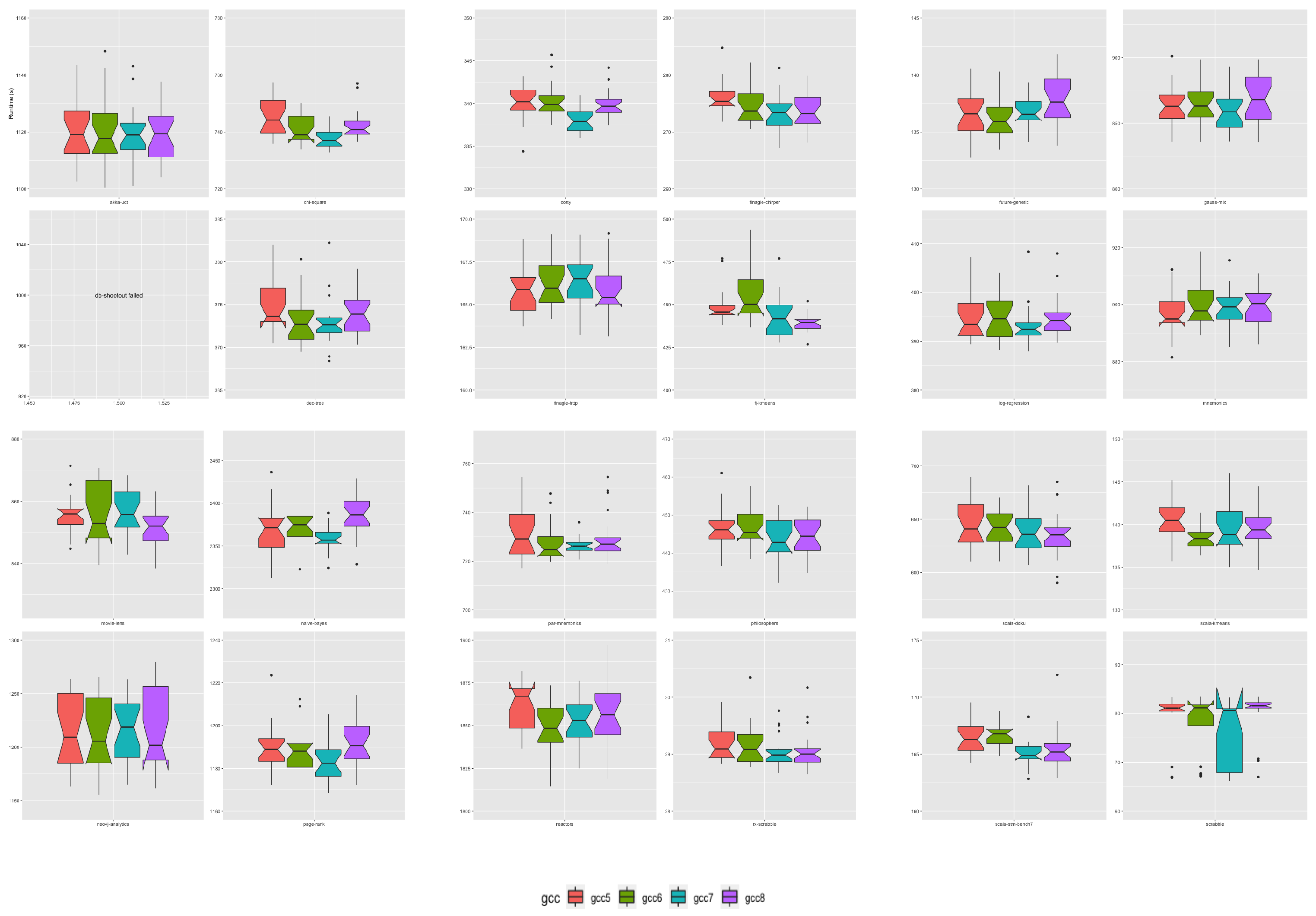
We assessed all JRE and their associated JVM interpreter runtime performance using the collection of 24 workloads composing the Renaissance Benchmark suite version 11 [
78]. The Renaissance Benchmark Suite workloads are partitioned into six classes of applications. Applications targeted for execution on the Apache Spark framework, applications that implement a concurrent programming paradigm, database applications, several applications developed using a functional paradigm and compiled to Java bytecode, web applications serving requests to HTTP servers, and several applications written in the Scala language with their compilation targeting Java bytecode.
Table 2 presents an overview of each application workload.
To assess JRE and JVM interpreter runtime performance: each of the 24 Renaissance benchmark application workloads was executed 20 times across all 24 JRE JVM builds, resulting in 11,520 execution runs. In total, we undertook 94 system days of data acquisition. Each JRE version accounts for 1920 of those runs. Individual JREs built using one of the four GCC compiler versions account for 480 runs each.
We observed several failed workload runs, specifically for the Renaissance Benchmark application db-shootout that failed to run on all JVM versions after OpenJDK11. In addition, several other applications reported deprecated API features, reporting that their dependencies cannot be guaranteed to be supported in later JVM runs, specifically after OpenJDK9. That said, none of the deprecated API features had been removed from the assessed OpenJDK versions.
3.3. Hardware
Our experimental set-up consists of a cluster of 10 Raspberry Pi4 Model B development boards, integrated with Broadcom BCM2711, Quad-core Cortex-A72 (ARM v8) 64-bit system-on-chip processors with an internal main reference clock speed of 1.5 GHz. Each Raspberry Pi has a 32 KB L1 data cache, a 48 KB L1 instruction cache per core, 1 MB L2 cache, and 4 GB of LPDDR4-3200 SDRAM. Network connectivity is provided by 2.4 GHz and 5.0 GHz IEEE 802.11ac wireless interfaces, Bluetooth 5.0, 2 USB 3.0 ports and 2 USB 2.0 ports. Each Raspberry Pi provides general-purpose input-output (GPIO) functionality through a 40 pin GPIO header. A Raspberry Pi can be powered over a 5V DC USB type C connector or 5v DC GPIO headers. All Raspberry Pi’s were powered from mains. The maximum tolerable current is 3 Amperes [
79]. A specification diagram is presented in
Figure 1. We ran each Raspberry Pi4 Model B with the Raspbian Buster Light Debian distribution of Linux, Kernel version 4.19. We loaded the operating system (OS) through an embedded Micro-SD card slot. All Raspberry Pi’s had the same OS clone installed. The Raspbian Buster Light distribution is a non-windowing version providing only a command-line interface. All Raspberry Pi4 were SSH enabled.
3.4. Runtime Stability across Cluster Nodes
A random sample of five applications were selected from the Renaissance Benchmark Suite, namely: chi-square, future-genetic, neo4j-analytics, scala-kmeans, and scrabble. A single build of OpenJDK9, built with GNU GCC version 8, was distributed across six of the cluster’s Raspberry Pi4. We executed the benchmark samples on each of the six Raspberry Pi4. We conducted an analysis of variance on their respective execution times. At the significance level, we observed no statistically significant differences in runtime performance for four of the benchmark applications, all . The single benchmark case scala-kmeans did show differences in runtime performance between the six Raspberry Pi4 development boards (). With that said, the average runtime across the scala-kmeans benchmark is approximately 155 s; the observed difference from the single Raspberry Pi4 accounts for an effect of approximately s (). Albeit cognoscente of the small effect difference associated with the scala-kmeans benchmark, predominately benchmark application runs across the Raspberry Pi4 development boards are stable.
3.5. JRE and JVM Build Stability
A more recent concern regarding consistency, reliability, and robustness of the analysis of runtime systems has raised an important question regarding the effects of application build order. In particular, questioning the determinism concerning the layout of an application in memory. An effect that can be attributed to application build cycle linking and later application loading into memory. Focusing on the impact attributable to build cycle linking, four homogeneous builds of OpenJDK9, built with GNU GCC compiler release version 7, were analysed. The results from an analysis of variance showed no statistically significant differences in application runtime performance across the four homogeneous builds (). An indicator that runtime environment stability is reliable and that there are no differences in OpenJDK JRE and associated JVM performance.
3.6. Statistical Analysis
To determine if there are differences in JRE performance depending on the GNU compiler build version used within the JDK build toolchain, we conducted an analysis of variance of the runtime behaviour of the 24 applications composing the Renaissance Benchmark suite. In the cases where statistically significant differences in JRE performance has been identified, follow-up Tukey HSD post hoc tests were carried out to identify specific differences between pair-wise comparisons of JRE build versions built with one of the four GNU compilers running on individual OpenJDK versions.
We also conducted a two-way analysis of variance to assess the interaction effects between the GNU GCC compiler version and the OpenJDK version. The analysis of variance evaluated the effects associated with updates to OpenJDK versions and updates to GNU GCC versions.
5. Discussion
This paper has focused on optimisation opportunities associated with switching GNU compiler versions within the JDK build toolchain. In this current work, we considered this question relative to six open source releases of OpenJDK, specifically; release versions 9 through 14; and the use of four GNU compiler release versions in the OpenJDK build toolchain, specifically versions 5.5.0, 6.5.0, 7.3.0, and 8.3.0.
Our analyses are multi-faceted; first, we have undertaken a within-JRE-JVM version analysis, focusing on the effect of a change of the GNU compiler release version within the build toolchain for specific OpenJDK JRE and their associated JVM interpreter. We believe our analysis is of interest to those constrained to a particular OpenJDK JRE and JVM. In addition, this tests the hypothesis that compiler selection, at build time, affects overall JRE performance. Second, we have undertaken a between-JRE-JVM version analysis and considered the overall effect of changing the GNU compiler release version within the JVM build toolchain. We have identified a pair of OpenJDK JRE with GNU compiler that provides the best performance based on workload type. In addition, this tests the hypothesis that there exists an optimum pairing of OpenJDK JRE with GNU compiler that provides the best overall performance opportunities.
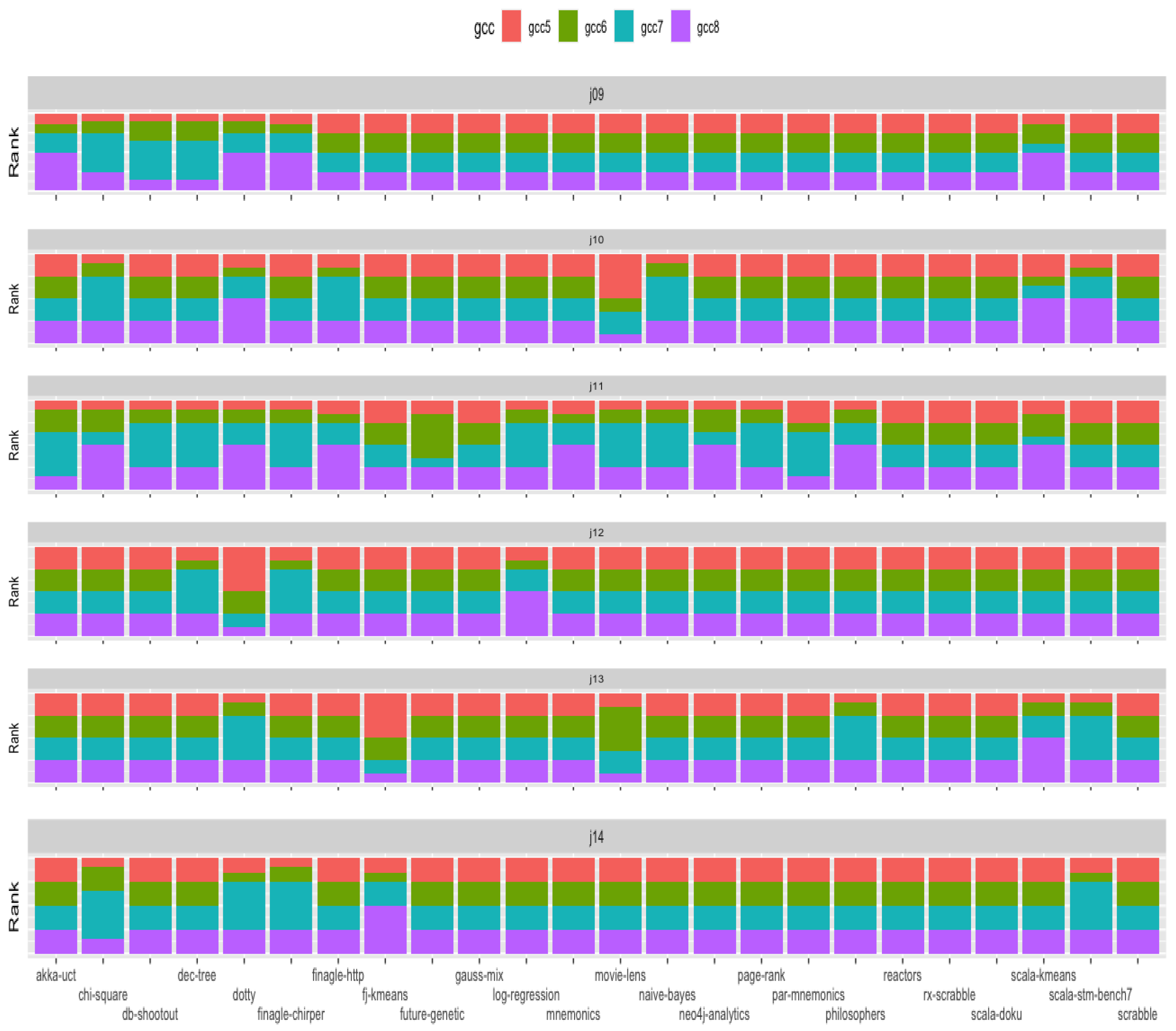
From a within-JRE release perspective, OpenJDK11 JRE had the greatest number of applications for which a change in GCC compiler in the JRE build toolchain had an effect. We observed the effect under loads from 17 (71%) of the 24 Renaissance applications running on OpenJDK11 builds. In these cases, GCC version 7 accounted for 51% of the observed differences, GCC version 8 accounted for 41%, and GCC version 6 was the best OpenJDK11 JVM build toolchain compiler for a single case, namely for the application future-genetic. GCC compiler version 7 was predominately associated with the Apache-spark category of applications, and GCC 8 was associated with better performance for Scala applications. A GNU GCC compiler version change did not affect JRE performance for seven Renaissance application workloads running on OpenJDK11 JRE builds. OpenJDK12 JRE had the smallest number of applications for which a change in GCC compiler in the JRE build toolchain had an effect. Only four cases showed statistically significant differences, two Apache-spark applications workloads, one Scala and the Web application finagle-chirper. The Scala dotty compiler was the only application workload with the best performance on a JRE built with the oldest GNU GCC compiler—GCC version 7. OpenJDK JRE performance degraded under load from dotty as newer compilers were used in the JRE build toolchain. We observed similar proportions of significant differences for OpenJDK9, OpenJDK10, and OpenJDK13 JREs. GNU Compiler version alternatives greatly influenced OpenJDK10 and OpenJDK13 JRE interpreters under load from the Scala applications.
Ranking JRE release performance across all six OpenJDK versions has shown that three of the six OpenJDK JRE choices provide the best runtime performance. The OpenJDK9 JRE and associated interpreter provided the best runtime performance under load from 13 (54%) of the 24 Renaissance benchmark applications. The OpenJDK JRE that provided the second to best overall performance opportunities was the OpenJDK14 JRE. It gives the best overall performance for 9 (38%) of the 24 Renaissance workloads. The only other OpenJDK JRE associated with better performance was the OpenJDK JRE version 12, which provided the best performance for 2 (8%) of the 24 workloads. The OpenJDK releases 10, 11, and 13, and their associated JRE provided no performance enhancement opportunities relative to either OpenJDK JRE 9, 12, and 14 releases.
Ranking of the GNU GCC compiler version used within the build toolchains of the OpenJDK releases showed that GCC version 7 provided the best performance in 12 (50%) workload cases. GCC version 8 delivered the best performance in 6 (25%) workload cases when specified as the build compiler. GCC versions 5 and 6 accounts for the remaining 25% of best build compilers.
Of all the compiler performance rankings, version ranking sequence 7-8-6-5 accounted for 25% of all performance rankings, with 7 providing the best performance and 5 delivering the worst performance. In addition, this was followed by the version ranking list 8-7-5-6, which accounted for 14%. The top-ranked GCC compilers were version rankings 7-8, which accounted for 33% of all performance rankings. Compiler version rankings 8-7 accounted for 21% of performance rankings. The third most prominent pairing of version rankings was 7-6, which accounted for approximately 14% of performance ranks.
The interacting playoff between the GNU GCC compiler version and the OpenJDK source bundle versions showed interacting effects for 67% of loads executed on the JRE associated JVMs. The workloads with no observed interaction effects were predominately associated with those written in a functional paradigm.
Overall our results show that from all the GNU GCC compiler comparisons undertaken across all OpenJDK builds, GCC versions 7 and 8 provide the best performance opportunities. Those GCC compilers used in the build toolchains of OpenJDK9 and OpenJDK14 give the best overall combination. Our results show that changing the OpenJDK version, which includes considering downgrading from a newer release to an older release, can positively impact performance. Using a recent GNU GCC compiler release in the build cycle can significantly affect performance. For example, the OpenJDK9 release date was September 2017, and the GNU GCC version 8 release date was February 2019. Our results show that builds of OpenJDK9 undertaken before 2019 would underperform relative to a new build of OpenJDK9 with the GNU GCC version 8 compiler collection released in 2019.
Attempting to isolate and attach meaning to the observed interactions between the GNU GCC version and the OpenJDK version and the effects on OpenJDK JRE runtime performance reported within this article, consideration must be given to the components within the JRE that could have been affected through the build processes. Some components, such as the garbage collector, have undergone several revisions across OpenJDK releases. For example, the G1 garbage collector has seen four major updates, OpenJDK10 saw G1 updated for full parallelisation of its full-collection phase, and OpenJDK12 implemented abortable mixed-collections as well as speedy reclamation of committed memory. Additionally, OpenJDK version 14 saw the G1 collector become NUMA aware. Those implementations filtered through to later OpenJDK versions without deprecation or removal.
It is possible that JEP enhancements have had a collective impact and contributed to the observed statistically significant interactions between the GNU GCC version and the OpenJDK version. Although, none of the interactions in OpenJDK versions 10, 11, or 13 appeared in the list of best performing OpenJDK JRE. In addition, concerning the parallelisation of the full G1GC cycles, we initiated all JRE instances with the default number of parallel GC threads set to 4 across all OpenJDK, from OpenJDK10 through 14. NUMA awareness does not impact the operational characteristics of the JRE and associated JVM interpreters assessed in this study, as the Raspberry Pi 4 model B system-on-chip is not a multi-socket processor. With that said, NUMA awareness is only available when running the parallel GC (
−XX:+UseParallelGC) [
81]. Also, the speedy reclamation of committed memory implemented in OpenJDK12 applies to cases when the JVM is idle, and the release of memory back to the operating system would have no impact. It is more relevant for cloud-based applications and not relevant in our system setting. In addition, an inspection of all G1GC runtime flags showed that all default settings are the same across OpenJDK releases. Other candidate JRE components that could have contributed to the observed interactions are concerned with the Java Native Interface (JNI) and the Java Class Library (JCL) that was built during the OpenJDK build cycle. There are a considerable number of those interface methods and library classes. Any impacts from a specific GNU GCC compiler would have a significant collective impact.
Additionally, the building of the Java compiler,
javac, with the different GNU GCC compilers could impact the generated Java library classes and their respective bytecodes, as the build
javac compiler is used to compile the JCL. Daly et al., in [
19] addressed the effect the Java-to-bytecode compiler has on the emitted bytecode was addressed. They showed that different Java-to-bytecode compilers implement vastly different bytecode optimisations. Although, Gregg et al., in [
54] showed that most Java-to-bytecode compilers fail to implement the simplest of optimisations to the emitted bytecode.
With that said, if the GNU GCC versions did not affect OpenJDK JRE performance, we would expect to find no significant differences in JRE performance when all JRE components are kept constant. Our analysis included that case by studying the effects of the GNU GCC compiler on specific versions of OpenJDK. For example, the four builds of the OpenJDK9 JRE all used the same source code bundle. As such, the OpenJDK version was constant.
Regarding workload factors, application workload is undoubtedly an essential factor. OpenJDK builds with specific compilers offer different performance opportunities for certain workloads. Our results have indicated that changing workload would, in many cases, necessitate a change of the compiler used within the build toolchain, even in cases where the same OpenJDK release is required. For example, OpenJDK9 or 14, built with GCC 7, provides the best performance opportunities for application workloads that target the Apache Spark framework. OpenJDK9 and OpenJDK14, made with GNU GCC version 8, give the best options for performance gains when workloads predominately involve concurrent execution. Of the two Database applications comprising the Renaissance Benchmark Suite, OpenJDK9 delivered the best overall performance coupled with GCC compiler versions 7 and 8. Of the applications written in a functional paradigm, three of the six OpenJDK builds provided the best results. Specifically, OpenJDK9, 12, and 14 built with GCC 5, 6, and 7. Scala applications performed best when running on OpenJDK14 built with GCC version 7. Our results also indicate that for the two web-based applications, finagle-http and finagle-chirper, that OpenJDK9 built with GNU compiler version 8 provided the best overall performance opportunities.
How much performance change can we expect? Our results have shown an average OpenJDK JRE performance increase of approximately 4.90% with an associated standard deviation of 4.89%. Interquartile measures show that, in approximately 50% of cases run with the optimal OpenJDK and GCC pairing, we can expect performance gains between 1.81% and 5.74%. In many instances, depending on the current OpenJDK JVM deployment, rebuilding the runtime environment can increase performance by as much as 20%.
6. Conclusions and Future Work
In this paper, we have considered the impact that GCC compiler releases used in the build toolchain of OpenJDK have on JVM interpreter performance under modern workloads. Our findings show that, when constrained to a particular OpenJDK release, the choice of GCC compiler version can significantly impact overall application performance for many application workloads. With the extra freedom to consider other OpenJDK versions and their associated JVM interpreters, there is an optimum pairing of OpenJDK and GCC compiler for each workload. Our results show that performance can be enhanced by, on average, 5%. Many workloads show performance gains above 10%, with a smaller number exceeding 20%, peaking at approximately 25%.
Our results have clearly shown that careful consideration needs to be given to the decision regarding which OpenJDK release to choose and specifically what compiler was used in its associated build toolchain. More importantly, our results would offer options to those who are constrained to working within a specific OpenJDK release and have shown that performance opportunities still exist through careful selection of compiler collection versions used within build toolchains. Interestingly, our results in this regard suggest that a richer set of OpenJDK binary distributions should be made available to the market, not just binary builds that target specific architectures but also binaries built using different compiler collections. Furthermore, OpenJDK binaries that have a specific target workload type would be of considerable interest.
Is there scope for leveraging performance? Our results have shown that this is undoubtedly the case. In particular, we have shown that the JVM interpreter can benefit from a rebuild using an alternative toolchain compiler. In particular, older versions of OpenJDK, for example OpenJDK9, predominately exhibit better performance if built with a later GNU GCC compiler.
Our future work will consider low level microarchitectural performance metrics, such as branch misprediction, and data cache behaviour, and the impact that build toolchain compiler choice has on those performance characteristics. In addition, we plan to expand this work and include the full set of available garbage collector algorithms and assess their impact on JRE performance. Additionally, we intend to explore the effects associated with the JRE Native Libraries and Java Class Libraries and the effect of building those with alternative GCC GNU compilers. In addition, we plan to explore similar effects associated with hotspot compilation. Finally, we are also interested in exploring if hotspot-style compilation, applied to internal JVM structures, could provide additional performance opportunities.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}