


Improved Optimization Algorithm in LSTM to Predict Crop Yield



Abstract
:1. Introduction
- Propose a new optimized IOF function to train the LSTM model to reduce the training and testing loss;
- LSTM uses the new optimization function to calculate the model error;
- The proposed IOFLSTM model was superior to most of the state-of-the-art LSTM models on the public crop yield and available production datasets;
- Evaluate the performance of the proposed optimizer IOF by comparing the proposed IOF with the standard Stohastic Gradient Descent (SGD), Momentum, AdaGrad, Root Mean Square prop, and Adam by training using the Root Mean Square (RMSE), Mean Square Error (MSE) functions. The results show that the proposed IOF prevents the model from overfitting by handling the bias-variance.
2. Materials and Methods
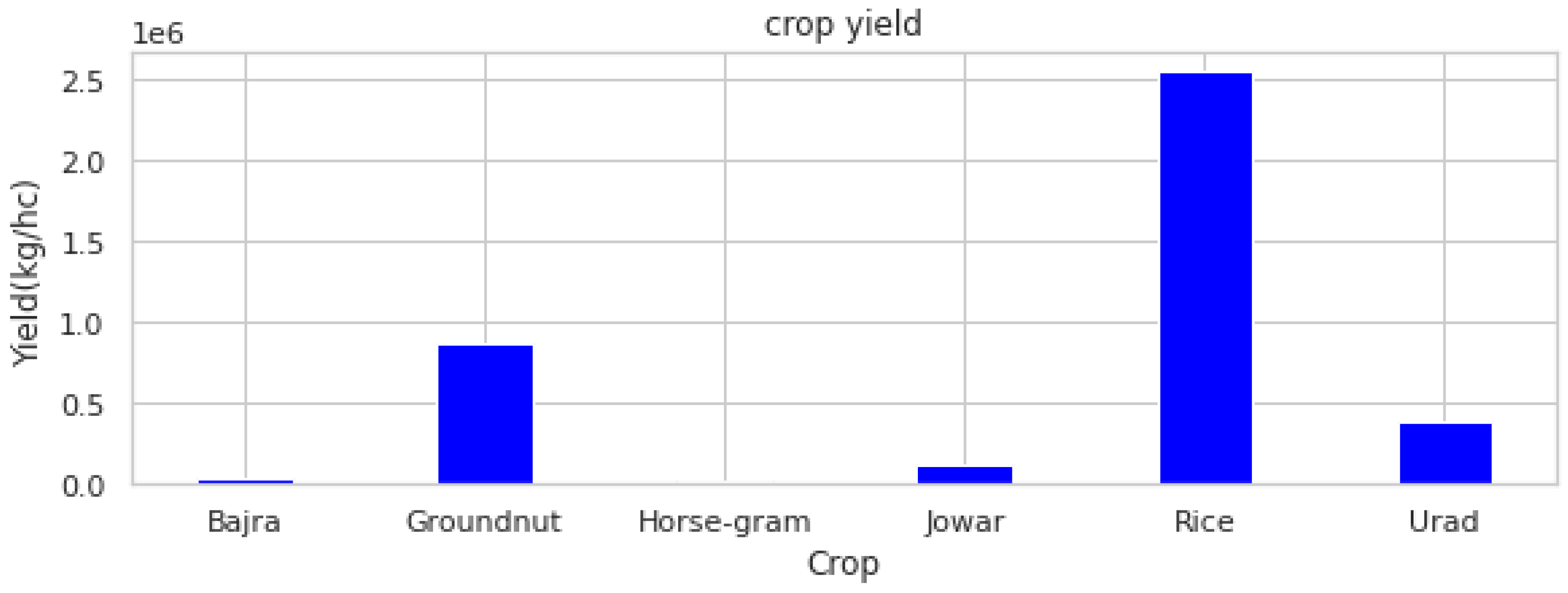
2.1. Dataset Description
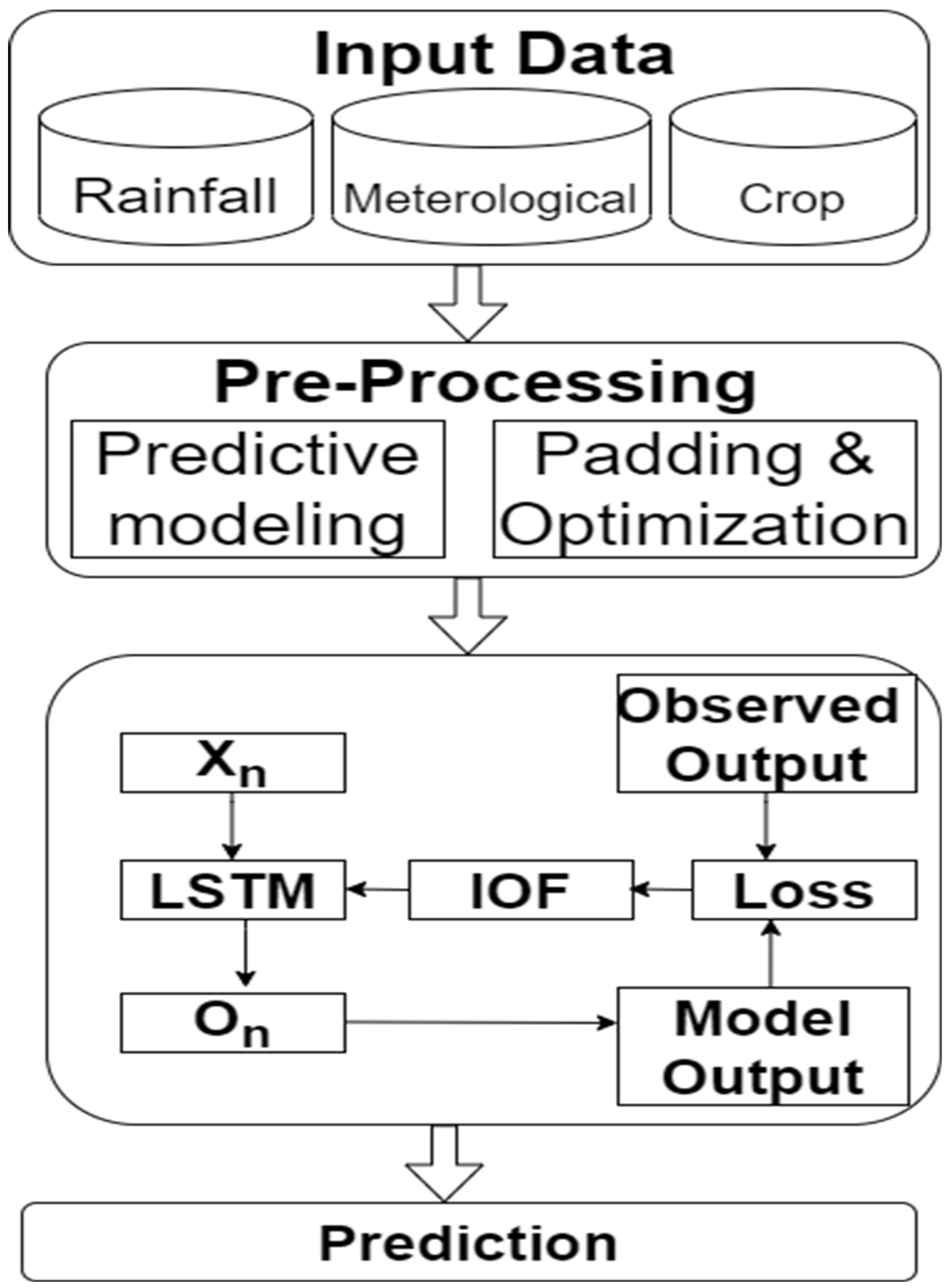
2.2. Predictive Modeling
2.3. Padding and Optimization
2.4. Existing Models with LSTM Model
2.4.1. Convolution Neural Network (CNN)
2.4.2. Recurrent Neural Network (RNN)
2.4.3. Gated Recurrent Unit (GRU)
2.4.4. Long Short-Term Memory (LSTM)
- It calculates the current memory (cgt), the weight matrix (wtCg), and the bias is the (bscg).
- The input gate manages the update of the current memory input data to the value of the memory cell, the weight matrix (wtig), and the bias (bsig) and the sigmoid function. The input gate is calculated as:
- The forget gate controls the update of the previous memory data to the value of the memory cell, the weight matrix (wtf), and the bias (bsfg) and is the sigmoid function. The forget gate is calculated as:
- lct−1 is the last LSTM cell value, and the current memory cell can be calculated as:
2.5. Proposed Approach
| Algorithm 1: IOF |
| α: step Size |
| η: Learning rate |
| β1, β2 ∈ [0,1]: Exponential Decay rate to the moment estimation |
| 1. while θt is not joined, repeat |
| 2. t < −t + 1 |
| 3. gt ← ▽θft(θt−1) |
| 4. mt ← log(β1mt−1+(1 – β1)gt) |
| 5. vt ← log(β2vt−1+(1 – β2)) |
| 6. mt ← mt/(1 – ) |
| 7. mt ← vt/(1 –) |
| 8. θt ← θt−1 – αmt/(+ ε) |
| end |
| return θt |
| Algorithm 2: Updated IOFLSTM |
| Dataset S = { }, 1 |
| Input: rainfall historical data, crop yield historical data |
| Output: reduced loss value and reduced processing time of the f(x) data |
| 1. Initialisation: , , , , , b |
| 2. |
| 3. |
| 4. |
| 5. |
| 6. Update weights and biases. |
2.6. Performance Metrics
3. Results
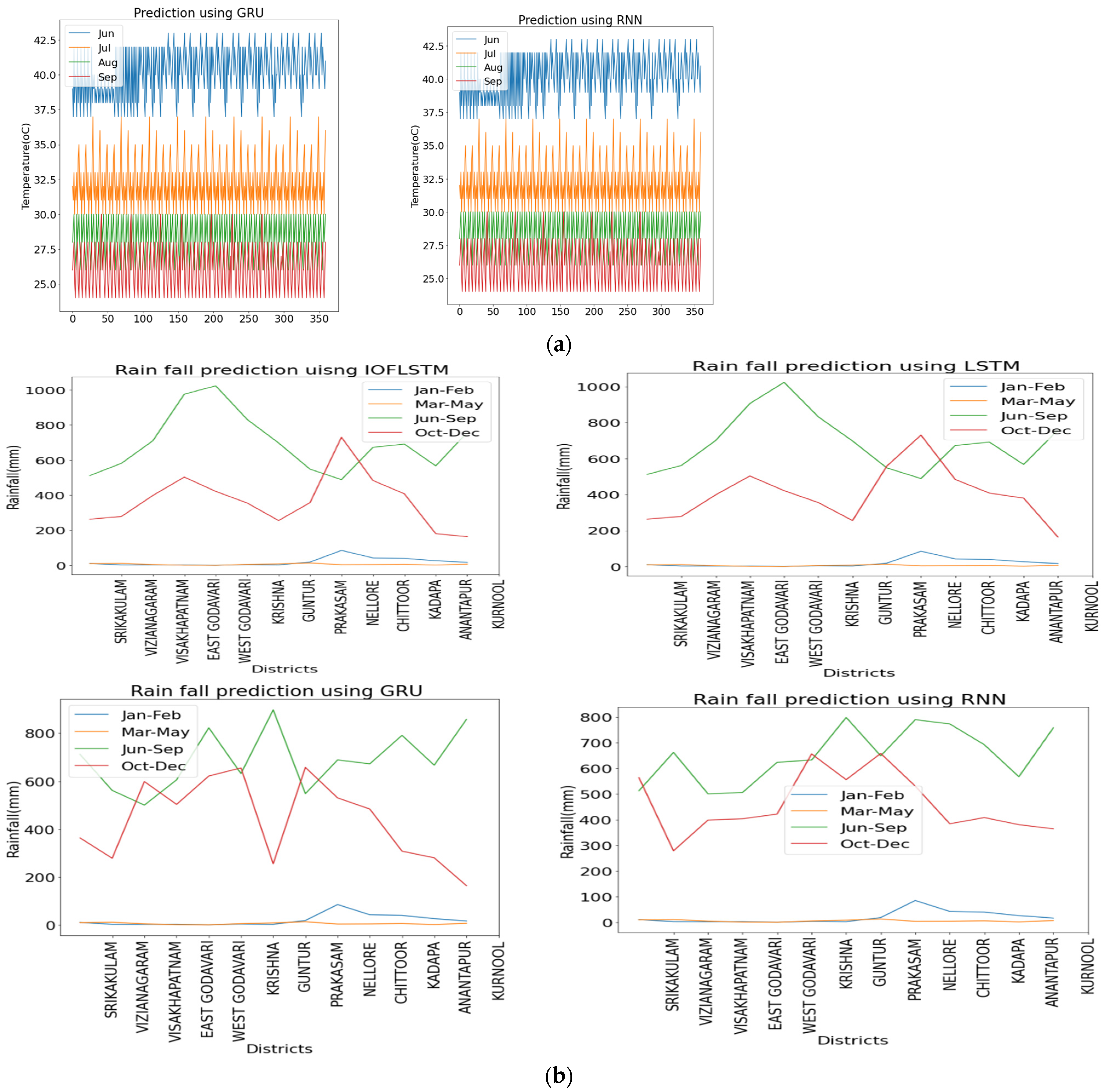
3.1. Prediction of the Temperature, Monsoon Rainfall, and Crop Yield
3.2. Performance Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, E.; Martre, P.; Zhao, Z.; Ewert, F.; Maiorano, A.; Rötter, R.P.; Kimball, B.; Ottman, M.; Wall, G.; White, J.; et al. The uncertainty of crop yield projections is reduced by improved temperature response functions. Nat. Plants 2017, 3, 17102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Annual Report 2020–21, Department of Agriculture, Cooperation and Farmers Welfare, Ministry of Agriculture and Farmers Welfare, Government of India. Available online: www.agricoop.nic.in (accessed on 23 May 2021).
- Sharifi, A. Yield prediction with machine learning algorithms and satellite images. J. Sci. Food Agric. 2020, 101, 891–896. [Google Scholar] [CrossRef] [PubMed]
- Obsie, E.Y.; Qu, H.; Drummond, F. Wild blueberry yield prediction using a combination of computer simulation and machine learning algorithms. Comput. Electron. Agric. 2020, 178, 105778. [Google Scholar] [CrossRef]
- Wu, R.; Yan, S.; Shan, Y.; Dang, Q.; Sun, G. Deep image: Scaling up image recognition. arXiv 2015, arXiv:1501.02876. [Google Scholar]
- Miotto, R.; Li, L.; Dudley, J.T. Deep learning to predict patient future diseases from the electronic health records. In European Conference on Information Retrieval; Springer: Cham, Switzerland, 2016; pp. 768–774. [Google Scholar]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop Yield Prediction Using Deep Neural Networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ehret, D.L.; Hill, B.D.; Helmer, T.; Edwards, D.R. Neural network modeling of greenhouse tomato yield, growth and water use from automated crop monitoring data. Comput. Electron. Agric. 2011, 79, 82–89. [Google Scholar] [CrossRef]
- Gholipoor, M.; Nadali, F. Fruit yield prediction of pepper using artificial neural network. Sci. Hortic. 2019, 250, 249–253. [Google Scholar] [CrossRef]
- Salazar, R.; López, I.; Rojano, A.; Schmidt, U.; Dannehl, D. Tomato yield prediction in a semi-closed greenhouse. In Proceedings of the XXIX International Horticultural Congress on Horticulture: Sustaining Lives, Livelihoods and Landscapes (IHC2014), Brisbane, Australia, 17 August 2014; pp. 263–270, 1107. [Google Scholar]
- Elavarasan, D.; Vincent, P.M.D. Crop Yield Prediction Using Deep Reinforcement Learning Model for Sustainable Agrarian Applications. IEEE Access 2020, 8, 86886–86901. [Google Scholar] [CrossRef]
- Sun, J.; Di, L.; Sun, Z.; Shen, Y.; Lai, Z. County-Level Soybean Yield Prediction Using Deep CNN-LSTM Model. Sensors 2019, 19, 4363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Lee, W.S.; Gan, H.; Peres, N.; Fraisse, C.; Zhang, Y.; He, Y. Strawberry Yield Prediction Based on a Deep Neural Network Using High-Resolution Aerial Orthoimages. Remote Sens. 2019, 11, 1584. [Google Scholar] [CrossRef]
- Russello, H.; Wenling, S. Convolutional Neural Networks for Crop Yield Prediction Using Satellite Images; IBM Center for Advanced Studies: Armonk, NY, USA, 2018. [Google Scholar]
- Kulkarni, S.; Mandal, S.N.; Sharma, G.S.; Mundada, M.R.; Meeradevi. Predictive Analysis to Improve Crop Yield using a Neural Network Model. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 74–79. [Google Scholar]
- Jiang, Z.; Liu, C.; Hendricks, N.P.; Ganapathysubramanian, B.; Hayes, D.J.; Sarkar, S. Predicting county level corn yields using deep long short term memory models. arXiv 2018, arXiv:1805.12044. [Google Scholar]
- Haider, S.A.; Naqvi, S.R.; Akram, T.; Umar, G.A.; Shahzad, A.; Sial, M.R.; Khaliq, S.; Kamran, M. LSTM Neural Network Based Forecasting Model for Wheat Production in Pakistan. Agronomy 2019, 9, 72. [Google Scholar] [CrossRef] [Green Version]
- Indian Metrological Department. Available online: https://www.imd.gov.in (accessed on 7 May 2021).
- Central Pollution Control Board. Available online: https://www.cpcb.gov.in (accessed on 7 May 2021).
- India Crop Production—State Wise. Available online: https://data.world/thatzprem/agriculture-india (accessed on 10 May 2021).
- Zhang, Z. Improved Adam Optimizer for Deep Neural Networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.W.; Nguyen, C.H.; Lee, K.; Heo, J. Regional-scale rice-yield estimation using stacked auto-encoder with climatic and MODIS data: A case study of South Korea. Int. J. Remote Sens. 2019, 40, 51–71. [Google Scholar] [CrossRef]
- You, J.; Li, X.; Low, M.; Lobell, D.; Ermon, S. Deep gaussian process for crop yield prediction based on remote sensing data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Kuwata, K.; Shibasaki, R. Estimating crop yields with deep learning and remotely sensed data. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 858–861. [Google Scholar]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop yield prediction with deep convolutional neural networks. Comput. Electron. Agric. 2019, 163, 104859. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, L.; Han, J.; Zha, Y.; Zhu, P. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crop. Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Alhnaity, B.; Pearson, S.; Leontidis, G.; Kollias, S. Using deep learning to predict plant growth and yield in greenhouse environments. In Proceedings of the International Symposium on Advanced Technologies and Management for Innovative Greenhouses: GreenSys2019, Angers, France, 16–20 June 2019; pp. 425–432, 1296. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; p. 28. [Google Scholar]
- Kar, S.; Das, N. Climate Change, Agricultural Production, and Poverty in India. In Poverty Reduction Policies and Practices in Developing Asia. Economic Studies in Inequality, Social Exclusion and Well-Being; Heshmati, A., Maasoumi, E., Wan, G., Eds.; Springer: Singapore, 2015. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Yang, G. Modified Convolutional Neural Network Based on Dropout and the Stochastic Gradient Descent Optimizer. Algorithms 2018, 11, 28. [Google Scholar] [CrossRef] [Green Version]
- Bello, I.; Zoph, B.; Vasudevan, V.; Le, Q.V. Neural optimizer search with reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 459–468. [Google Scholar]
- Elavarasan, D.; Durai Raj Vincent, P.M. Fuzzy deep learning-based crop yield prediction model for sustainable agronomical frameworks. Neural Comput. Appl. 2021, 33, 13205–13224. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, P.M.D.R. A reinforced random forest model for enhanced crop yield prediction by integrating agrarian parameters. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 10009–10022. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | Feature | Unit of Measurement |
|---|---|---|
| 1 | Min. temperature | °C |
| 2 | Max. temperature | °C |
| 3 | Avg. temperature | °C |
| 4 | Total rainfall | mm |
| 5 | Humidity | % |
| 6 | Solar radiance | w/m2 |
| 7 | Southwest monsoon rainfall | mm |
| 8 | Northeast monsoon rainfall | mm |
| 9 | Production | kg/hectare |
| 10 | Pest standing crop | Paddy, wheat, jowar, bajra … |
| 11 | District pest affected | Krishna, Guntur, … |
| 12 | Pest affected area | Hectares |
| 13 | Area treated | Hectares |
| 14 | Seasonal crop yield | Tones in millions |
| 15 | Total pulses | % |
| 16 | Total food grains | % |
| 17 | Total oilseeds | % |
| 18 | Total cropped area | Area in lakh hectares |
| 19 | Target sown area | Area in lakh hectares |
| 20 | District | Krishna, Guntur, … |
| 21 | Seasonal sown area | Area in lakh hectares |
| 22 | Seasonal area under production | Area in lakh hectares |
| 23 | Total yield | Tones in millions |
| 24 | Cropping season | Kharif or rabi |
| 25 | Crop | Paddy, wheat, jowar, bajra … |
| 26 | Total crop yield | kg/hectare |
| Year | CNN+ Adam | LSTM+ Adam | CNNLSTM+ Adam | GRU+ Adam | IOFLSTM | Observed |
|---|---|---|---|---|---|---|
| 2010 | 215.13 | 215.34 | 217.17 | 216.18 | 218.06 | 218.11 |
| 2011 | 246.44 | 245.56 | 244.33 | 245.43 | 244.44 | 244.49 |
| 2012 | 259.22 | 255.67 | 258.75 | 258.25 | 259.20 | 259.29 |
| 2013 | 257.18 | 258.67 | 256.86 | 256.16 | 256.56 | 257.12 |
| 2014 | 162.41 | 163.44 | 164.95 | 166.45 | 164.05 | 165.05 |
| 2015 | 250.54 | 252.76 | 252.16 | 251.56 | 252.07 | 252.02 |
| 2016 | 253.64 | 255.78 | 253.75 | 253.65 | 251.22 | 251.54 |
| 2017 | 272.15 | 274.54 | 275.05 | 274.15 | 274.67 | 275.11 |
| 2018 | 281.58 | 283.87 | 286.04 | 286.54 | 284.51 | 285.01 |
| 2019 | 282.59 | 283.22 | 284.16 | 284.56 | 285.31 | 285.21 |
| 2020 | 291.29 | 292.32 | 295.03 | 294.23 | 295.17 | 295.67 |
| Year | LSTM+ SGD | LSTM+ AdaGrad | LSTM+ RMSP | LSTM+ Adam | LSTM+ Momentum | IOFLSTM | Observed |
|---|---|---|---|---|---|---|---|
| 2010 | 214.45 | 216.54 | 212.85 | 215.34 | 214.05 | 218.06 | 218.11 |
| 2011 | 244.85 | 247.84 | 247.42 | 245.56 | 246.91 | 244.44 | 244.49 |
| 2012 | 256.29 | 252.89 | 254.26 | 255.67 | 257.29 | 259.20 | 259.29 |
| 2013 | 257.20 | 254.25 | 256.18 | 258.67 | 259.92 | 256.56 | 257.12 |
| 2014 | 166.84 | 167.68 | 164.29 | 163.44 | 165.08 | 164.05 | 165.05 |
| 2015 | 250.30 | 259.29 | 254.90 | 252.76 | 253.20 | 252.07 | 252.02 |
| 2016 | 252.20 | 257.52 | 250.04 | 255.78 | 250.23 | 251.22 | 251.54 |
| 2017 | 273.29 | 272.19 | 272.82 | 274.54 | 273.91 | 274.67 | 275.11 |
| 2018 | 282.19 | 289.39 | 281.02 | 283.87 | 284.61 | 284.51 | 285.01 |
| 2019 | 282.84 | 280.27 | 283.19 | 283.22 | 282.09 | 285.31 | 285.21 |
| 2020 | 290.73 | 297.85 | 291.94 | 292.32 | 293.75 | 295.17 | 295.67 |
| Crop | Metrics | RNN | LSTM | GRU | CNN | IOFLSTM |
|---|---|---|---|---|---|---|
| Paddy | MAE | 0.917 | 0.878 | 0.893 | 1.005 | 0.802 |
| RMSE | 1.243 | 1.211 | 1.221 | 1.868 | 1.145 | |
| r | 0.983 | 0.972 | 0.984 | 0.964 | 0.992 | |
| Red gram | MAE | 1.320 | 1.297 | 1.319 | 1.457 | 0.951 |
| RMSE | 3.036 | 3.039 | 3.044 | 3.545 | 2.879 | |
| r | 0.983 | 0.983 | 0.983 | 0.977 | 0.993 | |
| Sugarcane | MAE | 1.531 | 1.522 | 1.526 | 1.549 | 0.912 |
| RMSE | 2.035 | 2.045 | 2.032 | 2.065 | 1.948 | |
| r | 0.981 | 0.981 | 0.981 | 0.981 | 0.995 | |
| Cereals | MAE | 1.669 | 1.737 | 1.662 | 1.678 | 0.954 |
| RMSE | 2.248 | 2.332 | 2.242 | 2.273 | 2.045 | |
| r | 0.987 | 0.986 | 0.987 | 0.986 | 0.995 | |
| Pulses | MAE | 0.053 | 0.052 | 0.053 | 0.054 | 0.051 |
| RMSE | 0.074 | 0.074 | 0.074 | 0.077 | 0.069 | |
| r | 0.978 | 0.978 | 0.978 | 0.976 | 0.995 | |
| Groundnut | MAE | 1.198 | 1.157 | 1.899 | 1.937 | 0.936 |
| RMSE | 2.530 | 2.480 | 2.532 | 2.570 | 2.315 | |
| r | 0.990 | 0.990 | 0.990 | 0.989 | 0.997 | |
| Chilli | MAE | 1.228 | 1.211 | 1.226 | 1.341 | 0.994 |
| RMSE | 1.604 | 1.584 | 1.604 | 2.255 | 1.513 | |
| r | 0.983 | 0.983 | 0.983 | 0.967 | 0.993 |
| District | LSTM | GRU | IOFLSTM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | r | MAE | RMSE | r | MAE | RMSE | r | |
| Anantapur | 1.96 | 5.23 | 0.90 | 1.89 | 6.78 | 0.92 | 1.82 | 3.11 | 0.93 |
| Chittoor | 1.82 | 4.24 | 0.91 | 1.76 | 3.25 | 0.90 | 1.53 | 1.08 | 0.95 |
| East Godavari | 1.24 | 2.24 | 0.99 | 1.89 | 2.78 | 0.99 | 1.03 | 2.43 | 0.98 |
| Guntur | 1.46 | 4.25 | 0.99 | 1.31 | 3.67 | 0.90 | 1.27 | 2.22 | 0.97 |
| Kadapa | 1.56 | 1.46 | 0.92 | 1.43 | 1.01 | 0.91 | 1.31 | 2.31 | 0.96 |
| Krishna | 1.37 | 2.42 | 0.91 | 1.32 | 2.31 | 0.92 | 1.13 | 1.26 | 0.95 |
| Kurnool | 1.56 | 4.25 | 0.94 | 1.49 | 3.93 | 0.93 | 1.35 | 2.63 | 0.94 |
| Nellore | 1.82 | 5.61 | 0.91 | 1.76 | 5.32 | 0.91 | 1.49 | 2.42 | 0.94 |
| Prakasam | 1.49 | 5.63 | 0.90 | 1.63 | 4.63 | 0.91 | 1.42 | 2.45 | 0.96 |
| Srikakulam | 1.40 | 5.92 | 0.91 | 1.31 | 5.72 | 0.90 | 1.05 | 2.15 | 0.98 |
| Visakhapatnam | 1.37 | 5.21 | 0.92 | 1.43 | 4.96 | 0.91 | 1.18 | 2.73 | 0.91 |
| Vijayanagaram | 1.93 | 8.35 | 0.94 | 1.21 | 7.92 | 0.93 | 1.34 | 3.32 | 0.99 |
| West Godavari | 1.37 | 6.25 | 0.92 | 1.95 | 5.84 | 0.795 | 1.16 | 4.28 | 0.99 |
| Crop | Metrics | MLR | ANOVA | SVR | PLSR | IOFLSTM |
|---|---|---|---|---|---|---|
| Paddy | MAE | 0.907 | 0.956 | 0.914 | 1.005 | 0.802 |
| RMSE | 1.149 | 1.225 | 1.151 | 1.869 | 1.145 | |
| r | 0.989 | 0.971 | 0.987 | 0.964 | 0.992 | |
| MASE | 0.682 | 0.977 | 0.755 | 1.245 | 0.215 | |
| Red gram | MAE | 2.223 | 2.257 | 2.367 | 2.684 | 0.951 |
| RMSE | 2.890 | 3.134 | 2.896 | 3.321 | 2.879 | |
| r | 0.990 | 0.981 | 0.983 | 0.973 | 0.993 | |
| MASE | 0.894 | 1.153 | 0.986 | 1.198 | 0.455 | |
| Sugarcane | MAE | 1.528 | 1.548 | 1.530 | 1.569 | 0.912 |
| RMSE | 1.951 | 2.138 | 1.959 | 2.283 | 1.948 | |
| r | 0.991 | 0.985 | 0.989 | 0.971 | 0.995 | |
| MASE | 0.377 | 0.797 | 0.576 | 0.927 | 0.235 | |
| Cereals | MAE | 1.659 | 1.678 | 1.662 | 1.689 | 0.954 |
| RMSE | 2.248 | 2.332 | 2.242 | 2.373 | 2.045 | |
| r | 0.992 | 0.981 | 0.989 | 0.970 | 0.995 | |
| MASE | 0.424 | 0.736 | 0.515 | 0.836 | 0.314 | |
| Pulses | MAE | 0.054 | 0.072 | 0.056 | 0.074 | 0.051 |
| RMSE | 0.071 | 0.083 | 0.074 | 0.089 | 0.069 | |
| r | 0.993 | 0.981 | 0.990 | 0.974 | 0.995 | |
| MASE | 0.368 | 0.637 | 0.396 | 0.945 | 0.205 | |
| Groundnut | MAE | 1.841 | 1.863 | 1.845 | 1.945 | 0.936 |
| RMSE | 2.321 | 2.526 | 2.327 | 2.627 | 2.315 | |
| r | 0.994 | 0.984 | 0.990 | 0.979 | 0.997 | |
| MASE | 0.473 | 0.737 | 0.516 | 0.978 | 0.344 | |
| Chilli | MAE | 1.208 | 1.236 | 1.210 | 1.348 | 0.994 |
| RMSE | 1.527 | 1.670 | 1.531 | 1.738 | 1.513 | |
| r | 0.990 | 0.983 | 0.988 | 0.977 | 0.993 | |
| MASE | 0.357 | 0.583 | 0.389 | 0.847 | 0.248 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhimavarapu, U.; Battineni, G.; Chintalapudi, N. Improved Optimization Algorithm in LSTM to Predict Crop Yield. Computers 2023, 12, 10. https://doi.org/10.3390/computers12010010
Bhimavarapu U, Battineni G, Chintalapudi N. Improved Optimization Algorithm in LSTM to Predict Crop Yield. Computers. 2023; 12(1):10. https://doi.org/10.3390/computers12010010
Chicago/Turabian StyleBhimavarapu, Usharani, Gopi Battineni, and Nalini Chintalapudi. 2023. "Improved Optimization Algorithm in LSTM to Predict Crop Yield" Computers 12, no. 1: 10. https://doi.org/10.3390/computers12010010
APA StyleBhimavarapu, U., Battineni, G., & Chintalapudi, N. (2023). Improved Optimization Algorithm in LSTM to Predict Crop Yield. Computers, 12(1), 10. https://doi.org/10.3390/computers12010010