



Investigation of the Gender-Specific Discourse about Online Learning during COVID-19 on Twitter Using Sentiment Analysis, Subjectivity Analysis, and Toxicity Analysis

 ,
,
Abstract
:1. Introduction
1.1. Twitter: A Globally Popular Social Media Platform
1.2. Gender Diversity on Social Media Platforms
2. Literature Review
2.1. A Brief Review of Recent Works Related to Sentiment Analysis of Tweets about COVID-19
2.2. Review of Recent Works Related to Data Mining and Analysis of Tweets about Online Learning during COVID-19
3. Methodology
3.1. Data Description
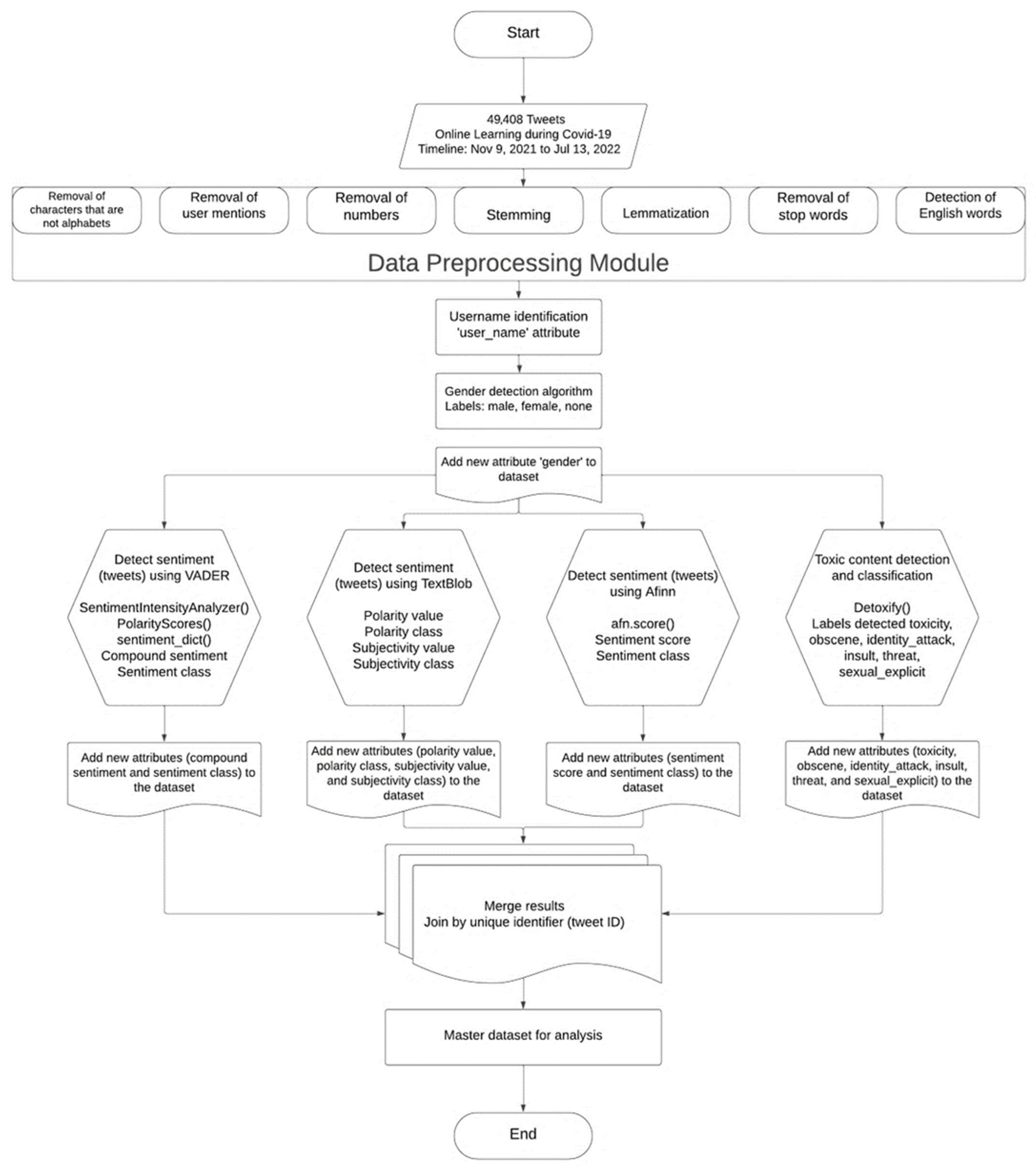
3.2. System Design and Development
- (a)
- Removal of characters that are not alphabets.
- (b)
- Removal of URLs
- (c)
- Removal of hashtags
- (d)
- Removal of user mentions
- (e)
- Detection of English words using tokenization.
- (f)
- Stemming.
- (g)
- Removal of stop words
- (h)
- Removal of numbers
| Algorithm 1: Data Preprocessing |
| Input: Dataset Output: New Attribute of Preprocessed Tweets File Path Read data as dataframe English words: nltk.download(‘words’) Stopwords: nltk.download(‘stopwords’) Initialize an empty list to store preprocessed text corpus[] for i from 0 to n do Obtain Text of the Tweet (‘text’ column) text = re.sub(‘[^a-zA-Z]’, whitespace, string) text = re.sub(r‘http\S+’, '', string) text = text.lower() text = text.split() ps = PorterStemmer() all_stopwords = english stopwords text = ps.stem(word) for word in text if not in all_stopwords text = whitespace.join(text) text = whitespace.join(re.sub(“(#[A-Za-z0-9]+)| (@[A-Za-z0-9]+)|([^0-9A-Za-z\t])| (\w+:\/\/\S+)", whitespace, string).split()) text = whitespace.join(if c.isdigit() else c for c in text) text = whitespace.join(w for w in wordpunct_tokenize(text) if w.lower() in words) corpus ← append(text) End of for loop New Attribute ← Preprocessed Text (from corpus) |
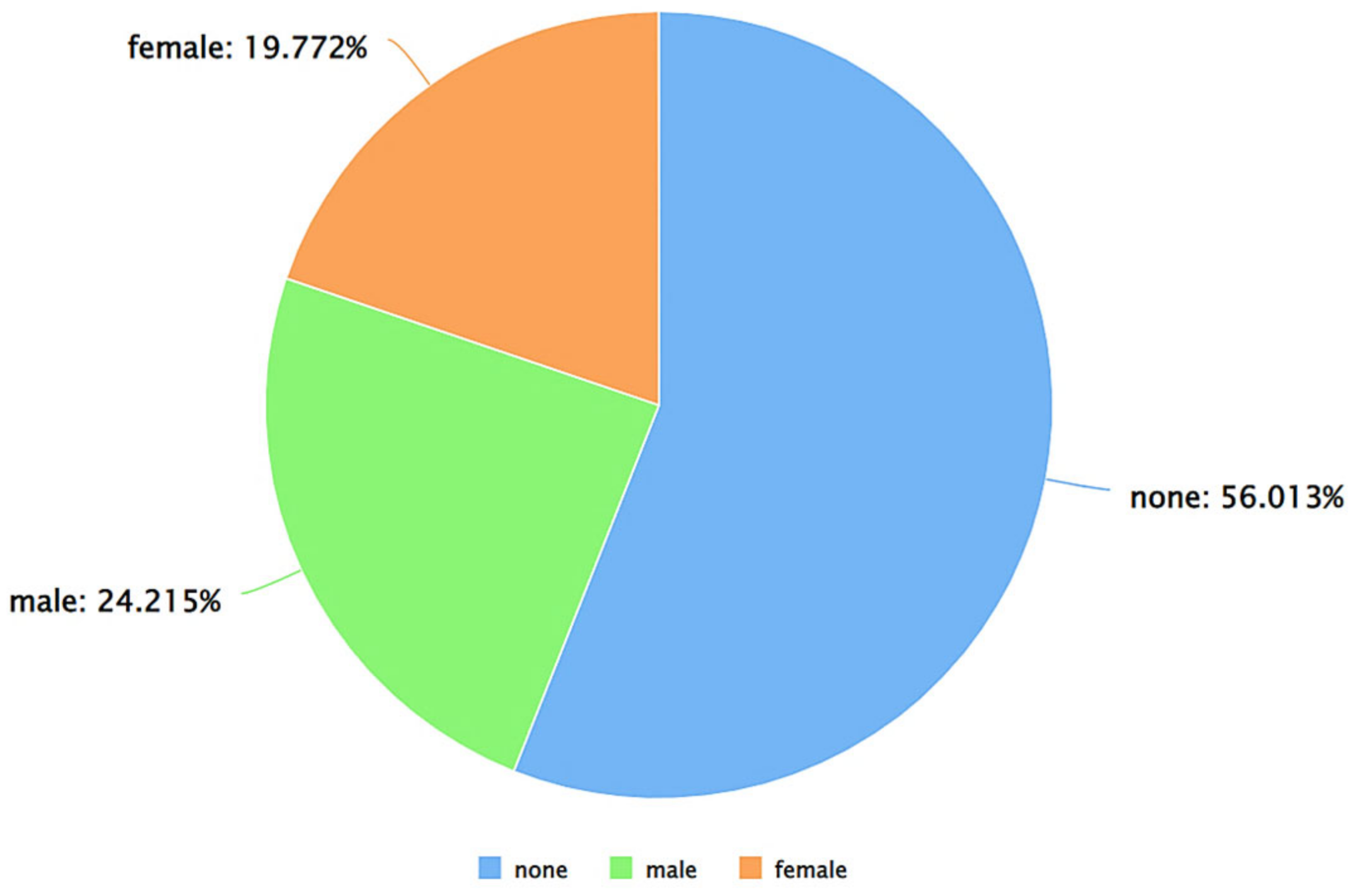
| Algorithm 2: Detect Gender from Twitter Usernames |
| Input: Dataset Output: File with the Gender of each Twitter User File Path Read data as dataframe procedure PredictGender (csv file) gp ← Initialize GenderPerformr output_file ← Initialize empty text file regex ← Initialize RegEx df ← Read csv file into Dataframe for each column in df do if column is user_name column then name_values ← Extract values of the column end if End of for loop for each name in name_values do if name is ”null”, ”nan”, empty, or None then write name and ”None” to Gender else if name does not match RegEx then write name to output file count number of words in name if words > 1 then splittedname ← split name by spaces name ← First element of splittedname end if str result ← Perform gender prediction using gp gender ← str result extract gender if gender is “M” then write ”Male” to Gender else if gender is ”F” then write ”Female” to Gender else if gender is empty or whitespace then write ”None” to Gender else if name in lowercase exists in set of english words then write ”None” to Gender else write ”Maybe” to Gender end if else write name and ”None” to Gender end if End of for loop End of procedure Write df with a new “Gender” attribute to a new .CSV file Export .CSV file |
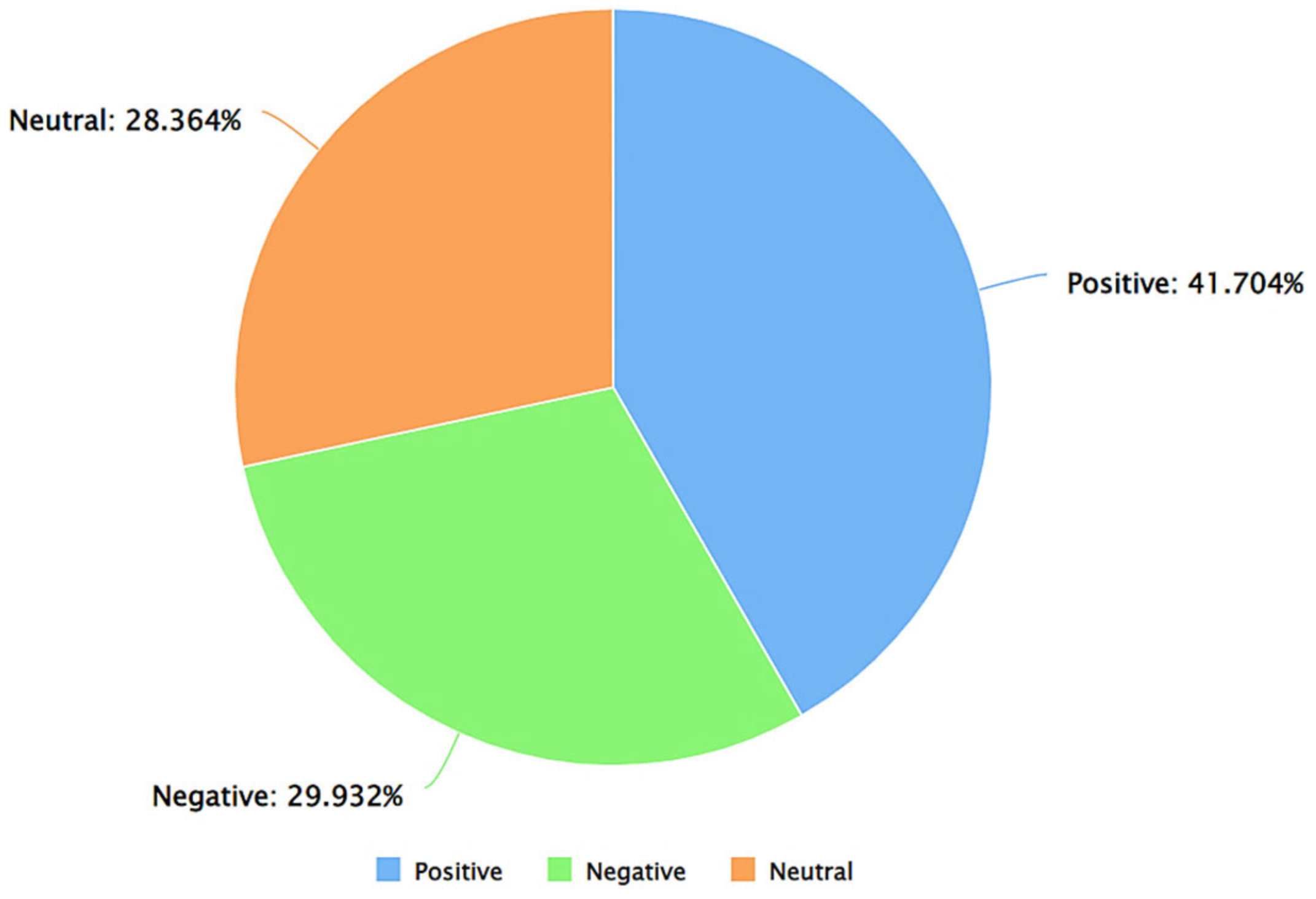
| Algorithm 3: Detect Sentiment of Tweets Using VADER |
| Input: Preprocessed Dataset (output from Algorithm 1) Output: File with Sentiment of each Tweet File Path Read data as dataframe Import VADER sid obj ← Initialize SentimentIntensityAnalyzer for each row in df[‘PreprocessedTweet’] do tweet_text ← df[‘PreprocessedTweet’][row] if tweet_text is null then sentiment score ← 0 else sentiment_dict = sid_obj.polarity_scores(df[‘PreprocessedTweet’][row]) compute sentiment_dict[‘compound’] sentiment score ← compound sentiment end if if sentiment score >= 0.05 then sentiment ← ‘positive’ else if sentiment score <= −0.05 then sentiment ← ‘negative’ else sentiment ← ‘neutral’ end if df [row] ← compound sentiment and sentiment score End of for loop Write df with new attributes – sentiment class and sentiment score to a new .CSV file Export .CSV file |
| Algorithm 4: Detect Sentiment of Tweets Using Afinn |
| Input: Preprocessed Dataset (output from Algorithm 1) Output: File with Sentiment of each Tweet File Path Read data as dataframe Import Afinn afn ← Instantiate Afinn for each row in df[‘PreprocessedTweet’] do tweet_text ← df[‘PreprocessedTweet’][row] if tweet_text is null then sentiment score ← 0 else apply afn.score() to df[‘PreprocessedTweet’][row] sentiment score ← afn.score(df[‘PreprocessedTweet’][row]) end if if sentiment score > 0 then sentiment ← ‘positive’ else if sentiment score < 0 then sentiment ← ‘negative’ else sentiment ← ‘neutral’ end if df [row] ← sentiment and sentiment score End of for loop Write df with new attributes – sentiment class and sentiment score to a new .CSV file Export .CSV file |
| Algorithm 5: Detect Polarity and Subjectivity of Tweets Using TextBlob |
| Input: Preprocessed Dataset (output from Algorithm 1) Output: File with metrics for polarity and subjectivity of each Tweet File Path Read data as dataframe Import TextBlob Initialize Lists for Blob, Polarity, Subjectivity, Polarity Class, and Subjectivity Class for row in df[‘PreprocessedTweet’] do convert item to TextBlob and append to Blob List End of for loop for each blob in Blob List do for each sentence in blob do calculate polarity and subjectivity append them to Polarity and Subjectivity Lists respectively End of for loop End of for loop for each value in Polarity List do if (p > 0): pclass.append(‘Positive’) else if (p < 0): pclass.append(‘Negative’) else: pclass.append(‘Neutral’) end if End of for loop for each value in Subjectivity List do if (s > 0.6): sclass.append(‘Highly Opinionated’) else if (s < 0.4): sclass.append(‘Least Opinionated’) else: sclass.append(‘Neutral’) end if End of for loop Write df with new attributes - polarity, polarity class, subjectivity, and subjectivity class to a new CSV file Export .CSV file |
| Algorithm 6: Perform Toxicity Analysis of the Tweets Using Detoxify |
| Input: Preprocessed Dataset (output from Algorithm 1) Output: File with metrics of toxicity for each Tweet File Path Read data as dataframe Import Detoxify Instantiate Detoxify predictor = Detoxify(‘multilingual’) Initialize Lists for toxicity, obscene, identity attack, insult, threat, and sexually explicit for each row in df[‘PreprocessedTweet’] do apply predictor.predict() to df[‘PreprocessedTweet’][row] data ← predictor.predict (df[‘PreprocessedTweet’][row]) toxic_value = data[‘toxicity’] obscene_value = data['obscene’] identity_attack_value = data[‘identity_attack’] insult_value = data[‘insult’] threat_value = data[‘threat’] sexual_explicit_value = data[‘sexual_explicit’] append ← lists for toxicity, obscene, identity attack, insult, threat, sexually explicit score [] ← toxicity, obscene, identity attack, insult, threat, and sexually explicit max_value = maximum value in Score[] label = class for max_value append values to the corpus End of for loop data = [] for each i from 0 to n do: create an empty list tmp append tweet id, text, score[],max_value, and label to tmp append tmp to data End of for loop Write new attributes - toxicity, obscene, identity attack, insult, threat, and sexually explicit, and label to a new CSV file Export .CSV file |
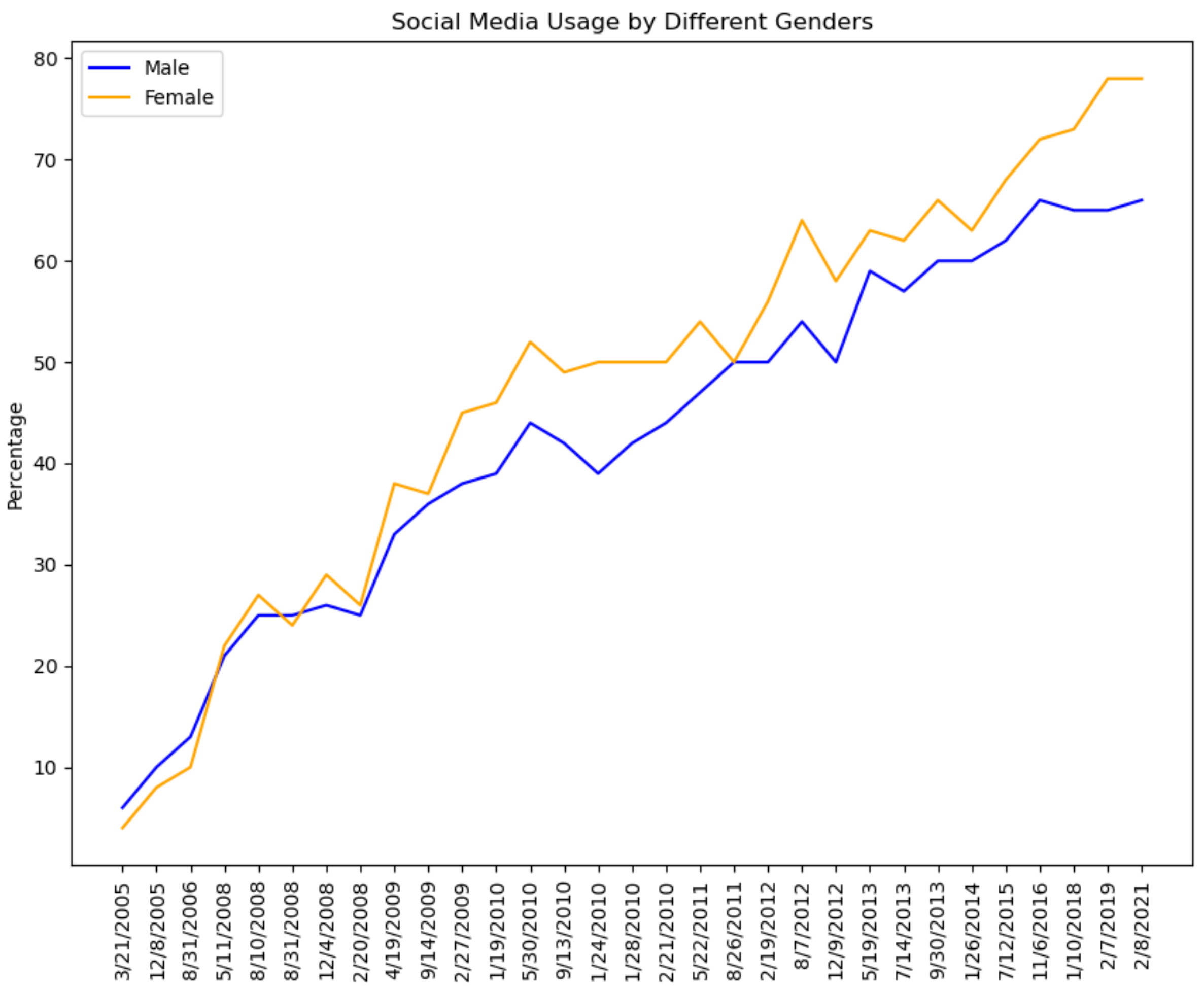
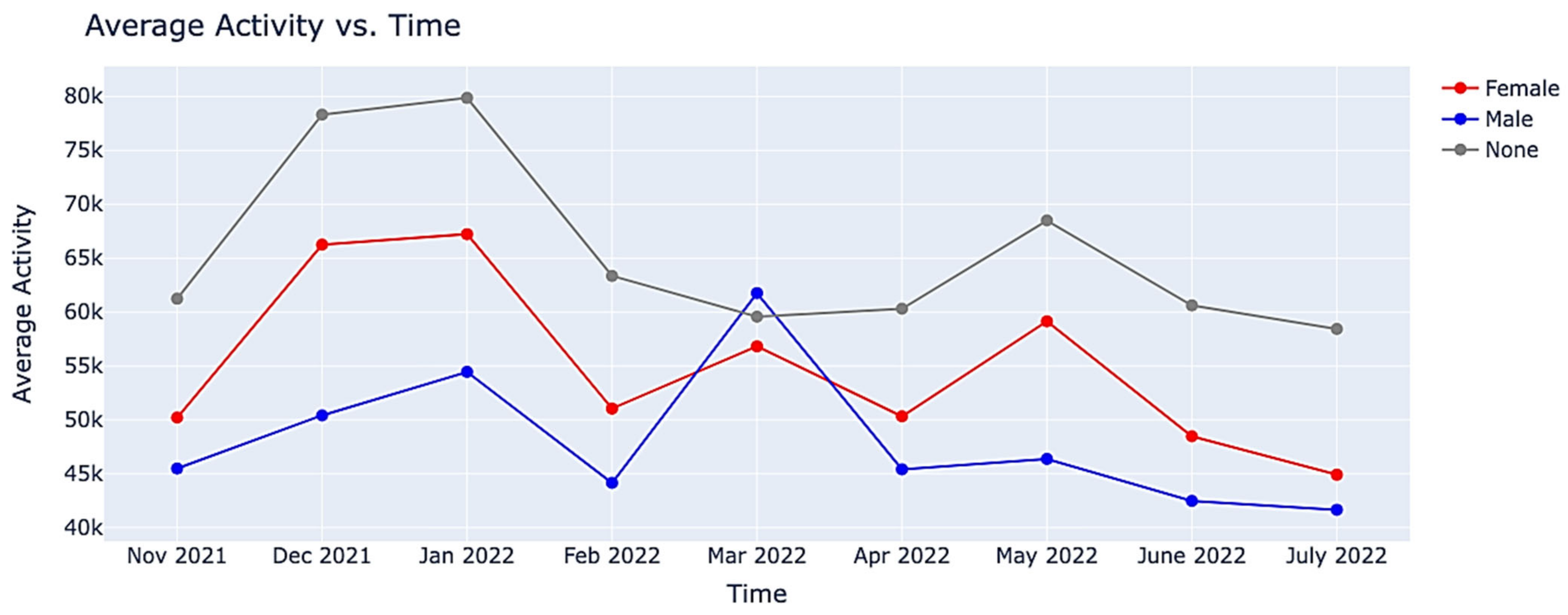
| Algorithm 7: Compute the Average Activity of different Genders on a monthly basis |
| Input: Preprocessed Dataset (output from Algorithm 1) Output: Average Activity per gender per month File Path Read data as dataframe Initialize lists for distinct males, distinct females, and distinct none for each row in df[‘created_at’] do extract month and year append data End of for loop Create new attribute month_year to hold month and year for each month in df[‘month_year’] do d_males = number of distinct males based on df[‘user_id’] and df[‘gender’] d_females = number of distinct females based on df[‘user_id’] and df[‘gender’] d_none = calculate number of distinct none based on df[‘user_id’] and df[‘gender’] for each male in d_males activity = author Tweets count + author favorites count males_total_activity = males_total_activity + activity End of for loop males_avg_activity = males_total_activity/d_males for each female in d_females activity = author Tweets count + author favorites count females_total_activity = females_total_activity + activity End of for loop females_avg_activity = females_total_activity/d_females for each none in d_none activity = author Tweets count + author favorites count none_total_activity = none_total_activity + activity End of for loop none_avg_activity = none_total_activity/d_none End of for loop |
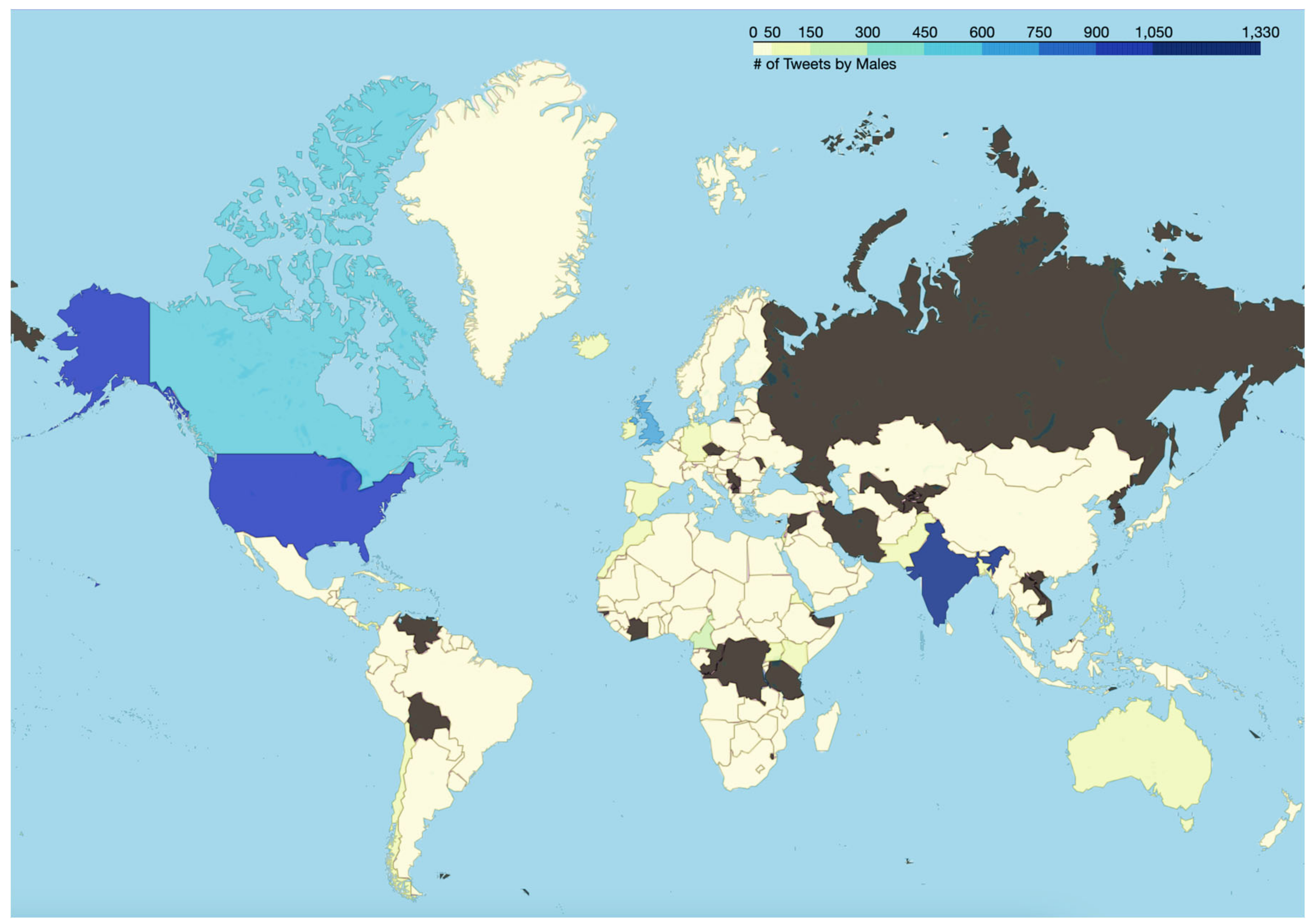
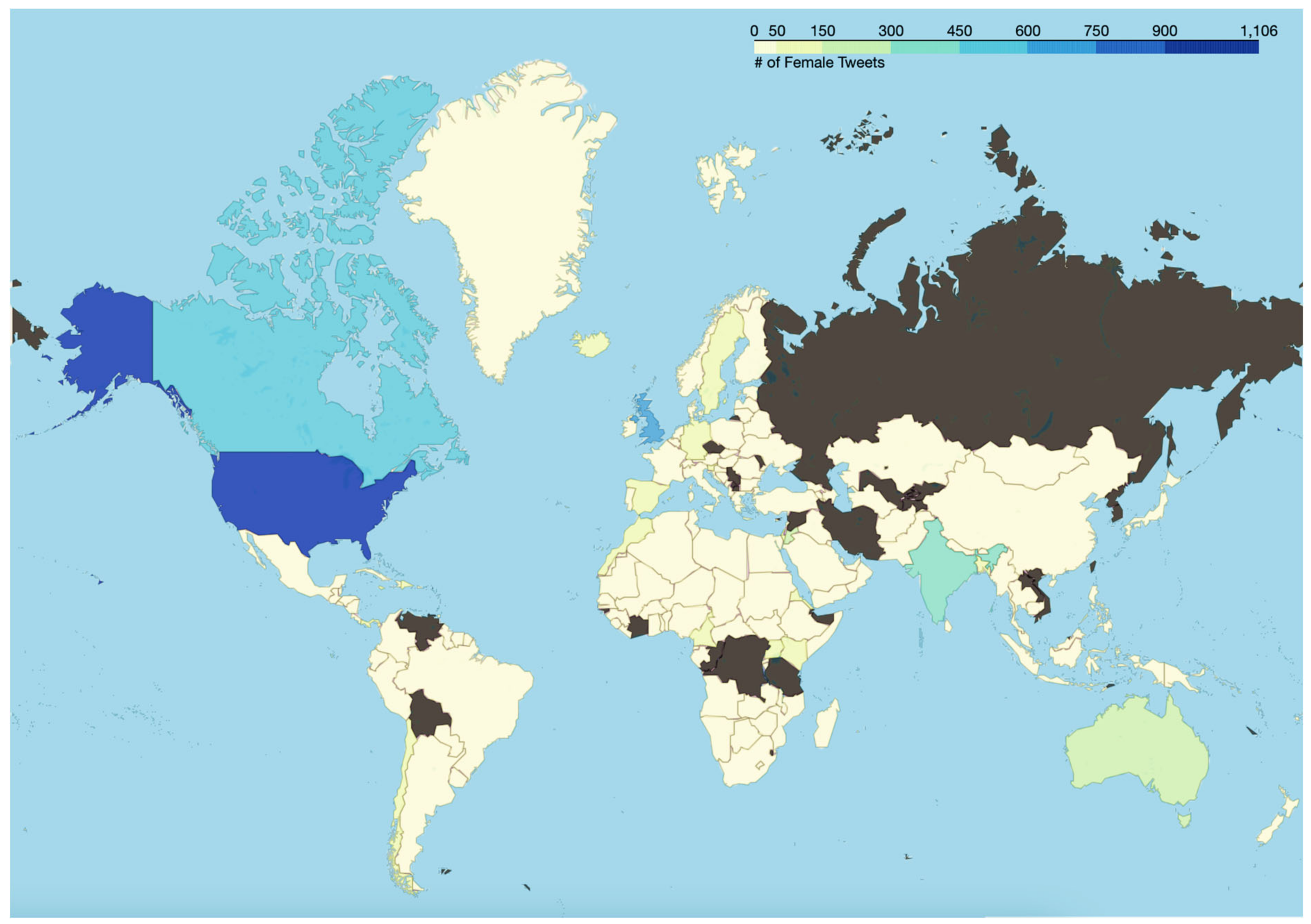
| Algorithm 8: Detect Locations of Twitter Users, Visualize Gender-Specific Tweeting Patterns |
| Input: Dataset Output: File with locations (country) of each user, visualization of gender-specific tweeting patterns File Path Read data as dataframe Import PyCountry Import Folium Import Geodata data package for each row in df[‘user_location’] do location_values = columnSeriesObj.values End of for loop For each location in location_values if location is “null”, “nan”, empty, or None then country = none else if spaces = location.count(‘ ’) if (spaces > 0): for word in location.split(): country = pycountry.countries.search_fuzzy(word) defaultcountry = country.name if (spaces = 0) country = pycountry.countries.search_fuzzy(location) end if append values to corpus End of for loop write new attribute “country” to the dataset df pivotdata ← “user location” as the index and “Gender” as attributes pivotdata [attributes] ← “Female”, “Male”, and “None” pivot data [total] ← add “Male”, “Female”, and “None” columns Instantiate Folium map m define threshold scale ← list of threshold values for colored bins choropleth layer ← custom color scale, ranges, and opacity pivotdata [key] ← mapping legend name ← pivotdata [attributes] GenerateMap() |
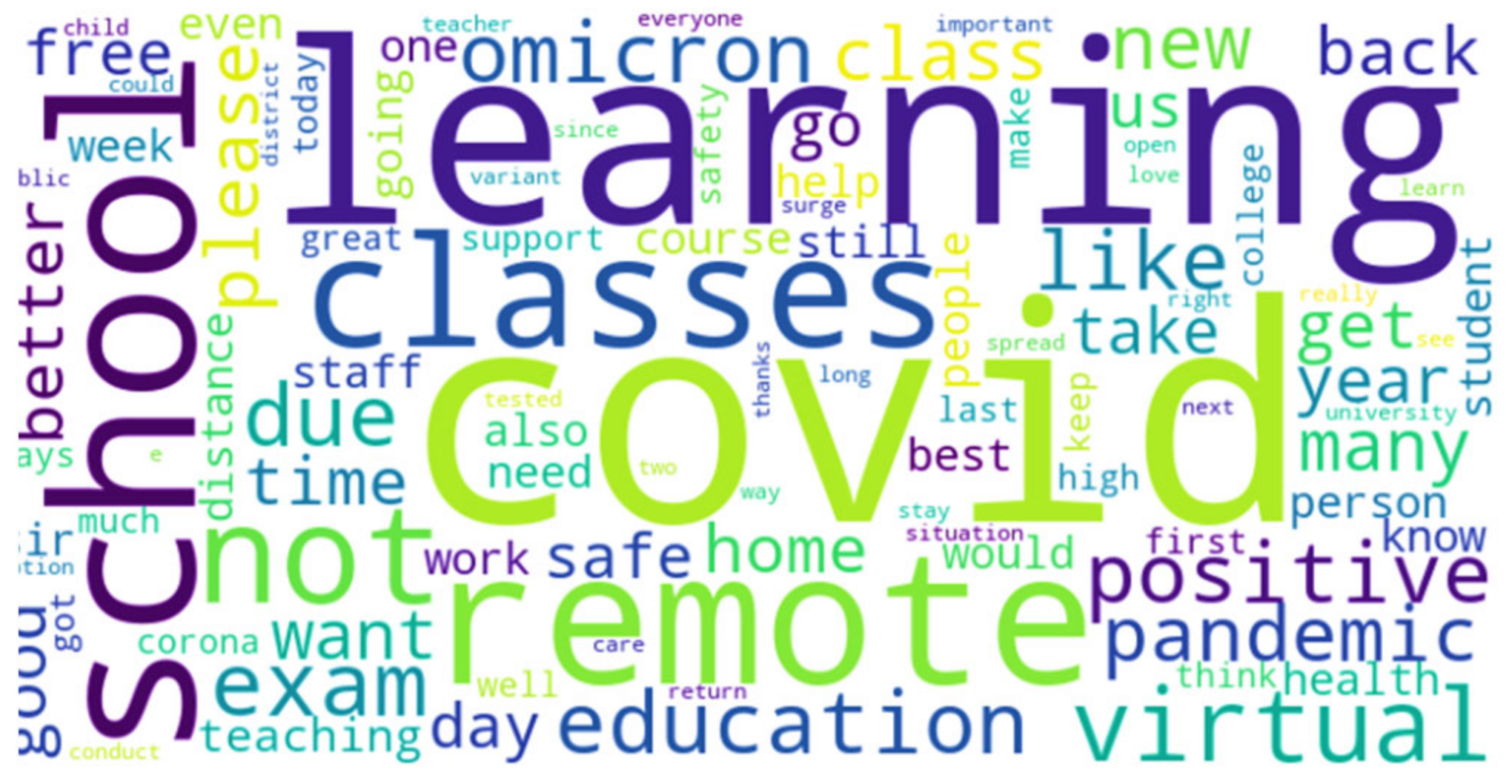
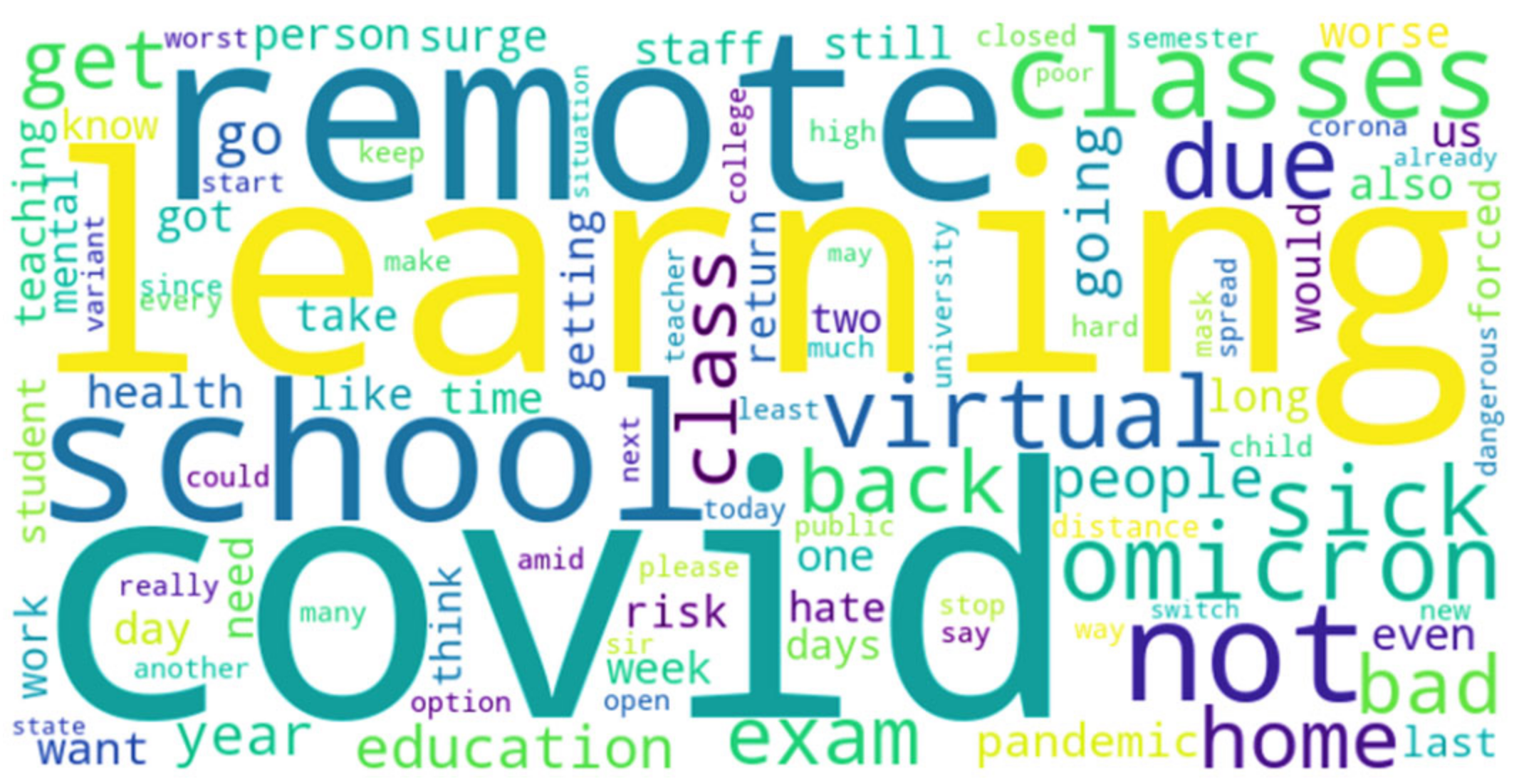
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A












References
- Fauci, A.S.; Lane, H.C.; Redfield, R.R. COVID-19—Navigating the Uncharted. N. Engl. J. Med. 2020, 382, 1268–1269. [Google Scholar] [CrossRef] [PubMed]
- Cucinotta, D.; Vanelli, M. WHO Declares COVID-19 a Pandemic. Acta Bio Medica Atenei Parm. 2020, 91, 157. [Google Scholar] [CrossRef]
- WHO Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 26 September 2023).
- Allen, D.W. COVID-19 Lockdown Cost/Benefits: A Critical Assessment of the Literature. Int. J. Econ. Bus. 2022, 29, 1–32. [Google Scholar] [CrossRef]
- Kumar, V.; Sharma, D. E-Learning Theories, Components, and Cloud Computing-Based Learning Platforms. Int. J. Web-based Learn. Teach. Technol. 2021, 16, 1–16. [Google Scholar] [CrossRef]
- Muñoz-Najar, A.; Gilberto, A.; Hasan, A.; Cobo, C.; Azevedo, J.P.; Akmal, M. Remote Learning during COVID-19: Lessons from Today, Principles for Tomorrow; World Bank: Washington, DC, USA, 2021. [Google Scholar]
- Simamora, R.M.; De Fretes, D.; Purba, E.D.; Pasaribu, D. Practices, Challenges, and Prospects of Online Learning during COVID-19 Pandemic in Higher Education: Lecturer Perspectives. Stud. Learn. Teach. 2020, 1, 185–208. [Google Scholar] [CrossRef]
- DeNardis, L. The Internet in Everything; Yale University Press: New Haven, CT, USA, 2020; ISBN 9780300233070. [Google Scholar]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Terracina, G.; Ursino, D.; Virgili, L. A Framework for Investigating the Dynamics of User and Community Sentiments in a Social Platform. Data Knowl. Eng. 2023, 146, 102183. [Google Scholar] [CrossRef]
- Belle Wong, J.D. Top Social Media Statistics and Trends of 2023. Available online: https://www.forbes.com/advisor/business/social-media-statistics/ (accessed on 26 September 2023).
- Morgan-Lopez, A.A.; Kim, A.E.; Chew, R.F.; Ruddle, P. Predicting Age Groups of Twitter Users Based on Language and Metadata Features. PLoS ONE 2017, 12, e0183537. [Google Scholar] [CrossRef]
- #InfiniteDial. The Infinite Dial 2022. Available online: http://www.edisonresearch.com/wp-content/uploads/2022/03/Infinite-Dial-2022-Webinar-revised.pdf (accessed on 26 September 2023).
- Twitter ‘Lurkers’ Follow–and Are Followed by–Fewer Accounts. Available online: https://www.pewresearch.org/short-reads/2022/03/16/5-facts-about-Twitter-lurkers/ft_2022-03-16_Twitterlurkers_03/ (accessed on 26 September 2023).
- Lin, Y. Number of Twitter Users in the US [Aug 2023 Update]. Available online: https://www.oberlo.com/statistics/number-of-Twitter-users-in-the-us (accessed on 26 September 2023).
- Twitter: Distribution of Global Audiences 2021, by Age Group. Available online: https://www.statista.com/statistics/283119/age-distribution-of-global-Twitter-users/ (accessed on 26 September 2023).
- Feger, A. TikTok Screen Time Will Approach 60 Minutes a Day for US Adult Users. Available online: https://www.insiderintelligence.com/content/tiktok-screen-time-will-approach-60-minutes-day-us-adult-users/ (accessed on 26 September 2023).
- Demographic Profiles and Party of Regular Social Media News Users in the U.S. Available online: https://www.pewresearch.org/journalism/2021/01/12/news-use-across-social-media-platforms-in-2020/pj_2021-01-12_news-social-media_0-04/ (accessed on 26 September 2023).
- Countries with Most X/Twitter Users 2023. Available online: https://www.statista.com/statistics/242606/number-of-active-Twitter-users-in-selected-countries/ (accessed on 26 September 2023).
- Kemp, S. Twitter Users, Stats, Data, Trends, and More—DataReportal–Global Digital Insights. Available online: https://datareportal.com/essential-Twitter-stats (accessed on 26 September 2023).
- Singh, C. 60+ Twitter Statistics to Skyrocket Your Branding in 2023. Available online: https://www.socialpilot.co/blog/Twitter-statistics (accessed on 26 September 2023).
- Albrecht, S.; Lutz, B.; Neumann, D. The Behavior of Blockchain Ventures on Twitter as a Determinant for Funding Success. Electron. Mark. 2020, 30, 241–257. [Google Scholar] [CrossRef]
- Kraaijeveld, O.; De Smedt, J. The Predictive Power of Public Twitter Sentiment for Forecasting Cryptocurrency Prices. J. Int. Financ. Mark. Inst. Money 2020, 65, 101188. [Google Scholar] [CrossRef]
- Siapera, E.; Hunt, G.; Lynn, T. #GazaUnderAttack: Twitter, Palestine and Diffused War. Inf. Commun. Soc. 2015, 18, 1297–1319. [Google Scholar] [CrossRef]
- Chen, E.; Ferrara, E. Tweets in Time of Conflict: A Public Dataset Tracking the Twitter Discourse on the War between Ukraine and Russia. In Proceedings of the International AAAI Conference on Web and Social Media, Limassol, Cyprus, 5–8 June 2023; Volume 17, pp. 1006–1013. [Google Scholar] [CrossRef]
- Madichetty, S.; Muthukumarasamy, S.; Jayadev, P. Multi-Modal Classification of Twitter Data during Disasters for Humanitarian Response. J. Ambient Intell. Humaniz. Comput. 2021, 12, 10223–10237. [Google Scholar] [CrossRef]
- Dimitrova, D.; Heidenreich, T.; Georgiev, T.A. The Relationship between Humanitarian NGO Communication and User Engagement on Twitter. New Media Soc. 2022, 146144482210889. [Google Scholar] [CrossRef]
- Weller, K.; Bruns, A.; Burgess, J.; Mahrt, M.; Twitter, C.P.T. Twitter and Society; 447p. Available online: https://journals.uio.no/TJMI/article/download/825/746/3768 (accessed on 26 September 2023).
- Li, M.; Turki, N.; Izaguirre, C.R.; DeMahy, C.; Thibodeaux, B.L.; Gage, T. Twitter as a Tool for Social Movement: An Analysis of Feminist Activism on Social Media Communities. J. Community Psychol. 2021, 49, 854–868. [Google Scholar] [CrossRef]
- Edinger, A.; Valdez, D.; Walsh-Buhi, E.; Trueblood, J.S.; Lorenzo-Luaces, L.; Rutter, L.A.; Bollen, J. Misinformation and Public Health Messaging in the Early Stages of the Mpox Outbreak: Mapping the Twitter Narrative with Deep Learning. J. Med. Internet Res. 2023, 25, e43841. [Google Scholar] [CrossRef] [PubMed]
- Bonifazi, G.; Corradini, E.; Ursino, D.; Virgili, L. New Approaches to Extract Information from Posts on COVID-19 Published on Reddit. Int. J. Inf. Technol. Decis. Mak. 2022, 21, 1385–1431. [Google Scholar] [CrossRef]
- Hargittai, E.; Walejko, G. THE PARTICIPATION DIVIDE: Content Creation and Sharing in the Digital Age1. Inf. Commun. Soc. 2008, 11, 239–256. [Google Scholar] [CrossRef]
- Trevor, M.C. Political Socialization, Party Identification, and the Gender Gap. Public Opin. Q. 1999, 63, 62–89. [Google Scholar] [CrossRef]
- Verba, S.; Schlozman, K.L.; Brady, H.E. Voice and Equality: Civic Voluntarism in American Politics; Harvard University Press: London, UK, 1995; ISBN 9780674942936. [Google Scholar]
- Bode, L. Closing the Gap: Gender Parity in Political Engagement on Social Media. Inf. Commun. Soc. 2017, 20, 587–603. [Google Scholar] [CrossRef]
- Lutz, C.; Hoffmann, C.P.; Meckel, M. Beyond Just Politics: A Systematic Literature Review of Online Participation. First Monday 2014, 19. [Google Scholar] [CrossRef]
- Strandberg, K. A Social Media Revolution or Just a Case of History Repeating Itself? The Use of Social Media in the 2011 Finnish Parliamentary Elections. New Media Soc. 2013, 15, 1329–1347. [Google Scholar] [CrossRef]
- Vochocová, L.; Štětka, V.; Mazák, J. Good Girls Don’t Comment on Politics? Gendered Character of Online Political Participation in the Czech Republic. Inf. Commun. Soc. 2016, 19, 1321–1339. [Google Scholar] [CrossRef]
- Gil de Zúñiga, H.; Veenstra, A.; Vraga, E.; Shah, D. Digital Democracy: Reimagining Pathways to Political Participation. J. Inf. Technol. Politics 2010, 7, 36–51. [Google Scholar] [CrossRef]
- Vissers, S.; Stolle, D. The Internet and New Modes of Political Participation: Online versus Offline Participation. Inf. Commun. Soc. 2014, 17, 937–955. [Google Scholar] [CrossRef]
- Vesnic-Alujevic, L. Political Participation and Web 2.0 in Europe: A Case Study of Facebook. Public Relat. Rev. 2012, 38, 466–470. [Google Scholar] [CrossRef]
- Krasnova, H.; Veltri, N.F.; Eling, N.; Buxmann, P. Why Men and Women Continue to Use Social Networking Sites: The Role of Gender Differences. J. Strat. Inf. Syst. 2017, 26, 261–284. [Google Scholar] [CrossRef]
- Social Media Fact Sheet. Available online: https://www.pewresearch.org/internet/fact-sheet/social-media/?tabId=tab-45b45364-d5e4-4f53-bf01-b77106560d4c (accessed on 26 September 2023).
- Global WhatsApp User Distribution by Gender 2023. Available online: https://www.statista.com/statistics/1305750/distribution-whatsapp-users-by-gender/ (accessed on 26 September 2023).
- Sina Weibo: User Gender Distribution 2022. Available online: https://www.statista.com/statistics/1287809/sina-weibo-user-gender-distibution-worldwide/ (accessed on 26 September 2023).
- QQ: User Gender Distribution 2022. Available online: https://www.statista.com/statistics/1287794/qq-user-gender-distibution-worldwide/ (accessed on 26 September 2023).
- Samanta, O. Telegram Revenue & User Statistics 2023. Available online: https://prioridata.com/data/telegram-statistics/ (accessed on 26 September 2023).
- Shewale, R. 36 Quora Statistics: All-Time Stats & Data (2023). Available online: https://www.demandsage.com/quora-statistics/ (accessed on 26 September 2023).
- Gitnux the Most Surprising Tumblr Statistics and Trends in 2023. Available online: https://blog.gitnux.com/tumblr-statistics/ (accessed on 26 September 2023).
- Social Media User Diversity Statistics. Available online: https://blog.hootsuite.com/wp-content/uploads/2023/03/Twitter-stats-4.jpg (accessed on 26 September 2023).
- WeChat: User Gender Distribution 2022. Available online: https://www.statista.com/statistics/1287786/wechat-user-gender-distibution-worldwide/ (accessed on 26 September 2023).
- Global Snapchat User Distribution by Gender 2023. Available online: https://www.statista.com/statistics/326460/snapchat-global-gender-group/ (accessed on 26 September 2023).
- Villavicencio, C.; Macrohon, J.J.; Inbaraj, X.A.; Jeng, J.-H.; Hsieh, J.-G. Twitter Sentiment Analysis towards COVID-19 Vaccines in the Philippines Using Naïve Bayes. Information 2021, 12, 204. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef]
- Marcec, R.; Likic, R. Using Twitter for Sentiment Analysis towards AstraZeneca/Oxford, Pfizer/BioNTech and Moderna COVID-19 Vaccines. Postgrad. Med. J. 2022, 98, 544–550. [Google Scholar] [CrossRef]
- Machuca, C.R.; Gallardo, C.; Toasa, R.M. Twitter Sentiment Analysis on Coronavirus: Machine Learning Approach. J. Phys. Conf. Ser. 2021, 1828, 012104. [Google Scholar] [CrossRef]
- Kruspe, A.; Häberle, M.; Kuhn, I.; Zhu, X.X. Cross-Language Sentiment Analysis of European Twitter Messages Duringthe COVID-19 Pandemic. arXiv 2020, arXiv:2008.12172v1. [Google Scholar]
- Vijay, T.; Chawla, A.; Dhanka, B.; Karmakar, P. Sentiment Analysis on COVID-19 Twitter Data. In Proceedings of the 2020 5th IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE), Jaipur, India, 1–3 December 2020; IEEE: New York, NY, USA, 2020. [Google Scholar]
- Shofiya, C.; Abidi, S. Sentiment Analysis on COVID-19-Related Social Distancing in Canada Using Twitter Data. Int. J. Environ. Res. Public Health 2021, 18, 5993. [Google Scholar] [CrossRef] [PubMed]
- Sontayasara, T.; Jariyapongpaiboon, S.; Promjun, A.; Seelpipat, N.; Saengtabtim, K.; Tang, J.; Leelawat, N. Twitter Sentiment Analysis of Bangkok Tourism during COVID-19 Pandemic Using Support Vector Machine Algorithm. J. Disaster Res. 2021, 16, 24–30. [Google Scholar] [CrossRef]
- Nemes, L.; Kiss, A. Social Media Sentiment Analysis Based on COVID-19. J. Inf. Telecommun. 2021, 5, 1–15. [Google Scholar] [CrossRef]
- Okango, E.; Mwambi, H. Dictionary Based Global Twitter Sentiment Analysis of Coronavirus (COVID-19) Effects and Response. Ann. Data Sci. 2022, 9, 175–186. [Google Scholar] [CrossRef]
- Singh, C.; Imam, T.; Wibowo, S.; Grandhi, S. A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews. Appl. Sci. 2022, 12, 3709. [Google Scholar] [CrossRef]
- Kaur, H.; Ahsaan, S.U.; Alankar, B.; Chang, V. A Proposed Sentiment Analysis Deep Learning Algorithm for Analyzing COVID-19 Tweets. Inf. Syst. Front. 2021, 23, 1417–1429. [Google Scholar] [CrossRef] [PubMed]
- Vernikou, S.; Lyras, A.; Kanavos, A. Multiclass Sentiment Analysis on COVID-19-Related Tweets Using Deep Learning Models. Neural Comput. Appl. 2022, 34, 19615–19627. [Google Scholar] [CrossRef] [PubMed]
- Sharma, S.; Sharma, A. Twitter Sentiment Analysis during Unlock Period of COVID-19. In Proceedings of the 2020 Sixth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 6–8 November 2020; IEEE: New York, NY, USA, 2020; pp. 221–224. [Google Scholar]
- Sanders, A.C.; White, R.C.; Severson, L.S.; Ma, R.; McQueen, R.; Alcântara Paulo, H.C.; Zhang, Y.; Erickson, J.S.; Bennett, K.P. Unmasking the Conversation on Masks: Natural Language Processing for Topical Sentiment Analysis of COVID-19 Twitter Discourse. AMIA Summits Transl. Sci. Proc. 2021, 2021, 555. [Google Scholar]
- Alabid, N.N.; Katheeth, Z.D. Sentiment Analysis of Twitter Posts Related to the COVID-19 Vaccines. Indones. J. Electr. Eng. Comput. Sci. 2021, 24, 1727–1734. [Google Scholar] [CrossRef]
- Mansoor, M.; Gurumurthy, K.; Anantharam, R.U.; Prasad, V.R.B. Global Sentiment Analysis of COVID-19 Tweets over Time. arXiv 2020, arXiv:2010.14234v2. [Google Scholar]
- Singh, M.; Jakhar, A.K.; Pandey, S. Sentiment Analysis on the Impact of Coronavirus in Social Life Using the BERT Model. Soc. Netw. Anal. Min. 2021, 11, 33. [Google Scholar] [CrossRef] [PubMed]
- Imamah; Rachman, F.H. Twitter Sentiment Analysis of COVID-19 Using Term Weighting TF-IDF and Logistic Regresion. In Proceedings of the 2020 6th Information Technology International Seminar (ITIS), Surabaya, Indonesia, 14–16 October 2020; IEEE: New York, NY, USA, 2020; pp. 238–242. [Google Scholar]
- Sahir, S.H.; Ayu Ramadhana, R.S.; Romadhon Marpaung, M.F.; Munthe, S.R.; Watrianthos, R. Online Learning Sentiment Analysis during the COVID-19 Indonesia Pandemic Using Twitter Data. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1156, 012011. [Google Scholar] [CrossRef]
- Althagafi, A.; Althobaiti, G.; Alhakami, H.; Alsubait, T. Arabic Tweets Sentiment Analysis about Online Learning during COVID-19 in Saudi Arabia. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 620–625. [Google Scholar] [CrossRef]
- Ali, M.M. Arabic Sentiment Analysis about Online Learning to Mitigate COVID-19. J. Intell. Syst. 2021, 30, 524–540. [Google Scholar] [CrossRef]
- Alcober, G.M.I.; Revano, T.F. Twitter Sentiment Analysis towards Online Learning during COVID-19 in the Philippines. In Proceedings of the 2021 IEEE 13th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Manila, Philippines, 28–30 November 2021; IEEE: New York, NY, USA, 2021. [Google Scholar]
- Remali, N.A.S.; Shamsuddin, M.R.; Abdul-Rahman, S. Sentiment Analysis on Online Learning for Higher Education during COVID-19. In Proceedings of the 2022 3rd International Conference on Artificial Intelligence and Data Sciences (AiDAS), Ipoh, Malaysia, 7–8 September 2022; IEEE: New York, NY, USA, 2022; pp. 142–147. [Google Scholar]
- Senadhira, K.I.; Rupasingha, R.A.H.M.; Kumara, B.T.G.S. Sentiment Analysis on Twitter Data Related to Online Learning during the COVID-19 Pandemic. Available online: http://repository.kln.ac.lk/handle/123456789/25416 (accessed on 27 September 2023).
- Lubis, A.R.; Prayudani, S.; Lubis, M.; Nugroho, O. Sentiment Analysis on Online Learning during the COVID-19 Pandemic Based on Opinions on Twitter Using KNN Method. In Proceedings of the 2022 1st International Conference on Information System & Information Technology (ICISIT), Yogyakarta, Indonesia, 27–28 July 2022; IEEE: New York, NY, USA, 2022; pp. 106–111. [Google Scholar]
- Arambepola, N. Analysing the Tweets about Distance Learning during COVID-19 Pandemic Using Sentiment Analysis. Available online: https://fct.kln.ac.lk/media/pdf/proceedings/ICACT-2020/F-7.pdf (accessed on 27 September 2023).
- Isnain, A.R.; Supriyanto, J.; Kharisma, M.P. Implementation of K-Nearest Neighbor (K-NN) Algorithm for Public Sentiment Analysis of Online Learning. IJCCS (Indones. J. Comput. Cybern. Syst.) 2021, 15, 121–130. [Google Scholar] [CrossRef]
- Aljabri, M.; Chrouf, S.M.B.; Alzahrani, N.A.; Alghamdi, L.; Alfehaid, R.; Alqarawi, R.; Alhuthayfi, J.; Alduhailan, N. Sentiment Analysis of Arabic Tweets Regarding Distance Learning in Saudi Arabia during the COVID-19 Pandemic. Sensors 2021, 21, 5431. [Google Scholar] [CrossRef]
- Asare, A.O.; Yap, R.; Truong, N.; Sarpong, E.O. The Pandemic Semesters: Examining Public Opinion Regarding Online Learning amidst COVID-19. J. Comput. Assist. Learn. 2021, 37, 1591–1605. [Google Scholar] [CrossRef]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Al-Obeidat, F.; Ishaq, M.; Shuhaiber, A.; Amin, A. Twitter Sentiment Analysis to Understand Students’ Perceptions about Online Learning during the COVID-19. In Proceedings of the 2022 International Conference on Computer and Applications (ICCA), Cairo, Egypt, 20–22 December 2022; IEEE: New York, NY, USA, 2022; p. 1. [Google Scholar]
- Waheeb, S.A.; Khan, N.A.; Shang, X. Topic Modeling and Sentiment Analysis of Online Education in the COVID-19 Era Using Social Networks Based Datasets. Electronics 2022, 11, 715. [Google Scholar] [CrossRef]
- Rijal, L. Integrating Information Gain Methods for Feature Selection in Distance Education Sentiment Analysis during COVID-19. TEM J. 2023, 12, 285–290. [Google Scholar] [CrossRef]
- Martinez, M.A. What Do People Write about COVID-19 and Teaching, Publicly? Insulators and Threats to Newly Habituated and Institutionalized Practices for Instruction. PLoS ONE 2022, 17, e0276511. [Google Scholar] [CrossRef] [PubMed]
- Thakur, N. A Large-Scale Dataset of Twitter Chatter about Online Learning during the Current COVID-19 Omicron Wave. Data 2022, 7, 109. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- Genderperformr. Available online: https://pypi.org/project/genderperformr/ (accessed on 27 September 2023).
- Wang, Z.; Jurgens, D. It’s Going to Be Okay: Measuring Access to Support in Online Communities. In Proceedings of the Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 33–45. [Google Scholar]
- Hutto, C.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 216–225. [Google Scholar] [CrossRef]
- Nielsen, F.Å. A New ANEW: Evaluation of a Word List for Sentiment Analysis in Microblogs. arXiv 2011, arXiv:1103.2903v1. [Google Scholar]
- TextBlob. Available online: https://media.readthedocs.org/pdf/textblob/latest/textblob.pdf (accessed on 27 September 2023).
- Jumanto, J.; Muslim, M.A.; Dasril, Y.; Mustaqim, T. Accuracy of Malaysia Public Response to Economic Factors during the COVID-19 Pandemic Using Vader and Random Forest. J. Inf. Syst. Explor. Res. 2022, 1, 49–70. [Google Scholar] [CrossRef]
- Bose, D.R.; Aithal, P.S.; Roy, S. Survey of Twitter Viewpoint on Application of Drugs by VADER Sentiment Analysis among Distinct Countries. Int. J. Manag. Technol. Soc. Sci. (IJMTS) 2021, 6, 110–127. [Google Scholar] [CrossRef]
- Borg, A.; Boldt, M. Using VADER Sentiment and SVM for Predicting Customer Response Sentiment. Expert Syst. Appl. 2020, 162, 113746. [Google Scholar] [CrossRef]
- Newman, H.; Joyner, D. Sentiment Analysis of Student Evaluations of Teaching. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; pp. 246–250. ISBN 9783319938455. [Google Scholar]
- Gan, Q.; Yu, Y. Restaurant Rating: Industrial Standard and Word-of-Mouth—A Text Mining and Multi-Dimensional Sentiment Analysis. In Proceedings of the 2015 48th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2015; IEEE: New York, NY, USA, 2015. [Google Scholar]
- Gabarron, E.; Dechsling, A.; Skafle, I.; Nordahl-Hansen, A. Discussions of Asperger Syndrome on Social Media: Content and Sentiment Analysis on Twitter. JMIR Form. Res. 2022, 6, e32752. [Google Scholar] [CrossRef]
- Lee, I.T.-L.; Juang, S.-E.; Chen, S.T.; Ko, C.; Ma, K.S.-K. Sentiment Analysis of Tweets on Alopecia Areata, Hidradenitis Suppurativa, and Psoriasis: Revealing the Patient Experience. Front. Med. 2022, 9, 996378. [Google Scholar] [CrossRef]
- Nalisnick, E.T.; Baird, H.S. Character-to-Character Sentiment Analysis in Shakespeare’s Plays. Available online: https://aclanthology.org/P13-2085.pdf (accessed on 27 September 2023).
- Hazarika, D.; Konwar, G.; Deb, S.; Bora, D.J. Sentiment Analysis on Twitter by Using TextBlob for Natural Language Processing. In Proceedings of the Annals of Computer Science and Information Systems, Nagpur, India, 5–6 December 2020; PTI: Warszawa, Poland, 2020; Volume 24. [Google Scholar]
- Mas Diyasa, I.G.S.; Marini Mandenni, N.M.I.; Fachrurrozi, M.I.; Pradika, S.I.; Nur Manab, K.R.; Sasmita, N.R. Twitter Sentiment Analysis as an Evaluation and Service Base on Python Textblob. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1125, 012034. [Google Scholar] [CrossRef]
- Mansouri, N.; Soui, M.; Alhassan, I.; Abed, M. TextBlob and BiLSTM for Sentiment Analysis toward COVID-19 Vaccines. In Proceedings of the 2022 7th International Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 1–3 March 2022; IEEE: New York, NY, USA, 2022. [Google Scholar]
- Hermansyah, R.; Sarno, R. Sentiment Analysis about Product and Service Evaluation of PT Telekomunikasi Indonesia Tbk from Tweets Using TextBlob, Naive Bayes & K-NN Method. In Proceedings of the 2020 International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, 19–20 September 2020; IEEE: New York, NY, USA, 2020. [Google Scholar]
- Detoxify. Available online: https://pypi.org/project/detoxify/ (accessed on 27 September 2023).
- Jigsaw Unintended Bias in Toxicity Classification. Available online: https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification (accessed on 27 September 2023).
- Jigsaw Multilingual Toxic Comment Classification. Available online: https://www.kaggle.com/c/jigsaw-multilingual-toxic-comment-classification (accessed on 27 September 2023).
- Toxic Comment Classification Challenge. Available online: https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge (accessed on 27 September 2023).
- Sharma, S.; Gupta, V. Role of Twitter User Profile Features in Retweet Prediction for Big Data Streams. Multimed. Tools Appl. 2022, 81, 27309–27338. [Google Scholar] [CrossRef] [PubMed]
- Pycountry. Available online: https://pypi.org/project/pycountry/ (accessed on 28 September 2023).
- Zambon, V. Gender Identity. Available online: https://www.medicalnewstoday.com/articles/types-of-gender-identity (accessed on 28 September 2023).
- X’s Inactive Account Policy. Available online: https://help.Twitter.com/en/rules-and-policies/inactive-x-accounts (accessed on 18 October 2023).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
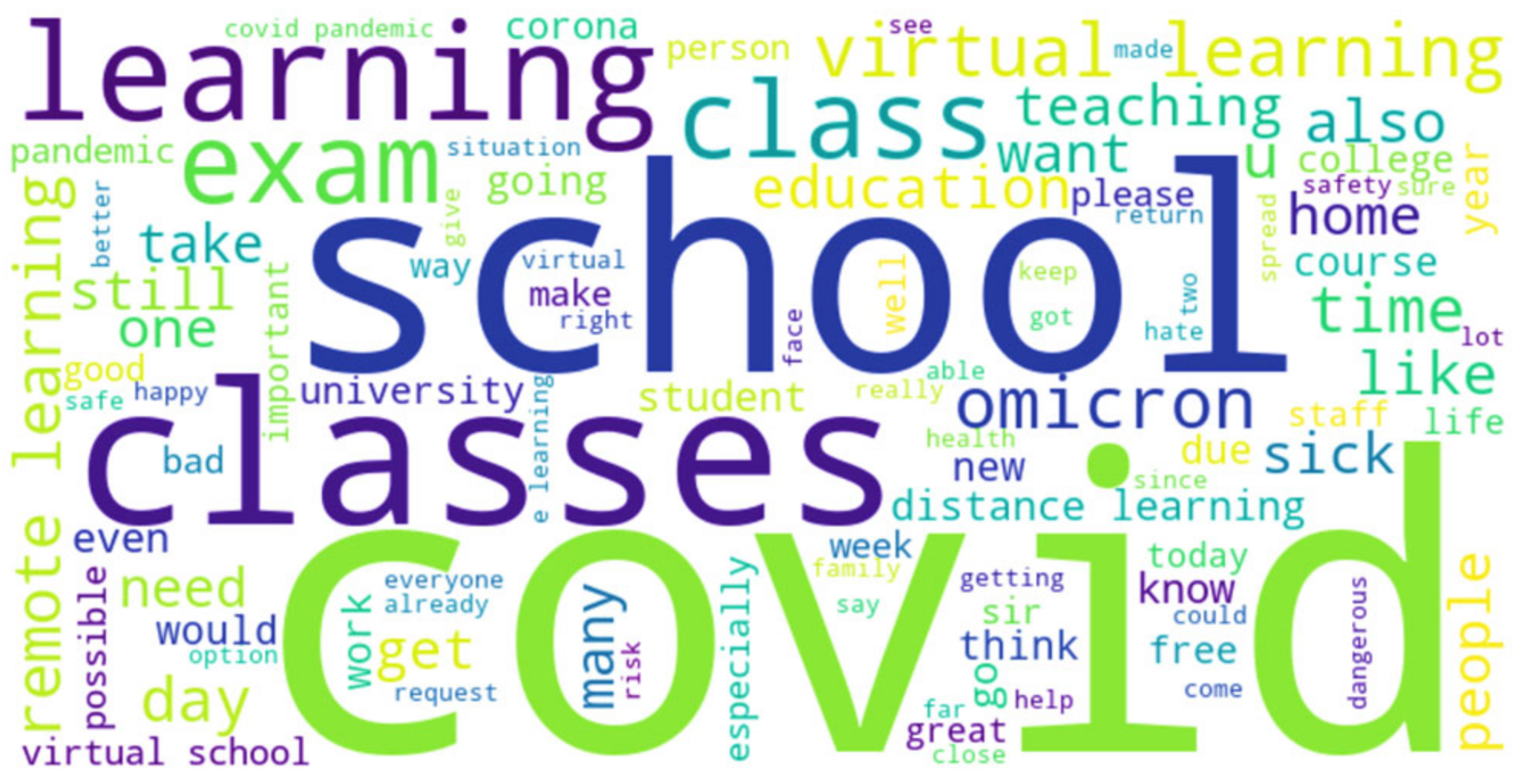{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
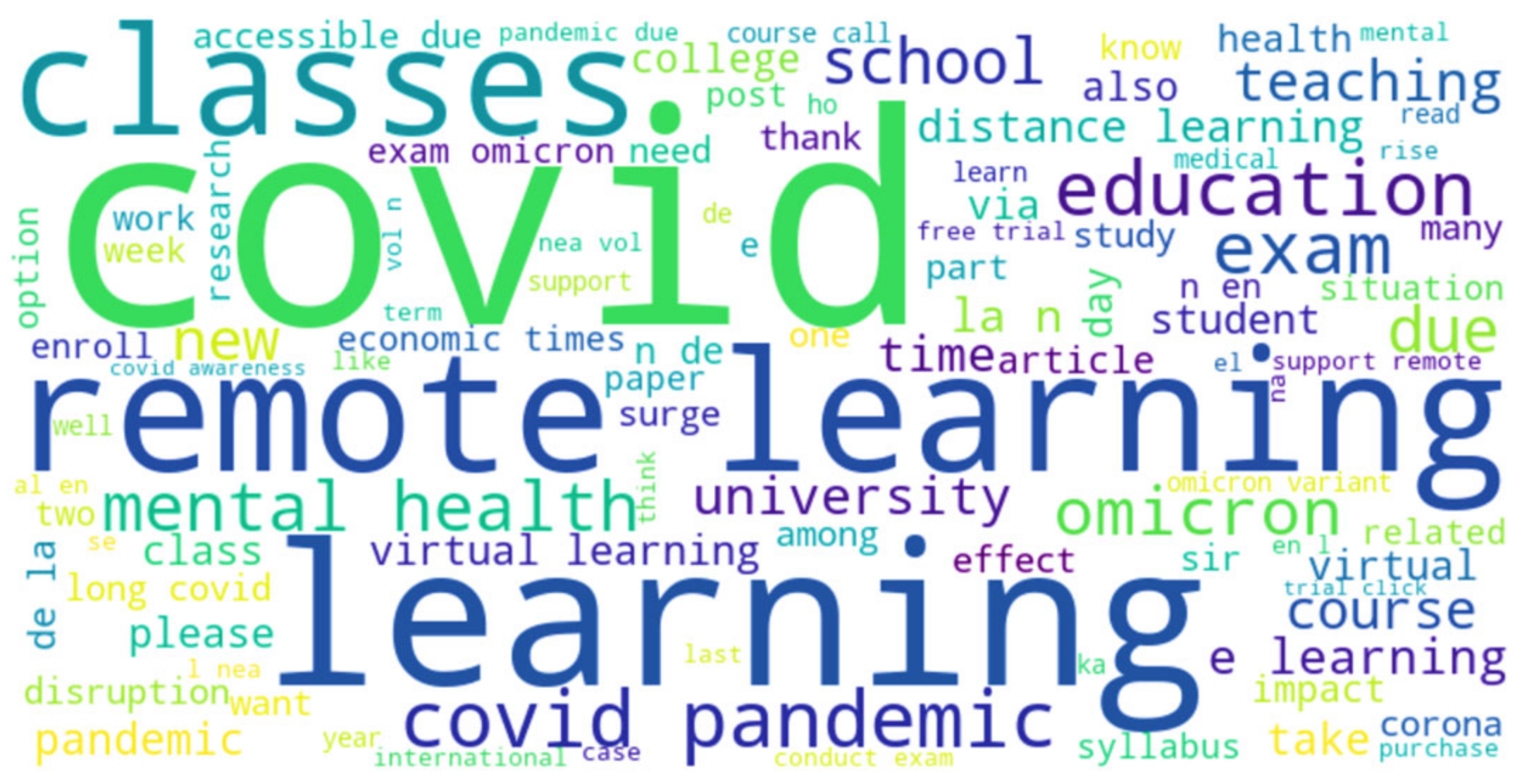{kind=link}
{kind=link}
{kind=link}
| Social Media Platform | Percentage of Male Users | Percentage of Female Users |
|---|---|---|
| 63 | 37 | |
| 51.8 | 48.2 | |
| Tumblr | 52 | 48 |
| 53.2 | 46.7 | |
| 53.5 | 46.5 | |
| Quora | 55 | 45 |
| 56.3 | 43.7 | |
| 57.2 | 42.8 | |
| Telegram | 58.6 | 41.4 |
| Sina Weibo | 51 | 49 |
| 51.7 | 48.3 | |
| SnapChat | 48.2 | 51 |
| Characteristics of Tweets Analyzed | Tweets Posted by Males | Tweets Posted by Females | Tweets Posted by None |
|---|---|---|---|
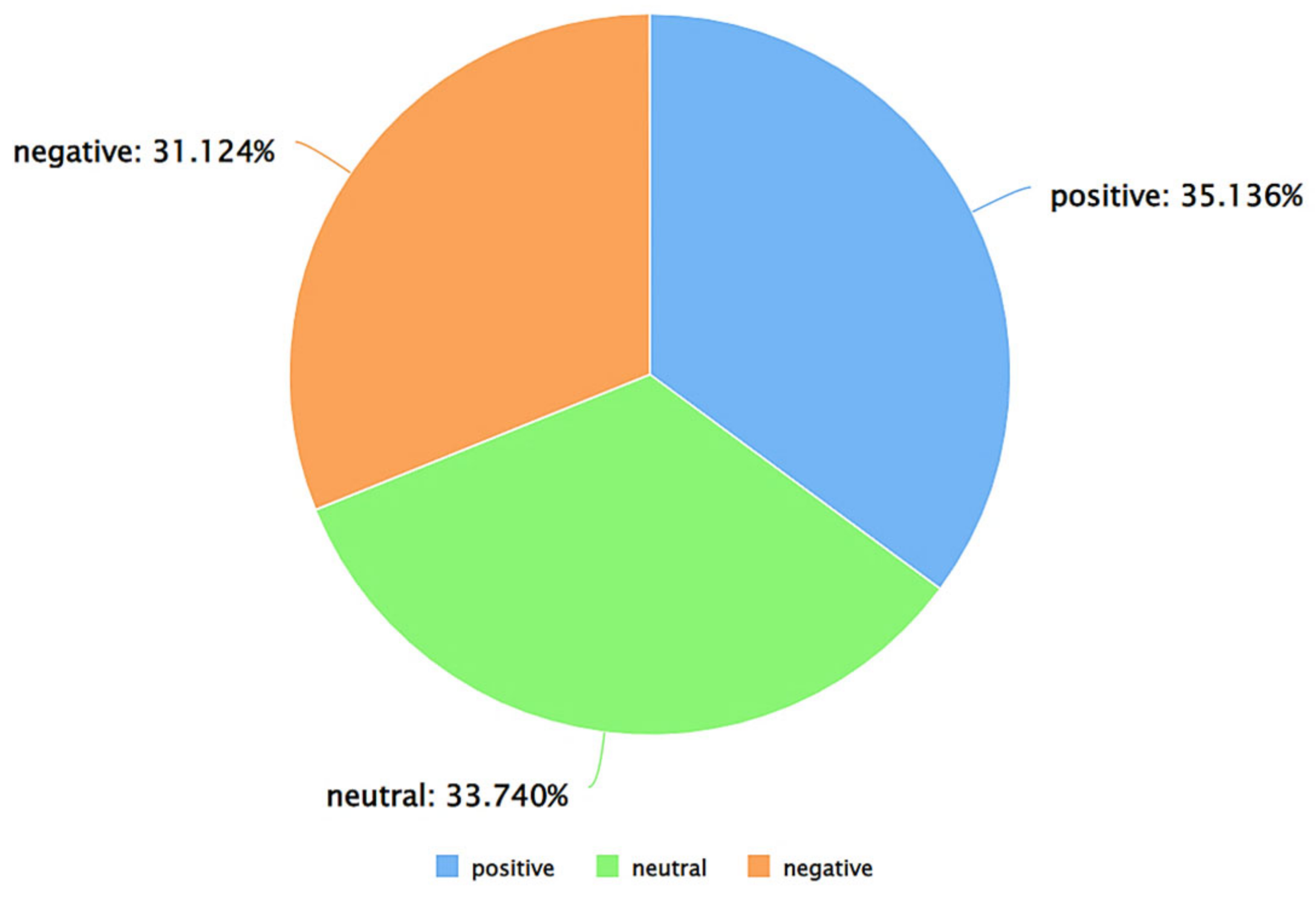
| Positive Tweets (as per VADER) | 25.402% | 21.403% | 53.196% |
| Negative Tweets (as per VADER) | 24.457% | 22.801% | 52.742% |
| Neutral Tweets (as per VADER) | 22.214% | 14.179% | 63.608% |
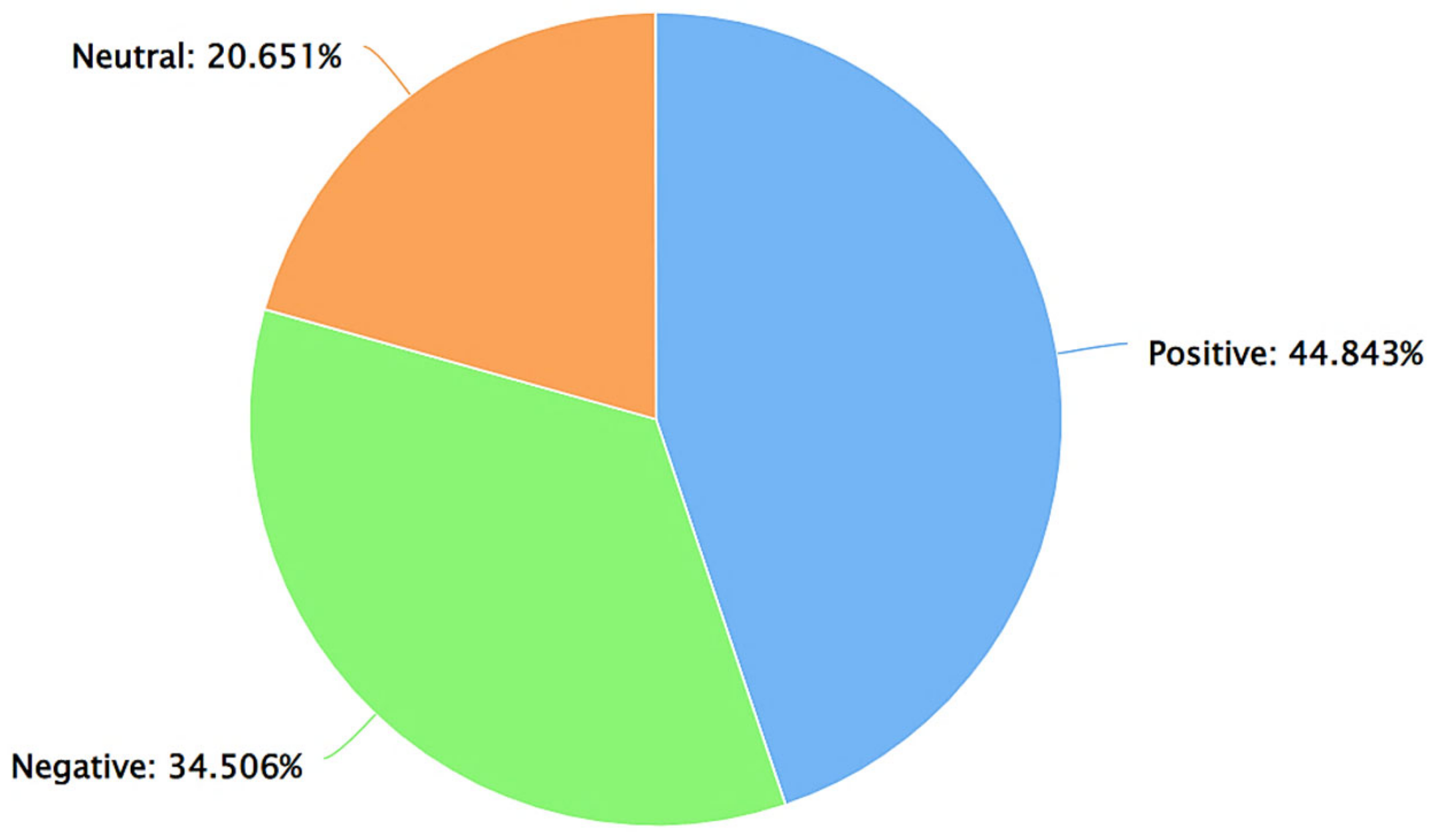
| Positive Tweets (as per Afinn) | 23.653% | 19.270% | 57.077% |
| Negative Tweets (as per Afinn) | 24.227% | 18.663% | 57.110% |
| Neutral Tweets (as per Afinn) | 25.037% | 21.475% | 53.488% |
| Positive Tweets (as per TextBlob) | 23.529% | 21.168% | 55.303% |
| Negative Tweets (as per TextBlob) | 22.905% | 20.494% | 56.602% |
| Neutral Tweets (as per TextBlob) | 27.894% | 15.535% | 56.572% |
| Characteristics of Tweets Analyzed | Tweets Posted by Males | Tweets Posted by Females | Tweets Posted by None |
|---|---|---|---|
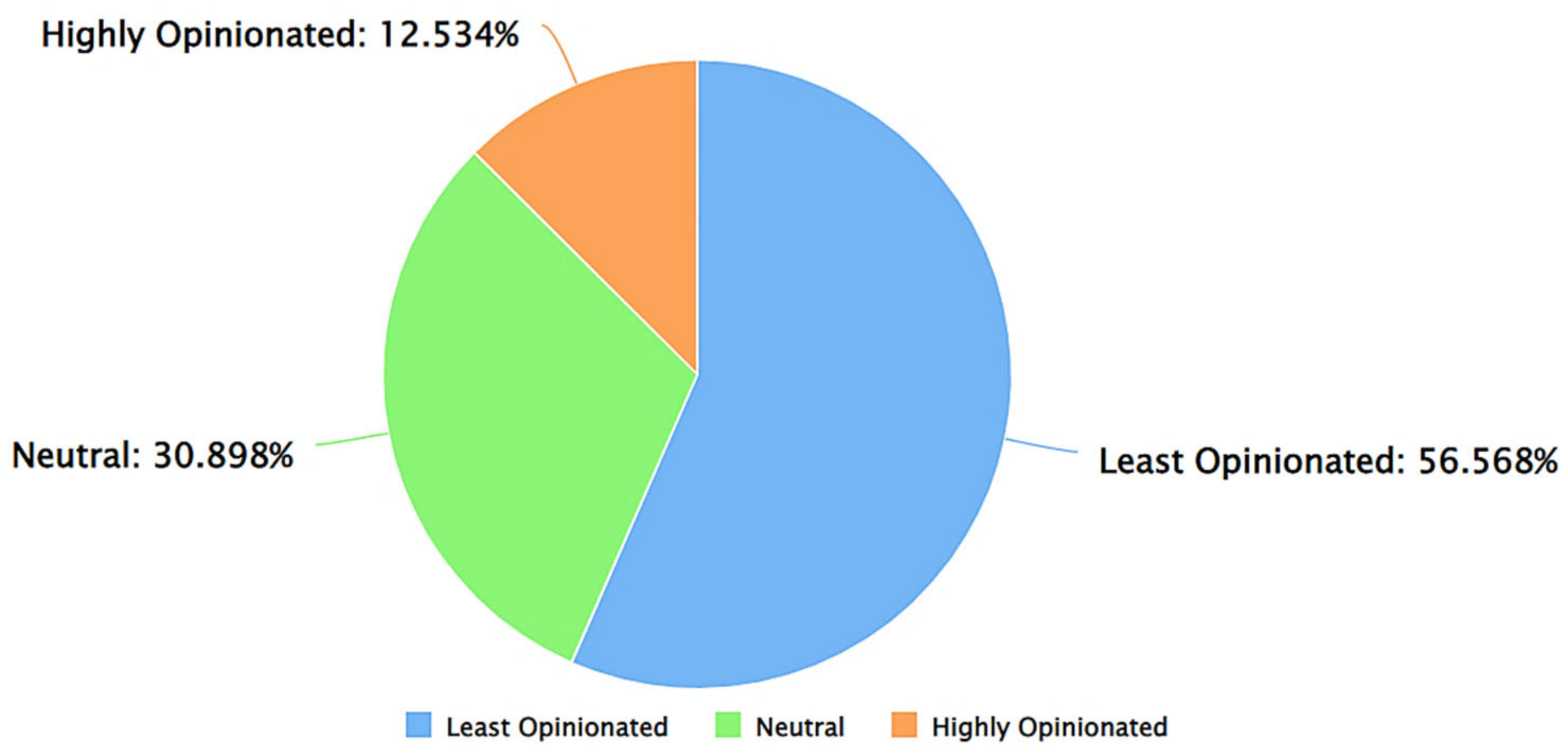
| Highly opinionated Tweets (as per TextBlob) | 26.094% | 27.735% | 51.171% |
| Least opinionated Tweets (as per TextBlob) | 23.618% | 18.355% | 58.027% |
| Neutral opinionated Tweets (as per TextBlob) | 24.545% | 21.165% | 52.291% |
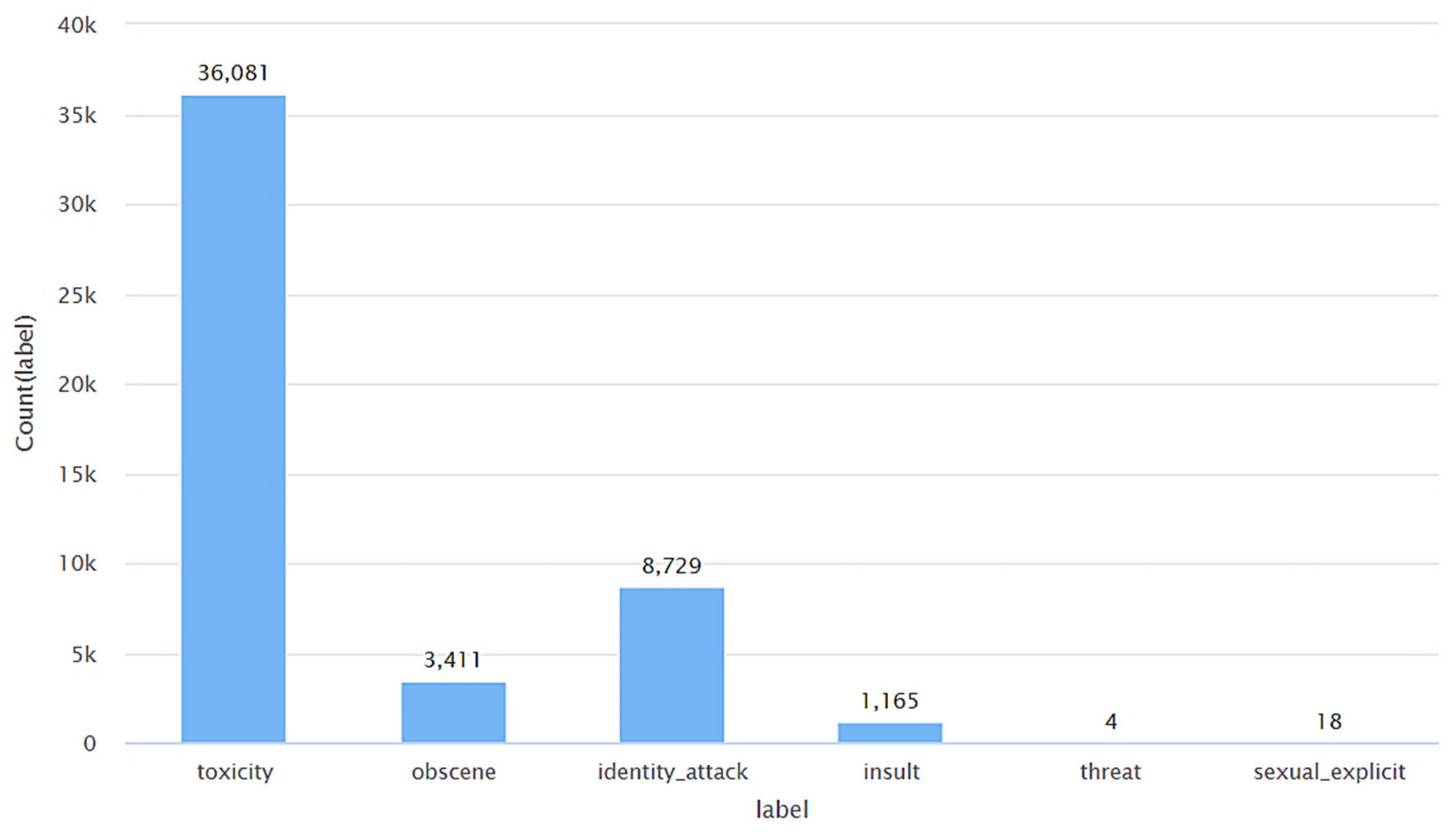
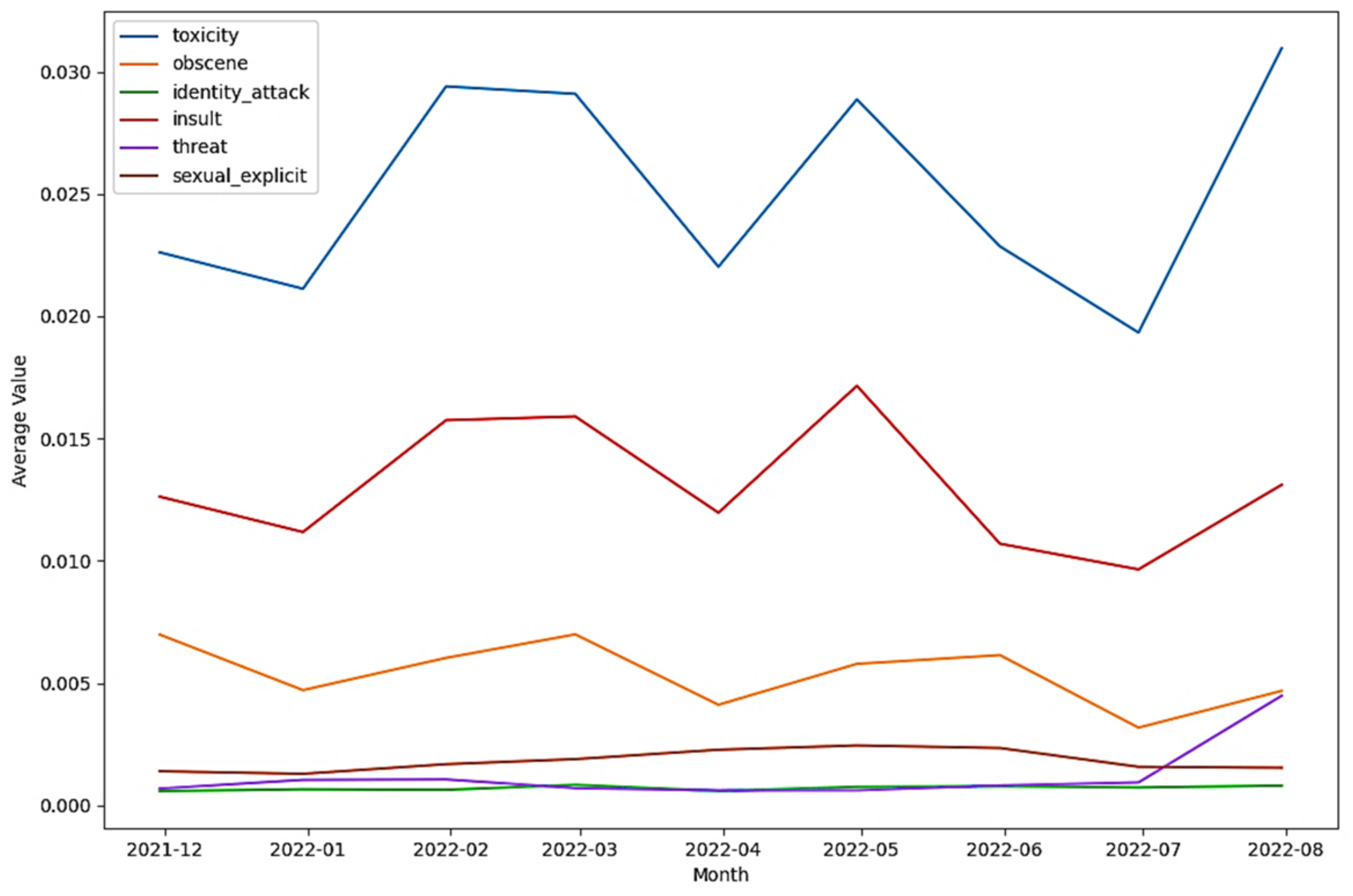
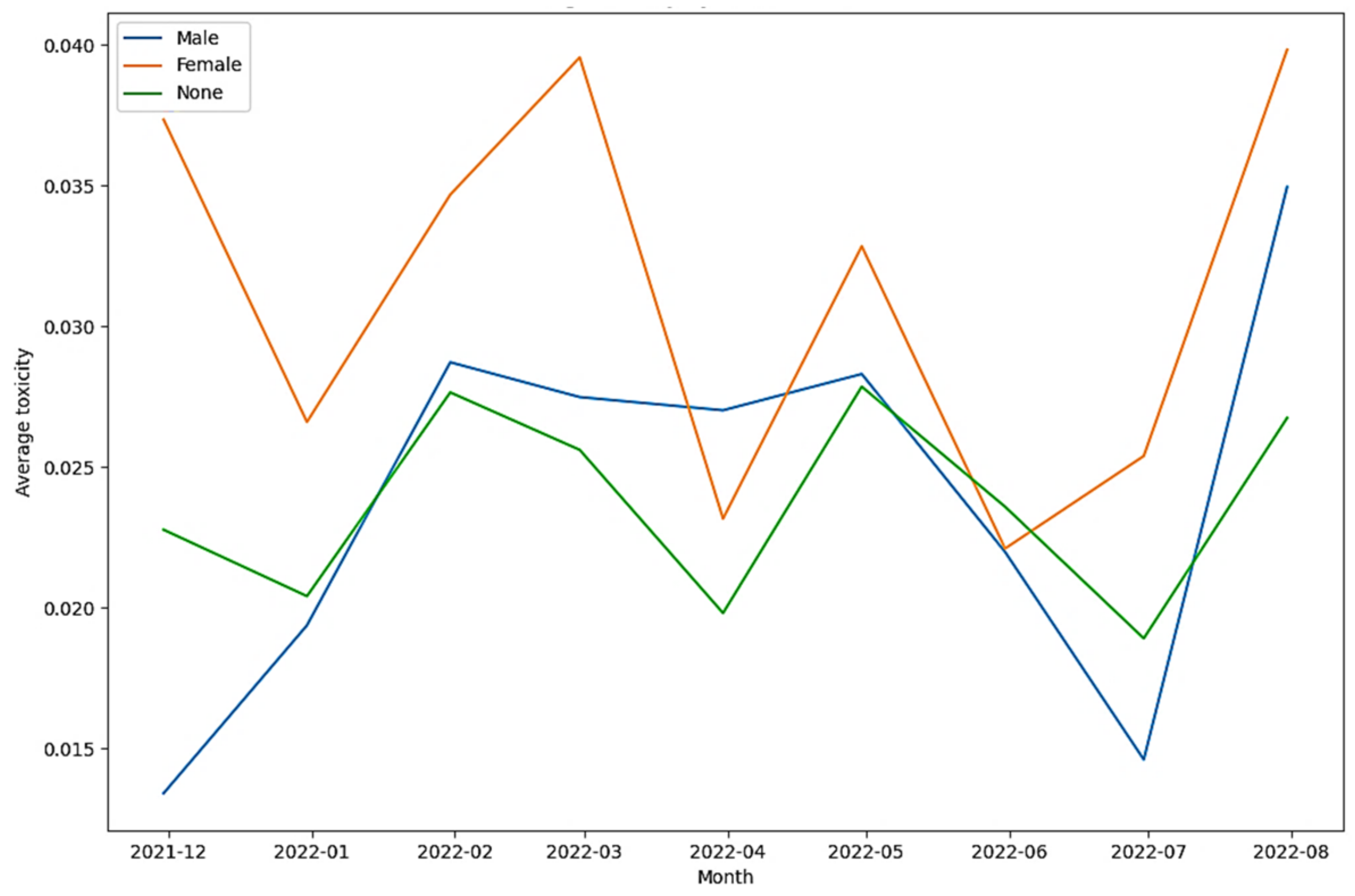
| Tweets in the toxicity class (as per Detoxify) | 23.680% | 20.119% | 56.201% |
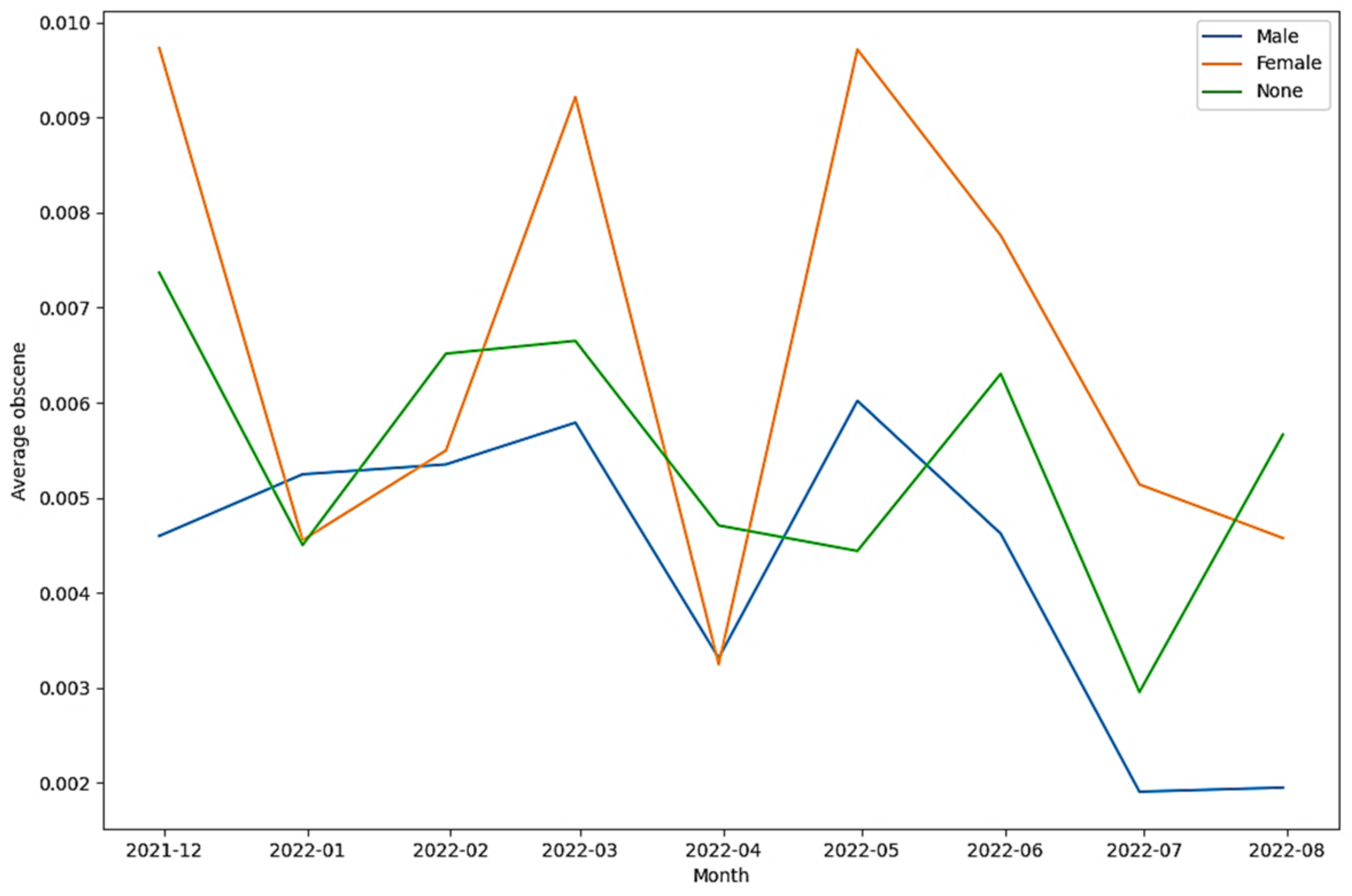
| Tweets in the obscene class (as per Detoxify) | 34.184% | 14.483% | 51.334% |
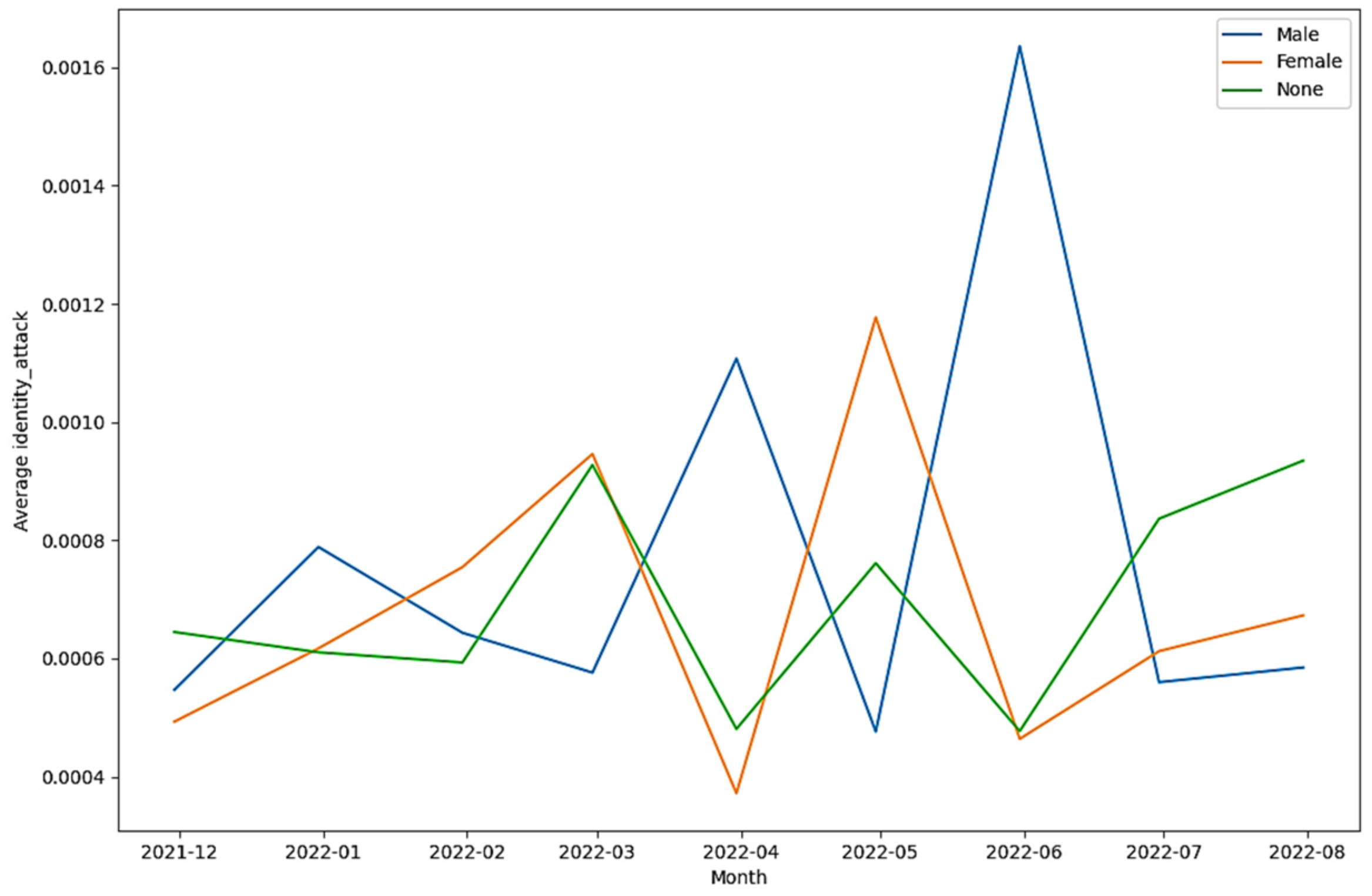
| Tweets in the identity attack class (as per Detoxify) | 22.339% | 21.045% | 56.616% |
| Tweets in the insult class (as per Detoxify) | 25.923% | 14.936% | 59.142% |
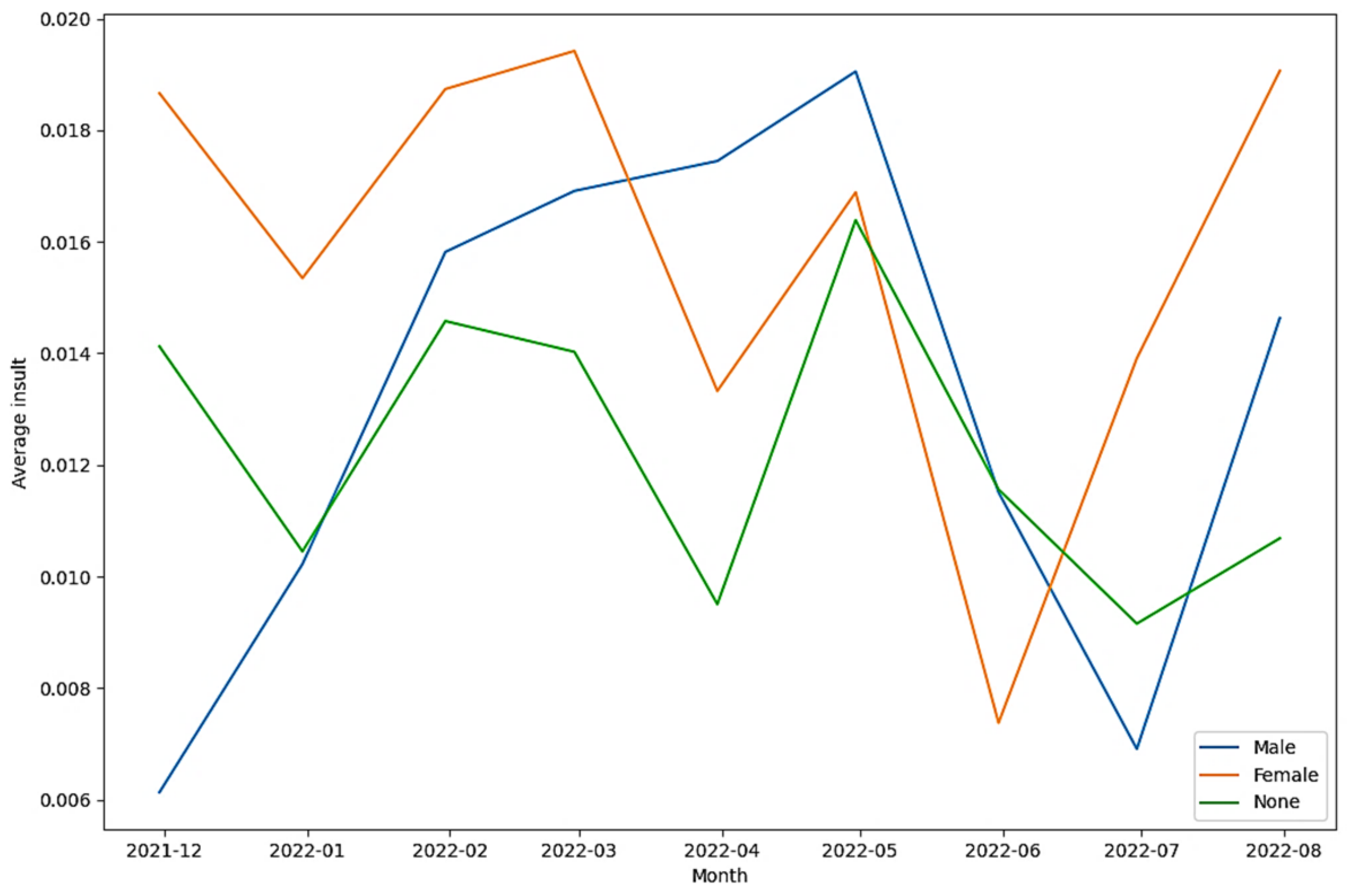
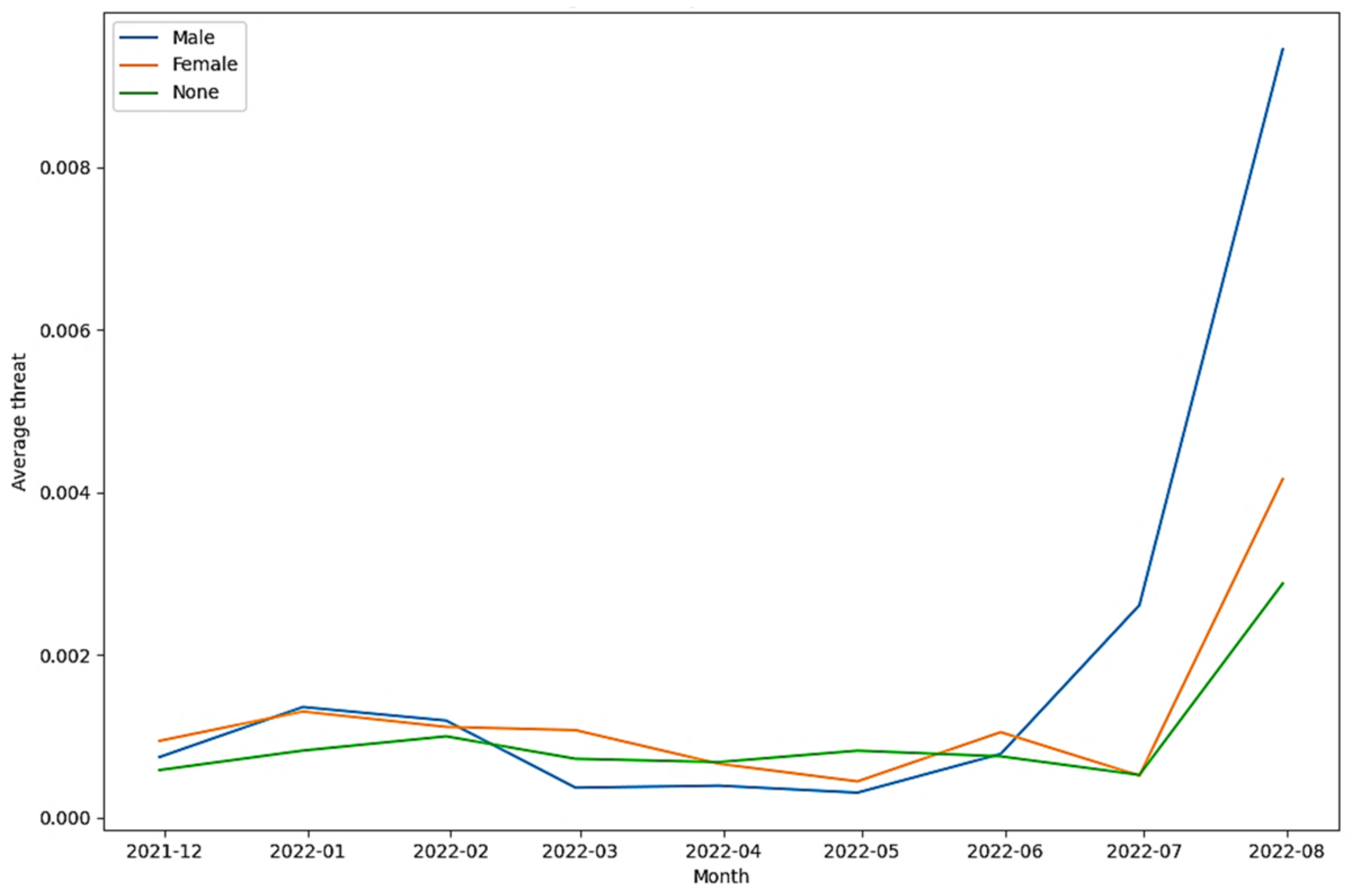
| Tweets in the threat class (as per Detoxify) | 25.000% | 0.000% | 75.000% |
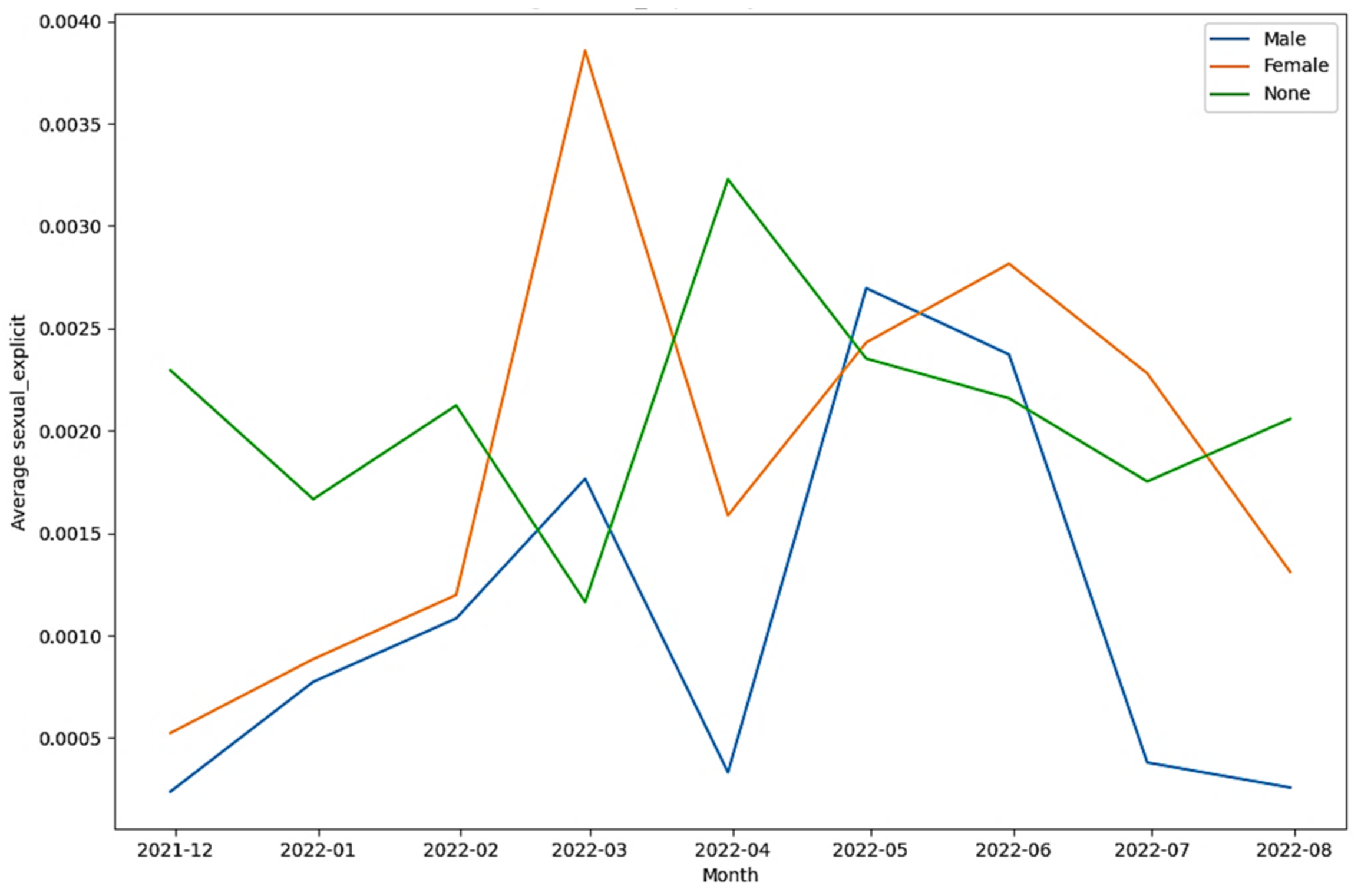
| Tweets in the sexually explicit class (as per Detoxify) | 5.556% | 27.778% | 66.667% |
| Work | Text Analysis of Tweets about Online Learning during COVID-19 | Sentiment Analysis of Tweets about Online Learning during COVID-19 | Analysis of Types of Toxic Content in Tweets about Online Learning during COVID-19 | Subjectivity Analysis of Tweets about Online Learning during COVID-19 |
|---|---|---|---|---|
| Sahir et al. [71] | ✓ | |||
| Althagafi et al. [72] | ✓ | |||
| Ali et al. [73] | ✓ | ✓ | ||
| Alcober et al. [74] | ✓ | |||
| Remali et al. [75] | ✓ | |||
| Senadhira et al. [76] | ✓ | ✓ | ||
| Lubis et al. [77] | ✓ | ✓ | ||
| Arambepola [78] | ✓ | ✓ | ||
| Isnain et al. [79] | ✓ | ✓ | ||
| Aljabri et al. [80] | ✓ | ✓ | ||
| Asare et al. [81] | ✓ | ✓ | ✓ | |
| Mujahid et al. [82] | ✓ | ✓ | ||
| Al-Obeidat et al. [83] | ✓ | |||
| Waheeb et al. [84] | ✓ | ✓ | ||
| Rijal et al. [85] | ✓ | |||
| Martinez et al. [86] | ✓ | |||
| Thakur et al. [this work] | ✓ | ✓ | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thakur, N.; Cui, S.; Khanna, K.; Knieling, V.; Duggal, Y.N.; Shao, M. Investigation of the Gender-Specific Discourse about Online Learning during COVID-19 on Twitter Using Sentiment Analysis, Subjectivity Analysis, and Toxicity Analysis. Computers 2023, 12, 221. https://doi.org/10.3390/computers12110221
Thakur N, Cui S, Khanna K, Knieling V, Duggal YN, Shao M. Investigation of the Gender-Specific Discourse about Online Learning during COVID-19 on Twitter Using Sentiment Analysis, Subjectivity Analysis, and Toxicity Analysis. Computers. 2023; 12(11):221. https://doi.org/10.3390/computers12110221
Chicago/Turabian StyleThakur, Nirmalya, Shuqi Cui, Karam Khanna, Victoria Knieling, Yuvraj Nihal Duggal, and Mingchen Shao. 2023. "Investigation of the Gender-Specific Discourse about Online Learning during COVID-19 on Twitter Using Sentiment Analysis, Subjectivity Analysis, and Toxicity Analysis" Computers 12, no. 11: 221. https://doi.org/10.3390/computers12110221
APA StyleThakur, N., Cui, S., Khanna, K., Knieling, V., Duggal, Y. N., & Shao, M. (2023). Investigation of the Gender-Specific Discourse about Online Learning during COVID-19 on Twitter Using Sentiment Analysis, Subjectivity Analysis, and Toxicity Analysis. Computers, 12(11), 221. https://doi.org/10.3390/computers12110221