
The Use of eXplainable Artificial Intelligence and Machine Learning Operation Principles to Support the Continuous Development of Machine Learning-Based Solutions in Fault Detection and Identification




Abstract
:1. Introduction
- A thorough product description that describes the expected comprehensive standards for an ML-based FDI solution from recent literature.
- A framework that acts as the road map/guideline for industrial practice and teamwork effort in developing such solutions.
- Facilitate the human-in-the-loop (HITL) system integration during the design, engineering, operation, and improvement phases.
2. Applicability and Potential Benefits of XAI and MLOps in FDI
- Extremely important features: These are “Must-have” functions of the product. The explanation in this step is a critical feature to the engineering, operation, and adjustment of the solution, which allows human users/developers to gain insight from the model development, and interfere with further modifications. The lack of this feature may affect the effective robustness and trustability.
- Performance features: These are “Should-have” functions of the product. The explanation in this step is a basic XAI concept feature that helps human users/developers understand and gain confidence with the output result. Some performance features, such as the confusion matrix, are already standardized in ML.
- Optional features: These are “Could-have” functions of the product. The explanation in this step is a nice-to-have feature, which does not have significant importance during intended usage.
- Conceptual level: Though the latent need emerged from the context, the necessary tool is still a suggestion, without any elaboration, validation, or evidence. (•)
- Validated level: The tool/method was a proof-of-concept version, validated by the use case, and the technical solution proved its applicability. (••)
- Qualified level: The tool/method is well-developed and introduced into a standard industrial level. (•••)
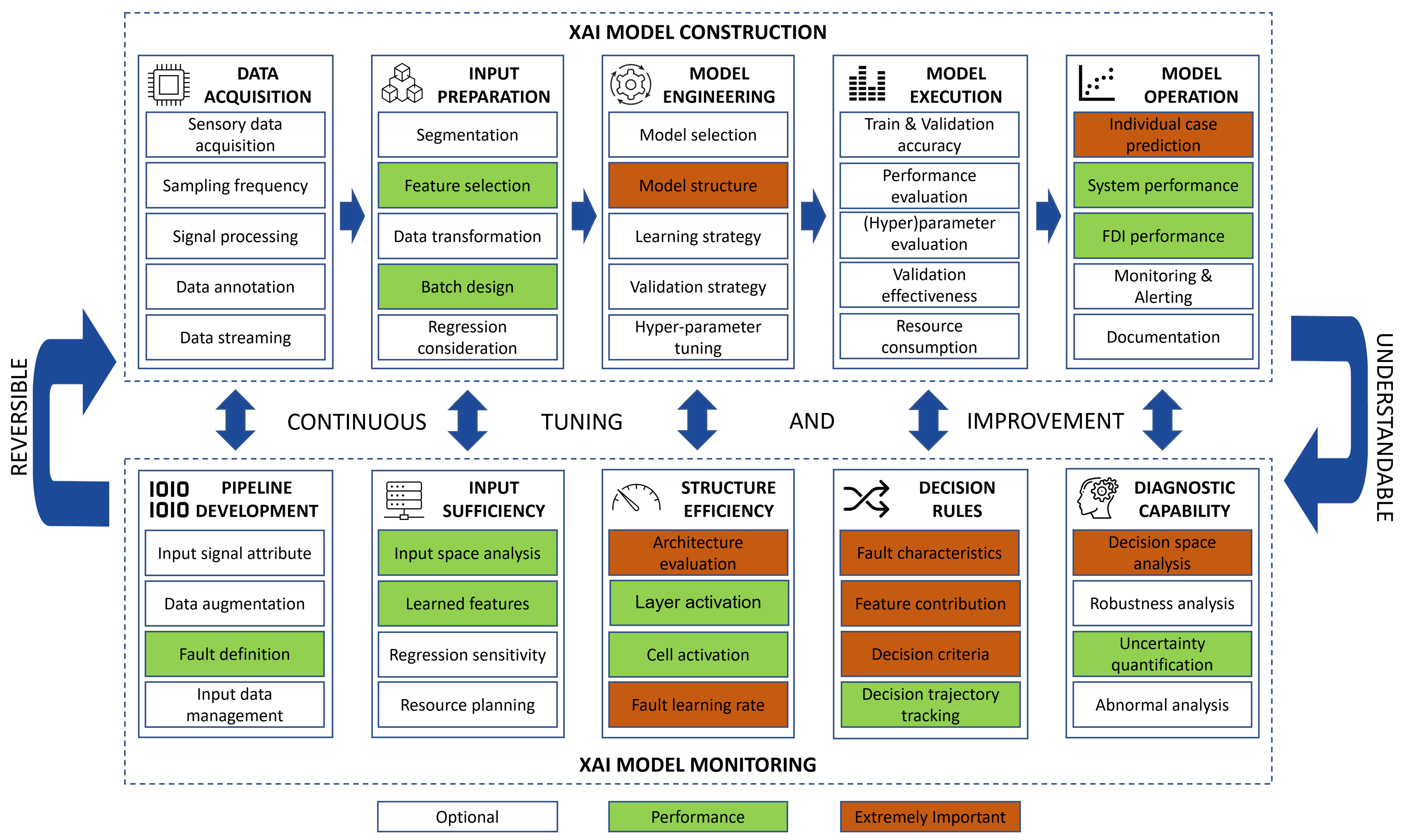
2.1. XAI Framework in Developing an ML-Based FDI Model
2.1.1. “XAI Model Construction” Block
- “Data acquisition” phase
- “Input preparation” phase
- “Model engineering” phase
- “Model execution” phase
- “Model operation” phase
2.1.2. “XAI Model Monitoring” Block
- “Pipeline development” phase
- “Input sufficiency” phase
- “Structure efficiency” phase
- “Decision rule” phase
- “Diagnostic capability” phase
2.2. Related Proposals for the XAI-Integrated ML-Based FDI Solution
- Requirement for input data: The causal inference between fault status and physical behavior of the system should be investigated [17] to create a physics-informed feedback loop. This aspect recently gained much attention, such as the use of an artificial sine cut-off data set for the visualization and evaluation of XAI algorithms on periodic time series [20]. On the other hand, the integration of prior knowledge and human effort in data annotation and preparation [54] should be optimized from the human resources viewpoint, but also from the active learning viewpoint as a learning process for human users [73].
- Requirement for the ML model structure: The core ML model should be compact to ensure solution scalability. A single model with the capability of detecting all fault types will be more favorable than separated models.
- Requirement for XAI tool selection: Some tools are suitable for certain types of DL types, e.g., CAM is only recommended for CNN. In certain cases, the combination of more than one XAI algorithm is necessary as their results are only partially correct and are complementary to each other [20].
- Requirement for continuous model (hyper)parameter tuning with XAI tools: Although many studies mention hyper-parameters and parameter tuning, mostly the reasoning is not clear as they are inferred by another study [66], taken as experience [20,74], set without any reference [17], or not even mentioned [24]. As with the proposed XAI framework, any factor that is affected by (hyper)parameters (e.g., model performance, fault learning rate, and resource consumption) can be diagnosed. This knowledge should be used for continuous model tuning and improvement. The explainability should not only explain the FDI result but suggest how to correct the monitored process [75].
- Requirement for uncertainty explanation: Most current XAI studies focus on how to explain the prediction rationale. However, in important usage, the FDI ML model should have the ability to be “aware” and “admit” its incompetence in ambiguous cases; therefore, a better sensitivity can be achieved [76].
- Requirement for human interference: The process operator should use XAI tools to gain an in-depth understanding of the fault characteristics [55] and behavior [60], along with the model decision rules [17], thus determining the corresponding operation/maintenance strategy. Typical interference is when the field technician of the chiller system will be the first user who deals with a stray alarm, and then the engineer can declare it is a minor fault or elevate it into costly replacement and procurement [18]. On the other hand, the involvement of human users during the evolution and development of the ML model is inevitable. Prior knowledge of the person who uses model prediction should be considered in fault definition and behavior [77], as through this knowledge integration with human feedback, the DL model can establish better generalization, especially towards dynamic systems [78].
- Requirement for human trust management: Even the XAI tools themselves can show inconsistency [66], and a good explanation does not reflect if the user trusts and uses the prediction result and offered initiatives. Therefore, selective methods should be deployed, e.g., not only the user evaluation and feedback are considered, but the solution should also perform self-validation, aiming to increase the frequency that users adopt and agree with offered decisions. As users with different knowledge depths (i.e., engineers versus operators) require different degrees of explainability [79], trust management should recognize user preferences and customize the explanation accordingly.
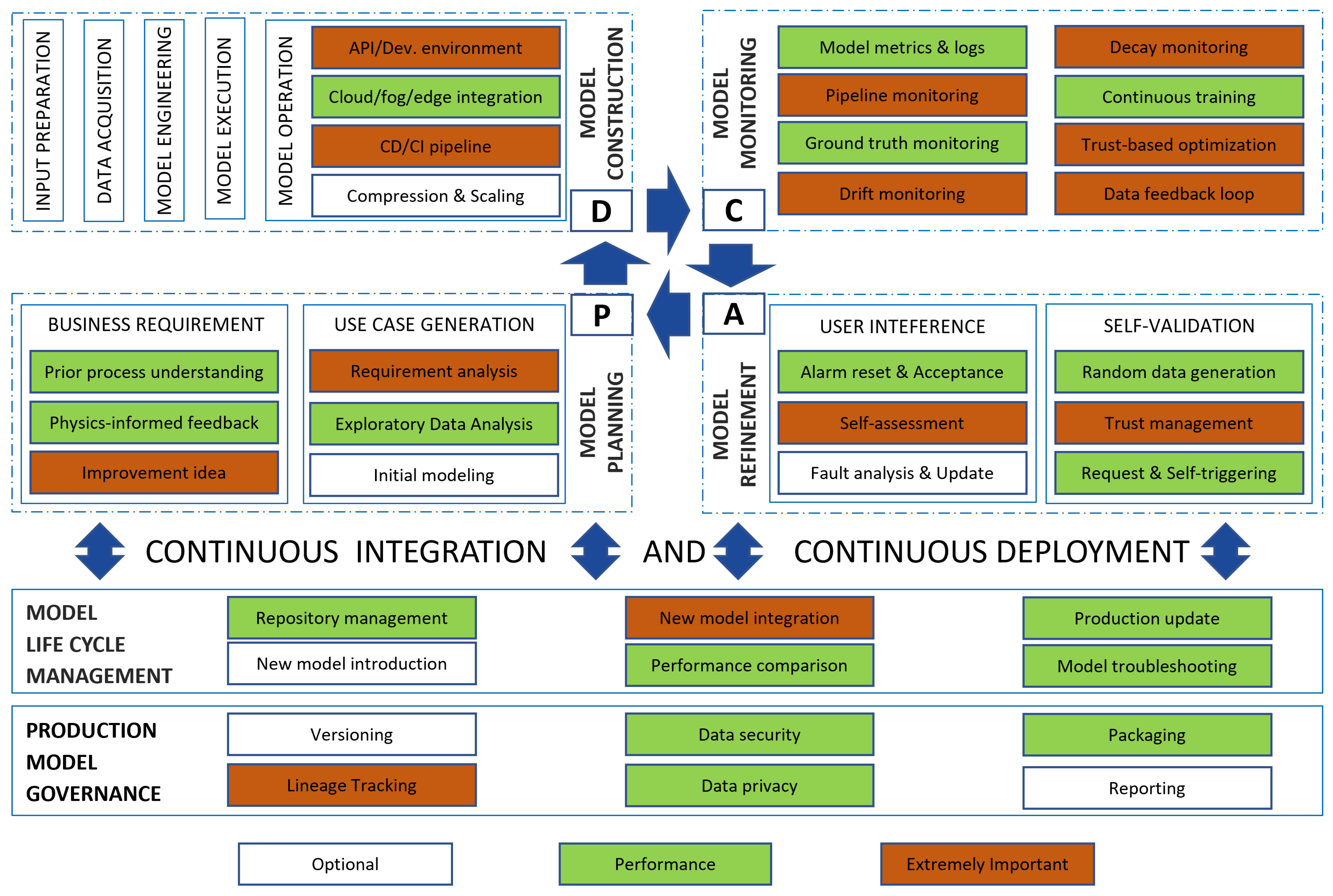
2.3. An ML-Ops Framework for an XAI ML-Based FDI
- Extremely important: This step is critical to the continuous development and operation of MLOps.
- Performance: This step is a basic requirement from the MLOps concept.
- Optional: This step does not have significant importance and can be optional.
- A business stakeholder (BS) defines the goals of FDI tools and economic constraints. This role can represent the product owner, production director, quality manager, etc.
- A data scientist (DS) is the translator between the business/process voice and ML/data problems with data-driven evidence.
- A data engineer (DE) is in charge of data management, data solution, and data system architecture.
- A software engineer (SE) works on the software architecture, including software-as-a-service and software-as-a-product management.
- A machine learning architect (MLA) is the main designer of the ML model. They are in charge of any changes to the core algorithm and model during initial construction, update, compression, and scaling.
- A DevOps engineer (DOE) bridges the gap between ML model development and FDI solution continuous development/deployment.
- Human users (HU) stem from the requirement of the human presence in the ML-based product operation. Inspired by the work of [84], this role represents machine operators, maintenance engineers, process engineers, etc., whose work is benefited by using the FDI solution.
- “Model planning” block: “Business requirement” and “Use case generation”
- “Model construction” block
- “Model monitoring” block
- “Model refinement” block: “User interference” and “Self- validation”
- “Model life cycle management” block
- “Production model governance” block
3. Demonstration of the Approach in Hydraulic System FDI Monitoring
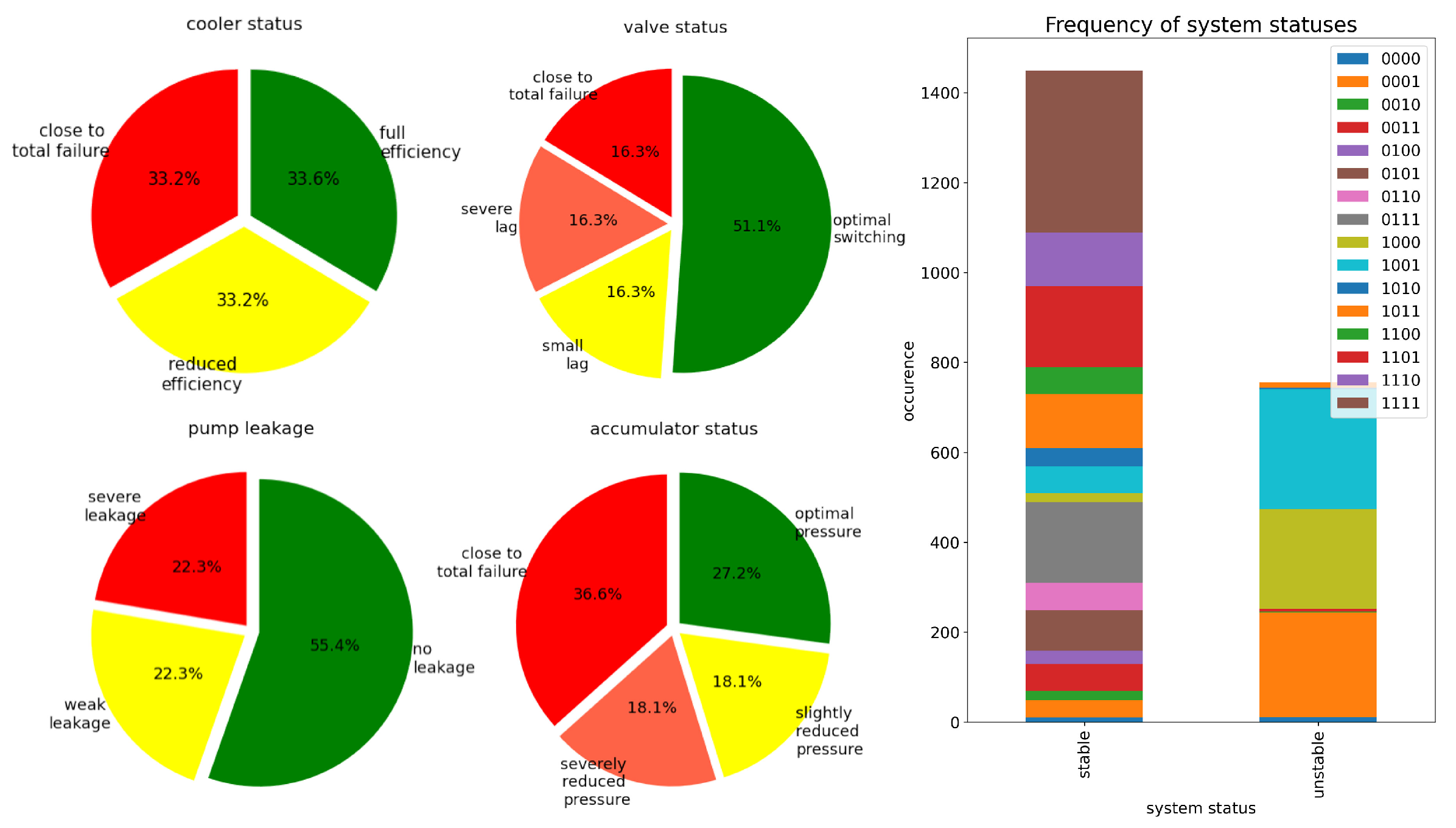
3.1. Description of the Use Case
- Cooler (three grades): 1: full efficiency, 2: reduced efficiency, and 3: close to total failure ( cases, respectively).
- Valve (four grades): 1: optimal behavior, 2: small lag, 3: severe lag, and 4: close to total failure ( cases, respectively).
- Internal pump (three grades): 1: no leakage, 2: weak leakage, and 3: severe leakage ( cases, respectively).
- Accumulators (four grades): 1: optimal pressure, 2: slightly reduced pressure, 3: severely reduced pressure, and 4: close to total failure ( cases, respectively). These grades are artificially stimulated by four accumulators (A1–A4).
3.2. Traditional FDI Approach with an ML-Based Model
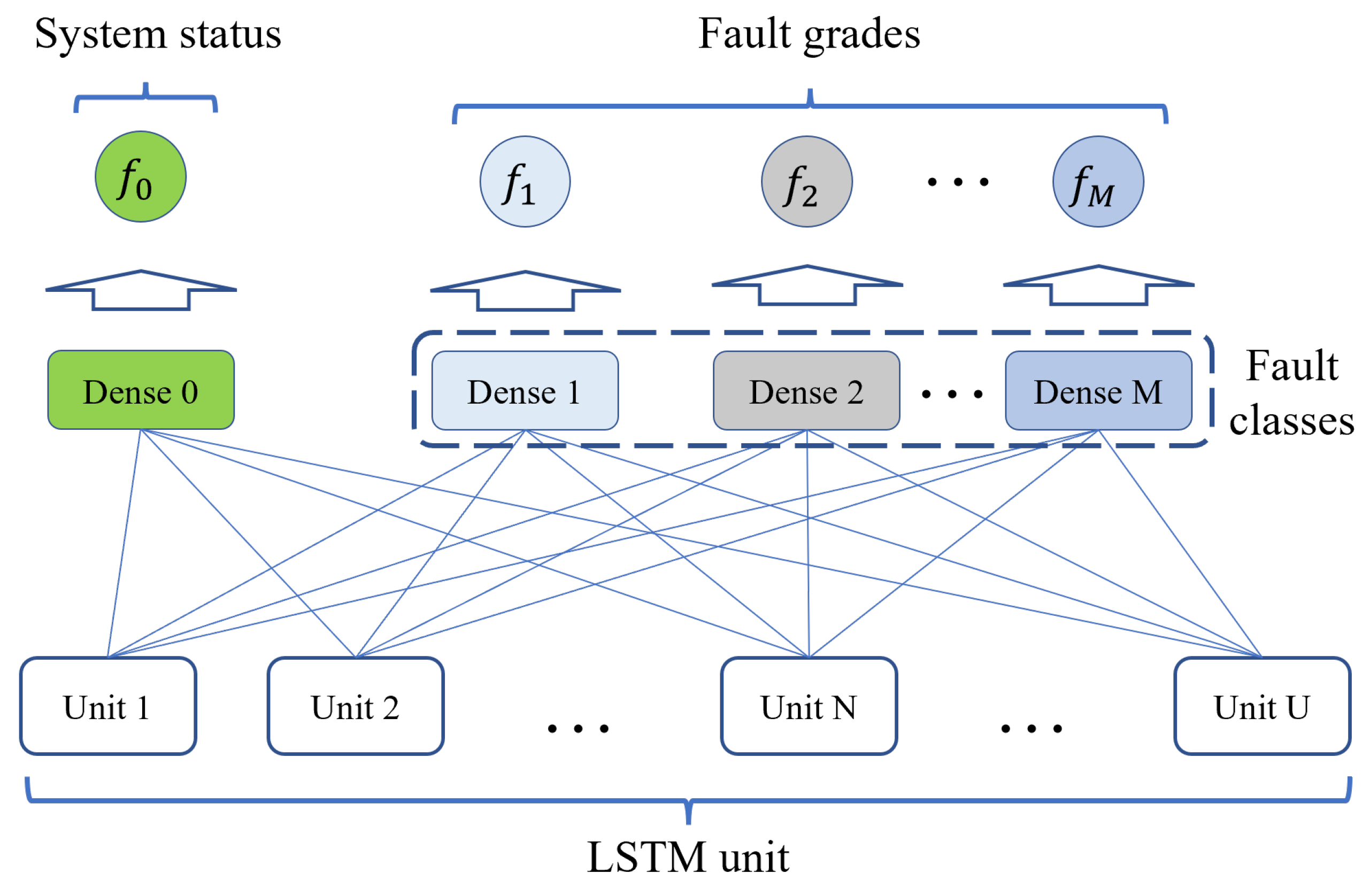
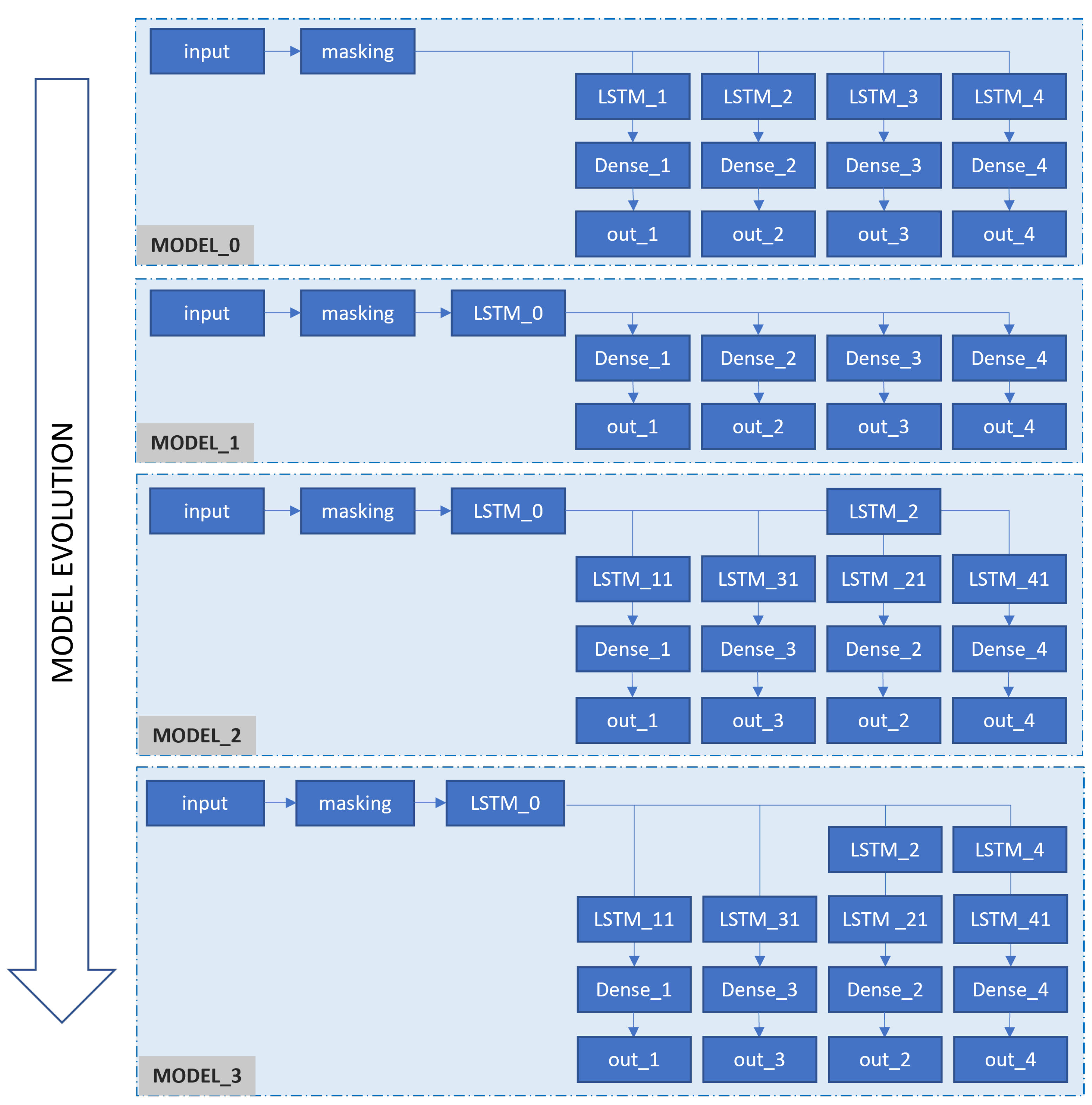
3.3. FDI Model with a LSTM Neural Network
3.4. Explainability during FDI Model Development
3.4.1. “Data Acquisition” and “Pipeline Development”
3.4.2. “Input Preparation” and “Input Sufficiency”
3.4.3. “Model Engineering” and “Structure Sufficiency”
3.4.4. “Model Execution” and “Decision Rules”
3.4.5. “Model Operation” and “Diagnostic Capability”
4. Discussion
4.1. The Maturity and Applicability of XAI for ML-Based FDI Solutions
4.2. Solution Development with MLOps Principles
4.3. Suggestion for a Collaborative Process Monitoring with Human-in-the-Loop Machine Learning
- Observation: Process the acquired data to obtain knowledge regarding the status of the process and occurring faults within the system.
- Orientation: Assess the overall situation and operating status of the system.
- Decision: Consider the initiatives or actions that should be taken given the current situation.
- Action: Perform the intervention that places an effect on the system.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADAS | Advanced Driver-Assistance System |
| AI | Artificial Intelligence |
| API | Application Programming Interface |
| CAM | Class Activation Mapping |
| CBM | Conditional Based Monitoring |
| CD/CI | Continuous Deployment/Continuous Integration |
| CNN | Convolutional Neural Networks |
| DiCE | Diverse Counterfactual Explanations |
| DL | Deep Learning |
| FDI | Fault Detection and Identification |
| HITL | Human-in-the-Loop |
| kNN | k-Nearest Neighbors Algorithm |
| KPIs | Key Performance Indicators |
| LDA | Linear Discriminant Analysis |
| LIME | Local Interpretable Model-agnostic Explanations |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MLOps | Machine Learning Operations |
| OODA | Observation–Orientation–Decision–Action |
| OPTICS | Ordering Points To Identify the Clustering Structure |
| PCA | Principal Component Analysis |
| PDCA | Plan–Do–Check–Act |
| PHM | Prognostic and Health Management |
| RUL | Remaining Useful Life |
| SHAP | SHapley Additive exPlanations |
| SMOTE | Synthetic Minority Oversampling TEchnique |
| SVM | Support Vector Machines |
| t-SNE | t-distributed Stochastic Neighbor Embedding |
| XAI | eXplainable Artificial Intelligence |
| The Dense layer | |
| The LSTM layer | |
| The Model | |
| The Output layer |
Appendix A. Reasoning from Relevant Literature

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D.P. | Aspect | Reasoning (System & Study) | Proposed Tools (Maturity Level) |
|---|---|---|---|
| Data acquisition | Sensory data acquisition | Show the monitored system diagram (hydraulic system [38]), Choose the input sensors, identify the Analog input/output (I/O) variables from sensors (i.e., temperature, pressures, power, voltage, etc.) (simulated pick/place system and electric furnace [33], photovoltaic panel [60]) | Labeling the fault type from input sensor data (•), system diagram with critical components (••) |
| Sampling frequency | Adjust the sampling frequency from sensor data (bearing test rig [19]) | ||
| Signal processing | Extract the working status of machines and digital input/output (I/O) variables (sensors and actuators) (simulated pick/place system and electric furnace [33]), visualize the use of different cut-off frequency and digital filters (bearing test rig [19], autonomous underwater vehicles [41]) | ||
| Data annotation | Visualize the rules of identifying and annotating fault conditions (chiller system [18], chemical process [17], bearing test rig [19], air handling unit [54]), defined the first event and variable types (simulated pick/place system and electric furnace [33]) | Event chart (•), Characteristics table (•), Hierarchical clustering on SHAP values of fault types (••) | |
| Data streaming | Explain problems associated with the time-series stream from the programmable logic controller, missing data (simulated pick/place system and electric furnace [33], chemical process [17], autonomous underwater vehicles [41]) | Data pipeline of collecting and normalizing online data (•) | |
| Input preparation | Segmentation | Define sequential cycles (simulated pick/place system and electric furnace [33]), segmenting the raw signal (motor bearing [23], bearing test rig [19], autonomous underwater vehicles [41], robotic system [136]) | Segmentation chart (this study) (••) |
| Feature selection | Prepare feature set from each segmented window (autonomous underwater vehicles [41]), choose the relevant features (motor bearing [23], bearing test rig [19], air handling unit [54]); Combining discrete events and continuous variables (simulated pick/place system and electric furnace [33]) | Visualized rule for feature set preparation (•), features–faults map (••), SHAP values to analyze the influence of features on each fault instance (•••) | |
| Data transformation | Transform the acquired data into frequency domain (rotating electric motor [20], rotating machinery [74], robotic system [136]), transform into spectrograms (motor bearing [23]) or scalogram (robotic system [136]); Scale and prepare the dataset into train and test set (chemical process [17]) | Frequency revolutions per minute (RPM) and order-RPM heat map (••), spectrograms (•••), scalogram (•••) | |
| Block design | Visualize the designed blocks (etching process [55]), the effect of block size and overlap on performance (autonomous underwater vehicles [41]) | Control chart in block (••), accuracy chart of different setup (••), block chart to visualize the fault distribution within input data (this study) (••) | |
| Regression consideration | Select the step of time-lag based on the fault detection delay (chemical process [137]) | Relative relevance plot (••) | |
| Model engineering | Model selection | Select the model based on prediction accuracy (simulated pick and place system and electric furnace machine [33], bearing test rig [19], photovoltaic panels [60]), or individual case explanation (chiller system [18]), or fault detection rate (FDR) and false alarm rate (FAR) (chemical process [17,75]) | F1-FDR-FAR score table (••), Contribution maps with SHAP values and reconstruction error (••) |
| Model structure | Deep explanation for the model structure (chiller system [18]) | Local Interpretable Model-agnostic Explanations (LIME) to explain the rationale of the decision from the model with triggered performance KPIs (•••) | |
| Learning strategy | Explain the learning strategy for each fault, based on fault characteristics | Batch-wise learning (•) | |
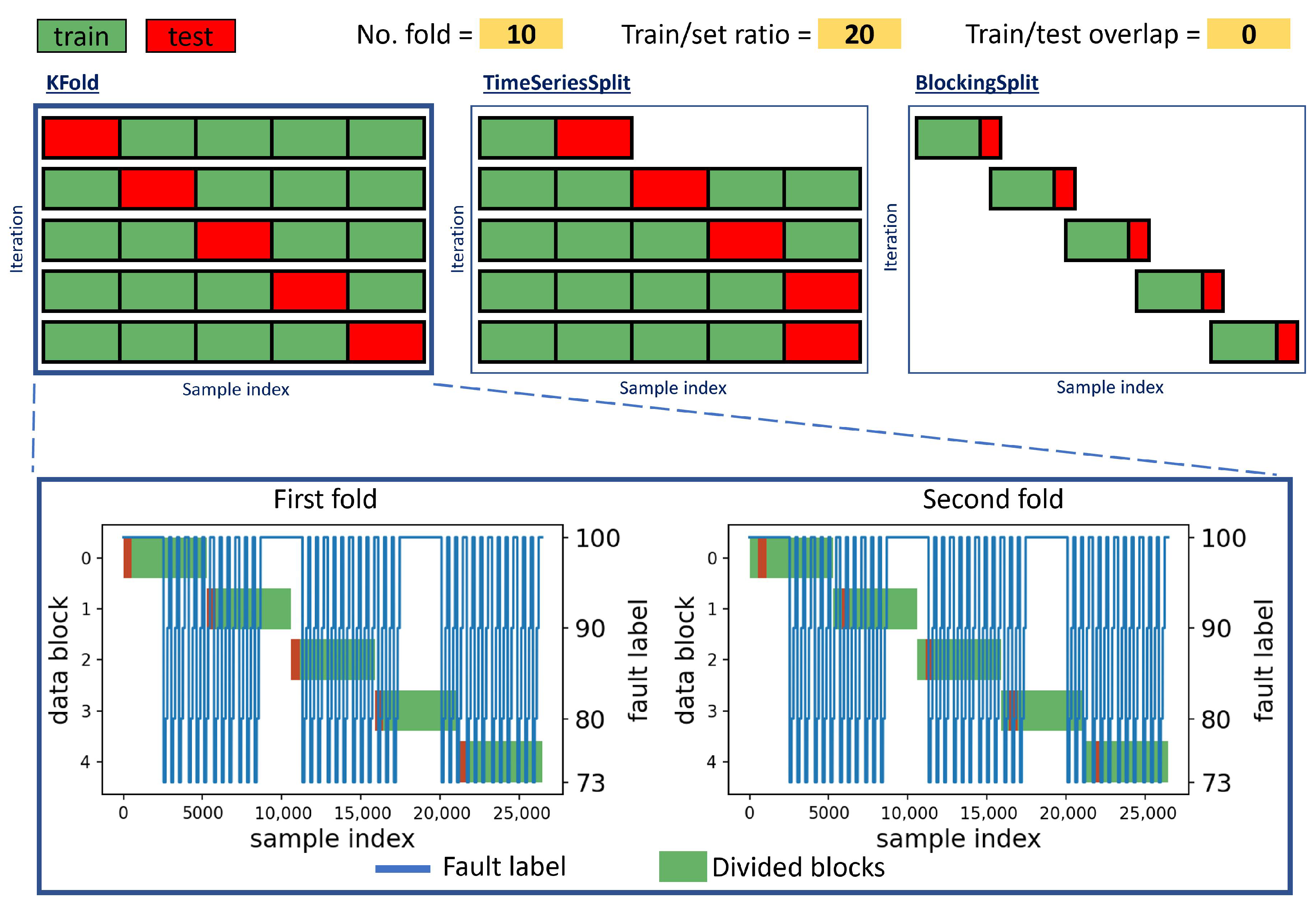
| Validation strategy | Define the set or permutation for validation method (rotating machinery [74]), different validation strategies | Validation selection (this study) (••) | |
| Hyper-parameter tuning | Fine tune the hyper-parameters to achieve the best performance of models (bearing test rig [19], rotating machinery [74], autonomous underwater vehicles [41]) | ||
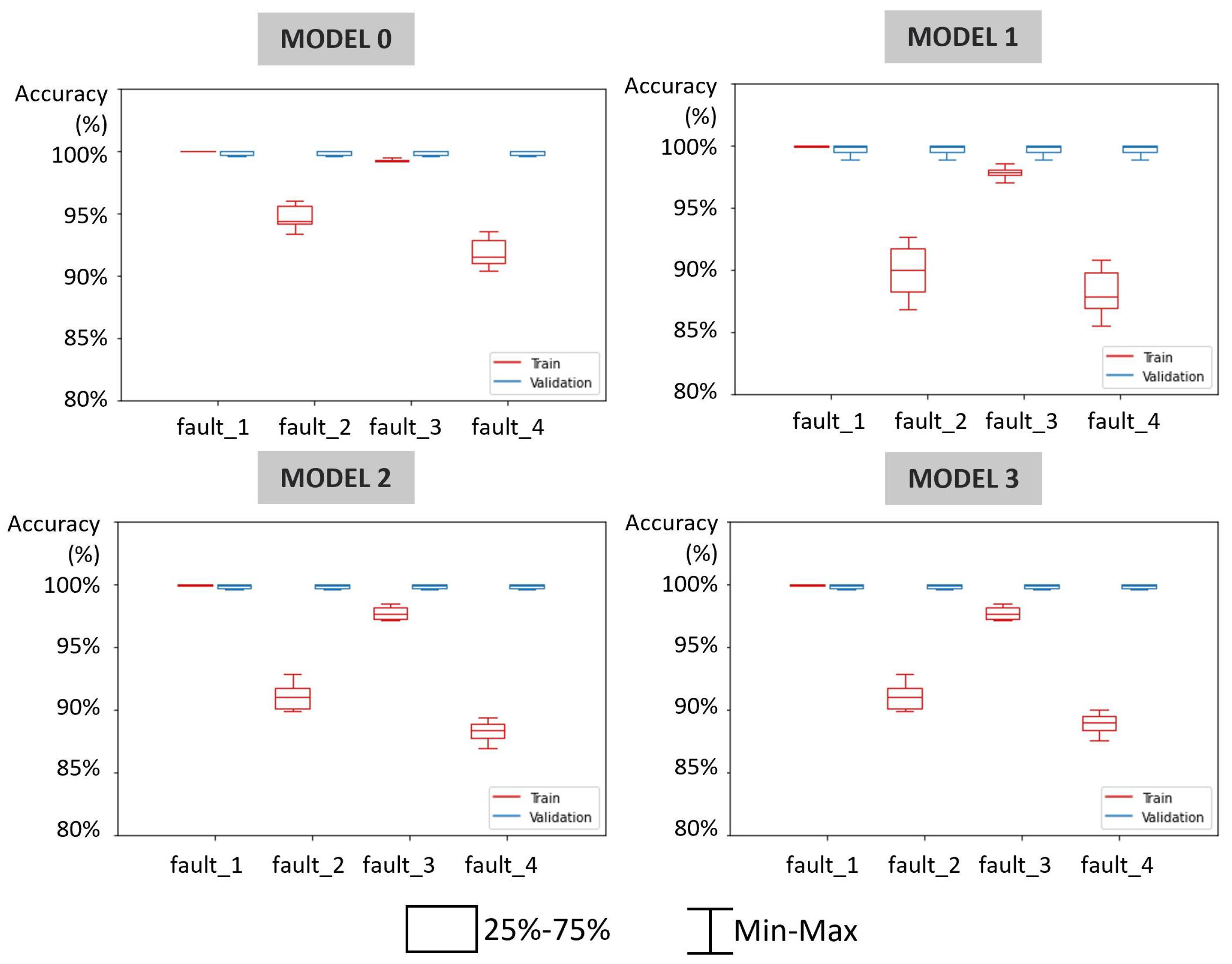
| Model execution | Training and Validation accuracy | Visualize train and validation accuracy and loss values (bearing test rig [19]) | Accuracy graph (•••) |
| Performance evaluation | Show the prediction accuracy (photovoltaic panels [60], autonomous underwater vehicles [41]) | Confusion matrix (•••) | |
| (Hyper)parameter evaluation | Visualize the effect of hyper-parameters and parameters (photovoltaic panels [60,66]) | Parameter score table by meta-heuristic algorithm (••) | |
| Validation effectiveness | Estimates the valid duration for each fault prediction, in which the predicted result holds acceptable accuracy | ||
| Resource consumption | Report the current time/resource/energy consumption [60,92] and carbon emission [57,58] to prepare for the model operation | Carbon-tracker to track the used energy from model training (••) | |
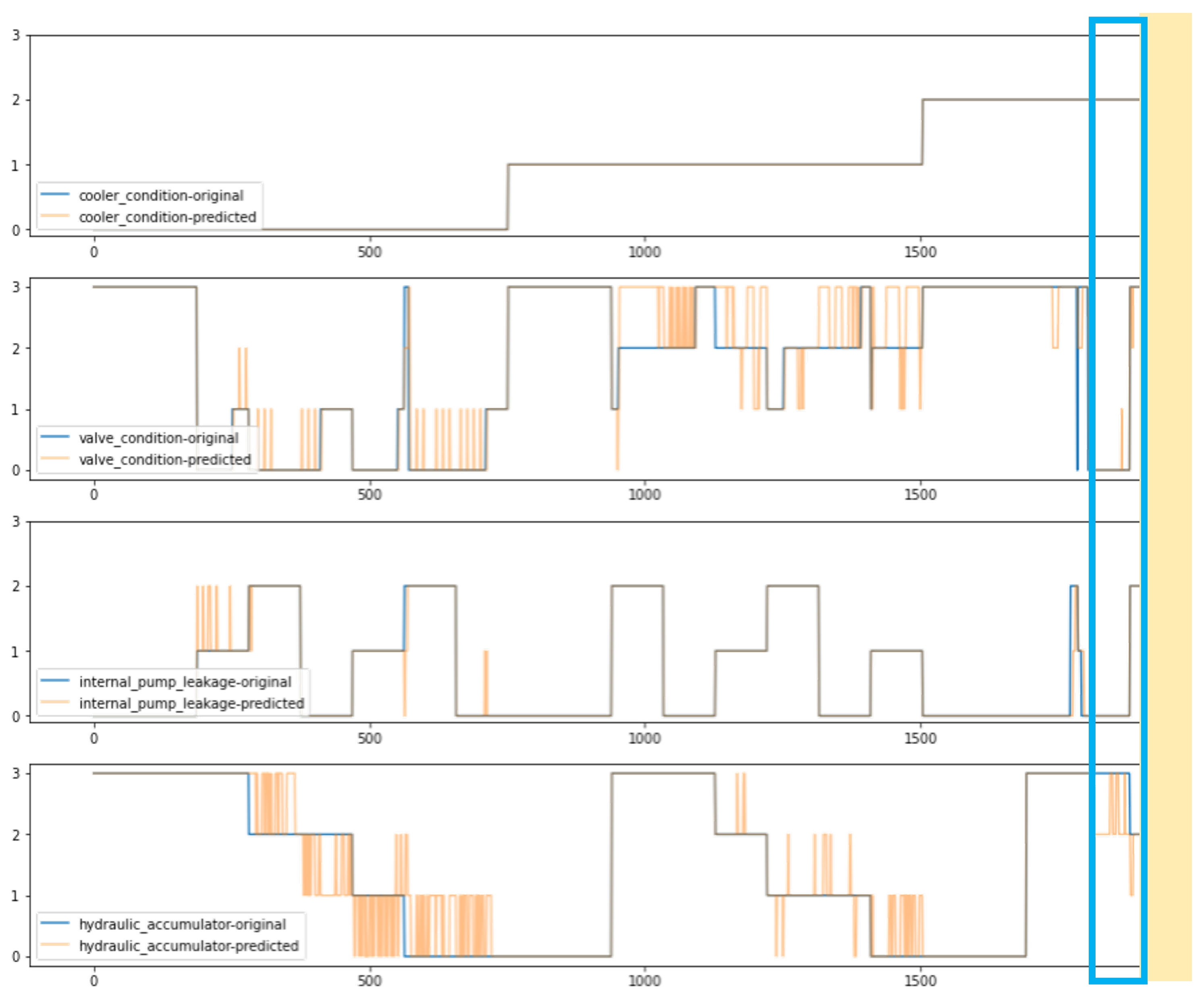
| Model operation | Individual case prediction | Explaining representative individual prediction with fault characteristics and weight (rotating machinery [74], chiller system [18], chemical process [17,75], motor bearing [23], heat recycler [138]), showing a sliding prediction window during operation (air handling unit [54]) | Fault isolation with reconstruction- and SHAP-based construction (••), SHAP to explain the weight of each feature in prediction of an individual case (•••), LIME to show the effect of variation signals from an individual case on prediction results (•••), sliding prediction window with new incoming sensor data (••) |
| System performance | Explain the impact of the fault to the monitored system (chiller system [18]), system Remaining Useful Life (RUL) prediction (motor bearing [23], turbofan engines [24], autonomous underwater vehicles [41]), process parameters (etching process [55]) | Impact analyzer with dialog system (••), RUL chart (••), control chart (••) | |
| FDI performance | Show the model performance with FDI task and preventive ability (turbofan engines [24], chemical process [17]), fault isolation rate (etching process [55], heat recycler [138]) | Root Mean Square Error and the Scoring function (•), FDR and FAR table (••), isolation rate table (••) | |
| Monitoring and Alerting | Provide real-time alert to field personnel (chiller system [18], chemical process [17], air handling unit [54,65], photovoltaic panels [60]) | Local explanation triggered by Key Performance Indicators (KPIs) (••) | |
| Documentation | Store documentation and reasoning during the model construction. |
| D.P. | Aspect | Reasoning (Study) | Proposed Tools (Maturity Level) |
|---|---|---|---|
| Pipeline development | Input signal attribute | Analyze the contribution of input frequency to the performance (rotating electric motor [20]) | LIME to elucidate important frequencies and orders in input data of each fault class (•••) |
| Data augmentation | Increase the number of data in case of data insufficiency or imbalanced data set (air handling unit [65]). | Table of fault type and sample size to adjust training data (this study) (••), Synthetic Minority Oversampling TEchnique (SMOTE) to enhance the fault class distribution and eliminate the extreme data unbalance in the training set (•••) | |
| Fault definition | Data profiling for each fault type (chiller system [18]), labeling faulty variable with the root cause (etching process [55], bearing test rig [19]), show the frequency distribution of associated sensor signals (hydraulic system [38]) determine the beginning of fault (rotating machinery [74]) | Operating condition chart (•), Fault table with fault rules (•), waterfall envelop spectrum (••), frequency distribution table (••) | |
| Input data management | Stores the current data set, and visualizes the changes in input data and a short history of faults (air handling unit [54]) | Moving window of fault frequency (this study) (••) | |
| Input sufficiency | Input space analysis | Analyze the effect of the input data set: data set size, the train/test split, number of faulty samples (simulated pick/place system & electric furnace [33]); data distribution (chemical process [17], motor bearing [23]), data imbalance (rotating electric motor [20], photovoltaic panel [66]), detect anomaly input sample (rotating machinery [74]) | K-means clustering on training data (••), LIME to analyze the local data points in the input space (•••), observation table (••) |
| Learned features | The feature characteristics of fault can be determined based on the knowledge from the previous sprint (bearing test rig [19], rotating machinery [74], air handling unit [65]) | Provide quantitative explanations of each feature to the fault prediction with SHAP (•••), signal samples of fault types (••) | |
| Regression sensitivity | Consider the effect of different values of regressive time step | Box-plot of model accuracy over regressive time step (this study) (••) | |
| Resource consumption | Consider the computational power for performing FDI tasks with the trained model on computers or embedded systems (simulated pick/place system and electric furnace [33]) | ||
| Structure efficiency | Architecture evaluation | Evaluate the compactness and utilization of the architecture; The appropriateness of the output for prediction purpose (turbofan engines [24]) | |
| Layer activation | Evaluate the activation map of layers (rotating electric motor [20]) | Class Activation Mapping (CAM) variants (•••), Layer-wise Relevance Propagation (LRP) variants (•••) | |
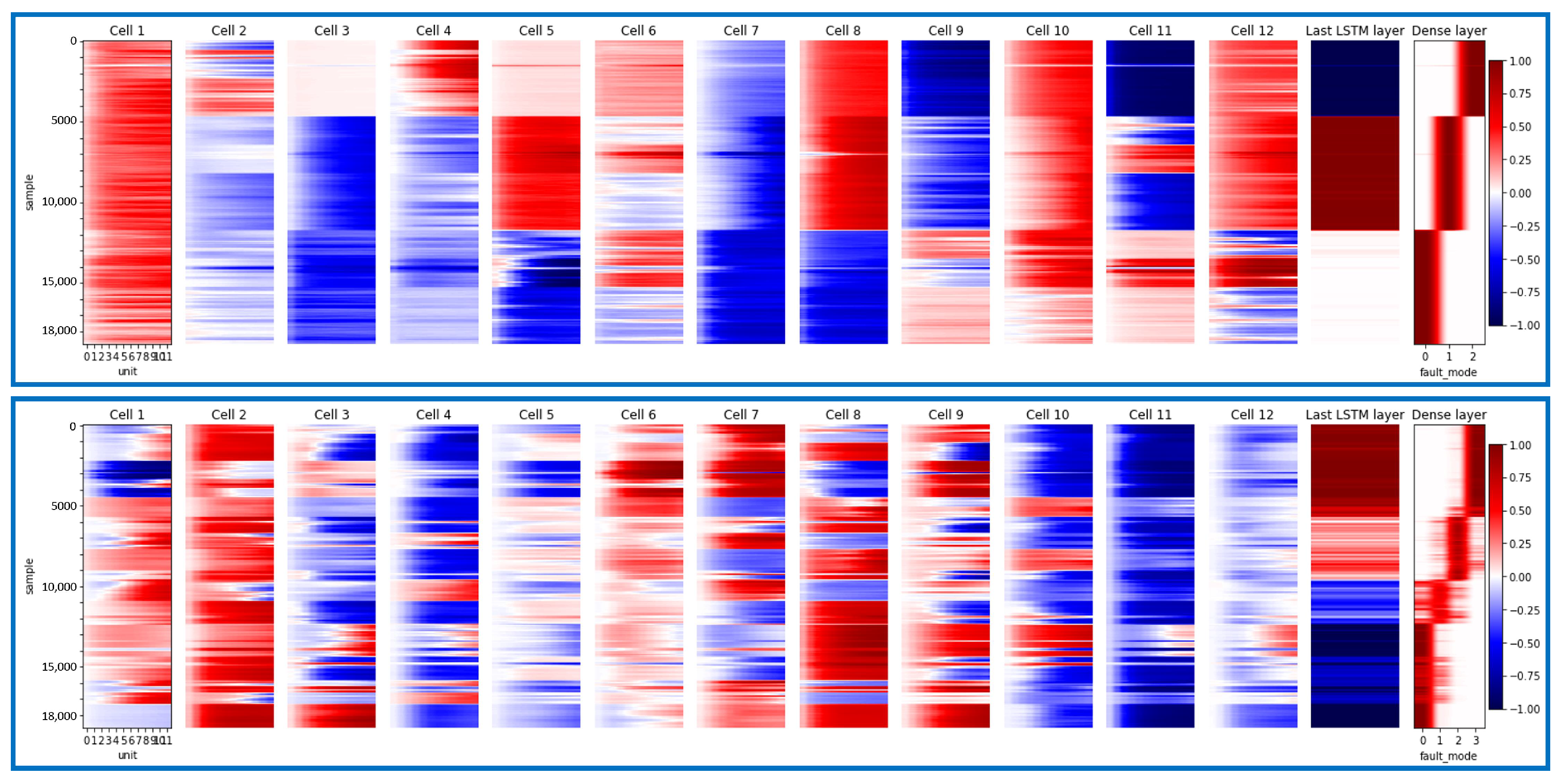
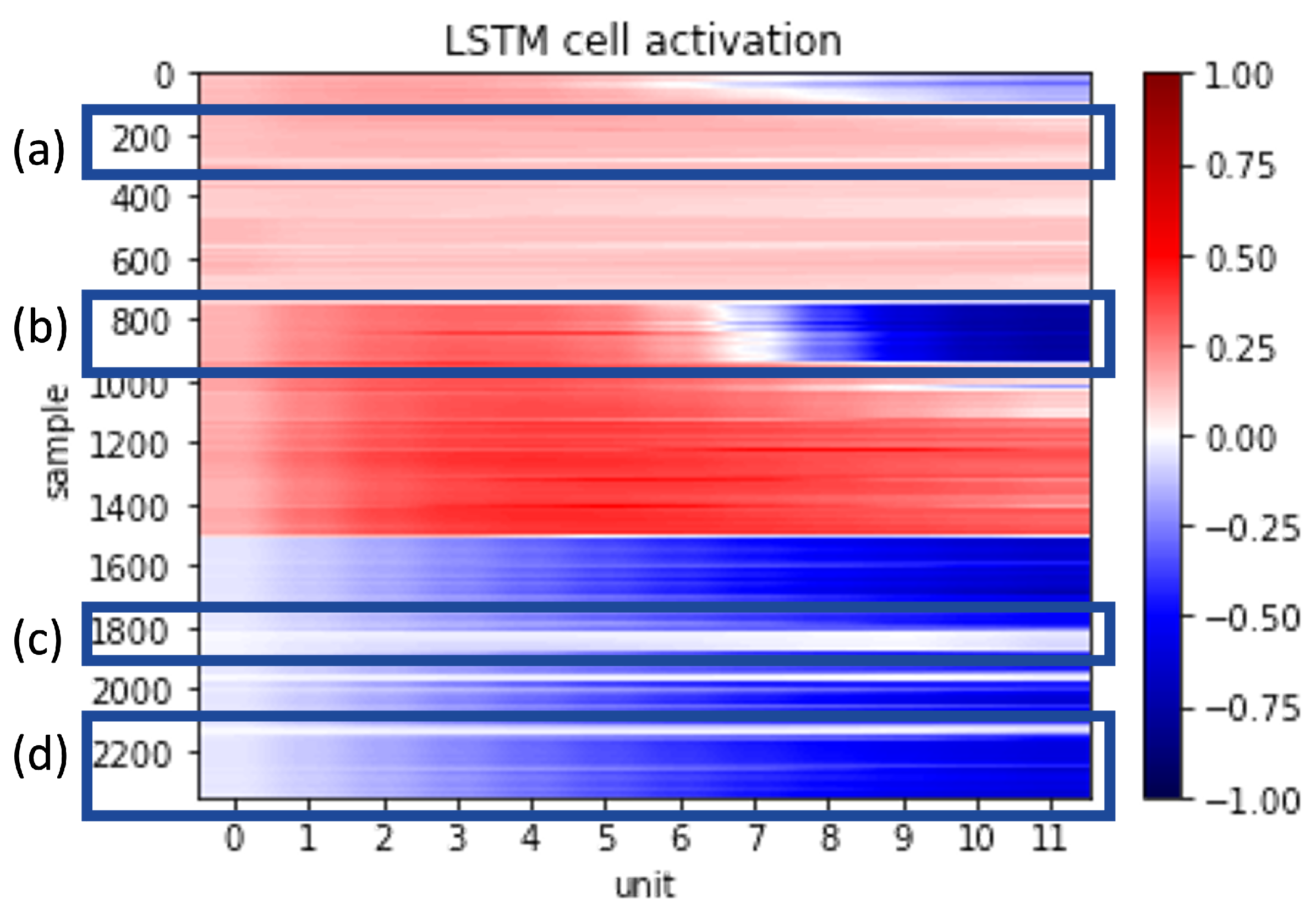
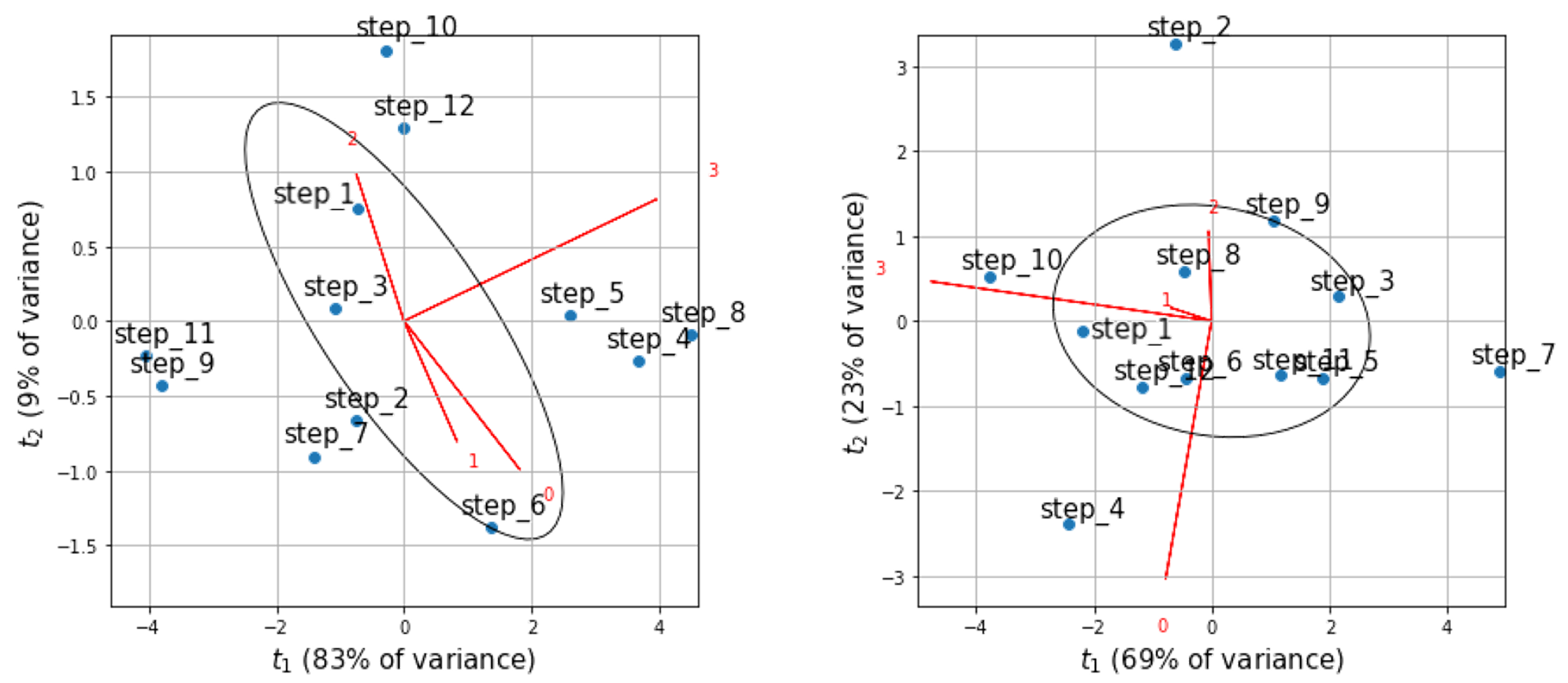
| Cell activation | Evaluate the utilization of unit in each LSTM cell | Principal Component Analysis (PCA) on cells in one layer (this study) (••) | |
| Fault learning rate | Evaluate how much data is required to learn each fault type | ||
| Decision rules | Fault diagnosis | Visualized fault characteristics and behaviors (photovoltaic panels [60]), visualized the causal interaction of process system (etching process [55]) | Characteristic curve of fault (••), fault causal network (••) |
| Feature contribution | Explain the relevance of timed-events and continuous variables features (simulated pick/place system & electric furnace [33]); the contribution of features (turbofan engines [24], chemical process [17], bearing test rig [19], rotating electric motor [20], rotating machinery [74], chiller system [18]) | SHAP to rate the contribution of features an individual case (•••), LIME to define the threshold of each feature on an individual case (•••), Ablation study by Pycaret library [139] (•••), Local-Depth-based Isolation Forest Feature Importance (Local-DIFFI) (•••) | |
| Decision criteria | Explain the decision range of each feature for an observation (photovoltaic panel [66]), the difference between faulty to normal operating condition (chemical process [75]), root cause analysis between different fault (rotating machinery [74]) | Anchors (•••), Diverse Counterfactual Explanations (DiCE) (•••), root cause feature ranking (••) | |
| Decision trajectory tracking | Explaining the inflation of monitoring index for both latent and construction space (chemical process [17]), Track the activation trajectory of fault cases (chemical process [140]) | Average gradient against scaled deviation (••), PCA trajectory of LSTM layer (this study) (••) | |
| Diagnostic capability | Decision space analysis | Analyze the capability of the model based on the distinguishability of faults in construction space (chemical process [17]), on the output layer (turbofan engines [24]), or based on the PCA on activation values of latent space (vinyl acetate simulated process [112]). | Hierarchical clustering on SHAP-based contribution (••), PCA on LSTM layer of fault branch (this study) (••) |
| Robustness analysis | Visualize the effect of signal-fluctuation faults (e.g., sensor drift and simultaneous faults) (chemical process [17]), false alarm (photovoltaic panels [60]), explanation stability and consistency (photovoltaic panels [66]) | Explanation chart with fault deviation (••), box plot of SHAP/DiCE values (••) | |
| Uncertainty quantification | Provide the uncertainty estimated for prediction results (turbofan engines [24]) | Rolling standard deviation plot of Health Index (••) | |
| Abnormal analysis | Analyze the diagnostic capability against rare and abnormal events (chemical process [17], rotating machinery [74]), abnormal working conditions (photovoltaic panels [60]) and hypothetical observation (photovoltaic panels [66]) | F1-FDR-FAR score table of faults (••), accuracy and error charts (••), DiCE (•••) |
| D.P. | Step | (Main) S.H. | Reasoning (Study) |
|---|---|---|---|
| Model planning | Prior process understanding | (BS, HU); DS | Sketch the model requirements based on prior knowledge and business requirement [30,54,56]. |
| Physics-informed feedback | (DS; HU); DE | Improve the model with the learned physics-informed feedback [17,87]. | |
| Improvement idea | (HU); BS | Ignite the next development/refinement loop via Kaizen activities [86]; | |
| Requirement analysis | (HU; DS;) MLA | Define a use case for the next development/refinement [81] | |
| Exploratory Data Analysis | (DA) | Analyze the data availability before the next development cycle [81] | |
| Initial modeling | (DE; MLA); SE | Prepare an initial model to assess model feasibility [81] | |
| Model construction | API/Development environment | (SE); MLA | Establish the API and development environment [27,60,81] |
| Cloud/fog/edge integration | (DOE); SE | FDI task execution can be implemented on cloud, fog, or edge services [33,60] | |
| Continuous Deployment/Continuous Integration pipeline (CD/CI) and platform | (DOE); SE | Establish an automated ML workflow [30,83,92] | |
| Compression and scaling | (SE; DOE); MLA | Build a compact model which is suitable for scaling [30] | |
| Model monitoring | Model metrics and logs | (DS); DE; HU | Manage the model registry with associated performance metrics and logs [27,30,60,81]. |
| Pipeline monitoring | (DOE); SE; DE | Monitoring the performance of the established pipeline [92] | |
| Ground truth monitoring | (DE); HU; DOE | Manage and track the ground truth of faults after each model development [19,24,94] | |
| Drift monitoring | (DE); DOE | Cope with the drift of incoming data from original Data/Model/Concept [27,81,95,141] | |
| Decay monitoring | (DOE; DE); DS | Establish a procedure to detect and alert the model decay during production [56,81] | |
| Continuous training | (DOE); DE | Develop a matured MLOps system by retraining [96] | |
| Trust-based optimization | (HU); DOE | Fine tune the model operation based on modeling the human trust [98] | |
| Data feedback loop | (DOE); MLA | Create an informed network with knowledge integration workflow [78] | |
| Model refinement | Alarm reset and Acceptance | (DOE), SE, HU | Refine the model by human request [84], or analyze the alarm acceptance rate [18,60] |
| Self-assessment | (DOE), SE, HU | Use random feedback from human users to update the next model revolution [84,94] | |
| Fault analysis and Update | (DA); HU; BS | Analyze the fault based on newly achieved knowledge, and update the fault characteristics | |
| Random data generation | (DS); MLA | Enrich data for self-validation, or solve data imbalance problems [99] | |
| Trust management | (DOE; SE;) HU; DS | Manage the required information and individual preference for trust establishment [101,102] | |
| Request and Self-triggering | (HU), BS | Self-execute [30], request for human clarification [94], adjustment [84], or retrain with predefined threshold [81] | |
| Model life cycle management | Repository management | (DOE); SE | Manage the data and source code throughout model revolutions [27,30,81] |
| New model introduction | (DOE; SE) | Introduce new model incremental updates or features into the staging/production environment [27,81]. | |
| New model integration and testing | (SE); DE; MLA | Gradually updating new model update after each testing trials [30,81] | |
| Performance comparison | (DOE; DS); DE; HU | Compare performance between newly deployed model with the previous versions [30,81] | |
| Approval and Production update | (DOE); SE; BS | Approve the new update and launch production phase [81] | |
| Model troubleshooting | (SE); DOE | Reset the model into previous version when necessary [81] | |
| Production model governance | Versioning | (DOE); SE | Record the previous models were deployed in production [81]. |
| Lineage tracking and Audit trials | (DOE); MLA; SE | Perform the regular audit trial and collect audit results during development and usage [81]. | |
| Data security | (SE); DE | Resolve security issues and grant control access to stakeholders [44,81] | |
| Data privacy | (DE); SE | Validate the conformity with privacy rights and regulations (i.e., General Data Protection Regulation (GDPA) and California Consumer Privacy Act (CCPA)) [81]. | |
| Packaging | (SE); DOE; DE | Warp up the necessary codes and platform for each model [81]. | |
| Reporting | (SE); BS | Provide requested documentation and information for model usage [81] |
References
- Haddad, D.; Wang, L.; Kallel, A.Y.; Amara, N.E.B.; Kanoun, O. Multi-sensor-based method for multiple hard faults identification in complex wired networks. In Proceedings of the 2022 IEEE 9th International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications (CIVEMSA), Chemnitz, Germany, 15–17 June 2022; pp. 1–5. [Google Scholar]
- Yu, W.; Wu, M.; Huang, B.; Lu, C. A generalized probabilistic monitoring model with both random and sequential data. Automatica 2022, 144, 110468. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Guo, L.; Lin, J.; Xing, S. A neural network constructed by deep learning technique and its application to intelligent fault diagnosis of machines. Neurocomputing 2018, 272, 619–628. [Google Scholar] [CrossRef]
- Su, K.; Liu, J.; Xiong, H. Hierarchical diagnosis of bearing faults using branch convolutional neural network considering noise interference and variable working conditions. Knowl.-Based Syst. 2021, 230, 107386. [Google Scholar] [CrossRef]
- Gupta, M.; Wadhvani, R.; Rasool, A. A real-time adaptive model for bearing fault classification and remaining useful life estimation using deep neural network. Knowl.-Based Syst. 2023, 259, 110070. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Yu, W.; Zhao, C.; Huang, B.; Xie, M. An unsupervised fault detection and diagnosis with distribution dissimilarity and lasso penalty. IEEE Trans. Control Syst. Technol. 2023, 32, 767–779. [Google Scholar] [CrossRef]
- Qin, S.J. Survey on data-driven industrial process monitoring and diagnosis. Annu. Rev. Control 2012, 36, 220–234. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Castelvecchi, D. Can we open the black box of AI? Nat. News 2016, 538, 20. [Google Scholar] [CrossRef]
- Lipton, Z.C. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, Y. A comprehensive survey on regularization strategies in machine learning. Inf. Fusion 2022, 80, 146–166. [Google Scholar] [CrossRef]
- Sevillano-García, I.; Luengo, J.; Herrera, F. SHIELD: A regularization technique for eXplainable Artificial Intelligence. arXiv 2024, arXiv:2404.02611. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Das, A.; Rad, P. Opportunities and challenges in explainable artificial intelligence (xai): A survey. arXiv 2020, arXiv:2006.11371. [Google Scholar]
- Ahmed, I.; Jeon, G.; Piccialli, F. From artificial intelligence to explainable artificial intelligence in industry 4.0: A survey on what, how, and where. IEEE Trans. Ind. Inform. 2022, 18, 5031–5042. [Google Scholar] [CrossRef]
- Jang, K.; Pilario, K.E.S.; Lee, N.; Moon, I.; Na, J. Explainable Artificial Intelligence for Fault Diagnosis of Industrial Processes. IEEE Trans. Ind. Inform. 2023; in press. [Google Scholar]
- Srinivasan, S.; Arjunan, P.; Jin, B.; Sangiovanni-Vincentelli, A.L.; Sultan, Z.; Poolla, K. Explainable AI for chiller fault-detection systems: Gaining human trust. Computer 2021, 54, 60–68. [Google Scholar] [CrossRef]
- Brusa, E.; Cibrario, L.; Delprete, C.; Di Maggio, L.G. Explainable AI for Machine Fault Diagnosis: Understanding Features’ Contribution in Machine Learning Models for Industrial Condition Monitoring. Appl. Sci. 2023, 13, 2038. [Google Scholar] [CrossRef]
- Mey, O.; Neufeld, D. Explainable AI Algorithms for Vibration Data-Based Fault Detection: Use Case-Adadpted Methods and Critical Evaluation. Sensors 2022, 22, 9037. [Google Scholar] [CrossRef]
- Hamilton, D.; Pacheco, R.; Myers, B.; Peltzer, B. kNN vs. SVM: A Comparison of Algorithms. Fire-Contin.-Prep. Future Wildland Fire Missoula USA 2018, 78, 95–109. [Google Scholar]
- Hasan, M.J.; Sohaib, M.; Kim, J.M. An explainable ai-based fault diagnosis model for bearings. Sensors 2021, 21, 4070. [Google Scholar] [CrossRef]
- Sanakkayala, D.C.; Varadarajan, V.; Kumar, N.; Soni, G.; Kamat, P.; Kumar, S.; Patil, S.; Kotecha, K. Explainable AI for Bearing Fault Prognosis Using Deep Learning Techniques. Micromachines 2022, 13, 1471. [Google Scholar] [CrossRef] [PubMed]
- Nor, A.K.M. Failure Prognostic of Turbofan Engines with Uncertainty Quantification and Explainable AI (XIA). Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 3494–3504. [Google Scholar] [CrossRef]
- Nor, A.K.B.M.; Pedapait, S.R.; Muhammad, M. Explainable ai (xai) for phm of industrial asset: A state-of-the-art, prisma-compliant systematic review. arXiv 2021, arXiv:2107.03869. [Google Scholar]
- Saeed, W.; Omlin, C. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowl.-Based Syst. 2023, 263, 110273. [Google Scholar] [CrossRef]
- Ruf, P.; Madan, M.; Reich, C.; Ould-Abdeslam, D. Demystifying mlops and presenting a recipe for the selection of open-source tools. Appl. Sci. 2021, 11, 8861. [Google Scholar] [CrossRef]
- Alla, S.; Adari, S.K.; Alla, S.; Adari, S.K. What is mlops? In Beginning MLOps with MLFlow: Deploy Models in AWS SageMaker, Google Cloud, and Microsoft Azure; Apress: New York, NY, USA, 2021; pp. 79–124. [Google Scholar]
- Lwakatare, L.E.; Kuvaja, P.; Oivo, M. Relationship of devops to agile, lean and continuous deployment: A multivocal literature review study. In Proceedings of the Product-Focused Software Process Improvement: 17th International Conference, PROFES 2016, Trondheim, Norway, 22–24 November 2016; Proceedings 17. Springer: Berlin/Heidelberg, Germany, 2016; pp. 399–415. [Google Scholar]
- Karamitsos, I.; Albarhami, S.; Apostolopoulos, C. Applying DevOps practices of continuous automation for machine learning. Information 2020, 11, 363. [Google Scholar] [CrossRef]
- Tamburri, D.A. Sustainable mlops: Trends and challenges. In Proceedings of the 2020 22nd International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 1–4 September 2020; pp. 17–23. [Google Scholar]
- Chen, Y.; Rao, M.; Feng, K.; Zuo, M.J. Physics-Informed LSTM hyperparameters selection for gearbox fault detection. Mech. Syst. Signal Process. 2022, 171, 108907. [Google Scholar] [CrossRef]
- Leite, D.; Martins, A., Jr.; Rativa, D.; De Oliveira, J.F.; Maciel, A.M. An Automated Machine Learning Approach for Real-Time Fault Detection and Diagnosis. Sensors 2022, 22, 6138. [Google Scholar] [CrossRef]
- Zöller, M.A.; Titov, W.; Schlegel, T.; Huber, M.F. XAutoML: A Visual Analytics Tool for Establishing Trust in Automated Machine Learning. arXiv 2022, arXiv:2202.11954. [Google Scholar]
- Helwig, N.; Pignanelli, E.; Schütze, A. Condition monitoring of a complex hydraulic system using multivariate statistics. In Proceedings of the 2015 IEEE International Instrumentation and Measurement Technology Conference (I2MTC) Proceedings, Pisa, Italy, 11–14 May 2015; pp. 210–215. [Google Scholar]
- Schneider, T.; Helwig, N.; Schütze, A. Automatic feature extraction and selection for classification of cyclical time series data. tm-Tech. Mess. 2017, 84, 198–206. [Google Scholar] [CrossRef]
- Huang, K.; Wu, S.; Li, F.; Yang, C.; Gui, W. Fault diagnosis of hydraulic systems based on deep learning model with multirate data samples. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6789–6801. [Google Scholar] [CrossRef] [PubMed]
- Keleko, A.T.; Kamsu-Foguem, B.; Ngouna, R.H.; Tongne, A. Health condition monitoring of a complex hydraulic system using Deep Neural Network and DeepSHAP explainable XAI. Adv. Eng. Softw. 2023, 175, 103339. [Google Scholar] [CrossRef]
- Goelles, T.; Schlager, B.; Muckenhuber, S. Fault detection, isolation, identification and recovery (fdiir) methods for automotive perception sensors including a detailed literature survey for lidar. Sensors 2020, 20, 3662. [Google Scholar] [CrossRef] [PubMed]
- Keipour, A.; Mousaei, M.; Scherer, S. Automatic real-time anomaly detection for autonomous aerial vehicles. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5679–5685. [Google Scholar]
- Das, D.B.; Birant, D. GASEL: Genetic algorithm-supported ensemble learning for fault detection in autonomous underwater vehicles. Ocean. Eng. 2023, 272, 113844. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Love, P.E.; Fang, W.; Matthews, J.; Porter, S.; Luo, H.; Ding, L. Explainable artificial intelligence (XAI): Precepts, models, and opportunities for research in construction. Adv. Eng. Inform. 2023, 57, 102024. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.C. Integration of blockchain, IoT and machine learning for multistage quality control and enhancing security in smart manufacturing. Sensors 2021, 21, 1467. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning, 2nd ed.; Lulu.com: Morrisville, NC, USA, 2022. [Google Scholar]
- Kravchenko, T.; Bogdanova, T.; Shevgunov, T. Ranking requirements using MoSCoW methodology in practice. In Proceedings of the Computer Science On-Line Conference, Virtual, 26–30 April 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 188–199. [Google Scholar]
- Paleyes, A.; Urma, R.G.; Lawrence, N.D. Challenges in deploying machine learning: A survey of case studies. Acm Comput. Surv. 2022, 55, 1–29. [Google Scholar] [CrossRef]
- Zhang, Y.; Patel, S. Agile model-driven development in practice. IEEE Softw. 2010, 28, 84–91. [Google Scholar] [CrossRef]
- Jäger, D.; Gümmer, V. PythonDAQ–A Python based measurement data acquisition and processing software. J. Phys. Conf. Ser. 2023, 2511, 012016. [Google Scholar] [CrossRef]
- Weber, S. PyMoDAQ: An open-source Python-based software for modular data acquisition. Rev. Sci. Instrum. 2021, 92, 045104. [Google Scholar] [CrossRef]
- Martins, S.A.M. PYDAQ: Data Acquisition and Experimental Analysis with Python. J. Open Source Softw. 2023, 8, 5662. [Google Scholar] [CrossRef]
- Mozafari, B.; Sarkar, P.; Franklin, M.; Jordan, M.; Madden, S. Scaling up crowd-sourcing to very large datasets: A case for active learning. Proc. Vldb Endow. 2014, 8, 125–136. [Google Scholar] [CrossRef]
- Ehrenberg, H.R.; Shin, J.; Ratner, A.J.; Fries, J.A.; Ré, C. Data programming with ddlite: Putting humans in a different part of the loop. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics, New York, NY, USA, 26 June–1 July 2016; pp. 1–6. [Google Scholar]
- Meas, M.; Machlev, R.; Kose, A.; Tepljakov, A.; Loo, L.; Levron, Y.; Petlenkov, E.; Belikov, J. Explainability and Transparency of Classifiers for Air-Handling Unit Faults Using Explainable Artificial Intelligence (XAI). Sensors 2022, 22, 6338. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.T.; Reis, M.S.; Borodin, V.; Juge, M.; Roussy, A. An interpretable unsupervised Bayesian network model for fault detection and diagnosis. Control Eng. Pract. 2022, 127, 105304. [Google Scholar] [CrossRef]
- Testi, M.; Ballabio, M.; Frontoni, E.; Iannello, G.; Moccia, S.; Soda, P.; Vessio, G. MLOps: A Taxonomy and a Methodology. IEEE Access 2022, 10, 63606–63618. [Google Scholar] [CrossRef]
- Budennyy, S.A.; Lazarev, V.D.; Zakharenko, N.N.; Korovin, A.N.; Plosskaya, O.; Dimitrov, D.V.; Akhripkin, V.; Pavlov, I.; Oseledets, I.V.; Barsola, I.S.; et al. Eco2ai: Carbon emissions tracking of machine learning models as the first step towards sustainable ai. Dokl. Math. 2022, 106 (Suppl. S1), S118–S128. [Google Scholar] [CrossRef]
- Anthony, L.F.W.; Kanding, B.; Selvan, R. Carbontracker: Tracking and predicting the carbon footprint of training deep learning models. arXiv 2020, arXiv:2007.03051. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Sairam, S.; Seshadhri, S.; Marafioti, G.; Srinivasan, S.; Mathisen, G.; Bekiroglu, K. Edge-based Explainable Fault Detection Systems for photovoltaic panels on edge nodes. Renew. Energy 2022, 185, 1425–1440. [Google Scholar] [CrossRef]
- Bouza, L.; Bugeau, A.; Lannelongue, L. How to estimate carbon footprint when training deep learning models? A guide and review. Environ. Res. Commun. 2023, 5, 115014. [Google Scholar] [CrossRef]
- Al-Aomar, R. A methodology for determining Process and system-level manufacturing performance metrics. Sae Trans. 2002, 1043–1056. [Google Scholar]
- Frank, S.M.; Lin, G.; Jin, X.; Singla, R.; Farthing, A.; Zhang, L.; Granderson, J. Metrics and Methods to Assess Building Fault Detection and Diagnosis Tools; Technical Report; National Renewable Energy Lab. (NREL): Golden, CO, USA, 2019. [Google Scholar]
- Zhu, T.; Lin, Y.; Liu, Y. Synthetic minority oversampling technique for multiclass imbalance problems. Pattern Recognit. 2017, 72, 327–340. [Google Scholar] [CrossRef]
- Belikov, J.; Meas, M.; Machlev, R.; Kose, A.; Tepljakov, A.; Loo, L.; Petlenkov, E.; Levron, Y. Explainable AI based fault detection and diagnosis system for air handling units. In Proceedings of the International Conference on Informatics in Control, Automation and Robotics, Lisbon, Portugal, 14–16 July 2022; pp. 14–16. [Google Scholar]
- Utama, C.; Meske, C.; Schneider, J.; Schlatmann, R.; Ulbrich, C. Explainable artificial intelligence for photovoltaic fault detection: A comparison of instruments. Sol. Energy 2023, 249, 139–151. [Google Scholar] [CrossRef]
- He, M.; Li, B.; Sun, S. A Survey of Class Activation Mapping for the Interpretability of Convolution Neural Networks. In Signal and Information Processing, Networking and Computers: Proceedings of the 10th International Conference on Signal and Information Processing, Networking and Computers (ICSINC), Xi’Ning, China, July 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 399–407. [Google Scholar]
- Montavon, G.; Binder, A.; Lapuschkin, S.; Samek, W.; Müller, K.R. Layer-wise relevance propagation: An overview. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Berlin/Heidelberg, Germany, 2019; pp. 193–209. [Google Scholar]
- Van den Broeck, G.; Lykov, A.; Schleich, M.; Suciu, D. On the tractability of SHAP explanations. J. Artif. Intell. Res. 2022, 74, 851–886. [Google Scholar] [CrossRef]
- Laves, M.H.; Ihler, S.; Ortmaier, T. Uncertainty Quantification in Computer-Aided Diagnosis: Make Your Model say “I don’t know” for Ambiguous Cases. arXiv 2019, arXiv:1908.00792. [Google Scholar]
- Shafaei, S.; Kugele, S.; Osman, M.H.; Knoll, A. Uncertainty in machine learning: A safety perspective on autonomous driving. In Proceedings of the Computer Safety, Reliability, and Security: SAFECOMP 2018 Workshops, ASSURE, DECSoS, SASSUR, STRIVE, and WAISE, Västerås, Sweden, 18 September 2018; Proceedings 37. Springer: Berlin/Heidelberg, Germany, 2018; pp. 458–464. [Google Scholar]
- Chen, N.C.; Drouhard, M.; Kocielnik, R.; Suh, J.; Aragon, C.R. Using machine learning to support qualitative coding in social science: Shifting the focus to ambiguity. Acm Trans. Interact. Intell. Syst. (TiiS) 2018, 8, 1–20. [Google Scholar] [CrossRef]
- Munro, R.; Monarch, R. Human-in-the-Loop Machine Learning: Active Learning and Annotation for Human-Centered AI; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Brito, L.C.; Susto, G.A.; Brito, J.N.; Duarte, M.A. An explainable artificial intelligence approach for unsupervised fault detection and diagnosis in rotating machinery. Mech. Syst. Signal Process. 2022, 163, 108105. [Google Scholar] [CrossRef]
- Harinarayan, R.R.A.; Shalinie, S.M. XFDDC: EXplainable Fault Detection Diagnosis and Correction framework for chemical process systems. Process. Saf. Environ. Prot. 2022, 165, 463–474. [Google Scholar] [CrossRef]
- Ghosh, A.; Nachman, B.; Whiteson, D. Uncertainty-aware machine learning for high energy physics. Phys. Rev. D 2021, 104, 056026. [Google Scholar] [CrossRef]
- Li, W.; Li, H.; Gu, S.; Chen, T. Process fault diagnosis with model-and knowledge-based approaches: Advances and opportunities. Control Eng. Pract. 2020, 105, 104637. [Google Scholar] [CrossRef]
- Kim, S.W.; Kim, I.; Lee, J.; Lee, S. Knowledge Integration into deep learning in dynamical systems: An overview and taxonomy. J. Mech. Sci. Technol. 2021, 35, 1331–1342. [Google Scholar] [CrossRef]
- Sovrano, F.; Vitali, F. An objective metric for explainable AI: How and why to estimate the degree of explainability. Knowl.-Based Syst. 2023, 278, 110866. [Google Scholar] [CrossRef]
- Breck, E.; Cai, S.; Nielsen, E.; Salib, M.; Sculley, D. The ML test score: A rubric for ML production readiness and technical debt reduction. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1123–1132. [Google Scholar]
- Larysa, V.; Anja, K.; Isabel, B.; Alexander, K.; Michael, P. MLOps Principles. 2022. Available online: https://ml-ops.org/content/mlops-principles (accessed on 11 September 2024).
- Treveil, M.; Omont, N.; Stenac, C.; Lefevre, K.; Phan, D.; Zentici, J.; Lavoillotte, A.; Miyazaki, M.; Heidmann, L. Introducing MLOps; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Kreuzberger, D.; Kühl, N.; Hirschl, S. Machine learning operations (mlops): Overview, definition, and architecture. IEEE Access 2023, 11, 31866–31879. [Google Scholar] [CrossRef]
- Abonyi, J.; Babuška, R.; Szeifert, F. Fuzzy expert system for supervision in adaptive control. Ifac Proc. Vol. 2000, 33, 241–246. [Google Scholar] [CrossRef]
- Shearer, C. The CRISP-DM model: The new blueprint for data mining. J. Data Warehous. 2000, 5, 13–22. [Google Scholar]
- Awad, M.; Shanshal, Y.A. Utilizing Kaizen process and DFSS methodology for new product development. Int. J. Qual. Reliab. Manag. 2017, 34, 378–394. [Google Scholar] [CrossRef]
- Karpatne, A.; Watkins, W.; Read, J.; Kumar, V. How can physics inform deep learning methods in scientific problems?: Recent progress and future prospects. In Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1–5. [Google Scholar]
- Cuomo, S.; Di Cola, V.S.; Giampaolo, F.; Rozza, G.; Raissi, M.; Piccialli, F. Scientific machine learning through physics–informed neural networks: Where we are and what’s next. J. Sci. Comput. 2022, 92, 88. [Google Scholar] [CrossRef]
- Arachchi, S.; Perera, I. Continuous integration and continuous delivery pipeline automation for agile software project management. In Proceedings of the 2018 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 30 May–1 June 2018; pp. 156–161. [Google Scholar]
- Neely, S.; Stolt, S. Continuous delivery? easy! just change everything (well, maybe it is not that easy). In Proceedings of the 2013 Agile Conference, Nashville, TN, USA, 5–9 August 2013; pp. 121–128. [Google Scholar]
- Humble, J.; Farley, D. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation; Pearson Education: London, UK, 2010. [Google Scholar]
- Zhou, Y.; Yu, Y.; Ding, B. Towards mlops: A case study of ml pipeline platform. In Proceedings of the 2020 International Conference on Artificial Intelligence and Computer Engineering (ICAICE), Beijing, China, 23–25 October 2020; pp. 494–500. [Google Scholar]
- Pathania, N. Learning Continuous Integration with Jenkins: A Beginner’s Guide to Implementing Continuous Integration and Continuous Delivery Using Jenkins 2; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Ding, K.; Li, J.; Liu, H. Interactive anomaly detection on attributed networks. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, New York, NY, USA, 11–15 February 2019; pp. 357–365. [Google Scholar]
- Baier, L.; Kühl, N.; Satzger, G. How to Cope with Change? Preserving Validity of Predictive Services over Time. In Proceedings of the Hawaii International Conference on System Sciences (HICSS-52), Wailea, HI, USA, 8–11 January 2019; University of Hawai’i at Manoa/AIS. pp. 1085–1094. [Google Scholar]
- Symeonidis, G.; Nerantzis, E.; Kazakis, A.; Papakostas, G.A. MLOps-definitions, tools and challenges. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 453–460. [Google Scholar]
- Gujjar, J.P.; Kumar, V.N. Demystifying mlops for continuous delivery of the product. Asian J. Adv. Res. 2022, 5, 19–23. [Google Scholar]
- Akash, K.; McMahon, G.; Reid, T.; Jain, N. Human trust-based feedback control: Dynamically varying automation transparency to optimize human-machine interactions. IEEE Control Syst. Mag. 2020, 40, 98–116. [Google Scholar] [CrossRef]
- Fan, Y.; Cui, X.; Han, H.; Lu, H. Chiller fault detection and diagnosis by knowledge transfer based on adaptive imbalanced processing. Sci. Technol. Built Environ. 2020, 26, 1082–1099. [Google Scholar] [CrossRef]
- Liao, Q.V.; Varshney, K.R. Human-centered explainable ai (xai): From algorithms to user experiences. arXiv 2021, arXiv:2110.10790. [Google Scholar]
- Drozdal, J.; Weisz, J.; Wang, D.; Dass, G.; Yao, B.; Zhao, C.; Muller, M.; Ju, L.; Su, H. Trust in AutoML: Exploring information needs for establishing trust in automated machine learning systems. In Proceedings of the 25th International Conference on Intelligent User Interfaces, Greenville, SC, USA, 18–21 March 2020; pp. 297–307. [Google Scholar]
- Ozsoy, M.G.; Polat, F. Trust based recommendation systems. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, New York, NY, USA, 25–28 August 2013; pp. 1267–1274. [Google Scholar]
- Katayama, H. Legend and future horizon of lean concept and technology. Procedia Manuf. 2017, 11, 1093–1101. [Google Scholar] [CrossRef]
- Lima, A.; Rossi, L.; Musolesi, M. Coding together at scale: GitHub as a collaborative social network. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 295–304. [Google Scholar]
- Directorate-General for Communications Networks, Content and Technology, European Commission. European Approach to Artificial Intelligence. 2023. Available online: https://digital-strategy.ec.europa.eu/en/policies/european-approach-artificial-intelligence (accessed on 11 September 2024).
- Burns, B.; Beda, J.; Hightower, K.; Evenson, L. Kubernetes: Up and Running; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Butcher, M.; Farina, M.; Dolitsky, J. Learning Helm; O’Reilly Media: Sebastopol, CA, USA, 2021. [Google Scholar]
- Helwig, N.; Pignanelli, E.; Schtze, A. Condition monitoring of hydraulic systems Data Set. Uci Mach. Learn. Repos. 2018, 46, 66121. [Google Scholar] [CrossRef]
- Helwig, N. Detecting and Compensating Sensor Faults in a Hydraulic Condition Monitoring System. In Proceedings of the SENSOR 2015—17th International Conference on Sensors and Measurement Technology, Nuremberg, Germany, 19–21 May 2015. oral presentation D8.1. [Google Scholar]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. In Proceedings of the ESANN, Bruges, Belgium, 22–24 April 2015; Volume 2015, p. 89. [Google Scholar]
- Lu, W.; Li, Y.; Cheng, Y.; Meng, D.; Liang, B.; Zhou, P. Early fault detection approach with deep architectures. IEEE Trans. Instrum. Meas. 2018, 67, 1679–1689. [Google Scholar] [CrossRef]
- Dorgo, G.; Pigler, P.; Abonyi, J. Understanding the importance of process alarms based on the analysis of deep recurrent neural networks trained for fault isolation. J. Chemom. 2018, 32, e3006. [Google Scholar] [CrossRef]
- Truong, C.; Oudre, L.; Vayatis, N. Selective review of offline change point detection methods. Signal Process. 2020, 167, 107299. [Google Scholar] [CrossRef]
- Law, S.M. STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining. J. Open Source Softw. 2019, 4, 1504. [Google Scholar] [CrossRef]
- Zhao, K.; Wulder, M.A.; Hu, T.; Bright, R.; Wu, Q.; Qin, H.; Li, Y.; Toman, E.; Mallick, B.; Zhang, X.; et al. Detecting change-point, trend, and seasonality in satellite time series data to track abrupt changes and nonlinear dynamics: A Bayesian ensemble algorithm. Remote. Sens. Environ. 2019, 232, 111181. [Google Scholar] [CrossRef]
- Schwartz, M.; Pataky, T.C.; Donnelly, C.J. seg1d: A Python package for Automated segmentation of one-dimensional (1D) data. J. Open Source Softw. 2020, 5, 2404. [Google Scholar] [CrossRef]
- Truong, C.; Oudre, L.; Vayatis, N. ruptures: Change point detection in Python. arXiv 2018, arXiv:1801.00826. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S.; Selim, B. Conceptual and empirical comparison of dimensionality reduction algorithms (pca, kpca, lda, mds, svd, lle, isomap, le, ica, t-sne). Comput. Sci. Rev. 2021, 40, 100378. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 11 September 2024).
- Holzinger, A. The next frontier: AI we can really trust. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Virtual, 13–17 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 427–440. [Google Scholar]
- Holzinger, A.; Dehmer, M.; Emmert-Streib, F.; Cucchiara, R.; Augenstein, I.; Del Ser, J.; Samek, W.; Jurisica, I.; Díaz-Rodríguez, N. Information fusion as an integrative cross-cutting enabler to achieve robust, explainable, and trustworthy medical artificial intelligence. Inf. Fusion 2022, 79, 263–278. [Google Scholar] [CrossRef]
- Saxena, D.; Lamest, M.; Bansal, V. Responsible machine learning for ethical artificial intelligence in business and industry. In Handbook of Research on Applied Data Science and Artificial Intelligence in Business and Industry; IGI Global: Hershey, PA, USA, 2021; pp. 639–653. [Google Scholar]
- Faubel, L.; Schmid, K. A Systematic Analysis of MLOps Features and Platforms. WiPiEC J.-Work. Prog. Embed. Comput. J. 2024, 10, 97–104. [Google Scholar]
- Holzinger, A. Interactive machine learning for health informatics: When do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.; Plass, M.; Holzinger, K.; Crişan, G.C.; Pintea, C.M.; Palade, V. Towards interactive Machine Learning (iML): Applying ant colony algorithms to solve the traveling salesman problem with the human-in-the-loop approach. In Proceedings of the Availability, Reliability, and Security in Information Systems: IFIP WG 8.4, 8.9, TC 5 International Cross-Domain Conference, CD-ARES 2016, and Workshop on Privacy Aware Machine Learning for Health Data Science, PAML 2016, Salzburg, Austria, 31 August–2 September 2016; Proceedings. Springer: Berlin/Heidelberg, Germany, 2016; pp. 81–95. [Google Scholar]
- Ramesh, P.V.; Subramaniam, T.; Ray, P.; Devadas, A.K.; Ramesh, S.V.; Ansar, S.M.; Ramesh, M.K.; Rajasekaran, R.; Parthasarathi, S. Utilizing human intelligence in artificial intelligence for detecting glaucomatous fundus images using human-in-the-loop machine learning. Indian J. Ophthalmol. 2022, 70, 1131. [Google Scholar] [CrossRef]
- Yang, Y.; Kandogan, E.; Li, Y.; Sen, P.; Lasecki, W.S. A Study on Interaction in Human-in-the-Loop Machine Learning for Text Analytics. In Proceedings of the IUI Workshops, Los Angeles, CA, USA, 19–20 March 2019; pp. 1–7. [Google Scholar]
- Chai, C.; Li, G. Human-in-the-loop Techniques in Machine Learning. IEEE Data Eng. Bull. 2020, 43, 37–52. [Google Scholar]
- Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A survey of human-in-the-loop for machine learning. Future Gener. Comput. Syst. 2022, 135, 364–381. [Google Scholar] [CrossRef]
- Johnson, J. Automating the OODA loop in the age of intelligent machines: Reaffirming the role of humans in command-and-control decision-making in the digital age. Def. Stud. 2022, 23, 43–67. [Google Scholar] [CrossRef]
- Brundage, M. Taking superintelligence seriously: Superintelligence: Paths, dangers, strategies by Nick Bostrom (Oxford University Press, 2014). Futures 2015, 72, 32–35. [Google Scholar] [CrossRef]
- Berthold, M.R.; Cebron, N.; Dill, F.; Gabriel, T.R.; Kötter, T.; Meinl, T.; Ohl, P.; Thiel, K.; Wiswedel, B. KNIME-the Konstanz information miner: Version 2.0 and beyond. ACM SIGKDD Explor. Newsl. 2009, 11, 26–31. [Google Scholar] [CrossRef]
- Warr, W.A. Scientific workflow systems: Pipeline Pilot and KNIME. J. Comput.-Aided Mol. Des. 2012, 26, 801–804. [Google Scholar] [CrossRef] [PubMed]
- Raouf, I.; Kumar, P.; Lee, H.; Kim, H.S. Transfer Learning-Based Intelligent Fault Detection Approach for the Industrial Robotic System. Mathematics 2023, 11, 945. [Google Scholar] [CrossRef]
- Agarwal, P.; Tamer, M.; Budman, H. Explainability: Relevance based dynamic deep learning algorithm for fault detection and diagnosis in chemical processes. Comput. Chem. Eng. 2021, 154, 107467. [Google Scholar] [CrossRef]
- Madhikermi, M.; Malhi, A.K.; Främling, K. Explainable artificial intelligence based heat recycler fault detection in air handling unit. In Proceedings of the Explainable, Transparent Autonomous Agents and Multi-Agent Systems: First International Workshop, EXTRAAMAS 2019, Montreal, QC, Canada, 13–14 May 2019; Revised Selected Papers 1. Springer: Berlin/Heidelberg, Germany, 2019; pp. 110–125. [Google Scholar]
- Ali, M. PyCaret: An Open Source, Low-Code Machine Learning Library in Python. PyCaret Version 1.0. 2020. Available online: https://github.com/pycaret/pycaret (accessed on 11 September 2024).
- Bhakte, A.; Pakkiriswamy, V.; Srinivasan, R. An explainable artificial intelligence based approach for interpretation of fault classification results from deep neural networks. Chem. Eng. Sci. 2022, 250, 117373. [Google Scholar] [CrossRef]
- Baier, L.; Schlör, T.; Schöffer, J.; Kühl, N. Detecting concept drift with neural network model uncertainty. arXiv 2021, arXiv:2107.01873. [Google Scholar]



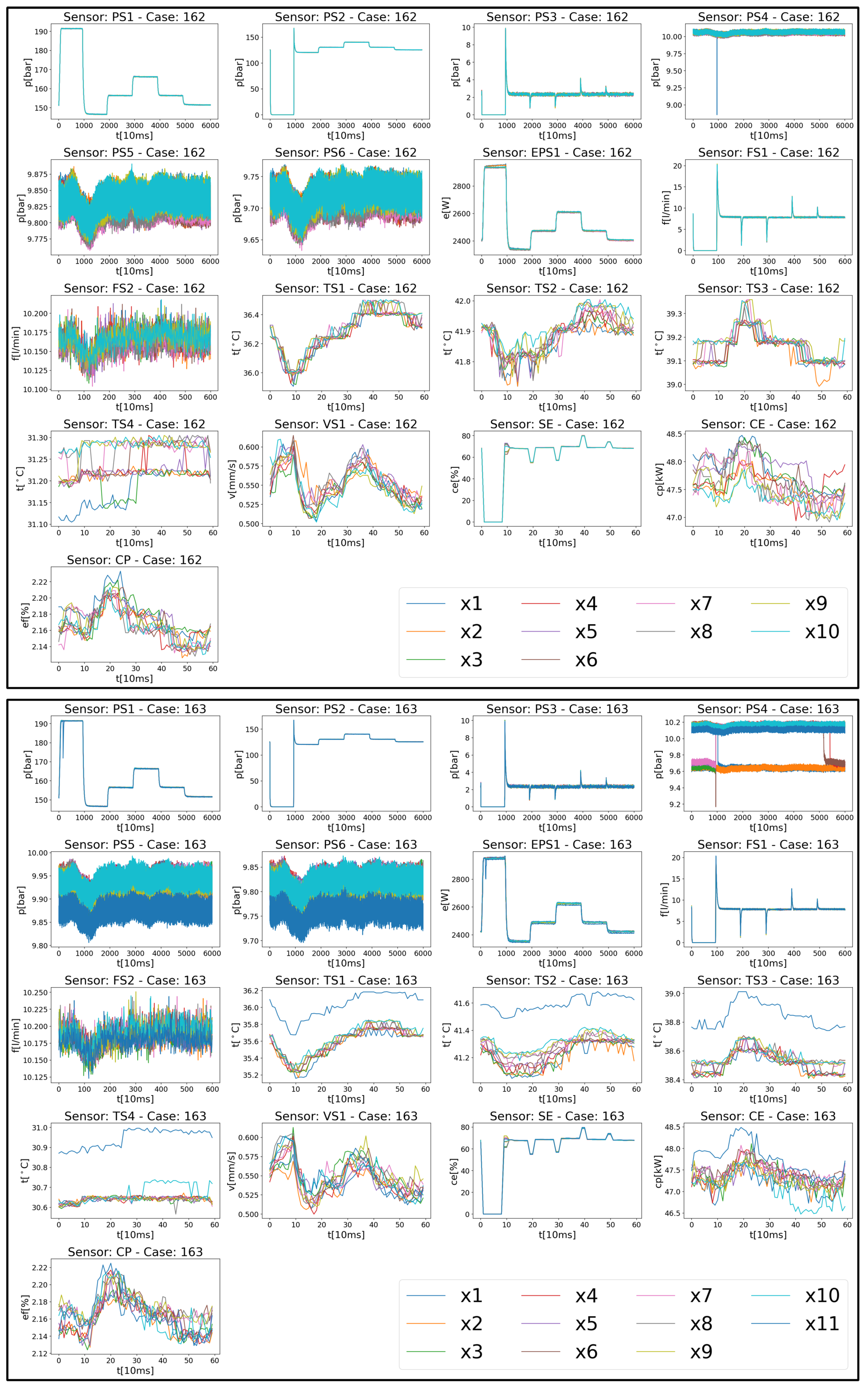
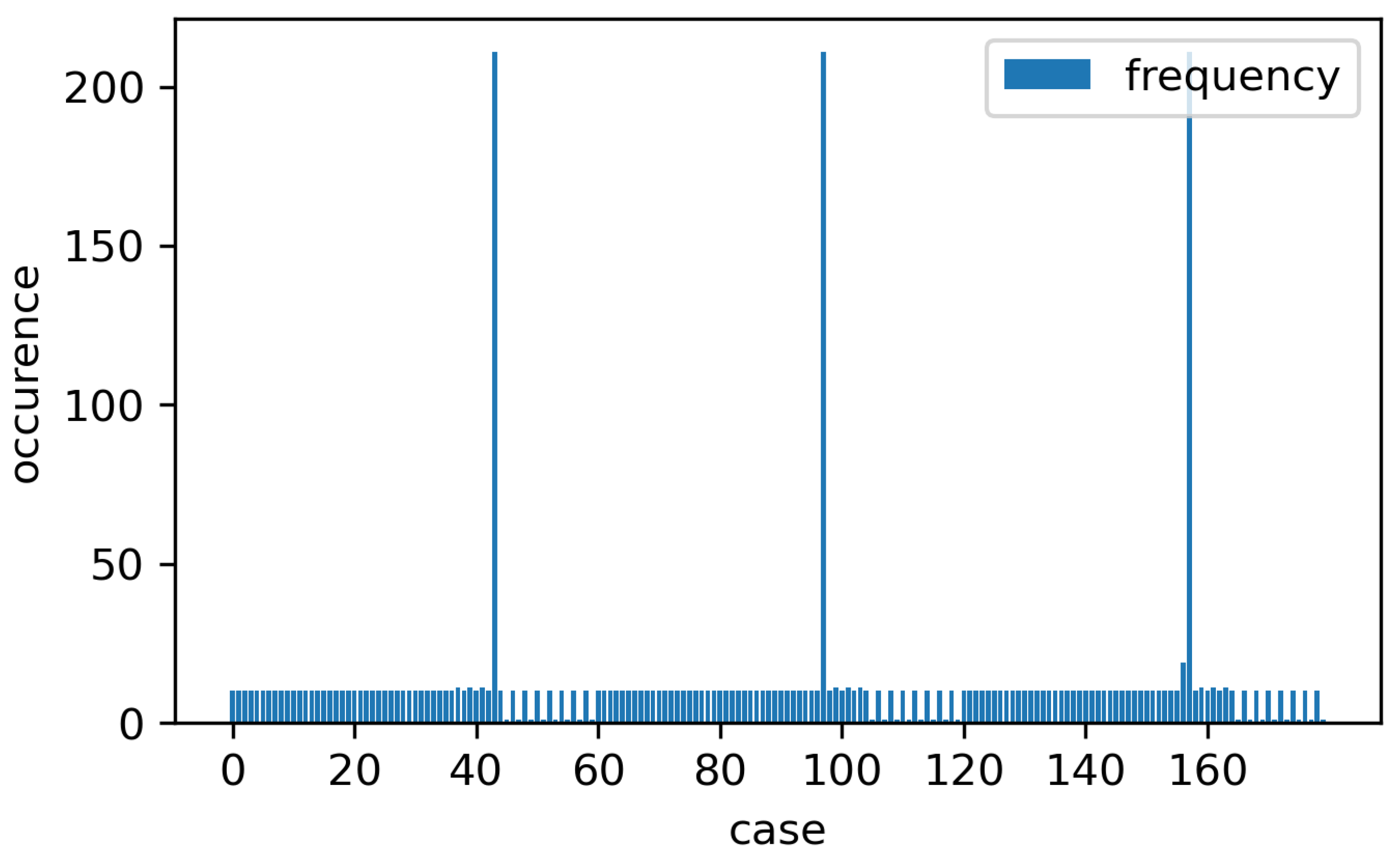



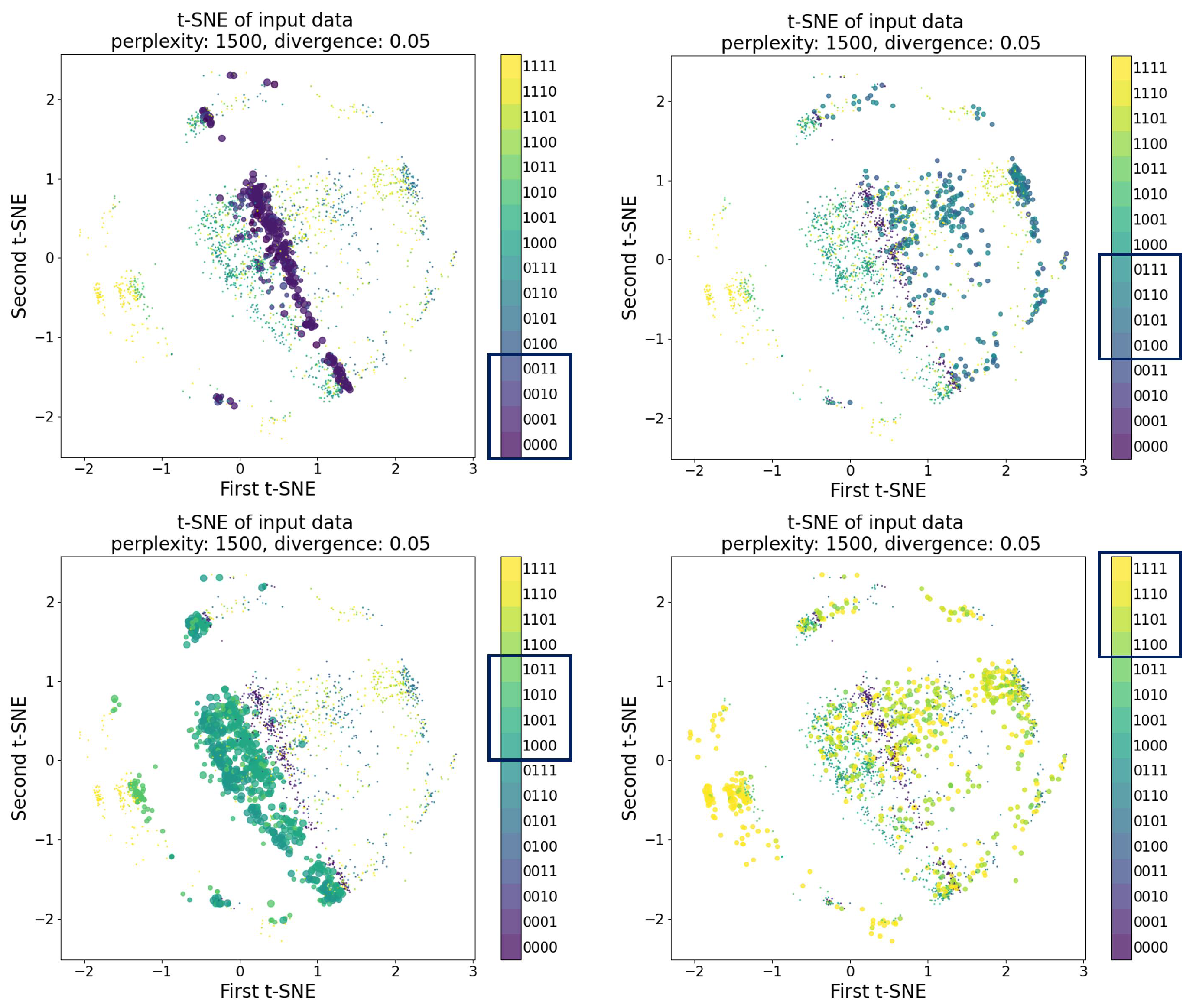
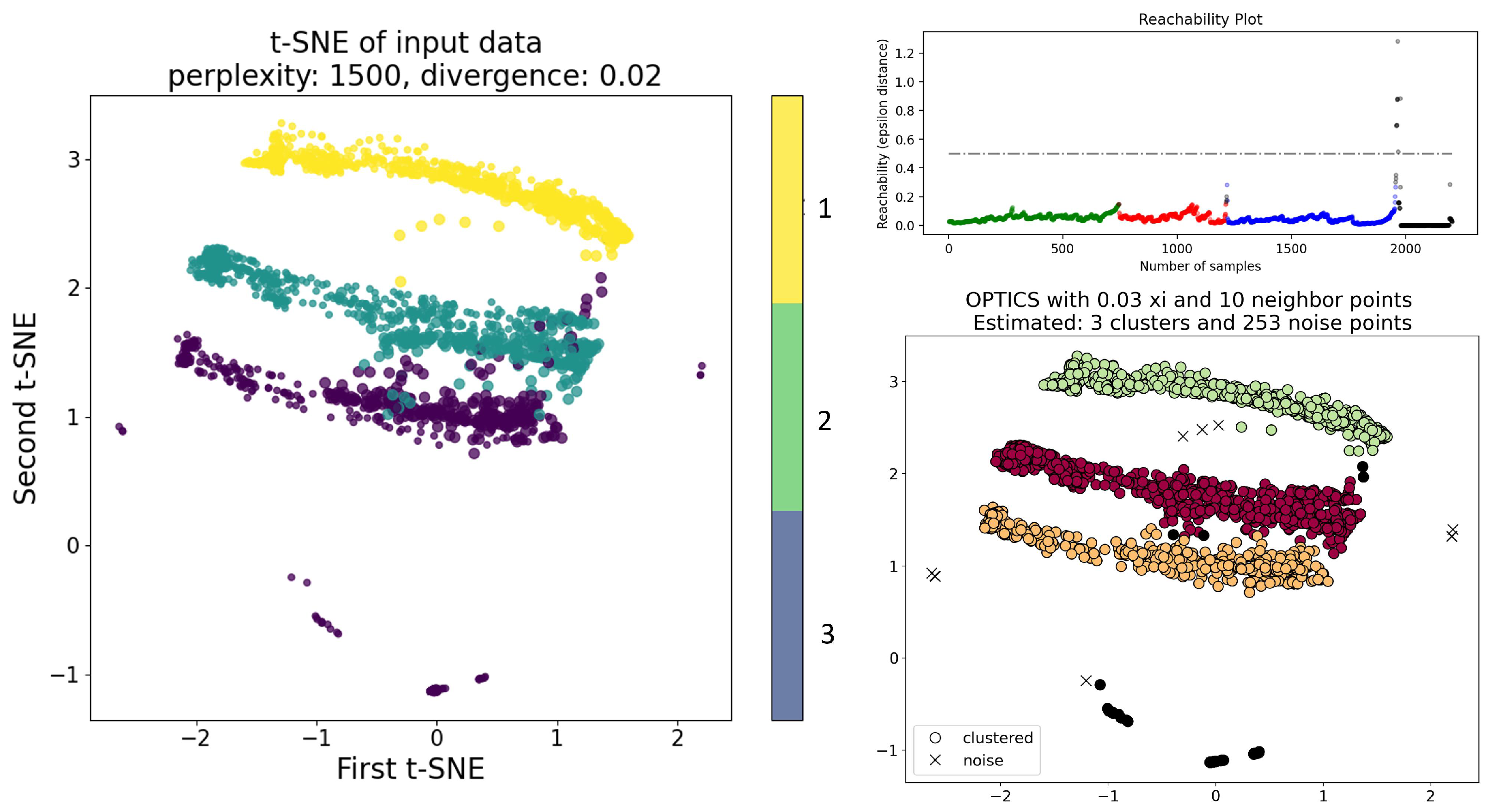







| Sensor | Physical Meaning | Unit | Sampling Rate | Data Points | Range [Min; Max Value] | Mean (Standard Deviation) | Skewness |
|---|---|---|---|---|---|---|---|
| PS1 | Pressure | bar | 100 Hz | 6000 | |||
| PS2 | Pressure | bar | 100 Hz | 6000 | |||
| PS3 | Pressure | bar | 100 Hz | 6000 | |||
| PS4 | Pressure | bar | 100 Hz | 6000 | |||
| PS5 | Pressure | bar | 100 Hz | 6000 | |||
| PS6 | Pressure | bar | 100 Hz | 6000 | |||
| EPS1 | Motor power | W | 100 Hz | 6000 | |||
| FS1 | Volume flow | L/min | 10 Hz | 600 | |||
| FS2 | Volume flow | L/min | 10 Hz | 600 | |||
| TS1 | Temperature | °C | 1 Hz | 60 | |||
| TS2 | Temperature | °C | 1 Hz | 60 | |||
| TS3 | Temperature | °C | 1 Hz | 60 | |||
| TS4 | Temperature | °C | 1 Hz | 60 | |||
| VS1 | Vibration | mm/s | 1 Hz | 60 | |||
| CE | Cooling efficiency (virtual) | % | 1 Hz | 60 | |||
| CP | Cooling power (virtual) | kW | 1 Hz | 60 | |||
| SE | Efficiency factor | % | 1 Hz | 60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, T.-A.; Ruppert, T.; Abonyi, J. The Use of eXplainable Artificial Intelligence and Machine Learning Operation Principles to Support the Continuous Development of Machine Learning-Based Solutions in Fault Detection and Identification. Computers 2024, 13, 252. https://doi.org/10.3390/computers13100252
Tran T-A, Ruppert T, Abonyi J. The Use of eXplainable Artificial Intelligence and Machine Learning Operation Principles to Support the Continuous Development of Machine Learning-Based Solutions in Fault Detection and Identification. Computers. 2024; 13(10):252. https://doi.org/10.3390/computers13100252
Chicago/Turabian StyleTran, Tuan-Anh, Tamás Ruppert, and János Abonyi. 2024. "The Use of eXplainable Artificial Intelligence and Machine Learning Operation Principles to Support the Continuous Development of Machine Learning-Based Solutions in Fault Detection and Identification" Computers 13, no. 10: 252. https://doi.org/10.3390/computers13100252
APA StyleTran, T.-A., Ruppert, T., & Abonyi, J. (2024). The Use of eXplainable Artificial Intelligence and Machine Learning Operation Principles to Support the Continuous Development of Machine Learning-Based Solutions in Fault Detection and Identification. Computers, 13(10), 252. https://doi.org/10.3390/computers13100252