1. Introduction
The future data economy [
1] is characterized by extreme exponential business models, where productivity and benefits are no longer related to the amounts of manufactured products, but to the level of knowledge that companies can create or extract [
2]. In this context, industrial efficiency is expected to suffer a sharp increase, and costs are to be reduced to the minimum value. New paradigms, such as Industry 5.0 [
3], or new economic sectors, such as data services [
4], are born and enabled thanks to this data revolution.
However, as in many other previous economic revolutions, the resulting and growing data market is asymmetric [
5]. And, against traditional assumptions, some agents have a relevant negotiation position [
6]. Thus, many companies cannot compete fairly. On the one hand, data-driven businesses require very specialized digital organizations, where technologies such as Artificial Intelligence or Data Science can be exhaustively exploited. These technologies allow massive automatization and generate great benefits from third-party data at a very low cost (in fact, the marginal cost is negligible). On the other hand, data are produced by regular companies while they perform common industrial activities. In the traditional economy, these data are valueless sub-products, which are used just as historical records. But their generation is associated with great costs and linked to standard industrial activities. Even when regular industrial companies are aware of the potential value of their data, they have no mechanisms to play an active role in the data market and negotiate a fair distribution of the benefits of these new data-driven businesses [
7]. In general, data have no value while they are not processed or integrated in a digital service that is able to extract knowledge from them. Thus, industrial agents are often forced to transfer their data for a reduced price or, more commonly, for free [
8].
Although, at first glance, this situation appears to be a market inefficiency which will be adjusted at some point by economic agents, it has a critical impact on the entire society [
9]: customers and final users will suffer high prices, which will reduce access to digital services; some industrial sections may disappear; and the strategic independence of countries and continents could be threatened.
Therefore, new data-driven marketplaces are needed to enable fair and active trading between all potential agents in the data economy. These marketplaces should be simple to facilitate the integration of all industrial partners, transparent to promote a fair negotiation, and they should ensure the preservation of industrial secrets (as only authorized buyers should access the data).
In this paper, we propose a blockchain-enabled web-based marketplace to fill this gap. The proposed solution uses the Ethereum network to define a transparent trading scheme controlled by smart contracts. The blockchain network is connected to different services. First, data owners can upload and deposit their data into an Inter-Planetary File System (IPFS) using a web interface. However, before completing the final deposit, the data are randomized to ensure the preservation of industrial privacy. The randomization algorithm is based on numerical stream ciphers, where the number in the stream indicates the random positions of characters in the IPFS. In parallel, the blockchain network receives a transaction and defines a Non-Fungible Token (NFT) to represent the new dataset. Only the NFT owner can request the essential seed to de-randomize the dataset and extract all of the information from the IPFS. Data trading, now transformed into an NFT market, is managed through a web interface where data owners and buyers are active and can define purchases and auctions. All transactions are transparent and public. Additionally, the data market is very volatile. Therefore, transactions in this data-driven marketplace are based on fungible tokens so it is easier to adapt prices to the real economy. Final monetization can be achieved by exchanging cryptocurrencies in any of the existing secondary markets.
The remainder of this paper is organized as follows:
Section 2 introduces the state of the art regarding data-driven and blockchain marketplaces.
Section 3 describes the proposed marketplace, including the randomization algorithm, the architecture, and the monetization instruments (tokens).
Section 4 describes the proposed experimental validation and discusses the results.
Section 5 concludes the paper.
2. State of the Art regarding Data-Driven and Blockchain Marketplaces
Blockchain-enabled data marketplaces have been proposed and discussed by many authors in recent years. However, most works propose high-level layered architectures [
10] whose real performances are unknown, abstract discussions about the upcoming change in the data management paradigm [
11], or theoretical proposals about how communication flows in interactions among participants should be organized [
12] in hypothetical future blockchain data marketplaces. Some works even focus on very specific functionalities, such as an optimal pricing algorithm [
13], which are described and validated in an isolated environment so that the real performance in a data marketplace is not reported.
However, some small implementations of blockchain data marketplaces may be found. But these solutions are either based on simulations [
14] or an initial proof of concept whose technical implementation is not provided [
15], and only the general architecture is described. Some evidence on the performance of these prototypes has been reported, but only emulated scenarios [
16] with no real blockchain networks can be found. In some cases, authors have replicated the behavior of blockchain networks using programming interfaces [
17], but still, no real information is provided about how these marketplaces would behave in a real ecosystem.
Data marketplaces have been used to enable the monetization of data from Internet-of-Things deployments [
18]. In general, these proposals replicate the traditional business model of Internet providers, where users or applications that consume network services must pay a fee [
19]. Related challenges such as personal data protection [
20] or different monetization models that may increase income [
21] have also been studied. But while this scheme could be extended to industrial scenarios, it fits much better applications, such as Smart Cities [
22]. In industrial ecosystems, it is difficult for non-technological companies to launch a new division on digital service commercialization. In fact, some authors have explored the challenges faced by data providers through small prototypes and experiments [
23]. They concluded that democratization in the access of data markets is still a pending question. Therefore, typical works on business-to-business data transference are oriented to “data sharing” [
24] instead of “data monetization”, promoting the free use of industrial data by digital companies.
When the blockchain revolution exploded, it was immediately adapted to data marketplaces. In the most common approach, blockchain systems act as brokers for publication/subscription networks [
25], where smart contracts apply fees [
26]. However, again, the proposed architectures are more suitable for smart environments [
27] than for industrial ecosystems [
28]. However, as all data must be managed by blockchain nodes, the performance of these marketplaces tends to be poor. Models to facilitate data trading through a blockchain have also been proposed [
29], together with rules for coherent and consistent smart contracts [
30] and protocols to ensure that delays and quality of service are not affected by heavy consensus algorithms [
31]. But the problem is only mitigated, and the final performance is still far from that of other digital platforms [
32]. Enhanced versions of these marketplaces, including additional security modules [
33] or machine learning [
34], have also been reported. However, the structural problems remain unsolved.
As a response, some authors have proposed models where data are not managed by blockchain nodes but stored in distributed databases (such as IPFS) whose consistencies are controlled through smart contracts [
35]. The results are promising, although the proposed schemes are fit for very restricted industries, such as city-region food systems. A similar proposal can be found for smart communities [
36], irrigation systems [
37], electricity grids [
38], art products [
39], digital libraries [
40], or agricultural markets [
41]. In addition, proposals to enable users to monetize their personal data have been analyzed [
42]. Regardless, more general architecture is needed.
On the other hand, key technologies that allow the implementation of blockchain-enabled marketplaces have also been studied [
43]. Contributions have been reported to facilitate the use of specific blockchain solutions, mainly Ethereum [
44], and general proposals [
45]. Authors have analyzed several different aspects of blockchain networks to enhance their efficiency and promote data trading and monetization. Schemes to reduce the cost of transactions [
46] or ease the interaction among industrial agents [
12] have been investigated. Technologies that allow for the autonomous operation and interconnection of data marketplaces [
47] with cyber-physical systems [
48] and other networked devices can also be found [
49].
The proposed marketplace in this paper also employs an IPFS to improve the general performance and avoid limitations related to data storage. Additionally, it uses NFTs to generalize the proposal to any kind of data and uses fungible tokens to allow its implementation in any blockchain network. Moreover, the web interface acts as a real marketplace, allowing industrial data owners to register products, prices, auctions, etc.
3. A Blockchain-Based Data-Driven Marketplace
In this section, we present the new data-driven marketplace. In
Section 3.1, we introduce the general architecture and global behavior.
Section 3.2 discusses the implementation of NFTs and monetization instruments. And finally,
Section 3.3 describes privacy-preserving algorithms.
3.1. General Overview
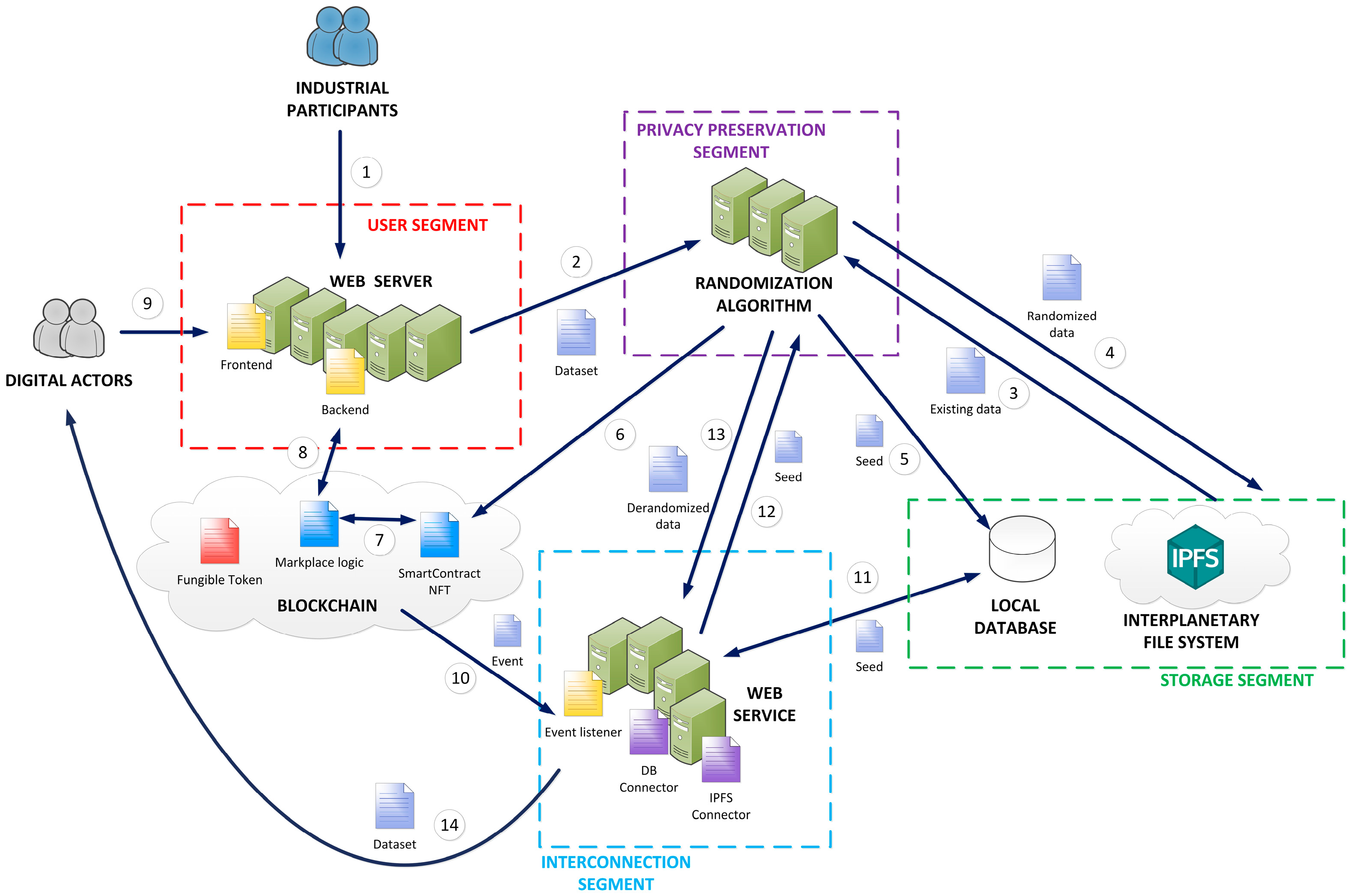
Figure 1 shows the proposed architecture for the blockchain-based data-driven marketplace. Five different segments can be distinguished. The user segment offers a web interface for industrial agents and digital actors to operate the marketplace. It consists of a web server, preferably based on JavaScript technologies, as this language provides stable libraries to interact with a blockchain and distributed storage. Actors within this marketplace can upload new datasets or bid on or buy available data.
Industrial partners, as data owners, typically upload data to the marketplace ①. The user segment then has a direct connection to the privacy-preservation segment, which receives the data and applies a randomization algorithm to guarantee industrial secrecy ②. To achieve this, the privacy preservation algorithm extracts previously existing data from the Interplanetary File System (IPFS) in a storage segment ③ and mixes the previous samples with the new ones by following a random variable. The mixed data are stored again in an IPFS ④. The randomization process needs a seed, which acts as a secret key for the security scheme. The seed is stored in a local database within the storage segment ⑤.
Once the randomization and storage processes are completed, a blockchain transaction is triggered by a privacy preservation segment ⑥. This transaction creates an NFT representing the new dataset. This NFT is added to the smart contract where all of the NFTs that are available for purchase are listed ⑦. The blockchain segment is connected to the user segment’s backend, so the web interfaces can display all of the available NFTs ⑧.
Industrial partners can decide how their datasets (now NFT) are offered: direct sale, auction, etc. The web interface in the user segment interacts with the blockchain segment to adapt the internal logic of every NFT to the owners’ preferences ⑧.
On the other hand, the digital actor can use the same web interface to review the offered datasets and acquire them ⑨. The transaction is supported by digital wallets and fungible tokens (see
Section 3.2). Fungible tokens can be acquired in a secondary market depending on the monetization model proposed for each scenario or marketplace implementation.
Once the NFT owner is changed in the blockchain system, the new proprietary can use the blockchain function to extract and obtain the raw data. The invoked transaction creates an event, which is received by the interconnection segment ⑩. The interconnection segment makes the event-oriented architecture of the blockchain networks and the remote call architecture in common services and servers compatible. It is typically a web service. It transforms the blockchain event into a call to recover the proper seed from the storage segment ⑪. This seed is forwarded to the privacy-preserving algorithm ⑫, which, with that information, derandomizes the information from the IPFS module ⑬. The data are returned to the NFT owner directly from the interconnection segment ⑭ to avoid heavy data transferences through the blockchain.
This workflow is repeated for each dataset to be monetized in the marketplace.
The user interface will be public and will include secondary functions, such as registering new participants or visualizing a historical register of transactions. The backend offers a REST API (Representational State Transfer Application Programming Interface), so the marketplace can be integrated into other platforms such as mobile devices.
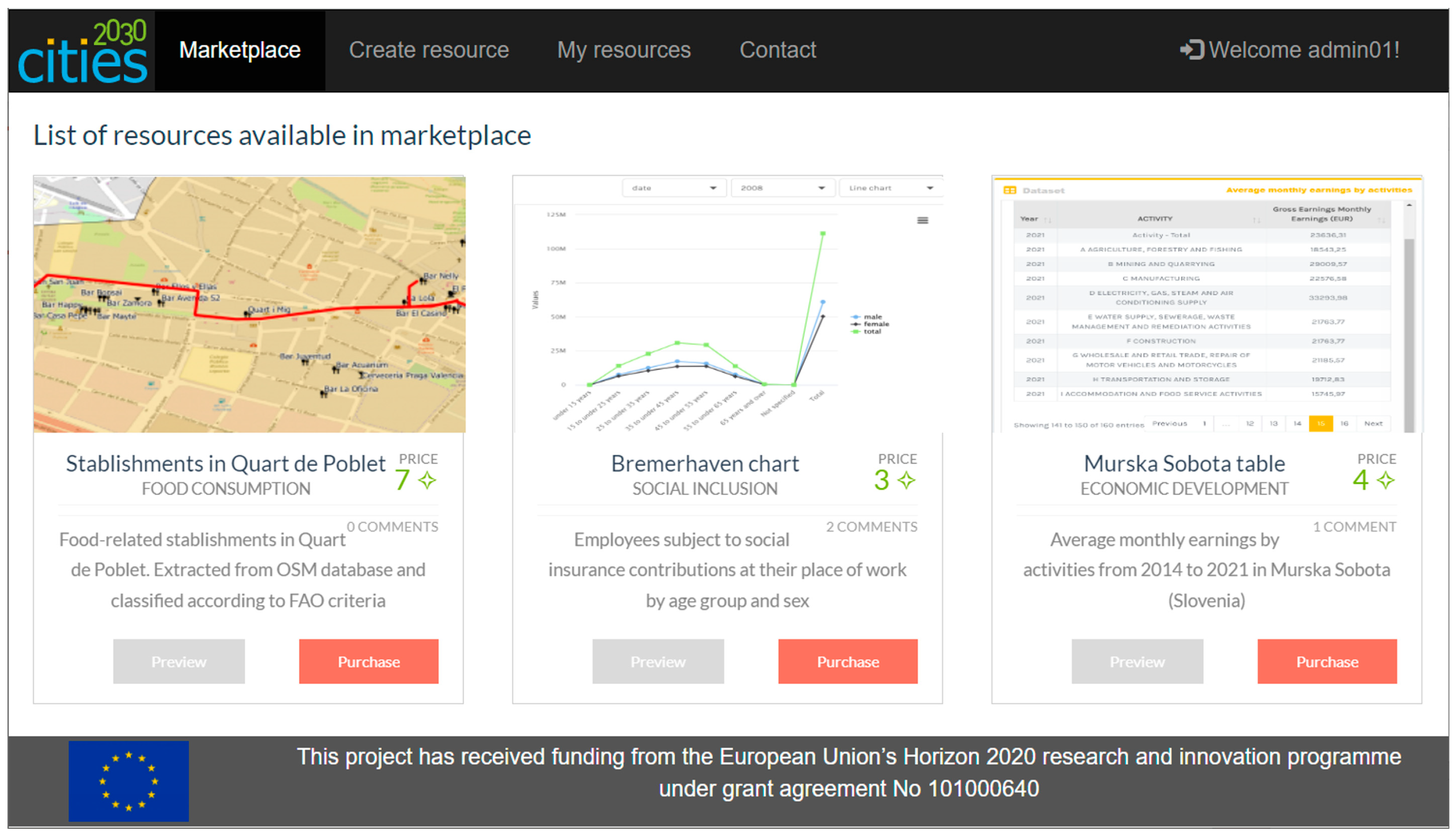
Figure 2 shows the proposed interface.
As a web module, it can create automatic connections to several digital wallets, so industrial and digital agents can operate the marketplace and their NFTs and fungible tokens in a standardized way. Digital wallets are installed as extensions in web browsers, reducing the complexity of the user segment. This offers additional advantages, such as the ability to use several crypto accounts or shared devices.
Regarding the blockchain network, existing public systems can be used. But for most solutions, the code is open, and the deployment works are not complex. Thus, a private blockchain network can be used as well if this business model is considered more suitable for some application scenarios. However, several authors have warned about the risks associated with these private networks [
50], as they need significant effort in software maintenance and operation. This network uses smart contracts (or other similar programming instruments) to define fungible tokens that are used as cryptocurrency in the marketplace (see
Section 3.2). Fungible tokens are implemented and initialized using a common function and invocation. As a result, a certain number of interchangeable and indistinguishable tokens are created. On the other hand, an NFT has a unique identifier, and the value can change from one token to another.
The interconnection segment is a collection of services, where the main one is an event listener. This listener is waiting for the event from the blockchain network. For each event, it establishes a connection to the storage segment through the proper connector. In general, there is a different connector for every storage module and technology in the storage segment.
In the storage segments, datasets and all persistent data structures are maintained. In general terms, this segment includes two modules. First, a local database is considered, where all of the seeds employed to randomize each of the datasets in the marketplace are considered. The database can be relational or non-relational. Second, IPFS technology is used for the preservation of datasets. An IPFS is a platform and a protocol used to store and share hypermedia through a distributed file system. It is specially designed to run together with distributed applications, such as the proposed marketplace. Somehow, an IPFS is similar to the World Wide Web, where a distributed hash table and a centralized name space guarantee that all content is accessible and reachable.
3.2. Token and Monetization Instruments
Data monetization in the proposed architecture is based on fungible tokens. Fungible tokens are interchangeable, identical software objects which can be used to represent a proprietary cryptocurrency. Although there are several different approaches to define and create a fungible token, in our marketplace, we follow the ERC20 standard [
51]. This standard is usually considered the most suitable scheme to define a fungible token. As they are non-unique, a large number of fungible tokens are generated through the same invocation. All of them have identical values. They are therefore the perfect instruments to define cryptocurrency.
The ERC20 standard was originally proposed in 2015. This standard is designed to operate in Ethereum networks, although it can be adapted to other blockchain technologies. The standard standardizes the attributes and functions to be implemented in a fungible token to ensure their operability. The ERC20 standard considers eight mandatory functions and three additional optional ones. In the proposed architecture, fungible tokens are programmed by encapsulating the following functions (see
Figure 3):
name: This returns the name of the token. Although this function is optional, we decided to include it to improve usability. However, in other marketplace implementations, interfaces and smart contracts must not expect the function to be present under all circumstances. In this first marketplace implementation, the token was named “Cities2030 token”.
symbol: This returns the symbol of the token. As in the previous one, this is an optional function. But we included it for clarity purposes. In this first data-driven marketplace implementation, the symbol for the fungible token was ✧.
decimals: This is also an optional function and returns the number of decimals that the token uses. As the proposed solution has monetization purposes, the use of a decimal facilitates economic transactions and negotiation.
totalSupply: This returns the total token supply.
balanceOf: This is employed to obtain the account balance of another user, so it can be decided whether the transaction is feasible or not.
transfer: This transfers a given number of tokens to the indicated user (address) and triggers an event to notify the transaction.
transferFrom: This transfers the indicated number of tokens from a referred original account (or address) to the target address (account). It also triggers an event to notify the transaction.
approve: This allows a user to withdraw from the account multiple times up to the maximum amount indicated in the function.
allowance: This returns the amount that a user is still allowed to withdraw from the target account as a charge for a bought dataset.
The ERC20 standard, on the other hand, employs two different types of events, which can be used to define the back-end logic of the web interface and the interconnection segment. The two events are as follows:
Transfer: This must be triggered when tokens are transferred, including zero-value transfers.
Approval: This must be triggered on any successful call to the approve function.
On the other hand, the proposed marketplace employs an NFT as well to represent datasets and operate with their ownership within the blockchain network. In this case, we also propose the use of a standard: the ERC721 standard [
52].
The key attribute for any NFT created according to the ERC721 standard is the
tokenId variable. This identifier must be unique in the entire system and allows any smart contract or software piece to refer to and operate with this NFT. The functions (optional and mandatory) in both standards (ERC20 and ERC721) are pretty similar, apart from the unique identifier and the “ownership" property.
Figure 4 represents an NFT implementation using the ERC721 standard. In ERC721 tokens, as they are unique, ownership can be defined. We take advantage of this property to manage seeds in the privacy preservation segment. The function ownerOf is used to identify the current owner of the NFT, labeled
tokenId.
But an NFT typically must implement other functionalities in addition to the basic ones. Specifically, it must implement the functions inherited from the application scenario and use the cases that will be covered by the marketplace. In order to combine standard functions and domain-specific functions, the NFT must also comply with the ERC165 standard [
53].
The ERC165 standard is a mechanism to automatically detect and publish the interface that any smart contract implements. A JSON-based description is generated and exchanged when ERC165 functions are invoked. For example, in the Ethereum context, this description is usually known as the ABI (Application Binary Interface). When any smart contract is a direct implementation of a public standard, the JSON description just indicates the version. In contrast, the full interface description must be shared among all interconnected smart contracts. The ERC165 standard includes only one function, indicating whether or not the NFT implements (boolean output) a given ABI. In the standard, this function is named supportInterface.
Given that the ERC20 standard and the ERC721 standard share several common functions, many codes could be reused, reducing the system complexity and fees associated with contract deployment. The ERC1155 standard [
54], known as the “multitoken standard”, is used for this purpose. This standard allows for the definition of a fungible token and NFT using the same smart contract. In the proposed marketplace, we use this approach because of its efficiency.
Figure 5 shows the structure of the ERC1155 multitoken standard in a flowchart.
3.3. Privacy-Preserving Algorithm
The proposed privacy preservation strategy consists of a random mixing scheme. Information units (letter, sentences, data samples, etc.) are randomly reordered, so recovering the dataset in the original form without the proper key is not feasible. In order to increase the level of randomization and privacy, fictitious information is also injected from previously stored datasets in the IPFS modules.
A dataset is composed of different information units. This dataset is transformed into a new randomized dataset including information units, where . Additionally, we assume that a collection of information units are extracted from the IPFS module to enrich the randomization process.
Function
maps data samples in dataset
into samples in dataset
, so a sample in the
-th position in dataset
is moved to the
-th position in dataset
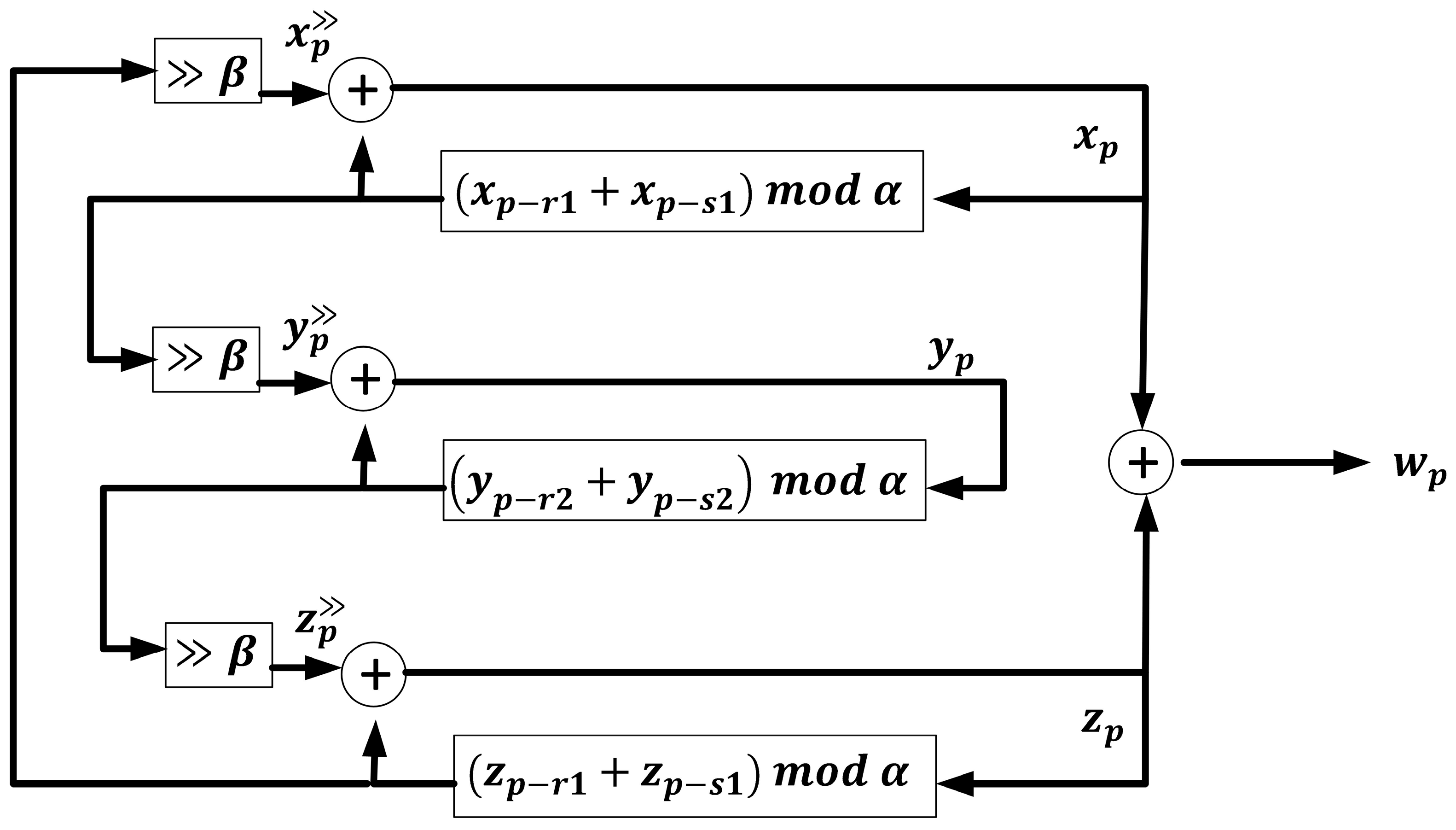
. This function is a Pseudorandom Number Generator (PRNG). Because it is computationally lightweight and easy to implement, in the proposed privacy-preserving algorithm, we use the Trifork PRNG (1) [
55].
Figure 6 presents the architecture of this PRNG.
Variables , , , and are configuration parameters. First, must be chosen to ensure that the Trifork PRNG is able to produce enough numbers to map all of the positions in the randomized dataset (2). Later, as the right-shift and XOR operations are bit-oriented, the parameter must be carefully chosen so that the value is lower than the maximum number of bits in random numbers (3). Finally, the and values can be freely selected.
The seed is composed of three vectors of information units,
,
, and
, whose lengths depend on the selected values for
and
(4).
Other PNRGs could be used to support this privacy-preserving scheme. However, Trifork offers some essential advantages over other existing generators in the state of the art. First, as datasets may be large, it is critical that the selected PRNG can produce very long random streams where no number or sequence is repeated (as that would cause a conflict when accessing the file system). Trifork, compared to other reported PRNGs, has a very large key space. Some studies [
56] have shown that Trifork multiplies the length of random streams several times compared to other common technologies. Second, the processing time should not affect the quality of experience and must be negligible compared to the standard data transmission delays. Trifork is known for its very reduced computational cost and scalability compared to any other PRNG previously reported [
57]. As it is only based on simple binary operations, the processing delay is almost negligible. So, it is the most suitable technology for our marketplace.
After all, original information units are placed in the randomized dataset , and the remaining positions are filled with random information units from the collection extracted from the IPFS module. This collection can be generated through a second PRNG or any other instrument for random access. When the randomized dataset is ready, it is stored in an IPFS again. And the seed is saved in the local database in the storage segment.
This privacy-preserving and data randomization algorithm ensures data security against unauthorized accesses or attacks against data storage. Even if authorized access is granted, data cannot be derandomized without the proper seed (key) and number stream. Although a brute force attack is still possible, the elevated entropy of the Trifork PRNG guarantees that the probability of making this attack successful is negligible. Moreover, the blockchain network and solidity language ensure that only the NFT owner obtains the seed to derandomize the data, as function modifiers to control access are embedded into the blockchain architecture and are now considered fully secure.
4. Experimental Validation and Results
In order to evaluate the performance of the proposed marketplace, an experimental validation process is designed and carried out. The experimental validation process was based on pilot experience and deployment. The proposed marketplace was implemented in the context of the Arganda living lab within the Cities2030 project.
The Cities2030 project is funded by the European Commission with the objective of defining new good practices, policies, and technologies to improve city-region food systems. To achieve this, fifteen different living labs were established in more than 12 European countries. The pilot marketplace was implemented in the Arganda lab (Spain). This living lab aims to explore new digital instruments to improve efficiency and monetization in the food processing industry. Previous experiments on controlling work conditions [
28] or increasing transparency in the food supply chain [
58] were successful in this context.
For this pilot, the user segment in the marketplace was implemented using Node.js technology (JavaScript). To be more specific, the Express framework was employed to create the entire segment. Node.js is a light technology that shows great scalability, so it is perfect for this kind of distributed application.
The blockchain network was based on Ethereum technology. But for this prototype, we do not use the public Ethereum network nor a private full implementation. Instead of that, we use Ganache as an Ethereum network. Ganache is a software suite for local and personal blockchain application development over Ethereum and Corda. It includes a graphic interface and a command line interface. Ganache offers the same API as the Ethereum network, but no distributed nodes must be deployed, and only a local process handles all transactions. This facilitates the creation of small pilots and prototypes.
The interconnection segment and the privacy preservation segment were implemented using Node.js, too. Libraries such as web3 allow for the integration of external services (event listeners, database managers, etc.) with blockchain in JavaScript environments. Then, the MongoDB database was used for local storage, as it can be easily operated through JavaScript scripts. MongoDB is a noSQL database oriented to collections and JSON objects.
The marketplace was deployed in a large industrial company belonging to the bakery sector in the context of the Cities2030 Arganda living lab. The company had more than three hundred workers who were free to use the marketplace according to their needs for three months. No control was proposed or established, and all participants could use the marketplace without supervision. A user manual and a video recording with guidelines were included to facilitate the use of this new tool. The research group was only available for incidents.
Participants in the pilot experience were divided into two groups with similar population characteristics. The first group was employed as the control group to ensure the significance of the reported improvements. The second group was employed as the pilot group. The experience was three months long. After the experience, both groups were asked to respond to a short survey with nine different questions to be answered using the Likert scale (with answers ranging from “Totally agree” to “Totally disagree”). The responses were collected and processed using the MATLAB 2022a software. The Mann–Whitney U test was used to detect relevant differences between the control and pilot groups.
During the experience, statistics about the use of the marketplace were collected to clarify the level of experience achieved by the participants. In addition, the processing delay required to upload or download a dataset was also monitored. Logs from the blockchain network, the web interface, and the IPFS storage were used for this purpose. As delays are proportional to the size of the datasets, the results were normalized to make all transactions comparable.
Table 1 shows the usage statistics that were collected after the three-month experience.
As can be seen, the usage level is relevant. Almost two new datasets were uploaded to the marketplace every year (1.8 datasets, to be precise). And more than sixty (60) transactions were also carried out every day. These results are comparable to the statistics reported in other similar experiences [
35], so we can conclude that the usage level is relevant. In addition, before the implementation of the marketplace, companies within the Arganda living lab were unable to monetize their internal datasets. The reported results represent a significant improvement in the number of data transactions and monetization in industrial companies.
Figure 7 shows a histogram where the processing delay per information byte in the proposed marketplace is represented. As can be seen, the most common processing delay is four milliseconds per uploaded byte. The maximum observed delay is around the double value (eight milliseconds per uploaded byte). It can also be seen that the aggregated probability concentrates a little bit around higher delay values, but it has a reduced effect. Compared to other local storage solutions (such as SQL databases), the delays are slightly higher. But this is common in IPFSs and blockchain networks. So, in general, the proposed marketplace has an average performance.
On the other hand, to analyze the improvement in the quality of experience of industrial agents, we used the Mann–Whitney U test and the responses from the surveys. Different significance thresholds were considered.
Table 2 shows the results obtained.
As can be seen, there is a significant improvement in all of the questions and in the global quality of experience. Questions related to the accountability and trustworthiness of the market are those where the biggest improvement is detected. The transparency and immutability of blockchain technology is clearly well received by industrial actors. Although most participants surely did not have to check the immutability or transparency of transactions in the marketplace, the experience was improved by the psychological confidence and expectations of users about blockchain networks. On the other hand, although this was significant as well, the participation of industrial companies in the data economy had a less significant improvement. The quality of experience is a subjective indicator, so it is affected by personal thoughts and external factors. For example, in this case, barriers to participate in this new economic paradigm may not be just technological, but also financial, legislative, etc., so the impact caused by the marketplace is more modest. Although it is an enabling tool, industrial agents still have other challenges in mind which cannot be addressed by the proposed marketplace but affect the global quality of experience.
All of the remaining six questions show an improvement with an equivalent significance level.
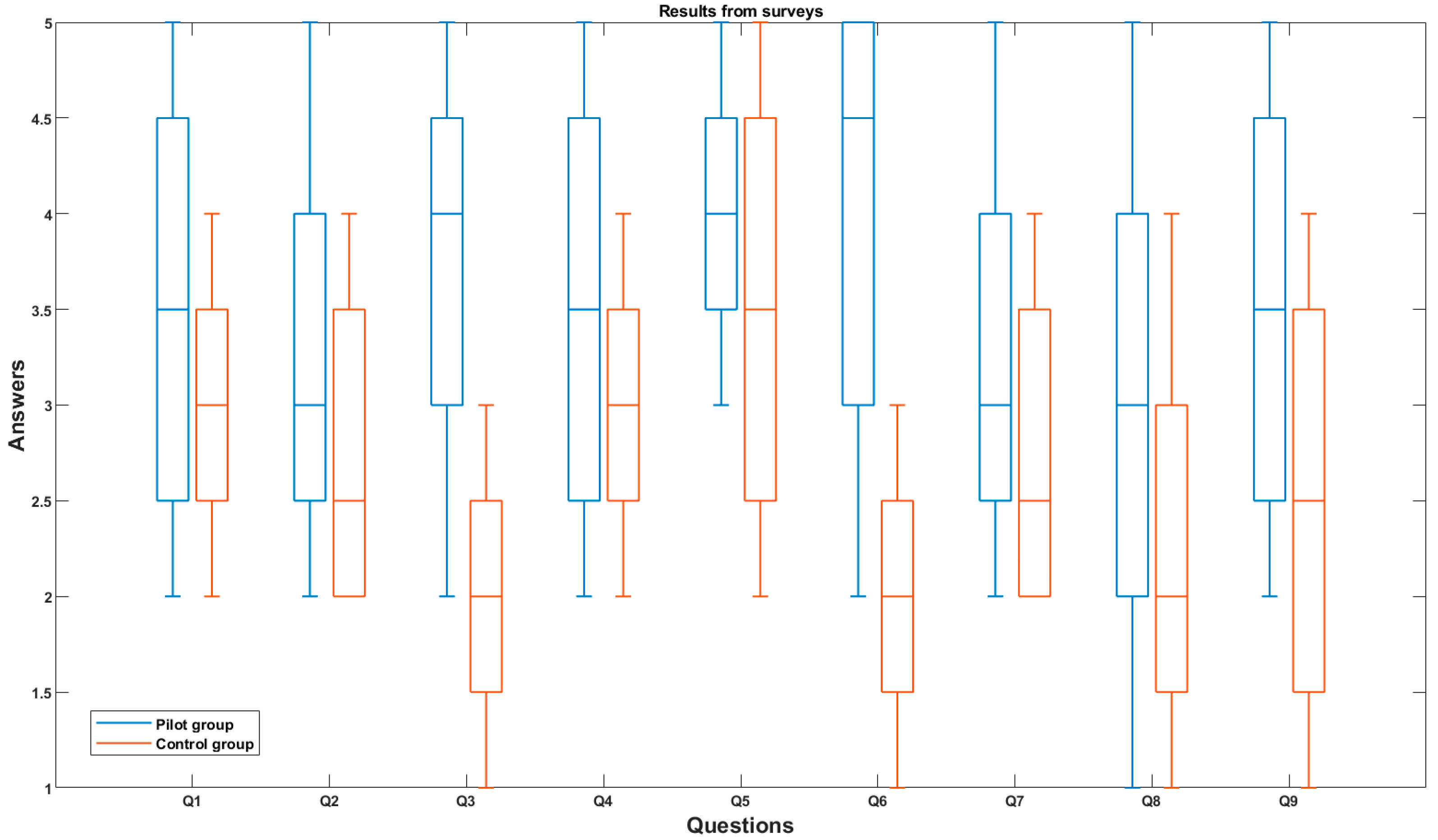
Figure 8 shows the results from the pilot and control groups in a boxplot in order to allow a deeper discussion.
Specifically, industrial companies report an improvement in data monetization (which is now perceived as fair). This is a critical point, as it is one of the main objectives of the proposed marketplace. As data owners can negotiate the value of their own data, the satisfaction is surely greater.
Figure 6 shows that the average response is more positive in the pilot group (for all questions) than in the control group. This represents a clear improvement in the general quality of experience. If we focus on Q8 (monetization), we can see that the dispersion is high in both the control group and the pilot group. However, only in the pilot group, some individuals’ answers were “Totally agree”.
In addition, the marketplace has created a solid reputation, and companies are confident that they will recommend other industrial agents to join this new digital platform. To promote the future adoption of the data-driven marketplace, interpersonal communication is essential. So, this is the first evidence of the potential success of this new monetization scheme. Actually, as seen in
Figure 8, the results for Q7 show that only the responders in the pilot group provided a “Totally agree” answer. In addition, the average answer is a half-point more positive for the pilot group.
Focusing on the promotion of an innovative ecosystem for open data, it can be seen that Q2 in
Figure 8 shows that participants in the pilot group feel more ready to share their industrial data. In this case, the impact of the proposed marketplace as a trustworthy instrument for sharing data according to the preferences of data owners is clear. The same conclusions may be extracted if we analyze the results for Q1. While the participants in the control group show a higher level of worry about the use of their industrial data and the possible leak of industrial secrets, these concerns are not as relevant in the pilot group, where some participants even gave a “Totally agree” answer.
Therefore, we can conclude that the proposed data-driven marketplace is technically sound and promotes an improvement in the quality of experience of industrial companies.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}