
Temporal-Logic-Based Testing Tool Architecture for Dual-Programming Model Systems



Abstract
:1. Introduction
2. Related Work
3. Runtime Errors
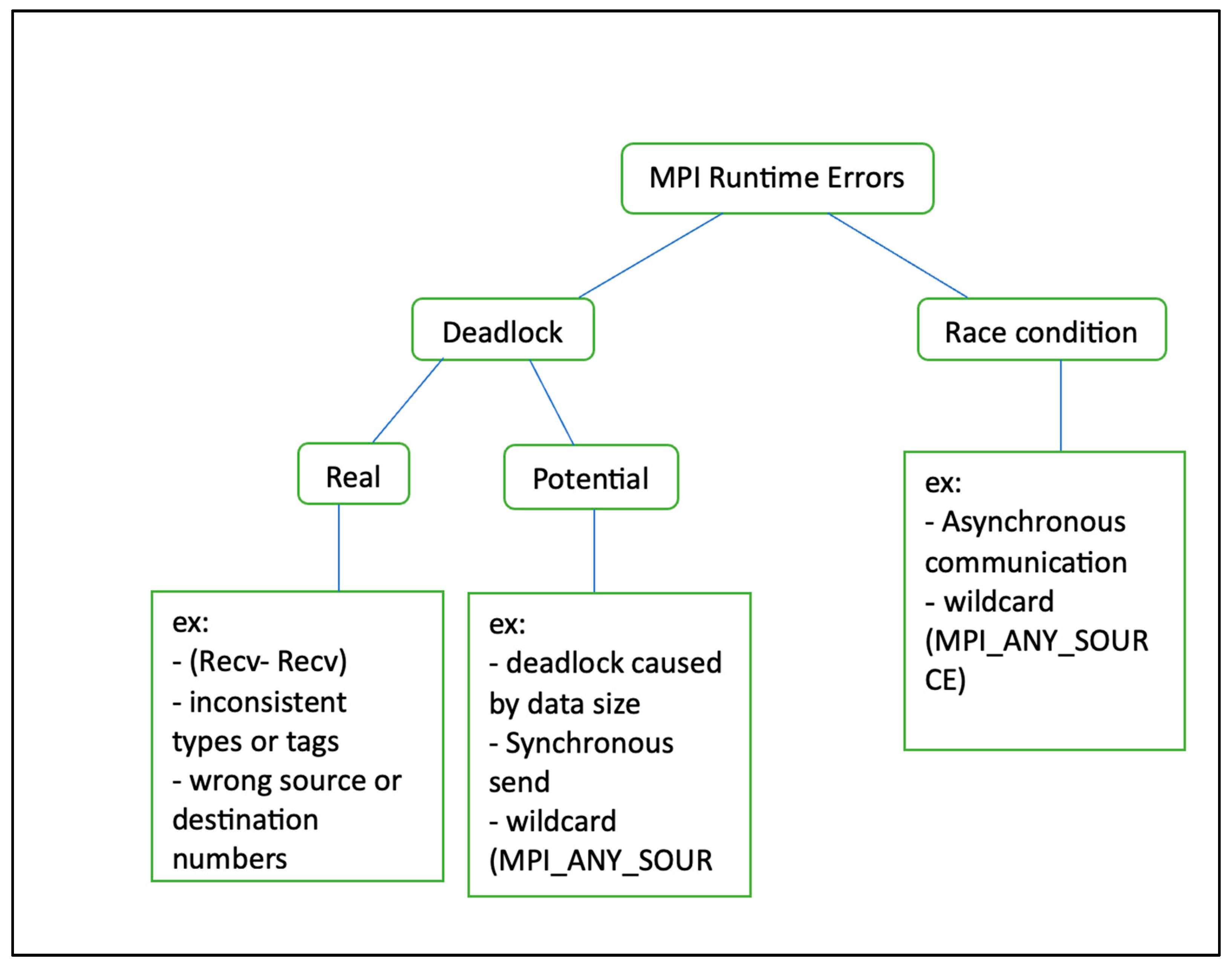
3.1. MPI Errors
| Listing 1. MPI send and receive. |
| 1: MPI_Send(void* data, int count, MPI_Datatype datatype, int destination, int tag, |
| 2: MPI_Comm communicator); |
| 3: MPI_Recv( void* data, int count,MPI_Datatype datatype, int source, int tag, 4: MPI_Comm communicator, MPI_Status* status); |
3.1.1. MPI Deadlock
| Listing 2. Recv–Recv error in MPI. |
| 1: if(rank==0) 2: { 3: MPI_Recv (&msg, 1, MPI_INT, 1, 0, MPI_COMM_WORLD, &status); 4: msg=42; 5: MPI_Send (&msg, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); 6: } 7: else if (rank == 1) 8: { 9: MPI_Recv (&msg, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &status); 10: msg=23; 11: MPI_Send (&msg, 1, MPI_INT, 0, 0, MPI_COMM_WORLD); 12: } |
| Listing 3. Synchronous send in MPI. |
| 1: if (rank==0) 2: { 3: msg=42; 4: MPI_SSend (&msg, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); 5: MPI_ Recv (&msg, 1, MPI_INT, 1, 0, MPI_COMM_WORLD, &status); 6: } 7: else if (rank == 1) 8: { 9: msg=23; 10: MPI_SSend (&msg, 1, MPI_INT,0, 0, MPI_COMM_WORLD); 11: MPI_ Recv (&msg, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &status); 12: } |
3.1.2. MPI Race Condition
| Listing 4. Isend in MPI. |
| 1: msg=42; 2: // send message asynchronously 3: MPI_ISend (&msg, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); 4: 5: // Do some other work while message is being sent 6: 7: msg=23; 8: 9: MPI_Wait(&request, MPI_STATUS_IGNORE); // it return when operation or request is complete |
| Listing 5. Wildcard in MPI. |
| 1: if (rank == 0) 2: { 3: msg = 42; 4: MPI_Send(&msg, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); 5: MPI_Recv(&msg, 1, MPI_INT, 1, 0, MPI_COMM_WORLD, &status); 6: } 7: else if (rank == 1) 8: { 9: msg = 23; 10: MPI_Send(&msg, 1, MPI_INT, 0, 0, MPI_COMM_WORLD); 11: MPI_Recv(&msg, 1, MPI_INT, MPI_ANY_SOURCE, 0, MPI_COMM_WORLD, &status); 12: MPI_Recv(&msg, 1, MPI_INT, 2, 0, MPI_COMM_WORLD, &status); 13: } 14: else if (rank == 2) 15: { 16: msg = 99; 17: MPI_Send(&msg, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); 18: } |
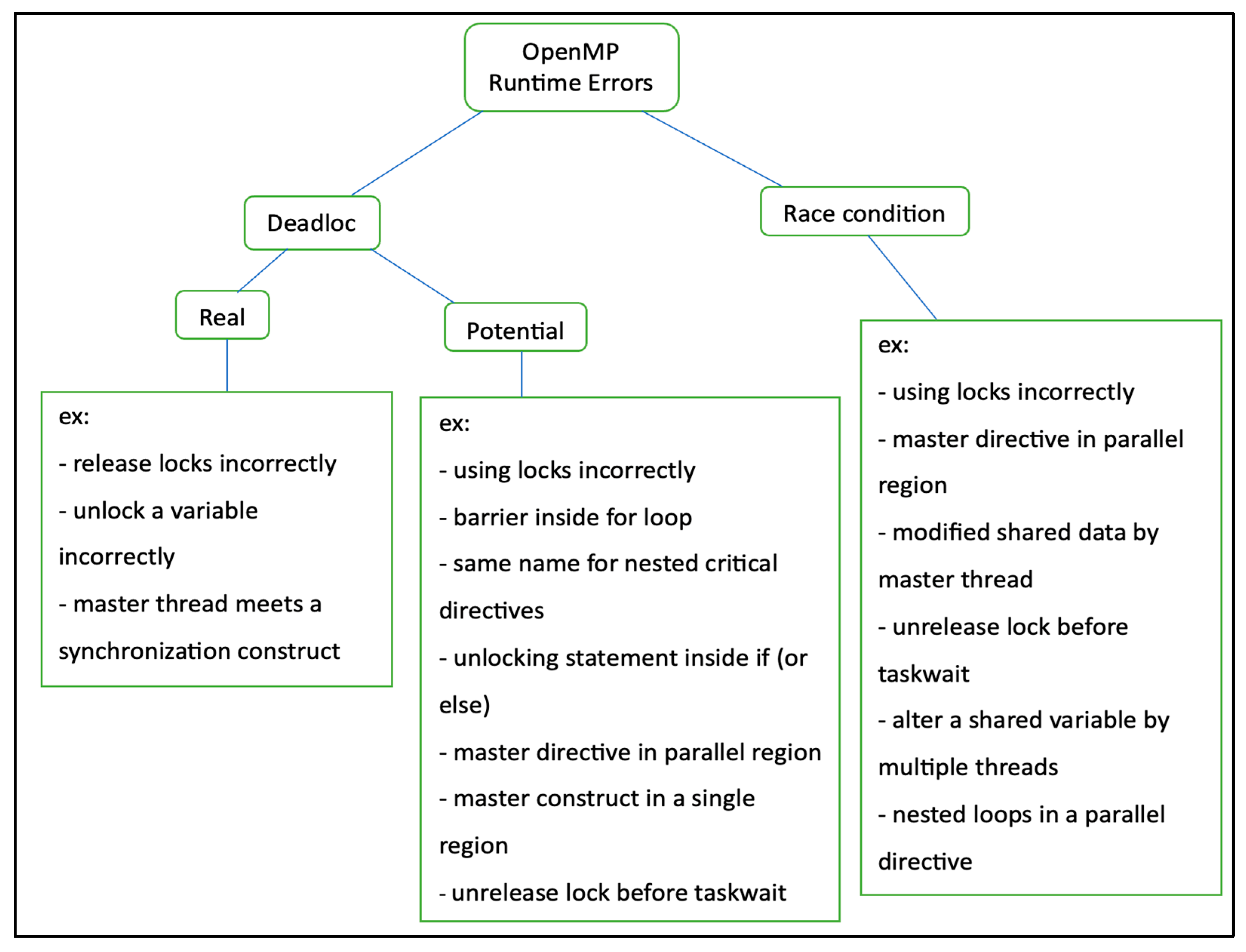
3.2. OpenMP Errors
3.2.1. OpenMP Deadlock
| Listing 6. Deadlock caused by nested locks within sections. |
| 1: #pragma omp sections 2: { 3: #pragma omp section 4: { 5: omp_set_lock(&lockk1); 6: omp_set_lock(&lockk2); 7: omp_unset_lock(&lockk1); 8: omp_unset_lock(&lockk2); 9: } 10: #pragma omp section 11: { 12: omp_set_lock(&lockk2); 13: omp_set_lock(&lockk1); 14: omp_unset_lock(&lockk2); 15: omp_unset_lock(&lockk1); 16: } 17: } |
| Listing 7. Barrier within for-loop error in OpenMP. |
| 1: void calculate(int *A, int size) 2: { 3: #pragma omp parallel for 4: for (int i = 0; i < size; i++) 5: { 6: // Perform some calculations on array A 7: A[i] = i * 2; 8: #pragma omp barrier // Potential deadlock here 9: } 10: } |
| Listing 8. Nested critical directives. |
| 1: int x = 0; 2: #pragma omp parallel num_threads(2) 3: { 4: #pragma omp critical 5: { 6: // Critical section 1 7: x++; 8: 9: #pragma omp critical 10: { 11: // Critical section 2 (nested) 12: x--; 13: } 14: } 15: } |
| Listing 9. A potential deadlock situation in OpenMP. |
| 1: #pragma omp parallel 2: { 3: #pragma omp critical 4: { 5: omp_set_lock(&lock1); 6: if (input_variable == value) 7: { 8: omp_unset_lock(&lock1); 9: } 10: else 11: { 12: // perform some code 13: } 14: } 15: } |
| Listing 10. Barrier inside a master directive-caused deadlock. |
| 1: #pragma omp parallel 2: { 3: // Do some parallel work 4: #pragma omp master 5: { 6: // Do some sequential work 7: #pragma omp barrier // Potential deadlock 8: // Modify shared data 9: } 10: // Do more parallel work 11: // Modify shared data lead to potential race condition 12: } |
| Listing 11. Potential deadlock caused by a master construct. |
| 1: /* Master thread attempts to enter the single region which is executed 2: by the first arrived thread */ 3: #pragma omp single 4: { 5: #pragma omp master 6: { 7: // Code must be executed by the master thread within the single region 8: } 9: } |
| Listing 12. Potential deadlock caused by a race on a lock. |
| 1: #pragma omp parallel 2: { 3: #pragma omp master 4: { 5: #pragma omp task 6: { 7: #pragma omp task 8: { 9: omp_set_lock(&lock); 10: // Perform some action 11: // Release the lock 12: omp_unset_lock(&lock); 13: } 14: omp_set_lock(&lock); 15: // Perform some action 16: #pragma omp taskwait 17: // Release the lock 18: omp_unset_lock(&lock); 19: } 20: } 21: } 22: omp_destroy_lock(&lock); |
| Listing 13. Potential deadlock caused by if statement. |
| 1: void performAction() 2: { 3: if( /*...*/ ) 4: { 5: #pragma omp parallel 6: { 7: If() 8: { 9: /*...*/ 10: #pragma omp single 11: { 12: /*...*/ 13: } // implicit barrier 14: #pragma omp barrier // explicit barrier 15: } 16: } 17: } 18: } |
3.2.2. OpenMP Race Condition
| Listing 14. Race condition caused by dependent computation. |
| 1: int main() 2: { 3: int sum = 0; 4: #pragma omp parallel for 5: for (int i = 0; i < 10; i++) 6: { 7: sum += i; 8: } 9: } |
| Listing 15. Race condition caused by “nowait” directive. |
| 1: // shared variable x 2: #pragma omp parallel 3: { 4: #pragma omp single 5: { 6: #pragma omp task shared(x) 7: { 8: // Task 1: access and modify shared variable x 9: } 10: #pragma omp nowait 11: } 12: //.... 13: #pragma omp task shared(x) 14: { 15: // Task 2: access and modify shared variable x 16: } // ...... 17: } |
3.3. Errors in Dual MPI and OpenMP Model
| Listing 16. (MPI + OpenMP) program with deadlock situation. |
| 1: void calculateA(int *A, int size) 2: { 3: #pragma omp parallel for 4: for (int i = 0; i < size; i++) 5: { 6: // Perform some calculations on array A 7: A[i] = i * 2; 8: } 9: } 10: 11: void calculateC(int *C, int *A, int size) 12: { 13: #pragma omp parallel for 14: for (int i = 0; i < size; i++) 15: { 16: // Perform some calculations on array C based on array A 17: C[i] = A[i] + 1; 18: } // Potential race condition occur if the ‘nowait’ clause is used 19: } 20: 21: int main(int argc, char **argv) 22: { 23: int rank, size; 24: MPI_Init(&argc, &argv); 25: MPI_Comm_rank(MPI_COMM_WORLD, &rank); 26: MPI_Comm_size(MPI_COMM_WORLD, &size); 27: int *A = new int[size]; 28: int *C = new int[size]; 29: calculateA(A, size); 30: // Potential data race here if threads writing to C before A is fully updated 31: calculateC(C, A, size); 32: // Potential deadlock here if not specifying the receiver in MPI_Send 33: if (rank == 0) 34: { 35: MPI_Send(C, size, MPI_INT, 1, 0, MPI_COMM_WORLD); 36: } 37: else if (rank == 1) 38: { 39: MPI_Recv(C, size, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); 40: } 41: } |
| Listing 17. Deadlock by MPI_Init(). |
| 1: int MPI_Init() 2: omp_set_num_threads(2); 3: #pragma omp parallel 4: { 5: #pragma omp sections 6: { 7: #pragma omp section 8: if (rank == 0 ) 9: MPI_Send(rank1); 10: #pragma omp section 11: if (rank ==0) 12: MPI_Recv(rank1); 13: } 14: } |
| Listing 18. Potential deadlock in (MPI + OpenMP) program. |
| 1: MPI_Init_thread(0,0,MPI_THREAD_MULTIPLE, & provided); 2: MPI_Comm_rank(MPI_COMM_WORLD, &rank); 3: 4: int tag=0; omp_set_num_threads(2); 5: #pragma omp parallel for private(i) 6: for(j = 0; j < 2; j++) 7: { 8: if(rank==0) 9: { 10: MPI_Send(&a, 1, MPI_INT, 1, tag, MPI_COMM_WORLD); 11: MPI_Recv(&a, 1, MPI_INT, 1, tag, MPI_COMM_WORLD, MPI_STATUS_IGNORE); 12: } 13: if(rank==1) 14: { 15: MPI_Recv(&a, 1, MPI_INT, 0, tag, MPI_COMM_WORLD,MPI_STATUS_IGNORE ); 16: MPI_Send(&a, 1, MPI_INT, 0, tag, MPI_COMM_WORLD); 17: } 18: } |
4. Temporal Logic
4.1. Linear Temporal Logic
4.2. Branching Temporal Logic
4.3. Interval Temporal Logic
4.4. LTL for Dual MPI and OpenMP
LTL for Runtime Errors in MPI and OpenMP
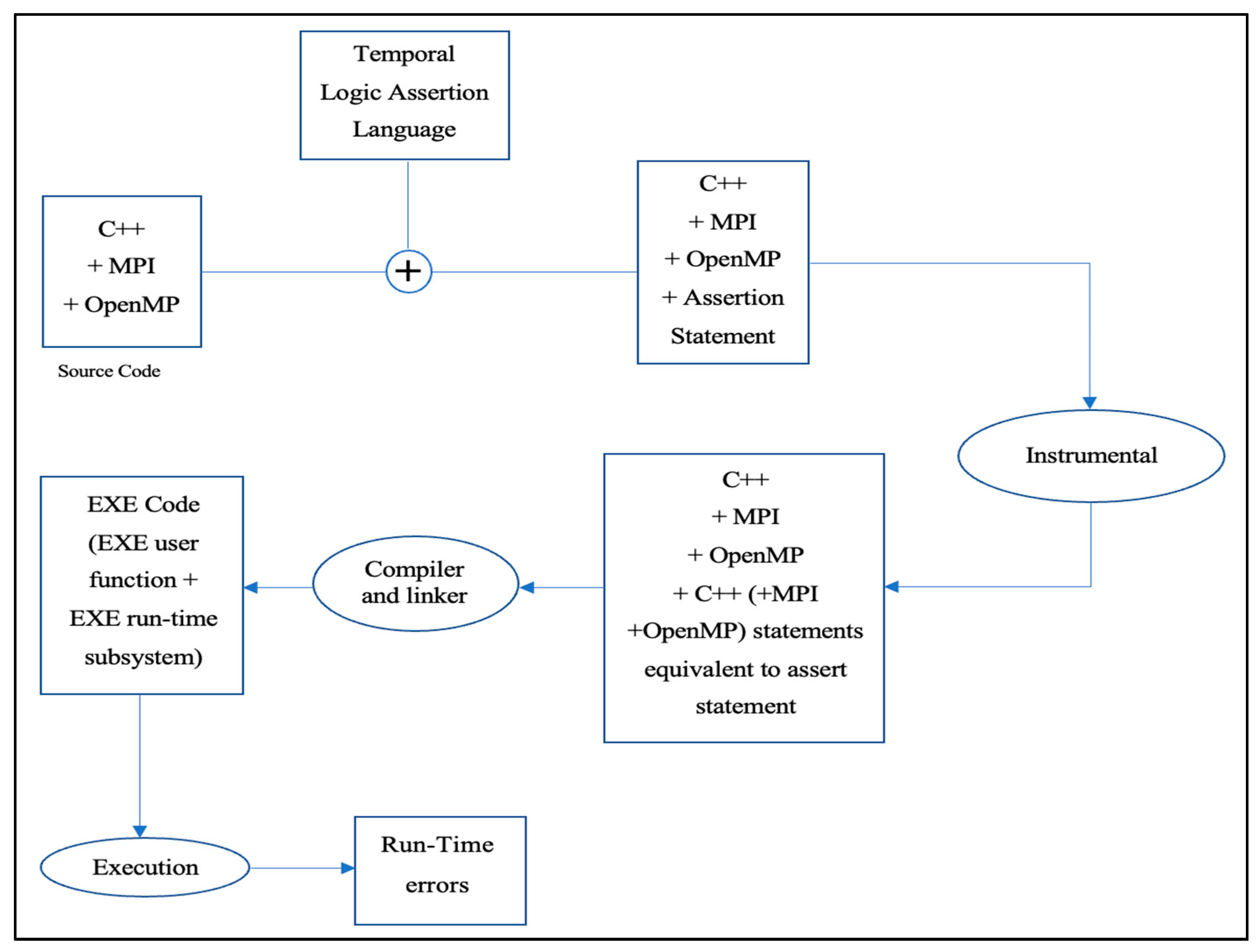
5. Proposed System Architecture
| Algorithm 1: The scanner module |
| 1: SELECT Folder() 2: FOREACH SourceFile in Folder 3: CREATE DestinationFile 4: WHILE line = SourceFile.ReadLine() != null 5: IF line HasAssert 6: IF line HasTemporalOperator 7: SendFileToParser(sourceFile) 8: SendLineToParser(line) 9: END IF 10: PerformOperations() 11: END IF 12: ELSE 13: WriteLineToDestinationFile(destinationFile, line) 14: END WHILE 15: generatedCodeFile = receiveGeneratedCodeFile() 16: 17: IF generatedCodeFile is != null 18: copyGeneratedCodeToFile(sourceFile, generatedCodeFile) 19: END IF 20: End FOREACH |
| Algorithm 2: The parser module |
| 1: RECEIVE (SourceFile, DestinationFile, line) 2: StrLine = Line 3: DECLARE (Label, Temporal, Condition, Semantic) 4: Array = StrLine.ToCharArray() 5: 6: FOR char in Array 7: IF char == ’(’ 8: WHILE char != ’)’ 9: Condition += char 10: END WHILE 11: END IF 12: END FOR 13: Array = StrLine.split([" "]+) 14: Label = Array[0] 15: Temporal = Array[1] 16: 17: SWITCH Temporal 18: case "[]": 19: Semantic = "Always CodeGenerator" 20: case "U": 21: Semantic = "Until CodeGenerator" 22: case "N": 23: Semantic = "Next CodeGenerator" 24: case "~": 25: Semantic = "Eventually CodeGenerator" 26: default: 27: Semantic = "Precede CodeGenerator" 28: END SWITCH 29: 30: SendToSemanticModule(SourceFile, DestinationFile, Label, Condition, Semantic) |
| Algorithm 3: The semantic and translator modules |
| 1: RECEIVE (SourceFile, DestinationFile, Label, Condition, Semantic) 2: 3: WHILE (Line = SourceFile.readLine() != null) 4: IF Line == "Assert" 5: Continue 6: END IF 7: 8: IF Line == Label 9: Break 10: END IF 11: 12: ConditionArray = ExtractVariables(Condition) 13: TokenizeArray = Tokenize(Line) 14: 15: FOR i = 0 to ConditionArray.length 16: FOR j = 0 to TokenizeArray.length 17: IF ConditionArray [i] == TokenizeArray [j] 18: WRITE Line to DestinationFile 19: WRITE Corresponding_C++_MPI_OpenMP_Code to DestinationFile 20: ELSE 21: WRITE Line to DestinationFile 22: END IF 23: END FOR 24: END FOR 25: 26: END WHILE 27: 28: SEND GeneratedCode to Compiler |
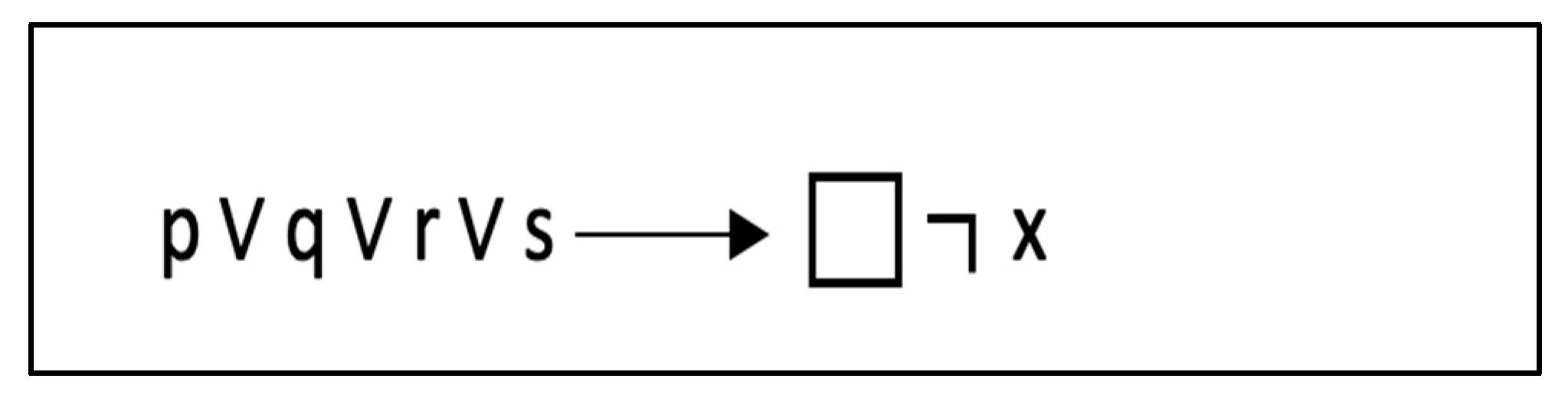
The Proposed Temporal Assertion Language
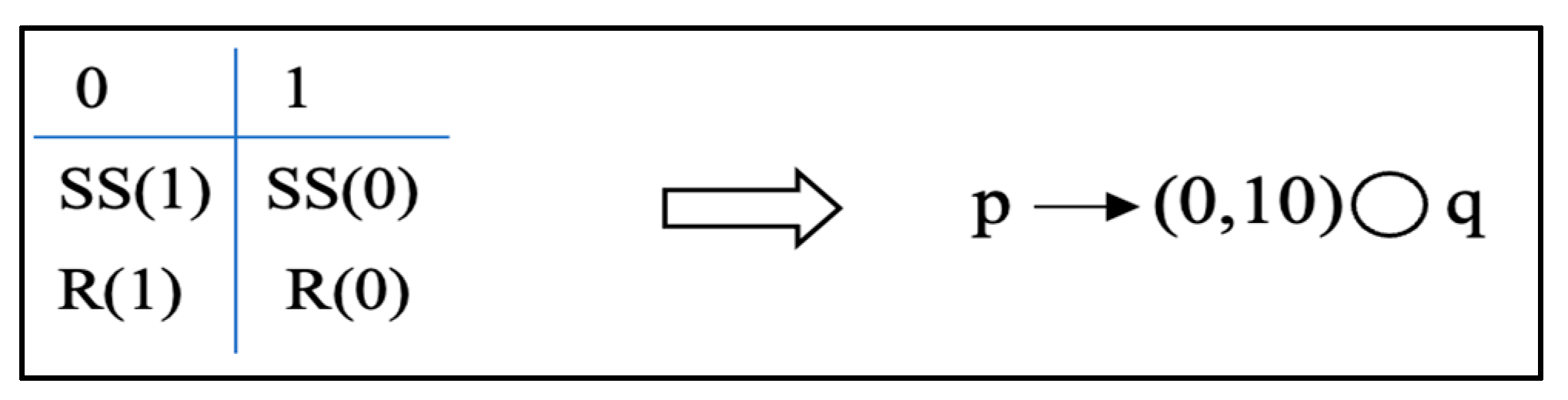
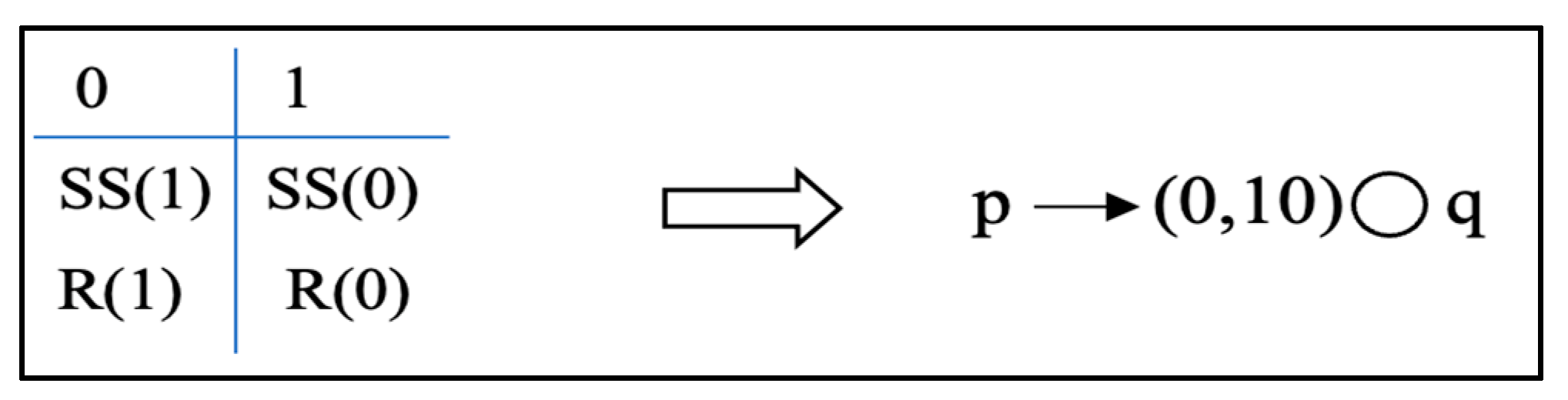
| Listing 19. Assertion language syntax for recv–recv. |
| 1: // A1.1 Assert [] ! (thread 1 and 2 start with receive operation) 2: { block of user code under testing } 3: // A1.1 End Assert |
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, D.; Li, H.-L. Microprocessor Architecture and Design in Post Exascale Computing Era. In Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 9–11 April 2021; pp. 20–32. [Google Scholar] [CrossRef]
- Basloom, H.S.; Dahab, M.Y.; Alghamdi, A.M.; Eassa, F.E.; Al-Ghamdi, A.S.A.-M.; Haridi, S. Errors Classification and Static Detection Techniques for Dual-Programming Model (OpenMP and OpenACC). IEEE Access 2022, 10, 117808–117826. [Google Scholar] [CrossRef]
- Bianchi, F.A.; Margara, A.; Pezze, M. A Survey of Recent Trends in Testing Concurrent Software Systems. IEEE Trans. Softw. Eng. 2017, 44, 747–783. [Google Scholar] [CrossRef]
- Jammer, T.; Hück, A.; Lehr, J.-P.; Protze, J.; Schwitanski, S.; Bischof, C. Towards a hybrid MPI correctness benchmark suite. In Proceedings of the 29th European MPI Users’ Group Meeting (EuroMPI/USA’22), New York, NY, USA, 14 September 2022; pp. 46–56. [Google Scholar] [CrossRef]
- Aguado, F.; Cabalar, P.; Diéguez, M.; Pérez, G.; Schaub, T.; Schuhmann, A.; Vidal, C. Linear-Time Temporal Answer Set Programming. Theory Pract. Log. Program. 2021, 23, 2–56. [Google Scholar] [CrossRef]
- Ramakrishnan, S.; Mcgregor, J. Modelling and Testing OO Distributed Systems with Temporal Logic Formalisms. In Proceedings of the 18th International IASTED Conference Applied Informatic, Innsbruck, Austria, 14–17 February 2000. [Google Scholar]
- Koteska, B.; Pejov, L.; Mishev, A. Formal Specification of Scientific Applications Using Interval Temporal Logic. In Proceedings of the 3rd Workshop on Software Quality Analysis, Monitoring, Improvement, and Applications, SQAMIA 2014; Faculty of Sciences, University of Novi Sad: Croatia, Serbia, 2014. [Google Scholar]
- Mahmud, N.; Seceleanu, C.; Ljungkrantz, O. Specification and semantic analysis of embedded systems requirements: From description logic to temporal logic. In Software Engineering and Formal Methods: 15th International Conference, SEFM 2017, Trento, Italy, 4–8 September 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 332–348. [Google Scholar] [CrossRef]
- Qi, Z.; Liang, A.; Guan, H.; Wu, M.; Zhang, Z. A hybrid model checking and runtime monitoring method for C++ Web Services. In Proceedings of the 2009 Fifth International Joint Conference on INC, IMS and IDC, Seoul, Republic of Korea, 25–27 August 2009. [Google Scholar]
- Baumeister, J.; Coenen, N.; Bonakdarpour, B.; Finkbeiner, B.; Sánchez, C. A temporal logic for asynchronous hyperproperties. In Computer Aided Verification; Springer International Publishing: Cham, Switzerland, 2017; pp. 694–717. [Google Scholar]
- Khan, M.S.A.; Rizvi, H.H.; Athar, S.; Tabassum, S. Use of temporal logic in software engineering for analysis and modeling. In Proceedings of the 2022 Global Conference on Wireless and Optical Technologies (GCWOT), Malaga, Spain, 14–17 February 2022. [Google Scholar]
- Havelund, K.; Roşu, G. An Overview of the Runtime Verification Tool Java PathExplorer. Form. Methods Syst. Des. 2004, 24, 189–215. [Google Scholar] [CrossRef]
- Aljehani, T.; Essa, F.M.A.; Abulkhair, M. Temporal Assertion Language for Testing Web Applications. World J. Comput. Appl. Technol. 2012, 1, 19–28. [Google Scholar]
- Tan, L.; Sokolsky, O.; Lee, I. Specification-based testing with linear temporal logic. In Proceedings of the 2004 IEEE International Conference on Information Reuse and Integration, Las Vegas, NV, USA, 8–10 November 2004. [Google Scholar]
- Panizo, L.; Gallardo, M.-D. Stan: Analysis of data traces using an event-driven interval temporal logic. Autom. Softw. Eng. 2022, 30, 3. [Google Scholar] [CrossRef]
- Althoff, M.; Mayer, M.; Muller, R. Automatic synthesis of human motion from Temporal Logic Specifications. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2020. [Google Scholar]
- Bonnah, E.; Hoque, K.A. Runtime Monitoring of Time Window Temporal Logic. IEEE Robot. Autom. Lett. 2022, 7, 5888–5895. [Google Scholar] [CrossRef]
- Ma, H.; Wang, L.; Krishnamoorthy, K. Detecting Thread-Safety Violations in Hybrid OpenMP/MPI Programs. In Proceedings of the 2015 IEEE International Conference on Cluster Computing, Chicago, IL, USA, 8–11 September 2015; pp. 460–463. [Google Scholar] [CrossRef]
- Krammer, B.; Müller, M.S.; Resch, M.M. MPI application development using the Analysis Tool MARMOT. In Computational Science—ICCS; Springer: Berlin/Heidelberg, Germany, 2004; pp. 464–471. [Google Scholar] [CrossRef]
- Saillard, E.; Carribault, P.; Barthou, D. PARCOACH: Combining static and dynamic validation of MPI collective communications. Int. J. High Perform. Comput. Appl. 2014, 28, 425–434. [Google Scholar] [CrossRef]
- Atzeni, S.; Gopalakrishnan, G.; Rakamaric, Z.; Ahn, D.H.; Laguna, I.; Schulz, M.; Lee, G.L.; Protze, J.; Muller, M.S. Archer: Effectively spotting data races in large openmp applications. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Chicago, IL, USA, 23–27 May 2016. [Google Scholar] [CrossRef]
- Intel® Inspector. Intel. Available online: https://www.intel.com/content/www/us/en/developer/tools/oneapi/inspector.html (accessed on 4 October 2023).
- Clang 18.0.0git Documentation. Threadsanitizer—Clang 18.0.0git Documentation. Available online: https://clang.llvm.org/docs/ThreadSanitizer.html (accessed on 4 October 2023).
- 7. Helgrind: A Thread Error Detector. Valgrind. Available online: https://valgrind.org/docs/manual/hg-manual.html (accessed on 4 October 2023).
- Basupalli, V.; Yuki, T.; Rajopadhye, S.; Morvan, A.; Derrien, S.; Quinton, P.; Wonnacott, D. OmpVerify: Polyhedral Analysis for the openmp programmer. In OpenMP in the Petascale Era: 7th International Workshop on OpenMP, IWOMP 2011, Chicago, IL, USA, 13-15 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 37–53. [Google Scholar] [CrossRef]
- Ye, F.; Schordan, M.; Liao, C.; Lin, P.-H.; Karlin, I.; Sarkar, V. Using polyhedral analysis to verify openmp applications are data race free. In Proceedings of the 2018 IEEE/ACM 2nd International Workshop on Software Correctness for HPC Applications (Correctness), Dallas, TX, USA, 12 November 2018. [Google Scholar] [CrossRef]
- Chatarasi, P.; Shirako, J.; Kong, M.; Sarkar, V. An Extended Polyhedral Model for SPMD Programs and Its Use in Static Data Race Detection. In Languages and Compilers for Parallel Computing: 29th International Workshop, LCPC 2016, Rochester, NY, USA, 28–30 September 2016; Springer: Cham, Switzerland, 2017; pp. 106–120. [Google Scholar] [CrossRef]
- Chatarasi, P.; Shirako, J.; Sarkar, V. Static data race detection for SPMD programs via an extended polyhedral representation. In Proceedings of the 6th International Workshop on Polyhedral Compilation Techniques; IMPACT: Singapore, 2016; Volume 16, Available online: https://pdfs.semanticscholar.org/a88e/2e8740416f35380fc664fcc201fb1014a08c.pdf (accessed on 1 November 2023).
- Swain, B.; Li, Y.; Liu, P.; Laguna, I.; Georgakoudis, G.; Huang, J. OMPRacer: A scalable and precise static race detector for openmp programs. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020. [Google Scholar] [CrossRef]
- Bora, U.; Das, S.; Kukreja, P.; Joshi, S.; Upadrasta, R.; Rajopadhye, S. Llov: A fast static data-race checker for openmp programs. ACM Trans. Arch. Code Optim. 2020, 17, 1–26. [Google Scholar] [CrossRef]
- Atzeni, S.; Gopalakrishnan, G.; Rakamaric, Z.; Laguna, I.; Lee, G.L.; Ahn, D.H. Sword: A bounded memory-overhead detector of openmp data races in production runs. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium (IPDPS), Vancouver, BC, Canada, 21–25 May 2018. [Google Scholar] [CrossRef]
- Gu, Y.; Mellor-Crummey, J. Dynamic Data Race Detection for openmp programs. In Proceedings of the SC18: International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, 11–16 November 2018. [Google Scholar] [CrossRef]
- Wang, W.; Lin, P.-H. Does It Matter?—OMPSanitizer: An Impact Analyzer of Reported Data Races in OpenMP Programs. In Proceedings of the ACM International Conference on Super Computing; Lawrence Livermore National Lab.(LLNL), Livermore, CA, USA, 3 June 2021. [Google Scholar] [CrossRef]
- Cai, Y.; Chan, W. Magiclock: Scalable Detection of Potential Deadlocks in Large-Scale Multithreaded Programs. IEEE Trans. Softw. Eng. 2014, 40, 266–281. [Google Scholar] [CrossRef]
- Eslamimehr, M.; Palsberg, J. Sherlock: Scalable deadlock detection for concurrent programs. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, Hong Kong, China, 16–22 November 2014; pp. 353–365. [Google Scholar] [CrossRef]
- Royuela, S.; Duran, A.; Serrano, M.A.; Quiñones, E.; Martorell, X. A functional safety OpenMP * for critical real-time embedded systems. In Scaling OpenMP for Exascale Performance and Portability; Springer: Berlin/Heidelberg, Germany, 2017; pp. 231–245. [Google Scholar] [CrossRef]
- Kroening, D.; Poetzl, D.; Schrammel, P.; Wachter, B. Sound static deadlock analysis for C/pthreads. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, Singapore, 3–7 September 2016. [Google Scholar] [CrossRef]
- Kowalewski, R.; Fürlinger, K. Nasty-MPI: Debugging Synchronization Errors in MPI-3 One-Sided Applications. In European Conference on Parallel Processing Euro-Par 2016; Springer: Cham, Switzerland, 2016; pp. 51–62. [Google Scholar] [CrossRef]
- Protze, J.; Hilbrich, T.; de Supinski, B.R.; Schulz, M.; Müller, M.S.; Nagel, W.E. MPI runtime error detection with MUST: Advanced error reports. In Tools for High Performance Computing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 25–38. [Google Scholar] [CrossRef]
- The Open MPI Organization, Open MPI: Open Source High Performance Computing. 2018. Available online: https://www.open-mpi.org/ (accessed on 5 November 2023).
- Wei, H.-M.; Gao, J.; Qing, P.; Yu, K.; Fang, Y.-F.; Li, M.-L. MPI-RCDD: A Framework for MPI Runtime Communication Deadlock Detection. J. Comput. Sci. Technol. 2020, 35, 395–411. [Google Scholar] [CrossRef]
- Schwitanski, S.; Jenke, J.; Tomski, F.; Terboven, C.; Muller, M.S. On-the-Fly Data Race Detection for MPI RMA Programs with MUST. In Proceedings of the 2022 IEEE/ACM Sixth International Workshop on Software Correctness for HPC Applications (Correctness), Dallas, TX, USA, 13–18 November 2022; pp. 27–36. [Google Scholar] [CrossRef]
- Alghamdi, A.M.; Eassa, F.E. OpenACC Errors Classification and Static Detection Techniques. IEEE Access 2019, 7, 113235–113253. [Google Scholar] [CrossRef]
- Basloom, H.; Dahab, M.; Al-Ghamdi, A.S.; Eassa, F.; Alghamdi, A.M.; Haridi, S. A Parallel Hybrid Testing Technique for Tri-Programming Model-Based Software Systems. Comput. Mater. Contin. 2023, 74, 4501–4530. [Google Scholar] [CrossRef]
- Altalhi, S.M.; Eassa, F.E.; Al-Ghamdi, A.S.A.-M.; Sharaf, S.A.; Alghamdi, A.M.; Almarhabi, K.A.; Khemakhem, M.A. An Architecture for a Tri-Programming Model-Based Parallel Hybrid Testing Tool. Appl. Sci. 2023, 13, 11960. [Google Scholar] [CrossRef]
- OpenMP. Available online: https://www.openmp.org/specifications/ (accessed on 7 November 2023).
- Konur, S. A survey on temporal logics for specifying and verifying real-time systems. Front. Comput. Sci. 2013, 7, 370–403. [Google Scholar] [CrossRef]
- Fisher, M. An Introduction to Practical Formal Methods Using Temporal Logic; Wiley: Chichester, UK, 2011. [Google Scholar]
- Abuin, Y.A. Certificates for Decision Problems in Temporal logic Using Context-Based Tableaux and Sequent Calculi. Ph.D. Thesis, Universidad del País Vasco-Euskal Herriko Unibertsitatea, Bizkaia, Spain, 2023. [Google Scholar]
- Alshammari, N.H. Formal Specification and Runtime Verification of Parallel Systems Using Interval Temporal Logic (ITL). Ph.D. Thesis, Software Technology Research Laboratory, Leicester, UK, 2018. [Google Scholar]
- Manna, Z.; Pnueli, A. The Temporal Logic of Reactive and Concurrent Systems: Specifications; Springer Science & Business Media: New York, NY, USA, 1992; Volume 1. [Google Scholar]
- Drusinsky, D. The temporal rover and the ATG rover. In SPIN Model Checking and Software Verification; Springer: Berlin/Heidelberg, Germany, 2000; pp. 323–330. [Google Scholar] [CrossRef]
- Li, Y.; Liu, W.; Wang, J.; Yu, X.; Li, C. Model checking of possibilistic linear-time properties based on generalized possibilistic decision processes. IEEE Trans. Fuzzy Syst. 2023, 31, 3495–3506. [Google Scholar] [CrossRef]
- Alghamdi, A.M.; Elbouraey, F. A Parallel Hybrid-Testing Tool Architecture for a Dual-Programming Model. Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef]
- Alghamdi, A.M.; Eassa, F.E.; Khamakhem, M.A.; Al-Ghamdi, A.S.A.-M.; Alfakeeh, A.S.; Alshahrani, A.S.; Alarood, A.A. Parallel Hybrid Testing Techniques for the Dual-Programming Models-Based Programs. Symmetry 2020, 12, 1555. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solution/Tool | Applied to | Techniques | Advantages | Disadvantages |
|---|---|---|---|---|
| [9] Hybrid model checking | C/C++ web services | dynamically search violations specified by LTL | checks the high-level properties | difficulties at the end of the trace |
| [10] A-HLTL | computational systems | uses two temporal logics and two model checkers | covers a rich set of security requirements | undecidable model-checking |
| [12] JPAX | Java | verified properties in temporal logic | detects concurrency errors | does not clarify next step if properties not satisfied |
| [13] IMATT | Java | apply static and dynamic testing | tests agent security | temporal assert statements inserted manually |
| [14] Specification testing with LTL | real-world systems | system requirements are encoded in LTL | offers a practical method for testing | not suitable for big real-world systems |
| [15] STAN | hybrid systems | performs runtime verification data traces | efficiency and flexibility | difficult to represent continuous variables |
| [17] Runtime monitoring algorithm | motion planning | uses TWTL | increasing number of traces | It is offline version |
| Tool | Targeted Errors | Programming Models | Technique | Temporal Logic Based |
|---|---|---|---|---|
| HOME [18] | data races and incorrect synchronization | MPI/OpenMP | hybrid | no |
| Marmot [19] | deadlock, race condition and mismatching | MPI/OpenMP | dynamic | no |
| PARCOACH [20] | deadlock, data race and mismatching | MPI/OpenMP | hybrid | no |
| ARCHER [21] | data race | OpenMP | hybrid | no |
| ompVerify [25] | data race | OpenMP | static | no |
| MUST [39] | deadlock and data race | MPI | dynamic | no |
| MPI-RCDD [41] | deadlock | MPI | dynamic | no |
| MUST-RMA [42] | data race | MPI | dynamic | no |
| Our tool | deadlock and data race | MPI/OpenMP | dynamic | yes |
| MPI | OpenMP | Effect on Entire System |
|---|---|---|
| no error | no error | no error |
| deadlock | no error | deadlock in system |
| potential deadlock | no error | potential deadlock in system |
| race condition | no error | race condition in system |
| potential race condition | no error | potential race condition in system |
| no error | deadlock | deadlock in system |
| no error | potential deadlock | potential deadlock in system |
| no error | race condition | race condition. |
| no error | potential race condition | potential race condition in system |
| deadlock | deadlock | deadlock in system |
| deadlock | OpenMP race condition | deadlock in system |
| race condition | deadlock | deadlock in system |
| race condition | race condition | potential deadlock or potential race condition in system |
| System Properties | LTL Properties |
|---|---|
| q holds at all states after p holds | p → q |
| p and q cannot hold at the same time | □ ((¬q) ∨ (¬p)) |
| q holds at some time after p holds | p → ◇q |
| If p repeatedly holds, q holds after some time | □◇ p → q |
| If p always holds, q holds after some time | □ p → ◇q |
| System Properties | BTL Properties |
|---|---|
| There exists a state where p holds but q does not hold | ∃(p ∧ ¬q) |
| At all paths p holds after some time | ∀ □(∃◇p) |
| Testing Tool | Assertion Technique | Programming Models | Targeted Errors |
|---|---|---|---|
| [44] (dynamic approach) | simple assert statements | MPI, OpenMP, and OpenACC | potential runtime errors |
| [45] (dynamic approach) | simple assert statements | MPI, OpenMP, and CUDA | potential runtime errors |
| [55] ACC_TEST (dynamic approach) | simple assert statements | MPI and OpenACC | potential runtime errors |
| our tool | assertion language based on temporal logic | MPI and OpenMP | potential and real runtime errors |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saad, S.; Fadel, E.; Alzamzami, O.; Eassa, F.; Alghamdi, A.M. Temporal-Logic-Based Testing Tool Architecture for Dual-Programming Model Systems. Computers 2024, 13, 86. https://doi.org/10.3390/computers13040086
Saad S, Fadel E, Alzamzami O, Eassa F, Alghamdi AM. Temporal-Logic-Based Testing Tool Architecture for Dual-Programming Model Systems. Computers. 2024; 13(4):86. https://doi.org/10.3390/computers13040086
Chicago/Turabian StyleSaad, Salwa, Etimad Fadel, Ohoud Alzamzami, Fathy Eassa, and Ahmed M. Alghamdi. 2024. "Temporal-Logic-Based Testing Tool Architecture for Dual-Programming Model Systems" Computers 13, no. 4: 86. https://doi.org/10.3390/computers13040086
APA StyleSaad, S., Fadel, E., Alzamzami, O., Eassa, F., & Alghamdi, A. M. (2024). Temporal-Logic-Based Testing Tool Architecture for Dual-Programming Model Systems. Computers, 13(4), 86. https://doi.org/10.3390/computers13040086