
Digital Genome and Self-Regulating Distributed Software Applications with Associative Memory and Event-Driven History



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Improved resilience using the concept of autopoiesis, which refers to the ability of a system to replicate itself and maintain identity and stability while facing fluctuations caused by external influences;
- Enhanced cognition using cognitive behaviors that model the system’s state, sense internal and external changes, analyze, predict, and take action to mitigate any risk to its functional fulfillment.
- We discuss the limitations of both the symbolic and sub-symbolic computing structures used in the current implementation of distributed software systems;
- We discuss GTI and its application to create a knowledge representation in the form of associative memory, as well as the event-driven transaction history of the distributed software system;
- We demonstrate a distributed software application with autopoietic and enhanced cognitive behaviors. An autopoietic manager configures and manages the components of the distributed software system, and a cognitive network manager provides enhanced cognition to manage the connections between the software components to maintain the quality of service. A policy manager’s policies are defined by best practices and experience to manage deviations from expected behaviors.
1.1. Limitations of the Current State of the Art
1.1.1. CAP Theorem Limitation
- Consistency: All users see the same data at the same time, no matter which node they connect to. For this to happen, whenever data are written to one node, they must be instantly forwarded or replicated to all the other nodes in the system before the write is deemed ‘successful’.
- Availability: Any client requesting data receives a response, even if one or more nodes are down. Another way to state this is that all working nodes in the distributed system return a valid response for any request, without exception.
- Partition Tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
1.1.2. Complexity
1.1.3. Computation and Its Limits
1.2. Stored Program Control Implementation of Symbolic and Sub-Symbolic Computing Structures
- Lack of Interpretability: Deep learning models, particularly neural networks, are often “black boxes”, because it is difficult to understand the reasoning behind how they respond to the queries.
- Need for Large Amounts of Data: These models typically require large data sets to train effectively.
- Overfitting: Deep learning models can overfit the training data, meaning they may not generalize well to unseen data.
- Vanishing and Exploding Gradient Problems: These are issues that can arise during the training process, making it difficult for the model to learn.
- Adversarial Attacks: Deep learning models are vulnerable to adversarial attacks, where small, intentionally designed changes to the input can cause the model to make incorrect predictions.
- Difficulty Incorporating Symbolic Knowledge: Sub-symbolic methods, such as neural networks, often struggle to incorporate symbolic knowledge, such as causal relationships and practitioners’ knowledge.
- Bias: These methods can learn and reflect biases present in the training data.
- Lack of Coordination with Symbolic Systems: While sub-symbolic and symbolic systems can operate independently, they often need to coordinate closely together to integrate the knowledge derived from them, which can be challenging.
1.3. The General Theory of Information and Super-Symbolic Computing
- The knowledge network captures the system state and its evolution caused by the event-driven interactions of various entities interacting with each other in the form of associative memory and event-driven interaction history. It is important to emphasize that the digital genome and super-symbolic computing structures differ from using symbolic and sub-symbolic structures together. For example, the new frameworks [36] from the MIT Computer Science and Artificial Intelligence Laboratory provide essential context for language models that perform coding, AI planning, and robotic tasks. However, this approach does not use associative memory and event-driven transaction history as long-term memory. The digital genome provides a schema for creating them using knowledge derived from both symbolic and sub-symbolic computing.
2. Distributed Software Application and Its Implementation
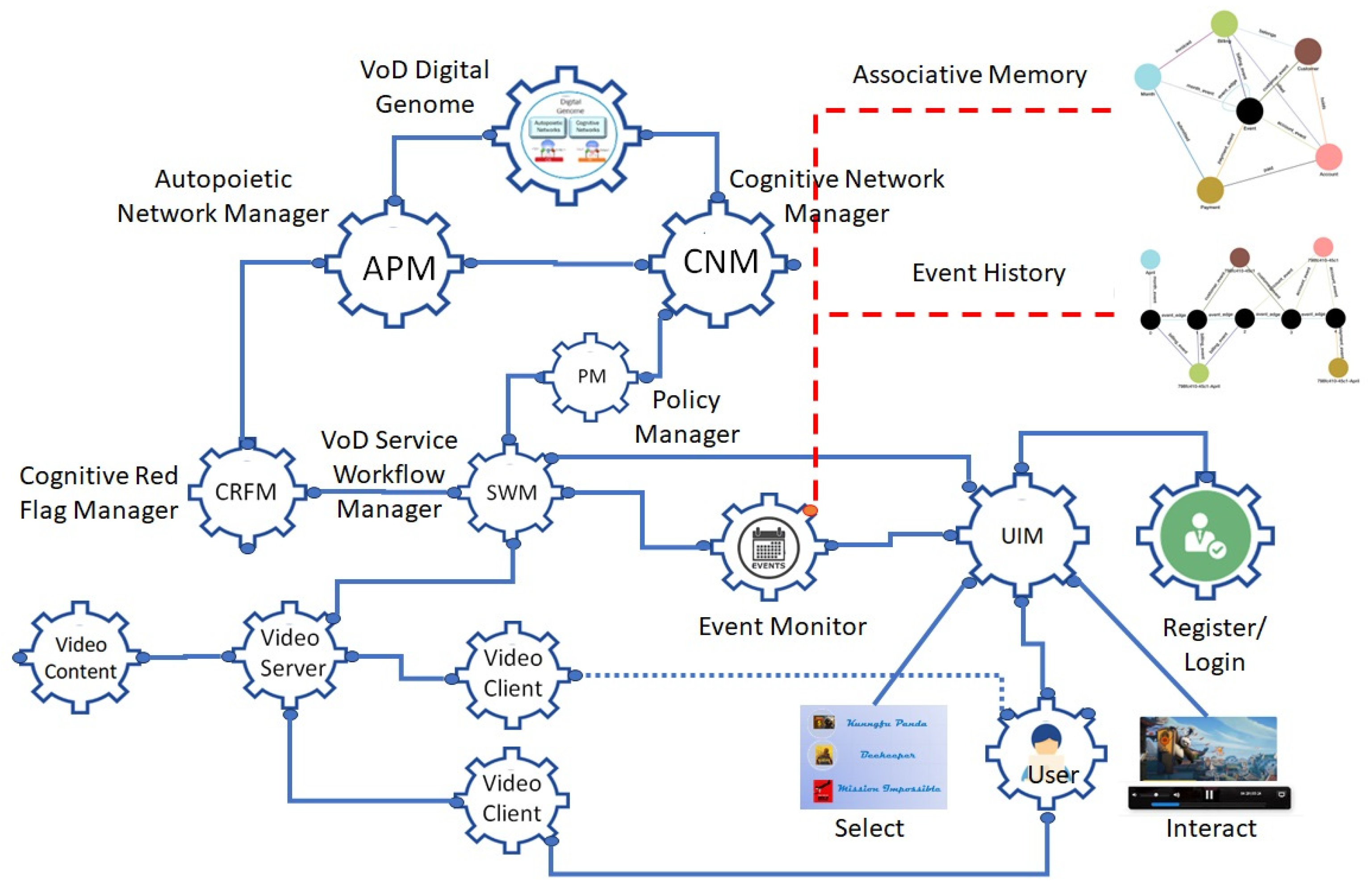
3. Video-on-Demand (VoD) Service with Associative Memory and Event-Driven Interaction History
- The user is given a service URL.
- The user registers for the service.
- An administrator authenticates with a user ID and password.
- The user logs into the URL with a user ID and Password.
- The user is presented with a menu of videos.
- The user selects a video.
- The user is presented with a video and controls to interact.
- The user uses the controls (pause, start, rewind, and fast forward) and watches the video.
- The Video Service consists of several components working together:
- ◦
- A VoD service workflow manager;
- ◦
- A video content manager;
- ◦
- A video server;
- ◦
- A video client.
- Auto-Failover: When a video service is interrupted by the failure of any component, the user service should not experience any service interruption.
- Auto-Scaling: When the end-to-end service response time falls below a threshold, necessary resource adjustments should be made to adjust the response time to the desired value.
- Live Migration: Any component should be easily migrated from one infrastructure to another without service interruption.
- Developers design the process workflow based on the functional requirements.
- Each process (a knowledge structure with a schema consisting of entities, relationships, and their event-driven interactions, which are defined by its inputs and actions) executes based on the inputs and generated outputs communicated with other processes using shared knowledge.
- All the knowledge structures are containerized and deployed as a knowledge network. For example, the user interface subnetwork contains the user registration, login, video selection, and use processes with specified inputs, behaviors, and outputs. The video service subprocess deals with video management and delivery processes. Wired knowledge structures fire together to execute autopoietic and enhanced cognitive behaviors managed by a service workflow manager under the supervision of the autopoietic and cognitive network managers.
- The autopoietic manager manages the deployment of knowledge structures using cloud resources.
- The cognitive network manager manages the workflow connections between the knowledge structures.
- Autopoietic and cognitive managers, along with a policy manager who dictates best-practice rules, manage the deviations from expected behavior caused by fluctuations in the availability of or demand for resources or workflow disruptions. The best practice policies are derived from history and experience. For example, if the service response time exceeds a threshold, auto-scaling is used to reduce it. Using the return time objective (RTO) and the return position objective (RPO), the structure of the knowledge network is configured by the autopoietic and cognitive network managers to maintain the quality of service using auto-failover or live migration.
4. Results
- Python programming for creating the schema and its evolution with various instances;
- Containers that were deployed using the Google Cloud;
- A graph database (Tiger Graph) that represents the schema and its evolution with various instances using the events that capture the interactions as associative memory and event-driven interaction history.
- A knowledge sub-network in action, where users interact with various entities delivering the service. They can register, log in, choose a video from a menu, and interact with it.
- A knowledge sub-network that manages and serves the video-on-demand service.
- A higher-level knowledge network with the service workflow manager, policy manager, autopoietic manager, and cognitive network manager provides structural stability and enhanced cognitive workflow management to address the impact of fluctuations in the interactions causing disruptions in the quality of service.
- A graph database demonstrates the system evolution using a service schema, associative memory, and event-driven interaction history of all the users.
5. Conclusions
5.1. Future Directions
5.2. Related Work and Contributions of This Paper
- Event-Driven Associative Memory Networks for Knowledge Graph Completion by X. Wang et al. [43]: This paper explores how event-driven associative memory networks can enhance knowledge graph completion tasks. It introduces a novel approach that combines temporal information with associative memory mechanisms to improve link prediction in knowledge graphs.
- Memory Networks by J. Weston et al. [44]: Although not exclusively focused on associative memory, this influential paper introduces the concept of memory networks. It discusses how external memory can augment neural networks, allowing them to store and retrieve information more effectively.
- Neural Turing Machines A. Graves et al. [45]: While not directly related to event-driven transaction history, this paper proposes a model called neural Turing machines (NTMs). NTMs combine neural networks with external memory, enabling them to learn algorithmic tasks and perform associative recall.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Explanation of Figures
- Data Sources, Data Structures, and Algorithms: Data can come from various sources such as text, audio, pictures, and videos. Data are organized using data structures. Algorithms are applied to process and manipulate this data.
- Computing Paradigms: Symbolic computing involves using symbols to represent problems and logical rules to solve them. Sub-symbolic computing involves techniques like neural networks and other forms of machine learning.
- Application in Robotics and Generative AI: The knowledge gained from machine learning and deep learning can be applied to robotics for automation and intelligent behavior.
- Transformers: A type of model architecture, especially useful for processing sequential data like language. Examples include BERT and GPT.
- GenAI: Generative AI models, which can generate new data similar to the data they were trained on.
- Question Answering: The ability of AI to provide answers to questions posed in natural language.
- Sentiment Analysis: Determining the sentiment expressed in text, such as positive, negative, or neutral.
- Information Extraction: Extracting structured information from unstructured data.
- AI Image Generation: Creating new images from textual descriptions or other inputs.
- Object Recognition: Identifying objects within images or videos.
- World of Ideal Structures: Information is seen as fundamental to the world of ideal structures. According to GTI, the ideal structures are represented by Named sets/Fundamental triads, where entities with established relationships interact with each other and evolve their state based on event-driven behaviors events, forming a basic knowledge structure.
- World of Material Structures: In the physical world, energy relates to matter, and material structures evolve as they are governed by the laws of the conversion of energy and matter. In the mental world, information received by observers is processed by the neural networks in biological systems. Neurons fired together wire together to create associative memory and event-driven transaction history.
- World of Digital Structures: In the digital world created by humans, information is processed in digital form using symbolic and sub-symbolic computing structures. In essence, this figure illustrates the comprehensive view of how information is processed, structured, and transformed into knowledge across different realms, linking theoretical foundations to practical implementations in computing.
- Reasoning Genome: Handles logical reasoning and decision making.
- Service Workflow Genome: Manages workflows and service operations.
- Event Genome: Tracks and processes events within the network.
- User Interface Genome: Manages interactions with users.
- Red Flag Genome: Identifies and handles anomalies or critical issues.
- Symbolic Computing Genomes: Handle different aspects of symbolic computation.
- Sub-Symbolic Computing Genomes: Handle pattern recognition and machine learning tasks.
Appendix B. Glossary of Terms
References
- 20 Best Distributed System Books of All Time—BookAuthority. Available online: https://bookauthority.org/books/best-distributed-system-books (accessed on 17 June 2024).
- Bohloul, S.M. Service-oriented Architecture: A review of state-of-the-art literature from an organizational perspective. J. Ind. Integr. Manag. 2021, 6, 353–382. [Google Scholar] [CrossRef]
- Söylemez, M.; Tekinerdogan, B.; Kolukısa Tarhan, A. Challenges and Solution Directions of Microservice Architectures: A Systematic Literature Review. Appl. Sci. 2022, 12, 5507. [Google Scholar] [CrossRef]
- “CAP Theorem (Explained)” Youtube, Uploaded by Techdose 9 December 2018. Available online: https://youtu.be/PyLMoN8kHwI?si=gtHWzvt2gelf3kly (accessed on 17 June 2024).
- Opara-Martins, J.; Sahandi, R.; Tian, F. Critical analysis of vendor lock-in and its impact on cloud computing migration: A business perspective. J. Cloud. Comp. 2016, 5, 4. [Google Scholar] [CrossRef]
- Vaquero, L.M.; Cuadrado, F.; Elkhatib, Y.; Bernal-Bernabe, J.; Srirama, S.N.; Zhani, M.F. Research challenges in nextgen service orchestration. Future Gener. Comput. Syst. 2019, 90, 20–38. [Google Scholar] [CrossRef]
- Burgin, M. Super-Recursive Algorithms; Monographs in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; ISBN 0-387-95569-0. [Google Scholar]
- Dodig Crnkovic, G. Info-Computationalism and Morphological Computing of Informational Structure; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar] [CrossRef]
- Burgin, M.; Mikkilineni, R. General Theory of Information Paves the Way to a Secure, Service-Oriented Internet Connecting People, Things, and Businesses. In Proceedings of the 2022 12th International Congress on Advanced Applied Informatics (IIAI-AAI), Kanazawa, Japan, 2–8 July 2022; pp. 144–149. [Google Scholar]
- Dodig Crnkovic, G. Significance of Models of Computation, from Turing Model to Natural Computation. Minds Mach. 2011, 21, 301–322. [Google Scholar] [CrossRef]
- Cockshott, P.; MacKenzie, L.M.; Michaelson, G. Computation and Its Limits; Oxford University Press: Oxford, UK, 2012; p. 215. [Google Scholar]
- van Leeuwen, J.; Wiedermann, J. The Turing machine paradigm in contemporary computing. In Mathematics Unlimited—2001 and Beyond; Enquist, B., Schmidt, W., Eds.; LNCS; Springer: New York, NY, USA, 2000. [Google Scholar]
- Wegner, P.; Eberbach, E. New Models of Computation. Comput. J. 2004, 47, 4–9. [Google Scholar] [CrossRef]
- Wegner, P.; Goldin, D. Computation beyond Turing Machines: Seeking appropriate methods to model computing and human thought. Commun. ACM 2003, 46, 100. [Google Scholar] [CrossRef]
- Rothman, D. Transformers for Natural Language Processing and Computer Vision: Explore Generative AI and Large Language Models with Hugging Face, ChatGPT, GPT-4V, and DALL-E 3; Packt Publishing Ltd.: Birmingham, UK, 2024. [Google Scholar]
- Hu, W.; Li, X.; Li, C.; Li, R.; Jiang, T.; Sun, H.; Huang, X.; Grzegorzek, M.; Li, X. A state-of-the-art survey of artificial neural networks for whole-slide image analysis: From popular convolutional neural networks to potential visual transformers. Comput. Biol. Med. 2023, 161, 107034. [Google Scholar] [CrossRef]
- Soori, M.; Arezoo, B.; Dastres, R. Artificial intelligence, machine learning and deep learning in advanced robotics, a review. Cogn. Robot. 2023, 3, 54–70. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed]
- Karimian, G.; Petelos, E.; Evers, S.M. The ethical issues of the application of artificial intelligence in healthcare: A systematic scoping review. AI Ethics 2022, 2, 539–551. [Google Scholar] [CrossRef]
- Groumpos, P.P. Artificial intelligence: Issues, challenges, opportunities and threats. In Creativity in Intelligent Technologies and Data Science: Third Conference, CIT&DS 2019, Volgograd, Russia, 16–19 September 2019, Proceedings, Part I 3; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 19–33. [Google Scholar]
- Mikkilineni, R. A New Class of Autopoietic and Cognitive Machines. Information 2022, 13, 24. [Google Scholar] [CrossRef]
- Burgin, M.; Mikkilineni, R. From Data Processing to Knowledge Processing: Working with Operational Schemas by Autopoietic Machines. Big Data Cogn. Comput. 2021, 5, 13. [Google Scholar] [CrossRef]
- Burgin, M. Mathematical Schema Theory for Modeling in Business and Industry. In Proceedings of the 2006 Spring Simulation Multi Conference (SpringSim‘06), Huntsville, AL, USA, 2–6 April 2006; pp. 229–234. [Google Scholar]
- Burgin, M. Unified Foundations of Mathematics. arXiv 2004, arXiv:math/0403186. [Google Scholar] [CrossRef]
- Burgin, M. Theory of Named Sets, Mathematics Research Developments; Nova Science: New York, NY, USA, 2011. [Google Scholar]
- Burgin, M. Structural Reality; Nova Science Publishers: New York, NY, USA, 2012. [Google Scholar]
- Burgin, M. Theory of Knowledge: Structures and Processes; World Scientific: New York, NY, USA; London, UK; Singapore, 2016. [Google Scholar]
- Burgin, M. Theory of Information: Fundamentality, Diversity, and Unification; World Scientific: Singapore, 2010. [Google Scholar]
- Burgin, M. Ideas of Plato in the Context of Contemporary Science and Mathematics. Athens J. Humanit. Arts 2017, 4, 161–182. [Google Scholar] [CrossRef]
- Burgin, M. Information Processing by Structural Machines. In Theoretical Information Studies: Information in the World; World Scientific: New York, NY, USA; London, UK; Singapore, 2020; pp. 323–371. [Google Scholar]
- Burgin, M. Elements of the Theory of Nested Named Sets. Theory Appl. Math. Comput. Sci. 2020, 10, 46–70. [Google Scholar]
- Renard, D.A. From Data to Knowledge Processing Machines. Proceedings 2022, 81, 26. [Google Scholar] [CrossRef]
- Burgin, M. Triadic Automata and Machines as Information Transformers. Information 2020, 11, 102. [Google Scholar] [CrossRef]
- Burgin, M.; Mikkilineni, R. Information Theoretic Principles of Software Development, EasyChair Preprint No. 9222. 2022. Available online: https://easychair.org/publications/preprint/jnMd (accessed on 31 August 2024).
- Shipps, A. MIT News. 2024. Available online: https://news.mit.edu/2024/natural-language-boosts-llm-performance-coding-planning-robotics-0501 (accessed on 20 June 2024).
- Mikkilineni, R. Mark Burgin’s Legacy: The General Theory of Information, the Digital Genome, and the Future of Machine Intelligence. Philosophies 2023, 8, 107. [Google Scholar] [CrossRef]
- Mikkilineni, R. Infusing Autopoietic and Cognitive Behaviors into Digital Automata to Improve Their Sentience, Resilience, and Intelligence. Big Data Cogn. Comput. 2022, 6, 7. [Google Scholar] [CrossRef]
- Krzanowski, R. Information: What We Do and Do Not Know—A Review. Available online: https://www.researchgate.net/publication/370105722_Information_What_We_Do_and_Do_Not_Know-A_Review (accessed on 30 June 2023).
- Floridi, L. Information. In A Very Short Introduction; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Naidoo, M. The open ontology and information society. Front. Genet. 2024, 15, 1290658. [Google Scholar] [CrossRef] [PubMed]
- Bawden, D. The Occasional Informationist. 2023. Available online: https://theoccasionalinformationist.com/2023/03/05/mark-burgin-1946-2023/ (accessed on 28 June 2024).
- Wang, X.; Zhang, J.; Wang, Y. Event-Driven Associative Memory Networks for Knowledge Graph Completion. In Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI), Virtual Event, 2–9 February 2021. [Google Scholar]
- Weston, J.; Chopra, S.; Bordes, A. Memory Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS), Montreal, QB, Canada, 7–12 December 2015. [Google Scholar]
- Graves, A.; Wayne, G.; Danihelka, I. Neural Turing Machines. arXiv 2014, arXiv:1410.5401. [Google Scholar]
- Goertzel, B. Artificial General Intelligence: Concept, State of the Art, and Future Prospects. J. Artif. Gen. Intell. 2009, 5, 1–46. [Google Scholar] [CrossRef]
- Everitt, T.; Lea, G.; Hutter, M. AGI safety literature review. arXiv 2018, arXiv:1805.01109. [Google Scholar]
- Garcez, A.D.; Besold, T.R.; de Raedt, L.; Földiak, P.; Hitzler, P.; Icard, T.; Kühnberger, K.-U.; Lamb, L.C.; Miikkulainen, R.; Silver, D.L. Neural-symbolic learning and reasoning: Contributions and challenges. In 2015 AAAI Spring Symposium Series; Association for the Advancement of Artificial Intelligence: Washington, DC, USA, 2015. [Google Scholar]
- Garcez, A.D.A.; Gori, M.; Lamb, L.C.; Serafini, L.; Spranger, M.; Tran, S.N. Neural-symbolic computing: An effective methodology for principled integration of machine learning and reasoning. arXiv 2019, arXiv:1905.06088. [Google Scholar]
- Lamb, L.C.; Garcez, A.; Gori, M.; Prates, M.; Avelar, P.; Vardi, M. Graph neural networks meet neural-symbolic computing: A survey and perspective. arXiv 2020, arXiv:2003.00330. [Google Scholar]
- Besold, T.R.; Garcez, A.D.; Bader, S.; Bowman, H.; Domingos, P.; Hitzler, P.; Kühnberger, K.-U.; Lamb, L.C.; Lima, P.M.V.; de Penning, L.; et al. Neural-symbolic learning and reasoning: A survey and interpretation 1. In Neuro-Symbolic Artificial Intelligence: The State of the Art; IOS Press: Amsterdam, The Netherlands, 2021; pp. 1–51. [Google Scholar]
- Hitzler, P.; Eberhart, A.; Ebrahimi, M.; Sarker, M.K.; Zhou, L. Neuro-symbolic approaches in artificial intelligence. Natl. Sci. Rev. 2022, 9, nwac035. [Google Scholar] [CrossRef]
- Digital Genome Implementation Presentations:—Autopoietic Machines (triadicautomata.com). Available online: https://triadicautomata.com/digital-genome-vod-presentation/ (accessed on 30 August 2024).
- Ueno, H.; Koyama, T.; Okamoto, T.; Matsubi, B.; Isidzuka, M. Knowledge Representation and Utilization; Mir: Moscow, Russia, 1987; (Russian translation from the Japanese). [Google Scholar]
- Osuga, S. Knowledge Processing; Mir: Moscow, Russia, 1989; (Russian translation from the Japanese). [Google Scholar]
- Dalkir, K. Knowledge Management Theory and Practice; Butterworth-Heinemann: Boston, MA, USA, 2005. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mikkilineni, R.; Kelly, W.P.; Crawley, G. Digital Genome and Self-Regulating Distributed Software Applications with Associative Memory and Event-Driven History. Computers 2024, 13, 220. https://doi.org/10.3390/computers13090220
Mikkilineni R, Kelly WP, Crawley G. Digital Genome and Self-Regulating Distributed Software Applications with Associative Memory and Event-Driven History. Computers. 2024; 13(9):220. https://doi.org/10.3390/computers13090220
Chicago/Turabian StyleMikkilineni, Rao, W. Patrick Kelly, and Gideon Crawley. 2024. "Digital Genome and Self-Regulating Distributed Software Applications with Associative Memory and Event-Driven History" Computers 13, no. 9: 220. https://doi.org/10.3390/computers13090220