
Parallel Attention-Driven Model for Student Performance Evaluation

 , , , and
, , , and
Abstract
:1. Introduction
- Development of a Holistic Evaluation Model: A novel student evaluation model that integrates a wide range of metrics beyond exams, including behavioral assessments, practical assignments, attendance, and participation.
- Application of Multi-Task Learning: The proposed model utilizes LSTM-based Multi-Task learning, simultaneously addressing regression (total score prediction) and classification (performance category) tasks, thus optimizing computational efficiency.
- Attention Mechanism: An attention mechanism is also introduced in order to render the model more focused on relevant features, enhancing both the accuracy and interpretability of its predictions.
- Extensive Performance Analysis: In this context, the proposed model is evaluated using a generated dataset that simulates detailed student performance metrics, demonstrating its ability to capture complex relationships across various evaluation criteria and provide valuable insights into overall student performance.
- Potential for Wide Application: The suggested method has great potential for use in many educational areas as a powerful tool for the comprehensive assessment of students in e-learning.
2. Related Works
3. Materials and Methods
3.1. Materials
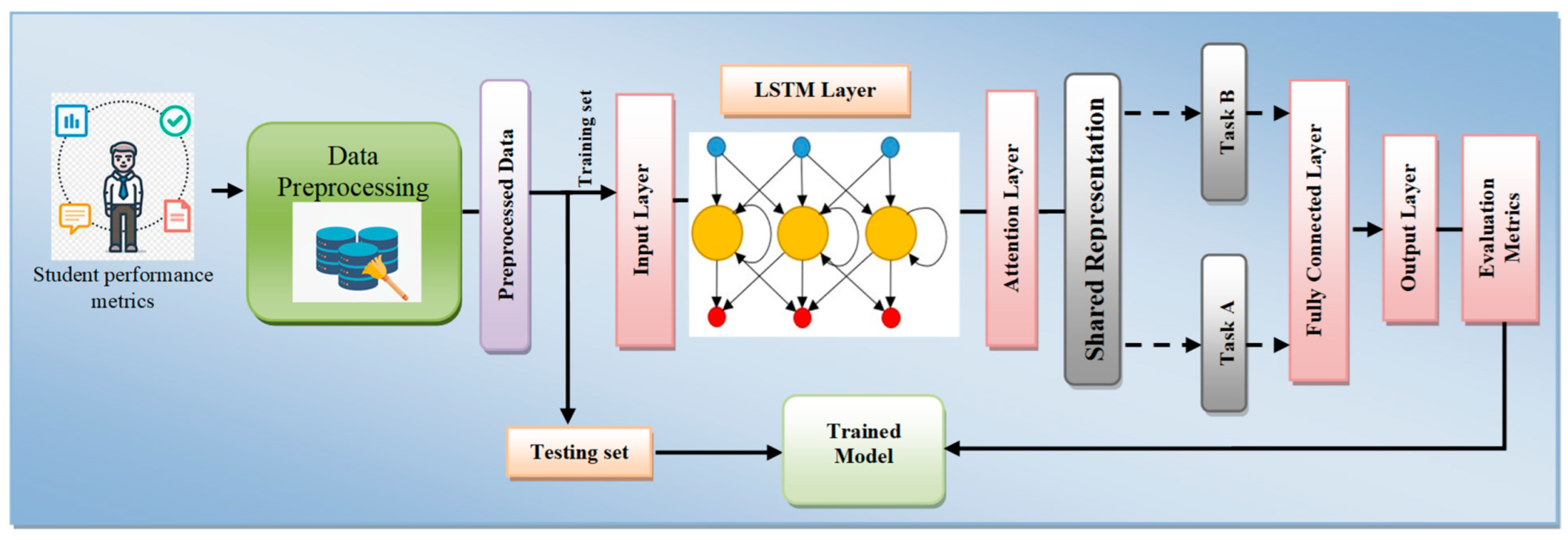
3.1.1. Proposed Architecture
3.1.2. Dataset Creation
| Algorithm 1: Pseudocode for data pre-processing |
| Input: combinations of values for x1 to x6, then appends x7 to each combination. Output: CSV file (“resultPredictionDataset.csv”) |
| import itertools import csv # Define the range of values for each variable range_values = range(11) # Values for x1 to x6 (0 through 10) range_x7 = range(41) # Values for x7 (0 through 40) # Generate all combinations of the variables x1 to x6 combinations = list(itertools.product(range_values, repeat=6)) # Append x7 to each combination combinations_with_x7 = [(c + (x7,)) for c in combinations for x7 in range_x7] # Calculate the total for each combination (sum of x1 to x7) combinations_with_total = [(c + (sum(c),)) for c in combinations_with_x7] # Specify the file name file_name = “resultPredictionDataset.csv” # Write combinations with total to CSV file withopen(file_name, ‘w’, newline=“) as csvfile: csvwriter = csv.writer(csvfile) # Write the header row csvwriter.writerow([“x1”, “x2”, “x3”, “x4”, “x5”, “x6”, “x7”, “total”]) #Write the data rows csvwriter.writerows(combinations_with_total) print(f”Final Dataset Generated Successfully to {file_name}”) |
3.1.3. Dataset Description
3.1.4. Data Analysis
3.1.5. Data Preprocessing
| Algorithm 2: Data Preprocessing |
| Input: X: Features, y_total: Total score, y_remarks: Performance levels Output: Input shape of the data for LSTM |
| function dataPreprocessing(dataset) # Step 1: Load the dataset from the CSV file X, y_total, y_remarks = extractFeaturesAndTargets(dataset) # Step 2: Adjust y_remarks for zero-based indexing (if needed) y_remarks = adjustZeroBasedIndex(y_remarks) # Step 3: Reshape the input features X to fit the LSTM input format # (samples, timesteps, features) X_reshaped = reshapeForLSTM(X) # Step 4: Split the dataset into training and testing sets X_train, X_test, y_total_train, y_total_test, y_remarks_train, y_remarks_test = splitData(X_reshaped, y_total, y_remarks) # Step 5: Define the input shape for the LSTM network based on the reshaped data input_shape = defineInputShape(X_reshaped) # Return processed datasets and input shape return X_train, X_test, y_total_train, y_total_test, y_remarks_train, y_remarks_test, input_shape end function |
3.2. Method
3.2.1. The Model
3.2.2. LSTM Layer
3.2.3. Attention Mechanism
3.2.4. Regression Analysis
3.2.5. Classification Analysis
3.2.6. Combined Regression and Classification
4. Results and Discussions
4.1. Performance Evaluation Metrics
4.1.1. Regression Task
4.1.2. Classification Task
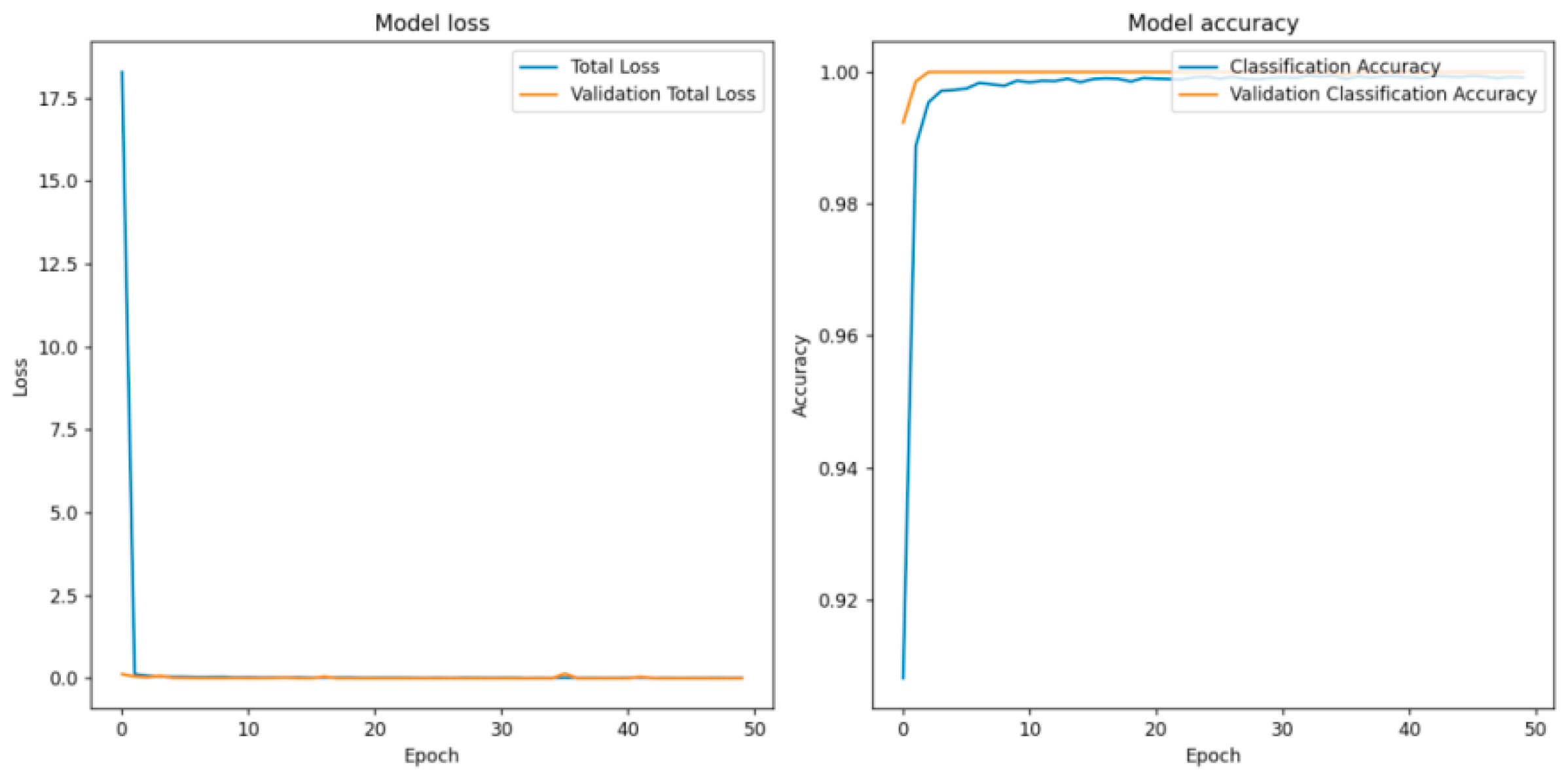
4.2. Training and Evaluation Results
4.2.1. Regression Task Result
4.2.2. Classification Task Result
4.2.3. Confusion Matrix
4.3. Comparative Analysis
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Suskie, L. Assessing Student Learning: A Common Sense Guide; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Scully, D. Constructing multiple-choice items to measure higher-order thinking. Pract. Assess. Res. Eval. 2019, 22, 4. [Google Scholar]
- Morley, J.; Floridi, L.; Kinsey, L.; Elhalal, A. From what to how: An initial review of publicly available AI ethics tools, methods and research to translate principles into practices. Sci. Eng. Ethics 2020, 26, 2141–2168. [Google Scholar] [CrossRef] [PubMed]
- Wei, L. Transformative pedagogy for inclusion and social justice through translanguaging, co-learning, and transpositioning. Lang. Teach. 2024, 57, 203–214. [Google Scholar] [CrossRef]
- Say, R.; Visentin, D.; Saunders, A.; Atherton, I.; Carr, A.; King, C. Where less is more: Limited feedback in formative online multiple-choice tests improves student self-regulation. J. Comput. Assist. Learn. 2024, 40, 89–103. [Google Scholar] [CrossRef]
- Li, S.; Zhang, X.; Li, Y.; Gao, W.; Xiao, F.; Xu, Y. A comprehensive review of impact assessment of indoor thermal environment on work and cognitive performance-Combined physiological measurements and machine learning. J. Build. Eng. 2023, 71, 106417. [Google Scholar] [CrossRef]
- Ramsey, M.C.; Bowling, N.A. Building a bigger toolbox: The construct validity of existing and proposed measures of careless responding to cognitive ability tests. Organ. Res. Methods 2024, 10944281231223127. [Google Scholar] [CrossRef]
- Maki, P.L. Assessing for Learning: Building a Sustainable Commitment across the Institution; Routledge: London, UK, 2023. [Google Scholar]
- Geletu, G.M.; Mihiretie, D.M. Professional accountability and responsibility of learning communities of practice in professional development versus curriculum practice in classrooms: Possibilities and pathways. Int. J. Educ. Res. Open 2023, 4, 100223. [Google Scholar] [CrossRef]
- Mohan, R. Measurement, Evaluation and Assessment in Education; PHI Learning Pvt. Ltd.: Dehli, India, 2023. [Google Scholar]
- Yuksel, P.; Bailey, J. Designing a Holistic Syllabus: A Blueprint for Student Motivation, Learning Efficacy, and Mental Health Engagement. In Innovative Instructional Design Methods and Tools for Improved Teaching; IGI Global: Hershey, PA, USA, 2024; pp. 92–108. [Google Scholar]
- Thornhill-Miller, B.; Camarda, A.; Mercier, M.; Burkhardt, J.M.; Morisseau, T.; Bourgeois-Bougrine, S.; Vinchon, F.; El Hayek, S.; Augereau-Landais, M.; Mourey, F.; et al. Creativity, critical thinking, communication, and collaboration: Assessment, certification, and promotion of 21st century skills for the future of work and education. J. Intell. 2023, 11, 54. [Google Scholar] [CrossRef]
- Zughoul, O.; Momani, F.; Almasri, O.H.; Zaidan, A.A.; Zaidan, B.B.; Alsalem, M.A.; Albahri, O.S.; Albahri, A.S.; Hashim, M. Comprehensive insights into the criteria of student performance in various educational domains. IEEE Access 2018, 6, 73245–73264. [Google Scholar] [CrossRef]
- AlAfnan, M.A.; Dishari, S. ESD goals and soft skills competencies through constructivist approaches to teaching: An integrative review. J. Educ. Learn. (EduLearn) 2024, 18, 708–718. [Google Scholar] [CrossRef]
- Wong, Z.Y.; Liem, G.A.D. Student engagement: Current state of the construct, conceptual refinement, and future research directions. Educ. Psychol. Rev. 2022, 34, 107–138. [Google Scholar] [CrossRef]
- Al-Adwan, A.S.; Albelbisi, N.A.; Hujran, O.; Al-Rahmi, W.M.; Alkhalifah, A. Developing a holistic success model for sustainable e-learning: A structural equation modeling approach. Sustainability 2021, 13, 9453. [Google Scholar] [CrossRef]
- Zaffar, M.; Garg, S.; Milford, M.; Kooij, J.; Flynn, D.; McDonald-Maier, K.; Ehsan, S. Vpr-bench: An open-source visual place recognition evaluation framework with quantifiable viewpoint and appearance change. Int. J. Comput. Vis. 2021, 129, 2136–2174. [Google Scholar] [CrossRef]
- Goodwin, B.; Rouleau, K.; Abla, C.; Baptiste, K.; Gibson, T.; Kimball, M. The New Classroom Instruction That Works: The Best Research-Based Strategies for Increasing Student Achievement; ASCD: Arlington, VA, USA, 2022. [Google Scholar]
- Sebbaq, H. MTBERT-Attention: An Explainable BERT Model based on Multi-Task Learning for Cognitive Text Classification. Sci. Afr. 2023, 21, e01799. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, Y.; Zang, T.; Xu, Y.; Yu, J.; Tang, F. Jointly modeling heterogeneous student behaviors and interactions among multiple prediction tasks. ACM Trans. Knowl. Discov. Data (TKDD) 2021, 16, 1–24. [Google Scholar] [CrossRef]
- Xie, Y. Student performance prediction via attention-based multi-layer long-short term memory. J. Comput. Commun. 2021, 9, 61–79. [Google Scholar] [CrossRef]
- He, L.; Li, X.; Wang, P.; Tang, J.; Wang, T. Integrating fine-grained attention into multi-task learning for knowledge tracing. World Wide Web 2023, 26, 3347–3372. [Google Scholar] [CrossRef]
- Su, Y.; Yang, X.; Lu, J.; Liu, Y.; Han, Z.; Shen, S.; Huang, Z.; Liu, Q. Multi-task Information Enhancement Recommendation model for educational Self-Directed Learning System. Expert Syst. Appl. 2024, 252, 124073. [Google Scholar] [CrossRef]
- Ren, X.; Yang, W.; Jiang, X.; Jin, G.; Yu, Y. A deep learning framework for multimodal course recommendation based on LSTM+ attention. Sustainability 2022, 14, 2907. [Google Scholar] [CrossRef]
- Hamidi, H.; Hejran, A.B.; Sarwari, A.; Edigeevna, S.G. The Effect of Outcome Based Education on Behavior of Students. Eur. J. Theor. Appl. Sci. 2024, 2, 764–773. [Google Scholar] [CrossRef]
- Anoling, K.M.; Abella CR, G.; Cagatao PP, S.; Bautista, R.G. Critical Perspectives, Theoretical Foundations, Practical Teaching, Technology Integration, Assessment and Feedback, and Hands-on Practices in Science Education. Am. J. Educ. Res. 2024, 12, 20–27. [Google Scholar] [CrossRef]
- Wicaksono, W.A.; Arifin, I.; Sumarsono, R.B. Implementing a Pesantren-Based Curriculum and Learning Approach to Foster Students’ Emotional Intelligence. Munaddhomah J. Manaj. Pendidik. Islam 2024, 5, 207–221. [Google Scholar] [CrossRef]
- Rencewigg, R.; Joseph, N.P. Enhancing presentation skills: A comparative study of students’ performance in virtual and physical classrooms. Multidiscip. Rev. 2024, 7, 2024156. [Google Scholar] [CrossRef]
- Smith, J. Attending School: A Qualitative Study Exploring Principals’ Strategies for Enhancing Attendance. Doctoral Dissertation, Trident University International, Cypress, CA, USA, 2024. [Google Scholar]
- Leino, R.K.; Gardner, M.R.; Cartwright, T.; Döring, A.K. Engagement in a virtual learning environment predicts academic achievement in research methods modules: A longitudinal study combining behavioral and self-reported data. Scholarsh. Teach. Learn. Psychol. 2024, 10, 149. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, J. Short-term wind power forecasting based on multivariate/multi-step LSTM with temporal feature attention mechanism. Appl. Soft Comput. 2024, 150, 111050. [Google Scholar] [CrossRef]
- Araf, I.; Idri, A.; Chairi, I. Cost-sensitive learning for imbalanced medical data: A review. Artif. Intell. Rev. 2024, 57, 80. [Google Scholar] [CrossRef]
- Ashraf, A.; Nawi, N.M.; Shahzad, T.; Aamir, M.; Khan, M.A.; Ouahada, K. Dimension Reduction using Dual-Featured Auto-encoder for the Histological Classification of Human Lungs Tissues. IEEE Access 2024, 12, 104165–104176. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, D.; Jiang, T.; Kang, A. Assessing Objective Functions in Streamflow Prediction Model Training Based on the Naïve Method. Water 2024, 16, 777. [Google Scholar] [CrossRef]
- Khan, M.; Anwar, W.; Rasheed, M.; Najeh, T.; Gamil, Y.; Farooq, F. Forecasting the strength of graphene nanoparticles-reinforced cementitious composites using ensemble learning algorithms. Results Eng. 2024, 21, 101837. [Google Scholar] [CrossRef]
- Chowdhury, M.S. Comparison of accuracy and reliability of random forest, support vector machine, artificial neural network and maximum likelihood method in land use/cover classification of urban setting. Environ. Chall. 2024, 14, 100800. [Google Scholar] [CrossRef]
- Yu, C.; Jin, Y.; Xing, Q.; Zhang, Y.; Guo, S.; Meng, S. Advanced user credit risk prediction model using lightgbm, xgboost and tabnet with smoteenn. arXiv 2024, arXiv:2408.03497. [Google Scholar]
- Ge, W.; Coelho, L.M.; Donahue, M.A.; Rice, H.J.; Blacker, D.; Hsu, J.; Newhouse, J.P.; Hernandez-Diaz, S.; Haneuse, S.; Westover, M.B.; et al. Automated identification of fall-related injuries in unstructured clinical notes. Am. J. Epidemiol. 2024, kwae240. [Google Scholar] [CrossRef] [PubMed]
- Peretz, O.; Koren, M.; Koren, O. Naive Bayes classifier—An ensemble procedure for recall and precision enrichment. Eng. Appl. Artif. Intell. 2024, 136, 108972. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Levene’s Test: p-Value = 0.0 | ||||
|---|---|---|---|---|
| Source | sum_sq | df | F | PR (>F) |
| C (remarks) | 3.701384 × 107 | 4.0 | 624,662.877938 | 0.0 |
| Residual | 2.962631 × 106 | 199,995 | NaN | NaN |
| Group1 | Group2 | Meandiff | p-Adj | Lower | Upper | Reject |
|---|---|---|---|---|---|---|
| 1 | 2 | 12.6824 | 0.0 | 12.6151 | 12.7497 | True |
| 1 | 3 | 22.5543 | 0.0 | 22.4871 | 22.6215 | True |
| 1 | 4 | 32.2145 | 0.0 | 32.1428 | 32.2863 | True |
| 1 | 5 | 42.6735 | 0.0 | 42.5821 | 42.765 | True |
| 2 | 3 | 9.8719 | 0.0 | 9.8036 | 9.9402 | True |
| 2 | 4 | 19.5321 | 0.0 | 19.4593 | 19.6049 | True |
| 2 | 5 | 29.9911 | 0.0 | 29.8998 | 30.0834 | True |
| 3 | 4 | 9.6602 | 0.0 | 9.5876 | 9.7329 | True |
| 3 | 5 | 20.1192 | 0.0 | 20.027 | 20.2114 | True |
| 4 | 5 | 10.459 | 0.0 | 10.3634 | 10.5546 | True |
| Metric | Value |
|---|---|
| Mean Absolute Error (MAE) | 0.012 |
| Mean Squared Error (MSE) | 0.000254 |
| Root Mean Squared Error (RMSE) | 0.01594 |
| Accuracy | 1.0 (100%) |
| Precision | 1.0 |
| Recall | 1.0 |
| F1 Score | 1.0 |
| Author | Focus Area | Techniques Used | Metrics | Gaps | Proposed Model |
|---|---|---|---|---|---|
| [19] | Cognitive classification of text | Multi-Task BERT (MTBERT-Attention) with co-attention mechanism | Superior performance and explainability in text classification | Focuses on text classification only, lacks holistic student evaluation | Integrates multiple performance metrics, captures complex relationships |
| [20] | Prediction of student behavior | LSTM with soft-attention mechanism | Effective in predicting student behaviors and improving academic outcomes | Does not consider holistic student performance, limited to behavior prediction | Uses LSTM with Multi-Task learning for both regression and classification |
| [21] | Predicting student performance | Attention-based Multi-layer LSTM (AML) | Improved prediction accuracy and F1 score using demographic and clickstream data | Limited to performance prediction, lacks comprehensive metric integration | Combines various metrics for a complete evaluation of student performance |
| [22] | Knowledge Tracing (KT) | Multi-Task Attentive Knowledge Tracing (MAKT) | Improved prediction accuracy in KT tasks | Focuses on KT, does not address real-time feedback or holistic evaluation | Provides real-time feedback, integrates multiple metrics for holistic evaluation |
| [23] | Cross-type recommendation in SDLS | Multi-Task Information Enhancement Recommendation (MIER) Model with attention and knowledge graph | Superior performance in concept prediction and exercise recommendation | Limited to recommendation systems, does not provide holistic student evaluation | Utilizes attention mechanisms for comprehensive evaluation of multiple student metrics |
| [24] | Course recommendation | Deep course recommendation model with LSTM and Attention | Higher AUC scores in course recommendations | Focuses on course recommendations, lacks integration of diverse metrics | Integrates multimodal data for comprehensive student performance evaluation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olaniyan, D.; Olaniyan, J.; Obagbuwa, I.C.; Esiefarienrhe, B.M.; Bernard, O.P. Parallel Attention-Driven Model for Student Performance Evaluation. Computers 2024, 13, 242. https://doi.org/10.3390/computers13090242
Olaniyan D, Olaniyan J, Obagbuwa IC, Esiefarienrhe BM, Bernard OP. Parallel Attention-Driven Model for Student Performance Evaluation. Computers. 2024; 13(9):242. https://doi.org/10.3390/computers13090242
Chicago/Turabian StyleOlaniyan, Deborah, Julius Olaniyan, Ibidun Christiana Obagbuwa, Bukohwo Michael Esiefarienrhe, and Olorunfemi Paul Bernard. 2024. "Parallel Attention-Driven Model for Student Performance Evaluation" Computers 13, no. 9: 242. https://doi.org/10.3390/computers13090242
APA StyleOlaniyan, D., Olaniyan, J., Obagbuwa, I. C., Esiefarienrhe, B. M., & Bernard, O. P. (2024). Parallel Attention-Driven Model for Student Performance Evaluation. Computers, 13(9), 242. https://doi.org/10.3390/computers13090242