
Redefining Event Detection and Information Dissemination: Lessons from X (Twitter) Data Streams and Beyond


Abstract
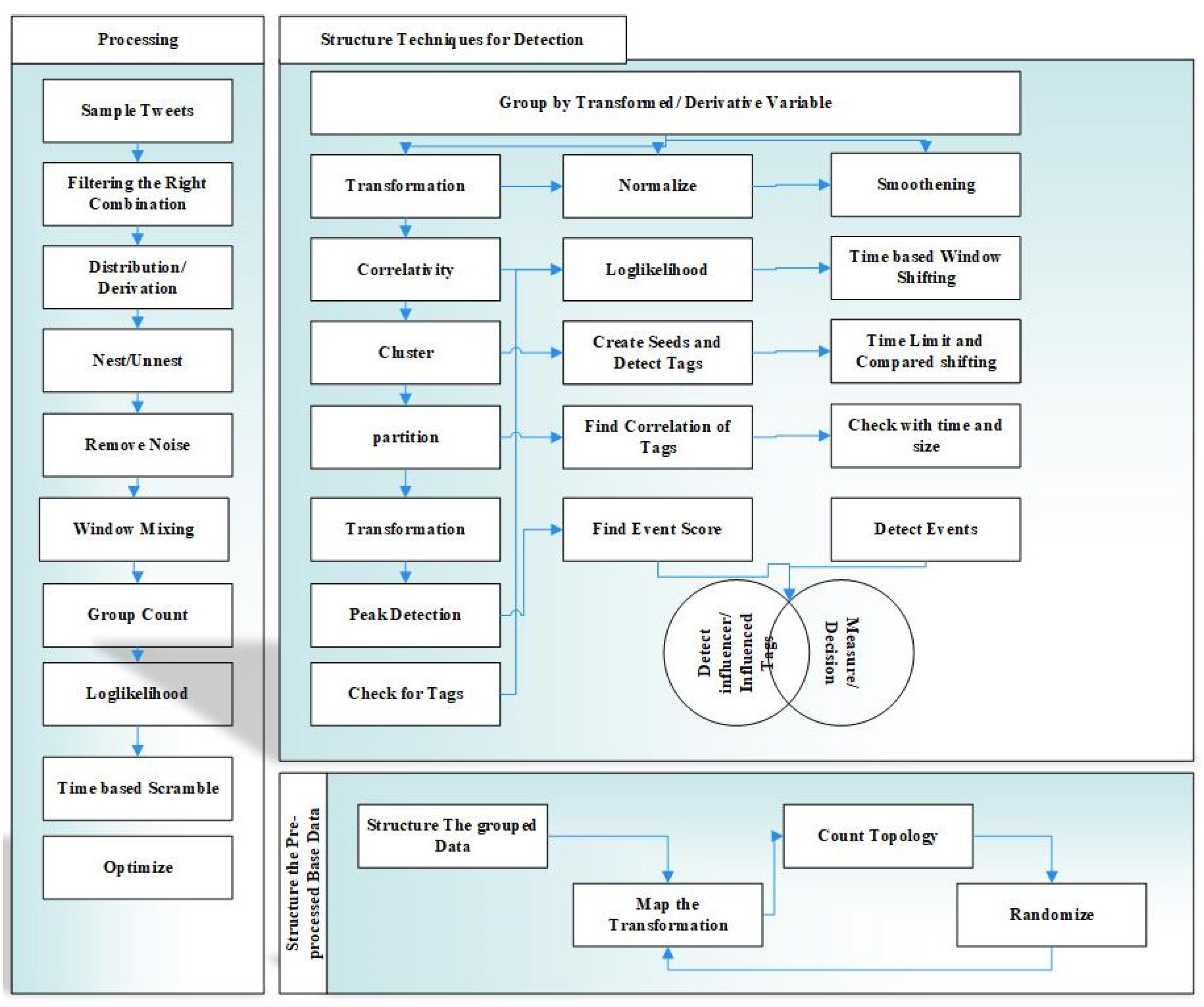
:1. Introduction
- An all-inclusive analysis of the state-of-the-art event detection algorithms for X data streams, incorporating findings from multipolar methods that have not been thoroughly investigated and bridged in prior surveys [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55].
2. Background on Social Data Sources
2.1. Survey of Event Detection Techniques
- Users’ direct following: This data collection process selects a default set of users which directly follow the users’ streams of data irrespective of their locations;
- Trends by global or geographical region: During this filtering process, the identification of trends is defined based on specific current topics in various applications with respect to geographic location or global level;
2.2. Survey of Cooperation in Event Detection Techniques
3. Evaluation and Comparison of Event Detection Techniques
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Srivastava, H.; Sankar, R. Information Dissemination From Social Network for Extreme Weather Scenario. IEEE Trans. Comput. Soc. Syst. 2020, 7, 319–328. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26 April 2010; pp. 851–860. [Google Scholar]
- Nurwidyantoro, A.; Winarko, E. Event detection in social media: A survey. In Proceedings of the International Conference on ICT for Smart Society, Jakarta, Indonesia, 13–14 June 2013; IEEE: New York, NY, USA, 2013; pp. 1–5. [Google Scholar]
- Madani, A.; Boussaid, O.; Zegour, D.E. What’s happening: A survey of tweets event detection. In Proceedings of the 3rd International Conference on Communications, Computation, Networks and Technologies (INNOV), Nice, France, 12–16 October 2014; pp. 16–22. [Google Scholar]
- Bontcheva, K.; Rout, D. Making sense of social media streams through semantics: A survey. Semant. Web 2014, 5, 373–403. [Google Scholar] [CrossRef]
- Atefeh, F.; Khreich, W. A survey of techniques for event detection in twitter. Comput. Intell. 2015, 31, 132–164. [Google Scholar] [CrossRef]
- Alvanaki, F.; Sebastian, M.; Krithi, R.; Gerhard, W. See what’s enBlogue: Real-time emergent topic identification in social media. In Proceedings of the 15th International Conference on Extending Database Technology, Berlin, Germany, 27–30 March 2012; pp. 336–347. [Google Scholar]
- Papadopoulos, S.; Corney, D.; Aiello, L.M. Snow 2014 data challenge: Assessing the performance of news topic detection methods in social media. In Proceedings of the SNOW 2014 Data Challenge, Seoul, Republic of Korea, 8 April 2014; pp. 1–8. Available online: http://ceur-ws.org (accessed on 22 January 2025).
- Li, R.; Lei, K.H.; Khadiwala, R.; Chang, K.C.C. TEDAS: A Twitter-based Event Detection and Analysis System. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 1273–1276. [Google Scholar] [CrossRef]
- Li, C.; Sun, A.; Datta, A. Twevent: Segment-based event detection from tweets. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October 2012; pp. 155–164. [Google Scholar]
- Abel, F.; Hauff, C.; Houben, G.J.; Stronkman, R.; Tao, K. Twitcident: Fighting fire with information from social web streams. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16 April 2012; pp. 305–308. [Google Scholar]
- Adam, N.; Eledath, J.; Mehrotra, S.; Venkatasubramanian, N. Social media alert and response to threats to citizens (SMART-C). In Proceedings of the 8th International Conference on Collaborative Computing: Networking, Applications and Worksharing (CollaborateCom), Pittsburgh, PA, USA, 14–17 October 2012; IEEE: New York, NY, USA, 2012; pp. 181–189. [Google Scholar]
- Terpstra, T.; Stronkman, R.; de Vries, A.; Paradies, G.L. Towards a Realtime Twitter Analysis During Crises for Operational Crisis Management; Iscram: Alexima, NT, USA, 2012. [Google Scholar]
- Winarko, E.; Roddick, J.F. ARMADA–An algorithm for discovering richer relative temporal association rules from interval-based data. Data Knowl. Eng. 2007, 63, 76–90. [Google Scholar] [CrossRef]
- Culotta, A. Towards detecting influenza epidemics by analyzing Twitter messages. In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25 July 2010; pp. 115–122. [Google Scholar]
- Bodnar, T.; Salathé, M. Validating models for disease detection using twitter. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13 May 2013; pp. 699–702. [Google Scholar]
- Ritterman, J.; Osborne, M.; Klein, E. Using prediction markets and Twitter to predict a swine flu pandemic. In Proceedings of the 1st International Workshop on Mining Social Media, Sevilla, Spain, 9 November 2009; Volume 9, pp. 9–17. [Google Scholar]
- Wakamiya, S.; Kawai, Y.; Aramaki, E. Twitter-based influenza detection after flu peak via tweets with indirect information: Text mining study. JMIR Public Health Surveill. 2018, 4, e65. [Google Scholar] [CrossRef] [PubMed]
- Asgari-Chenaghlu, M.; Nikzad-Khasmakhi, N.; Minaee, S. Covid-Transformer: Detecting COVID-19 Trending Topics on Twitter Using Universal Sentence Encoder. arXiv 2020, arXiv:2009.03947. [Google Scholar]
- Achrekar, H.; Gandhe, A.; Lazarus, R.; Yu, S.-H.; Liu, B. Predicting Flu Trends using Twitter data. In Proceedings of the 2011 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Shanghai, China, 10–15 April 2011; pp. 702–707. [Google Scholar]
- Sankaranarayanan, J.; Samet, H.; Teitler, B.E.; Lieberman, M.D.; Sperling, J. Twitterstand: News in tweets. In Proceedings of the 17th Acm Sigspatial International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009; pp. 42–51. [Google Scholar]
- Walther, M.; Kaisser, M. Geo-spatial event detection in the twitter stream. In Proceedings of the European Conference on Information Retrieval, Moscow, Russia, 24–27 March 2013; Springer: Berlin/Heidelberg, Germany; pp. 356–367. [Google Scholar]
- Meladianos, P.; Nikolentzos, G.; Rousseau, F.; Stavrakas, Y.; Vazirgiannis, M. Degeneracy-based real-time sub-event detection in twitter stream. In Proceedings of the International AAAI Conference on Web and Social Media, Oxford, UK, 26 May 2015; Volume 9, pp. 248–257. [Google Scholar]
- Guille, A.; Favre, C. Mention-anomaly-based event detection and tracking in twitter. In Proceedings of the 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014), Beijing, China, 17–20 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 375–382. [Google Scholar]
- Smith, M.; Rainie, L.; Shneiderman, B.; Himelboim, I. Mapping Twitter Topic Networks: From Polarized Crowds to Community Clusters. Pew Research Center in Association with the Social Media Research Foundation. 20 February 2014, pp. 1–56. Available online: http://www.pewinternet.org/2014/02/20/mapping-twitter-topic-networks-from-polarized-crowds-to-community-clusters (accessed on 22 January 2025).
- Petrović, S.; Osborne, M.; Lavrenko, V. Using paraphrases for improving first story detection in news and Twitter. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montréal, QC, Canada, 3 June 2012; pp. 338–346. [Google Scholar]
- Marcus, A.; Bernstein, M.S.; Badar, O.; Karger, D.R.; Madden, S.; Miller, R.C. Twitinfo: Aggregating and visualizing microblogs for event exploration. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7 May 2011; pp. 227–236. [Google Scholar]
- Popescu, A.M.; Pennacchiotti, M.; Paranjpe, D. Extracting events and event descriptions from twitter. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March 2011; pp. 105–106. [Google Scholar]
- Ishikawa, S.; Arakawa, Y.; Tagashira, S.; Fukuda, A. Hot topic detection in local areas using Twitter and Wikipedia. In Proceedings of the ARCS 2012, Munich, Germany, 28–29 February 2012; IEEE: New York, NY, USA, 2012; pp. 1–5. [Google Scholar]
- Nishida, K.; Hoshide, T.; Fujimura, K. Improving tweet stream classification by detecting changes in word probability. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12 August 2012; pp. 971–980. [Google Scholar]
- Aiello, L.M.; Petkos, G.; Martin, C.; Corney, D.; Papadopoulos, S.; Skraba, R.; Göker, A.; Kompatsiaris, I.; Jaimes, A. Sensing trending topics in Twitter. IEEE Trans. Multimed. 2013, 15, 1268–1282. [Google Scholar] [CrossRef]
- Petrović, S.; Osborne, M.; Lavrenko, V. Streaming first story detection with application to twitter. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2 June 2010; pp. 181–189. [Google Scholar]
- Osborne, M.; Petrović, S.; McCreadie, R.; Macdonald, C.; Ounis, I. Bieber no more: First story detection using twitter and wikipedia. In Proceedings of the Sigir 2012 Workshop on Time-Aware Information Access, Portland, OR, USA, 4 June 2012; pp. 16–76. [Google Scholar]
- Benhardus, J.; Kalita, J. Streaming trend detection in twitter. Int. J. Web Based Communities 2013, 9, 122–139. [Google Scholar] [CrossRef]
- Cataldi, M.; Di Caro, L.; Schifanella, C. Emerging topic detection on twitter based on temporal and social terms evaluation. In Proceedings of the Tenth International Workshop on Multimedia Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 1–10. [Google Scholar]
- Lee, R.; Sumiya, K. Measuring geographical regularities of crowd behaviors for Twitter-based geo-social event detection. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on Location Based Social Networks, San Jose, CA, USA, 2 November 2010; pp. 1–10. [Google Scholar]
- Mathioudakis, M.; Koudas, N. Twittermonitor: Trend detection over the twitter stream. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 6–10 July 2010; pp. 1155–1158. [Google Scholar]
- Allan, J. (Ed.) Topic Detection and Tracking: Event-based Information Organization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 12. [Google Scholar]
- Aggarwal, C.C.; Subbian, K. Event detection in social streams. In Proceedings of the 2012 SIAM International Conference on Data Mining, Anaheim, CA, USA, 26–28 April 2012; pp. 624–635. [Google Scholar]
- Phillips, W.D.; Sankar, R. Improved Transient Weather Reporting Using People Centric Sensing. In Proceedings of the First Workshop on People Centric Sensing and Communications in the 10th Annual IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 11–13 January 2013; pp. 913–918. [Google Scholar]
- Cordeiro, M. Twitter event detection: Combining wavelet analysis and topic inference summarization. In Proceedings of the Doctoral Symposium on Informatics Engineering, Porto, Portugal, 26 January 2012; Volume 1, pp. 11–16. [Google Scholar]
- Weiler, A.; Grossniklaus, M.; Scholl, M.H. Survey and experimental analysis of event detection techniques for twitter. Comput. J. 2017, 60, 329–346. [Google Scholar] [CrossRef]
- Ritter, A.; Etzioni, O.; Clark, S. Open domain event extraction from twitter. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1104–1112. [Google Scholar]
- Bahir, E.; Peled, A. Identifying and tracking major events using geo-social networks. Soc. Sci. Comput. Rev. 2013, 31, 458–470. [Google Scholar] [CrossRef]
- Martin, C.; Corney, D.; Goker, A. Mining newsworthy topics from social media. In Advances in Social Media Analysis; Springer: Cham, Switzerland, 2015; pp. 21–43. [Google Scholar]
- Parikh, R.; Karlapalem, K. Et: Events from tweets. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13 May 2013; pp. 613–620. [Google Scholar]
- Abdelhaq, H.; Sengstock, C.; Gertz, M. Eventweet: Online localized event detection from twitter. In Proceedings of the VLDB Endowment 6, Trento, Italy, 13 June 2013; Volume 12, pp. 1326–1329. [Google Scholar]
- Weiler, A.; Grossniklaus, M.; Scholl, M.H. Event identification and tracking in social media streaming data. In Proceedings of the EDBT/ICDT, Athens, Greece, 24–28 March 2014; pp. 282–287. [Google Scholar]
- Corney, D.; Martin, C.; Göker, A. Spot the ball: Detecting sports events on Twitter. In Proceedings of the European Conference on Information Retrieval, Amsterdam, The Netherlands, 13 April 2014; Springer: Cham, Germany, 2014; pp. 449–454. [Google Scholar]
- Ifrim, G.; Shi, B.; Brigadir, I. Event detection in twitter using aggressive filtering and hierarchical tweet clustering. In Proceedings of the Second Workshop on Social News on the Web (SNOW), Seoul, Korea, 8 April 2014. [Google Scholar]
- Zhou, X.; Chen, L. Event detection over twitter social media streams. VLDB J. 2014, 23, 381–400. [Google Scholar] [CrossRef]
- Thapen, N.; Simmie, D.; Hankin, C. The early bird catches the term: Combining twitter and news data for event detection and situational awareness. J. Biomed. Semant. 2016, 7, 61. [Google Scholar] [CrossRef] [PubMed]
- Monmousseau, P.; Marzuoli, A.; Feron, E.; Delahaye, D. Impact of COVID-19 on passengers and airlines from passenger measurements: Managing customer satisfaction while putting the US Air Transportation System to sleep. Transp. Res. Interdiscip. Perspect. 2020, 7, 100179. [Google Scholar] [CrossRef] [PubMed]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Hoffman, M.; Bach, F.; Blei, D. Online learning for latent dirichlet allocation. In Proceedings of the Advances in Neural Information Processing Systems 23, Vancouver, BC, Canada, 6 December 2010. [Google Scholar]
- McCreadie, R.; Soboroff, I.; Lin, J.; Macdonald, C.; Ounis, I.; McCullough, D. On building a reusable twitter corpus. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information retrieval, Portland, OR, USA, 12 August 2012; pp. 1113–1114. [Google Scholar]
- Cilibrasi, R.L.; Vitanyi, P.M.B. The Google Similarity Distance. IEEE Trans. Knowl. Data Eng. 2007, 19, 370–383. [Google Scholar] [CrossRef]
- Khatoon, S.; Asif, A.; Hasan, M.M.; Alshamari, M. Social Media-Based Intelligence for Disaster Response and Management in Smart Cities. In Artificial Intelligence, Machine Learning, and Optimization Tools for Smart Cities; Springer: Cham, Germany, 2022; pp. 211–235. [Google Scholar]
- Bellatreche, L.; Ordonez, C.; Méry, D.; Golfarelli, M. The central role of data repositories and data models in Data Science and Advanced Analytics. Future Gener. Comput. Syst. 2022, 129, 13–17. [Google Scholar] [CrossRef]
- Savic, N.; Bovio, N.; Gilbert, F.; Paz, J.; Guseva Canu, I. Procode: A Machine-Learning Tool to Support (Re-) coding of Free-Texts of Occupations and Industries. Ann. Work. Expo. Health 2022, 66, 113–118. [Google Scholar] [CrossRef] [PubMed]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Becker, R. Gender and Survey Participation: An Event History Analysis of the Gender Effects of Survey Participation in a Probability-based Multi-wave Panel Study with a Sequential Mixed-mode Design. Methods Data Anal. 2022, 16, 30. [Google Scholar]
- Srivastava, H.; Sankar, R. Cooperative Attention-Based Learning between Diverse Data Sources. Algorithms 2023, 16, 240. [Google Scholar] [CrossRef]
- Xiao, L.; Zheng, Z.; Peng, S. Cross-Domain Relationship Prediction by Efficient Block Matrix Completion for Social Media Applications. Int. J. Perform. Eng. 2020, 16, 1087–1094. [Google Scholar]
- Firoozeh, N.; Nazarenko, A.; Alizon, F.; Daille, B. Keyword extraction: Issues and methods. Nat. Lang. Eng. 2020, 26, 259–291. [Google Scholar] [CrossRef]
- Zurbenko, I.G.; Smith, D. Kolmogorov–Zurbenko filters in spatiotemporal analysis. Wiley Interdiscip. Rev. Comput. Stat. 2018, 10, e1419. [Google Scholar] [CrossRef]
- Li, J.; Maier, D.; Tufte, K.; Papadimos, V.; Tucker, P.A. No pane, no gain: Efficient evaluation of sliding-window aggregates over data streams. Acm Sigmod Rec. 2005, 34, 39–44. [Google Scholar] [CrossRef]

{kind=link}
| Applications and Key Datasets | Papers | Challenges | Result Parameters |
|---|---|---|---|
| Disaster Management Datasets: Twitter API, Disaster-related Tweets (e.g., Earthquakes, Tsunami), Social Media Datasets | Srivastava et al. [1] | Data Noise | Influence and Precision Score |
| Sakaki et al. [2] | Integration of geospatial model | Precision and F-Score | |
| Li et al. [9] and Li et al. [10] | Language Ambiguity | Precision Score | |
| Abel et al. [11] | Data Sparsity | Average Decision Score | |
| Adam et al. [12] | Dynamic Event patterns | Average Decision Score | |
| Terpstra et al. [13] | Vast Data Stream Management | Filtering Data from 100 K Tweets | |
| Nurwidyantoro et al. [3] | Feature Sets | Survey of Techniques | |
| Madani et al. [4] | Overlapping Event Signals | Survey of Techniques | |
| Winarko et al. [14] | Limited labeled Data | ||
| Aggarwal et al. [39] | Labor Intensive Annotations | Manual Tagging for Precision Score | |
| Phillips et al. [40] | Data Variability | Average Decision Score | |
| Disease Spread Datasets: Twitter, Flu Trends, Disease Outbreak Data (e.g., Zika, Influenza), | Nurwidyantoro et al. [3] Madani et al. [4] Culotta [15] | Noisy Signals, Overlapping Events and Feature Sets | Survey of Techniques Survey of Techniques Search of Correlation in Data |
| Bodnar et al. [16] | Sparse Ground Truth | Correlation | |
| Ritterman et al. [17] | Filtering of Data of 48 million Tweets | ||
| Wakamiya et al. [18] | Subtle Cues | ||
| Asgari-Chenaghlu et al. [19] | Noisy Correlation | ||
| Achrekar et al. [20] | Variable Reporting Rates | Search of Correlation in Data | |
| Alvanaki et al. [7] | Evolving Data Streams | ||
| Bontcheva et al. [5] | Too Complex Manipulations | Survey of Techniques | |
| Atefeh et al. [6] | Inconsistent Metrics | Survey on Evaluation Metrics | |
| Papadopoulos et al. [8] | Event Detection by Correlation | ||
| Sankaranarayanan et al. [21] | Real-time constraint | Crawling and Spread metrics | |
| Information Spread Datasets: Twitter, Reddit, Facebook, Wikipedia, Domain-specific Data | Walther et al. [22] | Overfitting | False Positive Detection |
| Meladianos et al. [23] | Unbalanced Data | False Positive Accuracy | |
| Guille et al. [24] | Manual Cost | Precision and F-Score with Manual Tagging | |
| Petrović et al. [26] | Scaling up | Average Precision Score with Manual Tagging | |
| Marcus et al. [27] | Domain Specific Jargons | Precision Score | |
| Popescu et al. [28] | Dynamic Markets | Precision and F-Score | |
| Ishikawa et al. [29] | Filtering Spam | Crawling and Spread metrics | |
| Nishida et al. [30] | Large Scale Noise | Filtering of Data of 300 K Tweets | |
| Aiello et al. [31] | Subtle Patterns | Precision and F-Score | |
| Petrović et al. [32] | Manual Effort | Manual Tagging to obtain Precision Score | |
| Osborne et al. [33] | Dynamic Patterns | Time Taken for Information Spread | |
| Business Analytics Datasets: Twitter, Amazon Reviews, Consumer Feedback, Marketing Campaign Data, | Benhardus et al. [34] | Evolving Slang | Precision and F-Score |
| Cataldi et al. [35] | Data Variations Issue | Filtering of Data | |
| Lee et al. [36] | Annotation Bottleneck | Average Precision Score | |
| Mathioudakis et al. [37] | Trend Shifts | Crawling and Spread metrics | |
| Allan J. [38] | Broad Applicability | Filtering, Crawling, and Correlation | |
| Aggarwal et al. [39] | Labor Costs | Precision Score | |
| Other Datasets: Multi-domain Data, Twitter, Public Web Data, Customer Support Data, Survey Data, | Cordeiro et al. [41] | Hetro Noises | Filtering and Reduction of Noise |
| Ritter et al. [43] | Scaling Annotations | Precision Score | |
| Bahir et al. [44] | Ambiguity in Signals | Filtering of Data | |
| Martin et al. [45] | Balancing and Tuning | Recall Metrics of Activities | |
| Parikh et al. [46] | Resource Intensive | Filtering of Data | |
| Abdelhaq et al. [47] | High Noise | Filtering of Data | |
| Weiler et al. [48] | Method Selection | Survey of Techniques | |
| Corney et al. [49] | Complexity | Survey of Techniques | |
| Ifrim et al. [50] | Evolving Topics | Filtering of Data | |
| Zhou et al. [51] | Manual Overhead | Filtering of Data | |
| Thapen et al. [52] | Slow Interation | Filtering of Data | |
| Monmousseau et al. [53] | Residual Noise | Filtering and Reduction of Noise | |
| Blei et al. [54] | Interpretablity | Concepts of Detection | |
| Hoffman et al. [55] | Scaling Models | ||
| McCreadie et al. [56] | Fast Changing Data | ||
| Cilibrasi et al. [57] | Complexity in Modeling | ||
| Khatoon et al. [58] | Hetro pattern | ||
| Bellatreche et al. [59] | Residuality | ||
| Savic et al. [60] | Ambiguity in Context | ||
| Jones [61] | Methodologies Evolution |
| Papers | Cooperation and Detection Techniques | Sensitivity/Accuracy |
|---|---|---|
| McCreadie et al. [56] | Data Distribution | Sensitivity—0.3 |
| Becker [62] | Skewed Compilation | Sensitivity—0.43 |
| Petrović et al. [26] | Diverse Classification | Accuracy—0.27 |
| Papadopoulos et al. [8] | GT was trained | Accuracy—0.59 |
| Aggarwal et al. [39], Petrović et al. [32], Allan [38], Guille et al. [24] | Event from Tagging | Accuracy—0.27 |
| Allan [38], Blei et al. [54], Jones [61] | Tracking with Specificity | Accuracy—0.56 |
| Step | Details | Tools/Techniques Used | Outcome |
|---|---|---|---|
| 1. Dataset and Setup | Sparse and noisy datasets from social media streams. | Testing adaptability and scalability of the system. | |
| 2. Preprocessing and Cleaning | Filtering relevant tweets, removing noise (non-English text, short/irrelevant phrases). | Keyword-based queries, filters | Ensured clean, relevant data for downstream processing. |
| 3. Clustering and Semantic Grouping | Grouping terms by similarity, outliers | Hierarchical Clustering | Created meaningful clusters, enhancing interpretability of detected events. |
| 4. Advanced Modeling Techniques | Applied sophisticated algorithms for event detection. | LLH, LDA, TF-IDF with Word Embeddings | Improved identification of emerging events and reduced impact of noisy data. |
| 5. Real-Time Processing | Integrated modular architecture for realtime event detection. | Niagarino system with Cooperative Attention Model | Handled throughput of 50,000 data points per second. |
| Technique | Precision (%) | Recall (%) | Processing Speed | Strengths | Limitations |
|---|---|---|---|---|---|
| Niagarino System [42] with Cooperative Attention [1,63] | 94 | 90 | 50,000 data points/s | High accuracy | Diverse datasets |
| LDA | 76 | 69 | 10,000 data points/s | Effective for topic modeling | Poor performance |
| Form Regroup (FR) | 57 | 42 | 20,000 data points/s | Simple and computational cost | Low relevance of detected events |
| Reform Event (RE) | 71 | 64 | 25,000 data points/s | Captures co-occurrence | Limited scalability and adaptability |
| Top N | 79 | 52 | 30,000 data points/s | Dominant trends | Ignores rare terms |
| Last N | 64 | 55 | 30,000 data points/s | Rare terms | Highlight irrelevant terms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Srivastava, H.; Sankar, R. Redefining Event Detection and Information Dissemination: Lessons from X (Twitter) Data Streams and Beyond. Computers 2025, 14, 42. https://doi.org/10.3390/computers14020042
Srivastava H, Sankar R. Redefining Event Detection and Information Dissemination: Lessons from X (Twitter) Data Streams and Beyond. Computers. 2025; 14(2):42. https://doi.org/10.3390/computers14020042
Chicago/Turabian StyleSrivastava, Harshit, and Ravi Sankar. 2025. "Redefining Event Detection and Information Dissemination: Lessons from X (Twitter) Data Streams and Beyond" Computers 14, no. 2: 42. https://doi.org/10.3390/computers14020042
APA StyleSrivastava, H., & Sankar, R. (2025). Redefining Event Detection and Information Dissemination: Lessons from X (Twitter) Data Streams and Beyond. Computers, 14(2), 42. https://doi.org/10.3390/computers14020042