
A Survey of Soft-Error Mitigation Techniques for Non-Volatile Memories

Abstract
:1. Introduction
2. Background and Motivation
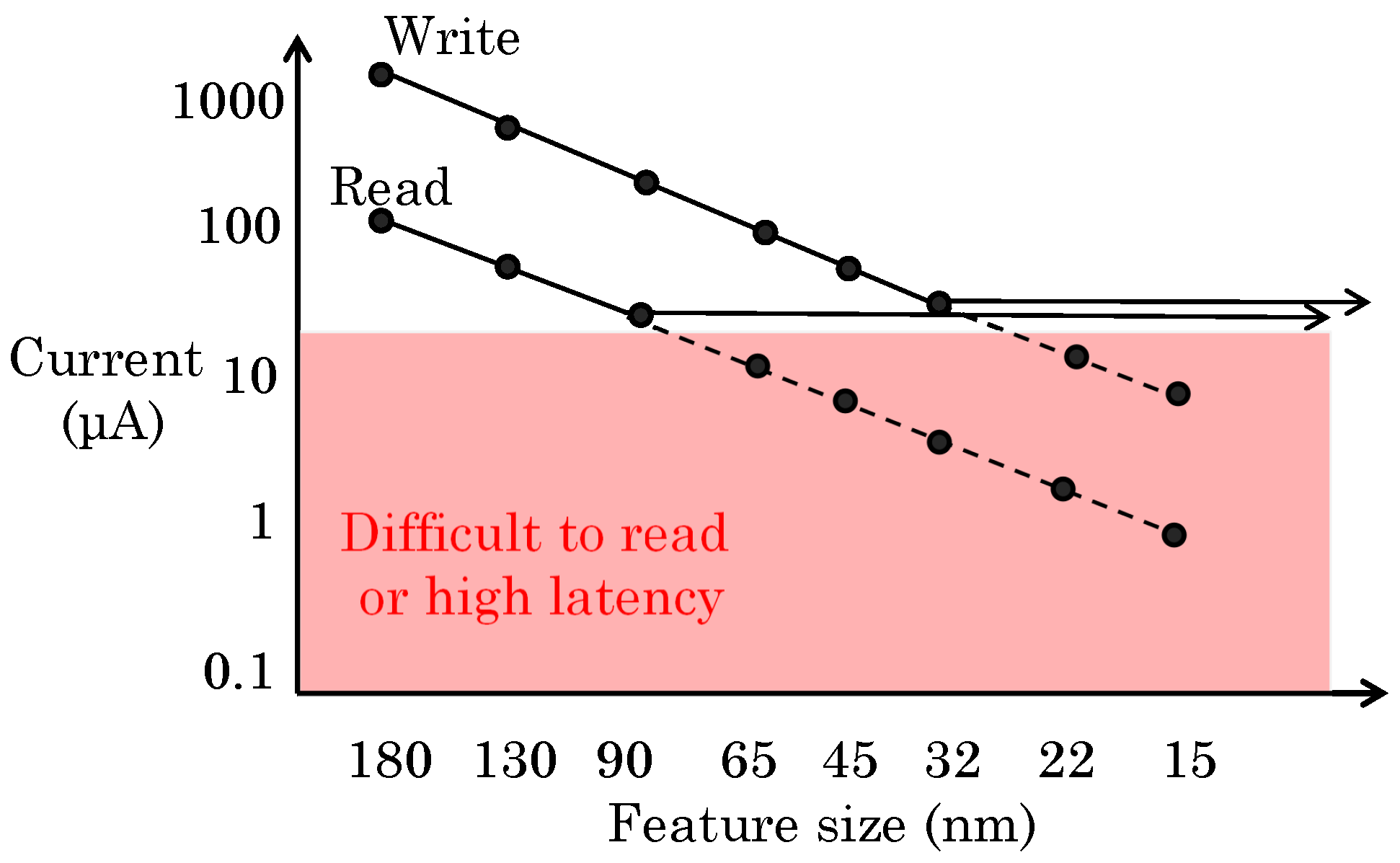
2.1. Need for Improving NVM Reliability
2.2. PCM Data Storage Mechanism
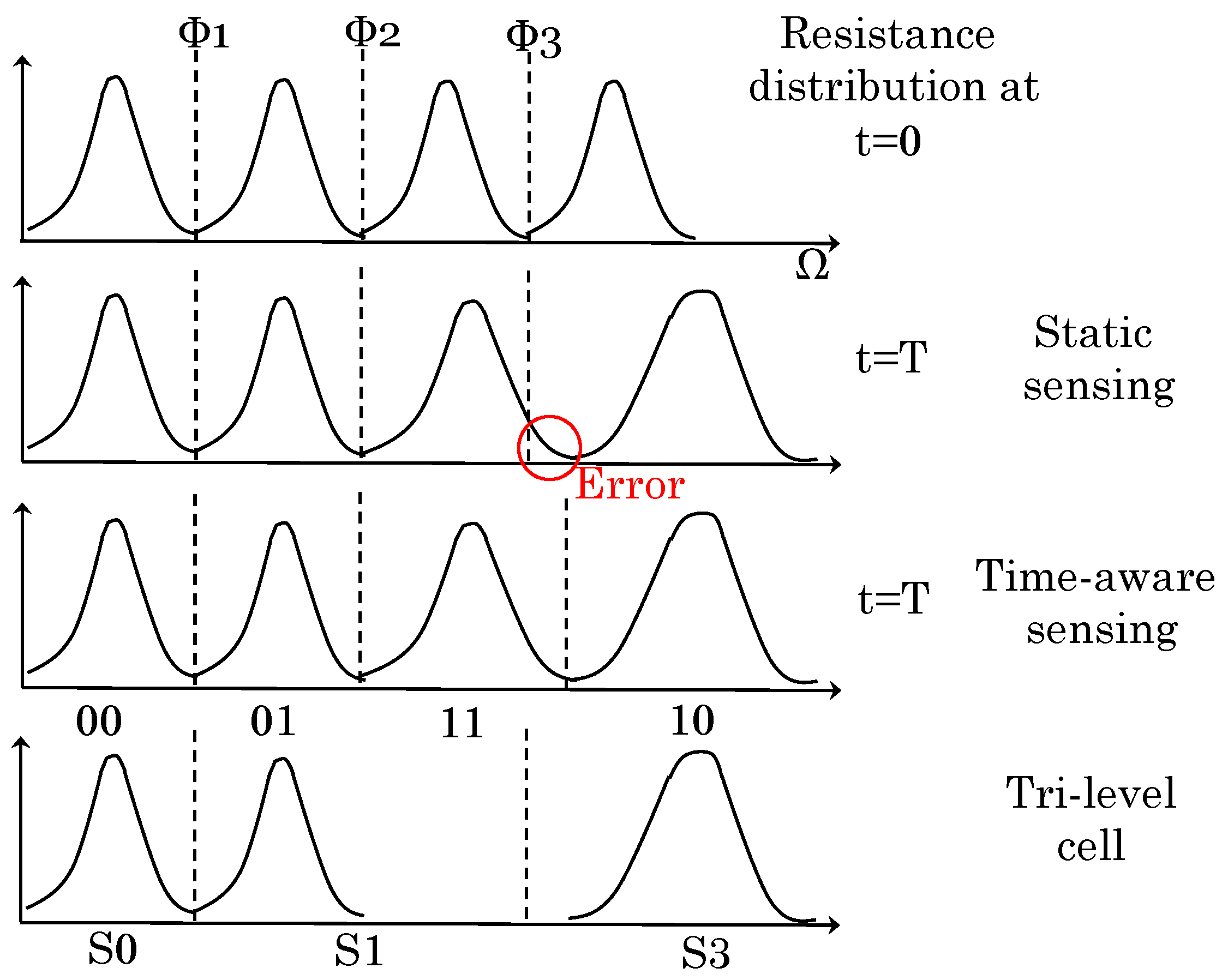
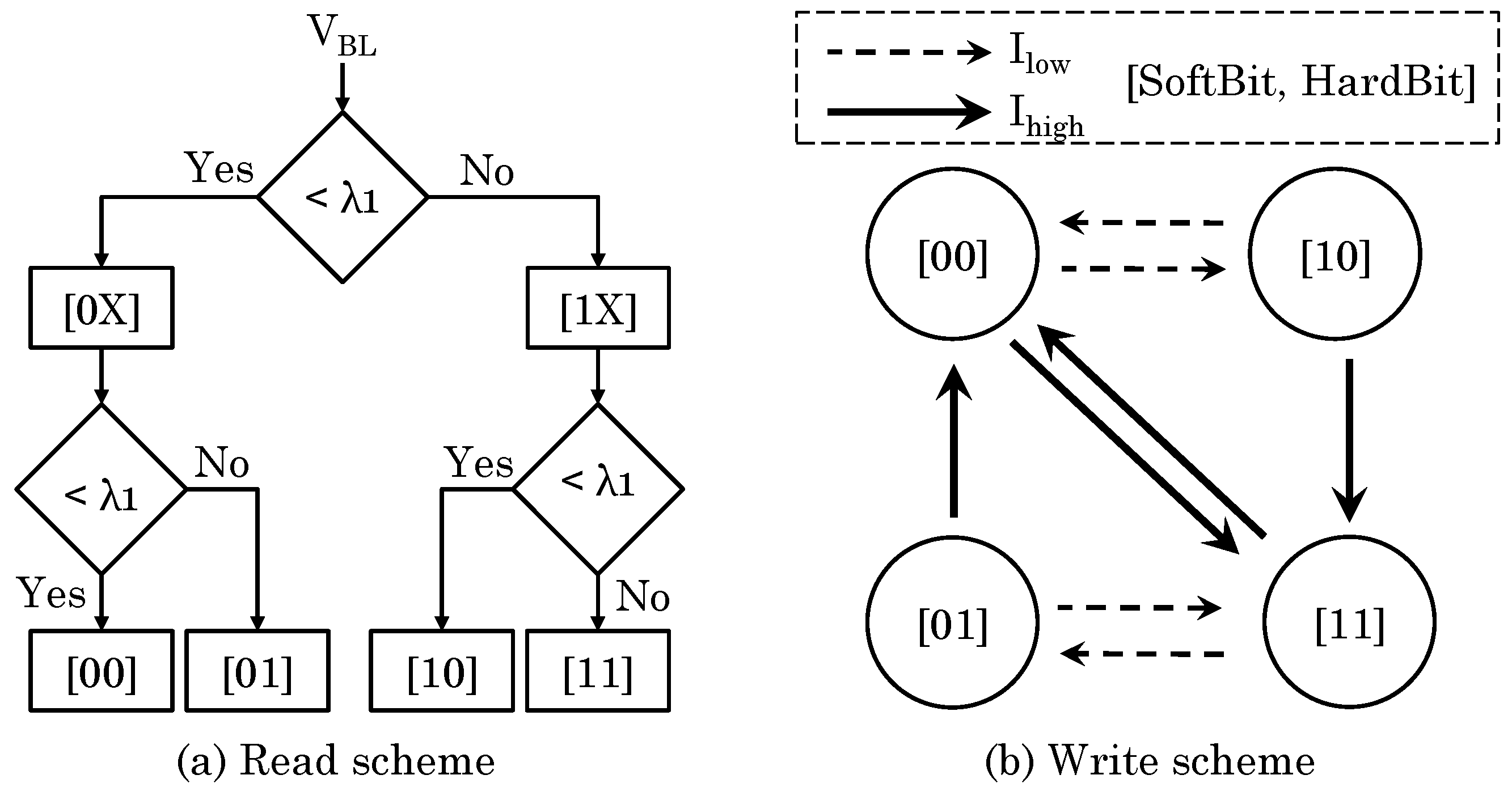
2.3. PCM Resistance Drift Error
- To correct drift errors in MLC PCM, scrubbing can be used. In DRAM, different bit errors happen independently, and hence, the probability of multi-bit errors is small. Due to this, even simple scrub schemes suffice for DRAM and incur very low overhead, for example one read and write needs to be issued only once every 200 K cycles [16]. However, in MLC PCM, if one cell drifts to the incorrect state, other cells are also highly likely to drift in the near future. Due to this correlation, multi-bit errors are much more likely in MLC PCM, and hence, a simple scrub scheme would need to read PCM in almost every cycle to keep the error rate at an acceptable level [2,16]. Furthermore, scrubbing leaves very little bandwidth for useful operations. Further, reducing the capacity of MLC PCM to reduce the scrubbing rate is infeasible since the memory capacity becomes too small to be useful [2].
- In MLC PCM, the resistance margins between consecutive levels increase exponentially, for example when the ratio of consecutive resistance values is five (i.e., ), data remain valid for two years; however, if this ratio is two, the data remain valid for 1 h only (assuming room temperature) [17]. Thus, a simple strategy to address drift errors is to widen the resistance margin between neighboring states. This, however, requires increasing the resistance of the largest resistance states [17], which degrades endurance and energy efficiency due to the requirement of increased programming current. The write endurance of MLC PCM is much smaller than that of SLC PCM ( vs. writes), and drift mitigation mechanisms may further aggravate the endurance issue [3,16,17], for example due to scrub operations or increased resistance margins.
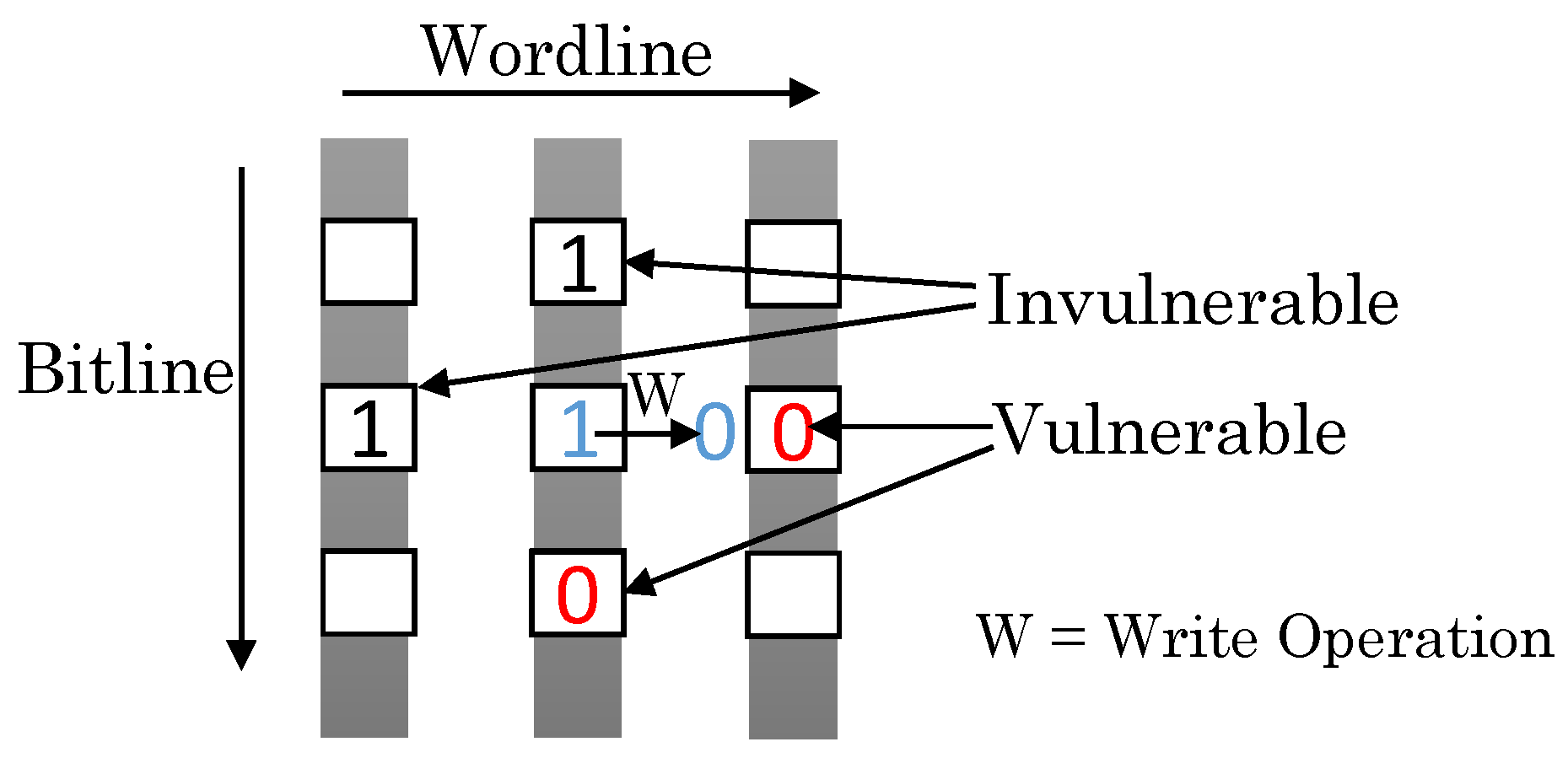
2.4. PCM Write Disturbance Error
- Increasing the inter-cell space reduces WDE; however, it nullifies the density advantage of PCM [22].
- Since WDE only happens in adjacent idle cells of a cell being written, another approach involves ascertaining all of the vulnerable cells and writing them irrespective of whether their values are changed [3]. However, since PCM has high write latency/energy and a short lifetime [25], this approach leads to very high overhead.
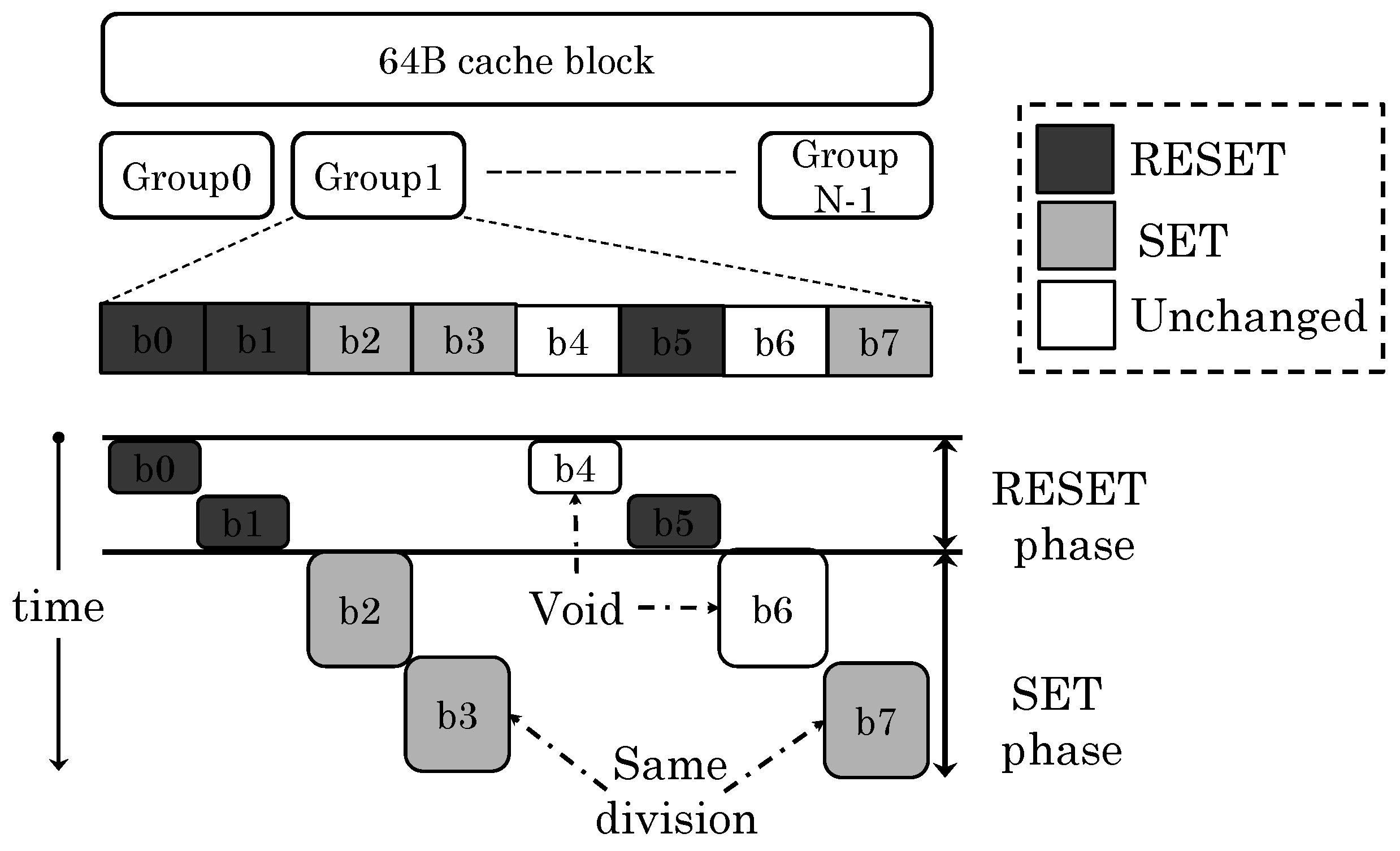
- The third approach, termed verify and correct (VnC), checks both the written cell and neighboring cells and performs RESET operations where required. However, VnC causes large performance loss [26]. Furthermore, since WDE affects nearby cells (and not the cell being written), performing VnC can disturb other cells, leading to cascading errors.
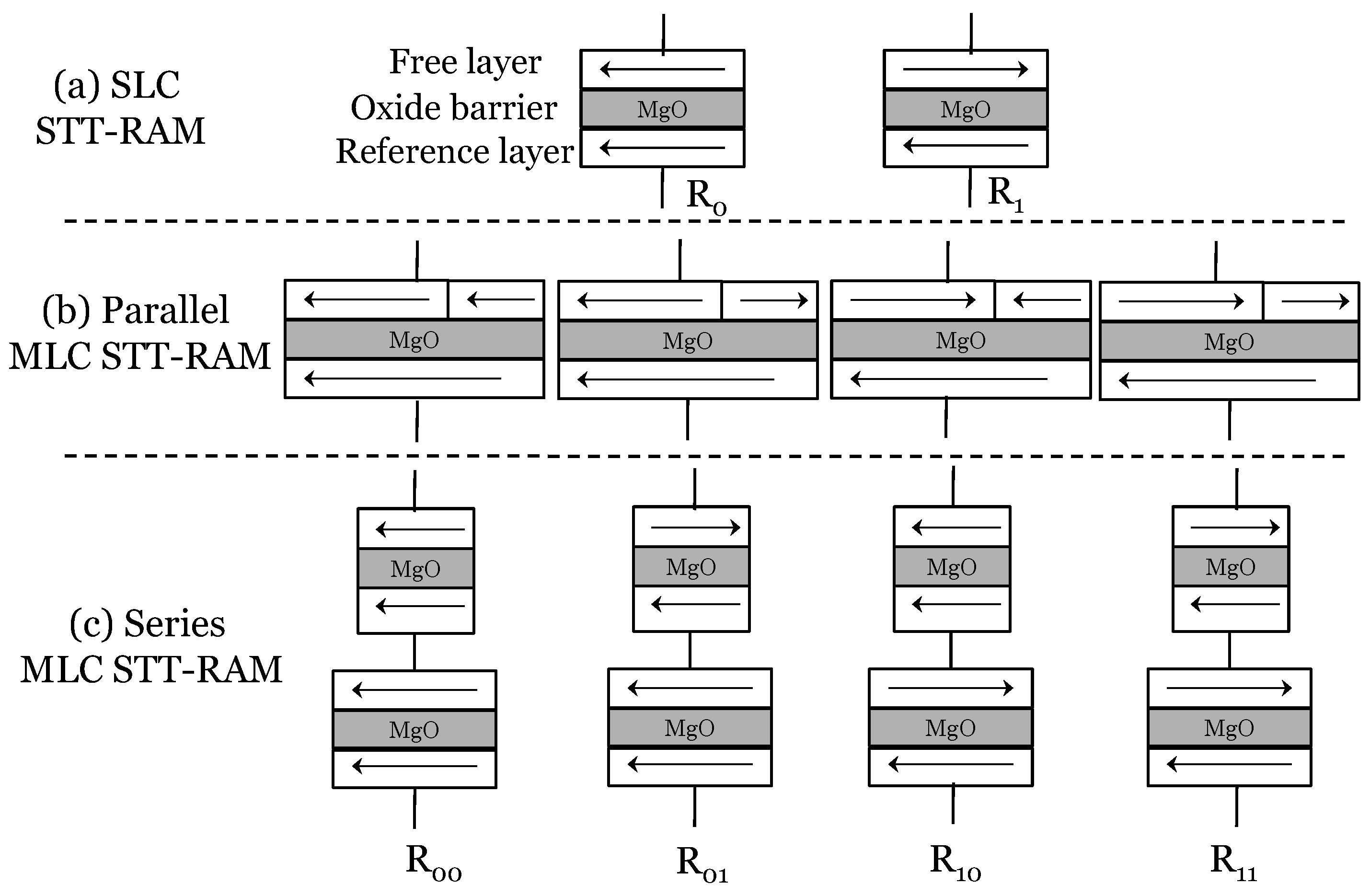
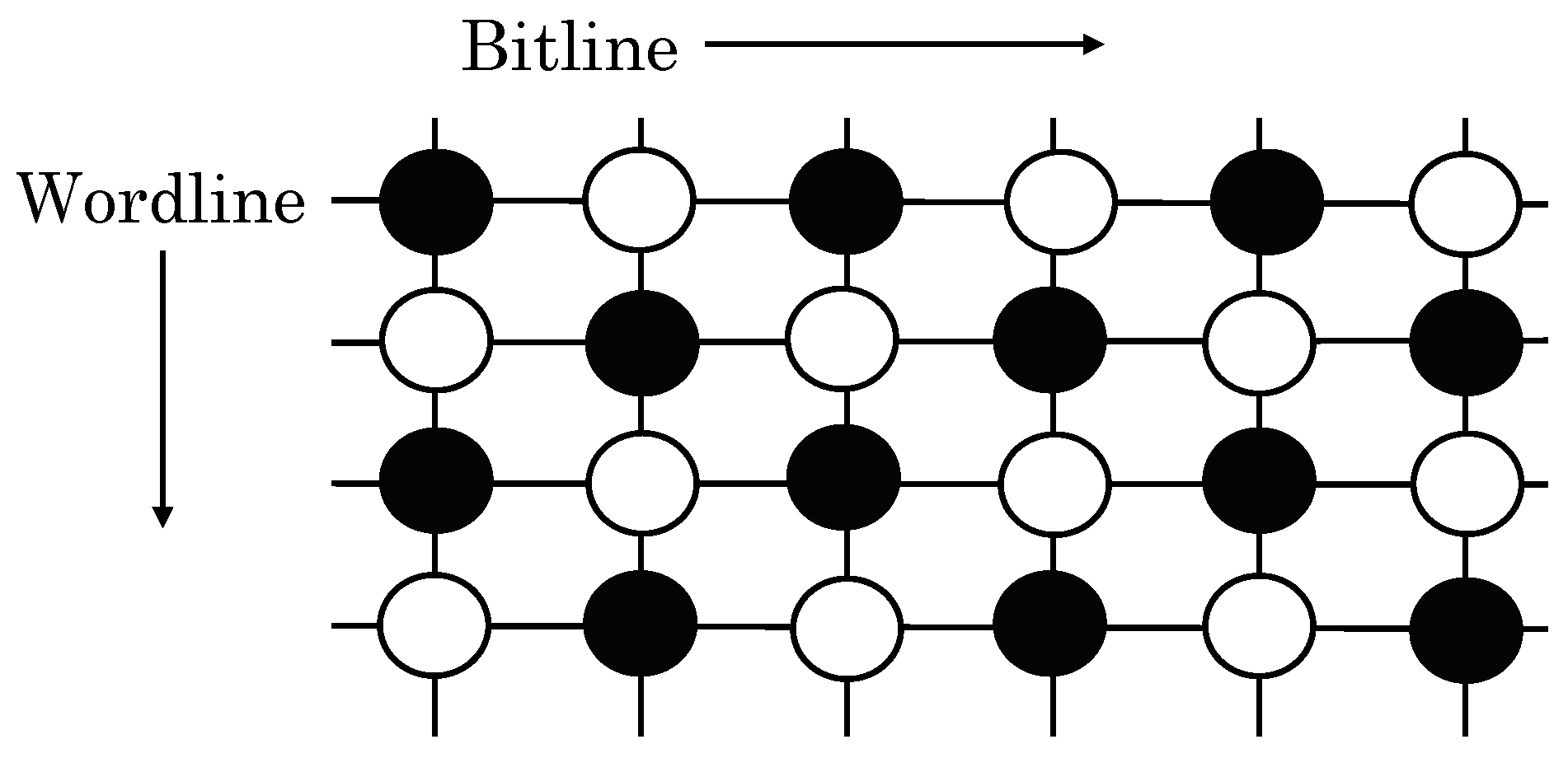
2.5. STT-RAM Data Storage Mechanism
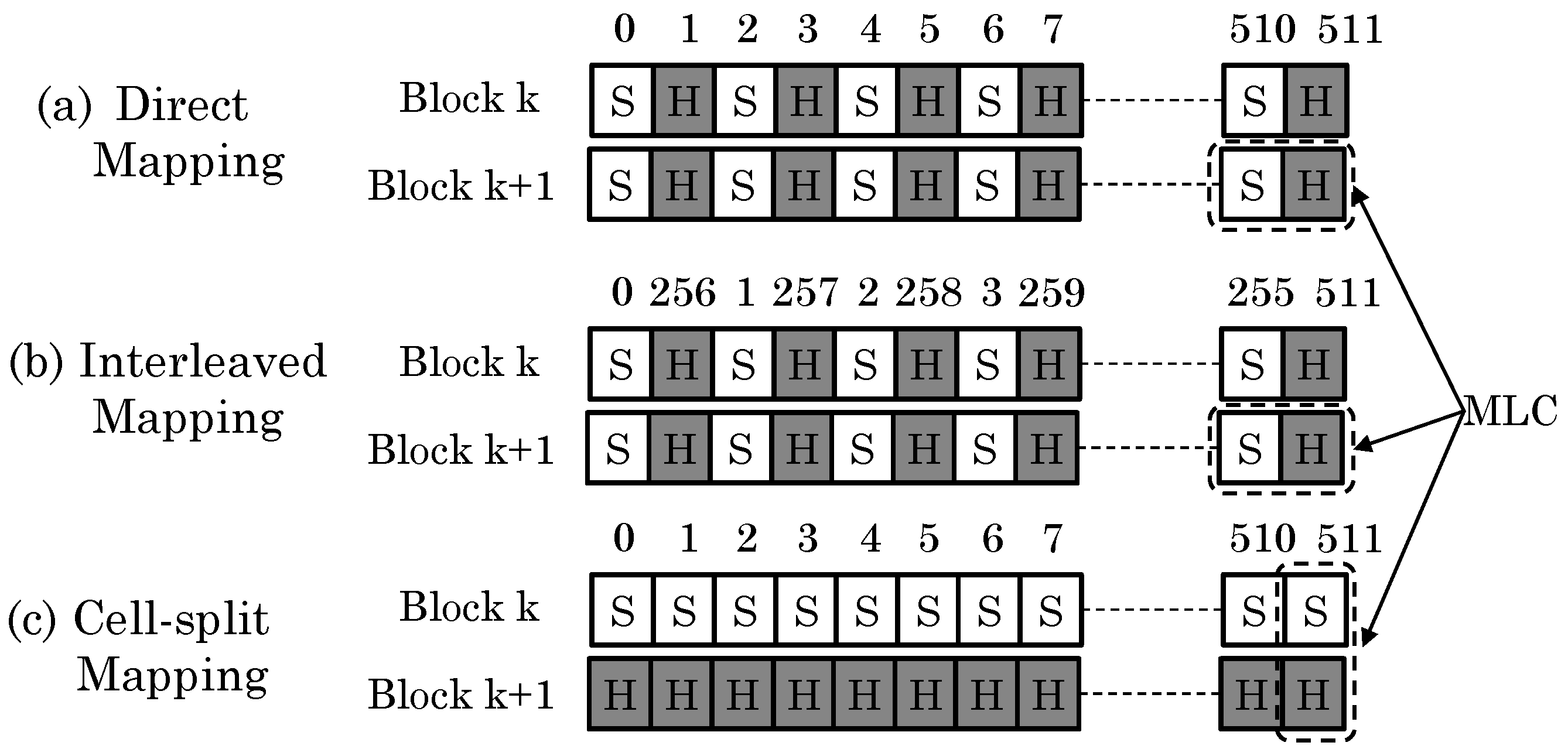
- Direct (or naive) mapping: An N-byte block can be stored in MLC STT-RAM cells, such that even bits are stored in soft-bits and odd bits stored in hard-bits. This cache line is referred to as the mixed line. This has the disadvantage that for any access, both soft and hard-bits need to be accessed, and hence, a two-step read/write is required.
- Interleaved mapping: The least-significant bits (LSBs) are stored in soft-bits, and most-significant bits (MSBs) are stored in hard-bits. This allows accessing LSBs with smaller latency. The limitation of interleaved mapping is that it requires additional circuitry to regenerate the original data.
- Cell-split mapping: Two N-byte blocks are stored in N MLC cells, such that one block is stored entirely in soft-bits and another block is stored entirely in hard-bits. Since only one-step read/write is required for accessing soft-bits, this strategy provides better performance if hot data blocks can be mapped to soft-bits.
2.6. STT-RAM Read Disturbance Error
- The margin between read and write currents can be increased by increasing the write current; however, this will further increase the already high write power of STT-RAM.
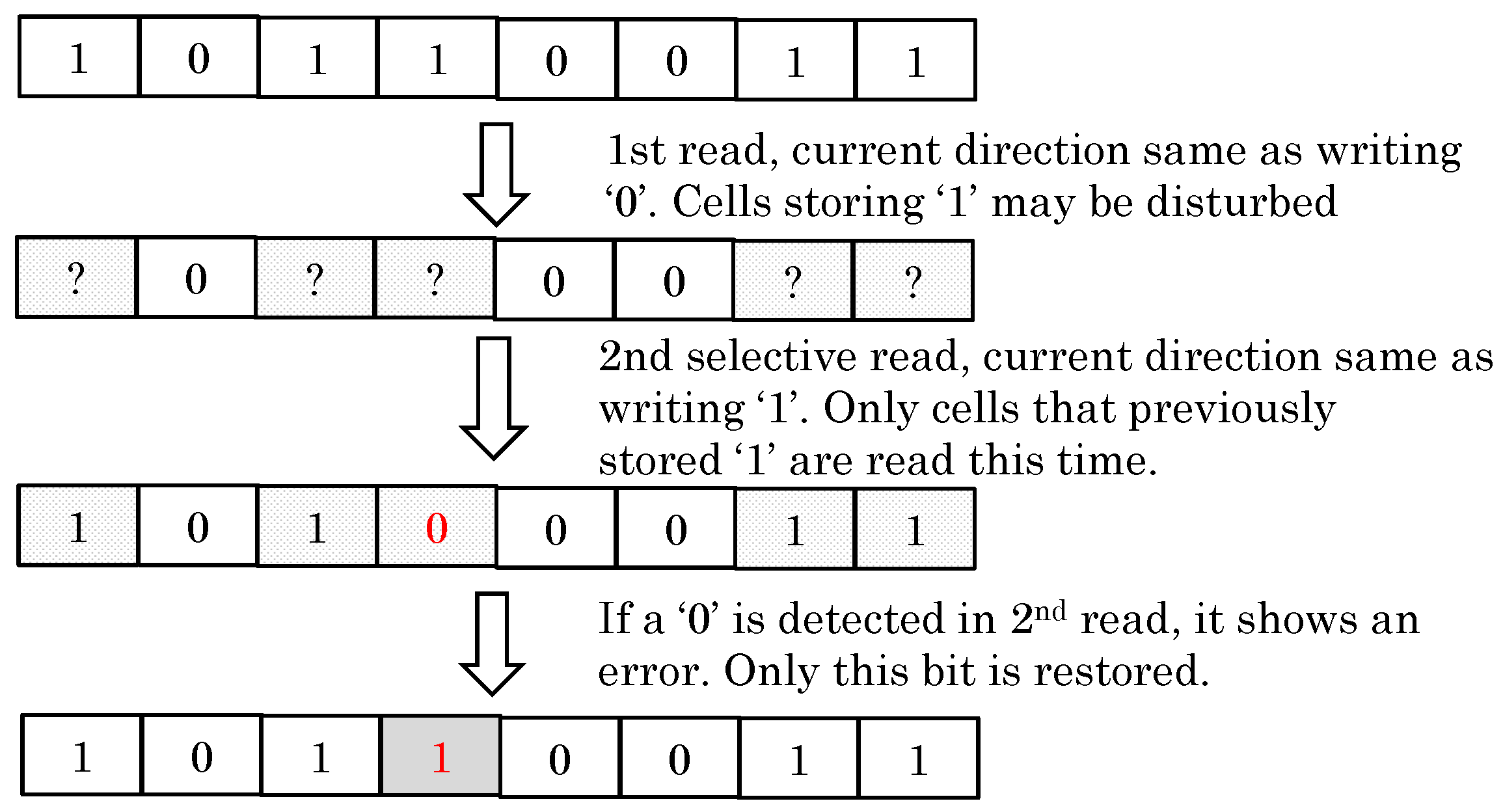
- Since after a read operation, the data value is stored in sense amplifiers and remains free of RDE, a third approach consists of writing this stored data value back to STT-RAM cells, and this is referred to as the restore/refresh-after-read [4,31] or high-current restore-required (HCRR) read approach [34]. However, these restore operations consume bandwidth and reduce cache/memory availability. Furthermore, this scheme does not leverage the properties of the data value (e.g., zero data) and cache access behavior to avoid unnecessary restore operations.
- A recently-proposed magnetic RAM, named SOT-RAM (spin orbit torque RAM), does not suffer from RDE [36], and hence, this can be used as an alternative of STT-RAM.
2.7. STT-RAM Write Errors
3. Classification and Overview
- Both ECC and data-duplication approaches increase the redundancy for enhancing reliability.
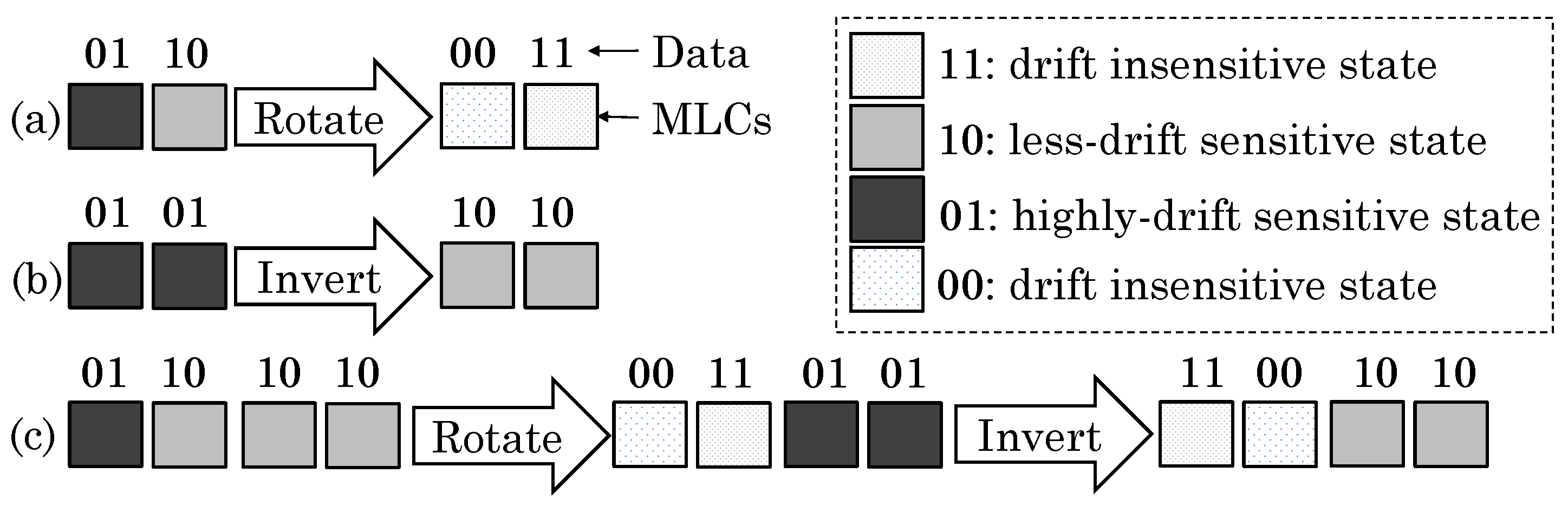
- In MLC PCM and MLC STT-RAM, some states show higher error rates than others (refer to Section 4.1 and Section 7.1). Hence, some works use the partial data mapping approach to avoid error-prone states. An example of this is ternary coding, where only three out of four states in a two-bit MLC are used for storing data. The limitation of partial data mapping, however, is that it may require additional conversion steps, since other processor components may still use binary coding. Other schemes to avoid error-prone or vulnerable states include bit-inversion and bit-rotation. A limitation of data-dependent techniques, such as rotation and inversion, is that they may not work well in the presence of random, encrypted or compressed data.
- Some works propose techniques based on asymmetric error rates of and transitions.
- Some works use different data-encoding schemes than the traditional binary encoding. For example, partial data mapping techniques may use ternary encoding, and some works use Graycoding to reduce the number of bit transitions. A few works use WOM (write-once-memory) codes [48].
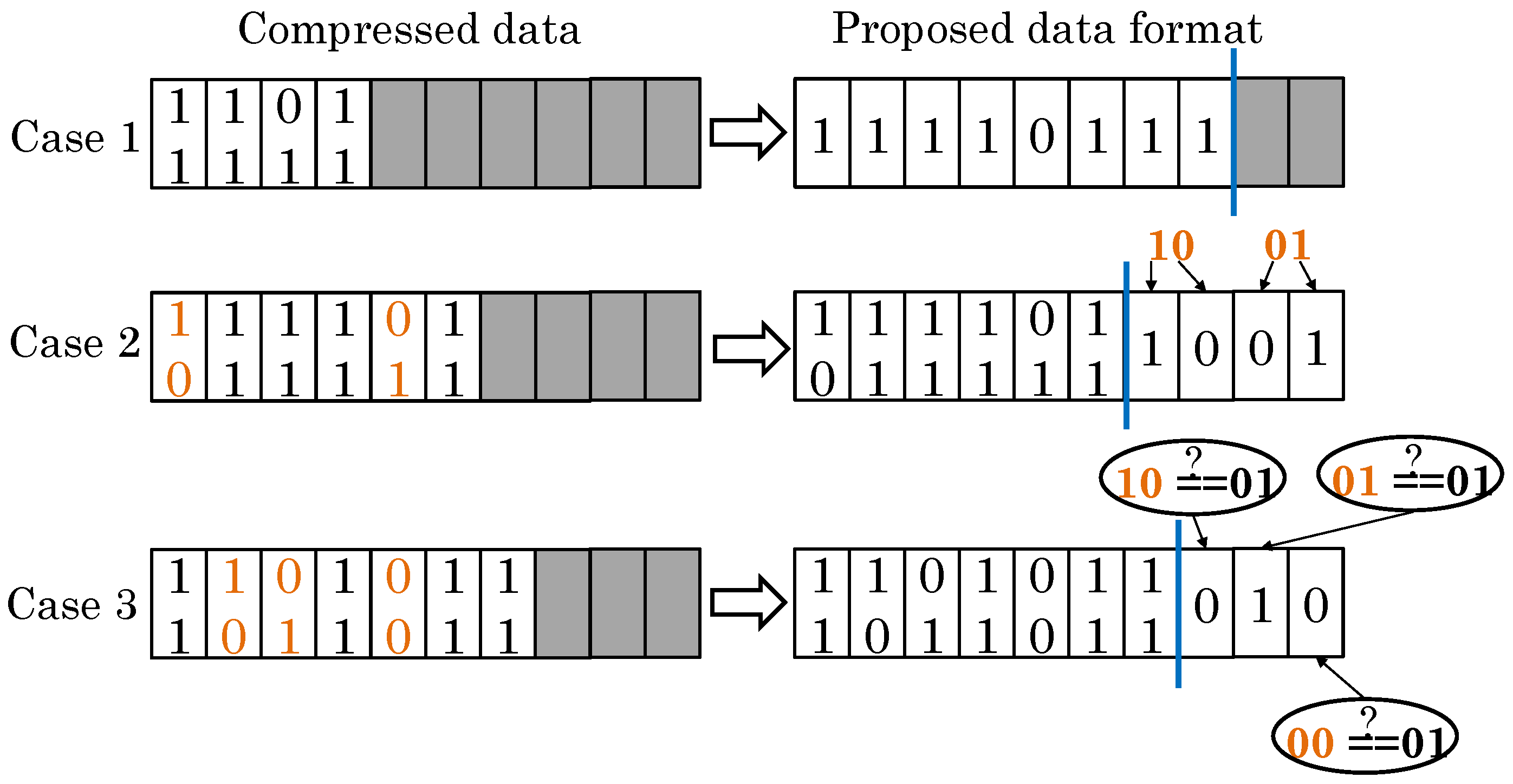
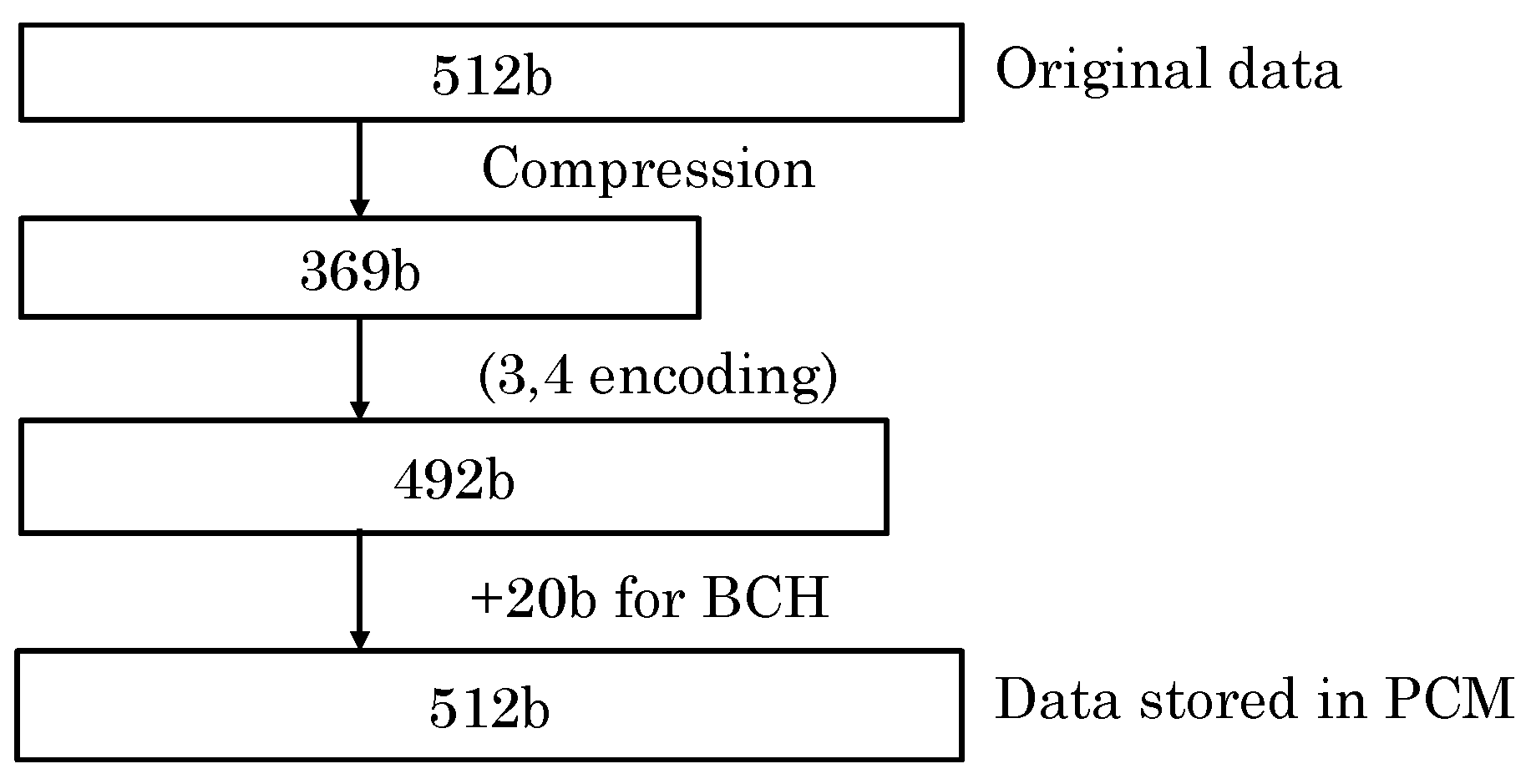
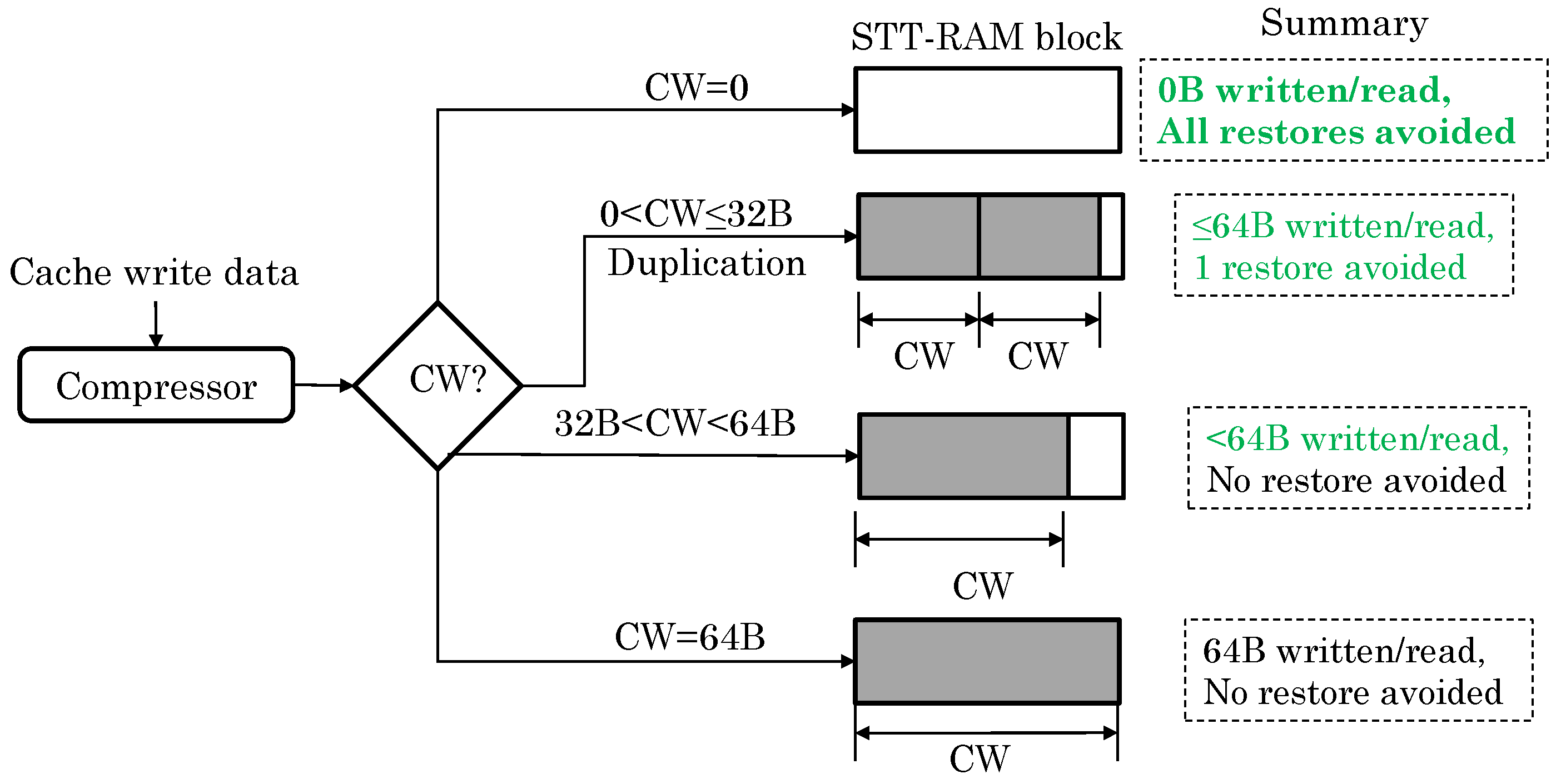
- Some works use data compression [53] for various optimizations, e.g., to make space for storing ECC [3] or for performing duplication [39], to compensate capacity loss due to partial data mapping [3], to facilitate switching from MLC to SLC mode [49] and to reduce the number of bits vulnerable to RDE [39] and WDE [26]. The efficacy of these techniques, however, depends on the compressibility of data.
- Some works perform VnC (also called write-read-verify) operations to reduce the error rate in write operations. Others perform scrubbing (which resembles DRAM refresh) to address PCM drift errors. The difference between these is that VnC is generally performed immediately after a write operation to remove the errors in the write operation, whereas scrubbing is performed periodically at idle times to remove the errors accumulated after a write operation. Furthermore, the scrubbing scheme reads and writes the same data assuming that stored data are correct, whereas the VnC scheme checks for the correctness of stored data and, in the case of errors, issues further writes.
- Some techniques combine multiple resilience strategies to lower their individual overheads. For example, on using VnC with ECC, VnC steps can be stopped once the number of errors is within the correction capability of ECC, which reduces VnC overhead. Similarly, the error rate reduction brought by VnC allows using an ECC with a lower error correction capability, which reduces ECC overhead.
- Some techniques hide the latency of WDE correction [22] by storing this in a buffer and scheduling it later when the cache or main memory is idle.
4. Addressing PCM Resistance Drift Errors
4.1. Partial Data Mapping
4.2. Selectively Using SLC Mode
4.3. Non-Uniform Partitioning of the Resistance Spectrum
4.4. Performing Reads in a Time- and Temperature-Aware Manner
4.5. Using Error Correction Strategies
4.6. Using Scrubbing
5. Addressing PCM Write Disturbance Errors
5.1. Using the Data-Encoding Scheme
5.2. Consolidating Correction Operations
5.3. Reducing Correction Overhead on the Critical Path
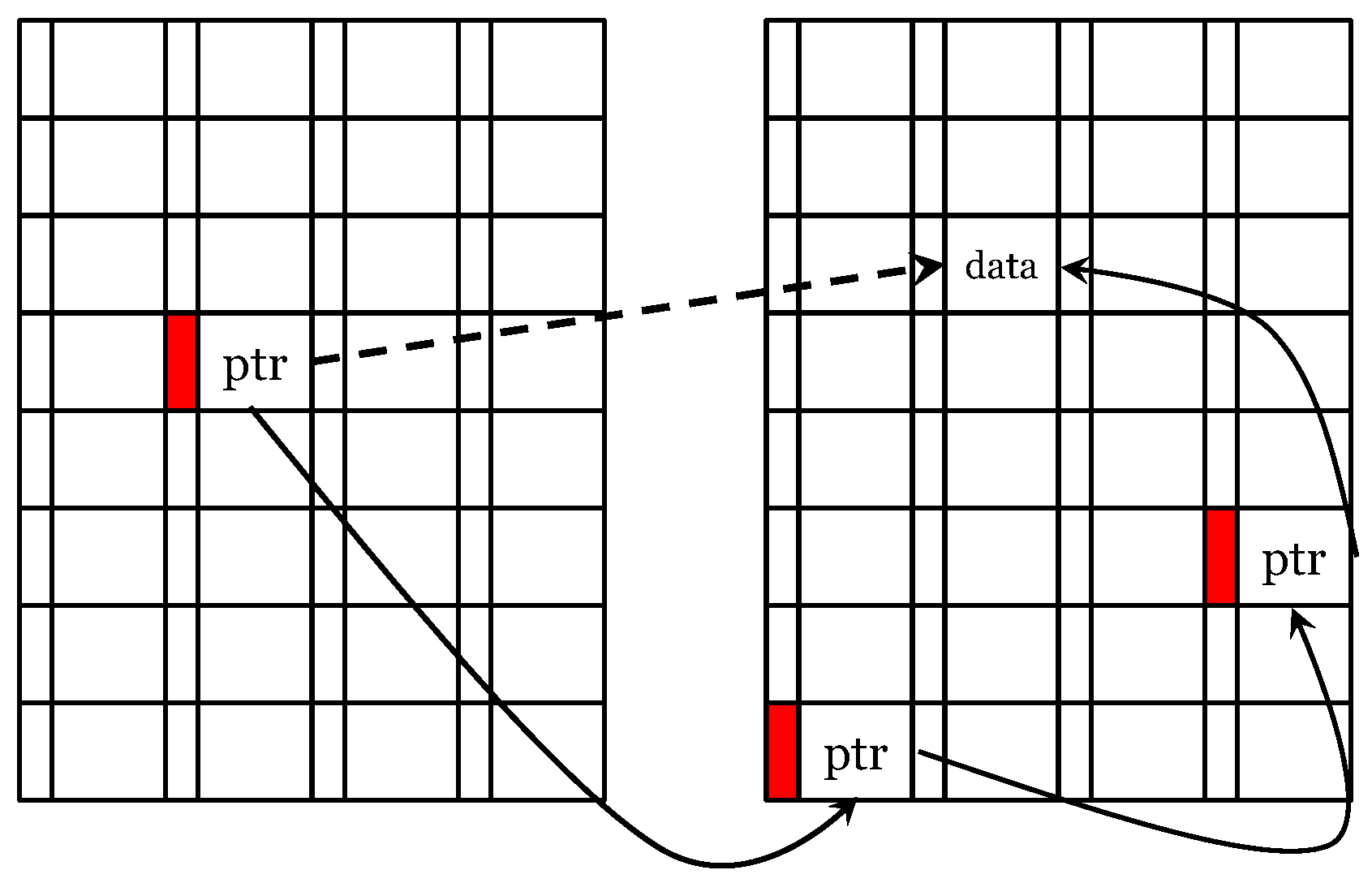
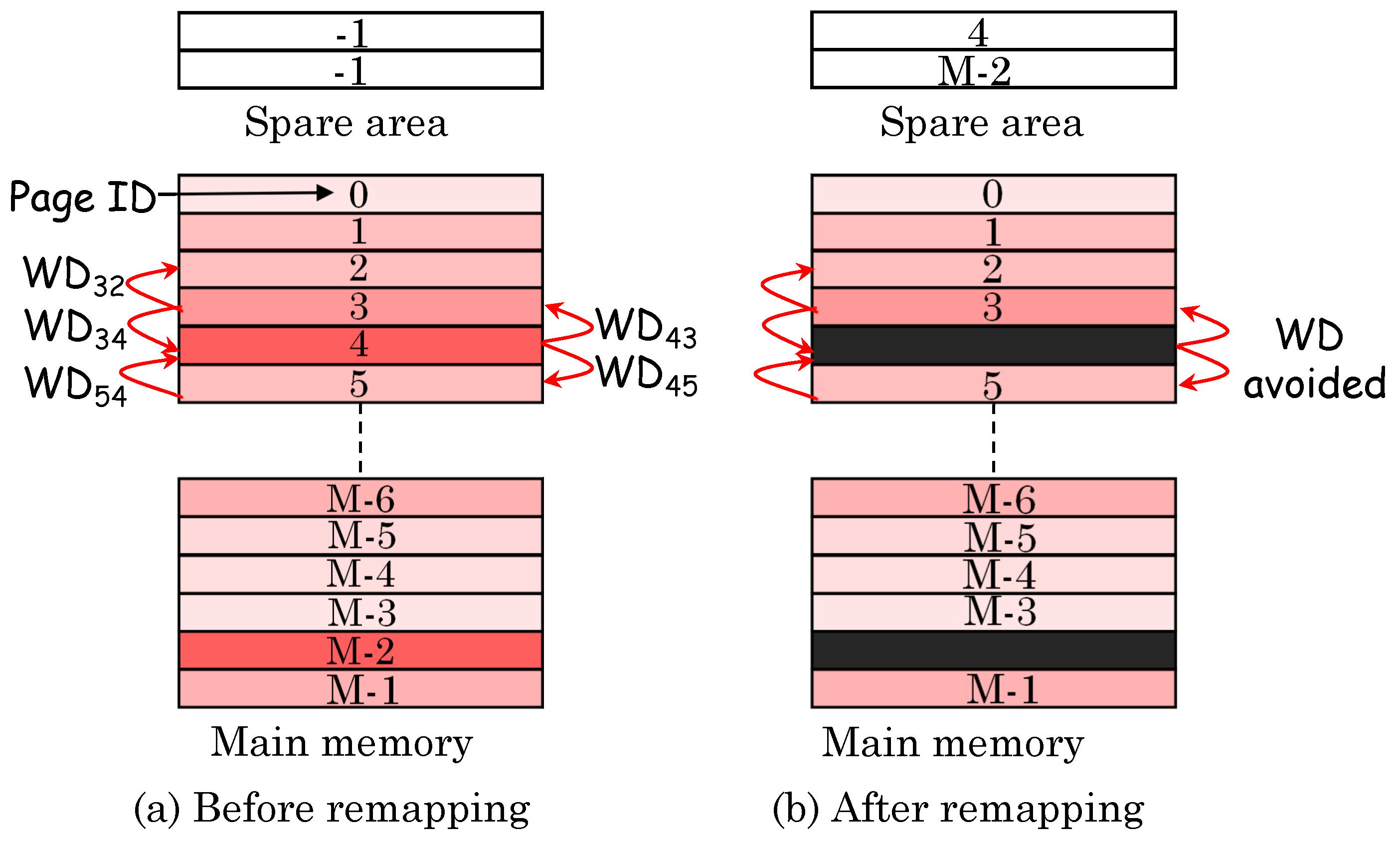
5.4. Using Page Remapping Scheme
5.5. Using Layout and Coding Schemes
6. Addressing STT-RAM Read Disturbance Errors
6.1. Avoiding Redundant Restore Operations
6.2. Compressing Data to Reduce RDEs
6.3. Selectively Using RDE-Free Cells or Reading Strategies
6.4. Tolerating RDE Using the Approximate Computing Approach
7. Addressing STT-RAM Write Errors
7.1. Partial Data Mapping
7.2. Using Heterogeneous Cells and/or ECCs
7.3. Using Error-Aware Cache Replacement Policy
7.4. Using VnC and ECC Schemes
8. Conclusions and Future Outlook
Conflicts of Interest
References
- Mittal, S.; Vetter, J.S. A Survey of Software Techniques for Using Non-Volatile Memories for Storage and Main Memory Systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1537–1550. [Google Scholar] [CrossRef]
- Seong, N.H.; Yeo, S.; Lee, H.H.S. Tri-level-cell phase change memory: Toward an efficient and reliable memory system. In Proceedings of the 40th Annual International Symposium on Computer Architecture, Tel-Aviv, Israel, 23–27 June 2013; pp. 440–451.
- Jiang, L.; Zhang, Y.; Yang, J. Mitigating write disturbance in super-dense phase change memories. In Proceedings of the International Conference on Dependable Systems and Networks (DSN), Atlanta, GA, USA, 23–26 June 2014; pp. 216–227.
- Wang, R.; Jiang, L.; Zhang, Y.; Wang, L.; Yang, J. Selective restore: an energy efficient read disturbance mitigation scheme for future STT-MRAM. In Proceedings of the 2015 52nd ACM/EDAC/IEEE Design Automation Conference, San Francisco, CA, USA, 8–12 June 2015; p. 21.
- Wen, W.; Zhang, Y.; Mao, M.; Chen, Y. State-restrict MLC STT-RAM designs for high-reliable high-performance memory system. In Proceedings of the 2014 51st ACM/EDAC/IEEE Design Automation Conference, San Francisco, CA, USA, –5 June 2014; pp. 1–6.
- Wen, W.; Mao, M.; Li, H.; Chen, Y.; Pei, Y.; Ge, N. A holistic tri-region MLC STT-RAM design with combined performance, energy, and reliability optimizations. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 1285–1290.
- Mittal, S.; Vetter, J. AYUSH: Extending Lifetime of SRAM-NVM Way-based Hybrid Caches Using Wear-leveling. In Proceedings of the 2015 IEEE 23rd International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems (MASCOTS), Atlanta, GA, USA, 5–7 October 2015.
- Mittal, S.; Vetter, J.S. EqualWrites: Reducing Intra-set Write Variations for Enhancing Lifetime of Non-volatile Caches. IEEE Trans. VLSI Syst. 2016, 24, 103–114. [Google Scholar] [CrossRef]
- Vetter, J.S.; Mittal, S. Opportunities for Nonvolatile Memory Systems in Extreme-Scale High Performance Computing. Comput. Sci. Eng. 2015, 17, 73–82. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J.S.; Li, D. A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 1524–1537. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J. Reliability Tradeoffs in Design of Volatile and Non-volatile Caches. J. Circuits Syst. Comput. 2016, 25, 11. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J. A Survey of Techniques for Modeling and Improving Reliability of Computing Systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1226–1238. [Google Scholar] [CrossRef]
- Xu, W.; Zhang, T. A time-aware fault tolerance scheme to improve reliability of multilevel phase-change memory in the presence of significant resistance drift. IEEE Trans. Very Large Scale Integr. Syst. 2011, 19, 1357–1367. [Google Scholar] [CrossRef]
- Mittal, S.; Poremba, M.; Vetter, J.; Xie, Y. Exploring Design Space of 3D NVM and eDRAM Caches Using DESTINY Tool; Technical Report ORNL/TM-2014/636; Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. [Google Scholar]
- Mittal, S. A Survey Of Architectural Techniques for Managing Process Variation. ACM Comput. Surv. 2016, 48, 54. [Google Scholar] [CrossRef]
- Awasthi, M.; Shevgoor, M.; Sudan, K.; Rajendran, B.; Balasubramonian, R.; Srinivasan, V. Efficient scrub mechanisms for error-prone emerging memories. In Proceedings of the International Symposium on High Performance Computer Architecture (HPCA), New Orleans, LA, USA, 25–29 February 2012; pp. 1–12.
- Zhang, W.; Li, T. Helmet: A resistance drift resilient architecture for multi-level cell phase change memory system. In Proceedings of the International Conference on Dependable Systems & Networks (DSN), Hong Kong, China, 27–30 June 2011; pp. 197–208.
- Jalili, M.; Arjomand, M.; Sarbazi-Azad, H. A reliable 3D MLC PCM architecture with resistance drift predictor. In Proceedings of the 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Atlanta, GA, USA, 23–26 June 2014; pp. 204–215.
- Liu, C.; Yang, C. Improving multilevel PCM reliability through age-aware reading and writing strategies. In Proceedings of the International Conference on Computer Design (ICCD), Seoul, Korea, 19–22 October 2014; pp. 264–269.
- Yang, C.; Emre, Y.; Cao, Y.; Chakrabarti, C. Multi-tiered approach to improving the reliability of multi-level cell PRAM. In Proceedings of the IEEE Workshop on Signal Processing Systems (SiPS), Seoul, Korea, 19–22 October 2012; pp. 114–119.
- Yoon, D.H.; Chang, J.; Schreiber, R.S.; Jouppi, N.P. Practical nonvolatile multilevel-cell phase change memory. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), Denver, CO, USA, 7–22 November 2013; pp. 1–12.
- Wang, R.; Jiang, L.; Zhang, Y.; Yang, J. SD-PCM: Constructing Reliable Super Dense Phase Change Memory under Write Disturbance. In Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems, Istanbul, Turkey, 14–18 March 2015; pp. 19–31.
- Wang, R.; Mittal, S.; Zhang, Y.; Yang, J. Decongest: Accelerating Super-Dense PCM under Write Disturbance by Hot Page Remapping; Technical Report; IIT Hyderabad: Telangana, India, 2016. [Google Scholar]
- Ahn, D.H.; Song, Y.; Jeong, H.; Kim, B.; Kang, Y.S.; Ahn, D.H.; Kwon, Y.; Nam, S.W.; Jeong, G.; Kang, H.; et al. Reliability perspectives for high density PRAM manufacturing. In Proceedings of the 2011 IEEE International Electron Devices Meeting (IEDM), Washington, DC, USA, 5–7 December 2011.
- Mittal, S. A Survey of Power Management Techniques for Phase Change Memory. Int. J. Comput. Aided Eng. Technol. 2014, 8, 424. [Google Scholar] [CrossRef]
- Wang, R.; Jiang, L.; Zhang, Y.; Wang, L.; Yang, J. Exploit imbalanced cell writes to mitigate write disturbance in dense phase change memory. In Proceedings of the 2015 52nd ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 8–12 June 2015; p. 88.
- Kwon, K.W.; Fong, X.; Wijesinghe, P.; Panda, P.; Roy, K. High-Density and Robust STT-MRAM Array Through Device/Circuit/Architecture Interactions. IEEE Trans. Nanotechnol. 2015, 14, 1024–1034. [Google Scholar] [CrossRef]
- Fong, X.; Kim, Y.; Choday, S.H.; Roy, K. Failure mitigation techniques for 1T-1MTJ spin-transfer torque MRAM bit-cells. IEEE Trans. Very Large Scale Integr. Syst. 2014, 22, 384–395. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, X.; Chen, Y. STT-RAM cell design optimization for persistent and non-persistent error rate reduction: A statistical design view. In Proceedings of the International Conference on Computer-Aided Design, San Jose, CA, USA, 7–10 November 2011; pp. 471–477.
- Hong, S.; Lee, J.; Kim, S. Ternary cache: Three-valued MLC STT-RAM caches. In Proceedings of the IEEE International Conference on Computer Design (ICCD), Seoul, Korea, 19–22 October 2014; pp. 83–89.
- Takemura, R.; Kawahara, T.; Ono, K.; Miura, K.; Matsuoka, H.; Ohno, H. Highly-scalable disruptive reading scheme for Gb-scale SPRAM and beyond. In Proceedings of the 2010 IEEE International Memory Workshop (IMW), Seoul, Korea, 16–19 May 2010; pp. 1–2.
- Zhang, Y.; Li, Y.; Sun, Z.; Li, H.; Chen, Y.; Jones, A.K. Read performance: The newest barrier in scaled STT-RAM. IEEE Trans. Very Large Scale Integr. Syst. 2015, 23, 1170–1174. [Google Scholar] [CrossRef]
- Kang, W.; Zhao, W.; Klein, J.O.; Zhang, Y.; Chappert, C.; Ravelosona, D. High reliability sensing circuit for deep submicron spin transfer torque magnetic random access memory. Electron. Lett. 2013, 49, 1283–1285. [Google Scholar] [CrossRef]
- Jiang, L.; Wen, W.; Wang, D.; Duan, L. Improving Read Performance of STT-MRAM based Main Memories through Smash Read and Flexible Read. In Proceedings of the 2016 21st Asia and South Pacific Design Automation Conference (ASP-DAC), Macao, China, 25–28 January 2016.
- Mittal, S. A Survey Of Cache Bypassing Techniques. MDPI J. Low Power Electron. Appl. 2016, 6, 5. [Google Scholar] [CrossRef]
- Oboril, F.; Bishnoi, R.; Ebrahimi, M.; Tahoori, M. Evaluation of Hybrid Memory Technologies using SOT-MRAM for On-Chip Cache Hierarchy. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2015, 34, 367–380. [Google Scholar] [CrossRef]
- Monazzah, A.; Farbeh, H.; Miremadi, S. LER: Least Error Rate Replacement Algorithm for Emerging STT-RAM Caches. IEEE Trans. Device and Mater. Reliab. 2016, 16, 220–226. [Google Scholar] [CrossRef]
- Mittal, S. A Survey of Architectural Techniques For Improving Cache Power Efficiency. Sustain. Comput. Inform. Syst. 2014, 4, 33–43. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J.; Jiang, L. Addressing Read-disturbance Issue in STT-RAM by Data Compression and Selective Duplication. IEEE Comput. Archit. Lett. 2016. [Google Scholar] [CrossRef]
- Wang, X.; Mao, M.; Eken, E.; Wen, W.; Li, H.; Chen, Y. Sliding Basket: An adaptive ECC scheme for runtime write failure suppression of STT-RAM cache. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 762–767.
- Wen, W.; Mao, M.; Zhu, X.; Kang, S.H.; Wang, D.; Chen, Y. CD-ECC: Content-dependent error correction codes for combating asymmetric nonvolatile memory operation errors. In Proceedings of the International Conference on Computer-Aided Design, San Jose, CA, USA, 18–21 November 2013; pp. 1–8.
- Sun, H.; Liu, C.; Zheng, N.; Min, T.; Zhang, T. Design techniques to improve the device write margin for MRAM-based cache memory. In Proceedings of the 21st edition of the great lakes symposium on Great lakes symposium on VLSI, Lausanne, Switzerland, 2–4 May 2011; pp. 97–102.
- Zhang, H.; Chen, X.; Xiao, N.; Liu, F.; Chen, Z. Red-Shield: Shielding Read Disturbance for STT-RAM Based Register Files on GPUs. In Proceedings of the 2016 International Great Lakes Symposium on VLSI (GLSVLSI), Boston, MA, USA, 18–20 May 2016; pp. 389–392.
- Ahn, J.; Yoo, S.; Choi, K. Selectively protecting error-correcting code for area-efficient and reliable STT-RAM caches. In Proceedings of the 2013 18th Asia and South Pacific Design Automation Conference (ASP-DAC), Yokohama, Japan, 22–25 January 2013; pp. 285–290.
- Ranjan, A.; Venkataramani, S.; Fong, X.; Roy, K.; Raghunathan, A. Approximate storage for energy efficient spintronic memories. In Proceedings of the Design Automation Conference, San Francisco, CA, USA, 7–11 June 2015; p. 195.
- Li, B.; Pei, Y.; Wen, W. Efficient Low-Density Parity-Check (LDPC) Code Decoding for Combating Asymmetric Errors in STT-RAM. In Proceedings of the 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, PA, USA, 11–13 July 2016.
- Wang, R.; Zhang, Y.; Yang, J. ReadDuo: Constructing Reliable MLC Phase Change Memory through Fast and Robust Readout. In Proceedings of the 2016 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Toulouse, France, 28 June–1 July 2016.
- Eslami, A.; Velasco, A.; Vahid, A.; Mappouras, G.; Calderbank, R.; Sorin, D.J. Writing without Disturb on Phase Change Memories by Integrating Coding and Layout Design. In Proceedings of the International Symposium on Memory Systems, Washington, DC, USA, 5–8 October 2015; pp. 71–77.
- Jalili, M.; Sarbazi-Azad, H. A compression-based morphable PCM architecture for improving resistance drift tolerance. In Proceedings of the International Conference on Application-specific Systems, Architectures and Processors (ASAP), Zurich, Switzerland, 18–22 June 2014; pp. 232–239.
- Asadinia, M.; Arjomand, M.; Sarbazi-Azad, H. Variable resistance spectrum assignment in phase change memory systems. IEEE Trans. VLSI 2015, 23, 2657–2670. [Google Scholar] [CrossRef]
- Swami, S.; Mohanram, K. E3R: Energy Efficient Error Recovery for Multi/Triple-Level Cell Non-volatile Memories. In Proceedings of the 2016 19th International Conference on VLSI Design and 2016 15th International Conference on Embedded Systems (VLSID), Kolkata, India, 4–8 January 2016; pp. 373–378.
- Yoon, D.H.; Muralimanohar, N.; Chang, J.; Ranganathan, P.; Jouppi, N.P.; Erez, M. FREE-p: Protecting non-volatile memory against both hard and soft errors. In Proceedings of the International Symposium on High Performance Computer Architecture (HPCA), San Antonio, TX, USA, 12–16 Feburary 2011; pp. 466–477.
- Mittal, S.; Vetter, J. A Survey Of Architectural Approaches for Data Compression in Cache and Main Memory Systems. IEEE Trans. Parallel and Distrib. Syst. 2016, 27, 1524–1536. [Google Scholar] [CrossRef]
- Schechter, S.; Loh, G.H.; Straus, K.; Burger, D. Use ECP, Not ECC, for Hard Failures in Resistive Memories. In Proceedings of the International Symposium on Computer Architecture (ISCA), Saint-Malo, France, 19–23 June 2010; pp. 141–152.
- NVIDIA. NVIDIA’s Next Generation CUDA Compute Architecture: Kepler GK110/210. 2014. Available online: http://goo.gl/qOSWW1 (accessed on 9 February 2016).
- Mittal, S. A Survey of Techniques for Architecting and Managing GPU Register File. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 16–28. [Google Scholar] [CrossRef]
- Mittal, S. A Survey Of Techniques for Approximate Computing. ACM Comput. Surv. 2016, 48, 62. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
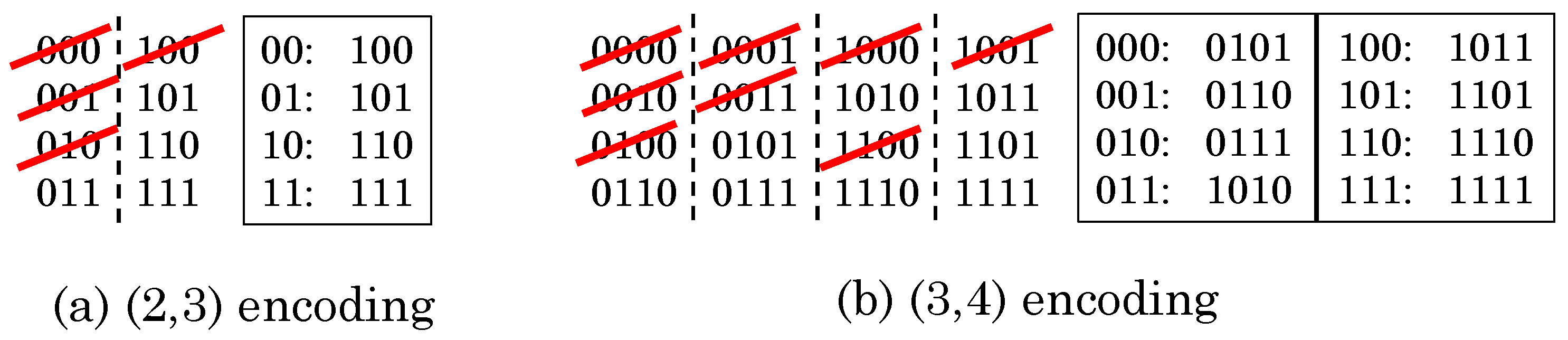{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
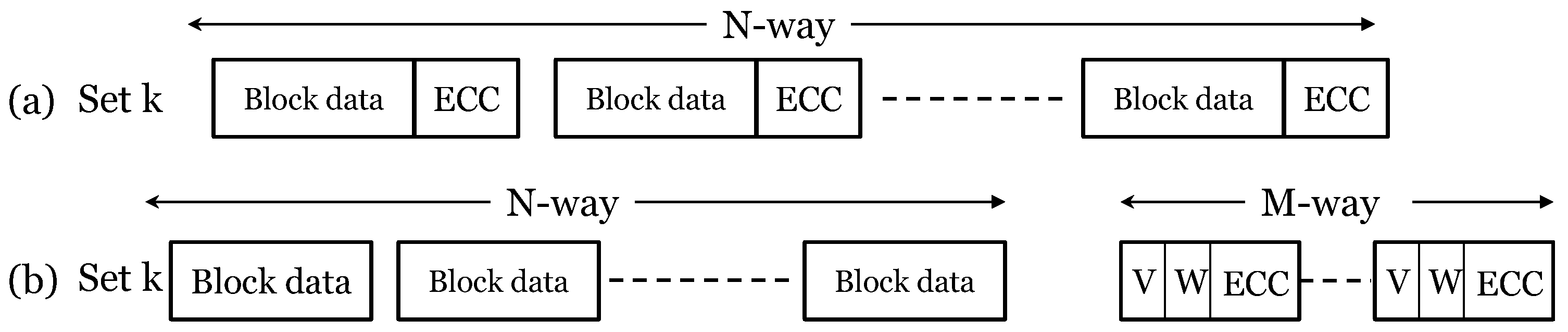{kind=link}
| Memory | SLC | MLC | Where | When | Comments | |
|---|---|---|---|---|---|---|
| Resistance drift | PCM | No† | Yes | Same cell | Over time | Change in resistance changes the bit stored |
| Write disturbance | PCM | Yes | Yes | Nearby cells | During write | Write to a cell changes neighboring cells |
| Read disturbance | STT-RAM | Yes | Yes | Same cell | During read | Read changes the stored value |
| Write failure | STT-RAM | Yes | Yes | Same cell | During write | Written value is incorrect |
| Classification | References |
|---|---|
| Memory technology | |
| STT-RAM | [4,6,27,30,32,34,36,37,39,40,41,42,43,44,45,46] |
| PCM | [2,3,13,16,17,18,19,20,21,22,23,26,47,48,49,50,51,52] |
| MLC or SLC | |
| MLC | [2,3,5,6,13,16,17,18,19,20,21,30,47,49,50,51] |
| SLC | Nearly all others |
| Vulnerability addressed | |
| Resistance drift | [2,13,16,17,18,20,21,47,49,50,52] |
| Write-disturbance | [3,22,23,26,48] |
| Read-disturbance | [4,32,34,36,39,43,45] |
| STT-RAM write error | [5,6,30,37,40,41,42,44,45,46] |
| Classification | References |
|---|---|
| Processing unit | |
| GPU | [43] |
| Vector processor | [45] |
| CPU | Nearly all others |
| Processor component where NVM is used | |
| Main memory | [2,3,16,18,21,22,23,26,34,47,49,50,51,52] |
| Last level Cache | [4,30,32,36,39,41,42,44] |
| First level cache | [32,36] |
| Register file | [43] |
| Scratchpad | [45] |
| Optimization objective | |
| Reliability | Nearly all |
| Performance | [2,4,5,6,22,23,30,32,34,36,37,39,40,41,42,43,44,47,49,50,51,52] |
| Energy | [4,6,16,17,18,23,30,32,34,36,37,39,40,42,43,45,47,49,50,51] |
| Architectural management approach | |
| ECC | [3,5,6,16,27,40,41,42,44,47,49,52] |
| Data-duplication | [39,49] |
| Partial data mapping | [2,3,5,21,30,51] |
| Leveraging asymmetry of and transitions | [37,40,41] |
| Gray coding | [5,18,20,21] |
| Bit-inversion | [3,17,20,27] |
| Bit-rotation | [17] |
| Compression | [3,26,39,49] |
| Use of buffer | [5,43] |
| VnC scheme | [3,22,37,42,44] |
| Scrubbing scheme | [16,21,47] |
| First Cell State | Second Cell State | 3-Bit Data |
|---|---|---|
| S0 | S0 | 000 |
| S0 | S1 | 001 |
| S0 | S3 | 010 |
| S1 | S0 | 011 |
| S1 | S1 | 100 |
| S1 | S3 | 101 |
| S3 | S0 | 110 |
| S3 | S1 | 111 |
| S3 | S3 | invalid |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mittal, S. A Survey of Soft-Error Mitigation Techniques for Non-Volatile Memories. Computers 2017, 6, 8. https://doi.org/10.3390/computers6010008
Mittal S. A Survey of Soft-Error Mitigation Techniques for Non-Volatile Memories. Computers. 2017; 6(1):8. https://doi.org/10.3390/computers6010008
Chicago/Turabian StyleMittal, Sparsh. 2017. "A Survey of Soft-Error Mitigation Techniques for Non-Volatile Memories" Computers 6, no. 1: 8. https://doi.org/10.3390/computers6010008
APA StyleMittal, S. (2017). A Survey of Soft-Error Mitigation Techniques for Non-Volatile Memories. Computers, 6(1), 8. https://doi.org/10.3390/computers6010008