Run-Time Mitigation of Power Budget Variations and Hardware Faults by Structural Adaptation of FPGA-Based Multi-Modal SoPC

Abstract
:1. Introduction
- In multi-task multi-modal systems, when the number of modes, tasks, and their ASP circuit variants increase, a large design space of system configurations is formed. For example, a system with a total of 16 tasks, 16 ASP circuit variants per task, 20 modes, and 5 tasks per mode will have a design space of = 1,048,576 system configurations per mode. Since a solution must be found at run-time, within the permitted adaptation time, it may not possible to exhaustively evaluate each configuration at run-time. As a result, there must be a Run-time Design Space Exploration (RT-DSE) method with a small execution-time overhead to select a suitable configuration that satisfies the tasks’ performance specifications, DPC and hardware resource constraints.
- The RT-DSE method will need the DPC of candidate system configurations to decide the most suitable solution. It is practically not feasible to measure and store the DPC of all the possible system configurations in a Look-Up-Table (LUT). In the above example, this would mean measuring the DPC of 20 modes configurations per mode during system design phase and feeding these values in a large LUT. Furthermore, any addition or modification of system modes, tasks, or their variants will imply re-doing the entire offline process all over again! Thus, it is necessary to have a run-time analytical model which can estimate the DPC of system configurations under evaluation during the run-time DSE process itself.
- Once a solution is provided by the run-time DSE method, the system needs to be dynamically reconfigured with the new chosen ASP circuit variants of the active tasks within the permitted adaptation time. It is to be noted that the permitted adaptation time is application specific. For a commercial video processing application, a loss of a couple frames can be permitted, but for a critical military application, loss of only one frame may be permitted for adaptation. A system must therefore have the infrastructure that allows a quick transformation to the new selected configuration. ‘Multi-mode Adaptive Collaborative Reconfigurable self-Organized System’ (MACROS) framework has been developed for this purpose [6]. It permits reconfiguration and automatic integration of ASP circuit variants with a very small time overhead in the order of only a couple clock cycles [7,8]. A brief description of MACROS is provided in Section 3.
- It proposes a method for FPGA-based multi-task multi-modal systems for their run-time structural adaptation to an extensive set of possible situations of: (a) changing system modes, (b) changing power budgets, and (c) occurrence of hardware faults. It incorporates an RT-DSE mechanism which finds the most suitable system configuration depending on the existing set of constraints, thus enabling RT-SA.
- It proposes a method to derive the complete Dynamic Power Consumption Estimation Model (DPCEM) of an FPGA in terms of all its reconfigurable resources; clock frequency, Logic slices, Block RAM (BRAM) slices, and DSP slices. The DPCEM is used by the RT-DSE method to evaluate DPC of potential configurations.
2. Literature Review
3. MACROS Framework
4. Method for Run-Time Structural Adaptation to Varying System Modes, Power Budget, and Occurrence of Hardware Faults
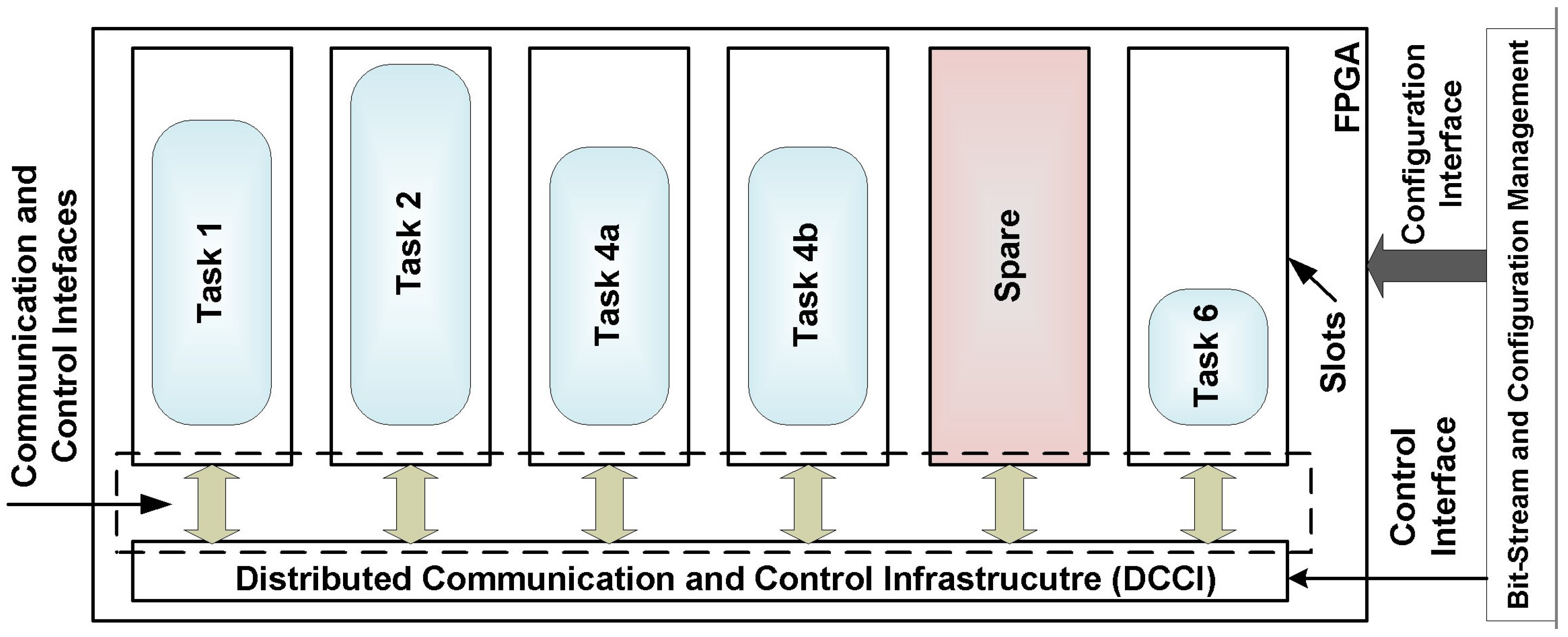
4.1. System Description
- Priority of the task in a mode— (highest priority), …, (lowest priority)
- Range of performance available for this task in a mode, i.e., from , the highest performance level (e.g., 240 frames per second () => 8) to , the lowest performance level (e.g., 60 => 2). These values are relative not absolute and thus, can be associated with different performance characteristics.
- Existence condition, , a parameter that determines whether a task in a mode can be eliminated or not. The task can be terminated if its ; not if its .
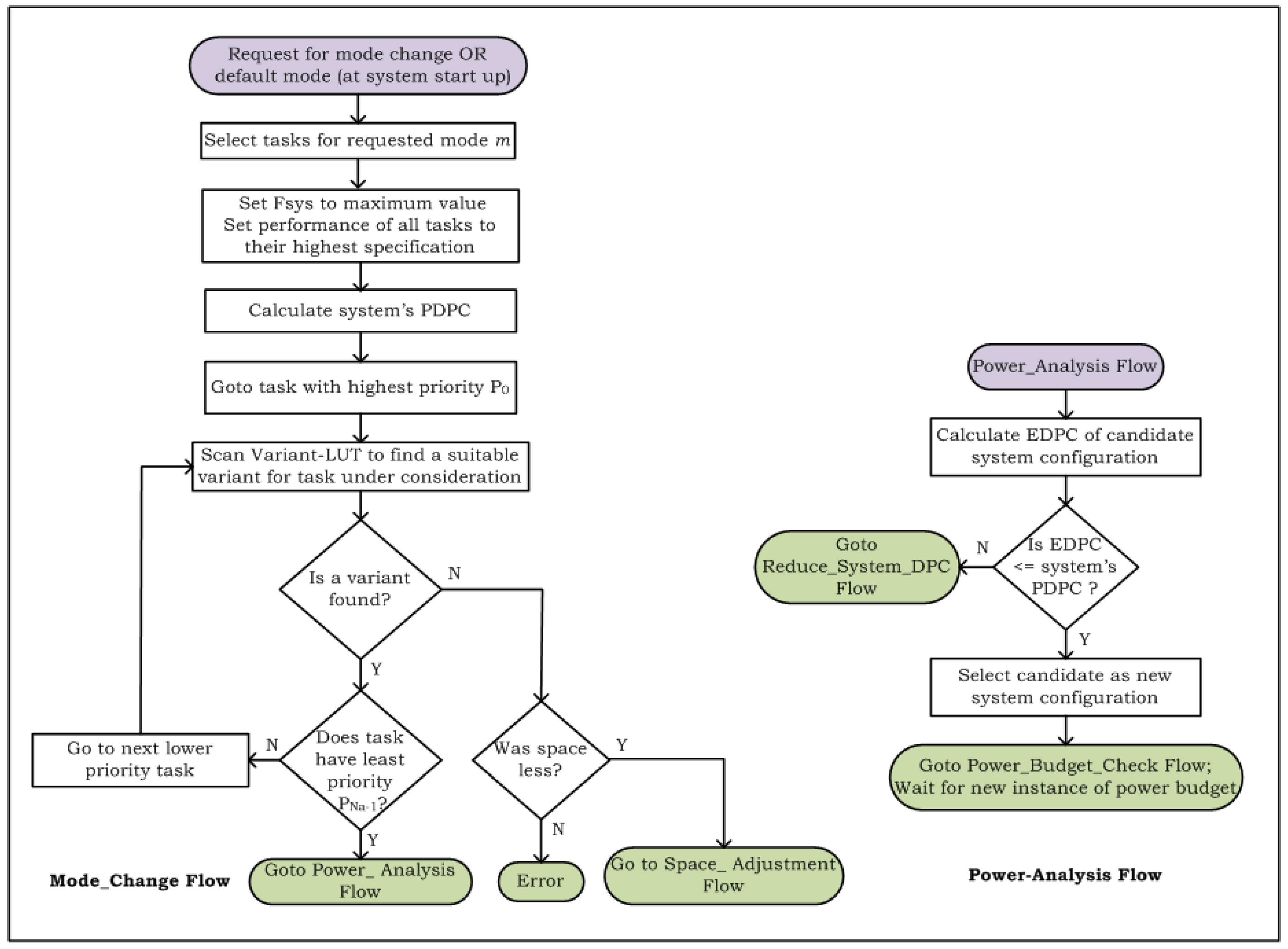
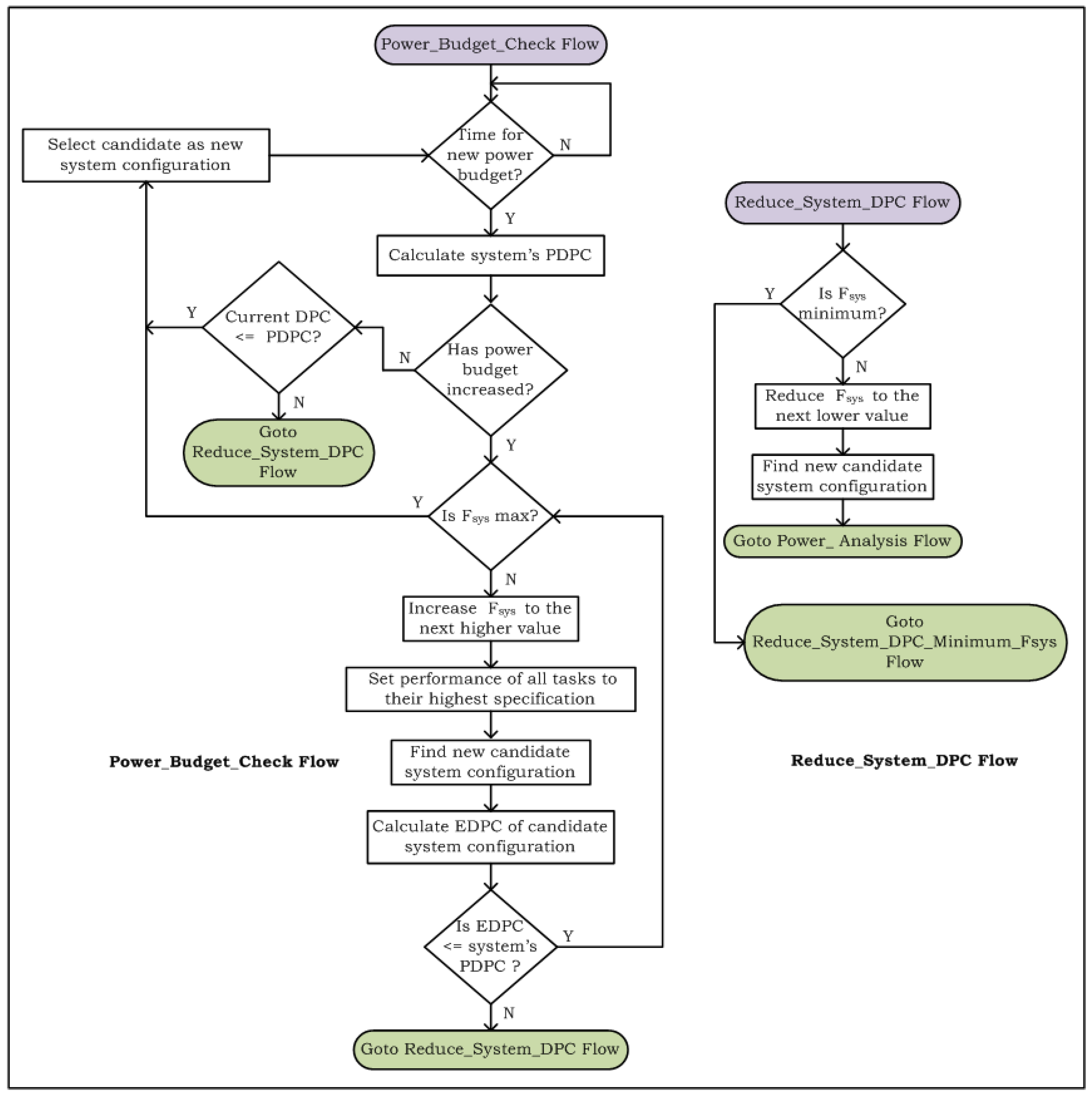
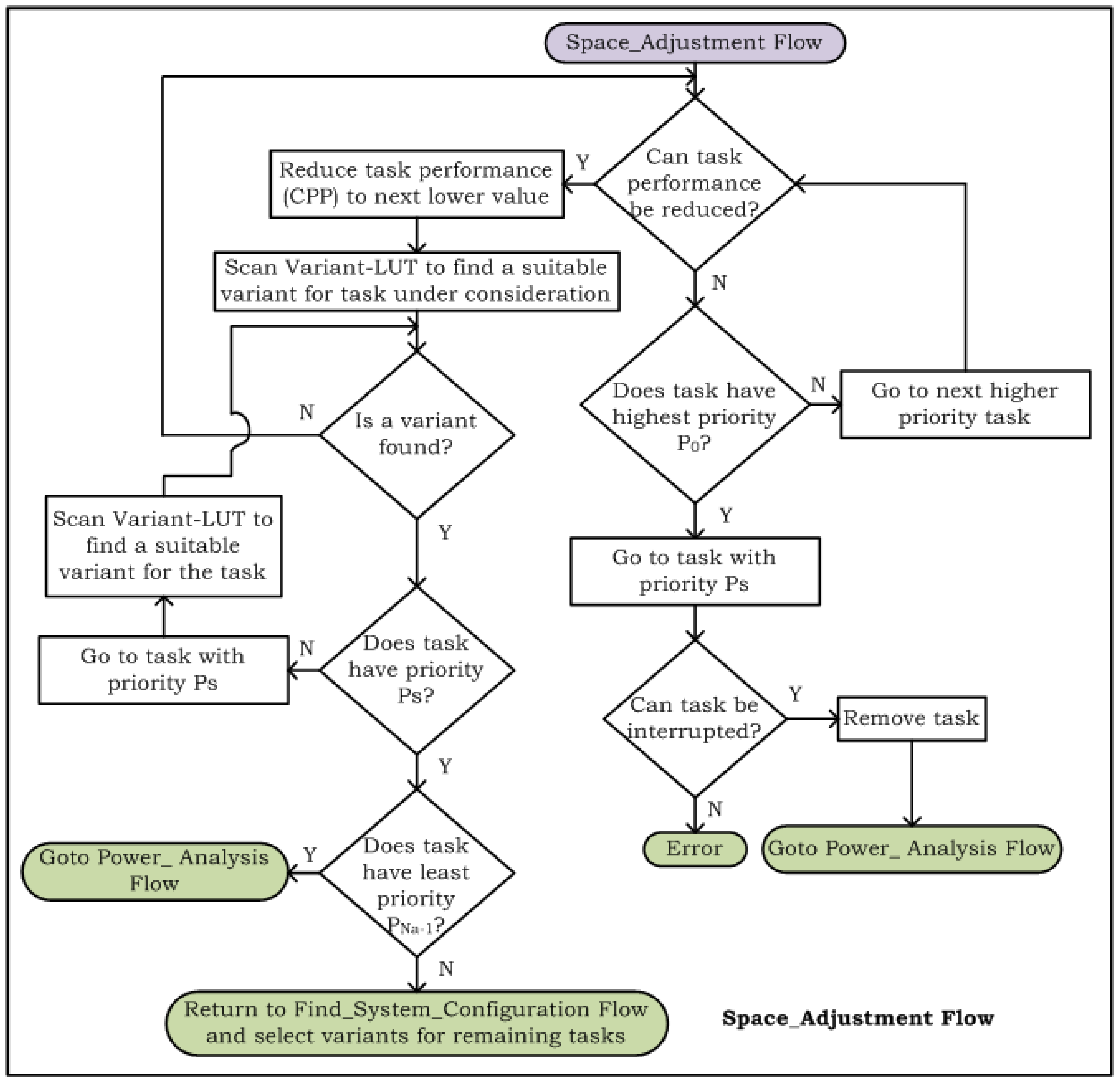
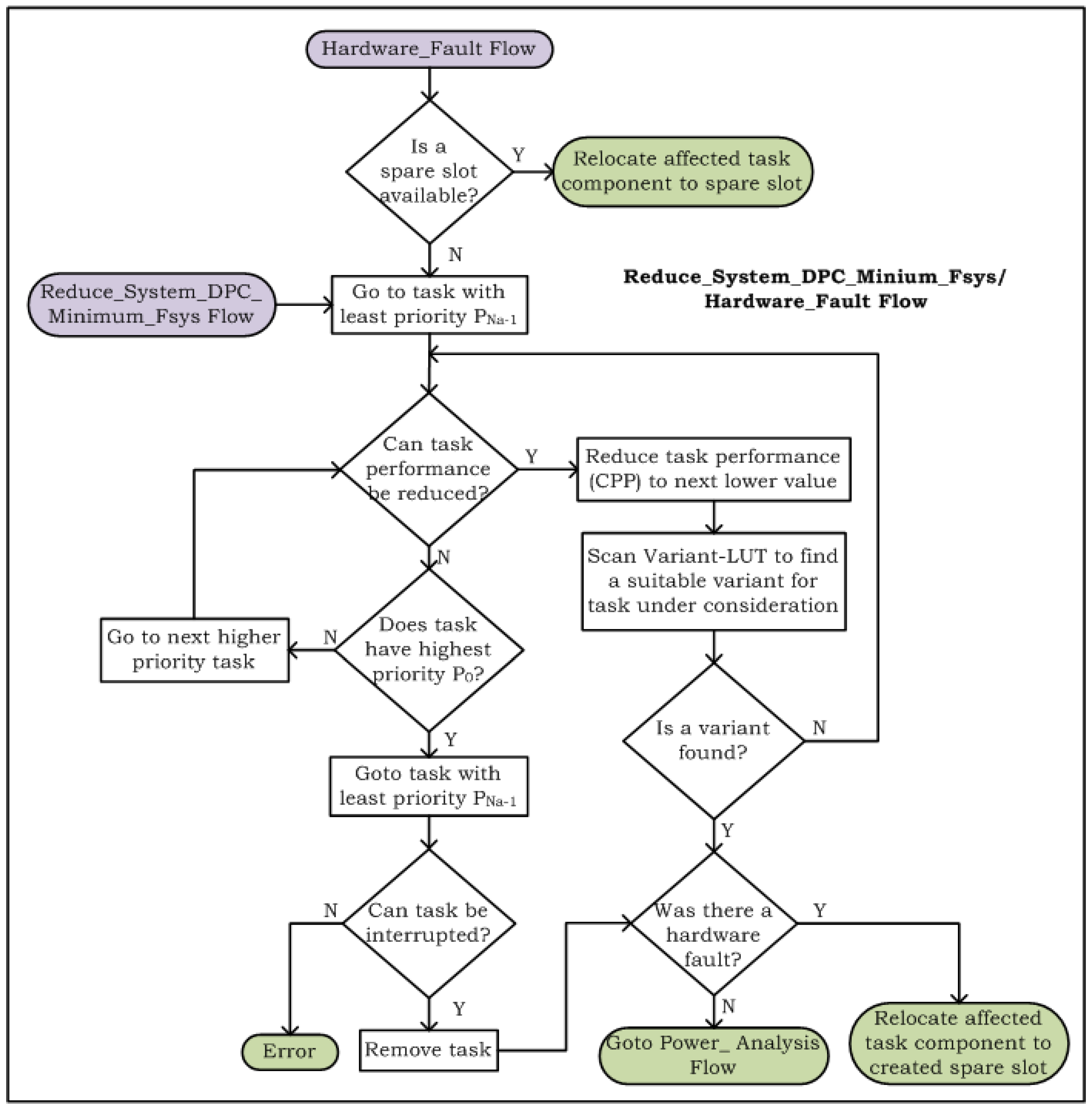
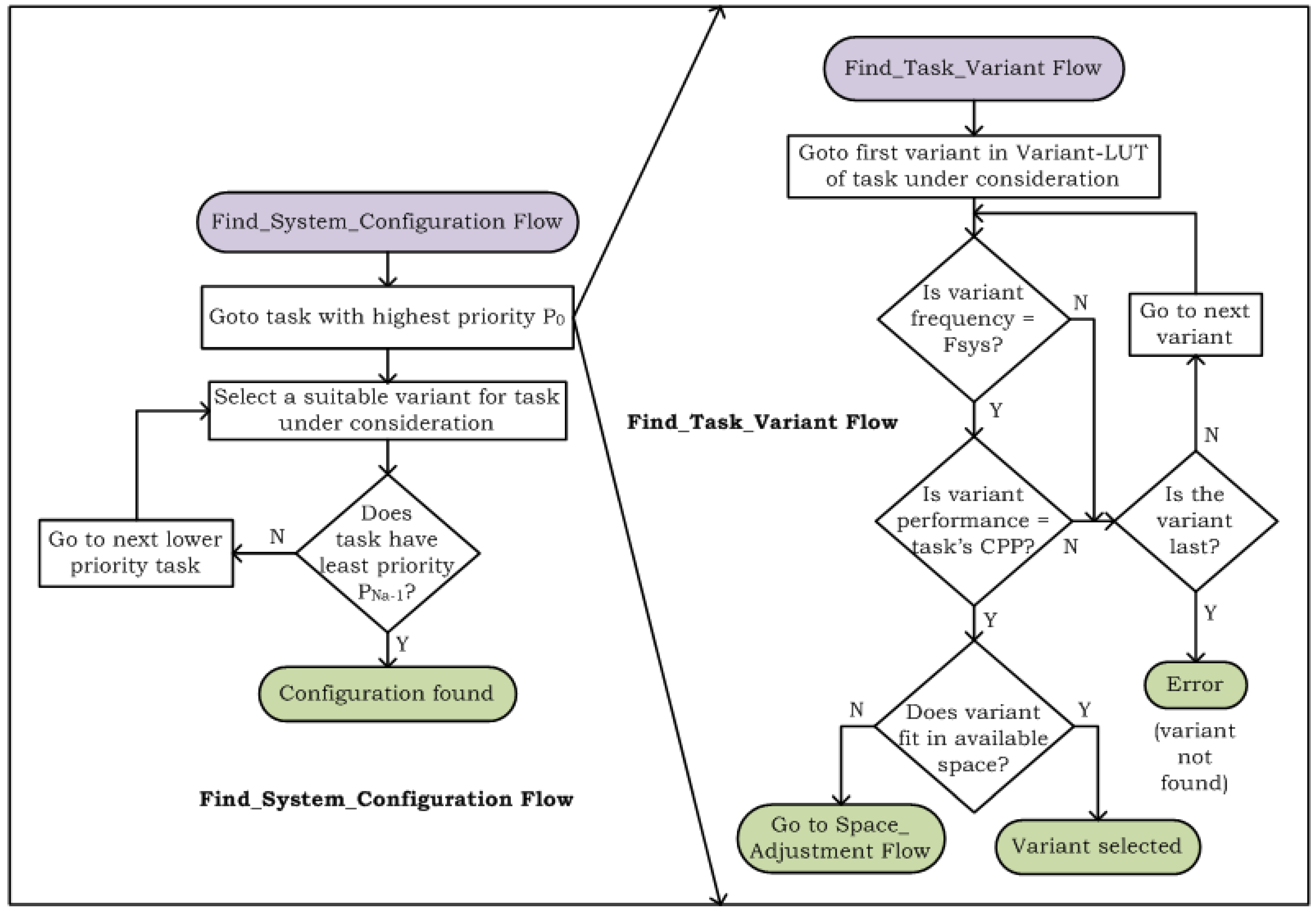
4.2. Decision-Making Run-Time Structural Adaptation Method
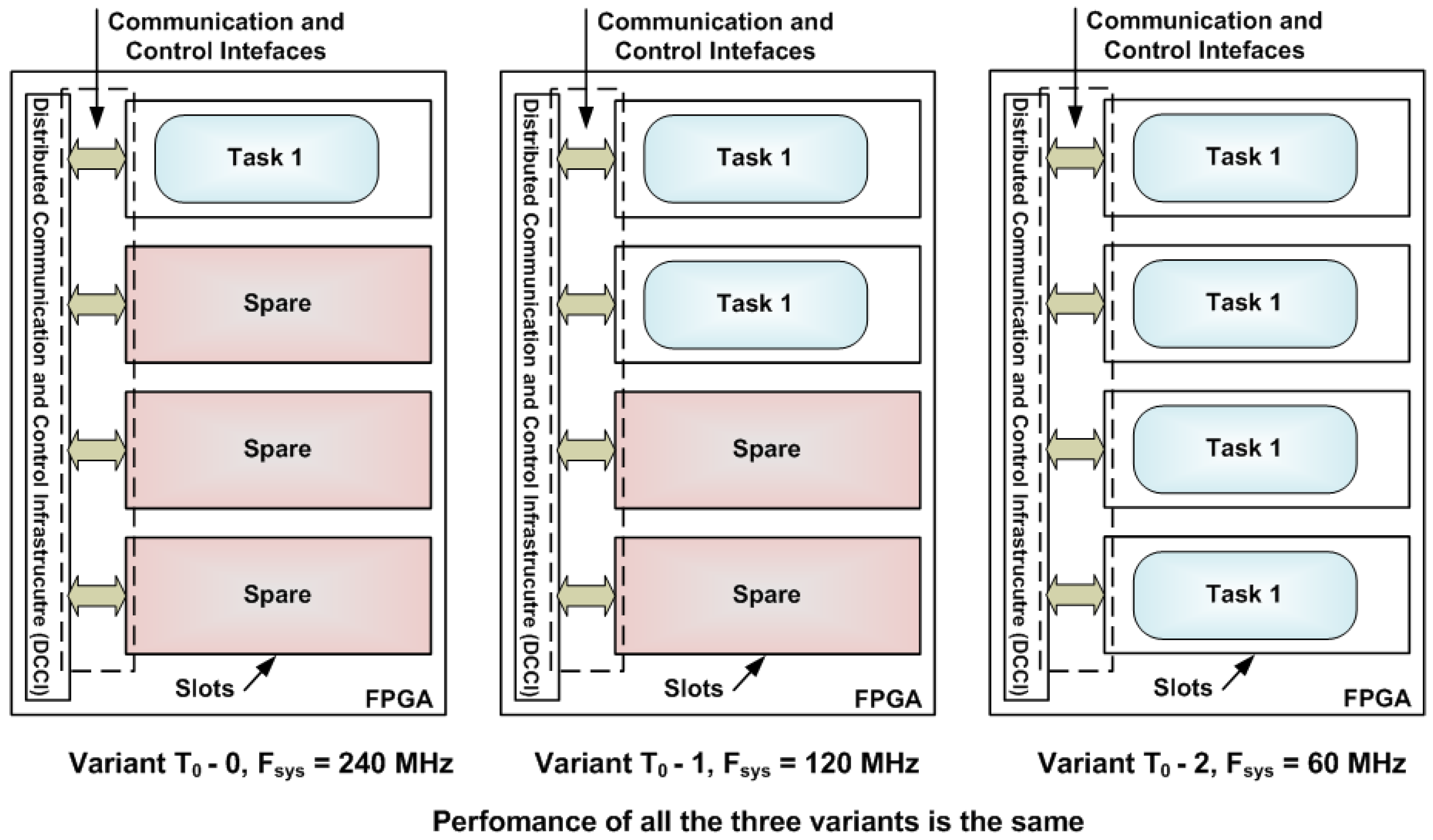
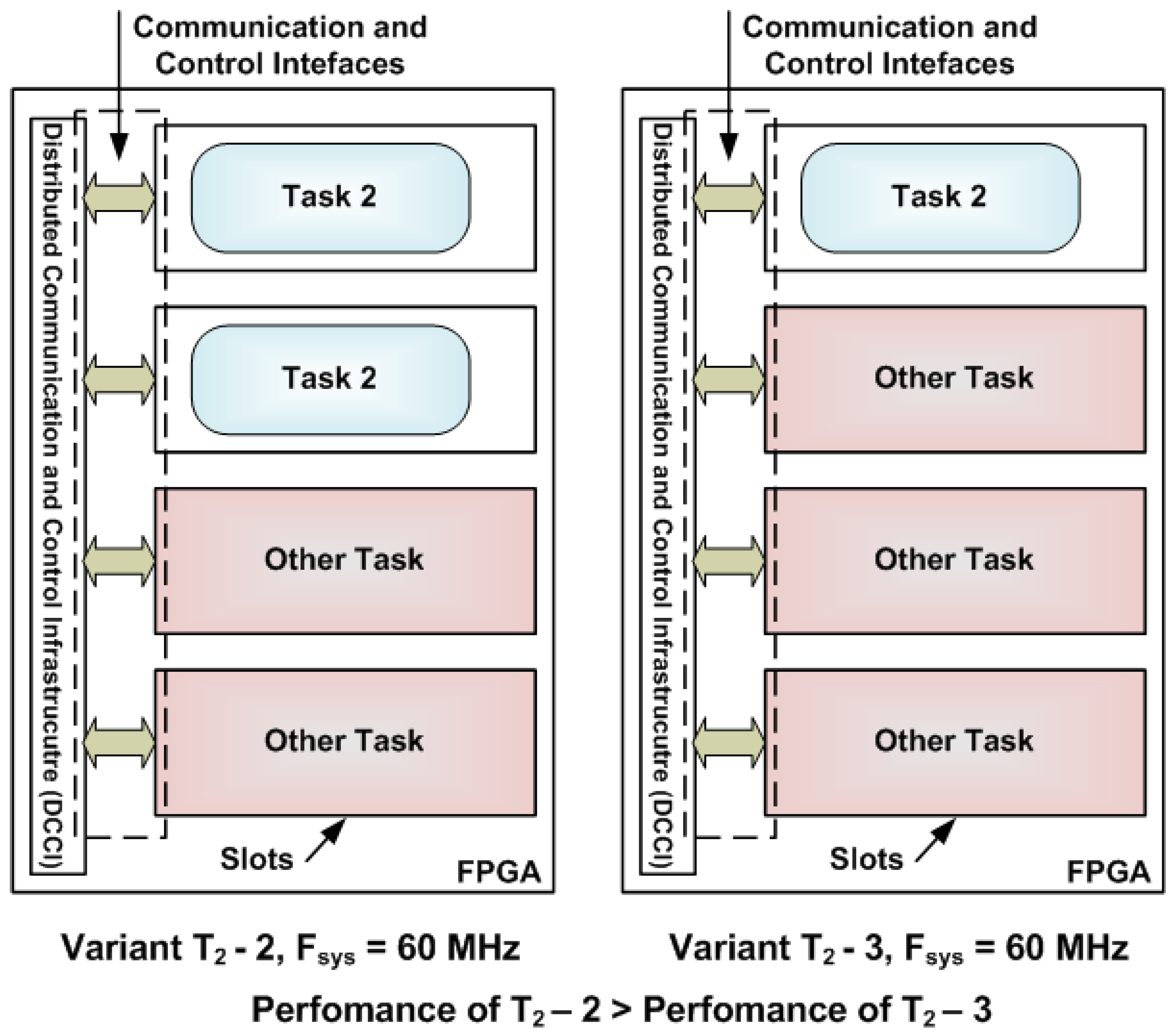
4.3. Analyzing Cost of Run-Time Structural Adaptation
5. Method for Derivation of DPC Estimation Model
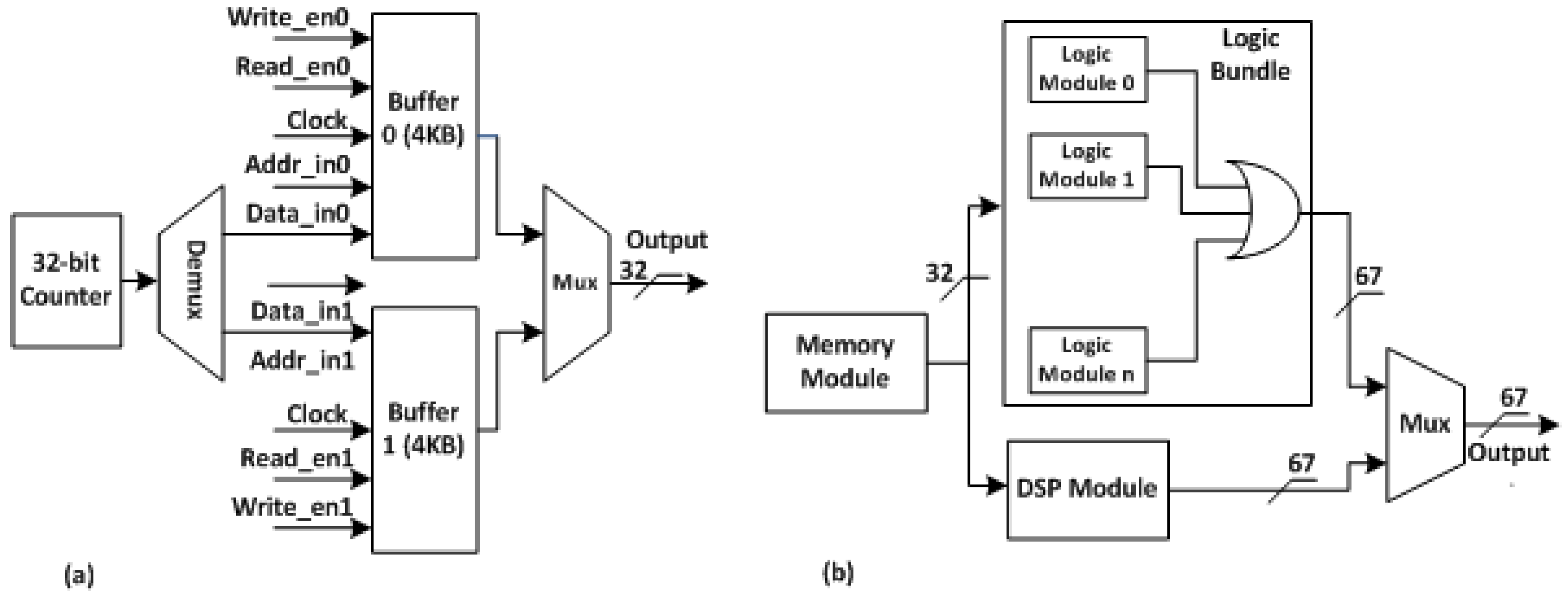
5.1. Experimental Setup for DPCEM Derivation
5.2. Setup for DPCEM Derivation for Real Applications
5.3. Power Consumption Measurement Methods
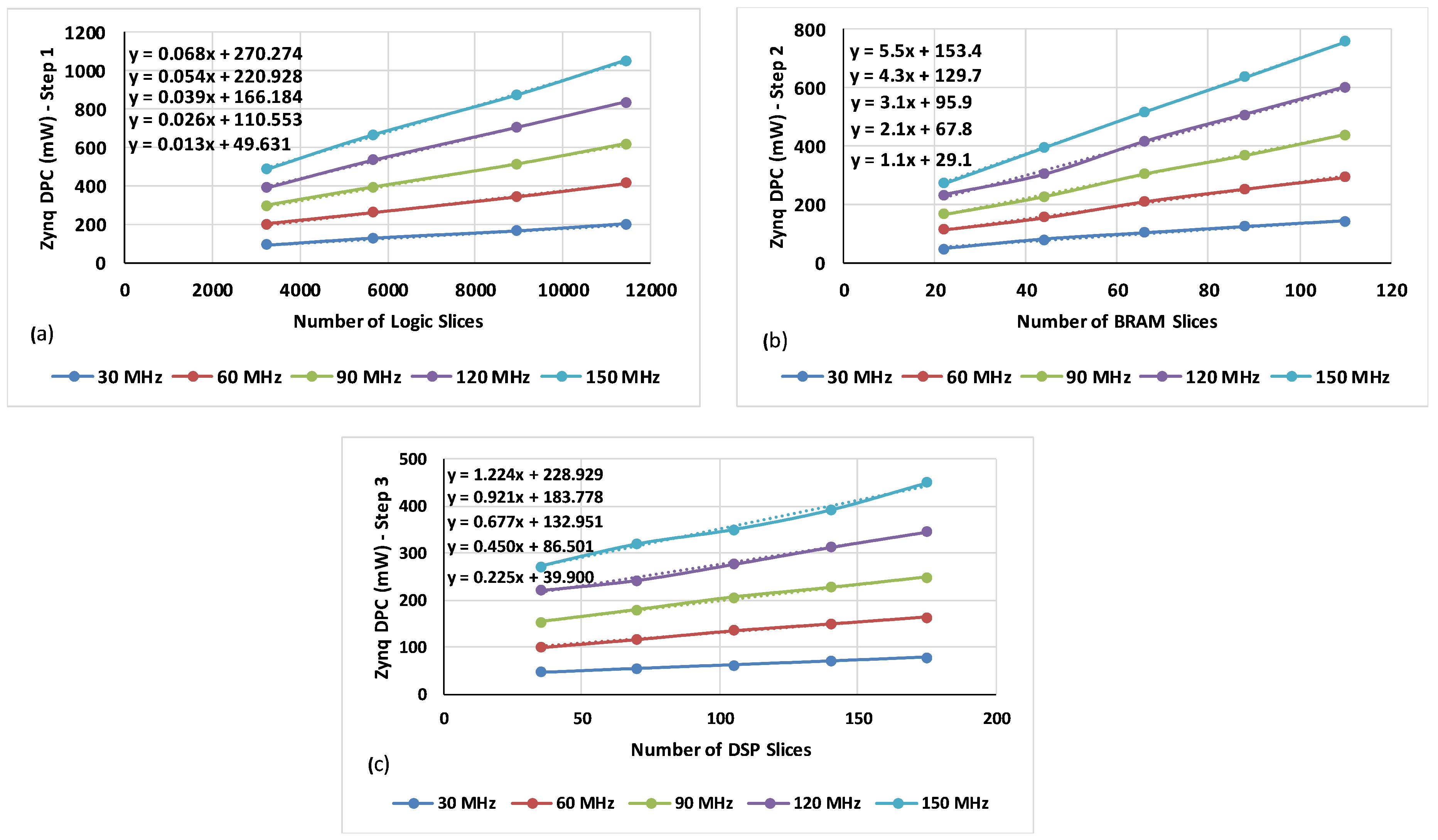
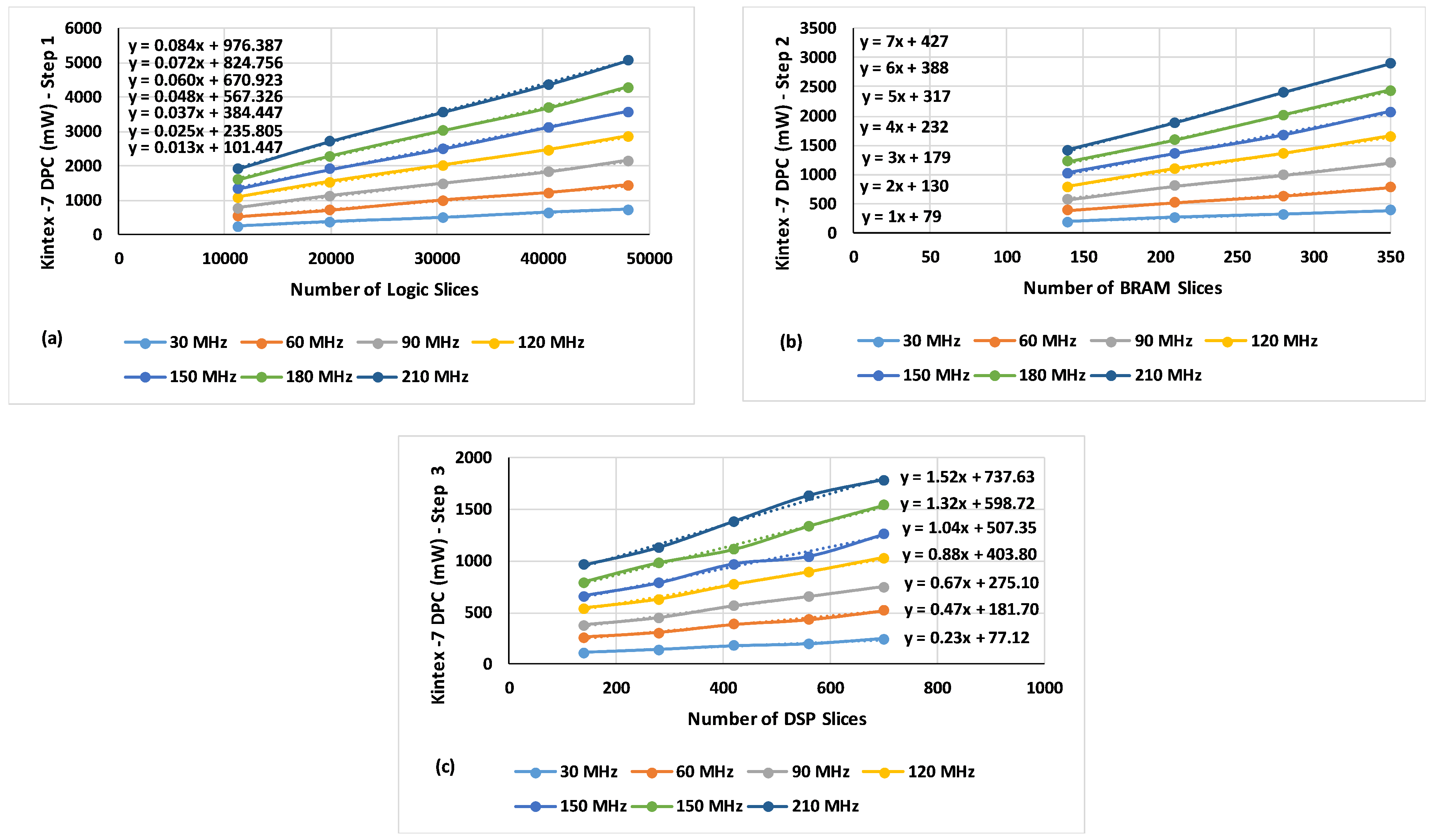
5.4. DPCEM Derivation Process
6. DPCEM Usage during Run-Time Structural Adaptation
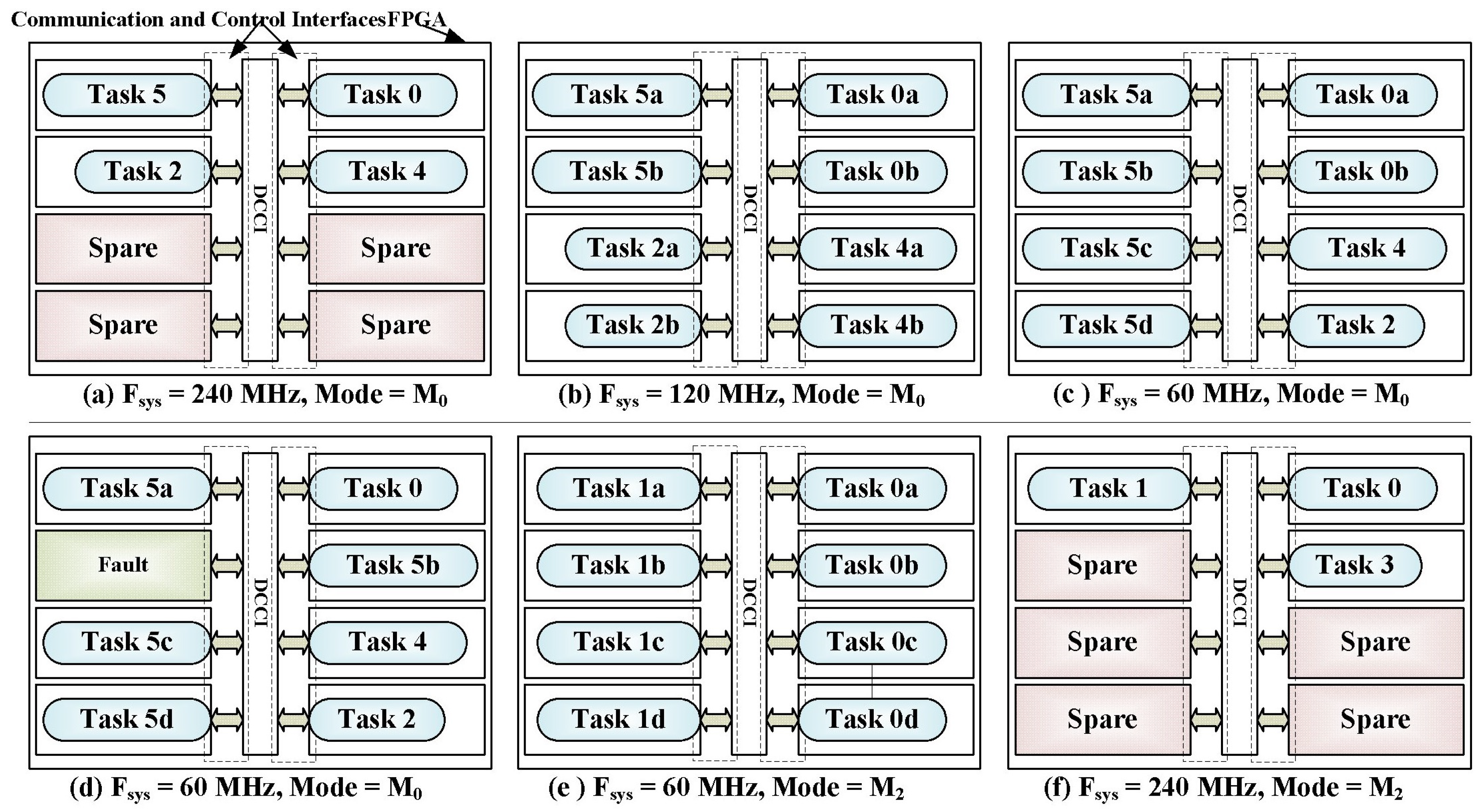
7. Example of Run-Time Adaptation in Different Scenarios
8. Experimental Results
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variant No. | No. of Slots | Perfor-Mance | Logic Slices | BRAM Slices | DSP Slices | |
|---|---|---|---|---|---|---|
| 1 | 240 | 8 | 3093 | 43 | 30 | |
| 2 | 120 | 8 | 6062 | 86 | 60 | |
| 1 | 120 | 4 | 3093 | 43 | 30 | |
| 4 | 60 | 8 | 11,877 | 172 | 120 | |
| 2 | 60 | 4 | 6062 | 86 | 60 | |
| 1 | 60 | 2 | 3093 | 43 | 30 | |
| 8 | 30 | 8 | 23,259 | 344 | 240 | |
| 4 | 30 | 4 | 11,877 | 172 | 120 | |
| 2 | 30 | 2 | 6062 | 86 | 60 | |
| 1 | 30 | 1 | 3093 | 43 | 30 | |
| 1 | 240 | 8 | 2061 | 22 | 82 | |
| 2 | 120 | 8 | 4040 | 44 | 164 | |
| 1 | 120 | 4 | 2061 | 22 | 82 | |
| 4 | 60 | 8 | 7914 | 88 | 328 | |
| 2 | 60 | 4 | 4040 | 44 | 164 | |
| 1 | 60 | 2 | 2061 | 22 | 82 | |
| 8 | 30 | 8 | 15,499 | 176 | 656 | |
| 4 | 30 | 4 | 7914 | 88 | 328 | |
| 2 | 30 | 2 | 4040 | 44 | 164 | |
| 1 | 30 | 1 | 2061 | 22 | 82 | |
| 1 | 240 | 8 | 5003 | 27 | 24 | |
| 2 | 120 | 8 | 9806 | 54 | 48 | |
| 1 | 120 | 4 | 5003 | 27 | 24 | |
| 4 | 60 | 8 | 19,212 | 108 | 96 | |
| 2 | 60 | 4 | 9806 | 54 | 48 | |
| 1 | 60 | 2 | 5003 | 27 | 24 | |
| 8 | 30 | 8 | 37,623 | 216 | 192 | |
| 4 | 30 | 4 | 19,212 | 108 | 96 | |
| 2 | 30 | 2 | 9806 | 54 | 48 | |
| 1 | 30 | 1 | 5003 | 27 | 24 | |
| 1 | 240 | 8 | 4009 | 16 | 46 | |
| 2 | 120 | 8 | 7858 | 32 | 92 | |
| 1 | 120 | 4 | 4009 | 16 | 46 | |
| 4 | 60 | 8 | 15,395 | 64 | 184 | |
| 2 | 60 | 4 | 7858 | 32 | 92 | |
| 1 | 60 | 2 | 4009 | 16 | 46 | |
| 8 | 30 | 8 | 30,148 | 128 | 368 | |
| 4 | 30 | 4 | 15,395 | 64 | 184 | |
| 2 | 30 | 2 | 7858 | 32 | 92 | |
| 1 | 30 | 1 | 4009 | 16 | 46 | |
| 1 | 240 | 8 | 5088 | 39 | 51 | |
| 2 | 120 | 8 | 9972 | 78 | 102 | |
| 1 | 120 | 4 | 5088 | 39 | 51 | |
| 4 | 60 | 8 | 19,538 | 156 | 204 | |
| 2 | 60 | 4 | 9972 | 78 | 102 | |
| 1 | 60 | 2 | 5088 | 39 | 51 | |
| 8 | 30 | 8 | 38,262 | 312 | 408 | |
| 4 | 30 | 4 | 19,538 | 156 | 204 | |
| 2 | 30 | 2 | 9972 | 78 | 102 | |
| 1 | 30 | 1 | 5088 | 39 | 51 | |
| 1 | 240 | 8 | 2567 | 33 | 73 | |
| 2 | 120 | 8 | 5031 | 66 | 146 | |
| 1 | 120 | 4 | 2567 | 33 | 73 | |
| 4 | 60 | 8 | 9857 | 132 | 292 | |
| 2 | 60 | 4 | 5031 | 66 | 146 | |
| 1 | 60 | 2 | 2567 | 33 | 73 | |
| 8 | 30 | 8 | 19,304 | 264 | 584 | |
| 4 | 30 | 4 | 9857 | 132 | 292 | |
| 2 | 30 | 2 | 5031 | 66 | 146 | |
| 1 | 30 | 1 | 2567 | 33 | 73 |
References
- Kirischian, L. Reconfigurable Computing Systems Engineering: Virtualization of Computing Architecture; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Architecture Brief—What Is an SOC FPGA? Available online: https://www.altera.com/en_US/pdfs/literature/ab/ab1_soc_fpga.pdf (accessed on 1 July 2018).
- Xilinx Explains Thinking Behind Zynq. Available online: https://www.electronicsweekly.com/news/products/fpga-news/xilinx-explains-thinking-behind-zynq-2011-11/ (accessed on 1 July 2018).
- MCUs or SoC FPGAs? Which Is the Best Solution for Your Application? Available online: https://www.digikey.ca/en/articles/techzone/2015/nov/mcus-or-soc-fpgas-which-is-the-best-solution-for-your-application (accessed on 1 July 2018).
- Dumitriu, V.; Kirischian, L.; Kirischian, V. Mitigation of variations in environmental conditions by SoPC architecture adaptation. In Proceedings of the 2015 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Montreal, QC, Canada, 15–18 June 2015; pp. 1–8. [Google Scholar]
- Dumitriu, V.; Kirischian, L. SoPC Self-Integration Mechanism for Seamless Architecture Adaptation to Stream Workload Variations. IEEE Trans. Very Large Scale Integr. Syst. 2016, 24, 799–802. [Google Scholar] [CrossRef]
- Dumitriu, V.; Kirischian, L.; Kirischian, V. Run-Time Recovery Mechanism for Transient and Permanent Hardware Faults Based on Distributed, Self-Organized Dynamic Partially Reconfigurable Systems. IEEE Trans. Comput. 2016, 65, 2835–2847. [Google Scholar] [CrossRef]
- Dumitriu, V.; Kirischian, L.; Kirischian, V. Decentralized run-time recovery mechanism for transient and permanent hardware faults for space-borne FPGA-based computing systems. In Proceedings of the 2014 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Leicester, UK, 14–17 July 2014; pp. 47–54. [Google Scholar] [CrossRef]
- Wigley, G.B.; Kearney, D.A. Research Issues in Operating Systems for Reconfigurable Computing. In Proceedings of the International Conference on Engineering of Reconfigurable System and Algorithms(ERSA), Las Vegas, NV, USA, 24–27 June 2002; pp. 10–16. [Google Scholar]
- Eckert, M.; Meyer, D.; Haase, J.; Klauer, B. Operating System Concepts for Reconfigurable Computing. Int. J. Reconfig. Comput. 2016, 2016, 2478907. [Google Scholar] [CrossRef]
- Santambrogio, M.D.; Rana, V.; Sciuto, D. Operating system support for online partial dynamic reconfiguration management. In Proceedings of the 2008 International Conference on Field Programmable Logic and Applications, Heidelberg, Germany, 8–10 September 2008; pp. 455–458. [Google Scholar]
- Jozwik, K.; Tomiyama, H.; Edahiro, M.; Honda, S.; Takada, H. Rainbow: An OS Extension for Hardware Multitasking on Dynamically Partially Reconfigurable FPGAs. In Proceedings of the 2011 International Conference on Reconfigurable Computing and FPGAs, Cancun, Mexico, 30 November–2 December 2011; pp. 416–421. [Google Scholar] [CrossRef]
- Steiger, C.; Walder, H.; Platzner, M. Operating systems for reconfigurable embedded platforms: Online scheduling of real-time tasks. IEEE Trans. Comput. 2004, 53, 1393–1407. [Google Scholar] [CrossRef]
- Clemente, J.A.; Beretta, I.; Rana, V.; Atienza, D.; Sciuto, D. A Mapping-Scheduling Algorithm for Hardware Acceleration on Reconfigurable Platforms. ACM Trans. Reconfig. Technol. Syst. 2014, 7, 9:1–9:27. [Google Scholar] [CrossRef]
- Iturbe, X.; Benkrid, K.; Erdogan, A.T.; Arslan, T.; Azkarate, M.; Martinez, I.; Perez, A. R3TOS: A reliable reconfigurable real-time operating system. In Proceedings of the 2010 NASA/ESA Conference on Adaptive Hardware and Systems, Anaheim, CA, USA, 15–18 June 2010; pp. 99–104. [Google Scholar]
- Iturbe, X.; Benkrid, K.; Hong, C.; Ebrahim, A.; Torrego, R.; Martinez, I.; Arslan, T.; Perez, J. R3TOS: A Novel Reliable Reconfigurable Real-Time Operating System for Highly Adaptive, Efficient, and Dependable Computing on FPGAs. IEEE Trans. Comput. 2013, 62, 1542–1556. [Google Scholar] [CrossRef]
- Iturbe, X.; Benkrid, K.; Hong, C.; Ebrahim, A.; Torrego, R.; Arslan, T. Microkernel Architecture and Hardware Abstraction Layer of a Reliable Reconfigurable Real-Time Operating System (R3TOS). ACM Trans. Reconfig. Technol. Syst. 2015, 8, 5:1–5:35. [Google Scholar] [CrossRef]
- So, H.K.H.; Brodersen, R. A Unified Hardware/Software Runtime Environment for FPGA-based Reconfigurable Computers Using BORPH. ACM Trans. Embed. Comput. Syst. 2008, 7, 14:1–14:28. [Google Scholar] [CrossRef] [Green Version]
- Göhringer, D.; Hübner, M.; Zeutebouo, E.N.; Becker, J. CAP-OS: Operating system for runtime scheduling, task mapping and resource management on reconfigurable multiprocessor architectures. In Proceedings of the 2010 IEEE International Symposium on Parallel Distributed Processing, Workshops and Phd Forum (IPDPSW), Atlanta, GA, USA, 19–23 April 2010; pp. 1–8. [Google Scholar]
- Agne, A.; Happe, M.; Keller, A.; Lübbers, E.; Plattner, B.; Platzner, M.; Plessl, C. ReconOS: An Operating System Approach for Reconfigurable Computing. IEEE Micro 2014, 34, 60–71. [Google Scholar] [CrossRef] [Green Version]
- Pellizzoni, R.; Caccamo, M. Real-Time Management of Hardware and Software Tasks for FPGA-based Embedded Systems. IEEE Trans. Comput. 2007, 56, 1666–1680. [Google Scholar] [CrossRef]
- Hsiung, P.A.; Huang, C.H.; Shen, J.S.; Chiang, C.C. Scheduling and Placement of Hardware/Software Real-Time Relocatable Tasks in Dynamically Partially Reconfigurable Systems. ACM Trans. Reconfig. Technol. Syst. 2010, 4, 9:1–9:32. [Google Scholar] [CrossRef]
- Tabkhi, H.; Schirner, G. Application-Guided Power Gating Reducing Register File Static Power. IEEE Trans. Very Large Scale Integr. Syst. 2014, 22, 2513–2526. [Google Scholar] [CrossRef]
- Hosseinabady, M.; Nunez-Yanez, J.L. Run-time power gating in hybrid ARM-FPGA devices. In Proceedings of the 2014 24th International Conference on Field Programmable Logic and Applications (FPL), Munich, Germany, 2–4 September 2014; pp. 1–6. [Google Scholar]
- You, D.; Chung, K.S. Quality of Service-Aware Dynamic Voltage and Frequency Scaling for Embedded GPUs. IEEE Comput. Arch. Lett. 2015, 14, 66–69. [Google Scholar] [CrossRef]
- Khan, M.U.K.; Shafique, M.; Henkel, J. Power-Efficient Workload Balancing for Video Applications. IEEE Trans. Very Large Scale Integr. Syst. 2016, 24, 2089–2102. [Google Scholar] [CrossRef]
- Kornaros, G.; Pnevmatikatos, D. Dynamic Power and Thermal Management of NoC-Based Heterogeneous MPSoCs. ACM Trans. Reconfig. Technol. Syst. 2014, 7, 1:1–1:26. [Google Scholar] [CrossRef]
- Carlo, S.D.; Gambardella, G.; Prinetto, P.; Rolfo, D.; Trotta, P. SATTA: A Self-Adaptive Temperature-Based TDF Awareness Methodology for Dynamically Reconfigurable FPGAs. ACM Trans. Reconfig. Technol. Syst. 2015, 8, 1:1–1:22. [Google Scholar] [CrossRef]
- Lu, Y.H.; Benini, L.; Micheli, G.D. Low-power task scheduling for multiple devices. In Proceedings of the Eighth International Workshop on Hardware/Software Codesign, CODES 2000 (IEEE Cat. No.00TH8518), San Diego, CA, USA, 5 May 2000; pp. 39–43. [Google Scholar] [Green Version]
- Yang, P.; Marchal, P.; Wong, C.; Himpe, S.; Catthoor, F.; David, P.; Vounckx, J.; Lauwereins, R. Managing dynamic concurrent tasks in embedded real-time multimedia systems. In Proceedings of the 2002 15th International Symposium on System Synthesis, Kyoto, Japan, 2–4 October 2002; pp. 112–119. [Google Scholar]
- Qiu, M.; Chen, Z.; Yang, L.T.; Qin, X.; Wang, B. Towards Power-Efficient Smartphones by Energy-Aware Dynamic Task Scheduling. In Proceedings of the 2012 IEEE 14th International Conference on High Performance Computing and Communication & 2012 IEEE 9th International Conference on Embedded Software and Systems, Liverpool, UK, 25–27 June 2012; pp. 1466–1472. [Google Scholar]
- Ganeshpure, K.; Kundu, S. Performance-driven Dynamic Thermal Management of MPSoC Based on Task Rescheduling. ACM Trans. Des. Autom. Electron. Syst. 2014, 19, 11:1–11:33. [Google Scholar] [CrossRef]
- Ost, L.; Mandelli, M.; Almeida, G.M.; Moller, L.; Indrusiak, L.S.; Sassatelli, G.; Benoit, P.; Glesner, M.; Robert, M.; Moraes, F. Power-aware Dynamic Mapping Heuristics for NoC-based MPSoCs Using a Unified Model-based Approach. ACM Trans. Embed. Comput. Syst. 2013, 12, 75:1–75:22. [Google Scholar] [CrossRef]
- Rodríguez, A.; Valverde, J.; Castañares, C.; Portilla, J.; de la Torre, E.; Riesgo, T. Execution modeling in self-aware FPGA-based architectures for efficient resource management. In Proceedings of the 2015 10th International Symposium on Reconfigurable Communication-Centric Systems-on-Chip (ReCoSoC), Bremen, Germany, 29 June–1 July 2015; pp. 1–8. [Google Scholar]
- Lin, K.W.; Chen, Y.S. Online Thermal-aware Task Placement in Three-dimensional Field-programmable Gate Arrays. In Proceedings of the 2015 RACS Conference on Research in Adaptive and Convergent Systems, Prague, Czech Republic, 9–12 October 2015; ACM: New York, NY, USA, 2015; pp. 412–417. [Google Scholar]
- Iturbe, X.; Benkrid, K.; Hong, C.; Ebrahim, A.; Arslan, T.; Martinez, I. Runtime Scheduling, Allocation, and Execution of Real-Time Hardware Tasks onto Xilinx FPGAs Subject to Fault Occurrence. Int. J. Reconfig. Comput. 2013, 2013. [Google Scholar] [CrossRef]
- Biedermann, A.; Huss, S.A.; Israr, A. Safe Dynamic Reshaping of Reconfigurable MPSoC Embedded Systems for Self-Healing and Self-Adaption Purposes. ACM Trans. Reconfig. Technol. Syst. 2015, 8, 26:1–26:22. [Google Scholar] [CrossRef]
- Xilinx. XAPP1088: Correcting Single Event Upsets in Virtex-4 FPGA Configuration Memory, v1.0. 2009. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.169.426&rep=rep1&type=pdf (accessed on 1 July 2018).
- Bolchini, C.; Miele, A.; Sandionigi, C. A Novel Design Methodology for Implementing Reliability-Aware Systems on SRAM-Based FPGAs. IEEE Trans. Comput. 2011, 60, 1744–1758. [Google Scholar] [CrossRef]
- Salvador, R.; Otero, A.; Mora, J.; de la Torre, E.; Sekanina, L.; Riesgo, T. Fault Tolerance Analysis and Self-Healing Strategy of Autonomous, Evolvable Hardware Systems. In Proceedings of the 2011 International Conference on Reconfigurable Computing and FPGAs, Cancun, Mexico, 30 November–2 December 2011; pp. 164–169. [Google Scholar] [CrossRef]
- Abramovici, M.; Breuer, M.A.; Friedman, A.D. Index. In Digital Systems Testing and Testable Design; Computer Science Press: New York, NY, USA, 1990; pp. 647–652. [Google Scholar]
- Zhang, H.; Bauer, L.; Kochte, M.A.; Schneider, E.; Braun, C.; Imhof, M.E.; Wunderlich, H.J.; Henkel, J. Module diversification: Fault tolerance and aging mitigation for runtime reconfigurable architectures. In Proceedings of the 2013 IEEE International Test Conference (ITC), Anaheim, CA, USA, 6–13 September 2013; pp. 1–10. [Google Scholar] [CrossRef]
- Vallero, A.; Carelli, A.; Carlo, S.D. Trading-off reliability and performance in FPGA-based reconfigurable heterogeneous systems. In Proceedings of the 2018 13th International Conference on Design Technology of Integrated Systems in Nanoscale Era (DTIS), Taormina, Italy, 9–12 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Carlo, S.D.; Gambardella, G.; Prinetto, P.; Rolfo, D.; Trotta, P.; Vallero, A. A novel methodology to increase fault tolerance in autonomous FPGA-based systems. In Proceedings of the 2014 IEEE 20th International On-Line Testing Symposium (IOLTS), Girona, Spain, 7–9 July 2014; pp. 87–92. [Google Scholar] [CrossRef]
- Carlo, S.D.; Prinetto, P.; Scionti, A. A FPGA-Based Reconfigurable Software Architecture for Highly Dependable Systems. In Proceedings of the 2009 Asian Test Symposium, Taichung, Taiwan, 23–26 November 2009; pp. 125–130. [Google Scholar] [CrossRef]
- Carlo, S.D.; Miele, A.; Prinetto, P.; Trapanese, A. Microprocessor fault-tolerance via on-the-fly partial reconfiguration. In Proceedings of the 2010 15th IEEE European Test Symposium, Praha, Czech, 24–28 May 2010; pp. 201–206. [Google Scholar] [CrossRef]
- De Sensi, D.; Torquati, M.; Danelutto, M. A Reconfiguration Algorithm for Power-Aware Parallel Applications. ACM Trans. Archit. Code Optim. 2016, 13, 43:1–43:25. [Google Scholar] [CrossRef]
- Sousa, E.; Hannig, F.; Teich, J.; Chen, Q.; Schlichtmann, U. Runtime Adaptation of Application Execution Under Thermal and Power Constraints in Massively Parallel Processor Arrays. In Proceedings of the SCOPES ’15 18th International Workshop on Software and Compilers for Embedded Systems, St. Goar, Germany, 1–3 June 2015; ACM: New York, NY, USA, 2015; pp. 121–124. [Google Scholar] [CrossRef]
- Loukil, K.; Amor, N.B.; Abid, M. Self adaptive reconfigurable system based on middleware cross layer adaptation model. In Proceedings of the 2009 6th International Multi-Conference on Systems, Signals and Devices, Djerba, Tunisia, 23–26 March 2009; pp. 1–9. [Google Scholar] [CrossRef]
- Wassi, G.; Benkhelifa, M.E.A.; Lawday, G.; Verdier, F.; Garcia, S. Multi-shape tasks scheduling for online multitasking on FPGAs. In Proceedings of the 2014 9th International Symposium on Reconfigurable and Communication-Centric Systems-on-Chip (ReCoSoC), Montpellier, France, 26–28 May 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Ullmann, M.; Jin, W.; Becker, J. Hardware Enhanced Function Allocation Management in Reconfigurable Systems. In Proceedings of the 19th IEEE International Parallel and Distributed Processing Symposium, Denver, CO, USA, 4–8 April 2005; p. 156a. [Google Scholar] [CrossRef]
- Gueye, S.M.K.; Rutten, E.; Diguet, J.P. Autonomic management of missions and reconfigurations in FPGA-based embedded system. In Proceedings of the 2017 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Pasadena, CA, USA, 24–27 July 2017; pp. 48–55. [Google Scholar] [CrossRef]
- Vipin, K.; Fahmy, S.A. Mapping adaptive hardware systems with partial reconfiguration using CoPR for Zynq. In Proceedings of the 2015 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Montreal, QC, Canada, 15–18 June 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Sharma, D.; Kirischian, L.; Kirischian, V. Run-time adaptation method for mitigation of hardware faults and power budget variations in space-borne FPGA-based systems. In Proceedings of the 2017 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Pasadena, CA, USA, 24–27 July 2017; pp. 32–39. [Google Scholar] [CrossRef]
- Rihani, M.A.; Nouvel, F.; Prévotet, J.C.; Mroue, M.; Lorandel, J.; Mohanna, Y. Dynamic and partial reconfiguration power consumption runtime measurements analysis for ZYNQ SoC devices. In Proceedings of the 2016 International Symposium on Wireless Communication Systems (ISWCS), Poznan, Poland, 20–23 September 2016; pp. 592–596. [Google Scholar] [CrossRef]
- Xilinx. Power vs. Performance: The 90 nm Inflection Point, v1.2. 2006. Available online: https://www.xilinx.com/support/documentation/white_papers/wp223.pdf (accessed on 1 July 2018).
- Shang, L.; Kaviani, A.S.; Bathala, K. Dynamic Power Consumption in Virtex™-II FPGA Family. In Proceedings of the FPGA ’02 2002 ACM/SIGDA Tenth International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 24–26 February 2002; ACM: New York, NY, USA, 2002; pp. 157–164. [Google Scholar] [CrossRef]
- Xilinx. ZedBoard Hardware Users Guide, v2.2. 2014. Available online: http://zedboard.org/sites/default/files/documentations/ZedBoard_HW_UG_v2_2.pdf (accessed on 1 July 2018).
- Xilinx. Zynq-7000 All Programmable SoC Overview, v1.10. 2016. Available online: https://cdn.hackaday.io/files/19354828041536/ds190-Zynq-7000-Overview.pdf (accessed on 1 July 2018).
- Xilinx. KC705 Evaluation Board for the Kintex-7 FPGA, v1.7. 2016. Available online: https://www.xilinx.com/support/documentation/boards_and_kits/kc705/ug810_KC705_Eval_Bd.pdf (accessed on 1 July 2018).
- Xilinx. 7 Series FPGAs Data Sheet: Overview, v2.5. 2017. Available online: https://www.xilinx.com/support/documentation/data_sheets/ds180_7Series_Overview.pdf (accessed on 1 July 2018).
- Xilinx. Vivado Design Suite User Guide—Partial Reconfiguration, v206.1. 2016. Available online: https://www.xilinx.com/support/documentation/sw_manuals/xilinx2015_4/ug909-vivado-partial-reconfiguration.pdf (accessed on 1 July 2018).
- Intel. Intel Quartus Prime Pro Edition Handbook Volume 1. 2017. Available online: https://people.ece.cornell.edu/land/courses/ece5760/DE1_SOC/qts-qpp-handbook.pdf (accessed on 1 July 2018).
- Meintanis, D.; Papaefstathiou, I. Power Consumption Estimations vs Measurements for FPGA-Based Security Cores. In Proceedings of the 2008 International Conference on Reconfigurable Computing and FPGAs, Cancun, Mexico, 3–5 December 2008; pp. 433–437. [Google Scholar] [CrossRef]
- Becker, J.; Huebner, M.; Ullmann, M. Power estimation and power measurement of Xilinx Virtex FPGAs: Trade-offs and limitations. In Proceedings of the 16th Symposium on Integrated Circuits and Systems Design, SBCCI 2003, Sao Paulo, Brazil, 8–11 September 2003; pp. 283–288. [Google Scholar] [CrossRef]
- Oliver, J.P.; Acle, J.P.; Boemo, E. Power estimations vs. power measurements in Spartan-6 devices. In Proceedings of the 2014 IX Southern Conference on Programmable Logic (SPL), Buenos Aires, Argentina, 5–7 November 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Sharma, D.; Dimitriu, V.; Kirischian, L. Architecture Reconfiguration as a Mechanism for Sustainable Performance of Embedded Systems in case of Variations in Available Power. In Applied Reconfigurable Computing(ARC 2017); Springer: Cham, Germany, 2017. [Google Scholar]












| Mode | # of Tasks () | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 8 | 8 | 8 | 2 | 8 | 2 | 8 | 2 | ||
| 1 | 0 | 0 | 0 | ||||||
| 8 | 8 | 8 | 2 | 8 | 2 | ||||
| 1 | 0 | 0 | |||||||
| 8 | 8 | 8 | 8 | 8 | 2 | ||||
| 1 | 1 | 0 | |||||||
| Variant No. | No. of Slots | ( | Performance | Logic Slices | BRAM Slices | DSP Slices |
|---|---|---|---|---|---|---|
| 1 | 240 | 8 | 3093 | 43 | 30 | |
| 2 | 120 | 8 | 6062 | 86 | 60 | |
| 4 | 60 | 8 | 11,877 | 172 | 120 | |
| 2 | 60 | 4 | 6062 | 86 | 60 | |
| 1 | 60 | 2 | 3093 | 43 | 30 | |
| 1 | 240 | 8 | 2061 | 22 | 82 | |
| 2 | 120 | 8 | 4040 | 44 | 164 | |
| 4 | 60 | 8 | 7914 | 88 | 328 | |
| 1 | 240 | 8 | 5003 | 27 | 24 | |
| 2 | 120 | 8 | 9806 | 54 | 48 | |
| 2 | 60 | 4 | 9806 | 54 | 48 | |
| 1 | 60 | 2 | 5003 | 27 | 24 | |
| 1 | 240 | 8 | 4009 | 16 | 46 | |
| 2 | 120 | 8 | 7858 | 32 | 92 | |
| 1 | 240 | 8 | 5088 | 39 | 51 | |
| 2 | 120 | 8 | 9972 | 78 | 102 | |
| 1 | 60 | 2 | 5088 | 39 | 51 | |
| 1 | 240 | 8 | 2567 | 33 | 73 | |
| 2 | 120 | 8 | 5031 | 66 | 146 | |
| 4 | 60 | 8 | 9857 | 132 | 292 |
| Step 1 | Step 2 | Step 3 | ||||
|---|---|---|---|---|---|---|
| Coefficient | Constant | Coefficient | Constant | Coefficient | Constant | |
| 1 | 0.013 | 49.631 | 1.1 | 29.1 | 0.225 | 39.9 |
| 2 | 0.026 | 110.553 | 2.1 | 67.8 | 0.45 | 86.501 |
| 3 | 0.039 | 166.184 | 3.1 | 95.9 | 0.677 | 132.951 |
| 4 | 0.054 | 220.928 | 4.3 | 129.7 | 0.921 | 183.778 |
| 5 | 0.068 | 270.274 | 5.5 | 153.4 | 1.224 | 228.929 |
| Approximation | ||||||
| Time Elapsed (hours) | System Mode | (%) | Current Lifetime (hours) | Needed Lifetime | Candi-Date | New Lifetime | ||
|---|---|---|---|---|---|---|---|---|
| 0 | 100.00 | 9.00 | 5.33 | 3.63 | 3.195 | 9.81 | ||
| 1 | 89.80 | 8.79 | 9.00 | 4.79 | 3.09 | 3.048 | 9.08 | |
| 1 | 79.91 | 8.05 | 9.00 | 4.26 | 2.56 | 1.440 | 12.22 | |
| 3.5 | 57.02 | 8.67 | 8.00 | 3.42 | 1.72 | 1.251 | 9.27 | |
| 0.5 | 53.94 | 8.72 | 5.00 | 5.18 | 3.48 | 2.039 | 6.93 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, D.; Kirischian, L.; Kirischian, V. Run-Time Mitigation of Power Budget Variations and Hardware Faults by Structural Adaptation of FPGA-Based Multi-Modal SoPC. Computers 2018, 7, 52. https://doi.org/10.3390/computers7040052
Sharma D, Kirischian L, Kirischian V. Run-Time Mitigation of Power Budget Variations and Hardware Faults by Structural Adaptation of FPGA-Based Multi-Modal SoPC. Computers. 2018; 7(4):52. https://doi.org/10.3390/computers7040052
Chicago/Turabian StyleSharma, Dimple, Lev Kirischian, and Valeri Kirischian. 2018. "Run-Time Mitigation of Power Budget Variations and Hardware Faults by Structural Adaptation of FPGA-Based Multi-Modal SoPC" Computers 7, no. 4: 52. https://doi.org/10.3390/computers7040052
APA StyleSharma, D., Kirischian, L., & Kirischian, V. (2018). Run-Time Mitigation of Power Budget Variations and Hardware Faults by Structural Adaptation of FPGA-Based Multi-Modal SoPC. Computers, 7(4), 52. https://doi.org/10.3390/computers7040052