Expressing the Tacit Knowledge of a Digital Library System as Linked Data


Abstract
1. Introduction
[…] capture the context of data […] high quality of Linked Data is obtained since capturing organizational knowledge about the meaning of the data within the Resource Description Framework (RDF) [7] data model means the data is more likely to be reused correctly. Well defined context ensures better understanding, proper reuse, and is critical when establishing linkages to other data sets.
2. Problem Statement and Contributions
3. The Semantic Data Management
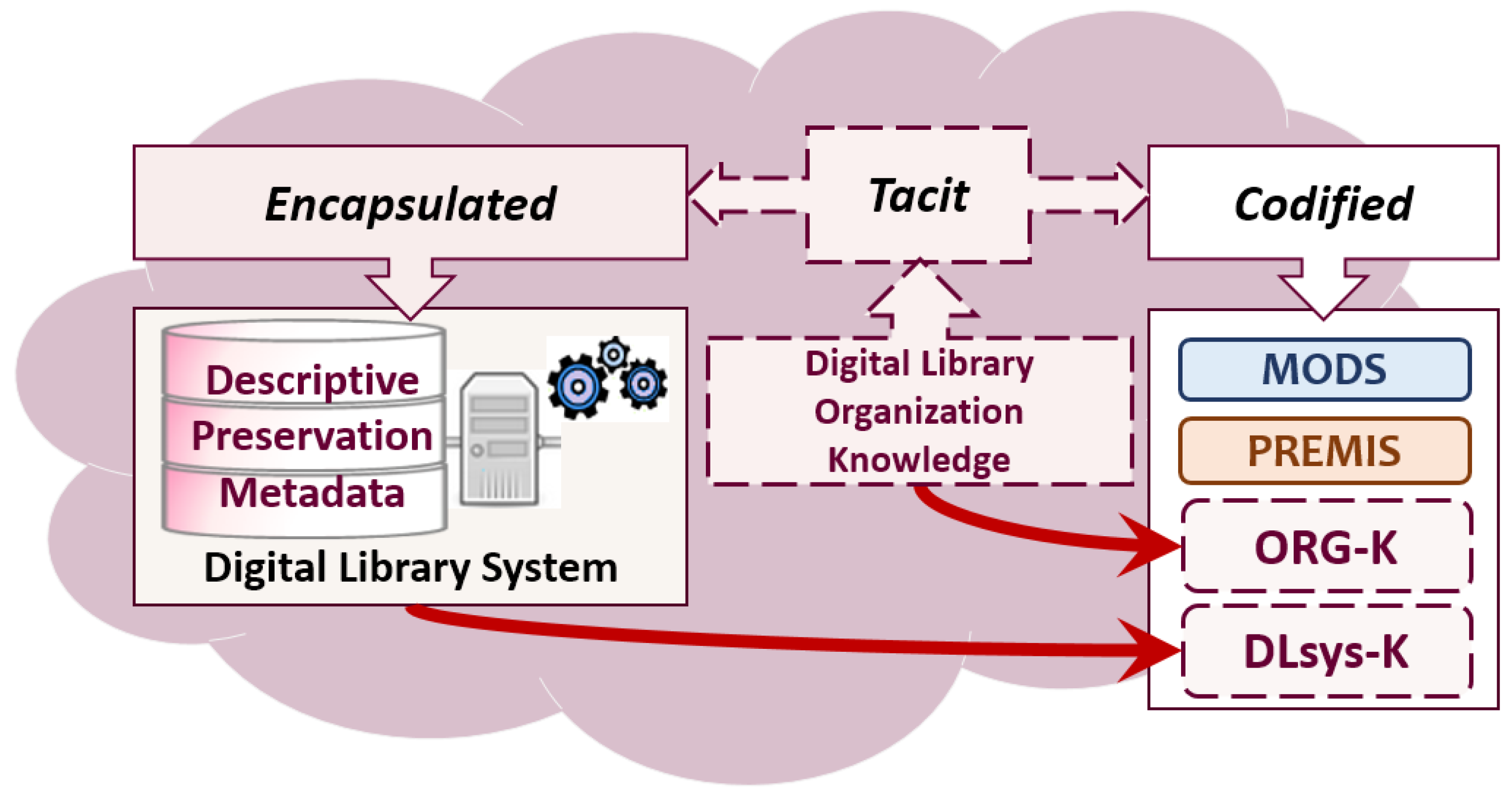
4. Focus on the Tacit Knowledge
- “Codified” knowledge is highly refined, and formalized, to the point in which it can be written down, lowering the risk information losses [22].SemWeb ontology supplies a way of formalizing knowledge “stocks”, and extends the re-use possibilities, not only to humans, but also to machines.
- “Encapsulated” knowledge is usually not completely codified, and it is object-embedded, since the knowledge necessary to the object design and development remains partially hidden from its users [23].Software artifacts and databases well represent this kind of knowledge. As we have already pointed out, many knowledge is given, missing, mis-documented or not easily understandable, due to the fast increase of systems’ complexity and the fast pace of InfSys evolution. This speed entails to neglect the slow and expensive task of documenting such kind of knowledge. Semantic data management practices focus on this kind of knowledge.
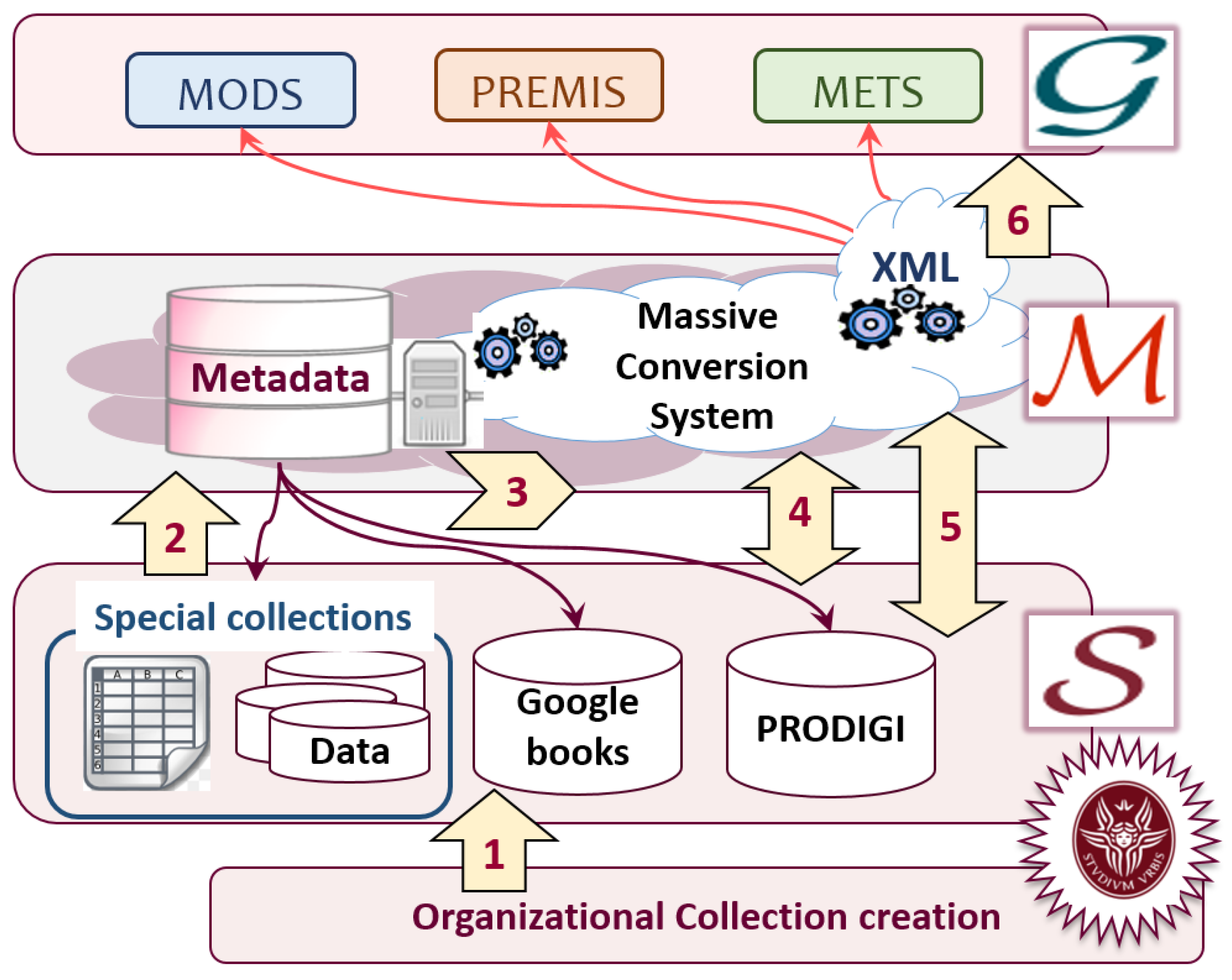
5. Digital Library System: A Case Study
- the metadata objects description schema (MODS) (metadata encoding transmission schema, www.loc.gov/standards/mods/), describes the intellectual contents represented by multimedia objects;
- the preservation metadata implementation strategies (PREMIS) [27] encompasses preservation metadata about multimedia objects;
- the metadata encoding and transmission standard (METS) (metadata encoding transmission standard, www.loc.gov/standards/mets/) comprehends the data for packaging descriptive and preservation metadata, and multimedia objects.
6. Detecting Knowledge Types in the Case Study
- “codified” knowledge: comprehends semantics already codified by MODS and PREMIS metadata standard (described in the Section 5) adopted by the system, and depicted as rounded boxes with a thick border. The rounded boxes, with a dashed border, represent knowledge to be codified from the “tacit” (ORG-K) and the “encapsulated” (DLsys-K).
- “tacit” knowledge: the capture was generically focused on the DigLib available documentation and software functions. We analyzed the knowledge elements that we used for communicating between people involved in the project, and for conceiving the system. Then we have outlined, what are the knowledge elements that are not explicitly codified in the MassConv system. We observed, that elements belonging to tacit knowledge were partially documented or considered as given in the software functions. Anyhow those elements are not codified in a SemWeb language for being used by humans and machines.
- “encapsulated” knowledge has to be extracted from the software artifacts, and used RDB.
6.1. “Codified” Knowledge Capture and Enrichment
- metadata object description ontology (MODS-O) [29] develops around the main class mods:ModsResource which represents “any library-related resource—such as a book, journal article, photograph, or born-digital image—that is described by a MODS resource description”.
- PREMIS ontology (PREMIS-OWL) [30,31,32] models the knowledge domain of digital preservation metadata, and develops around four main classes:premis:Object, premis:Event, premis:Agent and premis:Rights.
- provenance ontology (PROV-O) [33] describes the concepts related to the provenance in heterogeneous environments, and develops around three main classes: Agent, Entity, and Activity.
- organization ontology (ORG-O) [34] develops around the core class org:Organization which represents “a collection of people organized together into a community or other social, commercial or political structure”.
6.2. “Tacit” Knowledge Capture and Codification
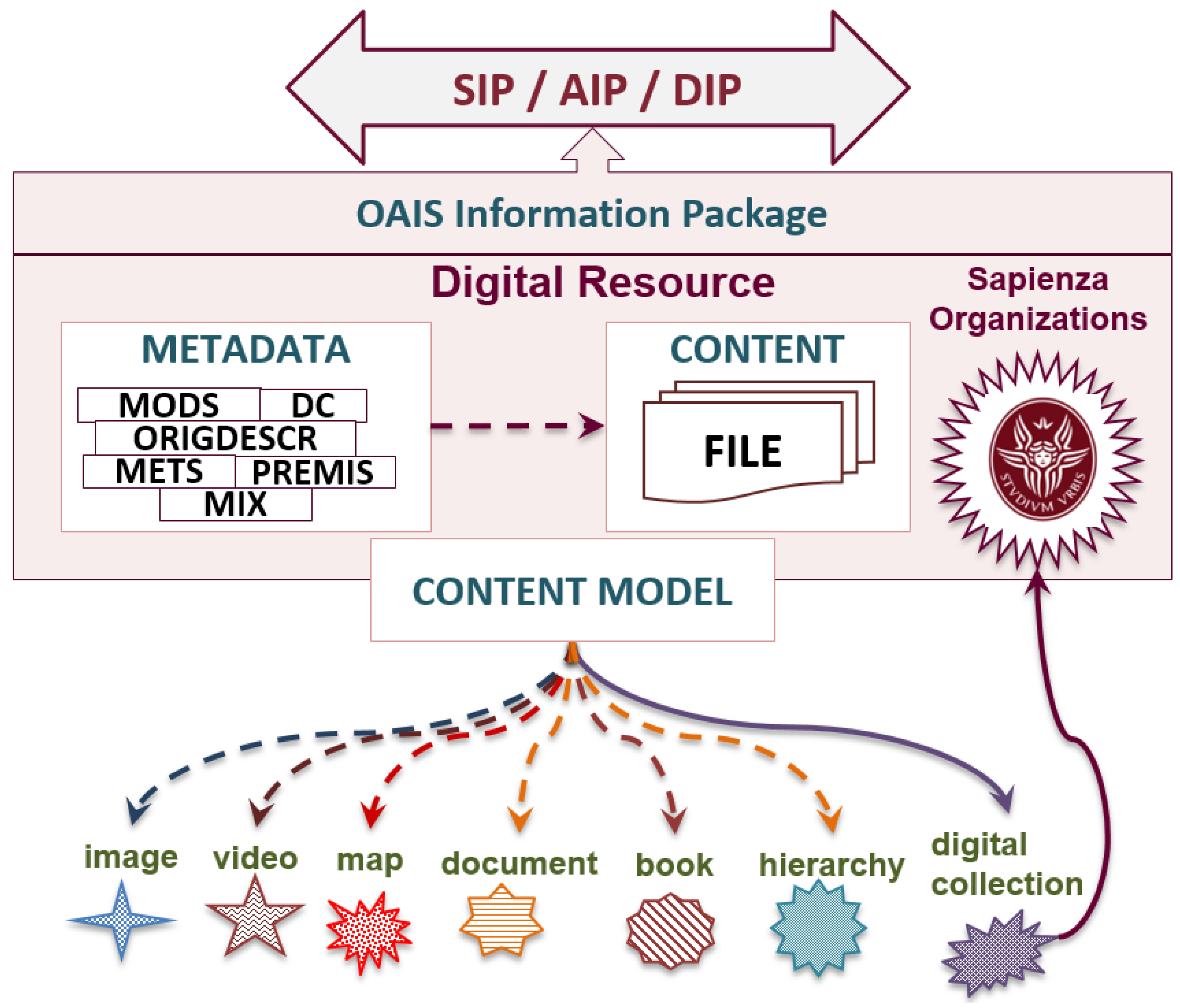
- organizational collection (OrgColl)identifies the university organization, responsible for the selection and production of digital materials, and collects related descriptive data.
- digital collection (DigColl)is a DigRes which represents a specific set of DigRess. It collects the minimal data of belonging DigRes, the self-descriptive data for being identified and retrieved by the information system, and the data about the workflow.
- digital resource (DigRes)coherent and minimal descriptive information for an intellectual entity which is uniquely identified in the local management system.
- digital metadata object (DMO)data file in text format, firstly encoded in XML (encoding=UTF-8) and using metadata semantics, based on the metadata standards, adopted by the local system.
- digital content object (DCO)file of whatever digital format, representing an intellectual content or part of it.
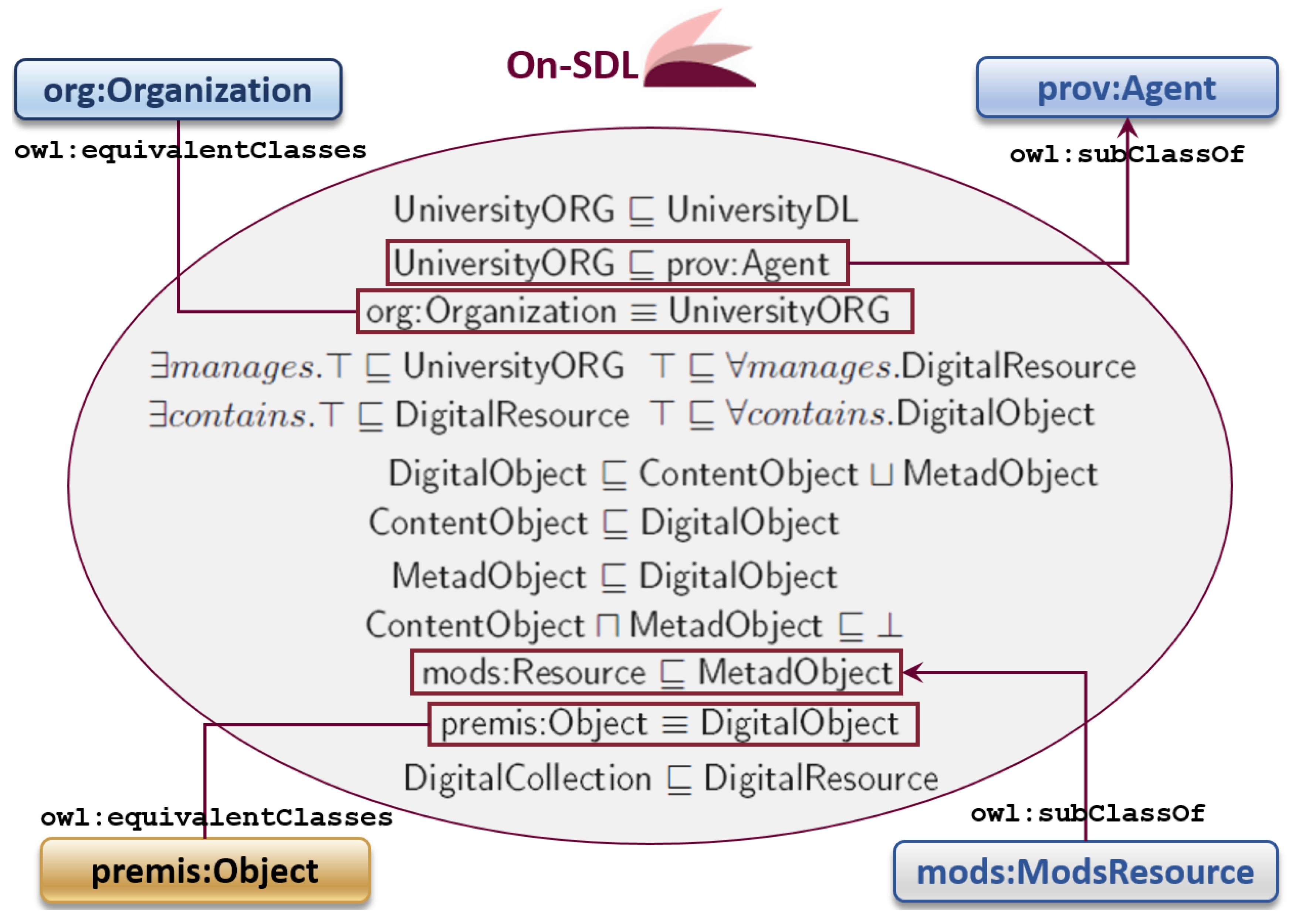
- UniversityORG ⊑ UniversityDL: ORGs belonging to Sapienza can be represented in the SDL.
- UniversityORG ⊑ prov:Agent: Sapienza ORG is a type of PROV-O agent.
- org:Organization ≡ UniversityORG: Sapienza ORG is a type of ORG.
- DigitalObject ⊑ ContentObject ⊔ MetadObject: DigObj is either a DCO or a DMO.
- ContentObject ⊑ DigitalObject: DCO is a type of DigObj.
- MetadObject ⊑ DigitalObject: DMO is a type of DigObj.
- ContentObject ⊔ MetadObject: nothing can be both DCO and DMO.
- mods:ModsResource ⊑ MetadObject: MODS resource is a type of DMO.
- premis:Object ≡ DigitalObject: PREMIS object is equivalent to DigObj.
- DigitalCollection ⊑ DigitalResource: DigColl is a type of DigRes.
- UniversityORG manages DigitalResource: ORG manages at least one individual and all those individuals are Digress.
- UniversityDL aggregates DigitalResource: DigLib aggregates at least one individual and all those individuals are DigRess.
- DigitalCollection collects DigitalResource: DigColl collects at least one individual and all those individuals are DigRess.
- DigitalResource contains DigitalObject: DigRes contains at least one individual and all those individuals are DigObjs.
6.3. “Encapsulated” Knowledge Capture and Enrichment
- organizational collection creation: Sapienza ORG is identified by an URI.
- object acquisition: from a Sapienza ORG collects and stores multimedia objects and descriptive metadata, into a working area, assigns to new DigRess a URI, extending the ORG URI, associates related descriptive data (MODS), and computes or collects (if existing) preservation data (PREMIS).
- mapping development: checks if there are new semantic entries, and in case, it learns the MassConv system with the new semantic, and a (manual) mapping development is requested.
- object accessioning: from the Acquisition working area, copies multimedia objects in the SDL repository as DCOs, by propagating and extending DigRess’ URIs to related DCOs.
- collecting preservation metadata: collects and computes metadata about DCOs, necessary to the preservation of DCOs.
- digital resource production: where required by the SDL ORG, DMOs and related DCOs are produced, according to the SDL XML metadata schemas , and conforming with DigRes content model.
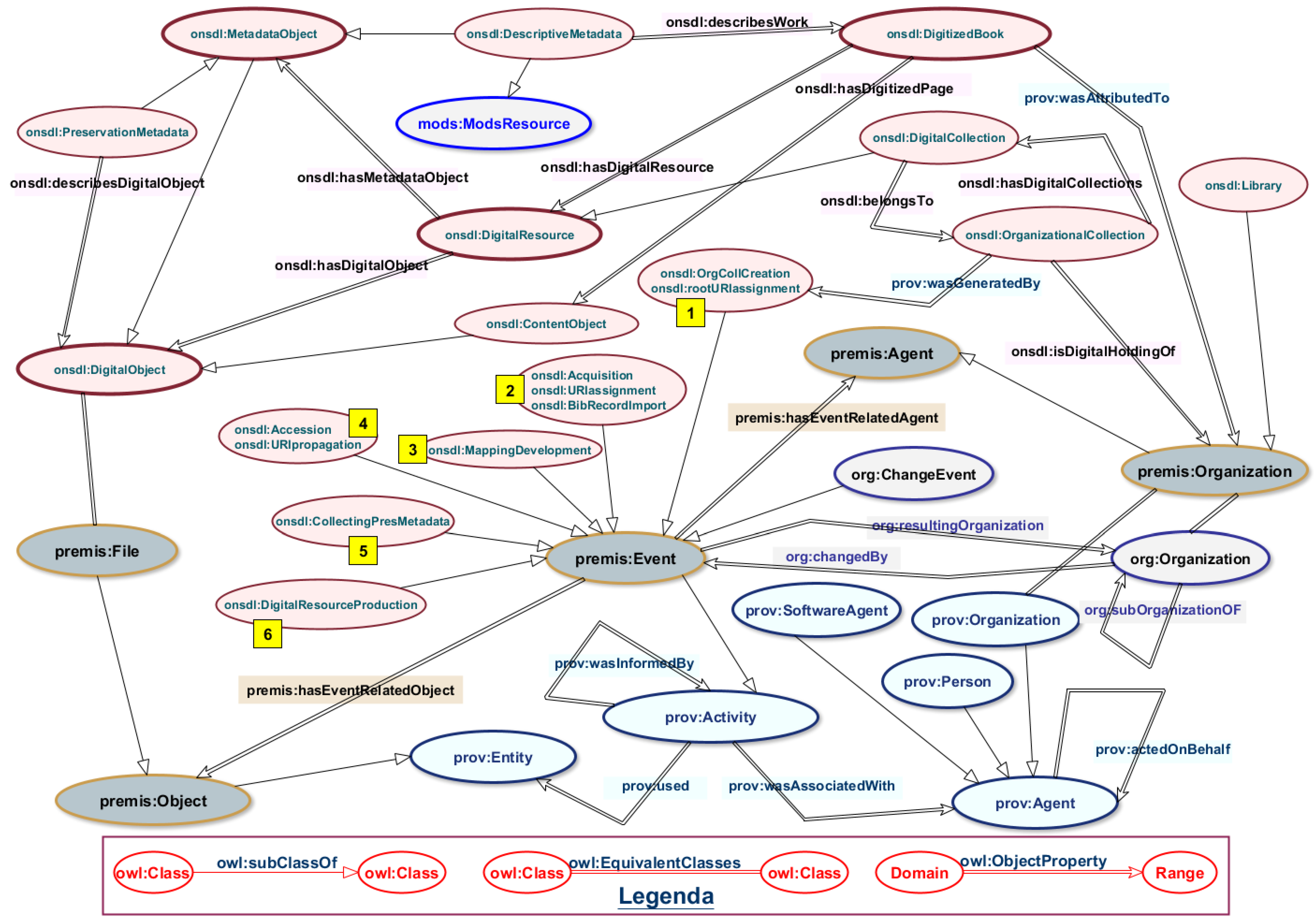
7. System Knowledge Codified as a Linked Data Vocabulary
- use URIs as names for things—“not just Web documents and digital content, but also real world objects and abstract concepts”.
- use HTTP URIs so that people can look up those names—“to identify objects and abstract concepts”.
- when someone looks up a URI, provide useful information, using the standards (RDF*, SPARQL)—“use of a single data model for publishing structured data on the web a simple graph-based data model that has been designed for use in the context of the web”.
- include links to other URIs, so that they can discover more things—“not only web documents, but any type of thing”.
8. Managing Data and Vocabularies, to Be Linked
8.1. Semantic Data Management for URIs
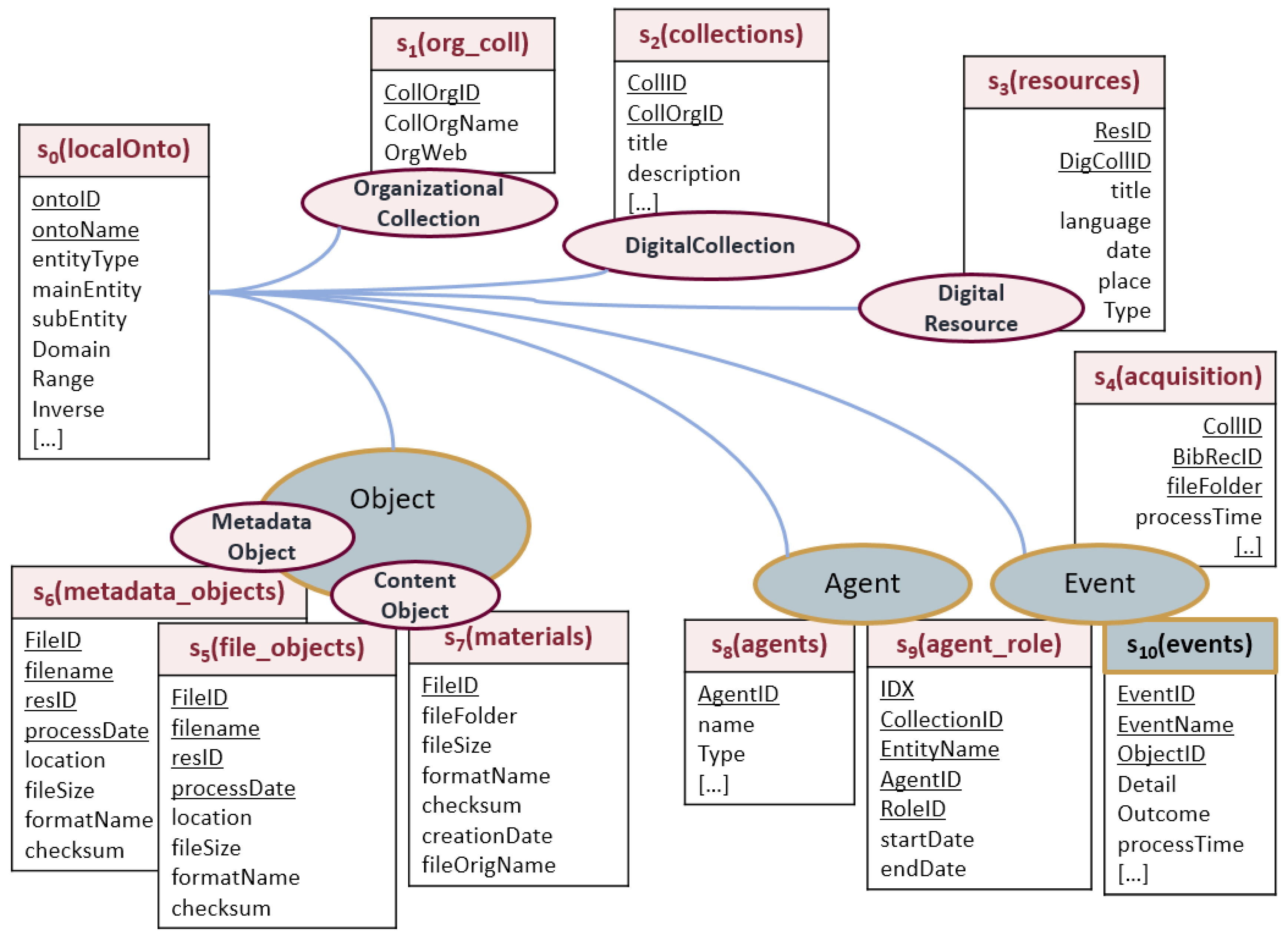
- premis:Agent ⊑ prov:AgentThe organizational perspective adopted for the data management of the MassConv has already identified all the Agents, participating to the production process of DigRess, and acted on behalf of the main Organization, the Sapienza University. According to the PREMIS-OWL ontology we collected the Agent data, distinguishing between Organization, Person, and SoftwareAgent, and identified them by adopting the same method for minting URIs.In order to make LD consumers aware about the source of data we used the global identifier, maintained by the Library of Congress (Library of Congress vocabularies, Cultural Heritage Organizations, http://id.loc.gov/vocabulary/organizations) for Cultural Heritage Organization, as the root identifier for minting local data URIs. Sapienza University is identified in the SemWeb space by the URL http://id.loc.gov/vocabulary/organizations/itrousr. In the Linked Dataset to be generated from the MassConv-RDB each resource URI is prefixed by that identifier (itrousr-), in order to allow a global recognizability of the exhibited resources. The following Turtle triples (Listing 1), expressed in Turtle syntax [43], provide an example of how Sapienza University as a cultural organization is represented as a LD resource, and how the Library is related to the Sapienza University:

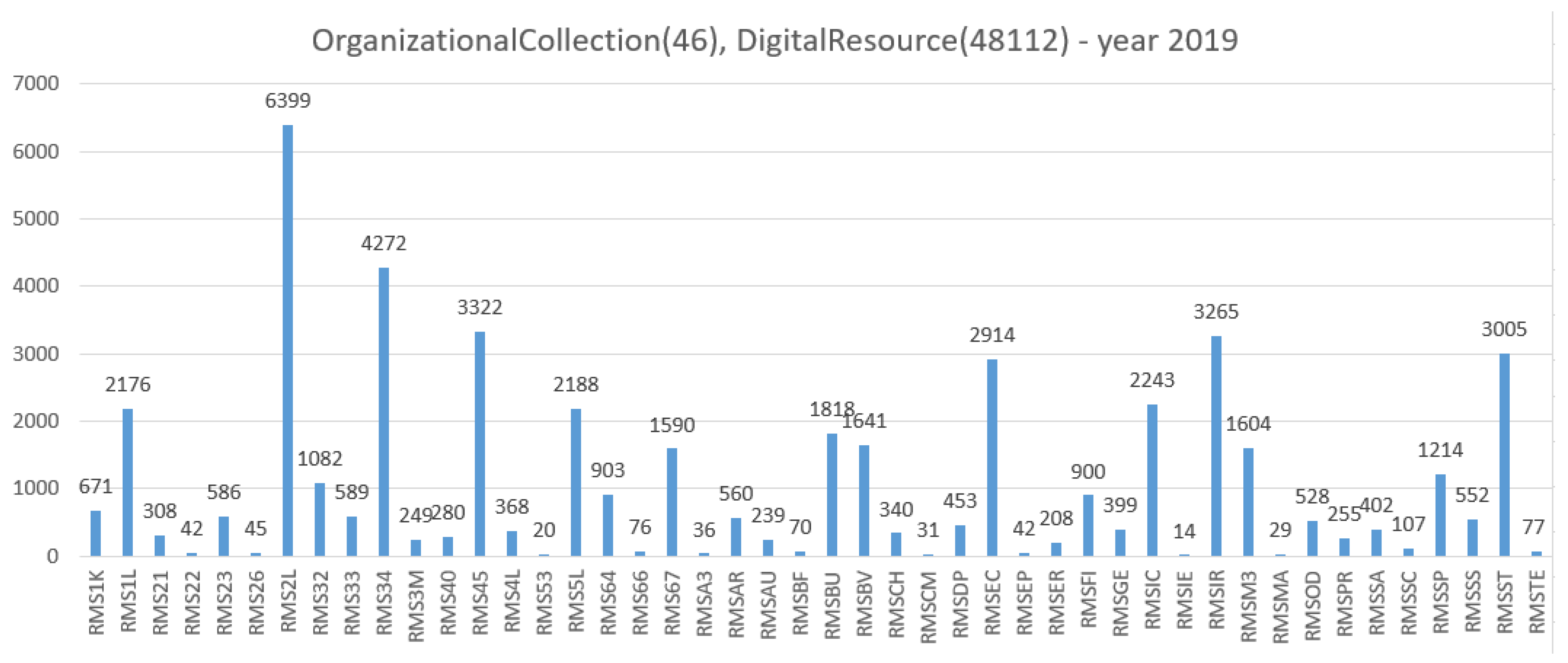
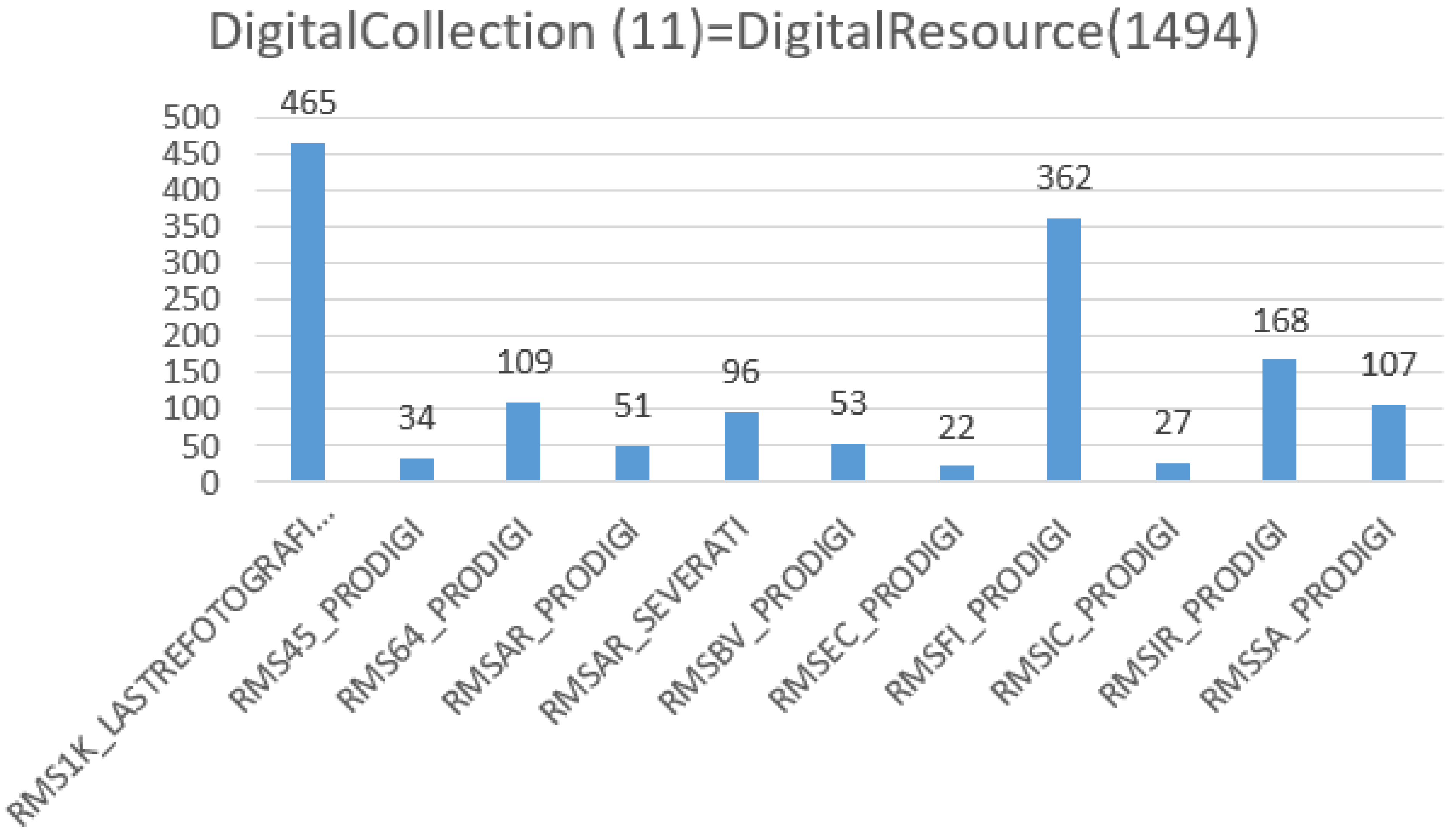
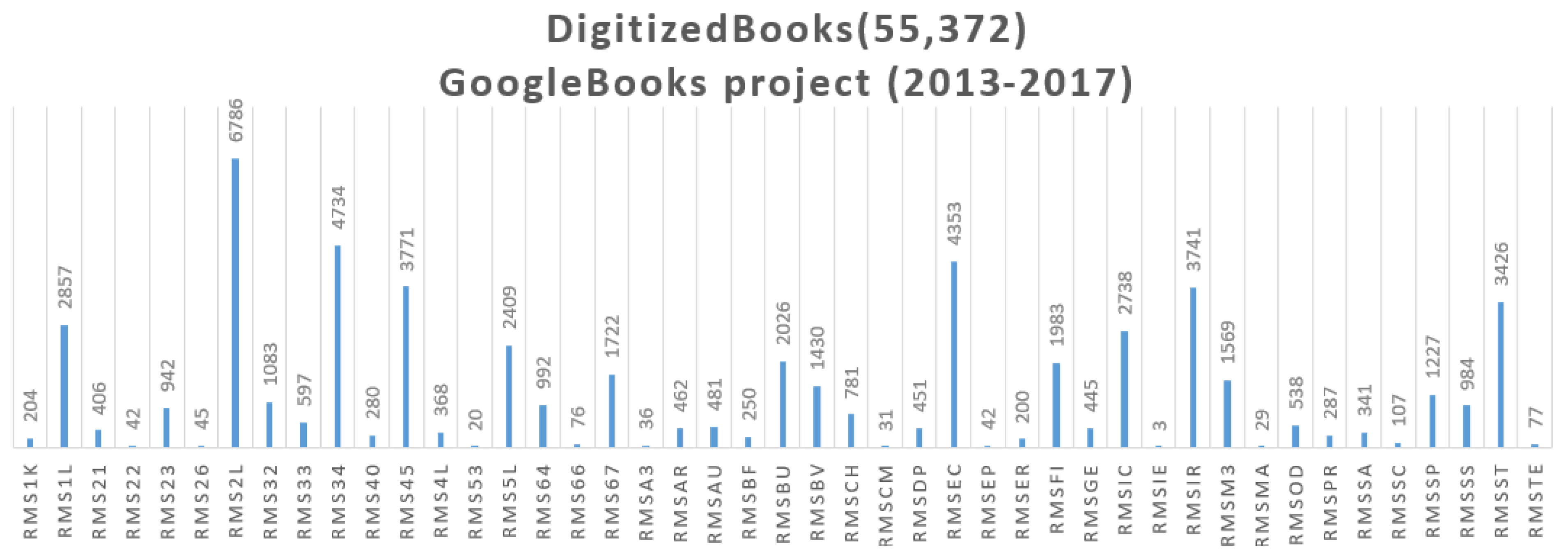
- premis:Object ⊑ prov:EntityMassConv system, as a DigLib, produces DigRess’ identifiers, based on the identifiers of the Italian National Bibliographic System (Anagrafe Biblioteche Italiane http://anagrafe.iccu.sbn.it/opencms/opencms/), that reflect the organizational structure of the Sapienza University libraries. A DigRes managed by the MassConv, is uniquely identified by the root identifier of the Sapienza’s library, as the holding organization of the physical books, that have been digitized and reproduced as DigRess. For example, the Sapienza Architecture Library is identified by “RMSAR”, the root identifier, used by the MassConv system, for identifying each DigRes to be produced, and which belongs to the identified library. (The reader can notice that the phrase segments underlined in the previous paragraph matches with some classes and properties defined by the ontology.) In 2013, the MassConv system produced 1067 MetadataObject as XML files (1057 DigitalResource and 10 DigitalCollection), that were published as Open Data since 2017 at the URL, https://sbs.uniroma1.it/sapienzadl/. For example the DigitalCollection of the Sapienza Architecture Library is retrievable at the URL https://sbs.uniroma1.it/data/opendata/itrousr-od_2017-SDL_2013_RMSAR. The XML file (a MetadataObject) of the Sapienza Architecture Library collection, the DigitalCollection identified by “RMSAR”, is at the URL https://sbs.uniroma1.it/openDataSets/sdl2013/METSXML/RMSAR/RMSAR.xml, while the MetadataObject of a belonging book (a DigitalResource) is retrievable at the URL https://sbs.uniroma1.it/openDataSets/sdl2013/METSXML/RMSAR/RMSAR_00000025.xml. According to the SemWeb vision, these objects, are informational (XML/HTML documents) resources for human consumption, while informational LD resources, are for machine [44] consumption, as well as the knowledge about “things” identified and codified in a SemWeb language (OWL).When an URI is already available for identifying OrganizationalCollection DigitalCollection, DigitalResource or DigitalObject, etc., the identifier is only prefixed by itrousr-, for distinguishing the URI of DigRess (also used for historical reasons) and the URI used for LD.Listing 2 shows prototype’s Turtle triples, that are related to the main classes of the On-SDL ontology, which defines “things” mainly managed by the DigLib system. The following Turtle triples express (1) why descriptive data are managed by the system: data describes the intellectual content of a digitized book, managed by the DigLib system; (2) how data is managed, and structurally collected in the context of the holding organization. Thus the organizational context is identified, and expressed, for each system’s object of concern.

 Listing 3 shows Turtle triples, related to the classes of the On-SDL ontology, defining “things” mainly managed by the DigLib system. The following Turtle triples provide details about how a type of entity, defined by an existing ontology (PREMIS_OWL) is further identified in the local system, in relation to its management. In the sample, Accession and DigitalResourceProduction.
Listing 3 shows Turtle triples, related to the classes of the On-SDL ontology, defining “things” mainly managed by the DigLib system. The following Turtle triples provide details about how a type of entity, defined by an existing ontology (PREMIS_OWL) is further identified in the local system, in relation to its management. In the sample, Accession and DigitalResourceProduction.
- premis:Event ⊑ prov:ActivityListing 4 shows the most representative Turtle triples, in the prototype, for expressing how a DigRes has been obtained.It is worth noticing that this is the last step performed by the MassConv system, all previous steps are identified and related to this event by means of prov:wasInformedBy. The digitized pages (from one to 341 for JPEG format, and from one to 342 for TIFF format), and the incoherence between the number of TIFF files and the JPEG, shows that some event was not completed, determining the object missing.








8.2. Semantic Data Management and the MassConv Data Source
8.3. Semantic Data Management and the Data Source Mapping
9. Implementing on the Data Management Case Study and First Results
10. Limitations, Conclusions and Future Developments
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Di Iorio, A.; Schaerf, M. Addressing the tacit knowledge of a digital library system. In Proceedings of the REMS 2018, Multidisciplinary Symposium on Computer Science and ICT, Stavropol, Russia, 15 October 2018; pp. 41–51. [Google Scholar]
- Zaveri, A.; Rula, A.; Maurino, A.; Pietrobon, R.; Lehmann, J.; Auer, S. Quality assessment for linked data: A survey. Semant. Web 2015, 7, 63–93. [Google Scholar] [CrossRef]
- Smith-Yoshimura, K. Analysis of International Linked Data Survey for Implementers. D-Lib Mag. 2016, 22. [Google Scholar] [CrossRef]
- Tosaka, Y.; Park, J.R. Continuing Education in New Standards and Technologies for the Organization of Data and Information. Libr. Res. Tech. Serv. 2018, 62, 4–15. [Google Scholar]
- Hyland, B.; Atemezing, G.; Villazón-Terrazas, B. Best Practices for Publishing Linked Data. Available online: https://www.w3.org/TR/ld-bp/ (accessed on 7 May 2019).
- Hyland, B.; Atemezing, G.; Pendleton, M.; Srivastava, B. Linked Data Glossary. Available online: http://www.w3.org/TR/ld-glossary/ (accessed on 7 May 2019).
- Cyganiak, R.; Wood, D.; Lanthaler, M.; Klyne, G.; Carroll, J.J.; McBride, B. RDF 1.1 concepts and abstract syntax. W3C Recomm. 2014, 25. Available online: https://www.w3.org/TR/rdf11-concepts/ (accessed on 7 May 2019).
- Vandenbussche, P.Y.; Atemezing, G.A.; Poveda-Villalón, M.; Vatant, B. Linked Open Vocabularies (LOV): A gateway to reusable semantic vocabularies on the Web. Semant. Web 2017, 8, 437–452. [Google Scholar] [CrossRef]
- Polanyi, M. The Tacit Dimension; University of Chicago Press: Chicago, IL, USA, 2009. [Google Scholar]
- Hayes, P.J.; Patel-Schneider, P.F. RDF 1.1 Semantics. W3C Recomm. 2014, 25, 7–13. [Google Scholar]
- Sahoo, S.S.; Halb, W.; Hellmann, S.; Idehen, K.; Thibodeau, T., Jr.; Auer, S.; Sequeda, J.; Ezzat, A. A survey of current approaches for mapping of relational databases to RDF. W3C RDB2RDF Incubator Gr. Rep. 2009, 1, 113–130. [Google Scholar]
- Bizer, C.; Cyganiak, R. D2r server-publishing relational databases on the semantic web. In Proceedings of the 5th International Semantic Web Conference, Athens, GA, USA, 5–9 November 2006; Volume 175. [Google Scholar]
- Beneventano, D.; Bergamaschi, S.; Sorrentino, S.; Vincini, M.; Benedetti, F. Semantic annotation of the CEREALAB database by the AGROVOC linked dataset. Ecol. Inf. 2015, 26, 119–126. [Google Scholar] [CrossRef]
- Alavi, M.; Leidner, D.E. Knowledge management and knowledge management systems: Conceptual foundations and research issues. MIS Q. 2001, 25, 107–136. [Google Scholar] [CrossRef]
- Ward, J.; Aurum, A. Knowledge management in software engineering-describing the process. In Proceedings of the Software Engineering Conference, Melbourne, Australia, 13–16 April 2004; pp. 137–146. [Google Scholar]
- De Vasconcelos, J.B.; Kimble, C.; Carreteiro, P.; Rocha, Á. The application of knowledge management to software evolution. Int. J. Inf. Manag. 2017, 37, 1499–1506. [Google Scholar] [CrossRef]
- Rowley, J.E. The wisdom hierarchy: Representations of the DIKW hierarchy. J. Inf. Sci. 2007, 33, 163–180. [Google Scholar] [CrossRef]
- Wiig, K.M. Knowledge Management Foundations: Thinking about Thinking-How People and Organizations Represent, Create, and Use Knowledge; Schema Press: Arlington, VA, USA, 1994. [Google Scholar]
- Evans, M.; Dalkir, K.; Bidian, C. A holistic view of the knowledge life cycle: the knowledge management cycle (KMC) model. Electron. J. Knowl. Manag. 2015, 12, 47. [Google Scholar]
- Boisot, M.H. Knowledge Assets: Securing Competitive Advantage in the Information Economy; OUP Oxford: Oxford, UK, 1998. [Google Scholar]
- Grant, R.M. Toward a knowledge-based theory of the firm. Strateg. Manag. J. 1996, 17, 109–122. [Google Scholar] [CrossRef]
- Choo, C.W. The knowing organization: How organizations use information to construct meaning, create knowledge and make decisions. Int. J. Inf. Manag. 1996, 16, 329–340. [Google Scholar] [CrossRef]
- Van den Berg, H.A. Three shapes of organisational knowledge. J. Knowl. Manag. 2013, 17, 159–174. [Google Scholar] [CrossRef]
- Radulovic, F.; Mihindukulasooriya, N.; García-Castro, R.; Gómez-Pérez, A. A comprehensive quality model for linked data. Semant. Web 2018, 9, 3–24. [Google Scholar] [CrossRef]
- Catarci, T.; Di Iorio, A.; Schaerf, M. The Sapienza Digital Library from the Holistic Vision to the Actual Implementation. Procedia Comput. Sci. 2014, 38, 4–11. [Google Scholar] [CrossRef]
- Lenzerini, M. Data Integration: A Theoretical Perspective. In Proceedings of the Twenty-first ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Madison, WI, USA, 2–6 June 2002; ACM: New York, NY, USA, 2002; pp. 233–246. [Google Scholar] [CrossRef]
- PREMIS Editorial Committee. PREMIS Data Dictionary for Preservation Metadata, Version 3.0. 2015. Available online: http://www.loc.gov/standards/premis/v3/premis-3-0-final.pdf (accessed on 7 May 2019).
- Consultative Committee for Space Data. Reference Model for an Open Archival Information System (OAIS), Recommended Practice CCSDS 650.0-M-2 Magenta Book; CCSDS Press: Washington, DC, USA, 2012. [Google Scholar]
- Denenberg, R.; Guenther, R.; Han, M.J.; Luna Lucero, B.; Mixter, J.; Nurnberger, A.L.; Pope, K.; Wacker, M. Making MODS to Linked Open Data: A Collaborative Effort for Developing MODS/RDF; Columbia University Press: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Coppens, S.; Verborgh, R.; Peyrard, S.; Ford, K.; Creighton, T.; Guenther, R.; Mannens, E.; Van de Walle, R. Premis owl. Int. J. Digit. Libr. 2015, 15, 87–101. [Google Scholar] [CrossRef]
- Di Iorio, A.; Caron, B. PREMIS 3.0 Ontology: Improving Semantic Interoperability of Preservation Metadata. In Proceedings of the 13th International Conference on Digital Preservation, Bern, Switzerland, 3–6 October 2016; pp. 32–36. [Google Scholar]
- Blair, C.; Bountouri, L.; Caron, B.; Cowles, E.; Di Iorio, A.; Guenther, R.; McLellan, E.; Roke, E.R. 305.2 PREMIS 3 OWL Ontology: Engaging sets of linked data—Award Winner: Best Short Paper. In Proceedings of the 15th International Conference on Digital Preservation, Boston, MA, USA, 24–27 September 2018. [Google Scholar] [CrossRef]
- Lebo, T.; Sahoo, S.; McGuinness, D.; Belhajjame, K.; Cheney, J.; Corsar, D.; Garijo, D.; Soiland-Reyes, S.; Zednik, S.; Zhao, J. PROV-O: The Prov Ontology: W3C Recommendation, 30 April 2013; World Wide Web Consortium: Cambridge, MA, USA, 2013. [Google Scholar]
- Reynolds, D. The Organization Ontology. 2014. Available online: http://www.w3.org/TR/vocab-org (accessed on 7 May 2019).
- Nardi, D.; Brachman, R.J. An introduction to description logics. In Description Logic Handbook; Cambridge University Press: Cambridge, UK, 2003; pp. 1–40. [Google Scholar]
- Baader, F. The Description Logic Handbook: Theory, Implementation and Applications; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Berners-Lee, T. Linked Data-Design Issues. 2006. Available online: http://www.w3.org/DesignIssues/LinkedData.html (accessed on 7 May 2019).
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data-the story so far. In Semantic Services, Interoperability and Web Applications: Emerging Concepts; IGI Global: Hershey, PA, USA, 2009; pp. 205–227. [Google Scholar]
- Heath, T.; Bizer, C. Linked data: Evolving the web into a global data space. Synth. Lect. Semant. Web Theory Technol. 2011, 1, 1–136. [Google Scholar] [CrossRef]
- Berners-Lee, T. Cool URIs don’t change. 1998. Available online: https://www.w3.org/Provider/Style/URI (accessed on 7 May 2019).
- Miles, A.; Bechhofer, S. SKOS simple knowledge organization system reference. W3C Recomm. 2009, 18, W3C. [Google Scholar]
- Di Iorio, A.; Schaerf, M. Identification Semantics for an Organization, establishing a Digital Library System. In Proceedings of the 4th International Workshop on Semantic Digital Archives (SDA 2014), Oxford, UK, 12 May 2014. [Google Scholar]
- Beckett, D.; Berners-Lee, T.; Prud’hommeaux, E.; Carothers, G. RDF 1.1 Turtle; World Wide Web Consortium: Cambridge, MA, USA, 2014. [Google Scholar]
- Michel, F.; Montagnat, J.; Zucker, C.F. A Survey of RDB to RDF Translation Approaches and Tools. Available online: https://hal.archives-ouvertes.fr/hal-00903568/file/Rapport_Rech_I3S_v2_-_Michel_et_al_2013_-_A_survey_of_RDB_to_RDF_translation_approaches_and_tools.pdf (accessed on 7 May 2019).
- Motik, B.; Patel-Schneider, P.F.; Parsia, B.; Bock, C.; Fokoue, A.; Haase, P.; Hoekstra, R.; Horrocks, I.; Ruttenberg, A.; Sattler, U.; et al. OWL 2 web ontology language: Structural specification and functional-style syntax. W3C Recomm. 2009, 27, 159. [Google Scholar]
- Schneider, M.; Carroll, J.; Herman, I.; Patel-Schneider, P.F. OWL 2 Web Ontology Language RDF-Based Semantics. 2009. Available online: https://www.w3.org/TR/owl2-rdf-based-semantics/ (accessed on 7 May 2019).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Table Name | Description | Rows |
|---|---|---|
| org_coll | University organizational collection | 157 |
| collections | Digital collections managed by the system | 57 |
| agent_roles | Information about the roles of agents in the events | 283 |
| agents | Agents involved in the DigLib system | 99 |
| acquisition | Workflow event for the identification of | |
| digitized materials | 1026+46,125 | |
| [OrgColl]_resources | Digital resource index | 96+48,112 |
| [OrgColl]_file_objects | Content objects’ inventory | 191+193,021 |
| [OrgColl]_file_objects | Content objects’ inventory (2015) | 36,358,076* |
| [OrgColl]_metadata_objects | Metadata objects’ inventory | 191+193,021 |
| [OrgColl]_materials | Digitized objects as submitted by provider | 193+224,503+ |
| 36,358,076* | ||
| [OrgColl]_Events | Workflow events | -- |
| Onto | OntoName | Named Individuals [45,46] | SuperClass |
|---|---|---|---|
| onsdl | Library | 46/65 | |
| onsdl | OrganizationalCollection | 46/157 | |
| onsdl | DigitalCollection | 46 + 11 | |
| onsdl | DescriptiveMetadata | 961 + 96 + 10 + 46,125 + 57 | MetadataObject |
| mods | ModsResource | 48,265 | |
| onsdl | DigitizedBook | 1805 + 55,372 | Book |
| onsdl | DigitalObject | (48,265*2) + 193,021 + | |
| 31,296 + 36,358,076* | |||
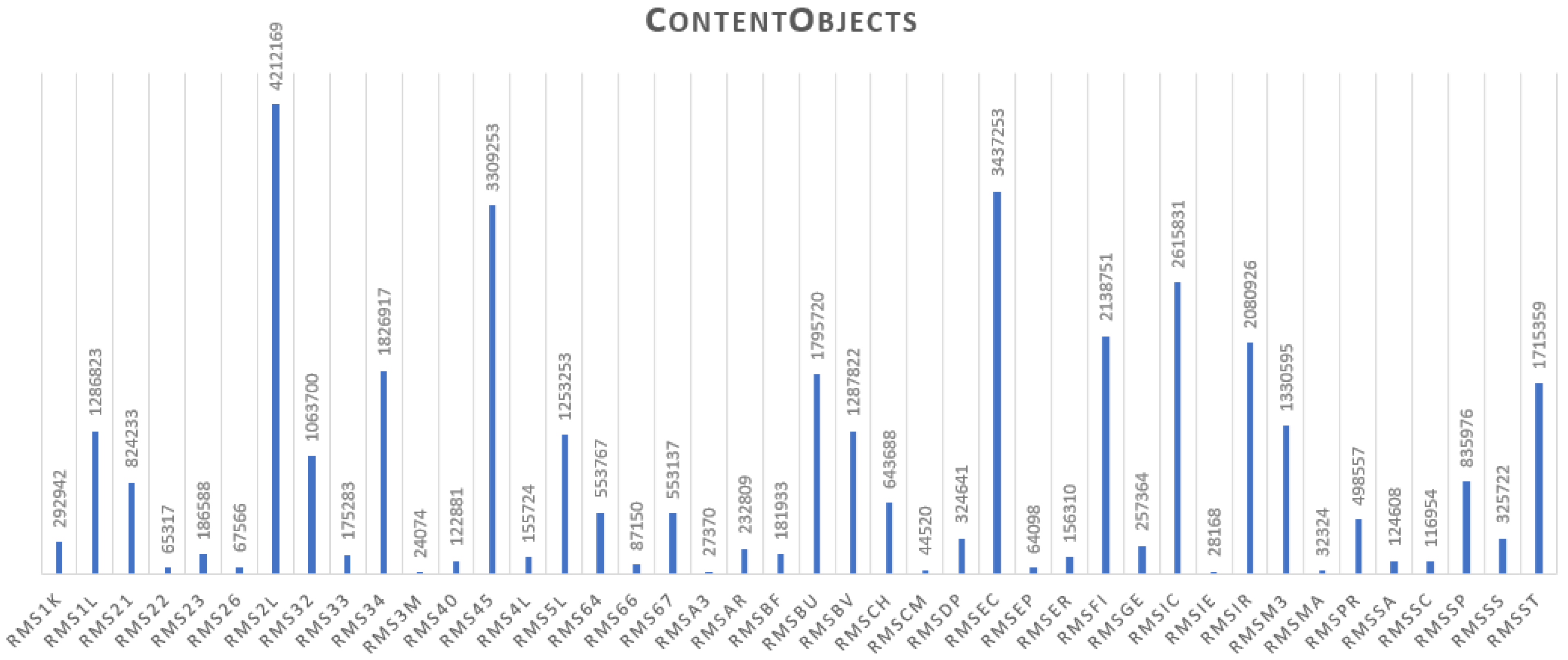
| onsdl | ContentObject | 193,021 + 31,296 + 36,358,076* | DigitalObject |
| onsdl | PreservationMetadata | 193,021 + 31,296 + 36,358,076* | MetadataObject |
| onsdl | MetadataObject | 48,265*2 | DigitalObject |
| onsdl | DigitalResource | 961 + 96 + 10 + 1026 + 46,125 + 47 | |
| mcwo | OrgCollCreation | 157 | Event |
| mcwo | RootURIassignment | 46 | Event |
| mcwo | Acquisition | 1,026 + 55,372 | Event |
| mcwo | URIassignment | 57 + 48,265 | Event |
| mcwo | BibRecordImport | 2,214,190 | Event |
| mcwo | MappingDevelopment | 143 | Event |
| mcwo | Accession | 961 + 96 + 10 | Event |
| mcwo | URIpropagation | 193,021 + 31,296 + 36,358,076* | Event |
| mcwo | CollectingPresMetadata | 193,021 + 31,296 + 36,358,076* | Event |
| mcwo | DigitalResourceProduction | 961 + 96 + 10 | Event |
| Onto | OntoName | Named Individuals [45,46] | Domain ⇒ Range |
|---|---|---|---|
| onsdl | hasDigitalCollection | 46 ⇒ 57 | OrganizationalCollection ⇒ |
| DigitalCollection | |||
| onsdl | hasDigitalObject | 48,265 ⇒ | DigitalResource ⇒ |
| (48,265*2) + 193,021 + 31,296 + 36,358,076* | DigitalObject | ||
| onsdl | hasDigitalResource | 57,177 ⇒ 48,265 | DigitizedBook ⇒ |
| DigitalResource | |||
| onsdl | hasDigitizedPage | 57,177 ⇒ 193,021 + 31,296+36,358,076* | DigitizedBook ⇒ |
| ContentObject | |||
| onsdl | hasMetadataObject | 48,265 ⇒ 48,265*2 | DigitalResource ⇒ |
| MetadataObject | |||
| onsdl | isDigitalHoldingOf | 46 ⇒ 46 | OrganizationalCollection ⇒ |
| Library | |||
| onsdl | belongsTo | 57 ⇒ 46 | DigitalCollection ⇒ |
| OrganizationalCollection | |||
| onsdl | describesDigitalObject | 193,021 + 31,296 + 36,358,076* ⇒ | PreservationMetadata ⇒ |
| 193,021 + 31,296 + 36,358,076* | DigitalObject | ||
| onsdl | describesWork | 961 + 96 + 10 + 46,125 + 57 ⇒ 961 + | DescriptiveMetadata ⇒ |
| 96+10 + 46,125 + 57 | DigitizedBook |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Iorio, A.; Schaerf, M. Expressing the Tacit Knowledge of a Digital Library System as Linked Data. Computers 2019, 8, 49. https://doi.org/10.3390/computers8020049
Di Iorio A, Schaerf M. Expressing the Tacit Knowledge of a Digital Library System as Linked Data. Computers. 2019; 8(2):49. https://doi.org/10.3390/computers8020049
Chicago/Turabian StyleDi Iorio, Angela, and Marco Schaerf. 2019. "Expressing the Tacit Knowledge of a Digital Library System as Linked Data" Computers 8, no. 2: 49. https://doi.org/10.3390/computers8020049
APA StyleDi Iorio, A., & Schaerf, M. (2019). Expressing the Tacit Knowledge of a Digital Library System as Linked Data. Computers, 8(2), 49. https://doi.org/10.3390/computers8020049