1. Introduction
The study of large-scale control distributed systems has been the focus of scientists in recent decades. Several models and techniques are used to deal with challenges related to this area such as the high cost in terms of computational requirements, the communication structure, and the estimation of the data needed to perform a task in large-scale systems. Multi-Agent Systems (MAS) is a tool for addressing this kind of problems and is usually employed in the framework of game theory. In this context, the study of interactions of agents have received special attention due to the use of strategies that allow agents maximizing their outcomes. In this regard, the work in [
1] provides connections among games, learning, and optimization in networks. Other works are focused on games and learning [
2] or studied algorithms for distributed computation in dynamic networks topologies [
3]. In [
4], authors analyzed applications of power control using both distributed and centralized game theory frameworks. Applications of smart grid control are found in [
5]. Other works focused on cases in which coordination and negotiation problems lead to the analysis of agents interactions [
6]. Other approaches related to applications in power control based on game theory are found in [
7].
The literature of game theory differentiates between three kinds of games. Continuous games where the concept of pure strategy is stated for agents and one agent can have many of it. Matrix games where agents are individually treated and allowed to take only one shot play simultaneously. The last case is related to dynamic games, which assume players can learn somehow about the actions and the states of the environment. This feature implies an agent can learn about the taken decision to adjust its behavior [
8]. This kind of games has to respond to the following challenges: the modeling of the environment where the interaction between players takes place, the modeling of players’ goals, and finally, how to prioritize players actions and how to estimate the amount of information a player has [
9].
Evolutionary game theory (EGT) introduces an approach that belongs to dynamic games related to the study of dynamics of agents that change over time [
10]. The evolutionary stable strategy was the concept that made EGT popular due to its relationship with biology and the way it supports the understanding of natural behaviors [
11]. For this reason, the use of EGT is traditionally assumed to be positive (descriptive), rather than normative (prescriptive). Nonetheless, when EGT is used in the study of particular empirical phenomena to predict some behavior, sometimes it appears to be more on the normative side [
12]. In this regard, the replicator dynamics (RD) approach is based on the understanding of EGT, which has been used in several real life control applications. The combination of revision protocols (which gives a description on how agents select and change strategies), and population games (which specifies interactions among agents) leads to the concept of evolutionary game dynamics [
11]. The process of modeling large-scale systems is usually developed using this evolution perspective, since its mathematical background allows describing this process by using differential equations [
10].
Applications of EGT can be found in many fields of Engineering, some of them focused on the economic dispatch problem (EDP) of microgrids for electric generators, control of systems of communications access, optimization problems, among others [
8]. Some of the advantages of modeling engineering problems using the EGT approach are the easiness to associate a game with a problem of the engineering field, where the objective function and the strategies can be stated as payoff functions, and the relationship between the concepts of optimization and Nash Equilibrium, which is possible under specific conditions that allow satisfying the first order optimization conditions of the Karush–Kuhn–Tucker. Finally, it is worth noting that EGT obtains games solutions using local information. In this sense, when addressing engineering problems, distributed approaches emerge, which is relevant due to the cost of implementation of centralized schemes and its high complexity [
8]. Distributed population dynamics has some advantages in comparison with some techniques such as the dual decomposition method, which needs a centralized coordinator [
13]. This property minimizes costs related to communication structure. Moreover, compared with distributed algorithms for learning in normal-form-games, distributed population dynamics have no fails in applications that use constraints over all the variables immersed in the decision process [
14]. This feature fits properly for dealing with problems related to resource allocation cases such as the smart city design [
15]. In this kind of applications, there is an increasing need for integration between the digital technologies and the distributed power generation to make electric networks robust, flexible, reliable and efficient. However, the actual model of a centralized grid must be changed to a distributed model based on microgrids [
16]. In this regard, microgrids consider control operations individually, as they separate the economic dispatch, the power generation and the secondary frequency [
17]. The economic dispatch action is managed with static optimization concepts [
18] or even methods such as the direct search operating off-line [
19]. When the analysis includes the generator, loads or power line losses into the distributed model, it is more difficult to analyze the problem. Other approaches are unable to analyze the dynamic conditions such as the time dependence of the economic dispatch [
20]. Several approaches have proposed to deal with these challenges. For example, in [
21] is proposed a microgrid centralized energy management system with an operation in stand-alone mode that analyzes the static behavior. Other approaches work with a distributed control strategy based on power line signaling used for energy storage systems [
22]. Some applications of the MAS technique for distributed economic problems are found in [
23], whose contribution was to consider the delays of the communication system. Other authors propose microgrid architectures based on distributed systems such as the microgrid hierarchical control [
24].
This paper proposes an approximation to tackle some of the challenges found in the revised literature. Our main objective is to introduce a more realistic control method of learning that allows analyzing the effect of the exploration concept in MAS, i.e., communication between agents. Since the RD has proven to emerge from simple learning models [
25], this work uses the Q-learning dynamics from the reinforcement learning theory as a way to include the concept of exploration into the classic exploration-less RD equation. Therefore, by merging these frameworks, it is feasible to find a way to deal with dynamics immersed in the environment where the feedback of each agent depends not only on itself but also on other agents, and where communications constraints between them are part of the system. To make the analysis, the Boltzmann distribution is used to introduce a distributed version of the RD as a tool for controlling the behavior of agents under specific conditions. In this regard, the obtained method uses a temperature parameter and an extra term after the derivation process, which allow adjusting the behavior of the learning agents and to give a connection between the selection-mutation mechanism from EGT and the exploitation-exploration scheme from RL. Although this feature meets the traditional positive condition of EGT techniques (i.e., models what happens when agents interact), its applications to the control area should be considered normative rather than positive, since the tuning factor can be used to meet the desired behavior beforehand. To understand these features, this approach attempts to explain agents decision-making using experimental data to deal with the economic dispatch problem, which is one of the common issues in a smart grid. The results of this solution are compared with the classic centralized approach of RD.
The rest of this paper is organized as follows. In
Section 2, a brief summary of game theory and Q-learning is introduced, and the replicator dynamics equations are presented from the perspective of EGT.
Section 3 describes a distributed neighboring approach for the Boltzmann control method, based on the replicator dynamics behavior.
Section 4 discusses some relevant concepts obtained in
Section 3 regarding the domains of reinforcement learning and the evolutionary game theory.
Section 5 introduces a smart grid application based on an economic dispatch problem, where the distributed approach of the Boltzmann control method is applied. Finally, some conclusions are outlined in
Section 6.
2. Theoretical Framework
Game theory presents a set of mathematical equations to analyze the background in decentralized control issues. A game is usually formed by a set of agents (players) with the same population behavior that select a strategy to perform an action. The strategy of an agent allows it to maximize rewards in cases where the action selected was appropriate or may result in punishment if it was not [
26]. This behavior is analyzed using theory of learning. In this context, the reinforcement learning (RL) scheme gives the main features to understand the direct relationship between signals, actions, states, and the environment. At each step of their interaction, each player receives a notification of the present environment state and a reinforcement signal, and consequently, it selects a strategy. Each player of the game has the purpose of finding a policy that provides him the best profits after mapping states to actions [
27].
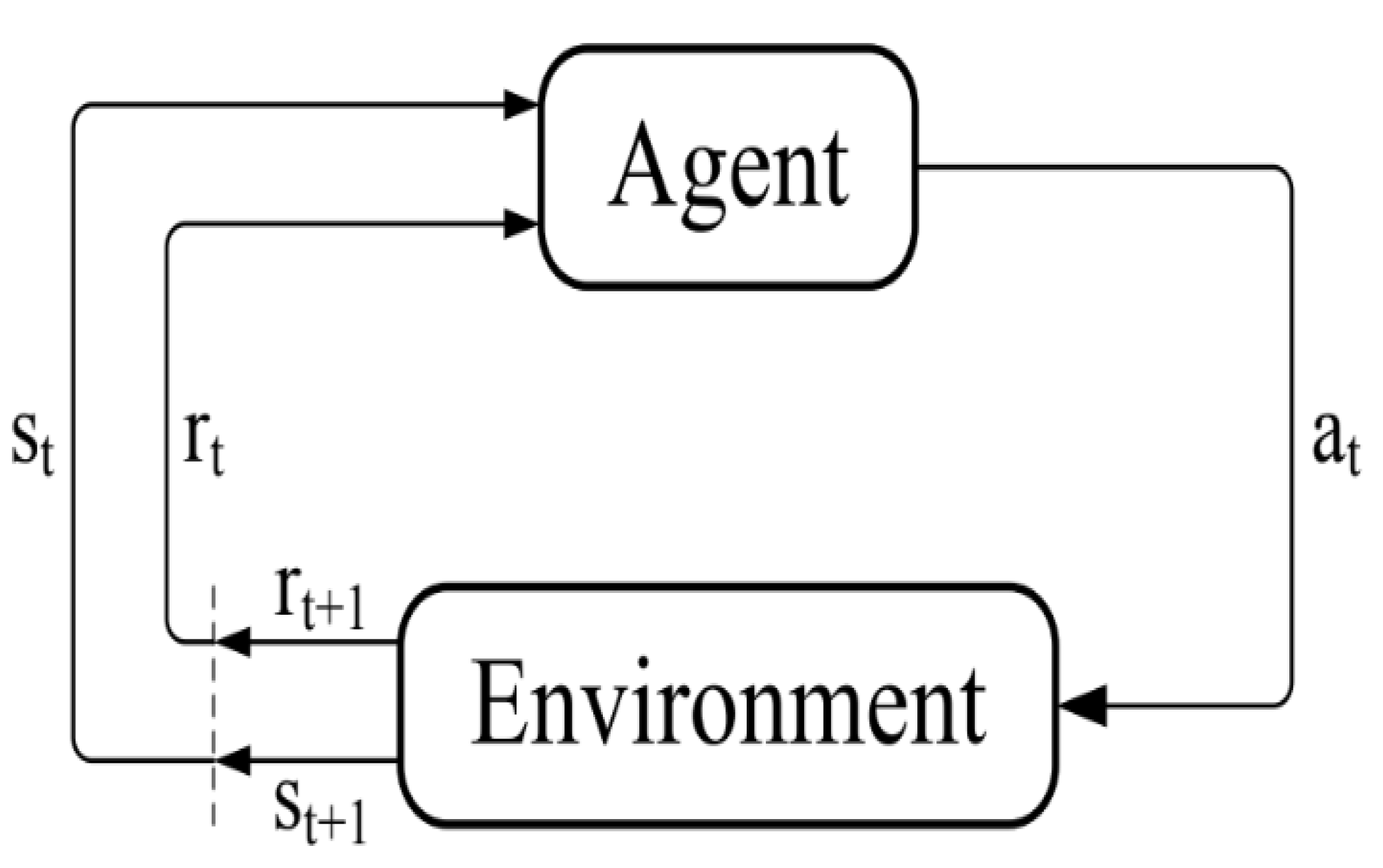
Figure 1 shows the RL framework, where an agent at time
t takes an action
depending on the information perceived in the environment state
. Then, the environment changes to state
and, consequently, the agent perceives a consequence of its taken actions
, e.g., reward or punishment.
Traditional RL methods are characterized by a structure of estimated value functions [
27]. A value of a state or a pair state-action is the total amount of reward an agent can achieve, starting from that state. This implies that the optimal value function has to be found to know the policy that best satisfies payoffs. This process can be done with the value iteration algorithm and the Markov decision process [
28] in cases where the environment is well-known. In other cases, Q-learning positions itself as an adaptive value iteration method, which needs no specific model of the environment. Equation (
1) describes how the Q-learning interaction is done [
29]:
The estimation starts in taking as time value, and reaches the , where is the most recent value of a player state s after executing action a. receives the highest Q Value from by choosing the action that maximizes the Q Value. The term describes the common step size parameter, R represents the immediate reinforcement, and represents a discount factor.
In cases where agents have full access to information of the game and no communication constraints, classical theory of games together with theory of learning are useful tools to model centralized control applications. However, these cases are a close representation of ideal situations, which have some limitations when representing real life conditions, interactions, and rationality of individuals. In this sense, Evolutionary Game Theory (EGT) intends to relax the concept of rationality, by replacing it with biological concepts and behaviors such as natural selection and mutation [
30]. The fundamental notions of EGT came from the evolutionary biology field [
31,
32]. In this scope, the strategies of the players are genetically encoded and called genotypes, which refer to the behavior of each player used to compute its payoff. Each player genotype outcome is conditioned by the number of other types of players in the environment.
EGT makes that the population strategies start to evolve through the construction of a dynamic process, where the Replicator Dynamics equation represent the expected value of this procedure. The context of an evolutionary system usually refers to two concepts: mutation and selection. Mutation gives variety to the population, while selection is related to prioritize some varieties in which each genotype represents a pure strategy
. All the replicator dynamics offspring inherits this behavior. Equation (
2) shows the general equation of the RD [
25]:
where
represents the amount of density of a specific population playing strategy
i, and the payoff matrix is represented by
A. This matrix has different payoff values that each replicator gets from the other players. The population state (
x) is usually described by the vector of probability
, which shows the different amount of densities of each type of replicator in the population. Therefore,
represents the payoff that the player
i obtains in a population with
x state. In this case, the average payoff will be represented as
. The growth rate
of the whole population using strategy
i equals the difference between the current strategy payoff and the average payoff in the population [
31].
Relating EGT and Q-Learning
The authors in [
33] considered a way to associate the schemes of Q-learning and RD in the context of a two-players game, in which agents play different strategies. This association is possible considering that players are Q-learners. To model this scenario, two systems of differential equations are stated: one for player Q (columns) and another for player P (rows). In case
, the general Equation (
2) for RD is used, in which
is replaced by
or
. The payoff matrix is stated by
A or
B, and the population state (
x) is represented by
p or
q, based on the behavior of the player to be modeled. Thus,
changes to
or
and represents the payoff that the player
i obtains in a population with
p or
q state. Similarly, the growth rate
changes to
or
for player Q and player P, respectively. The foregoing can be described by the following differential equations system [
25]:
Equations (
3) and (
4) represent the RD equations for two populations. The growth rate of each population depends on the other populations, where A and B represent two necessary payoff matrices to calculate the rate of change from these differential equation systems for the two different current players in the problem.
To see the relationship of the RD equations with the Q-learning approach, first, it is necessary to introduce Equation (
5), which describes the Boltzmann distribution:
where the probability of playing the
i strategy at
step time is represented by
, and
represents the temperature. The authors in [
33] used Equation (
5) to derive the Q-Learning continuous time model for a two-players game, where
is taken as
. This result is shown in Equation (
6).
In order to solve the expression
in Equation (
6), the Equation (
1) is used to model the update rule for the first Q-learner player, which yields an expression that describes the difference equation for the Q-function as shown in Equation (
7):
The time amount spent between two repetitions of the Q-values updates is stated by
with
, and
represents the Q-values at time
. Therefore, if this equation takes an infinitesimal scheme, after taking the limit
, Equation (
7) gets to Equation (
8).
Since
equals
, the second part of Equation (
8) can be expressed in logarithm terms:
After reorganizing and substituting the last expression in Equation (
8), it takes the form of Equation (
10).
To introduce the use of the payoff matrices in a two player games, it is possible to write
as
, where the expression for the first player is:
Equation (
11) is the representation of the derivation of the continuous time model for Q-learning developed by [
33], which uses the Boltzmann concept. This expression can be understood as a centralized approach, very similar to the original form of Equation (
3), which is the classic RD form to model the behavior of player P, in the context of a two-player game. The main differences are influenced by the Boltzmann model with the introduction of
and
constants, and the appearance of the second term. Applications of this approach have been developed in the context of 2 × 2 games, multiple state, and multiple player games [
25]. However, its application to solve real life problems is still an open issue.
The next Section introduces our proposal, which can be understood as a distributed control method of learning. This novel approach uses part of the bases proposed in [
33]. Our main contribution is the introduction of a Boltzmann distributed perspective, in which the concept of population dynamics from EGT is considered and where players can only play neighboring strategies. This control method considers communications constraints among agents, i.e., a context where agents have incomplete information of the system.
3. The Proposed Boltzmann Distributed Control Method
In this section, the proposed Boltzmann distributed replicator dynamics method is presented. From the perspective of the classic replicator dynamics, we use Equation (
11) as the depart point. This expression can be used not only in a two-players game, but in multi-players games. Consequently, Equation (
11) can be stated as shown in Equation (
12):
where a portion of a particular type of population will increase or decrease if its individuals have a higher/lower fitness than the population average. The state vector
with
and
is used to describe the population and represents the fractions belonging to each of n types. Consider the fitness function
, where
i represents the fitness type. Then, the population fitness average is described by
. By applying the last assumptions, this expression changes to
Considering that the first term of Equation (
14) takes the form of the centralized equation for the RD, this work proposes its adaptation to a decentralized form, looking forward to computing the agents local information to deal with communications constraints. Equation (
14) shows the decentralized form of this stage as follows:
where the expression
is equal to the unit. This is explained because the term
within the sum represents the probabilities of playing the
th strategy. Similarly, for the second term in Equation (
13), after doing some Algebra and applying logarithms rules, this expression takes the following form:
Finally, by replacing Equations (
14) and (
15) in Equation (
13), it gets to the form of Equation (
16), which represents the Decentralized Replicator Dynamics rule in terms of Boltzmann probabilities.
This expression is further analyzed in
Section 4 from the perspective of EGT and its relationship with the selection-mutation concept. It is also analyzed from the perspective of the exploration-exploitation approaches, and their effect in MAS. Meanwhile, the first parenthesis in Equation (
16) refers to changes in the individuals proportion playing the i-th strategy that needs full information of all the payoff functions and the entire population state. Therefore, population dynamics need full-information to evolve. Nonetheless, as one of the main objectives of this work is finding a way to control applications in which agents have no access to the entire information of the system, dependency on full-information must be avoided in some scenarios, where for instance, communication infrastructure limitations, size of systems and privacy issues hinder the availability of this information. Consequently, the analysis of the population structure defines the dynamics that describes the agent behavior. In this sense, the classic assumption for the population structure is that the population has a full and well-mixed structure, i.e., the population structure allows agents to select a specific strategy with the same probability of selecting any other.
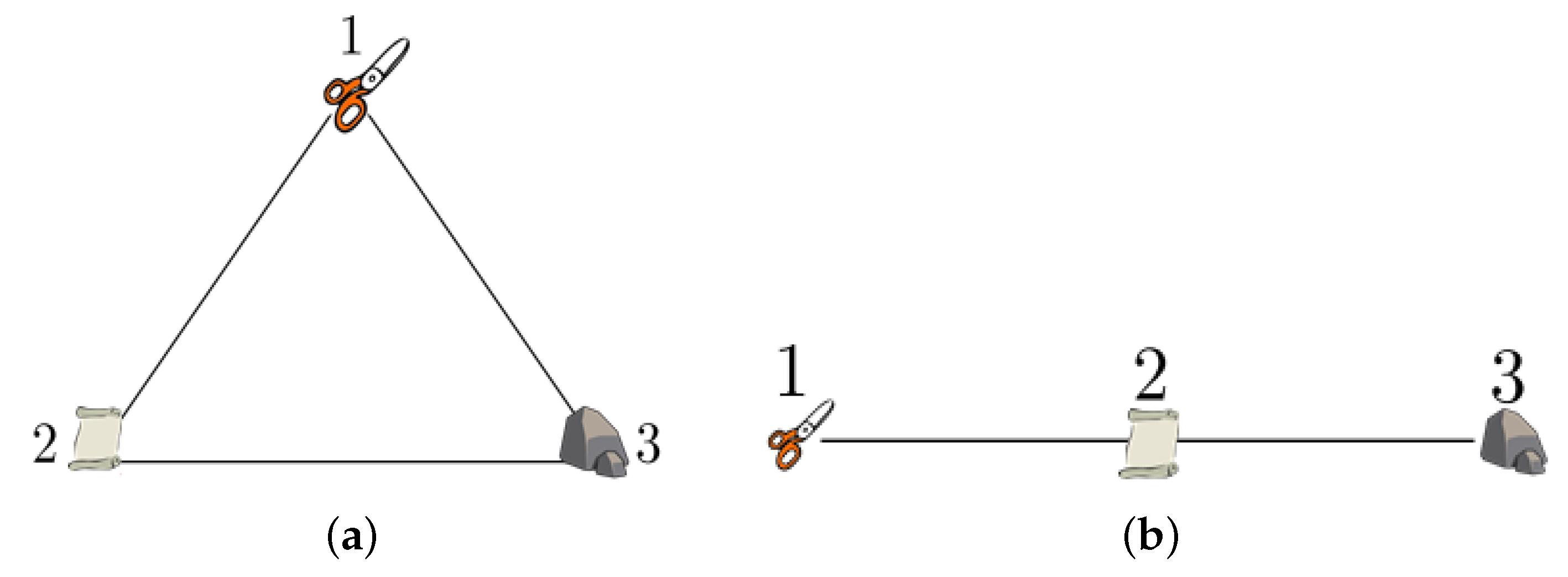
Figure 2a clarifies this concept by illustrating some agents playing a game. In this case, each agent is represented by an element and the strategies selected are denoted by the element shape, for example paper, stone, or scissors.
In EGT, each agent has the same probability of receiving a revision opportunity. At the moment of receiving it, agents randomly select one of their neighbors and, according to the revision protocol selected, they may change their own strategy to the one of their neighbors. Since players have been considered full-well-mixed in the population, the probability that any opponent chooses and plays any of the strategies of the structure is the same
Figure 2a. In contrast,
Figure 2b illustrates a non-full-well-mixed population, i.e., a more realistic approach. In this case, the probability of receiving an opportunity to make a revision is the same for all agents, but the probability that a neighbor chooses and plays a particular strategy is not the same. For example, if one agent receives a revision opportunity when playing a scissors strategy, the probability of selecting an opponent playing a paper strategy is null, because no scissors are near to any paper. However, for this same agent, the probability of selecting an opponent playing a scissors or stone strategy is more balanced and higher than in the paper case.
To obtain a mathematical representation of this behavior, the graph
represents the dynamics among agents. The group
T is linked with the strategies the agent can select. Set
L represents the meeting probability among strategies. It is very likely that
L is higher than zero if there is a link between two strategies. In order to contextualize the forecast in the adjacency matrix
means strategy
j and
i can meet each other, while
means strategy
j and
i cannot, in this way we define the neighborhood of agent
i as
. In this regard, full-well-mixed and non-full-well-mixed populations may be specified with two types of graphs.
Figure 3a shows a representation using a complete graph for the full-well-mixed populations and
Figure 3b for the case of non-full-well-mixed populations. The topology of the graph depends on the specific structure of the population. In the specific case of this work, undirected graphs are assumed, i.e., strategies
j and
i have the same probability as strategies
i and
j to meet each other.
Up to this point, in order to control agents interactions is needed to meet the population structure constraint of non-full-information dependency despite the distributed control model stated in Equation (
16) as depicted in
Figure 2b and
Figure 3b. To achieve this condition, the approach of [
34] is considered. The authors used the pairwise proportional-imitation protocol to introduce the neighboring concept, as shown in the following expression:
where the computation of
just needs the knowledge of the portions of the population playing neighboring strategies, which leads us to make the following assumption:
Assumption 1. Operations using the pairwise proportional-imitation protocol and its update are neighboring-based, i.e., the payoff function as well as the iterations in the sums depend on the neighbors that have effective communication with the i-th player.
Under this assumption, the resulting distributed replicator dynamics that meet the population structure constraints and allow agents to control the computation of non-full-information are stated in Equation (
18):
where
represents the payoff function for player
evaluated in the proportion of its effective communication neighbors, and the term
represents a sum only with the effective communication neighbors. Since our assumption of the neighboring concept has been only applied to the first part of Equation (
16), the introduction of this concept to the second part of the equation (second parenthesis) takes the following form:
where the term
k must be understood as the
i-th neighbor with an active communication link using strategy
j. The last couple of expressions represent the behavior of the
i-th player in terms of Boltzmann probabilities for the Distributed Replicator Dynamics or BBDRD. Equation (
20) shows the complete form of the control method grouping both approaches, i.e., the distributed and the neighboring concepts.
As mentioned before, the BBDRD equation also demonstrates the use of the exploitation and exploration concepts from RL, and the selection-mutation perspective from EGT, which are discussed in the next Section. The use of this approach and an illustration of its application to control in a smart grid context is presented in
Section 5 of this document.
5. Smart Grids Application
In this Section, the Boltzmann-based distributed replicator dynamics is used in a smart grid problem. In this case, we try to maximize the global utility of the power generators or to minimize the total cost of the power generation, in order to satisfy the restrictions on generation capacity and power balance at the same time [
37]. This work uses the maximization utility functions to clarify this, while the approaches to EDP have used the static optimization algorithms [
18] or methods of offline direct-search [
13,
19]. The distribution systems management demands works with dynamic environments that in turn need alternative control techniques and tools [
8]. A first solution to this problem was made from the perspective of a changing resource allocation approach, as introduced in [
38]. The authors modified the population dynamics concept to work in the context of microgrids, with the main purpose of controlling the devices that constitute it. This can be achieved if the loads, generators and other devices share information and cooperate with other elements of the grid. For the network, these elements are controllable devices.
This work presents now the study case, which consists in finding the place to execute the dispatch algorithm at the microgrid. Then, the distributed population dynamics concept is presented by using the BBDRD control approach.
5.1. Case Study
The authors in [
39] proposed two control levels. In the lower levels a controllable voltage source of distributed generators (DGs) is connected to loads with an inverter. The output voltage frequency and magnitude are controlled by a droop-gain controller [
17].
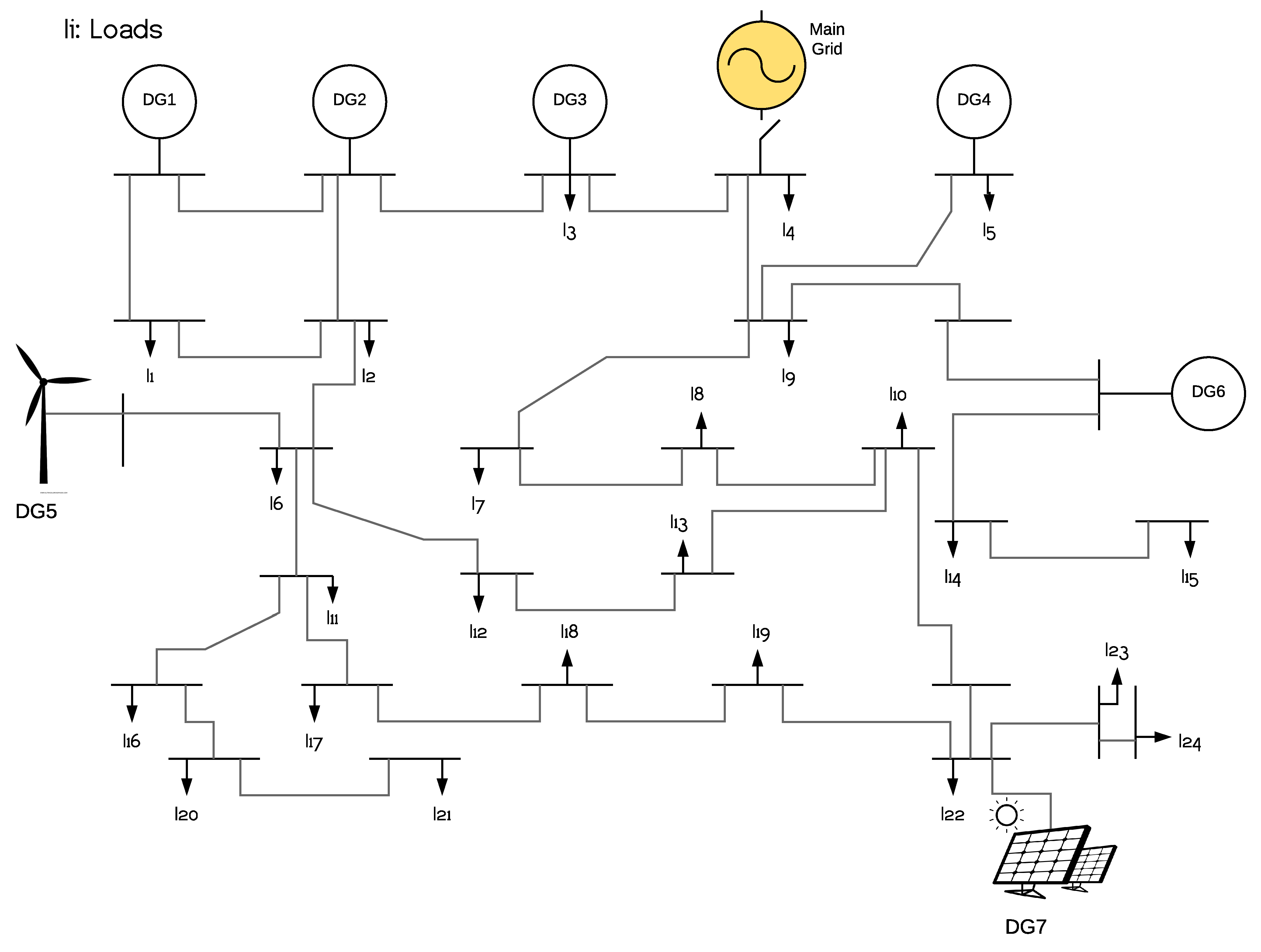
Figure 4 shows the general microgrid distribution composed of seven DGs.
At the highest level, a strategy able to dynamically dispatch set points of power is implemented. The economic constraints, such as the load demands and the power production costs, are sent from the lower level of control and toward the central controller of the microgrid; then, a classic RD is executed. The controller receives dynamical values for load demands and costs, which implies the possibility of including renewable energy resources. In this case, the dispatch is executed, i.e., the highest level of control. The formulation of the EDP is:
where
,
n is the total number of DGs,
represents the power set-point for the ith DG,
represents the loads,
is the total load required by the grid,
sets the maximum capacity of generation for the ith DG, and
is the utility function of each DG. The criterion of the economic dispatch sets the utility function [
37], which defines the operation of all generation units using the same marginal utilities as stated in Equation (
27)
For some
, such that
. Based on the EDP criterion of Equation (
27), the EDP stated in Equation (
26) can have a solution using utility functions with quadratic form for each DG [
38].
5.2. Population Games Approach
From population games point of view, this work uses RD to manage the EDP.
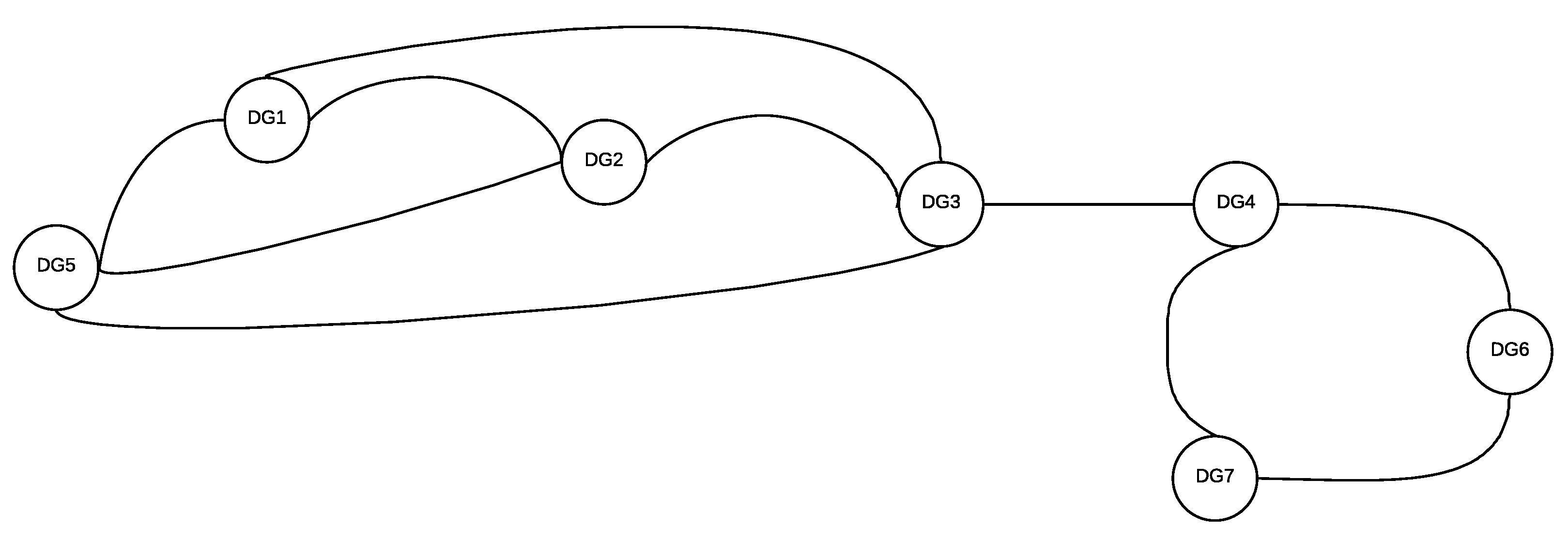
Figure 5 shows the topology proposed to simulate communication constrains between DGs.
For the distributed case,
n is the total number of DGs in the system. Let the ith strategy be defined as the act of selecting a DG in the network. In this sense, let
be the amount of power assigned to each DG, which is related to the number of individuals that select the ith strategy in S. The term
is defined as the sum of each power set-point, i.e.,
to get a suitable steady state performance. Similarly, to achieve the power balance, the use of
allows the invariance of set
[
40]. This expression guarantees that if
, then
,
, which means that the control strategy should define set-points to ensure the appropriate balance between the generated and the demanded power by the DGs. This behavior allows an appropriate regulation of frequency.
When analyzing the inclusion of technical and economic criteria in the control strategy, the cost and the capacity factors of power generation are very important to condition the final power dispatched to each DG. RD appears to fit appropriately, as its stationary state is reached when the average outcome is equal to all the outcome functions. This feature links RD and EDP, since it is equal to the economic dispatch criterion of Equation (
27) when selecting the outcome function as:
The economic dispatch approach of Equation (
27) ensures an optimal solution of the system if constrains are satisfied. The optimization issues may be tackled by marginal utilities in the outcome functions. This is possible because the outcome functions are equal to
. The outcome selected can be modeled as a function that increases/decreases depending on the distance of the power from/to the set-point desired. In this dynamic, RD allots resources to those DGs that depend on the average outcome. This behavior can be represented by the following function [
41]:
where
k represents the carrying capacity such that the independent variable
. Here, parameters such as the carrying capacity and the cost factor of generation are used by the outcome functions. Consequently, each DG has an outcome function that can be stated as:
The use of marginal utilities for the outcome functions allows the population game to become a potential game [
42]. In Equation (
30), the outcome functions lead to functions of quadratic utility for each DG in the optimal EDP [
38]. This outcome function has been used in other works such as [
38,
39,
43].
5.3. Boltzmann-Based Distributed Replicator Dynamics Approach
The previously described behavior implies the use of a centralized controller and the availability of a high bandwidth infrastructure for communication purposes between nodes. However, we analyze the dynamics immersed in the system, where these classic approaches, e.g., centralized perspectives, could fall short. Therefore, distributed control approximations receives significant attention in the context of a smart grid, because they have proved to be more flexible and adaptable to network variations.
The classic RD approaches assume that the agents have the complete information available to calculate . However, sometimes this assumption is not possible due to restrictions of the communication network. For that reason, if we want to analyze the outcomes of the availability of information for the EDP, a Boltzmann-based distributed version of the RD is proposed, as it assumes that the agents have incomplete available information of the system. In this scenario, RD considers the neighbor concept to share local information with other agents. To solve the optimization problem, the following assumptions are needed:
Assumption 2. The generation units communicate each other using a connected and undirected graph.
Assumption 3. The Nash Equilibrium belongs to the boundaries of a triangle to n-dimensions known as simplex Δ.
The first assumption means that communication between all generators is guaranteed. Assumption 2 is close in meaning to viability, i.e., if the generators capacity supports the demand of power, then, it is possible to find a solution for the optimization problem, which also means that the power generation capacity belongs to the simplex. If we analyze the concave feature of the utility functions, the problem has a unique solution and the condition of balance is satisfied at steady-state. It is necessary to include the communication graph between the generators to relax the information constraints for the average outcome. To secure the power balance, the results obtained in [
44] must be considered, and the invariance of the constraint set
is proven. Therefore, the BBDRD can be employed to meet the constraints of the network, given by the graph topology.
5.4. Simulation Results
The proposed BBDRD control model is tested in a study case of a smart grid, with seven distributed generators belonging to a low voltage network. The total power demand of the system is kW; DG 3 is the cheapest and DG 7 is the most expensive. The behavior of DGs 1, 4, 5, and 6 has no substantial cost differences, while DG 2 is the cheapest among them. The system works using a frequency of 60 Hz, where the nominal capacity of all generators is 3.6 kW, except for DG 6 that uses 2 KW.
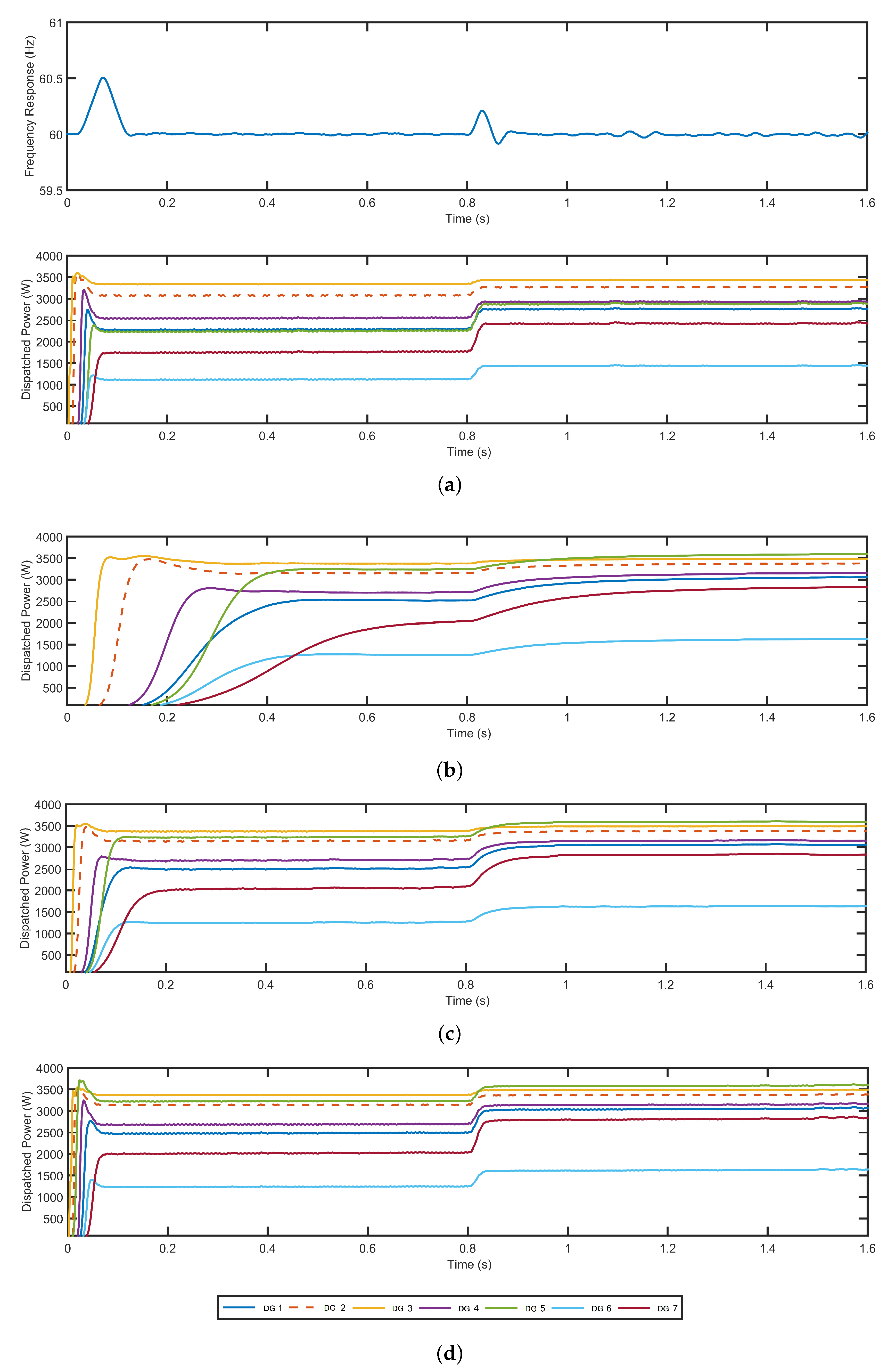
To have a comparison parameter, we first made the simulation of the classic centralized case, which considers the availability of full-information. Results of this stage are depicted in
Figure 6a. In this case, an unanticipated increase in the load of 3 KW and different costs for each generator are observed. The frequency behavior has no significant variations, except in t = 0.8, where the load increment produces a variation of approximately 0.2 Hz, but stabilizes its behavior right after it.
Figure 6a also shows the amount of power dispatched to each DG. At the beginning, generator DG 7 dispatches a minimum power in periods of low demand due to its expensive behavior. In contrast, DG 3 goes close to its maximum capacity and stays around this value without being affected by load variations. If the demand increases, DG 7 increases its capacity too, in order to compensate the demand. In the case of DG 6, it almost reaches all its capacity right after the load variation. DGs 1, 4, 5, and 6 have similar behavior because they also have comparable specifications. Finally, DG 2 goes towards its maximum performance due to its cheap behavior.
Once we had the results of the classic centralized case, we proceeded to use the BBDRD control method to compare its behavior. Results of this stage can be observed in
Figure 6b–d for different values of
. The topology shown in
Figure 5 was used for simulating the communication constraints in the graphs. As the
value increases, the system replicates the behavior of the centralized approach. The major differences are observed with low values of
(
Figure 6b), where DGs take more time to reach their working level. In contrast, when using high values of
(
Figure 6d), DGs reach their working levels faster. Regarding communication constraints, DG 5 has a different behavior compared with the centralized approach, i.e., after the increase in demand, it dispatches more power due to the communication constraints of the topology and the influence of the exploration concept of the second term in Equation (
20).
6. Conclusions
The Boltzmann-based distributed replicator dynamics presented in Equation (
20) can be described as a distributed control method of learning, which incorporates the exploration scheme from reinforcement learning into the replicator dynamics classic equation. In this regard, the exploration is close in meaning to the mutation concept of EGT, and introduces a way to measure variety in the system using the entropy approach. This distributed control method also uses the scheme of the Boltzmann distribution aiming to introduce the
parameter for controlling purposes. The selection of a suitable temperature function involves a methodological search and can now be consistently addressed to meet an expected convergence distribution. In this sense, the dynamics of the method have shown properties of the time dependency of the system, which allows using a structured framework in the design of parameters. In terms of stability, the derivation process in
Section 3 remains stable if multiple agents are allowed. This fact is evidenced with the incorporation of the population concept into the control method. In this sense, the contribution of the neighboring approach gives the key to avoid centralized schemes and forces agents to take into account only the available information of other players before executing an action. The method was evaluated in a smart grid problem and let us initialize parameters previously. Despite the evolutionary interpretation, this fact states the control method applications in the normative side, rather than in the positive side, which is the common use of EGT.
Problems in Engineering are the representation of real situations where the complexity of the systems can be analyzed using MAS, thanks to the study of the interactions between the agents. EGT has some useful tools to manage these interactions to obtain the control agents behavior. In this work, we show the benefits of using a distributed approach of the EGT for controlling a real life smart grid application. This paper shows the BBDRD performance in experiments where communications constraints are involved, thus becoming a useful tool for the implementation of control strategies in a more realistic Engineering with distributed schemes. This feature takes special relevance due to the possibility to tackle complex systems using local information, allowing considering communications constraints without using a centralized coordinator and avoiding high costs of implementation, which is the case of classic approaches, such as the dual decomposition method. In this regard, the distributed control concept used to deal with the EDP can be extended to other problems in the smart grid context, such as the lack of consistency of renewable generation, physical restrictions of power-flow, and inclusion of power losses.
Results showed that despite the limited information, as the value increases and reaches the value of = 5, the system replicates the behavior of the centralized approach. In contrast, for = 0.5 the performance of the method was far away from results obtained using ideal communication conditions (centralized scheme). Having the capacity to tune behavior of the method beforehand seems to be successful with systems modeled using graphs, where communications constraints between agents arise. This also naturally generalizes to any number of agents or populations. Results also showed that performance of the Boltzmann-based distributed method for solving the economic dispatch problem in a smart grid is convenient from the economic perspective. This feature is explained because the specificities of the DGs were consequent regarding their cost of operation and use of their power capacity. This feature is shown because DG 7 dispatches a minimum power in periods of low demand due to its expensive behavior. In contrast, DGs 2 and 3 are close to their maximum capacity and stay around this value due to their cheap behavior. If the demand increases, DG 7 increases its capacity too to compensate for the demand. The behavior of the other DG also has the expected performance. Ranges of the dispatched power were similar in DGs 1, 4, 5, and 6, which is explained by their similar cost features. When comparing results between centralized and decentralized approaches, it can be noted that both have almost the same performance, except in DG 5, which reaches its maximum right after the demand increased. This feature can be explained from the point of view of the communications constraints in the BBDRD control method.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





