1. Introduction
1.1. The Kolkata Paise Restaurant Problem
The Kolkata Paise Restaurant Problem (KPRP for short) is a repeated game that was named after the city Kolkata in India. In KPRP, there are n cheap restaurants (Paise Restaurants) and N laborers who choose among these places for their quick lunch break. If the restaurant they go to is crowded, they have to return to work hungry, since they do not have time to visit another restaurant. For a player to win, that is, to eat lunch, only one player should go to each restaurant. If two or more agents visit the same restaurant at the same time, one agent is chosen randomly, and only this agent is served. The player who eats has a payoff equal to 1, whereas all others who also chose this restaurant have a payoff equal to 0. Each agent prefers to go to an unoccupied restaurant rather than visit a restaurant where there are other agents as well. This realization, in turn, implies that the pure strategy Nash equilibria of the stage game are Pareto efficient. Consequently, there are exactly pure strategy Nash equilibria for the stage game. This, combined with the rationality of the players, leads to the conclusion that it is possible to sustain a pure strategy Nash equilibrium of the stage game as a sub-game perfect equilibrium of the KPRP.
1.2. The Traveling Salesman Problem
The Traveling Salesman Problem (TSP) is a famous optimization problem described as follows: a salesman has to visit all the nearby cities, starting from a specific city to which the salesman must return. The only constraints are that the salesman must start and finish at the same city and visit each other city only once. The visiting order is to be determined by the salesman each time the problem arises. The cities are connected through a railway or a road network, and the time it takes to move from one city to an adjacent one is modeled by the cost assigned to the corresponding edge of the graph. The salesman has just one purpose, and that is to visit all the cities with the minimum possible travel cost. In this problem, the optimum solution is the fastest, shortest and cheapest solution. The TSP is easily expressed as a mathematical problem that typically assumes the form of a graph, where the nodes represent the cities that the salesman has to visit. The TSP is an NP-hard problem, and the results of the practical, heuristic solutions are not always optimal, but approximate [
1]. The simplest “naive” solution to this problem is to try all possibilities and explore all paths, but the cost in time and complexity is so huge that it is practically impossible. To overcome that, when solving a TSP, the pragmatic focus is a near-optimal route instead of always the best route.
1.3. Related Work
1.3.1. The Kolkata Paise Restaurant Problem
The Kolkata Paise Restaurant Problem (KPRP) was initially introduced in an earlier form in 2007 [
2]. Its current formulation appeared in 2009 in [
3,
4]. Subsequently, many creative ideas from different lines of thought have been published, and even a quantum version of the game has arisen. In [
3], the importance of diversity is emphasized, while herd behavior is penalized. Some of the strategies developed for the KPRP are discussed in [
5], which also discusses problems where these strategies can be successfully applied. Ghosh et al. presented a dictator’s, or, as they call it, a social planner’s solution. In this solution, the agents form a queue, and the planner assigns each of them to a ranked restaurant depending on the queue of the first evening. The following evening, the agents go to the next-ranked restaurant, and the last in the queue goes to the first-ranked restaurant. This solution is called the fair social norm. In real life, each agent decides in parallel or democratically every evening, so this solution may be considered somewhat unrealistic. However, the parallel decision or democratic decision strategy is not as efficient as the dictated one, with the latter leading to one of the best solutions to this problem. Banerjee et al. in [
6] offered a generalization of the problem in such a way that the cyclically fair norm is sustained. Each strategy is viewed as a sub-game of perfect equilibrium of the KPRP. In 2013, Ghosh et al. published an article about stochastic optimization strategies in the KPRP [
7]. There, they point out that a stochastic crowd-avoiding strategy results in efficient utilization in the KPRP. Reinforcement learning was first introduced to the KPRP in [
8], together with six revision protocols aiming at efficient resource utilization. These protocols combine local information with reinforcement learning. Each revision protocol has two variants, depending on whether or not customers who were once served by a restaurant remain loyal to that restaurant in all subsequent periods. Some of these protocols were experimentally tested and shown to improve the utilization rate. Another generalization was introduced by Yang et al. in [
9], aiming at dynamic markets. They studied what happens when agents can either divert to another district or stay in the current one. Each agent may replace another agent with no prior knowledge of the game, following a Poisson distribution. Agarwal et al. in [
10] showed that the KPRP could be reduced to a Majority Game. In the latter, capacity is not restricted, and agents aim at choosing with the herd. If many agents choose the same option, the utility decreases (see also [
11,
12]). Abergel et al. in [
13] applied the KPRP to hospitals and beds. Among the local hospitals, the local patients choose those with the best ranking and compete with the other patients. If the patients are not treated in time, it is a clear case of social waste of service for the rest of the hospitals. Park et al. in [
14] introduced the KPRP to the context of the Internet of Things (IoT) and IoT devices. They used a KPRP approach to develop a scheme for these devices because it allowed them to model situations where multiple resources are shared among multiple users, each with individual preferences. In [
15], Sinha et al. proposed a phase transition behavior, where if two or more agents visit the same restaurant, one is randomly chosen to eat.
A significant trend, quite evident in the last two decades, is to enhance classical games using unconventional means. The most prominent direction is to cast a classical game in a quantum setting. Since the pioneering works of Meyer [
16] and Eisert et al. [
17], quantum versions for a plethora of well known classical games have been studied in the literature. Starting from the most famous of all games, the Prisoners’ Dilemma [
17,
18,
19,
20], many researchers have sought to achieve better solutions by employing quantumness (see the recent [
20,
21,
22] and references therein), or other tools, such as automata [
23]. It is not surprising that unconventional approaches to classical games are undertaken because they promise clear advantages over classical ones, or additional insights over traditional interpretations as in [
24]. Another line of research is to turn to biological systems for inspiration. Most game situations can easily find analogs in biological and bio-inspired processes (see also [
25]). A quantum version of the KPRP was proposed in [
26], where the agents cannot communicate with each other and have to choose among
m choices, but an agent wins by making a unique choice. Higher payoffs than the classical version were observed due to shared entanglement and the use of quantum operators. In Sharif’s [
27] review, quantum protocols for quantum games were introduced, including a protocol for a three-player quantum version of the KPRP. In [
28], the authors studied the effect of quantum decoherence on a three-player quantum KPRP using tripartite entangled qutrit states. They observed that, in the case of maximum decoherence, the influence of the amplitude-damping channel dominates over depolarizing and flipping channels.
1.3.2. The Traveling Salesman Problem
The first appearance of the term “Traveling Salesman Problem” probably occurred between 1931 and 1932, and it was first studied by Karl Menger during the 1930s at Harvard and Vienna. The core of the TSP problem, however, was first mentioned over a century before in an 1832 German book [
29]. The mathematical formulation was introduced by Sir William Rowan Hamilton and Thomas Kirkman.
Research efforts on the TSP and closely related problems include Ascheuer et al. [
30], who addressed the asymmetric TSP-TW using more than three alternative integer programming formulations and more than ten neighborhood structures. Gutin and Punnen [
31] studied the effect of sorting-based initialization procedures. The authors claimed that understanding the algorithmic behavior was the best way to find solutions since this would help in determining the best one out of those available.
The difficulty of tackling the TSP motivated researchers to explore other avenues. One such notable and particularly promising approach is based on metaheuristics. A metaheuristic is a high-level heuristic that is designed to recognize, build, or select a lower-level heuristic (such as a local search algorithm) that can provide a fairly good solution, particularly with missing or incomplete information or with limited computing capacity [
32]. The term “metaheuristics” was coined by Glover. Metaheuristics can be used for a wide range of problems. It must be noted of course that metaheuristic procedures, in contrast to exact methods, do not guarantee a globally optimal solution [
33]. Papalitsas et al. [
34] designed a metaheuristic based on VNS for the TSP, with emphasis on time windows. Another quantum-inspired method, based on the original General Variable Neighborhood Search (GVNS), was proposed to solve the standard TSP [
35]. This quantum-inspired procedure was also applied successfully to the solution of real-life problems that can be modeled as TSP instances [
36]. A quantum-inspired procedure for solving the TSP with time windows was also presented in [
37]. More recently, ref. [
38] applied a quantum-inspired metaheuristic for tackling the practical problem of garbage collection with time windows that produced particularly promising experimental results, as further comparative analysis demonstrated in [
39]. A thorough statistical and computational analysis of asymmetric, symmetric, and national TSP benchmarks from the well known TSPLIB benchmark library was conducted in [
40]. Very recently, Papalitsas et al. expressed the TSPTW in the Quadratic Unconstrained Binary Optimization (QUBO for short) framework [
41]. The QUBO formulation enables TSPTW to run on a quantum annealer and is a critical step towards the ultimate goal of running the TSPTW using pure quantum optimization methods. Stochastic optimization can be implemented through several metaheuristic processes. The obtained solution depends on the set of random variables [
32]. Metaheuristic processes may find successful solutions with less computational effort than accurate algorithms, iterative methods, or basic heuristic procedures by looking for a wide variety of feasible solutions [
33]. Hence, metaheuristic procedures are extremely useful and practical approaches for optimization because they can guarantee good solutions in a small amount of time. For example, a problem instance with thousands of nodes can be run for 30–40 s and produce a solution with a 3–5% deviation from the optimal. In view of the small amount of time they require and of the good quality of the solution they produce, we advocate their functional use in the Distributed Kolkata Paise Restaurant game.
Contribution. In this paper, we approach the Kolkata Paise Restaurant Problem from an entirely new perspective. This provides the opportunity for an entirely new setting and the adoption of a novel approach that leads to a new and more efficient strategy and, ultimately, to greater utilization of the restaurants. For the first time, to the best of our knowledge, we focus on the spatial setting of the game, and we propose a more realistic and plausible topological layout for the restaurants. We perceive the restaurants to be uniformly distributed over the entire city area. This has profound ramifications on the topological layout of the game: the restaurants now get closer and, as their number n increases, the distances between nearby restaurants decrease. Due to the distribution of the restaurants, the resulting version of the game is aptly named the Distributed Kolkata Paise Restaurant Game. Thus, it is now realistic to assume that every agent has a second, a third, and maybe even a fourth chance. The agent is no longer a single destination and back traveler. The agent now resembles the iconic traveling salesman, who must pass through a network of cities and come back to the starting point, all while following the optimal route. This entirely new setting is formalized and rigorously analyzed via probabilistic tools. We derive general formulas that mathematically confirm the advantages of this policy and the increase in utilization. The proposed scheme demonstrably achieves utilization ranging from to , and even beyond, from the first day. The steady-state utilization, to which the game rapidly converges, is, as expected, . The equations we derive generalize formulas that were previously presented in the literature, showing that the latter are special cases of our results.
1.4. Organization
The structure of this paper is as follows. In
Section 1, we provide a comprehensive description of the KPRP and the TSP. The rigorous formulations of the KPRP and the TSP are presented in
Section 2. In
Section 3, we give a thorough explanation and presentation of the distributed version of the game. We analyze mathematically the topological situation regarding the restaurants in
Section 4. We formally prove the main results of the paper in
Section 5. Finally, in
Section 6, we summarize our results and discuss future extensions of this work.
2. Background
2.1. Formulation of the Standard Kolkata Paise Restaurant Problem
In its most usual formulation, the Kolkata Paise Restaurant Problem is a repeated game with infinite rounds. There is a set of players, typically called
agents or
customers, that is denoted by
, a set of restaurants that is denoted by
, and a utility vector
that is associated with the restaurants and is common to every agent. On any given day, all agents decide to go to one of the
n restaurants for lunch. If just one agent arrives at a specific restaurant, she has lunch and is happy. If, however, two or more agents choose the same restaurant for lunch, just one of them eats. The one who eats is chosen randomly. So, in such a case, all but one are unhappy. The utility of a happy agent is 1 and 0 otherwise. In Chakrabarti et al. [
3], the KPRP is modeled as a general one-shot restaurant game, where the set of agents is considered to be finite, and the utilities are ranked as follows:
. The set of agents
A and the ranking of the utilities can be used to define the game. The latter can be represented as
, where
A is the set of agents,
S is the set of strategies available to all agents, and
stands for the payoff vector. If the
agent
decides to go to the
restaurant
, then the corresponding strategy is
. Every day, each agent decides which of the
n restaurants she visits. Given any strategy combination
, the associated payoff vector is defined as
, where the payoff
of player
is
, and
is the total number of players who have made the same choice. The strategy combination is the restaurants the agents choose to eat at, and their payoff depends on their decision and the number of other agents who have made the same choice. In the literature, a game such as KPRP, where there are potentially infinite rounds and the same stage game is played in each round, is referred to as a
supergame [
42].
2.2. Formulation of the TSP
The TSP is an NP-hard problem of great significance to different fields, e.g., operational research and theoretical computer science. Usually, the TSP is represented by a graph. The fact that the TSP is NP-hard implies that there is no known polynomial-time algorithm for finding an optimal solution [
43]. There are two types of models for the TSP:
symmetric and
asymmetric. The former is represented by a complete undirected graph
and the latter by a complete directed graph
. Assuming that
n denotes the number of cities (nodes),
is the set of vertices,
is the set of edges, and
is the set of arcs. A cost matrix
, which satisfies the triangle inequality
for every
, is defined for each edge or arc. If
is equal to
, the TSP is
symmetric (sTSP), otherwise it is
asymmetric (aTSP). In particular, this is the case for problems where the vertices are points
of the Euclidean plane, and
is the Euclidean distance. The triangle inequality holds if the quantity
represents the length of the shortest path from
i to
j in the graph
G [
44]. In the case of the symmetric TSP, the number of all possible routes covering all cities and corresponding to all feasible solutions is given by
(recall that the number of cities is
n). The cost of the route is the sum of the costs of the edges followed.
3. Formulation of the DKPRG
The Kolkata Paise Restaurant Problem (KPRP) involves multiple players (n), each having multiple choices (N). In its most general form, it is possible that . In this paper, we follow the standard approach that the number of agents is equal to the number of restaurants, i.e., . We advocate a spatially distributed and, in our view, more realistic version of the KPRP by taking into account the topology of the restaurants and by allowing the agents to begin their routes from different starting points. We call our version the Distributed Kolkata Paise Restaurant Game, or DKPRG from now on. In the original formulation of the KPRP, one may point out the following underlying assumptions.
- (A1)
The agents start from the same location.
- (A2)
All restaurants are close enough to the point of origin of every customer that each customer can, in principle, go to any restaurant, eat there, and return to work on time.
- (A3)
Every restaurant is sufficiently far away from every other restaurant to make prohibitive the possibility of any customer visiting a second restaurant if their first choice proved fruitless.
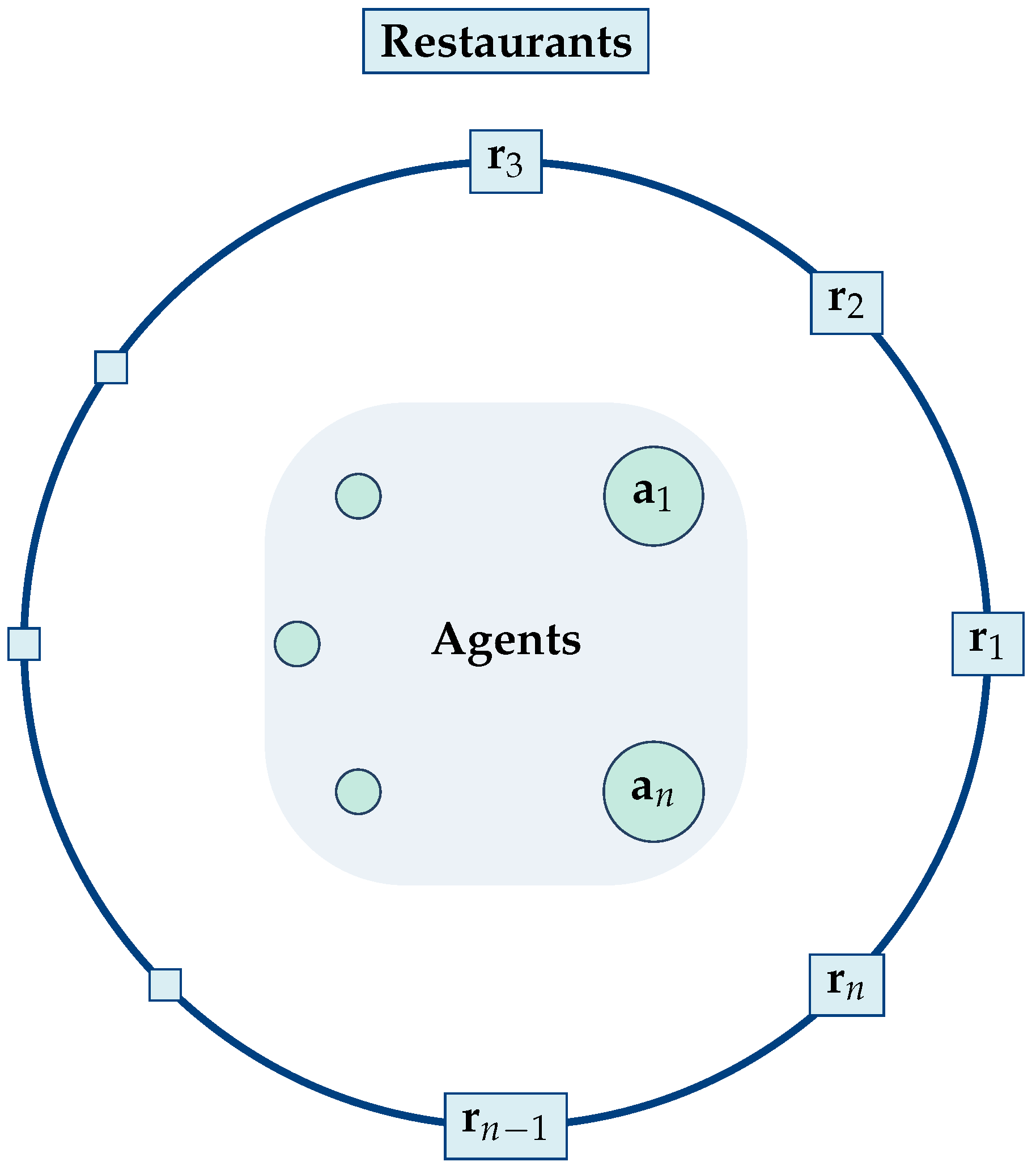
In the two-dimensional setting of Kolkata, the above assumptions taken together imply the topology depicted in
Figure 1. There, the agents are concentrated within a very narrow region, which can be viewed as the center of a conceptual “circle”. The restaurants are located on this “circle” and, since
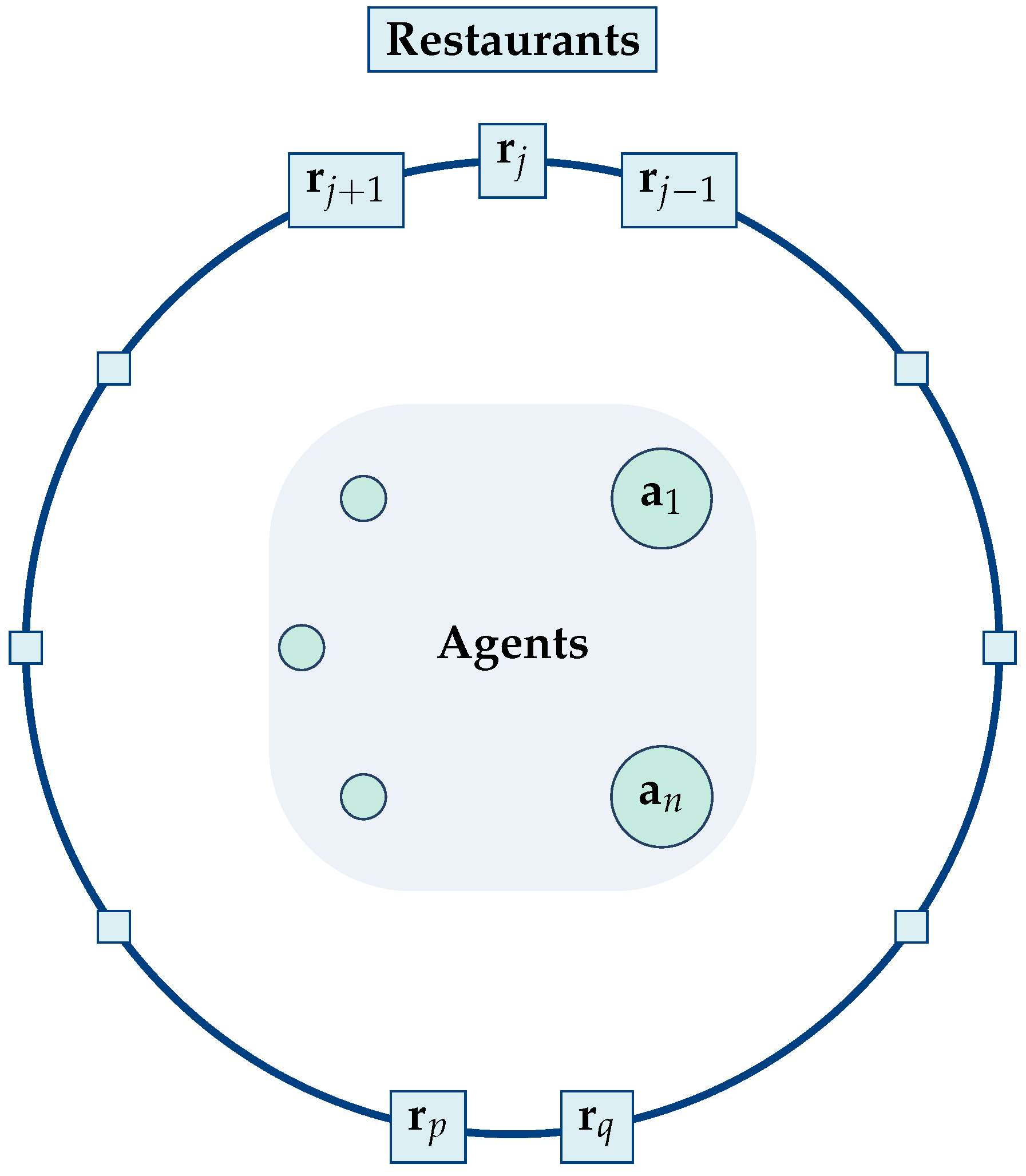
no two of them are allowed to be close, they form a “regular polygon”. This precludes a situation such as the one shown in
Figure 2. The spatial layout depicted there is strictly forbidden. The proximity of two, three, or more restaurants contradicts the impossibility of a second chance. In the standard KPRP, no agent is allowed a second chance. We write “circle” and “regular polygon” inside quotation marks because we are not dealing with a perfect geometric circle or a perfect regular polygon, but with two-dimensional approximations resembling the aforementioned symmetric shapes. Clearly, this is a very special topological layout, one that is highly unlikely to be observed in practice. There is no compelling reason for the restaurants to exhibit this regularity or the agents to be confined to approximately the same location. On the contrary, it would seem far more reasonable to assume that the restaurants and perhaps the agents are uniformly distributed. Moreover, the usual assumption that the preference ranking of the restaurants is common to all customers seems a bit too special and probably too restrictive.
With that motivation in mind, we propose to abolish all these assumptions. The resulting game is spatially distributed in terms of restaurants and is called the Distributed Kolkata Paise Restaurant Game (DKPRG). In our setting, each customer may have a unique starting point that is, in general, different from the starting locations of the other customers. The starting locations can either be concentrated in a small region of the Kolkata city area, precisely like the standard KPRP, or they may be assumed to follow a random distribution. The fundamental difference from prior approaches is that now the restaurants are viewed as being uniformly distributed over the city of Kolkata. This uniform randomness in the placement of the restaurants implies that there must be restaurants near each other. This conclusion becomes inescapable, particularly in the case where the number of restaurants is large (). As we show, the expected distance between “adjacent” restaurants is relatively short and decreases as the number n of restaurants increases. This leads to a personalized situation for each individual agent: each agent is faced with a personalized Traveling Salesman Problem. To every agent corresponds an individual graph. This graph has nodes, which are the locations of the n restaurants plus the location of the starting point of the customer. The costs assigned to the edges are also personalized; each agent combines an objective factor, namely, the spatial distances between the restaurants, with a subjective factor, her personal preferences. In the DKPRG, we forego the common preference restriction, and we let every customer have a distinct preference. Let us clarify, however, that being served, even at the least preferable restaurant, is more desirable than not being served at all. This, in turn, leads to a possibly unique ordering of the restaurants from the most preferable to the least preferable for each agent.
Hence, every agent is faced with a distinctive network topology that is the combined result of the inherent randomness of the spatial locations and the subjectiveness of the preferences. The topology of the restaurants has a further critical implication: a customer whose first choice is a particular restaurant now has, with very high probability, the opportunity to visit a second, a third, or even a fourth restaurant in the same area. For each agent, the time cost is dominated by the time taken to visit the first restaurant; the trip to other nearby restaurants in the same region incurs a negligible time cost due to their spatial proximity. The customer has a second (or even a third) chance to be served during the lunch break. Thus, an efficient, if not optimal, method for every customer to make well informed decisions regarding the first, second, third, etc., choice is to solve the Traveling Salesman Problem for her personalized graph. Although the TSP is an NP-hard problem, near-optimal solutions of practical value can be achieved in a very short time by employing metaheuristics. Starting from this perspective, we propose a distributed strategy that leads to an efficient global solution. All agents use a common high-level strategy that is fine-tuned according to their individual preferences. To enhance clarity, we explicitly state below the game settings that characterize the DKPRG variant.
- (1)
The Distributed Kolkata Paise Restaurant Game is an infinitely repeated game.
- (2)
The set of agents is denoted by . The nagents (also referred to as customers) may have different starting locations. The set of restaurants is denoted by . The n restaurants are uniformly distributed within the city area. All agents know the locations of the restaurants, but they need not know the starting locations of the other agents.
- (3)
To each agent corresponds a distinct personal preference ordering , such that restaurant is their first preference, is their second preference, and so on, with being the least preferable.
- (4)
Each restaurant can accommodate only one customer at a time; if two or more customers arrive at a restaurant, only one can be served. The one to be served is chosen randomly.
- (5)
Each agent perceives a personalized graph . is a complete undirected graph having vertices , where is the starting location of a and is the location of restaurant . The graph is complemented with the (symmetric) cost matrix that assigns to each edge a cost .
- (6)
Each agent solves the corresponding TSP using an efficient metaheuristic that outputs a near-optimal tour , where is the starting point of a and , is the index of the restaurant in the position of the tour.
- (7)
Endowed with their individual tour , all customers follow a common strategy. They travel from their starting location to the restaurant . If they are served, then they conclude their route successfully. If not, they proceed to . If their attempt at eating lunch there also fails, then they proceed to , and so on.
- (8)
The Revision Strategy. The agents operate independently, and no communication takes place between any two of them. Therefore, each customer is completely unaware of the routes of the other customers. Every evening they revise their strategy, taking into account only what happened during the current day. If they were served at a specific restaurant this day, then tomorrow they go straight to the same restaurant. This applies even if this restaurant is not the first destination of their tour. Those who failed to eat lunch only know which restaurants were left vacant. The unserved agents construct and solve their new personalized TSP, this time using as vertices only the vacant restaurants (plus of course their starting location).
4. Topological Considerations
We begin this section by fixing the notation and giving some definitions to clarify the most important concepts of our exposition.
Definition 1. The one-shot DKPRG takes place every day. We use the parameter to designate the day under consideration.
To every agent corresponds a personalized network with cost matrix . Agent a follows the tour , which is the solution to the personalized TSP.
The quality and efficiency of the strategy are measured by the utilization ratio f. This is the fraction of agents being served in a day, or, equivalently, the fraction of restaurants serving customers in a day.
An agent a who has opted to follow tour initially tries to eat lunch at restaurant . If she succeeds, she eats and returns to her starting point. If not, she visits the next restaurant of the tour, i.e., . If she eats lunch there, she goes back to work. This goes on until either she is served or runs out of time, in which case she must interrupt the tour and return to work. If the time constraints allow her to pass through the firstm restaurants in the tour, in the worst-case scenario of consecutive failures, then we say that is an m-stop tour. In the rest of this work, we study the case where because the case where reduces to the standard treatment of the KPRP, which has already been analyzed extensively in the literature.
Definition 2. The tour is an m-stop tour, , if, in the worst case, agent a can visit restaurants in this order without violating the time constraints. In such a tour, is the first stop, is the second stop, and so on, with being the final mth stop. If , is an m-stop tour, and the resulting game is the m-stop DKPRG.
Let us now explore the spatial ramifications of our assumption that the restaurants are uniformly distributed within the overall city area.
Definition 3. Given a region B on the plane, a random variable L that takes values in B has uniform distribution
on B, if for any subregion C the following holds:where P denotes the probability. The above definition is adapted from [
45]. For a more general and sophisticated definition in terms of measures, we refer the interested reader to [
46].
In order to enhance the readability of this work, we have placed the proofs of all the results that follow in the
Appendix A.
Proposition 1. Assuming that the n restaurants are uniformly distributed over the whole city area, then, if the city area is partitioned into n regions of equal area, the expected number
of restaurants in each region is exactly 1.
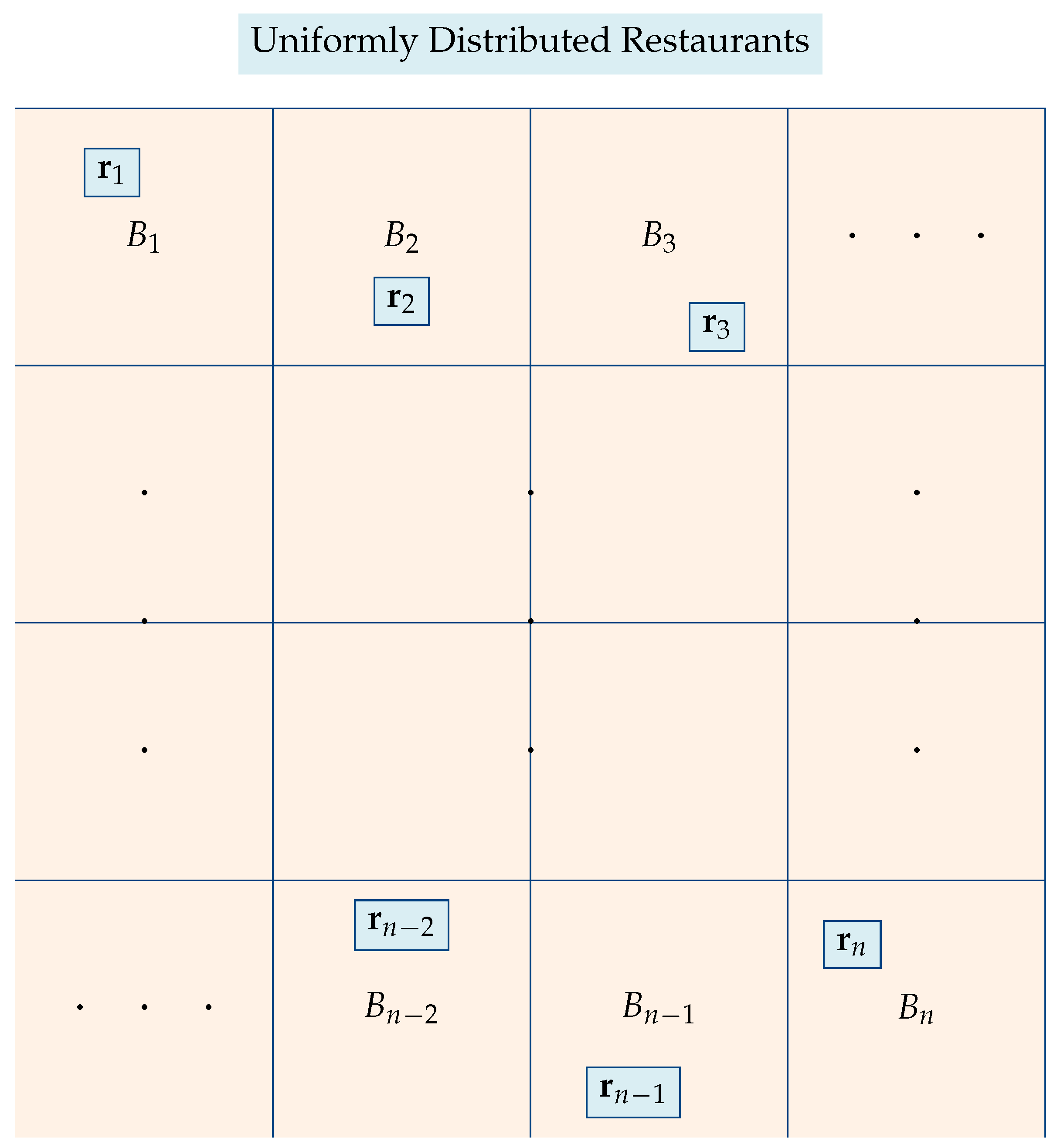
This topological layout of the restaurants is shown in
Figure 3. The regions are drawn are squares, but this is just for convenience and to facilitate their graphic depiction. For very large values of
n, partitioning a city into very small identical squares is a good approximation, as we know from the field of image representation. We emphasize that the use of squares does not lead to any loss of generality. From a theoretical point of view, the standard metric topology of
is the same irrespective of whether the topological basis consists of squares or circular balls or diamond shape regions (a thorough analysis of this fact can be found in [
47]).
Let us observe that there is a meaningful notion of distance between any two points in the city area. In reality, this can be the geographical distance between any two locations. Consider, for instance, two points x and y with spatial coordinates and , respectively. A typical manifestation of the notion of distance is the Euclidean distance: between x and y. We take for granted the existence of a distance function defined on every pair of points , denoted by .
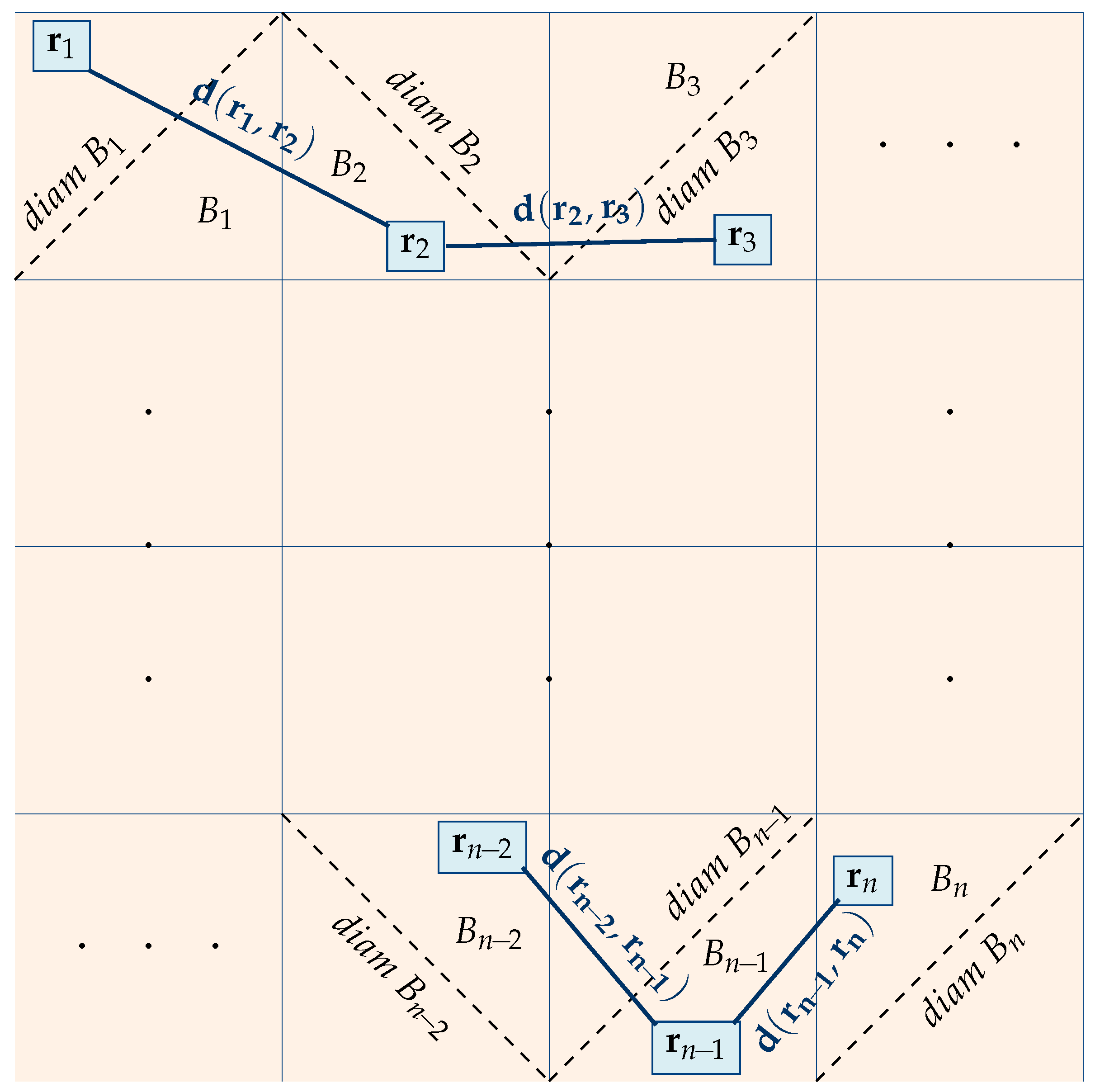
Definition 4. The distance between two regions and is defined as Two regions and are adjacent if The diameter
(see also [47]) of a region is defined as
Proposition 2. Let the n restaurants be uniformly distributed over the city area and assume that the whole area is partitioned into n regions of equal area. If and are located at adjacent regions and , , then As shown in
Figure 4 the expected distance between restaurants which lie in adjacent regions becomes shorter, as the number of restaurants increases. The above upper bound can be simplified if we assume that all regions have the same geometric shape. This implies that
, in which case inequality (
6) becomes:
In the special case where the regions are squares, .
The diameter of the regions decreases as n increases, and in the special case shown in the previous figures, the diameter decreases in proportion to . This means that adjacent restaurants are very close to each other as .
5. Mathematical Analysis of the Utilization
This section is devoted to the analytic estimation of the evolution of the game parameters and the daily utilization of the proposed strategy scheme.
Definition 5. The expected number of agents who had lunch during day 1 is denoted by and the expected number of those who failed to do so is denoted by .
The expected number of agents who ate for the first time during day , is denoted by . The expected number of agents who failed to eat during day , is denoted by .
Symmetrically, the expected number of restaurants that served lunch during day 1 is denoted by , the expected number of restaurants that did not is denoted by , the expected number of restaurants that served a customer for the first time during day , is denoted by , and the expected number of those who failed to do so is denoted by .
The vacancy probability of day 1 is the probability that a restaurant did not accommodate any customer during day 1 and is designated by . The vacancy probability of day , denoted by , is the probability that a restaurant that has not served any customer before day t did not serve a customer during day t either.
In the m-stop DKPRG, the agents who actively play the game at the beginning of day t, seeking a restaurant at which to eat lunch, are called active players, and their expected number is denoted by .
The expected utilization of day , designated by , is the fraction of the expected number of agents who were served during day t. The steady-state utilization is defined as .
The following analysis is based on the premise that all tours are equiprobable. We shall refer to it as the equiprobability of tours assumption (EPT for short). Given the discussion in the previous sections, this premise is well justified. An immediate consequence of the EPT assumption is the equiprobability of each restaurant appearing in any position. For easy reference, these facts are collected in the next Proposition 3, for which the proof is trivial and thus omitted.
Proposition 3. Assuming the equiprobability of tours, the following hold. The above can be generalized to handle the case of a restaurant r appearing in one of w distinct positions , where . Since the probability that restaurant
is in the
position of the tour of agent
a is
, the probability of the complementary event is
. If we deem as “success” the case where
r is indeed in the
kth position of
and as “failure” the case where
r is not, then this situation is a typical example of a
Bernoulli trial, having probability of success
(also referred to as
parameter, see [
48]) and probability of failure
. Analogously, the probability that restaurant
appears in
one of
,
distinct positions of the tour of agent
a is
. The probability of the complementary event is
. Again, this is a Bernoulli trial, this time with parameter
. The fact that the
n agents calculate their tours
independently implies that
n independent Bernoulli trials take place simultaneously, all with the same success and failure probabilities. This situation is described by the
binomial distribution with parameters
(see [
45,
48] for details), denoted by
, where
in the simple case of one position and
in the general case of
w positions. Using well known formulas from probability textbooks, we may assert the following Proposition 4, the proof of which is also trivial.
Proposition 4. Given a restaurant r, the probability of appearing in a specified position k exactly l times in total in n tours is given by In the special case, where r never
appears in position k, the above formula becomes: More generally, the probability that restaurant r appears exactly l times in total in one of the w distinct positions is given by The probability that r never
appears in the designated positions is According to the strategy scheme employed in the m-stop DKPRG, at the start of the second (third, etc.) day, the satisfied customers always go straight to the restaurant that eventually served them during the previous day. This strategy is followed by all agents, which guarantees that the customers who were satisfied the previous day remain satisfied today. Effectively, this implies that the satisfied agents have “won” the game and from now on they do not need to solve their personalized TSP. The game is played competitively by the unsatisfied agents of the previous day. We assume that they are aware of the unoccupied restaurants and, therefore, each one of them once again solves their personalized TSP to compute their tour. Of course, today the network of restaurants consists only of the unoccupied restaurants. The one-shot m-stop DKPRG of today is different from the one-shot game of the previous day in a critical factor: the number of “actively competing” players is significantly smaller. By the nature of the game, the number of active players at the beginning of stop 1 of the present day is equal to the number of unsatisfied customers at the end of the previous day. The expected number of active players varies with each passing day according to Theorem 1.
Theorem 1. The daily progression of the m-DKPRG is described by the following formulas, where t stands for the day in question. Let us now make an important observation: Formula (
17) that we derived above is completely general and subsumes more special formulas found in the literature. Take, for example, the special case where
and
. For these values, (
17) computes the expected number of vacant restaurants at the end of day 1 for the standard one-stop KPRP. We can readily derive the expected utilization ratio for day 1, as shown below.
One assumption that is taken for granted in the literature is that the number of agents n tends to infinity. By recalling that , we see that , which is in complete agreement with a well known result of the literature. When , the following Corollary 1 provides useful approximations of the formulas of Theorem 1. Its proof follows almost verbatim the proof of Theorem 1 and is, therefore, omitted.
Corollary 1. If we assume that , then the following approximations hold, where t is the day in question. To demonstrate how the exact Formulas (
16)–(
23) reflect the daily evolution of the
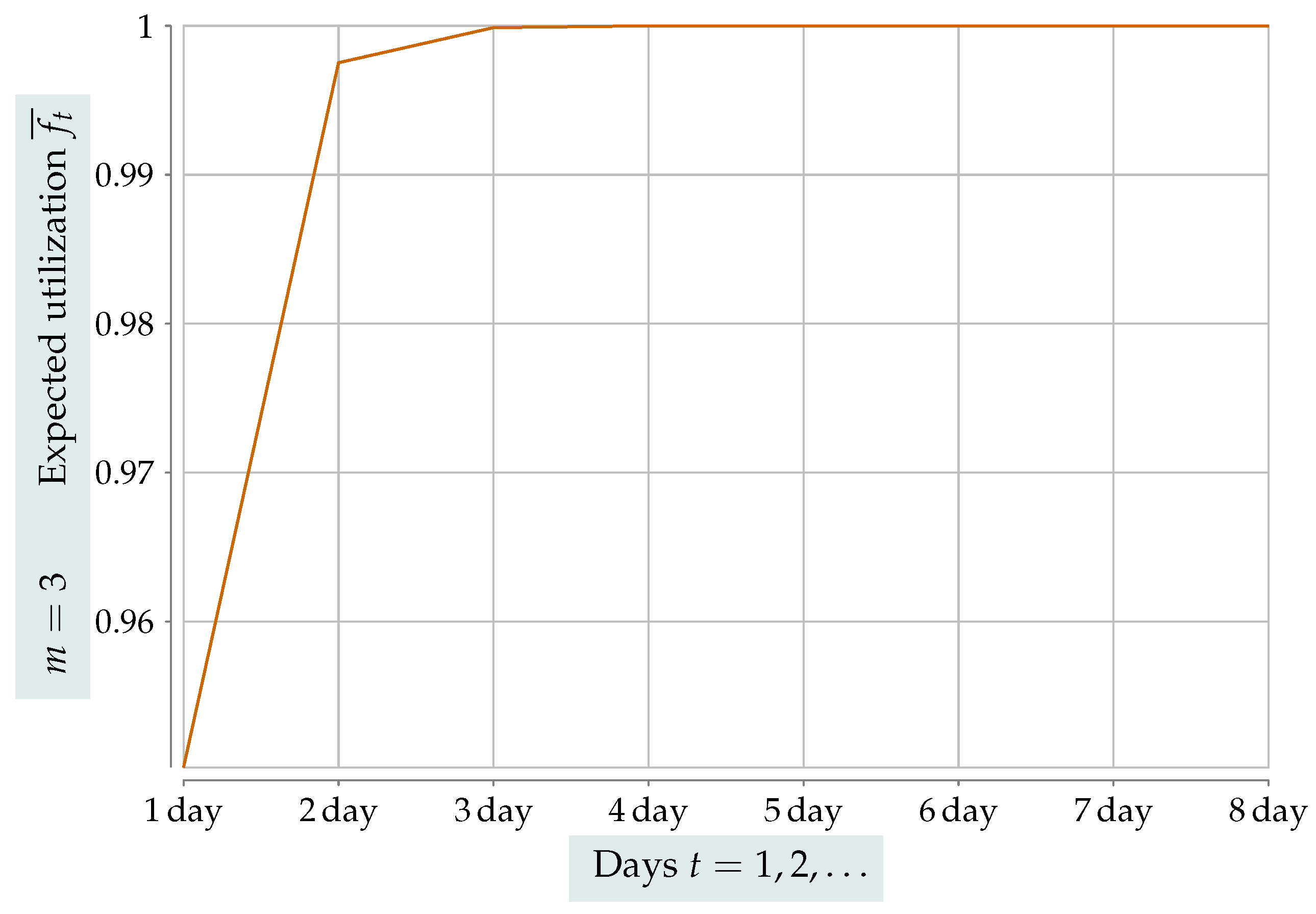
m-DKPRG, we study a 3-DKPRG game in the following example.
Example 1. In this game, the number m of steps is 3,
meaning that each agent may visit up to three
restaurants if need be, and the number n of agents is . Such an instance, with a large number of agents, can serve as the best demonstration of the dramatic improvement that can be obtained by an increase in the number of steps. Indeed, the numerical application of the Formulas (16)–(23) is depicted in Figure 5. A visual inspection corroborates this expectation, as one can see that all restaurants are utilized by the end of day 4,
and the utilization at the end of the first day is already up to an impressive and becomes 1,
for all practical purposes, at the end of day 3.
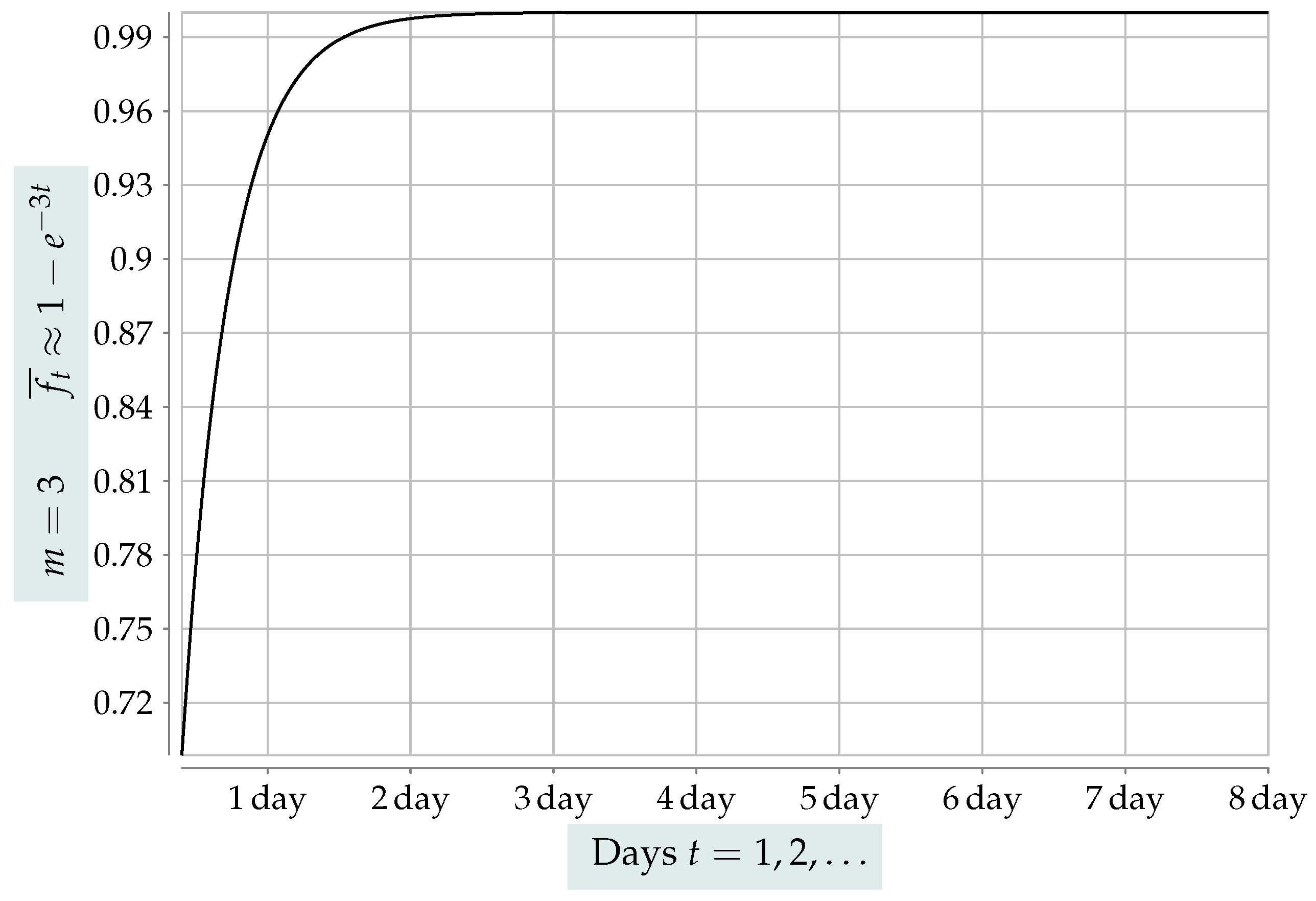
The value of the approximate Formulas (
25)–(
32) lies in the fact that they can provide easy-to-compute and particularly good approximations for a large
n. A simple comparison of the approximation shown in
Figure 5 with
Figure 6 ascertains their accuracy.
6. Discussion and Conclusions
This work explored a completely new angle of the Kolkata Paise Restaurant Problem. The topological layout of the restaurants takes center stage in this new paradigm. Initially, we explicitly stated certain assumptions that are only implicitly present in the standard formulation of the game. Having done that, we undertook the radical step of going past them and creating an entirely new setting. The critical examination of the topological setting of the game enhanced our perception regarding the locations of the restaurants and suggested a more realistic topological layout. We argued that their uniform distribution over the entire city area is the most logical, fair, and probable situation. As a result, we defined a new version of the game that is spatially distributed and is aptly named the Distributed Kolkata Paise Restaurant Game (DKPRG). The uniform probabilistic distribution of the restaurants enabled us to rigorously prove that, as their number n increases, the restaurants get closer, and the distance between adjacent restaurants decreases. In such a network, every customer has the opportunity to pass through more than one restaurant within the allowed time window. The agents now become traveling salesmen, and this led us to suggest the innovative idea that the TSP can be used to increase the chances of success in this game. This culminated in the development of a new and more efficient strategy where every agent uses metaheuristics to solve their personalized TSP, thereby achieving greater utilization.
After rigorously formulating the DKPRG, we proved completely general formulas that assert the increase in the utilization of our scheme. We established that utilization ranging from
to
is achievable. Apart from the exact formulas, we also derived the approximate Formulas (
25)–(
31). They can be quite useful because they are considerably easier to compute and are exceedingly good approximations for a large
n. This fact is easily corroborated by comparing
Figure 5 to the approximation shown in
Figure 6. Let us remark that the derived equations generalize previously presented formulas in the literature.
It is worth mentioning that the fact that our strategy exhibits very rapid convergence to the steady state of utilization, , can potentially be used to address the following situation. An issue that remains and is common to almost all works in the literature is the simple matter that a near-optimal utilization may not, in general, be optimal for every agent individually. A socially efficient outcome, where every agent eats lunch and every restaurant has a customer to serve, is not necessarily optimal for the individual customer, in the sense that an agent may be served in a restaurant of low preference. A possible solution to this might be to reset the game periodically. We expect that adopting a reset period, i.e., setting a specific period of days after which the system is reset, and the game starts from scratch, may alleviate this drawback.
We believe that the proposed game can be successfully applied to many real-life situations of practical importance. For example, the distributed nature of the proposed game would make it particularly suitable for tackling the problem studied in [
7]. There, a region or a country provides hospitals and beds in different parts of an area. However, there are cases of patients who prefer to go to higher-ranking hospitals at a greater distance than to lower-ranking hospitals at shorter distances. This results in a long waiting list as both local and non-local patients wait more, causing untimely treatment for patients (as the estimated number of patients increases) and a social waste of services for inaccessible hospitals. In the health care context, there are two more cases in which the game we suggest could offer a solution. The first concerns ambulance offload delays, i.e., when an ambulance arriving at the emergency department cannot leave the patient because there are no beds available. This solution can work on two levels, choosing the best route for the ambulance to arrive on time and contributing to better management of hospital resources in order for the treatment of the patient to start immediately [
49]. At the same time, numerous problems concerning route optimization, resource allocation, and utilization appear in the area of public transport. The most common question about transportation is how limited resources should be utilized to maximize social benefits, taking into consideration the peak periods and the unequal distribution of resources [
50]. A traffic problem that our proposal could tackle, similar to the previous one, is the school bus routing problem [
51]. The difficulty of the school bus routing problem stems from the strict routine and timetable the buses have to follow, the requirement that the students need to arrive on time for their classes, and the calculation of the optimal route for the bus in order to collect all the students.
Another possible direction for future work could include extensive experimental tests and further investigation of other versions of the TSP. For instance, there exists a more restrictive version of the TSP, the Traveling Salesman Problem with Time Windows (TSP-TW). TSP-TW is a constrained version of the TSP in which the salesman must visit the cities within a specific time window. This version is even more complicated and difficult to solve. However, the inherent time constraints built in to the TSP-TW may provide for even more realistic modeling of the DKPRG, so it is a research avenue that we believe is worth pursuing.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





