Abstract
I consider a class of dynamic Bayesian games in which types evolve stochastically according to a first-order Markov process on a continuous type space. Types are privately informed, but they become public together with actions when payoffs are obtained, resulting in a delayed information revelation. In this environment, I show that there exists a stationary Bayesian–Markov equilibrium in which a player’s strategy maps a tuple of the previous type and action profiles and the player’s current type to a mixed action. The existence can be extended to K-periodic revelation. I also offer a computational algorithm to find an equilibrium.
Keywords:
Bayesian game; stochastic game; existence; stationary Markov equilibrium; periodic revelation JEL Classification:
C62; C73
1. Introduction
In the parable of the blind men and the elephant1, individuals attempt to comprehend the concept of an elephant solely through the sense of touch. Each person, limited to exploring only a specific part of the elephant, such as the wriggling trunk, flapping ears, or swinging tail, reaches their own conclusions about the shape of an elephant. One perceives the elephant as resembling a snake, another as a fan, and yet another as a rope. The parable serves as an analogy to the situation where economic agents have incomplete perceptions about the true state of the world. Players choose actions based on their limited perception of the state of the economy, but, eventually, the true state of the world is revealed. Players’ actions accordingly yield rewards or penalties.2
To incorporate the above aspect of reality into a formal model, this paper considers a class of dynamic Bayesian games in which types evolve stochastically according to a first-order Markov process on a continuous type space (“Bayesian stochastic games”). It is well known that equilibria of stochastic games with the continuous state space are elusive. This paper overcomes the challenge with the Bayesian feature. Dynamic Bayesian games with serially correlated types, however, are notorious for the curse of dimensionality that the dimension of players’ beliefs grows over time, and, thus, equilibria of such games are generally not tractable. This paper introduces delayed revelation of private information which is referred to as “periodic revelation” to overcome the dimensionality issue of beliefs. Types remain private when players choose actions, but they are revealed alongside actions when payoffs are obtained. In this framework, there exist a class of stationary Markov perfect equilibria. The game structure and equilibrium concept can be applied to the analyses of dynamic oligopoly with asymmetric information or many other economic environments with a delay of information revelation.
Suppose, at each time t, a player has a limited piece of information about the true state of the world. It is defined as the type of the player in the t-stage Bayesian game. The type profile of all the players is the true state of the economy, and it is hidden when players choose actions. But type and action profiles are eventually revealed to everyone at the end of the stage when individual payoffs of the stage Bayesian game are obtained. Toward the next period, the type profile stochastically evolves according to a first-order Markov process based on the revealed type and action profiles. Especially, the previous type and action profiles , are publicly known at the beginning of time t, and all the players know the probability distribution over the new type profile as common knowledge.
To see the structure in a familiar setting, consider a duopoly playing a dynamic Cournot competition. At time t, firm i learns its cost type , which is drawn from a compact interval in the real line . However, firm i does not know firm j’s cost type, and vice versa. Firm i is aware that the cost type profile, which is the state of the economy, evolves stochastically over time according to a first-order Markov process, and that the stochastic process is based on the previous type and action profiles. Suppose the previous stage types and actions are publicly known, say, after the financial statements of firms are revealed. Then, firm i can have a belief over firm j’s current cost type based on the previous type profile and action profile. Conditional on their private cost types and beliefs about each other, firms choose optimal quantities to produce. Although similar approaches have appeared in the dynamic Bayesian games literature frequently, to the best of my knowledge, the models have suffered from the curse of dimensionality due to the history-dependent beliefs.3 This paper, by contrast, allows players to have time-invariant beliefs as long as the previous actions and types are the same under periodic revelation. Also, the models have never been treated in a continuous type space under a first-order Markov process. This paper shows existence of a class of stationary Markov perfect equilibria in this environment, which are termed “stationary Bayesian–Markov equilibria”.
Developing a framework for analyses of dynamic oligopolies with asymmetric information has been an open question for a long time due to the difficulty of dealing with the beliefs. Fershtman and Pakes [4] propose a framework for dynamic games with asymmetric information over a discrete type space focusing on empirical tractability. Their theoretical equilibrium concept is history-dependent, but they cleverly detour the dimensionality issue with the assumption that accumulated data include all the information about the history.4 Cole and Kocherlakota [5] and Athey and Bagwell [6], respectively, suggest new equilibrium concepts in a class of dynamic Bayesian games in which players’ beliefs are a function of the full history of public information.5 Hörner, Takahashi, and Vieille [7] characterize a subset of equilibrium payoffs, focusing on the case where players report their private information truthfully in dynamic stochastic Bayesian games.6
The key distinction of this paper from existing literature in dynamic Bayesian games is to add periodic revelation to mitigate the dimensionality problem. In the literature, it is conventional to formulate that private information remains hidden and never becomes public. If the game is under the serially correlated type evolution, without periodic revelation, players formulate their beliefs about other players’ current type based on the history of available past information. Then, the dimension of each player’s beliefs exponentially grows over time.7 Periodic revelation in this paper, however, enables players to have common prior for the current stage type distribution based on the revealed information, and, thus, players have time-invariant beliefs as long as the revealed information is the same regardless of the calendar time, which are consistent with the underlying type evolution. This helps to establish the stationary equilibrium concept even when types are serially correlated. Practically, it captures the economic environments where private information is periodically disclosed, either by legal requirements or voluntarily. Therefore, the model can be applied to dynamic oligopolies under the periodic disclosure requirement on the firms’ financial performance, e.g., Form 10-K in the U.S., or to the setting of Barro and Gordon [8] to analyze the effects of release of the Federal Open Market Committee (FOMC) transcripts with a five-year delay (See Ko and Kocherlakota [9]).
Levy and McLennan [10] show that, for stochastic games with complete information in a continuous state space, existence of stationary Markov equilibria is not guaranteed. In such environments, Nowak and Raghavan [11] show that there exists a stationary correlated equilibrium. Duggan [12] shows that there exists a stationary Markov equilibrium in cases where the state variable has an additional random component. The random component, so-called noise, can be viewed as an embedded randomization device for each state. In this perspective, a stationary Markov equilibrium in noisy stochastic games can be seen isomorphic to a stationary correlated equilibrium by Nowak and Raghavan [11]. Barelli and Duggan [13] formulate a dynamic stochastic game in which players’ strategies depend on the past and current information to show that Nowak and Raghavan’s stationary correlated equilibrium can be uncorrelated. By contrast, this paper considers the case where players have private information: the state is defined by a type profile of the game of incomplete information. As the players compute their interim payoff by integrating possible scenarios over their beliefs, the convexity of the set of interim payoffs is naturally obtained. It is more realistic that the convexity is obtained from the Bayesian structure, compared with previous approaches that utilize public randomization devices (Nowak and Raghavan [11]) or random noise (Duggan [12]).
The concept of the stationary Bayesian–Markov equilibrium is closely related to a stationary correlated equilibrium in Nowak and Raghavan [11]. That is, in a Bayesian game, players have beliefs about the type profile of their game, which is the state of the economy. Players then choose actions to maximize their expected payoffs considering their individual beliefs about the state of the economy. According to Aumann [14], a resulting Bayesian equilibrium can be regarded as a correlated equilibrium distribution, utilizing the collection of beliefs as a randomization device.
To prove existence of stationary Markov equilibria in conventional stochastic games, it is common to consider an induced game of the original stochastic games. The induced game is defined by a stage game that is indexed by the state of the world and a profile of continuation value functions. Then, the next step is to find a fixed point of the expected continuation value function in the induced game. Finally, one may apply the generalized implicit function theorem and a measurable selector theorem to extract an equilibrium strategy profile. During this process, it is crucial to have a convex set of the expected continuation value functions in order to ensure existence of a fixed point. Therefore, the key of proof is convexification of the set of continuation values in each state of the economy. Nowak and Raghavan [11] introduce a public randomization device, a so-called sunspot, as a means to convexification. In this paper, the idea of convexification is extended to the case where each player obtains private information according to common prior that depends on the past information from periodic revelation.
The model of a Bayesian stochastic game with periodic revelation is formally described in Section 2. Section 3 contains the existence theorem and the proof. Section 4 is devoted to a computational algorithm. Section 5 sketches the extension of proof to K-periodic revelation and concludes. In the Supplementary Materials, I present an application, specifically an incomplete information version of an innovation race between two pharmaceutical companies with periodic revelation.
2. The Basic Model
2.1. The Primitives
I use superscript “resp. ” to denote the next period (resp. the previous period). A discounted Bayesian stochastic game with periodic revelation is a tuple,
such that
- is a finite set of n players, and for each ,
- is a measurable space of player i’s types, regardless of the calendar time, i.e., ,
- is a measurable space of player i’s actions,
- is the feasible action correspondence,
- is the payoff function, where and ,
- is the discount factor,
- is a transition function8,
- is a transition function,
- is a transition function,
- It is an infinite horizon game.
Let denote the set of probability measures. I assume that
- ()
- For each , is a Borel subset of a complete separable metric space, and is its Borel -algebra. Endowed with the product topology, the Cartesian product S is a Borel subset of a complete separable metric space. A product of -algebras is its Borel -algebra (M10, Billingsley [16], p. 254).
- ()
- For each , there is an atomless probability measure such that is a complete measure space of player i’s types; is a product probability measure such that .9
- ()
- For each , is a compact metric space; is its Borel- algebra. Endowed with the product topology, the finite Cartesian product X is a compact metric space and is its Borel- algebra. A typical element is denoted by . There is a measure such that is a complete measure space.
- ()
- For each i, define . A typical element is denoted by or . Notice that is a complete separable metric space. Let be its Borel- algebra. There is an atomless probability measure such that is complete measure space. Endowed with the product topology, the Cartesian product T is also a complete separable metric space and a product of -algebras is its Borel- algebra’ is a product probability measure such that .
- ()
- For each , is nonempty, compact valued, and lower measurable.10
- ()
- The expression is bounded; there exists such that for each , . For each , is measurable; for each , , continuous.
- ()
- For each , there is a prior distribution for Nature, about the current type s. For each , is jointly measurable; is absolutely continuous with respect to the atomless measure .
- ()
- For each , there are beliefs about the other players’ current types. This is the -section of . Given and for each , the mapping is a regular conditional probability on . For each , is jointly measurable; is absolutely continuous with respect to the atomless product measure .
- ()
- For each , for each player i, there is an anticipation about the future type of player i oneself. This is a marginal distribution derived by (Note that ).11For each , is jointly measurable in ; is absolutely continuous with respect to the complete, atomless measure . For -almost all s, the mapping is norm-continuous.
- ()
- For each i, is decomposed into and : for each , and all , I have the following:
Example 1.
Consider a dynamic Bayesian Cournot competition as follows. There are two firms and these firms face unknown production cost types each period. Other than the cost type structure, the other components of Cournot competition are applied as usual. The price of the good is determined by a market demand function:
The condition helps the price remain above 0. The payoff functions and are as follows:
The key distinction of the model is at the cost type structure. Assume cost type space of player i is given by . Consider an area that is given by a square made of four points, , , , and , and called Region Z. Now, the cost types of firms are drawn from a joint probability distribution that is determined by the previous cost levels and the previous production levels of the firms: The shape of the joint probability distribution is determined by and over Region Z.12 For a specific example, assume the cost types are assumed to follow a joint distribution over Region Z:
Any joint probability measure with respect to is allowed as a cost type structure in this sample model if the following conditions are satisfied: (1) the joint probability measure has (Region Z) as its support; (2) it is differentiable with respect to over the type space ; and (3) it is continuous with respect to over the action space . For example, for each i, consider a concave quadratic function , which is peaked at and goes through zeros at or , i.e., or , as well as of which area is one (1). Compose a joint probability distribution by the product of the aforementioned functions .13 Then, the support of the joint distribution is the square made of four points, , , , and , and it satisfies . The joint probability distribution can be more general, not necessarily being a product of two marginal distributions. A uniform joint distribution over Region Z is also allowed.
In this example, the set of player indices . The costs of firms are considered as types in the above model setup, and the type space for each firm is given by a closed interval on the real line . Then, it satisfies the condition of a complete separable metric space. The produced quantities are actions in the above model setup. The action space for each firm is given by a compact metric space on the real line. As the type and action spaces are all on the real line, , , and are fulfilled. Assumption is satisfied as long as, for example, a pure action strategy and are continuous in and , respectively. As and are bounded, the market price is bounded. Then, it is clear that payoff function for firm i, for each , , is bounded and continuous. Also, given , is integrable.
The probability measures in this example are as follows: from player 1’s perspective,14
where is what player 1 believes as player 2’s type when player 1’s cost type is . Since the model is on the real line, assumptions are satisfied as long as the probability function (1) has Region Z as its support, (2) is differentiable with respect to over , and (3) is continuous with respect to over . By contrast, if Region Z were a triangle made of three points of , , and , it would violate because the conditional distribution for given has a jump on the cost type space . I keep using this example to describe the equilibrium concept and the sketch of the proof.
2.2. Timing
Suppose the game reaches the middle of the stage of time . Players choose actions given their own type without knowing others. However, the payoff function for player i depends on the types and actions of all players. At the end of the previous period, the type profile and action profile are revealed and the payoff is given to player i for all i. Next, the time-t stage game proceeds as follows (Figure 1 depicts the timeline):
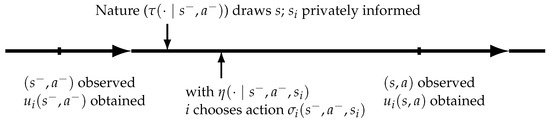
Figure 1.
Timeline.
- Nature moves to draw each player’s type based on the Markov process for all i.
- For each i, player i whose type is chooses actions based on their beliefs , maximizing their discounted sum of expected payoffs.
- At the end of the current period, the realized type profile and action profile are revealed, and player i earns payoff . Nature moves to draw each player’s next period type based on the Markov process for all i.
2.3. Stationary Bayesian–Markov Equilibrium
A stationary Bayesian–Markov strategy for player i is a measurable mapping . For each , a probability measure assigns probability one to . Let denote the set of stationary Bayesian–Markov strategies:
For each , let denote the product probability measure .15 In addition, denotes a profile of mappings and denotes the set of stationary Bayesian–Markov strategy profiles .
For each , player i’s interim expected continuation value function is a measurable function. To define the interim expected continuation value function , remember that player i with the current type only has beliefs over the current realization and the future type over . Then, player i will again imagine, in the next period , if they learn their type is , they will have new beliefs over the type and action profile realization and the future type in period , . That is, the interim expected continuation value function relies on the expectation over the current beliefs of player i and their conjecture over the future beliefs conditional on the current beliefs. Therefore, the value function demonstrates a fractal structure in which there is an expectation within an expectation ad infinitum. To see clearly, denote as follows when player i’s belief over the others’ type and realized action profile is given by :
In addition, denote as follows to express ex ante expected payoff at the beginning of time , which is before player i learns their type :
Then, the interim expected continuation value function is, for each ,16
As Equation (11) is a fractal, it is more convenient to express by recursion: For each ,
A profile of stationary Bayesian–Markov strategies is a stationary Bayesian–Markov equilibrium if, for each , each player i’s strategy maximizes i’s interim expected continuation values. That is, given , for each , puts probability one on the set of solution to
By the one-shot deviation principle, every stationary Bayesian–Markov equilibrium is subgame perfect.
Example 2.
Continued from the above dynamic Bayesian Cournot competition, the strategies for each player can be any mapping from a cost type of player i to a probability distribution over a subset of the action space, , e.g., , where , given previous . Among possible strategies, the equilibrium strategy is obtained by maximization of the interim expected continuous value function. Recall the stage payoff function is , and assume is a singleton, that is, is a pure action strategy. Solving the following dynamic optimization, equilibrium strategy for player 1 is given by
Then, by taking derivatives and solving the system of equations, for each
Observe that the equilibrium strategy is forward-looking: takes into account the variation in future cost type distribution due to changes in . However, it only cares about the next period because the optimization problem is recursive. Using this recursiveness, the existence theorem for the continuous space dynamic stochastic game is presented in the next section.
3. Existence Theorem
Theorem 1
(Existence Theorem). For every Bayesian stochastic game with periodic revelation, there exists a stationary Bayesian–Markov equilibrium.
First, I construct the set V of interim expected continuation value function profiles in the following two paragraphs.17 Fix . Let be the collection of -equivalence classes of -essentially bounded, measurable extended real-valued functions from to ; is equipped with the usual norm , which gives the smallest essential upper bound; that is, if for -almost all ; is the collection of -equivalence classes of integrable functions from to ; is equipped with such that .18 By the Riesz representation theorem (see Royden–Fitzpatrick ([19], hereafter RF, p. 400), is the dual space of , and it is endowed with weak-* topology. By Proposition 14.21 of RF (p. 287), is a locally convex Hausdorff topological vector space. Let denote the Cartesian product . Then, endowed with product topology, is a locally convex Hausdorff topological vector space.
Let consist of functions with ; that is, for -almost all . The constant is of which for all . Clearly, is nonempty and convex. Then, the Cartesian product is also non-empty and convex. By Alaoglu’s theorem (RF, p. 299), is compact. The finite product V is also compact (see Theorem 26.7, Munkres [20], p. 167).
Now I show V is metrizable in the weak-* topology. Since is separable metric space, its Borel -algebra is countably generated. is separable.19 By Corollary 15.11 of RF (p. 306), is metrizable in the weak-* topology. The Cartesian product V is metrizable in the product weak-* topology, so it is compact if and only if sequentially compact (see Theorem 28.2, Munkres [20], p. 179).
In order to see if the correspondence is nonempty, closed graph, and convex valued, I consider the following induced game. Eventually I want to show that the set of interim expected payoffs profiles from the induced game is in fact equivalent to its convexification . Let denote a state-s induced game of a Bayesian stochastic game given a profile of continuation value functions v and the realized state-action profiles in the previous period:
Here, is defined as follows: for each , each ,
In the interim stage of a general one-shot Bayesian game, suppose players use behavioral strategies. Knowing their realized type (), player i exerts a mixed action (), induced by their behavioral strategy (a measurable mapping ). In the induced game of the Bayesian stochastic game in this paper, players use stationary Bayesian–Markov strategies, and it is essentially the same to the behavioral strategy in a one-shot Bayesian game. The mixed actions induced by stationary Bayesian–Markov strategy profile of all players determine a product probability measure . The difference between a stationary Bayesian–Markov strategy and a behavioral strategy is that, in the former, beliefs are given by the consequence of the previous stage game, and, thus, mixed actions depend on the previously realized type and action profiles as well as the current own type of player i oneself.20
The space and are endowed with the product weak topology. By Theorem 2.8 of Billingsley ([16], p. 23), in if and only if in for each i.
Lemma 1.
Given , for each v and each σ, is measurable in . Then, is measurable in . Given , for each , is jointly continuous in .
Proof.
Define
and
For each , is measurable in ; is bounded, then Theorem 19.7 of Aliprantis and Border ([22], hereafter AB, p. 627) implies is measurable in . Recall that, given , for each , is measurable. Since is bounded, is measurable. Similarly, since for each , is measurable, is also measurable.
Fix . Consider a sequence , where for each i, in weak-* topology. I have
Since is continuous, , and
The first inequality is by the triangle inequality. The second inequality is by the fact that is essentially bounded by and that .
As in weak-* topology, by Proposition 3.13 of Brezis ([23], p. 63), for any given point of , . This induces . Moreover, as in X, , because for given s is continuous, and is a continuous linear functional of .21 This gives us . Then, combined with norm continuity of in a, I have the RHS of the last inequality converging to 0. Now, continuity of follows from that given s, the family of real valued functions is equicontinuous at each a, and the result of Rao [24] under the absolutely continuous information structure holds. □
Fix and v. For each s, let be the set of mixed action profiles induced by Bayesian–Nash equilibria of (s). Then
The condition holds if and only if player j’s equilibrium mixed action makes all the other player i’s choice of pure actions that belongs to the support of indifferent for player i in terms of the interim expected continuation value. This condition induces player i to mix their actions. As a result, player i’s mixed action gives the same payoff (in terms of the interim expected continuation value) to any pure action from the support of .
Now define
Then, for all . Below I follow Duggan’s [12] approach.
Lemma 2.
For each v, is nonempty, compact valued, and lower measurable.
Proof.
A correspondence is lower measurable, nonempty, and compact valued. To see this, I want, for each open subset G of X, the lower inverse image of G to be measurable; . Since is generated by measurable rectangles, if and only if , where is a subbasis element for the product topology on X. From , is lower measurable for each i, it is clear that is lower measurable. It is also nonempty and compact valued because so is each . Then, is lower measurable, nonempty, and compact valued by Himmelberg and Van Vleck [25].
Notice that
where, given , , and . Similarly, , and is the Dirac delta measure concentrated at . Define
Then, implies .22 By Lemma 2 of Duggan [12] and measurability of for each , is lower measurable. Given , Balder [18] gives us nonemptiness of for each s. Recall that the interim expected payoff function is continuous, and the finite product of is compact. By the theorem of maximum (Theorem 17.31, AB, p. 570), is compact subset of for each s. □
Given s as realized type profile, define the set of realized payoffs for player i from as . Then, is nonempty, compact valued, and lower measurable, since is continuous. By the Kuratowski–Ryll-Nardzewski measurable selection theorem (see Theorem 18.13, AB, p.600), it admits a measurable selector. Then, the correspondence is integrable. The set of interim expected payoffs for player i is denoted as . Let denote the Cartesian product .
Lemma 3.
For each v, each , .
Proof.
By Theorem 18.10 of AB (p. 598), the correspondence for each player i’s realized payoffs is, in fact, measurable. For any , consider the -section of the correspondence, ; it is clearly measurable. By Theorem 4 of Hildenbrand ([26], p. 64),
Hence, for each , . Since Cartesian product of convex sets of is convex in , . □
Lemma 4.
The mapping is lower measurable, nonempty, compact, and convex valued.
Proof.
Notice that for each , is nonempty and convex. Recall that admits a measurable selector. Let denote the set of measurable selectors from the correspondence. Note that . Since is compact, for each , there is a family of functions that converge pointwise to at each . Notice that is bounded, so a family of functions that converges pointwise to is uniformly integrable. Recall that each is a probability measure. Then, is a set of finite measure; the finite Cartesian product is also of finite measure. Obviously, the aforementioned family of functions is tight. Applying the Vitali convergence theorem (RF, p. 377), I obtain compactness of for each i. The finite product is therefore compact at each . Applying Tonelli’s theorem (RF, p. 420), I have measurable. Thus, I also get the lower measurability of . Then, by Proposition 2.3 (ii) of Himmelberg ([27], p. 67), is lower measurable. □
By the Kuratowski–Ryll-Nardzewski measurable selection theorem (Theorem 18.13, AB, p. 600), has a measurable selector. Given v, define to be the set of all -equivalence classes of measurable selectors of .
Lemma 5.
The mapping is nonempty, closed graph, and convex valued.
Proof.
By construction, for each v, is nonempty, closed, and convex. Recall that the interim expected payoff function is continuous. By the theorem of maximum, is upper hemicontinuous. Suppose a sequence , where and . Lemma 1 tells us that for each player i23,
Now I proceed similarly to Lemma 7 of Nowak and Raghavan [11]. Suppose and in the product weak-* topology on V. I want to show that . By Mazur’s theorem and Alaoglu’s theorem (Brezis [23], p. 61 and p. 66), there is sequence made up of convex combinations of the s that satisfies as . This implies that converges to g pointwise almost everywhere on T. Let for all where . Recall that . Then, for each , for each m, if , then ; since , ; thus, for each and clearly . Hence, is upper-hemicontinuous. In addition, I observe that for each m, is closed and is closed. By the closed graph theorem for correspondences (Theorem 17.11, AB, p. 561), is closed graph. □
Proof of Existence Theorem.
Obviously, . By the Kakutani–Fan–Glicksberg theorem (see Theorem 17.55, AB, p. 583), I have a fixed point of . Then, I have such that given , for all , . Recall that is measurable in , continuous in (Lemma 1). Now, by Filippov’s implicit function theorem (see Theorem 18.17, AB, p. 603), there exists a measurable mapping such that, given , for each s, and for all i, each ,
For each i, , admits a measurable selector by the Kuratowski–Ryll-Nardzewski measurable selection theorem (Theorem 18.13, AB, p. 600). Let be any measurable selector of . Given , put
Then, for all s, and
Therefore, f is the stationary Bayesian–Markov equilibrium strategy profile. □
4. Computational Algorithm
The flow of the proof in Section 3 can be used as a computational algorithm to find an equilibrium. The algorithm is especially useful for the environment of heterogeneous beliefs.24 First, find a fixed point in a set of interim expected continuous value functions, and second, extract an equilibrium strategy that generates the fixed point value function. In this sense, the computational algorithm for the dynamic Bayesian games in a continuous type space with periodic revelation is close to the value function iteration in macroeconometrics.25 The difference between the popular macroeconometrics technique and the following algorithm is, however, that there are multiple agents who have heterogeneous beliefs about the others’ types in dynamic Bayesian games. That is, the highlight of the computational algorithm in this section is to find a fixed point for a array of interim expected continuous value functions given the heterogeneous beliefs.
Start the algorithm by approximating interim expected continuous value function for player i by a polynomial, preferably a Chebyshev orthogonal polynomial.26 Accordingly, the type space and action space are given by grids of Chebyshev nodes. In addition, build the beliefs and transition probability distribution over different sets of grids for numerical integration, for example, a type space with equidistant nodes and an action space with equidistant nodes, for all i. Over the grids, construct the probability distribution over the collection of types for the current stage, , given any previous type and action profiles, . From this , beliefs for the other players and the future type distribution can be obtained.
Then, the main algorithm is given by the following backward iteration process: start with the jth guess of and plug it into the right-hand side. After numerical integration using and , the result from the right-hand side is fed to the loop as the th guess of . Repeat the iteration until converges. By the existence theorem, a fixed point for exists, and, thus, for large enough j, is guaranteed to be sufficiently close to .
Define an operator that implements Equation (29). That is, and, more precisely, it is an operation for coefficients of Chebyshev polynomials. As there are multiple players , by stacking all the vectors of for all i, in the jth iteration,
The sequence of the vectors for all i is guaranteed to converge as is a contraction mapping. Denote the solution as . Then, the associated equilibrium stationary Bayesian strategy profile in Equation (29) can be obtained by plugging in the solution to the both sides.
5. Conclusions and Extension
In reality, economic agents rarely have a true understanding about the state of the economy. Often they have their own biased perceptions which reflect only part of the true state of the economy, and their perceptions may remain private. Moreover, such biased perceptions tend to be serially correlated. To reflect such aspects of reality more closely, dynamic games with asymmetric information can be a better modeling choice than ones with symmetric information. This paper constructs a class of dynamic Bayesian games where types evolve stochastically according to a first-order Markov process depending on the type and action profiles from the previous period. In this class of dynamic Bayesian games, however, players’ beliefs exponentially grow over time. To mitigate the curse of dimensionality in the dynamic Bayesian game structure, this paper considers the environment where the asymmetric information in the past becomes symmetric with a delay (periodic revelation). Specifically, this paper considers the case where the previous type profile is revealed as public information with a one-period delay. That is, type profile remains hidden when players choose actions, but type and action profiles are revealed when players obtain their payoffs. As common prior for the next stage Bayesian game is pinned down by the type and action profiles, players’ beliefs do not explode over time.
Theoretically, in the dynamic Bayesian game of this paper, the type space is a complete separable metric space (Polish space) and the action space is a compact metric space. A stationary Bayesian–Markov strategy is constructed as a measurable mapping that maps a tuple of the previous type profile, action profile, and player i’s current type, i.e., , to a probability distribution over actions. Then, there exists a stationary Bayesian–Markov equilibrium. This stationary Bayesian–Markov equilibrium concept is related to the stationary correlated equilibrium concept in Nowak and Raghavan [11] through Aumann [14].
Similarly, the proof can be extended to a game with K-period lagged revelation, i.e., in each period t, players observe type and action profiles up to period , whereas for periods from to t, they only observe the history of their own types, their own actions, and their own payoffs. Then, existence of a stationary Bayesian–Markov equilibrium with K-period lagged revelation can be proved once players’ heterogeneous beliefs are adjusted judiciously: The unrevealed history from period to period t plays the role of individual player’s new “type”, and beliefs are assumed to be induced by a common prior conditional on the lagged information . Figure 2 depicts the timeline. See the Supplementary Materials for the formal proof.
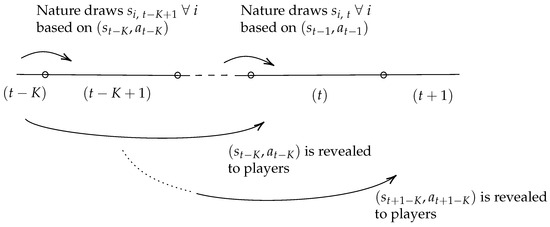
Figure 2.
The K-periodic revelation.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/g15050031/s1, References [15,31,32] are cited in the Supplementary Materials.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Acknowledgments
Eunmi Ko—Conceptualization; Data curation; Funding acquisition; Investigation; Methodology; Writing—original draft, review & editing. I am grateful to Narayana Kocherlakota and Paulo Barelli for invaluable support and guidance for this project. I thank three anonymous reviewers and the journal editor for helpful remarks that significantly improved this paper. I also thank (including but not limited to) Yu Awaya, David Besanko, Anmol Bhandari, Doruk Cetemen, Hari Govindan, Iru Hwang, Asen Kochov, Ichiro Obara, Ron Siegel, Takuo Sugaya, Yuichi Yamamoto, Haomiao Yu, and participants in the Midwest Theory Conference (Rochester, NY, Spring 2016), Stony Brook Festival (Summer 2016), Asian Meeting of the Econometric Society (Kyoto, Japan, Summer 2016) for helpful comments and suggestions. An earlier version of this paper was a chapter of my Ph.D. dissertation. I have read and agreed to the published version of the manuscript. All errors are my own.
Conflicts of Interest
The author declares no conflicts of interest.
Notes
| 1 | See Saxe [1], but it is also alleged that the parable originated in ancient India, as part of a Buddhist text. See https://en.wikipedia.org/wiki/Blind_men_and_an_elephant (accessed on 1 May 2024). |
| 2 | The limited perceptions of the state of the economy can be due to others’ non-disclosure, optimal choice of individuals themselves, i.e., rational inattention (Mackowiak et al. [2]), or due to their own biases. |
| 3 | This causes a severe computational burden in empirical analyses in dynamic structural estimation as well. See Aguirregabiria and Mira [3] for more detail. |
| 4 | The private information of each firm to be serially correlated, and, thus, the history of past payoff relevant information and past actions comprises the current payoff relevant information. Then, the dimension of beliefs of firms regarding other firms’ payoff relevant information may explode over time. To obtain computational tractability, they propose a new equilibrium concept that makes use of the empirical distribution from data. If data are accumulated over time, however, the framework would lose its strength. |
| 5 | In Cole and Kocherlakota [5], the beliefs also depend on player’s current type in addition to the history of public information. The equilibrium concept is referred to as Markov private perfect equilibrium. In Athey and Bagwell [6], the beliefs are a function of the history of public information only, and they refer to the equilibrium concept as perfect public Bayesian equilibrium. |
| 6 | Hörner, Takahashi, and Vieille [7] characterize the set of feasible payoffs under certain conditions: Any of these payoffs can be achieved as a result of playing the dynamic Bayesian game via any (either stationary or non-stationary) equilibria, where they do not specify existence of equilibria. In contrast, this paper focuses on stationary equilibria and proves existence. While the result of Hörner, Takahashi, and Vieille [7] is highly regarded in the mechanism design literature, showing existence of stationary equilibria in Bayesian stochastic games is particularly valued in the dynamic structural estimation literature because existence of stationary equilibria is crucial for model tractability and estimation. |
| 7 | Handling the belief system using the history of available past information is complicated. Previous literature has circumvented the issue by introducing the belief operator T(.). For example, in Athey and Bagwell [6], the type evolution process of Player i is given by a specific process, denoted by , relying on just the previous type of oneself. However, the beliefs of other players about the type of Player i, denoted by , are not related to . Rather, the belief can be any probability distribution based on the history of public information up to time t as long as its support includes the currently observed actions of Player i with nonzero probability. To be more concrete, Athey and Bagwell introduce an abstract belief updating operator T(.) such that allowing for any belief function to be chosen as as long as it is compatible with the current observations of (where denotes the vector of actions taken by all the players and stands for the possibly non-truthful actions taken by Player i). As Player i can act non-truthfully and other players presume Player i’s mimicry, the dimension of the belief grows over time: given the time-t belief, , the belief in time , , is based on the public information of actions in time t. The belief in time (t+2), , then, is based on the public information from actions in time t and , and so forth. This is why their equilibrium strategy depends on the entire history of public information and the players’ beliefs have a time-subscript in their model. |
| 8 | For the formal definition of a transition function, see Stokey and Lucas with Prescott ([15], p. 212). |
| 9 | Precisely, I mean the Caratheodory extension of premeasure over the -algebra of -measurable subsets of S; means the outer measure induced by a set function. The product measure is absolutely continuous with respect to . Thus, the information diffusion condition (Milgrom and Weber [17]) is satisfied. |
| 10 | Intuitively, a set-valued function is lower measurable if the inverse image of a closed set in the codomain, here , where is a measurable set in the domain with respect to the -algebra of the domain, here . |
| 11 | The expression works for Nature while and work for the individual players; means the individuals have consistent beliefs with Nature. It is possible that if individual players exhibit bounded rationality. |
| 12 | Here, , and as initial conditions are required to draw the cost distributions are in the first stage game. Assume that , and . |
| 13 | Assume . Then, with for all i, can be the joint probability distribution. In this case, . |
| 14 | The expression is a conditional distribution derived from ; is a marginal distribution of . |
| 15 | Precisely, I mean the Caratheodory extension of premeasure over the -algebra of -measurable subsets of ; means outer measure induced by a set function. |
| 16 | Fix . Then, common prior is specified and so are each player’s beliefs . The absolutely continuous information structure that allows us to express player i’s interim expected payoffs in this manner. See Milgrom and Weber [17] or Balder [18] Theorem 2.5. |
| 17 | This construction closely follows Duggan’s [12] approach. |
| 18 | Observe that I choose and weak-* topology for the space of continuation value functions of player i, similarly to the standard approach in general stochastic games. For the norm, , Tonelli’s theorem is applied; see Royden–Fitzpatrick ([19], p. 420). |
| 19 | See Rudin [21]. Otherewise, consider that the subspace of rational-valued simple functions with finite support is countable and dense in by Theorem 19.5 of RF (p. 398) and the fact that the set of rational numbers is countable and dense in . |
| 20 | With regard to terms, “Bayesian” is about beliefs and “Markov” is about current state (type) irrespective of the calendar time. If common prior on the current type profile is given by the fixed probability measure (i.i.d.), then and , and, thus, the stationary Bayesian–Markov strategy is simply . |
| 21 | Recall that is continuous for given s. In addition, is a dual space (a set of continuous linear functionals) of . For given s and , define a convergent sequence for a fixed value of a in , which assigns the same values of . Since is continuous and linear in , . Then, can be seen as continuous and linear in a. |
| 22 | Necessary and sufficient condition is that for -almost all s. |
| 23 | The expression is the -neighborhood of as . |
| 24 | For the literature about solving dynamic programming under heterogeneous expectations, see the lecture notes by Wouter den Haan, https://www.wouterdenhaan.com/numerical/heteroexpecslides.pdf (accessed on 1 May 2024). |
| 25 | See Judd [28], pp. 434–436, or DeJong and Dave [29], pp. 89–94. |
| 26 | See Chapter 4 of Ljungqvist and Sargent [30] for the definition of a Chebyshev polynomial (Section 4.7.2) and how the computation of dynamic programming works in a representative agent setting. |
References
- Saxe, J.G. The Blind Men and the Elephant; James R. Osgood and Company: Boston, MA, USA, 1873. [Google Scholar]
- Maćkowiak, B.; Matějka, F.; Wiederholt, M. Rational Inattention: A Review. J. Econ. Lit. 2023, 61, 226–273. [Google Scholar] [CrossRef]
- Aguirregabiria, V.; Mira, P. Dynamic discrete choice structural models: A survey. J. Econom. 2010, 156, 38–67. [Google Scholar] [CrossRef]
- Fershtman, C.; Pakes, A. Dynamic Games with Asymmetric Information: A Framework for Empirical Work. Q. J. Econ. 2012, 127, 1611–1661. [Google Scholar] [CrossRef]
- Cole, H.L.; Kocherlakota, N. Dynamic Games with Hidden Actions and Hidden States. J. Econ. Theory 2001, 98, 114–126. [Google Scholar] [CrossRef]
- Athey, S.; Bagwell, K. Collusion with Persistent Cost Shocks. Econometrica 2008, 76, 493–540. [Google Scholar] [CrossRef]
- Hörner, J.; Takahashi, S.; Vieille, N. Truthful Equilibria in Dynamic Bayesian Games. Econometrica 2015, 83, 1795–1848. [Google Scholar] [CrossRef][Green Version]
- Barro, R.J.; Gordon, D.B. Rules, discretion and reputation in a model of monetary policy. J. Monet. Econ. 1983, 12, 101–121. [Google Scholar] [CrossRef]
- Ko, E.; Kocherlakota, N. The Athey, Atkeson, and Kehoe Model with Periodic Revelation of Private Information. Available online: http://hdl.handle.net/1802/35442 (accessed on 28 July 2023).
- Levy, Y.J.; McLennan, A. Corrigendum to ‘Discounted Stochastic Games with No Stationary Nash Equilibrium: Two Examples’. Econometrica 2015, 83, 1237–1252. [Google Scholar] [CrossRef]
- Nowak, A.; Raghavan, T. Existence of Stationary Correlated Equilibria with Symmetric Information for Discounted Stochastic Games. Math. Oper. Res. 1992, 17, 519–526. [Google Scholar] [CrossRef]
- Duggan, J. Noisy Stochastic Games. Econometrica 2012, 80, 2017–2045. [Google Scholar]
- Barelli, P.; Duggan, J. A note on semi-Markov perfect equilibria in discounted stochastic games. J. Econ. Theory 2014, 151, 596–604. [Google Scholar] [CrossRef]
- Aumann, R.J. Correlated Equilibrium as an Expression of Bayesian Rationality. Econometrica 1987, 55, 1–18. [Google Scholar] [CrossRef]
- Stokey, N.L.; Lucas, R.E.; Prescott, E.C. Recursive Methods in Economic Dynamics; Harvard University Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Billingsley, P. Convergence of Probability Measures, 2nd ed.; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Milgrom, P.R.; Weber, R.J. Distributional Strategies for Games with Incomplete Information. Math. Oper. Res. 1985, 10, 619–632. [Google Scholar] [CrossRef]
- Balder, E.J. Generalized Equilibrium Results for Games with Incomplete Information. Math. Oper. Res. 1988, 13, 265–276. [Google Scholar] [CrossRef]
- Royden, H.L.; Fitzpatrick, P.M. Real Analysis, 4th ed.; Pearson: London, UK, 2010. [Google Scholar]
- Munkres, J.R. Topology, 2nd ed.; Pearson: London, UK, 2000. [Google Scholar]
- Rudin, W. Functional Analysis; McGraw-Hill Book Company: New York, NY, USA, 1973. [Google Scholar]
- Aliprantis, C.D.; Border, K. Infinite Dimensional Analysis: A Hitchhiker’s Guide, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Brezis, H. Functional Analysis, Sobolev Spaces and Partial Differential Equations; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Rao, R.R. Relations between Weak and Uniform Convergence of Measures with Applications. Ann. Math. Stat. 1962, 33, 659–680. [Google Scholar] [CrossRef]
- Himmelberg, C.J.; Van Vleck, F.S. Multifunctions with Values in a Space of Probability Measures. J. Math. Anal. Appl. 1975, 50, 108–112. [Google Scholar] [CrossRef]
- Hildenbrand, W. Core and Equilibria of a Large Economy; Princeton University Press: Princeton, NJ, USA, 1974. [Google Scholar]
- Himmelberg, C.J. Measurable Relations. Fund. Math. 1975, 87, 53–72. [Google Scholar] [CrossRef]
- Judd, K.L. Numerical Methods in Economics; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- DeJong, D.N.; Dave, C. Structural Macroeconometrics, 2nd ed.; Princeton University Press: Princeton, NJ, USA, 2011. [Google Scholar]
- Ljungqvist, L.; Sargent, T.J. Recursive Macroeconomic Theory, 3rd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Judd, K.L.; Schmedders, K.; Yeltekin, S. Optimal Rules for Patent Races. Int. Econ. Rev. 2012, 53, 23–52. [Google Scholar] [CrossRef]
- Zamir, S. Bayesian Games: Games with Incomplete Information. In Encyclopedia of Complexity and Systems Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 426–441. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).