Homophily and Social Norms in Experimental Network Formation Games


Abstract
:1. Introduction
2. Results
2.1. The Dataset
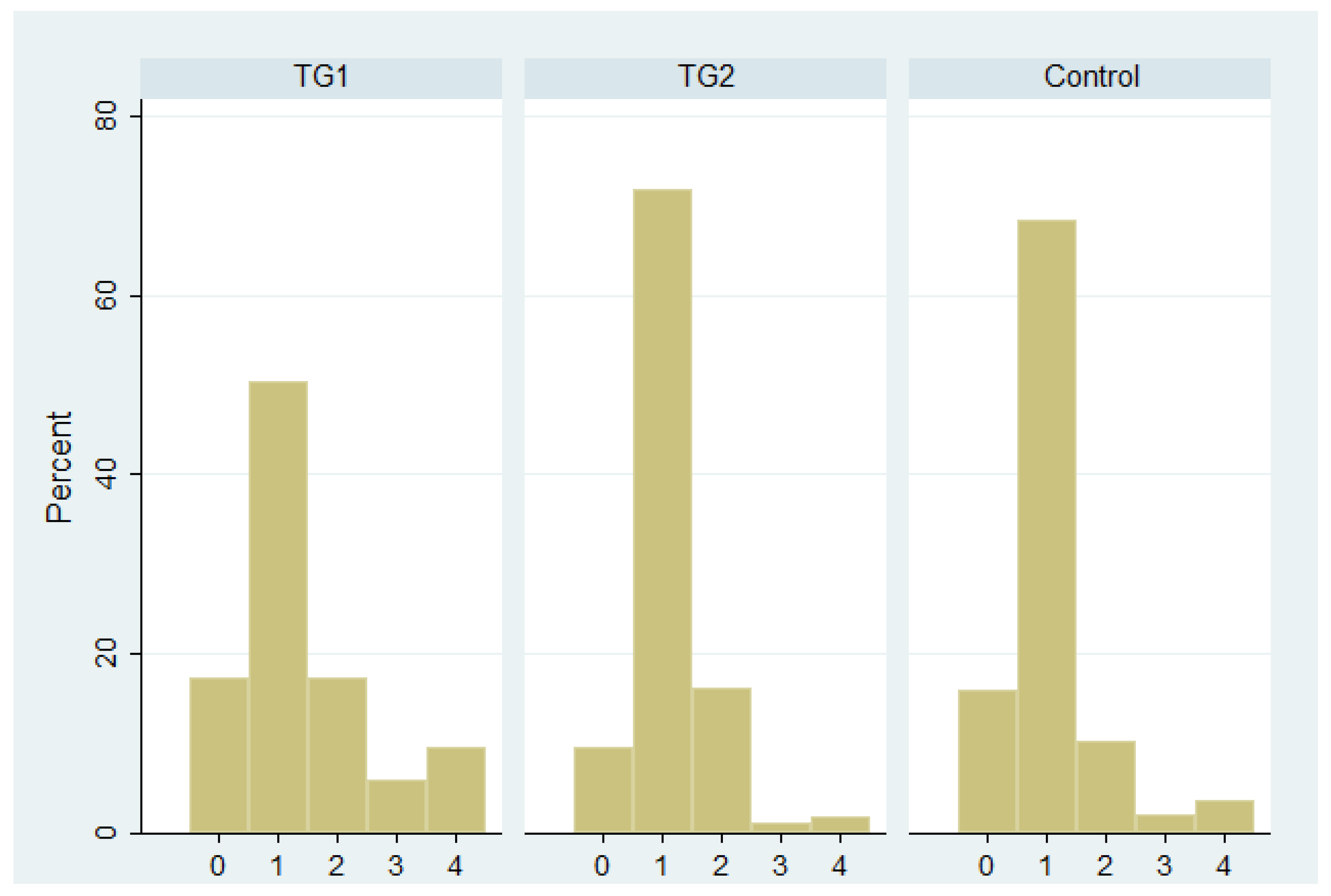
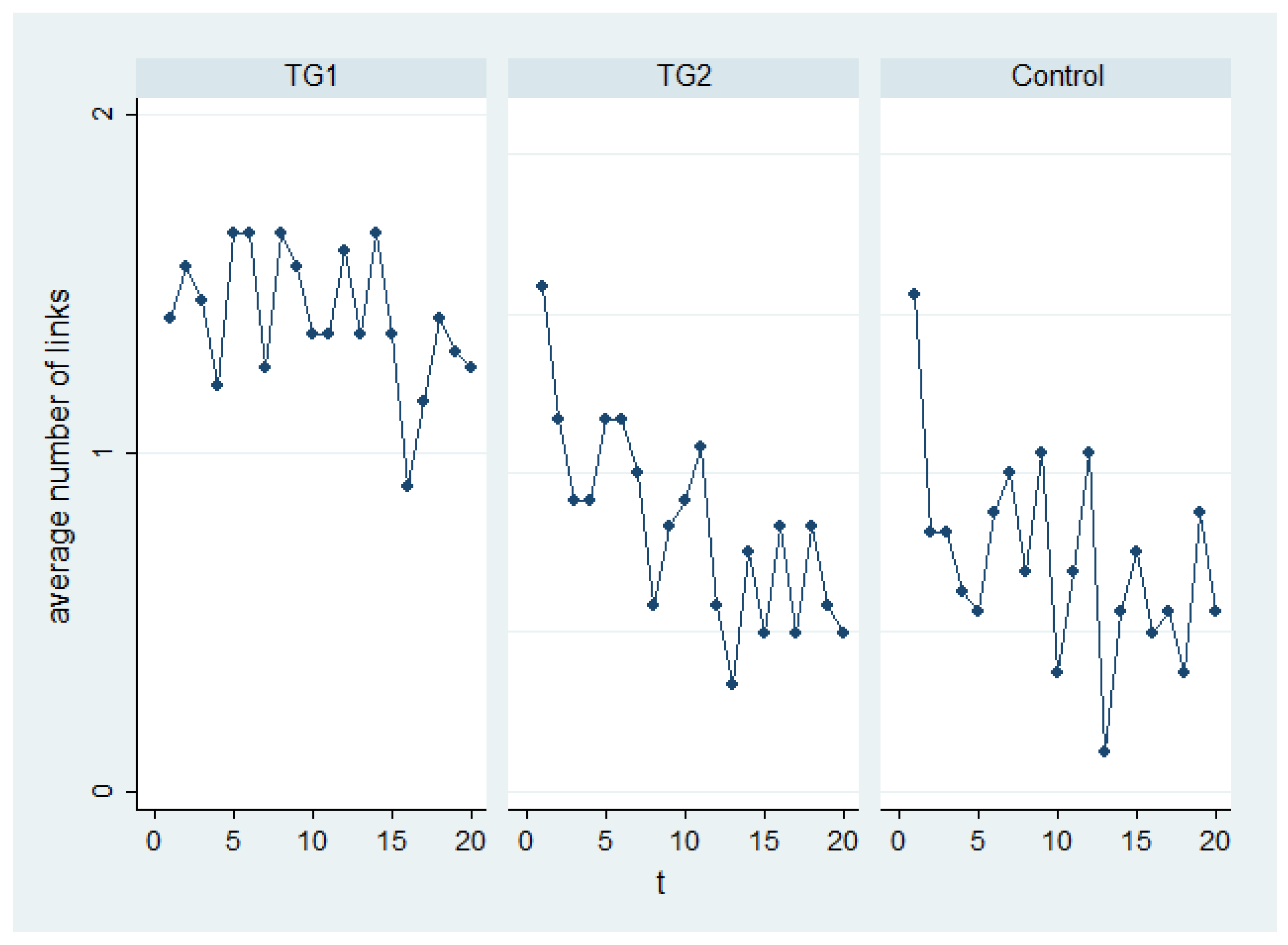
2.2. Descriptive Statistics
2.3. Constructing a Panel
2.4. The Data Generating Process
2.5. Challenges to Consistent Estimation
2.6. Estimation Results
2.7. Relation to Previous Literature
3. Discussion
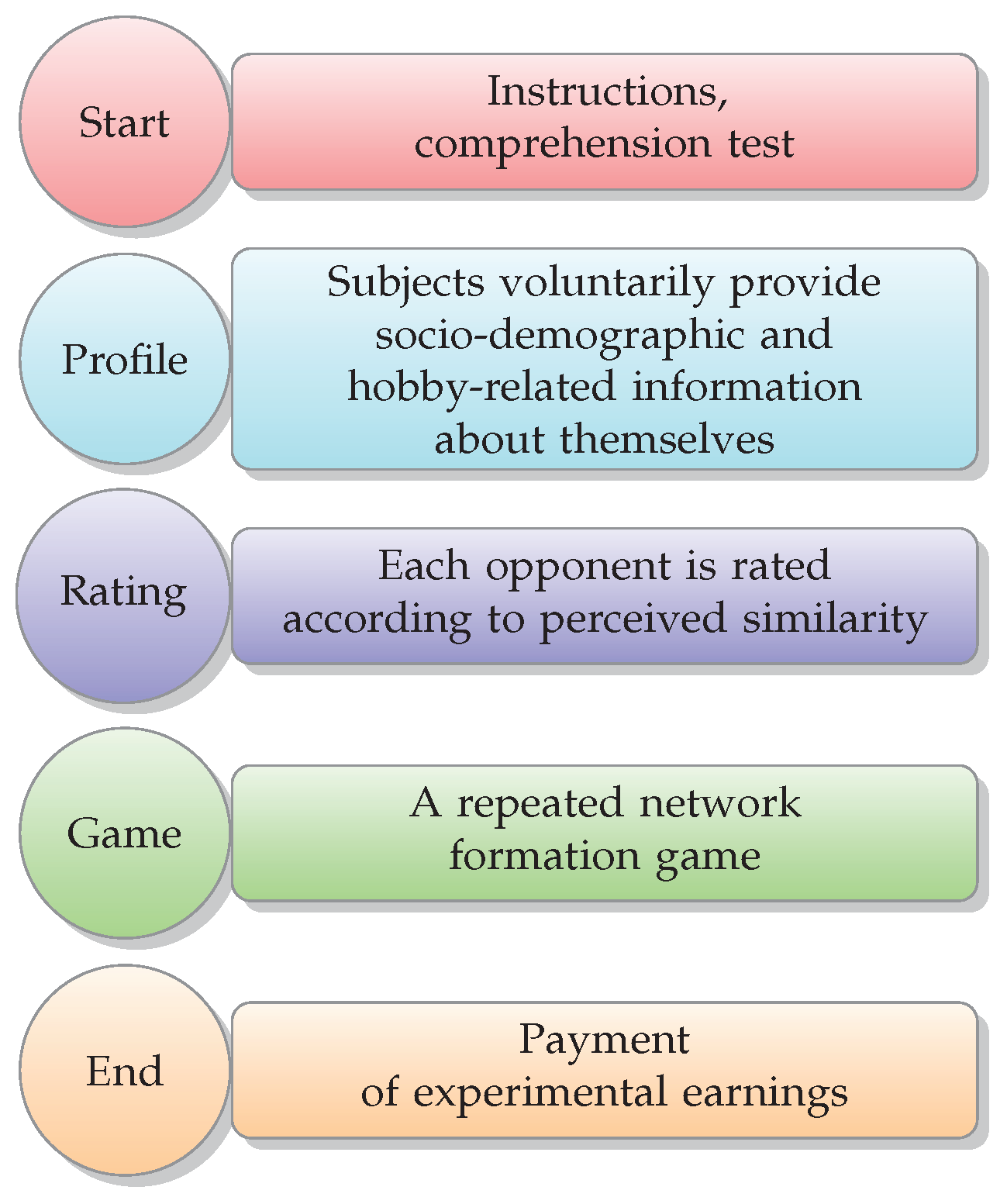
4. Materials and Methods
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| TLA | Three letter acronym |
| LD | linear dichroism |
Appendix A. Instructions: TG1 and TG2
- you make a link to that player, or
- if that player makes a link to you, or
- if both of you link to each other.
| Number of links you make | ||||||
| 0 | 1 | 2 | 3 | 4 | ||
| 0 | 0 | - | - | - | - | |
| 1 | 1 | 0.5 | - | - | - | |
| Number of people you are linked to | 2 | 2 | 1.5 | 1 | - | - |
| 3 | 3 | 2.5 | 2 | 1.5 | - | |
| 4 | 4 | 3.5 | 3 | 2.5 | 2 | |
Appendix B. Instructions: Control
- you make a link to that player, or
- if that player makes a link to you, or
- if both of you link to each other.
| Number of links you make | ||||||
| 0 | 1 | 2 | 3 | 4 | ||
| 0 | 0 | - | - | - | - | |
| 1 | 1 | 0.5 | - | - | - | |
| Number of people you are linked to | 2 | 2 | 1.5 | 1 | - | - |
| 3 | 3 | 2.5 | 2 | 1.5 | - | |
| 4 | 4 | 3.5 | 3 | 2.5 | 2 | |
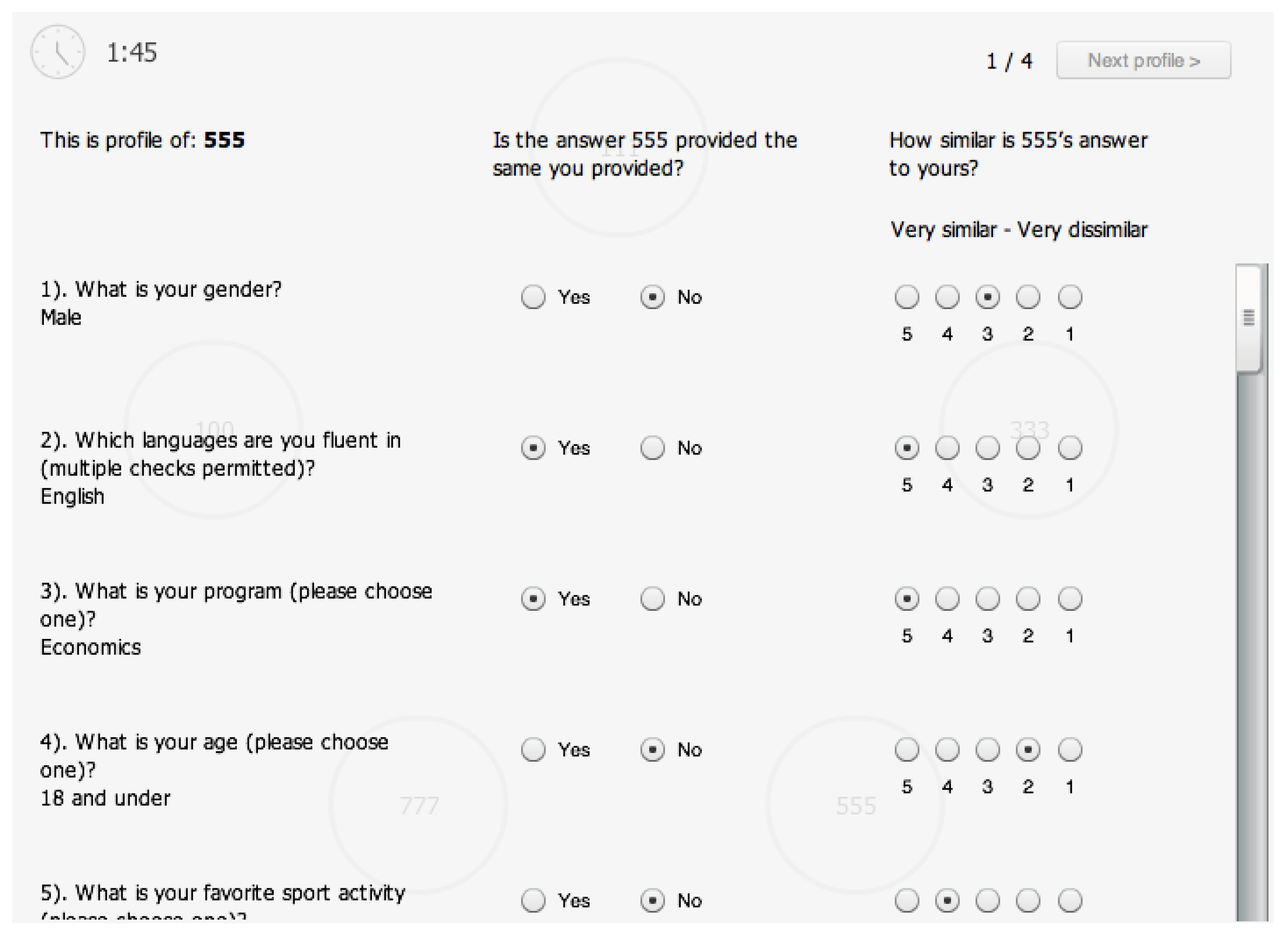
Appendix C. Longer Questionnaire
- What is your gender (please choose one)?a. Maleb. Femalec. Transgenderd. Two Spiritede. Prefer not to say/None of the above
- Which languages are you fluent in (multiple checks permitted)?a. Englishb. Frenchc. Spanishd. Mandarine. Cantonesef. Arabicg. Farsih. Japanesei. Prefer not to say/None of the above
- What is your program (please choose one)?a. Economicsb. Businessc. Communicationd. Artse. Criminologyf. Natural Sciencesg. Frenchh. General studiesi. Prefer not to say/None of the above
- What is your age (please choose one)?a. 18 and underb. 19c. 20d. 21e. 22f. 23 and aboveg. Prefer not to say
- What is your favorite sport activity (please choose one)?a. Hockeyb. Soccerc. Footballd. Basketball/Volleyballe. Badminton/Ping-Pongf. Tennisg. Swimmingh. Snowboarding/Skiingi. Prefer not to say/None of the above
- How would you describe your political views (please choose one)?a. Fiscally conservative, socially liberalb. Fiscally liberal, socially conservativec. Fiscally and socially liberald. Fiscally and socially conservativee. Greenf. Prefer not to say/None of the above
- Who is your favorite musician (please choose one)?a. Britney Spearsb. Sarah McLachlanc. Shakirad. Lady Gagae. Jay Chou (Jielun Zhou)f. Madonnag. David Guettah. Andy Liu (Dehua Liu)i. Ebij. Hayedehk. Coco Lee (Wen Li)l. Ghomeyshim. Girls’ generationn. IUo. Celine Dionp. Leonard Cohenq. Eminemr. Andrea Bocellis. Prefer not to say/None of the above
- How would you describe your behavior before taking a decision (please choose one)?a. I consider carefully all alternatives, and then decideb. I only examine few alternatives, until when I find a satisfactory onec. Prefer not to say/None of the above
- Do you participate in a goodwill activity (like volunteering)?a. Yesb. Noc. Prefer not to say/None of the above
- How much time do you spend on Facebook every day?a. Less than an hourb. Between 1 and 2 hoursc. More than 2 hoursd. I don’t use Facebooke. Prefer not to say/None of the above
- How often do you talk to close relatives during a week?a. Every dayb. Once a weekc. I rarely talk to my relativesd. Prefer not to say/None of the above
- How many text messages do you send every day with your phone?a. More than 10b. Between 5 and 10c. Less than 5d. I don’t text/ I don’t have a cell phonee. Prefer not to say/None of the above
References
- Lazarsfeld, P.F.; Merton, R.K. Friendship as a social process: A substantive and methodological analysis. In Freedom and Control in Modern Society; Berger, M., Ed.; Van Nostrand: New York, NY, USA, 1954; Volume 18, pp. 18–66. [Google Scholar]
- McPherson, M.; Smith-Lovin, L.; Cook, J.M. Birds of a feather: Homophily in social networks. Ann. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef]
- Bramoullé, Y.; Currarini, S.; Jackson, M.O.; Pin, P.; Rogers, B.W. Homophily and long-run integration in social networks. J. Econ. Theory 2012, 147, 1754–1786. [Google Scholar] [CrossRef] [Green Version]
- Pouli, V.; Kafetzoglou, S.; Tsiropoulou, E.E.; Dimitriou, A.; Papavassiliou, S. Personalized multimedia content retrieval through relevance feedback techniques for enhanced user experience. In Proceedings of the 2015 13th International Conference onTelecommunications (ConTEL), Graz, Austria, 13–15 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–8. [Google Scholar]
- Stai, E.; Kafetzoglou, S.; Tsiropoulou, E.E.; Papavassiliou, S. A holistic approach for personalization, relevance feedback & recommendation in enriched multimedia content. Multimed. Tools Appl. 2018, 77, 283–326. [Google Scholar]
- Zhao, T.; Hu, J.; He, P.; Fan, H.; Lyu, M.; King, I. Exploiting homophily-based implicit social network to improve recommendation performance. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2539–2547. [Google Scholar]
- Grossetti, Q.; Constantin, C.; du Mouza, C.; Travers, N. An Homophily-based Approach for Fast Post Recommendation on Twitter. In Proceedings of the 21th International Conference on Extending Database Technology, EDBT 2018, Vienna, Austria, 26–29 March 2018; pp. 229–240. [Google Scholar] [CrossRef]
- Ertug, G.; Gargiulo, M.; Galunic, C.; Zou, T. Homophily and Individual Performance. Organ. Sci. 2018. [Google Scholar] [CrossRef]
- Currarini, S.; Jackson, M.O.; Pin, P. An Economic Model of Friendship: Homophily, Min rities, and Segregation. Econometrica 2009, 77, 1003–1045. [Google Scholar]
- Goeree, J.K.; McConnell, M.A.; Mitchell, T.; Tromp, T.; Yariv, L. The 1/d Law of Giving. Am. Econ. J. Microecon. 2010, 2, 183–203. [Google Scholar] [CrossRef] [Green Version]
- Richmond, A.D.; Laursen, B.; Stattin, H. Homophily in delinquent behavior: The rise and fall of friend similarity across adolescence. Int. J. Behav. Dev. 2018. [Google Scholar] [CrossRef]
- Trinh, S.L.; Lee, J.; Halpern, C.T.; Moody, J. Our Buddies, Ourselves: The Role of Sexual Homophily in Adolescent Friendship Networks. Child Dev. 2018. [Google Scholar] [CrossRef] [PubMed]
- Davis, J.B. Social identity strategies in recent economics. J. Econ. Methodol. 2006, 13, 371–390. [Google Scholar] [CrossRef] [Green Version]
- Akerlof, G.A.; Kranton, R.E. Economics and identity. Q. J. Econ. 2000, 115, 715–753. [Google Scholar] [CrossRef]
- Wichardt, P.C. Identity and why we cooperate with those we do. J. Econ. Psychol. 2008, 29, 127–139. [Google Scholar] [CrossRef]
- Iijima, R.; Kamada, Y. Social Distance and Network Structures. Theor. Econ. 2017, 12, 655–689. [Google Scholar] [CrossRef]
- Tarbush, B.; Teytelboym, A. Social groups and social network formation. Games Econ. Behav. 2017, 3, 286–312. [Google Scholar] [CrossRef]
- Falk, A.; Kosfeld, M. It’s all about connections: Evidence on network formation. Rev. Netw. Econ. 2012, 11, 1–34. [Google Scholar] [CrossRef]
- Berninghaus, S.; Ehrhart, K.M.; Ott, M.; Vogt, B. Evolution of networks—An experimental analysis. J. Evol. Econ. 2007, 17, 317–347. [Google Scholar] [CrossRef]
- Chen, Y.; Li, S.X. Group identity and social preferences. Am. Econ. Rev. 2009, 99, 431–457. [Google Scholar] [CrossRef]
- Chakravarty, S.; Fonseca, M.A. The effect of social fragmentation on public good provision: An experimental study. J. Behav. Exp. Econ. 2014, 53, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Boosey, L.A. Conditional cooperation in network public goods experiments. J. Behav. Exp. Econ. 2017, 69, 108–116. [Google Scholar] [CrossRef]
- Güth, W.; Levati, M.V.; Ploner, M. Social identity and trust—An experimental investigation. J. Socio-Econ. 2008, 37, 1293–1308. [Google Scholar] [CrossRef] [Green Version]
- Bala, V.; Goyal, S. A Noncooperative Model of Network Formation. Econometrica 2000, 68, 1181–1230. [Google Scholar] [CrossRef]
- Fehr, E.; Schmidt, K. Theories of Fairness and Reciprocity-Evidence and Economic Applications; Technical Report, CESifo Working Paper; CESifo Group Munich: München, Germany, 2000. [Google Scholar]
- Rabin, M. Incorporating fairness into game theory and economics. Am. Econ. Rev. 1993, 83, 1281–1302. [Google Scholar]
- Guttman, J.M. On the evolutionary stability of preferences for reciprocity. Eur. J. Political Econ. 2000, 16, 31–50. [Google Scholar] [CrossRef]
- Fehr, E.; Fischbacher, U.; Gächter, S. Strong reciprocity, human cooperation, and the enforcement of social norms. Hum. Nat. 2002, 13, 1–25. [Google Scholar] [CrossRef] [PubMed]
- Goeree, J.K.; Riedl, A.; Ule, A. In search of stars: Network formation among heterogeneous agents. Games Econ. Behav. 2009, 67, 445–466. [Google Scholar] [CrossRef] [Green Version]
- Tversky, A.; Kahneman, D. Availability: A heuristic for judging frequency and probability. Cogn. Psychol. 1973, 5, 207–232. [Google Scholar] [CrossRef]
- Bicchieri, C. The Grammar of Society: The Nature and Dynamics of Social Norms; Cambridge University Press: New York, NY, USA, 2005. [Google Scholar]
- Bernasconi, M.; Galizzi, M. Network formation in repeated interactions: Experimental evidence on dynamic behaviour. Mind Soc. 2010, 9, 193–228. [Google Scholar] [CrossRef]
- Cameron, A.C.; Trivedi, P. Microeconometrics: Methods and Applications; Cambridge University Press: New York, NY, USA, 2005. [Google Scholar]
- Mundlak, Y. On the pooling of time series and cross section data. Econometrica 1978, 46, 69–85. [Google Scholar] [CrossRef]
- Schunck, R. Within and between estimates in random-effects models: Advantages and drawbacks of correlated random effects and hybrid models. Stata J. 2013, 13, 65–76. [Google Scholar]
- Greene, W. Discrete Choice Modelling. In The Handbook of Econometrics; Mills, T., Patterson, K., Eds.; Palgrave: London, UK, 2008; Volume 2. [Google Scholar]
- Dieleman, J.L.; Templin, T. Random-effects, fixed-effects and the within-between specification for clustered data in observational health studies: A simulation study. PLoS ONE 2014, 9, e110257. [Google Scholar] [CrossRef] [PubMed]
- Cameron, A.C.; Trivedi, P.K. Microeconometrics Using STATA; Stata Press: College Station, TX, USA, 2009; Volume 5. [Google Scholar]
- Schaffer, M.; Stillman, S. XTOVERID: Stata Module to Calculate Tests of Overidentifying Restrictions after xtreg, xtivreg, xtivreg2, xthtaylor. 2016. Available online: https://econpapers.repec.org/software/bocbocode/s456779.htm (accessed on 18 October 2018).
- Arellano, M. On the testing of correlated effects with panel data. J. Econ. 1993, 59, 87–97. [Google Scholar] [CrossRef]
- Clark, T.S.; Linzer, D.A. Should I use fixed or random effects? Political Sci. Res. Methods 2015, 3, 399–408. [Google Scholar] [CrossRef]
- Becchetti, L.; Pelloni, A.; Rossetti, F. Relational goods, sociability, and happiness. Kyklos 2008, 61, 343–363. [Google Scholar] [CrossRef] [Green Version]
- Rong, R.; Houser, D. Growing stars: A laboratory analysis of network formation. J. Econ. Behav. Organ. 2015, 117, 380–394. [Google Scholar] [CrossRef]
- Rockenbach, B.; Milinski, M. To qualify as a social partner, humans hide severe punishment, although their observed cooperativeness is decisive. Proc. Natl. Acad. Sci. USA 2011, 108, 18307–18312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fehr, E.; Schmidt, K.M. A Theory Of Fairness, Competition, and Cooperation. Q. J. Econ. 1999, 114, 817–868. [Google Scholar] [CrossRef]
| 1 | Cf., among many others, [2], discussing how homophily shapes the information channels and human sociality of the decision makers; [3] for a theoretical model that can accommodate type-dependent biases in network-based searches for connections; [4,5] for personalization in content retrieval on the web; [6], discussing the role of homophily to improve recommendation performance on the web; [7], studying homophily in recommendations on social media; [8], studying the relationship between homophily in the choice of instrumental relationships and performance in knowledge-intensive organizations. |
| 2 | |
| 3 | |
| 4 | The classical contribution discussing the “availability heuristic”, in terms of exaggerating the probability of events or, in our case, past choices, that can be easily recalled, is [30]. |
| 5 | This variable was computed for the last five rounds of play. We focus on the last five rounds because the subjects are likely to have gained considerable familiarity with the game and the other players’ behavior by then. |
| 6 | The number is thus obtained: 50 participants in our treatment sessions × 4 opponents in each round × 20 rounds of play = 4000. |
| 7 | The number is thus obtained: 50 participants × 4 opponents in each round × the last 5 rounds of play = 1000. |
| 8 | There are also other technical reasons for not using nonlinear estimation. It is not possible to use panel probit in the FE framework presented below, due to simplification issues. Logit transforms the dependent variable in such a way that in the transformed model, it takes a value equal to one if switches from zero to one, and zero if switches from one to zero (cf. [36]). |
| 9 | All statistical analyses were performed using STATA 13 (StataCorp LP). |
| 10 | We do not consider using heteroskedasticity-robust standard errors. In a panel setting, it is typically more important to correct for correlation in cluster errors, compared to correcting for heteroskedasticity alone ([33], p. 707). |
| 11 | The STATA command is vce(bootstrap, reps(500)) cluster (pers). |
| 12 | As a robustness checks, we re-ran all regressions after dropping the observations in which the player had a payoff of zero in round . In those instances, the hypothesized positive relationship between being better off in the previous round and creating links at t did not hold (cf. Section 4). Signs, magnitudes and p-values were unaffected. |
| 13 | Instructions for all studies can be found in the Appendix A to the paper. |
| 14 | The questionnaire for TG1 can be found in the Appendix C to the paper. |
| 15 | The work in [44] reported that individuals make a strategic choice regarding which information to disclose in a public good game, for example hiding their choices to punish and to contribute little. |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coefficient | (Std. Err.) | |
|---|---|---|
| Variable: | ||
| Control | 0.272 | (0.021) |
| TG1 | 0.35 | (0.046) |
| TG2 | 0.283 | (0.014) |
| Variable: connected | ||
| Control | 0.461 | (0.019) |
| TG1 | 0.552 | (0.035) |
| TG2 | 0.467 | (0.025) |
| Variable: bestresp | ||
| Control | 0.39 | (0.046) |
| TG1 | 0.23 | (0.043) |
| TG2 | 0.393 | (0.057) |
| Variable | RE | FE | Mixed |
|---|---|---|---|
| attshared | 0.0855 | 0.0581 | |
| avsimil | 0.0106 | 0.0231 | |
| crossimil | −0.0215 | −0.0148 | |
| lag1otherlinks | 0.04884 * | 0.033 | 0.033 |
| lag1betteroff | −0.0191 | 0.0034 | 0.0034 |
| tg1 | 0.013 | 0.0717 | |
| Averages | (omitted) | ||
| Intercept | (omitted) | (omitted) | (omitted) |
| R | 0.029 | 0.011 | 0.093 |
| Variable | RE | FE | Mixed |
|---|---|---|---|
| attshared | −0.0707 | −0.0603 | |
| avsimil | 0.0541 | 0.0479 | |
| crossimil | 0.0007 | -0.002 | |
| lag1otherlinks | −0.1366 *** | −0.0957 * | −0.1236 ** |
| lag1betteroff | −0.0106 | −0.036 | −0.0525 |
| tg1 | 0.0488 | 0.0146 | |
| Averages | (omitted) | ||
| Intercept | (omitted) | (omitted) | (omitted) |
| R | 0.075 | 0.008 | 0.12 |
| Coefficient | Hypothesized Sign | Finding |
|---|---|---|
| as dependent variable | ||
| , (similarity) | + | Null |
| (reciprocity) | + | + |
| (inequity aversion) | + | Null |
| as dependent variable | ||
| (reciprocity) | − | − |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arifovic, J.; Danese, G. Homophily and Social Norms in Experimental Network Formation Games. Games 2018, 9, 83. https://doi.org/10.3390/g9040083
Arifovic J, Danese G. Homophily and Social Norms in Experimental Network Formation Games. Games. 2018; 9(4):83. https://doi.org/10.3390/g9040083
Chicago/Turabian StyleArifovic, Jasmina, and Giuseppe Danese. 2018. "Homophily and Social Norms in Experimental Network Formation Games" Games 9, no. 4: 83. https://doi.org/10.3390/g9040083
APA StyleArifovic, J., & Danese, G. (2018). Homophily and Social Norms in Experimental Network Formation Games. Games, 9(4), 83. https://doi.org/10.3390/g9040083