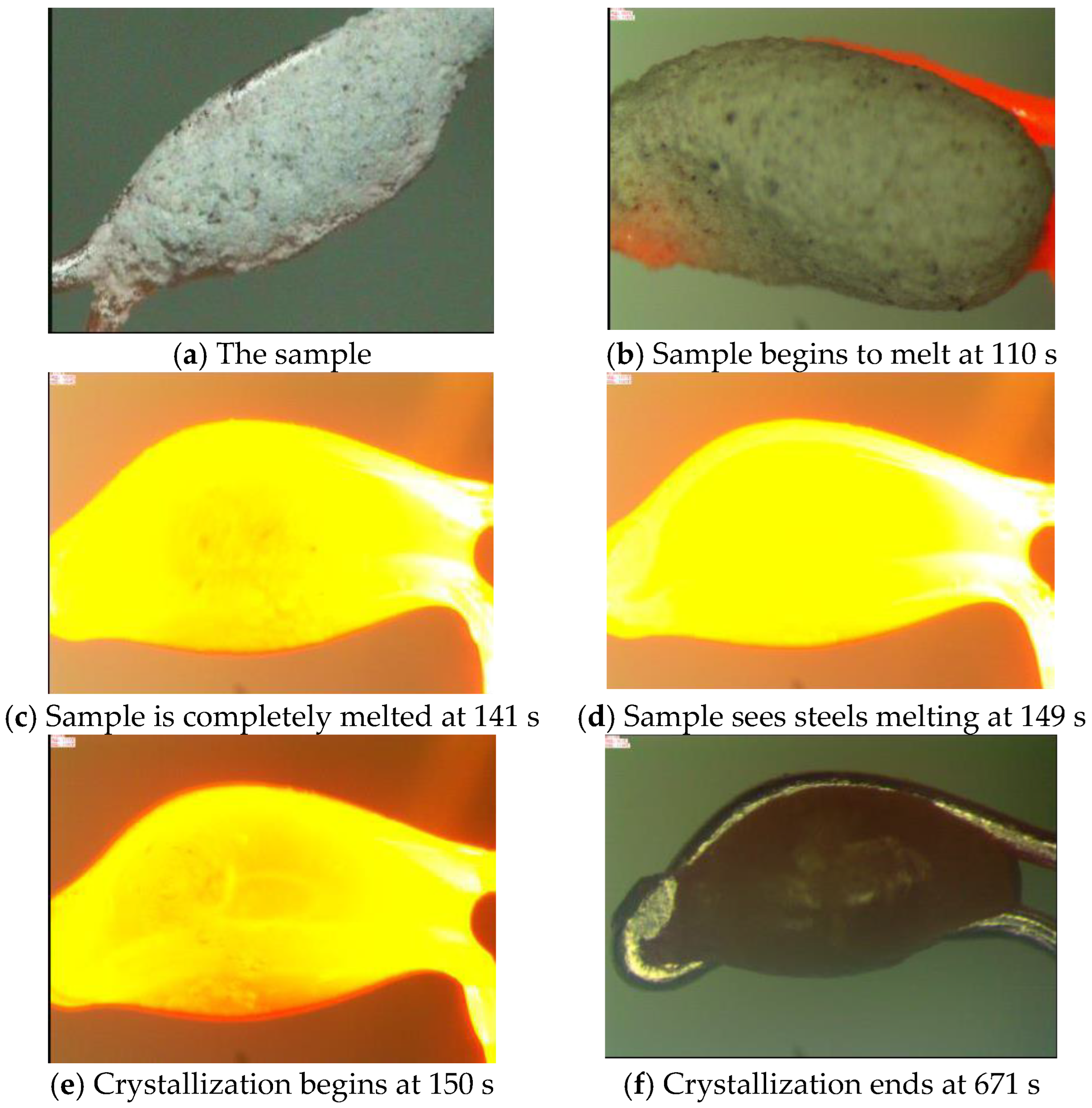
4.1. Extraction of Temperature Information
For the automatic extraction of temperature information, this paper adopts the method of converting color RGB (red, green and blue) image into grey value and then converting it into a binary image to obtain the digital information in the image. In a color RGB image, each pixel contains R, G and B information. Generally, the weighted sum of R, G and B is used as the calculation method of grey value, namely:
where,
greyij is the greyscale value corresponding to the pixel in column
j of row
i after the operation;
Rij, Gij and
Bij represent the RGB information corresponding to the pixel in column
j of row
i before the operation, respectively. After obtaining the corresponding grey value of the pixel in row
i and column
j, the threshold value is used to solve the corresponding binary graph of the pixel at that point, namely:
where
bwij is the binarization result corresponding to the pixel in row
i and column
j after the operation, and
ts is the threshold in the binarization process.
U is the unit step function. If the independent variable of the function is greater than or equal to 0, the value of the function is 1, and if the value of the function is less than 0, the value of the function is 0. Then the final binarization result can be expressed as the following matrix:
In the matrix above,
bw is the matrix representing the final digital information. An information matrix can be determined by comparing it with the information matrix of each standard number. To determine the information matrix with digital information, the difference between the information obtained and the standard digital information can be compared by comparing its two-dimensional correlation coefficient with the standard digital image:
where
r is the two-dimensional correlation coefficient between the digital information matrix and the standard digital information matrix.
bw′ij is the element in row
i, column
j of the standard numerical information matrix. The greater
r, the closer the numeric information matrix is to the standard numeric information matrix. For ten Arabic numerals, the following methods can be used to determine which digital information is contained in the matrix.
where
r0,
r1,…,
r9 represent the two-dimensional correlation coefficient between the matrix containing the information of a certain number and the matrix containing the information of nine Arabic numbers.
R represents the maximum of the two-dimensional correlation coefficient between the matrix of a given number and the matrix of the binary information of each Arabic numeral. The standard number corresponding to the maximum value can be considered as the digital information contained in the information matrix. The above process can be described in
Figure 3.
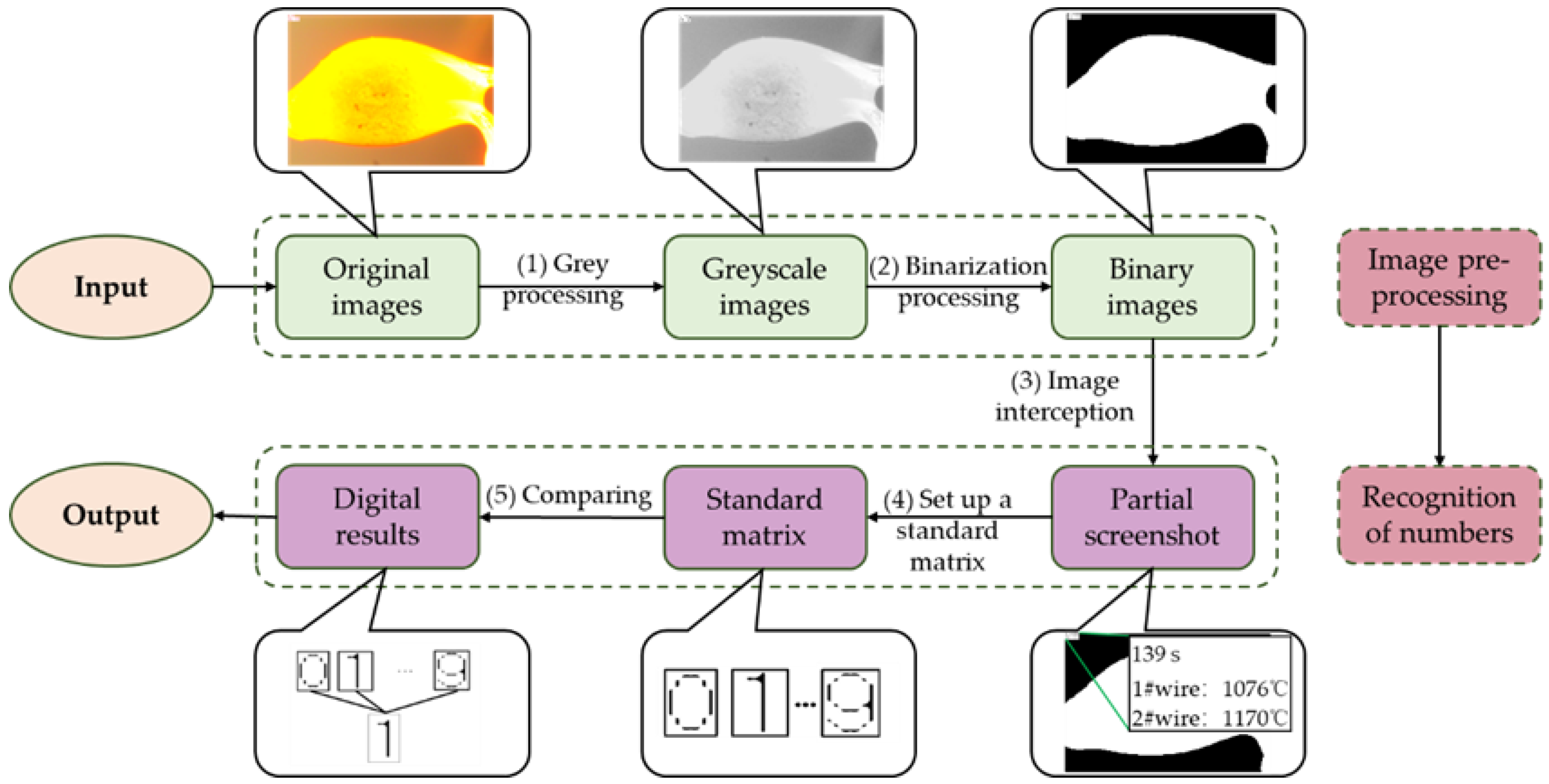
As shown in
Figure 3, for a given image, the temperature information in the upper left corner of the image can be read as follows: (1) Greyscale processing: calculate the greyscale value of each pixel by using the weighted sum of R, G and B as the greyscale value, and return the digital image after greyscale value processing. The enlarged figure contains the digital information after grey value processing. (2) Binarization processing: by setting a threshold of 0.5, the greyscale image can be converted into a binary graph, return the processed binary image. The enlarged part shows the digital information after binarization. (3) Image interception: in order to improve the efficiency and the accuracy of judgment, the digital part must be intercepted. By comparing the digital information of the image with the model, the matrix of binarization digital information can be obtained. (4) Set up a standard matrix: since the digital information contained in the matrix is affected by the font of the number, in order to obtain the number consistent with the font in the figure, ten Arabic numerals are manually selected from the image, a matrix containing the information of the ten numbers is established. (5) Comparing and determining the information: compare the obtained matrix of the numbers with the standard matrix of the ten Arabic numerals using a two-dimensional correlation coefficient, the temperature information can be automatically determined by using the value of the two-dimensional correlation coefficient.
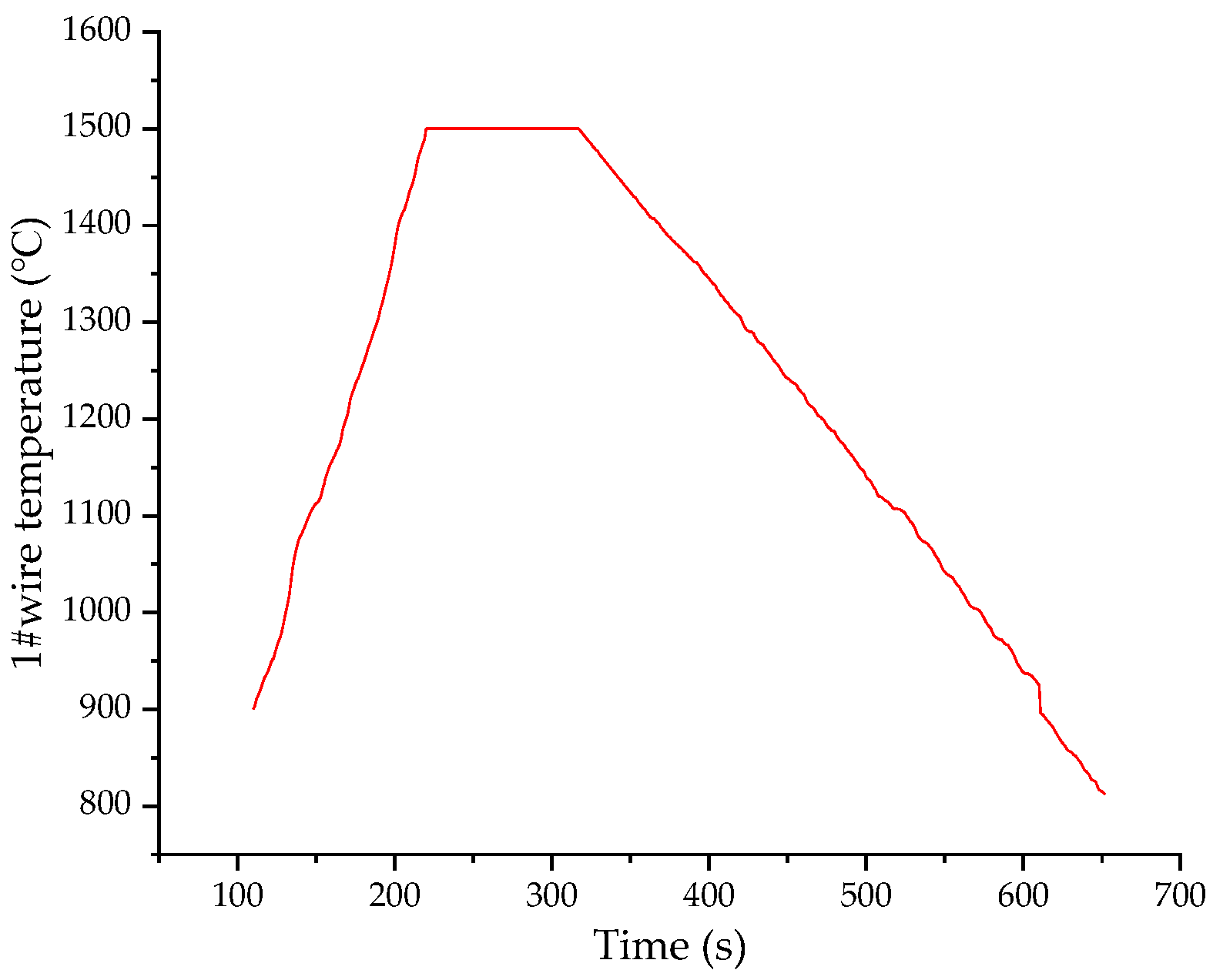
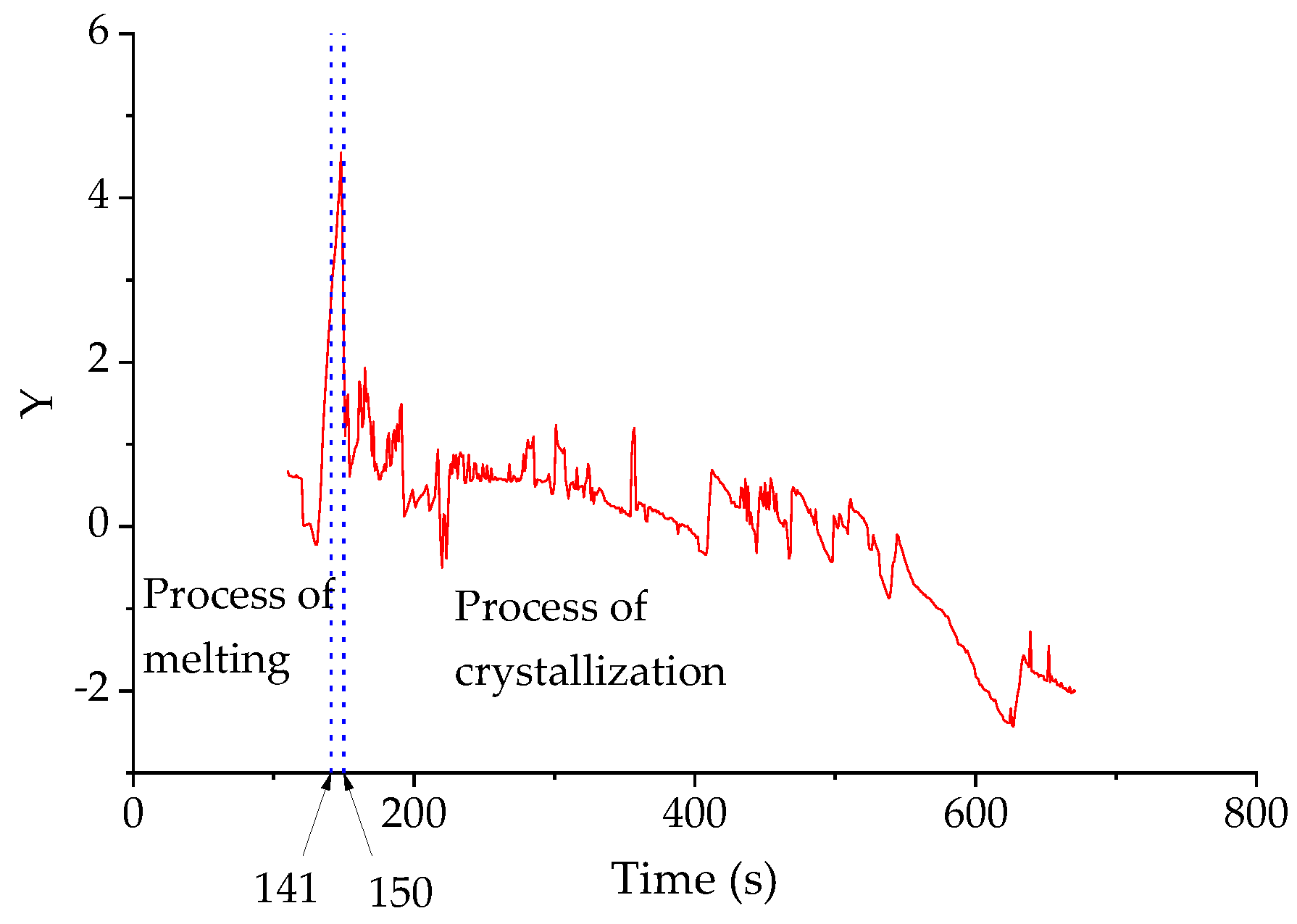
Figure 4 shows the variation of the thermocouple temperature over time obtained by the image processing method.
As shown in
Figure 4, the red solid line represents the curve of the temperature measured by the thermocouple over time. It can clearly be seen that as the time changes from 110 to 220 s, the temperature increases approximately linearly with time. When the time reaches 220 s, the measured temperature remains stable at 1500 °C (this is the upper limit of the SHTT-type melting temperature tester). When the time reaches 317 s, the temperature starts to decrease and the cooling rate remains basically constant during the cooling process. Finally, the measured temperature of the thermocouple reaches about 812 °C.
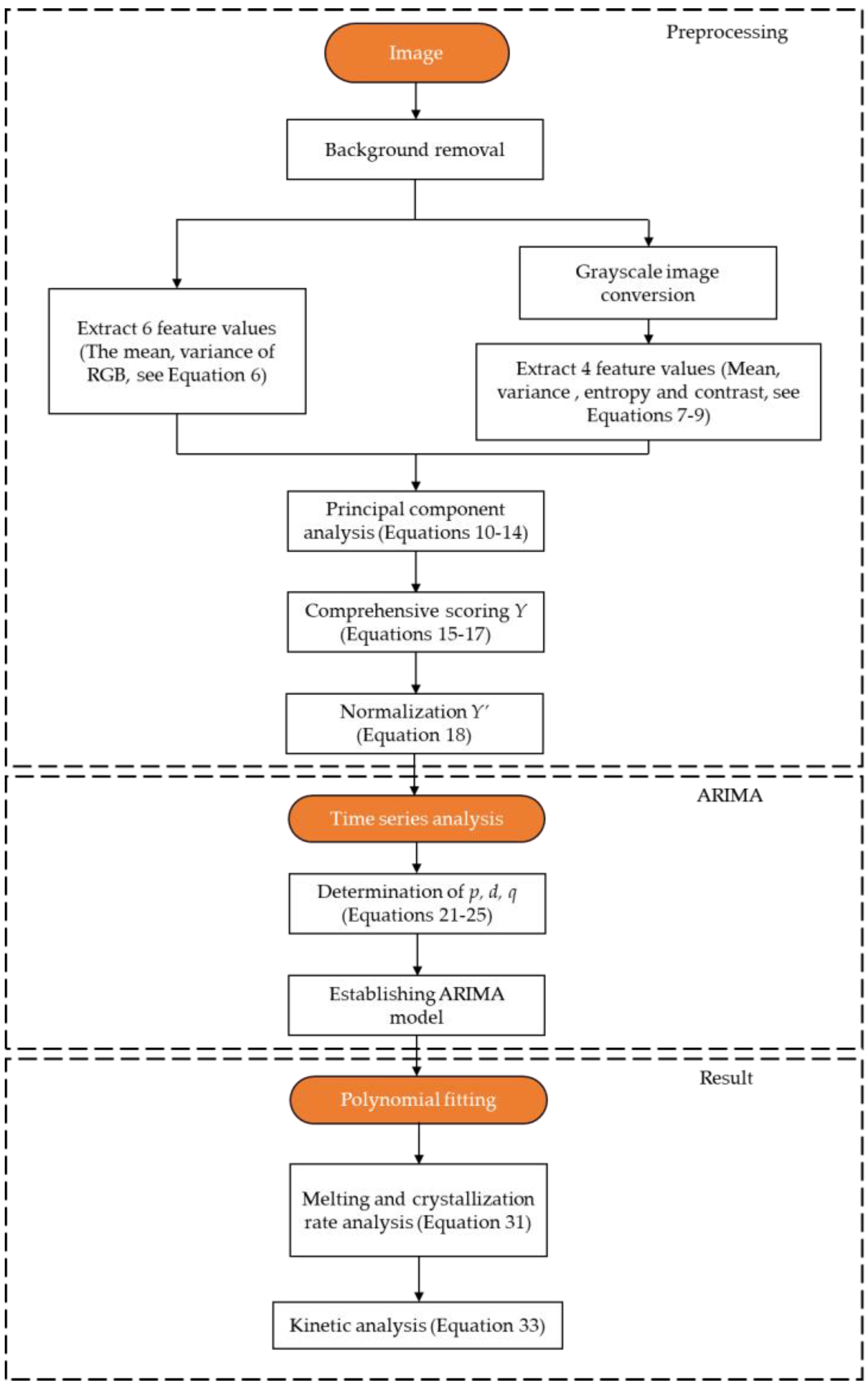
To ensure that the information obtained is from the slag, the images used in the following steps were removed from the background, which effectively reduces the background interference of the image and improves the accuracy of the model solution to some extent.
4.2. Extraction of the Image Feature Information
For this problem, the first thing to do is to obtain as many features as possible in the image. These features mainly include color momentum, grey mean value, energy and entropy, and so on. Using the information obtained, time series modeling is carried out using statistical methods. In addition, a special discussion is required for six node images to assess the validity of the selected features.
The image features can be divided into color features, shape features, grey features and edge features, and so on [
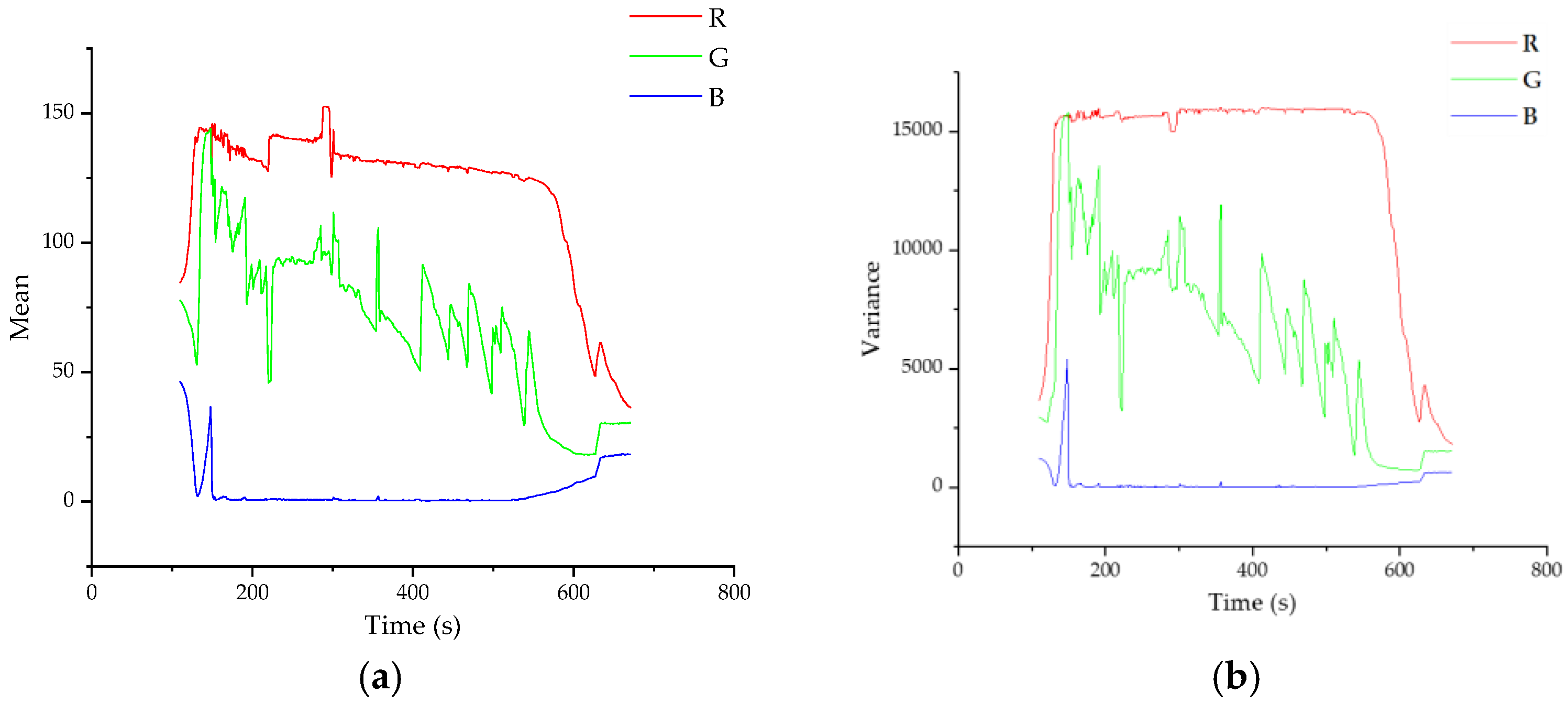
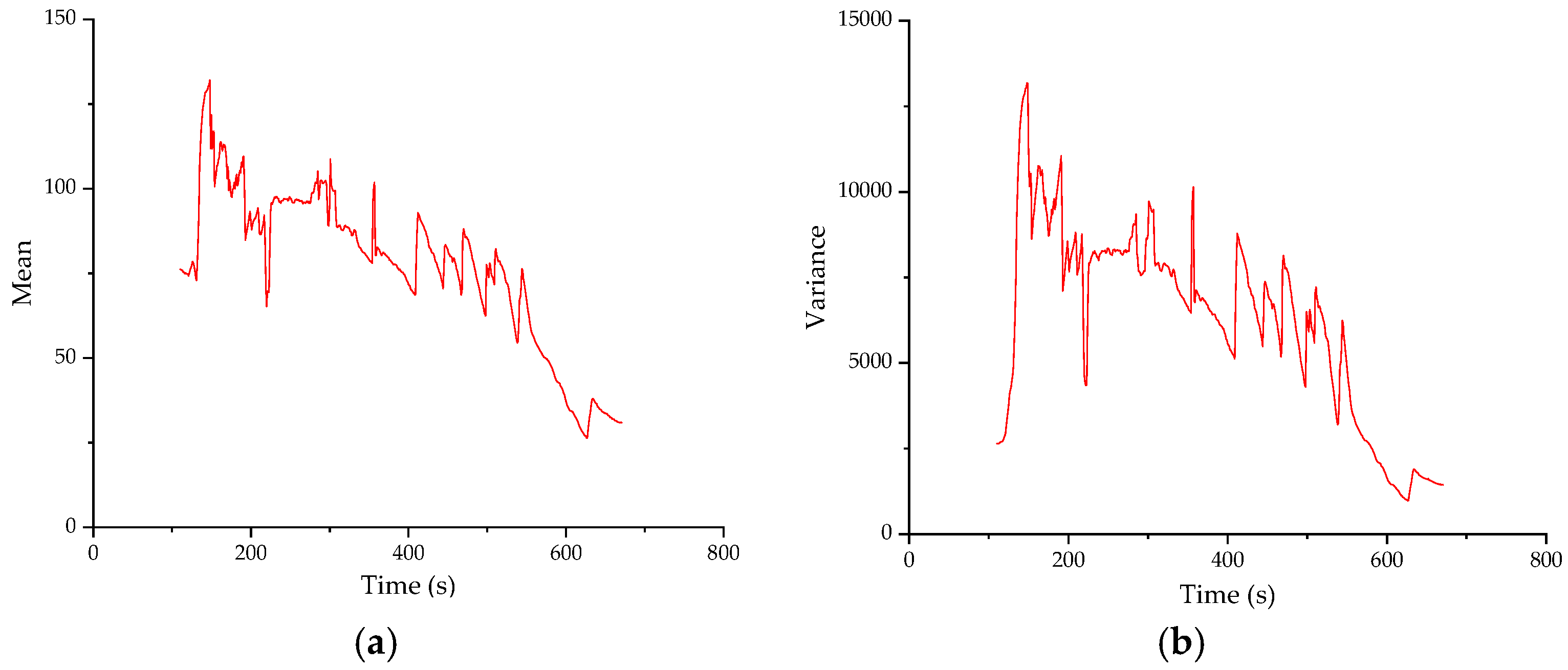
25]. However, the shape change and edge features are not obvious for the melting image of mold flux investigated in this paper, which are not considered. The color and grey features are mainly studied. Color features are quantified and analyzed mainly by means of the mean and variance of image RGB, the grey features are analyzed mainly by mean and variance of the grey image, entropy and contrast.
4.2.1. Extraction of Color Moment Features
For a color image in the RGB color space, the three-dimensional color moment is the mean value, variance and slope of the three-color components:
where
μn and
σn represent the mean and variance of the three-color components, respectively.
ni represents the value of the color component
n at the
i-th pixel.
N is the total number of pixels in the image.
4.2.2. Extraction of Grey Features
- (1)
Mean and variance of greyscale images
A similar method can be used to obtain the mean and variance of greyscale images. Firstly, the digital image information acquisition model is used to convert the original color image to grey scale. For each pixel of the grey scale, the mean value and variance of all pixels can be obtained through mathematical statistics.
where,
μgrey and
σgrey represent the variance and mean, respectively, of all the pixels in the grey image obtained by the transformation.
greyi represents the grey level of the
i-th pixel in the grey image.
N represents the total number of pixels in the greyscale image.
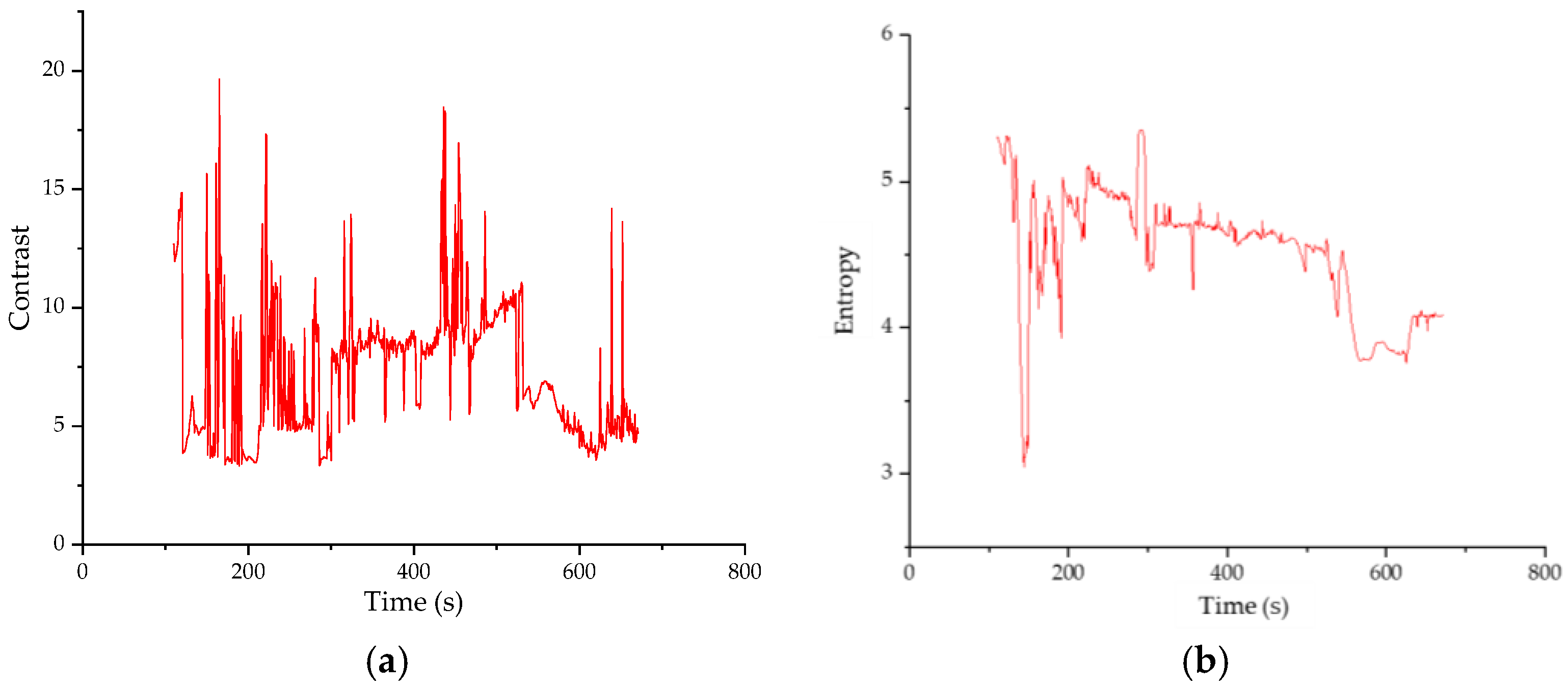
- (2)
Entropy of greyscale images
Image entropy is expressed as the bit average of the image grey level, which describes the degree of non-uniformity or complexity of the texture in the image. For a two-dimensional image in discrete form, its information entropy can be calculated as follows:
where
Ps is the number of times the grey value
s appears in the image, and
ent is the image entropy of the image.
s represents the grey value of a pixel and
t represents the mean value of the grey neighborhood of
s. f(
s,
t) is the frequency of the feature binary group (
s,
t) appearing in the image.
N is the total number of pixels in the greyscale image.
- (3)
Contrast of greyscale images
Image contrast refers to the measurement of different levels of brightness between the brightest white and the darkest black in an image, namely, the size of the gray contrast of an image. The formula is as follows:
where
CM is the contrast of an image,
Imax is the maximum brightness and
Imin is the minimum brightness.
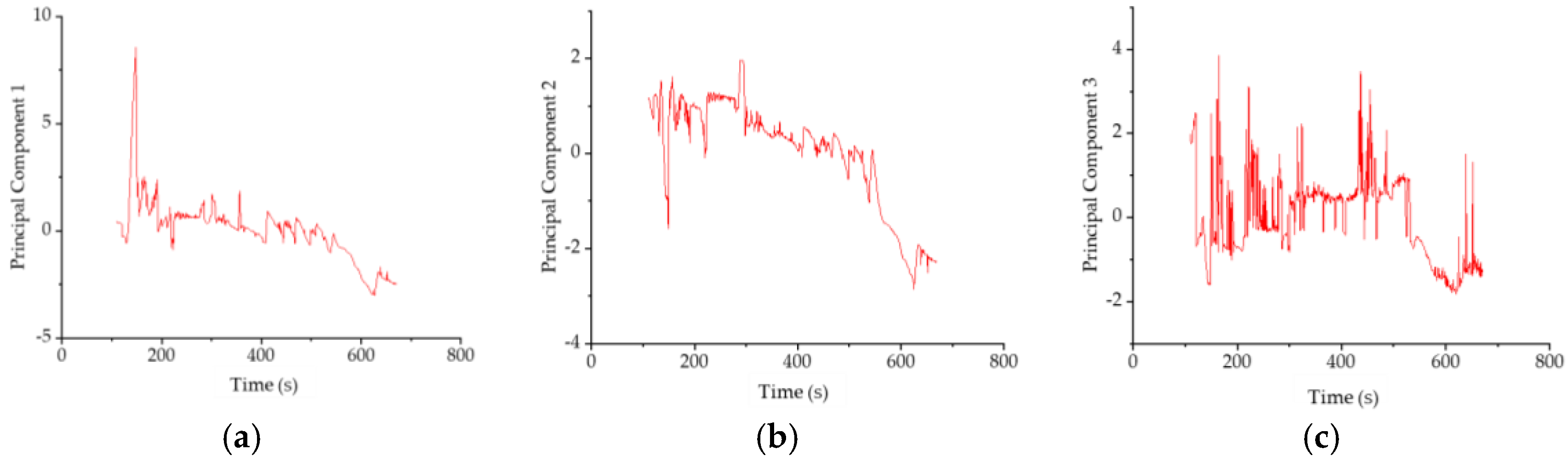
4.3. Principal Component Analysis of Image Information
Principal component analysis (PCA) [
26] is a data dimensionality reduction method that can transform a large number of related data into a small number of unrelated data and reflect the information in the original data as much as possible.
In the image feature extraction part, a total of ten features in the image were extracted. There is a certain correlation among the ten features, and different features have different dimensionalities. In order to fully exploit the information of the features and unify the dimensions, the PCA method is used to analyze the obtained image information and convert ten features into three main features. By constructing a comprehensive score model and using three main features, the comprehensive score of all the features can be obtained. Without PCA, it is difficult to make full use of the information of ten features.
Let
s be the weighted sum of the information
x1,
x2,…,
xn extracted from the image (the weights are
c1,
c2,…,
cn).
Since the extracted information usually has different dimensions and orders of magnitude, it is necessary to first standardize the obtained data information. Assuming that the
j-th data of the
i-th information are
xij,
ij and
j are the mean values, the processing method is as follows:
By choosing appropriate weights, the information in each photo can be better distinguished. Each photo corresponds to the sum of the weights, denoted s1, s2,…, sj. If the distribution of the sum of the weights in these photos is scattered, it means that the group of weights can be well distinguished.
Let us assume that
X1,
X2,…,
Xp are the random variables for the
p-th information. Since the variance reflects how discrete the data are, it is possible to find a set of
c1,
c2,…,
cp that gives the maximum value in the following formula.
This means that this group of weights can make the value of
s the most scattered. In order for the weight obtained to be meaningful, it must also meet the following requirements:
Under the constraint of Equation (13), the optimal solution of Equation (12) is a unit vector that represents a direction in the
p-dimensional space, namely, the principal component direction. Since one principal component is not enough to represent all the original variables, more principal components need to be found. The second principal component should not contain any information from the first principal component, so the directions of all principal components should be orthogonal. Now assuming that
Zi is the
i-th principal component, all principal components can be expressed as:
For each Z, the maximum value of Formula (12) should be solved under the condition that Equation (13) is satisfied, and the vectors (c11, c12,…, c1p), (c21, c22,…, c2p),…, (cp1, cp2,…, cpp) should not be perpendicular to each other.
During the solution process, the eigenvalue of each characteristic covariance matrix in the image,
λ, can be obtained. This eigenvalue reflects the amount of original information retained by the principal component. The percentage variance of each principal component can be calculated from the eigenvalue, as follows:
where
pi (
p1 <
p2 < … <
pi−1 <
pi <
pi+1 < … <
pn) refers to the variance percentage of the
i-th principal component. The closer the variance percentage is to one, the more original information is retained in the principal component.
Since the main purpose of principal component analysis is to reduce the number of variables, a small number of principal components are usually selected in the principal component solution process to ensure that their cumulative contribution rate reaches 70% to 80%. The cumulative contribution rate
qi is defined as
Suppose that
k principal components have been selected by the cumulative contribution rate, and the function s(
t) of
k principal components over time has been calculated. The comprehensive score of the
k principal components can be obtained from these variance percentages. The calculation method is as follows:
where,
si(
t) is the function of the
i-th principal component changing with time at time
t, and
Y(
t) is the comprehensive score of the
k components over time.
4.5. Time Series Modeling of Image Information
The ARIMA model [
27] is a well-developed time series prediction model, which is often used for prediction based on time series data. The image features of melting crystallization of mold flux are a data series with time, so the ARIMA model can be successfully used to analyze them. A typical ARIMA model, ARIMA(
p,
d,
q), can be written as:
where
L is a lag operator, satisfying
d∈
Z,
d >
A0.
ϕi is the autocorrelation coefficient,
θi is the moving average coefficient and
εt is the interference error.
Xt represents the value of the time series at time
t. As explained in Equation (19), in ARIMA(
p,
d,
q), AR is “autoregressive”, and
p is the order of autoregressive terms. MA is the “moving average”,
q is the order of moving average terms and
d is the number of differences made to make it a stationary sequence (order).
4.5.1. ADF Unit Root Test
Before establishing the ARIMA model, the data should be stabilized, that is, the data must be processed by the numerical difference method. The augmented Dickey–Fuller (ADF) unit root test can be used to determine the stationarity of a data set. For an AR(
p) model, it can be rewritten as follows:
where
yt is the current image information sequence,
t is the test statistic and
εt is the serially independent error term at time
t.
ρ is the ordinary least squares (OLS) estimate (based on an
p-observation time series) of the autocorrelation parameter.
4.5.2. Determination of ARIMA Model Parameters
Since the construction of AR (autoregressive) requires stationarity, the construction of ARIMA model also requires stationarity, the numerical difference method can be used to process the data. The first-order difference is the difference between t and t−1, the second-order difference is a difference based on the first-order difference, so that the number of differences after data stationarity is the parameter d that we want to determine. Therefore, continuous differential processing of the image information was performed to determine the final value of d.
In the ARIMA model, the order of the lag terms
p and
q should be determined by autocorrelation function (ACF) and partial autocorrelation function (PACF). The parameters
p and
q obtained are shown in
Table 1.
Among them, when PACF is truncated after stage p, the truncation order is the parameter p determined by the model; when ACF is truncated after stage q, the truncation order is the parameter q determined by the model. The calculation method of ACF and PACF is described below.
ACF is a complete autocorrelation function that describes the degree of correlation between the current and past values of the sequence. ACF takes into account the trend and residual of the image information when searching for correlation, and its formula is as follows:
where
yt is the current sequence of image information,
yt−k is the
k-order lag sequence of image information and
ρk is the coefficient of the autocorrelation function between the current sequence and the
k-order lag sequence of image information.
The partial autocorrelation function (PACF) only describes the relationship between the observed value and its lag term, that is, the relationship between the current image information sequence and the
p-order lagged image information sequence, while adjusting for the influence of other shorter lag terms. The formula is:
By inverting it, we can obtain:
where Φ′ is the autocorrelation coefficient of the lag period
p, and Φ
p is the partial autocorrelation coefficient.
4.6. Relationship between Temperature, Melting Rate and Crystallizing Rate
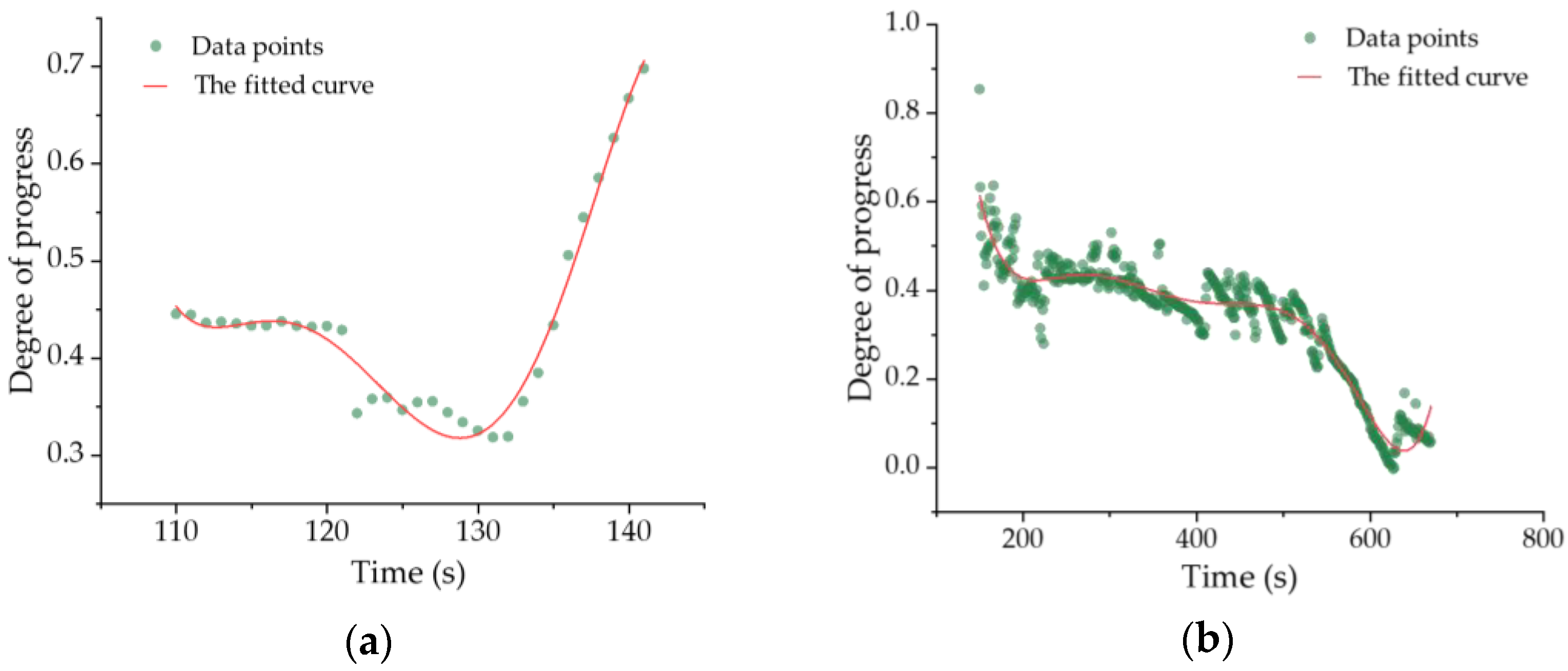
This part aims to obtain the relationship between temperature, time change and the melting and crystallization process of the mold flux based on the established time series model. Since temperature is linearly dependent on time, temperature can be expressed linearly by time. Therefore, the relationship between the melting and crystallization process of the mold flux and temperature can be converted into a relationship with time. For such problems, the least squares method, polynomial fitting and other methods can be used to fit them, so as to solve the melting and crystallization equation of the mold flux. In this paper, the bivariate polynomial fitting method under the least square method is used to obtain the functional relationship between the change of temperature, time and the melting and crystallization process of the slag. Assume that the function
H(
x) is a polynomial function, and its general formula is:
where
a1,
a2,…,
an are the binomial coefficients, the best fitting value can be obtained by the least squares method, namely:
where
G(
a1,
a2, …,
an) is the optimization objective of the least squares method,
a1,
a2,…,
an are the binomial coefficients and
xm and
ym are the horizontal and vertical coordinates of the point
m, respectively. When the binomial coefficient reaches a certain value,
G(
a1,
a2,…,
an) reaches the minimum value corresponding to the number of points where the binomial fitting effect is the best.
In the measurement process, the slag does not start melting or crystallizing at time 0. In order to better describe the melting and crystallization process. Time must be further converted.
where
tm0 and
tc0 represent the time of melting and crystallization, respectively.
tm and
tc represent the time of melting and crystallization after
t time.
Since the relationship between the determined principal component and time can be obtained by polynomial fitting, it is assumed that the principal component and time satisfy a polynomial function:
The above function shows the relationship between time and the melting and crystallization process. Temperature is linearly correlated with time, which can be expressed as:
where
Tm and
Tc are the melting and crystallization temperatures after time
t, respectively.
Tm0 and
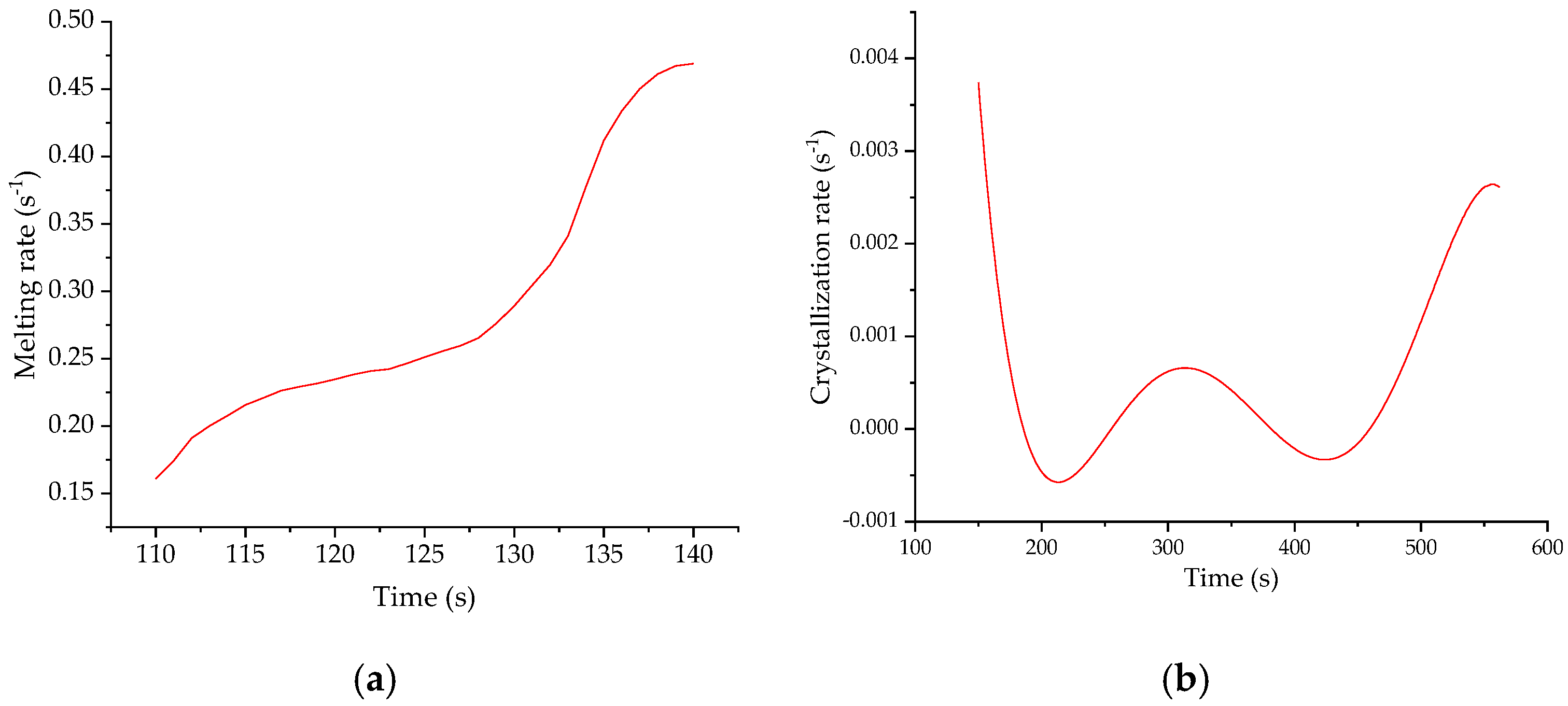
Tc0 represent the temperatures at which melting and crystallization start, respectively. The relationship between time and temperature is linear, and the rate of melting and crystallization process can be expressed as:
where
vm and
vc represent melting and crystallization rate, respectively.
Hm(
tm) and
Hc(
tc) represent the functional relationship between melting and crystallization process and time, respectively, that is, the relationship between the content of the selected principal component and the time. As the melting and crystallization rate are defined by the rate of change of the composite score, to avoid the crystallization rate value being less than 0, the crystallization rate was defined as the negative of the rate of change of the composite score. By combining Equation (30) with (31), we can obtain:
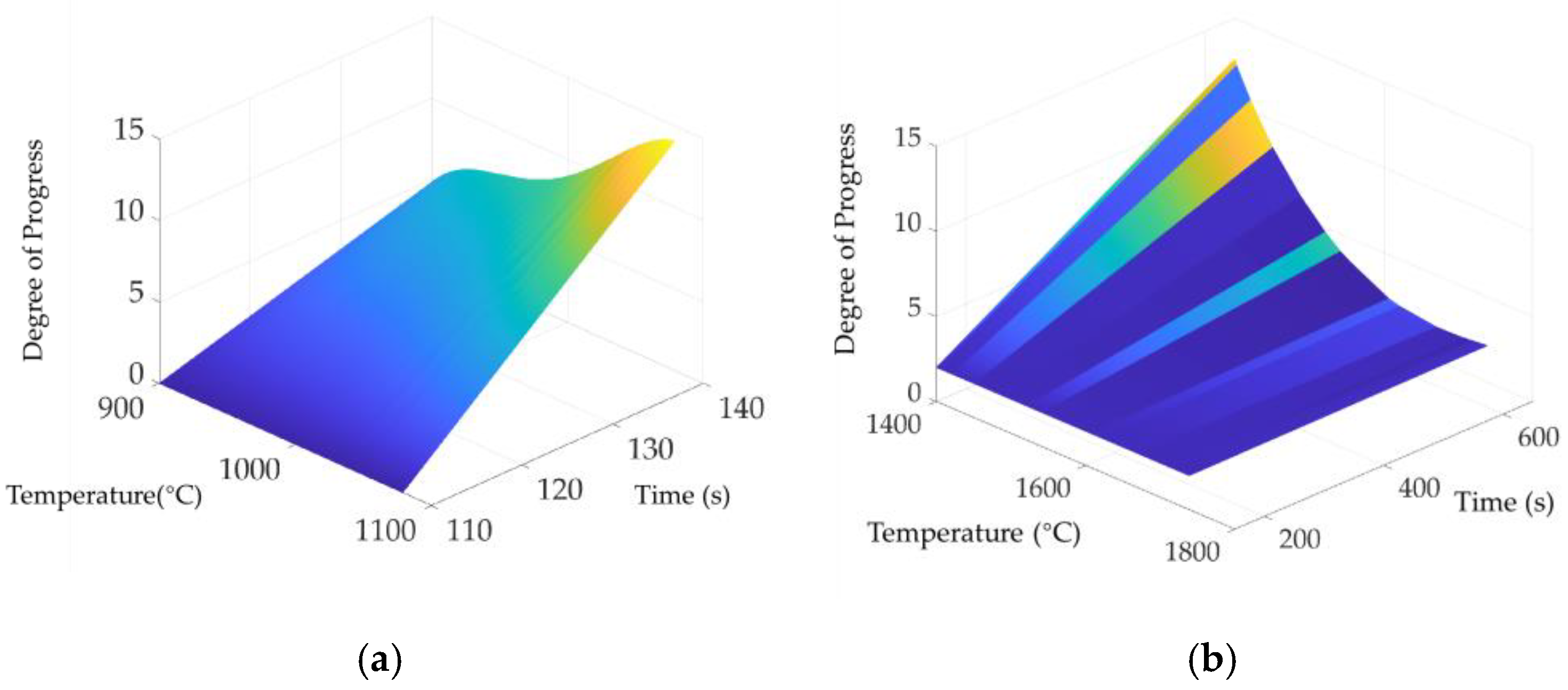
The function above shows the functional relationship between temperature and melting and crystallization rate. The process of melting and crystallization process can be further expressed as:
where
Hm(
tm,
Tm) and
Hc(
tc,
Tc) represent the melting and crystallization process after
Tm,
Tc time at
tm,
tc temperature, respectively, that is, the relationship between the content of the selected principle component and time and temperature.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}