

Intra-Plot Variable N Fertilization in Winter Wheat through Machine Learning and Farmer Knowledge

Abstract
:1. Introduction
2. Materials and Methods
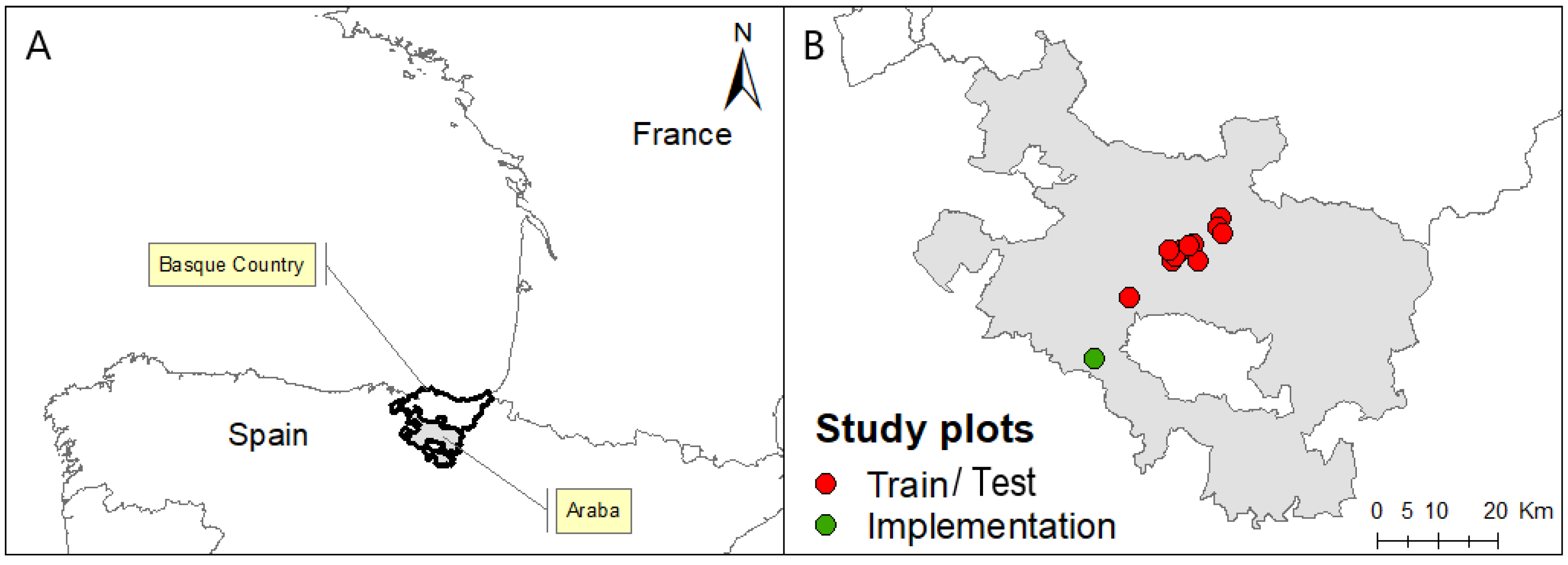
2.1. Field Sites
2.2. Working Procedure
2.3. Yield Data
2.4. Normalized Difference Vegetation Index (NDVI) and Digital Elevation Model (DEM)
2.5. Machine Learning Regression Algorithm
2.6. Statistics
2.6.1. Root Mean Square Error (RMSE)
2.6.2. Coefficient of Determination (R2)
2.6.3. Interpolation
2.6.4. ISODATA
3. Results and Discussion
3.1. NDVI Evolution and Correlation with Yield
3.2. Selecting the Best Machine Learning Regression Algorithm for Wheat Yield at S2 Pixel Resolution
3.3. Validation of RF Ability to Predict Whole-Plot Yield Using Data from the Remaining Fields
3.4. Fertilization Prescription Map
3.5. Variable Fertilizer Application Considerations and On-Farm Experimentation
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hansson, S.O. Farmers’ Experiments and Scientific Methodology. Eur. J. Philos. Sci. 2019, 9, 32. [Google Scholar] [CrossRef]
- Thompson, L.J.; Glewen, K.L.; Elmore, R.W.; Rees, J.; Pokal, S.; Hitt, B.D. Farmers as researchers: In-depth interviews to discern participant motivation and impact. Agron. J. 2019, 111, 2670–2680. [Google Scholar] [CrossRef]
- Marchant, B.; Rudolph, S.; Roques, S.; Kindred, D.; Gillingham, V.; Welham, S.; Coleman, C.; Sylvester-Bradley, R. Establishing the Precision and Robustness of Farmers’ Crop Experiments. Field Crops Res. 2019, 230, 31–45. [Google Scholar] [CrossRef]
- De Janvry, A.; Sadoulet, E.; Rao, M. Adjusting Extension Models to the Way Farmers Learn. Policy Brief 2016, 156, 1–12. [Google Scholar]
- Lacoste, M.; Cook, S.; McNee, M.; Gale, D.; Ingram, J.; Bellon-Maurel, V.; MacMillan, T.; Sylvester-Bradley, R.; Kindred, D.; Bramley, R.; et al. On-Farm Experimentation to Transform Global Agriculture. Nat. Food 2022, 3, 11–18. [Google Scholar] [CrossRef]
- Maurel, V.B.; Tremblay, N.; Cook, S.; Lacoste, M.; Taylor, J.; Lemarié, S.; Mangin, Z. Digital Tools for a Scalable Transformative Pathway. In Proceedings of the 1st International Conference on Farmer-Centric Onfarm Experimentation (OFE2021), Montpellier, France, 13–15 October, 2021. [Google Scholar]
- Diacono, M.; Rubino, P.; Montemurro, F. Precision Nitrogen Management of Wheat. A Review. Agron. Sustain. Dev. 2013, 33, 219–241. [Google Scholar] [CrossRef]
- Raun, W.R.; Solie, J.B.; Stone, M.L. Independence of Yield Potential and Crop Nitrogen Response. Precis. Agric. 2011, 12, 508–518. [Google Scholar] [CrossRef]
- Qiao, J.; Yang, L.; Yan, T.; Xue, F.; Zhao, D. Nitrogen Fertilizer Reduction in Rice Production for Two Consecutive Years in the Taihu Lake Area. Agric. Ecosyst. Environ. 2012, 146, 103–112. [Google Scholar] [CrossRef]
- Cameron, K.C.; Di, H.J.; Moir, J.L. Nitrogen losses from the soil/plant system: A review. Ann. Appl. Biol. 2013, 162, 145–173. [Google Scholar] [CrossRef]
- Aranguren, M.; Castellón, A.; Aizpurua, A. Crop Sensor-Based In-Season Nitrogen Management of Wheat with Manure Application. Remote Sens. 2019, 11, 1094. [Google Scholar] [CrossRef]
- Corwin, D.L. Site-Specific Management and Delineating Management Zones. In Precision Agriculture for Food Security and Environmental Protection. Earthscan; Oliver, M., Ed.; Taylor & Francis Group: London, UK, 2013; Chapter 8; pp. 135–157. [Google Scholar]
- Yao, R.-J.; Yang, J.-S.; Zhang, T.-J.; Gao, P.; Wang, X.-P.; Hong, L.-Z.; Wang, M.-W. Determination of Site-Specific Management Zones Using Soil Physico-Chemical Properties and Crop Yields in Coastal Reclaimed Farmland. Geoderma 2014, 232–234, 381–393. [Google Scholar] [CrossRef]
- Córdoba, M.A.; Bruno, C.I.; Costa, J.L.; Peralta, N.R.; Balzarini, M.G. Protocol for Multivariate Homogeneous Zone Delineation in Precision Agriculture. Biosyst. Eng. 2016, 143, 95–107. [Google Scholar] [CrossRef]
- Segarra, J.; Buchaillot, M.L.; Araus, J.L.; Kefauver, S.C. Remote Sensing for Precision Agriculture: Sentinel-2 Improved Features and Applications. Agronomy 2020, 10, 641. [Google Scholar] [CrossRef]
- Panda, S.S.; Ames, D.P.; Panigrahi, S. Application of Vegetation Indices for Agricultural Crop Yield Prediction Using Neural Network Techniques. Remote Sens. 2010, 2, 673–696. [Google Scholar] [CrossRef]
- Taylor, J.C.; Wood, G.A.; Thomas, G. Mapping yield potential with remote sensing. Precis. Agric. 1997, 1, 713–720. [Google Scholar]
- Sharma, A.; Jain, A.; Gupta, P.; Chowdary, V. Machine Learning Applications for Precision Agriculture: A Comprehensive Review. IEEE Access 2021, 9, 4843–4873. [Google Scholar] [CrossRef]
- Kamir, E.; Waldner, F.; Hochman, Z. Estimating Wheat Yields in Australia Using Climate Records, Satellite Image Time Series and Machine Learning Methods. ISPRS J. Photogramm. Remote Sens. 2020, 160, 124–135. [Google Scholar] [CrossRef]
- Hunt, M.L.; Blackburn, G.A.; Carrasco, L.; Redhead, J.W.; Rowland, C.S. High Resolution Wheat Yield Mapping Using Sentinel-2. Remote Sens. Environ. 2019, 233, 111410. [Google Scholar] [CrossRef]
- Barnes, A.P.; Soto, I.; Eory, V.; Beck, B.; Balafoutis, A.; Sánchez, B.; Vangeyte, J.; Fountas, S.; van der Wal, T.; Gómez-Barbero, M. Exploring the Adoption of Precision Agricultural Technologies: A Cross Regional Study of EU Farmers. Land Use Policy 2019, 80, 163–174. [Google Scholar] [CrossRef]
- Kottek, M.; Grieser, J.; Beck, C.; Rudolf, B.; Rubel, F. World Map of the Köppen-Geiger Climate Classification Updated. Metz 2006, 15, 259–263. [Google Scholar] [CrossRef]
- Uribeetxebarria, A.; Castellón, A.; Aizpurua, A. A First Approach to Determine If It Is Possible to Delineate In-Season N Fertilization Maps for Wheat Using NDVI Derived from Sentinel-2. Remote Sens. 2022, 14, 2872. [Google Scholar] [CrossRef]
- Becker-Reshef, I.; Vermote, E.; Lindeman, M.; Justice, C. A Generalized Regression-Based Model for Forecasting Winter Wheat Yields in Kansas and Ukraine Using MODIS Data. Remote Sens. Environ. 2010, 114, 1312–1323. [Google Scholar] [CrossRef]
- Aranguren, M.; Castellón, A.; Aizpurua, A. Wheat Yield Estimation with NDVI Values Using a Proximal Sensing Tool. Remote Sens. 2020, 12, 2749. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Kuhn, M. Caret: Classification and Regression Training, R Package Version 6.0–71. 2016. Available online: https://cran.r-project.org/web/packages/caret/caret.pdf (accessed on 23 August 2022).
- Glantz, S.; Slinker, B.; Neilands, T.B. Primer of Applied Regression & Analysis of Variance 3E; McGraw-Hill: New York, NY, USA, 1990; p. 37. [Google Scholar]
- Cambardella, C.A.; Moorman, T.B.; Novak, J.M.; Parkin, T.B.; Karlen, D.L.; Turco, R.F.; Konopka, A.E. Field-Scale Variability of Soil Properties in Central Iowa Soils. Soil Sci. Soc. Am. J. 1994, 58, 1501–1511. [Google Scholar] [CrossRef]
- Karydas, C.G.; Gitas, I.Z.; Koutsogiannaki, E.; Lydakis-Simantiris, E.; Silleos, G.N. Evaluation of spatial interpolation techniques for mapping agricultural topsoil properties in Crete. EARSel Eproceedings 2009, 8, 1. [Google Scholar]
- Guastaferro, F.; Castrignanò, A.; De Benedetto, D.; Sollitto, D.; Troccoli, A.; Cafarelli, B. A Comparison of Different Algorithms for the Delineation of Management Zones. Precis. Agric. 2010, 11, 600–620. [Google Scholar] [CrossRef]
- Magney, T.S.; Eitel, J.U.H.; Huggins, D.R.; Vierling, L.A. Proximal NDVI Derived Phenology Improves In-Season Predictions of Wheat Quantity and Quality. Agric. For. Meteorol. 2016, 217, 46–60. [Google Scholar] [CrossRef]
- Brisson, N.; Launay, M.; Mary, B.; Beaudoin, N. Conceptual Basis, Formalisations and Parameterization of the Stics Crop Model; Quae: Paris, France, 2009; p. 304. ISBN 978-2-7592-0-290-294. [Google Scholar]
- Marti, J.; Bort, J.; Slafer, G.A.; Araus, J.L. Can Wheat Yield Be Assessed by Early Measurements of Normalized Difference Vegetation Index? Ann. Appl. Biol. 2007, 150, 253–257. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- García-Martínez, H.; Flores-Magdaleno, H.; Ascencio-Hernández, R.; Khalil-Gardezi, A.; Tijerina-Chávez, L.; Mancilla-Villa, O.R.; Vázquez-Peña, M.A. Corn Grain Yield Estimation from Vegetation Indices, Canopy Cover, Plant Density, and a Neural Network Using Multispectral and RGB Images Acquired with Unmanned Aerial Vehicles. Agriculture 2020, 10, 277. [Google Scholar] [CrossRef]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop Yield Prediction Using Machine Learning: A Systematic Literature Review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Abbas, F.; Afzaal, H.; Farooque, A.A.; Tang, S. Crop Yield Prediction through Proximal Sensing and Machine Learning Algorithms. Agronomy 2020, 10, 1046. [Google Scholar] [CrossRef]
- Pantazi, X.-E.; Moshou, D.; Alexandridis, T.K.; Whetton, R.L.; Mouazen, A.M. Wheat yield prediction using machine learning and advanced sensing techniques. Computer. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Kayad, A.; Sozzi, M.; Gatto, S.; Marinello, F.; Pirotti, F. Monitoring within-field variability of corn yield using sentinel-2 and machine learning techniques. Remote Sens. 2019, 11, 2873. [Google Scholar] [CrossRef]
- Segarra, J.; Araus, J.L.; Kefauver, S.C. Farming and Earth Observation: Sentinel-2 data to estimate within-field wheat grain yield. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102697. [Google Scholar] [CrossRef]
- Groher, T.; Heitkämper, K.; Walter, A.; Liebisch, F.; Umstätter, C. Status Quo of Adoption of Precision Agriculture Enabling Technologies in Swiss Plant Production. Precis. Agric. 2020, 21, 1327–1350. [Google Scholar] [CrossRef]
- Martínez-Casasnovas, J.; Escolà, A.; Arnó, J. Use of Farmer Knowledge in the Delineation of Potential Management Zones in Precision Agriculture: A Case Study in Maize (Zea mays L.). Agriculture 2018, 8, 84. [Google Scholar] [CrossRef]
- Ilsemann, J.; Goeb, S.; Bachmann, J. How many soil samples are necessary to obtain a reliable estimate of mean nitrate concentrations in an agricultural field? J. Plant Nutr. Soil Sci. 2001, 164, 585–590. [Google Scholar] [CrossRef]
- Arritokieta Ortuzar-Iragorri, M.; Aizpurua, A.; Castellón, A.; Alonso, A.; Estavillo, J.M.; Besga, G. Use of an N-tester chlorophyll meter to tune a late third nitrogen application to wheat under humid Mediterranean conditions. J. Plant. Nutr. 2017, 41, 627–635. [Google Scholar] [CrossRef]
- Available online: https://www.mapa.gob.es/es/estadistica/temas/estadisticasgrarias/indicesypreciospagadosagrariospublicacion2022abril_tcm30-624388.pdf (accessed on 23 August 2022). (In Spanish).
- Sharma, L.; Bali, S. A Review of Methods to Improve Nitrogen Use Efficiency in Agriculture. Sustainability 2017, 10, 51. [Google Scholar] [CrossRef]
- Bongiovanni, R.; Lowenberg-Deboer, J. Precision Agriculture and Sustainability. Precis. Agric. 2004, 5, 359–387. [Google Scholar] [CrossRef]
- Argento, F.; Anken, T.; Abt, F.; Vogelsanger, E.; Walter, A.; Liebisch, F. Site-Specific Nitrogen Management in Winter Wheat Supported by Low-Altitude Remote Sensing and Soil Data. Precis. Agric. 2021, 22, 364–386. [Google Scholar] [CrossRef]
- Isik, M.; Khanna, M. Variable-Rate Nitrogen Application Under Uncertainty: Implications for Profitability and Nitrogen Use. J. Agric. Resour. Econ. 2002, 27, 61–76. [Google Scholar]
- Späti, K.; Huber, R.; Finger, R. Benefits of Increasing Information Accuracy in Variable Rate Technologies. Ecol. Econ. 2021, 185, 107047. [Google Scholar] [CrossRef]
- Sands, R.; Westcott, P. Impacts of Higher Energy Prices on Agriculture and Rural Economies; United States Department of Agriculture: Washington, DC, USA, 2011.
- Komarek, A.M.; Drogue, S.; Chenoune, R.; Hawkins, J.; Msangi, S.; Belhouchette, H.; Flichman, G. Agricultural Household Effects of Fertilizer Price Changes for Smallholder Farmers in Central Malawi. Agric. Syst. 2017, 154, 168–178. [Google Scholar] [CrossRef]
- Laurent, A.; Kyveryga, P.; Makowski, D.; Miguez, F. A Framework for Visualization and Analysis of Agronomic Field Trials from On-Farm Research Networks. Agron. J. 2019, 111, 2712–2723. [Google Scholar] [CrossRef]
- De Roo, N.; Andersson, J.A.; Krupnik, T.J. On-farm trials for development impact? The organisation of research and the scaling of agricultural technologies. Exp. Agric. 2019, 55, 163–184. [Google Scholar] [CrossRef]
- Cross, R.; Ampt, P. Exploring Agroecological Sustainability: Unearthing Innovators and Documenting a Community of Practice in Southeast Australia. Soc. Nat. Resour. 2017, 30, 585–600. [Google Scholar] [CrossRef]
- Dowd, A.-M.; Marshall, N.; Fleming, A.; Jakku, E.; Gaillard, E.; Howden, M. The Role of Networks in Transforming Australian Agriculture. Nat. Clim Chang. 2014, 4, 558–563. [Google Scholar] [CrossRef]
- Schrijver, R. Precision agriculture and the future of farming in Europe. STOA-Sci. Technol. Options Assess. 2016. [Google Scholar] [CrossRef]
- Byerlee, D.; de Janvry, A.; Sadoulet, E. Agriculture for Development: Toward a New Paradigm. Annu. Rev. Resour. Econ. 2009, 1, 15–31. [Google Scholar] [CrossRef]
- Huyer, S. Closing the Gender Gap in Agriculture. Gend. Technol. Dev. 2016, 20, 105–116. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plot | Yield (t ha−1) | Area (ha) | S2 Pixels within Plot | Elevation (m) |
|---|---|---|---|---|
| Alto | 8.6 | 5.1 | 426 | 502 |
| Apelarri | 8.2 | 2.6 | 207 | 505 |
| Apelarri F | 7.8 | 2.1 | 185 | 508 |
| Babea | 6.7 | 3.8 | 323 | 521 |
| Baratua | 5.6 | 2.7 | 217 | 511 |
| Foronda | 6.4 | 3.2 | 254 | 513 |
| Iruleku | 7.4 | 4.1 | 346 | 534 |
| Kukura | 6.3 | 5.0 | 417 | 508 |
| Menor | 5.2 | 4.6 | 358 | 538 |
| Ollavarre | 4.6 | 4.3 | 353 | 554 |
| Otatza | 6.3 | 3.0 | 246 | 541 |
| Parque | 4.7 | 5.2 | 413 | 531 |
| Prado | 7.1 | 2.5 | 208 | 501 |
| Torres | 12.2 | 916 | 511 |
| Coefficient of Determination (R2) | Root mean Square Error (RMSE) | |||||
|---|---|---|---|---|---|---|
| Plot | MTRY = 2 | MTRY = 7 | MTRY = 14 | MTRY = 2 | MTRY = 7 | MTRY = 14 |
| Alto | 0.57 | 0.59 | 0.54 | 1694.20 | 1672.14 | 1646.13 |
| Apelarri | 0.27 | 0.42 | 0.46 | 1094.64 | 898.26 | 849.75 |
| Apelarri F | 0.86 | 0.88 | 0.88 | 1442.18 | 1332.08 | 1299.37 |
| Babea | 0.86 | 0.85 | 0.82 | 1142.54 | 1144.78 | 1104.33 |
| Barataua | 0.56 | 0.58 | 0.57 | 1070.95 | 1085.19 | 1101.12 |
| Iruleko | 0.57 | 0.60 | 0.62 | 1266.80 | 1285.71 | 1240.43 |
| Foronda | 0.70 | 0.68 | 0.65 | 919.62 | 1025.61 | 1129.08 |
| Kukura | 0.86 | 0.86 | 0.83 | 941.36 | 1085.36 | 1197.14 |
| Menor | 0.85 | 0.83 | 0.79 | 556.34 | 562.92 | 577.14 |
| Ollavarre | 0.21 | 0.13 | 0.01 | 1647.95 | 1473.98 | 1331.94 |
| Otatza | 0.60 | 0.59 | 0.56 | 872.88 | 850.42 | 962.20 |
| Parque | 0.38 | 0.39 | 0.39 | 968.63 | 960.87 | 999.55 |
| Prado | 0.32 | 0.47 | 0.49 | 1750.24 | 2229.17 | 2463.87 |
| Variable N Application | Homogeneous N Application | ||||||
|---|---|---|---|---|---|---|---|
| Zone | kg N ha−1 | Area (ha) | kg N | Zone | kg N ha−1 | Area (ha) | kg N |
| 1 | 55 | 3.37 | 185 | 1,2,3,4 | 110 | 12.23 | 1345 |
| 2 | 88 | 2.95 | 259 | ||||
| 3 | 99 | 3.70 | 375 | ||||
| 4 | 110 | 2.21 | 244 | ||||
| 12.23 | 1064 | 12.23 | 1345 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uribeetxebarria, A.; Castellón, A.; Elorza, I.; Aizpurua, A. Intra-Plot Variable N Fertilization in Winter Wheat through Machine Learning and Farmer Knowledge. Agronomy 2022, 12, 2276. https://doi.org/10.3390/agronomy12102276
Uribeetxebarria A, Castellón A, Elorza I, Aizpurua A. Intra-Plot Variable N Fertilization in Winter Wheat through Machine Learning and Farmer Knowledge. Agronomy. 2022; 12(10):2276. https://doi.org/10.3390/agronomy12102276
Chicago/Turabian StyleUribeetxebarria, Asier, Ander Castellón, Ibai Elorza, and Ana Aizpurua. 2022. "Intra-Plot Variable N Fertilization in Winter Wheat through Machine Learning and Farmer Knowledge" Agronomy 12, no. 10: 2276. https://doi.org/10.3390/agronomy12102276