
WT-YOLOM: An Improved Target Detection Model Based on YOLOv4 for Endogenous Impurity in Walnuts

Abstract
:1. Introduction
- (1)
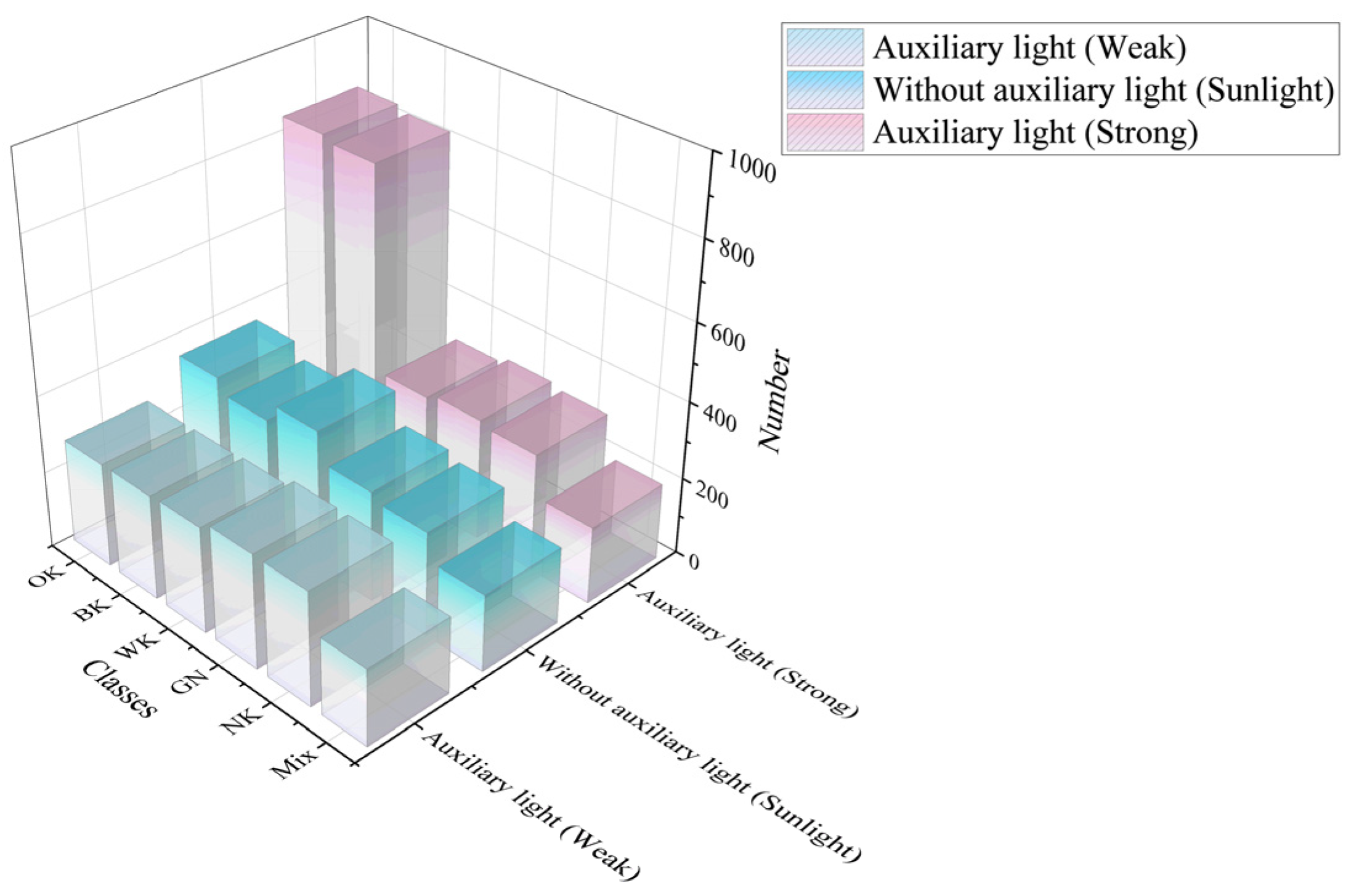
- A dataset of walnut shell-breaking materials was constructed under different lighting conditions and angles. It contains five types of images: black spot kernels (BKs), withered kernels (WKs), oily kernels (OKs), ground nutshells (GNs), and normal kernels (NKs). It provides rich scene data to promote research into technology for the automatic processing of walnuts.
- (2)
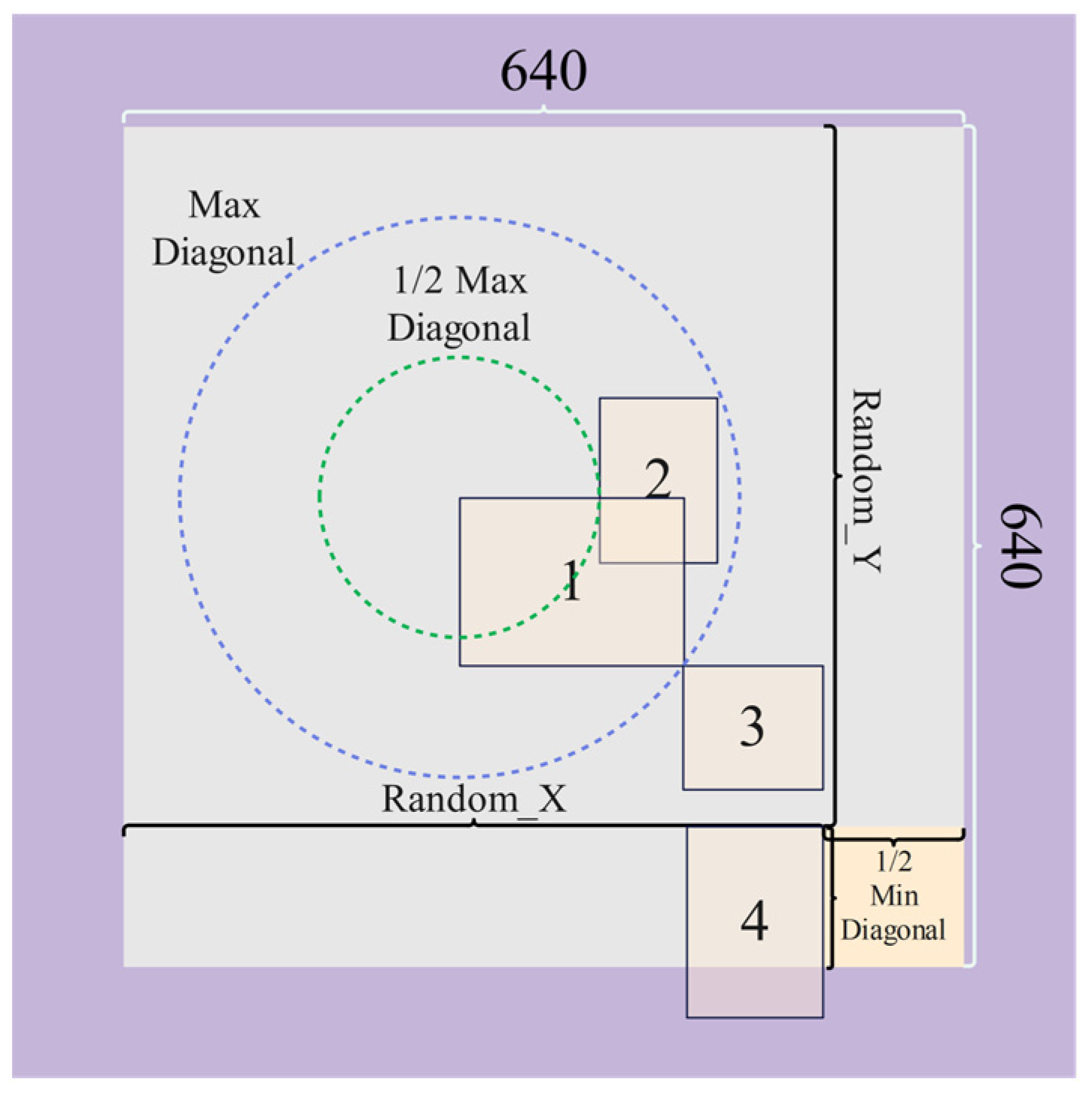
- An offline data enhancement method was proposed to enrich the diversity of the datasets and reduce the workload of data collection.
- (3)
- A lightweight target detection method, WT-YOLOM, was proposed to detect endogenous foreign bodies. It achieves a balance between precision and speed.
2. Experimental Data and Processing Methods
2.1. Image Acquisition and Annotation
2.2. Data Preprocessing
3. Methodologies
3.1. The Algorithmic Principle of YOLOv4
3.2. Improvement Based on YOLOv4
3.2.1. Removal and Detection of Endogenous Walnut Impurities Based on K-Means
3.2.2. MobileNetV3 as the Backbone Network
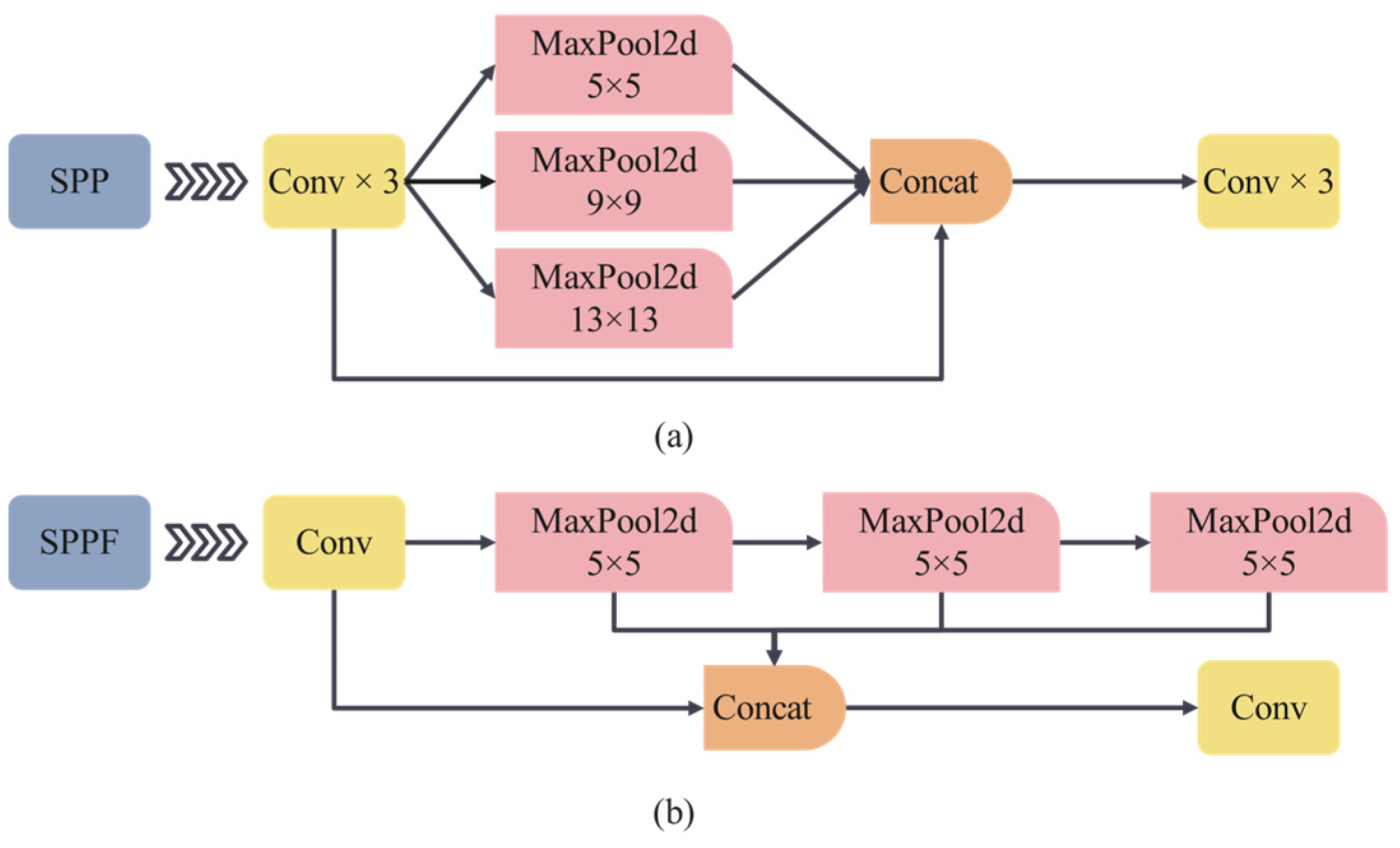
3.2.3. Importing the Spatial Pyramid Pooling—Fast Model and Improving the Neck Structure
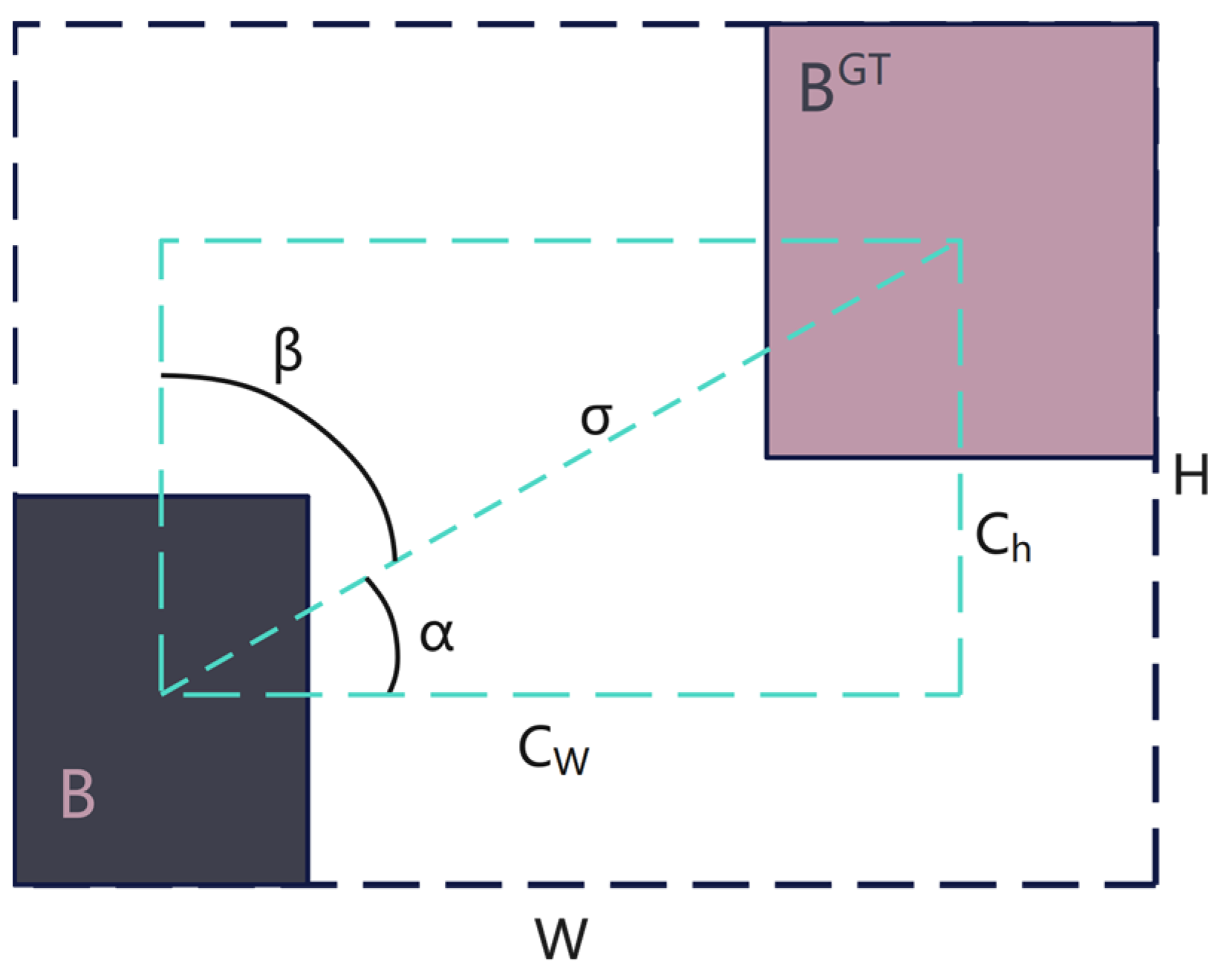
3.2.4. Loss Analysis and Improvement
3.2.5. Analysis of Feature Fusion and Improvement of the Attention Mechanism
4. Experimental Design and Analysis of Results
4.1. Experimental Environment and Parameter Setting
4.2. Experimental Datasets
4.3. Evaluation Metrics
4.4. Results and Analysis
4.4.1. Benchmark Model Performance Comparison
4.4.2. Ablation Study
4.4.3. Comparison of the Added Attention Models’ Performance
4.4.4. Visualization and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chan, M. Food safety must accompany food and nutrition security. Lancet 2014, 384, 1910–1911. [Google Scholar] [CrossRef] [PubMed]
- Unnevehr, L. Food safety in developing countries: Moving beyond exports. Glob. Food Secur.-Agric. Policy Econ. Environ. 2015, 4, 24–29. [Google Scholar] [CrossRef]
- Djekic, I.; Jankovic, D.; Rajkovic, A. Analysis of foreign bodies present in European food using data from Rapid Alert System for Food and Feed (RASFF). Food Control 2017, 79, 143–149. [Google Scholar] [CrossRef]
- Yin, J.F.; Hameed, S.; Xie, L.J.; Ying, Y.B. Non-destructive detection of foreign contaminants in toast bread with near infrared spectroscopy and computer vision techniques. J. Food Meas. Charact. 2021, 15, 189–198. [Google Scholar] [CrossRef]
- Wang, Q.; Hameed, S.; Xie, L.J.; Ying, Y.B. Non-destructive quality control detection of endogenous contaminations in walnuts using terahertz spectroscopic imaging. J. Food Meas. Charact. 2020, 14, 2453–2460. [Google Scholar] [CrossRef]
- Liu, M.Z.; Li, C.H.; Cao, C.M.; Wang, L.Q.; Li, X.P.; Che, J.; Yang, H.M.; Zhang, X.W.; Zhao, H.Y.; He, G.Z.; et al. Walnut Fruit Processing Equipment: Academic Insights and Perspectives. Food Eng. Rev. 2021, 13, 822–857. [Google Scholar] [CrossRef]
- Mollazade, K.; Omid, M.; Arefi, A. Comparing data mining classifiers for grading raisins based on visual features. Comput. Electron. Agric. 2012, 84, 124–131. [Google Scholar] [CrossRef]
- Xie, T.H.; Li, X.X.; Zhang, X.S.; Hu, J.Y.; Fang, Y. Detection of Atlantic salmon bone residues using machine vision technology. Food Control 2021, 123, 107787. [Google Scholar] [CrossRef]
- Chen, M.; Jin, C.Q.; Ni, Y.L.; Xu, J.S.; Yang, T.X. Online Detection System for Wheat Machine Harvesting Impurity Rate Based on DeepLabV3+. Sensors 2022, 22, 7627. [Google Scholar] [CrossRef]
- Wang, C.L.; Xiao, Z.F. Potato Surface Defect Detection Based on Deep Transfer Learning. Agriculture 2021, 11, 863. [Google Scholar] [CrossRef]
- Saeidan, A.; Khojastehpour, M.; Golzarian, M.R.; Mooenfard, M.; Khan, H.A. Detection of foreign materials in cocoa beans by hyperspectral imaging technology. Food Control 2021, 129, 108242. [Google Scholar] [CrossRef]
- Li, M.Z.; Huang, M.; Zhu, Q.B.; Zhang, M.; Guo, Y.; Qin, J.W. Pickled and dried mustard foreign matter detection using multispectral imaging system based on single shot method. J. Food Eng. 2020, 285, 110106. [Google Scholar] [CrossRef]
- Rong, D.; Wang, H.Y.; Xie, L.J.; Ying, Y.B.; Zhang, Y.S. Impurity detection of juglans using deep learning and machine vision. Comput. Electron. Agric. 2020, 178, 105764. [Google Scholar] [CrossRef]
- Wu, Z.M.; Luo, K.; Cao, C.M.; Liu, G.Z.; Wang, E.R.; Li, W.B. Fast location and classification of small targets using region segmentation and a convolutional neural network. Comput. Electron. Agric. 2020, 169, 105207. [Google Scholar] [CrossRef]
- Li, Z.B.; Li, Y.; Yang, Y.B.; Guo, R.H.; Yang, J.Q.; Yue, J.; Wang, Y.Z. A high-precision detection method of hydroponic lettuce seedlings status based on improved Faster RCNN. Comput. Electron. Agric. 2021, 182, 106054. [Google Scholar] [CrossRef]
- Wang, Q.F.; Cheng, M.; Huang, S.; Cai, Z.J.; Zhang, J.L.; Yuan, H.B. A deep learning approach incorporating YOLO v5 and attention mechanisms for field real-time detection of the invasive weed Solanum rostratum Dunal seedlings. Comput. Electron. Agric. 2022, 199, 107194. [Google Scholar] [CrossRef]
- Huang, Y.J.; Xiao, L.H.; Zhang, Z.R.; Zhang, R.; Wang, Z.J.; Huang, C.Y.; Huang, R.; Luan, Y.M.; Fan, T.Q.; Wang, J.H.; et al. The genomes of pecan and Chinese hickory provide insights into Carya evolution and nut nutrition. Gigascience 2019, 8, giz036. [Google Scholar] [CrossRef]
- Kim, T.; Kim, H.; Byun, H. Localization-Aware Adaptive Pairwise Margin Loss for Fine-Grained Image Recognition. IEEE Access 2021, 9, 8786–8796. [Google Scholar] [CrossRef]
- Huang, L.; Xu, L.J.; Wang, Y.C.; Peng, Y.Q.; Zou, Z.Y.; Huang, P. Efficient Detection Method of Pig-Posture Behavior Based on Multiple Attention Mechanism. Comput. Intell. Neurosci. 2022, 2022, 1759542. [Google Scholar] [CrossRef]
- Lawal, M.O. Tomato detection based on modified YOLOv3 framework. Sci. Rep. 2021, 11, 1447. [Google Scholar] [CrossRef]
- Xu, Y.L.; Chen, Q.Y.; Kong, S.L.; Xing, L.; Wang, Q.; Cong, X.; Zhou, Y. Real-time object detection method of melon leaf diseases under complex background in greenhouse. J. Real-Time Image Process. 2022, 19, 985–995. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M.J. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Gai, R.L.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2021, 35, 13895–13906. [Google Scholar] [CrossRef]
- Wu, W.S.; Lu, Z.M. A Real-Time Cup-Detection Method Based on YOLOv3 for Inventory Management. Sensors 2022, 22, 6956. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Washington, DC, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Zheng, Z.H.; Wang, P.; Ren, D.W.; Liu, W.; Ye, R.G.; Hu, Q.H.; Zuo, W.M. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Su, F.; Zhao, Y.P.; Wang, G.H.; Liu, P.Z.; Yan, Y.F.; Zu, L.L. Tomato Maturity Classification Based on SE-YOLOv3-MobileNetV1 Network under Nature Greenhouse Environment. Agronomy 2022, 12, 1638. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H.J. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Howard, A.; Zhmoginov, A.; Chen, L.-C.; Sandler, M.; Zhu, M. Inverted residuals and linear bottlenecks: Mobile networks for classification, detection and segmentation. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Dai, G.W.; Hu, L.; Fan, J.C.; Yan, S.; Li, R.J. A Deep Learning-Based Object Detection Scheme by Improving YOLOv5 for Sprouted Potatoes Datasets. IEEE Access 2022, 10, 85416–85428. [Google Scholar] [CrossRef]
- Qiu, M.L.; Huang, L.; Tang, B.H. ASFF-YOLOv5: Multielement Detection Method for Road Traffic in UAV Images Based on Multiscale Feature Fusion. Remote Sens. 2022, 14, 3498. [Google Scholar] [CrossRef]
- Du, S.J.; Zhang, B.F.; Zhang, P. Scale-Sensitive IOU Loss: An Improved Regression Loss Function in Remote Sensing Object Detection. IEEE Access 2021, 9, 141258–141272. [Google Scholar] [CrossRef]
- Li, Y.J.; Li, S.S.; Du, H.H.; Chen, L.J.; Zhang, D.M.; Li, Y. YOLO-ACN: Focusing on Small Target and Occluded Object Detection. IEEE Access 2020, 8, 227288–227303. [Google Scholar] [CrossRef]
- Gevorgyan, Z.J. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Han, G.J.; Li, T.; Li, Q.; Zhao, F.; Zhang, M.; Wang, R.J.; Yuan, Q.W.; Liu, K.P.; Qin, L. Improved Algorithm for Insulator and Its Defect Detection Based on YOLOX. Sensors 2022, 22, 6186. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Kim, M.; Jeong, J.; Kim, S. ECAP-YOLO: Efficient Channel Attention Pyramid YOLO for Small Object Detection in Aerial Image. Remote Sens. 2021, 13, 4851. [Google Scholar] [CrossRef]
- Yang, B.H.; Gao, Z.W.; Gao, Y.; Zhu, Y. Rapid Detection and Counting of Wheat Ears in the Field Using YOLOv4 with Attention Module. Agronomy 2021, 11, 1202. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Su, R.; Wang, Y.L.; Chen, G.F.; Wang, Z.Q.; Yin, P.J.; Wang, J.X. Automatic Estimation of Apple Orchard Blooming Levels Using the Improved YOLOv5. Agronomy 2022, 12, 2483. [Google Scholar] [CrossRef]
- Fu, L.H.; Yang, Z.; Wu, F.Y.; Zou, X.J.; Lin, J.Q.; Cao, Y.J.; Duan, J.L. YOLO-Banana: A Lightweight Neural Network for Rapid Detection of Banana Bunches and Stalks in the Natural Environment. Agronomy 2022, 12, 391. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.Y.; Wang, X.Y.; Liu, N.Y.; Cao, Z.J.; Yang, J.Y. Ship Detection in Large-Scale SAR Images Via Spatial Shuffle-Group Enhance Attention. IEEE Trans. Geosci. Remote Sens. 2021, 59, 379–391. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Small Size (PX) | Medium Size (PX) | Large Size (PX) |
|---|---|---|
| 50, 47, 49, 75, 74, 50 | 61, 63, 70, 75, 86, 64 | 61, 92, 81, 83, 94, 97 |
| Item | Parameters | Calculation Amount |
|---|---|---|
| Depthwise separable convolution | K × K × 1 × M + N × 1 × 1 × M | R × R × K × K × 1 × M + R × R × N × 1 × 1 × M |
| Traditional convolution | N × K × K × M | R × R × N × K × K × M |
| Ratio | ||
| Item | Configure |
|---|---|
| Operating system | Windows10 × 64 |
| CPU | R9-5950X |
| GPU | RTX 3090 (24 G) |
| Deep learning frame | PyTorch 1.7.1 |
| Programming language | Python 3.9 |
| Integrated development environment | Pycharm 2023.1.1 |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Parameters | Size (MB) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|
| YOLOv4 | 92.4 | 82.2 | 63,959,226 | 244 | 60.0 | 46.6 |
| Faster R-CNN | 93.4 | 72.2 | 136,770,964 | 522 | 369.8 | 26.0 |
| EfficientDet-D0 | 90.0 | 80.7 | 3,830,342 | 14 | 4.8 | 27.9 |
| CenterNet | 71.8 | 65.8 | 32,665,432 | 125 | 70.2 | 75.2 |
| YOLOv4-MobileNetV3 | 88.9 | 77.6 | 11,325,194 | 43 | 7.2 | 57.0 |
| Model | F1-Score | Recall (%) | Precision (%) | |
|---|---|---|---|---|
| YOLOv4 | Black spot kernels | 0.88 | 87.1 | 88.5 |
| Ground nutshell | 0.98 | 98.4 | 97.4 | |
| Normal kernels | 0.97 | 99.5 | 93.8 | |
| Oily kernels | 0.90 | 90.5 | 89.1 | |
| Withered kernels | 0.82 | 78.3 | 86.0 | |
| Faster R-CNN | Black spot kernels | 0.88 | 88.2 | 87.2 |
| Ground nutshell | 0.96 | 97.4 | 93.9 | |
| Normal kernels | 0.93 | 98.5 | 87.5 | |
| Oily kernels | 0.88 | 89.3 | 87.3 | |
| Withered kernels | 0.79 | 85.4 | 74.0 | |
| EfficientDet-D0 | Black spot kernels | 0.84 | 76.3 | 94.0 |
| Ground nutshell | 0.94 | 97.4 | 90.6 | |
| Normal kernels | 0.93 | 97.5 | 89.0 | |
| Oily kernels | 0.83 | 79.5 | 87.8 | |
| Withered kernels | 0.60 | 49.7 | 76.5 | |
| CenterNet | Black spot kernels | 0.65 | 51.1 | 90.5 |
| Ground nutshell | 0.84 | 85.2 | 82.1 | |
| Normal kernels | 0.89 | 86.9 | 91.5 | |
| Oily kernels | 0.67 | 56.1 | 84.0 | |
| Withered kernels | 0.18 | 10.2 | 72.7 | |
| YOLOv4 -MobileNetV3 | Black spot kernels | 0.86 | 86.6 | 86.1 |
| Ground nutshell | 0.97 | 97.4 | 95.8 | |
| Normal kernels | 0.96 | 99.5 | 92.5 | |
| Oily kernels | 0.87 | 87.0 | 87.3 | |
| Withered kernels | 0.72 | 68.8 | 74.5 | |
| Model | MobileNet v3 | SIoU | K-means | SPPF | Size (MB) | mAP@0.5 (%) | mAP@0.5: 0.95 (%) |
|---|---|---|---|---|---|---|---|
| ① | √ | 43.2 | 88.9 | 77.6 | |||
| ② | √ | √ | 43.2 | 91.5 | 80.4 | ||
| ③ | √ | √ | 43.2 | 93.4 | 82.7 | ||
| ④ | √ | √ | 33.5 | 91.7 | 81.0 | ||
| ⑤ | √ | √ | √ | 43.2 | 94.2 | 83.3 | |
| ⑥ | √ | √ | √ | 33.5 | 93.1 | 82.4 | |
| ⑦ | √ | √ | √ | 33.5 | 93.3 | 81.8 | |
| ⑧ | √ | √ | √ | √ | 33.5 | 94.1 | 82.5 |
| Baseline Model | Attention Model | mAP@0.5 (%) | mAP@0.5: 0.95 (%) | Parameters | Size (MB) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|---|
| WT-YOLO | ECA | 94.4 | 82.8 | 7,274,079 | 27.8 | 6.3 | 60.1 |
| CBAM | 93.7 | 82.0 | 8,800,360 | 33.6 | 6.3 | 49.2 | |
| SE | 94.0 | 82.9 | 8,807,962 | 33.6 | 6.3 | 57.3 | |
| CA | 93.1 | 82.4 | 7,577,313 | 28.9 | 6.3 | 50.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Dai, D.; Zheng, J.; Li, L.; Kang, H.; Zheng, X. WT-YOLOM: An Improved Target Detection Model Based on YOLOv4 for Endogenous Impurity in Walnuts. Agronomy 2023, 13, 1462. https://doi.org/10.3390/agronomy13061462
Wang D, Dai D, Zheng J, Li L, Kang H, Zheng X. WT-YOLOM: An Improved Target Detection Model Based on YOLOv4 for Endogenous Impurity in Walnuts. Agronomy. 2023; 13(6):1462. https://doi.org/10.3390/agronomy13061462
Chicago/Turabian StyleWang, Dongdong, Dan Dai, Jian Zheng, Linhui Li, Haoyu Kang, and Xinyu Zheng. 2023. "WT-YOLOM: An Improved Target Detection Model Based on YOLOv4 for Endogenous Impurity in Walnuts" Agronomy 13, no. 6: 1462. https://doi.org/10.3390/agronomy13061462
APA StyleWang, D., Dai, D., Zheng, J., Li, L., Kang, H., & Zheng, X. (2023). WT-YOLOM: An Improved Target Detection Model Based on YOLOv4 for Endogenous Impurity in Walnuts. Agronomy, 13(6), 1462. https://doi.org/10.3390/agronomy13061462