
Estimating Drought-Induced Crop Yield Losses at the Cadastral Area Level in the Czech Republic
 , , , , , , , , and
, , , , , , , , and
Abstract
:1. Introduction
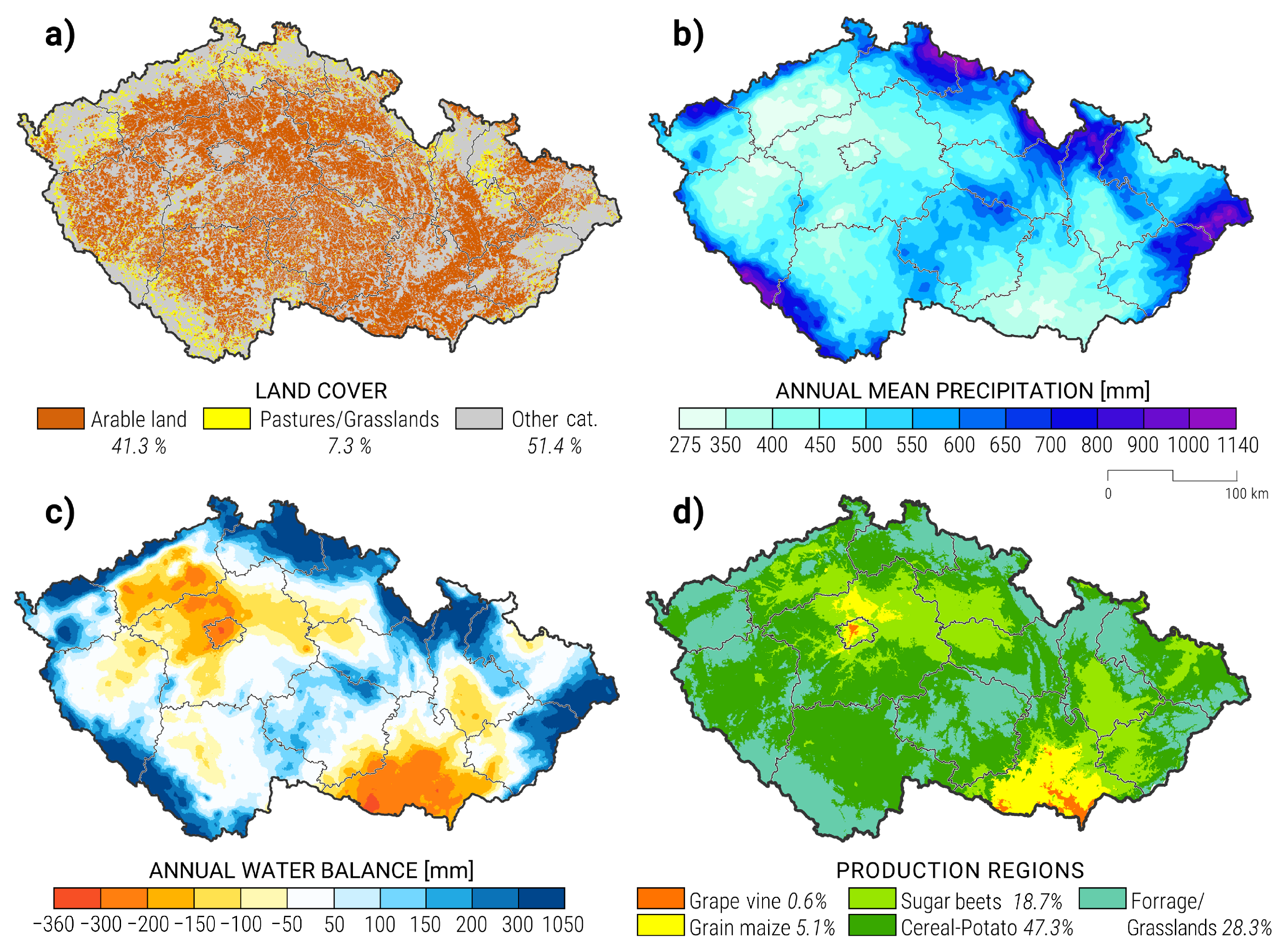
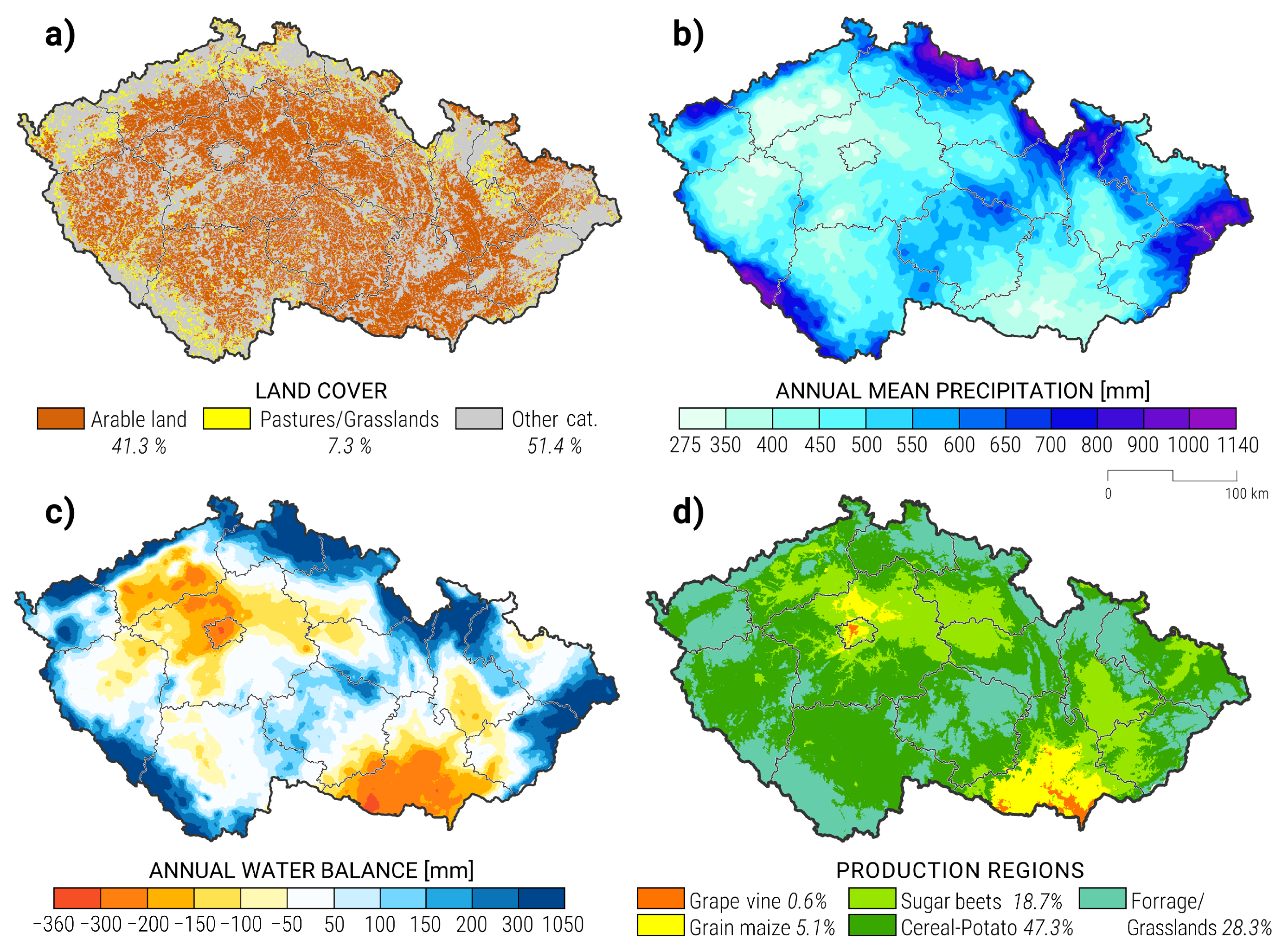
2. Materials and Methods
2.1. Data on Drought-Based Yield Losses
2.2. Yield Loss Predictors
2.3. Aggregating the Results of Reports on the Cadastral Area
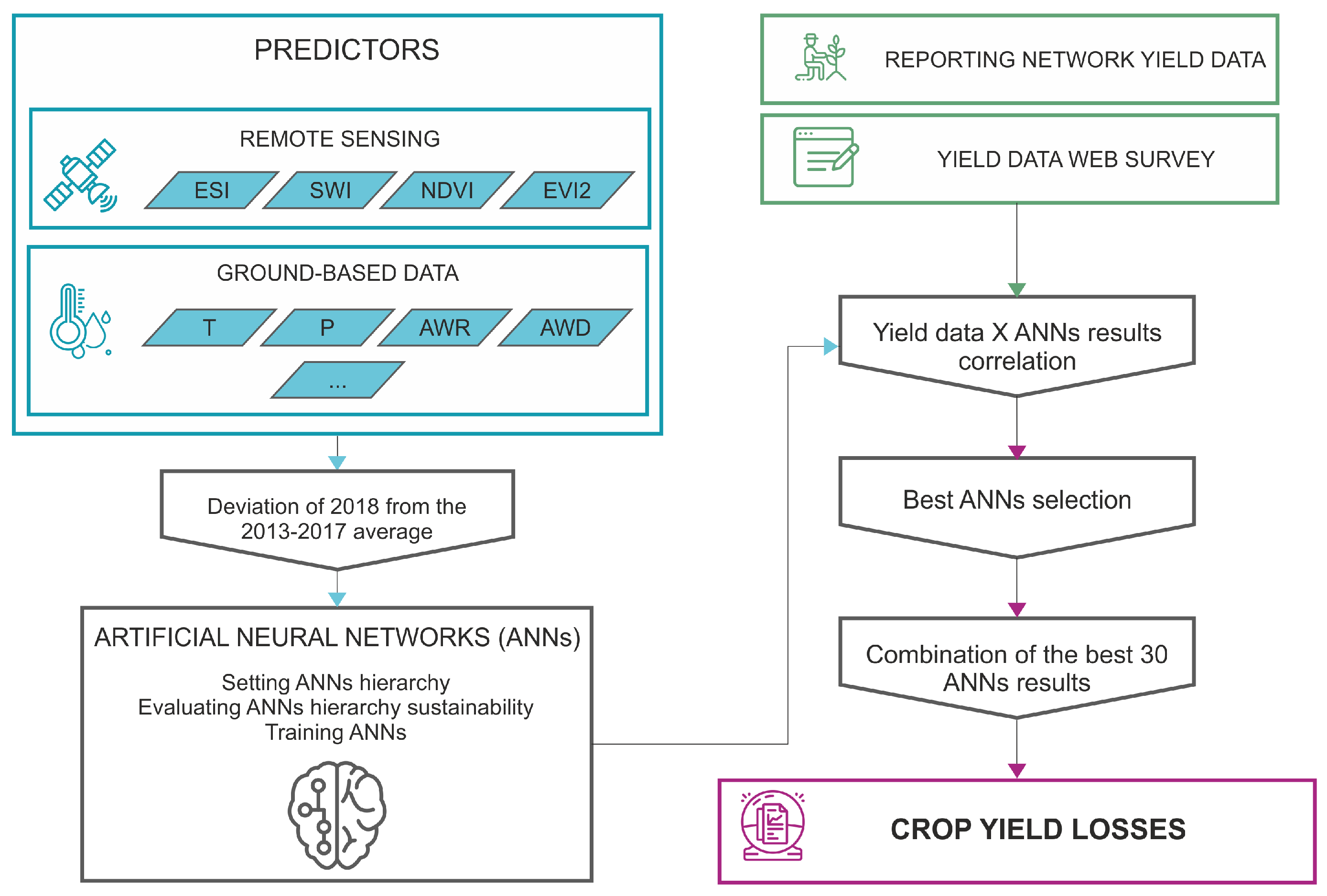
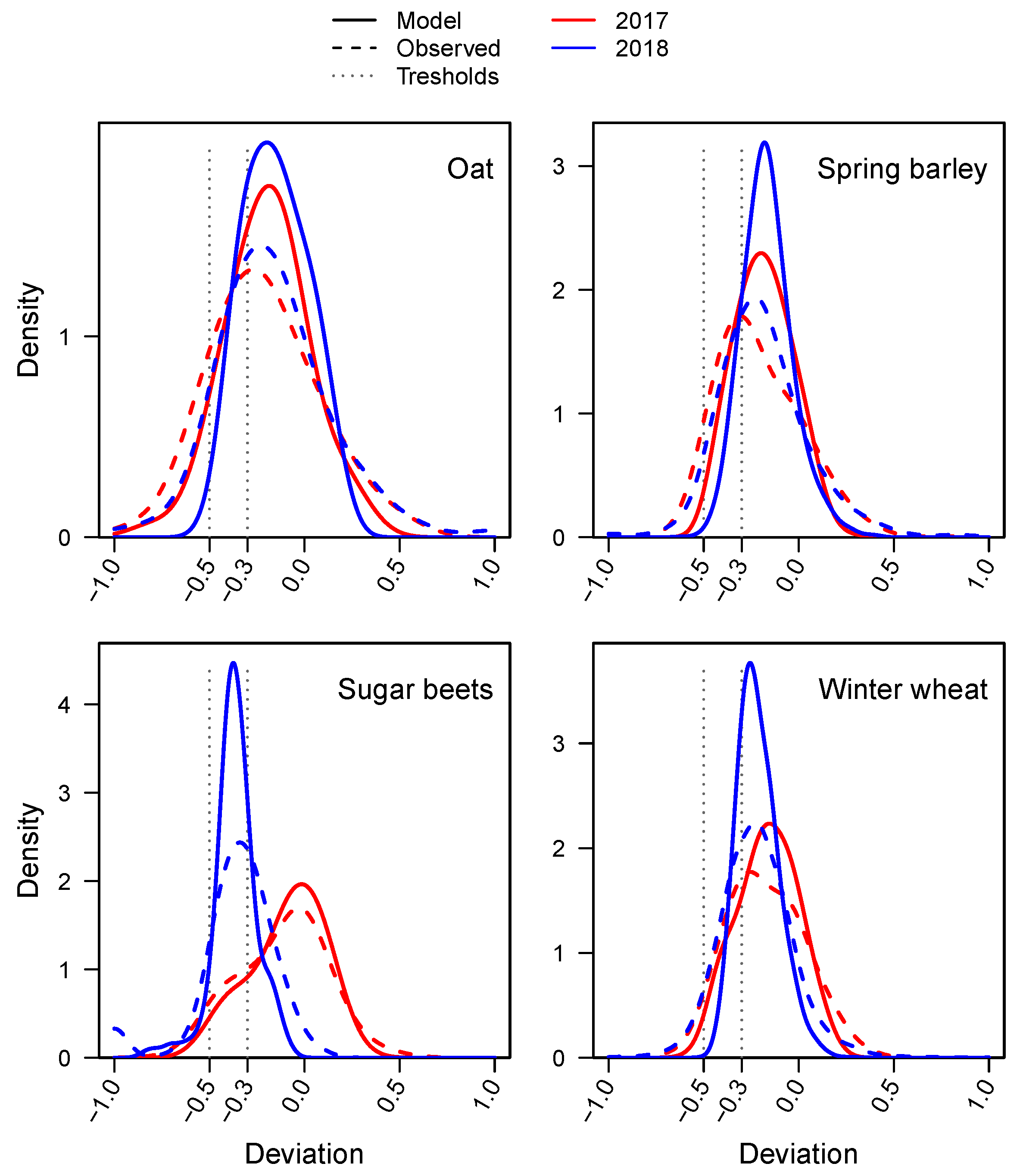
2.4. Development of the Crop Yield Loss Model
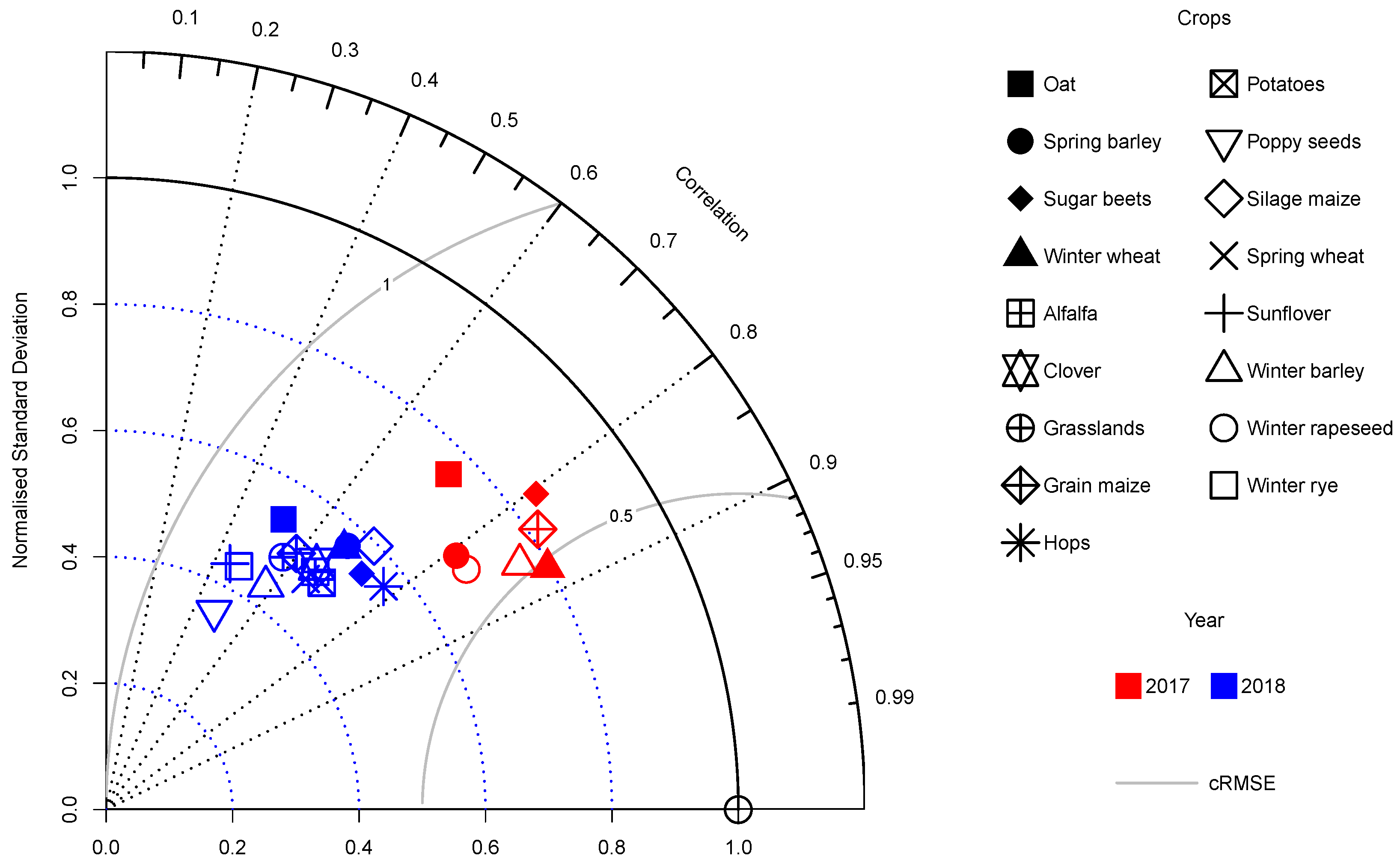
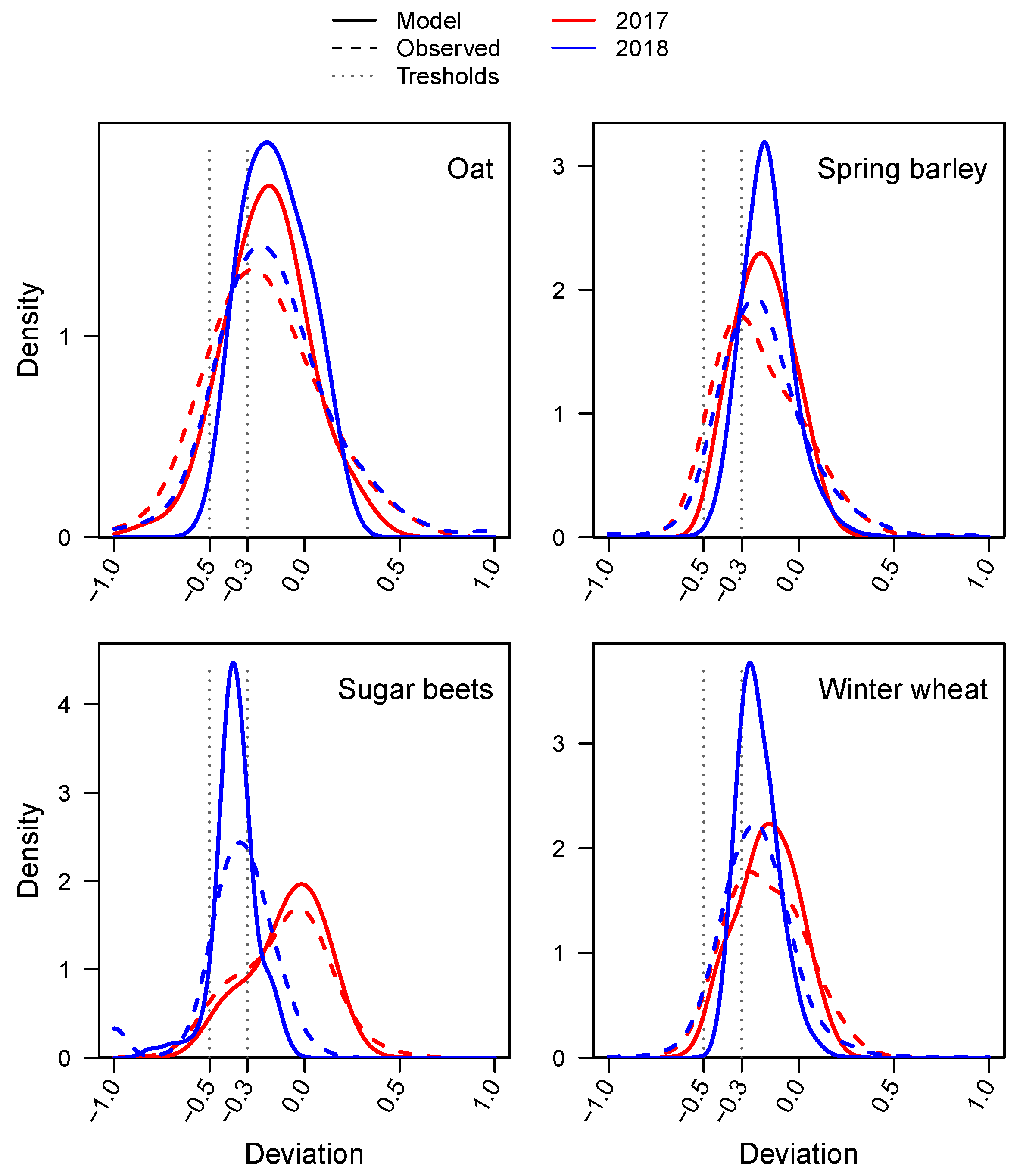
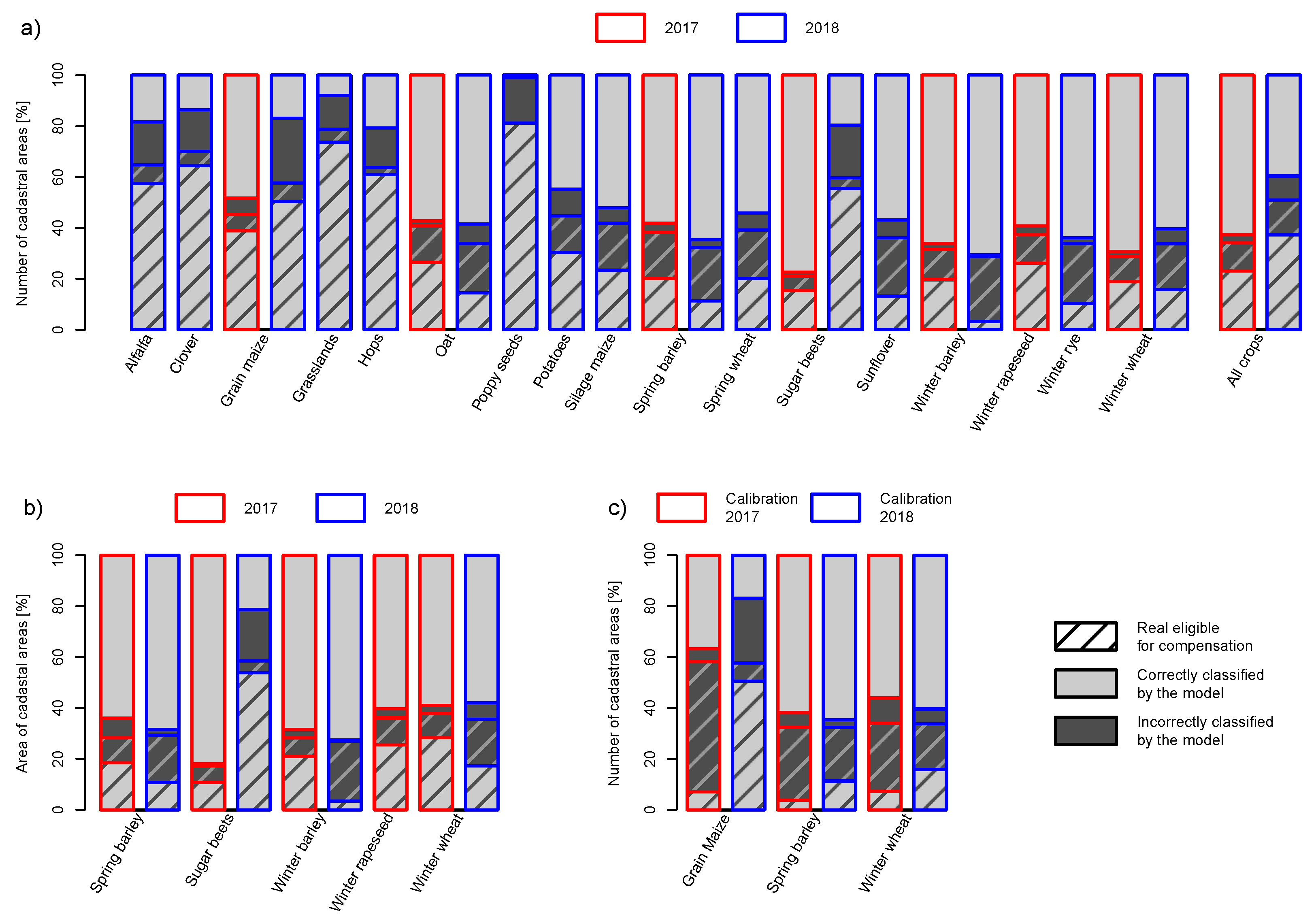
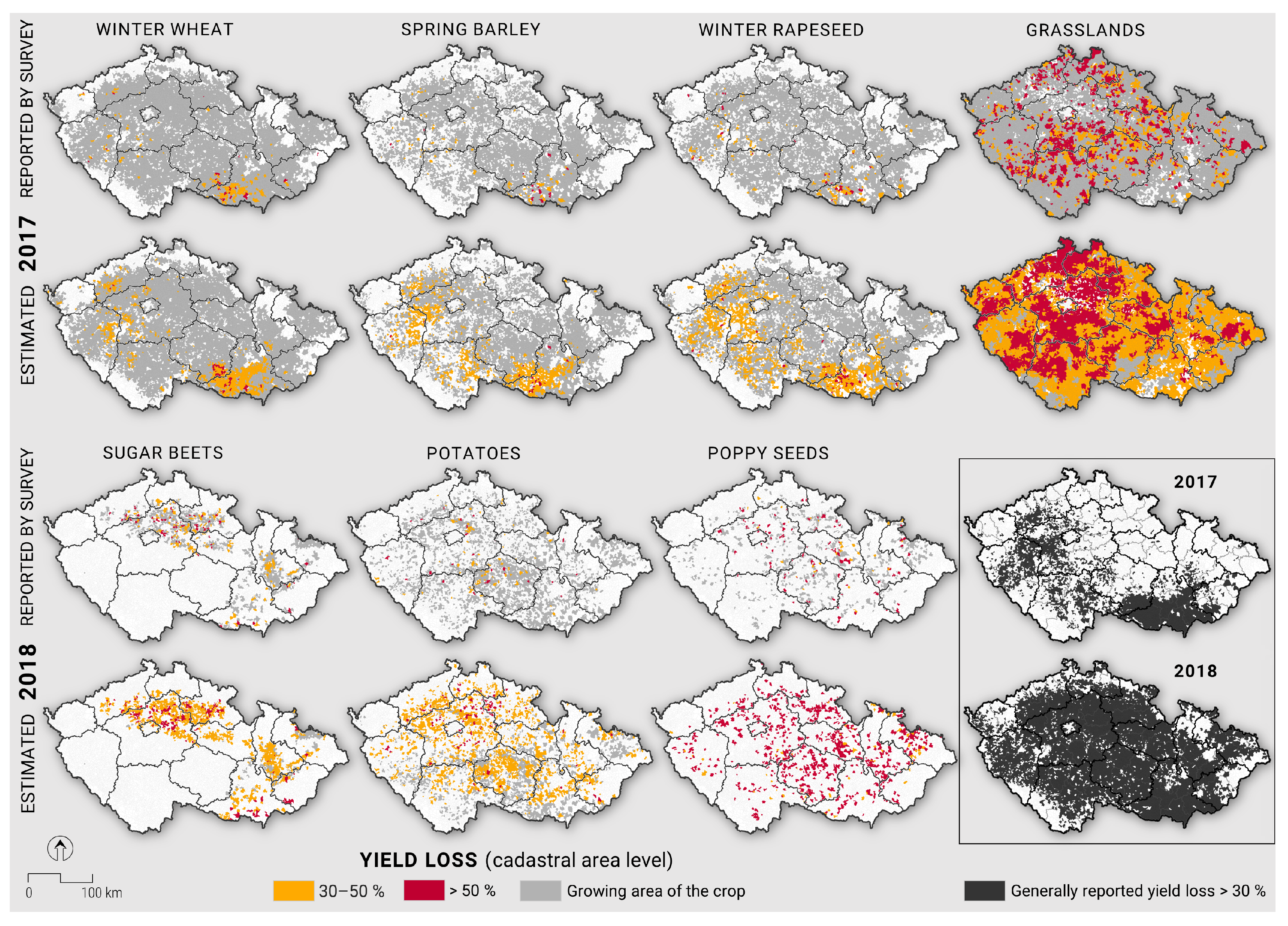
3. Results
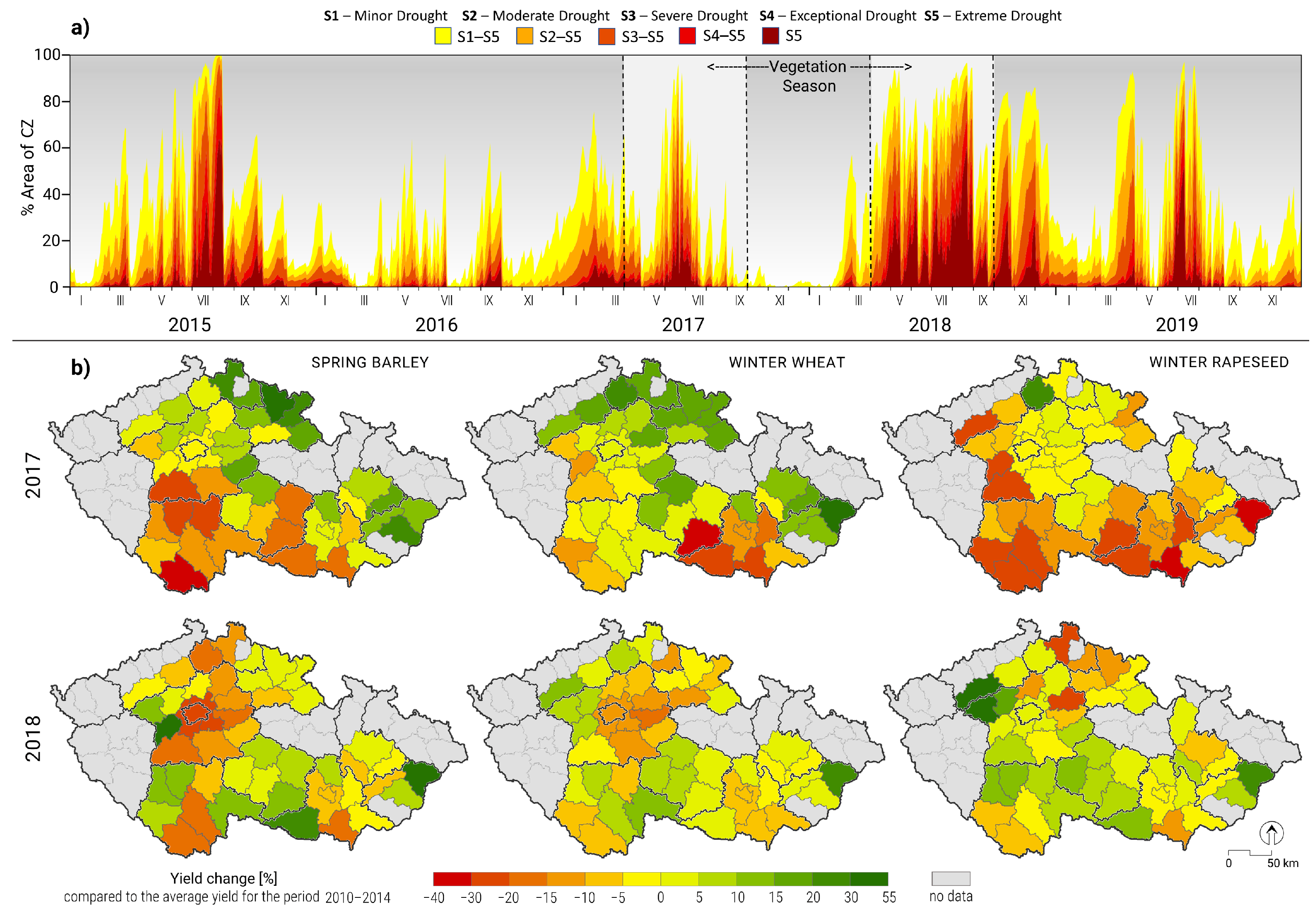
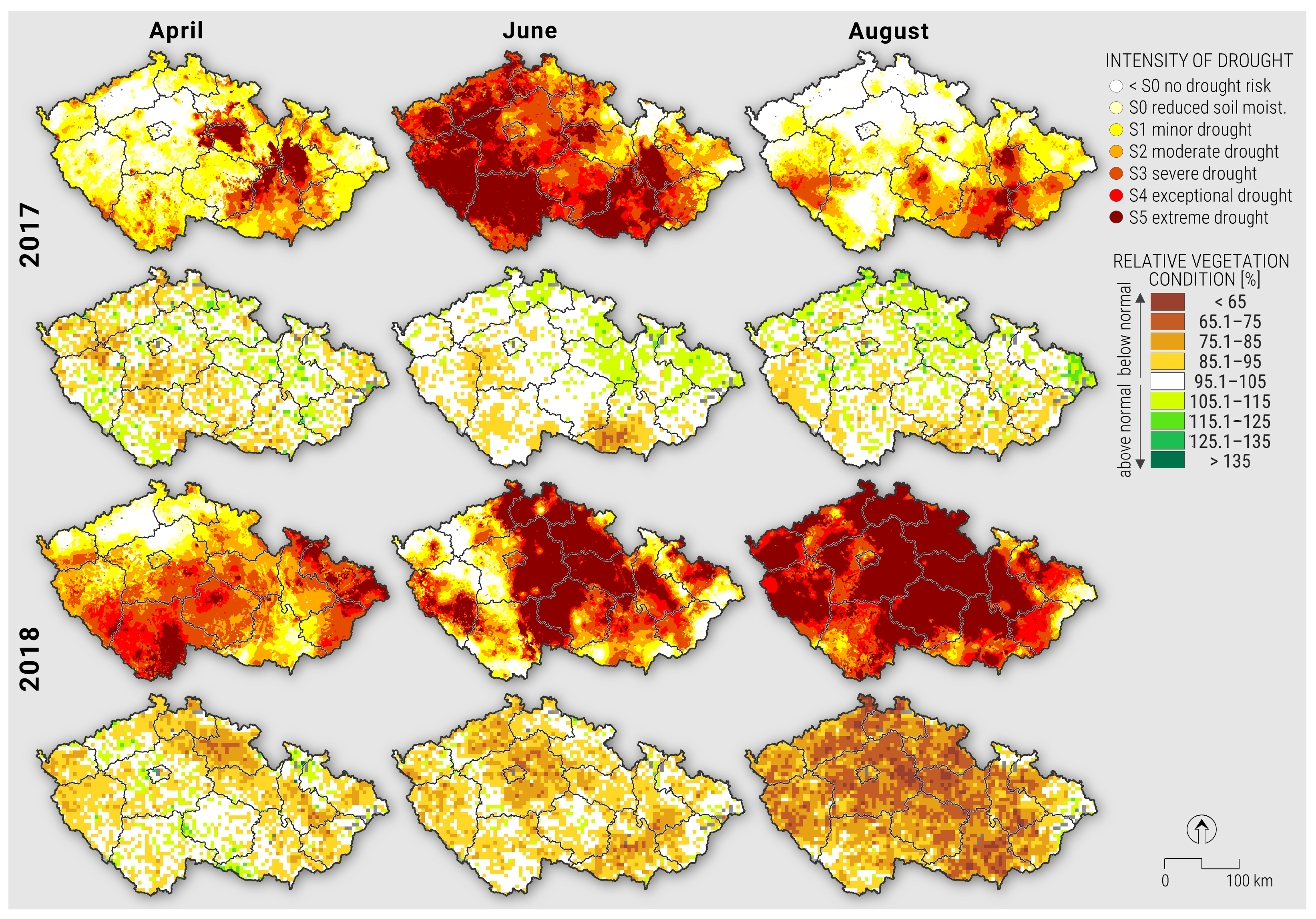
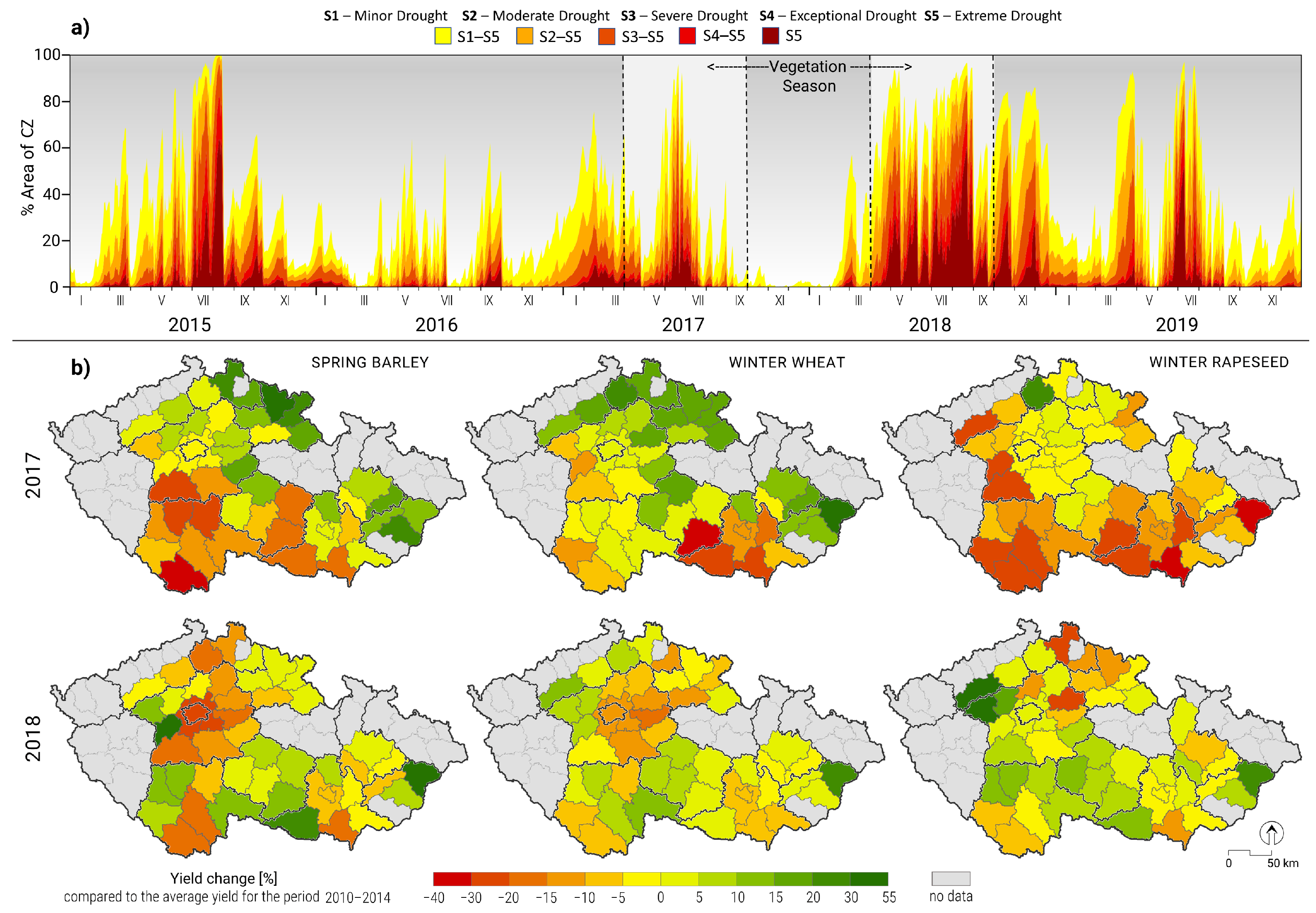
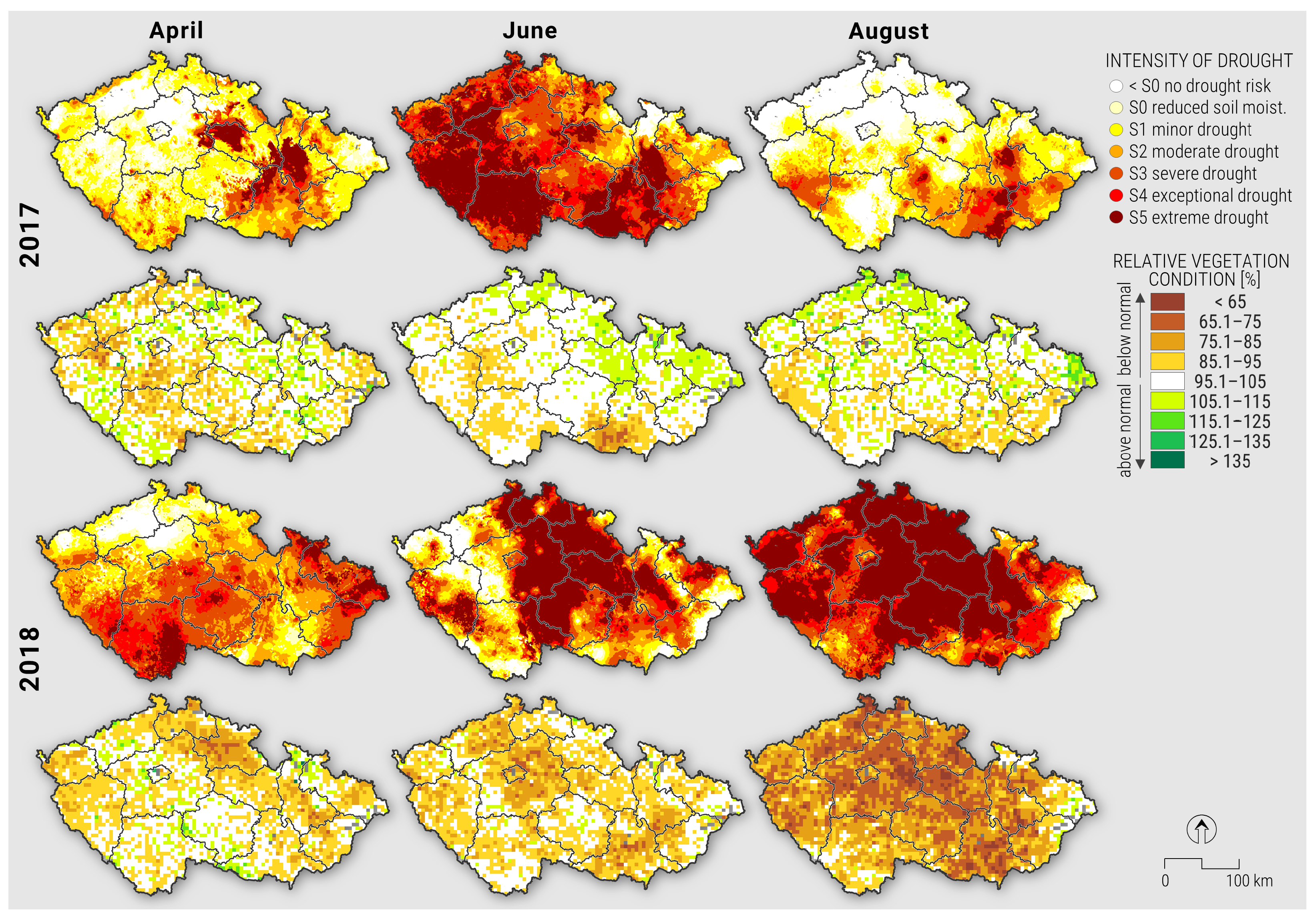
3.1. Droughts of 2017 and 2018
3.2. Predictors of Crop Loss
3.3. Estimating Yield Losses
3.4. Applicability of the Method
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Crop | Grain Maize | Oats | Spring Barley | Sugar Beets | Winter Barley | Winter Rapeseed | Winter Wheat |
|---|---|---|---|---|---|---|---|
| Samples for the ANN | 231 | 59 | 368 | 114 | 262 | 528 | 799 |
| ANN hierarchy | 7-5-1 | 3-3-1 | 10-5-1 | 5-3-1 | 7-5-1 | 10-9-1 | 15-10-1 |
| AWD1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| AWR | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
| AWR1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| AWV | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
| AWV1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
| daysAWP_S4+ | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
| daysAWP1_S2+ | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| daysAWP1_S4+ | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
| daysAWR1_30 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| EVI2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| EVI2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| NDVI | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| NDVI | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| P | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| T | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Crop | Alfalfa | Clover | Grain Maize | Grasslands | Hops | Oats | Poppy Seeds | Potatoes | Silage Maize | Spring Barley | Spring Wheat | Sugar Beets | Sunflowers | Winter Barley | Winter Rye | Winter Wheat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Samples for the ANN | 713 | 826 | 700 | 4014 | 77 | 396 | 277 | 417 | 1854 | 1711 | 209 | 556 | 144 | 992 | 484 | 3839 |
| ANN hierarchy | 15 - 7 - 1 | 15 - 10 - 1 | 15 - 7 - 1 | 20 - 20 - 1 | 6 - 2 - 1 | 10 - 7 - 1 | 9 - 5 - 1 | 10 - 7 - 1 | 20 - 15 - 1 | 20 - 15 - 1 | 7 - 5 - 1 | 15 - 6 - 1 | 7 - 3 - 1 | 15 - 10 - 1 | 15 - 5 - 1 | 20 - 20 - 1 |
| Alt | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
| AWD | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AWD1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
| AWP | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AWP1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| AWR | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| AWR1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| daysAwp_S2+ | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| daysAwp_S3+ | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| daysAwp1_S2+ | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| daysAwp1_S3+ | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 |
| daysAwr_50 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
| daysAwr1_30 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| daysAwr1_50 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| daysHeatDrought | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| daysTmax35 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| ESI | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| ESI | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
| ET | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| ET/ET | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| EVI2 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
| EVI2 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
| Lat | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
| NDVI | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| NDVI | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 |
| P | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| P-ET | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| SWI | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
| SWI | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| T | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
References
- Boyer, J.S.; Byrne, P.; Cassman, K.G.; Cooper, M.; Delmer, D.; Greene, T.; Gruis, F.; Habben, J.; Hausmann, N.; Kenny, N.; et al. The US drought of 2012 in perspective: A call to action. Glob. Food Secur. 2013, 2, 139–143. [Google Scholar] [CrossRef]
- Dannenberg, M.P.; Yan, D.; Barnes, M.L.; Smith, W.K.; Johnston, M.R.; Scott, R.L.; Biederman, J.A.; Knowles, J.F.; Wang, X.; Duman, T.; et al. Exceptional heat and atmospheric dryness amplified losses of primary production during the 2020 US Southwest hot drought. Glob. Chang. Biol. 2022, 28, 4794–4806. [Google Scholar] [CrossRef]
- Trnka, M.; Olesen, J.E.; Kersebaum, K.C.; Rötter, R.P.; Brázdil, R.; Eitzinger, J.; Jansen, S.; Skjelvåg, A.O.; Peltonen-Sainio, P.; Hlavinka, P.; et al. Changing regional weather crop yield relationships across Europe between 1901 and 2012. Clim. Res. 2016, 70, 195–214. [Google Scholar] [CrossRef] [Green Version]
- Blauhut, V.; Stoelzle, M.; Ahopelto, L.; Brunner, M.I.; Teutschbein, C.; Wendt, D.E.; Akstinas, V.; Bakke, S.J.; Barker, L.J.; Bartošová, L.; et al. Lessons from the 2018–2019 European droughts: A collective need for unifying drought risk management. Nat. Hazards Earth Syst. Sci. 2022, 22, 2201–2217. [Google Scholar] [CrossRef]
- Moravec, V.; Markonis, Y.; Trnka, M.; Hanel, M. Extreme Hydroclimatic Events Compromise Adaptation Planning in Agriculture Based on Long-term Trends. Sci. Total Enviorn. 2023, submitted.
- Trnka, M.; Feng, S.; Semenov, M.A.; Olesen, J.E.; Kersebaum, K.C.; Rötter, R.P.; Semerádová, D.; Klem, K.; Huang, W.; Ruiz-Ramos, M.; et al. Mitigation efforts will not fully alleviate the increase in water scarcity occurrence probability in wheat-producing areas. Sci. Adv. 2019, 5, eaau2406. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Štěpánek, P.; Zahradníček, P.; Farda, A.; Skalák, P.; Trnka, M.; Meitner, J.; Rajdl, K. Projection of drought-inducing climate conditions in the Czech Republic according to Euro-CORDEX models. Clim. Res. 2016, 70, 179–193. [Google Scholar] [CrossRef] [Green Version]
- Lhotka, O.; Trnka, M.; Kyselý, J.; Markonis, Y.; Balek, J.; Možný, M. Atmospheric circulation as a factor contributing to increasing drought severity in central Europe. J. Geophys. Res. Atmos. 2020, 125, e2019JD032269. [Google Scholar] [CrossRef]
- Jaagus, J.; Aasa, A.; Aniskevich, S.; Boincean, B.; Bojariu, R.; Briede, A.; Danilovich, I.; Castro, F.D.; Dumitrescu, A.; Labuda, M.; et al. Long-term changes in drought indices in eastern and central Europe. Int. J. Climatol. 2022, 42, 225–249. [Google Scholar] [CrossRef]
- The World Bank; Agriculture, Forestry, and Fishing, Value Added (% of GDP)-Czechia. Available online: https://data.worldbank.org/indicator/NV.AGR.TOTL.ZS?locations=CZ (accessed on 26 April 2023).
- Papadimitriou, L.; Trnka, M.; Harrison, P.; Holman, I. Cross-sectoral and trans-national interactions in national-scale climate change impacts assessment—the case of the Czech Republic. Reg. Environ. Chang. 2019, 19, 2453–2464. [Google Scholar] [CrossRef] [Green Version]
- Zahradníček, P.; Trnka, M.; Brázdil, R.; Možný, M.; Štěpánek, P.; Hlavinka, P.; Žalud, Z.; Malý, A.; Semerádová, D.; Dobrovolný, P.; et al. The extreme drought episode of August 2011–May 2012 in the Czech Republic. Int. J. Climatol. 2015, 35, 3335–3352. [Google Scholar] [CrossRef]
- Büntgen, U.; Urban, O.; Krusic, P.J.; Rybníček, M.; Kolář, T.; Kyncl, T.; Ač, A.; Koňasová, E.; Čáslavský, J.; Esper, J.; et al. Recent European drought extremes beyond Common Era background variability. Nat. Geosci. 2021, 14, 190–196. [Google Scholar] [CrossRef]
- Trnka, M.; Možný, M.; Jurečka, F.; Balek, J.; Semerádová, D.; Hlavinka, P.; Štěpánek, P.; Farda, A.; Skalák, P.; Cienciala, E.; et al. Observed and estimated consequences of climate change for the fire weather regime in the moist-temperate climate of the Czech Republic. Agric. For. Meteorol. 2021, 310, 108583. [Google Scholar] [CrossRef]
- Ceglar, A.; Toreti, A.; Prodhomme, C.; Zampieri, M.; Turco, M.; Doblas-Reyes, F.J. Land-surface initialisation improves seasonal climate prediction skill for maize yield forecast. Sci. Rep. 2018, 8, 1322. [Google Scholar] [CrossRef] [Green Version]
- Kogan, F.; Kussul, N.; Adamenko, T.; Skakun, S.; Kravchenko, O.; Kryvobok, O.; Shelestov, A.; Kolotii, A.; Kussul, O.; Lavrenyuk, A. Winter wheat yield forecasting in Ukraine based on Earth observation, meteorological data and biophysical models. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 192–203. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Minh, V.Q.; Trung, N.H. A comparative analysis of multitemporal MODIS EVI and NDVI data for large-scale rice yield estimation. Agric. For. Meteorol. 2014, 197, 52–64. [Google Scholar] [CrossRef]
- Büechi, E.; Fischer, M.; Crocetti, L.; Trnka, M.; Grlj, A.; Zappa, L.; Wouter, D. Crop yield anomaly forecasting in the Pannonian Basin using gradient boosting and its performance in years of severe drought. Agric. For. Meteorol. 2023, submitted.
- De Wit, A. Regional Crop Yield Forecasting Using Probalistic Crop Growth Modelling and Remote Sensing Data Assimilation; Wageningen University and Research; ProQuest Dissertations Publishing: Ann Arbor, MI, USA, 2007. [Google Scholar]
- Dorigo, W.A.; Zurita-Milla, R.; de Wit, A.J.; Brazile, J.; Singh, R.; Schaepman, M.E. A review on reflective remote sensing and data assimilation techniques for enhanced agroecosystem modeling. Int. J. Appl. Earth Obs. Geoinf. 2007, 9, 165–193. [Google Scholar] [CrossRef]
- Pagani, V.; Guarneri, T.; Busetto, L.; Ranghetti, L.; Boschetti, M.; Movedi, E.; Campos-Taberner, M.; Garcia-Haro, F.J.; Katsantonis, D.; Stavrakoudis, D.; et al. A high-resolution, integrated system for rice yield forecasting at district level. Agric. Syst. 2019, 168, 181–190. [Google Scholar] [CrossRef]
- Trnka, M.; Hlavinka, P.; Možný, M.; Semerádová, D.; Štěpánek, P.; Balek, J.; Bartošová, L.; Zahradníček, P.; Bláhová, M.; Skalák, P.; et al. Czech Drought Monitor System for monitoring and forecasting agricultural drought and drought impacts. Int. J. Climatol. 2020, 40, 5941–5958. [Google Scholar] [CrossRef]
- Intersucho. Available online: https://www.intersucho.cz/ (accessed on 26 April 2023).
- Svoboda, M.; LeComte, D.; Hayes, M.; Heim, R.; Gleason, K.; Angel, J.; Rippey, B.; Tinker, R.; Palecki, M.; Stooksbury, D.; et al. The drought monitor. Bull. Am. Meteorol. Soc. 2002, 83, 1181–1190. [Google Scholar] [CrossRef] [Green Version]
- Anderson, M.C.; Hain, C.R.; Jurecka, F.; Trnka, M.; Hlavinka, P.; Dulaney, W.; Otkin, J.A.; Johnson, D.; Gao, F. Relationships between the evaporative stress index and winter wheat and spring barley yield anomalies in the Czech Republic. Clim. Res. 2016, 70, 215–230. [Google Scholar] [CrossRef] [Green Version]
- Jurečka, F.; Fischer, M.; Hlavinka, P.; Balek, J.; Semerádová, D.; Bláhová, M.; Anderson, M.C.; Hain, C.; Žalud, Z.; Trnka, M. Potential of water balance and remote sensing-based evapotranspiration models to predict yields of spring barley and winter wheat in the Czech Republic. Agric. Water Manag. 2021, 256, 107064. [Google Scholar] [CrossRef]
- Bartošová, L.; Fischer, M.; Balek, J.; Bláhová, M.; Kudláčková, L.; Chuchma, F.; Hlavinka, P.; Možný, M.; Zahradníček, P.; Wall, N.; et al. Validity and reliability of drought reporters in estimating soil water content and drought impacts in central Europe. Agric. For. Meteorol. 2022, 315, 108808. [Google Scholar] [CrossRef]
- Wagner, W.; Lemoine, G.; Rott, H. A method for estimating soil moisture from ERS scatterometer and soil data. Remote Sens. Environ. 1999, 70, 191–207. [Google Scholar] [CrossRef]
- Crocetti, L.; Forkel, M.; Fischer, M.; Jurečka, F.; Grlj, A.; Salentinig, A.; Trnka, M.; Anderson, M.; Ng, W.T.; Kokalj, Ž.; et al. Earth Observation for agricultural drought monitoring in the Pannonian Basin (southeastern Europe): Current state and future directions. Reg. Environ. Chang. 2020, 20, 123. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Anderson, M.C.; Verdin, J.P. Remote Sensing of Drought: Innovative Monitoring Approaches; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Becker-Reshef, I.; Vermote, E.; Lindeman, M.; Justice, C. A generalized regression-based model for forecasting winter wheat yields in Kansas and Ukraine using MODIS data. Remote Sens. Environ. 2010, 114, 1312–1323. [Google Scholar] [CrossRef]
- Hayes, M.J.; Decker, W.L. Using NOAA AVHRR data to estimate maize production in the United States Corn Belt. Remote Sens. 1996, 17, 3189–3200. [Google Scholar] [CrossRef]
- Jackson, T.J.; Chen, D.; Cosh, M.; Li, F.; Anderson, M.; Walthall, C.; Doriaswamy, P.; Hunt, E.R. Vegetation water content mapping using Landsat data derived normalized difference water index for corn and soybeans. Remote Sens. Environ. 2004, 92, 475–482. [Google Scholar] [CrossRef]
- Kastens, J.H.; Kastens, T.L.; Kastens, D.L.; Price, K.P.; Martinko, E.A.; Lee, R.Y. Image masking for crop yield forecasting using AVHRR NDVI time series imagery. Remote Sens. Environ. 2005, 99, 341–356. [Google Scholar] [CrossRef]
- Doraiswamy, P.C.; Sinclair, T.R.; Hollinger, S.; Akhmedov, B.; Stern, A.; Prueger, J. Application of MODIS derived parameters for regional crop yield assessment. Remote Sens. Environ. 2005, 97, 192–202. [Google Scholar] [CrossRef]
- Johnson, D.M. An assessment of pre-and within-season remotely sensed variables for forecasting corn and soybean yields in the United States. Remote Sens. Environ. 2014, 141, 116–128. [Google Scholar] [CrossRef]
- Johnson, D.M. A comprehensive assessment of the correlations between field crop yields and commonly used MODIS products. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 65–81. [Google Scholar] [CrossRef] [Green Version]
- Ferencz, C.; Bognar, P.; Lichtenberger, J.; Hamar, D.; Tarcsai, G.; Timár, G.; Molnár, G.; Pásztor, S.Z.; Steinbach, P.; Székely, B.; et al. Crop yield estimation by satellite remote sensing. Int. J. Remote Sens. 2004, 25, 4113–4149. [Google Scholar] [CrossRef]
- Labus, M.P.; Nielsen, G.A.; Lawrence, R.L.; Engel, R.; Long, D.S. Wheat yield estimates using multi-temporal NDVI satellite imagery. Int. J. Remote Sens. 2002, 23, 4169–4180. [Google Scholar] [CrossRef]
- The Ministry of Agriculture of the Czech Republic; Public Land Registry-LPIS. Available online: https://eagri.cz/public/app/lpisext/lpis/verejny2/plpis/ (accessed on 26 April 2023).
- Moravec, V.; Markonis, Y.; Rakovec, O.; Svoboda, M.; Trnka, M.; Kumar, R.; Hanel, M. Europe under multi-year droughts: How severe was the 2014–2018 drought period? Environ. Res. Lett. 2021, 16, 034062. [Google Scholar] [CrossRef]
- Rakovec, O.; Samaniego, L.; Hari, V.; Markonis, Y.; Moravec, V.; Thober, S.; Hanel, M.; Kumar, R. The 2018–2020 Multi-year drought sets a new benchmark in Europe. Earth’s Future 2022, 10, e2021EF002394. [Google Scholar] [CrossRef]
- Hlaváček, V.; Czech Agrarian Chamber, Czech Republic. Personal communication, 2022.
- Filippi, P.; Jones, E.J.; Wimalathunge, N.S.; Somarathna, P.D.; Pozza, L.E.; Ugbaje, S.U.; Jephcott, T.G.; Paterson, S.E.; Whelan, B.M.; Bishop, T.F. An approach to forecast grain crop yield using multi-layered, multi-farm data sets and machine learning. Precis. Agric. 2019, 20, 1015–1029. [Google Scholar] [CrossRef]
- Kang, Y.; Özdoğan, M. Field-level crop yield mapping with Landsat using a hierarchical data assimilation approach. Remote Sens. Environ. 2019, 228, 144–163. [Google Scholar] [CrossRef]
- Guan, K.; Wu, J.; Kimball, J.S.; Anderson, M.C.; Frolking, S.; Li, B.; Hain, C.R.; Lobell, D.B. The shared and unique values of optical, fluorescence, thermal and microwave satellite data for estimating large-scale crop yields. Remote Sens. Environ. 2017, 199, 333–349. [Google Scholar] [CrossRef] [Green Version]
- Doraiswamy, P.C.; Hatfield, J.L.; Jackson, T.J.; Akhmedov, B.; Prueger, J.; Stern, A. Crop condition and yield simulations using Landsat and MODIS. Remote Sens. Environ. 2004, 92, 548–559. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Marais-Sicre, C. Improved early crop type identification by joint use of high temporal resolution SAR and optical image time series. Remote Sens. 2016, 8, 362. [Google Scholar] [CrossRef] [Green Version]
- Anderson, M.C.; Neale, C.M.U.; Li, F.; Norman, J.M.; Kustas, W.P.; Jayanthi, H.; Chavez, J.O.S.E. Upscaling ground observations of vegetation water content, canopy height, and leaf area index during SMEX02 using aircraft and Landsat imagery. Remote Sens. Environ. 2004, 92, 447–464. [Google Scholar] [CrossRef]
- Gaso, D.V.; Berger, A.G.; Ciganda, V.S. Predicting wheat grain yield and spatial variability at field scale using a simple regression or a crop model in conjunction with Landsat images. Comput. Electron. Agric. 2019, 159, 75–83. [Google Scholar] [CrossRef]
- Gaso, D.V.; de Wit, A.; Berger, A.G.; Kooistra, L. Predicting within-field soybean yield variability by coupling Sentinel-2 leaf area index with a crop growth model. Agric. For. Meteorol. 2021, 308, 108553. [Google Scholar] [CrossRef]
- Hunt, M.L.; Blackburn, G.A.; Carrasco, L.; Redhead, J.W.; Rowl, C.S. High resolution wheat yield mapping using Sentinel-2. Remote Sens. Environ. 2019, 233, 111410. [Google Scholar] [CrossRef]
- Sharifi, A. Estimation of biophysical parameters in wheat crops in Golestan province using ultra-high resolution images. Remote Sens. Lett. 2018, 9, 559–568. [Google Scholar] [CrossRef]
- Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Franz, T.E.; Pokal, S.; Gibson, J.P.; Zhou, Y.; Gholizadeh, H.; Tenorio, F.A.; Rudnick, D.; Heeren, D.; McCabe, M.; Ziliani, M.; et al. The role of topography, soil, and remotely sensed vegetation condition towards predicting crop yield. Field Crop. Res. 2020, 252, 107788. [Google Scholar] [CrossRef]



| Crop | Cadastral Areas Reported (Special Questionnaire) | Usable Records from the Special Questionnaire [%] | Cadastral Areas Reported (CzechDM) | Cadastral Areas with Yield Losses from 30 to 50% | Cadastral Areas with Yield Losses over 50% |
|---|---|---|---|---|---|
| Grain maize | 443 | 30.25 | 105 | 1104 | 88 |
| Spring barley | 843 | 30.96 | 116 | 947 | 17 |
| Winter barley | 636 | 24.06 | 116 | 423 | 4 |
| Winter rapeseed | 1165 | 37.25 | 99 | 1421 | 40 |
| Winter wheat | 1329 | 50.04 | 116 | 736 | 41 |
| Crop | Cadastral Areas Reported (Special Questionnaire) | Usable Records from the Special Questionnaire [%] | Cadastral Areas Reported (CzechDM) | Cadastral Areas with Yield Losses from 30 to 50% | Cadastral Areas with Yield Losses Over 50% |
|---|---|---|---|---|---|
| Alfalfa | 1015 | 57.93 | 130 | 2280 | 586 |
| Clover | 1401 | 49.89 | 133 | 3441 | 992 |
| Grain maize | 1243 | 32.66 | 297 | 4332 | 859 |
| Grasslands | 5022 | 74.07 | 330 | 6907 | 4142 |
| Hops | 113 | 59.29 | 10 | 131 | 42 |
| Oat | 1083 | 28.07 | 103 | 909 | 36 |
| Poppy seeds | 921 | 25.84 | 42 | 105 | 1030 |
| Potatoes | 584 | 44.18 | 160 | 1078 | 147 |
| Silage maize | 3139 | 49.57 | 300 | 2017 | 145 |
| Spring barley | 3694 | 37.28 | 336 | 1054 | 75 |
| Spring wheat | 1064 | 19.92 | - | 1063 | 42 |
| Sugar beets | 1315 | 37.11 | 69 | 1027 | 211 |
| Sunflower | 358 | 26.82 | 49 | 151 | 21 |
| Triticale | 929 | 25.51 | - | - | - |
| Winter barley | 2267 | 28.01 | 361 | 392 | 24 |
| Winter rye | 542 | 24.35 | 357 | 275 | 7 |
| Winter wheat | 6729 | 51.67 | 373 | 2051 | 186 |
| Acronym of the Indicator | Description | Time Step | Spatial Resolution | Data Provider |
|---|---|---|---|---|
| AWD | Soil water content anomaly from the reference period in mm for 0–100 cm soil depth | Daily | 500 m | |
| AWD1 | Soil water content anomaly from the reference period in mm for 0–40 cm soil depth | Daily | 500 m | |
| AWP | Drought intensity anomaly from the reference period for 0–100 cm soil depth | Daily | 500 m | |
| AWP1 | Drought intensity anomaly from the reference period for 0–40 cm soil depth | Daily | 500 m | |
| AWR | Relative soil moisture content as a share of the field capacity in % for 0–100 cm soil depth | Daily | 500 m | |
| AWR1 | Relative soil moisture content as a share of the field capacity in % for 0–40 cm soil depth | Daily | 500 m | |
| AWV | Soil moisture content in mm for 0–100 cm soil depth | Daily | 500 m | |
| AWV1 | Soil moisture content in mm for 0–40 cm soil depth | Daily | 500 m | |
| DaysAwp_S2+ | Number of days with AWP values of 2 or higher per season | 500 m | ||
| DaysAwp_S3+ | Number of days with AWP values of 3 or higher per season | 500 m | ||
| DaysAwp_S4+ | Number of days with AWP values of 4 or higher per season | 500 m | ||
| DaysAwp1_S2+ | Number of days with AWP1 values of 2 or higher per season | 500 m | ||
| DaysAwp1_S3+ | Number of days with AWP1 values of 3 or higher per season | 500 m | ||
| DaysAwp1_S4+ | Number of days with AWP1 values of 4 or higher per season | 500 m | ||
| DaysAwr_30 | Number of days with AWR values of 30 or lower per season | 500 m | ||
| DaysAwr_50 | Number of days with AWR values of 50 or lower per season | 500 m | ||
| DaysAwr1_30 | Number of days with AWR1 values of 30 or lower per season | 500 m | ||
| DaysAwr1_50 | Number of days with AWR1 values of 50 or lower per season | 500 m | ||
| DaysHeatDrought | Number of days with AWR < 30% and concurrent heatwaves (periods with average maximal temperature ≥ 30 °C and daily maximal temperature ≥ 30 °C for 3+ days in row) per season | 500 m | ||
| DaysTmax35 | Number of days with maximal temperatures > 35 °C per season | 500 m | ||
| ET | Reference evapotranspiration | Daily | 500 m | |
| ET/ET | Actual-to-reference evapotranspiration ratio | Daily | 500 m | |
| P | Daily precipitation in mm | Daily | 500 m | |
| P-ET | Sum of differences between the sum of daily precipitation and the sum of daily reference evapotranspiration for April–June period | Daily | 500 m | |
| T | Daily average temperature in °C | Daily | 500 m | |
| * ESI | 12-week accumulated evaporative stress index based on the ALEXI approach | Weekly | 3.5 km | USDA/NASA |
| * ESI | 4-week accumulated evaporative stress index based on the ALEXI approach | Weekly | 3.5 km | USDA/NASA |
| * EVI2 | MODIS-derived 2-band enhanced vegetation index calculated from surface reflectance bands | Daily | 5 km | NASA |
| * EVI2 | EVI2 anomaly | Weekly | 5 km | |
| * NDVI | MODIS-derived normalized difference vegetation index calculated from surface reflectance bands | Daily | 5 km | NASA |
| * NDVI | NDVI anomaly | Weekly | 5 km | |
| * SWI | Soil moisture content in % for 0–40 cm soil depth | Weekly | 11 km | Copernicus |
| * SWI | Soil moisture content in % for 0–100 cm soil depth | Weekly | 11 km | Copernicus |
| Crop | Winter Wheat | Spring Barley | Grain Maize | Sugar Beets | Potatoes | Poppy Seeds |
|---|---|---|---|---|---|---|
| Samples for the ANN | 3839 | 1711 | 700 | 556 | 417 | 277 |
| ANN hierarchy | 20-20-1 | 20-15-1 | 15-7-1 | 15-6-1 | 10-7-1 | 9-5-1 |
| Alt | 1 | 1 0 | 1 | 0 | 0 | |
| AWD | 0 | 0 | 0 | 0 | 0 | 1 |
| AWD1 | 1 | 1 | 1 | 0 | 1 | 0 |
| AWP1 | 1 | 1 | 1 | 0 | 0 | 0 |
| AWR1 | 1 | 1 | 1 | 1 | 1 | 0 |
| DaysAWP_S2+ | 1 | 1 | 1 | 0 | 0 | 0 |
| DaysAWP1_S3+ | 1 | 1 | 1 | 0 | 0 | 0 |
| DaysAWR_50 | 1 | 1 | 0 | 1 | 1 | 1 |
| DaysAWR1_30 | 1 | 1 | 0 | 1 | 1 | 0 |
| DaysHeatDrought | 1 | 1 | 1 | 1 | 1 | 1 |
| DaysTmax35 | 0 | 1 | 0 | 1 | 0 | 0 |
| ESI | 1 | 1 | 1 | 1 | 0 | 0 |
| ESI | 1 | 1 | 1 | 1 | 1 | 1 |
| ET | 0 | 1 | 1 | 1 | 1 | 1 |
| ET/ET | 1 | 1 | 0 | 0 | 0 | 0 |
| EVI2 | 1 | 1 | 1 | 0 | 0 | 0 |
| EVI2 | 1 | 1 | 1 | 1 | 0 | 0 |
| Lat | 1 | 1 | 0 | 1 | 0 | 0 |
| NDVI | 1 | 1 | 0 | 0 | 0 | 1 |
| NDVI | 1 | 1 | 0 | 0 | 0 | 1 |
| P-ET | 1 | 1 | 1 | 1 | 1 | 1 |
| SWI | 1 | 0 | 1 | 1 | 1 | 0 |
| SWI | 0 | 0 | 1 | 1 | 0 | 0 |
| T | 1 | 1 | 1 | 1 | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meitner, J.; Balek, J.; Bláhová, M.; Semerádová, D.; Hlavinka, P.; Lukas, V.; Jurečka, F.; Žalud, Z.; Klem, K.; Anderson, M.C.; et al. Estimating Drought-Induced Crop Yield Losses at the Cadastral Area Level in the Czech Republic. Agronomy 2023, 13, 1669. https://doi.org/10.3390/agronomy13071669
Meitner J, Balek J, Bláhová M, Semerádová D, Hlavinka P, Lukas V, Jurečka F, Žalud Z, Klem K, Anderson MC, et al. Estimating Drought-Induced Crop Yield Losses at the Cadastral Area Level in the Czech Republic. Agronomy. 2023; 13(7):1669. https://doi.org/10.3390/agronomy13071669
Chicago/Turabian StyleMeitner, Jan, Jan Balek, Monika Bláhová, Daniela Semerádová, Petr Hlavinka, Vojtěch Lukas, František Jurečka, Zdeněk Žalud, Karel Klem, Martha C. Anderson, and et al. 2023. "Estimating Drought-Induced Crop Yield Losses at the Cadastral Area Level in the Czech Republic" Agronomy 13, no. 7: 1669. https://doi.org/10.3390/agronomy13071669
APA StyleMeitner, J., Balek, J., Bláhová, M., Semerádová, D., Hlavinka, P., Lukas, V., Jurečka, F., Žalud, Z., Klem, K., Anderson, M. C., Dorigo, W., Fischer, M., & Trnka, M. (2023). Estimating Drought-Induced Crop Yield Losses at the Cadastral Area Level in the Czech Republic. Agronomy, 13(7), 1669. https://doi.org/10.3390/agronomy13071669