1. Introduction
Accurate estimates of citrus fruit yield before harvest are crucial for farmers and buyers, as they are necessary for devising effective marketing plans and securing temporary workers needed during harvest. In this process, estimating the fruit size is a pivotal factor because it directly influences yield estimation, working in conjunction with the total number of fruit sets. Since the fruit is packed in boxes based on size grades for shipment, packers also require advanced information about the fruit size to efficiently manage packaging and logistics.
Efforts to estimate the number of fruits and yield, particularly fruit weight, have been a persistent focus of research for several decades [
1,
2,
3,
4]. However, there are not so many studies focused on estimating fruit size. That is because fruit trees often bear several hundred or more fruits per tree, and large-scale sampling and detailed measurements are difficult in actual orchards. Recently, various methods utilizing machine vision have been developed for estimating individual fruit size in apples [
5,
6], mangoes [
7], vegetables [
8], and so on. However, even with these methods, estimating all fruit sizes remains a challenge, underscoring the necessity for effective sampling strategies. Apolo-Apolo et al. [
9] demonstrated methods using UAV images to assess the size of citrus fruits. The report is a valuable study because of comprehensive fruit size estimations by machine vision. However, their study revealed discrepancies between estimated and actual values in the distribution of fruit size. This disparity was attributed to their inability to estimate fruits concealed by leaves and branches, restricting their assessment to a partial surface area of the canopy. As a study of size estimation without using machine vision in citrus, there have been reports of a model to predict the ‘Washington Navel’ orange fruit diameter at harvest from five to six months before harvest using a cubic smoothing spline analysis [
10]. However, growth parameters must be investigated before conducting surveys. Implementing this approach is difficult for small-scale farmers where limited labor resources are available for precise measurement of fruit growth parameters. This model is also used for estimating individual fruit and is not a method for estimating fruit size per tree or orchard. In apple and kiwifruit, studies have been published on weight distributions applicable to size prediction [
11,
12]. However, some citrus fruit shipments are based on the fruit diameter. As an example of a sampling strategy, there is a sampling protocol, which was developed for use in size estimation models [
13,
14,
15], and multilevel systematic sampling, which was used to estimate fruit numbers for entire orchards of apple, grape, and kiwifruit [
16]. However, considering the recent advancements in machine vision technology, developing sampling strategies adapted for its application and creating comprehensive methods for estimating fruit sizes have become increasingly paramount. It is worthwhile to consider an alternative approach to estimating the fruit size of citrus, assuming the use of machine vision.
Therefore, emphasis was placed on estimating the proportions of fruit size grades. Obtaining information on the proportion of fruit size grades from a tree is more important than accurately estimating the size of individual fruits for efficient data acquisition in a limited resource. In this study, as an initial step towards establishing a method for pre-harvest prediction from small samples, a method was developed to estimate the proportion of fruit size grades using the mean fruit diameter of trees measured immediately after harvest. The accuracy and versatility of the estimation models developed by this method were assessed in eight orchards over three years.
2. Materials and Methods
2.1. Material, Experimental Site, and Methods of Constructing Datasets
The present study was conducted using a kind of citrus (
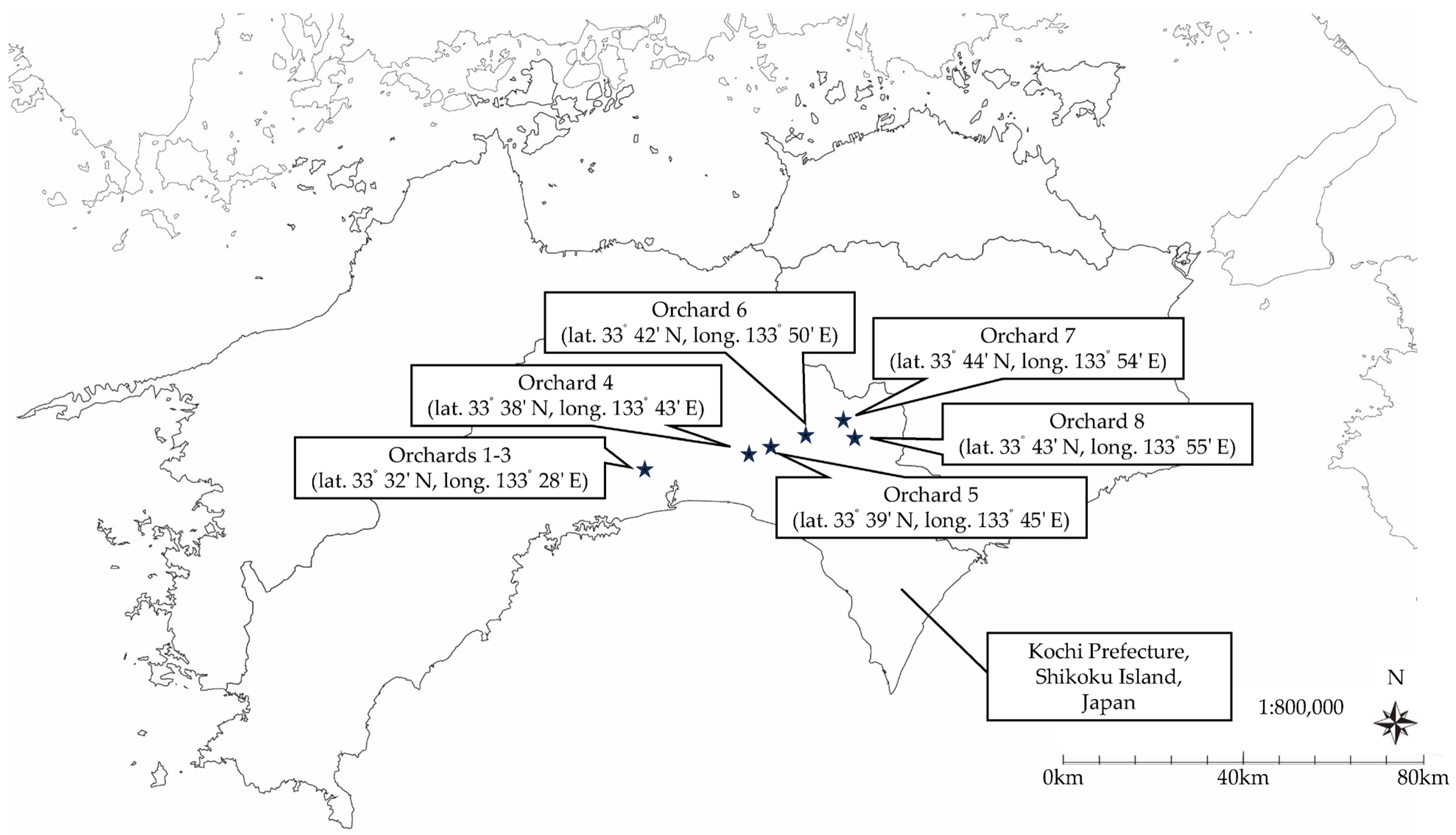
Citrus junos Sieb. ex Tanaka, also known as yuzu) on trifoliate orange rootstocks in three orchards (Orchards 1–3) at the Kochi Agricultural Research Center Fruit Tree Experiment Station in Kochi City and five farmer’s orchards (Orchards 4–8) in Kami City, Japan (
Figure 1).
Citrus junos is the commonly cultivated citrus cultivar in East Asia [
17,
18,
19]. The fruit has an attractive fragrance and strong acidity. In Japan, the juice has traditionally been used as a substitute for vinegar and seasonings instead of eating fresh fruit. Kami City is one of the significant
Citrus junos cultivation areas in Japan.
Table 1 presents the overview of the experimental orchards, and
Figure 2 shows the location of the experimental orchards. In Orchards 1–3, all trees of each orchard were investigated to construct and validate models. In Orchards 4–8, ten trees were randomly selected and investigated, excluding weakened trees due to disease based on the result of
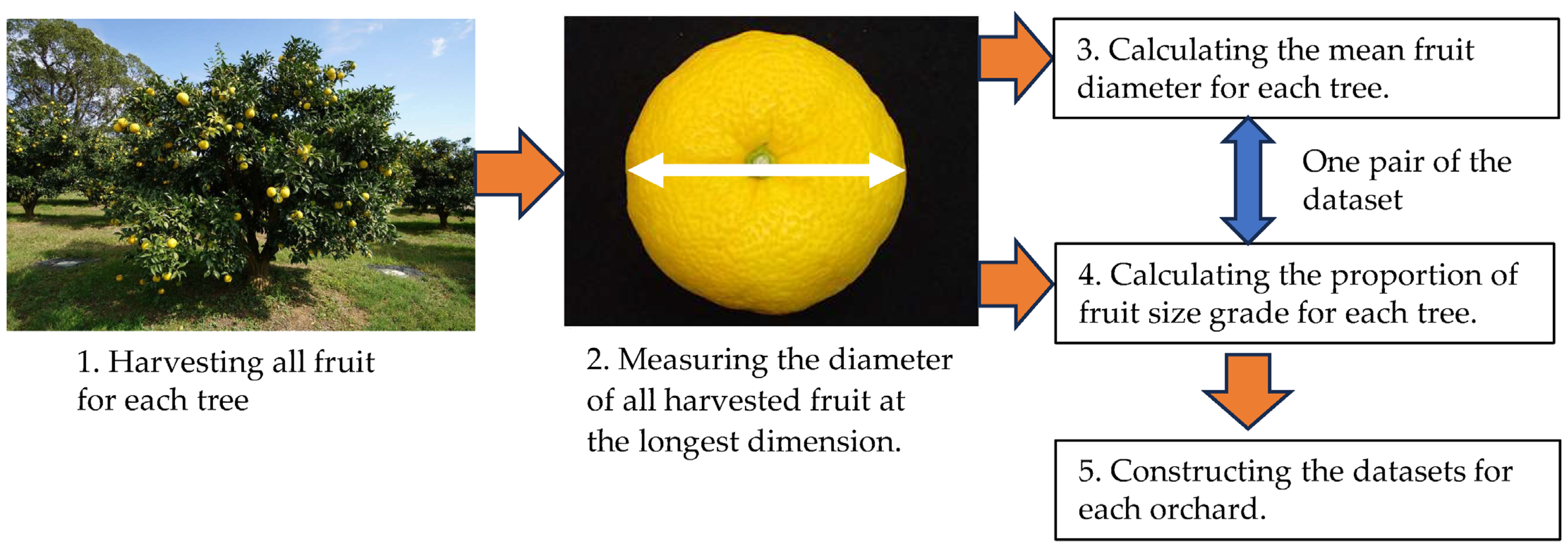
Section 3.3. Fruit thinning was not performed in all orchards. All fruit was harvested per tree in November, and the diameter of each fruit was measured at the longest dimension using a digital caliper. The mean fruit diameter and the proportion of fruit size grade were calculated for each tree, and datasets paired between these values for each tree were constructed in each orchard (
Figure 3). Fruit size grade is a standard defined by Japan Agricultural Co-operatives (JA Kochi, Kochi City, Japan) (
Table 2). Orchards 1–3 were used to construct and validate models, and Orchards 4–8 were used to validate models.
2.2. Construction of Models
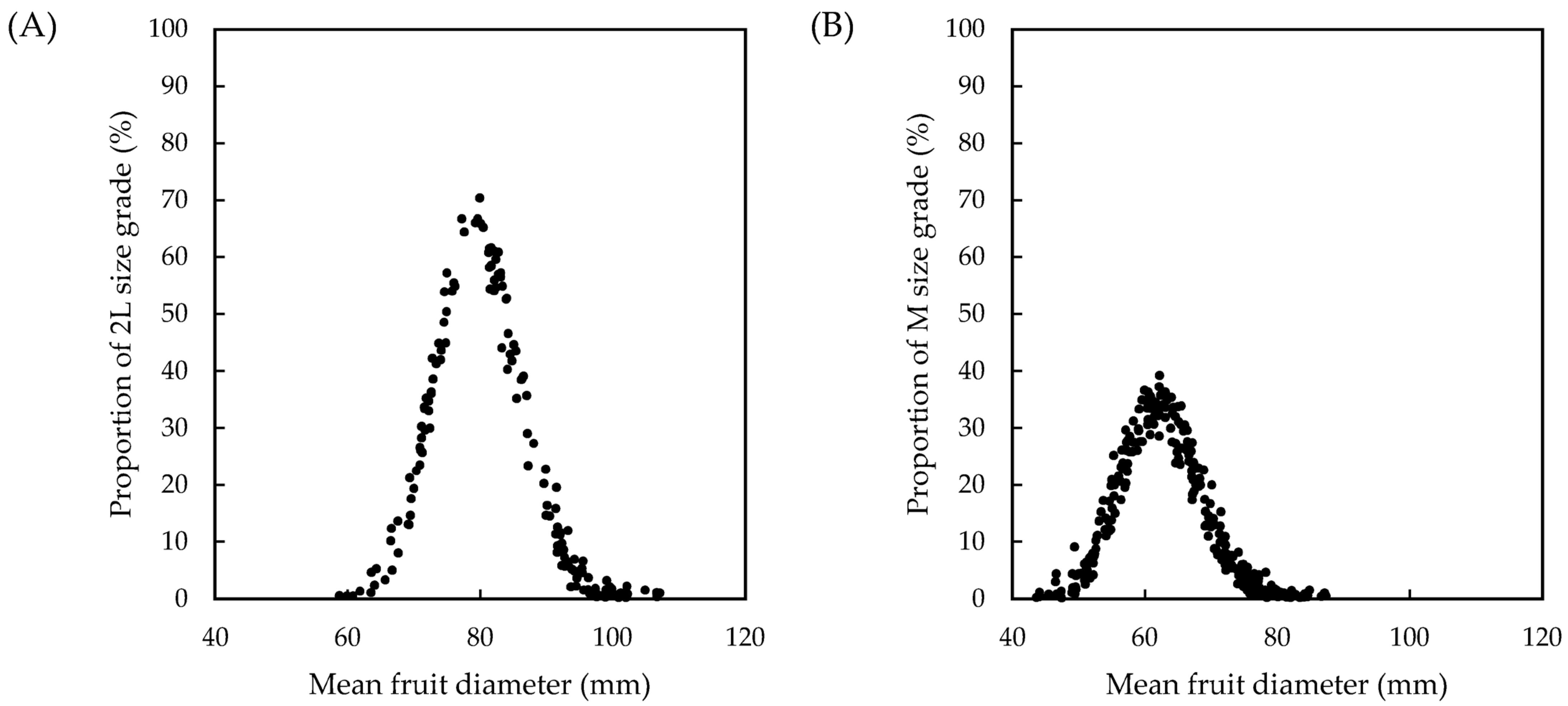
Based on the datasets of Orchard 1 in 2020, curvilinear regressions were conducted to construct models for estimating the proportion of fruit size grades at harvest. Although the difference in diameter interval between each grade (S, L, 2L, and 3L) was 10.0–11.0 mm, the interval between the M size grade was approximately half (5.0 mm) compared to that of other grades. Therefore, four models were constructed to correspond to the differences in the diameter intervals between M size and other fruit size grades. The following adjustments were made to construct each model.
To construct models to estimate the proportions of the S, L, 2L, and 3L grades, adjustments were made to align the proportions of each fruit size grade around a mean fruit diameter of 80.0 mm. If the number of datasets (number of trees) had been larger, the models could have been constructed by regression analysis for each size grade, but due to the limited number of datasets, the model was adjusted to a specific grade. The model was adjusted to 2L size grade in this study and constructed. These adjustments involved adding or subtracting the difference between the median of the 2L size grade interval (80.0 mm) and the median of each grade interval from the respective mean fruit diameter. The proportion of each size grade was considered the proportion of the 2L size grade. Separate curvilinear regressions were conducted for the datasets below and above 80.0 mm, with the mean fruit diameter as an independent variable and the proportion of 2L size grade as a dependent variable. The analysis excluded 0% of the data and apparent outliers.
To construct models to estimate the proportions of M size grades, adjustments were made to align the proportions of each fruit size grade around a mean fruit diameter of 62.5 mm. These adjustments involved adding or subtracting the difference between the median of the M size grade interval (62.5 mm) and the median of each grade interval divided into two parts from the respective mean fruit diameters. The proportion of each size grade was considered the proportion of the M size grade. Separate curvilinear regressions were conducted for the datasets below and above 62.5 mm, with the mean fruit diameters as an independent variable and the proportions of M size grade as a dependent variable. The analysis excluded 0% of the data and apparent outliers.
2.3. Evaluation of Models
The evaluation of the constructed estimation models (
Table 3) was conducted by adjusted R-squared (
R2) and Akaike’s information criterion (AIC).
R2 is an index used to evaluate the goodness of fit of a model, and AIC is used to compare the predictive performances of different models. In this study, both
R2 and AIC were used to determine the best model. Additionally, F-tests and Shapiro–Wilk tests were conducted to verify the normality of the models. Q-Q and residual plots were created to verify the assumptions of the regression models. All statistical analyses were performed using BellCurve for Excel, version 4.05 (Social Survey Research Information Co., Ltd., Tokyo, Japan).
2.4. Validation of Models
The validation was performed using the four datasets obtained from Orchards 1–3 to assess the generalization capability of the constructed estimation models in
Section 2.2. Four datasets were used to construct 14 models by selecting one, two, and three datasets separately. The construction methods of the estimation models were the same as in
Section 2.2. Twenty-eight validations were conducted using the remaining datasets. The estimation model’s accuracy (EMA) and Pearson’s chi-square test were used to assess each orchard. The EMA was calculated using the following equation:
where N_act and N_est represent the actual and estimated proportions of each grade, respectively.
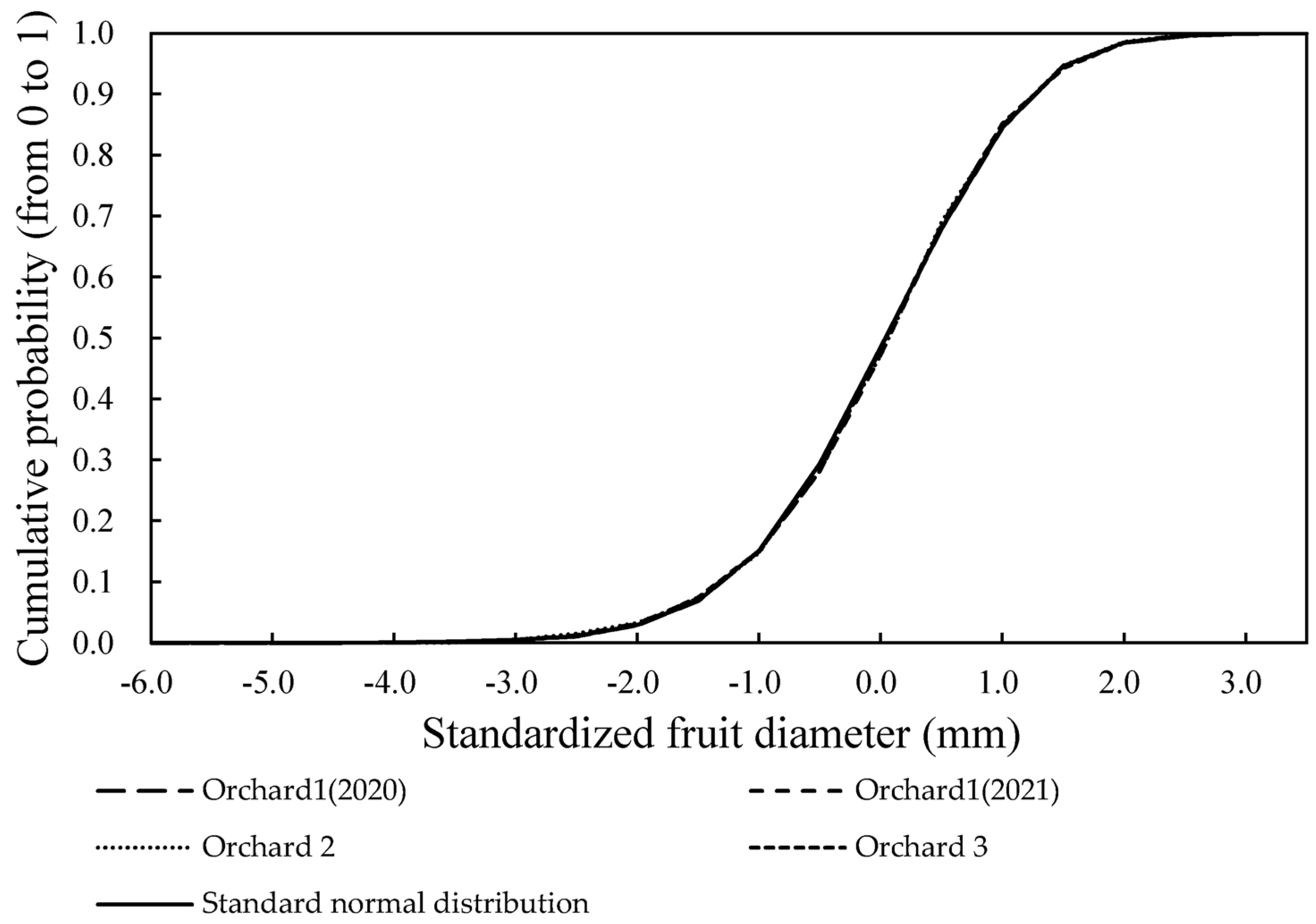
It is difficult to simultaneously evaluate the accuracy of the five fruit size grades. Particularly, differences between higher proportions of grades (M, L, and 2L grades) and lower proportions of grades (S and 3L grades) are significant. Mean absolute error is the mean of the absolute difference between the actual and estimated values; however, it was considered difficult to check the influence of size grades with large errors if the values were mean in this study. Therefore, the EMA, which is the sum of the absolute difference between the actual and estimated values, was adopted. Moreover, in order to compare the variation in fruit diameter between each orchard, each orchard’s empirical cumulative distribution function was generated and compared with the datasets of Orchard 1 in 2020 and with the standardized normal distribution.
2.5. Validation of the Number of Trees
The accuracy of the constructed estimation models in
Section 2.2. was validated with different numbers of trees using three datasets obtained from Orchards 1, 2, and 3 in 2021, 2021, and 2022, respectively. Five and ten trees per orchard were selected randomly, and the process was repeated 100 times. Firstly, the mean fruit diameter of the individual trees was fed into the constructed estimation models (
Table 3), and each estimated proportion was calculated. The estimated proportions were multiplied by the number of fruits harvested from the individual trees to calculate the estimated number of fruits for each grade. The estimated proportions for each orchard were recalculated by summing the estimated numbers of fruits from the selected trees. The actual proportions were recalculated using the same method. Finally, the EMA was used to assess each orchard.
2.6. Validation of Models in Farmer’s Orchards
The accuracy of the constructed estimation models in
Section 2.2. was validated using five datasets obtained from Orchards 4–8 of five farmers in 2023, respectively. The estimated and actual proportions for each orchard were calculated using the same method in
Section 2.5. The EMA and Pearson’s chi-square test were used to assess each orchard.
4. Discussion
In this study, emphasis was placed on estimating the proportion of fruit size grades. Previous studies have often focused on individual fruit measurements via machine vision or direct methods [
15,
20,
21]. For example, in the study of ‘Washington Navel’ oranges [
10], an individual fruit size prediction model was developed using cubic smoothing splines based on data measuring fruit diameter at fortnightly intervals until harvest, and the final proportion of fruit size grades was also estimated using the model. However, these estimates relied on the distribution derived from the size grading of 50 fruits per tree across 10 trees. This method requires an amount of measurement effort. In this study, our approach aimed at utilizing a single descriptive statistic, mean fruit diameter, which is relatively easy to measure. This choice was made due to its potential applicability even for small-scale farmers without requiring substantial cost measurement.
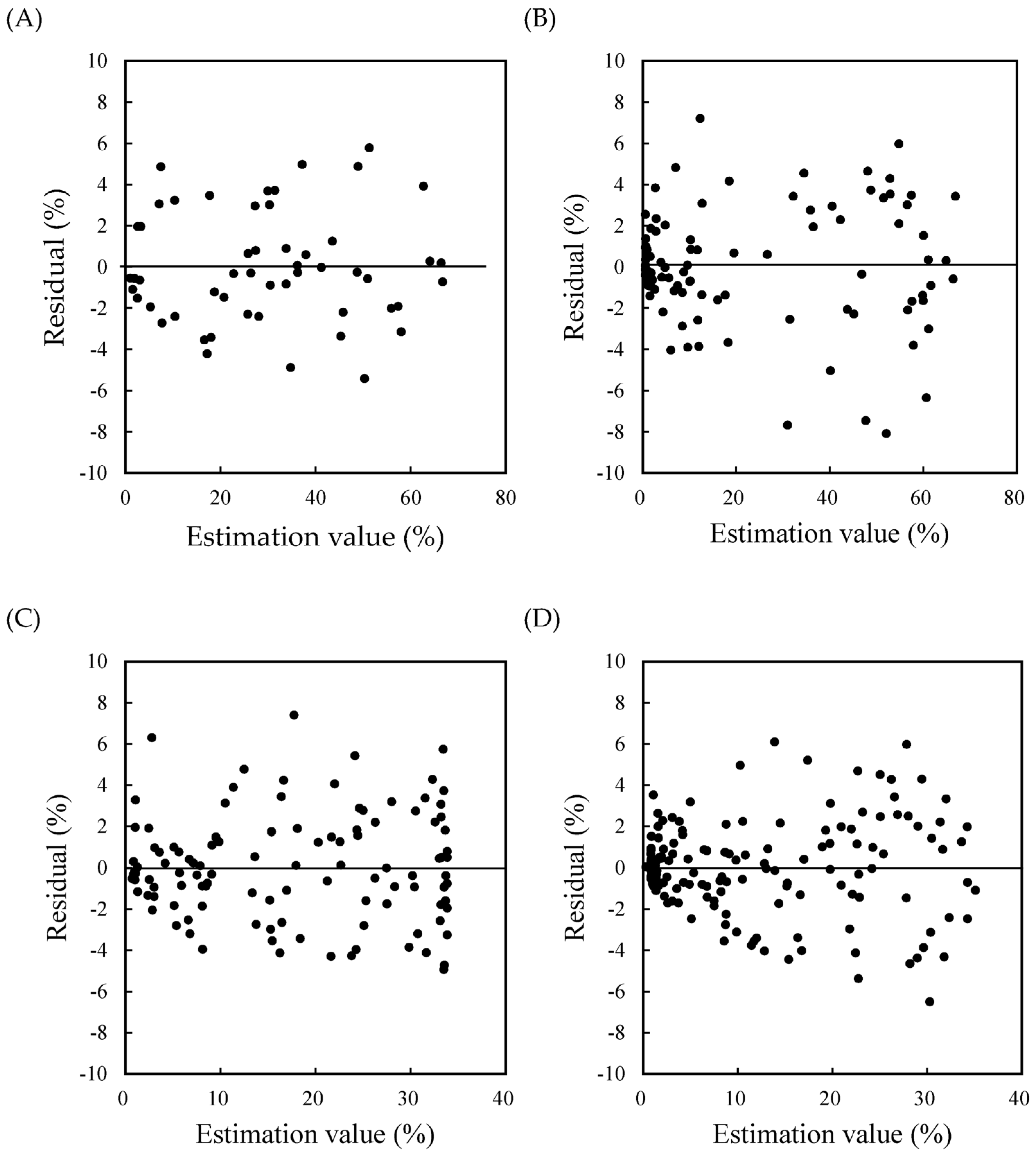
The method involved constructing models for estimating the proportion of fruit size grades using polynomial regression. To validate the reliability of the models, a series of assumptions were considered, including the requirements for linear regression analysis using the least squares method. The assumptions for linear regression analysis using the least squares method require that (a) independence, (b) normality, (c) homoscedasticity, and (d) linearity be satisfied [
22]. Of these, (a), (b), and (c) are related to the residuals. According to Aishah Ahad et al. [
23] and Ghasemi and Zahediasl [
24], the Shapiro–Wilk test [
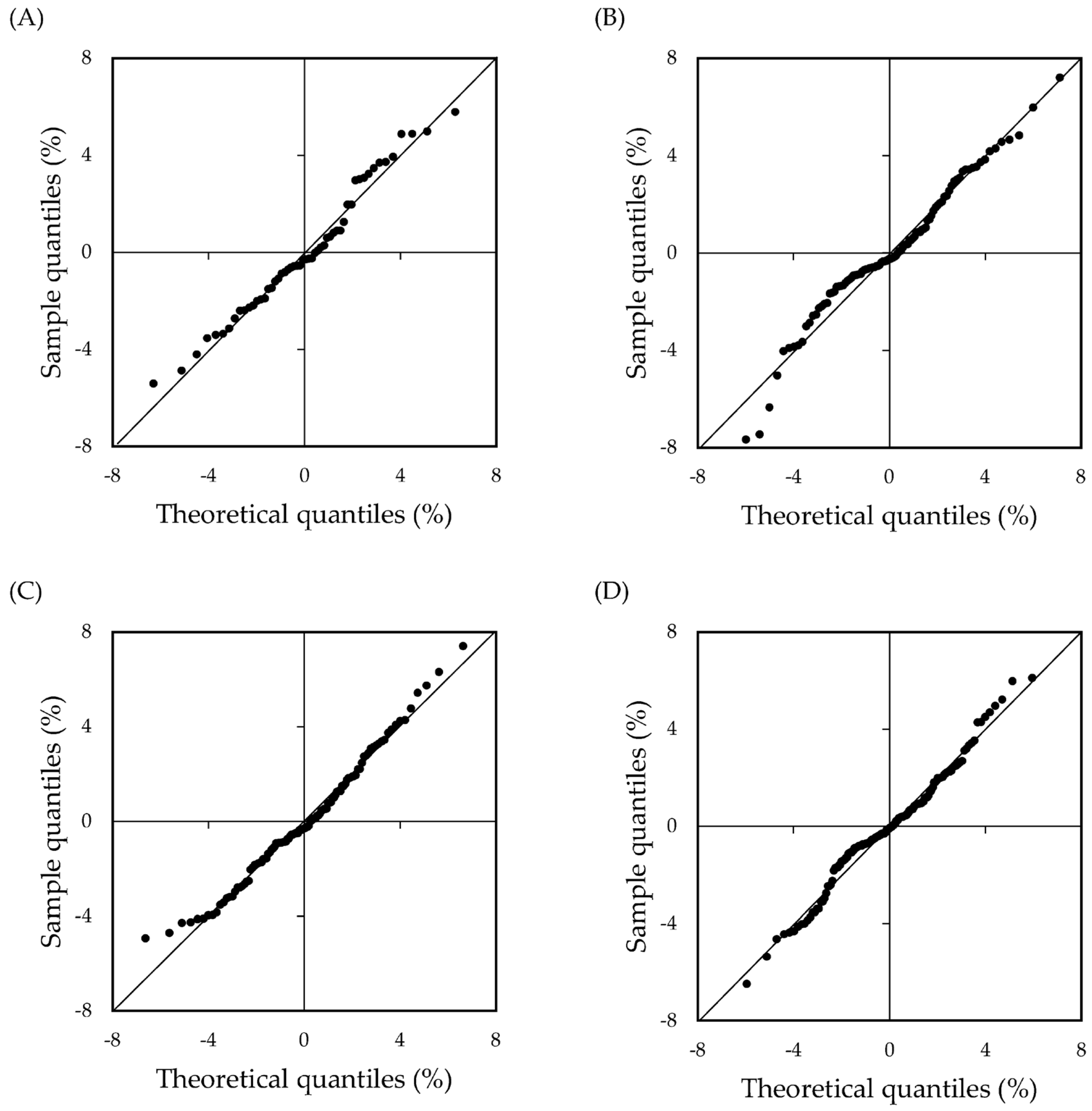
25] is a good test for verifying normality. The results of
Table 4 indicate that the two equations were rejected at the 5% significance level. However, none of the normal Q-Q plots showed significant distribution tendencies (
Figure 5). Therefore, assumption (b) was satisfied. All residual plots supported the assumptions (a) of independence and (c) of homoscedasticity, indicating that the distributions did not exhibit a constant trend (
Figure 6). Therefore, it was determined that four quartic equations with the highest
R2 and lowest AIC and that satisfied the assumptions of the regression analysis were chosen as the estimation models.
It should be noted with caution that the models did not account for variations in fruit diameter within individual trees because the proposed models aimed at the prediction in each orchard. Moreover, good estimation models need to be constructed with datasets obtained from multiple places in multiple years, whereas the estimation models were constructed with datasets obtained from one orchard in one year (Orchard 1, 2020). Zhang et al. [
11] highlighted that variations in apple fruit weight not only impact the estimates of mean fruit weight but also the estimations of the number of fruits in each size grade. Also, Marini et al. [
14] discussed that understanding the within-tree variation of fruit is vital to estimating the fruit size or fruit size distribution for a tree. Considering the strong biennial-bearing character of citrus cultivars and its potential impact on fruit size variations, further analysis was required to ensure the models’ predictability under fluctuating fruit-set conditions. The results showed no remarkable difference in estimation accuracy between constructing the estimation models on datasets with various numbers of fruit sets (
Table 5). Additionally, the empirical cumulative distribution function resembled a standard normal distribution across all the orchards (
Figure 7). According to a study by Judd and McAneney [
26], water stress was found to affect the mean fruit weight (μ) of kiwifruits but not the distribution’s shape. This suggests that the estimation models are applicable to orchards with different fruit sets. Therefore, it was decided to use the estimation model constructed on the dataset of Orchard 1 in 2020 for later validation.
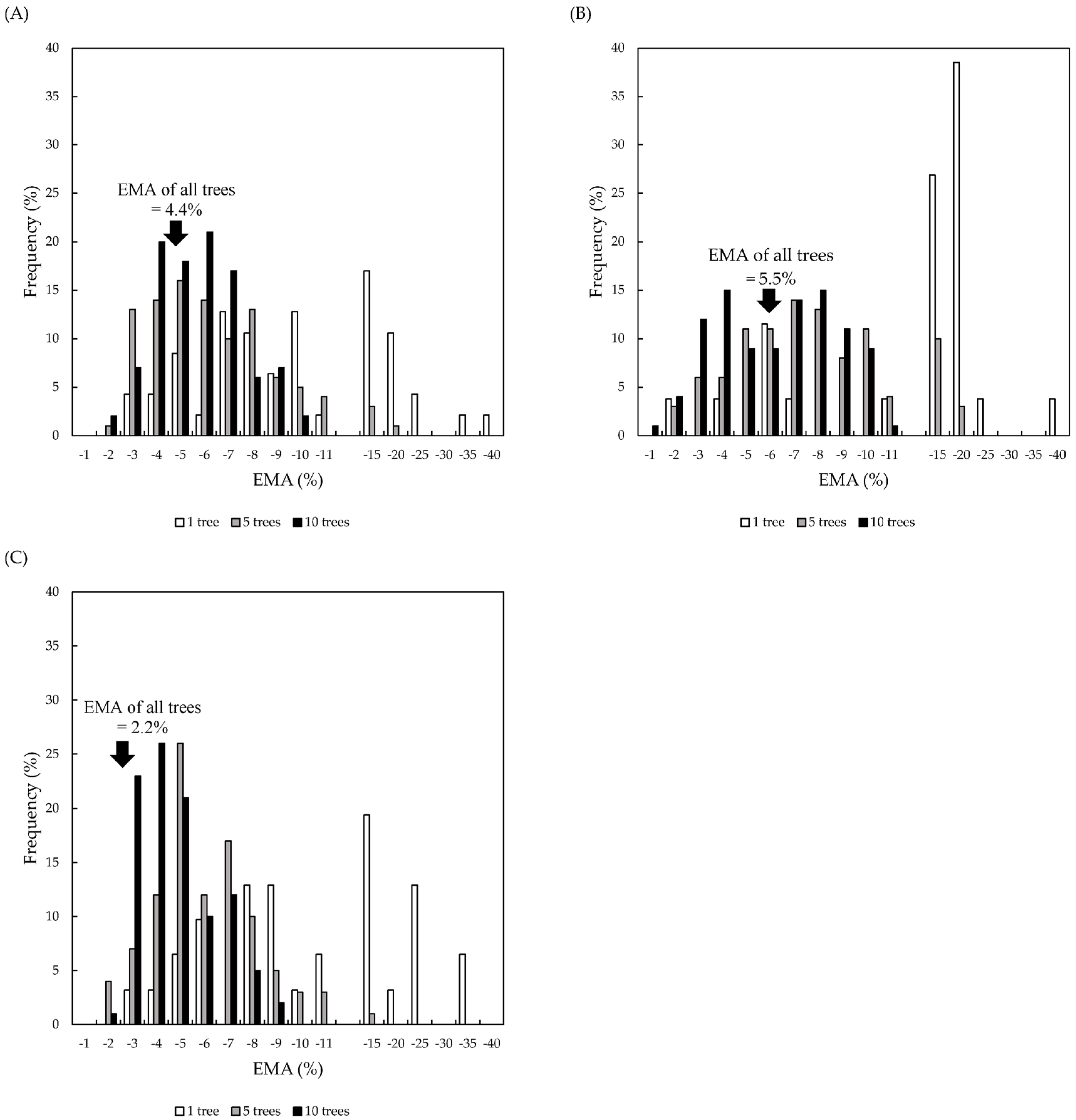
Regarding the validation of the number of trees, the result suggested increased stability in estimating the proportion of fruit size grades as the number of sampled trees increased (
Figure 8). Studies focusing on Navel oranges [
10] and apples [
15] also reported achieving high accuracy by aggregating data from more than 10 trees. This gradual convergence of estimations toward a consistent value with larger tree samples reaffirms the importance of sufficient sampling for robust and stable estimations at the orchard level. On the other hand, the selection of five or ten trees in this study was based on simple random sampling. As a method for selecting trees that are representative of the orchard, it may be possible to apply multilevel systematic sampling [
16] and ranked set sampling [
27], which estimates the total number of fruits and fruit load, for example, or random median sampling, which precisely estimates the population [
28]. In particular, multilevel systematic sampling enables accurate estimation of a number of fruits quickly. It is necessary to construct the sampling methods necessary for estimating the proportion of fruit size grade at an orchard level with reference to these sampling methods.
During the validation of models in the farmer’s orchard, distinct trends were observed across various orchards (
Table 6). Observation of orchards showed that trees in Orchards 5 and 8 had fewer leaves than the other orchards, and the trees were well exposed to light in the canopy’s interior. Verreynne et al. [
29]. reported larger fruit sizes on the top and outer area than the inside fruit fruits in three citrus cultivars, satsuma mandarin, clementine, and ‘Fairchild’ tangelo. Similarly, Suzuki et al. [
30] noted inferior fruit sizes at the bottom of satsuma mandarin trees compared to those in the middle and at the top, linked to variations in micro-meteorological conditions such as light intensity and air temperature within the tree canopy. The results in Orchards 5 and 8 may be attributed to more uniform fruit size among the fruit trees by uniform light conditions and air temperature inside and outside the canopy. For a more accurate estimation of fruit size in such trees, accounting for variations resulting from canopy differences may be necessary. In contrast, the differences in S and M size grades in Orchard 7 were higher than in other orchards (
Table 10). The fruit was smaller than the fruit in the other orchards, and there was more out-of-specification fruit than in other orchards. It was considered that the results were due to the weakening of the tree caused by wet damage. However, it is noteworthy that even in orchards such as Orchards 5, 7, and 8, the EMA was about 10%. It was suggested that the constructed estimation models may apply to various situations.
Overall, the proposed method is able to construct the prediction model of fruit yield per size grade in each orchard without additional measurement costs. The proposed construction method does not use the specific characteristics of Citrus junos, so it is applicable to other citrus orchards. For the future perspective, there is a need for refined methodologies that account for canopy variations and environmental stressors for more accurate estimations across diverse orchard conditions. Also, the method in this study will be more applicable when combined with accurate measuring techniques of the total number of fruits and true mean fruit diameter per tree.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}