
Combining UAV Multi-Source Remote Sensing Data with CPO-SVR to Estimate Seedling Emergence in Breeding Sunflowers

Abstract
1. Introduction
2. Materials and Methods
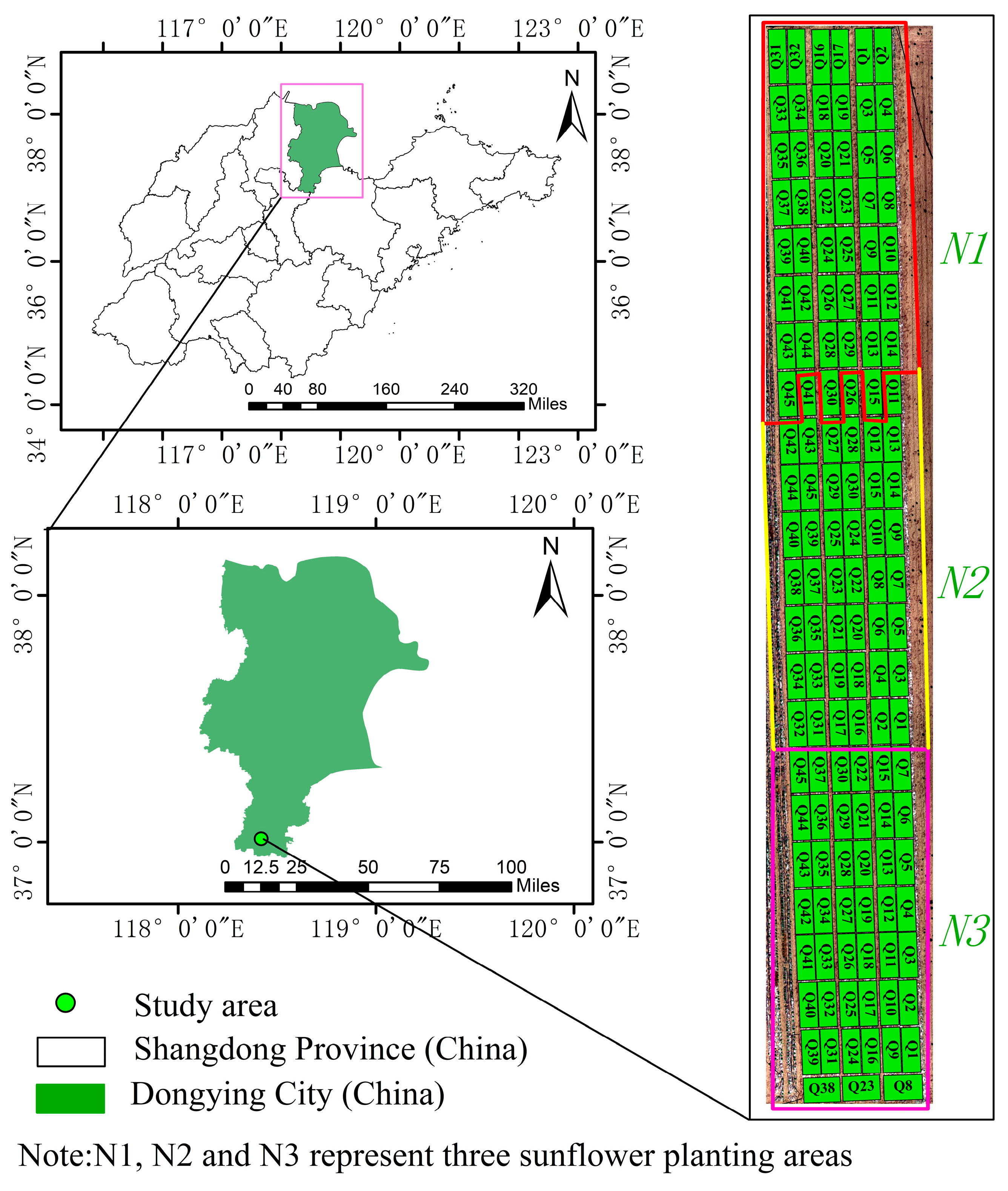
2.1. Overview of the Sunflower Breeding Research Area
2.2. Sunflower UAV Remote Sensing Image Data Acquisition
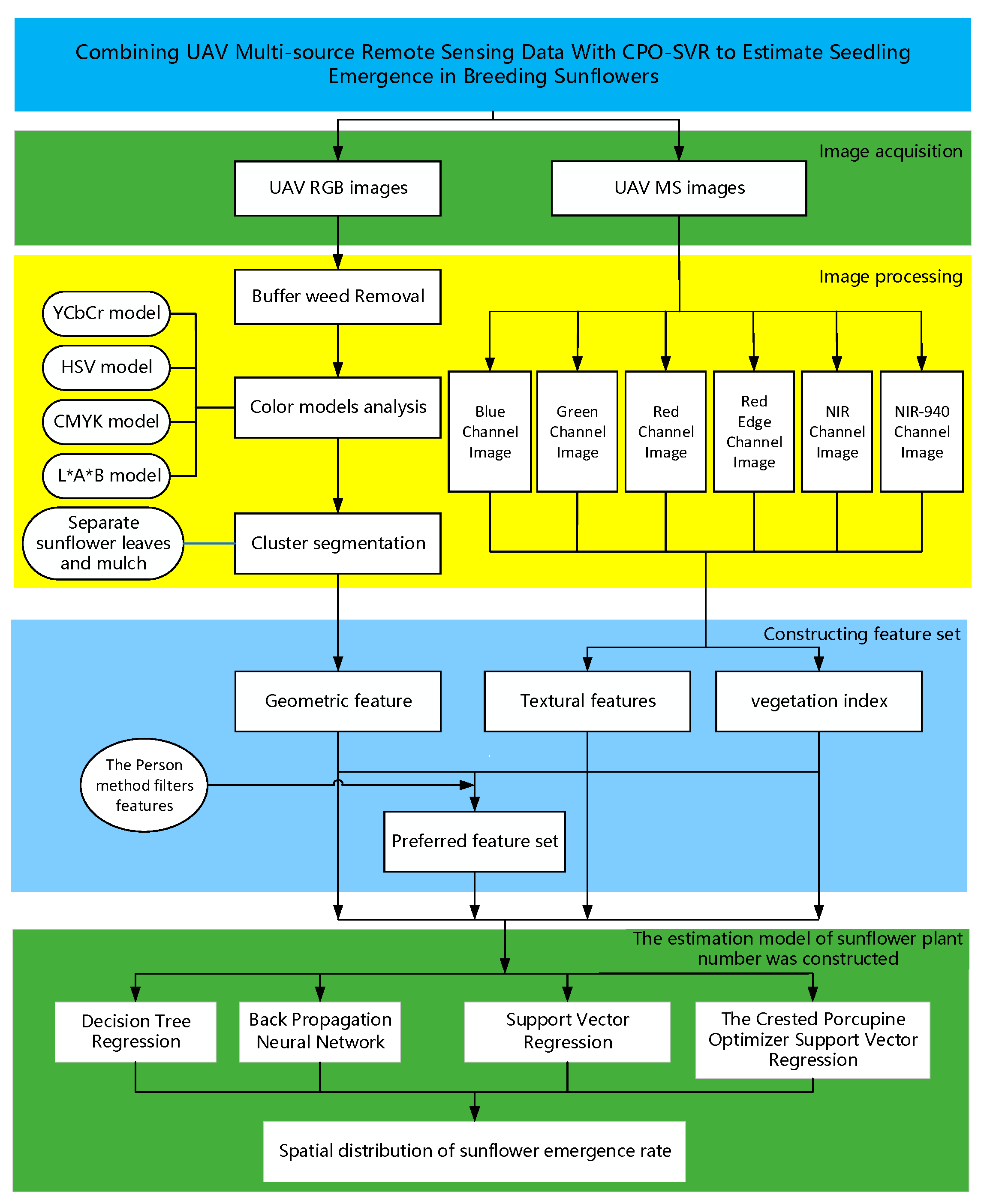
2.3. Research Program
2.4. Sunflower Visible Image Preprocessing
2.4.1. Weeds Removal
2.4.2. Choice of Color Model and Segmentation Algorithm
2.5. Sunflower Feature Extraction
2.5.1. Sunflower Geometric Feature Extraction
2.5.2. Sunflower Vegetation Index Extraction
2.5.3. Sunflower Texture Feature Extraction
2.6. Pearson’s Correlation Analysis
2.7. Construction of a Model for Estimating the Number of Sunflower Plants
- Decision tree regression (DTR) is a recursive process in which the algorithm begins at the root node and selects the optimal feature to split the dataset into two subsets. This selection is typically based on some partitioning criterion, such as minimizing the squared error, such that the squared error of the partitioned subset is minimized. The process is repeated recursively on each subset until the stopping condition is met. The decision tree regression algorithm was implemented using the Scikit-learn (Version 1.3.0) package in Python and executed in Visual Studio Code software (Version 1.82, Microsoft, Redmond, WA, USA). The parameters of the algorithm were set as follows: max_depth is 3.
- The back propagation neural network (BPNN) is an artificial neural network model based on the backpropagation algorithm, adapting to different data distributions and features, with strong adaptive ability, used to solve regression problems. BPNN consists of input, hidden, and output layers; it learns complex relationships between input data and predicts output values through connections between neurons across multiple layers. It optimizes the model fit by continuously adjusting connection weights and using gradient descent to minimize the prediction error. The BP Neural Network Regression algorithm was implemented using the TensorFlow (Version 2.16.1) library in Python and executed in Visual Studio Code (Version 1.82, Microsoft, Redmond, WA, USA). The parameters of the algorithm were set as follows: activation is relu, the loss is mean_squared_error, the optimizer is adam, epochs is 300, and the batch_size is 10.
- The support vector regression (SVR) can handle nonlinear relationships through the kernel function, mapping the original linearly indivisible data into the high-dimensional space, realizing the linear separability, and making the model more flexible. It is applicable to various types of data so that the effect of the data processing in high-dimensional space is significant. SVM’s objective function is a convex function; there are no local minima, which makes the training process more reliable. This ensures the stability of model training and convergence, providing a reliable foundation for practical applications. The SVM algorithm was implemented using the Scikit-learn (Version 1.3.0) package in Python and executed in Visual Studio Code (Version 1.82, Microsoft, Redmond, WA, USA). The parameters of the algorithm were set as follows: kernel is rbf, C parameter is 15.0, and gamma is 0.5.
- The crested porcupine optimizer support vector regression (CPO-SVR) algorithm efficiently searches the hyperparameter space, including the kernel function and regularization parameters. The global search capability makes finding the optimal hyperparameters in support vector regression faster and more reliable. In SVR models, there are often complex nonlinear relationships, and the CPO algorithm helps the model fit the data better, capture the complex relationships between features, and improve the predictive performance of the model [34]. The CPO-SVR algorithm was implemented using the Scikit-learn (Version 1.3.0) package in Python and executed in Visual Studio Code (Version 1.82, Microsoft, Redmond, WA, USA). The parameters of the algorithm were set as follows: pop_size is 10, dim is 2, and the kernel is rbf.
2.8. Evaluation of the Estimation Accuracy of Sunflower Plant Number Models
3. Results
3.1. Segmentation of Sunflower Seedlings and Mulch Film
3.2. Sunflower Characterization Screening
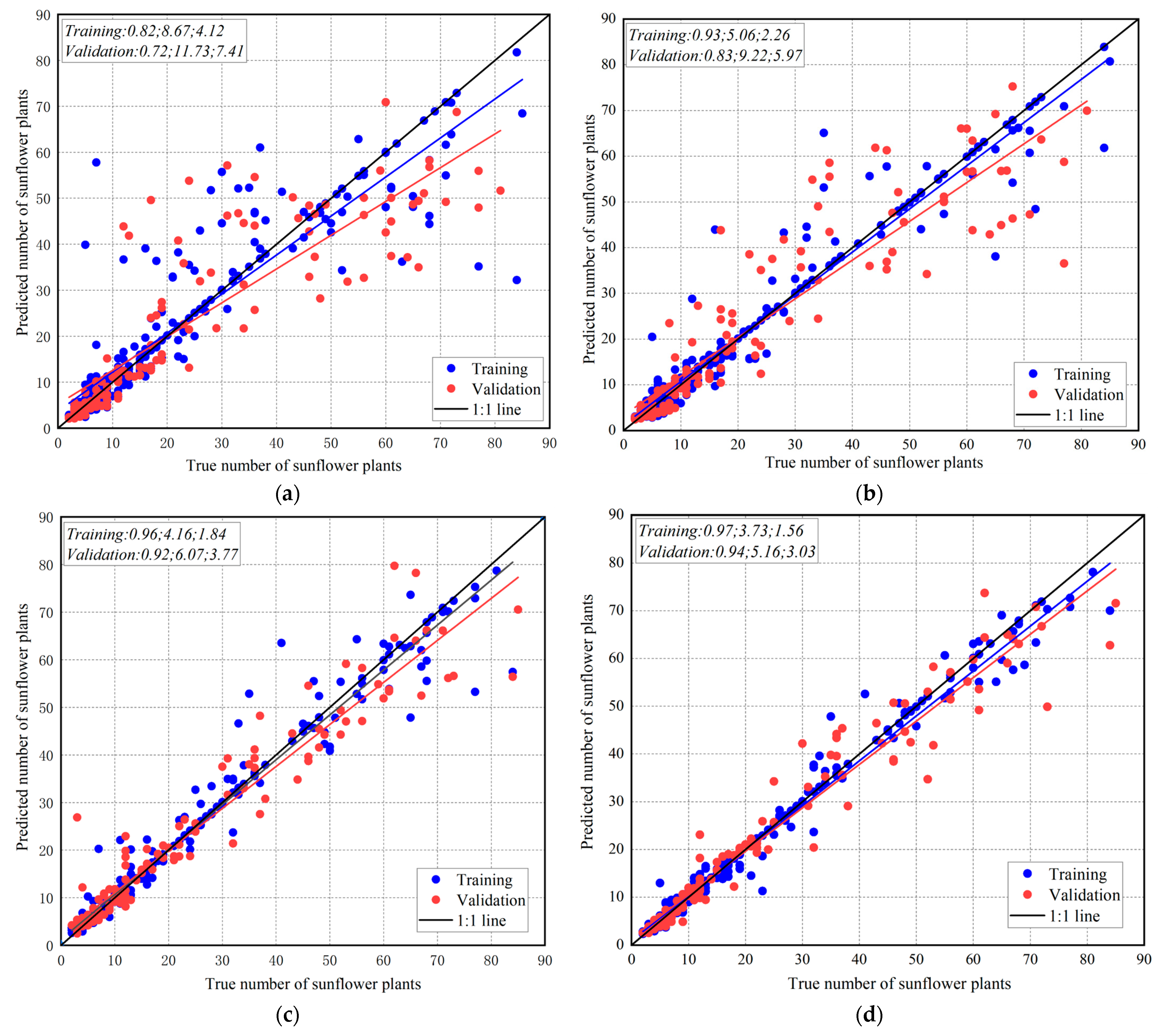
3.3. Analysis of the Results of the Model for Estimating the Number of Sunflower Plants
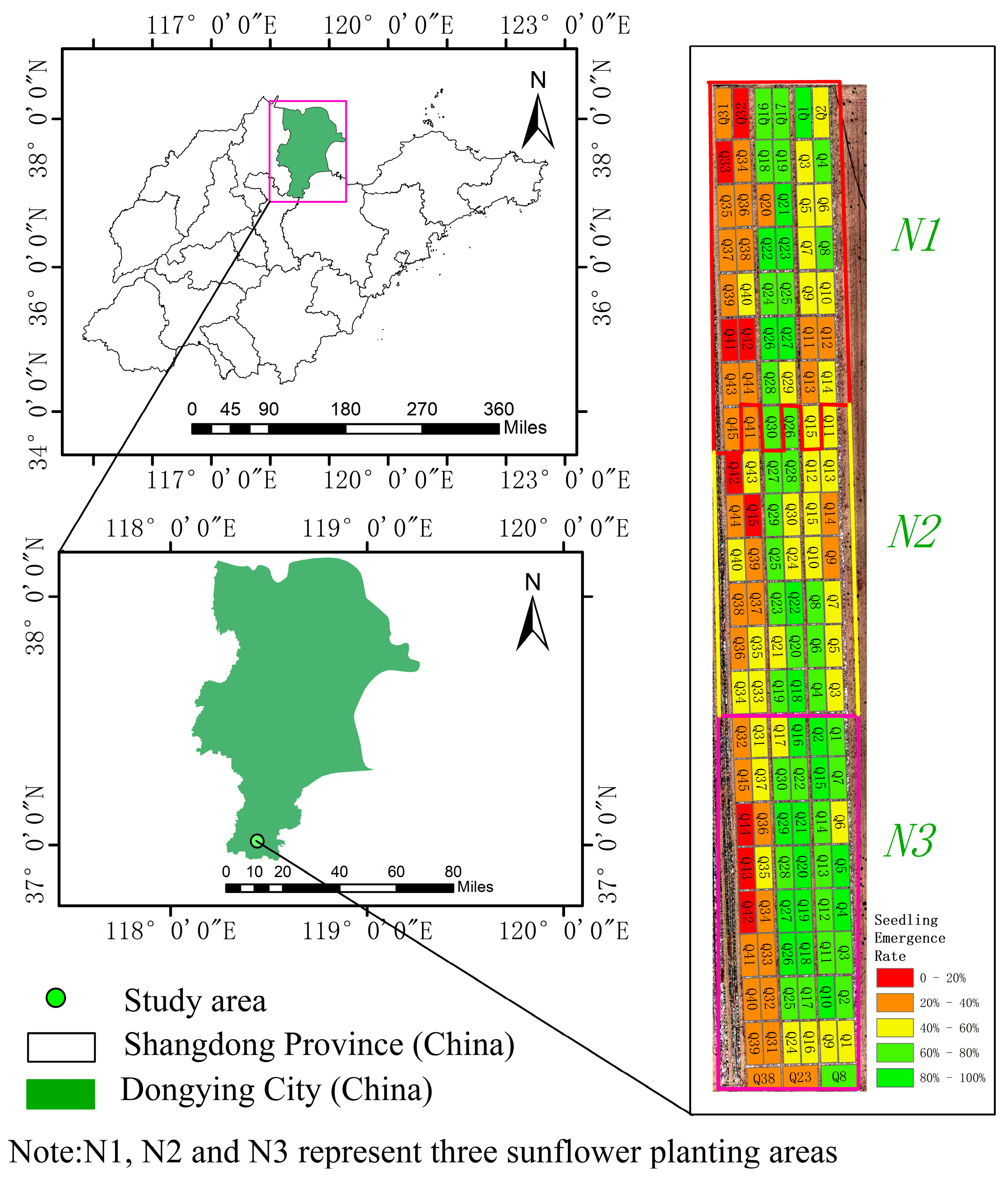
3.4. Analysis of Seedling Emergence of Sunflower Varieties
4. Discussion
5. Conclusions
- (1)
- By using the threshold method to process the EXG image to obtain the center point of sunflower seedlings to build a graphic buffer, masking UAV visible images can effectively remove weeds relative to morphological operations; this method can avoid the removal of weak seedlings mistaken for weeds.
- (2)
- The A component of the L*A*B model has the best recognition capability for sunflowers, and the segmentation accuracy of the A component image for segmenting mulch and seedlings using the genetic algorithm optimized K-means clustering improved by 4.6% compared to the segmentation accuracy of K-means clustering, which indicates that this method improves the segmentation accuracy of seedlings and mulch.
- (3)
- In the CPO-SVR model, the model using the preferred feature set as input variables achieved the highest accuracy, with an R2 of 0.94, an RMSE of 5.16, and an MAE of 3.03. Compared to the SVR model, the R2 value increased by 3.3%, the RMSE was reduced by 18.3%, and the MAE was reduced by 18.1%. Using this model, the highest seedling emergence rate of 100% was calculated for the N3-Q27 plot, and the lowest for the N3-Q42 plot was 5.8%, indicating that this model can provide technical support for sunflower breeders in screening varieties.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Han, D.; Yao, Y.-T.; Chen, C.; Wang, F.; Peng, H.; Hou, M.-M.; Zhong, F.-L.; Jin, Q. Evaluation on the Synergistic Effect of Sunflower and Subsurface Drainage on Reducing Salinity in Coastal Saline Alkali Land. Water Sav. Irrig. 2023, 7, 90–95. [Google Scholar]
- Cvejic, S.; Radanovic, A.; Dedic, B.; Jockovic, M.; Jocic, S.; Miladinovic, D. Genetic and Genomic Tools in Sunflower Breeding for Broomrape Resistance. Genes 2020, 11, 152. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Li, R.; Ma, X.; Li, M.; Liu, Y.; Lu, Y.; Ma, F. Estimation of the quantity of drip-irrigated cotton seedling bas ed on color and morphological features of UAV captured RGB images. Cotton Sci. 2022, 34, 508–522. [Google Scholar]
- Lin, Y.D.; Chen, T.T.; Liu, S.Y.; Cai, Y.L.; Shi, H.W.; Zheng, D.K.; Lan, Y.B.; Yue, X.J.; Zhang, L. Quick and accurate monitoring peanut seedlings emergence rate through UAV video and deep learning. Comput. Electron. Agric. 2022, 197, 11. [Google Scholar] [CrossRef]
- Dai, J.; Xue, J.; Zhao, Q.; Wang, Q.; Chen, B.; Zhang, G.; Jiang, N. Extraction of cotton seedling growth information using UAV visible light remote sensing images. Trans. Chin. Soc. Agric. Eng. 2020, 36, 63–71. [Google Scholar]
- Ranđelović, P.; Đorđević, V.; Milić, S.; Balešević-Tubić, S.; Petrović, K.; Miladinović, J.; Đukić, V. Prediction of Soybean Plant Density Using a Machine Learning Model and Vegetation Indices Extracted from RGB Images Taken with a UAV. Agronomy 2020, 10, 1108. [Google Scholar] [CrossRef]
- Yang, S.; Lin, F.; Xu, P.; Wang, P.; Wang, S.; Ning, J. Planting Row Detection of Multi-growth Winter Wheat Field Based on UAV Remote Sensing Image. Trans. Chin. Soc. Agric. Mach. 2023, 54, 181–188. [Google Scholar]
- Li, J.; Wei, J.; Kang, Y.; Xu, X.; Qi, L.; Shi, W. Research on soybean seedling number estimation based on UAV remote sensing technology. J. Chin. Agric. Mech. 2022, 43, 83–89. [Google Scholar]
- Zhu, S.; Deng, J.; Zhang, Y.; Yang, C.; Yan, Z.; Xie, Y. Study on distribution map of weeds in rice field based on UAV remote sensing. J. South China Agric. Univ. 2020, 41, 67–74. [Google Scholar]
- Ning, J.; Ni, J.; He, Y.; Li, L.; Zhao, Z.; Zhang, Z. Convolutional Attention Based Plastic Mulching Farmland Identification via UAV Multispectral Remote Sensing Image. Trans. Chin. Soc. Agric. Mach. 2021, 52, 213–220. [Google Scholar]
- Liang, C.; Wu, X.; Wang, F.; Song, Z.; Zhang, F. Research on recognition algorithm of field mulch film based on unmanned aerial vehicle. Acta Agric. Zhejiangensis 2019, 31, 1005–1011. [Google Scholar]
- Garcia, H.; Flores, H.; Khalil-Gardezi, A.; Roberto, A.; Chavez, L.; Peña, V.M.; Mancilla, O. Digital Count of Corn Plants Using Images Taken by Unmanned Aerial Vehicles and Cross Correlation of Templates. Agronomy 2020, 10, 469. [Google Scholar] [CrossRef]
- Machefer, M.; Lemarchand, F.; Bonnefond, V.; Hitchins, A.; Sidiropoulos, P. Mask R-CNN Refitting Strategy for Plant Counting and Sizing in UAV Imagery. Remote Sens. 2020, 12, 3015. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, X.; Cheng, J.; Ren, X. Using the multispectral image data acquired by unmanned aerial vehicle to build an estimation model of the number of seedling stage cotton plants. J. Image Graph. 2020, 25, 520–534. [Google Scholar]
- Zhang, H.; Fu, Z.; Han, W.; Yang, G.; Niu, D.; Zhou, X. Detection Method of Maize Seedlings Number Based on Improved YOLO. Trans. Chin. Soc. Agric. Mach. 2021, 52, 221–229. [Google Scholar]
- Liu, S.; Yin, D.; Feng, H.; Li, Z.; Xu, X.; Shi, L.; Jin, X. Estimating maize seedling number with UAV RGB images and advanced image processing methods. Precis. Agric. 2022, 23, 1604–1632. [Google Scholar] [CrossRef]
- Oh, S.; Chang, A.J.; Ashapure, A.; Jung, J.H.; Dube, N.; Maeda, M.; Gonzalez, D.; Landivar, J. Plant Counting of Cotton from UAS Imagery Using Deep Learning-Based Object Detection Framework. Remote Sens. 2020, 12, 2981. [Google Scholar] [CrossRef]
- Zhao, X.; Huang, Y.; Wang, Y.; Chu, D. Estimation of maize seedling number based on UAV multispectral data. Remote Sens. Nat. Resour. 2022, 34, 106–114. [Google Scholar]
- Niu, Y.; Zhang, L.; Han, W. Extraction Methods of Cotton Coverage Based on Lab Color Space. Trans. Chin. Soc. Agric. Mach. 2018, 49, 240–249. [Google Scholar]
- Zhang, X.; Zhou, X.; Zhao, R.; Chen, Y.; Zhou, P. Comparative study of crop row extraction methods based on three different color Spaces. Jiangsu Agric. Sci. 2023, 51, 211–219. [Google Scholar]
- Mao, Z.; Liu, Y. Corn tassel image segmentation based on color features. Transducer Microsyst. Technol. 2017, 36, 131–137. [Google Scholar]
- Xu, L.; Liu, D.; Zhao, Y.; Wang, L.; Xiao, J.; Qi, H.; Zhang, Y. Leaf color of autumn foliage plants based on color patterns. Jiangsu Agric. Sci. 2018, 46, 142–145. [Google Scholar]
- Li, K.; Zhang, J.; Feng, Q.; Kong, F.; Han, S.; Jianzai, W. Image segmentation method for cotton leaf undercomplex background and weather conditions. J. China Agric. Univ. 2018, 23, 88–98. [Google Scholar]
- Lee, G.; Hwang, J.; Cho, S. A Novel Index to Detect Vegetation in Urban Areas Using UAV-Based Multispectral Images. Appl. Sci. 2021, 11, 3472. [Google Scholar] [CrossRef]
- Pan, F.; Li, W.; Lan, Y.; Liu, X.; Miao, J.; Xiao, X.; Xu, H.; Lu, L.; Zhao, J. SPAD inversion of summer maize combined with multi-source remote sensing data. Int. J. Precis. Agric. Aviat. 2018, 1, 45–52. [Google Scholar] [CrossRef]
- Zheng, H.B.; Ma, J.F.; Zhou, M.; Li, D.; Yao, X.; Cao, W.X.; Zhu, Y.; Cheng, T. Enhancing the Nitrogen Signals of Rice Canopies across Critical Growth Stages through the Integration of Textural and Spectral Information from Unmanned Aerial Vehicle (UAV) Multispectral Imagery. Remote Sens. 2020, 12, 957. [Google Scholar] [CrossRef]
- Benedetti, Y.; Callaghan, C.T.; Ulbrichová, I.; Galanaki, A.; Kominos, T.; Abou Zeid, F.; Ibáñez-Alamo, J.D.; Suhonen, J.; Díaz, M.; Markó, G.; et al. EVI and NDVI as proxies for multifaceted avian diversity in urban areas. Ecol. Appl. 2023, 33, 17. [Google Scholar] [CrossRef]
- Zhou, J.; Yungbluth, D.; Vong, C.N.; Scaboo, A.; Zhou, J. Estimation of the Maturity Date of Soybean Breeding Lines Using UAV-Based Multispectral Imagery. Remote Sens. 2019, 11, 2075. [Google Scholar] [CrossRef]
- Kang, Y.; Nam, J.; Kim, Y.; Lee, S.; Seong, D.; Jang, S.; Ryu, C. Assessment of Regression Models for Predicting Rice Yield and Protein Content Using Unmanned Aerial Vehicle-Based Multispectral Imagery. Remote Sens. 2021, 13, 1508. [Google Scholar] [CrossRef]
- Liu, L.; Peng, Z.; Zhang, B.; Han, Y.; Wei, Z.; Han, N. Monitoring of Summer Corn Canopy SPAD Values Based on Hyperspectrum. J. Soil Water Conserv. 2019, 33, 353–360. [Google Scholar]
- Tahir, M.; Naqvi, S.; Lan, Y.; Zhang, Y.; Wang, Y.; Afzal, M.; Cheema, M.; Amir, S. Real time estimation of chlorophyll content based on vegetation indices derived from multispectral UAV in the kinnow orchard. Int. J. Precis. Agric. Aviat. 2018, 1, 24–31. [Google Scholar]
- Zhu, W.; Li, S.; Zhang, X.; Li, Y.; Sun, Z. Estimation of winter wheat yield using optimal vegetation indices from unmanned aerial vehicle remote sensing. Trans. Chin. Soc. Agric. Eng. 2018, 34, 78–86. [Google Scholar]
- Yan, H.; Zhuo, Y.; Li, M.; Wang, Y.; Guo, H.; Wang, J.; Li, C.; Ding, F. Alfalfa yield prediction using machine learning and UAV multispectral remote sensing. Trans. Chin. Soc. Agric. Eng. 2022, 38, 64–71. [Google Scholar]
- Mohamed, A.-B.; Reda, M.; Mohamed, A. Crested Porcupine Optimizer: A new nature-inspired metaheuristic. Knowl.-Based Syst. 2024, 284, 111257. [Google Scholar]
- Xu, X.; Li, H.; Feng, Y.; Ma, X.; Shen, S.; Qiao, X. Wheat Seedling Identification Based on K-means and Harris Corner Detection. J. Henan Agric. Sci. 2020, 49, 164–171. [Google Scholar]
- Zhang, X.; Xia, Y.; Xia, N.; Zhao, Y. Cotton image segmentation based on K-means clustering and marker watershed. Transducer Microsyst. Technol. 2020, 39, 147–149. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Segmentation Method | Advantage | Shortcoming |
|---|---|---|
| Expansion, corrosion | Suitable for objects with distinctive morphological features, improving segmentation quality by removing noise and small targets | Poor segmentation on complex backgrounds, difficult to handle overlapping or dense areas. |
| Color features | Segmentation of objects by analyzing color features (e.g., HSV, lab space), simple calculation, good real-time performance | Sensitive to light conditions and difficult to segment accurately when color features are similar. |
| The threshold method | Algorithms are simple and easy to implement | Sensitive to light changes and noise, threshold selection needs to be manually adjusted. |
| Support vector machine-supervised classification | Good classification of multidimensional features | Requires large amounts of labeled data, complex feature selection, and engineering. |
| Deep learning segmentation | High-precision segmentation of complex scenes | Complex network structure requires a large amount of training data and high computational power, high training cost. |
| Geometric Feature | Symbolic | Geometric Feature | Symbolic |
|---|---|---|---|
| Area | a1 | External Circle Perimeter | a6 |
| Perimeter | a2 | The ratio of the area of an external rectangle to its area | a7 |
| External Rectangle Area | a3 | The ratio of the perimeter of a rectangle to the perimeter of an externally connected circle | a8 |
| External Rectangle Perimeter | a4 | External circle area-to-area ratio | a9 |
| External Circle Area | a5 | The ratio of perimeter to circumference of an external circle | a10 |
| Vegetation Index | Definition | References |
|---|---|---|
| Blue Normalized Difference Vegetation Index | [24] | |
| Green Normalized Difference Vegetation Index | [25] | |
| Normalized Difference Red Edge Index | [26] | |
| Enhanced Vegetation Index | [27] | |
| Red-Blue Normalized Difference Vegetation Index | [28] | |
| Red-Green Normalized Difference Vegetation Index | [29] | |
| Optimization of Soil-Adjusted Vegetation Index | [30] | |
| Normalized Difference Vegetation Index | [31] | |
| Modified Chlorophyll Absorption Reflectance Index | [32] | |
| Structure-Independent Pigment Index | [33] |
| Geometric Feature | Correlation | Vegetation Index | Correlation | Texture Features | Correlation |
|---|---|---|---|---|---|
| a1 | 0.844 ** | BNDVI | 0.824 ** | Red-HOM | 0.815 ** |
| a2 | 0.940 ** | GRNDVI | 0.088 | Red-SEM | 0.813 ** |
| a3 | 0.854 ** | NRI | −0.752 ** | Red-COR | 0.821 ** |
| a4 | 0.942 ** | MCARI | 0.811 ** | Blue-HOM | 0.820 ** |
| a5 | 0.079 | NDVI | 0.825 ** | Blue-SEM | 0.817 ** |
| a6 | 0.932 ** | EVI | 0.811 ** | Blue-COR | 0.831 ** |
| a7 | 0.0255 | NDRE | 0.827 ** | Green-HOM | 0.817 ** |
| a8 | −0.266 ** | OSAVI | 0.819 ** | Green--SEM | 0.819 ** |
| a9 | 0.006 | GNDVI | 0.820 ** | Redge-HOM | 0.816 ** |
| a10 | −0.271 ** | SIPI | 0.827 ** | Redge-SEM | 0.814 ** |
| Model | Feature Set | Training | Validation | ||||
|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | R2 | RMSE | MAE | ||
| DTR | Texture Feature Set (A) | 0.73 | 10.60 | 6.30 | 0.71 | 11.90 | 7.52 |
| Vegetation Index Set (B) | 0.76 | 10.33 | 6.48 | 0.72 | 11.47 | 7.05 | |
| Geometric Feature Set (C) | 0.91 | 6.43 | 4.16 | 0.84 | 7.93 | 4.93 | |
| Preferred Feature Set (D) | 0.92 | 5.97 | 3.92 | 0.88 | 7.60 | 4.97 | |
| BPNN | Texture Feature Set (A) | 0.67 | 11.70 | 7.69 | 0.66 | 13.03 | 8.19 |
| Vegetation Index Set (B) | 0.70 | 11.13 | 6.95 | 0.70 | 12.27 | 7.12 | |
| Geometric Feature Set (C) | 0.89 | 6.84 | 4.52 | 0.89 | 7.38 | 4.55 | |
| Preferred Feature Set (D) | 0.89 | 6.66 | 4.29 | 0.89 | 7.36 | 4.45 | |
| SVR | Texture Feature Set (A) | 0.71 | 11.51 | 6.95 | 0.70 | 11.33 | 6.97 |
| Vegetation Index Set (B) | 0.74 | 10.09 | 5.81 | 0.73 | 12.09 | 7.55 | |
| Geometric Feature Set (C) | 0.93 | 5.43 | 3.27 | 0.90 | 6.11 | 3.69 | |
| Preferred Feature Set (D) | 0.93 | 5.41 | 3.24 | 0.91 | 6.32 | 3.70 | |
| CPO-SVR | Texture Feature Set (A) | 0.82 | 8.67 | 4.12 | 0.72 | 11.73 | 7.41 |
| Vegetation Index Set (B) | 0.93 | 5.06 | 2.26 | 0.83 | 9.22 | 5.97 | |
| Geometric Feature Set (C) | 0.96 | 4.16 | 1.84 | 0.92 | 6.07 | 3.77 | |
| Preferred Feature Set (D) | 0.97 | 3.73 | 1.56 | 0.94 | 5.16 | 3.03 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Yu, H.; Tian, B.; Wang, X.; Cui, W.; Yang, L.; Li, J.; Gong, H.; Zhao, J.; Lu, L.; et al. Combining UAV Multi-Source Remote Sensing Data with CPO-SVR to Estimate Seedling Emergence in Breeding Sunflowers. Agronomy 2024, 14, 2205. https://doi.org/10.3390/agronomy14102205
Zhang S, Yu H, Tian B, Wang X, Cui W, Yang L, Li J, Gong H, Zhao J, Lu L, et al. Combining UAV Multi-Source Remote Sensing Data with CPO-SVR to Estimate Seedling Emergence in Breeding Sunflowers. Agronomy. 2024; 14(10):2205. https://doi.org/10.3390/agronomy14102205
Chicago/Turabian StyleZhang, Shuailing, Hailin Yu, Bingquan Tian, Xiaoli Wang, Wenhao Cui, Lei Yang, Jingqian Li, Huihui Gong, Junsheng Zhao, Liqun Lu, and et al. 2024. "Combining UAV Multi-Source Remote Sensing Data with CPO-SVR to Estimate Seedling Emergence in Breeding Sunflowers" Agronomy 14, no. 10: 2205. https://doi.org/10.3390/agronomy14102205
APA StyleZhang, S., Yu, H., Tian, B., Wang, X., Cui, W., Yang, L., Li, J., Gong, H., Zhao, J., Lu, L., Zhao, J., & Lan, Y. (2024). Combining UAV Multi-Source Remote Sensing Data with CPO-SVR to Estimate Seedling Emergence in Breeding Sunflowers. Agronomy, 14(10), 2205. https://doi.org/10.3390/agronomy14102205