Abstract
This study conducted an analysis of zero-shot detection capabilities using two frameworks, YOLO-World and Grounding DINO, on a selection of images in the wild blueberry (Vaccinium angustifolium Ait.) cropping system. The datasets included ripe wild blueberries, hair fescue (Festuca filiformis Pourr.), blueberry buds, and red leaf disease (Exobasidium vaccinii). Key performance metrics such as Intersection over Union (IoU), precision, recall, and F1 score were utilized for model comparison. Grounding DINO consistently achieved superior performance across all metrics and datasets, achieving significantly higher mean IoUs on berries, red leaf, hair fescue, and buds (0.642, 0.921, 0.735, and 0.629, respectively) compared to YOLO-World (0.516, 0.567, 0.232, and 0.408, respectively). Evidenced by their high recall rates relative to precision, the models displayed a preference for identifying true positives at the cost of increasing false positives. Grounding DINO’s higher precision (overall mean of 0.672), despite the tendency to over-detect, indicated a better balance in minimizing false positives than YOLO-World (overall mean of 0.501). These findings contrast with the foundational study of YOLO-World where it demonstrated superior performance on standard datasets, highlighting the importance of dataset characteristics and optimization processes in model performance. The practical implications of this study include providing a solution for accelerated object detection image annotation in the wild blueberry cropping system. This work, representing a significant advancement in facilitating accurate and efficient annotation of wild blueberry datasets, guides future research in the application of zero-shot detection models to agricultural datasets.
1. Introduction
Image annotation is used in various agricultural techniques, including creating prescription maps, identifying plant species and diseases, and analyzing growth stages [1,2]. With advancements in machine learning, the importance of expedient data annotation has increased. Training robust machine learning models can require thousands of images, making precise annotation crucial, as it can take multiple seconds or even minutes per image [3,4]. In wild blueberry cultivation, image annotation is essential for ripe berry detection, monitoring growth stages, disease infection detection, and weed identification.
Identifying fruit in wild blueberry fields serves various purposes, including yield estimation, analyzing berry quality, and determining ripeness, where [5] found a direct correlation between yield and observed ripeness instances based on different stages of wild blueberry growth correlated to total harvest mass of 1 × 1 m plots. Accurate identification and analysis provides producers with crucial information for informed crop management decisions [6]. Proper analysis of fruit quality and ripeness requires experienced personnel with training in the area. Throughout the growing process, different agrochemicals are applied at various growth stages [7,8]. For example, pre-emergent or post-emergent herbicides for weed management [7] and fungicides for disease prevention [8]. Identifying the bud stage is crucial for optimal application of agrochemicals, ensuring maximum yield. However, this can be challenging for inexperienced personnel. Wild blueberries are susceptible to many diseases that substantially impact fruit yield and quality [8,9]. These diseases can be caused by environmental conditions or spread from nearby plants [8,9]. Identifying diseases is crucial for prevention in future cropping cycles. [8] found that foliar diseases harm the photosynthetic efficiency of the wild blueberry plant and result in reductions in bud numbers and, proportionally, yield. While many diseases have common, easily identifiable characteristics, some require experienced personnel to identify [4]. For example, red leaf (Exobasidium vaccinii) is a common foliar disease in wild blueberry fields [9,10], identifiable by red or brown leaf discoloration [9,10], and severely reduces yield [9].
Accurate weed identification allows producers to plan and apply a treatment that is more beneficial both environmentally and economically than traditional methods. Hair fescue (Festuca filiformis Pourr.), in particular, is present in 75% of wild blueberry fields in Nova Scotia as of 2019 [11], reducing crop yield in the affected area [12]. Traditional agrochemical application uses broadcast spraying, but the ability to identify the specific hair fescue locations allows for spot spraying, offering environmental and economic benefits [13]. These challenges highlight the need for precise identification and treatment of diseases and weeds in wild blueberry fields.
In modern machine learning applications within agriculture, particularly in image processing and precision agriculture, annotation presents substantial challenges. The primary issue is the labor-intensive and time-consuming nature of manual annotation, requiring domain-specific expertise to accurately label data such as crop types, disease symptoms, or pest infestations [14,15]. Disease symptoms can be visually similar across diseases; similarly, pests such as insects can be difficult to identify for untrained personnel [14,15]. Precision agriculture relies on detailed and accurate data for informed crop management decisions, necessitating high-resolution and diverse annotated datasets to capture subtle variations in plant health, weed presence, and growth stages [1,5,16]. The variability in agricultural data requires large and diverse annotated datasets for model generalizability. Additionally, the dynamic nature of agricultural environments demands continuous updating and re-annotation of datasets to maintain model relevance and accuracy [17].
Automated annotation techniques, while promising, still struggle with achieving the required precision and context-awareness, often resulting in suboptimal performance [18]. Machine learning models used in precision agriculture for tasks such as weed detection, yield prediction, and disease diagnosis require precise and contextually accurate annotations to function effectively [5,16,19]. This is primarily due to the large, varying nature of the agricultural environment, weather conditions, and camera resolution. Similarly, the variability in crop appearance, occlusions, varying lighting conditions, and other environmental factors further complicate the annotation process [20]. Addressing these issues is crucial for advancing machine learning in image processing and precision agriculture, ultimately contributing to increased agricultural productivity and sustainability.
Deep learning frameworks like “You Only Look Once” (YOLO) have been used with semi-supervised training approaches to expedite the training process. This involves preliminary training on a smaller dataset to achieve a baseline model with below optimal performance and deploying the model on a larger dataset to automatically annotate images, followed by manual re-adjustment of the outputted labels [21,22]. While this process accelerates annotation, it requires substantial time and resources to train the models and refine the labels outputted from the detection model [22].
Knowledge distillation models in machine learning use a “teacher” model to guide the training of a “student” model, transferring knowledge from a large, complex model to a smaller, more efficient one without requiring additional labeled data [23]. The DINO (DIstillation with NO labels) framework, developed by [24], capitalized on the power of knowledge distillation to facilitate the learning of robust visual features without reliance on labeled data. DINO uses Vision Transformers (ViTs) as the architecture for both student and teacher models [24]. ViTs leverage self-attention mechanisms to handle complex image data [25,26,27]. In DINO, the teacher model remains static during training, while the student model learns from pseudo-labels generated by the teacher. Empirical results demonstrated DINO’s efficacy in transferring learned representations to various downstream tasks [28,29]. These representations, when benchmarked on tasks like image classification, object detection, and segmentation, have outperformed supervised and other self-supervised learning frameworks [28,30]. DINO’s ability to learn without labels reduces the dependency on large, labeled datasets, offering powerful visual recognition systems.
Grounding DINO is an innovative model for open-set object detection, allowing for the detection of arbitrary objects specified by human language inputs by taking a textual prompt describing the target object and using that as the class during detection [31]. It integrates DINO with grounded pre-training to generalize object detection to new, unseen categories. Open-set object detection models can detect objects based on descriptions provided at the time of inference, which include categories not seen during training. Grounding DINO is composed of three main modules: a feature enhancer, language guided query selection, and a cross-modality decoder [31]. The feature enhancer module improves image and text features using self-attention, text-to-image cross-attention, and image-to-text cross-attention, ensuring accurate representation of the input data [31,32]. The language-guided query selection mechanism selects relevant features based on input text, aligning queries with textual descriptions [31,33]. The decoder refines object detection results by combining visual and textual information through cross-attention layers [31]. Grounding DINO has demonstrated exceptional performance on multiple benchmarks, achieving a 52.5 average precision (AP) on the COCO detection zero-shot transfer benchmark without using any COCO training data, highlighting its ability to generalize to new categories [31]. It also performed well on the LVIS dataset, proving its robustness in diverse scenarios [34]. Additionally, Grounding DINO set a new state-of-the-art performance level on the ODinW zero-shot benchmark [35], with a mean AP of 26.1, demonstrating its effectiveness in real-world object detection tasks [31].
Improvements in open-vocabulary object detection extended the capabilities of traditional YOLO models to recognize objects outside predefined categories through YOLO-World [36]. This model integrated advanced vision–language pre-training techniques with the efficient and real-time performance of YOLO, creating a robust framework for detecting a vast array of objects based on descriptive texts [36]. Built on the YOLOv8 architecture, YOLO-World leveraged its speed and accuracy while introducing innovations such as the YOLO detector, text encoder, and re-parameterizable vision–language path aggregation network (RepVL-PAN) [36]. The foundation of YOLO-World is the YOLOv8 detector, which includes a Darknet backbone for image feature extraction, a path aggregation network (PAN) for creating multi-scale feature pyramids, and a detection head for bounding box regression and object classification [36,37,38]. YOLO-World uses a text encoder pre-trained with the contrastive language–image pre-training (CLIP) model [36,39]. This encoder converts text inputs such as category names, phrases containing nouns, or object descriptions into text embeddings [36,39]. The RepVL-PAN component enhances the integration of text and image features using cross-modality fusion techniques, including text-guided CSPLayer and image-pooling attention, combining image features with text embeddings [36]. YOLO-World was pre-trained on large-scale datasets that include diverse region–text pairs such as Objects365v1, GQA, and Flickr30k. During inference, it uses a “prompt-then-detect” strategy, pre-computing custom prompts and storing them as offline vocabulary embeddings [36]. On the LVIS dataset, YOLO-World achieved a 35.4 AP while maintaining a high inference speed of 52.0 FPS on an NVIDIA V100 GPU [36]. It outperformed models like GLIP (26.9 AP), GLIPv2 (29 AP), and Grounding DINO (25.6–33.9 AP) in both zero-shot performance and inference speed [31,36,40,41] YOLO-World’s versatility and efficiency make it suitable for a wide range of applications, including real-time object detection and instance segmentation.
The primary objective of this study was to assess zero-shot mechanisms for accelerating image annotation in object detection tasks for wild blueberries using Grounding DINO and YOLO-World models. Specifically, we aim to evaluate the accuracy of these mechanisms across various datasets, including ripe berries, bud development, weed clusters, and diseases. The objectives of this study can be summarized as follows: (i) compare the performance of Grounding DINO and YOLO-World models in zero-shot object detection tasks within agricultural contexts. (ii) Assess the accuracy of these models across different datasets relevant to wild blueberry cultivation. (iii) Explore the potential of zero-shot mechanisms to provide insights and methodologies applicable to precision agriculture. The results of this study are expected to demonstrate the effectiveness of zero-shot mechanisms in reducing the labor and time required for image annotation by evaluating the accuracy and applicability of Grounding DINO and YOLO-World. The innovation of this study lays in the determination of the optimal zero-shot detection model for applications in the agricultural setting, as well as assessing the viability of the optimal model for expediting image annotation through the wild blueberry cropping system.
2. Materials and Methods
2.1. Dataset Preparation
The initial step in data preparation involved collecting a diverse set of images from various sources to ensure broad coverage of object categories (fruit, developmental buds (F2 stage), disease, and weeds). These images served as the base datasets for applying zero-shot learning techniques. A total of 66 red leaf images were captured using a Fujifilm FinePix HS30EXR (Fujifilm Holdings Corporation, Tokyo, Japan) DSLR camera no more than 1 m away from the plant in a field in Kemptown, Nova Scotia (45.500750, −63.107650), in June of 2022, in overcast conditions. A total of 66 Ripe wild blueberry images were collected in Glenholme, Nova Scotia (45.440839, −63.542934), during harvest in August of 2023 using a Canon EOS R mirrorless camera (Canon Inc., Tokyo, Japan) no more than 1 m away at varying angles from the berries, during full sun. A total of 20 aerial images of wild blueberry fields containing hair fescue clusters were captured at a height of 76 m using a DJI Matrice 300 RTK equipped with a Zenmuse P1 with a 35 mm lens (SZ DJI Technology Co., Ltd., Shenzhen, China) in various fields in May of 2024 (Table 1), each in partial sun and cloud conditions except Field 5 which was captured in overcast conditions. A total of 72 F2-stage developmental bud images were collected by cutting stems with attached buds from two fields in May of 2024 (Table 1), then photographing them on blank backgrounds of varying colors using an Apple iPhone 8 (Apple Inc., Cupertino, CA, USA). The smaller dataset samples from 2022 and 2023 were included to increase diversity and assess model robustness under varying conditions. As neither model requires training, these smaller datasets provided sufficient data for statistical analysis. The datasets, drawn from other active projects and compiled for this study, made the collection of entirely new data unnecessary.

Table 1.
Commercial wild blueberry fields utilized for the data collection of four categories of target objects (ripe wild blueberries, wild blueberry buds, hair fescue, and red leaf disease).
Each dataset was prepared separately and labelled with bounding boxes. Since zero-shot learning relies on textual descriptions of classes, a comprehensive list of class labels and their corresponding descriptions was compiled using OpenAI’s ChatGPT (OpenAI, San Francisco, CA, USA, 2024) using both GPT-3.5 and GPT-4o to give a variety of sample text prompts to accurately represent the objects within the images. GPT-3.5 and GPT-4o were employed to generate textual prompts due to their accessibility and robust language understanding at the time of this study. These models provided sufficient variability to capture the nuances of agricultural categories, such as ‘red leaf disease’ and ‘hair fescue’. While newer versions of GPT exist, they do not allow for image input like GPT-4o; therefore, the selected models met the project’s requirements. Images of ripe wild blueberries, developmental buds, hair fescue clusters, and red leaf diseases were used to assess the mechanisms. Each image was annotated manually using Roboflow’s online annotation software (Roboflow, Des Moines, IA, USA, 2024) (Figure 1). The platform supports exporting annotated datasets in various formats compatible with machine learning frameworks, enhancing the utility of the data for training and evaluating computer vision models.

Figure 1.
Examples from each dataset with ground truth detections overlayed where (A) is ripe wild blueberries, (B) is early developmental buds, specifically in the F2 stage (91%), (C) is hair fescue in a wild blueberry sprout field, and (D) is red leaf disease that is commonly found in commercial wild blueberry fields.
2.2. Model Selection
State-of-the-art zero-shot learning models suited for image annotation tasks were selected for the initial detection stage within the automatic annotation pipeline. ViT and CLIP models are known for their robust performance in zero-shot scenarios [42]. Given its promising results, Grounding DINO’s smallest model, Tiny Swin-T Transformer, leverages ViTs. The Swin-T backbone introduces hierarchical feature representation, enabling the model to efficiently capture both local and global image context. Grounding DINO extends this by incorporating a detection transformer-style mechanism for object detection. Grounding DINO was chosen for this study and compared to a similar zero-shot model, YOLO-World (s model), which uses the YOLOv8 backbone with a CLIP-based text encoder for pretraining and the detection class as the textual input. YOLOv8 introduces dynamic head scaling, deeper feature extraction layers, and advanced augmentation strategies during pretraining. It is combined with a CLIP-based encoder–decoder architecture, where the CLIP model aligns image and text embeddings through pretraining on datasets of paired image–text samples. The only parameter requiring optimization for both models was the confidence threshold. The confidence threshold was optimized based on the detection category. The models were deployed without additional training to ensure a true zero-shot scenario, with parameters tuned to maximize detection accuracy while minimizing false positives.
2.3. Evaluation Procedure
The zero-shot detection models were deployed without additional training. Each model was evaluated on an Alienware Aurora R11 desktop computer (Dell Inc., Round Rock, TX, USA) with a 3.7 GHz 10-core Intel Core i9-10900K CPU (Intel Corporation, Santa Clara, CA, USA), 128 GB of DDR4-3200 MHz, and an Nvidia GeForce RTX 3090 GPU (Nvidia Corp., Santa Clara, CA, USA). Both Grounding DINO and YOLO-World were assessed on the same datasets for consistent evaluation, calculating precision, recall, IoU, and an F1 score [43,44] for each image. Precision quantifies the accuracy of positive predictions by calculating the proportion of true positive instances among all instances predicted as positive, indicating the ability to minimize false positives. Similarly, recall measures the model’s effectiveness in identifying all relevant positive instances, emphasizing the reduction in false negatives. IoU assesses the overlap between predicted and actual bounding boxes, providing a measure of spatial accuracy. The F1 score harmonizes precision and recall into a single metric, offering a balanced evaluation by accounting for both false positives and false negatives.
For the detection models, both the textual input and the confidence thresholds were optimized. Starting with a minimum confidence (0.0001 for YOLO-World and 0.01 for Grounding DINO), a qualitative assessment of box fitment on the images was conducted. Text prompts were generated to refine the models: 50 prompts were generated using GPT–3.5 and 50 using GPT–4o. For GPT–3.5, a textual description of the dataset and target object was provided, followed by a request for 50 detection prompts. For GPT–4o, an example image was uploaded, followed by a request to generate prompts for detecting the target object within the image.
During the qualitative process, it was observed that at low confidence thresholds, the zero-shot models would classify the image and supply bounding boxes around the target (Figure 2). To mitigate this, a bounding box cleaning script was used to clear any boxes larger than 90% of the image size. After selecting the text prompt, the confidence threshold was increased and assessed both qualitatively and quantitatively through evaluation metrics.

Figure 2.
Image example of zero-shot model “classifying” the image as red leaf while detecting actual red leaf objects in smaller bounding boxes.
Additionally, for the fescue dataset, the high-resolution drone images were tiled into 8 × 8 chunks using the preprocessing option in Roboflow’s dataset generation, as the full-size images were too difficult for the zero-shot models to discern target boundaries effectively, likely due to the size of the fescue clusters relative to the image. The comprehensive methodology employed for the code component of this study is thoroughly illustrated in Figure 3.
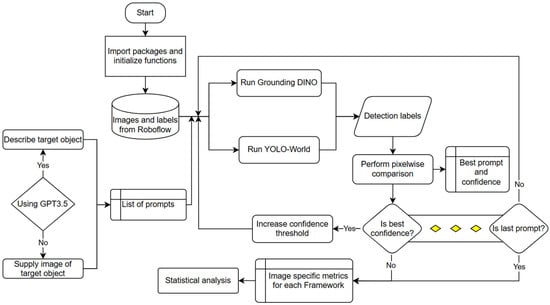
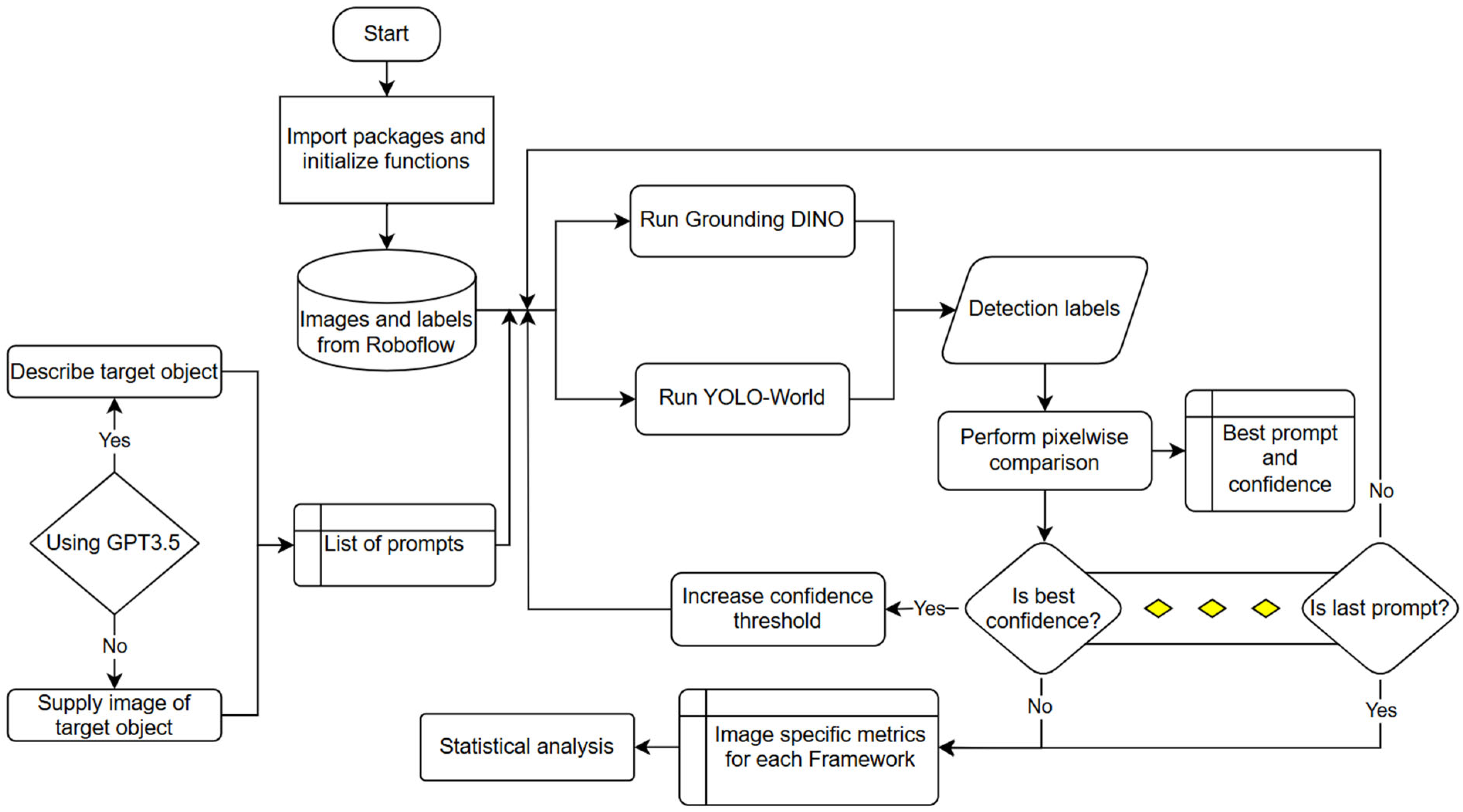
Figure 3.
Flowchart of code methodology utilized for prompt generation, model evaluation, and optimization.
2.4. Statistical Analysis
After the evaluations, the performance metrics were used for statistical analysis to denote any significant differences between annotation methods, where each dataset was compared separately. Since the models were compared using the same images, a paired t-test was used to discern statistical differences (1). To assess the effect on annotation time, the time taken to annotate each image was recorded and compared between each model after manual adjustments and manual annotation time. This was achieved through analysis of variance (ANOVA) multiple mean comparisons with Tukey’s honest significant difference (HSD) test using Minitab 21 (Minitab, LLC, Minitab 21, State College, PA, USA) with an acceptance level α of 0.05 to denote significant differences between performance metric means (2) [45].
where is the mean difference between paired values, SD is the standard deviation of differences, and n is the number of samples.
where q is the Studentized Range Statistic, α is the acceptance level, k is the number of groups, df represents the degrees of freedom, MSE represents the Mean Squares due to Error, and n is the number of samples.
3. Results and Discussion
The optimal prompt for the YOLO-World model was “a small blue sphere”, whereas for Grounding DINO it was “smooth blueberry”. The optimal confidence thresholds were 0.00365 for YOLO-World and 0.360 for Grounding DINO. Grounding DINO achieved a significantly higher mean IoU (0.642) compared to YOLO-World (0.503), indicating superior accuracy in predicting bounding box locations and sizes (Table 2). Despite a higher standard deviation in IoU (0.148), Grounding DINO’s mean precision (0.689 ± 0.146) was not significantly different from YOLO-World (0.648 ± 0.111). Grounding DINO excelled in recall (0.901 ± 0.091), significantly higher than YOLO-World’s results (0.719 ± 0.161) while achieving lower variability, indicating superiority at detecting true negatives. The F1 score further underscored Grounding DINO’s significantly superior performance (0.772 ± 0.108) over YOLO-World (0.662 ± 0.099), indicating a better balance between precision and recall, making it a more reliable model for the zero-shot detection of wild blueberries.
Table 2.
Zero-shot detection evaluation of YOLO-World and Grounding DINO on wild blueberry cropping system datasets (α = 0.05).
To further evaluate the models on small objects and numerous detections, the models were deployed to detect wild blueberry buds in developmental stages, specifically the F2 stage (91%). The optimal prompt for YOLO-World was “bud on shoot”, whereas for Grounding DINO it was “buds emerging”. The optimal confidence thresholds were 0.0365 for YOLO-World and 0.41 for Grounding DINO. Grounding DINO achieved a mean IoU of 0.629 (±0.161), significantly higher than YOLO-World’s 0.408 (±0.169) (Table 2), indicating superior localization of wild blueberry buds. Grounding DINO also showed significantly higher precision (0.682 ± 0.175) compared to YOLO-World (0.535 ± 0.217). Similarly, Grounding DINO demonstrated significantly higher recall values, with Grounding DINO achieving a mean recall of 0.919 (±0.135) and YOLO-World a mean recall of 0.709 (±0.245). The higher recall-to-precision ratios suggested a design preference for detecting as many buds as possible, which is crucial in agricultural applications, as missing a detection (false negative) could reduce efficiency across several applications. Although adjusting the confidence threshold can alter these ratios, it would result in lower IoU and F1 score metrics. Grounding DINO’s higher precision and recall demonstrates a better balance, reducing false positives more effectively than YOLO-World. The F1 score further highlights the overall performance differences, with Grounding DINO obtaining a mean F1 score of 0.760 (±0.125), significantly higher than YOLO-World’s 0.558 (±0.176), supporting the overall effectiveness of Grounding DINO.
For red leaf disease images, the optimal prompt for YOLO-World was “red-hued plant”, whereas Grounding DINO’s was “a red leaf plant”. The optimal confidence thresholds were 0.001 for YOLO-World and 0.40 for Grounding DINO. Grounding DINO demonstrated significant superiority in IoU (0.921 ± 0.135), precision (0.923 ± 0.134), and F1 score (0.954 ± 0.083), reflecting better spatial overlap, positive identification, and balanced accuracy (Table 2). Both models exhibited high recall (>0.996), but Grounding DINO’s higher precision translated into a higher F1 score (0.954 ± 0.083) compared to YOLO-World (0.686 ± 0.252), reinforcing its effectiveness in diverse detection scenarios. The superior performance of both models on red leaf disease images can be attributed to the distinct and uniform visual characteristics of the disease, such as red or brown discoloration against a predominantly green background. These traits allow for easier differentiation by zero-shot models. Unlike the other categories that exhibit subtle or overlapping colors, red leaf disease provides a clearer target, contributing to the higher detection accuracy observed in this study.
The models were evaluated on hair fescue aerial images to further test their abilities to adapt to non-uniform objects (Table 2). The optimal prompt for the YOLO-World model was “brown, dead patches”, and for Grounding DINO, it was “patches of fescue”. The optimal confidence thresholds were 0.04 for YOLO-World and 0.24 for Grounding DINO. Grounding DINO exhibited a significantly higher IoU (0.735 ± 0.213) compared to YOLO-World (0.232 ± 0.106), suggesting superior localization capabilities. In terms of precision, Grounding DINO also outperformed YOLO-World, with a precision score of 0.802 ± 0.215 compared to 0.252 ± 0.133, respectively, indicating a lower rate of false positives for Grounding DINO. Both models demonstrated high recall rates, with Grounding DINO achieving 0.912 ± 0.129 and YOLO-World achieving 0.874 ± 0.146, indicating their effectiveness in identifying hair fescue instances. Grounding DINO’s F1 score (0.832 ± 0.142) was significantly higher than that of YOLO-World (0.366 ± 0.136), reflecting a better balance between precision and recall and further demonstrating Grounding DINO’s robustness and adaptability to varying object shapes and sizes in aerial imagery.
These results differed from those of Cheng et al. (2024) [36], who showed a superior performance of YOLO-World over Grounding DINO on the standard dataset of diverse objects (LVIS). Model implementation, tuning, and optimization variations for different datasets could contribute to the observed differences. Cheng et al. (2024) [36] might have optimized YOLO-World more effectively for their particular dataset, while our study focused on wild-blueberry-based datasets. Differences in environmental conditions and image qualities could also be influencing factors. Additionally, during qualitative assessment, a frequent issue observed was double bounding boxing, where clusters of berries were encapsulated in a larger bounding box (Figure 4). This led to more false positives, decreasing the precision performance of both models.

Figure 4.
Visual example of double bounding boxing in ripe wild blueberry dataset with label prompt depicted with associated detection confidence.
The evaluation results demonstrate that Grounding DINO outperforms YOLO-World in detecting wild blueberry developmental buds across all key performance metrics. The higher IoU, precision, recall, and F1 score of Grounding DINO suggest it is more reliable for accurate and precise detection tasks, indicating superior localization accuracy in bounding box predictions. This higher IoU reflects Grounding DINO’s enhanced capability to delineate the precise edges of the blueberry buds, which is crucial in accurately identifying small and numerous objects within complex agricultural images. This underscored Grounding DINO’s potential to enhance precision agriculture by providing more accurate and efficient detection of developmental stages, which is essential for optimizing crop yield and quality.
The findings from the red leaf disease detection aligned with the results from the ripe wild blueberry and wild blueberry bud detection, showcasing Grounding DINO’s adaptability to objects of uniform and non-uniform shapes. This dataset’s complexity involved varied leaf shapes and overlapping structures. However, red leaf disease is easily identifiable in comparison to other diseases [10]. To extensively assess Grounding DINO’s and YOLO-World’s performance on disease datasets, it is suggested that more complex diseases such as Valdensia leaf spot, Sphaerulina leaf spot, or Botrytis blight be included.
The aerial hair fescue images were challenging primarily for the YOLO-World model, which underperformed compared to Grounding DINO. While both models achieved high recall (>0.85), Grounding DINO significantly outperformed YOLO-World in IoU (0.735) and F1 score (0.832), indicating superior localization and a better balance between precision and recall. Grounding DINO demonstrated consistency in its performance, whereas YOLO-World struggled with low precision, highlighting the issue of false positives and resulting in a reduced F1 score. The aerial imagery of hair fescue presented unique challenges due to the weed’s indistinct edges and spatial variability across fields. YOLO-World struggled with localization precision, providing more false positive detections, resulting in significantly lower IoU and F1 scores compared to Grounding DINO. Grounding DINO’s cross-modality decoder and enhanced feature representation allowed it to better capture the variability in hair fescue appearance, leading to superior performance.
These significant differences suggest that Grounding DINO was generally more reliable. Comparing prompt optimization results, YOLO-World’s optimal prompts were more generalized in describing the object, such as “a small blue sphere” for identifying ripe wild blueberries, while Grounding DINO’s prompts were more specific with “smooth blueberry”. This trend continued across other categories, except for bud detection, where the prompts were stylistically aligned.
Grounding DINO’s consistent outperformance suggested that it is a more effective model for zero-shot detection tasks, particularly in complex agricultural image datasets. Its higher IoU and F1 score indicated better detection accuracy and reliability, making it preferable over YOLO-World for these specific tasks. Although YOLO-World achieved superior results on the LVIS dataset [36], it underperformed in the specific environment of the wild blueberry cropping system.
The evaluation assessed annotation times for manual and automated methods, with manual annotation taking significantly longer. Grounding DINO reduced annotation time by 72% for ripe wild blueberries, from 91.0 to 25.2 s per image, while YOLO-World reduced it by 10%, taking 82.2 s. For wild blueberry buds, Grounding DINO cut time by 57%, to 24.8 s, and YOLO-World by 30%, to 40.3 s. Red leaf disease showed the largest reduction, with Grounding DINO at 83%, from 24.7 to 4.3 s, and YOLO-World at 47%, to 13.2 s. For hair fescue, Grounding DINO reduced time by 69%, to 6.8 s, whereas YOLO-World’s time of 28.2 s was 29% longer than manual annotation (Table 3).
Table 3.
Comparison of time required for manual annotation versus the automated annotation using YOLO-World and Grounding DINO across various datasets.
The results demonstrated significant time savings with zero-shot detection models, particularly Grounding DINO, which reduced annotation times by up to 82% for red leaf disease images. This highlights its efficiency in agricultural data processing. YOLO-World also reduced annotation times but was less consistent, particularly for hair fescue, where it offered no significant improvement over manual annotation. Grounding DINO’s superior performance makes it a valuable tool for automating image annotation in precision agriculture, facilitating faster machine learning model training. In contrast, YOLO-World may need further optimization to match Grounding DINO’s efficiency across all datasets. Adopting these automated methods can enhance productivity and improve resource management in agriculture.
The wild blueberry cropping system presents distinct challenges for zero-shot detection, such as irregular object shapes, overlapping structures, and variable lighting conditions. Zero-shot detection models like Grounding DINO and YOLO-World use textual prompts, enabling adaptation to new object categories without retraining. This capability is crucial in agricultural contexts characterized by diverse and dynamic conditions. This study demonstrates the suitability of zero-shot detection for agricultural applications by accurately identifying weeds and diseases. Differences in results compared to [36] arise from variations in datasets and model architecture. This study examined the wild blueberry system’s unique environmental conditions and image characteristics, while [36] employed the LVIS dataset, a standard dataset designed for general object detection. Cheng et al. (2024) [36] reported a mean average precision of 35.4 for YOLO World compared to values from 25.6 to 33.9 for Grounding DINO [31]. However, in agricultural-specific scenarios, Grounding DINO showed superior performance with significantly higher IoU and F1 scores across all categories. These differences highlight the importance of dataset characteristics in determining framework performance.
4. Conclusions
This study demonstrated that Grounding DINO consistently outperformed YOLO-World in zero-shot detection tasks across diverse wild blueberry datasets, showcasing its robustness and accuracy. The results highlighted several strengths of the overall method, particularly the advantages of employing zero-shot detection techniques in agricultural contexts. Grounding DINO achieved higher IoU (>0.628), precision (>0.681), recall (>0.900), and F1 scores (>0.759), particularly in complex tasks such as detecting red leaf plant diseases and developmental buds. The significant reduction in annotation time, particularly for Grounding DINO, highlights the efficiency of zero-shot methods in expediting the preparation of large datasets, which is critical for developing machine learning models in agriculture.
However, this study also identified some limitations. Both models were sensitive to image quality and environmental conditions, such as lighting variability and object occlusion, which are inherent challenges in agricultural datasets. Grounding DINO, while robust overall, struggled with fine-grained targets in low-resolution aerial imagery, such as hair fescue clusters. This limitation suggests that zero-shot detection methods may require further refinement to handle subtle, small-scale features effectively. YOLO-World’s performance was particularly inconsistent, with higher false positive rates and weaker precision, indicating it may not be well-suited to the variability present in agricultural environments.
Future research should investigate integrating the Segment Anything Model (SAM) [46] to address the challenges of instance segmentation, streamlining dataset annotation. Expanding the application of these models to other crops and agricultural contexts would further evaluate their adaptability and provide insights for optimizing their use in precision agriculture. By addressing these limitations, Grounding DINO and similar models can become even more effective tools for advancing agricultural practices.
Author Contributions
C.C.M.: Conceptualization, data curation, formal analysis, investigation, methodology, software, visualization, writing—original draft; T.J.E.: Funding acquisition, project administration, resources, supervision, writing—review and editing; Q.U.Z.: Supervision, writing—review and editing; C.L.T.: Data curation, writing—review and editing, writing—original draft; P.J.H.: Data curation, writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Natural Sciences and Engineering Research Council (NSERC) of Canada Discovery Grants Program (RGPIN-06295-2019).
Data Availability Statement
Data will be made available on request.
Acknowledgments
The authors would like to thank Bragg Lumber Company and both Nova Scotia and New Brunswick landowners for the use of their commercially managed wild blueberry fields. The authors would also like to acknowledge the efforts of Dalhousie’s Agricultural Mechanized Systems research team, in particular Riley Johnstone, for assistance in the prompt optimization.
Conflicts of Interest
The authors declare that they have no competing financial or personal interests that could influence the work reported in this study.
References
- Bilodeau, M.F.; Esau, T.J.; MacEachern, C.B.; Farooque, A.A.; White, S.N.; Zaman, Q.U. Identifying Hair Fescue in Wild Blueberry Fields Using Drone Images for Precise Application of Granular Herbicide. Smart Agric. Technol. 2023, 3, 100127. [Google Scholar] [CrossRef]
- Fiona, J.R.; Anitha, J. Automated Detection of Plant Diseases and Crop Analysis in Agriculture Using Image Processing Techniques: A Survey. In Proceedings of the 2019 IEEE International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 20–22 February 2019; pp. 1–5. [Google Scholar]
- Cordier, A.; Gutierrez, P.; Plessis, V. Improving Generalization with Synthetic Training Data for Deep Learning Based Quality Inspection. arXiv 2022, arXiv:2202.12818. [Google Scholar]
- Fenu, G.; Malloci, F.M. DiaMOS Plant: A Dataset for Diagnosis and Monitoring Plant Disease. Agronomy 2021, 11, 2107. [Google Scholar] [CrossRef]
- MacEachern, C.B.; Esau, T.J.; Schumann, A.W.; Hennessy, P.J.; Zaman, Q.U. Detection of Fruit Maturity Stage and Yield Estimation in Wild Blueberry Using Deep Learning Convolutional Neural Networks. Smart Agric. Technol. 2023, 3, 100099. [Google Scholar] [CrossRef]
- Verma, R. Crop Analysis and Prediction. In Proceedings of the 2022 5th International Conference on Multimedia, Signal Processing and Communication Technologies, Aligarh, India, 26–27 November 2022; pp. 1–5. [Google Scholar]
- Yarborough, D.; Cote, J. Pre-and Post-Emergence Applications of Herbicides for Control of Resistant Fineleaf Sheep Fescue in Wild Blueberry Fields in Maine. In Proceedings of the North American Blueberry Research and Extension Workers Conference, Atlantic City, NJ, USA, 24 June 2014. [Google Scholar]
- Percival, D.C.; Dawson, J.K. Foliar Disease Impact and Possible Control Strategies in Wild Blueberry Production. In Proceedings of the IX International Vaccinium Symposium 810, Corvallis, OR, USA, 14–18 July 2008; pp. 345–354. [Google Scholar]
- Jewell, L.E.; Compton, K.; Wiseman, D. Evidence for a Genetically Distinct Population of Exobasidium sp. Causing Atypical Leaf Blight Symptoms on Lowbush Blueberry (Vaccinium angustifolium Ait.) in Newfoundland and Labrador, Canada. Can. J. Plant Pathol. 2021, 43, 897–904. [Google Scholar] [CrossRef]
- Hildebrand, P.D.; Nickerson, N.L.; McRae, K.B.; Lu, X. Incidence and Impact of Red Leaf Disease Caused by Exobasidium vaccinii in Lowbush Blueberry Fields in Nova Scotia. Can. J. Plant Pathol. 2000, 22, 364–367. [Google Scholar] [CrossRef]
- Lyu, H.; McLean, N.; McKenzie-Gopsill, A.; White, S.N. Weed Survey of Nova Scotia Lowbush Blueberry (Vaccinium angustifolium Ait.) Fields. Int. J. Fruit Sci. 2021, 21, 359–378. [Google Scholar] [CrossRef]
- White, S.N. Evaluation of Herbicides for Hair Fescue (Festuca filiformis) Management and Potential Seedbank Reduction in Lowbush Blueberry. Weed Technol. 2019, 33, 840–846. [Google Scholar] [CrossRef]
- Esau, T.; Zaman, Q.; Groulx, D.; Farooque, A.; Schumann, A.; Chang, Y. Machine Vision Smart Sprayer for Spot-Application of Agrochemical in Wild Blueberry Fields. Precis. Agric. 2018, 19, 770–788. [Google Scholar] [CrossRef]
- Bator, M.; Pankiewicz, M. Image Annotating Tools for Agricultural Purpose-A Requirements Study. Mach. Graph. Vis. 2019, 28, 69–77. [Google Scholar] [CrossRef]
- Brenskelle, L.; Guralnick, R.P.; Denslow, M.; Stucky, B.J. Maximizing Human Effort for Analyzing Scientific Images: A Case Study Using Digitized Herbarium Sheets. Appl. Plant Sci. 2020, 8, e11370. [Google Scholar] [CrossRef] [PubMed]
- Hennessy, P.J.; Esau, T.J.; Farooque, A.A.; Schumann, A.W.; Zaman, Q.U.; Corscadden, K.W. Hair Fescue and Sheep Sorrel Identification Using Deep Learning in Wild Blueberry Production. Remote Sens. 2021, 13, 943. [Google Scholar] [CrossRef]
- Donatelli, M.; Magarey, R.D.; Bregaglio, S.; Willocquet, L.; Whish, J.P.; Savary, S. Modelling the Impacts of Pests and Diseases on Agricultural Systems. Agric. Syst. 2017, 155, 213–224. [Google Scholar] [CrossRef]
- Sun, X.; Chen, S.; Feng, Z.; Ge, W.; Huang, K. A Service Annotation Quality Improvement Approach Based on Efficient Human Intervention. In Proceedings of the 2018 IEEE International Conference on Web Services (ICWS 2018), San Francisco, CA, USA, 2–7 July 2018; pp. 107–114. [Google Scholar]
- Too, E.C.; Yujian, L.; Njuki, S.; Yingchun, L. A Comparative Study of Fine-Tuning Deep Learning Models for Plant Disease Identification. Comput. Electr. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Ahmed, N.; Asif, H.M.S.; Saleem, G.; Younus, M.U. Image Quality Assessment for Foliar Disease Identification (AgroPath). arXiv 2022, arXiv:2209.12443. [Google Scholar]
- Brust, C.-A.; Käding, C.; Denzler, J. Active Learning for Deep Object Detection. arXiv 2018, arXiv:1809.09875. [Google Scholar]
- Schmidt, S.; Rao, Q.; Tatsch, J.; Knoll, A. Advanced Active Learning Strategies for Object Detection. In Proceedings of the IEEE Intelligent Vehicles Symposium, IV 2020, Las Vegas, NV, USA, 19 October–13 November 2020; pp. 871–876. [Google Scholar]
- Tung, F.; Mori, G. Similarity-Preserving Knowledge Distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 1365–1374. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Virtual, 10–17 October 2021; pp. 9650–9660. [Google Scholar]
- Fu, Z. Vision Transformer: Vit and Its Derivatives. arXiv 2022, arXiv:2205.11239. [Google Scholar]
- Kwon, H.; Castro, F.M.; Marin-Jimenez, M.J.; Guil, N.; Alahari, K. Lightweight Structure-Aware Attention for Visual Understanding. arXiv 2022, arXiv:2211.16289. [Google Scholar]
- Naseer, M.; Ranasinghe, K.; Khan, S.H.; Hayat, M.; Khan, F.; Yang, M.-H. Intriguing Properties of Vision Transformers. In Proceedings of the Neural Information Processing Systems, Virtual, 6 December 2021. [Google Scholar]
- Gallego-Mejia, J.A.; Jungbluth, A.; Martínez-Ferrer, L.; Allen, M.; Dorr, F.; Kalaitzis, F.; Ramos-Pollán, R. Exploring DINO: Emergent Properties and Limitations for Synthetic Aperture Radar Imagery. arXiv 2023, arXiv:2310.03513. [Google Scholar]
- Vu, T.; Wang, T.; Munkhdalai, T.; Sordoni, A.; Trischler, A.; Mattarella-Micke, A.; Maji, S.; Iyyer, M. Exploring and Predicting Transferability across NLP Tasks. arXiv 2020, arXiv:2005.00770. [Google Scholar]
- Wanyan, X.; Seneviratne, S.; Shen, S.; Kirley, M. Extending Global-Local View Alignment for Self-Supervised Learning with Remote Sensing Imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Li, C.; Yang, J.; Su, H.; Zhu, J.; et al. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. arXiv 2023, arXiv:2303.05499. [Google Scholar]
- Wu, D.; Li, H.; Gu, C.; Liu, H.; Xu, C.; Hou, Y.; Guo, L. Feature First: Advancing Image-Text Retrieval through Improved Visual Features. IEEE Trans. Multimed. 2023, 26, 3827–3841. [Google Scholar] [CrossRef]
- Yang, L.; Xu, Y.; Yuan, C.; Liu, W.; Li, B.; Hu, W. Improving Visual Grounding with Visual-Linguistic Verification and Iterative Reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 9499–9508. [Google Scholar]
- Tan, J.; Li, B.; Lu, X.; Yao, Y.; Yu, F.; He, T.; Ouyang, W. The Equalization Losses: Gradient-Driven Training for Long-Tailed Object Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13876–13892. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Liu, H.; Li, L.; Zhang, P.; Aneja, J.; Yang, J.; Jin, P.; Hu, H.; Liu, Z.; Lee, Y.J. Elevater: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models. Adv. Neural Inf. Process. Syst. 2022, 35, 9287–9301. [Google Scholar]
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. YOLO-World: Real-Time Open-Vocabulary Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 3 August 2024).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, ICML 2021, Virtual, 18–24 June 2021; pp. 8748–8763. [Google Scholar]
- Li, L.H.; Zhang, P.; Zhang, H.; Yang, J.; Li, C.; Zhong, Y.; Wang, L.; Yuan, L.; Zhang, L.; Hwang, J.-N. Grounded Language-Image Pre-Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10965–10975. [Google Scholar]
- Zhang, H.; Zhang, P.; Hu, X.; Chen, Y.-C.; Li, L.; Dai, X.; Wang, L.; Yuan, L.; Hwang, J.-N.; Gao, J. Glipv2: Unifying Localization and Vision-Language Understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36067–36080. [Google Scholar]
- Esmaeilpour, S.; Liu, B.; Robertson, E.; Shu, L. Zero-Shot out-of-Distribution Detection Based on the Pre-Trained Model Clip. In Proceedings of the AAAI Conference on Artificial Intelligence 2022, Virtual, 22 February–1 March 2022; Volume 36, pp. 6568–6576. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In Advances in Visual Computing; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Porikli, F., Skaff, S., Entezari, A., Min, J., Iwai, D., Sadagic, A., et al., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 10072, pp. 234–244. ISBN 978-3-319-50834-4. [Google Scholar]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Montgomery, D.C. Design and Analysis of Experiments; John Wiley & Sons: Hoboken, NJ, USA, 2017; ISBN 978-1-119-11347-8. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment Anything. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4015–4026. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).