

Rapid pH Value Detection in Secondary Fermentation of Maize Silage Using Hyperspectral Imaging

 ,
,
Abstract
1. Introduction
2. Materials and Methods
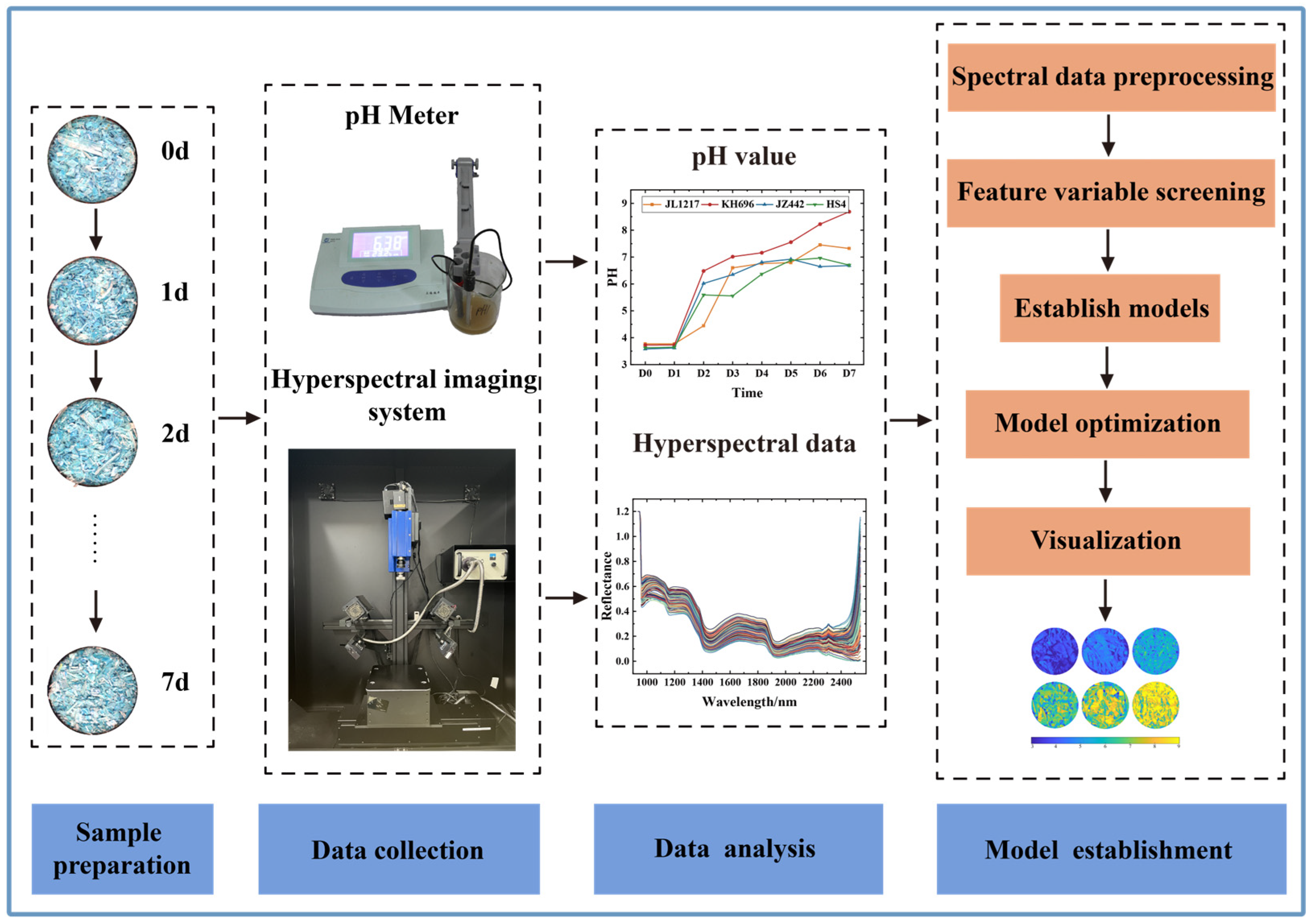
2.1. Sample Preparation
2.2. Hyperspectral Imaging System and Image Acquisition
2.3. HSI Data Extraction
2.4. pH Measurement
2.5. Spectral Data Preprocessing
2.6. Feature Variable Screening
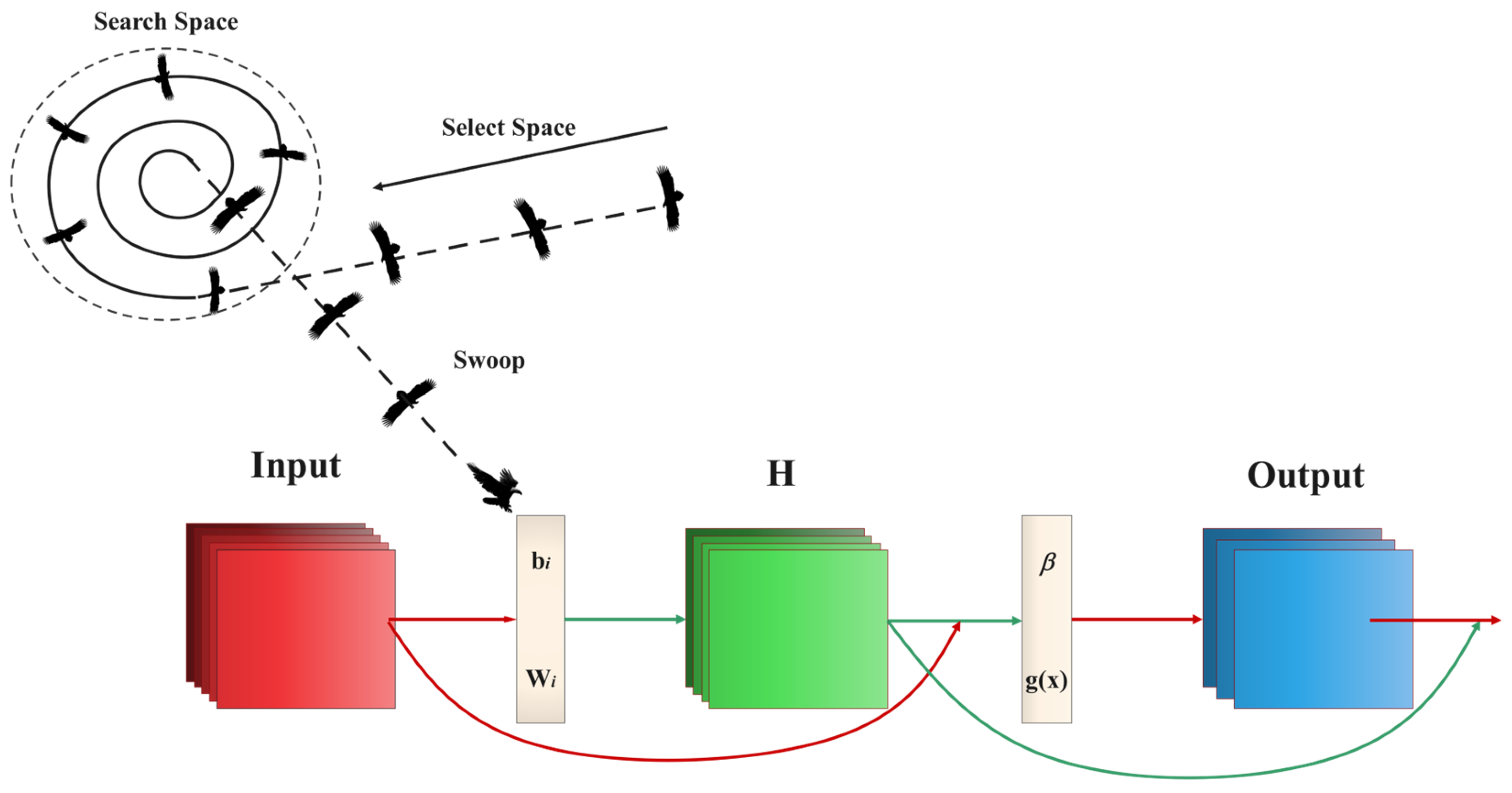
2.7. Establishment and Assessment of Models
3. Results
3.1. Original Spectral Analysis
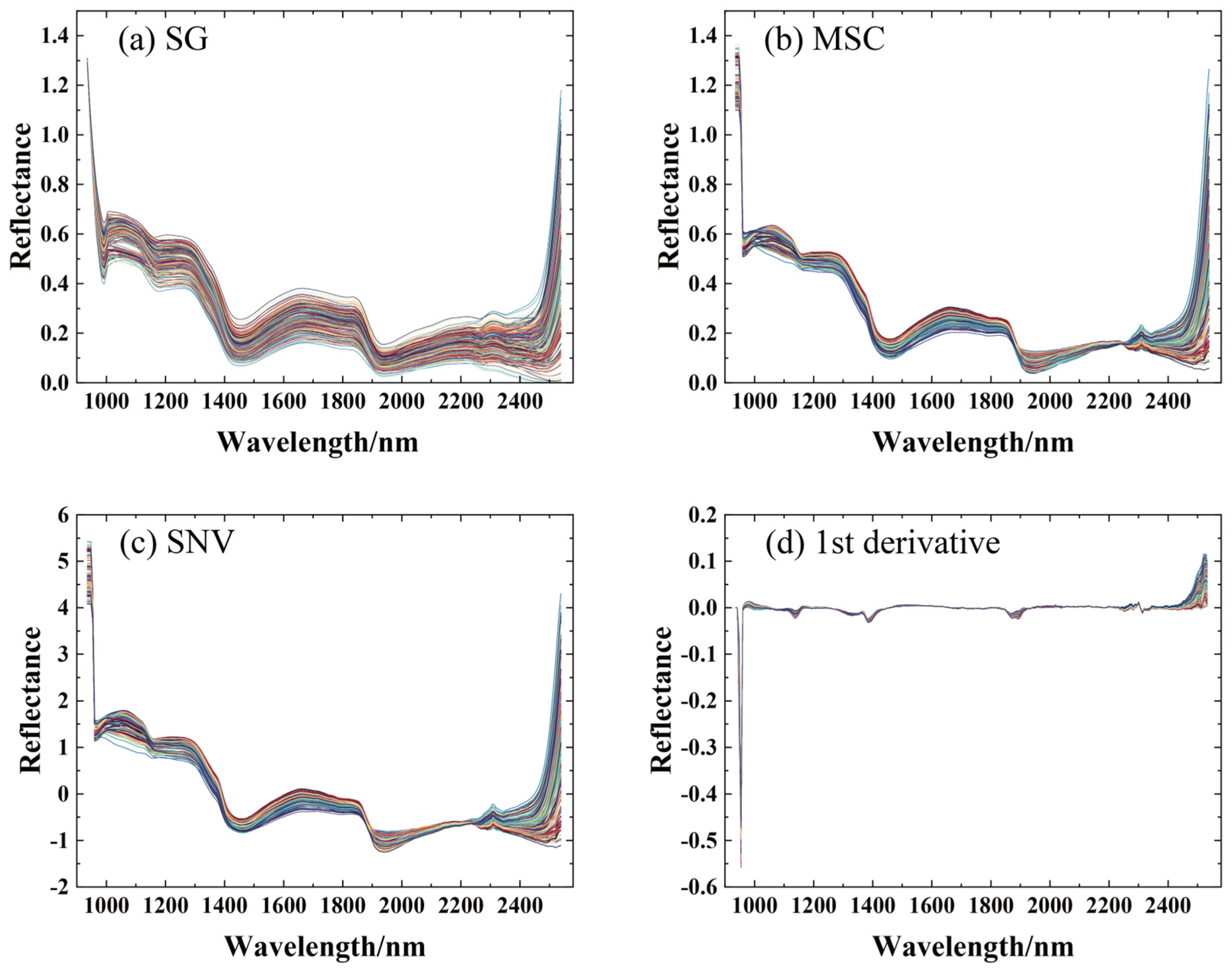
3.2. Spectral Data Preprocessing
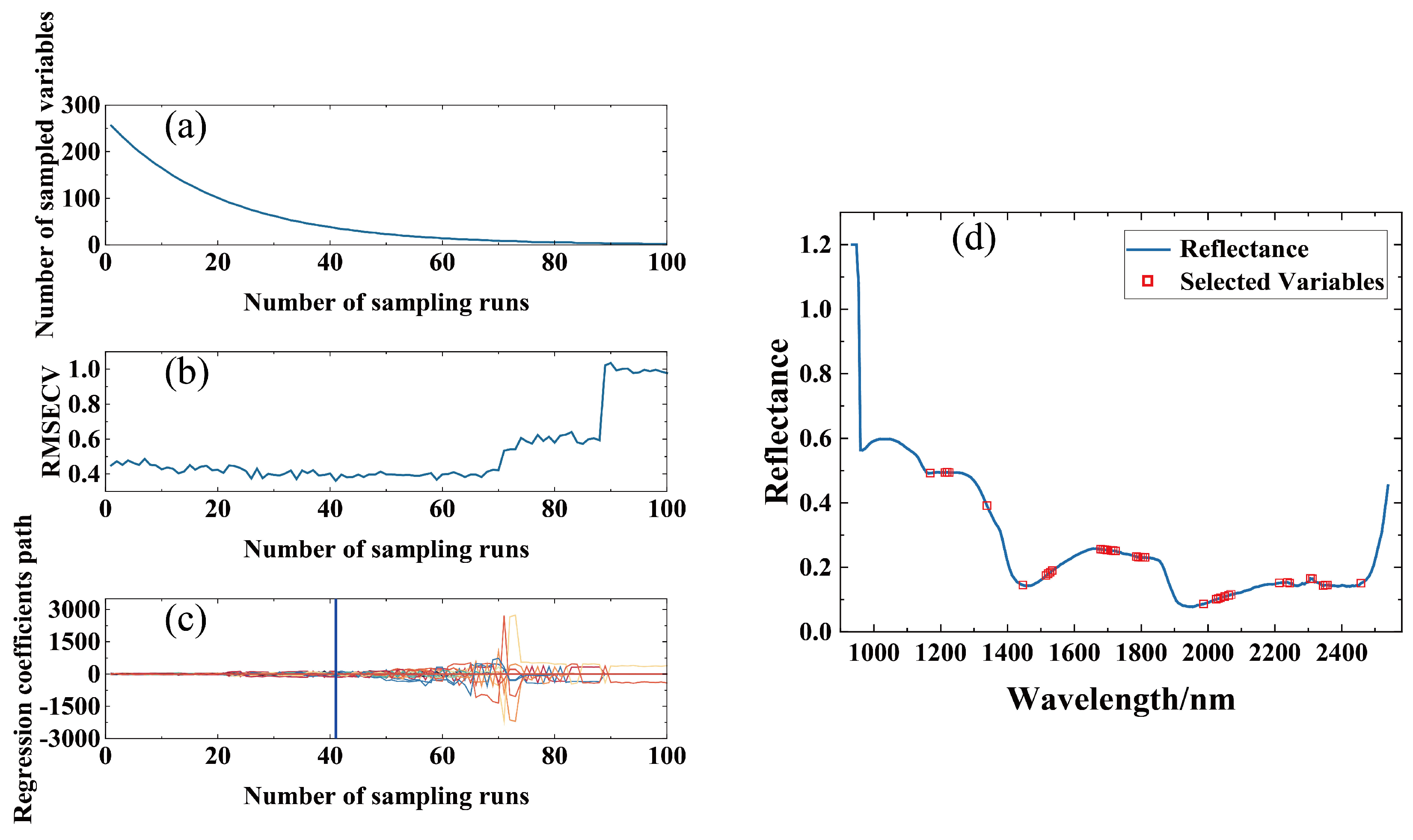
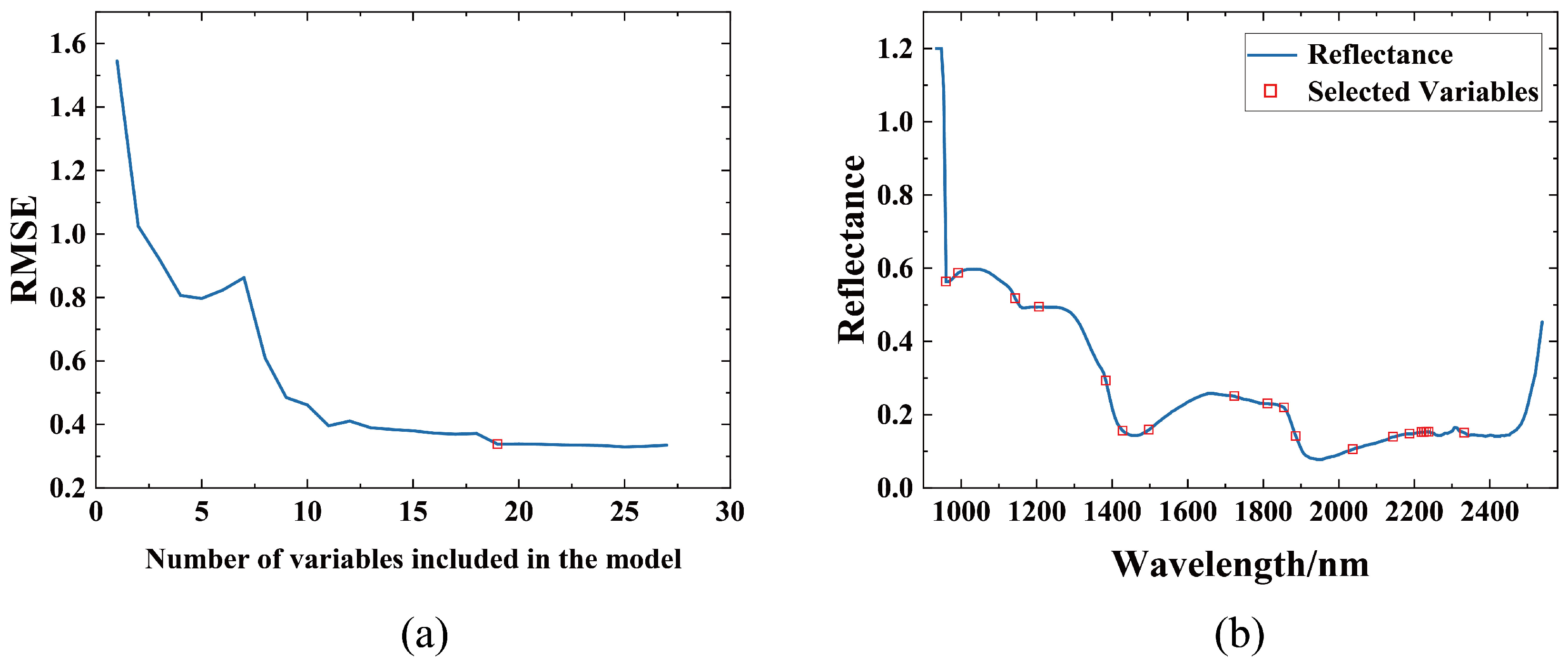
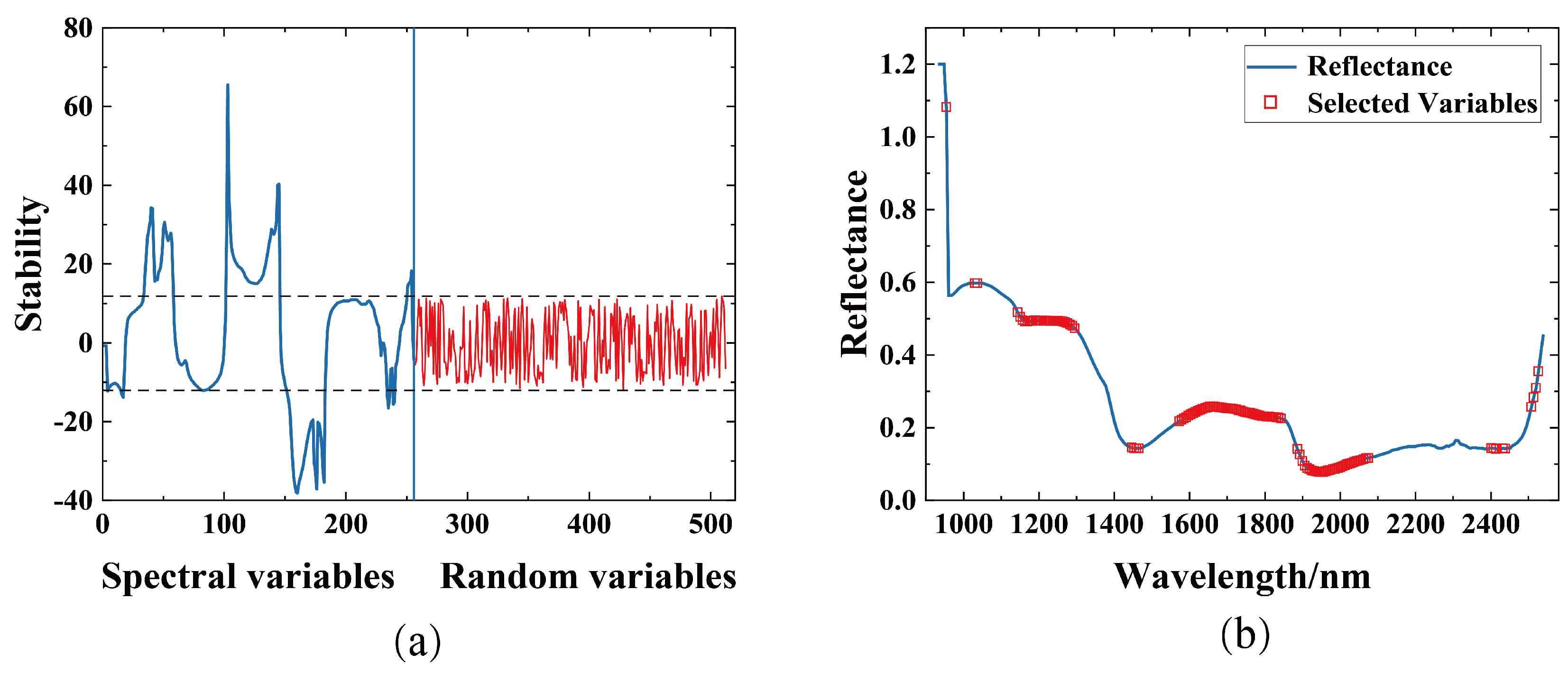
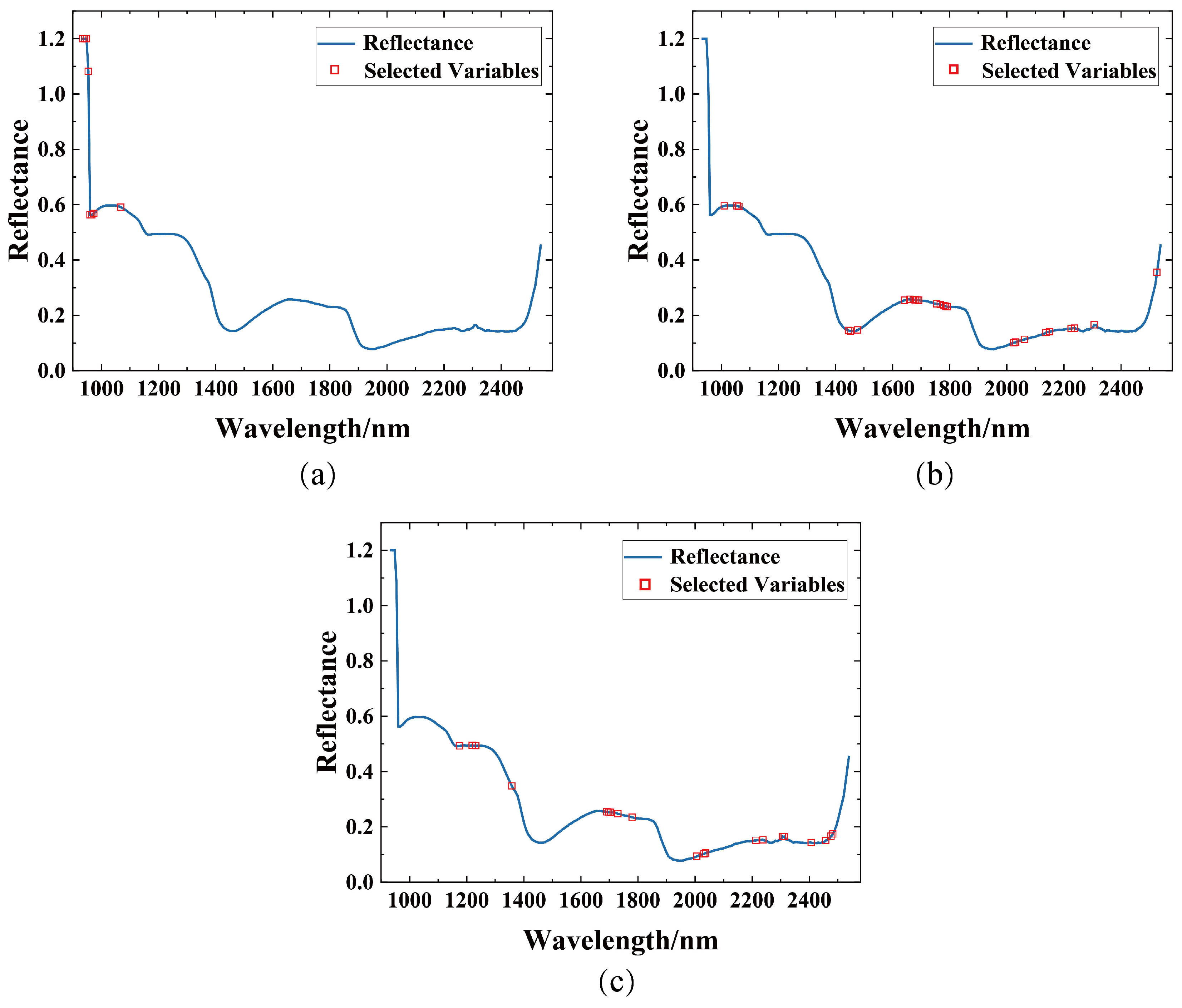
3.3. Spectral Feature Selection
3.4. Model Results and Analysis
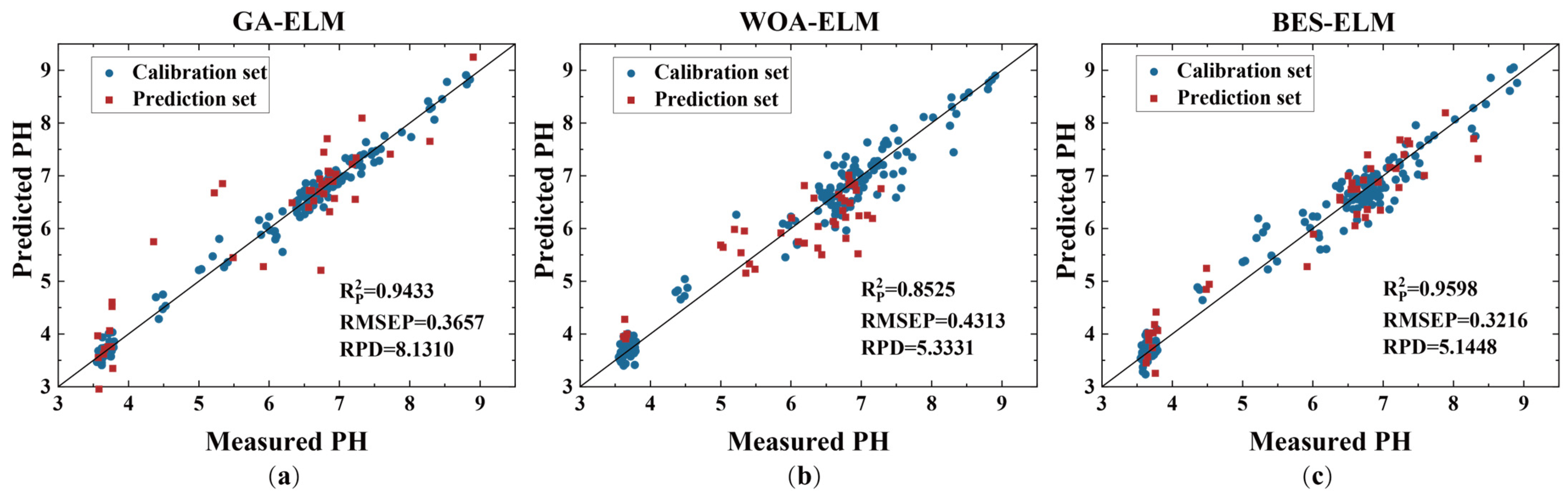
3.5. Model Optimization
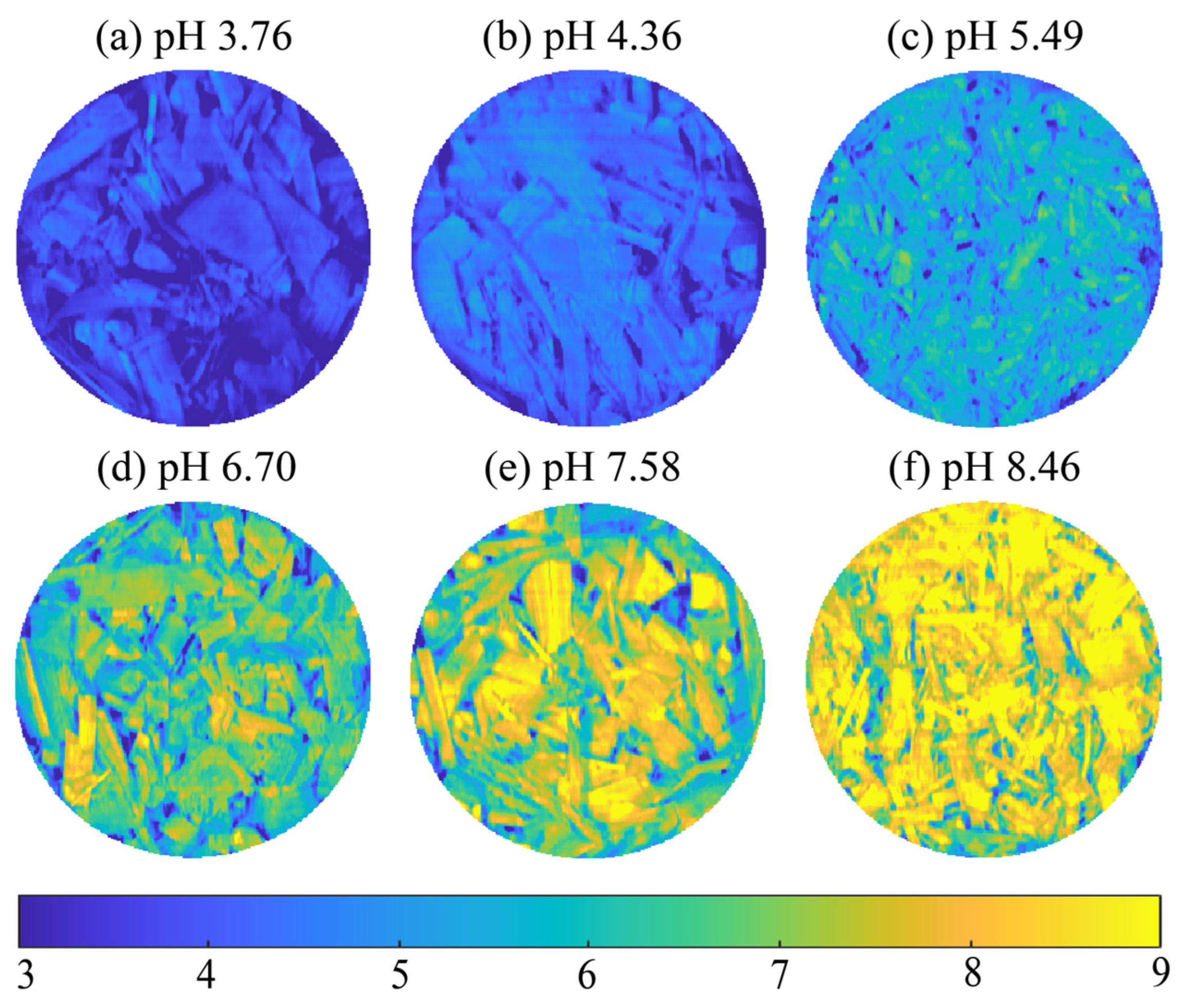
3.6. pH Value Visualization
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ferraretto, L.F.; Shaver, R.D.; Luck, B.D. Silage Review: Recent Advances and Future Technologies for Whole-Plant and Fractionated Corn Silage Harvesting. J. Dairy Sci. 2018, 101, 3937–3951. [Google Scholar] [CrossRef] [PubMed]
- Serva, L.; Andrighetto, I.; Segato, S.; Marchesini, G.; Chinello, M.; Magrin, L. Assessment of Maize Silage Quality under Different Pre-Ensiling Conditions. Data 2023, 8, 117. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, G.; Wu, H.; Meng, Q.; Khan, M.Z.; Zhou, Z. Effect of Hybrid Type on Fermentation and Nutritional Parameters of Whole Plant Corn Silage. Animals 2021, 11, 1587. [Google Scholar] [CrossRef] [PubMed]
- Wilkinson, J.M.; Davies, D.R. The Aerobic Stability of Silage: Key Findings and Recent Developments. Grass Forage Sci. 2013, 68, 1–19. [Google Scholar] [CrossRef]
- Borreani, G.; Tabacco, E.; Schmidt, R.J.; Holmes, B.J.; Muck, R.E. Silage Review: Factors Affecting Dry Matter and Quality Losses in Silages. J. Dairy Sci. 2018, 101, 3952–3979. [Google Scholar] [CrossRef] [PubMed]
- Tharangani, R.M.H.; Yakun, C.; Zhao, L.S.; Ma, L.; Liu, H.L.; Su, S.L.; Shan, L.; Yang, Z.N.; Kononoff, P.J.; Weiss, W.P.; et al. Corn Silage Quality Index: An Index Combining Milk Yield, Silage Nutritional and Fermentation Parameters. Anim. Feed Sci. Technol. 2021, 273, 114817. [Google Scholar] [CrossRef]
- Kung, L.; Shaver, R.D.; Grant, R.J.; Schmidt, R.J. Silage Review: Interpretation of Chemical, Microbial, and Organoleptic Components of Silages. J. Dairy Sci. 2018, 101, 4020–4033. [Google Scholar] [CrossRef] [PubMed]
- Kumaravelu, C.; Gopal, A. A Review on the Applications of Near-Infrared Spectrometer and Chemometrics for the Agro-Food Processing Industries. In Proceedings of the 2015 IEEE Technological Innovation in ICT for Agriculture and Rural Development (TIAR), Chennai, India, 10–12 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 8–12. [Google Scholar]
- Sørensen, L.K. Prediction of Fermentation Parameters in Grass and Corn Silage by Near Infrared Spectroscopy. J. Dairy Sci. 2004, 87, 3826–3835. [Google Scholar] [CrossRef]
- Liu, X.; Han, L. Prediction of Chemical Parameters in Maize Silage by near Infrared Reflectance Spectroscopy. J. Near Infrared Spectrosc. 2006, 14, 333–339. [Google Scholar] [CrossRef]
- Cozzolino, D.; Fassio, A.; Fernández, E.; Restaino, E.; La Manna, A. Measurement of Chemical Composition in Wet Whole Maize Silage by Visible and near Infrared Reflectance Spectroscopy. Anim. Feed Sci. Technol. 2006, 129, 329–336. [Google Scholar] [CrossRef]
- Zhang, M.; Zhao, C.; Shao, Q.; Yang, Z.; Zhang, X.; Xu, X.; Hassan, M. Determination of Water Content in Corn Stover Silage Using Near-Infrared Spectroscopy. Int. J. Agric. Biol. Eng. 2019, 12, 143–148. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, Y.; Lu, R. Innovative Hyperspectral Imaging-Based Techniques for Quality Evaluation of Fruits and Vegetables: A Review. Appl. Sci. 2017, 7, 189. [Google Scholar] [CrossRef]
- Özdoğan, G.; Lin, X.; Sun, D.-W. Rapid and Noninvasive Sensory Analyses of Food Products by Hyperspectral Imaging: Recent Application Developments. Trends Food Sci. Technol. 2021, 111, 151–165. [Google Scholar] [CrossRef]
- Hu, Y.; Huang, P.; Wang, Y.; Sun, J.; Wu, Y.; Kang, Z. Determination of Tibetan Tea Quality by Hyperspectral Imaging Technology and Multivariate Analysis. J. Food Compos. Anal. 2023, 117, 105136. [Google Scholar] [CrossRef]
- Wang, Z.; Fan, S.; Wu, J.; Zhang, C.; Xu, F.; Yang, X.; Li, J. Application of Long-Wave near Infrared Hyperspectral Imaging for Determination of Moisture Content of Single Maize Seed. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 254, 119666. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Fan, J.; Lu, X.; Wen, W.; Shao, S.; Liang, D.; Yang, X.; Guo, X.; Zhao, C. Deep Learning Models Based on Hyperspectral Data and Time-Series Phenotypes for Predicting Quality Attributes in Lettuces under Water Stress. Comput. Electron. Agric. 2023, 211, 108034. [Google Scholar] [CrossRef]
- Yao, X.; Cai, F.; Zhu, P.; Fang, H.; Li, J.; He, S. Non-Invasive and Rapid pH Monitoring for Meat Quality Assessment Using a Low-Cost Portable Hyperspectral Scanner. Meat Sci. 2019, 152, 73–80. [Google Scholar] [CrossRef] [PubMed]
- Ma, T.; Xia, Y.; Inagaki, T.; Tsuchikawa, S. Non-Destructive and Fast Method of Mapping the Distribution of the Soluble Solids Content and pH in Kiwifruit Using Object Rotation near-Infrared Hyperspectral Imaging Approach. Postharvest Biol. Technol. 2021, 174, 111440. [Google Scholar] [CrossRef]
- Wei, X.; Huang, L.; Li, S.; Gao, S.; Jie, D.; Guo, Z.; Zheng, B. Fast Determination of Amylose Content in Lotus Seeds Based on Hyperspectral Imaging. Agronomy 2023, 13, 2104. [Google Scholar] [CrossRef]
- Yang, C.; Zhao, Y.; An, T.; Liu, Z.; Jiang, Y.; Li, Y.; Dong, C. Quantitative Prediction and Visualization of Key Physical and Chemical Components in Black Tea Fermentation Using Hyperspectral Imaging. LWT 2021, 141, 110975. [Google Scholar] [CrossRef]
- GB/T 5009.237-2016; National Standard for Food Safety Determination of pH Value of Food. National Health and Family Planning Commission of the People’s Republic of China: Beijing, China, 2016.
- DB15/T 1458-2018; Determination of pH Value, Organic Acid and Ammonium Nitrogen in Silage. Inner Mongolia Autonomous Region Bureau of Quality and Technical Supervision: Hohhot of Inner Mongolia Autonomous Region, China, 2018.
- He, H.-J.; Wang, Y.; Wang, Y.; Liu, H.; Zhang, M.; Ou, X. Simultaneous Quantifying and Visualizing Moisture, Ash and Protein Distribution in Sweet Potato [Ipomoea batatas (L.) Lam] by NIR Hyperspectral Imaging. Food Chem. X 2023, 18, 100631. [Google Scholar] [CrossRef] [PubMed]
- Kamruzzaman, M.; Makino, Y.; Oshita, S. Parsimonious Model Development for Real-Time Monitoring of Moisture in Red Meat Using Hyperspectral Imaging. Food Chem. 2016, 196, 1084–1091. [Google Scholar] [CrossRef]
- Li, Y.; Ma, B.; Li, C.; Yu, G. Accurate Prediction of Soluble Solid Content in Dried Hami Jujube Using SWIR Hyperspectral Imaging with Comparative Analysis of Models. Comput. Electron. Agric. 2022, 193, 106655. [Google Scholar] [CrossRef]
- Kucha, C.T.; Liu, L.; Ngadi, M.; Claude, G. Hyperspectral Imaging and Chemometrics as a Non-Invasive Tool to Discriminate and Analyze Iodine Value of Pork Fat. Food Control 2021, 127, 108145. [Google Scholar] [CrossRef]
- Chu, Y.W.; Tang, S.S.; Ma, S.X.; Ma, Y.Y.; Hao, Z.Q.; Guo, Y.M.; Guo, L.B.; Lu, Y.F.; Zeng, X.Y. Accuracy and Stability Improvement for Meat Species Identification Using Multiplicative Scatter Correction and Laser-Induced Breakdown Spectroscopy. Opt. Express 2018, 26, 10119. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Xu, Y.; Huang, W.; Tian, X.; Xia, Y.; Xu, L.; Fan, S. Nondestructive Measurement of Soluble Solids Content in Apple Using near Infrared Hyperspectral Imaging Coupled with Wavelength Selection Algorithm. Infrared Phys. Technol. 2019, 98, 297–304. [Google Scholar] [CrossRef]
- Wang, Y.-J.; Jin, G.; Li, L.-Q.; Liu, Y.; Kianpoor Kalkhajeh, Y.; Ning, J.-M.; Zhang, Z.-Z. NIR Hyperspectral Imaging Coupled with Chemometrics for Nondestructive Assessment of Phosphorus and Potassium Contents in Tea Leaves. Infrared Phys. Technol. 2020, 108, 103365. [Google Scholar] [CrossRef]
- Bruce, L.M.; Koger, C.H.; Jiang, L. Dimensionality Reduction of Hyperspectral Data Using Discrete Wavelet Transform Feature Extraction. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2331–2338. [Google Scholar] [CrossRef]
- Dai, F.; Shi, J.; Yang, C.; Li, Y.; Zhao, Y.; Liu, Z.; An, T.; Li, X.; Yan, P.; Dong, C. Detection of Anthocyanin Content in Fresh Zijuan Tea Leaves Based on Hyperspectral Imaging. Food Control 2023, 152, 109839. [Google Scholar] [CrossRef]
- Centner, V.; Massart, D.-L.; De Noord, O.E.; De Jong, S.; Vandeginste, B.M.; Sterna, C. Elimination of Uninformative Variables for Multivariate Calibration. Anal. Chem. 1996, 68, 3851–3858. [Google Scholar] [CrossRef]
- Deng, B.-C.; Yun, Y.-H.; Cao, D.-S.; Yin, Y.-L.; Wang, W.-T.; Lu, H.-M.; Luo, Q.-Y.; Liang, Y.-Z. A Bootstrapping Soft Shrinkage Approach for Variable Selection in Chemical Modeling. Anal. Chim. Acta 2016, 908, 63–74. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Wang, L.; Liu, J.; Wang, Y.; Chang, Q. Evaluation of Leaf N Concentration in Winter Wheat Based on Discrete Wavelet Transform Analysis. Remote Sens. 2019, 11, 1331. [Google Scholar] [CrossRef]
- Yao, K.; Sun, J.; Chen, C.; Xu, M.; Cao, Y.; Zhou, X.; Tian, Y.; Cheng, J. Visualization Research of Egg Freshness Based on Hyperspectral Imaging and Binary Competitive Adaptive Reweighted Sampling. Infrared Phys. Technol. 2022, 127, 104414. [Google Scholar] [CrossRef]
- Yu, F.; Bai, J.; Jin, Z.; Zhang, H.; Guo, Z.; Chen, C. Research on Precise Fertilization Method of Rice Tillering Stage Based on UAV Hyperspectral Remote Sensing Prescription Map. Agronomy 2022, 12, 2893. [Google Scholar] [CrossRef]
- Yu, F.; Bai, J.; Jin, Z.; Zhang, H.; Yang, J.; Xu, T. Estimating the Rice Nitrogen Nutrition Index Based on Hyperspectral Transform Technology. Front. Plant Sci. 2023, 14, 1118098. [Google Scholar] [CrossRef] [PubMed]
- Mirjalili, S. Genetic Algorithm. In Evolutionary Algorithms and Neural Networks; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2019; Volume 780, pp. 43–55. ISBN 978-3-319-93024-4. [Google Scholar]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Alsattar, H.A.; Zaidan, A.A.; Zaidan, B.B. Novel Meta-Heuristic Bald Eagle Search Optimisation Algorithm. Artif. Intell. Rev. 2020, 53, 2237–2264. [Google Scholar] [CrossRef]
- Yu, S.; Bu, H.; Hu, X.; Dong, W.; Zhang, L. Establishment and Accuracy Evaluation of Cotton Leaf Chlorophyll Content Prediction Model Combined with Hyperspectral Image and Feature Variable Selection. Agronomy 2023, 13, 2120. [Google Scholar] [CrossRef]
- Xu, L.; Chen, Y.; Wang, X.; Chen, H.; Tang, Z.; Shi, X.; Chen, X.; Wang, Y.; Kang, Z.; Zou, Z.; et al. Non-Destructive Detection of Kiwifruit Soluble Solid Content Based on Hyperspectral and Fluorescence Spectral Imaging. Front. Plant Sci. 2023, 13, 1075929. [Google Scholar] [CrossRef]
- Wang, C.; Han, H.; Sun, L.; Na, N.; Xu, H.; Chang, S.; Jiang, Y.; Xue, Y. Bacterial Succession Pattern during the Fermentation Process in Whole-Plant Corn Silage Processed in Different Geographical Areas of Northern China. Processes 2021, 9, 900. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Chen, Y.; Cui, Q.; Li, L.; Ning, J.; Zhang, Z. Spatial Distribution of Total Polyphenols in Multi-Type of Tea Using near-Infrared Hyperspectral Imaging. LWT 2021, 148, 111737. [Google Scholar] [CrossRef]
- Andrighetto, I.; Serva, L.; Gazziero, M.; Tenti, S.; Mirisola, M.; Garbin, E.; Contiero, B.; Grandis, D.; Marchesini, G. Proposal and Validation of New Indexes to Evaluate Maize Silage Fermentative Quality in Lab-Scale Ensiling Conditions through the Use of a Receiver Operating Characteristic Analysis. Anim. Feed Sci. Technol. 2018, 242, 31–40. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Row | Model Parameters | Values and Specifications |
|---|---|---|---|
| PLS | 1 | F | 1–10 |
| SVR | 1 | c | 2−10–210 (value every 20.5) |
| 2 | g | 2−10–210 (value every 20.5) | |
| ELM | 1 | W | −1–1 |
| 2 | b | 0–1 |
| Sample Set | Sample Size | Max | Min | Mean | Standard Error |
|---|---|---|---|---|---|
| Total | 192 | 8.91 | 3.55 | 5.98 | 1.53 |
| Calibration set | 150 | 8.91 | 3.55 | 5.92 | 1.62 |
| Prediction set | 42 | 7.28 | 3.62 | 5.96 | 1.12 |
| Pretreatment Method | RMSEC | RMSEP | RPD | ||
|---|---|---|---|---|---|
| Raw | 0.9384 | 0.4214 | 0.6707 | 0.6821 | 1.9959 |
| SG | 0.9316 | 0.4440 | 0.7217 | 0.6270 | 2.0722 |
| MSC | 0.9435 | 0.4037 | 0.7933 | 0.5403 | 2.2012 |
| SNV | 0.9404 | 0.4145 | 0.7481 | 0.5965 | 2.1108 |
| First derivative | 0.9684 | 0.3017 | 0.5848 | 0.7659 | 1.7044 |
| Extraction Method | Number of Variables | Selected Wavelength (nm) |
|---|---|---|
| CARS | 38 | 1169, 1213, 1225, 1339, 1446, 1515–1534, 1679–1698, 1710–1723, 1786–1811, 1987, 2025, 2037, 2050, 2062, 2069, 2213, 2238, 2244, 2307, 2313, 2345, 2351, 2357, 2457 |
| SPA | 19 | 960, 992, 1143, 1207, 1383, 1427, 1496, 1723, 1811, 1855, 1887, 2037, 2144, 2188, 2219, 2225, 2232, 2238, 2332 |
| UVE | 116 | 954, 1030, 1036, 1143–1295, 1446, 1452, 1459, 1465, 1572–1836, 1887–2069, 2401, 2407, 2413, 2432, 2439, 2507, 2514, 2520, 2526 |
| DWT | 8 | 935–973, 1068 |
| VCPA-IRIV | 26 | 1011, 1055, 1061, 1446, 1452, 1478, 1641, 1660.66, 1673–1692 |
| BOSS | 20 | 1175, 1219, 1232, 1358, 1692–1704, 1729, 1780, 2006, 2031, 2037, 2213, 2238, 2307, 2313, 2407, 2457, 2476, 2482 |
| Extraction Method | Calibration Set | Prediction Set | ||||
|---|---|---|---|---|---|---|
| RMSEC | RMSEP | RPD | ||||
| PLS | CARS | 0.8905 | 0.5046 | 0.8889 | 0.5118 | 3.0258 |
| SPA | 0.7757 | 0.7237 | 0.7700 | 0.7321 | 2.0944 | |
| UVE | 0.7798 | 0.7130 | 0.7790 | 0.7255 | 2.1363 | |
| DWT | 0.5522 | 1.0252 | 0.5352 | 1.0316 | 1.4679 | |
| VCPA-IRIV | 0.8703 | 0.5447 | 0.8604 | 0.5897 | 2.6793 | |
| BOSS | 0.9118 | 0.4552 | 0.8937 | 0.4753 | 3.0933 | |
| RAW | 0.9384 | 0.4214 | 0.6707 | 0.6821 | 1.9959 | |
| SVR | CARS | 0.9666 | 0.2967 | 0.8335 | 0.4583 | 2.4514 |
| SPA | 0.9732 | 0.2653 | 0.7173 | 0.5973 | 2.3765 | |
| UVE | 0.9579 | 0.3329 | 0.7570 | 0.5537 | 2.3256 | |
| DWT | 0.8082 | 0.7108 | 0.0387 | 1.1451 | 1.1174 | |
| VCPA-IRIV | 0.9633 | 0.3107 | 0.7744 | 0.5335 | 2.1260 | |
| BOSS | 0.9621 | 0.3157 | 0.8413 | 0.4475 | 2.5495 | |
| RAW | 0.9692 | 0.2846 | 0.7162 | 0.5985 | 2.2118 | |
| ELM | CARS | 0.9220 | 0.4210 | 0.9092 | 0.4807 | 3.3238 |
| SPA | 0.8996 | 0.4924 | 0.8699 | 0.5136 | 2.7955 | |
| UVE | 0.8913 | 0.5089 | 0.8220 | 0.6206 | 2.3928 | |
| DWT | 0.6639 | 0.8789 | 0.6574 | 0.9183 | 1.7304 | |
| VCPA-IRIV | 0.9126 | 0.4286 | 0.9074 | 0.5398 | 3.3709 | |
| BOSS | 0.9289 | 0.4027 | 0.9241 | 0.4372 | 3.6565 | |
| RAW | 0.7900 | 0.6930 | 0.7886 | 0.7270 | 2.2169 | |
| Extraction Method | Calibration Set | Prediction Set | |||
|---|---|---|---|---|---|
| RMSEC | RMSEP | RPD | |||
| BOSS–GA–ELM | 0.9848 | 0.1868 | 0.9433 | 0.3657 | 8.1310 |
| BOSS–WOA–ELM | 0.9648 | 0.3044 | 0.8525 | 0.4313 | 5.3331 |
| BOSS–BES–ELM | 0.9622 | 0.2923 | 0.9598 | 0.3216 | 5.1448 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Y.; Tian, H.; Zhao, K.; Guo, L.; Zhang, J.; Liu, Z.; Xue, X.; Tao, Y.; Tao, J. Rapid pH Value Detection in Secondary Fermentation of Maize Silage Using Hyperspectral Imaging. Agronomy 2024, 14, 1204. https://doi.org/10.3390/agronomy14061204
Yu Y, Tian H, Zhao K, Guo L, Zhang J, Liu Z, Xue X, Tao Y, Tao J. Rapid pH Value Detection in Secondary Fermentation of Maize Silage Using Hyperspectral Imaging. Agronomy. 2024; 14(6):1204. https://doi.org/10.3390/agronomy14061204
Chicago/Turabian StyleYu, Yang, Haiqing Tian, Kai Zhao, Lina Guo, Jue Zhang, Zhu Liu, Xiaoyu Xue, Yan Tao, and Jinxian Tao. 2024. "Rapid pH Value Detection in Secondary Fermentation of Maize Silage Using Hyperspectral Imaging" Agronomy 14, no. 6: 1204. https://doi.org/10.3390/agronomy14061204
APA StyleYu, Y., Tian, H., Zhao, K., Guo, L., Zhang, J., Liu, Z., Xue, X., Tao, Y., & Tao, J. (2024). Rapid pH Value Detection in Secondary Fermentation of Maize Silage Using Hyperspectral Imaging. Agronomy, 14(6), 1204. https://doi.org/10.3390/agronomy14061204